Meta-Polyp: a baseline for efficient Polyp segmentation
Abstract
In recent years, polyp segmentation has gained significant importance, and many methods have been developed using CNN, Vision Transformer, and Transformer techniques to achieve competitive results. However, these methods often face difficulties when dealing with out-of-distribution datasets, missing boundaries, and small polyps. In 2022, MetaFormer was introduced as a new baseline for vision, which not only improved the performance of multi-task computer vision but also addressed the limitations of the Vision Transformer and CNN family backbones. To further enhance segmentation, we propose a fusion of MetaFormer with UNet, along with the introduction of a Multi-scale Upsampling block with a level-up combination in the decoder stage to enhance the texture, also we propose the Convformer block base on the idea of the MetaFormer to enhance the crucial information of the local feature. These blocks enable the combination of global information, such as the overall shape of the polyp, with local information and boundary information, which is crucial for the decision of the medical segmentation. Our proposed approach achieved competitive performance and obtained the top result in the State of the Art on the CVC-300 dataset, Kvasir, and CVC-ColonDB dataset. Apart from Kvasir-SEG, others are out-of-distribution datasets. The implementation link can be found at: https://github.com/huyquoctrinh/MetaPolyp-CBMS2023
Index Terms:
MetaFormer, Multi-scale Upsampling, UNet, polyp segmentationAcknowledgement
This research is supported by research funding from the Faculty of Information Technology, University of Science, Vietnam National University - Ho Chi Minh City.
I Introduction
Colorectal cancer is a significant health problem that poses a serious threat to human health and society. Polyps are growths that form in the colon or rectum, and they can develop into cancer over time. Early diagnosis of polyps is a crucial aspect of preventive healthcare, as it can significantly improve the prognosis and treatment outcomes of patients with colorectal cancer [1]. Detecting and removing polyps before they become cancerous is essential in preventing the development of the disease. Therefore, early polyp diagnosis is very crucial. It can prevent the progression of colorectal cancer and its widespread impact on society. As polyps can develop over time and some can become cancerous, early detection and removal are critical in preventing the progression of the disease. By identifying and removing polyps early, patients have a much higher chance of a successful outcome, and the overall impact of colorectal cancer can be reduced [1].
In recent years, early diagnosis plays a crucial role in the treatment of polyps and the prevention of colorectal cancer. However, despite its importance, the accuracy of early diagnosis is still limited by various external factors[2]. Therefore, polyp segmentation has become an integral part of the diagnostic process. In recent years, several Deep Learning approaches have demonstrated their effectiveness in segmenting polyp images, with some achieving competitive results in state-of-the-art performance. These approaches include UNet [3], PraNet [4], UNet++ [5], and ResUNet [5]. However, these methods often face a challenge in capturing the global information of polyp objects. While CNN models excel at capturing local information, they struggle to capture the overall shape of polyp objects, which is critical for accurate segmentation. This deficiency is a significant factor in the missed segment areas that are essential outputs for segmentation tasks [6]. To address these problems, many approaches of Vision Transformer [7] performed promising results while they can capture global information, loss of deep supervision is also a promising result for improving the boundary feature for the segmentation result. However, the deficiency of previous methods is the parameters, also the lack of local information and also global information [8] that the model learned can lead to the oversize of polyps or the missing texture in segmentation masks and it is still a challenge for the segmentation problem [9]. Moreover, the texture is not captured effectively in the preceding Upsampling layer [3] due to the loss of resolution in the upsampled output.
In late 2022, a new approach called MetaFormer was proposed as a baseline for combining CNN [9] and Transformer models [8]. MetaFormer [7] allows for the capture of both local and global information by utilizing downsampling via convolution to capture local features and a Transformer encoder to capture global features in later stages. This approach has been shown to improve performance in various tasks.
In our paper, we propose a Polyp MetaFormer that combines MetaFormer and UNet, a Multi-scale Upsampling block with our Level-up UpSampling technique. Our technique enhances the quality of texture in the decoder stage of UNet, which addresses the weakness of UNet in texture missing in the UpSampling stage and improves the segmentation results of the entire architecture. Our proposed method shows competitive results on state-of-the-art datasets, benchmarking our model against the weaknesses of other approaches.
