MIM: Multi-modal Content Interest Modeling Paradigm for User Behavior Modeling
Abstract.
Click-Through Rate (CTR) prediction is a crucial task in recommendation systems, online searches, and advertising platforms, where accurately capturing users’ real interests in content is essential for performance. However, existing methods heavily rely on ID embeddings, which fail to reflect users’ true preferences for content such as images and titles. This limitation becomes particularly evident in cold-start and long-tail scenarios, where traditional approaches struggle to deliver effective results. To address these challenges, we propose a novel Multi-modal Content Interest Modeling paradigm (MIM), which consists of three key stages: Pre-training, Content-Interest-Aware Supervised Fine-Tuning (C-SFT), and Content-Interest-Aware UBM (CiUBM). The pre-training stage adapts foundational models to domain-specific data, enabling the extraction of high-quality multi-modal embeddings. The C-SFT stage bridges the semantic gap between content and user interests by leveraging user behavior signals to guide the alignment of embeddings with user preferences. Finally, the CiUBM stage integrates multi-modal embeddings and ID-based collaborative filtering signals into a unified framework. Comprehensive offline experiments and online A/B tests conducted on the Taobao, one of the world’s largest e-commerce platforms, demonstrated the effectiveness and efficiency of MIM method. The method has been successfully deployed online, achieving a significant increase of +14.14% in CTR and +4.12% in RPM, showcasing its industrial applicability and substantial impact on platform performance. To promote further research, we have publicly released the code and dataset at https://pan.quark.cn/s/8fc8ec3e74f3.
1. Introduction
Click-Through Rate (CTR) prediction plays a vital role in applications such as recommendation systems, web searches, and online advertising(Covington et al., 2016; Yan et al., 2022), as it directly impacts user engagement and platform revenue. Among its key components, User Behavior Modeling (UBM) has emerged as a critical optimization direction. By leveraging users’ historical interactions, UBM effectively captures their underlying preferences, enabling more accurate predictions and enhancing overall system performance(Zhang et al., 2021; Zhou et al., 2018; Pi et al., 2020).
Traditional UBM methods predominantly rely on ID embeddings to represent items and user behaviors(see Figure1 blue part). While effective in some scenarios, ID-based approaches face inherent limitations. First, ID embeddings primarily encode collaborative filtering (CF) signals but fail to effectively capture user preferences for content, such as images and titles, resulting in a misalignment between representations and actual user interests. Second, these methods require abundant user-item interaction data, resulting in poor performance in cold-start and long-tail scenarios(Yuan et al., 2021, 2020).
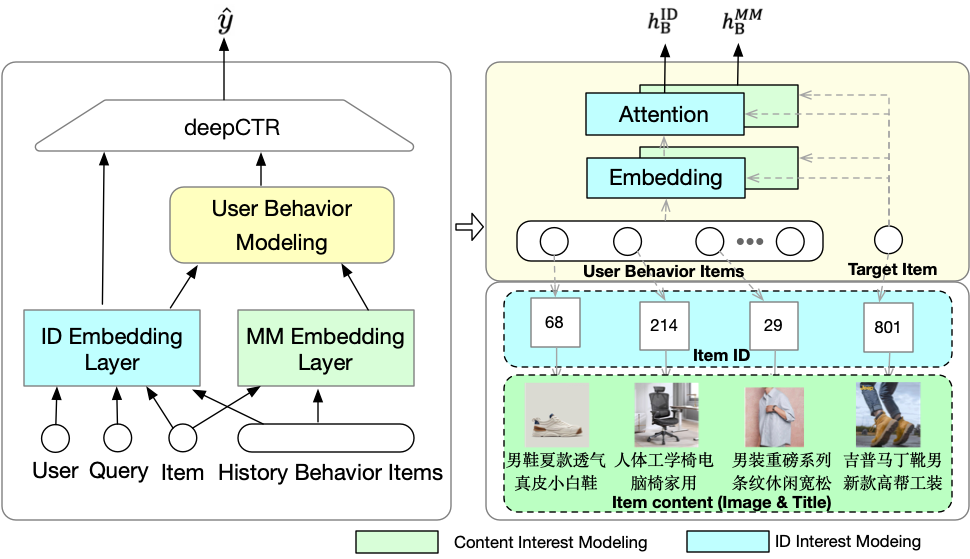
To overcome these limitations, there is a growing need for content-based multi-modal UBMs(see Figure1 green part). This shift is motivated by two key factors. First, user interactions with recommendation systems are predominantly mediated through visual and textual content, such as product images and descriptions. Modeling these features is essential for accurately reflecting user preferences. Second, recent advancements in multi-modal foundation models (FoMs), such as Vision Transformers (ViT)(Dosovitskiy et al., 2020; Liu et al., 2021), LLaMA(Touvron et al., 2023), Vicuna(Chiang et al., 2023), BEiT-3(Wang et al., 2022), GPT-4(OpenAI et al., 2024), and so on, provide powerful tools for extracting rich semantic information from the visual and textual content.
Existing multi-modal user behavior modeling methods can be broadly categorized into two classes: two-stage pretraining methods and end-to-end training methods. Two-stage pretraining methods leverage pre-trained foundation models to extract multi-modal features, which are then integrated into user behavior models. End-to-end methods, on the other hand, jointly optimize multi-modal models and user behavior modeling modules, demonstrating their potential in better aligning user interests with content semantics. Despite achieving considerable success, these approaches also have limitations: two-stage methods lack deep alignment between multi-modal content and user interests, which constrains their effectiveness; end-to-end methods, while offering better alignment, come with high training costs, complex deployment requirements, and limited generalizability, making them less adaptable to diverse recommendation tasks. These limitations underscore the need for a universal and efficient approach to construct high-quality representations that align content with user interests.To address these challenges, three core questions must be answered.
Q1: what kind of multi-modal embeddings are needed? Pre-trained FoMs often fail to fully understand domain-specific content, and a semantic gap exists between content embeddings and user interests.
Q2: how can multi-modal embeddings be effectively utilized in UBMs? A unified framework is needed to integrate ID-based CF signals and multi-modal embeddings seamlessly.
Q3: how can efficiency be ensured in large-scale applications? Multi-modal embedding extraction often introduces high computational and memory costs, posing challenges for practical deployment.
To solve these challenges, this paper introduces MIM (Multi-modal Content Interest Modeling), a universal and efficient paradigm for multi-modal UBM. MIM adopts a three-stage framework to address the core questions comprehensively. In the pretraining stage, foundation models are adapted to downstream data to capture domain-specific content and align multi-modal features. In the content-interest-aware supervised fine-tuning (C-SFT) stage, user interest signals, such as purchase behaviors, are introduced to bridge the semantic gap and guide embeddings to reflect user preferences. In the CiUBM stage, a modular content-interest-aware UBM integrates ID-based CF signals, multi-modal content embeddings, and their interactions, providing an effective and flexible framework for user behavior modeling. To ensure efficiency, MIM introduces a representation center that precomputes and stores embeddings for fast retrieval, significantly reducing training and inference costs.
