MC-GEN: Multi-level Clustering for Private Synthetic Data Generation
Abstract
With the development of machine learning and data science, data sharing is very common between companies and research institutes to avoid data scarcity. However, sharing original datasets that contain private information can cause privacy leakage. A reliable solution is to utilize private synthetic datasets which preserve statistical information from original datasets. In this paper, we propose MC-GEN, a privacy-preserving synthetic data generation method under differential privacy guarantee for machine learning classification tasks. MC-GEN applies multi-level clustering and differential private generative model to improve the utility of synthetic data. In the experimental evaluation, we evaluated the effects of parameters and the effectiveness of MC-GEN. The results showed that MC-GEN can achieve significant effectiveness under certain privacy guarantees on multiple classification tasks. Moreover, we compare MC-GEN with three existing methods. The results showed that MC-GEN outperforms other methods in terms of utility.
keywords:
synthetic data generation, differential privacy, machine learning1 Introduction
Machine learning has become an important technology in many fields, such as medical diagnosis, fraud detection, and product analysis. As a data-driven approach, data is considered as the fuel of machine learning algorithm [1], and the performance of the machine learning model often depends on the amount of data. To ensure the performance of machine learning, data sharing happens very often among organizations with similar research interests. For instance, if the research institutes do not have sufficient data for an illness diagnostic system, hospitals can share their data (patient records) to make up for the data gap. However, such data usually carry private information that can cause privacy leakage. Hence, sharing data in a privacy-preserving way for machine learning is of vital importance.
Sharing synthetic datasets generated from original datasets is a common way to protect data privacy. However, the individual information can be easily inferred with some background knowledge. To prevent this issue, differential privacy (DP)[2] has been widely used as a strong and provable privacy guarantee at the individual sample level. Synthetic data releasing under differential privacy emerges as a reliable solution for privacy-preserving data sharing in machine learning to protect individual records in the original datasets. It allows the data owner to publish synthetic datasets to data users without privacy concerns, and data users can make use of synthetic datasets for different purposes, such as machine learning, data mining, etc.
Designing a powerful privacy-preserving synthetic data generation method for machine learning purposes is of great challenge. First, a privacy-preserving method usually introduces perturbations on data samples that hurt the utility of data. Mitigating the perturbation to reach a certain level of utility is not easy. Second, machine learning has multiple tasks, like support vector machine, logistic regression, random forest, and k-nearest neighbor. An effective synthetic data generation method should be applicable to different tasks. Third, some data has a complex distribution. Forming an accurate generator based on the whole data distribution is hard.
In recent years, several works related to private synthetic data release have been proposed in the literature [3], [4], [5], [6], [7], [8], [9], [10]. One kind of method is to produce the synthetic database that preserved privacy and utility regarding query sets. These algorithm [3], [4] are usually designed to answer different query classes, and data samples in the dataset are not actually released. In [5], [6], they proposed algorithms for synthetic data release based on noisy histograms, which are more focused on the categorical feature variables. Algorithm [7], [8], [10] generate synthetic dataset under statistical model with some preprocessing on the original datasets. However, they only consider generating the synthetic data based on the whole data distribution.
Our primary motivation is to allow data owners to share their datasets without privacy concerns by using synthetic datasets instead of original datasets. We proposed Multiple-level Clustering based GENerator for synthetic data (MC-GEN), an approach that uses multi-level clustering (sample level and feature level) and differentially private multivariate Gaussian generative model to release synthetic datasets which satisfy -differential privacy. Extensive experiments on different original datasets have been conducted to evaluate MC-GEN and its parameters. The results demonstrate that synthetic datasets generated by MC-GEN maintain the utility of classification tasks while preserving privacy. Furthermore, we compared MC-GEN with other existing methods, and our results show that MC-GEN outperforms other existing methods in terms of effectiveness.
The main contributions of MC-GEN are summarized as follows:
-
1.
We proposed and released an innovative, effective synthetic data generation method, MC-GEN, which allows the data owners to share synthetic datasets for multiple classification tasks without privacy concerns111https://github.com/mingchenli/MCGEN-Private-Synthetic-Data-Generator.
-
2.
We demonstrated that applying feature clustering upon sample level clustering engages less differentially private noise to achieve the same level of privacy compared to sample level clustering.
-
3.
We conducted extensive experiments to investigate the effects of the parameters and the effectiveness of MC-GEN on three classification datasets. Meanwhile, we compared MC-GEN with three existing methods to demonstrate its utility.
2 Related Work
Moritz et al. [3] proposed an algorithm that combined the multiplicative weighs approach and exponential mechanism for differentially private database release. It finds and improves an approximation dataset to better reflect the original data distribution by using the multiplicative weighs update rule. The weight for each data record answer to desired queries in the approximation dataset will scale up or down depending on its contribution to the query result. The queries are sampled and measured by using the exponential mechanism and Laplace mechanism, which guarantee differential privacy. This work only considers the privacy solution to a set of linear queries.
Some of the research works applied the conditional probabilistic model to synthetic data generation. A new privacy notion, “ Plausible Deniability” [7], has been proposed and achieved by applying a privacy test after generating the synthetic data. The generative model proposed in this paper is a probabilistic model which captures the joint distribution of features based on correlation-based feature selection (CFS)[11]. The original data is transformed into synthetic data by using conditional probabilities in a probabilistic model. This work also proved that by adding some randomizing function to “ Plausible Deniability” can guarantee differential privacy. The synthetic data generated by this approach contains a portion of the original data, which may lead to a potential privacy issue. PrivBayes [8] generated the synthetic data by releasing a private Bayesian network. Starting from a randomly selected feature node, it extends the network iteratively by selecting a new feature node from the parent set using the exponential mechanism. They also applied the Laplace mechanism on the conditional probability to achieve the private Bayesian network. Bayesian network is a good approach for discrete data. However, using the encoding method to represent the dataset containing many numerical data introduced more noise to synthetic datasets.
Some works form a generative model on preprocessed original data. A non-interactive private data release method has been proposed in [9]. They projected the data into a lower dimension and proved it is nearly Gaussian distribution. After projecting the original data, the Gaussian mixture model (GMM) is used to model the original data based on the estimated statistical information. The synthetic data is generated by adding differential privacy noise on GMM parameters. However, there is some information loss while projection the data into a lower dimension. Josep Domingo-Ferrer et al. [10] proposed the release of a differentially private dataset based on microaggregation[12], which reduced the noise required by differential privacy based on kanonymity [13]. They clustered original data into clusters, and records in each cluster will be substituted by a representative record (mean) computed by each cluster. The synthetic data is generated by applying the Laplace mechanism to representative records. They also mentioned the idea to consider the feature relationship while clustering, but the paper does not come up with a detailed methodology. Using the representative records as seed data to generate synthetic data may lose some variance in the original datasets, which makes the synthetic data not accurate.
DPGAN [14], BGAN [15] and PATE-GAN [16] proposed differential private synthetic data release method based on generative adversarial network (GAN) [17]. Differentially private generative adversarial network (DPGAN) add noise on the gradient and clip the weight during the training process based on Wasserstein GAN to guarantee the privacy. PATE-GAN proposed private aggregation of teacher (PATE) ensembles teacher-student framework to generate synthetic data. It initialized k teacher models and k data subsets, and each teacher is trained to discriminate between the original and fake data using the corresponding subset. The student model is trained on the data label by ensemble results with the noise of teacher models. Then, the data generator is trained to fool the student model to get the synthetic data. However, using deep learning structures would lead to high demand for original data and a time-consuming training process. A recent benchmarking of differential private synthetic data generation [18] shows that the GAN-based methods are not good at preserving the critical statistical information from original data distributions. This paper focuses on non-image data and how to preserve the statistical characteristic. Thus, the GAN-based mechanisms are not considered in the comparison.
3 Preliminary
This section introduces the background knowledge of this paper.
3.1 Differential Privacy
Differential privacy proposed by D.work et al. [4] is one of the most popular privacy definitions which guarantee strong privacy protection on individual samples. The formal definition of - differential privacy for synthetic datasets generation is defined as below:
Definition 1.
(Differential Privacy)
A randomized mechanism provides - differential privacy, if for any pair of datasets , that differ in a single record (neighboring datasets) and for any possible synthetic data outputs S Range(M), it satisfies
| (1) |
The privacy parameter (privacy budget) is used to present the privacy level achieved by the randomized mechanisms . The privacy budget ranges from 0 to . If = 0, the probability of outputting synthetic dataset for and are exactly the same. It ensures the perfect privacy guarantee, which means , can not be distinguished by observing the synthetic datasets; if = , the synthetic datasets generated from and are always look different (like original datasets), there is no privacy guarantee at all. If differential privacy has been applied to synthetic datasets, it is hard to distinguish whether a specific individual is in the original dataset by observing synthetic datasets. In other words, differential privacy makes the synthetic dataset plausible. For example, there is a patient record dataset and a new patient record (privacy information) has been added recently. After publishing the differential private synthetic dataset, the data users can not infer the information of the new patient. It is because the original dataset with () or without () the new patient are most likely to generate the synthetic dataset().
In general, a differential privacy mechanism can be achieved by adding noise to the output (synthetic dataset) with a privacy parameter between 0 and 1. The mechanism used to achieve - differential privacy is called differentially private sanitizer and it is always associated with the sensitivity, also known as - Sensitivity, defined as follows:
Definition 2.
( - Sensitivity) For a function which maps datasets to real number domain, the sensitivity of the function f for all neighboring datasets pairs , is defined as follows:
| (2) |
Laplace mechanism achieves -differential privacy by adding noise drawn from Laplace distribution [19] to the output.
Definition 3.
(Laplace Mechanism) For a function which maps datasets to real number domain, the mechanism M defined in the following equation provides -differential privacy:
| (3) |
3.2 Agglomerative Hierarchical Clustering
An essential part of our methodology is hierarchical clustering [20]. Hierarchical clustering is an algorithm that clusters input samples into different clusters based on the proximity matrix of samples. The proximity matrix contains the distance between each cluster. Agglomerative hierarchical clustering is a bottom-up approach. It starts by assigning each data sample to its own group and merges the pairs of clusters that have the smallest distance to move up until there is only a single cluster left.
3.3 Microaggregation
Microaggregation [12] is a kind of dataset anonymization algorithm that can achieve k-anonymity. There are serval settings for microaggregation, notice, the microaggregation mentioned here is a simple heuristic method called maximum distance to average record (MDAV) proposed by Domingo-Ferrer et al. [12]. MDAV clusters samples into clusters, in which each cluster contains exactly k records, except the last one. Records in the same cluster are supposed to be as similar as possible in terms of distance. Furthermore, each record in the cluster will be replaced by a representative record of the cluster to complete the data anonymization.
3.4 Multivariate Gaussian Generative Model
The multivariate Gaussian generative model keeps the multivariate Gaussian distribution [21], which is parameterized by the mean and covariance matrix . Formally, the density function of multivariate Gaussian distribution is given by:
| (4) |
Data samples drawn from the Multivariate Gaussian generative model are under Multivariate Gaussian distribution.
4 Methodology
In this section, we present the methodology of our approach.
4.1 Problem Statement
Given a numerical dataset ( samples and features) which contains sensitive privacy records. The data owner expects to share dataset to an untrust party in a secure way. In this paper, we aim to use the synthetic dataset to substitute the original dataset in data sharing to prevent privacy leakage. The synthetic dataset not only maintains some certain information in original datasets but also protected by a certain level of privacy.
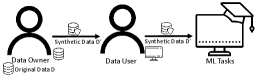
4.2 Methodology Overview
Fig. 2 illustrates the design of our approach. It includes four processes worked collectively to generate the synthetic dataset which satisfies differential privacy:
-
1.
Data preprocessing: Combining independent feature sets and microaggregation [12] (multi-level clustering) to produce data clusters.
-
2.
Statistic extraction: Extract the representative statistical information from each data cluster.
-
3.
Differential privacy sanitizer: Introduce differential private noise on extracted statistical information.
