Minimizing Ruin Probability Under Dependencies for Insurance Pricing
Abstract
In this work the ruin probability of the Lundberg risk process is used as a criterion for determining the optimal security loading of premia in the presence of price-sensitive demand for insurance. Both single and aggregated claim processes are considered and the independent and the dependent cases are analyzed. For the single-risk case, we show that the optimal loading does not depend on the initial reserve. In the multiple risk case we account for arbitrary dependency structures between different risks and for dependencies between the probabilities of a client acquiring policies for different risks. In this case, the optimal loadings depend on the initial reserve. In all cases the loadings minimizing the ruin probability do not coincide with the loadings maximizing the expected profit
1 Introduction
Insurance is based on the idea that society asks for protection against unforeseeable events which may cause serious financial damage. Insurance companies offer a financial protection against these events. The general idea is to build a community where everybody contributes a certain amount and those who are exposed to the damage receive financial reimbursement [35] .
When (non-life) insurers set premium prices they usually start by finding the so-called pure premium, which is the expected value of the total claims that will occur in one time unit. However, when pricing insurance policies, insurers must take into account the risk associated with the policy as well as additional costs (e.g. operational cost, capital cost, etc.). Therefore, a so-called security loading is added to cover the risk and additional costs. The security loading is often calculated using some premium calculation principle, and the insurance premium is obtained once the security loading has been determined and added to the pure premium. The main concerns are usually whether the loading is an appropriate measure of the risk and which premium principle to choose. The higher the loading the higher the premium and consequently, the underwriting risk will be lower. However, if the premium price is too high then the exposure will be too low due to competition, and the operational cost of the insurer will engulf the premium income resulting in financial instability. Therefore, insurers usually require sophisticated premium calculations in order to secure stability.
Collective risk models are fundamental in actuarial science to model the aggregate claim amount of a line of business in an insurance company. The collective risk model has two random components, the number of claims and the severity of claims, and is usually modelled with a compound process [15, Chapter 3]. The classical Lundberg risk process has been studied extensively and there exist many variations, for example including reinsurance or investments [14]. It assumes that premia come in a continuous stream while claims happen at discrete times according to a Poisson distribution.
Another common assumption is that the risk can be divided into groups of homogeneous risks such that the pure premia and security loadings can be estimated separately for each risk group. The pure premia of these individual groups are usually modelled with generalized linear models (GLM). GLM’s have been applied extensively in actuarial work and a good overview is provided in [26, 36]. Traditional risk theory has usually assumed independence between risks due to its convenience, but it is generally not very realistic. Claims in an insurer’s risk portfolio are correlated as they are subject to the same event causes [7]. Completely homogeneous risk groups are extremely rare and dependence among risks has become a flourishing topic in actuarial literature [2]. Dependence has mostly been measured through linear correlation coefficients [4]. The popularity of linear coefficient is mainly due to the ease with which dependencies can be parameterized, in terms of correlation matrices. Most random variables, however, are not jointly elliptically distributed and it could be very misleading to use linear coefficients [30]. This motivated the use of concordance measures. Two random variables are concordant when large values of one go with large values of the other [25]. The Lundberg risk model is a Lévy jump process, [8] which means that the dependency of two claim processes is best explained through their Lévy measure [32]. This study will not go into details about Lévy processes, but both [8] and [27] provide a very good introduction, and [2, 5, 28, 34, 1] are examples of applications of Lévy copulas to risk processes. For example, van Velesen [34] showed how Lévy copulas can be used in operational modelling and discussed how dependence is implied by the Lévy copula. In this work we consider bivariate claim processes, but the presented theory can be straightforwardly extended to multiple claim processes.
Ruin probability is a classical measure of risk and has been extensively studied [15, 14, 18, 33]. Although there is no absolute meaning to the probability of ruin, it still measures the stability of insurance companies. A high ruin probability indicates instability, and risk mitigation techniques should be used, like reinsurance or raising premia [15]. Most non-life insurance products have a term of one year and therefore it can be argued that the one year ruin probability should be used. The one year ruin probability is the probability that the capital of an insurance company will hit zero within one year. However, the appropriateness of risk measures defined over fixed time horizons can be questioned, since ruin in a given time span can be minimized by increasing the probability of ruin in the aftermath of that period. Lundberg concluded that the actual assumptions behind the classical collective risk model are in fact less restrictive when time-invariant quantities like the infinite time ruin probability are considered [33]. Therefore, we focus on the infinite time ruin probability in this paper.
In this work, the optimal loadings based on two strategies are derived, and compared. One strategy maximizes the profit and the other minimizes the ruin probability. We show that the two loading strategies give different results. Furthermore, we show how the optimal loading with respect to the ruin probability can be found and compare it to the one obtained when the expected profit is maximized. We consider dependencies and illustrate how Lévy copulas can be used to model claim process dependencies and how dependencies can affect the riskiness of the insurance portfolio. We take this idea further and consider dependency between the acquisition of insurance for different risks by policyholders. This is a realistic assumption as policyholders usually buy multiple insurance products from the same insurance company. We also take into account the fact that the market risk process and the company’s risk process are not the same, and how the company’s risk process depends on its exposure to the market. This is, to our knowledge, the first analysis of the interplay of the ruin probability, the dependency structure of claim, and the dependency structure of acquisition of insurance. We demonstrate that even if there is a strong dependency between insurance products within the market, small insurance companies have less dependency and therefore less risk than bigger insurance companies, provided the dependency between acquisition of insurance for different risks is not too strong.
The paper is organized as follows: Section 2 contains some background material about ruin probabilities in the Lundberg process and aggregation of compound Poisson processes. Section 3 deals with the single-risk case. We characterize the optimal loading and compare it with the loading maximizing the expected profit. Section 4 handles the multiple risks case. We show how the dependency structure existing in the market (i.e. the general population) translates into the risk exposure of the company through its market shares on different risks and the likelihood that clients acquire insurance for more than one risk. Section 5 contains a numerical illustration. A numerical scheme to compute the ruin probabilities is given in the appendix.
2 Preliminaries
2.1 Claim and Surplus Processes
The Lundberg risk model describes the evolution of the capital of an insurance company and assumes that exposure is constant in time, losses follow a compound Poisson process, and premia arrive at a fixed continuous rate:
where is the initial surplus, is the risk premium rate, is a time homogeneous Poisson process with intensity parameter , and are i.i.d. random variables representing the severity of claim , . Here it is assumed that are positive. In the following sections, denotes an arbitrary random variable with the same distribution as any . The severity distribution is denoted as and the severity survival distribution as . is a compound Poisson process and thus is a stochastic process (sometimes called the surplus process) representing the insurance wealth at time . increases because of earned premia and decreases when claims occur. When the capital of an insurance company hits zero, the insurance company is said to be ruined. Formally, the ruin probability is defined as follows.
