MIG Median Detectors with Manifold Filter
Abstract
In this paper, we propose a class of median-based matrix information geometry (MIG) detectors with a manifold filter and apply them to signal detection in nonhomogeneous environments. As customary, the sample data is assumed to be modeled as Hermitian positive-definite (HPD) matrices, and the geometric median of a set of HPD matrices is interpreted as an estimate of the clutter covariance matrix (CCM). Then, the problem of signal detection can be reformulated as discriminating two points on the manifold of HPD matrices, one of which is the HPD matrix in the cell under test while the other represents the CCM. By manifold filter, we map a set of HPD matrices to another set of HPD matrices by weighting them, that consequently improves the discriminative power by reducing the intra-class distances while increasing the inter-class distances. Three MIG median detectors are designed by resorting to three geometric measures on the matrix manifold, and the corresponding geometric medians are shown to be robust to outliers. Numerical simulations show the advantage of the proposed MIG median detectors in comparison with their state-of-the-art counterparts as well as the conventional detectors in nonhomogeneous environments.
Keywords: Matrix information geometry (MIG) detector, geometric median, manifold filter, signal detection, clutter covariance matrix
1 Introduction
Signal detection in nonhomogeneous environments is an important and fundamental problem in the studies of radar, sonar and communications. Typically, to achieve satisfactory detection performance, the unknown clutter covariance matrix (CCM) should be estimated accurately. The problem of CCM estimation has been extensively studied during the latest decades [27, 1, 46, 39, 25, 3, 4]. One major limitation of the classical CCM estimators is that the accuracy depends heavily on the number of homogeneous secondary data, which is independent and identically distributed and is collected from the range cells adjacent to the range cell under test. In practical applications, the number of homogeneous secondary data is often very limited in nonhomogeneous environments. In addition, the secondary data is often contaminated by outliers due to the environmental nonhomogeneity caused by the interfere signal or the variation of clutter power. Both factors make the classical signal detection techniques, such as Kelly’s detector [36], adaptive matched filter (AMF) [47, 21] and adaptive coherence estimator (ACE) [37] derived by exploiting the CCM estimator suffer from a severe performance degradation.
To address these drawbacks, lots of attempts are made to improve the estimation accuracy of CCM. For instance, De Maio et al. [23] exploited a priori information on the covariance structure to design an adaptive detection of point-like target in interference environments. Specifically, a symmetrically structured power spectral density is assumed to agree with the clutter properties. Based on this assumption, three adaptive decision schemes leveraging on the symmetric power spectral density structure for the interference are proposed, whose performance advantage was confirmed by simulation as well as experimental analysis using real radar data. In [4], a special structure that the covariance matrix is described as the sum of an unknown positive semi-definite matrix and a matrix proportional to the identity one, and a condition number upper-bound constraint are enforced on the estimated matrix. The constrained structure both accounting for the clutter and the white interference can achieve signal-to-interference-plus-noise ratio (SINR) improvements over their conventional counterparts, especially in the case of limited data. Similar studies concerning the priori information on the structure of the estimated covariance matrix can also be found in [6, 20, 5, 35]. Other possible strategies to improve the performance of CCM estimation are mainly focused on resorting to the Bayesian covariance matrix estimation method [13, 12], using knowledge-based covariance models [7, 22, 42, 43, 49], or considering shrinkage estimation methods [18, 17]. A fatal drawback on these methods is that the performance gain relies on the known or assumed statistical characteristics of clutter environments, which is often difficult to be acquired in advance in practical applications.
Recently, a new signal detection scheme designed in the framework of matrix information geometry (MIG) was proposed by Lapuyade-Lahorgue and Barbaresco [38] and developed by Hua et al. [31], etc. This technique is often referred to as matrix constant false alarm rate detector or MIG detector. MIG studies intrinsic properties of matrix models, and many information processing problems can be transformed into discriminational or optimization problems on matrix spaces equipped with a metric. Based on the MIG theory, an MIG detector designed by using the Riemannian metric or affine invariant Riemannian metric (AIRM) has been successful applied to target detection in coastal X-band and HF surface wave radars [2, 9, 8], burg estimation of radar scatter matrix [24], the analysis of statistical characterization [10] and the monitoring of wake vortex turbulences [40, 11]. The detection framework has been extended by replacing the AIRM distance with other different geometric measures. In [32], the authors developed the MIG detector based on the symmetrized Kullback–Leibler divergence (SKLD) and total Kullback–Leibler divergence. In [30, 33], the total Bregman and total Jensen–Bregman divergences were used to design effective MIG detectors. It is noticed that MIG detectors designed by using different measures have different detection performances. As MIG detectors do not rely on the statistical characteristics of clutter environment and take into account the underlying geometry of matrix manifolds, they have the potential to achieve a performance improvement over the conventional detection techniques in nonhomogeneous environments.
It is well known that a filter can often remove unwanted information from a signal, which can be the noise or the clutter in signal detection. As a consequence, discrimination of the signal and the clutter/noise will be enhanced and hence the signal can be detected more easily. To improve the discriminative power on matrix manifolds, we propose a class of MIG median detectors with a manifold filter, that will improve detection performances by reducing the intra-class distances while increasing the inter-class distances. The main contributions are described as follows:
-
1.
We define a map (see Eq. (4.5)) on the manifold of Hermitian positive-definite (HPD) matrices by a manifold filter. Consequently, each HPD matrix is mapped to a weighted average of several surrounding HPD matrices, which is again Hermitian positive-definite.
-
2.
We reformulate the problem of signal detection into discriminating two points on the HPD matrix manifold, and then design three MIG median detectors by resorting to the Log-Euclidean metric (LEM), SKLD and the Jensen–Bregman LogDet (JBLD) divergence, respectively. In particular, the median matrices related to the three metrics for a set of HPD matrices are computed by using the fixed-point algorithm and are used as the CCM estimate. Moreover, the anisotropy indices associated with the three metrics are defined to analyze the difference in discriminative power on the HPD manifold and the other manifold.
-
3.
Simulation results verify that the geometric median matrix is robust and reliable, and the proposed MIG median detectors with manifold filter can achieve performance improvements over state-of-the-art counterparts as well as the AMF in nonhomogeneous environments.
