Manga Rescreening with Interpretable Screentone Representation
Abstract
The process of adapting or repurposing manga pages is a time-consuming task that requires manga artists to manually work on every single screentoned region and apply new patterns to create novel screentones across multiple panels. To address this issue, we propose an automatic manga rescreening pipeline that aims to minimize the human effort involved in manga adaptation. Our pipeline automatically recognizes screentone regions and generates novel screentones with newly specified characteristics (e.g., intensity or type). Existing manga generation methods have limitations in understanding and synthesizing complex tone- or intensity-varying regions. To overcome these limitations, we propose a novel interpretable representation of screentones that disentangles their intensity and type features, enabling better recognition and synthesis of screentones. This interpretable screentone representation reduces ambiguity in recognizing intensity-varying regions and provides fine-grained controls during screentone synthesis by decoupling and anchoring the type or the intensity feature. Our proposed method is demonstrated to be effective and convenient through various experiments, showcasing the superiority of the newly proposed pipeline with the interpretable screentone representations.
1 Introduction
Japanese manga is a worldwide entertainment art form. It is unique in its region-filling with specially designed bitonal patterns, called screentones, to enrich its visual contents. During manga production, artists will carefully select these screentones considering both intensity and pattern type to express various shading effects [28]. The screentone intensity, similarly as the luminance channel in color images, plays the key role to render and represent shading among different regions, while the screentone type is an alternative to the chrominance channel in color images to differentiate semantics over regions. However, once the manga is produced, this screening process is hard to be reverted for editing or adaptation to other types of medium, such as e-readers, Webtoons, etc. Even if the extraction and editing of ink line drawings are easy, the adaptation of screentones is exceptionally challenging, as simple pixel-level transformation of screentoned area tend to break the intended visual delivery by the artists, such as the fading effects or region contrast. As a result, it usually requires a complete rescreening of the whole manga frame. In such a process, the artists have to manually identify and amend the regions for correction (Fig. 1(b)). The overall process is tedious and labor-intensive, as one has to handle diverse cases of screentone variation in both screentone intensity and type.
To save time and cost, computer techniques are considered to be employed to ease the rescreening process, but the bitonal and discrete screentones hinder both manga segmentation and screentone synthesis. To segment the region filled with the same screentone, recent approaches [22, 29] focus on the discovery of efficient texture descriptors, like Gabor filter banks [24]. However, these methods cannot tackle intensity-varying screentones (background in Fig. 1(a)) since they did not disentangle the type feature from the intensity information. For screentone synthesis and manga generation, several attempts are proposed to produce screened manga [13, 31, 6, 26, 28, 39]. But, they either generated more or less uniform patterns or failed to generate intensity-varying effects. Recently, Xie et al. [35] proposed a representation for screentone, which supports both region discrimination and screentone synthesis. However, since intensity and type features are unrecognizable in their model, it limits the user to identifying screentone regions with varying intensity and synthesizing screentones with given intensity or type. As can be observed in Fig. 1, manga artists commonly use the same type of screentone, sometimes with intensity variation, to fill the same semantic region, which requires segmenting regions based on screentone type.
In this paper, we propose a framework to implement intuitive and convenient manga rescreening. The framework can recognize semantic continuous regions based on the screentone type, and manages to enable individual tuning of screentone type or intensity while maintaining the other one. The framework starts by learning an interpretable screentone representation with disentangled intensity and type features. The intensity feature is expected to visually conform to the tone/shading intensity of manga, and the type feature should have the same representation over the same screentone type. Such a representation allows discrimination of the same screentone type with varying intensity and also precise control on screentone generation given a specific tone intensity and type.
To disentangle the intensity and type features, we propose to encode the latent domain with intensity as one independent axis. Yet, we observed that the diversity of screentone types is correlated with the intensity, where darker or lighter tone intensity shall gradually suppress the tone diversity. Thus, we propose to model the domain as a hypersphere space, and screentones with the same intensity are encoded as a normal distribution with standard deviation conditioned on the intensity. The disentangled representation greatly benefits region semantic understanding and segmentation of manga. While all existing texture descriptors fail in distinguishing a semantic consistent screentone region with varying intensities, the proposed representation manages to catch this consistency to produce better segmentations (Fig. 1(b)). With manga regions segmented, our framework can further synthesize screentones with any specified effects by editing the intensity or type features. Our method can generate various screentones preserving the original intensity variation (Fig. 1(c)) or the original screentone types (Fig. 1(d)).
