MambaNUT: Nighttime UAV Tracking via Mamba and Adaptive Curriculum Learning
Abstract
Harnessing low-light enhancement and domain adaptation, nighttime UAV tracking has made substantial strides. However, over-reliance on image enhancement, scarcity of high-quality nighttime data, and neglecting the relationship between daytime and nighttime trackers, which hinders the development of an end-to-end trainable framework. Moreover, current CNN-based trackers have limited receptive fields, leading to suboptimal performance, while ViT-based trackers demand heavy computational resources due to their reliance on the self-attention mechanism. In this paper, we propose a novel pure Mamba-based tracking framework (MambaNUT) that employs a state space model with linear complexity as its backbone, incorporating a single-stream architecture that integrates feature learning and template-search coupling within Vision Mamba. We introduce an adaptive curriculum learning (ACL) approach that dynamically adjusts sampling strategies and loss weights, thereby improving the model’s ability of generalization. Our ACL is composed of two levels of curriculum schedulers: (1) sampling scheduler that transforms the data distribution from imbalanced to balanced, as well as from easier (daytime) to harder (nighttime) samples; (2) loss scheduler that dynamically assigns weights based on data frequency and the IOU. Exhaustive experiments on multiple nighttime UAV tracking benchmarks demonstrate that the proposed MambaNUT achieves state-of-the-art performance while requiring lower computational costs. The code will be available.
1 Introduction
00footnotetext: Corresponding Author: Shuiwang Li.Unmanned aerial vehicles (UAV) tracking has emerged as a significant research area in robot vision, with various real-world applications, including navigation [58], traffic monitoring [53], and autonomous landing [16]. While significant advancements utilizing deep neural networks [31, 24, 9] and large-scale datasets [10, 25, 47] have led to promising tracking performance in well-illuminated scenarios, existing state-of-the-art (SOTA) UAV trackers [38, 40, 37] still struggle in more challenging nighttime environments. Specially, when trackers work under the challenging nighttime conditions, where images captured by UAVs have significantly lower contrast, brightness, and signal-to-noise ratios [67] than those captured during the daytime, these approaches often experience a severe degradation in tracking performance. Therefore, it is essential to develop robust nighttime UAV trackers to enhance the versatility and survivability of UAV vision systems.
In recent years, many researchers are eager to use low-light image enhancement techniques for nighttime UAV tracking [66, 12, 65, 63]. For example, Fu et al. [12] propose a light enhancer called ”HighlightNet” designed to illuminate specific target areas for UAV trackers. To avoid excessive enhancement in scenarios with complex illumination, LDEnhancer [63] improves nighttime UAV tracking by suppressing light distribution. On the other hand, domain adaptation (DA) is introduced in nighttime UAV tracking, providing an effective solution to the challenges of domain discrepancy. UDAT [67] generate nighttime training samples and adversarially train a model for narrowing the gap between day and night circumstances. TDA-Track [13] proposes a prompt-driven temporal domain adaptation training framework to fully utilize temporal contexts for nighttime UAV tracking. Despite these advancements, current solutions for nighttime tracking continue to face substantial limitations. The development of an end-to-end trainable UAV vision system is hindered by over-reliance on image enhancement, limited availability of high-quality nighttime data, and an often-overlooked relationship between daytime and nighttime trackers. Current CNN-based trackers have limited receptive fields, leading to suboptimal performance, whereas ViT-based trackers demand substantial memory and computational resources due to their reliance on the self-attention mechanism. Additionally, in UAV tracking, the inconsistent feature distribution across consecutive frames hampers long-term object tracking, making long sequence modeling capabilities essential. Recently, the State Space Model has excelled in modeling long-range dependencies with linear complexity, leading to Mamba’s [17] success across visual tasks, particularly in long sequence modeling like video understanding [36, 61] and high-resolution medical image processing [59, 49]. These successful applications inspired us to adapt Mamba for nighttime UAV tracking, leveraging its long-sequence modeling capabilities to learn robust feature representations in low-illuminated scenarios while maintaining lower computational requirements for effective nighttime tracking. Hence, we propose a compact Mamba-based nighttime UAV tracking framework, termed MambaNUT, which adopts a one-stream architecture with a Vision Mamba backbone and a prediction head.
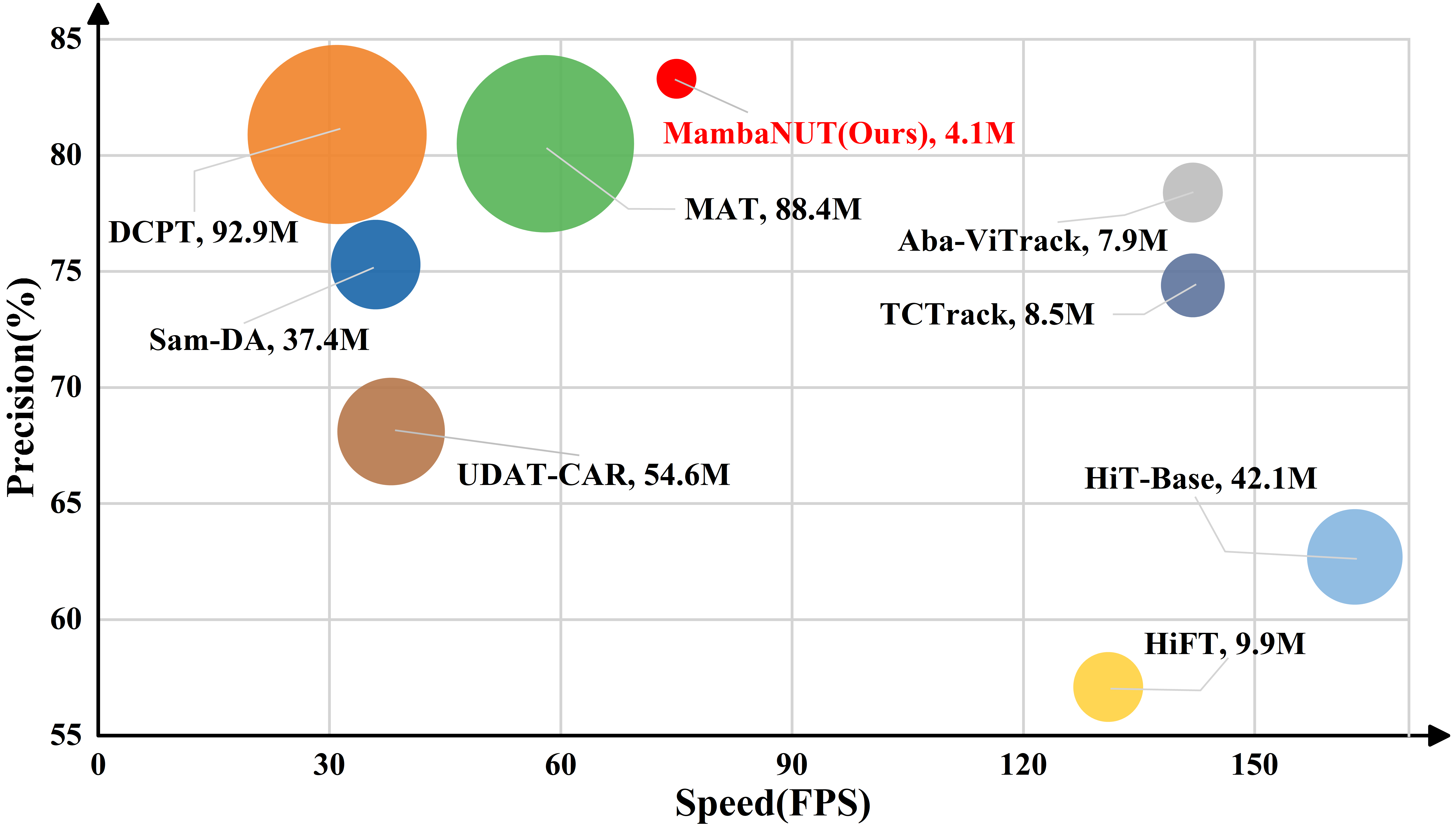
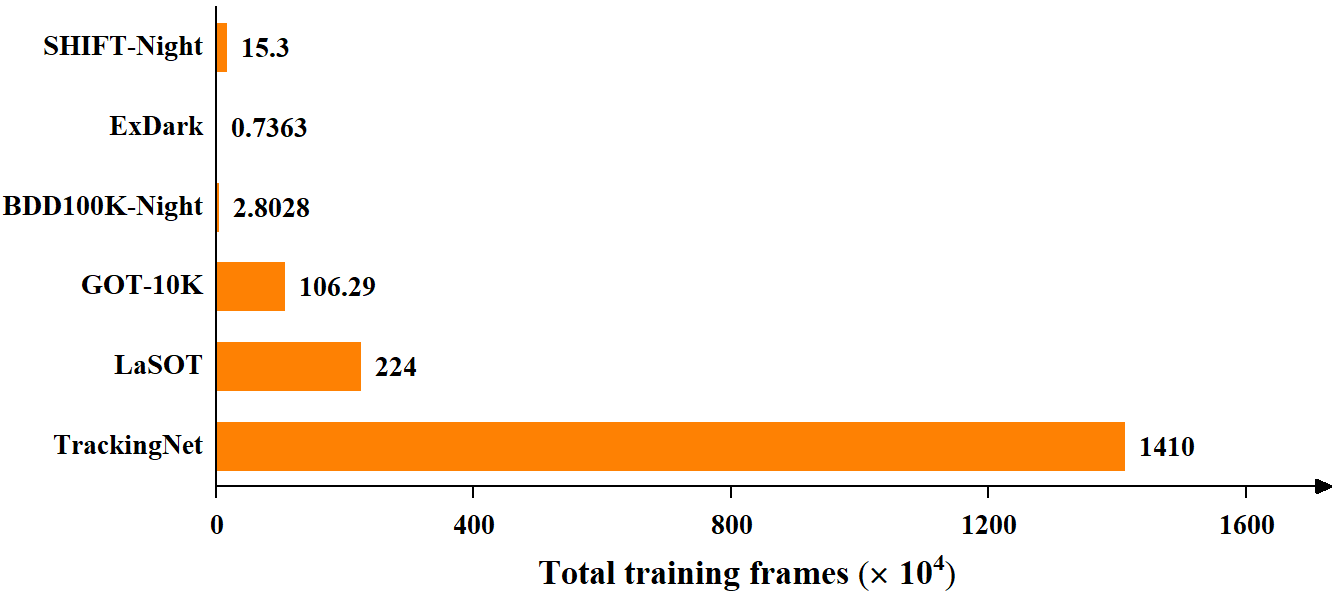