The remainder of this paper is organized as follows. Relevant fundamental theories of MIG are introduced in Section 2. Section 3 is devoted to formulation of detection problems on matrix manifolds. Derivation of the detection architecture is presented in Section 4 with numerical simulations given in Section 5. Finally, we conclude in Section 6.
Notations: In the sequel, scalars, vectors and matrices are denoted by lowercase, boldface lowercase and boldface uppercase letters, respectively. The symbols , and stand for the conjugate, the transpose, and the conjugate transpose, respectively. The operators and denote the determinate and trace of a matrix, respectively. The identity matrix is denoted by or if no confusion would be caused. We use and to denote the set of -dimensional complex vectors and complex matrices, respectively.
2 Preliminary of matrix information geometry
MIG studies intrinsic properties of matrix manifolds, whose elements, e.g., matrix-valued data, can be discriminated by a geometric measure. Many problems in information science related to matrix-valued data can be equivalently formulated as measuring the difference of two points in a matrix manifold. In this section, we briefly introduce the theory of HPD manifolds and define several geometric measures as the discrimination functions using the Frobenius metric.
2.1 HPD matrix manifolds
Let be the set of Hermitian matrices, given by
| (2.1) |
A Hermitian matrix is positive-definite, expressed as , if the quadratic expression holds for all . The set of HPD matrices is
| (2.2) |
The subspace becomes a Riemannian manifold of non-positive curvature equipped with an AIRM [15], which has been extensively studied during the recent few decades [51, 50, 41]. The HPD matrix manifold has many interesting properties [48]. For instance,
-
1.
Its closure forms a closed, nonpolyhedral, self-dual convex cone.
-
2.
It embodies a canonical higher-rank symmetric space.
Each element of the matrix manifold denotes an HPD matrix. Given any two HPD matrices, their difference on the HPD matrix manifold can be measured by a metric, a divergence or other measures. Different measures amount to different geometric structures. Thus, it is important to choose an appropriate measure function for a specific application. In the following, we introduce several geometric measures on the HPD matrix manifold.
2.2 Geometric measures on HPD matrix manifolds
We first introduce the AIRM and AIRM distance on the HPD matrix manifold . The tangent space at a point is . A well-known AIRM defined in is
| (2.3) |
There are natural exponential map and logarithm map on the tangent bundle using the geodesics. They are related to matrix exponentials and matrix logarithms. Matrix exponential for a general matrix is given by
| (2.4) |
The following proposition defines the principle logarithm of an invertible matrix.
Lemma 2.1 ([28, 44]).
Suppose is an invertible matrix that does not have eigenvalues in the closed negative real line. Then, there exists a unique logarithm with eigenvalues lying in the strip . This logarithm is called the principle logarithm and denoted by .
Moreover, the matrix satisfies the following properties.
-
(i)
Both and commute with for any real number .
-
(ii)
The following identity holds that
-
(iii)
Suppose is an invertible matrix which does not have eigenvalues lying in the closed real line. Then, we have
The AIRM distance of two points is defined as length of the local geodesic connecting them, which is given by
| (2.5) | ||||
where is the -th eigenvalue of . Here is the Frobenius norm of a matrix , induced from the Frobenius metric.
Unfortunately, the computational cost of the AIRM distance is expensive in practical applications. An alternative selection, the Log-Euclidean metric (LEM), is derived by defining the metric in the tangent space using the Frobenius metric as follows:
| (2.6) |
where denotes the directional derivative of the logarithm function along direction at a point . The LEM metric is more efficient in the sense of computational cost, compared with the AIRM metric. In addition to them, many geometric measures that possess good properties have also been introduced on the manifold , for instance, the JBLD divergence [19], the KLD [14], and the SKLD [32]. Among these geometric measures, only the AIRM and LEM metrics lead to a true geodesic distance on the manifold . It should also be noted that only the AIRM, the JBLD divergence and the SKLD are invariant w.r.t. affine transformations. In this paper, we will mainly be focused on the LEM, the JBLD divergence and the SKLD, defined in the manifold .
Definition 2.2.
The LEM distance between two matrices is defined as
| (2.7) |
Definition 2.3.
The JBLD divergence of two matrices is defined as
| (2.8) |
Definition 2.4.
The SKLD divergence of two matrices is defined as
| (2.9) |
3 Problem formulation
Consider the detection of a target signal embedding into a clutter environment. We assume that a set of secondary data, free of signal components, is available. As customary, the detection problem can be formulated as the following binary hypotheses test,
| (3.1) |
where and denote the primary data and secondary data, respectively, and are the clutter data, is a deterministic but unknown real number, which stands for the target property and channel propagation effects, and is a known signal steering vector. The purpose of signal detection is to discriminate the target signal from the clutter data. Generally, this problem is considered as the estimation of the logarithm likelihood function of the statistical models of and , and can be solved by resorting to the generalized likelihood ratio test criteria. One crucial drawback of this method is that it treats the statistical models independently regardless of their intrinsic connections due to the manifold structure. At the moment, we assume that the sample data is modeled as an HPD matrix and then reformulate the problem of signal detection as discriminating the target signal and clutter on the HPD matrix manifold . Specifically, the decision on the presence or absence of a target is made by comparing the geometric distance (or difference) between the matrix in the range cell under test (CUT) and the estimated CCM with a given threshold . Consequently, the rule of signal detection can be formulated as follows:
| (3.2) |
where denotes a geometric measure, and is the detection threshold that is set to maintain a constant false alarm rate. It can be noted from (3.2) that the detection performance greatly depends on the measure function used to discriminate two points on the HPD matrix manifold. Moreover, robustness of the estimated CCM to outliers also has an effect on the detection performance. The commonly used CCM estimator is the sample covariance matrix (SCM). For a set of secondary data , the SCM is the maximum likelihood estimation (MLE) of secondary data given by
| (3.3) |
Note that the SCM estimator can be viewed as the arithmetic mean of autocorrelation matrices with rank one. The matrix is the MLE of the secondary data . To analyze the matrix data on the HPD matrix manifold, for any a sample data , a suboptimal estimation that is positive-definite can be derived as
| (3.4) |
with entries
| (3.5) |
where is the -th correlation coefficient of the data and denotes the statistical expectation. According to the ergodicity of stationary Gaussian process, the correlation coefficient of the data can be calculated by averaging over time instead of its statistical expectation, as follows:
| (3.6) |
The estimation in (3.4) allow us to model each sample data as an HPD matrix. Then, the CCM can be estimated according to a set of HPD matrices . It is known that the SCM is sensitive to outliers in nonhomogeneous environments. Take the nonlinear geometric structure of HPD matrix manifolds into consideration, a robust CCM estimator can be chosen as the geometric mean or median. The geometric mean estimator has been discussed in details [29]. In this paper, we devote to studying geometric median estimators. The geometric median is defined as follows.