To validate the effectiveness of our method, we apply our method in various real-world cases and receive convincing results. We conclude our contributions as follows.
-
•
We propose a practical manga rescreening method with an interpretable screentone representation to enable manga segmentation and user-expected screentone generation.
-
•
We disentangle the intensity information from the screentones by modeling a hypersphere space with intensity as the major axis.
2 Related Work
Manga Segmentation
Existing manga segmentation approaches focus on the discovery of efficient texture descriptors as screentones are laid over regions rather than individual pixels. Traditional texture analysis usually analyzes the texture by first applying filtering techniques and then representing the textures with statistical models [33, 32, 7, 24]. Gabor Wavelet features [24] has been demonstrated as an effective texture discrimination technique for screentones [29] and utilized for measuring pattern-continuity in various manga tasks [29, 28]. However, all the above texture features are windowed-based and usually fail at boundary and thin structures. Convolutional Neural Network (CNN) has also been shown to be suitable for texture analysis, in which trainable filter banks make an excellent tool in the analysis of repetitive texture patterns [3, 5, 4]. But these methods are tailored for extracting texture features in natural images and usually fail for screened manga. Recently, Xie et al. [35] attempted to identify regions in manga by mapping screentones into an interpolative representation with a Screentone Variational AutoEncoder (ScreenVAE). The model features a vast screentone encoding space, which generates similar representations for similar screentones. However, it cannot handle screentone regions of varying intensity. In comparison, we disentangle intensity feature from type feature and can identify the same screen type without being confused by the intensity variation.
Manga Generation
Traditional manga generation shades grayscale/color images to produce screened manga through halftoning [13, 31, 26, 39] or hatching [34, 6]. But these methods reproduce the intensity with more or less uniform patterns and cannot satisfy the requirement for manga which uses a rich set of screentone types to enrich the viewing experience. Qu et al. [28] screened color images by selecting various screentones considering tone similarity, texture similarity, and chromaticity distinguishability. However, with the limited screentone set, it may not generate screentones with user-expected intensity and types, even generate smooth transitions with the same screentone type. ScreenVAE [35] produced screened manga with an interpolative screentone representation. However, since intensity and type features are unrecognizable in their model, it limits the user to synthesizing new types of screentone that retain special effects. In comparison, we propose an interpretable representation disentangling intensity and type of screentones, which enables controllable generation and manipulation on both intensity and type.
Representation Learning and Disentanglement
Variational AutoEncoders (VAE) [18] and Generative Adversarial Networks (GAN) [8] are two of the most popular frameworks for representation learning. VAE learns a bidirectional mapping between complex data distribution and a much simpler prior distribution while GAN learns a unidirectional mapping that only allows sampling of data distribution. Disentanglement is a useful property in representation learning which increases the interpretability of the latent space, connecting certain parts of the latent representation to semantic factors, which would enable a more controllable and interactive generation process. InfoGAN [2] disentangles latent representation by encouraging the mutual information between the observation and a small subset of the latent variables. -VAE [12] and some follow-up studies [1, 16, 37] introduced various extra constraints and properties on the prior distribution. However, the above disentanglement is implicit. Though the model separates the latent space into subparts, we cannot define their meanings beforehand. On the contrary, some approaches aim at controllable image generation with explicit disentanglement [38, 15]. Disentangled Sequential Autoencoder [38] learns the latent representation of high dimensional sequential data, such as video or audio, by splitting it into static and dynamic parts with a partially time-invariant encoder. StyleGAN [15] defined the meanings of different parts of the latent representation by the model structure, making the generation controllable and more precise. In this paper, we attempt to disentangle the type and intensity information in the latent representation, so that the screentone generation can be controllable with type and intensity.