To summarize our contribution, there are 3 main ideas:
- We propose the MetaFormer Baseline with our proposed Convformer block as 4 stages as MetaFormer for capturing the fusion of global features and local features from the encoder stage.
- The Level-up Upsampling technique is proposed to enhance the texture missing in the Decoder stage of UNet.
- Demonstrate the effectiveness of the method on out-of-distribution datasets, and also get competitive results on the state-of-the-art.
II Related Work
II-A Early diagnosis
Colorectal cancer, arising from polyp growth in the colon or rectum, is a significant health concern with severe implications [1]. Early identification of polyps is vital in improving prognosis and treatment outcomes [1]. Detecting and removing polyps prior to malignancy is crucial for preventing disease progression. Early diagnosis of polyps is paramount in averting the extensive consequences of colorectal cancer [10]. However, current black-box methods lack explanatory transparency, posing challenges in the medical imaging field [1].
II-B Polyps segmentation
Endoscopic image segmentation is a well-studied research field [10]. Early research relied on handcrafted descriptors and a machine learning (ML) classifier that distinguished lesions from the background based on attributes like color, shape, texture, and edges [11]. In recent years, deep learning and convolutional neural networks have led to many new segmentation techniques, such as UNet [3]. The UNet [3] model is considered groundbreaking as it was the first to introduce skip connections in the encoder-decoder architecture for medical segmentation tasks. This innovative technique allows for the combination of both shallow and deep features to improve the accuracy and reliability of the segmentation process. Since its inception, numerous studies and research have been conducted to further enhance the performance of this technique in the segmentation field. As a result, many advancements have been made, and the UNet [3] model has become a crucial tool for medical imaging professionals and researchers in their pursuit of more accurate and efficient segmentation methods [12, 13].
II-C MetaFormer
It has been observed that the abstracted architecture of the Transformer, known as MetaFormer [7], plays a crucial role in achieving high levels of performance. This innovative architecture has demonstrated its effectiveness in various applications, particularly in natural language processing (NLP) and image recognition. By leveraging the powerful capabilities of MetaFormer [7], researchers and developers have been able to achieve competitive results and make significant advancements in their respective fields.
III Methods
III-A General architecture
We have developed a network that builds on Encoder-Decoder architecture with modifications such as the combination of the ConvFormer and Transformer blocks from the MetaFormer baseline in the encoder stage. In addition, we have proposed the use of the Level-up Upsampling stage and use the Multi-scale Upsampling block to improve the performance of the Up-Sampling layer in the decoder stage. The full architecture is described in the 1. The input of the architecture has shape , and the encoder extracts the feature where is the filter at step of the encoder and the decoder stage. Whereas, in the decoder stage, although the feature is decoded 2 times in each step through Convolution Transpose 2D, the feature at the step is also decoded 4 times by our Multi-scale Upsampling block and then it is merged to the step for enhancing the feature while Upsampling the previous features. From then, the decoder stage with generate the mask with the shape , then a Convolution layer is applied to map the feature map from 64 filters to 1 filter. In the initial two stages, the emphasis lies on acquiring significant local features, which is why the Convformer Encoder is employed. Conversely, in the subsequent stages, the overall information pertaining to the object becomes more crucial. Therefore, the Transformer Encoder is incorporated in the last two stages of the model to capture the global context effectively.
