Mesoscopic Bayesian Inference by Solvable Models
Abstract
The rapid advancement of data science and artificial intelligence has affected physics in numerous ways, including the application of Bayesian inference, setting the stage for a revolution in research methodology. Our group has proposed Bayesian measurement, a framework that applies Bayesian inference to measurement science with broad applicability across various natural sciences. This framework enables the determination of posterior probability distributions of system parameters, model selection, and the integration of multiple measurement datasets. However, applying Bayesian measurement to real data analysis requires a more sophisticated approach than traditional statistical methods like Akaike information criterion (AIC) and Bayesian information criterion (BIC), which are designed for an infinite number of measurements . Therefore, in this paper, we propose an analytical theory that explicitly addresses the case where is finite in the linear regression model. We introduce mesoscopic variables for observation noises. Using this mesoscopic theory, we analyze the three core principles of Bayesian measurement: parameter estimation, model selection, and measurement integration. Furthermore, by introducing these mesoscopic variables, we demonstrate that the difference in free energies, critical for both model selection and measurement integration, can be analytically reduced by two mesoscopic variables of observation noises. This provides a deeper qualitative understanding of model selection and measurement integration and further provides deeper insights into actual measurements for nonlinear models. Our framework presents a novel approach to understanding Bayesian measurement results.
I Introduction
The rapid development of data science and artificial intelligence has led to numerous studies in physics that actively incorporate these fields [1, 2], aiming for new developments in physics. Among them, Bayesian inference shows high compatibility with traditional physics. Our group has proposed Bayesian measurement as a framework for applying Bayesian inference from statistics to measurement science [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]. Bayesian measurement can be applied to almost all natural sciences, including physics, chemistry, life sciences, and earth and planetary sciences. In this framework, one can determine the posterior probability distribution of parameters for a mathematical model constituting a system. Additionally, if there are multiple mathematical models explaining the same phenomenon, one can perform model selection to determine the most appropriate model solely on the basis of measurement data. Furthermore, Bayesian integration, i.e., measurement integration, enables the integration of multiple data obtained from multiple measurements on the same system and determines how to integrate this data solely on the basis of the data itself. Bayesian measurement consists of three core principles: estimation of the posterior probability distribution of parameters, model selection, and Bayesian integration.
When performing Bayesian measurement, the results of model selection and Bayesian integration vary depending on the fluctuation of measurement data when the number of data is finite. While Bayesian inference was first proposed by Thomas Bayes in the 18th century, its theoretical framework was traditionally developed under the assumption of an infinite number of measurement data , as represented by Bayesian information criterion (BIC) [19]. Consequently, conventional BIC theory proves ineffective for model selection using Bayes Free Energy when dealing with a finite number of data N. The construction of theories that explicitly address finite N has become a crucial test of the practicality of Bayesian measurement. Our goal is to go beyond existing theories for an infinite number of data .
The purpose of this paper is to propose a novel theoretical framework for the three core principles of Bayesian measurement: estimation of the posterior probability distribution of parameters, model selection, and Bayesian integration, when the number of measurement data is finite within the linear regression model. The proposed theory for finiteness aims to analytically address the results of model selection and Bayesian integration. In the conventional framework that assumes the infinite limit of measurement data , which is typically seen in many theoretical frameworks of Bayesian inference, it is impossible to consider the fluctuations as random variables arising from the finiteness of . The proposed theory is an innovative framework that is fundamentally different from conventional theories. In this paper, we develop a solvable theory for the linear regression model with Gaussian noise as the measurement noise based on quantity measurement data. This model, while seemingly simple, is not merely for theoretical analysis. It is widely used in real measurement settings, such as with linear system responses. Furthermore, insights gained from this model can be extended to general nonlinear models.
Let us assume that the observation noise in observation data follows a Gaussian distribution. We define mesoscopic variables consisting of the Gaussian noises within the linear regression model. Specifically, we define two Gaussian distributions and a chi-square distribution defined by the sum of Gaussian noises. Using these mesoscopic variables, we propose a mesoscopic theory of the three core principles of Bayesian measurement: estimation of the posterior probability distribution of parameters, model selection, and Bayesian integration.
This paper is structured as follows. In Section II, we develop a theory using mesoscopic variables to express the estimation of the posterior probability distribution of parameters in Bayesian measurement using the linear regression model . In Section III, we build on the mesoscopic theory in Section II to propose a mesoscopic theory for model selection. This theory shows that the Bayesian free energy difference that determines model selection fluctuates greatly when the number of data is small. Furthermore, we show that by introducing mesoscopic variables, the free energy difference necessary in model selection can be analytically expressed with one mesoscopic variable of observation noise. In Section IV, we propose a mesoscopic theory for Bayesian integration building on the mesoscopic theory in Section II, and show that the Bayesian free energy difference that determines the Bayesian integration fluctuates significantly when the number of data is small. Furthermore, by introducing mesoscopic variables, we show that the free energy difference necessary in the Bayesian integration can be analytically expressed with several mesoscopic variables of observation noises. In Sections III and IV, we provide the results of numerical calculations of model selection and Bayesian integration, respectively.
II Bayesian Inference with Linear Models
In this section, we will demonstrate how the probability distribution of Bayesian free energy for finite data size in linear models can be described using a small number of variables within the basic framework of Bayesian inference. To advance the logic of Bayesian inference in linear models, we will first explain the mean squared error (MSE) associated with these models. Subsequently, we will derive the Bayesian posterior probability, enabling model parameter estimation, and the Bayesian free energy, which facilitates model selection.