3 Overview
As highlighted in Sec. 1, the key to intuitive user-friendly rescreening is to train an interpretable screentone representation that explicitly encodes the complex screentone intensity and type features into a low-frequency latent space. The orthogonal encoding of screentone type and intensity empowers the model to recognize screentone type similarity or equivalence without being confused by the variation of screentone intensity, and vice versa. More importantly, the representation is invertible, so that one can easily modify the low-frequency representation to generate new screentones with desired screen type or intensity. To enable this controllable and user-friendly encoding, we build the whole framework upon a disentangled VAE model. Different from ScreenVAE [35], we explicitly enforce one of the feature descriptors to encode the intensity of manga, and the screentones with the same intensity are mapped to space following a normal distribution. We will describe our interpretable representation in Sec. 4 in more detail.
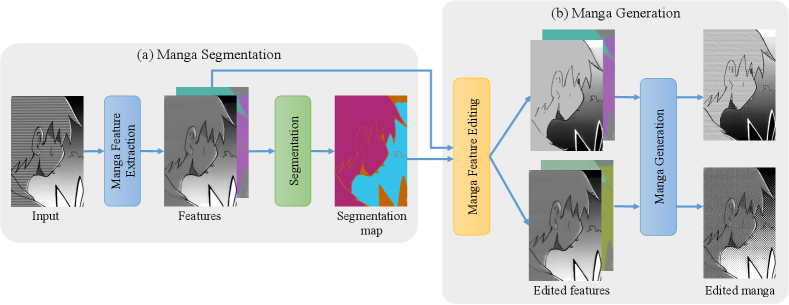
With the screentone representation learned, we propose our manga rescreening framework in two stages (detailed in Sec. 5.2). In the first stage, identifies semantic continuous regions based on the screen type similarity and segments them with a Gaussian mixture model (GMM) analysis (Fig. 2(a)). With the region segmented, for each screentone region, the users can directly edit the latent representation to alter either the screentone intensity (Fig. 2(b) upper branch) or the screentone type (Fig. 2(b) lower branch).
4 Interpretable Screentone Representation
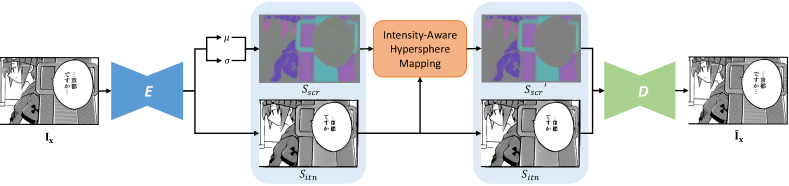
Fig. 3 illustrates our framework for learning interpretable screentone representation, which consists of two jointly trained networks, an encoding neural network and a decoding neural network . The encoder converts any screened manga to a latent representation , where is the dimensionality of each latent embedding vector. On the contrary, the decoder converts any latent representation to its original screened appearance . The latent representation is defined as 4 dimensions () including one dimension for the intensity of screentone and three for the type of screentone . Besides, variational inference [18] is employed to ensure the latent representation to be interpolative. The encoder adopts a 3-level downscaling-upscaling structure with 6 residual blocks [11] and the decoder adopts a 7-level U-net structure [30] with strided deconvolution operations to generate screentones of different scales.
To improve the generalization and fully disentangle the intensity, we impose an extra path by introducing a random intensity map. A random latent representation is generated by combining the encoded latent type feature and random intensity map . Given the random latent representation , the decoder is expected to generate a realistic image , and the reconstructed latent representation generated by the encoder should also be as similar as the given latent representation .

4.1 Intensity-Aware Hypersphere Modeling
We observed that the diversity of screentones with different intensities has the following properties. Firstly, the domain conditioned on intensity should be a symmetric space, as each pattern can transform into a new pattern with opposite intensity by inverting the black and white pixels. Second, the screentone diversity is correlated with its intensity. The diversity gradually decreases when annihilated into a pure black or pure white pattern from 50% intensity, as shown in Fig. 5(b). In particular, when the intensity is 100% or 0%, there is no variation of screentones. Considering the above properties, we propose to model the domain as a hypersphere with intensity as one independent axis, as illustrated in Fig. 5(a).
