ifaamas \acmConference[AAMAS ’21]Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021)May 3–7, 2021OnlineU. Endriss, A. Nowé, F. Dignum, A. Lomuscio (eds.) \copyrightyear2021 \acmYear2021 \acmDOI \acmPrice \acmISBN \acmSubmissionID667 \affiliation \institutionInstitute of Informatics - Federal University of Rio Grande do Sul \cityPorto Alegre, RS - Brazil \affiliation \institutionInstitute of Informatics - Federal University of Rio Grande do Sul \cityPorto Alegre, RS - Brazil \affiliation \institutionCICS - University of Massachusetts \cityAmherst, MA
Minimum-Delay Adaptation in Non-Stationary Reinforcement Learning via Online High-Confidence Change-Point Detection
Abstract.
Non-stationary environments are challenging for reinforcement learning algorithms. If the state transition and/or reward functions change based on latent factors, the agent is effectively tasked with optimizing a behavior that maximizes performance over a possibly infinite random sequence of Markov Decision Processes (MDPs), each of which drawn from some unknown distribution. We call each such MDP a context. Most related works make strong assumptions such as knowledge about the distribution over contexts, the existence of pre-training phases, or a priori knowledge about the number, sequence, or boundaries between contexts. We introduce an algorithm that efficiently learns policies in non-stationary environments. It analyzes a possibly infinite stream of data and computes, in real-time, high-confidence change-point detection statistics that reflect whether novel, specialized policies need to be created and deployed to tackle novel contexts, or whether previously-optimized ones might be reused. We show that (i) this algorithm minimizes the delay until unforeseen changes to a context are detected, thereby allowing for rapid responses; and (ii) it bounds the rate of false alarm, which is important in order to minimize regret. Our method constructs a mixture model composed of a (possibly infinite) ensemble of probabilistic dynamics predictors that model the different modes of the distribution over underlying latent MDPs. We evaluate our algorithm on high-dimensional continuous reinforcement learning problems and show that it outperforms state-of-the-art (model-free and model-based) RL algorithms, as well as state-of-the-art meta-learning methods specially designed to deal with non-stationarity.
Key words and phrases:
Reinforcement Learning; Non-stationarity; Model-based RL; Change-Point Detection1. Introduction
Reinforcement learning (RL) techniques have been successfully applied to solve high-dimensional sequential decision problems. However, if the state transition and/or reward functions change unexpectedly, according to latent factors unobservable to the agent, the system is effectively tasked with optimizing behavior policies that maximize performance over a (possibly infinite) random sequence of Markov Decision Processes (MDPs). Each MDP is drawn from an unknown distribution and is henceforth referred to as a context. This is known as a non-stationary setting. Designing efficient algorithms to tackle this problem is a known challenge in RL Padakandla (2020). The key difficulties here result from (i) the need to quickly and reliably detect when the underlying system dynamics has changed; and (ii) the need to effectively learn and deploy adaptable prediction models and policies, specialized in particular contexts, while allowing the agent to (when appropriate) reuse previously-acquired knowledge. Non-stationary environments often result from systems whose dynamics are inherently time-dependent; from agents that are tasked with learning policies under noisy or missing sensors; or from problems where the agent faces sequences of unlabeled/unidentified tasks, each one with its own transition dynamics and reward functions.
Non-stationary settings arise naturally in many situations. Humans, for instance, are capable of learning to solve sequences of tasks from few experiences while preserving knowledge from older experiences Lake et al. (2015). Consider, for example, a person realizing the need to adapt their gait after an accident, learning novel gait patterns to use when walking with crutches, and then, after a period of recovery, successfully re-deploying normal walking gaits. This corresponds to a non-stationary scenario where the agent needs to learn specialized dynamics models and policies for tackling different contexts/learning scenarios.
We introduce an algorithm that efficiently learns decision-making strategies in this setting. It assumes that an agent experiences random sequences of contexts (MDPs) drawn from some unknown distribution, and it is capable of optimizing behaviors even when a pre-training phase (during which the agent interacts with sample contexts) is not available. The agent’s goal is to rapidly deploy policies that are appropriate for each randomly-arriving context—even when the number of latent contexts is unknown and when the context distribution cannot be modeled nor controlled by the agent. We are particularly interested in the case where quick readaptation and sample efficiency are paramount to achieving good performance; for instance, in novel contexts where collecting experiences and acquiring policies from scratch is unfeasible.
Many existing related works tackle non-stationary problems either by detecting when the underlying MDP changes, or via meta-learning approaches that construct a prior model (or policy) capable of rapidly generalizing to novel contexts. Hadoux et al., for example, introduced a technique based on change-point detection algorithms to deal with non-stationary problems with discrete state spaces Hadoux et al. (2014); Banerjee et al. (2017). We, by contrast, address the more general setting of high-dimensional continuous RL problems. Supervised meta-learning algorithms Finn et al. (2017) have also been recently combined with RL to enable fast adaptation under changing domains Nagabandi et al. (2019a); Nagabandi et al. (2019b). Nagabandi et al. introduced a model-based algorithm where a meta-learning technique is used to construct dynamics models capable of rapidly adapting to recent experiences—either by updating the hidden state of a recurrent neural network Duan et al. (2016), or by updating the model parameters via a small number of gradient steps Finn et al. (2017). Meta-learning methods typically assume disjoint training and testing phases, so that an agent can be pre-trained over randomly sampled contexts prior to its deployment. We, however, do not require a pre-training phase. Meta-learning methods also typically assume that the distribution over contexts experienced during training is the same as the one experienced during testing, so that agents can adapt to novel environments with structural similarities to those previously experienced. We, by contrast, do not require that contexts are sampled from a previously-seen distribution, nor that contexts share structural similarities with previously-experienced ones.
