- POI
- Point-of-Interest
- MM
- membership maintenance
- C2
- Command and Control
- gcc
- GNU Compiler Collection
- MSB
- most significant byte
- LSB
- least significant byte
- DBI
- dynamic binary instrumentation
- RPC
- Remote Procedure Call
- LICA
- Less Invasive Crawling Algorithm
- BFS
- Breadth first search
- DFS
- Depth first search
- ASLR
- Address Space Layout Randomization
- P2P
- Peer-to-Peer
- JSON
- JavaScript Object Notation
- OS
- operating system
- VM
- virtual machine
Malware Sight-Seeing: Accelerating Reverse-Engineering via Point-of-Interest-Beacons
Abstract.
New types of malware are emerging at concerning rates. However, analyzing malware via reverse engineering is still a time-consuming and mostly manual task. For this reason, it is necessary to develop techniques that automate parts of the reverse engineering process and that can evade the built-in countermeasures of modern malware. The main contribution of this paper is a novel method to automatically find so-called Point-of-Interests in executed programs. POIs are instructions that interact with data that is known to an analyst. They can be used as beacons in the analysis of malware and can help to guide the analyst to the interesting parts of the malware. Furthermore, we propose a metric for POIs, the so-called confidence score that estimates how exclusively a POI will process data relevant to the malware.
With the goal of automatically extract peers in P2P botnet malware, we demonstrate and evaluate our approach by applying it on four botnets (ZeroAccess, Sality, Nugache, and Kelihos). We looked into the identified POIs for known IPs and ports and, by using this information, leverage it to successfully monitor the botnets.
Furthermore, using our scoring system, we show that we can extract peers for each botnet with high accuracy.
1. Introduction
Malicious software (malware) is a severe threat to every IT system and its numbers are steadily increasing. In 2018 alone, Symantec reported (Symantec, 2019) more than Million new variants of malware. Security researchers and analysts are always in the look out for new emerging malware as well as existing ones to protect end users and organizations. To understand a new type of malware, analysts often need to reverse engineer it by focusing on the inner-workings of the malware. This process helps to derive unique signatures of its behavior, which can be used in security tools like antivirus software and intrusion detection systems.
Reverse-engineering is mostly a manual task and requires a specialized and trained personel. Thus, the automation of reverse-engineering to support the human analyst is an ongoing research field and has led to an ongoing arms race between analysts and malware authors. Meanwhile, more advanced reverse engineering techniques encompass methods for the replay of protocols using symbolic execution (Newsome et al., 2006), analysis of data structures (Lin et al., 2010), taint tracking of data (Clause et al., 2007), and sophisticated reverse-engineering suites and tools like IDA111https://www.hex-rays.com/products/ida/ and Ghidra222https://ghidra-sre.org/. Nevertheless, even these advanced techniques fall short in the analysis of novel malware equipped with advanced countermeasures to impede its analysis (Cavallaro et al., 2007; Babil et al., 2013; Banescu et al., 2016).
In this paper, we propose a new reverse-engineering technique to identify so-called POIs in applications that can guide analysts as beacons in the process of analysing malware. Our method exploits that all data used by an application is at some point is either loaded in a register, written to, or read from the memory. POIs are instructions that interact with data that is known to an analyst. Thus, using a priori information, e.g., Command and Control (C2) IP addresses, our proposed technique leverages dynamic binary instrumentation tools to identify specific instruction addresses within a malware binary that are used to access these values during their execution. This may result in a large number of POIs from general purpose functions such as memcpy or strcpy. The fact that the searched data is copied using a general purpose function may not necessarily be important information for the analyst. However, the points at which the searched data is mainly processed are of interest. A so-called confidence score is therefore calculated for the POIs. This score indicates how exclusively a POI handles the searched data. Based on the scores, analysts can focus on POIs that are useful to them.
As a proof of concept, we demonstrate the feasibility of using POIs to automatically monitor four Peer-to-Peer (P2P) botnets without the need to reverse-engineer them. This involves extracting IPs and ports from a running bot. In evaluating our proof of concept implementation, we show that the confidence score overestimates the quality for only out of a total of POIs. It is thus a good conservative estimator for the quality of the results that is expected. For all botnets we analyzed, our filtering based on the confidence score improves the results. For instance, within the ZeroAccess botnet, the number of incorrectly extracted peers drops from to zero while retaining correct results.
The remainder of this paper is structured as follows. In Section 2, we introduce the necessary background in reverse engineering and botnet malware. Section 3 introduces our proposed technique and Section 4 details the implementation of our POI technique and the setup for automatic monitoring of P2P botnets. Then, Section 5 discusses our evaluation along with the corresponding results. Finally, Section 6 introduces the related work and Section 7 concludes this paper.
2. Background
This section provides an overview of reverse engineering techniques, anti-reverse engineering techniques employed by malware authors, P2P botnets, and botnet monitoring.
2.1. Reverse Engineering
Reverse engineering can be divided into static and dynamic analysis. Both methods aim to reconstruct and modify the functions, objectives, or artifacts of a program. For this purpose, binaries are often analyzed at assembler instruction level. When manually performing this process, reverse engineers often times rely on common patterns or contextual information like annotations, used strings or function names to infer the purpose of a code region. This information behaves as beacons (Votipka et al., 2019) and can accelerate the work because the reverse engineer already has clues where to start his work, so that it is not necessary to start at the entry point of the binary. Tools like sandboxes or software reverse engineering suites can provide further static and dynamic information about a malware sample. The information collected by such tools ranges from created files, contacted IPs to marking instructions with certain functionality in the binary333https://www.hex-rays.com/products/ida/lumina/. In most cases, both methods are used to complement each other.
Static analysis is everything that can be obtained about the program without executing it. This include the knowledge about the functionality of the binary, as well as the extraction of data such as strings and metadata. Well known tools for this process are e.g., IDA and Ghidra. Both tools bring functionalities like identifying individual functions, finding strings, and locating where system functions are called.
In contrast to static analysis, dynamic analysis executes actual parts of the program in an analysis environment. This allows runtime information to be extracted from the binary. A very common type of tool used for dynamic analysis is a debugger like GDB444https://www.gnu.org/software/gdb/. \AcDBI is a kind of dynamic analysis. With dynamic binary instrumentation (DBI), new code is inserted into a binary at runtime. This code can access registers and analyze the data that instructions are reading and writing. This way one can log instructions and accessed data, i.e., registers and memory, for every executed instruction. The code can be added at different granularity’s, e.g., for every instruction or for every function. Furthermore DBI can also be used to change an application’s behavior, e.g., by modifying registers. \AcDBI is often faster than conventional debuggers, since no breakpoints have to be set which generate an interrupt and therefore a context switch to the debugger (Eilam, 2011). Frameworks in this area are among others Intel Pin (Luk et al., 2005) and DynamoRIO (Bruening et al., 2012).
As malware authors want to prevent reverse engineering, they develop more and more sophisticated anti-reverse engineering techniques. These are meant to make the work of the reverse engineer more difficult. A detailed overview is given by the authors of (Or-Meir et al., 2019; Yan et al., 2008; You and Yim, 2010), however, in the following we will highlight two such techniques.
Packers change a binary so that (a part) of the binary is encrypted. This part is then decrypted when the binary is executed. A packer may not be deterministic, it can decrypt the same malware multiple times and creates every time a binary with a different hash value (Yan et al., 2008).
Debugger detection techniques prevent or detect the presence of a debugger (e.g. checkRemoteDebuggerPresent555https://docs.microsoft.com/en-us/windows/win32/api/debugapi/nf-debugapi-checkremotedebuggerpresent, isDebbugerPresent666https://docs.microsoft.com/en-us/windows/win32/api/debugapi/nf-debugapi-isdebuggerpresent). This can be a simple search for processes or window names up to the detection of artifacts in memory or in the execution environment (Chen et al., 2008).
2.2. P2P Botnets and Botnet Monitoring
Botnets can be divided into different categories based on the network architecture they use. Depending on the architecture, a botnet can, for example, be deployed easier or harder, be more resilient to takedowns, or be more efficient in internal communication (Karuppayah, 2018). P2P botnets do not use dedicated C2 servers, but are, as the name suggests, connected in a peer-to-peer network.