In summary, this paper makes the following contributions: (1) We propose a universal and effective multi-modal UBM method, MIM, which shifts the paradigm from ID-based to content-based interest modeling, enabling broad applicability and performance improvements across existing UBMs. (2) MIM demonstrates significant performance advantages, achieving lightweight training and efficient inference, making it scalable for industrial applications. (3) MIM has been successfully deployed in large-scale industrial scenarios, achieving 14.14% CTR gains and 4.12% RPM gains. To foster further research, we have publicly released the code and datasets.
2. Related Works
2.1. User Behavior Modeling
User Behavior Modeling (UBM) has been widely studied as a critical component of Click-Through Rate (CTR) prediction due to its ability to capture users’ historical preferences and predict their future interactions. Traditional UBM methods, such as DIN(Zhou et al., 2018), use attention mechanisms to selectively focus on relevant behaviors, while extensions like DIEN(Zhou et al., 2019) incorporate sequential modeling to capture the temporal evolution of user interests. Despite their success, these methods heavily rely on ID-based embeddings, which primarily encode collaborative filtering (CF) signals but fail to effectively model content-based preferences, particularly for items such as images and texts. This limitation becomes pronounced in cold-start and long-tail scenarios where interaction data is sparse(Yuan et al., 2021, 2020). Recent efforts, such as the introduction of hybrid UBM approaches, have attempted to integrate content features but still lack a unified framework for aligning content semantics with user-specific interests.
2.2. Multi-modal Recommendation
Multi-modal recommendation integrates diverse content features such as images, texts, and videos to improve user understanding and prediction accuracy. Traditional methods often augment CTR models with multi-modal (MM) features as additional attributes, directly feeding them into the models to enhance representation power (Mo et al., 2015). While effective to some extent, these approaches neglect the critical need to align MM features with user-specific interests, resulting in a limited understanding of user preferences.Recent advancements focus on bridging the domain gap between pre-trained foundation models and downstream recommendation tasks(Yuan et al., 2023; Wang et al., 2023; Wu et al., 2021; Liu et al., 2023). However, these methods largely ignore the role of explicit user interest modeling in refining MM embeddings, limiting their ability to capture sophisticated user preferences. Moreover, the practicality of existing methods in industrial applications remains a challenge. Many end-to-end frameworks incur high computational and memory costs, making them inefficient for large-scale deployment (Yuan et al., 2023). To address these issues, our proposed MIM paradigm systematically bridges the semantic gap between MM features and user interests while maintaining scalability and efficiency, achieving significant performance gains in real-world applications.
2.3. Foundation Models
Pre-trained Foundation Models have significantly advanced the fields of Computer Vision (CV) and Natural Language Processing (NLP) by learning transferable representations from large-scale data. In CV, models like iGPT(Chen et al., 2020) and ViT(Dosovitskiy et al., 2020) have pioneered the application of transformer architectures for image recognition, leveraging self-supervised tasks such as masked patch prediction to capture rich visual semantics. Further advancements, such as Swin Transformer(Liu et al., 2021) and BEiT(Bao et al., 2021), improved efficiency and scalability, making transformers a dominant paradigm in vision tasks.In NLP, foundational models like BERT(Devlin et al., 2019),GPT-2(Radford et al., 2019), and XLNet(Yang et al., 2019) introduced pre-training on large corpora followed by task-specific fine-tuning, establishing a new standard for natural language understanding. These models have been extended to handle complex tasks, such as question answering, summarization, and sentiment analysis. The integration of multi-modal learning has further broadened the applicability of foundation models. Methods like CLIP(Radford et al., 2021) propose contrastive pre-training techniques to align visual and textual modalities, enabling robust joint representations. Meanwhile, ViL-BERT(Lu et al., 2019) and LXMERT(Tan and Bansal, 2019) extend the transformer framework to learn cross-modal interactions, achieving state-of-the-art performance on vision-language tasks. More recent models such as Flamingo(Alayrac et al., 2022) and BEiT-3(Wang et al., 2022) demonstrate the effectiveness of scaling multi-modal architectures for a variety of downstream applications.
Despite these advancements, challenges remain in achieving efficient training and deployment of multi-modal foundation models, particularly in scenarios requiring alignment between diverse modalities and scalability in large-scale applications.
3. MIM
3.1. Preliminaries and Method Overview
3.1.1. Preliminaries.
CTR Prediction. Considering a typical item search scenario111Note that in this section, we take the item search scenario as an example. Our proposed paradigm can also be applied in other industrial applications. Experiments all show the effectiveness of MIM on various scenarios 4.7)., given a set of users , a set of items , and a set of queries , the CTR prediction task is to predict whether a user will click the item when searches a query . It can be formulated as: where is the predicted click-through rate score. Note that query can be a text query and can also be an image query, which refers to a user wanting to search for an item with similar content to the image query.
User Behavior Modeling. Given user behavior , where is the behavior length, a general UBM is expressed as
| (1) |
where is the ID embedding of item , is the relevant score between and target item via attention mechanism based on item ID embeddings. Then is fed into deepCTR. In this way, the relative user interest to target item can be captured.