To address these limitations, we introduce an algorithm that analyzes a possibly infinite stream of data and computes, in real-time, high-confidence change-point detection statistics that reflect whether novel, specialized policies need to be deployed to tackle new contexts, or whether a previously-optimized policy may be reused. We call our algorithm Model-Based RL Context Detection, or MBCD. We formally show that it minimizes the delay until unforeseen changes to a context are detected, thereby allowing for rapid responses, and that it allows for formal bounds on the rate of false alarm—which is of interest when minimizing the agent’s regret over random sequences of contexts. Our method constructs a mixture model composed of a (possibly infinite) ensemble of probabilistic dynamics predictors that model the different modes of the distribution over underlying latent MDPs. Our method is capable of optimizing policies based on streams of arbitrarily different contexts, with unknown boundaries, and which may be drawn from an arbitrary, unknown distribution.
We evaluate our algorithm on high-dimensional continuous reinforcement learning tasks and empirically show (i) that state-of-the-art reinforcement learning algorithms struggle to deal with non-stationarity; and (ii) that our method outperforms state-of-the-art meta-learning methods specifically tailored to deal with non-stationary environments—in particular, when the agent is faced with MDPs that are off-distribution with respect to the set of training contexts provided to the agent, or when novel contexts are structurally different from previously-observed ones.
2. Problem Formulation
We define a non-stationary environment as a family of MDPs . Each MDP is a tuple , where is a (possibly continuous) state space, is a (possibly continuous) action space, is a transition function specifying the distribution over next states, given the current state and action, is a reward function, is the discount factor, and is an initial state distribution. In what follows, , , and are the random variables corresponding to the state, action, and reward at time step . We assume that the agent observes a random sequence of MDPs—called contexts—drawn independently from some unknown distribution. We assume that the number of contexts, , is unknown. These definitions are similar to those discussed in Banerjee et al. (2017) and Padakandla (2020). Let be a latent index variable indicating a particular MDP, . We assume that each MDP’s transition and reward function are parameterized by a latent vector . Let denote the joint conditional probability distribution over next-state and reward associated with MDP . We do not impose any smoothness assumptions on how variations to affect and : contexts may be arbitrarily different and share no structural similarities.
Let the time steps in which context changes occur be an increasing sequence of integer random variables, , for which a prior is unknown or cannot be defined. We call each a change-point. At every change-point , the current context is replaced by a new randomly drawn MDP. To perform well, an agent must rapidly detect context changes and deploy an appropriate policy. If a new random context differs significantly from previously-experienced ones, the agent may have to learn a policy from scratch; otherwise, it may choose to reuse previously-acquired knowledge to accelerate learning and avoid catastrophic forgetting.
At each time , when interacting with its environment, the agent selects an action based on its state according to a stochastic policy . Let be the value function associated with policy , MDP , and defined over a horizon :
| (1) |
To simplify our analysis, we first consider (without loss of generality) the simpler case of a family of MPDs , where a context change occurs from to at some unobserved random time . The mathematical arguments that follow can be extended to the more general setting with an arbitrary number of contexts. Let be a policy that follows the optimal policy for , , before , and the optimal policy for , , afterwards. This policy’s value function is defined as:
| (2) |
where denotes the distribution of states reachable after following policy for steps under MDP . Notice that Eq. 2 models the case when starts in the (random) state where terminated, that is, immediately prior to the random time . This implies that .
By contrast, consider an alternative policy that follows policy only after a random time , for ; that is, a policy that deploys the correct decision-making strategy for with a delay of steps. Its value function is given by:
| (3) |
Notice that we can rewrite Eq. 2 in the same form as Eq. 3:
| (4) |
We now define the regret as the expected discounted sum of rewards lost due to the delay , when changing from to only at time step . This quantity is given by the difference between Eq. 3 and Eq. 4. Since we are interested in minimizing the delay , we assume the adversarial case when policies and do, in the short-term (i.e., within the delay window ), have a nearly indistinguishable distribution over the states that are reachable in steps. In particular, we assume that the KL divergence between and is bounded and small for small values of . In this case, the regret can be approximated by111This definition can be extended in a straightforward way to the case where there is a sequence of random change-points, . In particular, the regret will be defined in terms not of a single random delay, but of a sequence of random delays associated with the corresponding random contexts that are observed by the agent.:
| (5) |
as . From Eq. 5, it should be clear that to maximize the expected return over the random sequence of MDPs, one needs to minimize regret; and to minimize regret, one needs to minimize the random delay . In the next section, we introduce a method capable of minimizing the worst-case delay until unforeseen changes to a stochastic process are detected, while also bounding the rate of false alarm—i.e., the likelihood that the method will incorrectly indicate that a context change occurred.
3. High-Confidence Change-Point Detection
Change-point detection (CPD) algorithms Aminikhanghahi and Cook (2016); Veeravalli and Banerjee (2012) are designed to detect whether (and when) a change occurs in the distribution generating random observations from an arbitrary stochastic process. These methods have been widely used in a variety of fields—from financial markets Lam and Yam (1997) to biomedical signal processing Sibanda and Sibanda (2007). Although CPDs have been applied to reinforcement learning problems Banerjee et al. (2017); Hadoux et al. (2014), the application and formal analysis of such methods have been restricted to discrete state spaces settings.
In the online CPD setting, a sequential detection procedure is defined to rapidly and reliably estimate when the parameter of some underlying distribution or stochastic process has changed. Online CPD algorithms should produce high-confidence estimates, , of the true change-point time, . Notice that is a random variable whose stochasticity results from the unknown stochastic prior over context changes, , and from the fact that each MDP in produces random trajectories of states, actions, and rewards.