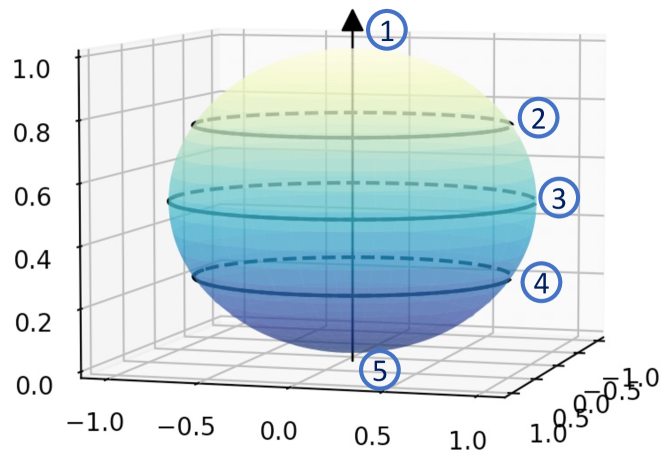
(a) Latent space with intensity as one axis 
(b) Example screentones with different intensity
Intensity-Aware Hypersphere Mapping (IAHM) is proposed to achieve the modeling. Considering the diversity of the screen types is conditioned by the intensity information, we hereby model the types of screentones with the same intensity as a normal distribution instead of projecting all screentones to a standard normal distribution in high dimensions. Meanwhile, we force the embedding domain to be hyperspherical with constraints of . As we can have with , our Intensity-Aware Hypersphere Mapping (IAHM) is then defined as
| (1) |
where indicates point-wise multiplication. In particular, it is deterministic with at black and white intensity.
(a) w/o IAHM









(b) w IAHM

The IAHM encoding substantially improves the usage efficiency of latent space, which helps to avoid the model bias due to imbalanced varieties of different intensities. As shown in Fig. 6, the model without IAHM will not be able to generate screentones with darker or lighter tone intensity. Specifically, for some screentones with darker or lighter intensity, although they may be quite similar at the pixel level, they may have a large distance in the latent space without the proposed IAHM, which will make the model fail to learn these screentones.
4.2 Loss Function
Our model is trained with the loss function defined in Equ.2, consisting of reconstruction loss , adversarial loss , intensity loss , KL divergence loss , feature consistency loss , and feature reconstruction loss . The objective is formulated as
| (2) |
where the hyper-parameters = 10, = 1, = 5, = 1, = 20, and = 1 are set empirically.
Reconstruction loss. The reconstruction loss ensures that the reconstructed manga is as similar to the input as possible, formulated in pixel level. The reconstruction loss is defined as
| (3) |
where denotes the norm.
Adversarial loss. The adversarial loss encourages the decoder to generate manga with clear and visually pleasant screentones. We treat our model as a generator and define an extra discriminator with 4 strided downscaling blocks to judge whether the input image is generated or not [8]. Given the input image and the reconstructed image and , we formulate the adversarial loss as
| (4) |
Intensity loss. The intensity loss ensures the generated intensity map visually conforms to the intensity of the manga image. We formulate it as
| (5) |
KL divergence loss. The KL divergence loss ensures that the statistics of the type feature are normally distributed. Given an input manga and the encoded representation and , we compute the KL divergence loss as the summed Kullback-Leibler divergence [19] of and over the standard normal distribution .
| (6) |
Here, denotes the KL divergence between two probability distributions.
Feature consistency loss. The feature consistency loss ensures that the type feature can summarize the local texture characteristics in the input [35]. Given the type feature and its label map which labels the screentone of each pixel, we encourage a uniform region representation within the region filled with the same screentone [20]. The feature consistency loss is formulated as
| (7) |
where is the binary mask to filter out structure lines (0 for structural lines). is a map in which each pixel is replaced by the average value of the corresponding region indexed by in the representation .