II.1 Mean Squared Error of Linear Models
Here, to prepare for the discussion on Bayesian inference, we present the conventional MSE for linear models. Consider regressing data with samples using a two-variable linear model as follows:
| (1) |
In this context, the MSE is given by
| (2) | |||||
| (3) |
Here, we introduce the empirical means of the variables
| (4) | |||||
| (5) | |||||
| (6) | |||||
| (7) | |||||
| (8) |
For simplicity, let us assume the input mean of the data, . Under this assumption, the MSE can be reformulated as:
| (9) |
where , , and . The minimum value of the MSE is referred to as the residual error.
II.2 Representation Through Microscopic Variables
II.2.1 Microscopic Notation of Mean Squared Error
From this section, we introduce a noise model to facilitate the discussion of Bayesian inference. At this point, we have not addressed the noise model added to the data. Here, we assume the true parameters of and to be and , respectively, and that the noise added to the data , denoted as , follows a normal distribution with mean zero and variance . The process of generating the data is assumed to adhere to the following relation:
| (10) |
where the probability distribution for the noise is given by:
| (11) |
In this section, we delve deeper into understanding linear models by examining the dependency of the MSE on the stochastic variables . Given that , the empirical means of inputs and outputs can be described as follows:
| (12) | |||||
| (13) | |||||
| (14) | |||||
| (15) | |||||
| (16) | |||||
| (17) | |||||
| (18) |
This can be described by introducing:
| (19) | |||||
| (20) |
Therefore, the MSE can be expressed as:
| (21) |
II.2.2 Bayesian Inference for Linear Models
From Equation (11), the conditional probability of observing the output given the input variables and model parameters is described by
| (22) |
Consequently, the joint conditional probability of all observed outputs can be expressed as
| (23) | |||||
| (24) |
Utilizing the prior distributions of the linear model parameters and , denoted as and , respectively, the posterior distribution of the model parameters according to Bayes’ theorem can be formulated as:
| (25) |
When the prior distributions of the model parameters and are independently assumed to be uniform within the ranges and , respectively, the prior distributions for each parameter can be expressed as follows:
| (26) | |||||
| (27) |
The term , known as the marginal likelihood, is given by
| (28) |
Given that the prior distributions are uniform, the posterior distribution can be expressed as
| (30) |
This expression enables us to compute the conditional probability of the model parameters given the data, as the posterior distribution.
Here, we derive the Bayesian free energy, which serves as an indicator for model selection and is defined as the negative logarithm of the marginal likelihood.
| (32) | |||||
II.3 Representation Through Mesoscopic Variables
Up to this point, each statistical quantity has been treated empirically as an average. This section introduces the concept of mesoscopic variables, which enables a theoretical treatment of these quantities.
II.3.1 Residual Error Through Mesoscopic Variables
In the previous sections, the residual error was obtained as a probabilistic variable dependent on the stochastic variables . Here, we discuss the probability distribution of the value and demonstrate that it follows a chi-squared distribution. The residual error was given by
| (33) |
The first and second terms on the right side of Equation (33) are independently distributed. Therefore, follows a chi-squared distribution with degrees of freedom (proof A). Introducing a probability variable that follows a chi-squared distribution with degrees of freedom, we can write
| (34) |
Hence, the left side of Equation (33), which is the residual error, can be expressed as
| (35) |
Furthermore, the first and second terms on the right side of Equation (33) can be expressed using independent stochastic variables , each following a normal distribution , as
| (36) | |||||
| (37) |
This approach enables us to theoretically analyze the residual error, understand its distribution and behavior within the framework of Bayesian inference, and provide a more nuanced understanding of the error’s properties. The respective representations of the derived micro variables and meso variables are summarized in Table 1.
|
II.3.2 Posterior Distribution Through Mesoscopic Variables
Using the mesoscopic variables introduced in the previous section, we can reformulate the posterior distribution. From Equation (30), the posterior distribution can be rewritten as:
| (38) | |||||
Here, and . Hence, the posterior distribution is determined solely by the two stochastic variables and . Moreover, since Equation (38) enables independent calculations for and , the distribution of model parameters given the model, denoted as , can be expressed as
| (39) | |||||
| (40) | |||||
| (41) | |||||
| (42) |
This shows that the posterior distribution can be represented in terms of mesoscopic variables, providing a theoretical framework to understand the distribution of model parameters and on the basis of observed data and assumed noise characteristics.
Here, we reformulate the Bayesian free energy using mesoscopic variables. From Equation (32), the Bayesian free energy can be rewritten as
| (43) | |||||
Note that in the limit of large , the negative logarithmic terms in the second and third lines of Equation (43) converge to . Therefore, the effect of stochastic fluctuations is effectively captured solely by the term .
Thus, the Bayesian free energy is determined by three stochastic variables , and can be expressed as . The probability distribution of the Bayesian free energy is
| (44) |
In this section, we derive the representation of the probability distribution using mesoscopic variables. Although it is possible to describe the probability distribution without introducing mesoscopic variables, using microscopic variables leads to a computational complexity that scales proportionally with the number of data points . In contrast, the mesoscopic variable representation enables us to compute the probability distribution independently of the number of data points .
II.4 Numerical Experiments: Bayesian Inference
Here, we numerically verify that the results of Bayesian estimation using the microscopic and mesoscopic expressions coincide. First, Figure 1 presents the probability distributions of residual errors calculated from the microscopic expression (33) and mesoscopic expression (35) for stochastically generated data. Panels (a)–(c) of Figure 1 show the probability distribution of normalized residual errors calculated using the microscopic expression (33) for 100,000 artificially generated data patterns with model parameters . On the other hand, panels (d)–(f) display the probability distribution obtained from 100,000 samplings of the probability distribution of residual errors under the mesoscopic expression (35). Comparing the top and bottom rows of Figure 1, we can confirm that the distributions of residual errors from both microscopic and mesoscopic expressions match. As seen in Equation (35), the residual error can be described as a chi-squared distribution, and Figure 1 demonstrates that as the number of data points increases, the chi-squared distribution asymptotically approaches a Gaussian distribution.