Definition 2.1 (Probability of Ruin).
Let be a filtered probability space and a surplus process which is adapted and Markov with respect to the filtration. The state space is . If X is time homogeneous, the infinite time ruin probability is the function such that
Sometimes it is useful to use the survival (non-ruin) probability, defined as . The ruin probability can be calculated using the following integro-differential equation [11].
Proposition 2.1.
Assume that is defined as above and the premium rate satisfies . If then the probability of ruin with infinite time horizon satisfies the following equation:
| (2.1) |
with the following boundary condition:
Furthermore, the probability of non-ruin satisfies the following equation:
| (2.2) |
for with the following boundary condition:
2.2 Accounting for Claim Dependencies
Consider the surplus process where
| (2.3) |
If these processes are independent, it is relatively easy to combine them into a single process using the aggregation property of compound Poisson processes as described in Wütrich [35]. The aggregation property allows the combination of multiple surplus processes into a single risk process as follows:
where is a Poisson r.v. with and are i.i.d. random variables, which follow the severity distribution . This aggregation property allows us to use the integro-differential equation (2.1) to calculate the ruin of multiple surplus processes.
If the risks are not independent, then we can use the fact that compound Poisson processes are characterized by their Lévy measure to decompose the claim process into independent processes to which the aggregation property can be applied. In particular, for risks, we obtain the decomposition:
where and are compound Poisson processes accounting for events concerning only risk 1 and risk 2, respectively. is a compound Poisson process accounting for events concerning both risks simultaneously. Furthermore, , and are mutually independent.
In this section, we briefly explain how this can be achieved. Further details can be found in [32]. We will use the following definitions:
Definition 2.2.
The tail integral of a Lévy measure on is given by a function
| (2.4) |
Definition 2.3 (Lévy Copula for Processes with Positive Jumps).
A two-dimensional Lévy copula for Lévy processes with positive jumps, or for short, a positive Lévy copula, is a 2-increasing grounded function with uniform margins, that is, .
Similarly to Sklar’s theorem for ordinary copulas [25], it has been shown that the dependency structure of can be characterized by a Levy copula such that where and are the marginal tail integrals for and . If and are absolutely continuous, this Lévy copula is unique, otherwise it is unique on , the product of ranges of one-dimensional tail integrals, [8, Theorem 5.4]
Consider a two dimensional claim process:
| (2.5) |
where is a Poisson process with intensity and , are independent random variables with common joint distribution . The components of , and , are one-dimensional compound Poisson processes with intensities and and severity distributions and , respectively. We wish to obtain a decomposition:
| (2.6) |
where , and are independent compound Poisson processes with intensities , , and severity distributions ,,, respectively. In the above setting, we consider
| (2.7) |
A compound Poisson process, , is a Lévy process with Lévy measure , with tail integral
The components and are independent if and only if for every , i.e., if and only if .
The Lévy measure of the processes , , have tail integrals
Taking equation (2.7) into account, one obtains
The severity distributions , , and can be recovered from the tail integrals:
If the dependency between and is characterized by a Lévy copula, , i.e. for , then the relations above can be written using the Lévy copula and one-dimensional tail integrals:
Using the above methodology, the surplus process can be represented as:
where , , is a Poisson process with intensity and are i.i.d. random variables with distribution:
where
3 The Optimal Loading for a Single Risk
An insurer can control the volume of its business through the premium loading . A reasonable assumption is that the higher the loading, the smaller the number of contracts in its portfolio, which means that the claim intensity (or business volume) will decrease. Therefore, both the claim intensity , and the premium rate , will depend on . It is reasonable to assume that , as abnormal premium rates will not attract customers [13]. To capture these concepts let . Here is the average number of claims per unit of time for the whole market, and is the probability that a potential claim is filed as an actual claim to the particular insurer under consideration. In other words, reflects the demand or the market share sensitivity to the loading parameter . can be interpreted as a probability that a customer buys an insurance product. For example, we may assume that demand of insurance contracts is described by a logit glm model as in Hardin and Tabari [12]. Thus, , will be :
| (3.1) |
where and are determined from the glm and is the loading parameter. will be a positive number so when and when . Assuming that the company has some fixed costs, independent of the risk exposure, denoted by , the expression for the net premium income becomes:
The following proposition characterizes the behaviour of the solution of equation (2.1) with respect to the loading .
Proposition 3.1.
If satisfies equation (2.1) then is strictly increasing with respect to the parameter .
Proof.
It is possible to integrate Equation (2.1) on the interval to obtain:
| (3.2) |
To prove the proposition, we will study equations of the general form:
| (3.3) |
We introduce the operator , acting on measurable locally bounded functions , as:
| (3.4) |
Notice that the transformation is linear and for every , is continuous, hence measurable and locally bounded. Thus, powers of the operator are defined in the usual way.
Let, . Then:
If the inequality
| (3.5) |
holds, for some , then
Thus, by induction, (3.5) holds for every . Therefore, for every , fixed, there is some such that is a contraction in the space of measureable and bounded functions . It follows from the contraction principle that equation (3.2) has one unique solution. Further, , uniformly in for any given and any fixed .
Let be the solution of equation (3.3) for given and . Then,
Since , this shows that admits the series representation:
which converges uniformly with respect to on compact intervals. Thus, we can differentiate term by term and obtain
For any locally absolutely continuous function:
Thus, implies , which implies , , and therefore for any . This argument shows that as . Therefore is strictly increasing with . ∎
According to Proposition 3.1, in order to find minimizing the probability of ruin, it is sufficient to find minimizing . For example, using the logit demand model (3.1), the optimal loading is found with direct differentiation of and is given by:
| (3.6) |
However, the loading that maximizes the expected profit is:
which is, in the case of logit demand (3.1), the unique solution of:
| (3.7) |
Thus, in general, does not coincide with .
4 The Multiple Risk Case
In this section, we explore how dependencies between risks available in an insurance market translate into risk exposure for a company through its market shares on the different risks. It turns out that this mechanism is non trivial when the risks are dependent. For the sake of simplicity, we assume that the company offers insurance for two risks in a market constituted by identical individuals, all of them exposed to both risks. Using the notation in equations (2.5) and (2.6) to denote the market claim process, is the vector of the total (accumulated) amount of claims of each risk that occurred in the market, up to time . The marginal distributions of and are characterized by claim intensities and and the severity distributions , and their dependency structure is characterized by a parameter and a joint distribution , as explained in Section 2.
4.1 Risk Exposure as a Function of Market Shares
To extend the demand model outlined in Section 3 to a market with multiple risks where the acquisition of insurance for different risks may not be independent, we propose the following interpretation for the function .