3.1.2. Method Overview.
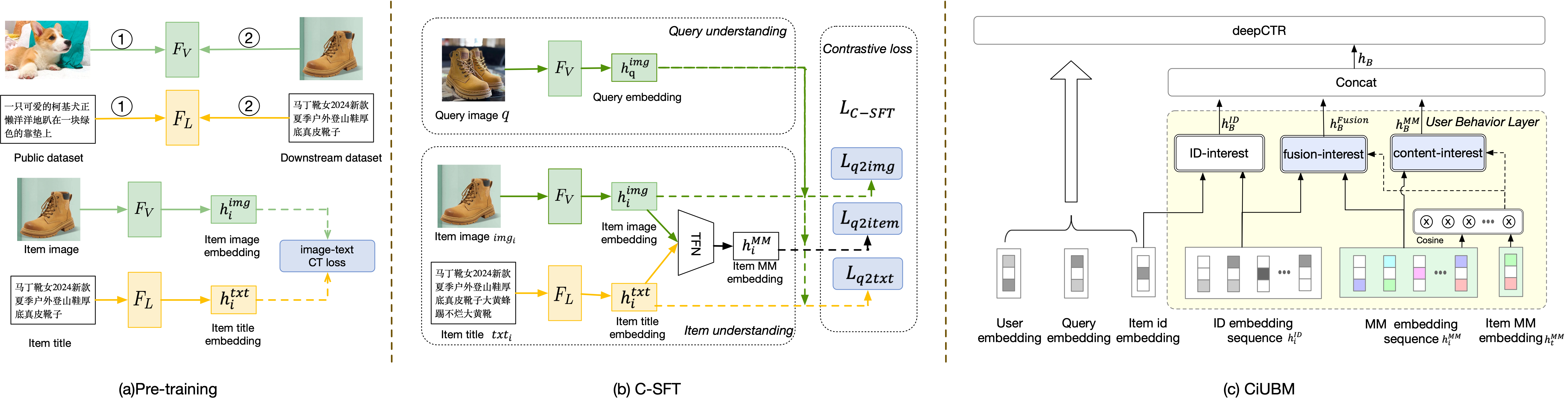
The overall framework is illustrated in Figure 2. The proposed MIM paradigm comprises three key stages designed to address the limitations of existing approaches and enhance user behavior modeling. In the pre-training stage, the primary focus is on adapting foundational models to domain-specific data, ensuring the extraction of high-quality multi-modal embeddings capable of understanding diverse item content. Subsequently, the Content-Interest-Aware Supervised Fine-Tuning (C-SFT) stage bridges the semantic gap between user interests and content representations by leveraging explicit user behavior signals, such as purchase actions, to guide embeddings in aligning with user preferences. Finally, the CiUBM stage integrates the refined multi-modal embeddings with ID-based collaborative filtering signals into a unified and flexible framework, enhancing the overall representation power. To address efficiency challenges in large-scale industrial applications, a representation center is introduced, which precomputes and stores embeddings for efficient retrieval, significantly reducing both training and inference costs.
3.2. Pre-training
The pre-training stage focuses on equipping the multi-modal embeddings with the ability to understand item content effectively. This stage leverages foundational models (FoMs) pre-trained on public datasets (e.g., ImageNet and Wikipedia), which are further adapted to downstream domains. We define vision-based and language-based pre-trained FoMs as and respectively. To address the limitations of general pre-trained models, two aspects of adaptation need to be considered.:
Downstream Data Adaptation (DDA). Knowledge learned from generic datasets may not align well with domain-specific item content. To overcome this, and are continually pre-trained on downstream datasets containing item images and textual descriptions. This process ensures that the resulting models are fine-tuned to the unique characteristics of domain-specific data, enabling a deeper understanding of visual and textual content.
Different Modal Alignment (DMA). Effective multi-modal representation requires a seamless alignment between embeddings from different modalities. Following the contrastive learning framework proposed in (Radford et al., 2021), we perform image-text contrastive pre-training on downstream data. This process aligns image and text embeddings, ensuring a coherent representation that bridges the semantic gap between modalities.
By achieving these adaptation, the pre-training stage lays the foundation for robust multi-modal embeddings capable of effectively representing diverse item content.
3.3. Content-Interest-Aware Supervised Fine-tuning
After the pre-training stage, FoM can understand what content an item has. However, To enhance its effectiveness in user behavior modeling, the focus of embeddings must shift from representing "what the content is" to "what users are interested in. Ideally, multi-modal embeddings for items with similar user interests should be drawn closer together in the latent space, while embeddings for unrelated items should be pushed farther apart. Inspired by the recent advancements in contrastive learning (Long et al., 2024; Wu et al., 2018; Clark et al., 2020; Mikolov et al., 2013), we propose a content-interest-aware supervised contrastive fine-tuning (C-SFT) method to effectively model user interest similarity within the multi-modal (MM) embedding space.
To design such a contrastive fine-tuning, we need to answer the following three questions: Q1: How to define user interest pairs? Q2: How to encode multi-modal features? Q3: What is a proper learning objective? Next, we present the design strategies for C-SFT by correspondingly answering the aforementioned questions.
Q1: User Interest Pairs Definition.
The success of the contrastive learning framework largely relies on the definition of the user interest pairs(Qiu et al., 2020). It drives us to seek a strong and direct user interest signal.
In this paper, we leveraged data from visual search scenario, we define the user interest pair as <an image query , an item >, which refers to a user who has searched an image query and purchased an item . Compared to textual queries, image queries carry richer semantic meanings and can more accurately express users’ intentions and interests
The reason to use purchase behaviors rather than click behaviors is that purchase actions provide a clearer and more reliable indication of user interests. We also conduct experiments to show the impacts of different signals in Section 4.3.2.
Q2: Multi-modal Encoder. Given the user interest pairs <, >, a multi-modal encoder extracts embeddings for both the query and the item. The query image and item image are processed using , while the item title is encoded by :
| (2) |
To integrate the item’s multi-modal content, we fuse the image and title embeddings using a tensor-based approach inspired by TFN (Zadeh et al., 2017), capturing both intra- and inter-modal interactions. The fused embedding is defined as:
| (3) |
where indicates the outer product. Finally, the fused representation is refined using an MLP:
| (4) |
producing a comprehensive multi-modal embedding that effectively represents the item’s content.
Q3: Loss Function Design. To model the similarity between the pair <,>, we adopt the standard InfoNCE loss function:
| (5) |
where , and is the number of negative samples taken from other pairs in the same batch.