Next, Figure 2 presents the probability distributions of free energy calculated from the microscopic expression (32) and the mesoscopic expression (43) for stochastically generated data. Panels (a)–(c) of Figure 2 show the probability distribution of normalized values of free energy calculated using the microscopic expression (32) for 100,000 artificially generated data points with model parameters . Meanwhile, panels (d)–(f) display the probability distribution obtained from 100,000 samples of the probability distribution of free energy using the mesoscopic expression (43). A comparison between the top and bottom rows of Figure 2 confirms that the distributions of free energy from both the microscopic and mesoscopic expressions match.






III Model Selection
This section explores model selection between a two- and one-variable linear regression model using the Bayesian free energy, as discussed in previous sections. That is, we deal with the problem of which model best fits a given dataset . Here, both models are defined as follows.
| (45) | |||||
| (46) |
Since the theoretical analysis of the two-variable model was covered in the previous section, this section first discusses the theoretical analysis of the one-variable model. Then, by considering the relationship between the two models via meso variables, we discuss the difference in free energy and the nature of model selection. In this section, the noise level is assumed to be predefined. The case where the noise level is also estimated is discussed in Appendix B.
III.1 Representation of the One-Variable Linear Regression Model Using Microscopic Variables
In this section, we assume that the data are generated from the one-variable model. That is, the following equation is assumed to be generated.
| (47) |
where are normally distributed with mean zero and variance .
III.1.1 Microscopic Notation of Mean Squared Error for One-Variable Linear Model
The MSE, similar to the discussions in the previous sections, can be written as
| (48) | |||||
| (49) | |||||
| (50) |
Given that , the empirical means of input and output can be described as
| (51) | |||||
| (52) | |||||
| (53) | |||||
| (54) | |||||
| (55) | |||||
| (56) | |||||
| (57) |
Here, the residual error can be expressed as
| (58) |
III.1.2 Bayesian Inference for One-Variable Linear Model
Assuming that each noise added to the data independently follows a normal distribution with mean zero and variance , the conditional probability of the output given the input variables and model parameters can be written as
| (59) | |||||
| (60) |
Therefore, the joint conditional probability of all output data can be expressed as
| (61) |
According to Bayes’ theorem, the posterior distribution is
| (63) |
Here, we derive the Bayesian free energy for a one-variable linear regression model. The Bayesian free energy is obtained by taking the negative logarithm of the marginal likelihood.
| (64) |
III.2 Representation of the One-Variable Linear Regression Model Using Mesoscopic Variables
Up to this point, each statistical quantity has been considered as an empirical mean. This section, following the approach of the previous one, introduces mesoscopic variables to provide a theoretical framework for handling these quantities.
III.2.1 Residual Error in One-Variable Linear Regression Model Through Mesoscopic Variables
In the previous sections, the residual error was obtained as a probabilistic variable dependent on the stochastic variables . Here, we discuss the probability distribution of the value and demonstrate that it follows a chi-squared distribution. The residual error was given by
| (65) |
The terms on the right side of Equation (65) are independently distributed. Therefore, follows a chi-squared distribution with degrees of freedom. Introducing a probability variable that follows a chi-squared distribution with degrees of freedom, we can write
| (66) |
Thus, the left side of Equation (65), which is the residual error, can be expressed as
| (67) |
Furthermore, the first term on the right side of Equation (65) can be expressed using an independent stochastic variable , following a normal distribution , as
| (68) |
III.2.2 Posterior Distribution in One-Variable Linear Regression Model Through Mesoscopic Variables
Using the mesoscopic variables introduced in the previous section, we can reformulate the posterior distribution. From Equation (63), the posterior distribution can be rewritten as
| (69) |
Thus, the posterior distribution is determined solely by the stochastic variable . Moreover, the distribution of the model parameter , given the model, denoted as , can be expressed as
| (70) | |||||
| (71) |
Here, we reformulate the Bayesian free energy using mesoscopic variables. From Equation (64), the Bayesian free energy can be rewritten as
| (72) | |||||
Therefore, the Bayesian free energy is determined by two stochastic variables, and , and can be expressed as . The probability distribution of the Bayesian free energy can be described as
| (73) |
III.2.3 Model Selection Through Bayesian Free Energy
This section compares the Bayesian free energy of a two- and one-variable linear regression model to perform model selection. First, we will discuss the relationship between mesoscopic variables . The residual error for the two models can be expressed as
| (74) | |||||
| (75) |
leading to the relationship between and as
| (76) |
The Bayesian free energy for each model, from Equations (43) and (72), is given by:
| (77) | |||||
| (78) |
Hence, the difference in the Bayesian free energy () depends only on the stochastic variable , and can be expressed as
| (80) |
Note that the logarithmic term in the second line converges to in the limit of large , thereby indicating that the stochastic fluctuations are primarily affected by the third term . Since follows a normal distribution with mean and variance , follows a non-central chi-squared distribution. This enables analytical treatment of the distribution of the free energy difference. The probability distribution of the difference in the Bayesian free energy is
| (81) |
We can effectively assess the fluctuations of model selection by mesoscopic variables as described in Section II.
III.3 Numerical Experiments: Model Selection
Here, we examine the impact of data quantity and noise intensity inherent in the data on the outcomes of model selection using the mesoscopic representation. Figure 3 shows the two-dimensional frequency distribution from 100,000 samples of the Bayesian free energy difference (Equation (81)) and . The model parameters are , , and , for data sizes . The vertical and horizontal axes represent the frequency distributions of the free energy difference and of , respectively. Figure 3(a) shows that with a small number of data points, the frequency of is high, indicating frequent failures in model selection. Conversely, Figures 3(b) and (c) show that with a larger number of data points, failures in model selection become negligible.












