Minimum Gamma Divergence for
Regression and Classification Problems
Preface
In an era where data drives decision-making across diverse fields, the need for robust and efficient statistical methods has never been greater. As a researcher deeply involved in the study of divergence measures, I have witnessed firsthand the transformative impact these tools can have on statistical inference and machine learning. This book aims to provide a comprehensive guide to the class of power divergences, with a particular focus on the -divergence, exploring their theoretical underpinnings, practical applications, and potential for enhancing robustness in statistical models and machine learning algorithms.
The inspiration for this book stems from the growing recognition that traditional statistical methods often fall short in the presence of model misspecification, outliers, and noisy data. Divergence measures, such as the -divergence, offer a promising alternative by providing robust estimation techniques that can withstand these challenges. This book seeks to bridge the gap between theoretical development and practical application, offering new insights and methodologies that can be readily applied in various scientific and engineering disciplines.
The book is structured into four main chapters. Chapter 1 introduces the foundational concepts of divergence measures, including the well-known Kullback-Leibler divergence and its limitations. It then presents a detailed exploration of power divergences, such as the , , and -divergences, highlighting their unique properties and advantages. Chapter 2 explores minimum divergence methods for regression models, demonstrating how these methods can improve robustness and efficiency in statistical estimation. Chapter 3 extends these methods to Poisson point processes, with a focus on ecological applications, providing a robust framework for modeling species distributions and other spatial phenomena. Finally, Chapter 4 explores the use of divergence measures in machine learning, including applications in Boltzmann machines, AdaBoost, and active learning. The chapter emphasizes the practical benefits of these measures in enhancing model robustness and performance.
By providing a detailed examination of divergence measures, this book aims to offer a valuable resource for statisticians, machine learning practitioners, and researchers. It presents a unified perspective on the use of power divergences in various contexts, offering practical examples and empirical results to illustrate their effectiveness. The methodologies discussed in this book are designed to be both insightful and practical, enabling readers to apply these concepts in their work and research.
This book is the culmination of years of research and collaboration. I am grateful to my colleagues and students whose questions and feedback have shaped the content of this book. Special thanks to Hironori Fujisawa, Masayuki Henmi, Takashi Takenouchi, Osamu Komori, Kenichi Hatashi, Su-Yun Huang, Hung Hung, Shogo Kato, Yusuke Saigusa and Hideitsu Hino for their invaluable support and contributions.
I invite you to explore the rich landscape of divergence measures presented in this book. Whether you are a researcher, practitioner, or student, I hope you find the concepts and methods discussed here to be both insightful and practical. It is my sincere wish that this book will contribute to the advancement of robust statistical methods and inspire further research and innovation in the field.
Tokyo, 2024 Shinto Eguchi
Chapter 1 Power divergence
We present a mathematical framework for discussing the class of divergence measures, which are essential tools for quantifying the difference between two probability distributions. These measures find applications in various fields such as statistics, machine learning, and data science. We begin by discussing the well-known Kullback-Leibler (KL) Divergence, highlighting its advantages and limitations. To address the shortcomings of KL-divergence, the paper introduces three alternative types: , , and -divergences. We emphasize the importance of choosing the right ”reference measure,” especially for and divergences, as it significantly impacts the results.
1.1 Introduction
We provide a comprehensive study of divergence measures that are essential tools for quantifying the difference between two probability distributions. These measures find applications in various fields such as statistics, machine learning, and data science [1, 6, 19, 79, 20]. See also [98, 17, 58, 34, 72, 80, 50].
We present the , , and divergence measures, each characterized by distinctive properties and advantages. These measures are particularly well-suited for a variety of applications, offering tailored solutions to specific challenges in statistical inference and machine learning. We further explore the practical applications of these divergence measures, examining their implementation in statistical models such as generalized linear models and Poisson point processes. Special attention is given to selecting the appropriate ’reference measure,’ which is crucial for the accuracy and effectiveness of these methods. The study concludes by identifying areas for future research, including the further exploration of reference measures. Overall, the paper serves as a valuable resource for understanding the mathematical and practical aspects of divergence measures.