However, there are two shortcomings in directly using the basic InfoNCE.: (1) The number of negative samples is limited by the batch size, which is insufficient for industrial-scale applications where billions of items exist. (2) Single-modal embeddings, such as and , are ignored, which may result in a loss of modality-specific details.To address these, we propose two extensions:
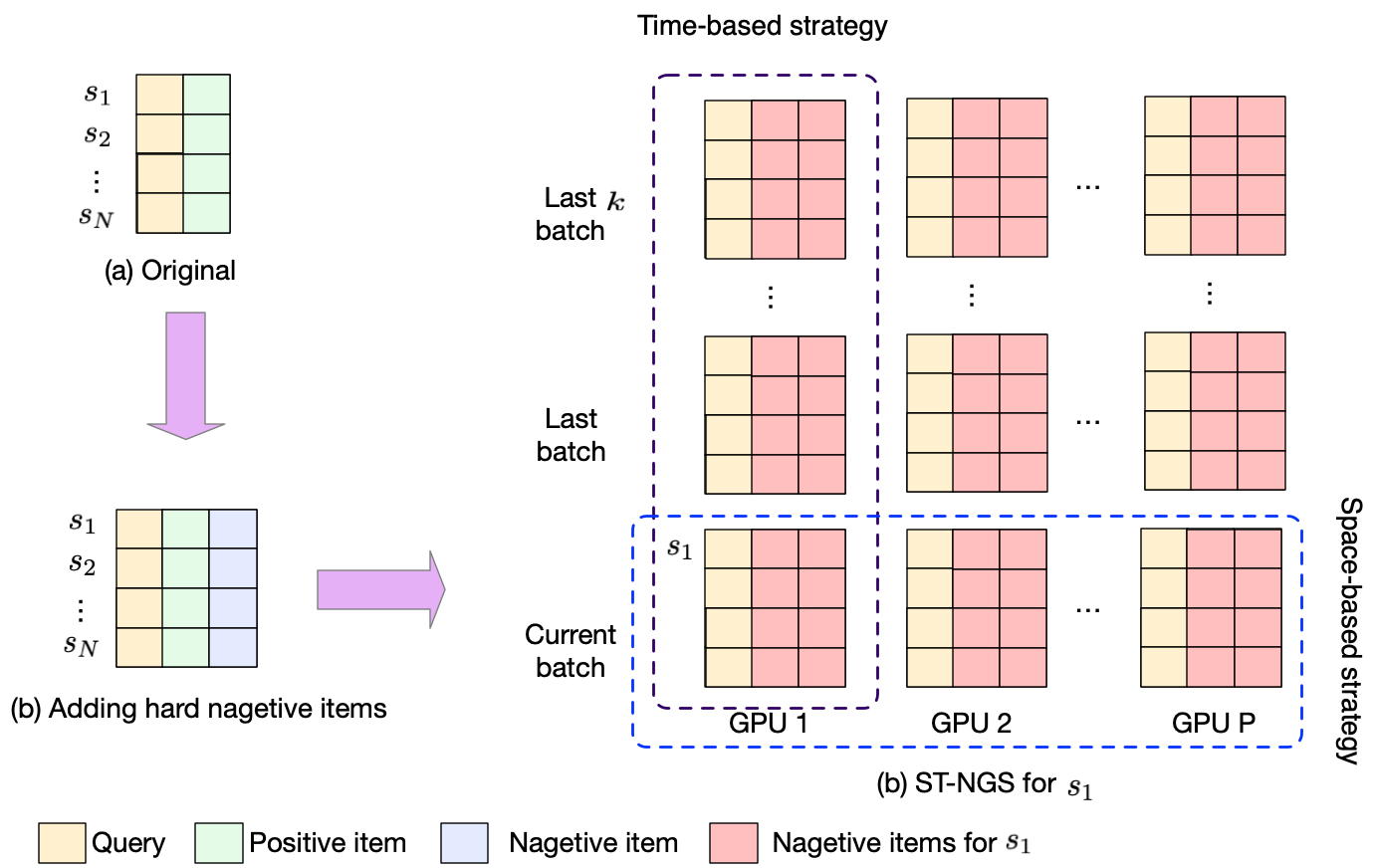
Extension 1: Space-time-based negative sample generation (ST-NSG). As shown in Figure 3, to address the limitation of limited negative samples, we propose the Space-Time Negative Sampling (ST-NSG) method. First, for each sample , we add a hard negative item from the same category, forming the triplet . To expand the negative sample set, we use two strategies: (1) Time-based strategy: Negative items are collected from the current batch and the last batches, increasing the number of negatives to , where is the batch size. (2) Space-based strategy: In distributed training, items from GPUs across recent batches are added as negatives, resulting in total negatives. Combined, these strategies provide nearly more negative samples compared to basic InfoNCE, significantly enhancing model performance in practice.
Extension 2: Multi-level InfoNCE. Although MM embeddings provide a holistic view of item content across modalities, they may lack details specific to each modality. To address this, we propose multi-level InfoNCE, which incorporates signals from both single-modality and multi-modal embeddings. The overall loss function is defined as:
| (6) |
where and represent the InfoNCE loss for the pairs and , respectively. The weights and balance the contributions of each modality, ensuring a more comprehensive modeling of user interests.
3.4. CiUBM: Content-interest-aware UBM
After obtaining the multi-modal (MM) embedding for item , we design a content-interest-aware user behavior model (CiUBM) to enhance the existing UBMs by integrating ID and content-based signals. CiUBM consists of three components:
ID Interest Module. This module uses existing UBM techniques to model user preferences based on ID embeddings, capturing collaborative filtering (CF) signals. It provides a straightforward integration of prior UBM methods.
Content Interest Module. This module leverages the high-quality MM embeddings to calculate user content interest relative to the target item . Similarity scores between the target and historical behavior items are used to weight the MM embeddings, creating a representation that reflects user content preferences. Formally:
| (7) |
where is the MM embedding of the historical item , and is the number of user behaviors.
Fusion Interest Module. This module combines ID and content interest. By using to weight ID embeddings , it produces , which aligns content-based and collaborative filtering signals:
| (8) |
Final Representation. The overall user behavior representation is obtained by concatenating the outputs of the three modules:
| (9) |
and is then fed into the deepCTR model for improved prediction.
3.5. Representation Center
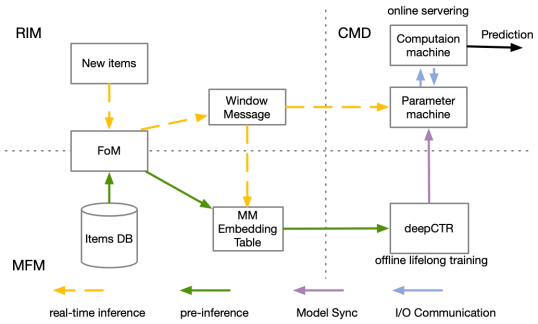
In general, the decomposed paradigm allows MIM to train different stage models in parallel to save time cost. However, the MM embedding extraction in CiUBM stage will definitely consume more time and GPU memory. Even worse, all items in user behavior are needed to be extracted, aggravating the time and GPU memory cost (see Section 4.5). To address this problem, we proposed the representation center, which contains three key components (Figure 4).
MM Features Memorization (MFM). Rather than directly inferring the MM embedding during deepCTR training or inferencing, we pre-infer the MM embeddings of all items. Then we memorize these features as an embedding table, where the key is the item ID and the value is the MM embedding. In this way, we can directly obtain MM embedding from the embedding table without any extra time and GPU memory cost.
Real-time Inference Module (RIM). The key problem of maintaining the MM embedding table is that it cannot obtain the MM features of new items in time. However, in practice, it is a very common situation where new items are shown all the time. Thus, RIM is designed to address this problem. Specifically, when a new item is added to industrial applications, RIM will infer the MM embedding of this new item in real-time. Then, this inferred MM embedding will be collected as a window message, which is sent to the MM embedding table for offline training and to the parameter machine (see the following part for details) for online serving in a short window time.