Figure 4 shows the relationship between the differential free energy and the estimated parameter for the case . Formula (80) shows that is distributed with the true parameter in the center. Therefore, should Figures 4(), is distributed with positive values, so that is concentrated at positive values. This enables us to understand why the two-variable model is mainly selected should Figures 4 in this analysis.
Next, Figure 5 shows the two-dimensional frequency distribution from 100,000 samples of the Bayesian free energy difference (Equation (81)) and . The model parameters are , , and , for data sizes . The vertical and horizontal axes represent the frequency distributions of the free energy difference and of , respectively. Figures 5(a)–(c) show that as the number of data points increases, the frequency of gradually decreases, but even at , the occurrence of remains, indicating failures in model selection are still present. The minimum value of the distribution, as evident from Equation (81), shifts negatively on a scale. Therefore, when is the true model, the pace of improvement in model selection by increasing the number of data points is slower compared with when is the true model.
In the case shown in Figures 6(), the value of is distributed around zero, so that the value of becomes negatively distributed due to the effect of other terms. This suggests that the one-variable model is selected should Figures 6.
Figure 7 shows the probability of selecting the two-variable model on the basis of the Bayesian free energy difference (Equation (81)) for model parameters . Here, we set and display the frequency distribution as a two-dimensional histogram from 100,000 samples across the dimensions of data number and data noise intensity . Figure 7(a) shows that model selection tends to fail along the diagonal line where and have similar values. As the data number increases from this line, appropriate model selection gradually becomes possible. Conversely, as the data number decreases away from this diagonal line, discerning the correct model selection becomes challenging. This diagonal line, as shown in Figures 7(b) and (c), broadens as the value of decreases, and at , the probability of selecting the model disappears.



IV Bayesian Integration
In this section, we explore a framework for Bayesian inference of model parameters by integrating multiple sets of measurement data under varying conditions. The primary focus here is to demonstrate that the use of Bayesian free energy can determine whether integrated or independent analysis of multiple measurement datasets can be performed using a small number of variables, similar to the previous sections.
We specifically address the regression problem involving two sets of one-dimensional data: with sample size , and with sample size . The regression is formulated with a two-variable linear model as follows:
| (82) | ||||
| (83) |
where the noise terms and are assumed to follow normal distributions with mean zero and variances and , respectively. This setup enables us to perform integrated analysis that considers different noise levels and relationships in the data from two distinct experimental conditions.
As in the previous section, the noise variances and are assumed to be known in this section. However, we will discuss the estimation of these noise variances for each model in Appendix B, and how these estimates affect the Bayesian inference process.
IV.1 Representation through Microscopic Variables in Bayesian Integration
IV.1.1 Microscopic Notation of Mean Squared Error for Bayesian Integration
In this case, we define the MSE as
| (84) |
When each dataset has independent parameters , the combined MSE after integration can be written as
| (85) |
Since there are two two-variable linear regression models, we can complete the square independently for each model. Therefore, the expression for the total MSE is:
| (86) |
This matches the results that would be obtained by treating the datasets and independently with linear regression models. If we infer a common model parameter from each dataset, then the expression for the MSE becomes:
| (87) |
Further transformations will be applied to and . Let , , , , , and . Then, the error function can be written as:
| (88) |
Let us define the integrated errors for parameters and as follows:
| (89) | ||||
| (90) |
The optimal parameters and are given by:
| (91) | |||||
| (92) |
The residual error can be expressed as:
| (93) |
IV.1.2 Bayesian Inference in Bayesian Integration
Given the input variables and model parameters, the conditional probability of the output can be expressed as:
| (94) |
Therefore, when we have independent parameters , the joint conditional probability of all output data can be expressed as:
| (95) |
The posterior distribution can be independently analyzed for each model parameter , and can be computed as:
| (96) |
When the range of the prior distribution is sufficiently large, the posterior distributions of each model parameter can be described as Gaussian distributions centered around . On the other hand, when the estimated parameters from both datasets share common model parameters , the joint conditional probability is given by:
| (97) |
The posterior distribution can then be expressed as:
| (98) | |||||
Here, we derive the Bayesian free energy from the results of the previous section, which is used as a criterion for model selection. The Bayesian free energy is the negative logarithm of the marginal likelihood. Assuming a uniform prior distribution and that model parameters are independent for each dataset, the Bayesian free energy can be expressed as:
| (99) | |||
| (100) |
On the other hand, if this model has common model parameters, the Bayesian free energy is obtained by taking the negative logarithm of the marginal likelihood:
| (101) | |||||
IV.2 Representation through Mesoscopic Variables in Bayesian Integration
Up to this point, each statistical measure has been handled as an empirical average. In this section, similar to the previous section, we introduce mesoscopic variables to theoretically manage these statistical measures.
IV.2.1 Residual Error with Mesoscopic Variables in Bayesian Integration
In the previous sections, the residual error was derived as a probability variable dependent on the set of random variables . In this section, we discuss the probability distribution of the residual error and demonstrate that it follows a chi-squared distribution. The expression for the residual error is given by:
| (102) |
In this case,
| (103) |
is established. From the content of the previous sections,
| (104) | |||||
| (105) | |||||
| (106) |
can be expressed by introducing mesoscopic variables. Thus, and can be expressed similarly to the previous section as:
| (107) | |||||
| (108) |
Hence, the residual error in Bayesian integration can be expressed as:
| (109) | ||||
| (110) |
and can be described by six mesoscopic variables .
IV.2.2 Posterior Distribution with Mesoscopic Variables in Bayesian Integration
In this section, we use the mesoscopic variables introduced in the previous section to reformulate the posterior distribution. The error functions can be expressed using mesoscopic variables as:
| (111) | |||||
| (112) | |||||
| (113) | |||||
| (114) |
Therefore, the posterior distribution as per Equation (98) can be described as:
| (115) | |||||
Thus, the posterior distribution is determined solely by the four stochastic variables . Also, given the model, the distributions of the model parameters , can be described as:
| (116) | ||||
| (117) | ||||
| (118) | ||||
| (119) |
Here, we reformulate the Bayesian free energy using mesoscopic variables. From Equation (101),
| (120) |
is rewritten. Therefore, the Bayesian free energy is determined by six stochastic variables , and can be expressed as . Consequently, the probability distribution of the Bayesian free energy is
| (121) |
IV.2.3 Model Selection in Bayesian Integration
In this section, we compare the Bayesian free energy of the linear regression model by Bayesian integration with that of the independent analysis linear regression model, to perform model selection. The Bayesian free energy for independent analysis is given by:
| (123) | |||||
and the Bayesian free energy through integration is:
| (124) |
If the noise intensity is known, is equal to , leading to a difference in the residual error contributions given by:
| (125) |
which is found that mesoscopic variables and disappear from this equation. Therefore, the difference in the Bayesian free energy is determined by four stochastic variables , and can be expressed as
| (126) |
Consequently, the probability distribution of the difference in the Bayesian free energy can be expressed as:
| (127) |
We can effectively assess the fluctuations of Bayesian integration by mesoscopic variables as described in Section II.
IV.3 Numerical Experiment: Bayesian Integration
Here, we examine the effects of the number of data points and the noise intensity of the data on estimation from the results of Bayesian integration via meso-expression. Figure 8 shows the frequency distribution from 100,000 samples of the probability distribution of the difference of the Bayesian free energy with model parameters . Here, for simplicity, we omit the terms and from Equations (82) and (83). Consequently, we proceed to calculate the difference in the residual error
| (128) |
and the difference of the Bayesian free energy
| (129) |
| (130) |
which is derived from the Bayesian integration of these simplified equations and thus does not account for the effect of mesoscopic variables and associated with and .
Figure 8(a) shows that with a small number of data points, the frequency of is high, and failures in model selection occur frequently. Conversely, Figures 8(b) and 8(c) show that with a larger number of data points, failures in model selection do not occur.