-
4.
Data generator: Generate synthetic data sample by sample from the noisy generative model.

We will explain each component in our design in the following sections.
4.3 Data Preprocessing
The conventional way to generate data clusters only groups the data at the sample level. For example, microaggregation (MDAV) [12] cluster the data in full feature dimension and add the differentially private noise on the representative records. Two kinds of errors may be introduced to jeopardize the utility of this process:
-
1.
The false feature correlation introduced by sample level clustering. When modeling the output clusters from sample level clustering, some clusters may carry some correlation which not exist while looking into all data samples. This false feature correlation may apply unnecessary constraints when modeling the data clusters, which may lead the synthetic data into a different shape.
-
2.
The noise variance introduced by DP mechanism. Intuitively, the less noise introduced from differential privacy results in higher utility. Hence, reducing the noise from DP mechanism also helps us to improve the data utility.
To smooth these two errors, we design multi-level clustering that combines independent feature sets (IFS) with microaggregation in our approach consecutively. Namely, we not only cluster the data at the sample level but also the feature level. Feature level clustering helps the generative model to capture the correct correlation of features. Compared to sample level clustering, using multi-level clustering also reduced the total noise variance introduced to the synthetic datasets, detailed proof shown in section 4.4.
4.3.1 Feature Level Clustering
Given a numerical dataset , we divided data features into m independent feature sets using agglomerative hierarchical clustering. A distance function that converts Pearson correlation to distance has been designed to form the proximity matrix in hierarchical clustering. Features that have a higher correlation should have a lower distance and a lower correlation corresponding to the higher distance. This approach results in that features in the same set are more correlated to each other and less correlated to the features in other feature sets. However, hierarchical clustering needs to specify the number of clusters to be divided. We use Davies-Bouldin [22] index to choose the best split from all possible numbers of clusters. The distance function in the proximity matrix is shown below:
| (5) |
where Corr(X, Y) is the Pearson correlation between two random variables, e.g., feature pair in original datasets.
4.3.2 Sample Level Clustering
Based on the output of feature level clustering, we applied microaggregation [12] on each independent feature set (IFS). The purpose of microaggregation is to assign the homogeneous samples to the same cluster, which preserves more information from the original data. On the other hand, referring to [12], sensitivity on each sample cluster can be potentially reduced compared to the global sensitivity. This reduction will result in involving less noise in the differential privacy mechanism. In other words, it enhances the data utility under the same level of privacy guarantee.
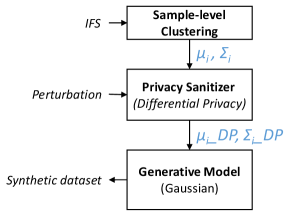
4.4 Statistic Extraction and Privacy Sanitizer
4.4.1 Statistic Extraction
For a given dataset , features are divided into IFSs on the feature level. In each IFS, the data with selected features is clustered into clusters by microaggregation on the sample level. The combination of feature and sample level clustering is called multi-level clustering. It outputs clusters in which each cluster has at least k records. The statistical information is extracted from each cluster to generate the synthetic data.
4.4.2 Privacy Sanitizer
Assuming each cluster forms a multivariate Gaussian distribution, the mean () and covariance matrix () are computed for each cluster . To ensure differential privacy, the generative model is built based on and which are achieved by the privacy sanitizer, as shown in Fig. 3. The privacy sanitizer adds differentially private noise on and . Algorithm 1 illustrates the process of privacy sanitizer. and denote the noise perturbation on mean and covariance matrix.
The differentially private noise added on and suppose to be as little as possible to preserve the utility of synthetic data. It refers to the generative model captures the statistical information more precisely. Thus, it is very critical to investigate and control the noise variance introduced by privacy sanitizer. A contribution of MC-GEN is applying multi-level clustering reduces the overall noise introduced from differential privacy mechanism compared to sample level clustering. The following proof demonstrates the noise variance of multi-level clustering.
Theorem 1.
The noise variance introduced by multi-level clustering on mean vector is .
Proof.
If multi-level clustering is applied, dataset D has been vertically partitioned into IFSs with corresponding data, and data in each IFS has been clustered into clusters by microaggregation.
Let denotes the - sensitivity of IFS, denotes the cluster in , denotes the size of , and denotes the total number of features. The noise variance of IFS is the sum of noise variances on each cluster in this IFS. Noise on a single cluster by microaggragation has been shown in [10]. Thus, noise variance can be written as:
| (6) |
where the has been divided proportionally based on the size of each IFS:
| (7) |
The noise on each IFS is independent, and the total noise variance on the mean vector by multi-level clustering is the sum of noise on all IFSs.
| (8) |
Based on equation (6) and equation (7), use addition commutative to rewrite equation (8) as following:
| (9) |
∎
Theorem 2.
The noise variance introduced by multi-level clustering on covariance matrix is .
Proof.
Use the same notation in Theorem 1 to describe the noise variance on the covariance matrix:
| (10) |
The noise on each IFS is independent, and the total noise variance on the mean vector by multi-level clustering is the sum of noise on all IFSs.
| (11) |
∎
The following proofs demonstrates the noise variance of sample level clustering.
Theorem 3.
The noise variance introduced by sample level clustering on mean vector is .
Proof.
If sample level clustering is applied, dataset D has been clustered into clusters. Let denote the - sensitivity of dataset D, and denote the cluster. Refer to [10], the total noise variance on the mean vector by sample level clustering can be written as follows:
| (13) |
∎
Theorem 4.
The noise variance introduced by sample level clustering on covariance matrix is .
Proof.
Using the same notation in Theorem 3, the total noise variance on the covariance matrix by sample level clustering can be written as follows:
| (14) |
∎
Proposition 1.
The overall noise introduced by multi-level clustering is less than the overall noise introduced by sample clustering .
Proof.
Since the differentially private noise is applied to the mean and covariance matrix respectively. The overall noise introduced on multi-level clustering can be written as:
| (15) |
The overall noise introduced on sample level clustering can be written as:
| (16) |
Since data in each IFS has been clustered by microaggregation with the same cluster size, which means:
| (17) |
and each cluster j is a subset of the original dataset:
| (18) |
Equation (9) can be rewritten as:
| (19) | ||||
Equation (12) can be rewritten as:
| (20) | ||||
Using feature level clustering not only mitigates the false feature correlation error but also helps to reduce the noise variance. Generally, the synthetic datasets generated with less noise will have better utility.
4.5 Synthetic Data Generator
The original multivariate Gaussian model is parameterized by mean () and covariance matrix (). The algorithm 1 outputs two parameters and that are protected by differential privacy. Hence the multivariate Gaussian model that is parameterized by and is also protected by differential privacy. Depending on the post-processing invariance of different privacy, all the synthetic data derived from differential private multivariate Gaussian models are protected by differential privacy as well. The synthetic data is synthesized sample by sample from the private multivariate Gaussian generative models with perturbed mean () and covariance matrix () based on Eq. (4). These multivariate Gaussian generative models are determined by the multiple-level clustering result of corresponding original data.
5 Experimental Evaluation
In this section, we show the experimental design and discuss the results of our approach.
| SVM | Logistic Regression | Gradient Boosting | |
| Scenario 1 | |||
| Diabetes [23] | 0.80 | 0.78 | 0.75 |
| Adult [24] | 0.84 | 0.89 | 0.91 |
| Phishing [25] | 0.96 | 0.98 | 0.96 |
| Scenario 2 | |||
| Diabetes [23] | 0.82 | 0.80 | 0.85 |
| Adult [24] | 0.85 | 0.86 | 0.83 |
| Phishing [misc_phishing_websites_327] | 0.96 | 0.94 | 0.94 |
5.1 Experiment Setting
To evaluate the performance of the proposed method, we have implemented MC-GEN based on JAVA 8. We generated synthetic datasets and performed experiments under different cluster sizes () and different privacy parameters (). The setting of varies from 0.1 to 1 and cluster size k is picked proportionally (20%, 40%, 60%, 80%, 100%) based on the corresponding seed dataset. For each synthetic dataset, we evaluate the performance of three classification tasks: support vector machine (SVM), logistic regression, and gradient boosting. The classification models are implemented using python scikit-learn library [26][27]. We also compared our method with other private synthetic data release methods. All the experiments are performed in two scenarios:
-
1.
Original data training, synthetic data testing (Scenario 1):
The classification algorithm trains on original data and tests on the synthetic data. For each experimental dataset, 20% of the samples are used as seed dataset to generate the synthetic dataset, and 80% is used as original data to train the model. -
2.
Synthetic data training, original data testing (Scenario 2):
The classification algorithm trains on synthetic data and tests on the original data. For each experimental dataset, 80% of the samples are used as seed dataset to generate the synthetic dataset, and 20% is used as original data to test the model.
5.2 Experiment Dataset
We conducted three datasets in our experiments from public sources (e.g. UCI repository [28], kaggle, libsvm datasets [29]) to examine the performance of different classification algorithms. For dataset that contains categorical variables, we use one-hot encoding to convert it to numerical variables. All the features in the dataset are scaled to [-1,1]:
5.2.1 Diabetes
This dataset contains the diagnostic measurements of patient records. It has 768 samples and 8 features. The features include some patient information, such as blood pressure, BMI, insulin level, and age. The objective is to identify whether a patient has diabetes.
5.2.2 Adult
This dataset is extracted from the census bureau database. It has 48,842 samples and 14 features. The features include some information, such as age, work class, education, sex, and capital gain/loss. The objective is to predict the annual salary (over 50k or not) of each person.
5.2.3 Phishing
This dataset is used to predict phishing websites. It has 11,055 samples and 30 features. The features include information related address, HTML and JavaSrcipt, such as website forwarding, request URL, and domain registration length.
5.3 Experiment Setup and Metric
In each round of experiments, we assume the data owners randomly select data from the original dataset as seed data. The size of seed data depends on the scenario. The seed data is input to MC-GEN to generate the synthetic dataset under different parameter combinations ( and ). Then, the synthetic dataset is tested on three classification tasks to evaluate the performance. Accuracy is used as the evaluation metric, shown in Eq. 21. For each scenario on each dataset, we ran 100 rounds to get the average performance.