Computation and Memory Decomposition (CMD). Although introducing MFM will not cost too much GPU memory, the embedding table still needs a large amount of random access memory (e.g., nearly 300G in our experiments), which also influences the efficiency (e.g., the computation of some operations in CPU and I/O between GPU and CPU). To solve this problem, we propose a separate strategy where the model parameters (including embedding tables and dense layer parameters) and the computation of inference are divided into different machines, i.e., the parameter machine and the computation machine. In this way, the computation machine only needs to care about the memory cost during the feed-forward and is not restricted by the huge embedding tables222During inference, the computation machine can only request the embedding vectors of the corresponding keys rather than the whole embedding table to save memory. Meanwhile, with the help of MFM, there are no additional parameters needed for loading and maintaining a number of temporary tensors of MM feature extraction by large-scale FoM.
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets.
(1) Pre-training Datasets. As introduced in Section 3.2, a downstream-related dataset is applied to align the style and modal distribution. We collect images and titles of items from Taobao, one of the world’s largest online retail platforms. There are a total of 1.42+B items. (2) C-SFT Datasets. We collect purchase logs in the last 6 months from the visual search scenario in Taobao and construct the C-SFT dataset as introduced in Section 3.3. There are a total of 0.14 B user interest pairs. (3) Downstream Datasets. The dataset is collected from the real-world traffic logs in Taobao. Each sample refers to a user who searches a query on this platform and observes an item and contains the necessary information about the queries and items, including multi-modal embedding, product IDs, categories, brands, prices, sales, etc. The label is defined as whether the user clicks this item. Besides, we further adopt 7 subsets to sufficiently evaluate the performance of MIM. More detailed information about the dataset is summarized in Table 1. Note that, due to the limited space, apart from Section 4.2, we report the results on the whole downstream dataset by default, and similar conclusions can be obtained from other sub-datasets.
| ALL | Home Decoration | Clothes | Sports | Toys | FMCG | Pets | Cars | |
| #Data | 1.83+ B | 0.15+ B | 0.91+ B | 0.1+ B | 51.6+ M | 0.21+ B | 24.81+ M | 60,75+ M |
| #Query | 56.34+ M | 5.32+ M | 15.07+ M | 3.56+ M | 2.32+ M | 6.72+ M | 0.73+ M | 3,66+ M |
| #Users | 0.12+ B | 14.04+ M | 55.77+ M | 16.34+ M | 7.04+ M | 25.95+ M | 2.63+ M | 6.62+ M |
| #Items | 16.16+ M | 1.50+ M | 3.74+ M | 0.65+ M | 0.42+ M | 1.11+ M | 0.22+ M | 0.91+ M |
4.1.2. Baselines
Here, we compare our method with various UBM methods, including Avg Pooling333averaging the embedding of different items in user behaviors, DIN(Zhou et al., 2018), DIEN(Zhou et al., 2019), BST(Chen et al., 2019), and SIM(Pi et al., 2020), TWIN(Chang et al., 2023). By default, the base backbone of UBM is set as SIM (Pi et al., 2020).
4.1.3. Training Details.
We use the Adam optimizer with a learning rate of 0.005 for all methods. The batch size N is 1024 for all methods.
By default, we take EVA-2 (Woo et al., 2023) for images and BGE(Xiao et al., 2023) for texts. We set hyper-parameters , for loss weights and for negative samples by grid searching. Besides, we also evaluate the impact of different FoM, including ResNet50(He et al., 2019), SwinTransformer(Liu et al., 2021), ConvNext v1(Liu et al., 2022), ConvNext V2(Woo et al., 2023), ConvNext v2 large(Woo et al., 2023), EVA-2(Fang et al., 2023), Bert(Devlin et al., 2018), GPT-2(Radford et al., 2019), BEiT-3(Wang et al., 2022) and BGE(Xiao et al., 2023) in Section4.3.
MIM is trained by 64 A100 GPUs in the pre-training stage, 40 A100 GPUs in the C-SFT stage, and 100 V100 GPUs in the CiUBM training stage. We run all experiments multiple times with different random seeds and report the average results.
| Model | Version | ALL | Toys | FMCG | Sports | Cars | Clothes | Pets | Home Decoration |
| Avg Pooling | Base | 0.6965 | 0.6958 | 0.7044 | 0.7045 | 0.6965 | 0.6810 | 0.6844 | 0.6748 |
| Base+MIM | 0.7030 | 0.6989 | 0.7168 | 0.7148 | 0.7065 | 0.6828 | 0.6911 | 0.6796 | |
| +0.0066 | +0.0032 | +0.0123 | +0.0104 | +0.0100 | +0.0017 | +0.0067 | +0.0048 | ||
| DIN | Base | 0.7004 | 0.6969 | 0.7187 | 0.6986 | 0.6928 | 0.6753 | 0.7099 | 0.6802 |
| Base+MIM | 0.7047 | 0.7006 | 0.7225 | 0.7027 | 0.6963 | 0.6812 | 0.7126 | 0.6864 | |
| +0.0042 | +0.0037 | +0.0039 | +0.0041 | +0.0036 | +0.0058 | +0.0028 | +0.0062 | ||
| DIEN | Base | 0.7010 | 0.6975 | 0.7190 | 0.6989 | 0.6934 | 0.6761 | 0.7102 | 0.6809 |
| Base+MIM | 0.7055 | 0.7013 | 0.7233 | 0.7033 | 0.6970 | 0.6822 | 0.7131 | 0.6872 | |
| +0.0046 | +0.0038 | +0.0044 | +0.0045 | +0.0036 | +0.0061 | +0.0029 | +0.0063 | ||
| BST | Base | 0.6995 | 0.6965 | 0.7177 | 0.6973 | 0.6924 | 0.6740 | 0.7093 | 0.6796 |
| Base+MIM | 0.7049 | 0.7000 | 0.7229 | 0.7026 | 0.6964 | 0.6807 | 0.7129 | 0.6861 | |
| +0.0054 | +0.0035 | +0.0053 | +0.0053 | +0.0040 | +0.0068 | +0.0036 | +0.0065 | ||
| TWIN | Base | 0.7028 | 0.6992 | 0.7214 | 0.7013 | 0.6951 | 0.6776 | 0.7126 | 0.6825 |
| Base+MIM | 0.7051 | 0.7010 | 0.7229 | 0.7032 | 0.6968 | 0.6813 | 0.7134 | 0.6867 | |
| +0.0023 | +0.0018 | +0.0016 | +0.0019 | +0.0017 | +0.0037 | +0.0009 | +0.0042 | ||
| SIM | Base | 0.7024 | 0.7017 | 0.7111 | 0.7024 | 0.6945 | 0.6869 | 0.7058 | 0.6928 |
| Base+MIM | 0.7062 | 0.7067 | 0.7153 | 0.7065 | 0.6993 | 0.6893 | 0.7112 | 0.6951 | |
| +0.0038 | +0.0050 | +0.0042 | +0.0041 | +0.0048 | +0.0024 | +0.0054 | +0.0023 |
4.2. Performance on CTR Prediction Tasks
We evaluated the performance of MIM on CTR prediction tasks by applying it to various existing UBM methods. As a universal paradigm, MIM is compatible with most UBM frameworks. To assess its effectiveness, we compared the AUC scores of the original models (denoted as Base) with those enhanced by MIM. The AUC metric (Fawcett, 2006) is reported. As shown in Table 2, integrating MIM leads to consistent performance improvements across all baseline methods and datasets. For example, SIM achieves AUC gains of 0.23pt to 0.54pt, and similar gains are observed for other UBMs. While these improvements may appear modest, in large-scale scenarios such as Taobao, a 0.1pt improvement in AUC can result in several percentage points of uplift in online CTR. This uplift can bring billions in revenue to the platform, highlighting the economic value of our approach. These results validate the effectiveness and generalizability of MIM. Which can significantly enhances user behavior modeling by bridging the gap between content and user interest embeddings. Furthermore, its universal design ensures compatibility with a wide range of existing UBM frameworks, making it a practical solution for industrial-scale CTR prediction tasks.