Definition 3.1.
For HPD matrices , the geometric median estimator associated with a geometric measure is the unique solution of the minimizer of the sum of the geometric measure
| (3.7) |
Based on the geometric median estimator , we can design the MIG detector by replacing the CCM with . Different geometric measures possess different discriminative power. Besides, the robustness of different geometric estimators to outliers are also different. These will be clarified later.
4 The proposed detectors
According to the principle of signal detection mentioned above, we present the block-scheme of the proposed detector in Fig. 1. We first model each sample data as an HPD matrix, and then map each HPD matrix to another HPD matrix. The detection statistic is computed by the geometric distance between the HPD matrix in the CUT and the CCM estimated by the geometric median related to a measure. Finally, the decision on the existence or absence of a target is made by comparing the detection statistic with a given threshold. Here, the manifold-to-manifold map and the geometric median are the two essential tools for designing the detector. In the following, we introduce a manifold-to-manifold map by a manifold filter and deduce geometric medians for a set of HPD matrices. We also define the anisotropy index to analyze the discriminative power of a geometric measure.
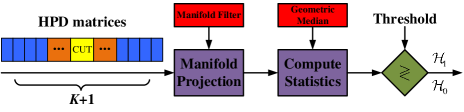
4.1 Manifold filter: Weighting a set of HPD matrices
In this subsection, a weighting map in the HPD manifold is defined to derive a more discriminative measure of a given set of HPD matrices.
Suppose that the HPD matrix modeled using the sample data contains some redundant information, which would often limit the discriminative power of the intra-class and the inter-class. As illustrated by Fig. 2, given the data collected from two classes on an HPD manifold, marked as the blue circle and the red square, we propose a manifold filter that cuts down the redundant information contained in the sample data to improve the discriminative power. The improvement is achieved by reducing the intra-class distance while increasing the inter-class distance.
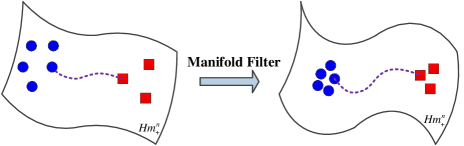
The manifold filter is designed by mapping an HPD matrix to the weighted average of its surrounding HPD matrices. Suppose that is an HPD matrix in one cell, and its surrounding HPD matrices is denoted as . The weighted average matrix is given by
| (4.1) |
where is the -th weight. The weighted average matrix can be chosen as the arithmetic mean, geometric mean or geometric median. In each case, the matrix is still HPD and this defines a map from a HPD matrix to another HPD matrix: . Analogous to the filter in image denoising, the arithmetic mean can be viewed as a mean filter [26] and the geometric mean or median can be viewed as nonlocal mean filters [45]. In this paper, we choose the arithmetic mean as the weighted average matrix. Other means or medians will be reported separately. Thus, the weighted average matrix reads
| (4.2) |
where a further constraint of the weights are imposed, namely
| (4.3) |
We define each weight to represent the similarity between the matrix and the matrix such that the smaller their difference, the greater the weight. For simplicity, we use an exponential function to define the weights as follows
| (4.4) |
where is a constant parameter. Substituting (4.4) into (4.2), we obtain
| (4.5) |
In the manifold filter, and are free parameters, which can be adjusted properly in practical applications to monitor the filter. In general, bigger leads to better filter results as more information is included. The parameter is related to the influence of data on the filter weight: a bigger usually means a smaller variation of the weights.
4.2 Geometric medians
Geometric median of the weighted HPD matrices is considered as the estimate of CCM. According to (3.7), we can obtain the geometric median related to a measure for a set of HPD matrices. The fixed-point iteration algorithms for computing the LEM, JBLD divergence and SKLD medians are given below. Be noted that fixed-point iteration for a given fixed-point problem is not unique.
To find the median minimizing the function
| (4.6) |
it suffices to solve the vanishment of its gradient, i.e., , which is defined using the Frobenius metric as (see, e.g., [34])
| (4.7) |
In this paper, we show fixed-point iteration algorithms for solving the algebraic equation . Note that the algorithms may not be unique.
Proposition 4.1.
The LEM median of a set of HPD matrices can be computed via the following fixed-point iteration
| (4.8) |
where is a nonnegative integer. Uniqueness of the median is proved in [16].
Proof.
It was shown in [16] that median related to the function
| (4.9) |
is characterized by
| (4.10) |
The fixed-point iteration follows immediately.
∎
Proposition 4.2.
The JBLD median of a set of HPD matrices can be computed by using the fixed-point iteration
| (4.11) |
Proof.
Denote as the function to be minimized, namely
| (4.12) |
Its gradient can be computed via the definition (4.7) and we obtain
| (4.13) |
Moving the terms of the equation to one side, we obtain the fixed-point iteration.
∎
Proposition 4.3.
The SKLD median of a set of HPD matrices can be computed by the fixed-point iteration
| (4.14) |
where
| (4.15) |
and
| (4.16) |
Proof.
For the function
| (4.17) |
direct computation using definition (4.7) gives
| (4.18) |
The equation can be rewritten as follows
| (4.19) |
which looks like a special algebraic Riccati equation but note that the matrices and also depend on , given by
| (4.20) |
and
| (4.21) |
Since both and are HPD matrices, we multiply on both sides of (4.19) by from both the left and the right, amounting to
| (4.22) |
The matrix can hence be solved in terms of and as follows
| (4.23) |
The fixed-point iteration is proposed according to the final equation.