Each bot in a P2P botnet has a peer list that contains the information necessary to contact other bots, such as IP addresses, ports, and unique identifiers. In this paper we denote bootstrap list to the initial peer list a bot carries before it is executed. The bootstrap list is used by a bot after infecting a machine to join the botnet. The peer list denotes the list of peers that a bot holds after it has joined the P2P overlay of the botnet. The peer list is not static, as new bots join the network (new infections) and other bots leave the network (removals of bots). To ensure persistent connectivity, P2P botnets use an membership maintenance (MM)-mechanism to maintain the peer list. In general, this is done by periodically contacting existing peers from the peer list and, if there are too few responsive peers, requesting new ones. Especially the message to request new peers is interesting and is called getL message in the following. The response to a getL message is a retL message containing a list of shared peers.
In P2P botnet monitoring the getL message is used to recursively crawl for peers. This can reveal the extent of a botnet. For this, however, the protocol that the bots speak among themselves must be known, e.g., message format and encryption. This knowledge is achieved by reverse-engineering the binary. This requires time and expertise and at the same time the result is only valid for only one botnet. In the worst case, even only for one version of the botnet.

3. POI as Beacons
In this section, we first introduce the concept of Points-of-Interest (POI) as a type of beacon to accelerate reverse-engineering efforts. Next, we explain the steps of identifying all POI candidates. Then, we discuss strategies to evaluate and pick the best POIs to be used as beacons.
As discussed in Section 2, beacons can serve as an excellent guidance for malware analysts to focus and accelerate their reverse engineering efforts. Beacons are essentially patterns and markers that are used by analysts to either focus or ignore certain parts of the binary, e.g., known encryption routines or anti-reverse engineering components (Votipka et al., 2019).
As most malware are programmed to carry out some read/write operations on the infected machine, e.g., registry, file, or network access, this behaviour would also be reflected at the instructions level of the binary of the malware sample. During the execution of these instructions, various data would be accessed through registers and memory regions of the infected machine which are often managed directly by the operating system (OS). If the data/value accessed by the malware is known, e.g., specific file names or IP addresses, one could observe the data being accessed by specific instruction address(es) within the binary, i.e., either through memory or registers. These addresses are referred by us as POIs. In reality, the details of the exact data accessed by the malware can be easily obtained through behavioural analysis carried out using malware sandboxes.
As an example, a typical operation a malware would perform is constructing a data buffer and writing it into a configuration file. 1 illustrates an example assembly code that represents the behavior of a malware that writes a static header to a file. In Lines , the static header for the configuration is generated. In Lines , the write_config function is called with the generated buffer data. Assuming the header data is known upfront, the instruction in Line 4 would represent a POI, i.e., the instruction when the expected header data is observed in the memory.
If an analyst is interested in finding out the operations that are relevant prior or after the creation of the configuration file, the POI can be used as a starting point of starting the analysis. However, the process of identifying POI candidates is not trivial and may sometime yield inaccurate results. In the next sections, we discuss our methodology in identifying and selecting high-quality POIs.
3.1. Methodology
In this section, we briefly introduce the various stages within our methodology on extracting POI beacons as illustrated in Figure 1. We will elaborate the relevant stages in the subsequent subsections.
Firstly, a valid malware sample needs to be identified and retrieved for further analysis. Using this sample, data or values that are accessed by the malware, e.g., IP addresses, accessed files, etc., need to be identified. Next, the execution trace of the malware needs to be recorded. This can be achieved using DBI or debuggers such as GDB (see Section 2.1).
Using information obtained from the previous steps, we perform our POI candidates identification. Finally, we filter out POIs to ensure we retain only high-quality POIs and use them as POI beacons for guiding malware analysts to reverse engineer the malware. The remainder part of this section elaborates each of the steps introduced within this methodology accordingly.
3.2. Identifying Malware Artifacts
As our methodology requires a priori information pertaining the malware sample, some information, , needs to be extracted from the sample. This information can be obtained using malware sandboxes to identify artifacts introduced/accessed by the malware sample. Alternatively, one could leverage general purpose interactions of the malware with the OS, e.g., writing files, using the OS API monitoring tools such as API Monitor777http://www.rohitab.com/apimonitor, Process Monitor888https://docs.microsoft.com/en-us/sysinternals/downloads/procmon, and strace999https://linux.die.net/man/1/strace during runtime. Finally, the analyst could also add manual entries, e.g., expert information, to the overall set .
Choosing the information for a sample is closely related to the main goal of the analyst in obtaining relevant beacons. For instance, if the analyst is interested in studying the network communication modules of the malware, the set of IP addresses and ports that are used by the malware for network communication would be a suitable choice. Nevertheless, it is important to ensure that only unique information are picked to increase the likelihood of generating high-quality POI beacons.
For instance, assuming a sandbox analysis reported an outgoing connection from the malware to a remote host with the IP address and port , it would be suitable to include only the IP address in the set . The reason for leaving the port value out would be because the (decimal) value for port could be used by other components also for network communication purposes. Moreover, the value could also be used as an internal counter or as the ASCII character ’P’ withing the malware. In contrast, the likelihood of observing that the data corresponding to the IP is processed within another context is rather low.
Another consideration that is worth noting would be the representation of the data added in . The data could be processed differently during the execution of a malware depending on various factors such as the computer architecture and the OS system. For instance, the IP address from the previous example could be accessed in any one of the following manners during execution:
-
(1)
0x0A141E28, i.e., the IP in binary form with most significant byte (MSB) first.
-
(2)
0x281E140A, i.e., the IP in binary form with least significant byte (LSB) first.
-
(3)
The ASCII strings "10.20.30.40" and "0A141E28" if the malware handles the IP address as ASCII text.
Hence, whenever possible, all possible representations of the data that could uniquely identify the malware-related artifact should be included in .
3.3. Identifying POI Candidates
As explained earlier, POIs are defined as instruction addresses that accesses, i.e, read or write operations, registers or memory regions that has the value of any one of the elements within . Hence, in this step, suitable POIs candidates are identified by iterating the malware execution trace while looking for instructions that access any of the expected malware artifacts in .
Nevertheless, the process of finding matching instructions is not trivial. The main reason for this is the manner data or values processed by an OS. Depending on the CPU architecture supported by the OS, i.e., -bit vs -bit, the maximum length of data that could be processed in one (assembly) instruction execution varies between bytes. Hence, the elements within may or may not fit a single instruction within the malware trace. For instance, an IPv4 address could be matched in a single instruction unlike a long string value that would require multiple consecutive instructions.
Hence, in this step, we introduce two strategies to identify POIs: Standalone POI and Contiguous POI. As the name implies, the first strategy handles POI identification for values that fit a standalone (single) instruction. The second strategy handles POIs identification for values that cannot be processed within a single instruction.
3.3.1. Standalone POI
This strategy attempts to identify POIs related to data which can be processed by a single instruction. There are three possible ways such an instruction could interact with :
-
•
writing to memory, e.g., a push eax instruction
-
•
reading from memory, e.g., a mov eax, [esp] instruction
-
•
reading from or writing to a register
Hence, this strategy loops over each line of the trace file and compares the registers, memory reads, and memory writes with every . Whenever data access of an instruction in the trace matches some , the corresponding instruction’s address is marked as a POI candidate.
3.3.2. Contiguous POI
This strategy is responsible to handle scenarios when data requires more than one consecutive instruction for handling it. In comparison to the previous scenario, multi-instruction scenarios are more complicated because the order how data is accessed could be sequential, reversed, or even random. Hence, this strategy needs to iteratively search for an expected pattern, i.e., , after each memory write-operation.
In order to make the search for the pattern more efficient, the memory should not be searched exhaustively. Only the memory written by the malware should be searched. However, the memory allocation information by the OS only reports the allocation to an application or process. It does not inform on the exact utilization of the block. Hence, we needed the ability to track the utilization of the allocated memory by the malware process, i.e., actual memory writes. For this purpose, we leveraged lookup tables as illustrated in Figure 2 to facilitate our tracking purposes.