Let be the loadings charged by the company for each risk. We assume that every individual in the market (a potential client) is provided with a vector of bid prices (, ). The client acquires the insurance for risk if (for convenience, we consider prices net of the pure premium). The distribution of the price vectors in the market is modelled by a random vector . Thus, is the company’s market share for the insurance of risk at equilibrium, given the loadings . Let be the proportion of individuals in the market holding a policy for risk 1 and no policy for risk 2. Similarly, and denote the proportion of individuals holding a policy only for risk 2 and for both risks, respectively. If the acquisition of polices for different risks is independent, then:
| (4.1) |
Dependency between the acquisition of different risks can be introduced by considering dependent bid prices . In particular, if the joint distribution of is characterized by an ordinary copula , then, according to Sklar’s theorem [25]. This gives:
Under this model, the company’s surplus process is:
| (4.2) |
where , , and count the number of claims received by the company concerning only risk 1, only risk 2, and both risks, respectively. Their intensities are, respectively,
The distribution of the single risk claim amounts (resp., ) is a mixture of the distributions and (resp., and ):
This is because some customers insure risk 1, but not risk 2 and vice-versa. Therefore, the aggregate process for the insurer is
| (4.3) |
where is a Poisson process with intensity
| (4.4) |
and , are i.i.d random variables with distribution
| (4.5) |
Thus, if the risks in the market are independent (i.e. if ), then the risk in the company’s portfolio is just a sum of the risks and , weighted by the respective market shares, and , irrespective of any dependency between sales of policies for different risks. However, if the risks in the market are dependent ( ), then the company’s risk is not, in general, a weighted sum of and . Further, this effect persists even in the case where sales of different policies are independent (i.e., ). On the other hand, equalities (4.4) and (4.5) show that in the (unlikely) situation where clients always buy insurance for only one risk, the risk exposure of the insurer is accurately computed using only the marginal distributions of each risk (i.e. assuming that the risks are independent). This is due to the static nature of our model. For example, it does not take into account the possibility of external factors changing the frequency of claim events in both risks simultaneously.
4.2 The Impact of Dependencies on Ruin Probability
From the discussion above and Proposition 3.1, it follows that the ruin probability of a company with market shares (, , ) solves the equation
| (4.6) | ||||
| (4.7) |
Since estimating the dependency structure may pose substantial difficulties, we may wish to have an a-priori bound for the error introduced by neglecting dependencies, that is, by substituting the probability for , where solves the equation.
| (4.8) |
where and . Notice that and therefore the boundary condition for (4.8) is again (4.7).
The discussion in Subsection 4.1 shows that the difference is expected to be small when is small compared to . The following proposition gives a precise meaning for this statement.
Proposition 4.1.
With the notation above:
for every amount of initial reserve .
4.3 The Impact of Dependencies on Small Companies
Now, we proceed with the argument above to explore how dependencies affect companies of different size. We measure the size of the company by it’s expected total value of claims, and, to make comparisons meaningful, we consider that the total revenue is proportional to the company’s size, i.e.
Similarly, we consider the initial reserve to be proportional to size, i.e.:
Notice that, due to equations (4.6), (4.7) and (4.8), the effect of dependencies must be bounded in the sense that
for some constants . However, we can use Proposition 4.1 to obtain a better estimate:
| (4.10) |
Notice that the right-hand side of (4.10) has the same asymptotic behaviour as
Further, if the sales of policies for different risks to the same individual are independent, then goes to zero faster than , when . Thus, a small company selling policies for different risks independently is relatively immune to the effects of dependencies between the risks, contrary to a large company (it is obvious that a monopolistic company is fully exposed to the dependencies between risks). This immunity to risk’s dependencies may persist even when sales of policies for different risks are not independent, provided the dependency in sales is sufficiently mild. For example, if the dependency between sales is modelled by a Clayton or a Frank copula in (4.1). However, small companies are not specially protected from risk dependencies if the dependency between sales is modelled by a Pareto or a Gumbel copula.
4.4 Optimal Loadings and Market Shares
Since the right-hand sides of equalities (4.6) and (4.7) depend on the loadings through both and , Proposition 3.1 can not be generalized to models with multiple risks. However, it is possible to provide optimality conditions for the loadings minimizing the ruin probability.
To do this, we extend the notation introduced in the proof of Proposition 3.1. For any distribution function , we consider the compounding operator of type (3.4)
Thus, the 2-risk version of equation (3.2) can be written as
| (4.11) |
where
Since , (4.11) becomes
We write this in abbreviated form:
where is the vector
is the vector function
is the vector of operators
and is the usual inner product in .
Using the argument in the proof of Proposition 3.1, we see that admits the series representation
Similarly, any vector and any bounded measurable function define one unique function
This function is analytic with respect to , with partial derivatives
Taking into account the chain rule for derivatives, this proves the following proposition.
Proposition 4.2.
If is differentiable, then is differentiable for every and
By Proposition 4.2, the optimal loadings satisfy the equation
| (4.12) |
Contrary to the single-risk case, the odds of finding explicit solutions for this equation seem very low, even in simple cases. However, (4.12) can be numerically solved by Newton’s algorithm, the second-order partial derivatives being
Notice that the expected profit is
Thus, it depends only on the marginal distribution of the claim processes , , being independent of the dependency structure. It follows that the loadings minimizing the joint profit coincide with the loadings minimizing the profit on each risk, separately. That is, a pricing strategy that completely focus on expected profit completely fails to take both dependencies between risks and dependencies between sales of policies into account.
5 Numerical Results
Throughout this section, are assumed to be i.i.d gamma distributed random variables with shape parameter, , and scale parameters, , which means that the mean is, , for . In the following numerical analysis let , , , , and . That is, the difference stems from surplus process 2 being more sensitive to the loading via the parameter . is taken to be of the pure premium if the exposure was , that is . The operational cost is therefore of the expected total amount of claims in the market. The Clayton Lévy copula is considered for positive dependence and the parameter is set to . Finally, let and denote the optimal loading when the ruin probability and expected profit criterion is used, respectively. The programming language R was used for every calculation.
5.1 Single Surplus Process
The surplus processes are first considered separately. The ruin probability and the expected profit is plotted as a function of for the two processes in Figures 1 and 2. was found by minimizing .

From Figure 1 it can be seen that the optimal security loading parameter for the ruin probability is, , while the that maximizes the expected profit is lower, . Moreover, in this example, the maximum expected profit is 22.843 units and is given at . The expected profit taken at the point is lower, close to 20.000 units.
