Memory-efficient -projection with the fast Gauss transform
Abstract
We describe a method performing -projection using the fast Gauss transform of Strain (1991). We derive the theoretical performance, and simulate the actual performance for a range of for a canonical array. While our implementation is dominated by overheads, we argue that this approach could for the basis of a higher-performing algorithms with particular application to the Square Kilometre Array.
keywords:
techniques: interferometric1 Introduction
Interferometers are composed of an array of antennas arranged in a 3 dimensional volume. For long observations, even instantaneously planar arrays have baselines that are non-coplanar due to Earth rotation synthesis. Correcting non-coplanar baselines in interferometers require the use of a de-projection technique to compensate for the non-coplanarity. To date, -projection (Cornwell et al., 2008) is the most computationally efficient algorithm known.
Interferometric images are usually formed by convolutional resampling of the measured visibilities on a regularly sampled, two dimensional plane. Convolutional resampling operates by multiplying each visibility by a convolution function and adding the result to the -plane. In the simplest case, the convolution function is used for anti-aliasing purposes, although it can be used to compensate for primary beam affects, or in the case of -projection, to compensate for non-coplanar baselines. -projection uses a convolution function that is dependant on , which is the convolution of an anti-aliasing function, and a Fresnel term.
While more efficient that other methods (Cornwell et al., 2008), -projection does have some shortcomings. Firstly, the convolution functions take time to compute, and for a short observation, can dominate the time to compute an image. Secondly, the amount of memory to store the convolution functions can be large, and can exhaust the capabilities of a computing node. Finally, multiply-add operation is generally memory-bandwidth bound, so that the central processing unit (CPU) spends the majority of the time waiting for the data to arrive, and relatively little time doing the multiply-add operation.
The memory constraints of -projection are of particular concern. The trend in computing has been for memory bandwidth to increase much more slowly than arithmetic capacity, which has roughly doubled every 18 months (Moore’s law), with this trend likely to continue for the foreseeable future. Therefore, the performance of memory-bandwidth bound algorithms such as -projection will not improve as quickly as an algorithm which is bound by arithmetic capacity. Furthermore, modern high performance computers rely on having a very large number of small nodes, with each node having relatively limited memory. The requirement to store large convolution functions is, therefore, at odds with having nodes with small amounts of memory.
Memory efficient algorithms, therefore, will be an important step on the path to implementing wide-field imaging capabilities for the Square Kilometre Array (SKA). We have embarked on an program to research new approaches to interferometric imaging, with particular emphasis on algorithms that align more closely with the memory-bound computing that will be available in the time frame of the SKA.
In this paper we describe a different approach to -projection. The key to our method is to represent the convolution function, including the -projection term, and an anti-aliasing function, as a complex Gaussian. The gridding and degridding problems can then be solved using the variable-width fast Gauss transform (FGT; Strain (1991)). One advantage of this approach is that it does not require convolution functions to be computed and stored, and the theoretical memory bandwidth is less than standard gridding, in some situations.
In section 2 we describe Gaussian anti-aliasing functions used for projection and in section 3 we apply these functions with the Fast Gauss Transform, to the gridding and degridding problems. In section 4 we derive the theoretical operations and memory requirements, and in section 5 we compare the theoretical requirements for our method and the standard methods. In section 6 we compare the theoretical results with a real-world implementation. We discuss our results in 7 and we draw our conclusions in section 8.
2 -projection with a Gaussian anti-aliasing function
In this section we describe the gridding process, and use a Gaussian anti-aliasing function to obtain a closed form expression for the convolution function.
We acknowledge that the anti-aliasing properties of a Gaussian are not ideal. Typical interferometric imaging uses prolate spheroidal wavefunctions, which have a optimal out-of-band rejection (Schwab, 1980). Nonetheless, Gaussian functions have simple analytical relationships (e.g. the convolutions and Fourier transforms of Gaussians are both Gaussians) that allow us to proceed.
2.1 Gridding
The aim of convolutional gridding is to take visibilities sampled on arbitrary coordinates and interpolate them onto a regular grid so that a 2D fast Fourier transform (FFT) can be used to estimate the sky brightness distribution (Taylor et al., 1999, p. 134ff). Mathematically, the grid is evaluated at a point by multiplying each visibility by a shifted convolution function according to:
| (1) |
where is the number of visibilities in to be gridded, , , and are the coordinates of the projected baseline (in wavelengths), is a convolution function and is the measured visibility weight. Typically, is assumed to be zero outside some region of support (6–8 pixels). If we take no account for the term, then the convolution function is chosen to be an anti-aliasing function, and is independent of , i.e. . If we account for the term using -projection of Cornwell et al. (2008), then the convolution function is given by
| (2) |
where denotes convolution, is an anti-aliasing function, and
| (3) |
is the Fresnel diffraction term required by the projection algorithm.
2.2 Radially symmetric Gaussian anti-aliasing functions
For a fixed , equation 2 is the convolution of the anti-aliasing function with a complex Gaussian. If we choose a Gaussian for the anti-aliasing function , the resulting convolution function is also Gaussian. To simplify notation, we will consider the radially symmetric problem by introducing a new parameter , and can now write the Fresnel term as:
| (4) | |||||
| (5) |
with . We can also write the Gaussian anti-aliasing function as
| (6) |
The gridding function is given by the convolution , which is another Gaussian, whose variance is equal to the sum of the variances of the original Gaussians, i.e., to within a scaling factor:
| (7) | |||||
| (8) | |||||
| (9) | |||||
| (10) |
The width of the envelope is given by
| (12) |
and width of the complex chirp is
| (13) |
The convolution function is, therefore, a complex Gaussian, which can be expressed as the product of real-valued Gaussian envelope (the term in equation 10) with a complex chirp (the term). Clearly, as increases, the width of the Gaussian envelope increases.
For a given visibility indexed by the form of the convolution function can be calculated from its coordinate using:
| (14) |
where
| (15) |
is the width of the relevant convolution function, and is the coordinate of the visibility.
2.3 Conversion from wavelengths to pixels
Up to this point, the co-ordinates and the Gaussian widths have been in units of wavelength. For the remainder of this paper, width will often be quoted in terms of pixels. We use the terms pixel and -cell interchangeably. To convert from wavelengths to pixels, a size of -cell is required. The size of the -cell, (in wavelengths) is set by the inverse of the desired field of view (in radians) i.e. .
Therefore, a Gaussian width in pixels can be calculated from the width in wavelength by:
| (16) |
3 projection with the Fast Gauss Transform
3.1 A brief introduction to the Fast Gauss Transform
In this section we introduce the Fast Gauss Transform (FGT) with variable scales (Strain, 1991) (hereafter S91), which is an approximate technique for calculating the sum of Gaussians. We conform to the language of S91, which uses the term ‘source’ to describe a Gaussian function with a given position, amplitude and width. We will describe the application of the FGT onto the gridding problem in section 3.2.