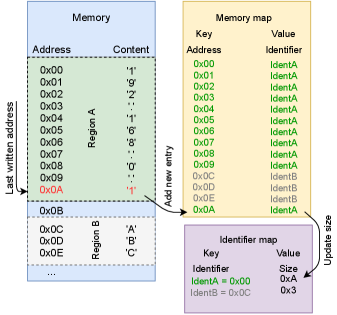
Lookup Tables
To track the memory write operations for a process, we need to introduce two custom lookup tables:Memory Map and Identifier Map . For each memory block assigned to the malware process, we need to keep track of all write operations, i.e., content written, during runtime. Using the Memory Map, a memory region should be dynamically assigned and tracked such that each address within a contiguous block of written memory is mapped to its corresponding region. To effectively track memory regions, all memory write-operations from the trace file must be considered with an assumption that the file includes all execution details of the malware, right from the beginning. Finally, the Identifier Map should be used to keep track the size of each memory region being tracked. Hence, for each change recorded in the Memory Map, the corresponding new size of the affected memory region should also be updated accordingly in the Identifier Map.
Memory Pattern Search
As mentioned earlier, for each memory write-operation recorded within the malware trace file, we need to search if any memory region in the memory matches the patterns of . Leveraging the lookup tables introduced previously, for each accessed memory address, a memory pattern search is executed for each based on Algorithm 1. First, the information of the memory region for the currently accessed memory address is retrieved from the lookup tables (Line ). Then, the algorithm checks if the considered pattern ’s size is smaller or equal the size of the currently considered memory region (Line ). If the size of the pattern fits the considered region, the contents within the memory region is compared to the pattern of (Line ). If a match was successfully found, the algorithm returns the address of the match, i.e., as a POI candidate.
3.4. Filtering POIs
The POI candidates identified in the previous section are merely pointing to addresses that were used to access data during execution. However, due to the nature of low quality values of , i.e., non-unique, or simply due to chance, not all POIs are suitable as beacons, i.e., may introduce false positives. This is also highly dependent on the exact use case for the POIs as beacons. If they are used only for guiding manual reverse engineering, low quality POIs can be easily ignored by a skilled analyst. For instance, a POI candidate might be flagged due to the address referring to a general purpose memory copying function, e.g., memcpy. This may or may not be of interest to the analyst, i.e., information about the flows of data in within the malware binary. However, for tools that depends on the POIs for further analysis or those that rely on POI instructions that are known to always access some data from , a low-quality POIs could be detrimental (see Section 4).
As the quality of a POI is not an absolute measure and the fact that determining the quality is only possible with manual reverse engineering, we introduce confidence score as a metric to estimate the quality of a POI. This metric assesses the frequency of an address associated to a particular POI being used to access only elements of . By assigning a score between for each POI, the quality of the address can be estimated. A score of would indicate that the POI is used exclusively by the malware for accessing only data in . Meanwhile, scores of indicate that other contents (not in ) are also accessed using the address of POI.
In the following, we elaborate the details of the metric which needs to be adapted accordingly to the search strategies outlined in Section 3.3, i.e., Standalone and Contiguous POIs.
3.4.1. Standalone POIs
In this section, the adaptation of the confidence score metric for Standalone POIs is described based on Algorithm 2. The confidence score of each Standalone POI (Line ) can be expressed as the ratio of instructions within the malware binary that processes data from (Line ) compared to all data processed by those instructions (Line ).
The confidence score of these kind of POI is most reliable when the malware is iterating a command with multiple different values, e.g., conducting DDoS attack with multiple spoofed addresses. Once the confidence score for the POIs are calculated, a certain threshold can be used to provide a cutoff in selecting high-quality POIs as beacons. Discussion on how to select the threshold value is provided in Section 5.2.3.
3.4.2. Contiguous POIs
The adaptation of the confidence score metric for Contiguous POIs is not as straightforward as it was for Standalone POIs. For Contiguous POIs, a mapping from memory address to the last instruction address that wrote to the memory address is required to determine the confidence score. This can be achieved through the lookup tables introduced in Section 3.3.
In more detail, let be a list of sequences of instruction addresses that wrote the bytes of the found patterns where wrote the ith byte of a found pattern. Then, let be the number of elements of a sequence that are equal to . In addition, let be the number of bytes a POI writes in the runtime of the process. With that, the confidence score for a POI is calculated using
Simply put, for a POI, we calculate the number of pattern bytes written, divided by the total number of bytes it wrote. It is important to note that for pattern bytes that are written, we count only the bytes that occurred in a complete pattern, i.e., full. This is required to prevent an instruction that only writes parts of the pattern from not receiving a high score. The confidence score for a read-memory pattern POIs is also calculated analogously.
Unlike Standalone POIs, the presence of overlapping data is not much of a problem. This is because data that cannot be processed within one instruction is usually much longer. So the probability that an ASCII string ”192.168.0.1” is not an IP but some other data is much lower than if it is represented as an integer, e.g., 3232235521. However, this is only valid for data that are lengthy and not shorter ones like the representation of a port (decimal) value in ASCII. Once again, after obtaining the relevant confidence scores for all POIs, a threshold value can be selected to filter out only high-quality POIs as beacons. Please refer to Section 5.2.3 for discussion on choosing the suitable threshold value.
After filtering out the high-quality POIs, malware analysts can integrate the beacons into their reverse engineering workflows. To assist with that, we have additionally implemented two plugins for IDA Pro and Ghidra that can highlight the instructions that accesses the POIs for the given malware sample. Appendix D provides further details about the plugins.
Even though malware analysts benefits from using our proposed POIs as beacons for manual reverse engineering, this is not the only use case. Our POIs can also be used by more advanced analysis tools to simplify the analysis of a malware sample. In the next section, we introduce PinPuppet as a tool that leverages our POIs to automatically monitor P2P botnets.
4. PinPuppet Monitoring
Based on our approach from Section 3 we developed a proof-of-concept prototype called PinPuppet. PinPuppet extends the POI mechanism with additional components as described in Algorithm 1 to enable features to automatically instrument a malware to conduct botnet monitoring. The overall goal of PinPuppet is to crawl a P2P botnet without requiring detailed knowledge about the sample or the botnet itself, e.g., the MM-protocol.
Our prototype can be used to evaluate whether POIs can be used for advanced malware analysis and to verify that the methodology for identifying and filtering POIs works. We decided to go on with this evaluation strategy in comparison to a more subjective evaluation of how the beacons are useful for malware analysts.
The scope of PinPuppet is limited to botnets which do not rely on destination-dependent messages, e.g., encrypted with a recipient’s public key. Furthermore, PinPuppet assumes that the malware sample is instrumentable by Intel Pin (in the following only Pin), the choice of our DBI framework. Consequently, all anti-Pin (Kirsch et al., 2018; D’Elia et al., 2019; Gorgovan, 2016) mechanisms of the sample are assumed to be circumvented.
The information in the form of bootstrap list of a sample is assumed to be known and access to a virtual machine (VM) with snapshot functionality is available. The former can be done automatically, e.g. by running the sample on a sandbox and logging all peers contacted by it. In addition, it is assumed that all anti-VM countermeasures of the malware (if applicable) are also circumvented.
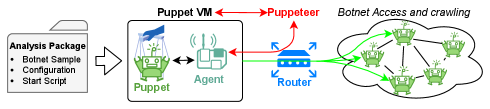
4.1. System Overview
PinPuppet is not a monolithic system. It consists of multiple components, which each fulfills their own purpose. Considering that PinPuppet implements crawling functionality, we need to repeatedly evoke the getL function (cf. Section 2.2). As this is typically one of the first messages sent after the initial connection, we could achieve this by restarting the sample, however, two problems arise: Firstly, the duration from restart to performing the connection could be relatively long (e.g., approximately 5 minutes for Sality) and, secondly, POIs would not stay valid throughout consecutive restarts.
POIs reference the addresses of instructions and thus, they only stay valid as long as the sample’s memory layout is not reorganized or the content is not changed. This requires that neither Address Space Layout Randomization (ASLR) nor any malware anti-reverse engineering mechanism that modifies the corresponding instruction address. This can be achieved by relying on virtualization and live snapshots to keep a state where the POIs reference to the corresponding instructions in memory is retained.
Thus, we utilize a VM with a “live” snapshot where the sample is already running. This prevents ASLR or even the malware itself from randomizing the memory layout. The interaction between the various components within PinPuppet is illustrated in Figure 3. Each component is detailed individually in the following.
An Analysis Package bundles all information that is needed for crawling a botnet. It contains the malware sample, a configuration file, and a script that describes how to start the sample and how to attach Pin to the running malware. The configuration contains the bootstrap list, and the values and which will be explained later on.