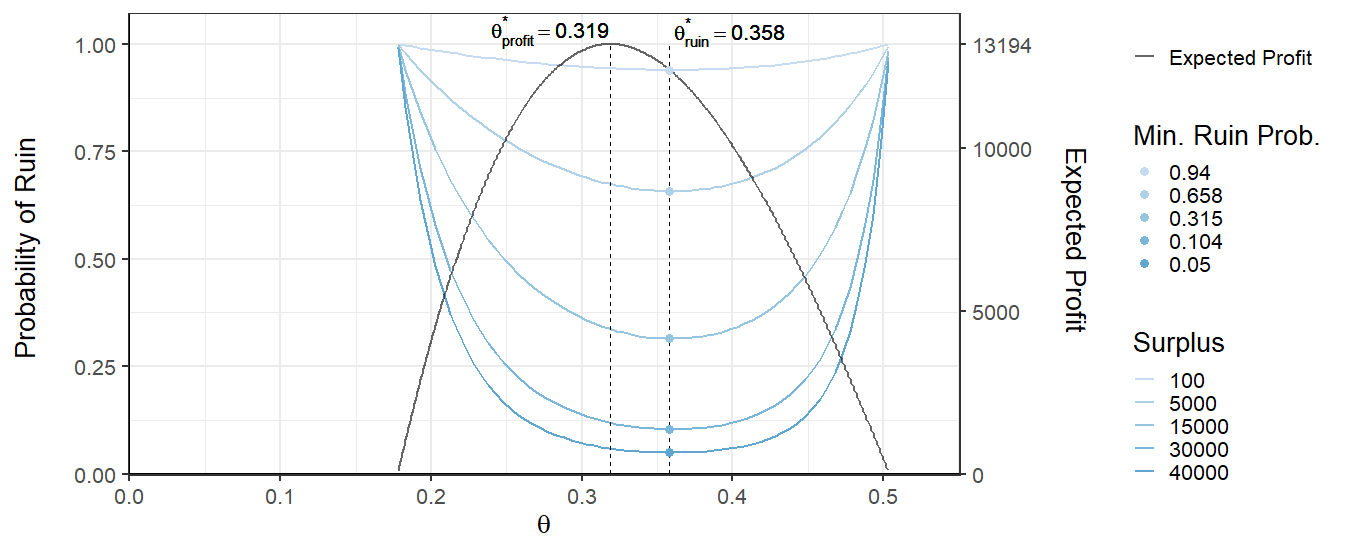
From Figure 2 it can be seen that the optimal security loading parameter for the ruin probability is , while the that maximizes the expected profit is again lower or .
Obviously, for both processes, the ruin probability decreases with increasing surplus. Moreover, it can be seen that surplus process has higher probability of ruin than surplus process for the same amount of surplus. The sensitivity of the demand curve affects the ruin probability and greatly. The more sensitive to the exposure the demand curve is, the closer the and are. This more sensitive curve also has higher probability of ruin for a given surplus, which indicates that more competitive insurance products are riskier. These effects can be seen if the two Figures (1 and 2) are compared. Conversely, if the demand curve is not sensitive to the price, then the gap between and can become quite large. Additionally, it can be seen from the curve at surplus = 100 that the ruin probability for and are similar but as the surplus grows the values start to differ and once the surplus is great enough the two values and result in similar ruin probabilities again. This means that if the insurance firm has high enough surplus then they can choose arbitrary without risking the chance of ruin. If the surplus is great enough then the value of does not matter as much. However, having too much reserves can be bad for insurance companies as it can be seen as a negative leverage. The bowl shape of the blue curves in the two Figures (1 and 2) is because of the interplay between the fixed cost and the demand curve.
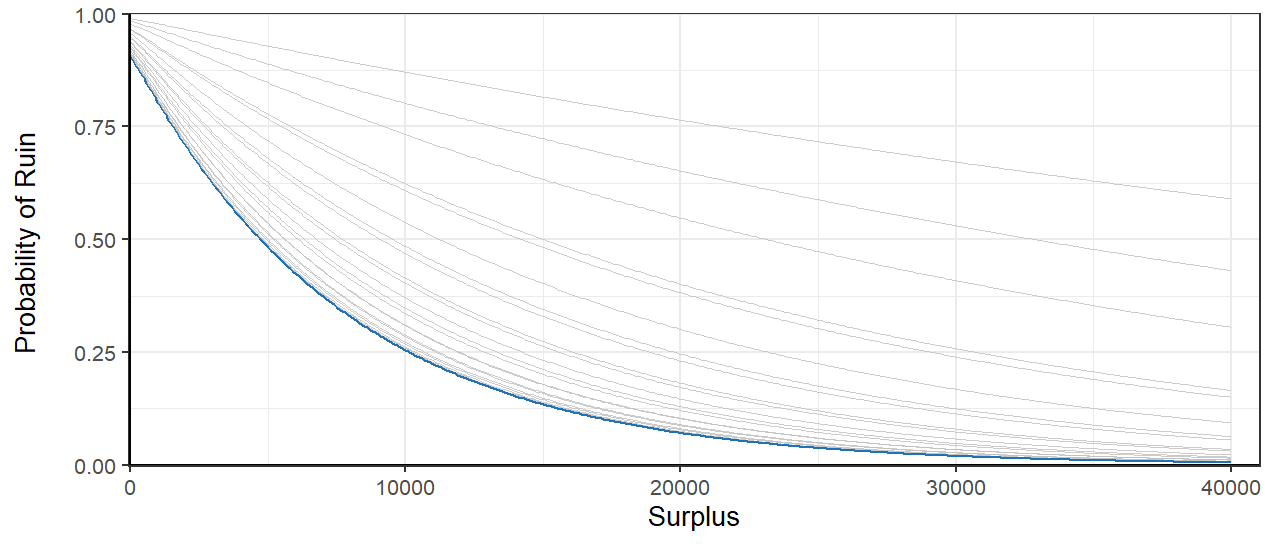
should give the minimum ruin probability at all surplus values. This can be tested by graphing multiple ruin probability curves and compare it with the one obtained by . Figure 3 shows that gives the minimum ruin probability indeed.
5.2 Two Aggregated Surplus Processes with Common Loading
Next, the two surplus processes, and are aggregated, both when the claims are independent and dependent. The acquisition is independent in this subsection.
