11email: llshen@szu.edu.cn 22institutetext: Tencent Jarvis Lab, Shenzhen, China
22email: vicyxli@tencent.com
MI2GAN: Generative Adversarial Network for Medical Image Domain Adaptation using Mutual Information Constraint
Abstract
Domain shift between medical images from multicentres is still an open question for the community, which degrades the generalization performance of deep learning models. Generative adversarial network (GAN), which synthesize plausible images, is one of the potential solutions to address the problem. However, the existing GAN-based approaches are prone to fail at preserving image-objects in image-to-image (I2I) translation, which reduces their practicality on domain adaptation tasks. In this paper, we propose a novel GAN (namely MI2GAN) to maintain image-contents during cross-domain I2I translation. Particularly, we disentangle the content features from domain information for both the source and translated images, and then maximize the mutual information between the disentangled content features to preserve the image-objects. The proposed MI2GAN is evaluated on two tasks—polyp segmentation using colonoscopic images and the segmentation of optic disc and cup in fundus images. The experimental results demonstrate that the proposed MI2GAN can not only generate elegant translated images, but also significantly improve the generalization performance of widely used deep learning networks (e.g., U-Net).
Keywords:
Mutual Information Domain Adaptation.1 Introduction
Medical images from multicentres often have different imaging conditions, e.g., color and illumination, which make the models trained on one domain usually fail to generalize well to another. Domain adaptation is one of the effective methods to boost the generalization capability of models. Witnessing the success of generative adversarial networks (GANs) [4] on image synthesis [8, 19], researchers began trying to apply the GAN-based networks for image-to-image domain adaptation. For example, Chen et al. [1] used GAN to transfer the X-ray images from a new dataset to the domain of the training set before testing, which increases the test accuracy of trained models. Zhang et al. [21] proposed a task driven generative adversarial network (TD-GAN) for the cross-domain adaptation of X-ray images. Most of the existing GAN-based I2I domain adaptation methods adopted the cycle-consistency loss [9, 20, 24] to loose the requirement of paired cross-domain images for training. However, recent studies [7, 22] proved that cycle-consistency-based frameworks easily suffer from the problem of content distortion during image translation. Let be a bijective geometric transformation (e.g., translation, rotation, scaling, or even nonrigid transformation) with inverse transformation , the following generators and are also cycle consistent.
| (1) |
where the and are the original cycle-consistent generators establishing two mappings between domains and . Consequently, due to lack of penalty in content disparity between source and translated images, the content of a translated image by cycle-consistency-based frameworks may be distorted by , which is unacceptable in medical image processing.
To tackle the problem, we propose a novel GAN (MI2GAN) to maintain the contents of Medical Image during I2I domain adaptation by maximizing the Mutual Information between the source and translated images. Our idea relies on two observations: 1) the content features containing the information of image-objects can be fully disentangled from the domain information; and 2) the mutual information, measuring the information that two variables share, can be used as a metric for image-object preservation. Mutual information constraint has been widely used for various medical image processing tasks, such as image registration [14]. Given two variables and , the mutual information shared by and can be formulated as:
| (2) |
where and are joint distribution and the product of marginals of and ; is the KL-divergence. Specifically, and , where and ; and are the distributions of and , respectively; is the conditional probability of given .
Since the posterior probability is difficult to be directly estimate [3], we measure and maximize the MI between source and translated images based on the approach similar to [6, Belghazi18]. Specifically, the content features of source and translated images are first extracted by the paired adversarial auto-encoders, which are then fed to a discriminator for the estimation of mutual information. Extensive experiments are conducted to validate the effectiveness of our MI2GAN. The experimental results demonstrate that the proposed MI2GAN can not only produce plausible translated images, but also significantly reduce the performance degradation caused by the domain shift.