The FGT works by partitioning the evaluation region into square boxes, with each box containing a set of Taylor coefficients (Fig. 1). For each Gaussian ‘source’, the Taylor coefficients for the boxes surrounding the source position are updated, with the size of the updated region being defined by the ‘width’ of the source, i.e. wider Gaussians update more boxes. When all sources have been applied, the Taylor coefficients are evaluated at any number of target locations. The algorithm is parameterised by three numbers: , which sets the box size, , which defines number of Taylor coefficients to consider, and which sets the smallest size of Gaussian that will be considered. Reducing the box size, or increasing the number of Taylor coefficients increases the accuracy of the sum.
3.2 Gridding with the Fast Gauss Transform
Now that we have a Gaussian convolution function (Equation 14), we can solve the sum of Equation 1 the FGT with source-dependant scales. In the language of gridding visibilities, the evaluation region is the plane. The ‘sources’ are the visibilities, with the source position being given by the coordinates of the visibility on the plane. The width of the source is related to the coordinate of the visibility as in Equation 15, with the minimum width when , being essentially the width of the anti-aliasing function. When all the visibilities have been applied to the Taylor coefficients, the Taylor coefficients are evaluated on a regular grid, for each cell on the plane.
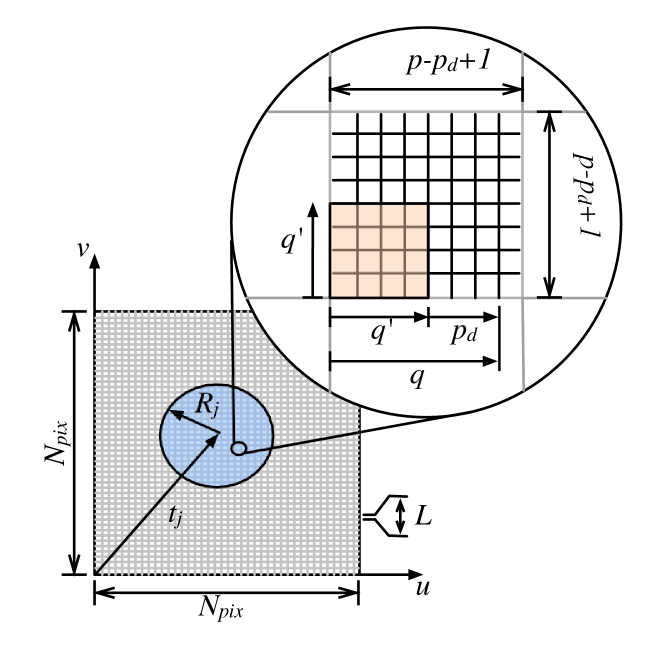
For a detailed description of the algorithm, we refer the reader to S91. For the purposes of explaining our implementation, we outline the algorithm in the following text, using similar notation to S91. This description applies to the one-dimensional case, but S91 describes the relationships to extend it to the multi-dimensional case (using multi-index notation), for which the 2D case is relevant here. Additionally, this description is only valid for real Gaussians. The extension to complex Gaussians will be considered in the next section.
The algorithm proceeds as follows:
-
1.
Given values of and calculate:
(17) where
(18) -
2.
Partition the plane into the set of boxes with centers , and side length parallel to the axes, where is the smallest Gaussian width to be considered.
-
3.
For each visibility indexed by , calculate the range . Also calculate the order satisfying
(19) where .
-
4.
For each box within of the visibility position , update the Taylor coefficients according to:
(20) where runs from to , is the visibility weight, and is the Hermite function (see S91).
-
5.
Once all the visibilities have been applied, evaluate the Taylor coefficients at each cell in the plane, by finding the box in which the cell is situated, and calculating the sum:
(21) where is the position of the cell, and runs from to .
The error in the evaluation of the sum is bounded by:
| (22) |
where
| (23) |
and are chosen to make .
3.3 Extension to complex Gaussians
The formulation of S91 is explicitly for real Gaussians, i.e. with , but in our case . A full derivation of the algorithm for complex values is outside the scope of this work . The important questions are whether the series of Equation 20 converges (and for what values of a complex ) and what is a suitable range ().
Empirically, we have determined that:
-
1.
Using a range of provides good results. This also makes sense because it is the amplitude of the envelope that determines the range.
-
2.
For calculating the order (Equation 19) we used
(24) Other possibilities (e.g. ) reduced too aggressively as increased, which resulted in very large errors.
In our case, the minimum value of occurs when which also coincides with so the box size is easily set as equal to .
3.4 Optimisations
S91 describes a number of optimisations that can be used in the FGT with source-dependent scales:
-
1.
S91 introduces a single set of Taylor coefficients, positioned at the center of the plane, to capture Gaussians with the largest scales. Visibilities larger than an upper scale size can be added to this single set, rather than the sets associated with the boxes. S91 recommends the upper scale size be at least 10% of the size of the evaluation region, in order to allow for practical precision in evaluating the large number of Taylor coefficients. In practice, most array configurations would have relatively few baselines with such a large that their convolution functions would span 10% of the plane, so this optimisation has limited impact.
-
2.
S91 introduces a lower scale below which the Gaussian sum is directly evaluated. If there are only a few Gaussians with scales smaller than , we can increase the box size, which reduces the memory and arithmetic capacity required, while incurring minimal penalty from direct evaluation. In practice, any interferometric observation is likely to be arranged such that the mean value of is approximately zero. Therefore, there are unlikely to be outlying, small Gaussians that would allow for increasing the box size. Once again, this optimisation has limited impact.
-
3.
S91 proposes doing direct evaluation for boxes containing only a few evaluation points. As we are evaluating on a regular grid, we have the same number of evaluation points inside each box, so applying this optimisation would degenerate into standard gridding.
-
4.
S91 proposes a method for avoiding needlessly accurate computation, i.e. for large scales (which are smoother than small ones) more boxes are updated, but smaller number of Taylor coefficients (i.e. the order described in Section 3.2) per box can be updated. This optimisation is useful and derives the most benefit for visibilities with large scales ( large, see section 4.). We have incorporated this optimisation in Equation 19.
- 5.
-
6.
The fact that each uv-cell contains a number of Taylor terms affords an additional axis available for parallelisation. The strategy is described in section 3.4.2.
3.4.1 Cheating
There are two sources of error when a sample is gridded (see Figure 3). The first is from truncating the support; that is, only boxes only within a finite range are updated. Convolutional gridding suffers from the same type of truncation error. The second source of error is from truncation of the Taylor terms; that is, only Taylor terms are updated. S91 notes that the equation for calculating the error from truncation of Taylor terms (Equation 19) overestimates the error by several orders of magnitude. If this is the case, for a given value of , the error will be dominated by the truncated support, and the contribution from the truncation of the Taylor terms will be negligible. In principle, therefore, one can reduce the number of Taylor terms without substantially increasing the overall error, as long as it remains less than the error from the truncation of support.