Figure 9 shows the relationship between the differential free energy and . Here, model parameters are set as for data sizes . The region being depicted corresponds to the main area where and are generated. In this case, Equation (128) shows that the difference in free energy is primarily due to the difference in the estimated parameter . In this case, since there is a significant difference with , the result selected by the free energy suggests that they should be treated as almost independent. However, in situations with a small amount of data, the effect of and due to the fluctuation in the estimation of the parameter becomes relatively large, which also indicates that the posterior probability of treating them as independent slightly decreases.
Next, Figure 10 shows the frequency distribution from 100,000 samples of the probability distribution of the difference in the Bayesian free energy with model parameters (Equation (130)). Figures 10(a)–(c) show that as the number of data points increases, the frequency of gradually decreases. However, even at , the frequency of remains, indicating that failures in model selection are occurring. The minimum value of the distribution transitions negatively on a scale, as evident from Equation (127).






Figure 11 shows the relationship between the differential free energy and . Here, model parameters are set as for data sizes . In this case, since there is no significant difference between , the result indicates that they should be integrated, as shown in this figure. Furthermore, as the amount of data increases, the difference in free energy decreases in the negative direction, suggesting that the posterior probability of integration increases.
Finally, Figure 12 shows the selection probabilities of the separate model derived from the probability distribution of the difference in the Bayesian free energy with model parameters (Equation (130)). Here, we display the frequency distribution as a two-dimensional histogram from 100,000 samples in a two-dimensional space of the number of data points and data noise intensity . Figure 12(a) shows that model selection tends to fail along the diagonal line where and have similar values. As the number of data points increases from this line, model selection gradually becomes more effective. Conversely, as the number of data points decreases from the diagonal line, discrimination in model selection is eliminated. This diagonal line, as shown in Figures 12(b) and (c), widens as the value of approaches that of , and when , only the selection probabilities of the integrated model remain.