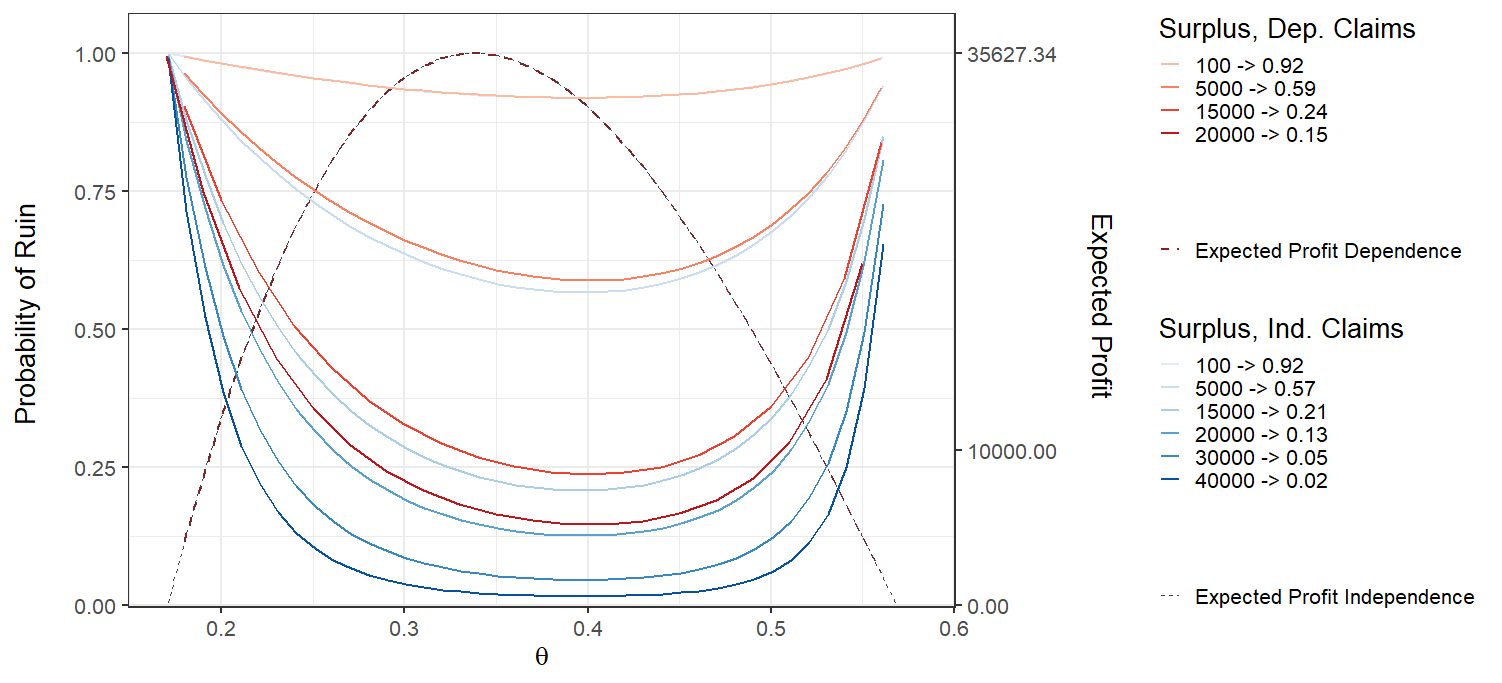
Figure 4 shows the ruin probability of the aggregated surplus process as a function of the security loading parameter, , both when they are independent and dependent via Clayton Lévy copula. The red curves represent dependence while the blue curves represent independence.
Firstly, it can be seen that the expected profit is the same for dependence and independence and from the figure, . The reason is that the claim mean and the claim frequency is almost the same (numerically) for dependence and independence.
Secondly, the dependent case has a higher probability of ruin than the independent case for the same amount of surplus. However, the ruin probability is almost the same for small surplus values as can be seen from the figure. Interestingly, the optimal loading for dependence and independence seem to be the same and numerically the values are . The surplus value does not change the optimal loading , as expected. The reason why the ruin probability difference between the dependent and independent cases is relatively small is because of the probability . The fact that the insurance company does not always have the both claims and when a common jump occurs reduces the risk.
Finally, the difference of the two ruin probability curves (red and blue) for a given surplus seems to be increasing with increasing surplus, meaning that the ruin probability in the independent case decreases more rapidly with increasing surplus then for the dependent case. Therefore, it is clear that the positive dependent case is riskier.
Note that , which is very close to the weighted average of the optimal loading parameter of the isolated surplus processes where the weight is the exposure ratio of each surplus process, that is
which strongly indicates that the optimal value, , is simply the weighted average.
5.2.1 Two Aggregated Surplus Processes with Separate Loadings