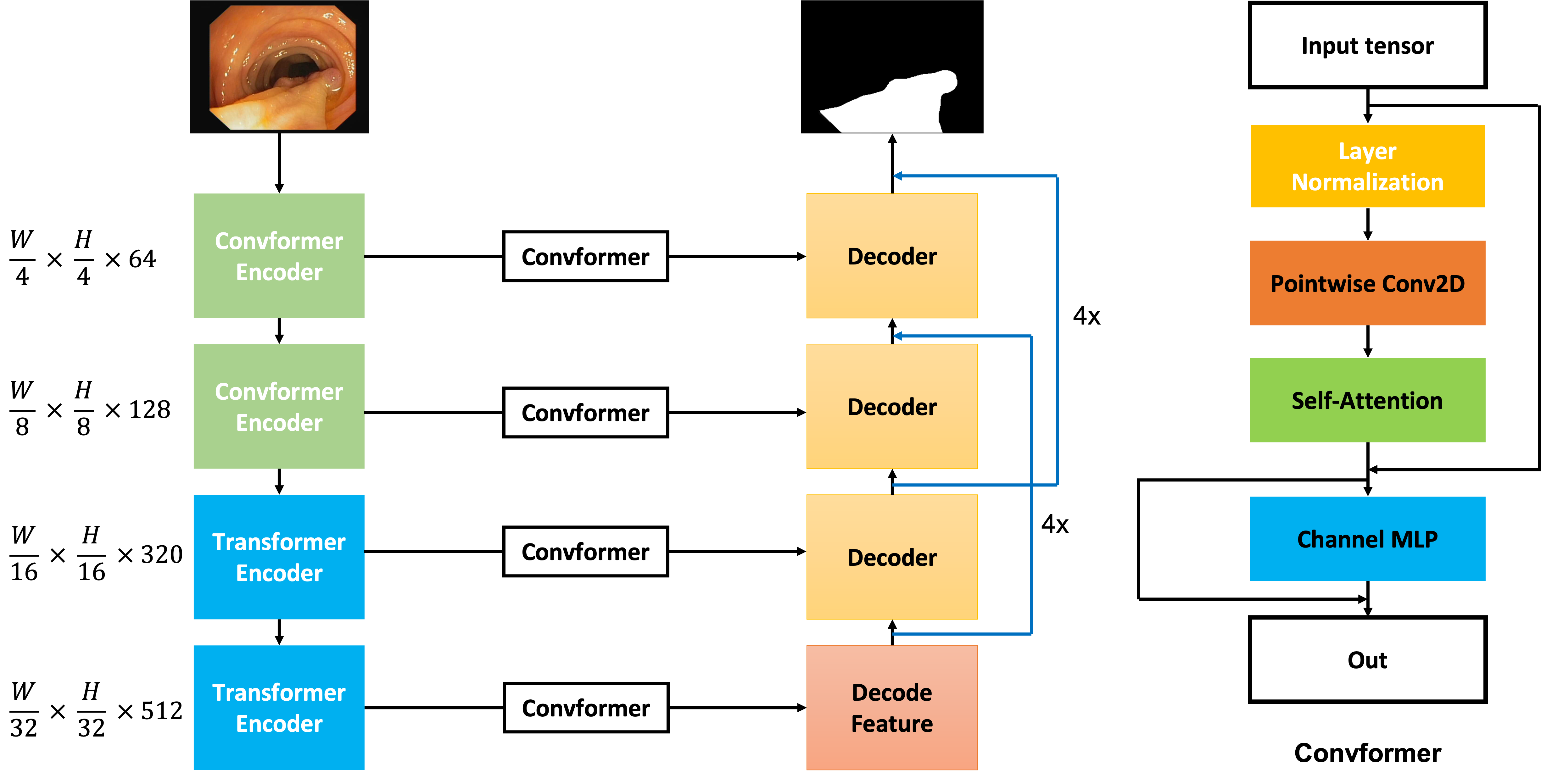
III-B ConvFormer Encoder
The MetaFormer baseline [7] investigates how existing token mixers can achieve exceptional performance. Rather than inventing new token mixers, our work relies on the MetaFormer architecture. The ConvFormer encoder in the MetaFormer follows a four-step process. The first step involves generating token mixers, achieved through Depthwise Convolution and Separable Convolution for the creation of these mixers.
| (1) |
| (2) |
| (3) |
The equation.1 which is mentioned in the [7], the at is the Convolution pointwise, while denotes the Depth-wise Convolution. Then for the next stages, the output of the equation.1 is normalized before the skip connection is applied to the output, and the demonstration follows by the equation.2. The output then is learnable by and through the Channel MLP layer, which is demonstrated by the equation.3.In addition, in the equation.3, the denotes the activation function that is used in the ConvFormer block. The use of the Convformer concept in the encoder is helping the model focus on learning the important texture
III-C Convformer Block
In the Convformer block, by the idea of MetaFormer [7], we create our module Convformer block (in fig.1), which is different from the Convformer encoder, but have the idea of the previous Convformer block from MetaFormer [7], that can capture the global information, also we include the local feature by the Pointwise Convolution, then the Self-Attention mechanism [14] is applied, in this case, the weights is kept, this weight helps to generate the attention mask, which helps model learn the crucial information from the local information, therefore, the local information is added with the attention mask, and a Channel MLP layer is applied to help model learn the fusion of the local information and the crucial information of the local information.