∎
4.3 Anisotropy index
The discriminative power of weighted HPD matrices can be shown through the corresponding anisotropy indices. The anisotropy index associated with a measure, e.g., a metric or a divergence, at any point of a matrix manifold reflects the local geometric structure around this point.
Definition 4.4.
The anisotropy index related to a geometric measure at a point is defined by
| (4.24) |
Namely, the anisotropy index is the minimum square of a geometric distance between and (). This distance represents the projection distance from matrix to the subspace . Bigger the distance, lagger the anisotropy index. Next, we will show the anisotropy indices for the LEM, JBLD divergence and SKLD, respectively. They can be simply calculated by considering minimum of the function
| (4.25) |
Proposition 4.5.
The anisotropy index related to the LEM metric at is given by
| (4.26) |
where .
Proof.
Now the function reads
| (4.27) |
whose derivative can immediately be computed:
| (4.28) | ||||
Note that Lemma 2.1 is used here. Stationary condition that gives the unique positive solution, denoted by :
| (4.29) |
∎
Proposition 4.6.
The anisotropy index associated with the JBLD divergence at a point is given by
| (4.30) |
where is the unique positive solution of the equation
| (4.31) |
for all , where are the eigenvalues of .
Proof.
See Appendix A. ∎
Proposition 4.7.
The anisotropy index associated with the SKLD divergence at a point is
| (4.32) |
where
| (4.33) |
Proof.
The proof is similar by considering stationary condition of the function
| (4.34) |
whose derivative is
| (4.35) |
By solving , the proof is complete. ∎
5 Numerical results
The class of MIG detectors we propose in this paper is based on medians of a set of HPD matrices with a manifold filter, corresponding to various geometric measures. To illustrate the effectiveness of those MIG median detectors, in this section, numerical simulations are provided to analyze them from three aspects: robustness to outliers; the discriminative power on the matrix manifold before and after taking the manifold filter, e.g., matrix weighting, into consideration (see Section 4.1); and detection performances.
5.1 Robustness of geometric medians
In this subsection, we investigate the robustness of geometric medians in terms of the sensitivity to the number of interferences as well as to the number of samples, respectively. The sample dataset is generated according to a multivariate complex Gaussian distribution with zero mean and the following covariance matrix
| (5.1) |
where and denote the noise component with power and the clutter component with power , respectively. The clutter-to-noise ratio (CNR) is defined by CNR. Entries of are given by
| (5.2) |
where is the one-lag correlation coefficient, and denotes the clutter normalized Doppler frequency. In the simulations, the parameter are fixed with , , dB, . A set of sample data is generated without interferences, and then, a number of interferences are respectively injected into the sample data. The normalized Doppler frequency of all interferences is set to be . The SCNR is defined as
| (5.3) |
where denotes the amplitude coefficient and is the steering vector. Here, SCNR is set to be dB. An offset error that denotes the difference between the median of the sample data without interferences and the median of the sample data with interferences is defined by
| (5.4) |
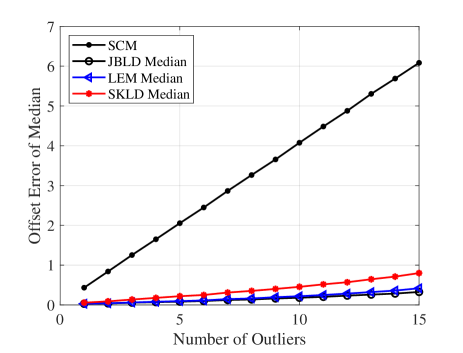
Fig. 3 shows offset errors of the SCM and geometric medians under different number of interferences. It is clear that geometric medians are more robust than the SMC, and among them, the JBLD median is the most robust against interferences.
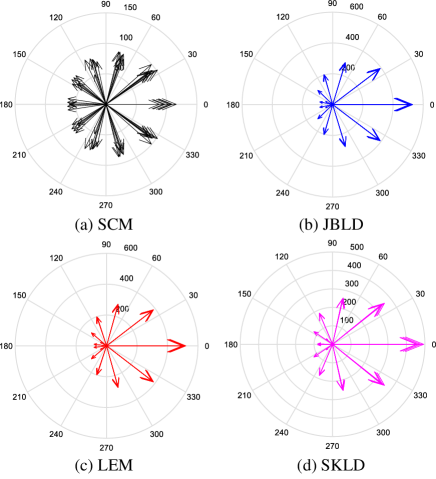
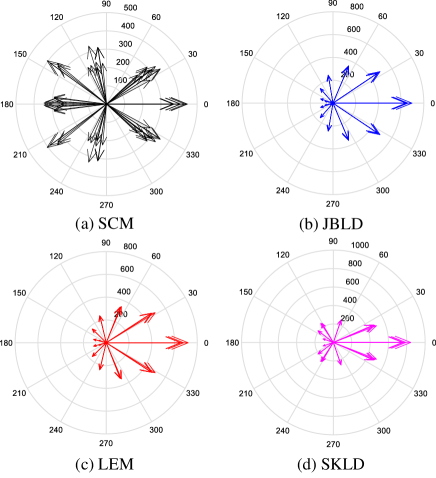
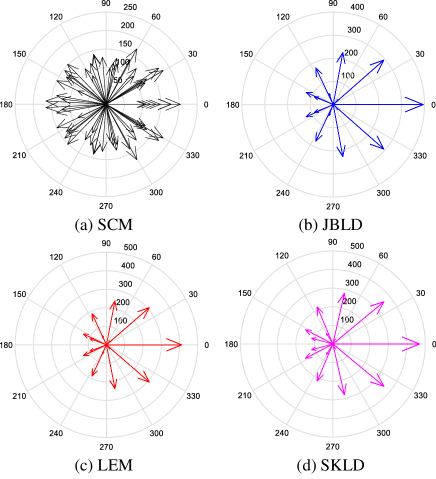
We further analyze their robustness through energy distribution analysis based on either of the following criteria: 1) a method is more robust if smaller change about its energy distribution occurs w.r.t. the same number of interferences; 2) a method is more robust if its energy distribution is more compact, namely with smaller covariance. Fig. 4 and Fig. 5 show the energy distributions without and with interferences, respectively. From criterion 1), the JBLD median and the LEM median are the most robust, while the SKL median is less robust but more robust compared with the SCM. From criterion 2), it is obvious that the geometric medians are more compact and hence more robust than the SCM. In particular, the JBLD median and the LEM median are again the most robust. In summary, energy distribution analysis shows that the geometric medians are more robust than the SCM and the JBLD and LEM medians are the most robust.