In order to balance the errors from both effects, we introduce an additional parameter to the algorithm , which decrements value of , so that the actual value of that is used is . This reduces the CPU and memory requirements of updating a given box, at the expense of increasing the errors due to truncating the Taylor terms.
3.4.2 Parallelisation
One interesting property of our approach is that affords an additional axis of parallelisation (the Taylor terms) in addition to those available for standard gridding (typically, data parallelisation over frequency channels). We assume that the parallelism is achieved through message passing.
In section 4 we show that the memory bandwidth and operations count for the FGT is dominated by updating the Taylor terms. As each of the Taylor terms is independent, one can in principle store each of the Taylor terms on (up to) as many nodes, thereby dividing the per-node storage requirement by the number of nodes. For the case where is a multiple of the number of nodes, the work is spread equally among the nodes. Each node can update its Taylor terms for the boxes within range, and, the total memory bandwidth is increased by the number of nodes.
One penalty of parallelising in this way is that each node must calculate the same interim values (e.g. the values of the Hermite polynomials). This duplication can be reduced by partitioning the Taylor terms among fewer nodes, with each node being responsible for a particular row or column of the Taylor terms.
If is less than the number of nodes, then some nodes will have no work to perform, as they are responsible for Taylor coefficients that are not being updated. One must be careful, therefore, to choose an algorithm parameterisation i.e. (, and ) that guarantees never to give less than the number of nodes.
The efficiency of this approach depends crucially on the properties of the computing nodes. It is useful if the nodes are storage or memory bound, but not if the cost of computing the interim values dominates the computing time. As this tradeoff requires intimate knowledge of the particular computing architecture, we will not pursue a detailed analysis of parallelisation in this paper.
3.5 Degridding with the Fast Gauss Transform
Degridding is used as part of the major cycle of Cotton-schwab clean (Rau & Cornwell, 2011). Degridding involves taking the dot-product of the plane with the convolution function shifted to the location of a visibility at an arbitrary location (i.e. not at the center of a cell). It is the dual of gridding.
Degridding can be performed analogously to gridding using the fast Gauss transform with target-dependent scales (S91). All the same comments about optimisations for gridding (Section 3.4) apply as for degridding.
3.6 Key differences between classical gridding and the FGT
The key conceptual differences between classical gridding and FGT gridding are described in Table 1
| Property | Classical Gridding | Fast Gauss Transform |
|---|---|---|
| Accuracy: | Exact | Approximate, but with controllable error. |
| Anti-aliasing function: | Arbitrary. | Gaussian only. |
| Fundamental scale: | A -cell, set by imaging geometry. | A box, which can be smaller, or larger than a -cell. |
| Gridding a single visibility updates: | Cells on the -plane. | Taylor coefficients in a set of boxes. The cells of the -plane is calculated as a post-processing step. |
4 Theoretical performance
Here we derive the theoretical performance of the gridding and degridding processes using the fast Gauss transform, and traditional convolutional gridding.
4.1 Operations count of the fast Gauss transform
4.1.1 Gridding
To grid a single visibility of width , the number of boxes that are within a circular region within the range is approximately:
| (25) |
The the order is chosen to satisfy the error estimate:
| (26) |
where .
To apply cheating (Section 3.4.1), we decrement the value of , such that .
Now we consider work required to update the Taylor coefficients in each box (Eq. 20). The key is to compute and store the Hermite functions, and powers of separately, and perform the sum at the end, by taking advantage of the product form of the multi-index notation for multiple dimensions.
The Hermite function is a polynomial multiplied by a complex exponential. The argument for the complex exponential is the same for every order , so only one calculation is required per set of Hermite function evaluations. The way in which a complex exponential is computed by a CPU is highly implementation-dependant, so we simplify the analysis here and assume that it requires floating point operations.
We observe that the Hermite function of order has only nonzero coefficients. Second, we note that we will evaluate the Hermite functions for order with the same argument. Therefore, we can calculate the powers of the argument initially with operations. Evaluating each Hermite function requires only additional operations. Therefore, to compute all Hermite functions up to order requires approximately:
| (27) | |||||
The multi-index powers of can be computed recursively, by computing with , and . This requires operations .
The weight can be folded into the power values also, with operations.
Finally, the full sum to update over two dimensions requires the multiplication of Hermite functions for 2 dimensions, and the powers, plus the accumulation, which requires operations in total.
The total number of operations to update a single box is therefore the sum of two Hermite evaluations (one for each dimension), plus the powers of , the weights and the final sum, i.e.:
| (28) |
For small , the cost is dominated by the cost of evaluating the complex exponential. For large , it is dominated by the multiply-add step in the final sum.
4.1.2 Degridding
The operations count for the degridding process is similar to the gridding case. The order is evaluated identically, as are the Hermite functions and the powers of . The only difference is that no weight is included, and the multiply-add stage includes the product of the two hermite functions, the power and the Taylor term, requiring operations.
The number of operations per visibility is therefore:
| (29) |
Once again, for small , the cost is dominated by the cost of evaluating the complex exponential. For large , it is dominated by the multiply-add step in the final sum.
4.1.3 Memory bandwidth
Calculating memory bandwidth is complicated by the issue of cache hierarchy. We assume the simplest case: i.e. no caching. In practice, this is a reasonable assumption, as visibilities are often stored in no particular order. Therefore, the desired grid (and convolution functions in the case of convolutional gridding) are essentially random, meaning that all memory accesses go to the main memory and bypass the caches.
For the fast Gauss transform, gridding a visibility requires the updating of complex coefficients. The coefficients must be read into the processor, updated, and written back to memory, requiring memory transactions per visibility.
For degridding, the coefficients do not need to be written back to memory, therefore the only memory transactions are required.
4.1.4 Storage
For an image size of , the gridding operation requires storage for complex coefficients. Degridding requires the same storage.
4.2 Performance of convolutional gridding and degridding
In this section we derive the operations count, memory bandwidth and storage required to perform gridding and degridding with stored convolution funcitons. In order to put the two methods on equal footing in terms of imaging performance, we will use Gaussian anti-aliasing functions for the -projection, rather than the commonly-used prolate spheroidal wavefunctions. This means that the imaging performance of the two approaches is essentially the same (except for the errors in truncating the Taylor series of the FGT) and the support size of the convolution functions is also easily computed.
We assume standard projection computes the convolution functions in advance and stores them in memory. We assume a convolution function of 1-D size for the th -plane , where is an integer, and difference in size between different planes. Usually the cached convolution function is oversampled by a factor of 4–8 in order to accurately grid visibilities whose coordinates are not exactly in the center of a cell.
We assume that we truncate the convolution function when the real envelope reaches a value , which is at a distance from the centre of the convolution function. Therefore, the 1D support size in pixels, of the th -plane is (by substituting Equation 12)
| (30) | |||||
4.2.1 Operations count
Gridding a visibility requires two operations per point (weight times convolution function, add to grid), for a total of operations per visibility. Degridding also requires two operations per point(convolution function times grid, add to result) and and therefore requires operations per visibility.