Additionally, class imbalance is an inherent problem in real-world object detection and classification, often causing algorithms to be biased toward the majority classes [30]. In visual tracking, there is a similar imbalance in data distribution between day and night, with more data available during the day. As shown in Fig. 2, compared to current large-scale datasets such as GOT-10K [25], LaSOT [10], and TrackingNet [47], which predominantly consist of daytime images with few or no nighttime images, labeled nighttime data (i.e., SHIFT-Night [52], ExDark [46], and BDD100K-Night [68]) remains relatively scarce. Addressing data imbalance is crucial in this context, as the minority (nighttime) data is the key focus of our work. Training the tracking model with equal weight for samples under varying light conditions may lead to bias toward the majority daytime data and reduced accuracy for the minority nighttime data. Two promising solutions to the imbalanced data learning challenge are resampling [23, 22, 21] and cost-sensitive learning [72, 30, 8]. However, oversampling can lead to overfitting from repeated minority samples, downsampling may discard valuable majority data, and cost-sensitive learning struggles with defining precise costs for samples across different distributions. Curriculum learning (CL) is the learning paradigm inspired by the way humans and animals learn, gradually progressing from easier to more complex samples during training [3, 26]. Inspired by CL, we introduce Adaptive Curriculum Learning (ACL) into our framework to address this issue, based on the following considerations. We aim for the model to first learn appropriate feature representations during the day to enhance its generalization ability, which will improve the learning of more robust feature representations at night. Hence, we propose a dynamic sampling strategy for assigning data weights that emphasizes hard instances, such as nighttime samples, and introduce a novel loss function called Adaptive Data Balance (ADB) Loss, which effectively addresses the data imbalance between daytime and nighttime while enhancing calibration performance. Extensive experiments substantiate the effectiveness of our method and demonstrate that our MambaNUT achieves state-of-the-art performance. As shown in Fig. 1, our method sets a new record with a precision of 83.3, running efficiently at around 75 frames per second (FPS) on the NAT2024-1 [13] and using only 4.1 million parameters, the lowest in comparison. The contributions of our work are summarized as follows:
-
•
We propose a novel Mamba-based tracking framework, termed MambaNUT, which utilizes a purely Mamba-based model for accurate and low-consumption tracking. To the best of our knowledge, this is the first Mamba-based tracking framework specifically designed for nighttime UAV tracking.
-
•
We introduce a simple yet effective Adaptive Curriculum Learning component to address the learning imbalance between daytime and nighttime data, featuring two curriculum schedulers: a dynamic sampling scheduler and a dynamically weighted loss scheduler.
-
•
Extensive experiments validate that our MambaNUT surpasses state-of-the-art methods on multiple nighttime tracking benchmarks while using fewer parameters and FLOPs.
2 Related work
Nighttime UAV Tracking. Real-world UAV tracking applications encounter considerable challenges in low-illumination nighttime scenarios, as generic trackers are primarily designed for daytime conditions. Recently, low-light enhancement and domain adaptation (DA) have emerged as the two primary methods for improving nighttime UAV tracking performance. In enhancement-based nighttime UAV tracking [66, 12, 65], numerous types of enhancers are proposed to improve image illumination prior to processing by the trackers. Specifically, Li et al. [34] integrate a low-light image enhancer into a CF-based tracker for robust nighttime tracking, while DarkLighter [66] and HighlightNet [12] also develop low-light enhancers to mitigate extreme illumination and emphasize potential objects. However, the limited relationship between low-light image enhancement and UAV tracking leads to suboptimal performance and increased computational costs when enhancers and trackers are integrated in a plug-and-play manner. For DA training-based nighttime UAV tracking [67, 14, 13], trackers utilize domain adaptation to transfer daytime tracking capabilities to nighttime scenarios. For instance, UDAT [67] proposes using a transformer-based bridging layer to align image features from daytime and nighttime domains, thereby transferring somewhat tracking capabilities to the nighttime domain. TDA-Track [13] introduces a novel temporal domain adaptation training framework for nighttime UAV tracking, making it the first to leverage temporal contexts in training nighttime UAV trackers. Unfortunately, DA-based methods incur higher training costs and are limited by the lack of high-quality target domain data for tracking. To build an end-to-end trainable vision system, DCPT [73] introduces a novel architecture that enables robust nighttime UAV tracking by efficiently generating darkness clue prompts without needing a separate enhancer. However, this enhanced tracker burdens resource-limited UAV platforms by adding even more parameters to an already substantial fully transformer-based base tracker, increasing computational resource requirements and hindering efficiency. In our work, we explore the adaptation of Vision Mamba for nighttime UAV tracking for the first time, leveraging its powerful long-sequence modeling capabilities while ensuring computational costs grow linearly for efficient and accurate tracking.