III-D Transformer Encoder
The Transformer encoder shares a similar concept with the ConvFormer encoder, but with a different token mixer. Instead of using Convolution Block to create the token mixer, the Transformer block uses a classic self-attention mechanism to create an attention mask, which is used as the token mixer. The self-attention mechanism allows the model to attend to different parts of the input sequence and identify relevant features. The attention mask is generated based on the similarity between the input tokens and is used to weight the contribution of each token to the final output. This mechanism allows the model to capture long-range dependencies and contextual information.
| (4) |
III-E Level-Upsampling technique
For the Upsampling block, there are 2 stages in this block, the first stage is the Feature extraction stage, and the second stage is the Upsampling stage.
| (6) |
| (7) |
Equation.[6, 7] describes the Multi-scale block with as the input tensor. In this block, we utilize the Convolution module feature by extracting the input tensor by convolution layers, this one can be used with the others convolution kernel size or the others convolution components, then, the skip connection is used, the is the activation for the output of the step.
IV Experimental evaluation
IV-A Dataset
In the experiment, we follow the merged dataset between the ClinicDB dataset and the Kvasir-SEG dataset [15] which is mentioned in the PraNet [4] experiment setup, and also this training set is widely used in various experiments on the later methods. This dataset contains 2 subsets: Kvasir-SEG [15] (900 train samples) and CVC-ClinicDB [16] (550 train samples).
For benchmarking, we choose 4 datasets: Kvasir-SEG [15], ColonDB [17], CVC300 [16] and the Etis [18] dataset for the benchmarking. In those 4 datasets, apart from the Kvasir-SEG [15] dataset, others are out of the distribution datasets.



For research and study purposes, we split the merged dataset into 3 parts, one for training, one for validating, and one for testing; and do experiments on all these 3 parts. The training, validating, and testing make up 60%, 20%, and 20%, respectively, this data split method is used for evaluating our model before benchmarking on various datasets.
IV-B Augmentation
While training the model, we also use the Augmentation technique to improve the number of data in the dataset. Augmentation also creates a beneficial impact on the domain of the dataset by making the distribution of the data more complex [19]. To enrich the dataset, we propose some augmentation methods. We use Center Crop [20], Random Rotate [20], GridDistortion [20], Horizontal [20], and Vertical Flip to improve the quantity of the dataset. Moreover, some advanced augmentation methods were applied to improve the distribution of the feature in the data sample.

CutOut augmentation [21] is also applied in our experiments, this advanced method adds the noise, which is the area with all pixel values are 0, to the image randomly and then the mask has also added that area in the same position. Moreover, the CutMix augmentation is used, in this case, the original image is added with a patch from another image, and their corresponding masks are also combined in the same way.
IV-C Loss function
We utilize the Jaccard Loss Function [22] with the following formula
| (8) |
This loss function enables the segmentation process better and can control the model’s performance on the pitch of the tissues. The Jaccard Loss [22] is also known as the IOU metric, with y as the true label and the predicted label being , these two labels are demonstrated in the one-hot vector to present classes being their length. However, to prevent the exploding gradient, there is a smoothing factor called alpha , which helps stabilize the training result.
IV-D Implementation details
All architectures were implemented using the Keras framework with TensorFlow as the backend. The input volumes are normalized to [-1, 1]. All networks were trained with described augmentation methods. We used Adam optimization [23] with an initial learning rate of 1e-4. After that, we use the Cosine Annealing learning rate schedule to stable the training process. The smoothing factor alpha in the Jaccard Loss is . We performed our experiment on a single NVIDIA Tesla A100 40GB. The batch size is 128, and it takes around 6 hours to train the entire dataset. Finally, we trained all the models for 300 epochs.
IV-E Metrics
We use IOU and Dice-Coefficient metrics to evaluate our method’s performance. The metrics evaluate the ground truth mask with the predicted mask from the test dataset.
The following is the formula of mIOU [24]:
| (9) |
The Area of overlap is the common area of two predicted masks, and the Area of Union is all of the areas of two masks.