| (21) |
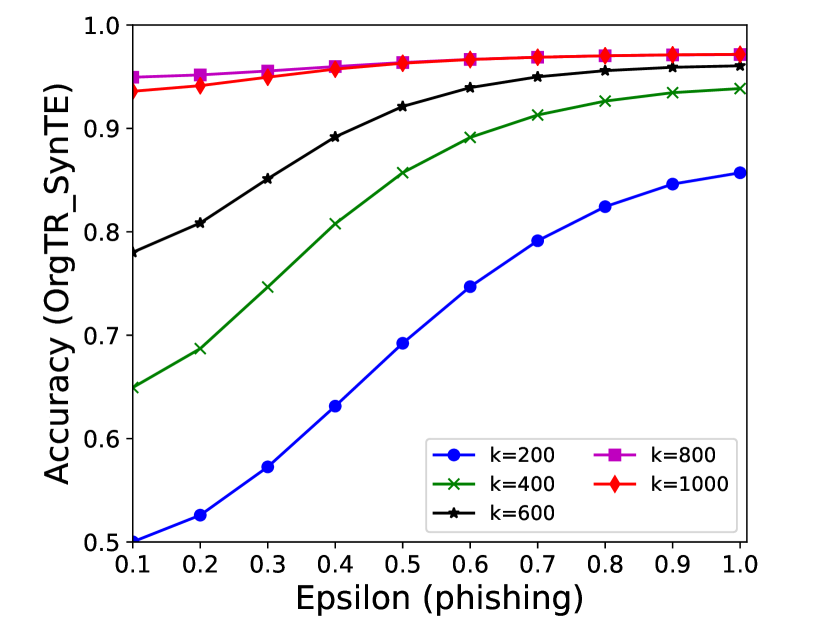
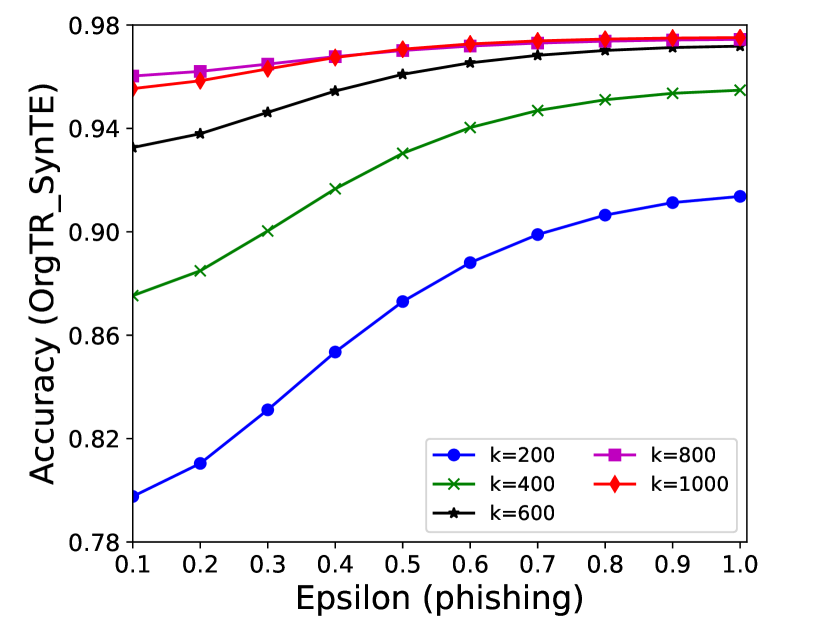
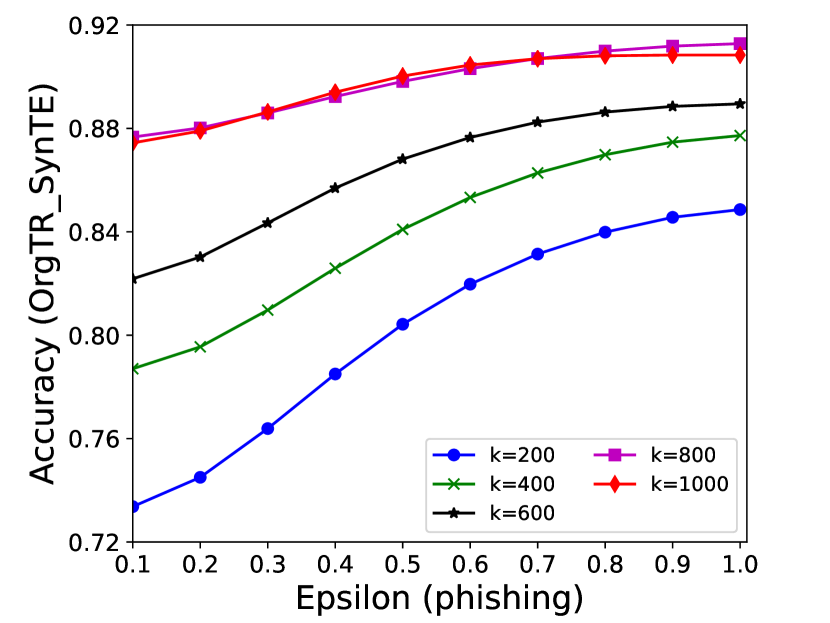
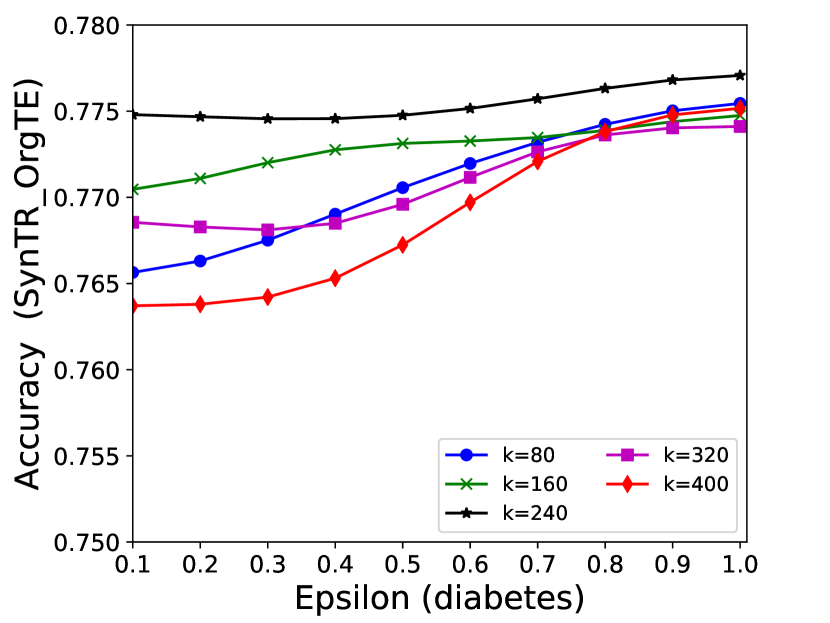
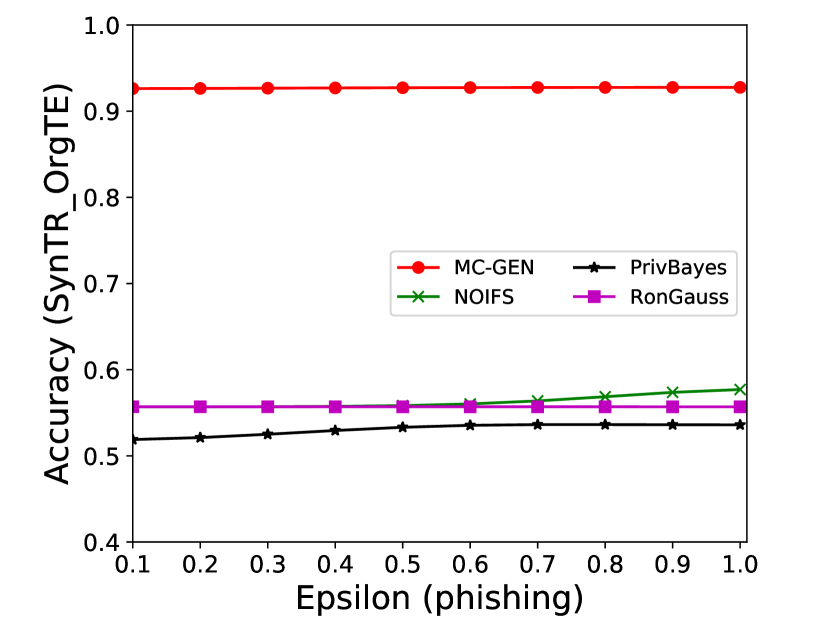
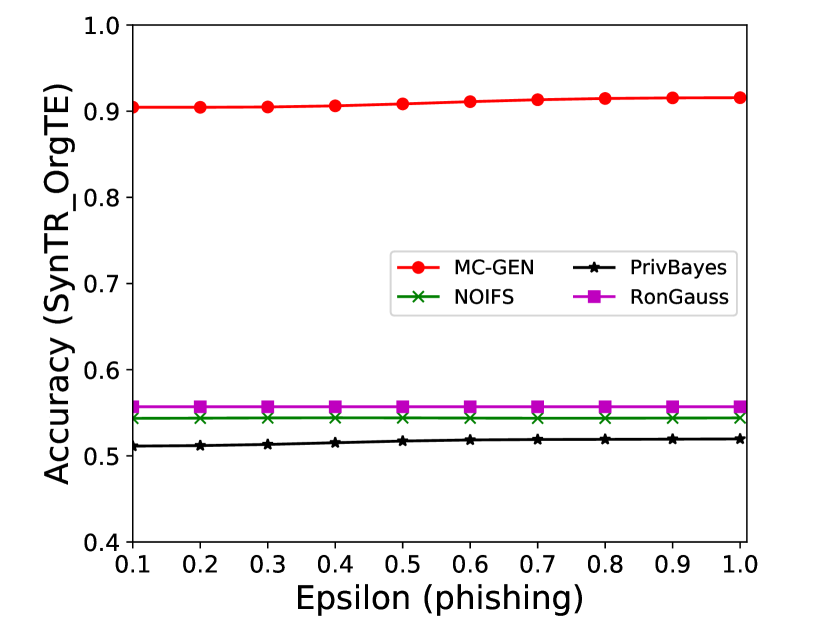
5.4 Effectiveness Analysis
In this section, we evaluate the effectiveness of our approach on three classification datasets with three classification algorithms. The best performance of MC-GEN on each dataset is always very close to the baseline (Table. 1). Baselines were trained and tested on the corresponding model using original datasets. Each baseline takes the average performance of 100 experiments.