The Puppet VM, as the name suggests, is a virtual machine (Windows 7 32-bit). The two main components that are running on this VM are the Puppet and the Agent. The Agent is our foothold in the Puppet VM. It allows uploading analysis packages, running them, and downloading the results. Meanwhile, the Puppet is the botnet sample with Pin attached to it. Pin is then used to trace instructions based on filtering criteria – we will elaborate those later on in Section 4.2.2. Additionally, the Puppet wraps calls to the Windows socket API (winsock2.h101010https://docs.microsoft.com/en-us/windows/win32/api/winsock2/). We call this component the Socket Wrapper. Whenever a sending API function is called, the IP and port parameters are first sent over the network using the Agent. The Socket Wrapper then waits for a response (which contains no data) before executing the original API call. For receiving API calls, the order is reversed, i.e., the API call is executed before the results are sent using the Agent. The Socket Wrapper again waits for a reply before continuing. By not replying to such a message, we can thus pause a VM immediately before performing a sending network operation or after performing a receiving network operation.
The Router is used for routing the traffic between the Puppet VM, the Puppeteer, and the botnet itself. Before crawling a peer, the Router is reconfigured by the Puppeteer. Afterwards, the configuration is rolled back to allow crawling the next peer.
The Puppeteer is the brain of PinPuppet. It sets up the Router, controls the Puppet VM (e.g., creating snapshots, starting, and stopping it). It communicates with the Agent via the network and sends commands to it. Data collected by the Puppet, is downloaded by the Puppeteer using the Agent for further processing.
4.2. Methodology
The automated crawling performed by PinPuppet is a five step process. The first step sets up a snapshot where the sample is running. As explained in the previous section, this is required to make sure that the memory layout does not change and thus our POIs stay valid throughout the whole process. Steps two, three and four correspond to the equally named steps from the POIs beacon methodology (cf. Figure 1). The process explained in the final step then allows one to a) contact a user specified peer and b) extract peers that were shared by the contacted peer in getL replies. This can be used to crawl the botnet. In the following, we will explain the individual steps in detail.
4.2.1. Snapshot Creation
In this step, PinPuppet firstly uses the Socket Wrapper to pause the sample by pausing the VM directly before it initiates the connection to a peer and, secondly, creates a snapshot of the VM where the sample is in the paused state. We only pause the sample when the address it is trying to contact is in . This ensures, that it is contacting a real peer and, for example, not a multicast or local address. We call the peer it is about to contact the original peer . The sample is kept disconnected from the botnet in this step and thus never establishes a connection. For UDP, we pause the malware before calling a sendto-family API call. For TCP, we pause the malware before calling a connect-family API call. The snapshot that results from this process is called “running snapshot.”
4.2.2. Trace Data Collection
As a requirement for extracting POIs is the existence of an instruction trace (cf. Figure 1), we record such a trace in this step. For this recording step, the Puppet VM has access to the Botnet, i.e., it will exchange MM-messages with bots in the botnet. It is then restored to the running snapshot and where the sample is resumed. The sample is then left running for a fixed amount of time (configured using the Analysis Package) to allow for the bot to perform MM-communications with the botnet. We have used a duration longer than the length of one MM-cycle. The length of one MM-cycle can either be taken from existing literature or by analyzing the traffic generated by the sample (e.g., using Cuckoo Sandbox). In general, running the sample for longer is always an option which only improves the quality of the results. However, the processing time required in the next two steps will increase with the amount of data collected in this step.
While the botnet is running, it generates trace data and Socket Wrapper logs. After time has elapsed, the Puppeteer downloads the generated data from the VM and, lastly, shuts it down. The Socket Wrapper logs are of particular interest to us, because they give us the information of which peers were contacted by the Puppet (outgoing) and which peers it was contacted by (incoming). The set of all peers identified using the Socket Wrapper logs is called .
Tracing all instructions with Pin can introduce a significant runtime overhead for the application being traced and creates enormous amounts of data. Since the tracing of programs becomes so slow that it is no longer practical, we have added various filtering options. They allow the user to more closely specify the instructions which should be traced. The implemented filtering options are:
-
•
whether instructions belonging to named regions should be traced and, if so, for which regions.
-
•
whether instructions not belonging to named regions should be traced (e.g., a memory region where the sample stores unpacked code).
In addition, one can specify the maximum number of times an instruction is traced – the maximum trace count. This prevents instructions which are executed very often from unnecessarily bloating the generated trace data with useless information. We have observed this behavior with Sality, which, without the maximum trace count, creates a 30GB trace containing mostly data from a small set of instructions. These filtering options are also specified as part of the analysis package.
4.2.3. POI Candidate Identification
In this step, the Puppeteer performs the POI candidate identification (cf. Section 3.3 and Figure 1) for identifying IP- and port-POIs, i.e., POIs corresponding to instructions frequently processing IPs or ports. Port-POIs are especially important for botnets using varying listening ports, however, for botnets with a fixed listening port, Port-POIs can be skipped as they would provide no additional information.
The identification process uses the data set for the IP-POIs and, if applicable, the data set for port-POIs. Both data sets are constructed based on the IPs and ports in . For both the IPs and the ports, the following representations are added to and , respectively:
- •
-
•
ASCII representation, used for identifying memory pattern POIs.
The intuition behind using as the basis for our data sets is that it approximates all peers that the puppet can know. The true set of known peers is where are all peers that were shared with the Puppet in the trace data collection step. Of course, we do not know which peers were shared with the Puppet, however, as bots who request new shared peers oftentimes contact these shared peers, there is an overlap between and . Thus the difference between and is relatively small.
4.2.4. POI Filtering
In this step, the Puppeteer performs POI filtering (cf. Section 3.3 and Figure 1) for the IP-POIs identified in the previous step. The puppeteer calculates the confidence score of each IP-POI. Using the confidence score threshold, the IP-POIs are filtered. In this case, confidence score threshold is required to compensate for the aforementioned difference between and .
For port-POIs (if applicable), we perform a different process: as we want to extract IP and port tuples from traces in the next step, we need to find the mapping between IP- and port-POIs. To obtain the mapping, we first, for every POI, extract all IPs and ports using the POIs from the trace data generated in the second step. We then use Algorithm 3 to create the mapping. All port-POIs which are not in the resulting mapping are discarded (regardless of confidence score).
4.2.5. Crawling Primitive
In this step, the crawling is performed. In the following we present the primitive that is used to a) contact a specified “crawl peer” , and b) extract peers shared by .
First, the router is configured to redirect outgoing traffic destined to to . For any replies sent by the Router is configured to change the source to . Thus, the Puppet assumes it is talking to even though it is communicating with .
To prevent unsolicited requests to the Puppet, e.g., because it previously contacted which now tries to probe the puppet, all traffic that is not between the Puppet and is blocked. This is to make sure, that the extracted peers are only based on the short communication with .
The sample is now left running for a short time period (configured using the Analysis Package) after which the trace data is downloaded. Using the IP- and port-POIs, the Puppeteer extracts IPs and ports from the trace data. For every IP- and port-POI which are mapped together in the POI mapping, the extracted IPs and ports are combined to form full addresses.
Finally, the Puppet VM is stopped and all settings made on the router are reverted. The resulting address list is returned as the result of the primitive.
The primitive introduce in this step can then be used to implement a fully fledged crawler, for example, using Breadth first search (BFS) or Depth first search (DFS) (Rossow et al., 2013), or more advance algorithms such as the Less Invasive Crawling Algorithm (LICA) (Karuppayah et al., 2014). PinPuppet implements a BFS crawler using this primitive.
4.3. Monitoring Live Botnets
When running PinPuppet with a live botnet on the Internet, additional measures need to be taken to ensure that the Puppet employed by PinPuppet does not contribute to the malicious activity of a botnet. This is especially relevant in the trace data collection step (cf. Section 4.2.2) where the Puppet is left running for a longer duration. In these cases we suggest measures like blocking relevant ports (e.g., SMTP), significantly limiting the available bandwidth to reduce the possible participation in DDoS attacks, and reducing the time . When using the crawling primitive (cf. Section 4.2.5), the problem is still relevant, however, the problem is reduced as the sample is only running for shorter periods of time before being reset. In addition, the router configuration in the primitive prevents any access to peers except the one being crawled. Overall, before using PinPuppet to monitor a live botnet on the Internet, a botnet should be studied thoroughly to ensure proper containment mechanisms are set up.