4.3. Effectiveness Evaluation
In this section, we conduct various experiments to detailedly evaluate the effectiveness of MIM.
4.3.1. Effectiveness of high-quality MM embeddings.
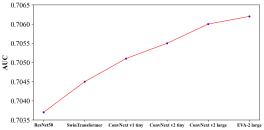
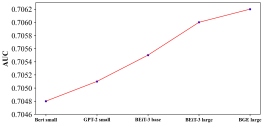
The impact of FoM. The experimental results in Figure 5 demonstrate the effectiveness of upgrading FoM. For , the shift from ResNet50 to EVA-2 yields constant performance improvements, demonstrating the ability of stronger visual FoMs to capture richer content semantics. Similarly, for , upgrading from smaller to larger models (e.g., BEiT-3 base to large) improves AUC, highlighting the benefits of scaling parameter sizes. These findings confirm that enhancing FoM, both in terms of model strength and parameter size, significantly improves the representation and alignment of user interests across modalities.
| Version | AUC | |
| Base | 0.7024 | - |
| Plain FoM | 0.7030 | +0.0060 |
| +DDA | 0.7034 | +0.0010 |
| +DDA+DMA | 0.7040 | +0.0016 |
| +DDA+DMA+C-SFT(i.e., MIM) | 0.7062 | +0.0038 |
The impact of pre-training. We evaluate the impact of different strategies used in the pre-training stage. The results are presented in Table 3. Here, Plain FoM refers to the FoM that is only pre-trained on general datasets. From Table 3, it shows (1) directly applying Plain FoM only achieves limited improvement due to the sub-effectiveness in item content understanding. (2) Both downstream data adaption and different modal alignment can help FoM better capture the item content and provide a significant improvement.
| Version | LF | Signal | AUC | |
| Base | - | - | 0.7024 | - |
| v1 | CE | Category | 0.7043 | +0.0019 |
| v2 | CE | Click | 0.7053 | +0.0029 |
| v3 | CE | Purchase | 0.7059 | +0.0035 |
| v4 | CL | Click | 0.7055 | +0.0031 |
| v5 | CL | Purchase | 0.7062 | +0.0038 |
4.3.2. Effectiveness of C-SFT
As presented in Section 3.3, there are two important factors that influence C-SFT, i.e., the user interest signal and loss function. Thus, we train different versions of C-SFT (see Table 4) and evaluate the performance of these versions in CTR prediction tasks. Specifically, for the user interest signal, we take the users’ clicking and users’ purchase as the expression of user interest. Furthermore, we also take an interest-irrelevant signal (item categories) with Cross Entropy loss as a comparison. For the loss function, the contrastive loss (i.e., Equ 5) and Cross Entropy loss are compared. The AUC results are reported in Table 4.
The impact of user interest signal. Compared with the performance of version v1, v2 and v3 achieves a better performance. It demonstrates the importance of introducing the user interest signal. Without such signals, MM features can hardly achieve a positive effect on CTR prediction. Furthermore, v3 (or v5) obtains a better performance than v2 (or v4). One of the possible reasons is that the purchase behavior is more strong and precise, resulting in a better expression of user interest. It also shows that understanding user interest plays an important role in MIM.
The impact of loss function. Compared with the baselines, both of the two loss functions perform better via bridging the semantic gap. Furthermore, compared with the performance of version v2 (or v3), it shows that adopting contrastive loss (i.e., version v4 or v5) performs better, which indicates contrastive loss can better model the alignment between user interest and the target item, thereby further improving prediction performance.
| Version | AUC |
| MIM | 0.7062 |
| C-SFT stage | |
| w/o TFN | 0.7058 |
| w/o ST-NSG | 0.7056 |
| w/o Multi-level InfoNCE | 0.7052 |
| w/o C-SFT | 0.7040 |
| CiUBM | |
| w/o ID interest module | 0.7057 |
| w/o content interest module | 0.7052 |
| w/o fusion interest module | 0.7054 |
4.4. Ablation Study
In this section, we conduct an ablation study to analyze the impact of different components. The results are presented in Table 5. Some observations are summarized as follows: 1) For the C-SFT stage, it shows that C-SFT takes an important role and improves AUC from 0.7040 to 0.7062. Besides, different components in C-SFT contribute to the final performance. 2) For the CiUBM, different interest modules contribute to the final improvement. It demonstrates that it is important to take both ID interest and content interest into consideration. Note the analysis for the pre-training stage has been discussed in Section 4.3.1.
4.5. Efficiency Evaluation
In this section, we analyze the efficiency of the proposed paradigm, including time and GPU memory efficiency. Detailedly, we develop two versions: (1) MIM (w/o RC) refers to MIM without representation center, i.e., MM embedding is real-time inferred by FoM. (2) MIM (E2E) refers to jointly training FoM and CiUBM in an E2E manner. We report the GFLOPs (the number of giga floating-point operations) per sample to reflect the train and inference time cost and GPU memory usage in deepCTR 444Since the pre-training stage can be pre-processed and C-SFT can be trained in parallel, the cost of these two stages can be ignored and is not included here.. The results are presented in Table 6. We can find that (1) Compared with Base, both of MIM(w/o RC) and MIM(E2E) need a large number of extra computations (773.55 6318.12 higher than Base) and is GPU memory costly (8.23 26.41 higher than Base). Note the architecture of the MIM(w/o RC) and MIM(E2E) is the same, resulting in the same GFLOPs and GPU memory cost during inference. (2) Compared with MIM(E2E), MIM(w/o RC) does not need to jointly train FoM and Base, which saves computation and GPU memory cost by the backward of FoM. (3) For MIM, thanks to the decomposed paradigm and representation center, it has significantly reduced the cost introduced by FoM and only needs 0.59 and 0.387 extra computation in training and inference, respectively, and 0.01 and 0.81 extra GPU memory cost in training and inference, respectively.