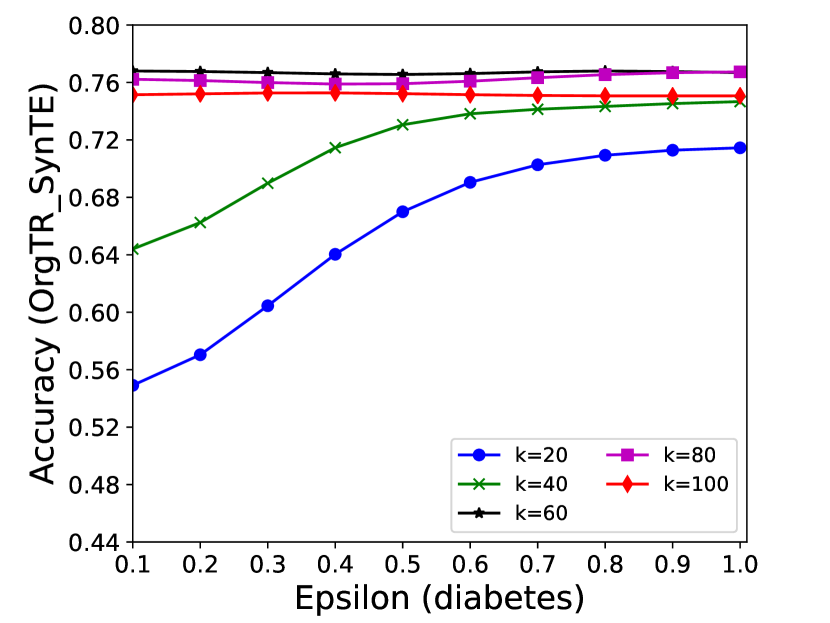
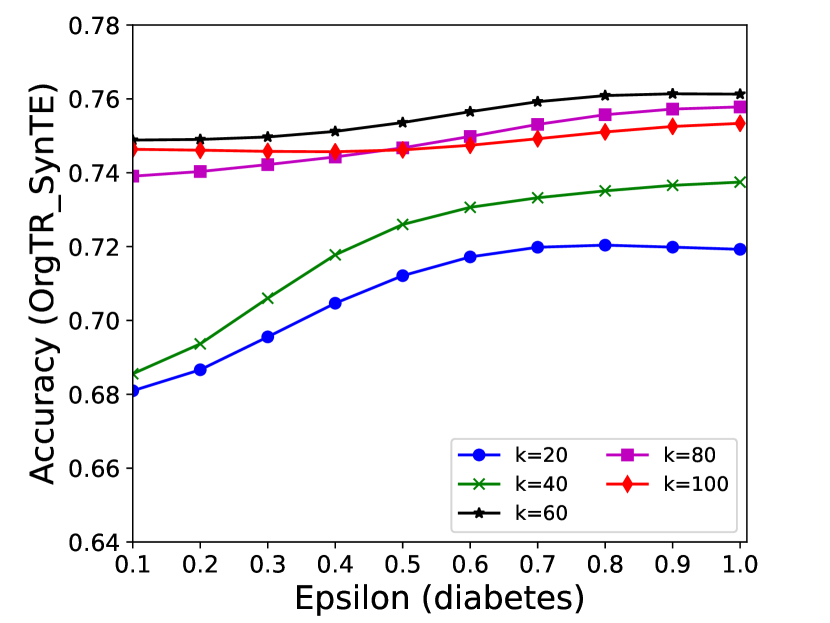
5.4.1 Effectiveness Analysis of Different Parameters
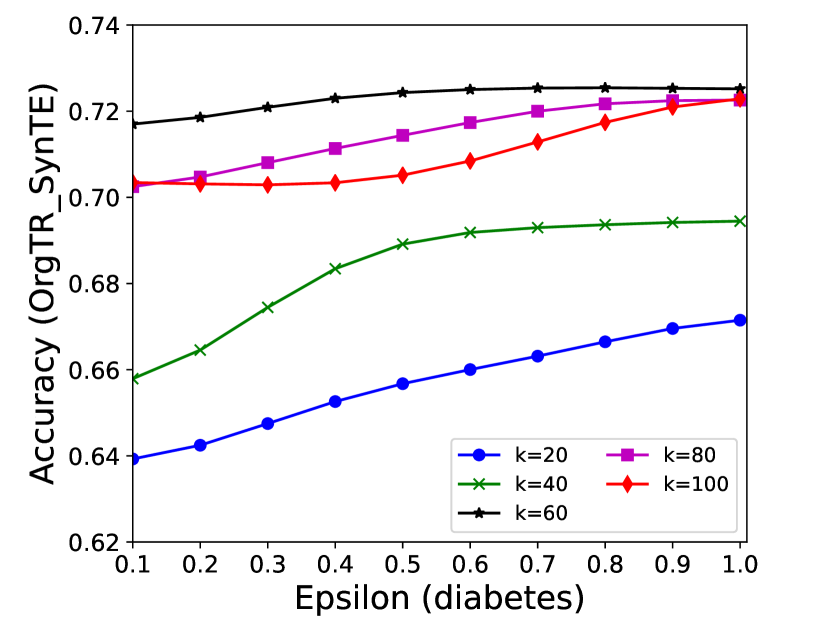
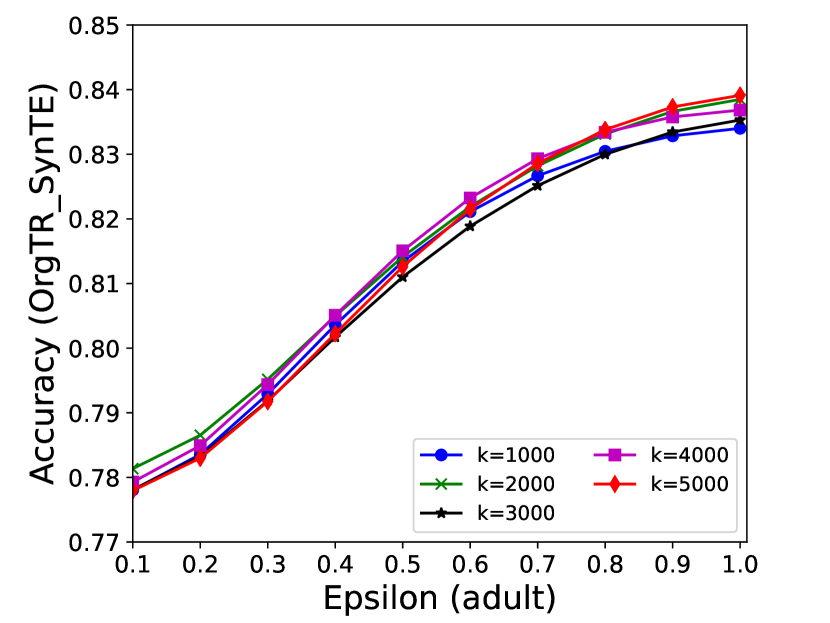
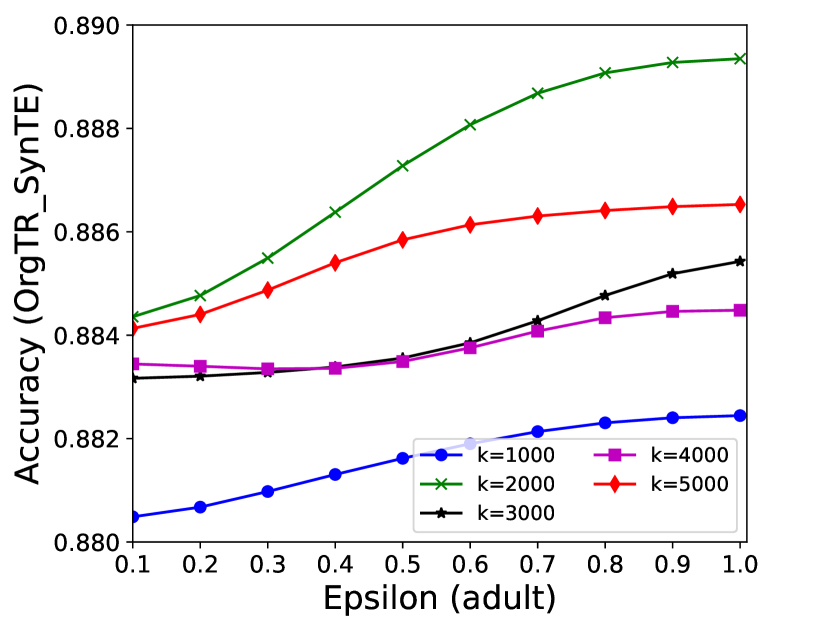
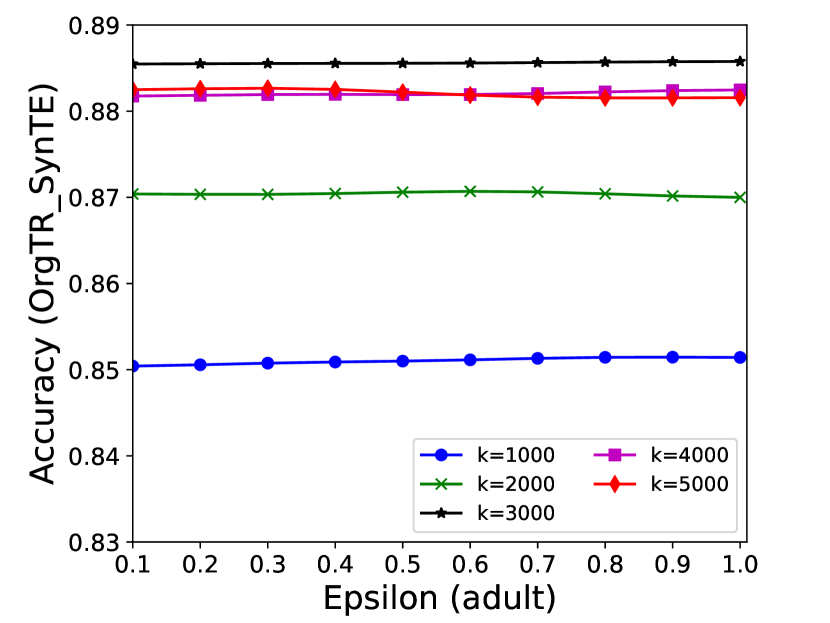
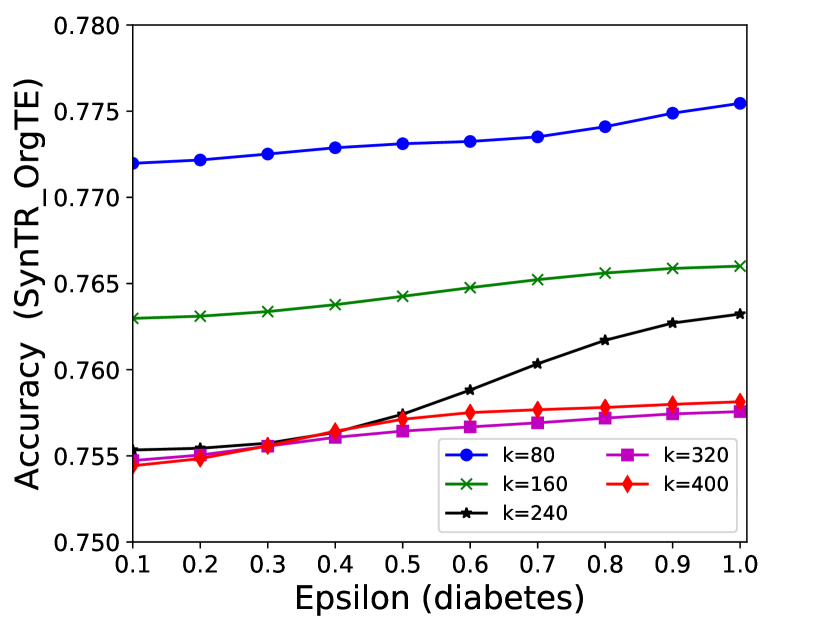
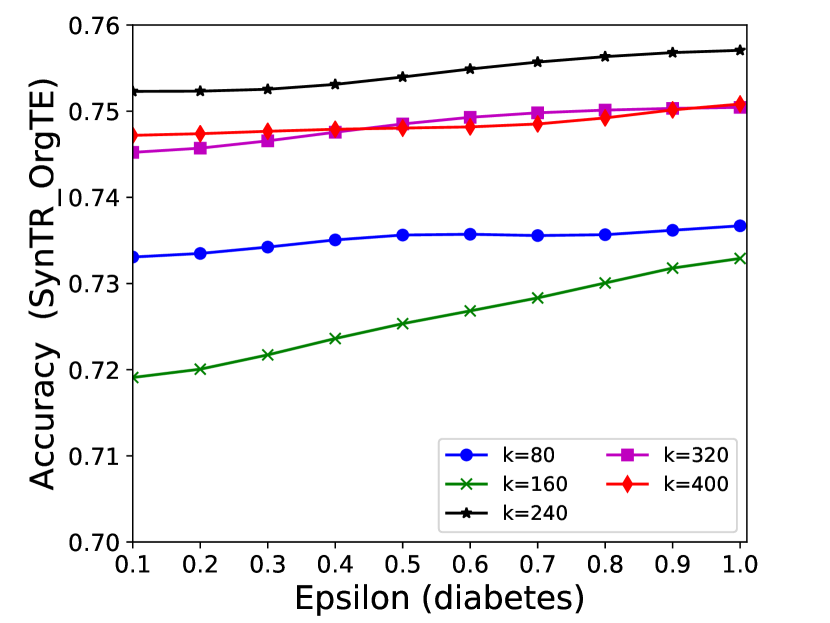
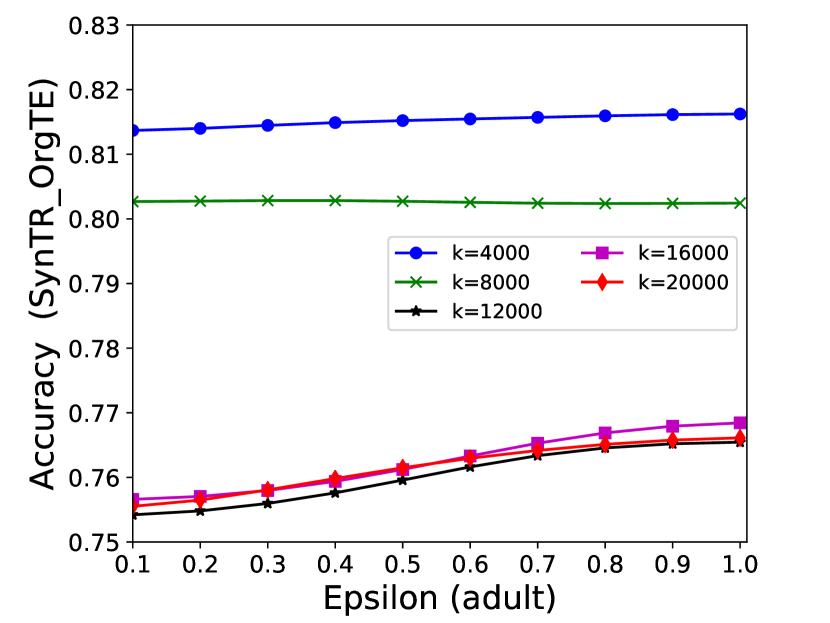
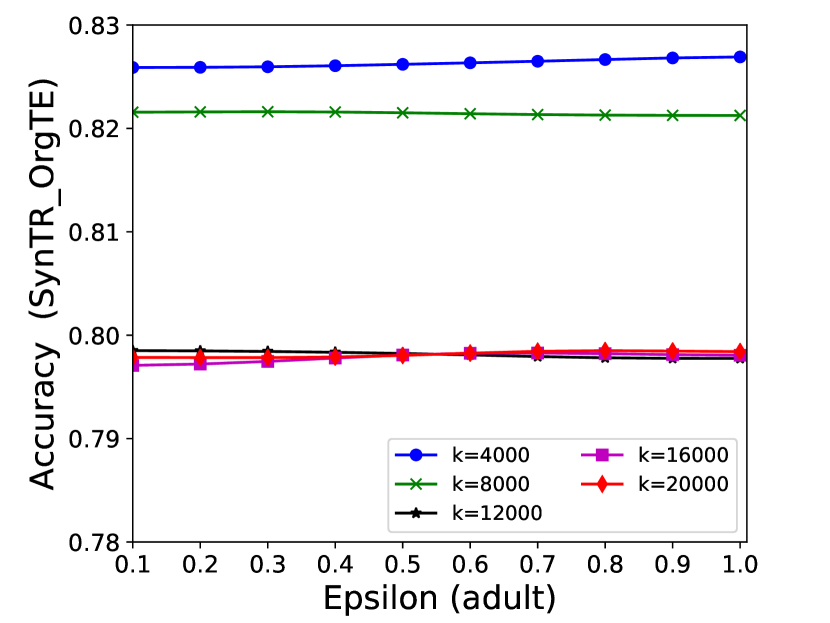
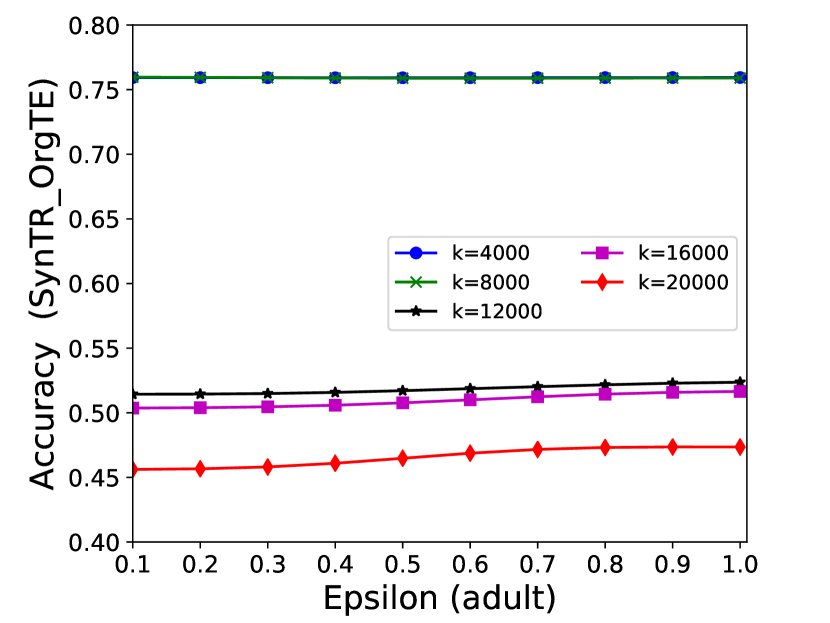
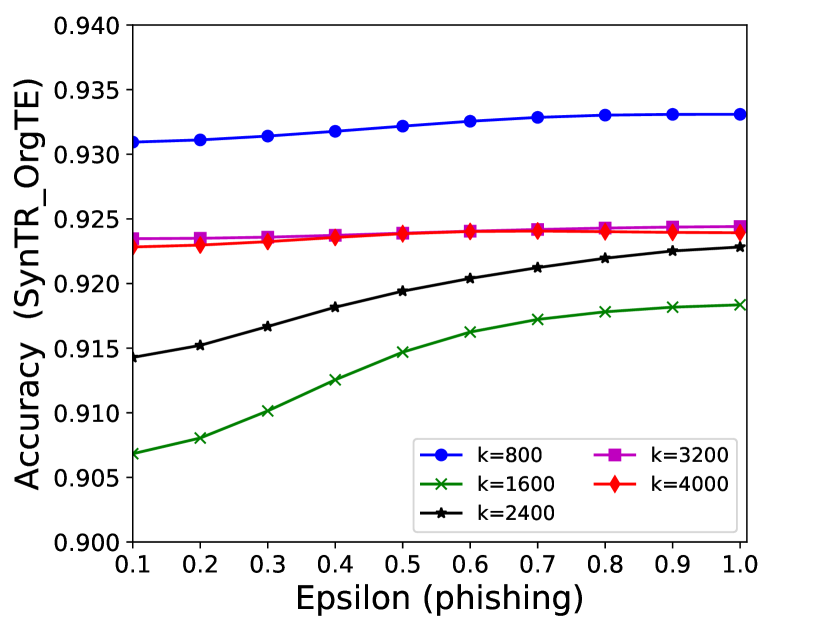
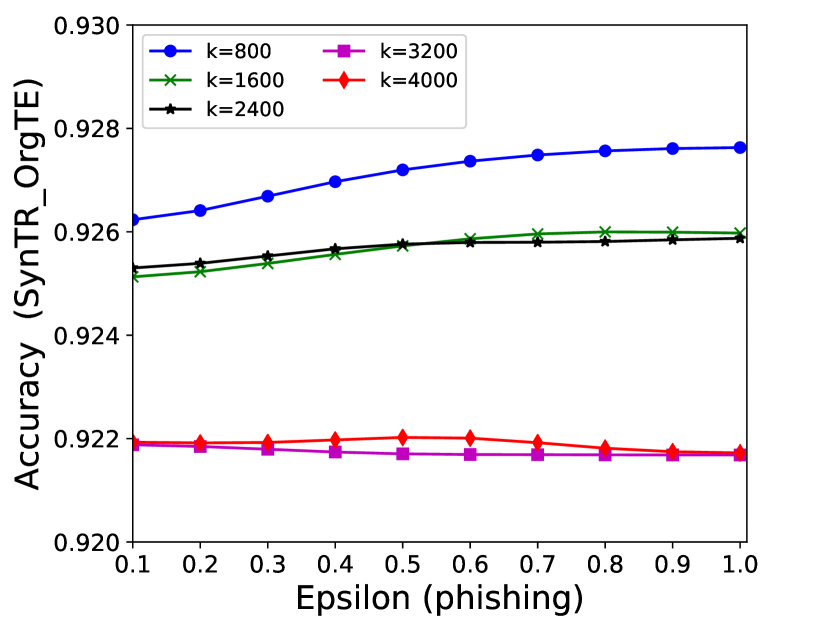
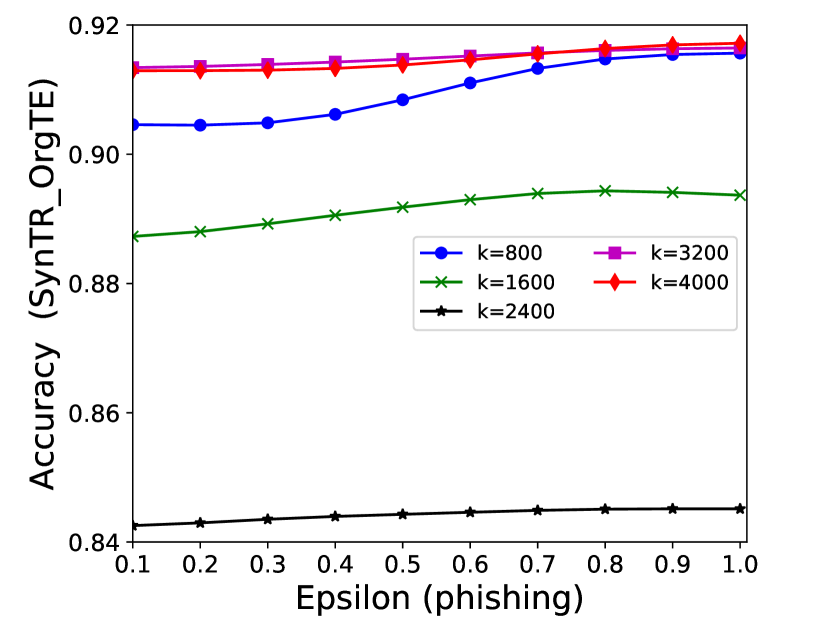
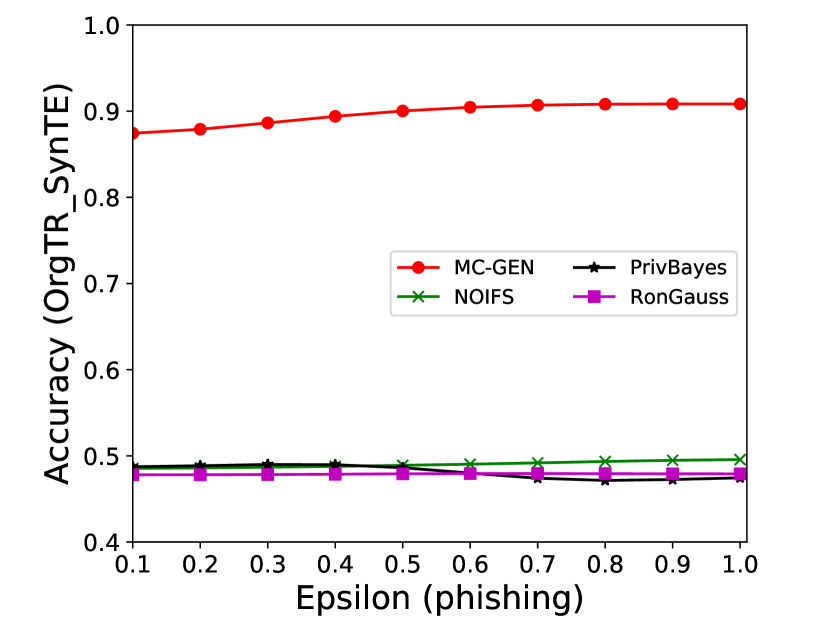
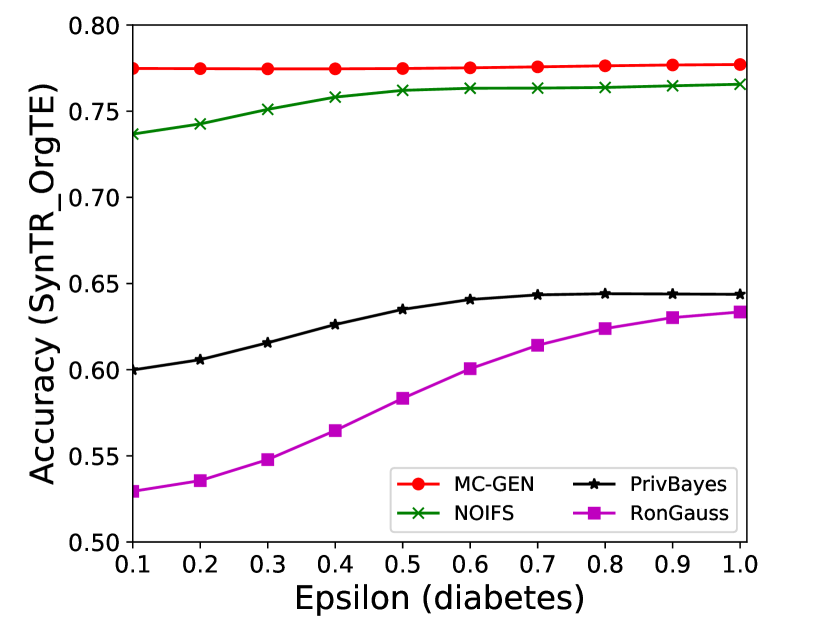
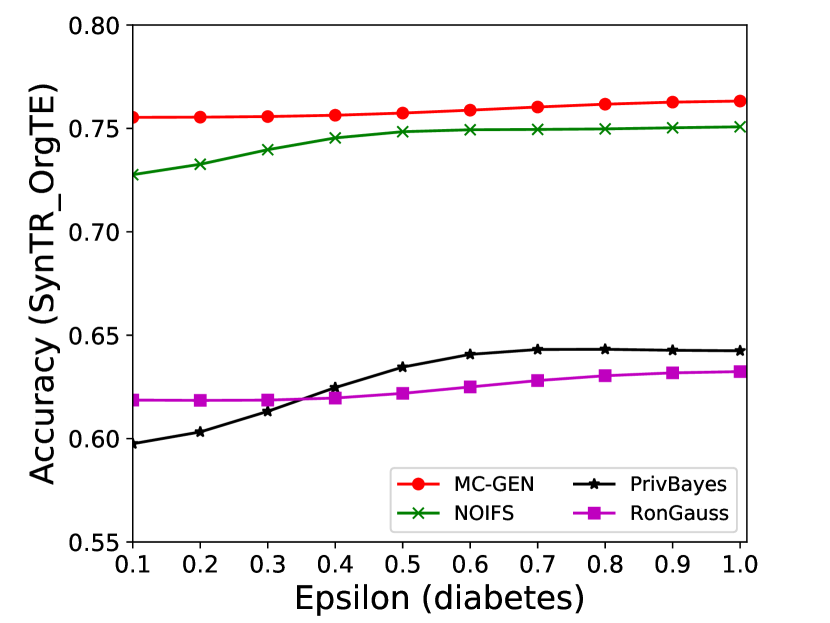
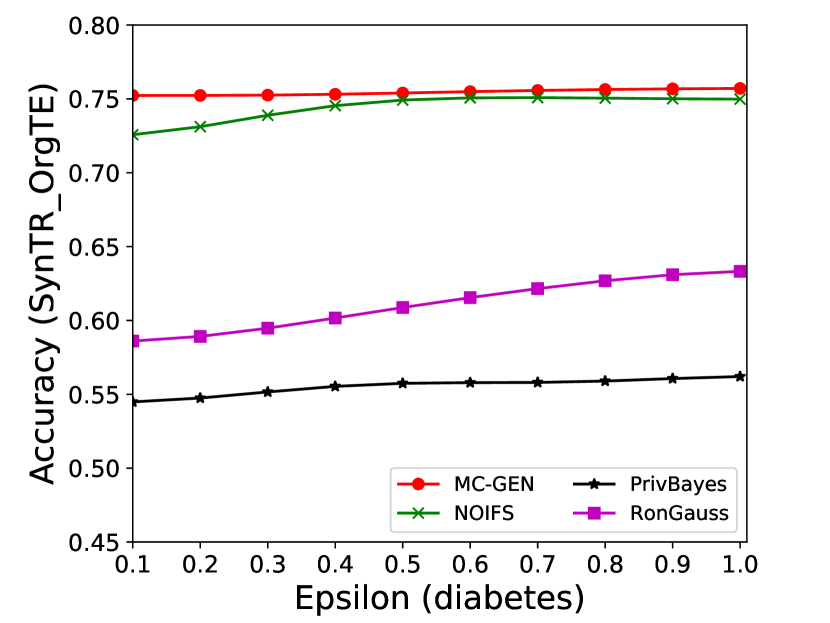
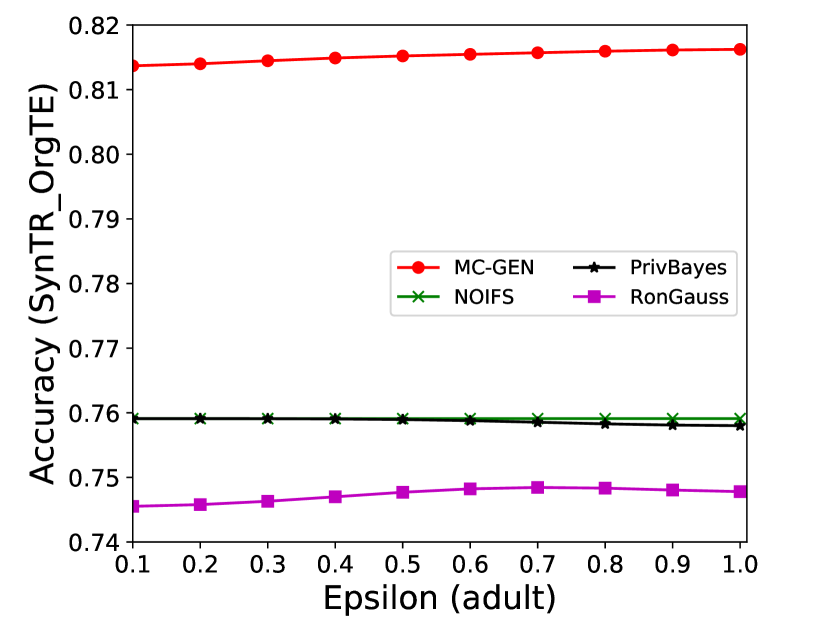
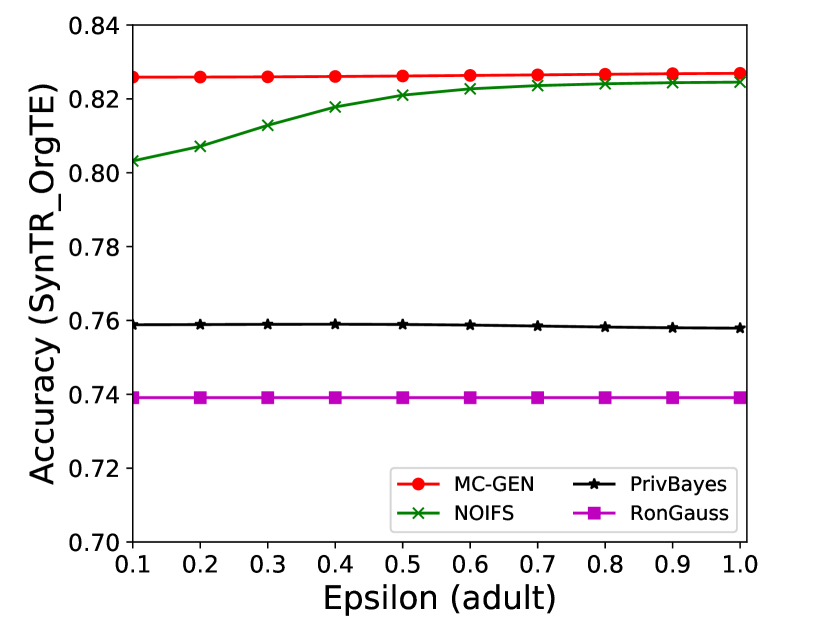
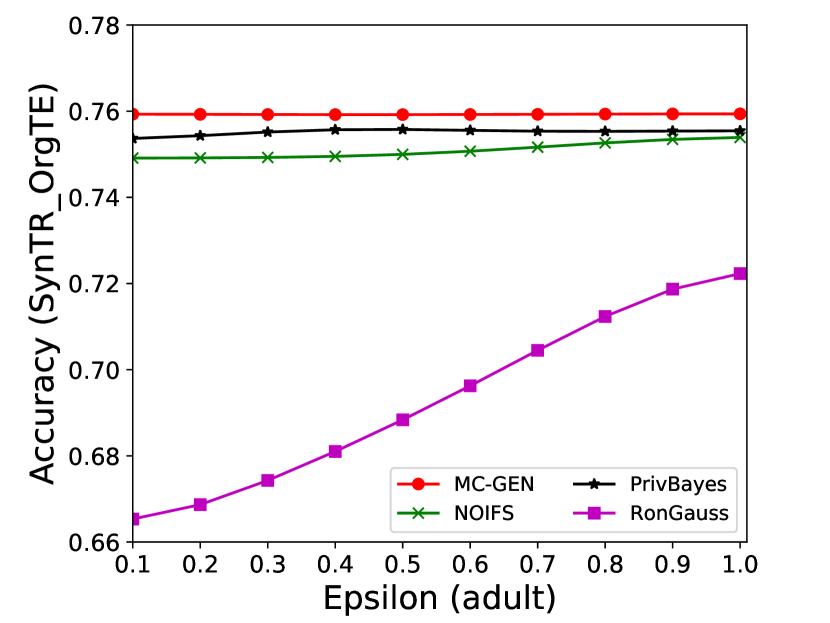
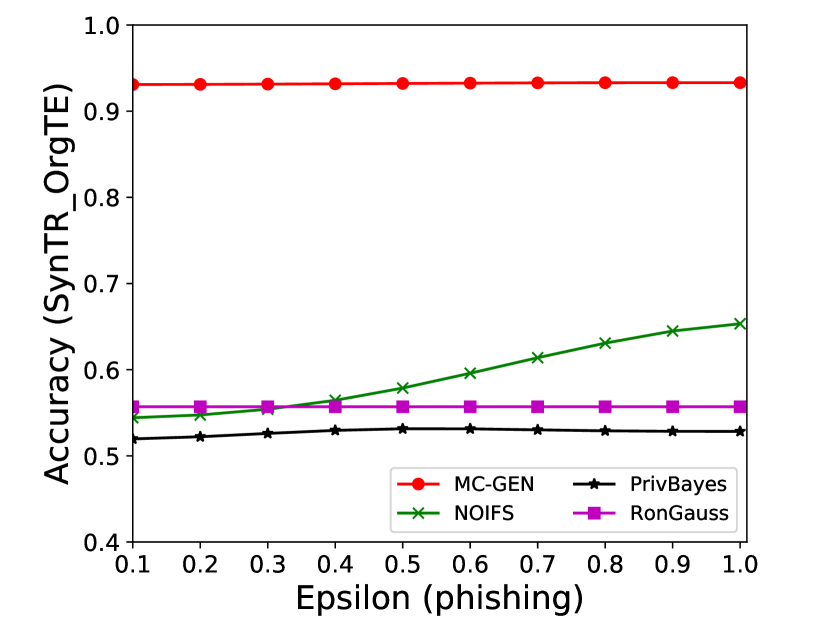