Vision Mamba Models. Unlike traditional structured State Space Models [18], Mamba employs an input-dependent selection mechanism and a hardware-aware parallel algorithm [17], enabling it to model long-range dependency linearly with sequence length. In the field of natural language processing (NLP), it exhibits comparable performance and better efficiency than Transformers in language modeling for long-sequence. Recently, Mamba’s linear complexity in long-range modeling has proven effective and superior across various visual tasks. In classification tasks, Vim [74] and VMamba [45] have shown outstanding performance by building on Mamba’s success, utilizing a bidirectional scanning mechanism and a four-way scanning mechanism, respectively. It also exhibits great potential in high-resolution image tasks, with many notable works proposed in medical image segmentation, including VM-UNet [49] and Swin-UMamba [44]. Subsequently, in the field of video, VideoMamba [36] offers a scalable and efficient solution for comprehensive video understanding, encompassing both short-term and long-term content. MambaTrack [57] explores a Mamba-based learning motion model for multiple object tracking (MOT). In our work, we propose a novel Mamba-based framework for nighttime UAV tracking that incorporates a Adaptive Curriculum Learning (ACL) component to adaptively optimize the sampling strategy and loss weight, enhancing generalization and discrimination in night tracking.
Curriculum learning. The concept of curriculum learning (CL), first proposed in [3], shows that the strategy of learning from easy to hard significantly enhances the generalization of deep models. While these approaches [1, 20, 29] improve convergence speed and local minima quality, pre-determining the order can create inconsistencies between the fixed curriculum and the model being learned. To address this, Kumar et al. [32] proposed the concept of self-paced learning, where the curriculum is constructed dynamically and without supervision to adjust to the learner’s pace. This seminal concept has inspired numerous variations across a range of computer vision applications, including classification [15, 55, 56], action recognition [54], and object [69, 50] / face detection [41, 60]. Despite its efficacy in these domains, the exploration of curriculum learning in the context of visual tracking remains limited. In contrast, our work is the first to explore the integration of Vision Mamba with curriculum learning in a unified framework for nighttime UAV tracking, introducing two levels of curriculum schedulers: one for dynamic sampling and another for dynamically weighted the loss function, where weights are assigned based on data frequency and the IoU.
3 Methodology
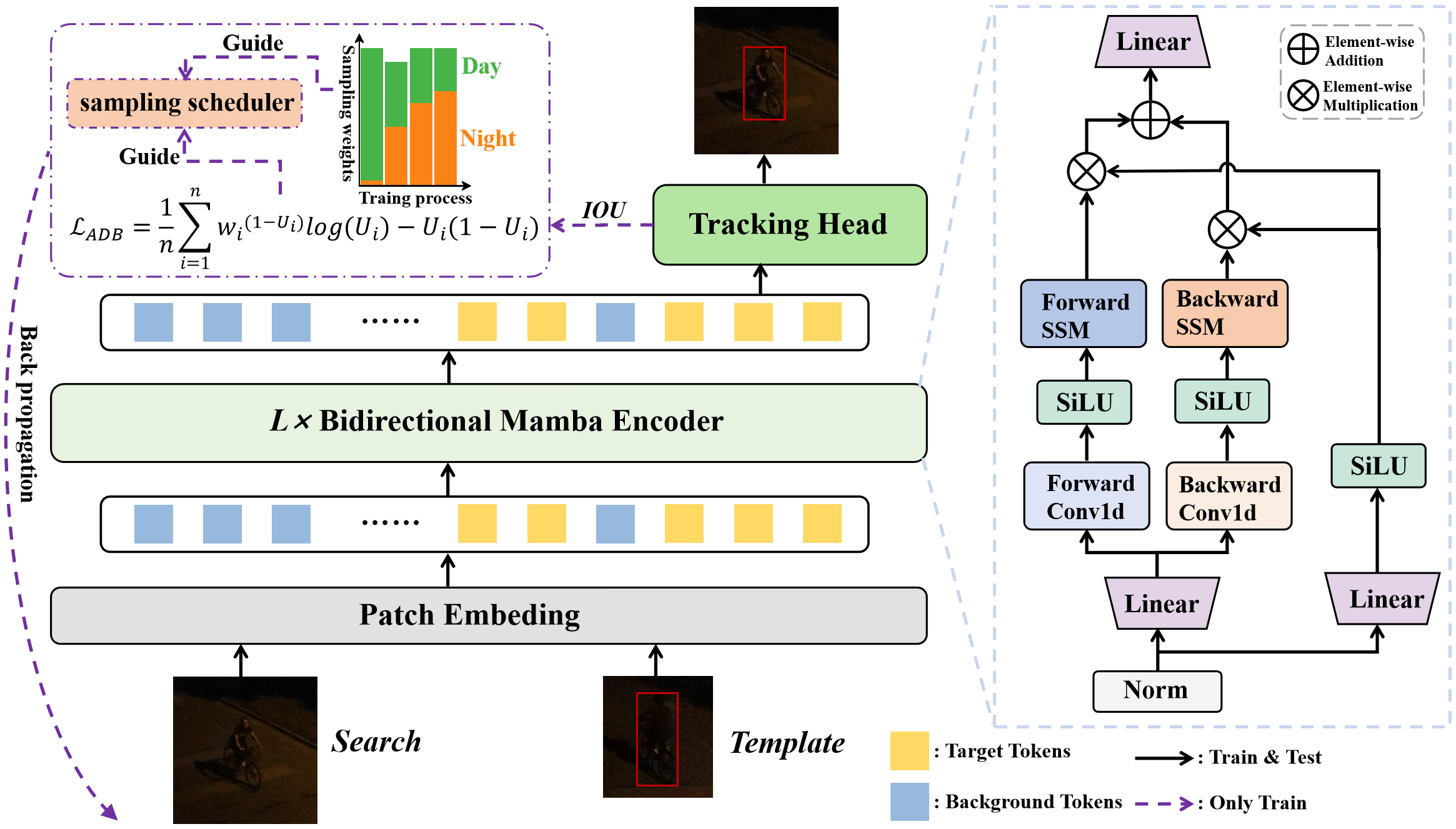
In this section, we detail the proposed end-to-end tracking framework, termed MambaNUT. First, we begin with the preliminary of state space models (SSM) and the Mamba. Then, we introduce the Adaptive Curriculum Learning (ACL) component for addressing imbalanced data learning problems, which include two-level curriculum schedulers: the sampling scheduler and the loss function scheduler. Last, the overall architecture of the proposed MambaNUT was described in detail, as shown in Fig. 3.