It is more realistic to consider as a vector so that the loading parameter can be different for each surplus process separately, to spread the total premium over the policies in an optimal way. The two surplus processes, and , are aggregated as before and the constants are the same, but let .
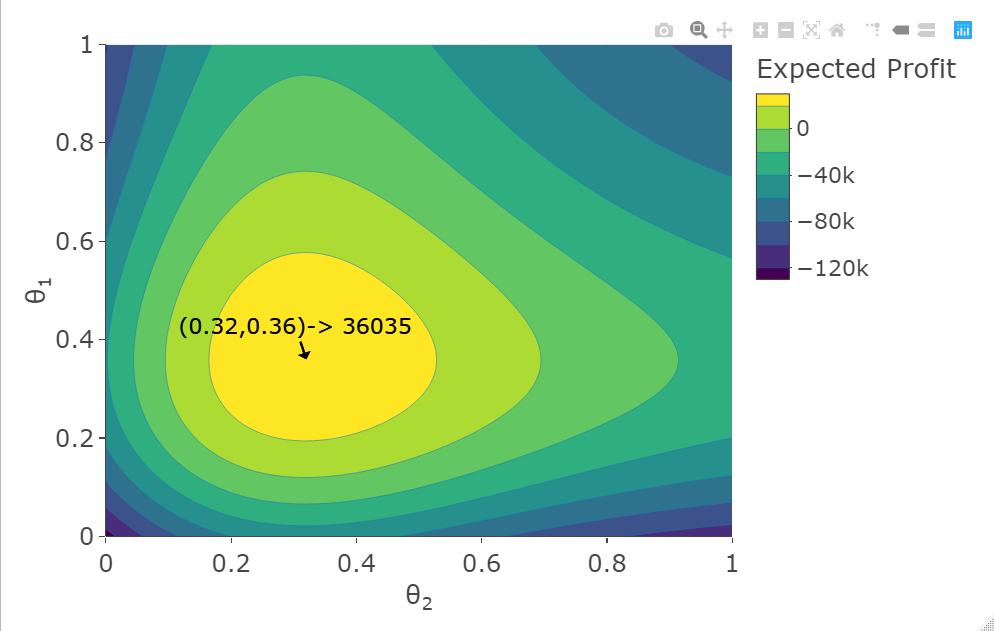
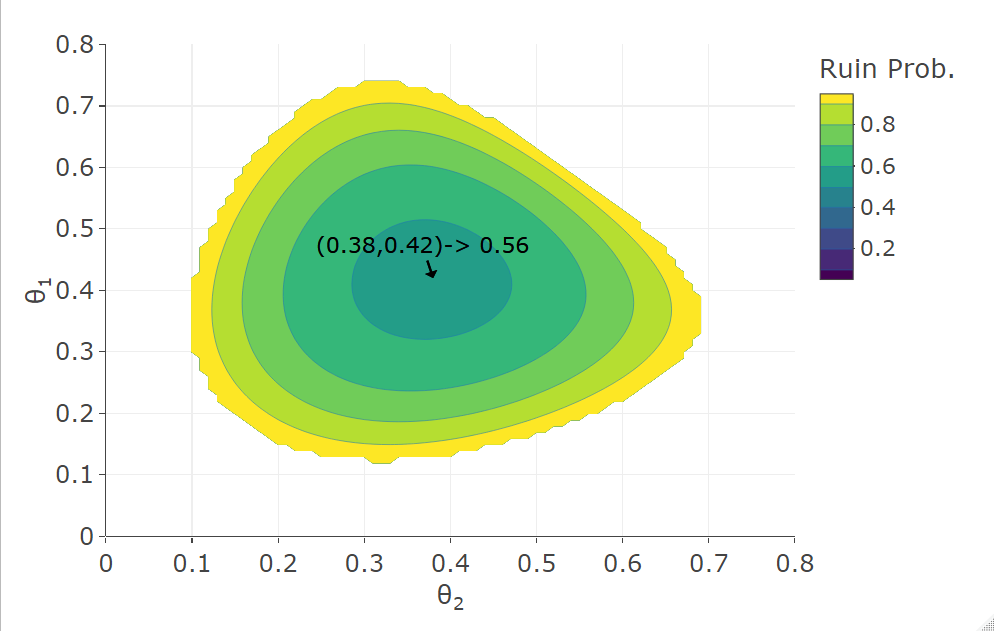
Figure 5 shows the expected profit (left) and the ruin probability (right), when and are assumed to be independent and aggregated, as a function of the security loading parameters, and . The surplus is fixed at and the optimal values are shown. It should be noted that many surplus values were tested and they all gave the same value for , , , and as shown, only the ruin probability level changed. Note that the optimal loading parameters for the expected profit are the same as those for the individual surplus processes. However, the optimal loading parameters for the ruin probability change when compared to the individual one (compare it with Figures 1 and 2). When compared to the optimal loading parameter for the individual surplus process, decreases from to and increases from 0.358 to 0.38. Therefore, the optimal security loading parameter decision is to decrease the loading parameter of the less sensitive surplus process while increasing the loading parameter of the more sensitive surplus process. Additionally, when compared to Figure 4, the minimum ruin probability for one shared loading is while the ruin for two loadings is , showing only a marginal difference. When the same is done for other surplus values a similar difference is found. The expected profit is marginally higher.
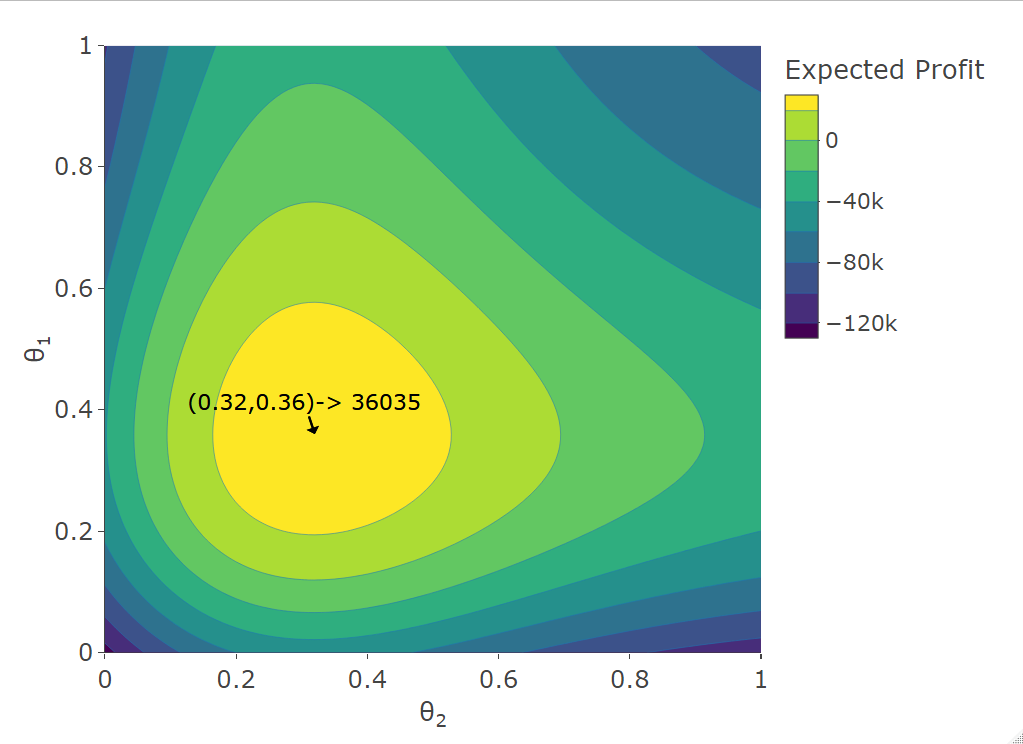
Lastly, consider the case when the surplus processes are assumed to be dependent via Lévy Clayton copula and the loadings can be different for each surplus process separately. Figure 6 shows the ruin probability when and are aggregated as a function of the security loading parameters, and . The shape of the contour plots is due to the fact that the grid considered is sparser for values that give high ruin probability. The surplus is fixed at .