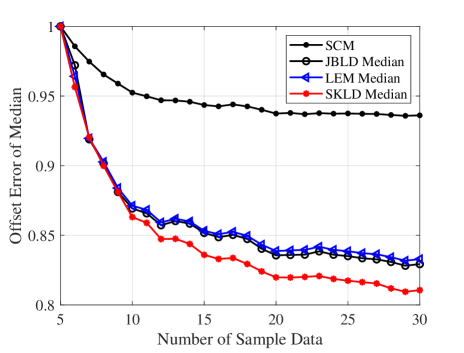
Next, we are going to show their robustness against the number of sample data. The sample dataset is generated according to a multivariate complex Gaussian distribution with zero mean and the covariance matrix. Denote the covariance matrix of those samples by , and define the error against the number of sample data by
| (5.5) |
It is shown in Fig. 6 that the SKL median is the most robust and geometric medians are much more robust than the SCM.
In Fig. 7, we show the energy distributions with sample data. It is clear that the geometric medians are more compact and hence more robust compared with the SCM.
5.2 The discriminative power
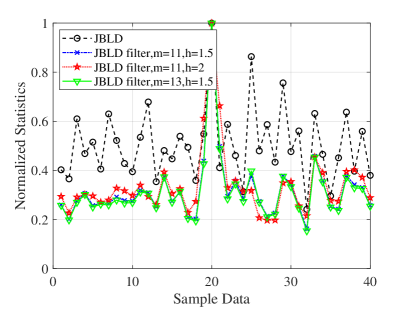
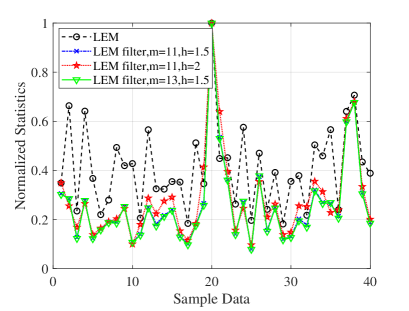
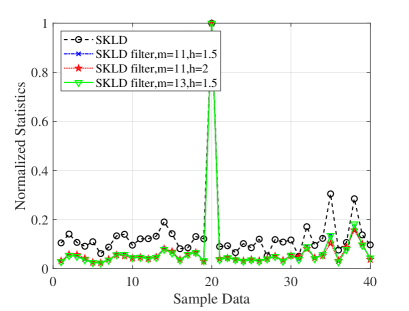
In this subsection, we analyze the discriminative power by comparing the statistics with and without manifold filter. First of all, we compare the normalized detection statistics before and after weighting the matrices; see Eq. (4.5) in Section 4.1. A number of sample data is simulated and an interference is injected into the -th sample with dB and . Parameters and are chosen to be , and , respectively. The detection statistic, namely the distance between the CMM and the HPD matrix in the CUT, is computed with and without manifold filter. The normalized detection statistics are plotted in Fig. 8. Obviously, the detection statistic after manifold filter is smaller than that before filter in the cell without target signal. In other words, after manifold filter, the distance between clutter and clutter becomes smaller while the distance between target and clutter becomes larger.
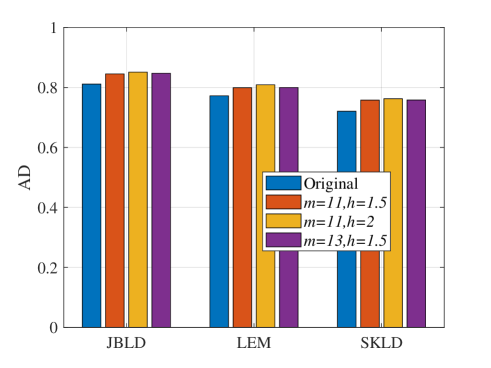
Anisotropy analysis is also used to illustrate the discriminative power. To analyze the difference between the target signal and the CCM in terms of the anisotropy on the matrix manifold, we define an anisotropy index of discrimination (AD) to measure the difference on the matrix manifold as
| (5.6) |
Here, and denote the target and clutter anisotropies, respectively reflecting the local geometric structures at locations of the target and the CCM on the matrix manifold. AD represents the difference in the anisotropy for the target and the CCM. The larger the value of AD, the greater the difference between the two points. Fig. 9 shows the AD with Monte Carlo trials. It can be seen that after manifold filter, the values of AD become larger, implying that the difference in local geometric structures between target signal and clutter becomes larger after manifold filter.