3.1 Preliminary
The raw State Space Model (SSM) is developed for the continuous system, whih is derived from the classical Kalman filter [27]. It maps the 1-dimensional sequence via a learnable hidden state . In the continuous state, the specific expression of SSM is formulated by a set of first-order following linear ordinary differential equations:
| (1) | ||||
where matrices represents the evolution parameters and , are the projection parameters.
The modern SSMs, i.e., S4 [18] and Mamba [17] are the discrete forms of this continuous state. By introducing the time scale parameter , the process of discretization is typically accomplished using a rule called zero-order hold (ZOH):
| (2) | ||||
where and are the discrete counterparts of parameters and . and denote the discrete hidden states at various time steps, respectively. Unlike traditional models that depend heavily on linear time-invariant state space models (SSMs), Mamba [17] improves the SSM by incorporating the Selective Scan Mechanism (S6) as its core operator. This is achieved by parameterizing the SSM parameters , and using linear projection based on the input .
3.2 Overview
As shown in Fig. 3, our proposed MambaNUT adopts a one-stream framework, which includes a Visison Mamba-based backbone and a tracking head. The framework takes a pair of images as input, namely the template image and the search image . These images are respectively split and flattened into patch sequences , and the number of patches for and are and . The features extracted from the Vision Mamba backbone are input into the prediction head to generate the final tracking results. To enhance the learning of robust feature representations from nighttime samples, we propose a Adaptive Curriculum Learning (ACL) component for the imbalanced data learning problem, which features two-level curriculum schedulers: (1) a sampling scheduler that transforms the data distribution from imbalanced to balanced, as well as from easier (daytime) to harder (nighttime) samples; (2) a data-dependent dynamically weighted loss function that assigns weights based on data frequency and the IOU. The details of the this component will be elaborated in the subsequent subsections.
3.3 Adaptive Curriculum Learning
Sampling is one of the simple and effective methods to deal with imbalanced data learning. Our sampling scheduler is a key element of the Adaptive Curriculum Learning (ACL) component, dynamically adapting the daytime and nighttime data distribution in a batch from imbalanced to balanced throughout the training process. During training, we assign equal sampling weights to all datasets within each epoch; however, for nighttime datasets, their weights are adjusted by dividing by a constant and multiplying by the epoch number, resulting in a smaller initial proportion of nighttime data that gradually increases as training advances. Given a dataset , its assigned sampling weight can be expressed as follows:
| (3) |
where refers to current training epoch, represents a constant, set to 150, which is half of the total training epochs. are the nighttime datasets. Then, the final sampling ratio for a given dataset among the combination of training sets is: , where denotes the number of training datasets. Usually, the model learns lots of easy (daytime) samples in early stage of the training process. Going further with the training process, the data distribution between daytime and nighttime is gradually getting balanced. During the training phase, the backpropagation algorithm updates the network’s parameters based on the errors computed by the loss function. Training the tracking model with equal weights for samples under varying lighting conditions leads to imbalanced adaptation, caused by the significant distribution disparity between daytime and nighttime, where nighttime images have lower contrast, brightness, and signal-to-noise ratio, causing the tracker to be biased toward daytime conditions. In our work, the minority nighttime samples are the key instances of interest in this learning task.
In view of this, we introduce an Adaptive Data Balanced (ADB) Loss that assigns weights based on the frequency of daytime/nighttime data and IoU, thereby dynamically focusing more on the challenging minority samples, i.e., the nighttime data. For convenience, let the between the predicted boxes and the ground truth be denoted as . Thus, is the of the instance . Inspired by [11], the proposed ADB is formulated as follows:
| (4) |
where is a hyperparameter determined based on the frequency of data. In the context of classification, is typically inversely proportional to the frequency of the classes, allowing it to effectively penalize the majority classes. In our implementation, we define as the logic ratio of the data frequency of the majority type, defined as: , where denotes the total sample size of the largest training dataset, specifically one of the daytime datasets, and represents the total sample size of the dataset to which the -th sample belongs. Adding 0.5 to the log weights to avoid situations where the weight equals zero. If an instance belongs to a dataset with a large number of samples, its weight is relatively small, and vice versa. With this setup, the minority nighttime data contribute more to the network’s gradient calculation, allowing the network to focus less on the majority daytime data and more on the minority during training. is the regularization term that penalizes overconfident predictions on the target. As the modulating factor, directs the network to focus more on samples with lower IoU values.
| Method | Source | NAT2024-1[13] | NAT2021[67] | UAVDark135[35] | Avg.FPS | FLOP(G) | Params.(M) | ||||||
| Prec. | Norm.Prec. | Succ. | Prec. | Norm.Prec. | Succ. | Prec. | Norm.Prec. | Succ. | |||||
| MambaNUT-Small | Ours | 83.3 | 76.9 | 63.6 | 70.1 | 64.6 | 52.4 | 70.0 | 69.3 | 57.1 | 72 | 1.1 | 4.1 |
| MambaNUT-Tiny | 78.6 | 72.6 | 60.5 | 64.4 | 58.8 | 47.6 | 66.2 | 65.9 | 54.6 | 113 | 0.69 | 2.6 | |
| DCPT [73] | ICRA 24 | 80.9 | 75.4 | 62.1 | 69.0 | 63.5 | 52.6 | 69.2 | 69.8 | 56.7 | 35 | 29.4 | 92.9 |
| AVTrack-DeiT [39] | ICML 24 | 75.3 | 68.2 | 56.7 | 61.5 | 55.6 | 45.5 | 58.6 | 59.2 | 47.6 | 212 | 0.97-1.9 | 3.5-7.9 |
| TDA-Track [13] | IROS 24 | 75.5 | 53.3 | 51.4 | 61.7 | 53.5 | 42.3 | 49.5 | 49.9 | 36.9 | 114 | 18.2 | 9.2 |
| Sam-DA [14] | ICARM 24 | 75.3 | 64.9 | 53.4 | 67.3 | 59.2 | 47.1 | 60.4 | 59.4 | 47.6 | 37 | 27.1 | 37.4 |
| SGDViT [62] | ICRA 23 | 53.1 | 47.2 | 38.1 | 53.1 | 47.9 | 37.5 | 40.2 | 40.6 | 32.7 | 93 | 11.3 | 23.3 |
| Aba-ViTrack [38] | ICCV 23 | 78.4 | 72.2 | 60.1 | 60.4 | 57.3 | 46.9 | 61.3 | 63.5 | 52.1 | 134 | 2.4 | 7.9 |
| HiT-Base [28] | ICCV 23 | 62.7 | 56.9 | 48.2 | 49.3 | 44.2 | 36.4 | 48.9 | 48.7 | 41.1 | 156 | 4.4 | 42.1 |
| MAT [71] | CVPR 23 | 80.5 | 76.3 | 61.9 | 64.8 | 58.8 | 47.7 | 57.2 | 57.6 | 47.1 | 56 | 42.9 | 88.4 |
| TCTrack++ [7] | TPAMI 23 | 70.5 | 50.8 | 46.6 | 61.1 | 52.8 | 41.7 | 47.4 | 47.4 | 37.8 | 122 | 17.6 | 8.8 |