4.2.2 Memory bandwidth
Gridding requires the convolution function, and the grid position to be retrieved and written back to memory, requiring memory transactions per visibility. Degridding has no requirement to write back the result, (as the intermediate sum is stored in a register), so only memory transactions are required.
4.2.3 Storage
To compute the total memory required, we will determine the amount required to store -planes for values of between , uniformly sampled with width . In practice, we need to store -planes for , so we will take the above result and multiply by two.
The amount of memory required to store the convolution functions is therefore equal to the sum of the oversampled convolution functions, i.e.:
| (31) | |||||
| (32) |
5 Theoretical Performance Comparison for Gridding
We consider the gridding problem for two scenarios, and . We assuming pixel, a required accuracy of , a 1 degree field of view and a 6 km maximum baseline at giving a of . The convolution function size at maximum of pixels. We assume the cost of evaluating a complex exponential is flops. This estimate is also justified by measurements of our implementation (Fig. 5).
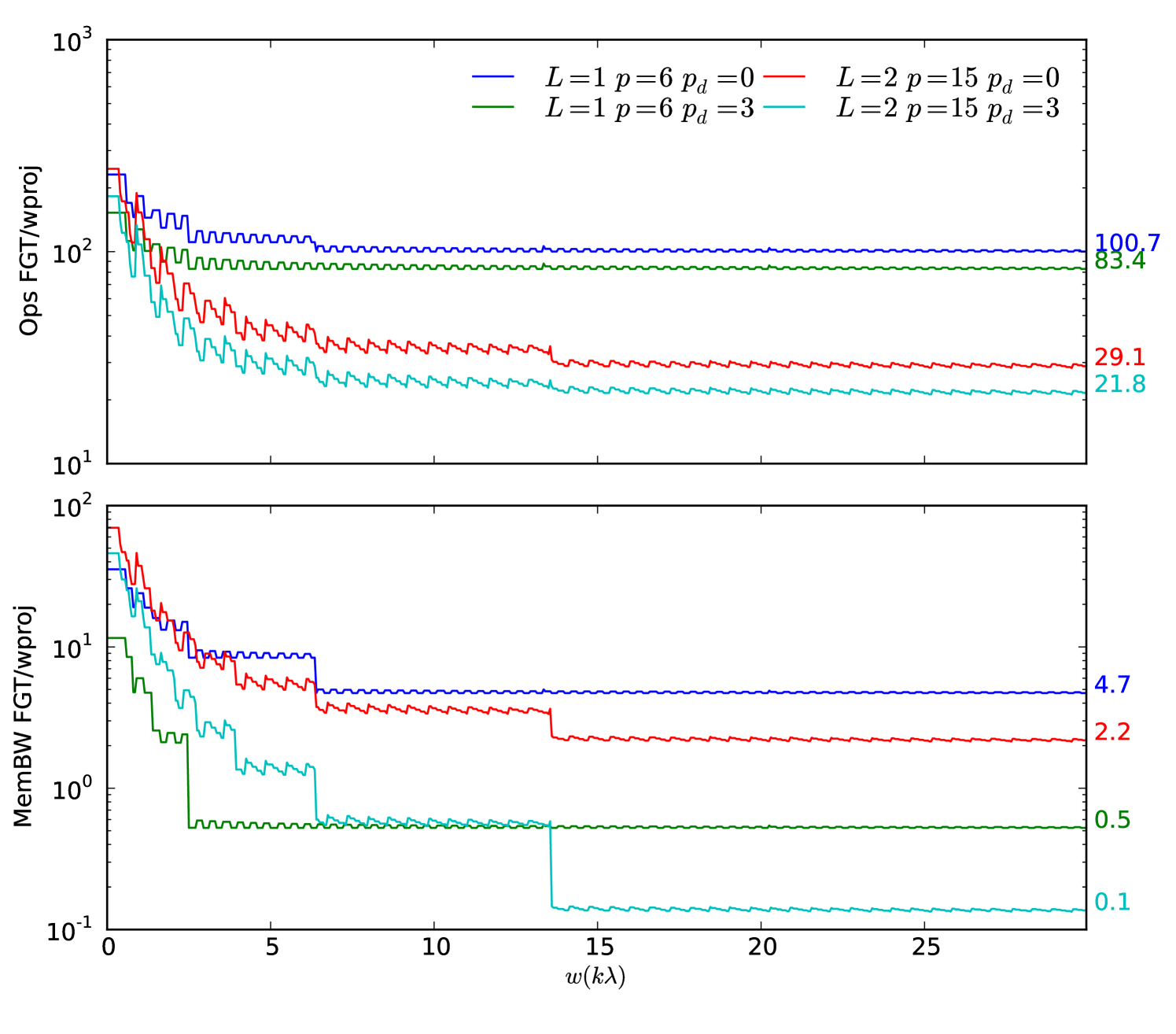
The FGT method for and is outperformed by standard gridding both in terms of operations and memory bandwidth, if cheating is not enabled (Figure 2). For the case in particular, the operations count is dominated by the complex exponential.
If cheating is enabled, then the situation is substantially improved. Once the value reaches above a certain threshold, the order , and only one Taylor coefficient is updated per box. In the case, the memory bandwidth is reduced to 0.5 of the standard gridding case, because the FGT only requires only two memory transactions per pixel (read + write coefficient), while standard gridding requires three (read pixel + read convolution function + write pixel). For the improvement in memory bandwidth is even more with the FGT requiring 10 times less memory bandwidth than standard gridding. The FGT is more efficient as it only updates one coefficient for each box, which encapsulates 4 pixels. The FGT case is also improved because it only updates boxes within a circular region, while standard gridding updates all pixels within a square.
This encouraging result leads to a number of questions: is the FGT bound by memory bandwidth? Can these performance gains be realised in practice? Can cheating with give reasonable image errors? We will address these questions in the following section.
6 Implementation
We implemented the gridding and degridding algorithms as described in Section 3 in C++. As with the theoretical simulation, we set the width of the anti-aliasing function equal to cell. We aim explore the parameter space similar to the theoretical analysis, i.e. around and and ranges of errors around .
To compare the gridding errors, we compared the relative error of a visibility gridded with the FGT with the equivalent complex Gaussian (Equation 9), calculated over pixels (which is larger than the 191 pixels we expect for and ) . To compare the compute times, we compare the time to grid 100 visibilities of fixed coordinates with the FGT, with the same number of visibilities gridded with standard gridding. The support size of the gridding kernel was chosen to have with equivalent error to the FGT error, i.e. pixels. We chose 101 planes from to . The processing was performed on an Intel Core 2 Duo processor running at 2.66 GHz, with 32 kB of L1 cache, 3 MB of L2 cache and with 8 GB of 1057 MHz DDR3 RAM.