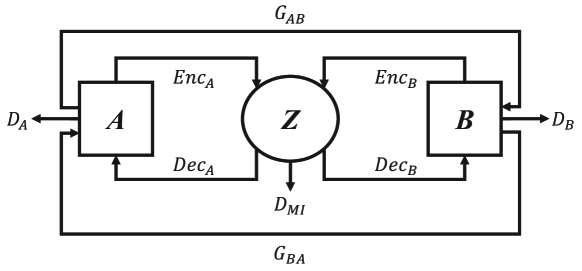
2 MI2GAN
The pipeline of our MI2GAN is presented in Fig. 1. Similar to current cycle-consistency-based GAN [24], our MI2GAN adopts paired generators ( and ) and discriminators ( and ) to achieve cross-domain image translation without paired training samples. To distill the content features from domain information, X-shape dual auto-encoders (i.e., , , , and ) are implemented. The encoders (i.e., and ) are responsible to embed the content information of source and translated images into the same latent space , while the decoders (i.e., and ) aim to transform the embedded content features to their own domains using domain-related information. Therefore, to alleviate the content distortion problem during image translation, we only need to maximize the mutual information between the content features of source and translated images, which is achieved by our mutual information discriminator. In the followings, we present the modules for content feature disentanglement and mutual information maximization in details.
2.1 X-shape Dual Auto-Encoders
We proposed the X-shape dual auto-encoders (AEs), consisting of , , , and , to disentangle the features containing content information. As the mappings between domains A and B are symmetrical, we take the content feature distillation of images from domain A as an example. The pipeline is shown in Fig. 2 (a). Given an input image (), the auto-encoder ( and ) embeds it into a latent space, which can be formulated as:
| (3) |
where is the reconstruction of . The embedded feature contains the information of content and domain A. To disentangle them, is mapped to domain B via :
| (4) |
where is the mapping result of .
As shown in Fig. 2, apart from the X-shape dual AEs, there is another translation path between domain A and B: , where is the translated image yielded by . Through simultaneously minimizing the pixel-wise L1 norm between and , and reconstruction error between and , and are encouraged to recover domain-related information from the latent space (in short, the encoders remove domain information and the decoders recover it), which enable them to map the to two different domains. Therefore, the information contained in is highly related to the image-objects without domain bias. The content feature distillation loss (), combining aforementioned two terms, can be formulated as:
| (5) |
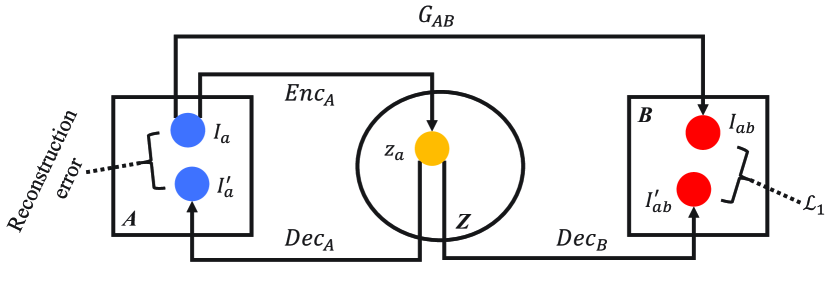
(a) Content feature distillation
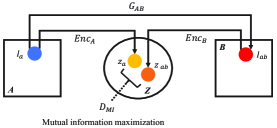
(b) Mutual information maximization
2.2 Mutual Information Discriminator
Using our X-shape dual AEs, the content features of source and translated images can be disentangled to and , respectively. The content feature of translated image preserving image-objects should contain similar information to that of source image. To this end, the encoder () needs to implicitly impose statistical constraints onto learned representations, which thereby pushes the translated distribution of to match the source (i.e., mutual information maximization between and ), where and are two sub-spaces of .
Referred to adversarial training, which matches the distribution of synthesized images to that of real ones, this can be achieved by training a mutual information discriminator () to distinguish between samples coming from the joint distribution, , and the product of marginals, , of the two sub-spaces and [6]. We use a lower-bound to the mutual information ( defined in Eq. 2) based on the Donsker-Varadhan representation (DV) of the KL-divergence, which can be formulated as:
| (6) |
where is a discriminator function modeled by a neural network.
To constitute the real () and fake () samples for the , an image is randomly selected from domain B and encoded to . The is then concatenated to and , respectively, which forms the samples from the joint distribution () and the product of marginals () for the mutual information discriminator.
Objective.
With the previously defined feature distillation loss () and mutual information discriminator, the full objective for the proposed MI2GAN is summarized as:
| (7) | ||||
where and are adversarial and cycle-consistency losses, the same as that proposed in [24]. The weights and for and respectively are all set to 10.
2.3 Implementation Details
Network architecture.