The performance of MC-GEN is affected by two parameters: privacy budget () and cluster size (). To evaluate the effectiveness of a single parameter, the other parameter remains the same. As shown in Fig.4, 5, 6, 7, 8 and 9, we observe that:
-
1.
Privacy budget (): This parameter controls the noise variance on the synthetic datasets. In DP mechanism, greater results in smaller-scaled noise, and vice versa. In our experiments, we investigate from 0.1 to 1. As shown in the results, the performance in all classification tasks increased as the privacy budget increased. While DP sanitizer adds noise on extracted statistical information (Fig. 3), large (small-scaled noise) make and closer to and , which results in less noise on synthetic datasets. In other words, the generative model captures more accurate statistical information. Thus, a greater would result in a better performance.
-
2.
Cluster size (): This parameter controls the number of data points in each cluster. Namely, the number of data points used to build each generative model. We investigate it from 20% to 100% based on the total number of seed data. Intuitively, the smaller would make synthetic data generation more precise since the data is captured in a high-resolution way. However, based on the results shown in Fig. 5, 6, 7, 8 and 9, small does not always result in the best performance. For instance, Fig. 5 (b), Fig. 7 (b) and 9 (a), (b) show that a moderate k achieve the best performance. Fig. 6 and Fig. 9 show that using a large k achieve the best performance. The local optimal k varies on different classification tasks and datasets. As such, it is hard to determine a perfect that covers all use cases. Finding a local optimal k helps MC-GEN capture the statistical representation of the dataset (clusters) in a good manner. Hence, when the classification task and datasets are assigned, it is worth investigating the local optimal k value for the dataset to ensure performance.
| Component | Time Complexity |
|---|---|
| Feature level Clustering | |
| Sample level Clustering | |
| Privacy Sanitizer and Generative Model |
5.4.2 Comparing with Existing Methods
In this section, we compared MC-GEN with three existing private synthetic data release methods:
-
1.