V Conclusion
In this study, we proposed an innovative theory that can address finite measurement datasets in a linear regression model, a previously unaddressed challenge. This is the first step towards a new theoretical framework that goes beyond the conventional Bayesian measurement framework. Through our results, we confirmed that the outcomes of Bayesian estimation using theoretically derived microscopic and mesoscopic representations are consistent.
We summarize the insights gained from our results in the following. In conventional theoretical frameworks, only asymptotic characteristics such as the number of observation data approaches infinity are discussed, making it difficult to consider fluctuations due to finite data [19]. By introducing mesoscopic variables defined from Gaussian noises, we succeeded in theoretically determining how important statistics such as the free energy difference converge to a limit as increases to infinity. We have established a theoretical foundation that can handle fluctuations due to finite data in the estimation of the posterior probability distribution of parameters, model selection, and Bayesian integration—the three core principles of Bayesian measurement. This is a groundbreaking achievement in the history of Bayesian inference.
As a result, the estimation of the posterior probability distribution of parameters in a linear regression model could be analytically expressed in terms of mesoscopic variables consisting of a sum of Gaussian variables when using microscopic and mesoscopic representations. The residual error can be described using Gaussian and chi-squared distributions of mesoscopic variables, enabling the posterior probability distribution to be analytically derived even for a finite number of observed data . This is particularly important in real measurements where data is limited, demonstrating the potential for practical applications.
Regarding model selection, the proposed theory proved particularly useful. In conventional Bayesian measurements based on numerical calculations, fluctuations due to the finite number are often overlooked, leading to erroneous model selection results. The proposed theory addressed this by analytically evaluating the Bayesian free energy difference , which depends on the number of observed data . This enables us to quantitatively evaluate the variation in the free energy difference distribution obtained from the microscopic and mesoscopic representations, demonstrating how the number of observational data and the observation noise variance affect model selection. Theoretically, we demonstrate that the model selection results are stable when the number of observational data is about 100, suggesting that the proposed theory can provide guidelines for actual measurements.
The proposed theory also proved useful in Bayesian integration, enabling analytical evaluation even when the number of observational data is finite, and showing how the number of observational data and the observation noise variance affect the results of Bayesian integration. Theoretically, we demonstrated that the Bayesian integration results are stable when the number of observational data is about 100, again suggesting that the proposed theory can provide guidelines for data analysis and design of actual measurements.
The proposed theory establishes a new paradigm in Bayesian measurement, leading to more accurate and reliable scientific and technological results. The linear regression model , while seemingly simple, is not merely for theoretical analysis. It is widely used in real measurement settings, such as linear system responses. Furthermore, insights gained from this model can be extended to general nonlinear models. We hope that this research will contribute to the development of measurement and data analysis and design in various fields of natural science.
Acknowledgements.
This work was supported by JSPS KAKENHI Grant Numbers JP23H00486, 23KJ0723, and 23K16959, and CREST Grant Numbers JPMJCR1761 and JPMJCR1861 from the Japan Science and Technology Agency (JST).References
- [1] Giuseppe Carleo, Ignacio Cirac, Kyle Cranmer, Laurent Daudet, Maria Schuld, Naftali Tishby, Leslie Vogt-Maranto, and Lenka Zdeborová. Machine learning and the physical sciences. Rev. Mod. Phys., 91:045002, Dec 2019.
- [2] H. Wang, T. Fu, Y. Du, et al. Scientific discovery in the age of artificial intelligence. Nature, 620:47–60, 2023.
- [3] K. Nagata, S. Sugita, and M. Okada. Bayesian spectral deconvolution with the exchange monte carlo method. Neural Networks, 28:82, 2012.
- [4] K. Nagata, R. Muraoka, Y. Mototake, T. Sasaki, and M. Okada. Bayesian spectral deconvolution based on poisson distribution: Bayesian measurement and virtual measurement analytics (vma). J. Phys. Soc. Jpn., 88:044003, 2019.
- [5] S. Tokuda, K. Nagata, and M. Okada. Simultaneous estimation of noise variance and number of peaks in bayesian spectral deconvolution. J. Phys. Soc. Jpn., 86:024001, 2017.
- [6] S. Katakami, H. Sakamoto, K. Nagata, T. Arima, and M. Okada. Bayesian parameter estimation from dispersion relation observation data with poisson process. Phys. Rev. E, 105:065301, 2022.
- [7] H. Ueda, S. Katakami, S. Yoshida, T. Koyama, Y. Nakai, T. Mito, M. Mizumaki, and M. Okada. Bayesian approach to t1 analysis in nmr spectroscopy with applications to solid state physics. J. Phys. Soc. Jpn., 92:054002, 2023.
- [8] R. Nishimura, S. Katakami, K. Nagata, M. Mizumaki, and M. Okada. Bayesian integration for hamiltonian parameters of crystal field. J. Phys. Soc. Jpn., 93:034003, 2024.
- [9] Y. Yokoyama, T. Uozumi, K. Nagata, M. Okada, and M. Mizumaki. Bayesian integration for hamiltonian parameters of x-ray photoemission and absorption spectroscopy. J. Phys. Soc. Jpn., 90:034703, 2021.
- [10] R. Moriguchi, S. Tsutsui, S. Katakami, K. Nagata, M. Mizumaki, and M. Okada. Bayesian inference on hamiltonian selections for mössbauer spectroscopy. J. Phys. Soc. Jpn., 91:104002, 2022.
- [11] Y. Hayashi, S. Katakami, S. Kuwamoto, K. Nagata, M. Mizumaki, and M. Okada. Bayesian inference for small-angle scattering data. J. Phys. Soc. Jpn., 92:094002, 2023.
- [12] Y. Yokoyama, S. Kawaguchi, and M. Mizumaki. Bayesian framework for analyzing adsorption processes observed via time-resolved x-ray diffraction. Sci. Rep., 13:14349, 2023.
- [13] Y. Yokoyama, N. Tsuji, I. Akai, K. Nagata, M. Okada, and M. Mizumaki. Bayesian orbital decomposition and determination of end condition for magnetic compton scattering. J. Phys. Soc. Jpn., 90:094802, 2021.
- [14] T. Yamasaki, K. Iwamitsu, H. Kumazoe, M. Okada, M. Mizumaki, and I. Akai. Bayesian spectroscopy of synthesized soft x-ray absorption spectra showing magnetic circular dichroism at the ni-l3,-l2 edges. Sci. Technol. Adv. Mater. Methods, 1:75, 2021.
- [15] K. Iwamitsu, T. Yokota, K. Murata, M. Kamezaki, M. Mizumaki, T. Uruga, and I. Akai. Spectral analysis of x-ray absorption near edge structure in -fe2o3 based on bayesian spectroscopy. Phys. Status Solidi B, 257:2000107, 2020.
- [16] H. Kumazoe, K. Iwamitsu, M. Imamura, K. Takahashi, Y. Mototake, M. Okada, and I. Akai. Quantifying physical insights cooperatively with exhaustive search for bayesian spectroscopy of x-ray photoelectron spectra. Sci. Rep., 13:13221, 2023.
- [17] S. Kashiwamura, S. Katakami, R. Yamagami, K. Iwamitsu, H. Kumazoe, K. Nagata, T. Okajima, I. Akai, and M. Okada. Bayesian spectral deconvolution of x-ray absorption near edge structure discriminating between high-and low-energy domains. J. Phys. Soc. Jpn., 91:074009, 2022.
- [18] S. Tokuda, K. Nagata, and M. Okada. Intrinsic regularization effect in bayesian nonlinear regression scaled by observed data. Phys. Rev. Res., 4:043165, 2022.
- [19] G. Schwarz. Estimating the dimension of a model. Ann. Stat., 6:461, 1978.
- [20] Serge Lang. Linear algebra. Springer Science & Business Media, 1987.
- [21] G. A. F. Seber and A. J. Lee. Linear regression analysis. John Wiley & Sons, Hoboken, NJ, 2012.
Appendix A Proof that Residual Errors Follow a Chi-squared Distribution
Consider an orthogonal matrix whose first and second rows are defined as follows:
| (131) |
| (132) |
The existence of such an orthogonal matrix is guaranteed by Basis Extension Theorem in linear algebra[20, 21]. From the properties of orthogonal matrices, we have:
| (133) |
The random variables independently follow a Gaussian distribution , so let . The probability density function of is given by:
| (134) |
Applying the orthogonal transformation , we have:
| (135) |
At this time, the elements of obtained by the orthogonal transformation are independent. In addition, and are given by:
| (136) | |||||
| (137) | |||||
| (138) | |||||
| (139) |
where each corresponds to the second and first terms of the right-hand side of Equation (33), respectively. From this, the residual error is:
| (140) | |||||
| (141) | |||||
| (142) | |||||
| (143) |
Thus, follows a chi-squared distribution with degrees of freedom, independent of the first and second terms on the right-hand side of Equation (33).
Appendix B Noise Estimation
In this section, we examine how the inclusion of noise estimation affects the results of model selection and Bayesian integration, using mesoscopic variables for Bayesian representation.
B.1 Bayesian Inference with Noise Estimation
In this subsection, we explore the impact of noise estimation on Bayesian inference. We extend the previous models to include noise variance as a probabilistic variable, making the framework applicable to realistic situations where the noise intensity is unknown beforehand.
B.1.1 Noise Variance Estimation
Up to this point, the noise variance has been treated as a constant. By considering the noise variance as a probabilistic variable , this section demonstrates how to estimate the noise variance from the data by maximizing posterior distribution on the basis of Bayesian inference.
The posterior probability of the noise variance can be determined from the joint probability as
| (144) |
The dependency part of the posterior probability on is
| (145) | |||||
| (147) |
When the prior distribution is considered uniform, the posterior probability of the noise variance can be equated to the marginal likelihood for model parameters , thus enabling us to treat Equation (145) similarly to the calculation of Equation (32). The free energy , obtained by taking the negative log of , is
| (149) |
The optimal noise variance can be obtained by
| (150) | |||||
| (151) |
B.1.2 Noise Variance Through Mesoscopic Variables
Here, we describe the noise variance using mesoscopic variables. Since cannot be analytically determined, we assume it has been numerically estimated. The probability distribution of the noise variance can then be described as
| (152) |
B.1.3 Numerical Experiment Including Noise Estimation: Bayesian Inference
Here, we numerically verify the results of Bayesian estimation including noise estimation. Initially, noise estimation is performed using Equation (149), and the estimated noise is used to calculate the free energy from Equation (43).
Figure 13 shows the probability distribution of the free energy density during noise estimation and that of the estimated noise. Figures 13(a)–(c) show the probability distributions of the normalized free energy values, calculated from Equation (43) for 100,000 artificially generated data patterns with model parameters , where noise estimation was performed. Figures 13(d)–(f) show the frequency distribution of the noise estimated for each dataset.