Suppose that at each time , while the agent interacts with , sample next-state and rewards are drawn from , where is the latent vector parameterizing ’s transition and reward functions. At some unknown random change-point , the context changes to , and experiences that follow are drawn from . We propose to identify such a change by computing high-confidence statistics that reflect whether has changed. This can be achieved by introducing a minimax formulation of the CPD problem, as discussed by Pollak Pollak (1985). In this formulation, the goal of a CPD algorithm is to compute a random estimate, , of the latent change-point time , such that (i) it minimizes the worst-case expected detection delay, , associated with the random estimates produced by a particular CPD algorithm, when considering all possible change-points ; and (ii) bounds on the maximum false alarm rate (FAR) may be imposed. The worst-case expected detection delay, , and the FAR, are defined as:
| (6) |
| (7) |
where the expectations in Eq. 6 and Eq. 7 are over the possible histories of experiences produced by the stochastic process, and where conditioning on indicates the random event where the context never changes. Given these definitions, the objective of a high-confidence change-point detection process is the following:
| (8) |
where denotes the desired upper-bound on the false alarm rate.
When and are known, the Log-Likelihood Ratio (LLR) statistic can be used to recursively compute the CUSUM statistic Page (1954). As we will discuss next, such a statistic can be used to construct a high-confidence change-point detection method. The LLR statistic, , and the CUSUM statistic, , are updated at each time as follows:
| (9) |
| (10) |
Importantly, notice that before the change-point is reached, , which implies that the expected value of is zero. After the change-point is reached, , and therefore will tend to increase. Higher values of , thus, serve as principled statistics reflecting evidence that a change-point has occurred between to . The random time when a change-point is estimated to have happened is defined as the first time when the CUSUM metric becomes greater than a detection threshold :
| (11) |
In Lorden (1971), Lorden shows that choosing ensures that . Furthermore, Lai demonstrated that the CUSUM detection time is asymptotically optimum Lai (1998) with respect to the problem specified in Eq. 6. In particular, they showed that the worst expected detection delay (under ) respects the following approximation:
| (12) |
In Eq. 12, the denominator is the Kullback–Leibler divergence under . Eq. 12 implies that the larger the difference between the distributions and , the smaller the expected delay () for detecting a change-point. The above results allow us to construct high-confidence statistics reflecting whether (and when) a context has changed; importantly, they are both accurate and have bounded false alarm rate.
4. Model-Based RL Context Detection
In this section, we introduce an algorithm that iteratively applies a CUSUM-related procedure to detect context changes under the assumptions discussed in Section 2. The algorithm incrementally builds a library of models and policies for tackling arbitrarily different types of contexts; i.e., contexts that may result from quantitatively and qualitatively different underlying causes for non-stationarity—ranging from unpredictable environmental changes (such as random wind) to robot malfunctions. Our method can rapidly deploy previously-constructed policies whenever contexts approximately re-occur, or learn new decision-making strategies whenever novel contexts, with no structural similarities with respect to previously-observed ones, are first encountered. Unlike existing approaches (see Section 6), our method is capable of (i) optimizing policies online; (ii) without requiring a pre-training phase; (iii) based on streams of arbitrarily different contexts, with unknown change-point boundaries; and (iv) such that contexts may be drawn from an arbitrary, unknown distribution.
We now introduce a high-level description of our method (Model-Based RL Context Detection, or MBCD). In subsequent subsections, we provide details for each of the method’s components. As the agent interacts with a non-stationary environment, context changes are identified via a multivariate variant of CUSUM Healy (1987), called MCUSUM. MCUSUM-based statistics inherit the same formal properties as those presented in Section 3. In particular, they formally guarantee that MBCD can detect context changes with minimum expected delay, while simultaneously bounding the false alarm rate. As a consequence, MBCD can effectively identify novel environmental dynamics while ensuring, with high probability, that new context-specific policies will only be constructed when necessary.
As new contexts are identified by this procedure, MBCD updates a mixture model, , composed of a (possibly infinite) ensemble of probabilistic context dynamics predictors, whose purpose is to model the different modes of the distribution over underlying latent MDPs/contexts. New models are added to the ensemble as qualitatively different contexts are first encountered. The mixture model associates, with each identified context , a learned joint distribution over next-state dynamics and rewards associated. Let be the number of context models currently in the mixture. After each agent experience, MBCD identifies the most likely context, , by analyzing a set of incrementally-estimated MCUSUM statistics (see Section 4.2). Whenever a novel context—one with dynamics that are qualitatively different from those previously-experienced—is observed, a new model is added to the mixture. Context-specific policies, , are trained via a Dyna-style approach Sutton (1990) based on the corresponding learned joint prediction model of , (see Section 4.3). We provide details in the next subsections. Pseudocode for MBCD is shown in Algorithm 1.
4.1. Stochastic Mixture Model of Dynamics
In this paper, we assume that , the joint distribution over next-state dynamics and rewards associated with context , can be approximated by a multivariate Gaussian distribution. In particular, following recent work on model-based RL Janner et al. (2019); Chua et al. (2018), MBCD models the dynamics of a given environment , , via a bootstrap ensemble of probabilistic neural networks whose outputs parameterize a multivariate Gaussian distribution with diagonal covariance matrix. The bootstrapping procedure accounts for epistemic uncertainty (i.e. uncertainty about model parameters), which is crucial when making predictions about the agent’s dynamics in regions of the state space where experiences are scarce. For each context identified by MBCD, an ensemble of stochastic neural networks is instantiated and added to the mixture model . Each network in the ensemble is parameterized by and computes a probability distribution, , that approximates by predicting the mean and covariance over next-state and rewards conditioned on the current state and action:
| (13) |
where and are the network outputs given input . To simplify notation, let and . We follow Lakshminarayanan et al. Lakshminarayanan et al. (2017) and model the ensemble prediction as a Gaussian distribution whose mean and covariance are computed based on the mean and covariances of each component of the ensemble. In particular, the ensemble predictive model, , associated with a given context , is defined as:
| (14) |
where
| (15) | |||
| (16) |
MBCD stores all experiences collected while in context in a buffer . After every steps, it uses data in to update the ensemble model by minimizing the negative log prediction likelihood loss function, .