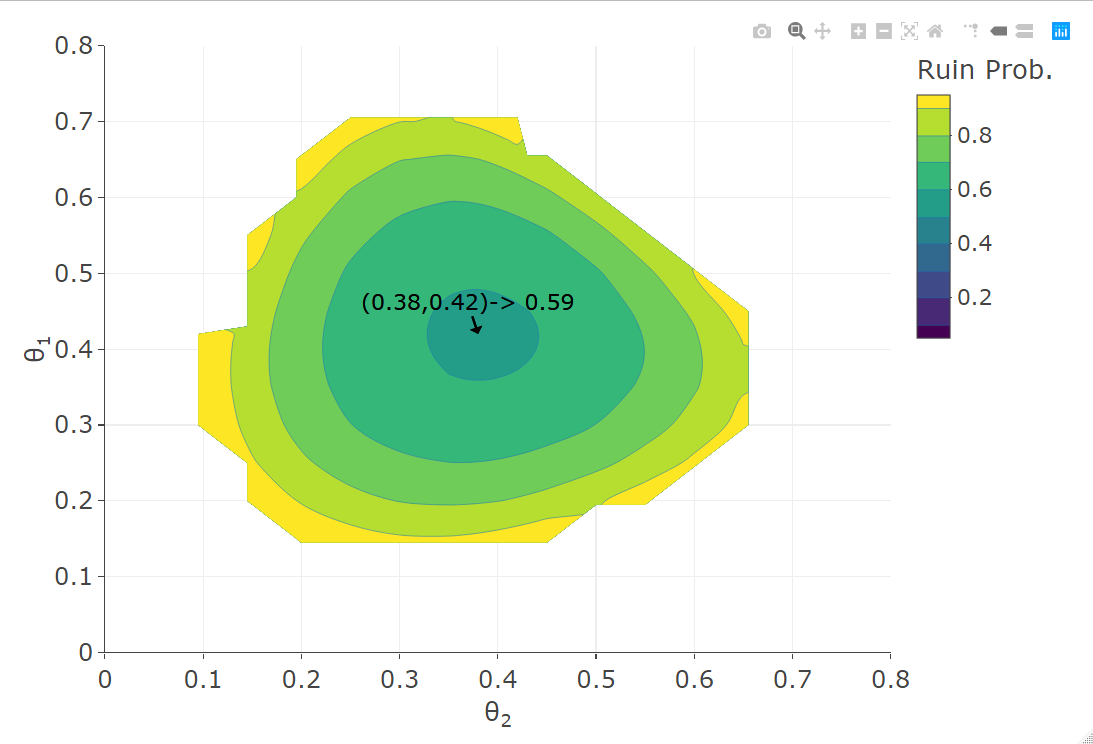
It can be seen that the optimal loadings and are the same as the ones in the case of independence and the minimum ruin probability is higher (compared to the case in Figure 5). Both the values and the optimal loadings of the expected profit are the same as the independent case.
Again, the optimal security loading parameter decision is to decrease the loading parameter of the less sensitive surplus process while increasing the loading parameter of the more sensitive surplus process. The difference between the ruin probability in Figure 6 vs Figure 5 is only but in this case the surplus is low compared to the expected profit. If the surplus would be increased to the difference would become greater. The difference would then decrease again if the surplus were increased to .
Additionally, when compared to Figure 4, the minimum ruin probability for one common loading is , which is the same as the ruin probability for separate loading selections, therefore the difference is only marginal.
5.3 Dependent Claims and Dependent Acquisition
It is time to look at the case when we have dependent claims and dependent acquisition. Note that the case when we have independent claims and dependent acquisition is the same as the total independence case. We will look both at the case when the acquisition is modelled with a Gumbel and Clayton dependency structure. To compare these two structures we use Kendell’s tau. The following equations relate the copula parameters, and to kendell’s tau, .
We know that the expected profit is the same as before for all values of . Therefore, we analyze the ruin probability.
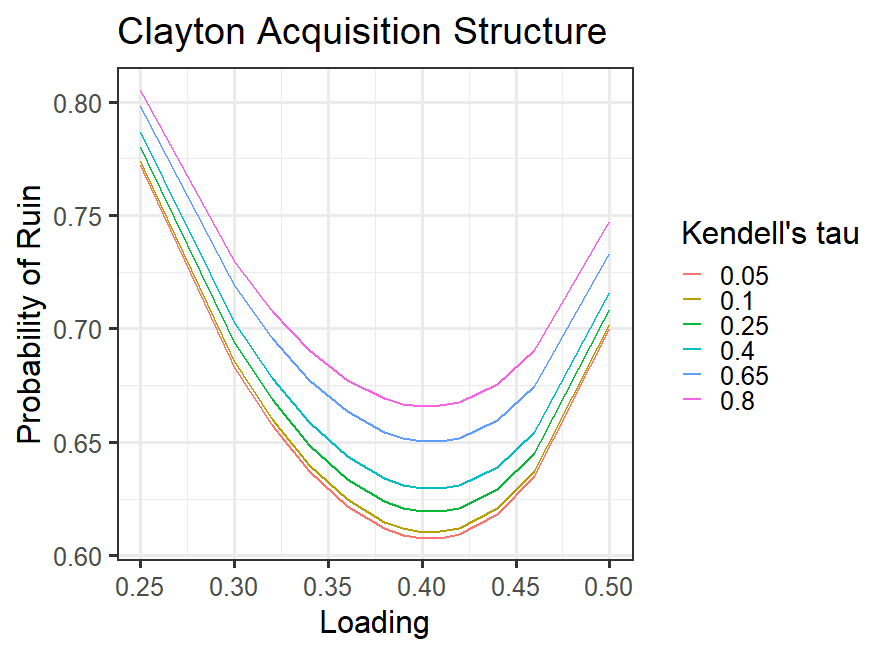
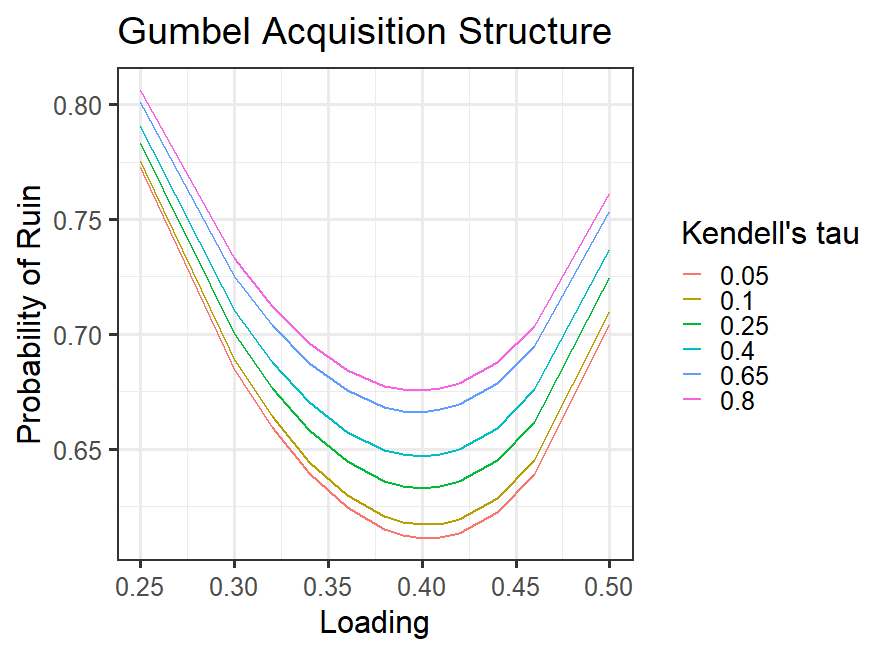
In Figure 7 we can see the ruin probability for different dependency values when the surplus is fixed at 5000 units. We can see that the ruin probability is higher for more dependent acquisition, as we expected. Also, we can see that the Gumbel acquisition model gives higher ruin probabilities than the Clayton model for the same Kendell’s tau value. They give the same optimal loading parameter. It can also be seen that when kendell’s tau is (close to ) the ruin probability is close to the case of independent acquisition, as expected. The optimal loading parameter is the same for all dependency levels.