Consistent to the standard of CycleGAN [24], the proposed MI2GAN involves paired generators (, ) and discriminators (, ). Instance normalization [17] is employed in the generators to produce elegant translation images, while PatchGAN is adopted in the discriminators [8, 11] to provide patch-wise predictions. Our X-shape AEs and mutual information discriminator adopt instance normalization and leaky ReLU in their architectures, and the detailed information can be found in the arXiv version.
Optimization process.
The optimization of and is performed in the same manner of —fixing X-shape dual AEs, and / to optimize / first, and then optimize AEs, and / respectively, with fixed /. Therefore, similar to discriminators, our X-shape dual AEs and mutual information discriminator can directly pass the knowledge of image-objects to the generators, which helps them to improve the quality of translated results in terms of object preservation.
3 Experiments
Deep neural networks often suffer from performance degradation when applied to a new test dataset with domain shift (e.g., color and illumination) caused by different imaging instruments. Our MI2GAN tries to address the problem by translating the test images to the same domain of the training set. In this section, to validate the effectiveness of the proposed MI2GAN, we evaluate it on several publicly available datasets.
3.1 Datasets
Colonoscopic datasets.
The publicly available colonoscopic video datasets, i.e., CVC-Clinic [18] and ETIS-Larib [16], are selected for multicentre adaptation. The CVC-Clinic dataset is composed of 29 sequences with a total of 612 images. The ETIS-Larib consists of 196 images, which can be manually separated to 29 sequences as well. Those short videos are extracted from the colonoscopy videos captured by different centres using different endoscopic devices. All the frames of the short videos contain polyps. In this experiment, the extremely small ETIS-Larib dataset (196 frames) is used as the test set, while the relatively larger CVC-Clinic dataset (612 frames) is used for network optimization (80:20 for training and validation).
REFUGE.
The REFUGE challenge dataset [13] consists of 1,200 fundus images for optic disc (OD) and optic cup (OC) segmentation, which were partitioned to training (400), validation (400) and test (400) sets by the challenge organizer. The images available in this challenge were acquired with two different fundus cameras—Zeiss Visucam 500 for the training set and Canon CR-2 for the validation and test sets, resulting in visual gap between training and validation/test samples. Since the test set is unavailable, we conduct experiment on I2I adaptation between the training and validation sets. The public training set is separated to training and validation sets according to the ratio of 80:20, and the public validation set is used as the test set.
Baselines overview & evaluation criterion.
Several unpaired image-to-image domain adaptation frameworks, including CycleGAN [24], UNIT [12] and DRIT [10], are taken as baselines for the performance evaluation. The direct transfer approach, which directly takes the source domain data for testing without any adaptation, is also involved for comparison. The Dice score (DSC), which measures the spatial overlap index between the segmentation results and ground truth, is adopted as the metric to evaluate the segmentation accuracy.
3.2 Ablation Study
Content feature distillation.
We invite three experienced experts to manually tune two CVC images to the domain of ETIS (as shown in the first row of Fig. 3), i.e., tuning the image conditions such as color and saturation based on the statistical histogram of the ETIS domain. The two paired images contain the same content information but totally different domain-related knowledge. To ensure our X-shape dual auto-encoders really learn to disentangle the content features from domain information, we sent the paired images to X-shape dual AEs and visualize the content features produced by and using CAM [23] (as illustrated in the second row of Fig. 3). For comparison, the CVC images are also sent to for content feature distillation. It can be observed that the CVC and ETIS images respectively going through and result in the similar activation patterns, while the encoders yield different patterns for the CVC images. The experimental result demonstrate that the encoders of our X-shape dual AEs are domain-specific, which are able to remove the their own domain-related information from the embedding space.
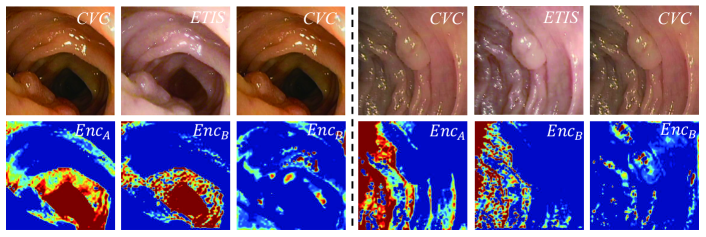
Mutual information discriminator.