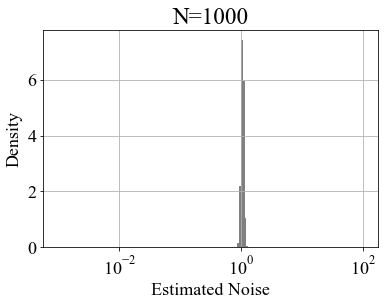
Figure 14 shows the frequency distribution of the estimated noise for 10,000 artificially generated data patterns with model parameters and . Figure 14shows that as increases, the frequency distribution of the estimated noise converges towards the true value.

Figure 15 shows the frequency distribution of the estimated noise for 10,000 artificially generated data patterns with , , and model parameters . Figure 15 shows that the estimation accuracy of the frequency distribution of the estimated noise depends only on and not on .



B.2 Model Selection with Noise Estimation
In this subsection, we delve into how noise estimation affects the process of model selection. By incorporating the noise variance as a probabilistic variable, we refine the Bayesian framework to better handle realistic scenarios where the noise intensity is unknown.
We will specifically explore how the estimation of noise variance affects the comparison between different models. This includes demonstrating the application of Bayesian free energy to select between one- and two-variable linear regression models with the additional complexity of noise estimation.
B.2.1 Noise Variance Estimation for One-Variable Linear Regression Model
Up to this point, the noise variance was treated as known. By considering the noise variance as a probabilistic variable and building upon the discussions in previous sections, this section demonstrates a method for estimating the noise variance from data by maximizing posterior distribution on the basis of Bayesian inference.
Given the joint probability , the posterior probability of the noise variance is derived as
| (153) |
The portion of the posterior probability dependent on is
| (154) | |||||
| (155) | |||||
| (156) |
Assuming a uniform prior distribution , the right side of Equation (155) can be executed similarly to the calculation of Equation (64). Taking the negative logarithm of Equation (155), the free energy is expressed as
| (158) | |||||
Here, note that is constant with respect to .
The optimal noise variance can be obtained by
| (159) | |||||
| (160) |
B.2.2 Noise Variance in One-Variable Linear Regression Model Through Mesoscopic Variables
Here, we describe the noise variance using mesoscopic variables. Since cannot be analytically determined, assuming it has been numerically determined, the probability distribution of the noise variance can be described as:
| (161) |
B.2.3 Model Selection Through Bayesian Free Energy with Noise Estimation
Up to this point, we have considered model selection on the basis of known true noise variance. Now, let us consider model selection when also estimating noise variance within each model, denoted as and for the two models, respectively. The Bayesian free energy for each model, after estimating noise variance, is
| (162) |
for the two-variable model and
| (163) |
for the one-variable model.
From these expressions, the difference in the Bayesian free energy, taking into account noise variance estimation, can be described as
| (164) |
This difference is determined on the basis of mesoscopic variables and their relationships as noted in Equation (75), enabling us to depict the probability distribution of the difference in the Bayesian free energy as a function of mesoscopic variables:
| (165) |
B.2.4 Numerical Experiment Including Noise Estimation: Model Selection
Here, we examine the impact of the number of data points and the noise strength of the data on estimation from the results of model selection performed with noise estimation using mesoscopic representation.
Figure 16 shows the frequency distribution from 100,000 samples of the probability distribution of the difference in the Bayesian free energy when noise estimation is performed and when noise is assumed known, with model parameters (Equation (81)). The horizontal and vertical axes represent the frequency distribution of the free energy when noise is known and estimated, respectively. Figure 16 shows that as increases, the difference in the frequency distributions between the cases of noise estimation and known noise diminishes.