5. Evaluation
In the evaluation, we want to answer the question of whether PinPuppet is able to leverage POIs to crawl P2P botnets. For this, we will analyze multiple aspects of our PinPuppet implementation using multiple tailored analysis packages for several botnets. For each of these botnets we have a local botnet set up to provide real-world MM-communications.
For the foundation, we want to analyze whether the execution overhead introduced by PinPuppet affects the sample’s speed. This is important, as too high of an overhead can lead to the sample crashing or altering it behavior, e.g., due to transmission timeouts.
The next part of our evaluation targets the number, category, and confidence score of POIs identified by PinPuppet. For our crawling primitive to work, we need to identify POIs that have a high quality, i.e., confidence score (cf. Section 3.4). Without high quality POIs, we would not be able to correctly extract peers in the crawling primitive. In addition, the more POIs PinPuppet identifies, the more information a reverse engineer has for future manual reverse engineering.
As we use the confidence score to predict the quality of an IP-POIs, it is important that the confidence score is a good estimator for this quality. The quality of a POI directly affects the quality of the IPs extracted by it. On the one hand, if the confidence score were to overestimate the quality, we would extract spurious IPs using the POIs. On the other hand, if the confidence score were to underestimate the quality, we would disregard good POIs and potentially miss IPs which we could have extracted using these POIs. Thus, we analyze how well of an estimator the confidence score is.
The last part of our evaluation focuses on the amount and types of extracted peers, i.e., on how effective PinPuppet is in crawling a botnet. This is a crucial aspect, as the ability to crawl a botnet, would also indirectly validate the methodology for POIs identification and prove their usefulness as beacons for reverse engineering.
5.1. Evaluation Set
For the evaluation of PinPuppet and POIs we decided not to rely on live botnets, as we needed a reproducible environment. Instead we bootstrapped botnets – using real-world malware samples – locally, i.e., isolated from the Internet. For the identification of POIs, this has no negative impact, because the bot will not realize that it is only talking to a local botnet. Thus it behaves the same and uses the same instructions as if it were talking to a real botnet.
Our used approach is similar to the one used by Calvet et al. for creating an in-the-lab Waledac botnet (Calvet et al., 2010). However, their approach includes many aspects of a botnet, such as the C2, and thus requires significant reverse engineering efforts. Our approach, in contrast, is more general and focuses on the MM-mechanism and -protocol. It thus needs less reverse engineering, requiring only the bootstrap list as prior knowledge of a sample. Our process for bootstrapping such a local botnet with peers (denoted by the set ) is as follows:
-
(1)
Create -VMs with IPs from the bootstrap list and run the sample on the VMs. We call these peers the “local bootstrap peers.”
-
(2)
Wait for the local bootstrap peers to establish a local botnet. In case of , one needs to wait for the peer to be fully initialized.
-
(3)
Create -VMs with arbitrary public IP addresses. These peers will contact the local bootstrap peers and join the botnet overlay network.
After this process, we use live snapshots to store the state of the botnet and, later on, restore the state when running PinPuppet.
For the evaluation, we use four botnets: ZeroAccess (Neville and Gibb, 2013; Karuppayah, 2018), Sality (Karuppayah, 2018), Nugache (Stover et al., 2007) , and Kelihos (Kerkers et al., 2014).
For Nugache, we have local bootstrap peers and other peers. For the other botnets we have local bootstrap peer and other peers. The hashes for the samples used are given in the Appendix A. ZeroAccess and Sality utilize UDP. Nugache and Kelihos utilize TCP.
The Nugache local botnet requires eight local bootstrap peers, as every peer has at most 15 active connections (Stover et al., 2007). Thus, only having one local bootstrap peer is not enough. Not all peers who join the overlay receive new local peers.
Sality does not use a fixed port and, instead, uses ports which depend on the computer name (Karuppayah, 2018). To make our Sality local botnet more realistic, all peers in the local botnet have unique computer names. In addition, we have added NAT rules to set the correct port for MM-traffic being sent to the local bootstrap peer.
As additional data for PinPuppet we have identified the bootstrap list for each botnet (cf. Section 4). For ZeroAccess our identified bootstrap list contains 256 peers, for Sality 740, for Nugache 24, and for Kelihos 316. The exact configuration, i.e., the analysis package, used for each botnet and PinPuppet is available in our Git repository111111The git repository will be made available for the camera-ready version of this paper..
5.2. Experiments and Results
In the following, we will present our evaluation results and an analysis. In the analysis, we will cover the aspects mentioned in Section 5, namely, that one can use PinPuppet and POIs to crawl a P2P botnet. The results were gathered by running PinPuppet for the evaluation set (cf. Section 5.1) while having access to the corresponding local botnet.
5.2.1. How does the execution overhead introduced by PinPuppet affects the sample’s speed?
For analyzing the overhead, we run each sample five times with and five times without Pin attached to it. As metric we use the execution time with and without PinPuppet for the points , , and . At the sample is started. , , and are the times where the sample sends out the first, 20th, and 40th message, respectively.
As expected, the differences between and or and with and without PinPuppet are minimal. The largest average difference measured for these metric is a 6.5% increase for the duration from to for Sality. Botnet malware are not necessarily designed as time-critical applications. Especially after the initialization when the botnet sample is contacting peers from its neighbor list, i.e., after , the overhead is minimal as this phase involves a lot of waiting on the samples side. Additionally, our filtering mechanisms (cf. Section 4.2.2) limit the number of instrumented instructions and thus reduce the overall overhead.
In the duration until contacting the first peer, i.e., until , we have observed that PinPuppet incurs a significant runtime overhead. The most extreme example is Sality that, coupled with PinPuppet, reaches at and at without PinPuppet. We speculate that this is due to the complex unpacking process happening in this first interval, and, depending on the trace filter settings, the instructions for this unpacking are being traced, introducing the overhead. The full table with our results can be seen in Appendix C.
5.2.2. How many and which POIs are identified by PinPuppet and what is their respective confidence score?

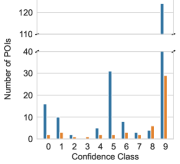
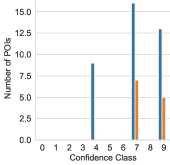
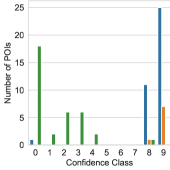
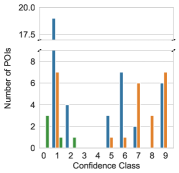
The distribution of POIs identified by PinPuppet for each botnet in the evaluation set can be seen in Figure 4. The confidence class in the plot refers to the confidence score of the POIs. A POI with the confidence score is in the confidence class when , e.g., for x is in the range . Because the confidence score is not used for filtering the port-POIs (cf. Section 4.2.3), the plots only contain the data for IP-POIs.
The first observation is that, as expected, Standalone-POIs, i.e., the types “Register (Standalone)” and “Memory (Standalone)”, are identified for all botnets. For each botnet, both register and memory POIs are found with high confidence scores, i.e., a confidence class of eight or nine.
In contrast, Contiguous-POIs were only identified for Kelihos and Nugache. For ZeroAccess and Sality, this is due to them storing IPs internally in a binary format.
Nugache, in contrast, stores its peer list in the registry. For each neighbor, the entry HKCU\Software\GNU\Data\{ip} is created, where {ip} is the decimal ASCII representation of the IP for the respective peer. Thus, it handles the decimal ASCII representation and PinPuppet identifies Contiguous-POIs. For Kelihos, we were not able to identify the reason for the Contiguous-POIs being found. As a sanity check we further investigated the Contiguous-POIs utilizing our IDA and Ghidra plugins. We were able to determine that two of Kelihos’s Contiguous-POIs, the ones with the lowest confidence score, are part of a memcpy function. This makes sense, as a memcpy function is a general purpose memory copying function. I.e., it copies values for various unrelated contexts and not only the one we are interested in.