| TCTrack [6] | CVPR 22 | 74.4 | 51.2 | 47 | 60.8 | 51.9 | 40.8 | 49.8 | 50.0 | 37.7 | 136 | 16.9 | 8.5 |
| UDAT-BAN [67] | CVPR 22 | 71.2 | 64.9 | 51.1 | 68.9 | 58.8 | 47.2 | 61.1 | 61.7 | 48.4 | 41 | 21.9 | 54.1 |
| UDAT-CAR [67] | CVPR 22 | 68.1 | 61.6 | 49.6 | 68.2 | 61.3 | 48.7 | 60.9 | 61.3 | 48.6 | 36 | 22.3 | 54.6 |
| HiFT [4] | ICCV 21 | 57.1 | 44.5 | 40.8 | 54.5 | 46.7 | 37.0 | 44.8 | 45.2 | 35.3 | 123 | 7.2 | 9.9 |
| SiamAPN++ [5] | IROS 21 | 68.9 | 57.9 | 47.8 | 60.2 | 51.4 | 41.2 | 42.7 | 41.6 | 33.5 | 114 | 8.2 | 14.7 |
| SiamCAR [19] | CVPR 20 | 68.7 | 62.6 | 51.2 | 65.8 | 59.5 | 45.7 | 65.8 | 65.7 | 52.3 | 37 | 59.3 | 51.3 |
| Ocean [70] | ECCV 20 | 67.6 | 50.3 | 44.0 | 58.1 | 49.9 | 38.6 | 60.1 | 58.9 | 47.3 | 43 | 23.7 | 25.8 |
3.4 Vision Mamba for Tracking
Given the template image and search image , we first embed and flatten them into one-dimensional tokens by a trainable linear projection layer. This process is called patch embedding and results in tokens, formulated by:
| (5) |
where is the embedding dimension of each token. After obtaining the input tokens , we feed them into the encoding layer, where they are processed through stacked L layers of bidirectional Vision Mamba (Vim) encoders. Let denote the Vim layer at layer , where forward propagation procedure involves all tokens from the layer via . The detailed structure of the bidirectional Vision Mamba encoders is illustrated on the right side of Fig. 3. The input is first normalized and then processed separately through two distinct linear projection layers to obtain the intermediate features and :
| (6) | |||
Next, we process in both forward and backward directions. In each direction, a 1D convolution followed by a SiLU activation function is applied to to produce :
| (7) | ||||
where the subscript are the two scan orientations: forward and backward. Bidirectional scanning enables mutual interactions among all elements within the sequence, thereby establishing a global and unconstrained receptive field. The information flow of SSM is described in Eq. 2. Subsequently, the search region vectors from the output of the last encoder are added element-wise and fed into the tracking head to generate the final tracking results.
3.5 Tracking head and loss function
In line with OSTrack [64], we implement a center-based head comprised of multiple Conv-BN-ReLU layers to directly estimate the target’s bounding box. The head outputs local offsets to correct for discretization errors caused by resolution reduction, normalized bounding box sizes, and an object classification score map. The position with the highest classification score is selected as the object’s location, resulting in the final bounding box for the object.
During training, we adopt the weighted focal loss [33] for classification, a combination of loss and Generalized Intersection over Union (GIoU) loss [48] for bounding box regression. The total loss function is defined as follows:
| (8) |
where the trade-off parameters are set as = 2 and = 5, and = 0.00001 in our experiments.
4 Experiment
In this section, we provide a thorough evaluation of our method using three nighttime UAV tracking benchmarks: NAT2024-1 [13], NAT2021 [67], and UAVDark135 [35]. Our evaluation is performed on a PC that was equipped with an i9-10850K processor (3.6GHz), 16GB of RAM, and an NVIDIA TitanX GPU. We evaluate our approach by comparing it with 16 state-of-the-art (SOTA) trackers, as detailed in Table 1.
4.1 Implementation Details
Model Variants. We trained two variants of MambaNUT, each with different configurations, as described below:
-
•
MambaNUT-Tiny. Backbone: Vim-Tiny; Search region size: [256×256]; Template size: [128×128];
-
•
MambaNUT-Small. Backbone: Vim-Small; Search region size: [256×256]; Template size: [128×128];
Training. We use training splits from multiple datasets, including four daytime datasets: GOT-10k [25], LaSOT [10], COCO [43], and TrackingNet [47], and three nighttime datasets: BDD100K-Night, SHIFT-Night, and ExDark [46]. Notably, we select the images labeled as ”night” from the BDD100K [68] and SHIFT [52] datasets to construct the BDD100K-Night and SHIFT-Night. During training, the two variants of the tracker share the same training pipeline to maintain consistency and comparability. The batch size is consistently set to 32. We use the AdamW optimizer with a weight decay of , and an initial learning rate of . The total number of training epochs is fixed at 300, with 60,000 image pairs processed per epoch. The learning rate is reduced by a factor of 10 after 240 epochs.
Inference. In the inference phase, following standard practices [70], we apply Hanning window penalties during inference to incorporate positional priors into the tracking process. Specifically, we multiply the classification map by a Hanning window of the same size, and the bounding box with the highest score is then selected as the tracking result.

4.2 Overall Performance
NAT2024-1: NAT2024-1 [13] is a long-term tracking benchmark featuring multiple challenging attributes, comprising 40 long-term image sequences with a total of over 70K frames. As shown in Table 1, our MambaNUT-Small tracker outperforms 16 state-of-the-art (SOTA) trackers on this benchmark, achieving a precision of 83.3%, a normalized precision of 76.9%, and a success rate of 63.6%. This surpasses the second-best tracker by 2.4%, 1.5%, and 1.5% in each metric, respectively. We also select three representative video sequences from NAT2024-1 for visualization in Fig. 4. As shown, MambaNUT-Small tracks the target objects more accurately than the seven SOTA trackers.
NAT2021: NAT2021 [67] includes 180 testing videos, offering a challenging and large-scale benchmark for nighttime tracking. As shown in Table 1, MambaNUT-Small demonstrates competitive performance compared to the SOTA trackers. It achieves the highest precision and normalized precision, outperforming the previous top-performing tracker, DCPT, by more than 1.0% in both metrics, with only a slight 0.2% gap in success rate compared to DCPT.
UAVDark135: The UAVDark135[35] benchmark consists of 135 test sequences and is widely used as the benchmark for nighttime tracking. From Table 1, MambaNUT-Small achieved a new state-of-the-art score of 70.0% in precision and 57.1% in success rate. Additionally, our MambaNUT-Tiny ranks third in all three metrics.
UAV123: UAV123 [2] is a large-scale aerial tracking benchmark with 123 challenging sequences and over 112K frames. To demonstrate that our proposed strategy of learning from easy (daytime) to hard (nighttime) significantly improves the generalization of the deep model, we compare our tracker with eight SOTA trackers on this daytime UAV tracking benchmark. Table 2 presents the Prec. and Succ. of the competing trackers on UAV123. MambaNUT ranks second, with only slight gaps of 0.2% in Prec. and 0.3% in Succ. compared to MAT.