Figure 17 shows the frequency distribution from 100,000 samples of the probability distribution of the difference in the Bayesian free energy when noise estimation is performed and when noise is assumed known, with model parameters (Equation (81)). The horizontal and vertical axes represent the frequency distribution of the free energy when noise is known and estimated, respectively. Figure 17 shows that as increases, the difference in the frequency distributions between the cases of noise estimation and known noise diminishes.



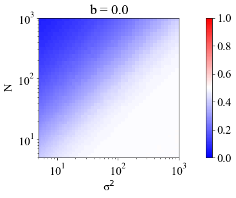
Finally, Figure 18 shows the selection probabilities of the two-variable model derived from the probability distribution of the difference in the Bayesian free energy with model parameters (Equation (81)). Here, we set and display the frequency distribution as a two-dimensional histogram from 100,000 samples in a two-dimensional space of the number of data points and data noise intensity . Figure 18 (a) shows that along the diagonal line where and have similar values, there is a tendency for model selection to fail. As the number of data points increases from this line, gradually more appropriate model selections become possible. Conversely, as the number of data points decreases from the diagonal line, discrimination in model selection is eliminated. This diagonal line, as shown in Figures 18 (b) and (c), widens as the value of decreases, and at , the selection probability of disappears. The overall behavior of the probability distribution does not change regardless of whether noise estimation is performed.
From the aforementioned results, we found that the difference between simultaneously estimating two noises and estimating each noise independently becomes negligible with large data sizes. The former method involves optimization in a high-dimensional space, while the latter involves that in a one-dimensional space. Estimating multiple noises simultaneously increases the search space exponentially. Optimizing each noise independently ensures sufficient accuracy, which is beneficial for real-world applications.


B.3 Bayesian Integration with Noise Estimation
In this subsection, we examine how noise estimation affects the process of Bayesian integration when multiple datasets are involved. By treating the noise variances as probabilistic variables, we enhance the Bayesian framework to accommodate realistic situations where the noise levels are unknown and may vary between datasets.
B.3.1 Bayesian Integration of Noise Variance Estimation
In this section, we consider the noise variances as random variables and demonstrate a method to estimate these variances by maximizing posterior distribution on the basis of Bayesian inference. When the model parameters are inferred independently for each dataset, the noise variances should be inferred independently as well. Consider the case where the model parameters are common across datasets.
Let us assume the joint probability of is given by:
| (166) |
From this, the posterior probability of the noise variances can be expressed as:
| (167) | ||||
| (168) | ||||
| (169) |
Here, note that is constant with respect to and . At this time, the portion of the posterior probability that depends on can be expressed as:
| (171) |
When the prior distribution is considered uniform, the right-hand side of Equation (B.3.1) can be computed similarly to Equation (101), and the free energy derived from taking the negative logarithm of Equation (B.3.1) is given by:
| (173) |
Minimizing the free energy can numerically determine the values of and that maximize the posterior probability. The optimal noise variance and can be obtained by
| (174) | ||||
| (175) |
B.3.2 Noise Variance Through Mesoscopic Variables in Bayesian Integration
Noise estimation numerically determines that minimizes Equation 173. Since the estimated noise variance depends on six random variables , it can be expressed as . The probability distribution of the noise variance is given by
| (176) |
B.3.3 Model Selection in Bayesian Integration with Noise Estimation
The difference in the Bayesian free energy, , is determined by six stochastic variables , and can be expressed as:
| (177) |
This indicates that the calculation of the Bayesian free energy differences incorporates these six variables, reflecting the complex dynamics when noise intensity is part of the estimation process.
Consequently, the probability distribution of the difference in the Bayesian free energy can be expressed as:
| (178) |
B.3.4 Numerical Experiment Including Noise Estimation: Bayesian Integration
Here, we examine the impact of the number of data and the noise intensity inherent in the data on estimation through the results of Bayesian integration, which includes noise estimation using meso-expressions.
Figure 19 shows the frequency distribution of the difference in the Bayesian free energy, sampled from 100,000 instances with model parameters (see Equation (127)). The methods for noise estimation include simultaneous estimation of two noises from two datasets by minimizing free energy using Equation (173), and independent estimation of each noise from each dataset using Equation (149). The results of simultaneous estimation are shown in the upper section and those of independent noise estimation in the lower section. The horizontal and vertical axes represent the frequency distribution of the free energy when noise is known and estimated, respectively. Figure 19shows that as increases, the difference in the frequency distribution between the cases with estimated noise and known noise diminishes.






Next, Figure 20 shows the frequency distribution obtained from sampling 100,000 times from the probability distribution of the difference in the Bayesian free energy, with model parameters (Equation (127)). The horizontal and vertical axes represent the frequency distribution of the free energy when noise is known and estimated, respectively. There are two methods for estimating noise: one is to estimate two noises simultaneously by minimizing the free energy using Equation (173) from two data points, and the other is to independently estimate each noise from each data using Equation (149). The results of simultaneous estimation are shown in the upper section, and those of independent noise estimation are displayed in the lower section. Figure 20shows that as increases, the difference in the frequency distributions between the cases of estimated noise and known noise disappears.






Finally, Figure 21 displays the probabilities of selecting the integrated model obtained from the probability distribution of the difference in the Bayesian free energy with model parameters (Equation (127)). Here, we set and show the frequency distribution as a two-dimensional histogram, sampled 100,000 times from the two-dimensional space of the number of data points and the noise strength . Two methods for estimating noise are used: one involves simultaneously estimating two noises by minimizing free energy using Equation (173) from two data points, and the other involves independently estimating each noise from each data using Equation (149). The results of simultaneous estimation are shown in the upper section, and those of independent noise estimation are shown in the lower section.
From the aforementioned results, we found that the difference between simultaneously estimating two noises and estimating each noise independently becomes negligible with large data sizes. The former method involves optimization in a high-dimensional space, while the latter involves optimization in a one-dimensional space. Estimating multiple noises simultaneously increases the search space exponentially. Optimizing each noise independently ensures sufficient accuracy, and it is beneficial for real-world applications.