The Dice Coefficient [25] which calculates the division between the common area of two masks and the union area of two masks has the following formula:
| (10) |
V Result
V-A Qualitative Result
For the relevance of our results, we also benchmark our model with previous methods from UNet [3] in 2015 to the newest method which is on the top of the state-of-the-art in early 2023 is FCB-SwinV2 Transformer [26]. Below is the result on the Kvasir-SEG dataset[15] and CVC-300 dataset [16] with results that are competitive on state-of-the-art as shown in Table.I, and Table.II. In addition, to evaluate the deficiency of our approach, we propose to do experiments on the Etis dataset [18], and the Colon-DB dataset [17]. From the experiment, results are observed in Table.III and Table.IV.

| Model | |||
|---|---|---|---|
| UNet (MICCAI 2015) [3] | 0.756 | 0.821 | 0.055 |
| PraNet (MICCAI 2020) [4] | 0.840 | 0.898 | 0.030 |
| MSEG Net (arxiv’21) [27] | 0.857 | 0.912 | 0.025 |
| SANet (MICCAI 2021) [28] | 0.847 | 0.904 | 0.028 |
| MSNet (MICCAI 2021) [29] | 0.862 | 0.907 | 0.028 |
| Polyp-PVT (arXiv’21) [9] | 0.864 | 0.917 | 0.023 |
| PEFV2 (MMM 2023) [30] | 0.8163 | 0.8818 | nan |
| Polyp2Seg (MIUA 2022) [31] | 0.882 | 0.929 | 0.018 |
| FCB-SwinV2 (arXiv’23) [26] | 0.8973 | 0.942 | nan |
| Our | 0.921 | 0.959 | 0.004 |
| Model | |||
|---|---|---|---|
| UNet (MICCAI 2015) [3] | 0.449 | 0.519 | 0.022 |
| PraNet (MICCAI 2020) [4] | 0.797 | 0.871 | 0.010 |
| SANet (MICCAI 2021) [28] | 0.815 | 0.888 | 0.008 |
| MSNet (MICCAI 2021) [29] | 0.807 | 0.869 | 0.010 |
| Polyp-PVT (arXiv’21) [9] | 0.833 | 0.8900 | 0.007 |
| Polyp2Seg (MIUA 2022) [31] | 0.818 | 0.890 | 0.007 |
| Our | 0.862 | 0.926 | 0.006 |
| Model | |||
|---|---|---|---|
| UNet (MICCAI 2015) [3] | 0.343 | 0.406 | 0.036 |
| PraNet (MICCAI 2020) [4] | 0.567 | 0.628 | 0.031 |
| SANet (MICCAI 2021) [28] | 0.654 | 0.750 | 0.015 |
| MSNet (MICCAI 2021) [29] | 0.664 | 0.719 | 0.020 |
| Polyp-PVT (arXiv’21) [9] | 0.706 | 0.787 | 0.013 |
| Polyp2Seg (MIUA 2022) [31] | 0.738 | 0.820 | 0.015 |
| Our | 0.704 | 0.780 | 0.035 |
| Model | |||
|---|---|---|---|
| UNet (MICCAI 2015) [3] | 0.449 | 0.519 | 0.061 |
| PraNet (MICCAI 2020) [4] | 0.640 | 0.712 | 0.043 |
| SANet (MICCAI 2021) [28] | 0.670 | 0.753 | 0.043 |
| MSNet (MICCAI 2021) [29] | 0.678 | 0.755 | 0.041 |
| Polyp-PVT (arXiv’21) [9] | 0.727 | 0.808 | 0.031 |
| Polyp2Seg (MIUA 2022) [31] | 0.727 | 0.808 | 0.031 |
| Our | 0.790 | 0.867 | 0.009 |
Overall, the Table.II, Table.I, and Table.IV, our method achieves the state-of-the art on the Kvasir-SEG [15], CVC-ColonDB dataset [17], and CVC-300 [16] dataset. These results evaluate the effectiveness of our proposed Convformer and Multiscale Upsampling block. However, the weakness of the method is on the small object which is illustrated by the result from the Table.III from the Etis dataset [18].
V-B Qualitative visualization
The fig.4 visualizes masks that are generated from our method when compared with other methods each year. The dataset that is used for this visualization is the Kvasir dataset [32]. From the results, our method is demonstrated to improve the weakness of the previous method to identify the shape of some difficult polyp objects, however, with many polyps in the image, our method also shows a worse result than some methods in the previous year.