4.3 Efficiency Comparison
In Table 1, we also compare the inference speed on GPU, floating-point operations per second (FLOPs), and number of parameters of the proposed trackers with SOTA trackers to highlight the proposed superior efficiency. Notably, as AVTrack-DeiT feature adaptive architectures, the FLOPs and Params of it vary within a range, spanning from the minimum to the maximum values. As observed, although DCPT achieves comparable performance to our MambaNUT-Small, MambaNUT-Small runs in real-time at over 75 fps, i.e., more than twice DCPT’s speed, and uses only 1.1 GMacs and 4.1 million parameters, significantly less than DCPT’s 42 GMacs and 99 million parameters. While trackers like AVTrack-DeiT and Aba-ViTrack achieve higher tracking speeds than our method, their performance across multiple nighttime UAV tracking benchmarks is significantly lower. This comparison in terms of computational complexity also underscores the efficiency of our methods.
| LAI | IV | |||
|---|---|---|---|---|
| Trackers | Prec. | Succ. | Prec. | Succ. |
| MambaNUT-Small(Ours) | 0.877 | 0.672 | 0.772 | 0.556 |
| DCPT[73] | 0.854 | 0.658 | 0.693 | 0.513 |
| AVTrack-DeiT[39] | 0.787 | 0.594 | 0.662 | 0.463 |
| TDA-Track[13] | 0.773 | 0.519 | 0.504 | 0.328 |
| Sam-DA[14] | 0.852 | 0.571 | 0.600 | 0.404 |
| SGDViT[62] | 0.569 | 0.403 | 0.343 | 0.249 |
| Aba-ViTrack[38] | 0.824 | 0.628 | 0.627 | 0.464 |
| HiT-Base[28] | 0.668 | 0.512 | 0.470 | 0.346 |
| MAT[71] | 0.854 | 0.655 | 0.705 | 0.532 |
| TCTrack++[7] | 0.732 | 0.497 | 0.515 | 0.333 |
| TCTrack[6] | 0.786 | 0.514 | 0.593 | 0.358 |
| UDAT-BAN[67] | 0.750 | 0.543 | 0.500 | 0.323 |
| UDAT-CAR[67] | 0.722 | 0.524 | 0.568 | 0.395 |
| HiFT[4] | 0.642 | 0.455 | 0.390 | 0.262 |
| SiamAPN++[5] | 0.720 | 0.502 | 0.586 | 0.374 |
| SiamCAR[19] | 0.739 | 0.545 | 0.528 | 0.389 |
| Ocean[70] | 0.704 | 0.459 | 0.629 | 0.379 |
4.4 Illumination-Oriented Evaluation
To further evaluate the performance of MambaNUT in nighttime scenarios, we conduct an analysis focused on the challenges of Low Ambient Illumination (LAI) and Illumination Variation (IV) on NAT2024-1. The evaluation results are shown in Table 3, and more attribute-based evaluation results are provided in the supplemental materials. As observed, our tracker significantly outperforms the SOTA trackers in these two attributes, achieving over a 2.0% improvement in both precision and success rate compared to the second-best tracker, with a remarkable 6.7% improvement in precision on the IV challenge.
4.5 Ablation Study
To validate the effectiveness of our proposed adaptive curriculum learning method, we conducted ablation studies using MambaNUT-Small as the baseline on the NAT2024-1 [13] dataset. Comprehensive results are provided in the supplementary material.
| Method | SS | LS | Prec. | Norm.Prec | Succ. |
|---|---|---|---|---|---|
| MambaNUT-Small | 79.6 | 73.8 | 60.6 | ||
| 81.5↑1.9 | 75.3↑1.5 | 61.8↑1.2 | |||
| 83.3↑3.7 | 76.9↑3.1 | 63.6↑3.0 |
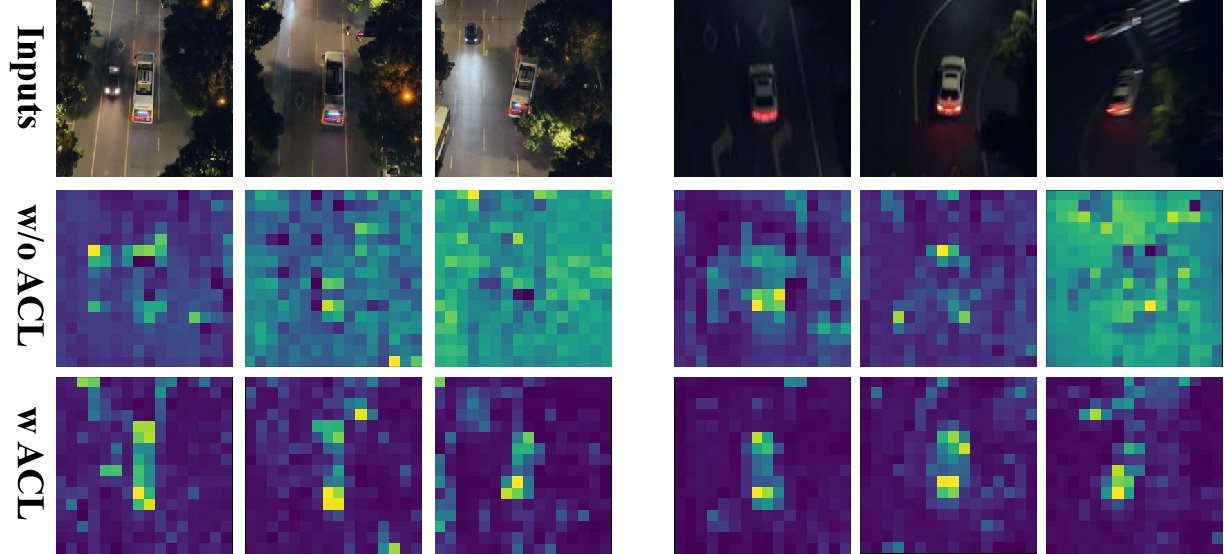
Impact of Adaptive Curriculum Learning (ACL) strategy: To validate the effectiveness of the proposed adaptive curriculum learning strategy, Table 4 presents the evaluation results on NAT2024-1, progressively incorporating two levels of curriculum schedulers, i.e., sampling scheduler (SS) and loss scheduler (LS), into the baseline. As observed, the incorporation of SS significantly enhances both Prec., Norm.Prec, and Succ. for the baseline tracker. With the further application of LS, the improvements become even more significant, with all increases exceeding 3.0%. Fig. 5 also demonstrates that by incorporating our ACL into the baseline tracker, more robust and discriminative feature representations are achieved, particularly enhancing the consistency of feature distribution across consecutive frames in long-term tracking. This comparison further demonstrates the effectiveness of our method in enhancing robust feature representations learning under low-light conditions using Mamba.