4.2. Online Context Change-Point Detection
As previously discussed, MBCD employs a multivariate variant of CUSUM, MCUSUM, to detect context changes with high confidence. Healy demonstrated that, when detecting shifts in the mean of a multivariate Gaussian distribution, MCUSUM inherits all theoretical optimality guarantees possessed by the univariate CUSUM procedure Healy (1987). Furthermore, he also proved that the detection delay is independent of the dimensionality of the data.
In the particular case where the dynamics of each context are modeled as multivariate Gaussians, the LLR statistic can be computed as follows. To simplify notation, let and . It is then possible to show that the LLR statistic, , between distributions and , is given by:
| (17) |
where is the dimensionality of the multivariate Gaussian. At each time step , MBCD uses to compute MCUSUM statistics for each known context , plus an additional statistic , used to infer, with high probability, whether a novel context has been first encountered:
| (18) |
Here, can be seen as evidence that a previously-unseen context has been first encountered, based on whether the likelihood of all known contexts is smaller than , where
| (19) |
and
| (20) |
Intuitively, indicates whether none of the known contexts is likely to have generated the observed transitions. In Eq. 19, is the likelihood of a new context under the alternative hypothesis that the true observation is standard deviations away from the true observation . In particular, indicates the minimum meaningful change in the distribution’s mean that we are interested in detecting. Given updated statistics , the most likely current context, (which may or may not have changed) can then be identified as:
| (21) |
If no alternative contexts are more likely to have generated the observations collected up to time , no context change is detected and .
Notice that in Eq. 18, models are assumed to be known a priori. In our setting, these models are estimated based on samples. MCUSUM has been studied in scenarios where the parameters of the distribution are known only approximately Mahmoud and Maravelakis (2013). In our work, we address this challenge by computing change-point detection statistics only after a small warm-up period within which the agent is allowed to operate in a given context. In particular, and similarly to Sekar et al. Sekar et al. (2020), we define the warm-up period by using ensemble disagreement as a proxy to quantify the system’s uncertainty regarding the current distributions. Assuming a warm-up period where the agent is allowed to operate within each newly-encountered context is a common assumption in the area Nagabandi et al. (2019a); Nagabandi et al. (2019b); Rakelly et al. (2019). In fact, it is a necessary assumption: if contexts are allowed to change arbitrarily fast, adversarial settings can be constructed where all methods for dealing with non-stationary scenarios fail.
Finally, notice that a key element of Eq. 21 is the threshold , against which each is compared in order to check if a context change has occurred. Different methods have been proposed to set Sahki et al. (2020). Here, we take a conservative approach. As discussed in Section 3, setting ensures that . In this work, we set by considering negligible values of ; e.g. if . In our experiments, we observed that detection delays remain low even for very conservative values of .
4.3. Policy Optimization
Since MBCD estimates dynamics models for each context, it is natural to exploit such models to accelerate policy learning by deploying model-based RL algorithms. MBCD learns context-specific policies via a Dyna-style approach Sutton (1990). In particular, at every time step during which the model is trained, 1-step simulated rollouts are sampled using . Each rollout starts from a random state drawn from . All rollouts are stored in a buffer, .222Notice that, in Algorithm 1, is cleared every time a context change is detected in order to avoid negative transfer from experiences drawn from previous contexts. Notice that this is similar to the procedure used by the Model-Based Policy Optimization (MBPO) algorithm Janner et al. (2019). Each context-specific policy is optimized by taking into account both real experiences (stored in ) and simulated experiences (stored in ). Policy optimization is performed using the Soft Actor-Critic (SAC) algorithm Haarnoja et al. (2018). SAC alternates between a policy evaluation step, which estimates using the Bellman backup operator, and a policy improvement step, which optimizes the policy by minimizing the expected KL-divergence between the current policy and the exponential of a soft Q-function Haarnoja et al. (2018). Optimizing the policy, then, corresponds to minimizing the following loss function:
| (22) |
5. Experiments
We evaluate MBCD in challenging continuous-state, continuous-action non-stationary environments, where the non-stationarity may result from qualitatively different reasons—ranging from abrupt changes to the system’s dynamics (such as changes to the configuration of the agent’s workspace); external latent environmental factors that impact the distribution over next states (such as random wind); robot malfunctions; and changes to the agent’s goals (its reward function). We compare MBCD both against state-of-the-art RL algorithms and against state-of-the-art meta-learning methods specifically tailored to deal with non-stationary environments.
We investigate the performance of MBCD in two settings: (i) a setting that satisfies all standard requirements made by meta-learning algorithms; in particular, that all contexts in are structurally similar, and that the agent is tested on a distribution of contexts that matches the training distribution; and (ii) a more general setting where such requirements are not be satisfied: contexts may differ arbitrarily, and future contexts experienced by the agent may be off-distribution with respect to those sampled during the training phase. We show that our method outperforms both standard state-of-the-art RL algorithms and also specialized meta-learning algorithms in both settings.