Appendix A Numerical scheme for equation 2.2, using linear approximation
Consider the process
where are iid continuous random variables and is a . To approximate equation 2.2, take a grid of points , , with equal interval lengths, . A linear approximation is used to approximate
where is an approximation of the derivative, , using the so-called forward difference
Let denote the approximation of . Let and . For each solve the following equation
The goal is to develop a recursive method from as the value of is known.
Set
Calculate
Calculate
Acknowledgements
The second and third authors acknowledge financial support from FCT – Fundação para a Ciência e Tecnologia (Portugal), national funding, through research grant UIDB/05069/2020.
References
- [1] Benjamin Avanzi, Luke C. Cassar, and Bernard Wong. Modelling dependence in insurance claims processes with lévy copulas. ASTIN Bulletin, 41(2):575–609, 2011.
- [2] Frank Barning. Counting processes and copulas: Applications in insurance. Master’s thesis, Université du Québec à Montréal, 2018.
- [3] Fred Espen Benth, Valery A Kholodnyi, and Peter Laurence. Quantitative energy finance. In Modelling, pricing, and hedging in energy and commodity markets. Springer, 2014.
- [4] Stephen Britt and Albert Napoli. Linear correlation as a measure of dependency. In XVth General Insurance Seminar, Institute of Actuaries of Australia, 2005.
- [5] Nicole Bäuerle and Anja Blatter. Optimal control and dependence modeling of insurance portfolios with lévy dynamics. Insurance: Mathematics and Economics, 48(3):398–405, 2011.
- [6] Hans Bühlmann. Premium calculation from top down. Astin Bulletin - ASTIN BULL, 15:89–101, 11 1985.
- [7] Antonella Campana, Paola Ferretti, et al. Distortion risk measures and discrete risks. Technical report, 2005.
- [8] R Cont and P Tankov. Financial Modelling with Jump Processes. Chapman & Hall/CRC, 2004.
- [9] Michel Denuit, Xavier Maréchal, Sandra Pitrebois, and Jean-François Walhin. Actuarial modelling of claim counts: Risk classification, credibility and bonus-malus systems. John Wiley & Sons, 2007.
- [10] Sever S Dragomir. Some Gronwall type inequalities and applications. Nova Science, 2003.
- [11] Jan Grandell. Aspects of risk theory. Springer Science & Business Media, 2012.
- [12] Patrik Hardin and Sam Tabari. Modelling non-life insurance policyholder price sensitivity: A statistical analysis performed with logistic regression, 2017.
- [13] Christian Hipp. Stochastic control with application in insurance. In Stochastic methods in finance, pages 127–164. Springer, 2004.
- [14] Christian Hipp and Michael Plum. Optimal investment for insurers. Insurance: Mathematics and Economics, 27(2):215–228, 2000.
- [15] Rob Kaas, Marc Goovaerts, Jan Dhaene, and Michel Denuit. Modern actuarial risk theory: using R, volume 128. Springer Science & Business Media, 2008.
- [16] Yehuda Kahane. The theory of insurance risk premiums—a re-examination in the light of recent developments in capital market theory. ASTIN Bulletin: The Journal of the IAA, 10(2):223–239, 1979.
- [17] Hilbert J Kappen. An introduction to stochastic control theory, path integrals and reinforcement learning. In AIP conference proceedings, volume 887, pages 149–181. American Institute of Physics, 2007.
- [18] Christian Kasumo, Juma Kasozi, and Dmitry Kuznetsov. On minimizing the ultimate ruin probability of an insurer by reinsurance. Journal of Applied Mathematics, 2018, 2018.
- [19] Paul C Kettler. Lévy-copula-driven financial processes. Preprint series. Pure mathematics http://urn. nb. no/URN: NBN: no-8076, 2006.
- [20] Doron Kliger and Benny Levikson. Pricing insurance contracts—an economic viewpoint. Insurance: Mathematics and Economics, 22(3):243–249, 1998.
- [21] Stuart A Klugman, Harry H Panjer, and Gordon E Willmot. Loss models: from data to decisions, volume 715. John Wiley & Sons, 2012.
- [22] Elena Krasheninnikova, Javier García, Roberto Maestre, and Fernando Fernández. Reinforcement learning for pricing strategy optimization in the insurance industry. Engineering Applications of Artificial Intelligence, 80:8–19, 2019.
- [23] Hanson Li and Ruodu Wang. Pelve: Probability equivalent level of var and es. Available at SSRN, 2019.
- [24] Ronnie Loeffen, Irmina Czarna, Zbigniew Palmowski, et al. Parisian ruin probability for spectrally negative lévy processes. Bernoulli, 19(2):599–609, 2013.
- [25] Roger B Nelsen. An introduction to copulas. Springer Science & Business Media, 2007.
- [26] Esbjörn Ohlsson and Björn Johansson. Non-life insurance pricing with generalized linear models, volume 2. Springer, 2010.
- [27] Antonis Papapantoleon. An introduction to lévy processes with applications in finance, 2008.
- [28] Ken-Iti Sato. Lévy processes and infinitely divisible distributions. Cambridge university press, 1999.
- [29] Timothy Sauer. Numerical Analysis. Pearson, 2013.
- [30] Daniel Yannik Straumann. Correlation and dependency in risk management: properties and pitfalls. In Risk Management: Value at Risk and Beyond. Cambridge University Press, 2001.
- [31] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- [32] Peter Tankov. Lévy copulas: review of recent results. In The fascination of probability, statistics and their applications, pages 127–151. Springer, 2016.
- [33] Julien Trufin, Hansjoerg Albrecher, and Michel M Denuit. Properties of a risk measure derived from ruin theory. The Geneva Risk and Insurance Review, 36(2):174–188, 2011.
- [34] J. L. van Velsen. Parameter estimation of a lévy copula of a discretely observed bivariate compound poisson process with an application to operational risk modelling, 2012.
- [35] Mario V Wuthrich. Non-life insurance: mathematics & statistics. Available at SSRN 2319328, 2019.
- [36] Ji Yao. Generalized linear models for non-life pricing-overlooked facts and implications. Institute and Faculty of Actuaries, 2013.
- [37] Yuqing Zhang and Neil Walton. Adaptive pricing in insurance: Generalized linear models and gaussian process regression approaches. arXiv preprint arXiv:1907.05381, 2019.