Overall, such nice properties in terms of high performance, efficient GPU memory usage, and low time requirements of our proposed model are welcomed for web-scale applications.
| GFLOPs | GPU Memory (G) | |||||||
| Train | Inference | Train | Inference | |||||
| Cost | Cost | Cost | Cost | |||||
| Base | 0.114 | - | 0.31 | - | 1.1 | - | 0.68 | - |
| Base+MIM(w/o RC) | 240.24 | +2106.37 | 240.11 | +773.55 | 10.15 | +8.23 | 9.85 | +13.49 |
| Base+MIM(E2E) | 720.38 | +6318.12 | 240.11 | +773.55 | 30.15 | +26.41 | 9.85 | +13.49 |
| Base+MIM | 0.182 | +0.59 | 0.43 | +0.38.7 | 1.11 | +0.01 | 0.81 | +0.19 |
4.6. Generalization in Cold Start Scenarios
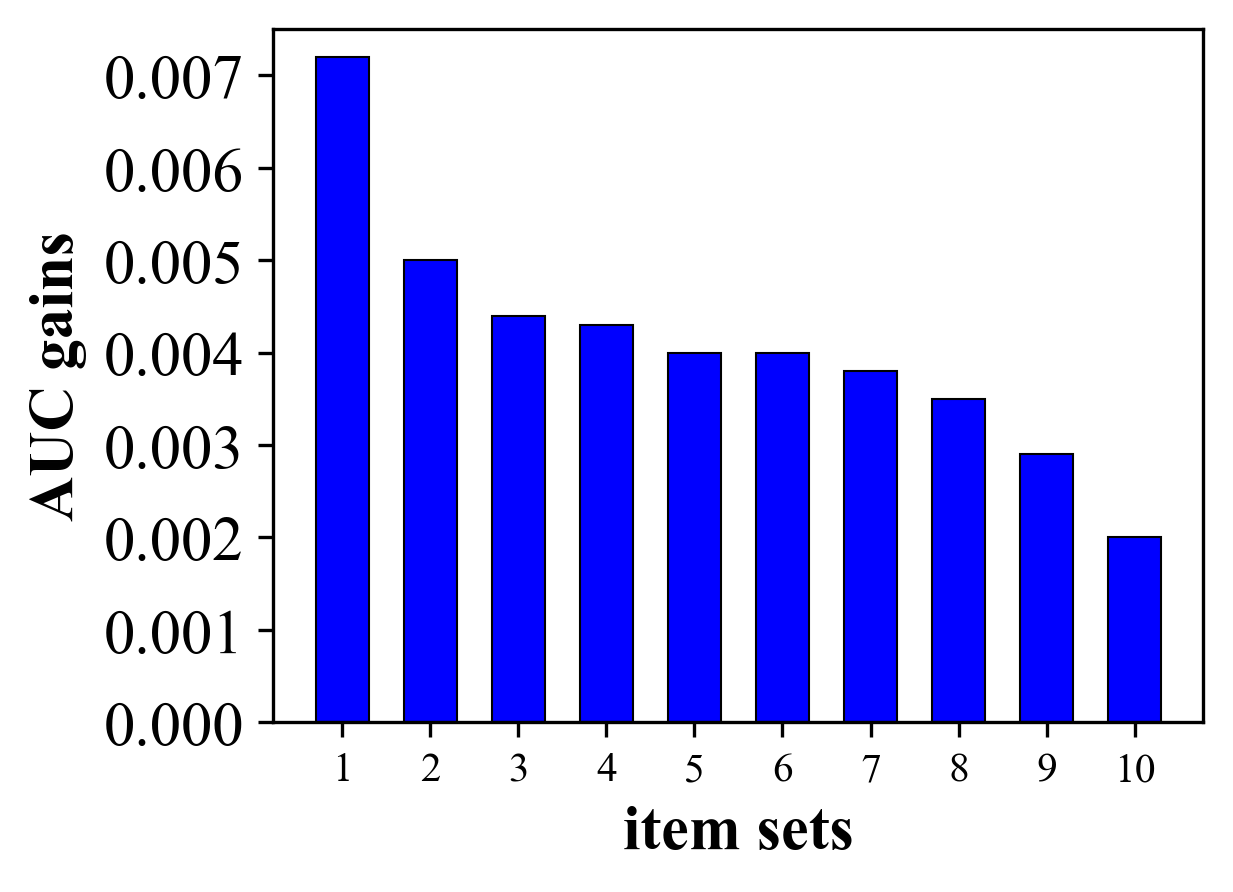
Here we analyze the performance of the cold start items to show the generalization of our proposed paradigm. Detailedly, we divide different items into 10 sets (denoted as S1 to S10), where S1S10 refers to the newestoldest item sets. Then we evaluate the improvement of different sets respectively. The results are presented in Figure 6. It shows that MIM contributes more to the newest items (e.g., S1) and achieves more AUC gains. This demonstrates that MM features enable new items to better represent their features, leading to better performance.
4.7. Evaluation of Industrial Applications
Here, we first develop MIM on a real-world industrial application, i.e., the sponsored search system in Taobao, and have continually achieved three releases of MIM in our industrial application in the past year.
Online A/B Testing for CTR Prediction Tasks. Compared with the online model, these three releases achieved 0.81pt AUC gains in total, and 0.26pt, 0.25pt, and 0.30pt AUC gains for each. During the online A/B test, we observed 14.14% CTR gains in total, and 5.1%, 4.75%, and 4.29% CTR gains for each release. It also achieves 4.12% RPM (Revenue Per Mile) gain in total, and 1.5%, 1.19% and 1.43% RPM gains for each release.