To validate the contribution made by the mutual information discriminator, we evaluate the performance of MI2GAN without . The evaluation results are presented in Table 1. The segmentation accuracy on the test set significantly drops to 65.96%, 77.27% and 92.17% for polyp, OC and OD, respectively, with the removal of , which demonstrates the importance of for image-content preserving domain adaptation.
| Colonoscopy | Fundus | |||||
|---|---|---|---|---|---|---|
| CVC (val.) | ETIS (test) | |||||
| Direct transfer | 80.79 | 64.33 | 85.83 | 95.42 | 81.66 | 93.49 |
| DRIT [10] | 28.32 | 64.79 | 69.03 | |||
| UNIT [12] | 23.46 | 71.63 | 74.58 | |||
| CycleGAN [24] | 52.41 | 71.53 | 85.83 | |||
| MI2GAN (Ours) | 72.86 | 83.49 | 94.87 | |||
| MI2GAN w/o | 65.96 | 77.27 | 92.17 | |||
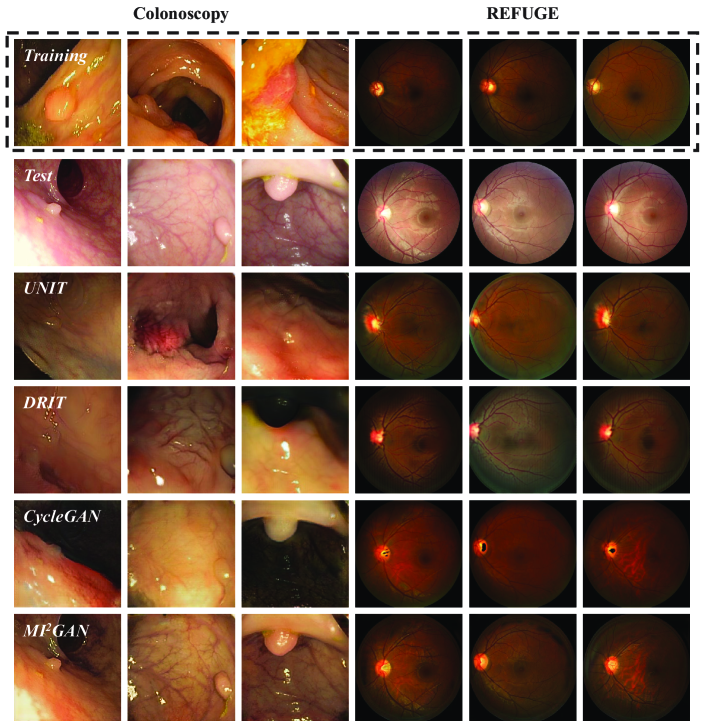
3.3 Comparison to State of the Art
Different I2I domain adaptation approaches are applied to the colonoscopic and fundus image datasets, respectively, which translate the test images to the domain of the training set to narrow the gap between them and improve the model generalization. The adaptation results generated by different I2I domain adaptation approaches are presented in Fig. 4. The first row of Fig. 4 shows the examplars from the training sets of colonoscopy and REFUGE datasets. Content distortions are observed in the adaptation results produced by most of the existing I2I translation approaches. In contrast, our MI2GAN yields plausible adaptation results while excellently preserving the image-contents.
For quantitative analysis, we present the segmentation accuracy of deep learning networks with different adaptation approaches in Table 1. To comprehensively assess the adaptation performance of our MI2GAN, we adopt two widely-used deep learning networks, i.e., ResUNet-50 [5, 15] and DeepLab-V3 [2], for the polyp segmentation, and OC/OD segmentation, respectively. As shown in Table 1, due to the lack of capacity of image-content preservation, most of existing I2I domain adaptation approaches degrade the segmentation accuracy for both tasks, compared to the direct transfer. The DRIT [10] yields the highest degradation of DSC, , and for polyp, OC and OD, respectively. Conversely, the proposed MI2GAN remarkably boosts the segmentation accuracy of polyp (), OC (), and OD () to the direct transfer, which are closed to the accuracy on validation set.
4 Conclusion
In this paper, we proposed a novel GAN (namely MI2GAN) to maintain image-contents during cross-domain I2I translation. Particularly, we disentangle the content features from domain information for both the source and translated images, and then maximize the mutual information between the disentangled content features to preserve the image-objects.