5.3 Detection performances
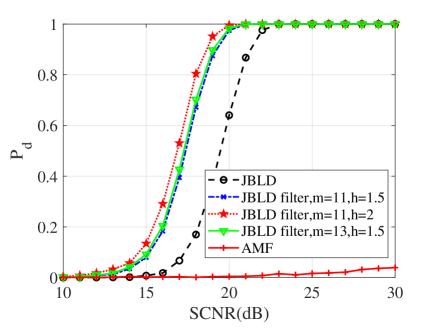
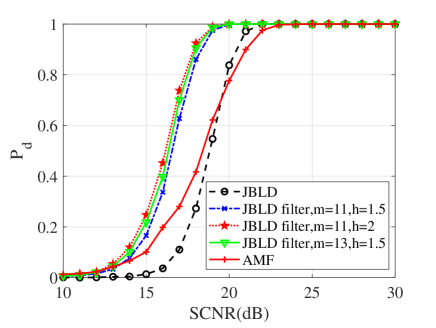
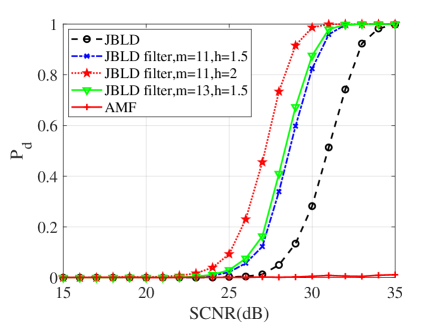
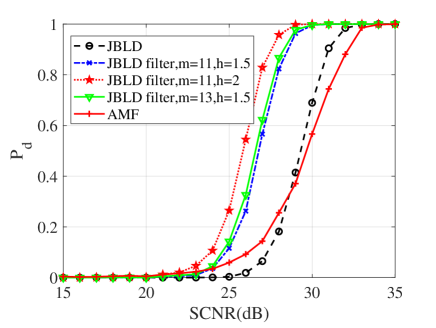
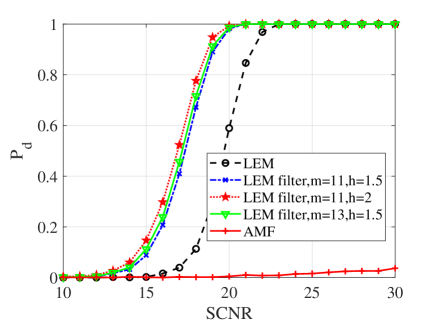
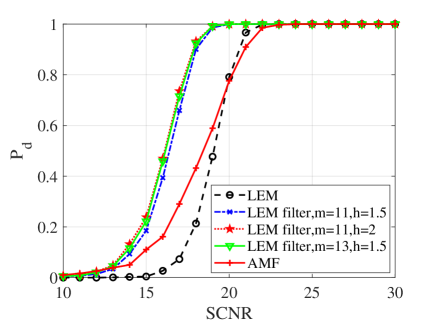
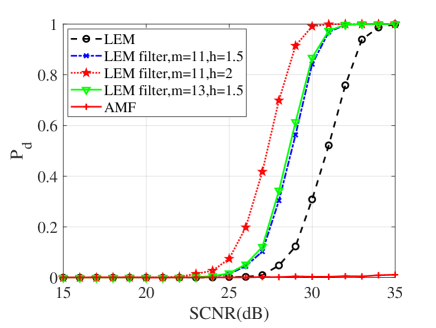
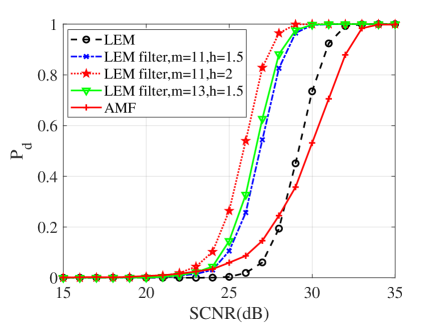
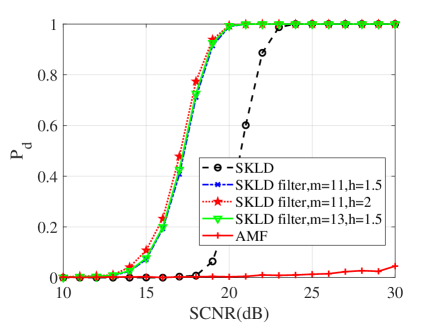
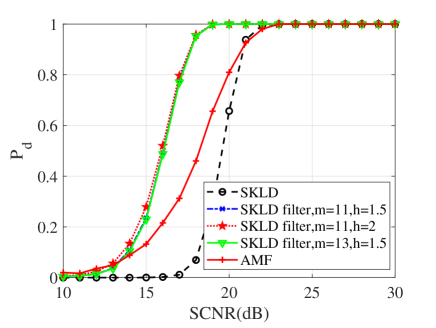
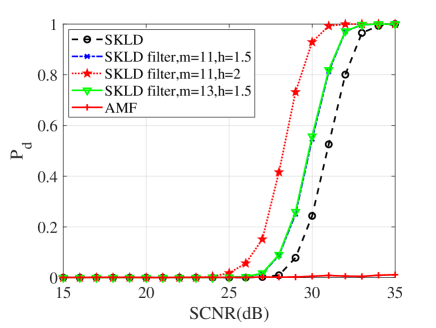
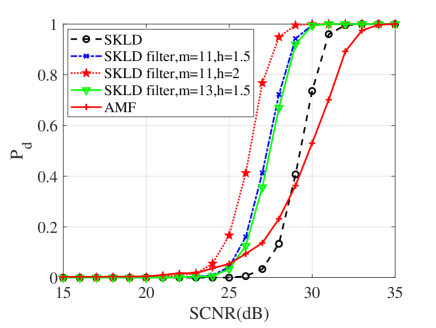
In this subsection, numerical simulations are conducted to validate performances of the proposed detectors in comparison with their counterparts and the AMF. To ease from huge computational load, the probability of false alarm is chosen to be . For the Monte Carlo simulations, the detection threshold and the detection probability are obtained from and independent trials, respectively. In the following simulations, the dimension of matrices is ; two interferences are randomly added to the supplementary data with dB and the normalized frequency . Figs. 10, 11 and 12 show the detection performances of the proposed MIG median detectors in Gaussian and non-Gaussian clutter with two interferences. The number of sample data is or . When , the AMF is much worse compared with the MIG median detectors with or without manifold filter. Moreover, the MIG median detectors with manifold filter have better performance than the MIG median detectors without manifold filter. When , the AMF and the geometric median detectors behave very similarly while geometric median detectors with manifold filter are slightly better than the AMF.
6 Conclusions
In this paper, we designed a class of MIG median detectors with manifold filter to detect signals embedded in nonhomogeneous environments. The sample data was modeled as an HPD matrix with the Toeplitz structure. Particularly, the clutter covariance matrix was estimated as a geometric median for a set of HPD matrices w.r.t. various geometric measures. Then, the problem of signal detection was formulated into the discrimination of two points on the HPD matrix manifold. Furthermore, a manifold-to-manifold map was defined by using the manifold filter to alter the manifold structure, that consequently improved the discrimination power on the matrix manifold. Numerical simulations showed the performance advantages of those MIG median detectors compared with the AMF and their state-of-the-art counterparts. Similar to the AMF, MIG detectors can also be widely applied in practical problems, for instance, target detection in sea or ground clutter, sonar signal detection, and signal detection in communication system. Potential future research will concern the subspace signal detection and their applications for range distributed target detection and synthetic aperture radar image target detection.