Feature reconstruction loss. We find that intensity information may still entangle with type feature when only the above losses are imposed. To disentangle intensity feature from type feature, we encourage the type feature can still be reconstructed through the extra path with random intensity map. The feature reconstruction loss is measured as the pixel-wise difference between the random representation and the reconstructed representation .
| (8) |
5 Experiments









5.1 Implementation Details
Data Preparation. We use two types of data to train our model, including synthetic manga data and real manga data. For the synthetic manga data, we manually collected 100 types of screentones and generated their tone inverse by swapping the black and white pixels. We then collected 500 line arts and generated synthetic manga following Li et al. [21] which randomly choose and place screentones in each closed region. We synthesized 5,000 manga images of resolution 2,048 1,536, together with the intensity and the screentone type labels of each pixel. Intensity maps and label maps are used to calculate intensity loss and feature consistency loss , respectively. For the real manga data, we manually collected 5,000 screened manga of resolution 2,048 1,536 to train our model. For each screened manga, we extract the structural lines using the line extraction model [21] and the intensity maps using total-variation-based smoothing [36]. Note that we do not label their ground truth screen type, so the feature consistency loss is not calculated for this portion of data.
Training. We trained the model with PyTorch [27]. The network weights are initialized with [10]. During training, we empirically set parameters as = 10, = 1, = 5, = 1, = 20 and = 1. Adam solver [17] is used with a batch size of 8 and an initial learning rate of 0.0001. All image pairs are cropped to before feeding to the networks. Considering the bias problem of real data, the whole model is first trained with synthetic data to obtain a stable latent space. Then, both synthetic and real data are imposed for training to improve generalization.
5.2 The Rescreening Pipeline
With the learned representation of screentones, users can easily edit the screentones in manga by segmenting the screentone region and generating new screentones.
Manga Segmentation. To perform automatic manga segmentation, we adopt the Gaussian mixture model (GMM) analysis [9] on the proposed representation. The optimal number of clusters is selected by the silhouette coefficient [14], a clustering validation metric. As the screentone types in a single page of manga are usually limited for visual comfort, we find the optimal number of clusters ranges from 1 to 10. We illustrate the consistency of the encoded screen type feature for regular patterns (dot pattern in Fig. 1) and noisy patterns (first row in Fig. 8). All features are visualized after principal component analysis (PCA) [23].
Controllable Manga Generation. After segmentation, each segmented region can be rescreened by modifying its latent and decoding the latent back to screentones. Users can either modify the screentone type while preserving the original intensity variation (Fig. 7(e)), or the intensity feature to change the intensity (Fig. 7(f)). Interestingly, the editing of the intensity is very flexible. The artist can either replace an intensity-varying region with an intensity-constant one, or preserve the visual effects by increasing/decreasing the overall tone intensity proportionally, as shown in the hair region in Fig.7(f)).







5.3 Qualitative Evaluation
As there is no method tailored for manga rescreening, we compare with approaches on manga segmentation and controllable manga generation respectively.
Comparison on Manga Segmentation. In Fig. 8, we visually compare our method with the classic Gabor wavelet texture analysis [24] and the learning-based ScreenVAE model [35]. All results are visualized by considering the three major components as color values. We also apply the same segmentation to each feature by measuring texture similarity. As observed, all features have the capability of summarizing the texture characteristics in a local region and can distinguish different types of screentones. However, Gabor wavelet feature exhibits severe artifacts near region boundaries with blurry double edges due to its window-based analysis. ScreenVAE map can have tight boundaries towards structural lines, but it failed to segment regions with varying intensity (second row in Fig. 8). In contrast, our representation explicitly encodes the intensity information and can disentangle the types. We can generate a consistent type feature for varying intensity regions.



Comparison on Controllable Manga Generation. Manga artists commonly use smoothly changing screentones to express shading or atmosphere, such as the hair of the third example in Fig. 8 and the background in Fig. 1, which requires the intensity feature to be interpolated in tone. With our design, our representation can provide controllable generation and manipulation on both the intensity and types of screentones. Fig. 9 (a) shows image synthesis by replacing the screentone type features of [35] and our method. Note that although [35] can also generate various screentones, it is not providing stable controls of screentones, as the screentone intensity and type are non-linearly coupled in their model. As observed, the screentone types are disentangled with intensity in our model, and we can generate screentones with expected types while preserving the original intensity during rescreening.