Impact on Content-Sensitive Categories. We also report AUC, CTR, and RPM gains in different item categories in one of the releases (others have similar results). Table 7 shows more improvement can be archived on the content-sensitive categories (e.g., Clothes), where users more care about the styles of items and can be easily attracted by item images or titles. On the contrary, lower improvement is obtained from content-insensitive categories (e.g., Cars). It demonstrates user interest can be well modeled by MIM and improve the performance of CTR prediction.
| Category | AUC Gains | CTR Gains | RPM Gains |
| All | +0.0038 | +5% | +1% |
| Home Decoration | +0.0047 | +4.63% | +3.04% |
| Clothes | +0.0037 | +8.69% | +4.44% |
| Sports | +0.003 | +3.48% | +1.86% |
| Toys | +0.0024 | +4.44% | +1.89% |
| FMCG | +0.0028 | +3.98% | +2.74% |
| Pets | +0.0024 | +3.02% | +2.69% |
| Cars | +0.0028 | +2.54% | +0.02% |
Universality in Recommendation Tasks. Furthermore, we also try to apply MIM in a recommendation system, i.e., the display advertising system in Taobao, and achieve similar improvements. Inspired by this method, the final deployed version achieved 0.4pt offline AUC gains, 3.5% CTR gain and 1.5% RPM gain online. From the success of different systems, we believe MIM is a universal and industrial welcomed multi-modal content interest modeling paradigm.
5. Conclusion
In this paper, we propose MIM, a novel and universal multi-modal content interest modeling paradigm for industrial-scale applications. By introducing a decomposed training paradigm and a representation center, MIM effectively integrates multi-modal features into User Behavior Modeling (UBM), addressing the limitations of traditional ID-based methods and existing multi-modal approaches. The proposed method aligns user interests with content embeddings, significantly enhancing prediction performance while maintaining efficiency in large-scale real-world applications. Extensive experiments validate the effectiveness and generalizability of MIM, showing consistent improvements across diverse baselines and datasets. These results demonstrate MIM’s practical value and its potential to drive further innovation in multi-modal user modeling for industrial applications.
References
- (1)
- Alayrac et al. (2022) Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. 2022. Flamingo: a visual language model for few-shot learning. (2022).
- Bao et al. (2021) Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. 2021. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 (2021).
- Chang et al. (2023) Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. 2023. TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3785–3794.
- Chen et al. (2020) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. 2020. Generative pretraining from pixels. In International conference on machine learning. PMLR, 1691–1703.
- Chen et al. (2019) Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data. 1–4.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/
- Clark et al. (2020) Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=r1xMH1BtvB
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems (Sept. 2016), 191–198. doi:10.1145/2959100.2959190
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. doi:10.48550/arXiv.1810.04805 arXiv:1810.04805 [cs]
- Dosovitskiy et al. (2020) A. Dosovitskiy, L. Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G. Heigold, S. Gelly, Jakob Uszkoreit, and N. Houlsby. 2020. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. ArXiv (Oct. 2020).
- Fang et al. (2023) Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. 2023. EVA-02: A Visual Representation for Neon Genesis. arXiv:2303.11331 [cs.CV]
- Fawcett (2006) Tom Fawcett. 2006. An introduction to ROC analysis. Pattern recognition letters 27, 8 (2006), 861–874.
- He et al. (2019) Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. 2019. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 558–567.
- Liu et al. (2023) Qidong Liu, Jiaxi Hu, Yutian Xiao, Jingtong Gao, and Xiang Zhao. 2023. Multimodal Recommender Systems: A Survey. ArXiv (2023).
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision. 10012–10022.
- Liu et al. (2022) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A ConvNet for the 2020s. doi:10.48550/arXiv.2201.03545 arXiv:2201.03545 [cs]
- Long et al. (2024) Xianzhong Long, Han Du, and Yun Li. 2024. Two momentum contrast in triplet for unsupervised visual representation learning. Multim. Tools Appl. 83, 4 (2024), 10467–10480. doi:10.1007/S11042-023-15998-3
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. (2019).
- Mikolov et al. (2013) Tomás Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani, and Kilian Q. Weinberger (Eds.). 3111–3119. https://proceedings.neurips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html
- Mo et al. (2015) Kaixiang Mo, Bo Liu, Lei Xiao, Yong Li, and Jie Jiang. 2015. Image feature learning for cold start problem in display advertising. In Twenty-Fourth International Joint Conference on Artificial Intelligence.
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, and Lama Ahmad… 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
- Pi et al. (2020) Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692.
- Qiu et al. (2020) Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. 2020. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). ACM, 1150–1160. doi:10.1145/3394486.3403168
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Tan and Bansal (2019) Hao Tan and Mohit Bansal. 2019. Lxmert: Learning cross-modality encoder representations from transformers. arXiv preprint arXiv:1908.07490 (2019).
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL] https://arxiv.org/abs/2302.13971
- Wang et al. (2023) Jinpeng Wang, Ziyun Zeng, Yunxiao Wang, Yuting Wang, Xingyu Lu, Tianxiang Li, Jun Yuan, Rui Zhang, Hai-Tao Zheng, and Shu-Tao Xia. 2023. MISSRec: Pre-training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation. In Proceedings of the 31st ACM International Conference on Multimedia. 6548–6557.
- Wang et al. (2022) Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. 2022. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442 (2022).
- Woo et al. (2023) Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. 2023. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. arXiv:2301.00808 [cs.CV]
- Wu et al. (2021) Chuhan Wu, Fangzhao Wu, Tao Qi, and Yongfeng Huang. 2021. Empowering news recommendation with pre-trained language models. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1652–1656.
- Wu et al. (2018) Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin. 2018. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 3733–3742. doi:10.1109/CVPR.2018.00393
- Xiao et al. (2023) Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv:2309.07597 [cs.CL]
- Yan et al. (2022) Bencheng Yan, Pengjie Wang, Kai Zhang, Feng Li, Hongbo Deng, Jian Xu, and Bo Zheng. 2022. Apg: Adaptive parameter generation network for click-through rate prediction. Advances in Neural Information Processing Systems 35 (2022), 24740–24752.
- Yang et al. (2019) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems 32 (2019).
- Yuan et al. (2020) Fajie Yuan, Xiangnan He, Alexandros Karatzoglou, and Liguang Zhang. 2020. Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. arXiv:2001.04253 [cs]
- Yuan et al. (2021) Fajie Yuan, Guoxiao Zhang, Alexandros Karatzoglou, Joemon Jose, Beibei Kong, and Yudong Li. 2021. One Person, One Model, One World: Learning Continual User Representation without Forgetting. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (July 2021), 696–705. doi:10.1145/3404835.3462884
- Yuan et al. (2023) Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (July 2023), 2639–2649. doi:10.1145/3539618.3591932
- Zadeh et al. (2017) Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1103–1114.
- Zhang et al. (2021) Weinan Zhang, Jiarui Qin, Wei Guo, Ruiming Tang, and Xiuqiang He. 2021. Deep learning for click-through rate estimation. arXiv preprint arXiv:2104.10584 (2021).
- Zhou et al. (2019) Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068.