Acknowledgements
This work was partially supported by the National Natural Science Foundation of China under Grant No. 61901479 and JST-CREST. L. Peng is an adjunct faculty member of Waseda Institute for Advanced Study, Waseda University, Japan, and School of Mathematics and Statistics, Beijing Institute of Technology, China.
References
- [1] A. Ali, N. González-Prelcic, and R. W. Heath. Spatial covariance estimation for millimeter wave hybrid systems using out-of-band information. IEEE Transactions on Wireless Communications, 18(12):5471–5485, 2019.
- [2] M. Arnaudon, F. Barbaresco, and L. Yang. Riemannian medians and means with applications to radar signal processing. IEEE Journal of Selected Topics in Signal Processing, 7(4):595–604, 2013.
- [3] A. Aubry, A. De Maio, and L. Pallotta. A geometric approach to covariance matrix estimation and its applications to radar problems. IEEE Transactions on Signal Processing, 66(4):907–922, 2018.
- [4] A. Aubry, A. De Maio, L. Pallotta, and A. Farina. Maximum likelihood estimation of a structured covariance matrix with a condition number constraint. IEEE Transactions on Signal Processing, 60(6):3004–3021, 2012.
- [5] A. Aubry, A. D. Maio, L. Pallotta, and A. Farina. Covariance matrix estimation via geometric barycenters and its application to radar training data selection. IET Radar, Sonar & Navigation, 7(6):600–614, July 2013.
- [6] A. Aubry, A. D. Maio, L. Pallotta, and A. Farina. Median matrices and their application to radar training data selection. IET Radar, Sonar & Navigation, 8(4):265–274, 2014.
- [7] F. Bandiera, O. Besson, and G. Ricci. Knowledge-aided covariance matrix estimation and adaptive detection in compound-Gaussian noise. IEEE Transactions on Signal Processing, 58(10):5391–5396, 2010.
- [8] F. Barbaresco. Innovative tools for radar signal processing Based on Cartan’s geometry of SPD matrices & Information Geometry. In 2008 IEEE Radar Conference, pages 1–6, 2008.
- [9] F. Barbaresco. RRP 3.0: 3rd generation Robust Radar Processing based on Matrix Information Geometry (MIG). In 2012 9th European Radar Conference, pages 42–45, 2012.
- [10] F. Barbaresco. Coding statistical characterization of radar signal fluctuation for Lie group machine learning. In 2019 International Radar Conference (RADAR), pages 1–6, 2019.
- [11] F. Barbaresco and Uwe Meier. Radar monitoring of a wake vortex: Electromagnetic reflection of wake turbulence in clear air. Comptes Rendus Physique, 11(1):54–67, 2010.
- [12] O. Besson, J. Tourneret, and S. Bidon. Knowledge-aided Bayesian detection in heterogeneous environments. IEEE Signal Processing Letters, 14(5):355–358, 2007.
- [13] S. Bidon, O. Besson, and J. Tourneret. A Bayesian approach to adaptive detection in nonhomogeneous environments. IEEE Transactions on Signal Processing, 56(1):205–217, 2008.
- [14] N. Bouhlel and A. Dziri. Kullback–Leibler divergence between multivariate generalized Gaussian distributions. IEEE Signal Processing Letters, 26(7):1021–1025, 2019.
- [15] M. R. Bridson and A. Häfliger. Metric Spaces of Non-Positive Curvature, volume 319. Springer Science & Business Media, 2013.
- [16] M. Charfi, Z. Chebbi, M. Moakher, and B. C. Vemuri. Bhattacharyya median of symmetric positive-definite matrices and application to the denoising of diffusion-tensor fields. In Proc IEEE Int Symp Biomed Imaging, pages 1227–1230, 2013.
- [17] X. Chen, Z. J. Wang, and M. J. McKeown. Shrinkage-to-tapering estimation of large covariance matrices. IEEE Transactions on Signal Processing, 60(11):5640–5656, 2012.
- [18] Y. Chen, A. Wiesel, Y. C. Eldar, and A. O. Hero. Shrinkage algorithms for MMSE covariance estimation. IEEE Transactions on Signal Processing, 58(10):5016–5029, 2010.
- [19] A. Cherian, S. Sra, A. Banerjee, and N. Papanikolopoulos. Jensen–Bregman LogDet divergence with application to efficient similarity search for covariance matrices. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(9):2161–2174, 2013.
- [20] D. Ciuonzo, A. De Maio, and D. Orlando. On the statistical invariance for adaptive radar detection in partially homogeneous disturbance plus structured interference. IEEE Transactions on Signal Processing, 65(5):1222–1234, 2017.
- [21] E. Conte, M. Lops, and G. Ricci. Adaptive matched filter detection in spherically invariant noise. IEEE Signal Processing Letters, 3(8):248–250, 1996.
- [22] A. De Maio, A. Farina, and G. Foglia. Knowledge-aided Bayesian radar detectors & their application to live data. IEEE Transactions on Aerospace and Electronic Systems, 46(1):170–183, Jan 2010.
- [23] A. De Maio, D. Orlando, C. Hao, and G. Foglia. Adaptive detection of point-like targets in spectrally symmetric interference. IEEE Transactions on Signal Processing, 64(12):3207–3220, 2016.
- [24] A. Decurninge and F. Barbaresco. Robust Burg estimation of radar scatter matrix for autoregressive structured SIRV based on Fréchet medians. IET Radar, Sonar & Navigation, 11(1):78–89, 2017.
- [25] J. Duník, O. Straka, and M. Šimandl. On autocovariance least-squares method for noise covariance matrices estimation. IEEE Transactions on Automatic Control, 62(2):967–972, 2017.
- [26] R. G. Gavaskar and K. N. Chaudhury. Fast adaptive bilateral filtering. IEEE Transactions on Image Processing, 28(2):779–790, 2019.
- [27] L. I. Gliga, H. Chafouk, D. Popescu, and C. Lupu. A method to estimate the process noise covariance for a certain class of nonlinear systems. Mechanical Systems and Signal Processing, 131:381–393, 2019.
- [28] N. J. Higham. Functions of Matrices: Theory and Computation. SIAM, Philadelphia, 2008.