V-C Ablation study
The experiments to compare the MetaFormer UNet with the combination of Meta-UNet and our proposed block are done to evaluate the effectiveness of our method. It seems that the Multi-scale Upsampling block has led to significant improvements in the performance of the MetaFormer UNet on the Kvasir dataset, while the Convformer block can help the model learn the local feature and also can learn the captured global feature. The increase in mean Intersection over Union (mIOU) score from 0.877 to 0.921 with the addition of the Multi-scale Upsampling block and Convformer block indicates that this technique has effectively improved the model’s ability to capture fine details and produce more accurate segmentation results. Furthermore, the best-proposed model achieving a 0.921 mIOU score on the Kvasir dataset suggests that the MetaFormer UNet with Multi-scale Upsampling block and Convformer block is capable of achieving state-of-the-art performance in this task. It would be important to consider the computational cost and other practical considerations of the Multi-scale Upsampling block, as well as potential trade-offs in other performance metrics when deciding whether to incorporate it into other models or applications.
VI Conclusion
In conclusion, we propose the MetaFormer baseline with UNet and our Multi-scale Upsampling block with the Level-up augmentation technique for the segmentation. Our approach is evaluated to solve the problem from the previous methods which is the lack of local features with global features that the model learned, which can help the model capture the full shape and the texture inside the mask. Moreover, our results achieve the state-of-the-art of Kvasir-SEG dataset, the CVC-ColonDB dataset, and the CVC300 dataset. This result demonstrates that our method enhances the weakness of previous methods with our proposed modules. On the other hand, there are some limitations of the MetaFormer that need to be improved such as small polyps in the segmentation or multiple polyps also make our method obtains lower performance than usual. However, this is a promising method for the medical segmentation task and can be improved in the future.
References
- [1] M. M. Center, A. Jemal, R. A. Smith, and E. Ward, “Worldwide variations in colorectal cancer,” CA: a cancer journal for clinicians, 2009.
- [2] C. Niek van Dijk, G. E. van Dyk, P. E. Scholten, and N. P. Kort, “Endoscopic calcaneoplasty,” The American journal of sports medicine, vol. 29, no. 2, pp. 185–189, 2001.
- [3] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” 2015. [Online]. Available: https://arxiv.org/abs/1505.04597
- [4] D.-P. Fan, G.-P. Ji, T. Zhou, G. Chen, H. Fu, J. Shen, and L. Shao, “Pranet: Parallel reverse attention network for polyp segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part VI 23. Springer, 2020, pp. 263–273.
- [5] Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: A nested u-net architecture for medical image segmentation", booktitle="deep learning in medical image analysis and multimodal learning for clinical decision support,” 2018.
- [6] Q.-H. Trinh, M.-V. Nguyen, T.-G. Huynh, and M.-T. Tran, “Hcmus-juniors 2020 at medico task in mediaeval 2020: Refined deep neural network and u-net for polyps segmentation.” in MediaEval, 2020.
- [7] W. Yu, C. Si, P. Zhou, M. Luo, Y. Zhou, J. Feng, S. Yan, and X. Wang, “Metaformer baselines for vision,” 2022. [Online]. Available: https://arxiv.org/abs/2210.13452
- [8] K. Han, A. Xiao, E. Wu, J. Guo, C. Xu, and Y. Wang, “Transformer in transformer,” Advances in Neural Information Processing Systems, 2021.
- [9] B. Dong, W. Wang, D.-P. Fan, J. Li, H. Fu, and L. Shao, “Polyp-pvt: Polyp segmentation with pyramid vision transformers,” 2021. [Online]. Available: https://arxiv.org/abs/2108.06932
- [10] K. Semm, “Endoscopic appendectomy,” Endoscopy, vol. 15, no. 02, 1983.
- [11] J. Bernal, J. Sánchez, and F. Vilarino, “Towards automatic polyp detection with a polyp appearance model,” Pattern Recognition, vol. 45, no. 9, pp. 3166–3182, 2012.
- [12] F. I. Diakogiannis, F. Waldner, P. Caccetta, and C. Wu, “Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data,” ISPRS Journal of Photogrammetry and Remote Sensing, 2020.