| Method | Prec. | Norm.Prec | Succ. | |
|---|---|---|---|---|
| MambaNUT-Small | - | 79.6 | 73.8 | 60.6 |
| Focal[42] | 80.7↑1.1 | 74.4↑0.6 | 61.3↑0.7 | |
| WCE[51] | 81.8↑2.2 | 75.5↑1.7 | 61.9↑1.3 | |
| Ours | 83.3↑3.7 | 76.9↑3.1 | 63.6↑3.0 |
Impact of Loss Function Scheduler: To demonstrate the superiority of the proposed ADB loss in performance, we train separately MambaNUT-Small using Focal[42] and WCE [51] loss for comparison. The evaluation results on NAT2024-1 are shown in Table 5. From the table, while using Focal and WCE loss as the loss scheduler improves performance, the best precision improvement is only 2.2%, and the improvements in norm.precision and success rate remain below 2.0%, which is far behind our approach, where all three metrics show improvements above 3.0%.
| Method | Prec. | Norm.Prec | Succ. | |
|---|---|---|---|---|
| MambaNUT-Small | - | 79.6 | 73.8 | 60.6 |
| 100 | 81.9↑2.3 | 75.1↑1.3 | 61.6↑1.0 | |
| 150 | 83.3↑3.7 | 76.9↑3.1 | 63.6↑3.0 | |
| 200 | 82.3↑2.7 | 75.6↑1.8 | 62.4↑1.8 |
Impact of Sampling Weight on Nighttime Data: In the proposed sampling scheduler, we set a constant (Seeing Eq (3)) to control the sampling weight of nighttime data as the training process progresses. We trained MambaNUT-Small using varied values of ranging from 100 to 200 with increments of 50. Evaluation results are presented in Table 6. As shown, our tracker achieves best performance when the constant is set to 150. These significant differences clearly highlight the substantial impact of nighttime data weight on tracking performance.
5 Conclusion
In this work, we propose MambaNUT, a novel Mamba-based nighttime UAV tracking framework that exploits Mamba’s exceptional ability to model long-range dependencies with linear complexity. Additionally, we incorporate an adaptive curriculum learning strategy into this framework by designing two curriculum schedulers for sampling and loss propagation. These schedulers dynamically guide the model to progress from imbalance to balance and from easy to hard across daytime and nighttime data. Extensive experiments demonstrate that our MambaNUT achieves state-of-the-art results on three nighttime UAV tracking benchmarks, while offering advantages in computational complexity and parameter efficiency.
References
- [1] Sumit Basu and Janara Christensen. Teaching classification boundaries to humans. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 27, pages 109–115, 2013.
- [2] UT Benchmark. A benchmark and simulator for uav tracking. In European Conference on Computer Vision, 2016.
- [3] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48, 2009.
- [4] Ziang Cao, Changhong Fu, Junjie Ye, Bowen Li, and Yiming Li. Hift: Hierarchical feature transformer for aerial tracking. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 15457–15466, 2021.
- [5] Ziang Cao, Changhong Fu, Junjie Ye, Bowen Li, and Yiming Li. Siamapn++: Siamese attentional aggregation network for real-time uav tracking. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3086–3092, 2021.
- [6] Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, and Changhong Fu. Tctrack: Temporal contexts for aerial tracking. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14778–14788, 2022.
- [7] Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, and Changhong Fu. Towards real-world visual tracking with temporal contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [8] Nontawat Charoenphakdee, Zhenghang Cui, Yivan Zhang, and Masashi Sugiyama. Classification with rejection based on cost-sensitive classification. In International Conference on Machine Learning, pages 1507–1517. PMLR, 2021.
- [9] Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [10] Heng Fan, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Hexin Bai, Yong Xu, Chunyuan Liao, and Haibin Ling. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5374–5383, 2019.
- [11] K Ruwani M Fernando and Chris P Tsokos. Dynamically weighted balanced loss: class imbalanced learning and confidence calibration of deep neural networks. IEEE Transactions on Neural Networks and Learning Systems, 33(7):2940–2951, 2021.
- [12] Changhong Fu, Haolin Dong, Junjie Ye, Guangze Zheng, Sihang Li, and Jilin Zhao. Highlightnet: highlighting low-light potential features for real-time uav tracking. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12146–12153. IEEE, 2022.
- [13] Changhong Fu, Yiheng Wang, Liangliang Yao, Guangze Zheng, Haobo Zuo, and Jia Pan. Prompt-driven temporal domain adaptation for nighttime uav tracking. arXiv preprint arXiv:2409.18533, 2024.
- [14] Changhong Fu, Liangliang Yao, Haobo Zuo, Guangze Zheng, and Jia Pan. Sam-da: Uav tracks anything at night with sam-powered domain adaptation. In 2024 International Conference on Advanced Robotics and Mechatronics (ICARM), pages 31–38. IEEE, 2024.
- [15] Chen Gong, Dacheng Tao, Stephen J Maybank, Wei Liu, Guoliang Kang, and Jie Yang. Multi-modal curriculum learning for semi-supervised image classification. IEEE Transactions on Image Processing, 25(7):3249–3260, 2016.
- [16] Javier González-Trejo, Diego Mercado-Ravell, Israel Becerra, and Rafael Murrieta-Cid. On the visual-based safe landing of uavs in populated areas: a crucial aspect for urban deployment. IEEE Robotics and Automation Letters, 6(4):7901–7908, 2021.
- [17] Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
- [18] Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021.
- [19] Dongyan Guo, Jun Wang, Ying Cui, Zhenhua Wang, and Shengyong Chen. Siamcar: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6269–6277, 2020.
- [20] Guy Hacohen and Daphna Weinshall. On the power of curriculum learning in training deep networks. In International conference on machine learning, pages 2535–2544. PMLR, 2019.
- [21] Hui Han, Wen-Yuan Wang, and Bing-Huan Mao. Borderline-smote: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing, pages 878–887. Springer, 2005.
- [22] Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. Adasyn: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence), pages 1322–1328. Ieee, 2008.
- [23] Haibo He and Edwardo A Garcia. Learning from imbalanced data. IEEE Transactions on knowledge and data engineering, 21(9):1263–1284, 2009.
- [24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [25] Lianghua Huang, Xin Zhao, and Kaiqi Huang. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE transactions on pattern analysis and machine intelligence, 43(5):1562–1577, 2019.
- [26] Lu Jiang, Deyu Meng, Qian Zhao, Shiguang Shan, and Alexander Hauptmann. Self-paced curriculum learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015.
- [27] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960.
- [28] Ben Kang, Xin Chen, D. Wang, Houwen Peng, and Huchuan Lu. Exploring lightweight hierarchical vision transformers for efficient visual tracking. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9578–9587, 2023.
- [29] Faisal Khan, Bilge Mutlu, and Jerry Zhu. How do humans teach: On curriculum learning and teaching dimension. Advances in neural information processing systems, 24, 2011.
- [30] Salman H Khan, Munawar Hayat, Mohammed Bennamoun, Ferdous A Sohel, and Roberto Togneri. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE transactions on neural networks and learning systems, 29(8):3573–3587, 2017.
- [31] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- [32] M Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models. Advances in neural information processing systems, 23, 2010.
- [33] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), pages 734–750, 2018.
- [34] Bowen Li, Changhong Fu, Fangqiang Ding, Junjie Ye, and Fuling Lin. Adtrack: Target-aware dual filter learning for real-time anti-dark uav tracking. In 2021 IEEE international conference on robotics and automation (ICRA), pages 496–502. IEEE, 2021.
- [35] Bowen Li, Changhong Fu, Fangqiang Ding, Junjie Ye, and Fuling Lin. All-day object tracking for unmanned aerial vehicle. IEEE Transactions on Mobile Computing, 22(8):4515–4529, 2022.