- [29] X. Hua, Y. Cheng, H. Wang, and Y. Qin. Robust covariance estimators based on information divergences and Riemannian manifold. Entropy, 20(4), 2018.
- [30] X. Hua, Y. Cheng, H. Wang, Y. Qin, and D. Chen. Geometric target detection based on total Bregman divergence. Digital Signal Processing, 75:232–241, 2018.
- [31] X. Hua, Y. Cheng, H. Wang, Y. Qin, and Y. Li. Geometric means and medians with applications to target detection. IET Signal Processing, 11(6):711–720, 2017.
- [32] X. Hua, Y. Cheng, H. Wang, Y. Qin, Y. Li, and W. Zhang. Matrix CFAR detectors based on symmetrized Kullback–Leibler and total Kullback–Leibler divergences. Digital Signal Processing, 69:106–116, 2017.
- [33] X. Hua, H. Fan, Y. Cheng, H. Wang, and Y. Qin. Information geometry for radar target detection with total Jensen–Bregman divergence. Entropy, 20(4), 2018.
- [34] X. Hua, Y. Ono, L. Peng, Y. Cheng, and H. Wang. Target detection within nonhomogeneous clutter via total Bregman divergence-based matrix information geometry detectors. 2020. arXiv:2012.13861.
- [35] B. Kang, V. Monga, and M. Rangaswamy. Computationally efficient Toeplitz approximation of structured covariance under a rank constraint. IEEE Transactions on Aerospace and Electronic Systems, 51(1):775–785, 2015.
- [36] E. J. Kelly. An adaptive detection algorithm. IEEE Transactions on Aerospace and Electronic Systems, AES-22(2):115–127, 1986.
- [37] S. Kraut and L. L. Scharf. The CFAR adaptive subspace detector is a scale-invariant GLRT. IEEE Transactions on Signal Processing, 47(9):2538–2541, 1999.
- [38] J. Lapuyade-Lahorgue and F. Barbaresco. Radar detection using Siegel distance between autoregressive processes, application to HF and X-band radar. In 2008 IEEE Radar Conference, pages 1–6, 2008.
- [39] J. Li, A. Aubry, A. De Maio, and J. Zhou. An EL approach for similarity parameter selection in KA covariance matrix estimation. IEEE Signal Processing Letters, 26(8):1217–1221, 2019.
- [40] Z. Liu and F. Barbaresco. Doppler information geometry for wake turbulence monitoring. In Frank Nielsen and Rajendra Bhatia, editors, Matrix Information Geometry, pages 277–290, Berlin, Heidelberg, 2013. Springer.
- [41] G. Luo, J. Wei, W. Hu, and S. J. Maybank. Tangent Fisher Vector on Matrix Manifolds for Action Recognition. IEEE Transactions on Image Processing, 29:3052–3064, 2020.
- [42] A. D. Maio, A. Farina, and G. Foglia. Design and experimental validation of knowledge-based constant false alarm rate detectors. IET Radar, Sonar & Navigation, 1(4):308–316, Aug 2007.
- [43] A. D. Maio, S. D. Nicola, L. Landi, and A. Farina. Knowledge-aided covariance matrix estimation: a MAXDET approach. IET Radar, Sonar & Navigation, 3(4):341–356, 2009.
- [44] M. Moakher. A differential geometric approach to the geometric mean of symmetric positive-definite matrices. SIAM Journal on Matrix Analysis and Applications, 26(3):735–747, 2005.
- [45] P. Nair and K. N. Chaudhury. Fast high-dimensional bilateral and nonlocal means filtering. IEEE Transactions on Image Processing, 28(3):1470–1481, 2019.
- [46] S. Park, A. Ali, N. González-Prelcic, and R. W. Heath. Spatial channel covariance estimation for hybrid architectures based on tensor decompositions. IEEE Transactions on Wireless Communications, 19(2):1084–1097, 2020.
- [47] F. C. Robey, D. R. Fuhrmann, E. J. Kelly, and R. Nitzberg. A CFAR adaptive matched filter detector. IEEE Transactions on Aerospace and Electronic Systems, 28(1):208–216, 1992.
- [48] S. Sra. Positive definite matrices and the S-divergence. Proceedings of the American Mathematical Society, 144(7):2787–2797, 2016.
- [49] P. Wang, Z. Wang, H. Li, and B. Himed. Knowledge-aided parametric adaptive matched filter with automatic combining for covariance estimation. IEEE Transactions on Signal Processing, 62(18):4713–4722, 2014.
- [50] K. M. Wong, J. Zhang, J. Liang, and H. Jiang. Mean and Median of PSD Matrices on a Riemannian Manifold: Application to Detection of Narrow-Band Sonar Signals. IEEE Transactions on Signal Processing, 65(24):6536–6550, 2017.
- [51] O. Yair, M. Ben-Chen, and R. Talmon. Parallel Transport on the Cone Manifold of SPD Matrices for Domain Adaptation. IEEE Transactions on Signal Processing, 67(7):1797–1811, 2019.
Appendix A Anisotropy index of the JBLD divergence: Proof of Proposition 4.6
Denote as the function to be minimized, namely
whose derivative can be computed directly and reads
Let be the eigenvalues of the matrix , and we have
Then, the equation becomes
It can be rearranged as an -th order polynomial for the unknown variable , which has one unique positive solution for all , denoted by . The unique existence is verified in the next Lemma A.1.
Lemma A.1.
The rational equation
has only one positive solution for all .
Proof.
First of all, we rearrange the equation into the vanishment of a polynomial () where
satisfying
Here means this term does not appear in the calculation. As all eigenvalues are positive, searching for positive solutions of the rational equation is equivalent to finding positive solutions of .
By mathematical induction, we have
We will consider when is even only; the proof for an odd is analogous. Note that there is no term in , and all coefficients for the terms , , are positive while all coefficients for the terms , , are negative. Starting from -th order derivative of , we have
Furthermore, since
we know passes the -axis once and only once for . Again, since
the function decreases from a negative value and then increases to positive infinity. Consequently, also passes the -axis once and only once for .
Continuing this procedure of analysis, we conclude that the function passes the -axis only once for . Namely, has only one positive solution.
∎