We consider here only the results for the gridding operation, as the degridding algorithm results essentially the same.
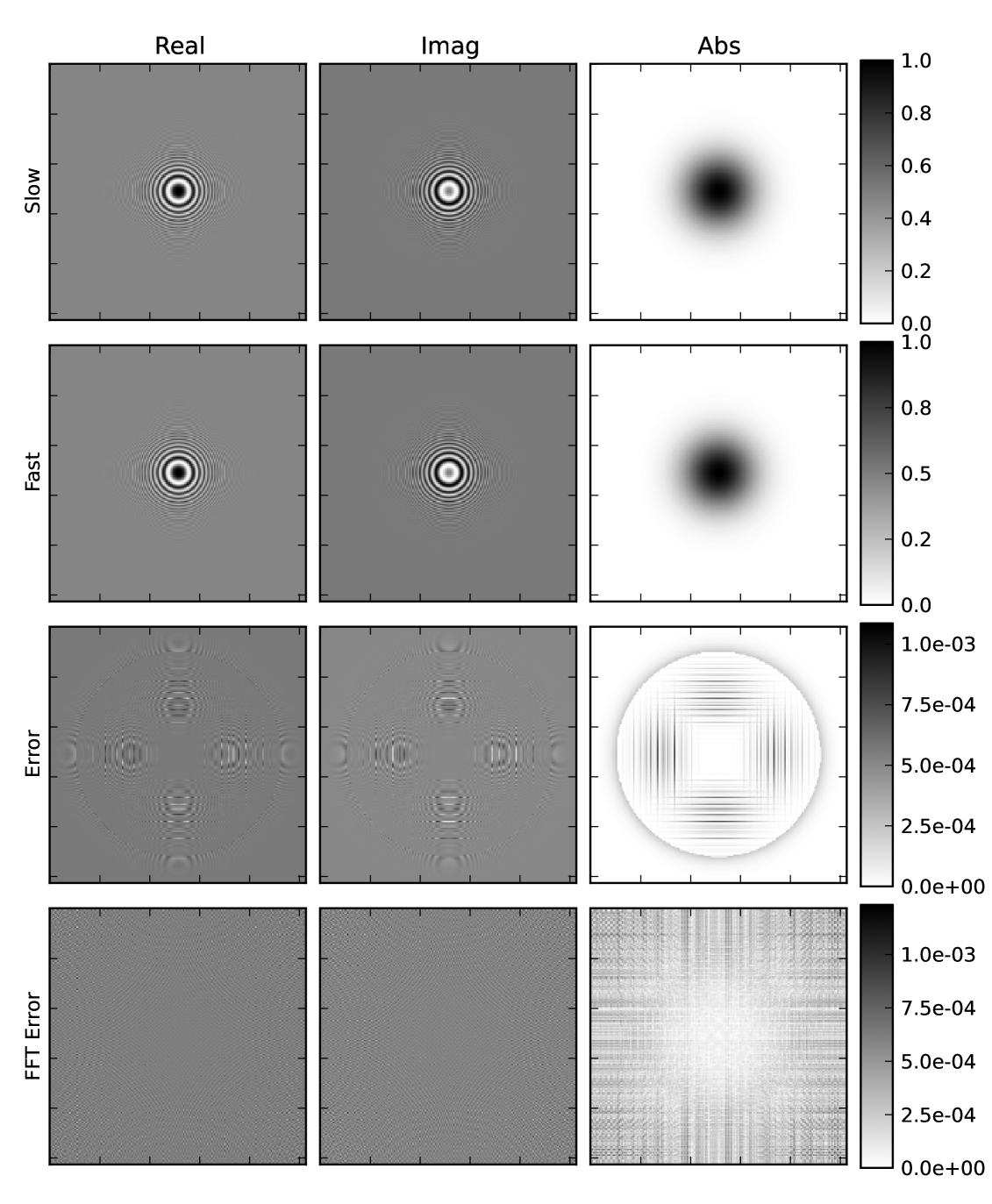
6.1 Error patterns
A typical error pattern is shown in Figure 3. The absolute error in the gridded visibility contains two components. The circular component is due to the truncation to finite support, i.e. boxes outside the circle were not updated. The vertical and horizontal lines are due to truncation to a finite number of Taylor terms, with the largest error where the grid is evaluated near the boundary of adjacent boxes. The box structure of the gridding process can also be clearly seen in the FFT error, which also shows a box structure.
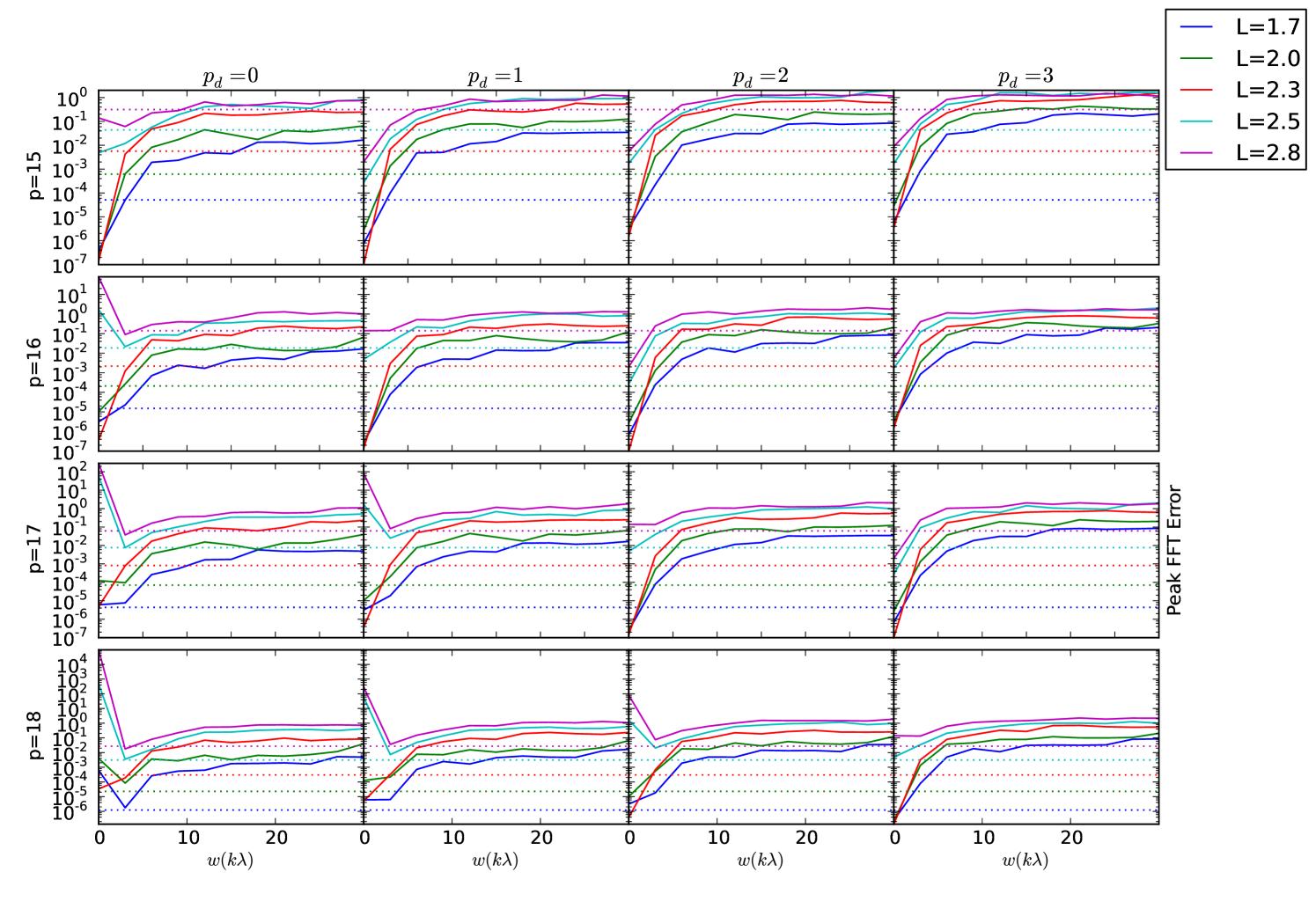
6.2 Peak Image Errors vs
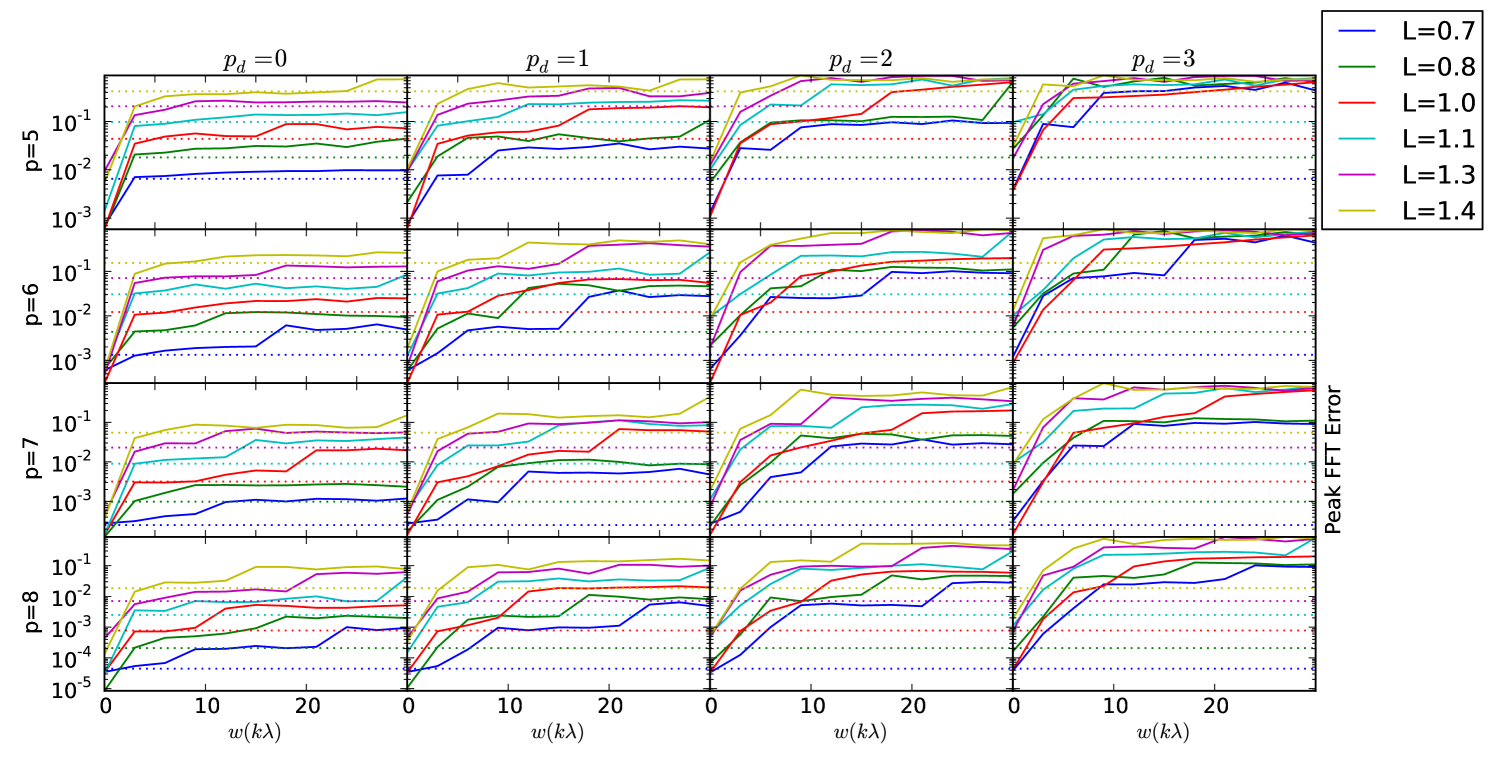
The peak error in the FFT of the visibility (i.e. the image plane), as a function of the for a range of algorithm parameterisations are shown in Figure 4. To begin with, we consider the case for . Somewhat surprisingly, Equation 17, which describes the error in gridding a single visibility on plane, also predicts the error the image plane for many parameterisations and values of . For , and small , the errors are substantially smaller than the predicted . As increases, is reduced, and the error generally matches the predicted . For some parameterisations (e.g. , ) there is a jump in error above predicted at a particular .
For the case, for small , the errors are at or below the theoretical limits in most cases, however in many cases the errors are considerably worse than for . For example, for small in some cases (e.g. , , ) the error increases far beyond the theoretical limit. For large , the errors are several orders of magnitude worse than predicted.