- [36] Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977, 2024.
- [37] Shuiwang Li, Xiangyang Yang, Xucheng Wang, Dan Zeng, Hengzhou Ye, and Qijun Zhao. Learning target-aware vision transformers for real-time uav tracking. IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [38] Shuiwang Li, Yangxiang Yang, Dan Zeng, and Xucheng Wang. Adaptive and background-aware vision transformer for real-time uav tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13989–14000, 2023.
- [39] Yongxin Li, Mengyuan Liu, You Wu, Xucheng Wang, Xiangyang Yang, and Shuiwang Li. Learning adaptive and view-invariant vision transformer for real-time uav tracking. In Forty-first International Conference on Machine Learning.
- [40] Yongxin Li, Mengyuan Liu, You Wu, Xucheng Wang, Xiangyang Yang, and Shuiwang Li. Learning adaptive and view-invariant vision transformer for real-time uav tracking. In Forty-first International Conference on Machine Learning, 2024.
- [41] Liang Lin, Keze Wang, Deyu Meng, Wangmeng Zuo, and Lei Zhang. Active self-paced learning for cost-effective and progressive face identification. IEEE transactions on pattern analysis and machine intelligence, 40(1):7–19, 2017.
- [42] T Lin. Focal loss for dense object detection. arXiv preprint arXiv:1708.02002, 2017.
- [43] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), 2014.
- [44] Jiarun Liu, Hao Yang, Hong-Yu Zhou, Yan Xi, Lequan Yu, Cheng Li, Yong Liang, Guangming Shi, Yizhou Yu, Shaoting Zhang, et al. Swin-umamba: Mamba-based unet with imagenet-based pretraining. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 615–625. Springer, 2024.
- [45] Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. Vmamba: Visual state space model. arXiv preprint arXiv:2401.10166, 2024.
- [46] Yuen Peng Loh and Chee Seng Chan. Getting to know low-light images with the exclusively dark dataset. Computer Vision and Image Understanding, 178:30–42, 2019.
- [47] Matthias Muller, Adel Bibi, Silvio Giancola, Salman Alsubaihi, and Bernard Ghanem. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European conference on computer vision (ECCV), pages 300–317, 2018.
- [48] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666, 2019.
- [49] Jiacheng Ruan and Suncheng Xiang. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491, 2024.
- [50] Petru Soviany, Radu Tudor Ionescu, Paolo Rota, and Nicu Sebe. Curriculum self-paced learning for cross-domain object detection. Computer Vision and Image Understanding, 204:103166, 2021.
- [51] Carole H Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M Jorge Cardoso. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pages 240–248. Springer, 2017.
- [52] Tao Sun, Mattia Segu, Janis Postels, Yuxuan Wang, Luc Van Gool, Bernt Schiele, Federico Tombari, and Fisher Yu. Shift: a synthetic driving dataset for continuous multi-task domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21371–21382, 2022.
- [53] Bin Tian, Qingming Yao, Yuan Gu, Kunfeng Wang, and Ye Li. Video processing techniques for traffic flow monitoring: A survey. In 2011 14th international IEEE conference on intelligent transportation systems (ITSC), pages 1103–1108. IEEE, 2011.
- [54] Anyang Tong, Chao Tang, and Wenjian Wang. Semi-supervised action recognition from temporal augmentation using curriculum learning. IEEE Transactions on Circuits and Systems for Video Technology, 33(3):1305–1319, 2022.
- [55] Yiru Wang, Weihao Gan, Jie Yang, Wei Wu, and Junjie Yan. Dynamic curriculum learning for imbalanced data classification. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5017–5026, 2019.
- [56] Xiaowen Wei, Xiuwen Gong, Yibing Zhan, Bo Du, Yong Luo, and Wenbin Hu. Clnode: Curriculum learning for node classification. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pages 670–678, 2023.
- [57] Changcheng Xiao, Qiong Cao, Zhigang Luo, and Long Lan. Mambatrack: a simple baseline for multiple object tracking with state space model. arXiv preprint arXiv:2408.09178, 2024.
- [58] Xuesu Xiao, Jan Dufek, Tim Woodbury, and Robin Murphy. Uav assisted usv visual navigation for marine mass casualty incident response. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6105–6110. IEEE, 2017.
- [59] Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 578–588. Springer, 2024.
- [60] Pengfei Xu, Songtao Guo, Qiguang Miao, Baoguo Li, Xiaojiang Chen, and Dingyi Fang. Face detection of golden monkeys via regional color quantization and incremental self-paced curriculum learning. Multimedia Tools and Applications, 77:3143–3170, 2018.
- [61] Yijun Yang, Zhaohu Xing, and Lei Zhu. Vivim: a video vision mamba for medical video object segmentation. arXiv preprint arXiv:2401.14168, 2024.
- [62] Liangliang Yao, Changhong Fu, and et al. Sgdvit: Saliency-guided dynamic vision transformer for uav tracking. arXiv preprint arXiv:2303.04378, 2023.
- [63] Liangliang Yao, Changhong Fu, Yiheng Wang, Haobo Zuo, and Kunhan Lu. Enhancing nighttime uav tracking with light distribution suppression. arXiv preprint arXiv:2409.16631, 2024.
- [64] Botao Ye, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Joint feature learning and relation modeling for tracking: A one-stream framework. In European Conference on Computer Vision, pages 341–357. Springer, 2022.
- [65] Junjie Ye, Changhong Fu, Ziang Cao, Shan An, Guangze Zheng, and Bowen Li. Tracker meets night: A transformer enhancer for uav tracking. IEEE Robotics and Automation Letters, 7(2):3866–3873, 2022.
- [66] Junjie Ye, Changhong Fu, Guangze Zheng, Ziang Cao, and Bowen Li. Darklighter: Light up the darkness for uav tracking. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3079–3085. IEEE, 2021.
- [67] Junjie Ye, Changhong Fu, Guangze Zheng, Danda Pani Paudel, and Guang Chen. Unsupervised domain adaptation for nighttime aerial tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8896–8905, 2022.
- [68] Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2636–2645, 2020.
- [69] Dingwen Zhang, Deyu Meng, Long Zhao, and Junwei Han. Bridging saliency detection to weakly supervised object detection based on self-paced curriculum learning. arXiv preprint arXiv:1703.01290, 2017.
- [70] Zhipeng Zhang, Houwen Peng, Jianlong Fu, Bing Li, and Weiming Hu. Ocean: Object-aware anchor-free tracking. In European Conference on Computer Vision (ECCV), 2020.
- [71] Haojie Zhao, Dong Wang, and Huchuan Lu. Representation learning for visual object tracking by masked appearance transfer. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18696–18705, 2023.
- [72] Zhi-Hua Zhou and Xu-Ying Liu. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Transactions on knowledge and data engineering, 18(1):63–77, 2005.
- [73] Jiawen Zhu, Huayi Tang, Zhi-Qi Cheng, Jun-Yan He, Bin Luo, Shihao Qiu, Shengming Li, and Huchuan Lu. Dcpt: Darkness clue-prompted tracking in nighttime uavs. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 7381–7388. IEEE, 2024.
- [74] Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417, 2024.