Acknowledge
This work is supported by the Natural Science Foundation of China (No. 91959108 and 61702339), the Key Area Research and Development Program of Guangdong Province, China (No. 2018B010111001), National Key Research and Development Project (2018YFC2000702) and Science and Technology Program of Shenzhen, China (No. ZDSYS201802021814180).
References
- [1] Chen, C., Dou, Q., Chen, H., Heng, P.A.: Semantic-aware generative adversarial nets for unsupervised domain adaptation in chest X-ray segmentation. In: International Workshop on Machine Learning in Medical Imaging (2018)
- [2] Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017)
- [3] Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., Abbeel, P.: InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In: Annual Conference on Neural Information Processing Systems (2016)
- [4] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Annual Conference on Neural Information Processing Systems (2014)
- [5] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition (2016)
- [6] Hjelm, R.D., Fedorov, A., Lavoie-Marchildon, S., Grewal, K., Bachman, P., Trischler, A., Bengio, Y.: Learning deep representations by mutual information estimation and maximization. In: International Conference on Learning Representations (2019)
- [7] Huang, S., Lin, C., Chen, S., Wu, Y., Hsu, P., Lai, S.: AugGAN: Cross domain adaptation with GAN-based data augmentation. In: European Conference on Computer Vision (2018)
- [8] Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with conditional adversarial networks. In: IEEE Conference on Computer Vision and Pattern Recognition (2017)
- [9] Kim, T., Cha, M., Kim, H., Lee, J., Kim, J.: Learning to discover cross-domain relations with generative adversarial networks. In: International Conference on Machine Learning (2017)
- [10] Lee, H.Y., Tseng, H.Y., Huang, J.B., Singh, M.K., Yang, M.H.: Diverse image-to-image translation via disentangled representations. In: European Conference on Computer Vision (2018)
- [11] Li, C., Wand, M.: Precomputed real-time texture synthesis with Markovian generative adversarial networks. In: European Conference on Computer Vision (2016)
- [12] Liu, M.Y., Breuel, T., Kautz, J.: Unsupervised image-to-image translation networks. In: Annual Conference on Neural Information Processing Systems (2017)
- [13] Orlando, J.I., Fu, H., Breda, J.B., van Keer, K., Bathula, D.R., Diaz-Pinto, A., Fang, R., Heng, P.A., Kim, J., Lee, J., et al.: Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Medical Image Analysis 59, 101570 (2020)
- [14] Pluim, J.P.W., Maintz, J.B.A., Viergever, M.A.: Mutual-information-based registration of medical images: A survey. IEEE Transactions on Medical Imaging 22(8), 986–1004 (2003)
- [15] Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer Assisted Intervention (2015)
- [16] Silva, J., Histace, A., Romain, O., Dray, X., Granado, B.: Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer. International Journal of Computer Assisted Radiology and Surgery 9(2), 283–293 (2014)
- [17] Ulyanov, D., Vedaldi, A., Lempitsky, V.: Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022 (2016)
- [18] Vazquez, D., Bernal, J., Sanchez, F.J., Fernandez-Esparrach, G., Lopez, A.M., Romero, A., Drozdzal, M., Courville, A.: A benchmark for endoluminal scene segmentation of colonoscopy images. Journal of Healthcare Engineering 2017 (2017)
- [19] Wang, T., Liu, M., Zhu, J., Tao, A., Kautz, J., Catanzaro, B.: High-resolution image synthesis and semantic manipulation with conditional GANs. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
- [20] Yi, Z., Zhang, H., Tan, P., Gong, M.: DualGAN: Unsupervised dual learning for image-to-image translation. In: IEEE International Conference on Computer Vision (2017)
- [21] Zhang, Y., Miao, S., Mansi, T., Liao, R.: Task driven generative modeling for unsupervised domain adaptation: Application to X-ray image segmentation. In: International Conference on Medical Image Computing and Computer Assisted Intervention (2018)
- [22] Zhang, Z., Yang, L., Zheng, Y.: Translating and segmenting multimodal medical volumes with cycle- and shape-consistency generative adversarial network. In: IEEE conference on Computer Vision and Pattern Recognition (2018)
- [23] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: IEEE Conference on Computer Vision and Pattern Recognition (2016)
- [24] Zhu, J., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: IEEE International Conference on Computer Vision (2017)