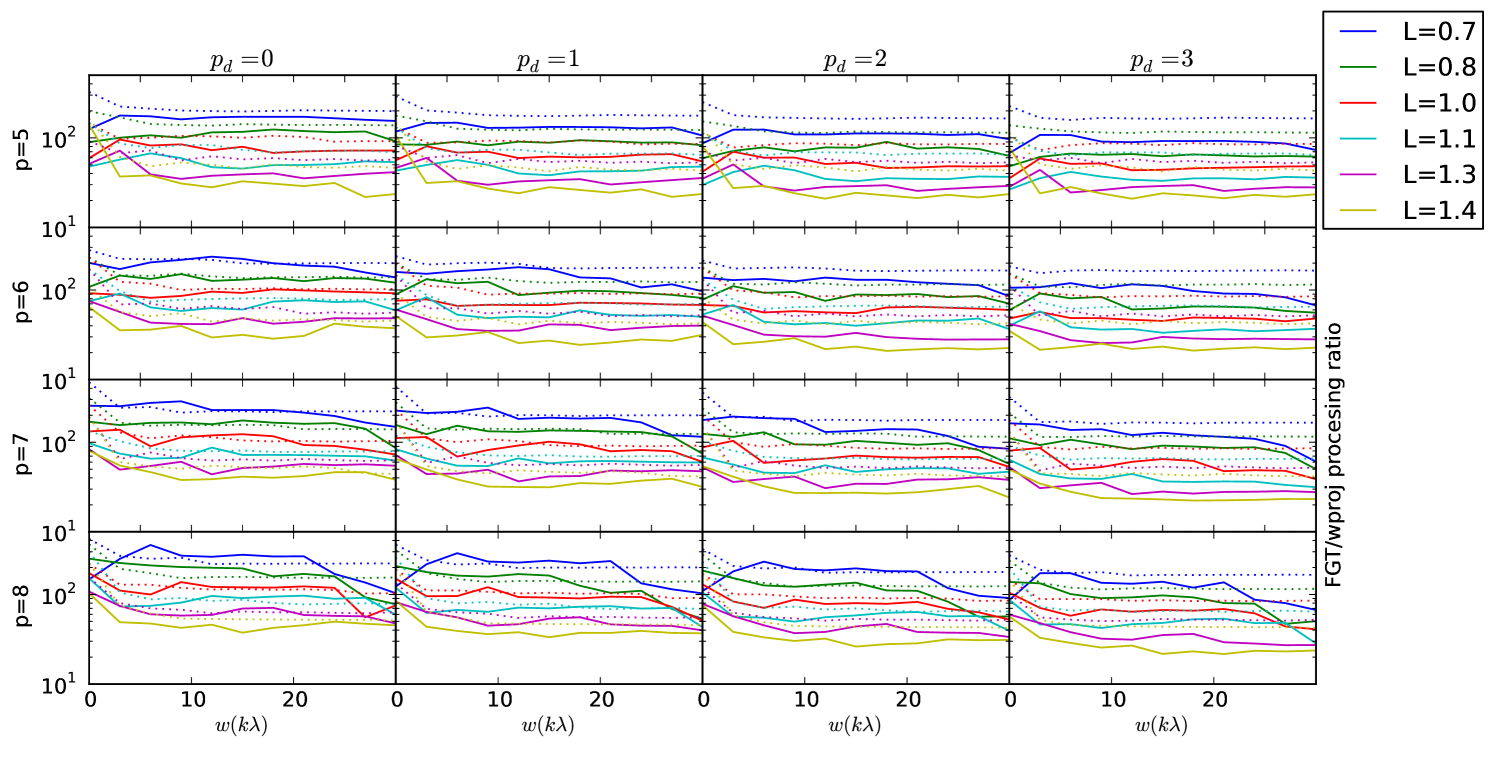
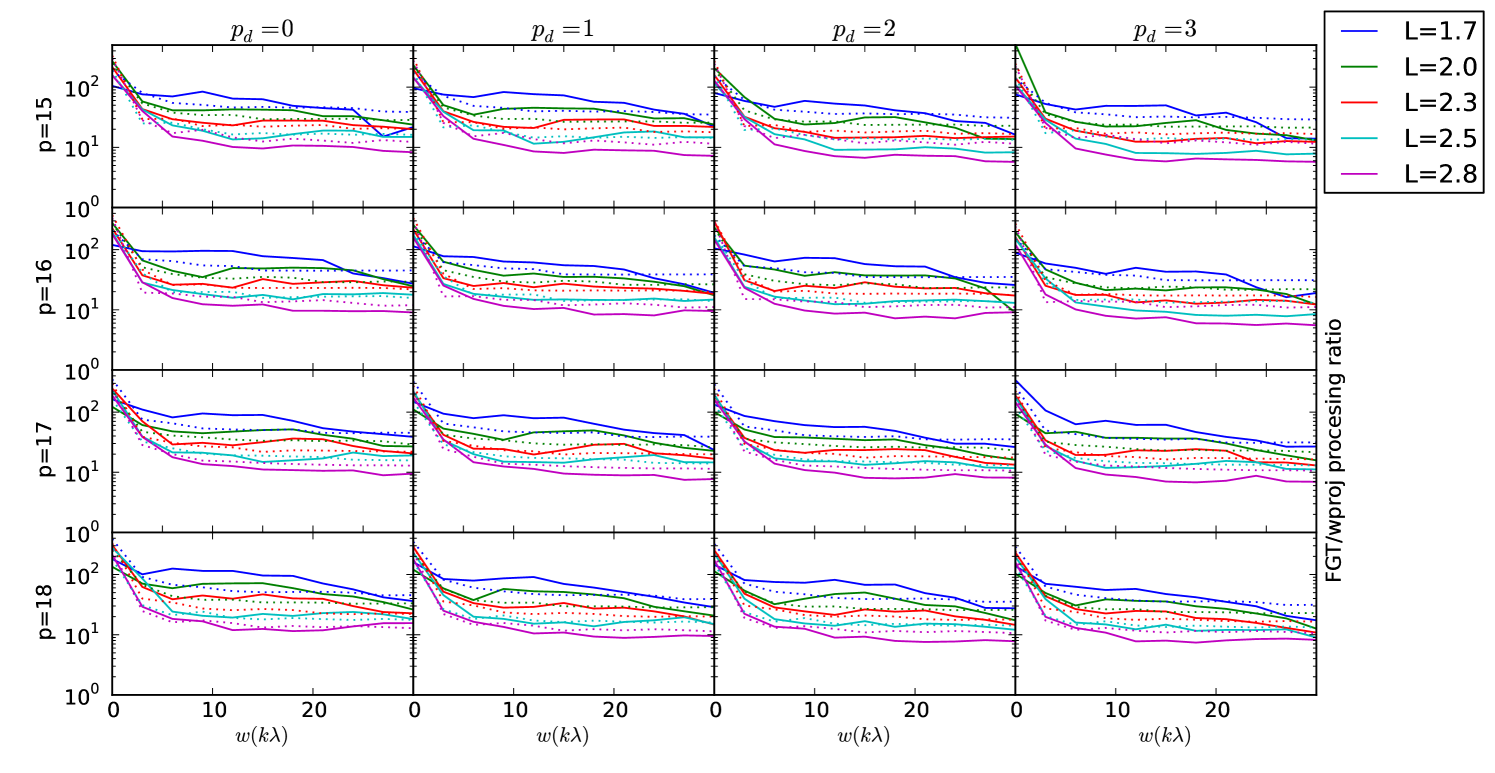
6.3 Processing time
The measured processing time for the FGT vs. standard gridding is shown in Figure 5. Our implementation operates substantially slower than standard gridding for all parameterisations and ranges of , and the operations rate is well matched by the our theoretical model for the operations count.