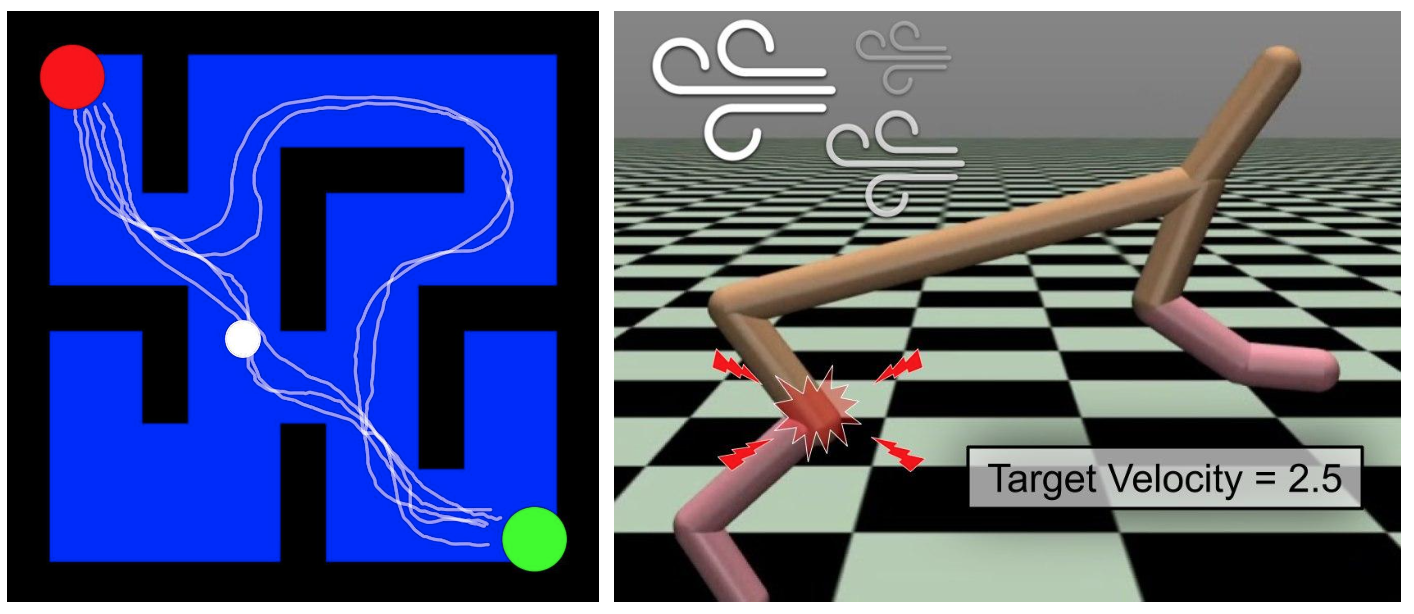
In what follows, we evaluate MBCD in two domains with qualitatively different non-stationary characteristics (see Fig. 1):
Non-Stationary Continuous Particle Maze
This domain simulates a family of two-dimensional continuous mazes where a particle must reach a non-observable goal location. The reward function corresponds to the Euclidean distance between the particle and the goal location. Non-stationarity is introduced by either changing the location of walls or by randomly changing the latent goal location.
Half-Cheetah in a Non-Stationary World
This domain consists of a simulation of the high-dimensional Half-Cheetah robot Todorov et al. (2012). The agent’s goal is to move forward while reaching a particular target-velocity and minimizing control costs. We introduce three sources of non-stationarity:
-
(1)
random wind: an external latent horizontal force, opposite to the agent’s movement direction, is applied;
-
(2)
joint malfunction: either the torque applied to a joint of the robot has its polarity/sign changed; or a joint is randomly disabled;
-
(3)
target velocity: the target velocity of the robot is sampled from the interval 1.5 to 2.5, causing a non-stationary change to the agent’s reward function.
 \Description
\Description
(a) Non-Stationary Continuous Particle Maze; (b) Half-Cheetah in a Non-Stationary World.
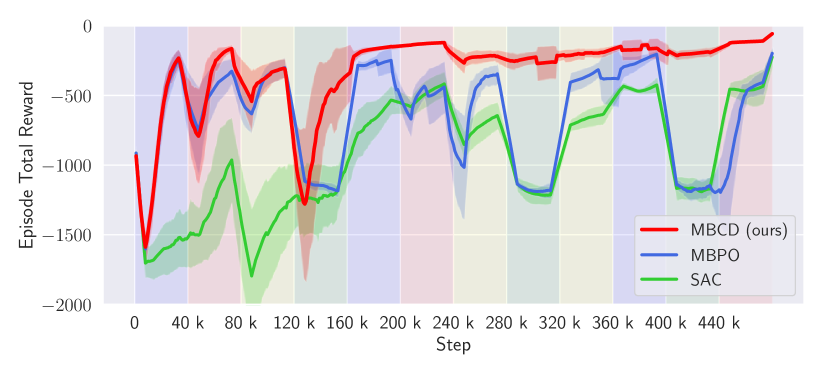
Total reward achieved by different methods (MBCD, MBPO, and SAC) as contexts change.
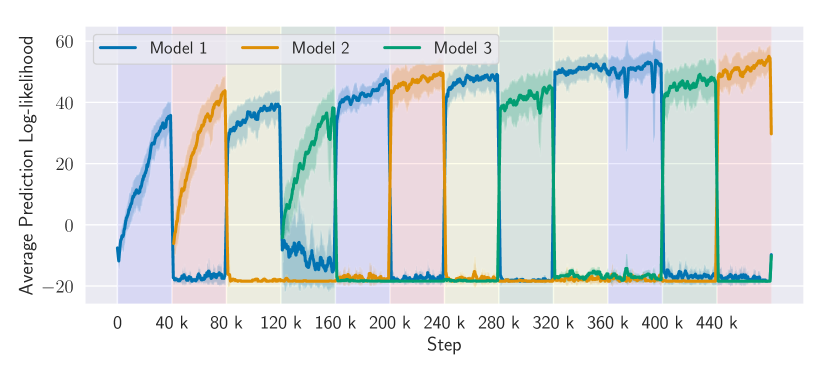
Log-likelihood of the predictions made by each context model learned by MBCD as contexts change.
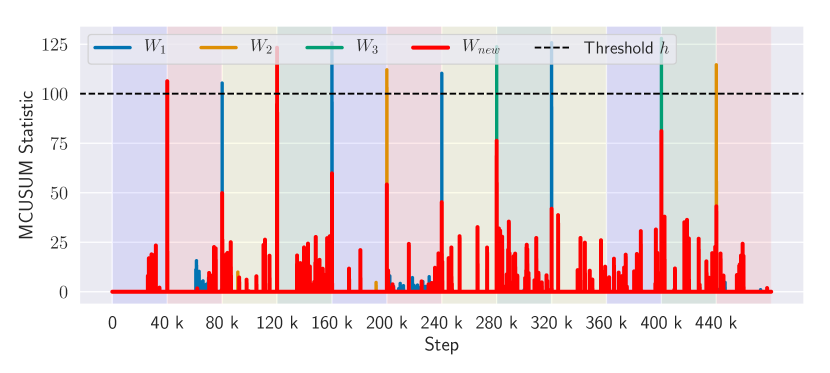
Time evolution, as contexts change, of the MCUSUM statistics, , for each model . A context change is detected online whenever one of the statistics crosses the threshold .