PrivBayes [30] [8]: PrivBayes is designed on the Bayesian network with differential privacy. Starting from a randomly selected feature node, it extends the network iteratively by selecting a new feature node from the parent set using the exponential mechanism. Then it applied the Laplace mechanism on the conditional probability to achieve the private Bayesian network. The synthetic datasets are generated by using the perturbated Bayesian network. PrivBayes [30] [8] are evaluated on the code provided by the paper authors.
-
2.
RonGauss [9]: RonGauss [9] releases the synthetic data based on Gaussian mixture model. It builds the Gaussian mixture model on the projected data in a lower dimension and generates the synthetic dataset based on the Gaussian mixture model with differential privacy noise. RonGauss [9] are evaluated on the code provided by the paper authors.
-
3.
NoIFS: NOIFS follows the same procedure (Fig. 2) as MC-GEN to generate the synthetic data. The difference between NOIFS and MC-GEN is that NOIFS only applies the sample level clustering (MDAV) in the data prepossessing. Comparing it with MC-GEN helps us to evaluate the effectiveness of feature level clustering.
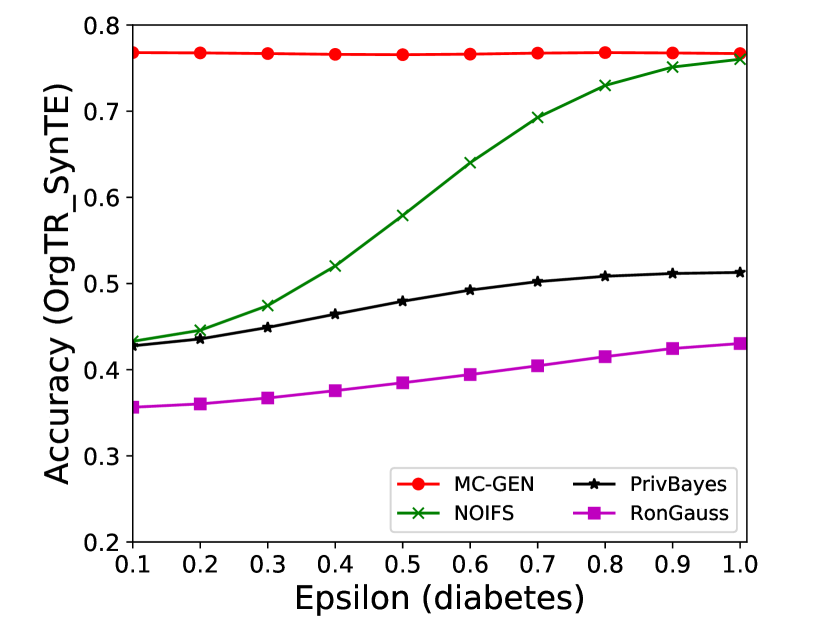
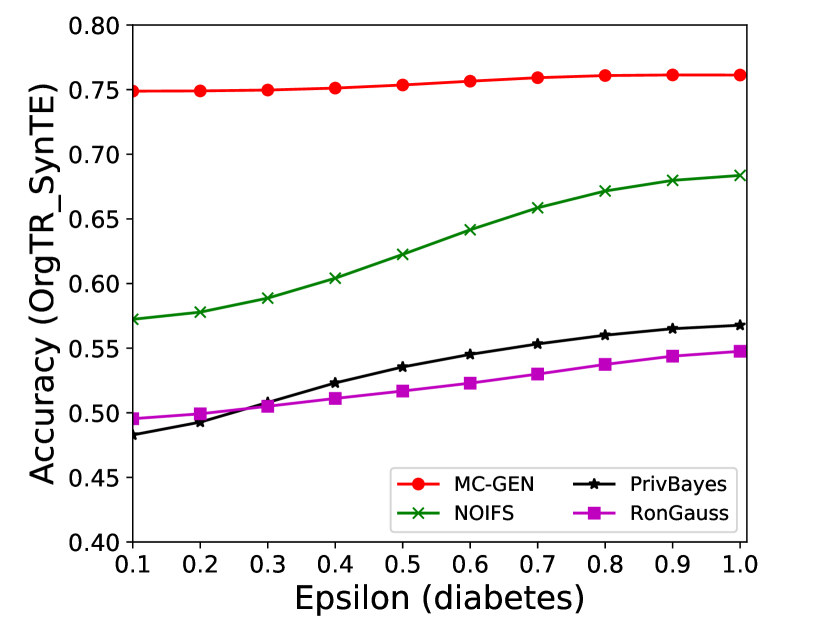
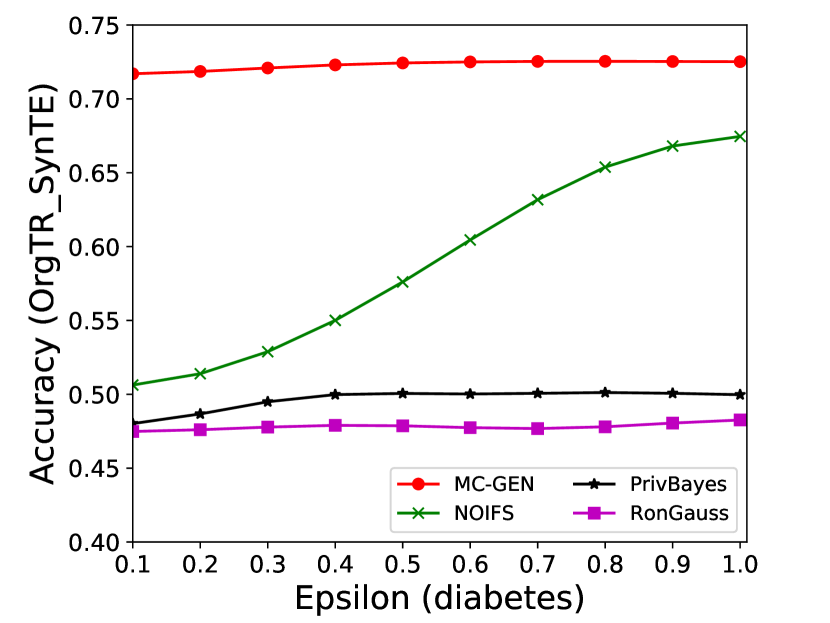
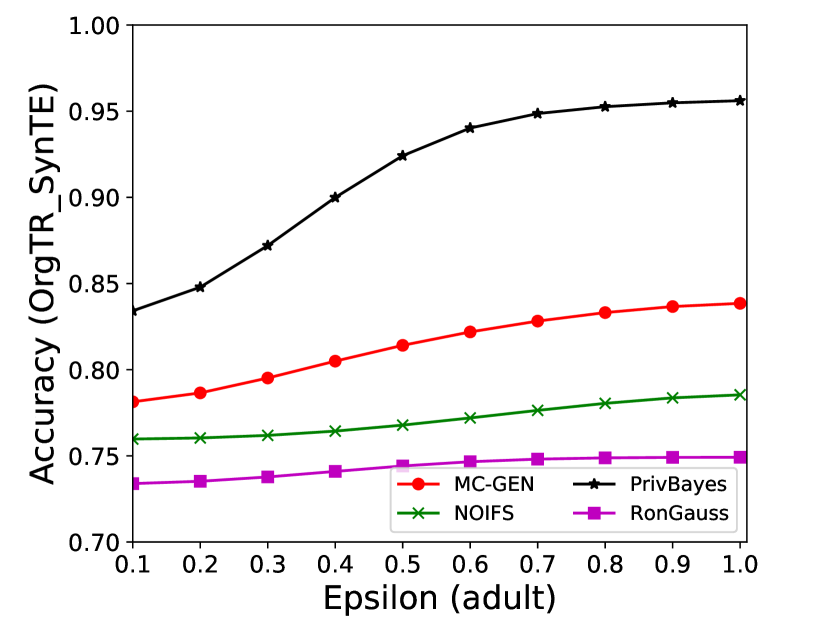
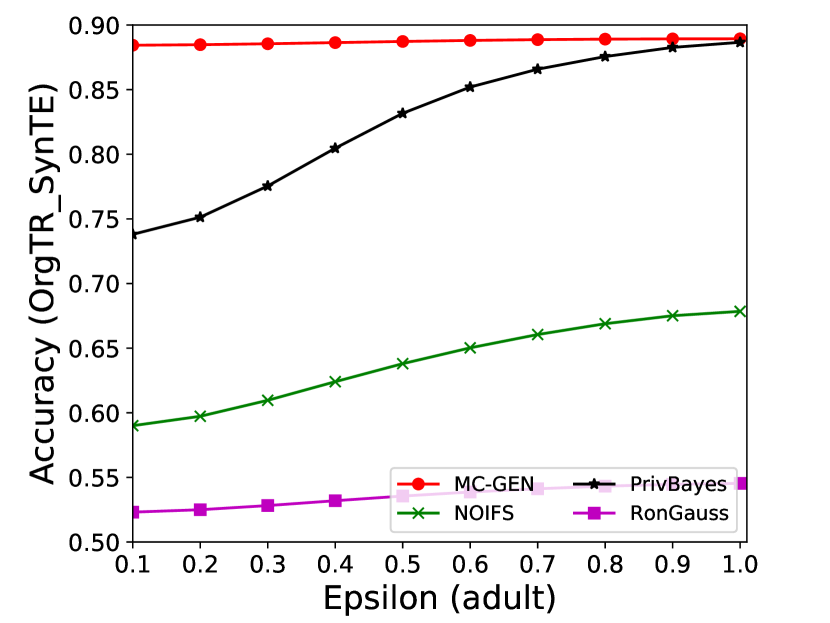
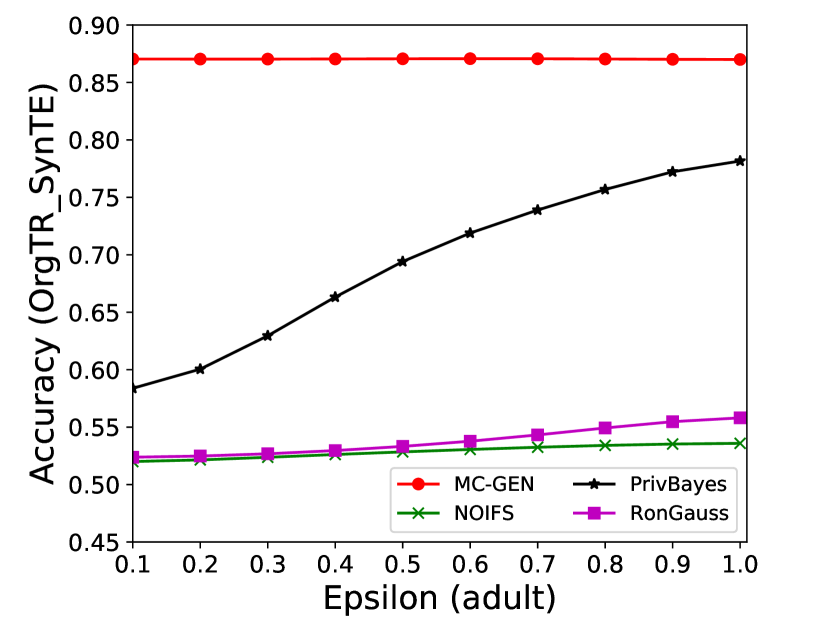
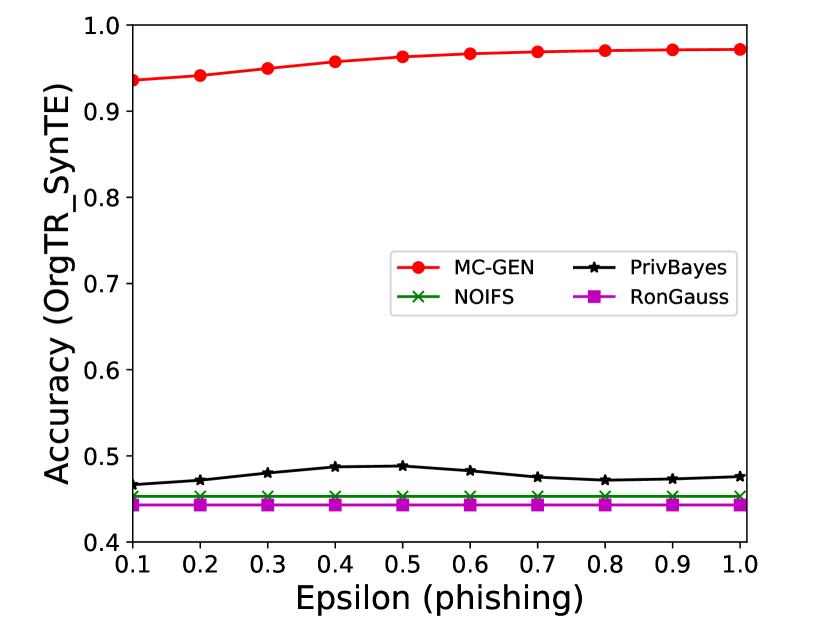
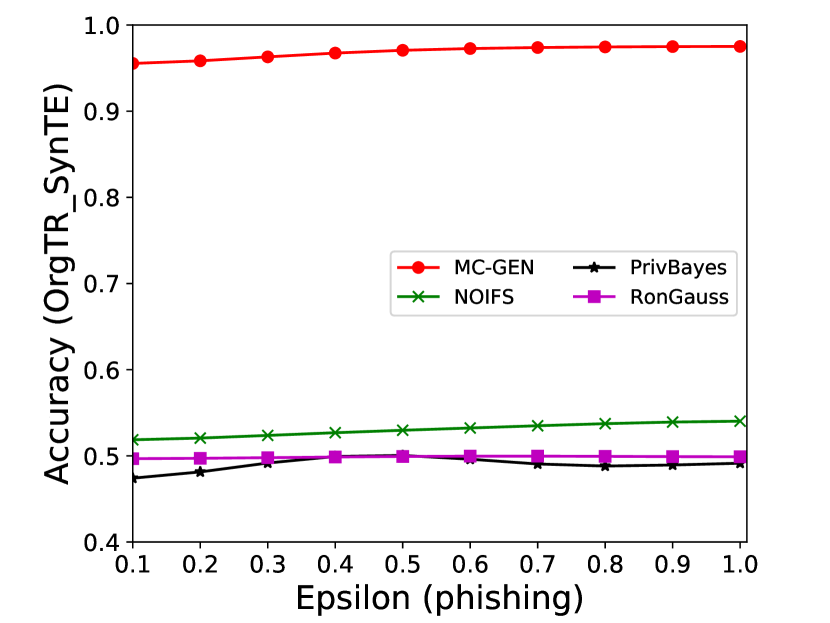
The performance of MC-GEN is evaluated under the local optimal parameter combination. For other methods, we follow the exact settings mentioned in the corresponding paper. Each method is evaluated on an average of 100 experiments. Fig. 10, 11, 12, 13, 14 and 15 show the results of different methods under the same privacy budgets. We can observe that MC-GEN outperforms the other methods in most cases. Besides, there are several findings during the comparison:
-
1.
MC-GEN always outperforms NOIFS due to the reduction in noise variance by feature level clustering (proof in section 4.4).
-
2.
In Fig. 11, PrivBayes has similar performance as MC-GEN, even outperform on SVM. However, in Fig. 14, MC-GEN outperforms PrivBayes consistently. It may cause by the number of seed data and data types in the datasets. The seed data in scenario 1 is much less than in scenario 2. Limited seed data may affect the performance of MC-GEN. On the other hand, most of the features in adult datasets are categorical features. The Bayesian network can be more effective than the multivariate Gaussian model on categorical data. Therefore, the utility of MC-GEN can be diminished on the small categorical dataset.
5.5 Time complexity of MC-GEN
The time complexity of MC-GEN is discussed in this section. In MC-GEN, there are 4 major components: feature level clustering, sample level clustering, privacy sanitizer, and generative model. Assuming the original data set has samples and features, feature level clustering vertically divided the dataset into IFSs. Then, each IFS with corresponding data is horizontally clustered into clusters. At this point, the original dataset is separated into clusters and each cluster has samples. In the end, the privacy sanitizer and generative model are applied simultaneously on each cluster. Since privacy sanitizer and generative model take effect at the same time, we consider it as the same part while discussing the time complexity. Table 2 illustrates the detailed time complexity of each component. Feature level clustering mainly relies on agglomerative hierarchical clustering which has time complexity . The time complexity of sample level clustering can be found in [31]. For privacy sanitizer and generative model, it applies the noise on data in each cluster, so the time complexity should be . Since , the time complexity can be rewritten as . All the components are sequentially applied, the total time complexity of MC-GEN is .
6 Conclusion
We proposed a novel and effective synthetic data generation method, MC-GEN, which targets on generating a private synthetic dataset for data sharing. We demonstrate MC-GEN improves the utility of synthetic datasets by using multi-level clustering. In the experimental evaluation, we show the effectiveness of synthetic datasets generated by MC-GEN and investigate the parameter effect of MC-GEN. With the best parameter settings, synthetic datasets generated by MC-GEN can achieve similar performance as original datasets. Moreover, we compared MC-GEN with three existing methods. The experimental results show that MC-GEN outperforms the other existing methods in terms of utility. In the future, we will apply and enhance the proposed method on different data types and different machine learning tasks. Meanwhile, as the complexity of data increases, a more powerful and precise model is worth exploring.
References
- [1] E. Talavera, G. Iglesias, Á. González-Prieto, A. Mozo, S. Gómez-Canaval, Data augmentation techniques in time series domain: A survey and taxonomy, arXiv preprint arXiv:2206.13508 (2022).