7 Discussion
7.1 FGT Implementation
The results from testing our implementation are somewhat conflicting. On the plus side, Figure 4 clearly shows that, for small values of , Equation 19 is overestimating the truncation error, and the value of being used is too large. This was the original motivation for introducing cheating, and it is clear that the error is still overestimated even for in some cases.
Unfortunately, for larger values of , the fact that the error jumps above the predicted , even with no cheating, implies that our empirical extension to the FGT to complex Gaussians, (in particular Equation 19, and Equation 24) is not correct. As a result of this incorrectness, our current cheating algorithm has limited value. Even with , most parameterisations contain jumps in error of factors of few to 100 over the range of . A different mapping between and is required to maintain a constant error across .
Increasing the box size above appears to have catastrophic affects on the error for small . We suspect this is due either to numerical instability in evaluating high-order polynomials, or more likely, the Hermite expansions simply fail to converge when the Gaussian width is less than some function of the box size.
Our implementation’s processing time is clearly compute-bound as our computing times match our theoretical model for the operations count almost exactly in most instances. The theoretical model suggests the operations count is dominated by the cost of computing the complex exponential, and we expect that is the case, although other overheads may also be responsible. Sadly, we were not able to approach the memory-bound performance that originally motivated this work.
7.2 Future work
In spite of the disappointing performance of our implementation, we hope that some of the ideas from this work could be extended in future. In particular:
-
•
The idea of having tuneable error is attractive. For arrays with high sidelobes in their synthesised beams (i.e. poor coverage), large gridding errors can be made, as long as they remain below the clean threshold for the given major cycle.
-
•
The required memory bandwidth of our algorithm is only weakly dependant on , so for arrays with very long baselines, our algorithm may be suitable.
-
•
The Hermite expansions were originally proposed by Greengard & Strain (1991) for real Gaussians. It may be that faster-converging expansions can be found for complex Gaussians - particularly in the case for large where the real envelope is smooth and the complex chirp contains many peaks.
-
•
The form of the convolution function is smooth at the centre and oscillates more rapidly as increases, with the fastest oscillations being damped at the edges by the envelope. Currently, our approach is to use the same order for all boxes, which leads to the largest errors being made away from the centre of the convolution function (Figure 3) where the oscillations are the fastest and largest. There may, therefore, be some value in varying the order as a function of the distance from the centre, thereby applying the majority of the computational effort where the errors are likely to be worst.
-
•
We implemented the polynomial evaluations in a naive manner. More sophisticated methods exist (Knuth, 1997, p. 485ff) that could reduce the operations count and improve numerical stability.
-
•
To calculate the complex exponential, we used the CEXP function from the standard C library, which is accurate but slow. Faster, approximate methods are available111http://gruntthepeon.free.fr/ssemath/ (e.g. (Schraudolph, 1998). For an implementation whose run time is dominated by CEXP such as ours, these methods could improve speed by a factor of a few, albeit at the cost of some accuracy.
-
•
Gaussian anti-aliasing functions are not well suited to imaging, as the alias rejection is not very good. The modern state of the art is to use prolate spheroidal wavefunctions (Schwab, 1980), that have better alias rejection. Unfortunately, the Hermite functions are not a suitable basis for Taylor expansion of the prolate spheroidal wavefunctions. If suitable analytic multipole expansions of the convolution of the complex chirp, and the prolate spheroidal wavefunctions can be found, then they can be applied with the fast multiple method (Greengard & Rokhlin, 1987; Greengard, 1988) to obtain a similar result as our FGT, but with better anti-aliasing properties.
-
•
The fast multipole method could also be used to compensate for the primary beam in the -plane (AW-projection, (Bhatnagar et al., 2008)). Once again, this would require analytic multipole expansions of the required convolution functions. While this may not be possible with an arbitrary primary beam, it may be more tractable if we assume Gaussian primary beams.
-
•
For problems where the compute time of -projection is dominated by the time to compute convolution functions (by Fourier transforming a phase screen in the image plane), using standing gridding with Gaussian anti-aliasing functions could be preferable, as they can be directly and efficiently computed in the domain.
-
•
Easily parallelised algorithms will clearly be important for large arrays such as SKA, where the computational work is likely to be spread over many thousands of nodes. Once the gridding problem has been distributed over the usual axes of frequency, pointing direction and polarisation, it is possible that problem may still be too large to be efficiently computed by a single node. For the gridding operation, the option of distributing and parallelising over Taylor coefficients adds an additional axis which an be exploited when distributing work among processors, over and above the traditional axes.
8 Conclusions
We have described a procedure to perform -projection with the fast Gauss transform with variable scales, where the anti-aliasing function is chosen to be a Gaussian. The gridding problem is solved by the FGT with source variable scales, and the degridding problem by the FGT with target variable scales. While the theoretical efficiency of our approach is encouraging, we were not able to approach the the theoretical performance gains with our implementation. Nonetheless, we find that projection with approximate algorithms such as the FGT or fast multipole methods may yet have promise, by having the attractive properties of tuneable error, an additional parallelisation axis, and no calculation and storage of convolution functions. The methods require additional research, to improve the practical implementation, find expansions with faster convergence, and find closed forms with better anti-aliasing properties.
9 Acknowledgements
The authors would like to thank Maxim Voronkov and Ben Humphries for invaluable help with C++ coding, Matthew Whiting for the idea of tuneable errors within major cycles, and Oleg Smirnov for his insightful referee comments.
References
- Bhatnagar et al. (2008) Bhatnagar, S., Cornwell, T. J., Golap, K., Uson, J. M. 2008, A&A, 487, 419
- Cornwell et al. (2008) Cornwell, T. J., Golap, K., Bhatnagar, S. 2008, IEEE Journal of Selected Topics in Signal Processing, 2, 647
- Greengard (1988) Greengard, L. 1988, The rapid evaluation of potential fields in particle systems, Vol. 1987 (the MIT Press)
- Greengard & Rokhlin (1987) Greengard, L. Rokhlin, V. 1987, Journal of computational physics, 73, 325
- Greengard & Strain (1991) Greengard, L. Strain, J. 1991, SIAM Journal on Scientific and Statistical Computing, 12, 79
- Knuth (1997) Knuth, D. E. 1997, The Art of Computer Programming, 3rd edn., Vol. 2 (Addison-Wesley)
- Rau & Cornwell (2011) Rau, U. Cornwell, T. J. 2011, A&A, 532, A71
- Schraudolph (1998) Schraudolph, N. N. 1998, Neural Computation, 11, 853
- Schwab (1980) Schwab, F. R. 1980, Optimal Gridding, Tech. rep., VLA Scientific Memoranda 132
- Strain (1991) Strain, J. 1991, SIAM Journal on Scientific and Statistical Computing, 12, 1131
- Taylor et al. (1999) Taylor, G. B., Carilli, C. L., Perley, R. A., eds. 1999, Astronomical Society of the Pacific Conference Series, Vol. 180, Synthesis Imaging in Radio Astronomy II (Orem, Utah, USA: ASP)