Compared to Standalone-POIs, only very few Contiguous-POIs with a high confidence score are found. This is due to the fact that the concept and definition of confidence scores is not as robust for Contiguous-POIs as it is for Standalone-POIs. Whereas Standalone-POIs represent an atomic operation, e.g., a register contains data from the data set or an instruction writes data from the data set, Contiguous-POIs represent a multi step process. Contiguous-POIs do reference an instruction using its address, however, patterns are (usually) not satisfied by executing the instruction once. Depending on the implementation and the compiler, other instructions or repeated execution of an instruction might be required to, for example, write an IP address. Both of these problems mean that a definition like with Standalone-POIs is not possible. Instead, the definition from Section 3.3.2 relies on the number of pattern bytes written which can be skewed by, for example, the malware zeroing memory first. All this leads to the fact that the extraction of data from Contiguous-POIs is limited. The task is basically to extract an unknown pattern from one or more instructions. The challenge here is to determine when an unknown pattern is complete. This can be done for patterns with fixed length or which follow a strict scheme, e.g. ending with a 0 byte. Both is not given for IPs and ports. Therefore, PinPuppet does not utilize Contiguous-POIs for extracting peers and instead outputs them for further reverse engineering, the confidence score is less important. For PinPuppet, i.e., peer extraction, the confidence score plays a central part in ensuring that the extracted peers are correct. For reverse engineering, even finding a pattern is useful (cf. Section 3.4).
5.2.3. How well does the confidence score predict the quality of extracted IPs for IP-POIs?
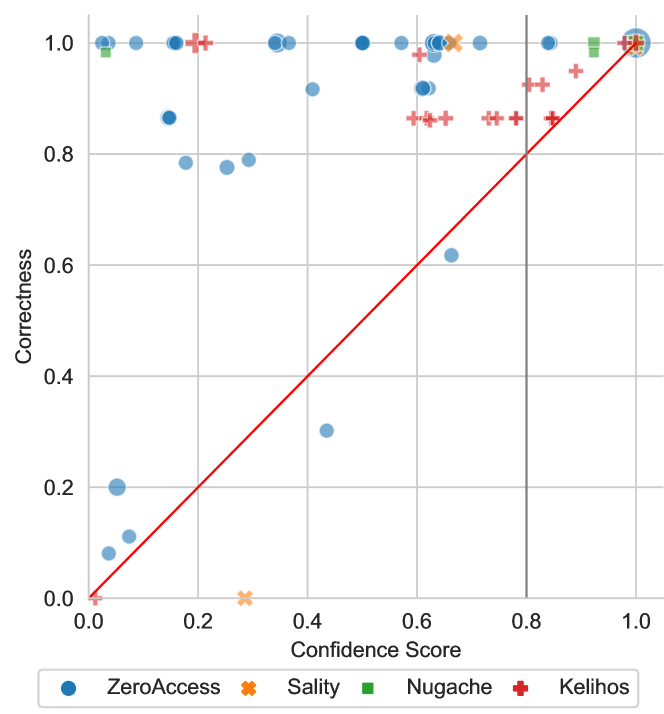
To better quantify the quality of the results extracted by a POIs, we introduce the correctness metric. For this we are using the previously introduced notation of that is the set of all extracted peers, are all peers in the local botnet, and are all peers on the samples bootstrap list. It is important to note that, due to the local bootstrap peers in our local botnet, . A peer is seen as correct if and only if it is in the set , i.e., all peers that a bot in our local system could know. The correctness for a POI is then defined as
An analysis of the data for all botnets and all POIs can be seen in Figure 5. When multiple POIs of a botnet have the exact same confidence score and , they are merged and the size of the corresponding dot increases by one. The red line is the identity line () and the bold, gray, vertical line indicates our confidence score threshold of 0.8. We have determined this confidence score threshold in a parameter study (see Appendix B for the results). Our confidence score threshold needs to be below 1.0, as our data sets for searching for POIs is not complete. As mentioned in Section 4.2.3, a complete data set would contain all peers from , however, we only know .
The correctness, as it is defined here, can only be calculated when is known, i.e., with a real-world botnet, the correctness would be unknown. The goal for the confidence score is thus to estimate the correctness and, most importantly, not overestimate it. For example, if a POI with a confidence score of 0.9 has a correctness of 0.2, this would mean that a lot of spurious peers were extracted even though the confidence score did not indicate this fact. For Figure 5 this means that the POIs should be above the red line. As one can see, this is mostly the case. There are only very few POIs below the red line, however, compared to the total number of POIs this is negligible. In particular, all POIs with a confidence score greater than 0.8 (to the right of the green line) are above the red line, i.e., are not overestimated.
Underestimation is expected because our data set is, as explained in Section 4.2.3, not necessarily complete. This can be seen in the scatter plot with POIs being significantly above the red line.
5.2.4. How effective is PinPuppet in crawling a botnet?
| Without confidence score threshold | With confidence score threshold () | |||||
|---|---|---|---|---|---|---|
| Average Value () | Average confidence score | Average Value () | Average confidence score | |||
| ZeroAccess | () | ( ) | () | ( ) | ||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | n/a | |||
| Sality | () | ( ) | () | ( ) | ||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| Nugache | () | ( ) | () | ( ) | ||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| Kelihos | () | ( ) | () | ( ) | ||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
| () | ( ) | () | ( ) | |||
For this part of the evaluation, we are analyzing the types of peers extracted by the crawling primitive. To gather data, the crawling primitive was used to crawl random peers from repeatedly (100 peers in total). We do not use a full crawler implementation to make sure that we only evaluate the shared peer extraction instead of the crawling algorithm, i.e., DFS.
To classify the extracted peers, we define three categories: CORRECT, WRONG, and BOOTSTRAP. The first category is . It contains all extracted peers that are in our local botnet and thus correctly extracted by PinPuppet. The second category is . It contains all extracted peers that are not in our local botnet, but that are still on the bootstrap list. The third category is . It contains all extracted peers except for the ones that are on the bootstrap list or in our local botnet. Those peers are incorrect, because the botnet could not have known about any of these peers as all bots in our local system know at most the bootstrap list and the local peers.
Number of peers extracted peer category and botnet are given in Table 1. The results are split up between “Without confidence score threshold”, i.e., by using all identified POIs, and “With confidence score threshold”, i.e., removing results from POIs with a confidence score below . In addition, we show the average confidence score used by the POIs to extract the results of this category. For the sake of simplicity, the term ”correct” is used in the following if a peer falls into the CORRECT category. This applies analogously to wrong peers and bootstrap peers.
First and most importantly, each crawl cycle extracts correct peers. This is important to note as it shows that the extraction is working. Of course, the more peers that are extracted per crawl cycle, the better a crawler works. However, the maximum number of correct peers that can be extracted per crawl cycle is dependent on the MM-protocol and -mechanism used by the botnet.
Secondly, one can see that applying the confidence score threshold decreases . For ZeroAccess, this results in no wrong peers. For Sality, the number of wrong peers is almost zero. However, sometimes a wrong peer is extracted by a POI with a high confidence score. This is not a problem, as it only happens very rarely (in this case three times). For Nugache, exactly one wrong peer remains and looking at the data, the wrong peer is always the same. This can indicate that our bootstrap list is incomplete (which results in this wrong classification) or that this is a value that only appear once, e.g., in an initialization phase. While for Kelihos the confidence score threshold removes a lot of wrong peers, a consistent set of 32 wrong peers remains. Our assumption is that it is a kind of secondary peer list, which is only contacted in certain circumstances. This is supported by the fact that it is always exactly the same 32 peers and 26 of the 32 IPs have already occurred in connection with Kelihos 121212https://pastebin.com/9euC4K9N, however, we were not able to validate the source.
Looking at the average confidence score, the results are mostly as we have expected. Our expectation was that the average confidence score for and for would be greater than the one for . This is mostly the case with the only exception being Sality after applying the confidence score threshold and Kelihos. For Kelihos, we attribute this to the fact that our estimation of the bootstrap list is probably incomplete. For Sality, the reason is the aforementioned peer that is infrequently extracted by a high confidence score POIs.
Two additional interesting observation are that for Sality and Kelihos, a big part of the bootstrap list is extracted each crawl cycle, and that Kelihos extracts almost all local peers each crawl cycle ( compared to ). For Sality but due to the fact that , we get that is the maximum amount possible for this metric.
Based on the results outlined above, we can conclude that extracting shared peers from a running malware sample is possible using PinPuppet. Thus, one can use this crawling primitive to develop a fully fledged crawler, for example, utilizing algorithms such as BFS or DFS (Rossow et al., 2013), or more advance algorithms such as the LICA (Karuppayah et al., 2014).
6. Related Work
In this section, we discuss the related work that are relevant to our work. Starting with reverse engineering techniques and tools, up to methods for automated monitoring of botnets.