- [2] C. Dwork, Differential privacy: A survey of results, in: International Conference on Theory and Applications of Models of Computation, Springer, 2008, pp. 1–19.
- [3] M. Hardt, K. Ligett, F. McSherry, A simple and practical algorithm for differentially private data release, in: Advances in Neural Information Processing Systems, 2012, pp. 2339–2347.
- [4] C. Dwork, Differential privacy, Encyclopedia of Cryptography and Security (2011) 338–340.
- [5] K. Taneja, T. Xie, Diffgen: Automated regression unit-test generation, in: Proceedings of the 2008 23rd IEEE/ACM International Conference on Automated Software Engineering, IEEE Computer Society, 2008, pp. 407–410.
- [6] D. Su, J. Cao, N. Li, M. Lyu, Privpfc: differentially private data publication for classification, The VLDB JournalThe International Journal on Very Large Data Bases 27 (2) (2018) 201–223.
- [7] V. Bindschaedler, R. Shokri, C. A. Gunter, Plausible deniability for privacy-preserving data synthesis, Proceedings of the VLDB Endowment 10 (5) (2017) 481–492.
- [8] J. Zhang, G. Cormode, C. M. Procopiuc, D. Srivastava, X. Xiao, Privbayes: Private data release via bayesian networks, ACM Transactions on Database Systems (TODS) 42 (4) (2017) 25.
- [9] T. Chanyaswad, C. Liu, P. Mittal, Coupling dimensionality reduction with generative model for non-interactive private data release, arXiv preprint arXiv:1709.00054 (2017).
- [10] J. Soria-Comas, J. Domingo-Ferrer, Differentially private data sets based on microaggregation and record perturbation, in: Modeling Decisions for Artificial Intelligence, Springer, 2017, pp. 119–131.
- [11] M. A. Hall, Correlation-based feature selection for machine learning (1999).
- [12] J. Domingo-Ferrer, V. Torra, Ordinal, continuous and heterogeneous k-anonymity through microaggregation, Data Mining and Knowledge Discovery 11 (2) (2005) 195–212.
- [13] L. Sweeney, k-anonymity: A model for protecting privacy, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (05) (2002) 557–570.
-
[14]
L. Xie, K. Lin, S. Wang, F. Wang, J. Zhou,
Differentially private generative
adversarial network (2018).
doi:10.48550/ARXIV.1802.06739.
URL https://arxiv.org/abs/1802.06739 - [15] S. Imtiaz, M. Arsalan, V. Vlassov, R. Sadre, Synthetic and private smart health care data generation using gans, in: 2021 International Conference on Computer Communications and Networks (ICCCN), 2021, pp. 1–7. doi:10.1109/ICCCN52240.2021.9522203.
-
[16]
J. Yoon, J. Jordon, M. van der Schaar,
PATE-GAN: Generating
synthetic data with differential privacy guarantees, in: International
Conference on Learning Representations, 2019.
URL https://openreview.net/forum?id=S1zk9iRqF7 - [17] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial nets, Advances in neural information processing systems 27 (2014).
-
[18]
Y. Tao, R. McKenna, M. Hay, A. Machanavajjhala, G. Miklau,
Benchmarking differentially private
synthetic data generation algorithms, CoRR abs/2112.09238 (2021).
arXiv:2112.09238.
URL https://arxiv.org/abs/2112.09238 - [19] C. Dwork, F. McSherry, K. Nissim, A. Smith, Calibrating noise to sensitivity in private data analysis, in: Theory of cryptography conference, Springer, 2006, pp. 265–284.
- [20] S. C. Johnson, Hierarchical clustering schemes, Psychometrika 32 (3) (1967) 241–254.
- [21] P. Ahrendt, The multivariate gaussian probability distribution, Technical University of Denmark, Tech. Rep (2005) 203.
- [22] D. L. Davies, D. W. Bouldin, A cluster separation measure, IEEE transactions on pattern analysis and machine intelligence (2) (1979) 224–227.
-
[23]
R. A. Rossi, N. K. Ahmed, The network data
repository with interactive graph analytics and visualization, in: AAAI,
2015.
URL https://networkrepository.com - [24] Adult, UCI Machine Learning Repository (1996).
- [25] R. M. Mohammad, F. Thabtah, L. McCluskey, An assessment of features related to phishing websites using an automated technique, in: 2012 international conference for internet technology and secured transactions, IEEE, 2012, pp. 492–497.
- [26] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Machine Learning Research 12 (2011) 2825–2830.
- [27] L. Buitinck, G. Louppe, M. Blondel, F. Pedregosa, A. Mueller, O. Grisel, V. Niculae, P. Prettenhofer, A. Gramfort, J. Grobler, R. Layton, J. VanderPlas, A. Joly, B. Holt, G. Varoquaux, API design for machine learning software: experiences from the scikit-learn project, in: ECML PKDD Workshop: Languages for Data Mining and Machine Learning, 2013, pp. 108–122.
-
[28]
D. Dua, C. Graff, UCI machine learning
repository (2017).
URL http://archive.ics.uci.edu/ml - [29] C.-C. Chang, C.-J. Lin, Libsvm: a library for support vector machines, ACM transactions on intelligent systems and technology (TIST) 2 (3) (2011) 27.
-
[30]
J. Zhang, G. Cormode, C. M. Procopiuc, D. Srivastava, X. Xiao,
Privbayes: Private data
release via bayesian networks, SIGMOD ’14, Association for Computing
Machinery, New York, NY, USA, 2014.
doi:10.1145/2588555.2588573.
URL https://doi.org/10.1145/2588555.2588573 - [31] A. Oganian, J. Domingo-Ferrer, On the complexity of optimal microaggregation for statistical disclosure control, Statistical Journal of the United Nations Economic Commission for Europe 18 (4) (2001) 345–353.