Evaluation of MBCD on the non-stationary Half-Cheetah domain. Colored shaded areas represent different contexts: (blue) default context; (red) joint malfunction; (yellow) wind; (green) novel target velocity.
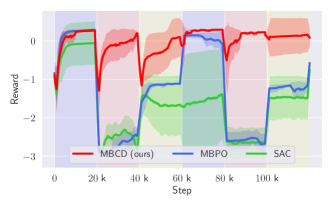
We first evaluate our method on the non-stationary Half-Cheetah domain and compare it with two state-of-the-art RL algorithms: MBPO Janner et al. (2019) and SAC Haarnoja et al. (2018). In our setting, MBPO can be seen as a particular case of our algorithm, where a single dynamics model and policy are tasked with optimizing behavior under changing contexts. SAC works similarly to MBPO but does not perform Dyna-style planning steps using a learned dynamics model.
Fig. 2(a) shows the total reward achieved by different methods (ours, MBPO, SAC) as contexts change. Colored shaded areas depict different contexts, as discussed in the figure’s caption. Notice that our method and MBPO have similar performances when interacting for the first time with the first three random contexts. In particular, both MBCD and MBPO’s performances temporarily drop when a novel context is encountered for the first time. MBCD’s performance drops because it instantiates a new dynamics model for the newly encountered context, while MBPO’s performance drops because it undergoes negative transfer. SAC, which is model-free, never manages to achieve reasonable performance during the duration of each context, due to sample inefficiency. However, as the agent encounters contexts with structural similarities with respect to previously-encounters ones (around time step 160k), MBCD’s performance becomes near-optimal: it rapidly identifies whenever a context change has occurred and deploys an appropriate policy.333Notice that MBCD modeled the wind context (yellow area) using the same model as the default context (blue area). This is because wind did not introduce a significant change to the MDPs state transition function. Consequently, MBCD automatically inferred that a single policy could perform well in both contexts and operated without significant reward loss in the long term—see, e.g., time steps 320k to 400k. MBPO and SAC, on the other hand, suffer from negative transfer due to learning average policies or dynamics models. They are also subject to catastrophic forgetting and do not reuse previously-acquired, context-specific knowledge.
Fig. 2(b) and Fig. 2(c) allow us to observe the inner workings of MBCD and understand the reasons that underlie its performance. Fig. 2(b) shows the log-likelihood of the predictions made by each context model learned by MBCD as contexts change. Notice that all context changes in this experiment—even those caused by qualitatively different sources of non-stationarity—are detected with minimal delay. As contexts change, MBCD rapidly detects each change and instantiates new specialized joint prediction models for each context. Furthermore, when structurally similar contexts are re-encountered (e.g., at time steps 160k and timestep 360k), MBCD successfully recognizes that previously-learned models may be redeployed and avoids having to relearn context-specific dynamics or policies. Fig. 2(c) shows the time evolution, as contexts change, of the MCUSUM statistics, , for each model in the ensemble. A context change is detected, online, whenever one of the statistics crosses the threshold . Notice that MCUSUM statistics grow rapidly and cross the threshold almost instantaneously—only a few steps after a context change. This empirically confirms the minimum-delay guarantees provided by our change-point detection method.
 \Description
\Description
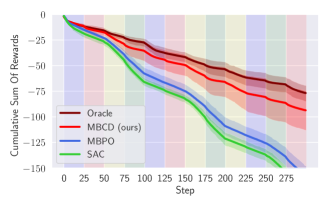
Regret of different methods (MBCD, MBPO, SAC) in the non-stationary Half-Cheetah domain, as contexts change rapidly, compared to an Oracle algorithm.
We now evaluate MBCD’s ability to rapidly detect context changes after an initial training period. Fig. 3 shows the cumulative sum of rewards achieved by MBCD, MBPO, SAC, and by an Oracle algorithm that is initialized with optimal policies for all contexts and that detects context changes with zero delay. This is a challenging setting where contexts change very rapidly—after only 25 steps. Notice that our algorithm closely matches the performance of the zero-delay Oracle, thus empirically confirming its ability to minimize regret (Eq. 5).
 \Description
\Description
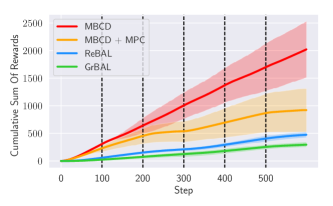
Performance of MBCD and meta-learning methods (after a pre-training phase) in the Half-Cheetah domain with non-stationary malfunctions that disable random joints. Vertical dashed lines indicate context changes.
Next, we analyze how MBCD performs when compared with state-of-the-art meta-learning methods specifically tailored to deal with non-stationary environments: Gradient-Based Adaptive Learner444We used the authors’ implementation of the method, publicly available at https://github.com/iclavera/learning_to_adapt. (GrBAL) Nagabandi et al. (2019a) and Recurrence-Based Adaptive Learner4 (ReBAL) Nagabandi et al. (2019a). GrBAL employs the Model-Agnostic Meta-Learning (MAML) Finn et al. (2017) method to learn the parameters of a meta-learning prior over the dynamics model, given a set of training contexts. This prior is constructed so that it serves as a good initial model for any new contexts that the agent encounters after a pre-training phase. After training, such a meta-learned dynamics model is capable of quickly adapting to a current task’s dynamics by taking only a few gradient steps. ReBAL works similarly to GrBAL, but instead of taking gradient steps to adapt a prior model to novel contexts, it uses a recurrent neural network that learns its own update rule (vs. a gradient update rule) through its hidden state. Both ReBAL and GrBAL use Model-Predictive Control (MPC) García et al. (1989) for selecting actions by planning for a certain horizon using the learned dynamics model.