In recent years, a number of studies have been conducted on the robustness of machine learning models using the -divergence, which was proposed in [33]. This book highlights that the -divergence can be defined even when the power exponent is negative, provided certain integrability conditions are met [26]. Specifically, one key condition is that the probability distributions are defined on a set of finite discrete values. We demonstrate that the -divergence with is intimately connected to the inequality between the arithmetic mean and the geometric mean of the ratio of two probability mass functions, thus terming it the geometric-mean (GM) divergence. Likewise, we show that the -divergence with can be derived from the inequality between the arithmetic mean and the harmonic mean of the mass functions, leading to its designation as the harmonic-mean (HM) divergence.
1.2 Probabilistic framework
Let be a random variable with a set of possible values in . We denote as a -finite measure, referred to as the reference measure. The reference measure is typically either the Lebesgue measure for a case where is a continuous random variable or the counting measure for a case where is a discrete one. Let us define as the space encompassing all probability measures ’s that are absolutely continuous with respect to each other. The probability for an event can be expressed as:
where is referred to as the Radon-Nicodym (RN) derivative. Specifically, is referred to as the probability density function (pdf) and the probability mass function (pmf) if is a continuous and discrete random variable, respectively.
Definition 1.
Let denote a functional defined on . Then, we call a divergence measure if for all and of , and means .
Consider two normal distributions and . If both distributions have the same mean and variance , they are identical, and their divergence is zero. However, as the mean and variance of one distribution diverge from those of the other, the divergence measure increases, quantifying how one distribution is different from the other. Thus, a divergence measure quantifies how one probability distribution diverges from another. The key properties are non-negativity, asymmetry and zero when identical. The asymmetry of the divergence measure helps one to discuss model comparisons, variational inferences, generative models, optimal control policies and so on. Researchers have proposed various divergence measures in statistics and machine learning to compare two models or to measure the information loss when approximating a distribution. It is more appropriately termed ‘information divergence’, although here is simply called ‘divergence’ for simplicity. As a specific example, the Kullback-Leibler (KL) divergence is given by the following equation:
| (1.1) |
where and . The KL-divergence is essentially independent of the choice since it is written without as
This implies that any properties for the KL-divergence directly can be thought as intrinsic properties between probability measures and regardless of the RN-derivatives with respect to the reference measure. The definition (1.1) implicitly assumes the integrability. This implies that the integrals of their products with the logarithm of their ratio must be finite. Such assumptions are almost acceptable in the practical applications in statistics and the machine learning. However, if we assume a Cauchy distribution as and a normal distribution , then is not a finite value. Thus, the KL-divergence is associated with instable behaviors, which arises non-robustness for the minimum KL-divergence method or the maximum likelihood. This aspect will be discussed in the following chapter.
If we write the cross-entropy as
| (1.2) |
then the KL-divergence is written by the difference as
The KL-divergence is a divergence measure due to the convexity of the negative logarithmic function. In foundational statistics, the Neyman-Pearson lemma holds a pivotal role. This lemma posits that the likelihood ratio test (LRT) is the most powerful method for hypothesis testing when comparing a null hypothesis distribution against an alternative distribution . In this context, the KL-divergence can be interpreted as the expected value of the LRT under the null hypothesis distribution . For a more in-depth discussion of the close relationship between and the Neyman-Pearson lemma, the reader is referred to [25].
In the context of machine learning, KL-divergence is often used in algorithms like variational autoencoders. Here, KL-divergence helps quantify how closely the learned distribution approximates the real data distribution. Lower KL-divergence values indicate better approximations, thus helping in the model’s optimization process.
1.3 Power divergence measures
The KL-divergence is sometimes referred to as log divergence due to its definition involving the logarithmic function. Alternatively, a specific class of power divergence measures can be derived from power functions characterized by the exponent parameters , , and , as detailed below. Among the numerous ways to quantify the divergence or distance between two probability distributions, ‘power divergence measure’ occupies a unique and significant property. Originating from foundational concepts in information theory, these measures have been extended and adapted to address various challenges across statistics and machine learning. As we strive to make better decisions based on data, understanding the nuances between different divergence measures becomes crucial. This section introduces the power divergence measures through three key types: , , and divergences, see [9] for a comprehensive review. Each of these offers distinct advantages and limitations, and serves as a building block for diverse applications ranging from robust parameter estimation to model selection and beyond.