5.4 Quantitative Evaluation
Besides visual comparison, we also quantitatively evaluate the performance of our interpretable representation. In this evaluation, we mainly compare with Gabor Wavelet [24] and ScreenVAE [35]. The evaluation is on four aspects: i) screentone summarization to measure the standard deviation within each screentone region; ii) screentone distinguishability to measure the standard deviation among different screentone regions; iii) intensity accuracy to measure the difference (Mean Absolute Error) between the generated intensity map and the target intensity map; iv) reconstruction accuracy to measure the difference (LPIPS [40]) between the input image and the reconstructed image. Table 1 lists the evaluation results for all methods. Although Gabor Wavelet feature [24] obtains the lowest value of summarization score, it got a low score on distinguishability, which means it is difficult to distinguish different screentones. ScreenVAE [35] and ours achieve better performance for both screentone summarization and distinguishability. Furthermore, Gabor Wavelet feature [24] cannot reconstruct the original screentones, while the other two methods can be used to synthesize the screentones. More importantly, our method explicitly extracts the intensity of manga, which is critical for practical manga parsing and editing.
5.5 Ablation Study
To study the effectiveness of individual loss terms, we performed ablation studies for each module by visually comparing the generated latent representation and the reconstructed image, as shown in Fig. 10. Note that for better visualization, we did not normalize the type feature here. In addition, there is no loss configuration without reconstruction loss or intensity loss . The reconstruction loss is necessary to preserve information in latent space, while our model will degrade to the original ScreenVAE [35] without the intensity loss. Without adversarial loss , blurry and noisy screentones may be generated (background in the bottom row of Fig. 10(b)). Without KL convergence loss , the latent space is not normally distributed and balanced representations may not be generated, which will fail the segmentation (top row of Fig. 10(c)). Without feature consistency loss , the network may not recognize multiscale screentones, and may generate inconsistent representation for the same screentone (top row of Fig. 10(d)). Without feature reconstruction loss , inconsistent screentones may be generated among local regions (background in the bottom row of Fig. 10(e)). In comparison, the combined loss can help the network recognize the type and intensity of screentones and generate a consistent appearance (Fig. 10(f)).
5.6 Limitations
While our method can manipulate manga by segmenting the screentone region and generating screentones with desired screen type or intensity, our method may not extract some tiny screentones and some extra user hint may be required to generate good results (hair in Fig. 11(b)). In addition, some structural lines that are not extracted may be recognized as strip screentones (background in Fig. 11(b)).


6 Conclusion
We propose an automatic yet controllable approach for rescreening regions in manga with user-expected screen types or intensity. It frees manga artists from the tedious manga rescreening process. In particular, we learn a screentone representation disentangled type and intensity of screentone, which is friendly for region discrimination and controllable screentone generation. With the interpretable representation, we can segment different screentone regions by measuring feature similarity. Users can generate controllable screentones to simulate various special effects.
References
- [1] Ricky TQ Chen, Xuechen Li, Roger B Grosse, and David K Duvenaud. Isolating sources of disentanglement in variational autoencoders. Advances in neural information processing systems, 31, 2018.
- [2] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29, 2016.
- [3] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3606–3613, 2014.
- [4] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, and Andrea Vedaldi. Deep filter banks for texture recognition, description, and segmentation. International Journal of Computer Vision, 118(1):65–94, 2016.
- [5] Mircea Cimpoi, Subhransu Maji, and Andrea Vedaldi. Deep filter banks for texture recognition and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3828–3836, 2015.
- [6] Frédo Durand, Victor Ostromoukhov, Mathieu Miller, Francois Duranleau, and Julie Dorsey. Decoupling strokes and high-level attributes for interactive traditional drawing. In Eurographics Workshop on Rendering Techniques, pages 71–82. Springer, 2001.
- [7] Meirav Galun, Eitan Sharon, Ronen Basri, and Achi Brandt. Texture segmentation by multiscale aggregation of filter responses and shape elements. In ICCV, volume 3, page 716, 2003.
- [8] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- [9] Lalit Gupta and Thotsapon Sortrakul. A gaussian-mixture-based image segmentation algorithm. Pattern recognition, 31(3):315–325, 1998.
- [10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [12] Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. 2016.
- [13] John F Jarvis, C Ni Judice, and WH Ninke. A survey of techniques for the display of continuous tone pictures on bilevel displays. Computer graphics and image processing, 5(1):13–40, 1976.