- [13] D. Jha, P. H. Smedsrud, M. A. Riegler, D. Johansen, T. De Lange, P. Halvorsen, and H. D. Johansen, “ResUNet++: An Advanced Architecture for Medical Image Segmentation,” in Proc. of International Symposium on Multimedia, 2019, pp. 225–230.
- [14] P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” arXiv preprint arXiv:1803.02155, 2018.
- [15] D. Jha, S. A. Hicks, K. Emanuelsen, H. Johansen, D. Johansen, T. de Lange, M. A. Riegler, and P. Halvorsen, “Medico multimedia task at mediaeval 2020: Automatic polyp segmentation,” arXiv preprint arXiv:2012.15244, 2020.
- [16] D. Vázquez, J. Bernal, F. J. Sánchez, G. Fernández-Esparrach, A. M. López, A. Romero, M. Drozdzal, and A. C. Courville, “A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images,” Journal of Healthcare Engineering, 2017.
- [17] N. Tajbakhsh, S. R. Gurudu, and J. Liang, “Automated Polyp Detection in Colonoscopy Videos Using Shape and Context Information,” TMI, pp. 630–644, 2016.
- [18] J. S. Silva, A. Histace, O. Romain, X. Dray, and B. Granado, “Towards embedded detection of polyps in WCE images for early diagnosis of colorectal cancer,” IJCARS, pp. 283–293, 2014.
- [19] T. DeVries and G. W. Taylor, “Dataset augmentation in feature space,” arXiv preprint arXiv:1702.05538, 2017.
- [20] D. A. Van Dyk and X.-L. Meng, “The art of data augmentation,” Journal of Computational and Graphical Statistics, 2001.
- [21] T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv:1708.04552, 2017.
- [22] J. Bertels, T. Eelbode, M. Berman, D. Vandermeulen, F. Maes, R. Bisschops, and M. B. Blaschko, “Optimizing the dice score and jaccard index for medical image segmentation: Theory and practice,” in International conference on medical image computing and computer-assisted intervention, 2019.
- [23] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [24] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-iou loss: Faster and better learning for bounding box regression,” in Proceedings of the AAAI conference on artificial intelligence, 2020.
- [25] R. R. Shamir, Y. Duchin, J. Kim, G. Sapiro, and N. Harel, “Continuous dice coefficient: a method for evaluating probabilistic segmentations,” arXiv preprint arXiv:1906.11031, 2019.
- [26] K. Fitzgerald and B. Matuszewski, “Fcb-swinv2 transformer for polyp segmentation,” 2023. [Online]. Available: https://arxiv.org/abs/2302.01027
- [27] C.-H. Huang, H.-Y. Wu, and Y.-L. Lin, “Hardnet-mseg: A simple encoder-decoder polyp segmentation neural network that achieves over 0.9 mean dice and 86 fps,” 2021. [Online]. Available: https://arxiv.org/abs/2101.07172
- [28] R. Zhang, P. Lai, X. Wan, D.-J. Fan, F. Gao, X.-J. Wu, and G. Li, “Lesion-aware dynamic kernel for polyp segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part III. Springer, 2022, pp. 99–109.
- [29] X. Zhao, L. Zhang, and H. Lu, “Automatic polyp segmentation via multi-scale subtraction network,” in MICCAI. Springer, 2021.
- [30] T.-H. Nguyen-Mau, Q.-H. Trinh, N.-T. Bui, P.-T. V. Thi, M.-V. Nguyen, X.-N. Cao, M.-T. Tran, and H.-D. Nguyen, “Pefnet: Positional embedding feature for polyp segmentation,” in MultiMedia Modeling, D.-T. Dang-Nguyen, C. Gurrin, M. Larson, A. F. Smeaton, S. Rudinac, M.-S. Dao, C. Trattner, and P. Chen, Eds. Cham: Springer Nature Switzerland, 2023, pp. 240–251.
- [31] V. Mandujano-Cornejo and J. A. Montoya-Zegarra, Polyp2Seg: Improved Polyp Segmentation with Vision Transformer, 07 2022, pp. 519–534.
- [32] D. Jha, P. H. Smedsrud, M. A. Riegler, P. Halvorsen, T. d. Lange, D. Johansen, and H. D. Johansen, “Kvasir-seg: A segmented polyp dataset,” in International Conference on Multimedia Modeling, 2020.