Fig. 4 compares the adaptation performance of MBCD and the meta-learning methods in a non-stationary setting where (inspired by Nagabandi et al. (2019a)) random joints of the Half-Cheetah robot are disabled after every 100 time steps. In this experiment we compare MBCD, ReBAL, GrBAL, and also (for fairness) a variant of MBCD that chooses actions using MPC instead of SAC. All implementations of MPC make use of the cross entropy method (CEM) Botev et al. (2013) to accelerate action selection. All methods are allowed to interact with each randomly-sampled context during a training phase comprising 60000 time steps. Although the meta-learning methods have lower-variance, their meta-prior models do not perform as well as the MBCD context-specific dynamics models and policies. We also observe that when MBCD uses parameterized policies, learned through Dyna-style planning, it performs better than MBCD coupled with MPC.
 \Description
\Description
Rewards in the non-stationary continuous particle maze domain. Shaded colored areas indicate different contexts: (blue) default maze; (red) maze with non-stationary wall positions; (yellow) non-stationary target positions.
We now evaluate MBCD in a setting where contexts may differ arbitrarily and where future contexts may be off-distribution with respect to those sampled during the training phase. To do this, we compare MBCD, MBPO, SAC, ReBAL, and GrBAL, in the non-stationary continuous particle maze domain, where the sources of non-stationarity are as discussed earlier. Fig. 5 compares MBCD, MBPO, and SAC in the fully-online setting—no pre-training phase is allowed. Notice that, even in this relatively simple scenario, state-of-the-art RL algorithms may fail if the underlying state transition or reward function changes drastically. MBCD’s performance, by contrast, remains approximately constant (and high) as contexts change.
 \Description
\Description
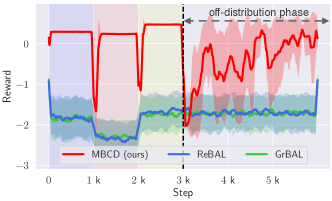
Rewards in the non-stationary maze domain. We introduce a phase with off-distribution contexts—contexts unlike those observed during pre-training.
In Fig. 6, we compare MBCD with meta-learning methods after a phase of pre-training. All contexts observed up to time step are on-distribution: they are similar to those experienced during training. MBCD outperforms ReBAL and GrBAL because the meta-learning approaches construct models that try to average characteristics of structurally different contexts. At time , we initiate a phase with off-distribution contexts—contexts unlike those observed during training. When this occurs, MBCD faces a short adaption period and degrades gracefully, while meta-learning techniques perform poorly. This emphasizes MBCD’s advantages over meta-learning models, both when a pre-training phase is not allowed/possible (e.g., Fig 5) and also when testing contexts arise from a distribution different from the training distribution.
6. Related Work
Dealing with non-stationary environments in RL via context change-point detection has been studied in discrete state and action spaces settings. da Silva et al. Silva et al. (2006) introduced Reinforcement Learning Context Detection (RLCD). RLCD is a model-based algorithm that estimates the prediction quality of different models, and instantiates new ones when none of the existing models performs well. Even though it does not require a pre-training phase (like meta-learning algorithms), it is only applicable to purely discrete settings. Hadoux et al. introduced an extension of RLCD that uses a CUSUM-based method to perform change-point detection Hadoux et al. (2014). Unlike our method, however, it is only applicable to discrete state settings. Banerjee et al. proposed a two-threshold switching policy based on KL divergence between transition models in order to rapidly detect context changes Banerjee et al. (2017). This is a principled method but—unlike MBCD—requires prior knowledge of the dynamics model of all contexts.
In Nagabandi et al. (2019a) and Nagabandi et al. (2019b), meta-learning algorithms are used to train a prior over dynamics models that can, when combined with recent data, be rapidly adapted to novel contexts. These methods, unlike MBCD, were designed to tackle settings where the non-stationarity solely results from changes to the dynamics, but not to the agent’s goals/reward function. Reward functions are assumed to be known a priori. These methods also require an explicit pre-training train phase, prior to deployment, and assume that the distribution of training and testing contexts is the same. Our method, by contrast, is better suited to continual online settings where a pre-training phase is not possible, and where the agent is tasked with dealing with streams of arbitrarily different contexts with unknown boundaries.
7. Conclusion
We introduced a model-based reinforcement learning algorithm (MBCD) that learns efficiently in non-stationary settings with continuous states and actions. It makes use of high-confidence change-point detection statistics to detect context changes with minimum delay, while bounding the rate of false alarm. It is capable of optimizing policies online, without requiring a pre-training phase, even when faced with streams of arbitrarily different contexts drawn from unknown distributions. We empirically show that it outperforms state-of-the-art (model-free and model-based) RL algorithms, and that it outperforms state-of-the-art meta-learning methods specially designed to deal with non-stationarity—in particular, if the agent is faced with MDPs that are off-distribution with respect to the set of training contexts. As future work, we would like to extend our method so that it can actively transfer knowledge of learned policies between contexts. This research direction suggests that our method may be combined with meta-learning techniques that operate over policies, instead of over dynamics models.
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. Ana Bazzan was partially supported by CNPq under grant no. 307215/2017-2.
References
- (1)
- Aminikhanghahi and Cook (2016) Samaneh Aminikhanghahi and Diane Cook. 2016. A Survey of Methods for Time Series Change Point Detection. Knowledge and Information Systems 51 (Sept. 2016).
- Banerjee et al. (2017) Taposh Banerjee, Miao Liu, and Jonathan P. How. 2017. Quickest change detection approach to optimal control in Markov decision processes with model changes. In 2017 American Control Conference (ACC). IEEE, Seattle, WA, USA, 399–405.