Reverse-engineering
IDA and Ghidra are both sophisticated reverse-engineering suites. They give the user many beacons in the code. This goes from basic block representations to the identification of single functions, cross references, resolving of strings, debugger support, and pseudo C code generation. Furthermore, both IDA and Ghidra have a features that automatically identify known functions, even within a binary stripped from symbols and names 131313https://www.hex-rays.com/products/ida/tech/flirt/in_depth/. Both tools are designed as manual reverse-engineering tools, but are also platforms to develop custom tools. To the best of our knowledge none if them utilize a POI style beacons. However, they would benefit from an implementation of POIs.
PANDA (Dolan-Gavitt et al., 2015)141414https://github.com/panda-re/panda is a platform dedicated to dynamic analysis based on QEMU. It stands out because it it allows to record and accurately replay a whole system execution with all running processes. This allows the reproducible analysis and execution of samples. PANDA can not be used for monitoring a botnet because the sample being analyzed is only communicating with the outside world when recording the system. In particular, PANDA cannot be used to resume after a recording or modify the execution of an existing recording151515https://github.com/panda-re/panda/blob/master/panda/docs/manual.md.
Taint analysis is used to mark certain data to trace the data flow in a binary from data sources, like user input, to sinks where the input is used, e.g., in SQL statements. Taint analysis can, for example, be used to determine where a user input is being processed. This way, possible SQL injections and XSS can be detected automatically (Nguyen-Tuong et al., 2005). The main difference to the POIs is that taint analysis marks all instructions that interact with (parts of) the data from one origin (source). These markers can be a kind of beacon for the reverse-engineer (Biondi et al., 2017)161616https://github.com/airbus-seclab/bincat. The POI approach in contrast finds and scores individual instructions that access the data . Furthermore, no sources need to be defined as with taint analysis, but only the relevant data.
Automated P2P Botnet Monitoring
A honeypot may be an alternative for collecting peers of a botnet. The honeypot runs the malware sample and records the IPs of outgoing and incoming messages. As the peer running in the honeypot is integrated into the botnet’s overlay network, botnet peers start communicating with the local peer. This serves as a kind of passive peer enumeration, however, compared to active crawling, this method is inherently slower and less directed.
7. Conclusion
The reverse-engineering of malware is a crucial and labor-intensive task. In this paper, we introduce a new method to guide reverse-engineers in analyzing malware via Point-of-Interest beacons. These POIs are instructions that process data in which an analyst is interested. We introduce a method to identify them automatically and rate them based on how often a POI is used by the binary to access relevant data.
We demonstrate the usage of our method by applying it to monitor P2P botnets to show that POIs can be used for advanced, malware analysis without prior reverse engineering.. Using our PinPuppet prototype, we demonstrate how both the identification and the scoring of POIs works. Our evaluation indicates that we could successfully leverage PinPuppet to crawl four different botnets. Utilizing our scoring mechanism we were able to significantly reduce the number of falsely extracted peers in our crawling primitive.
As future work, we would like to further investigate on automating our PinPuppet by integrating it to a sandbox, so that all required information such as IPs are obtained automatically. In addition, we would also like to explore extending our PinPuppet and POI approaches on botnets with destination-dependent payloads.
References
- (1)
- Babil et al. (2013) Golam Sarwar Babil, Olivier Mehani, Roksana Boreli, and Mohamed-Ali Kaafar. 2013. On the effectiveness of dynamic taint analysis for protecting against private information leaks on Android-based devices. In 2013 International Conference on Security and Cryptography (SECRYPT). 1–8.
- Banescu et al. (2016) Sebastian Banescu, Christian Collberg, Vijay Ganesh, Zack Newsham, and Alexander Pretschner. 2016. Code obfuscation against symbolic execution attacks. In Proceedings of the 32nd Annual Conference on Computer Security Applications. 189–200.
- Biondi et al. (2017) Philippe Biondi, Raphaël Rigo, Sarah Zennou, and Xavier Mehrenberger. 2017. BinCAT: purrfecting binary static analysis. In Symposium sur la sécurité des technologies de l’information et des communications.
- Bruening et al. (2012) Derek Bruening, Qin Zhao, and Saman Amarasinghe. 2012. Transparent dynamic instrumentation. In Proceedings of the 8th ACM SIGPLAN/SIGOPS conference on Virtual Execution Environments. 133–144.
- Calvet et al. (2010) Joan Calvet, Carlton R. Davis, Jose M. Fernandez, Jean-Yves Marion, Pier-Luc St-Onge, Wadie Guizani, Pierre-Marc Bureau, and Anil Somayaji. 2010. The case for in-the-lab botnet experimentation: creating and taking down a 3000-node botnet. In Proceedings of the 26th Annual Computer Security Applications Conference. 141–150.
- Cavallaro et al. (2007) Lorenzo Cavallaro, Prateek Saxena, and R Sekar. 2007. Anti-taint-analysis: Practical evasion techniques against information flow based malware defense. Secure Systems Lab at Stony Brook University, Tech. Rep (2007), 1–18.
- Chen et al. (2008) Xu Chen, Jon Andersen, Z Morley Mao, Michael Bailey, and Jose Nazario. 2008. Towards an understanding of anti-virtualization and anti-debugging behavior in modern malware. In 2008 IEEE international conference on dependable systems and networks with FTCS and DCC (DSN). IEEE, 177–186.
- Clause et al. (2007) James Clause, Wanchun Li, and Alessandro Orso. 2007. Dytan: a generic dynamic taint analysis framework. In Proceedings of the 2007 international symposium on Software testing and analysis. 196–206.
- D’Elia et al. (2019) Daniele Cono D’Elia, Emilio Coppa, Simone Nicchi, Federico Palmaro, and Lorenzo Cavallaro. 2019. SoK: Using Dynamic Binary Instrumentation for Security (And How You May Get Caught Red Handed). In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security (Asia CCS ’19). Association for Computing Machinery, New York, NY, USA, 15–27.
- Dolan-Gavitt et al. (2015) Brendan Dolan-Gavitt, Josh Hodosh, Patrick Hulin, Tim Leek, and Ryan Whelan. 2015. Repeatable reverse engineering with PANDA. In Proceedings of the 5th Program Protection and Reverse Engineering Workshop. 1–11.
- Eilam (2011) Eldad Eilam. 2011. Reversing: secrets of reverse engineering. John Wiley & Sons.
- Gorgovan (2016) Cosmin Gorgovan. 2016. Escaping DynamoRIO and Pin. Retrieved May 6, 2021 from https://github.com/lgeek/dynamorio_pin_escape
- Karuppayah (2018) Shankar Karuppayah. 2018. Advanced Monitoring in P2P Botnets: A Dual Perspective. Springer.
- Karuppayah et al. (2014) Shankar Karuppayah, Mathias Fischer, Christian Rossow, and Max Mühlhäuser. 2014. On Advanced Monitoring in Resilient and Unstructured P2P Botnets. In 2014 IEEE International Conference on Communications (ICC). 871–877.
- Kerkers et al. (2014) Max Kerkers, José Jair Santanna, and Anna Sperotto. 2014. Characterisation of the kelihos. b botnet. In IFIP International Conference on Autonomous Infrastructure, Management and Security. Springer, 79–91.
- Kirsch et al. (2018) Julian Kirsch, Zhechko Zhechev, Bruno Bierbaumer, and Thomas Kittel. 2018. PwIN – Pwning Intel piN: Why DBI Is Unsuitable for Security Applications. In Computer Security (Lecture Notes in Computer Science), Javier Lopez, Jianying Zhou, and Miguel Soriano (Eds.). Springer International Publishing, Cham, 363–382.
- Lin et al. (2010) Zhiqiang Lin, Xiangyu Zhang, and Dongyan Xu. 2010. Automatic reverse engineering of data structures from binary execution. In Proceedings of the 11th Annual Information Security Symposium.
- Luk et al. (2005) Chi-Keung Luk, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser, Geoff Lowney, Steven Wallace, Vijay Janapa Reddi, and Kim Hazelwood. 2005. Pin: building customized program analysis tools with dynamic instrumentation. Acm sigplan notices 40, 6 (2005), 190–200.
- Neville and Gibb (2013) Alan Neville and Ross Gibb. 2013. ZeroAccess Indepth. Symantec Security Response (2013).