- [14] Nuntawut Kaoungku, Keerachart Suksut, Ratiporn Chanklan, Kittisak Kerdprasop, and Nittaya Kerdprasop. The silhouette width criterion for clustering and association mining to select image features. International journal of machine learning and computing, 8(1):69–73, 2018.
- [15] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019.
- [16] Hyunjik Kim and Andriy Mnih. Disentangling by factorising. In International Conference on Machine Learning, pages 2649–2658. PMLR, 2018.
- [17] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [18] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [19] Solomon Kullback and Richard A Leibler. On information and sufficiency. The annals of mathematical statistics, 22(1):79–86, 1951.
- [20] Suha Kwak, Seunghoon Hong, and Bohyung Han. Weakly supervised semantic segmentation using superpixel pooling network. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [21] Chengze Li, Xueting Liu, and Tien-Tsin Wong. Deep extraction of manga structural lines. ACM Transactions on Graphics (SIGGRAPH 2017 issue), 36(4):117:1–117:12, July 2017.
- [22] Xueting Liu, Chengze Li, and Tien-Tsin Wong. Boundary-aware texture region segmentation from manga. Computational Visual Media, 3(1):61–71, 2017.
- [23] Andrzej Maćkiewicz and Waldemar Ratajczak. Principal components analysis (pca). Computers & Geosciences, 19(3):303–342, 1993.
- [24] Bangalore S Manjunath and Wei-Ying Ma. Texture features for browsing and retrieval of image data. IEEE Transactions on pattern analysis and machine intelligence, 18(8):837–842, 1996.
- [25] Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Yamasaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools and Applications, 76(20):21811–21838, 2017.
- [26] Wai-Man Pang, Yingge Qu, Tien-Tsin Wong, Daniel Cohen-Or, and Pheng-Ann Heng. Structure-aware halftoning. In ACM Transactions on Graphics (TOG), volume 27, page 89. ACM, 2008.
- [27] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- [28] Yingge Qu, Wai-Man Pang, Tien-Tsin Wong, and Pheng-Ann Heng. Richness-preserving manga screening. ACM Transactions on Graphics (SIGGRAPH Asia 2008 issue), 27(5):155:1–155:8, December 2008.
- [29] Yingge Qu, Tien-Tsin Wong, and Pheng-Ann Heng. Manga colorization. In ACM Transactions on Graphics (TOG), volume 25, pages 1214–1220. ACM, 2006.
- [30] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [31] Robert Ulichney. Digital halftoning. MIT press, 1987.
- [32] Manik Varma and Andrew Zisserman. Texture classification: Are filter banks necessary? In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings., volume 2, pages II–691. IEEE, 2003.
- [33] Thomas P Weldon, William E Higgins, and Dennis F Dunn. Efficient gabor filter design for texture segmentation. Pattern recognition, 29(12):2005–2015, 1996.
- [34] Georges Winkenbach and David H Salesin. Computer-generated pen-and-ink illustration. In Proceedings of the 21st annual conference on Computer graphics and interactive techniques, pages 91–100. ACM, 1994.
- [35] Minshan Xie, Chengze Li, Xueting Liu, and Tien-Tsin Wong. Manga filling style conversion with screentone variational autoencoder. ACM Transactions on Graphics (SIGGRAPH Asia 2020 issue), 39(6):1–15, 2020.
- [36] Li Xu, Cewu Lu, Yi Xu, and Jiaya Jia. Image smoothing via l 0 gradient minimization. In ACM Transactions on Graphics (TOG), volume 30, page 174. ACM, 2011.
- [37] Ruihan Yang, Tianyao Chen, Yiyi Zhang, and Gus Xia. Inspecting and interacting with meaningful music representations using vae. arXiv preprint arXiv:1904.08842, 2019.
- [38] Li Yingzhen and Stephan Mandt. Disentangled sequential autoencoder. In International Conference on Machine Learning, pages 5670–5679. PMLR, 2018.
- [39] Lvmin Zhang, Xinrui Wang, Qingnan Fan, Yi Ji, and Chunping Liu. Generating manga from illustrations via mimicking manga creation workflow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5642–5651, 2021.
- [40] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.