- Botev et al. (2013) Zdravko I. Botev, Dirk P. Kroese, Reuven Y. Rubinstein, and Pierre L’Ecuyer. 2013. Chapter 3 - The Cross-Entropy Method for Optimization. In Handbook of Statistics. Handbook of Statistics, Vol. 31. Elsevier, 35–59.
- Chua et al. (2018) Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. 2018. Deep Reinforcement Learning in a Handful of Trials Using Probabilistic Dynamics Models. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18). Montréal, Canada, 4759–4770.
- Duan et al. (2016) Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, and Pieter Abbeel. 2016. RL2: Fast Reinforcement Learning via Slow Reinforcement Learning. arXiv e-prints (Nov. 2016). arXiv:1611.02779 [cs.AI]
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 70). PMLR, Sydney, Australia, 1126–1135.
- García et al. (1989) Carlos E. García, David M. Prett, and Manfred Morari. 1989. Model predictive control: Theory and practice—A survey. Automatica 25, 3 (1989), 335–348.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80). PMLR, Stockholmsmässan, Stockholm Sweden, 1861–1870.
- Hadoux et al. (2014) Emmanuel Hadoux, Aurélie Beynier, and Paul Weng. 2014. Sequential Decision-Making under Non-stationary Environments via Sequential Change-point Detection. In Learning over Multiple Contexts (LMCE). Nancy, France.
- Healy (1987) John D. Healy. 1987. A Note on Multivariate CUSUM Procedures. Technometrics 29, 4 (1987), 409–412.
- Janner et al. (2019) Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. 2019. When to Trust Your Model: Model-Based Policy Optimization. In Advances in Neural Information Processing Systems (NIPS) 32. Curran Associates, Inc., Vancouver, Canada, 12519–12530.
- Lai (1998) Tze Leung Lai. 1998. Information bounds and quick detection of parameter changes in stochastic systems. IEEE Transactions on Information Theory 44, 7 (1998), 2917–2929.
- Lake et al. (2015) Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum. 2015. Human-level concept learning through probabilistic program induction. Science 350, 6266 (2015), 1332–1338.
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS) (NIPS’17). California, USA, 6405–6416.
- Lam and Yam (1997) Kin Lam and H. Yam. 1997. Cusum Techniques for Technical Trading in Financial Markets. Asia-Pacific Financial Markets 4 (Jan. 1997), 257–274.
- Lorden (1971) Gary Lorden. 1971. Procedures for Reacting to a Change in Distribution. The Annals of Mathematical Statistics 42 (Dec. 1971), 1897–1908.
- Mahmoud and Maravelakis (2013) Mahmoud A. Mahmoud and Petros E. Maravelakis. 2013. The performance of multivariate CUSUM control charts with estimated parameters. Journal of Statistical Computation and Simulation 83, 4 (2013), 721–738.
- Nagabandi et al. (2019a) Anusha Nagabandi, Ignasi Clavera, Simin Liu, Ronald S. Fearing, Pieter Abbeel, Sergey Levine, and Chelsea Finn. 2019a. Learning to Adapt in Dynamic, Real-World Environments through Meta-Reinforcement Learning. In 7th International Conference on Learning Representations (ICLR). New Orleans, LA, USA.
- Nagabandi et al. (2019b) Anusha Nagabandi, Chelsea Finn, and Sergey Levine. 2019b. Deep Online Learning via Meta-Learning: Continual Adaptation for Model-Based RL. In 7th International Conference on Learning Representations (ICLR). New Orleans, LA, USA.
- Padakandla (2020) Sindhu Padakandla. 2020. A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments. arXiv e-prints (May 2020). arXiv:2005.10619 [cs.LG]
- Page (1954) E. S. Page. 1954. Continuous Inspection Schemes. Biometrika 41, 1/2 (1954), 100–115.
- Pollak (1985) Moshe Pollak. 1985. Optimal Detection of a Change in Distribution. The Annals of Statistics 13 (March 1985), 206–227.
- Rakelly et al. (2019) Kate Rakelly, Aurick Zhou, Chelsea Finn, Sergey Levine, and Deirdre Quillen. 2019. Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables. In Proceedings of the 36th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 97). PMLR, Long Beach, California, USA, 5331–5340.
- Sahki et al. (2020) Nassim Sahki, Anne Gegout-Petit, and Sophie Wantz-Mézières. 2020. Performance study of change-point detection thresholds for cumulative sum statistic in a sequential context. Quality and Reliability Engineering International 36, 8 (July 2020), 2699–2719.
- Sekar et al. (2020) Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. 2020. Planning to Explore via Self-Supervised World Models. In Proceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119). PMLR, Virtual, 8583–8592.
- Sibanda and Sibanda (2007) Thabani Sibanda and Nokuthaba Sibanda. 2007. The CUSUM chart method as a tool for continuous monitoring of clinical outcomes using routinely collected data. BMC medical research methodology 7 (Nov. 2007), 46.
- Silva et al. (2006) Bruno Castro da Silva, Eduardo W. Basso, Ana L. C. Bazzan, and Paulo M. Engel. 2006. Dealing with Non-Stationary Environments using Context Detection. In Proceedings of the 23rd International Conference on Machine Learning ICML. New York, ACM Press, Pittsburgh, USA, 217–224.
- Sutton (1990) Richard S. Sutton. 1990. Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming. In Proceedings of the 7th International Conference on Machine Learning (ICML). Austin, TX, USA, 216–224.
- Todorov et al. (2012) Emanuel Todorov, Tom Erez, and Yuval Tassa. 2012. MuJoCo: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’12). Vilamoura, Portugal, 5026–5033.
- Veeravalli and Banerjee (2012) Venugopal Veeravalli and Taposh Banerjee. 2012. Quickest Change Detection. Academic Press Library in Signal Processing 3 (Oct. 2012), 209–255.