- Newsome et al. (2006) James Newsome, David Brumley, Jason Franklin, and Dawn Song. 2006. Replayer: Automatic protocol replay by binary analysis. In Proceedings of the 13th ACM conference on Computer and communications security. 311–321.
- Nguyen-Tuong et al. (2005) Anh Nguyen-Tuong, Salvatore Guarnieri, Doug Greene, Jeff Shirley, and David Evans. 2005. Automatically hardening web applications using precise tainting. In IFIP International Information Security Conference. Springer, 295–307.
- Or-Meir et al. (2019) Ori Or-Meir, Nir Nissim, Yuval Elovici, and Lior Rokach. 2019. Dynamic Malware Analysis in the Modern Era—A State of the Art Survey. ACM Computing Surveys (CSUR) 52, 5, Article 88 (Sept. 2019), 48 pages.
- Rossow et al. (2013) Christian Rossow, Dennis Andriesse, Tillmann Werner, Brett Stone-Gross, Daniel Plohmann, Christian J. Dietrich, and Herbert Bos. 2013. SoK: P2PWNED - Modeling and Evaluating the Resilience of Peer-to-Peer Botnets. In 2013 IEEE Symposium on Security and Privacy. 97–111.
- Stover et al. (2007) S. Stover, D. Dittrich, John Hernandez, and S. Dietrich. 2007. Analysis of the Storm and Nugache Trojans: P2P Is Here. login Usenix Mag. 32 (2007).
- Symantec (2019) Symantec. 2019. Internet Security Threat Report 2019. https://docs.broadcom.com/doc/istr-24-2019-en.
- Votipka et al. (2019) Daniel Votipka, Seth M. Rabin, Kristopher Micinski, Jeffrey S. Foster, and Michelle L. Mazurek. 2019. An Observational Investigation of Reverse Engineers’ Processes. arXiv:1912.00317 [cs] (Nov. 2019).
- Yan et al. (2008) Wei Yan, Zheng Zhang, and Nirwan Ansari. 2008. Revealing Packed Malware. IEEE Security Privacy 6, 5 (2008), 65–69.
- You and Yim (2010) Ilsun You and Kangbin Yim. 2010. Malware Obfuscation Techniques: A Brief Survey. Proceedings - 2010 International Conference on Broadband, Wireless Computing Communication and Applications, BWCCA 2010, 297–300.
| Botnet | SHA-256 | MD5 |
|---|---|---|
| ZeroAccess | 69e966e730557fde8fd84317cdef1ece00a8bb3470c0b58f3231e170168af169 | ea039a854d20d7734c5add48f1a51c34 |
| Sality | 0b283b3ee065c2a1a5d9b5fef691be7b70cf5c5f1371f5a6653ec35a998602a0 | d35cf3c2335666ac0be74f93c5f5172f |
| Nugache | fcb69486e3f4745d90a26446ec07925eb2f1f8812a3a676495d72cd1a9951f68 | 0c859cfad2fa154f007042a1dca8d75b |
| Kelihos | b71a4a57d21742797ec9079c745e2f884cb9379717069189bf0839078b0e2c62 | 9b68b45afa269ba1b0c01749fa4b942f |
Appendix A Hashes of malware Samples used for the Evaluation
Table 2 contains the SHA256 and MD-5 hashes of the samples used in our evaluation.
Appendix B Confidence Score Threshold Parameter Study
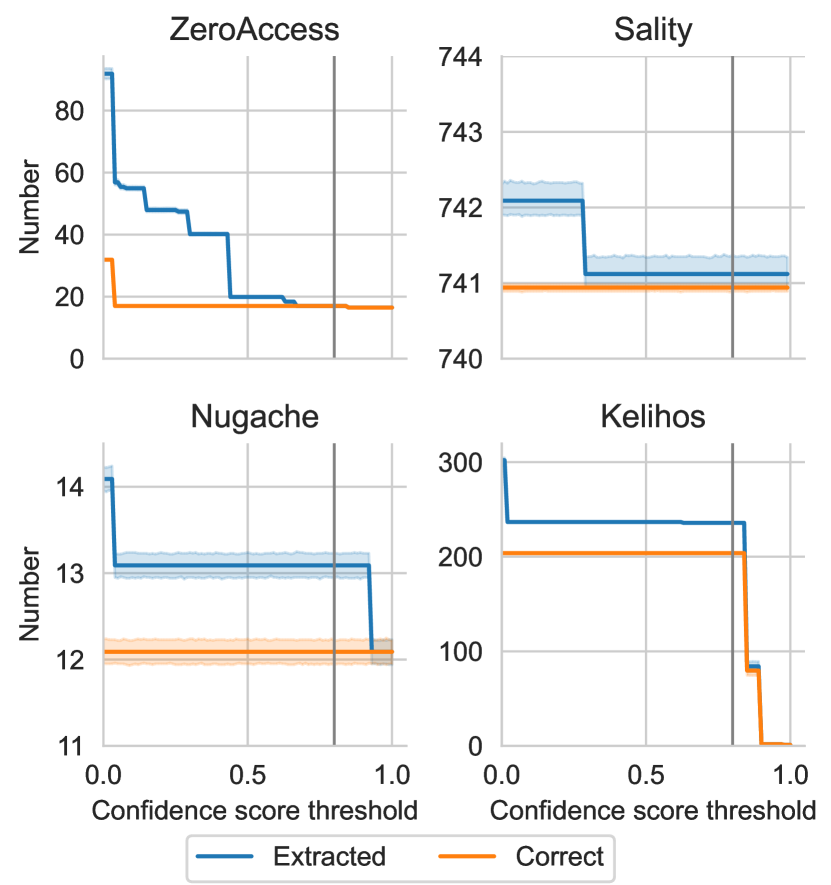
The confidence score threshold needs to be carefully chosen to find the balance between a) wrong peers being extracted and b) how many peers are extracted. We have analyzed these metrics in Figure 6 and have determined 0.8 as the threshold (marked with a gray line). As can be seen in the plot, strikes a good balance between the number of wrong extracted peers, i.e., the distance between the upper and the lower lines, and the total number of extracted peers. , for example, would not have been suitable as then, Kelihos only extracts very few peers.
Appendix C Overhead Measurement Results
Table 3 contains our raw measurement data of the overhead introduced by using Pin to trace a sample. For each botnet, the measurement was repeated times. The evaluation in Section 5.2.1 is based on that data.
| Without puppeteering | With puppeteering | ||||||
|---|---|---|---|---|---|---|---|
| ZeroAccess | () | () | () | () | () | () | |
| Sality | () | () | () | () | () | () | |
| Nugache | () | () | () | () | () | () | |
| Kelihos | () | () | () | () | () | () | |


Appendix D IDA and Ghidra Plugins for Importing and Displaying POIs
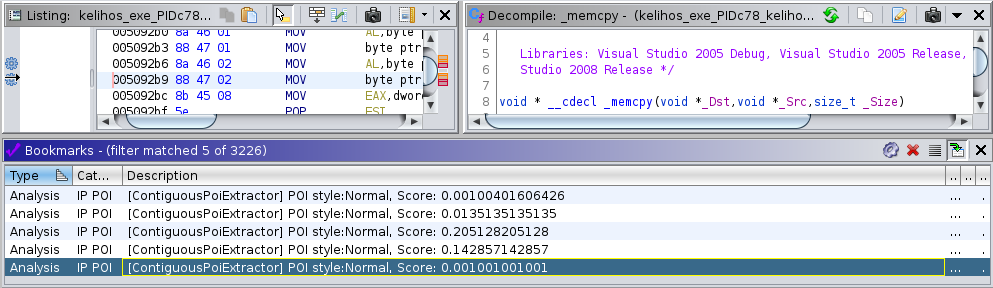
It is important that the image loaded in IDA is aligned with the one from which the POIs have been extracted. The IDA plugin is a python script which is read by IDA. Via the menu file-¿Script File…, this script can be selected. Afterwards a dialog box appears which allows the selection of a JavaScript Object Notation (JSON) file where the exported POIs are stored. These POIs are then imported into IDA as disabled breakpoints. They are then visible as an overview in the breakpoint view and also in the disassembler view (see Figure 7).
For Ghidra, the plugin is also implemented in Python. After enabling the Plugin in the script manager, it can be activated in the toolbar. Like with IDA, one is presented with a dialog box where one needs to select the POIs JSON file. Afterwards, the POIs show up as bookmarks in the disassembled code (see Figure 8).