(1) -divergence:
where belongs to , cf. [8, 1] for further details. Let us introduce
as a generator function for . Then the -divergence is written as
Note that . Equality is achieved if and only if , indicating that is a convex function. This implies with equality if and only if . This shows that is a divergence measure. The log expression [8] is given by
The -divergence is associated with the Pythagorean identity in the space . Assume that a triple of , and satisfies
This equation reflects a Pythagorean relation, wherein the triple forms a right triangle if is considered the squared Euclidean distance between and . We define two curves and in such that the RN-derivatives of and is given by and
respectively, where is a normalizing constant. We then observe that the Pythagorean relation remains unchanged for the triple , as illustrated by the following equation:
In accordance with this, The -divergence allows for to be as if it were an Euclidean space. This property plays a central role in the approach of information geometry. It gives geometric insights for statistics and machine learning [73].
For example, consider a multinomial distribution MN with a probability mass function (pmf):
| (1.3) |
for with , where . The -divergence between multinomial distributions and can be expressed as follows:
| (1.4) |
where is the counting measure.
The -divergence is independent of the choice of since
This indicates that is independent of the choice of , as for any . Consequently, equation (1.4) is also independent of . In general, the Csisar class of divergence is independent of the choice of the reference measure [26].
(2) -divergence:
| (1.5) |
where belongs to . For more details, refer to [2, 65]. Let us consider a generator function defined as follows:
It follows from the convexity of that This concludes that is a divergence measure due to
We also observe the property preserving the Pythagorean relation for the -divergence. When , and form a right triangle by the -divergence, then the right triangle is preserved for the triple , anf .
It’s worth noting that the -divergence is dependent on the choice of reference measure . For instance, if we choose as the reference measure, then the -divergence is given by:
Here, and . This can be rewritten as
| (1.6) |
where . Hence, the integrands of are given by the integrands of multiplied by . The choice of the reference measure gives a substantial effect for evaluating the -divergence.
We again consider a multinomial distribution MN defined in (1.3). Unfortunately, the -divergence with the counting measure would have an intractable expression. Therefore, we select in a way that the Radon-Nikodym (RN) derivative is defined as
| (1.7) |
as a reference measure. Accordingly, , and hence
which is equal to . Using this approach, a closed form expression for -divergence can be derived:
| (1.8) |
due to (1.6). In this way, the expression (1.8) has a tractable form, in which this is reduced to the standard one of -divergence when . Subsequent discussions will explore the choice of reference measure that provides the most accurate inference within statistical models, such as the generalized linear model and the model of inhomogeneous Poisson point processes.
(3) -divergence [33]:
| (1.9) |
If we define the -cross entropy as:
then the -divergence is written by the difference:
It is noteworthy that the cross -entropy is a convex-linear functional with respect to the first argument:
where ’s are positive weights with and . This property gives explicitly the empirical expression for the -entropy given data set . Consider the empirical distribution as , where is the Dirac measure at the atom . Then
If we assume that is a sequence of identically and independently distributed with , then
and hence almost surely converges to due to the strong law of large numbers. Subsequently, this will be used to define the empirical loss based on the dataset. Needless to say, the empirical expression of the cross entropy in (1.2) is the negative log likelihood. The -diagonal entropy is proportional to the Lebesgue norm with exponent as
Considering the conjugate exponent , the Hölder inequality for and states
This holds for any with the equality if and only if . This implies the -divergence satisfies the definition of ‘divergence measure’ for any . It should be noted that the Hölder inequality is employed for not the pair and but that of and , which yields the property ‘zero when identical’ as a divergence measure. Also, the -divergence approaches the KL-divergence in the limit:
This is because for all as well as the and divergence measures.
We observe a close relationship between and divergence measures. Consider a maximum problem of the -divergence: . By definition, if we write , then for all . Thus, the maximizer of is given by
If we confuse with , then the close relationship is found in
In accordance with this, the -divergence can be viewed as the -divergence interpreted in a projective geometry [27]. Similarly, consider a dual problem: . Then, the maximizer of is given by
Hence, the scale adjusted divergence is given by
| (1.10) |
Thus, we get a dualistic version of the -divergence as
| (1.11) |
We refer to as the dual -divergence. If we define the dual -entropy as
then . In effect, the -divergence and its dual are connected as follows.
1.4 The -divergence and its dual
In the evolving landscape of statistical divergence measures, a lesser-explored but highly potent member of the family is the divergence. This divergence serves as an interesting alternative to the more commonly used and divergences, with unique properties and advantages that make it particularly suited for certain classes of problems. The dual divergence offers further flexibility, allowing for nuanced analysis from different perspectives. The following section is dedicated to a deep-dive into the mathematical formulations and properties of these divergences, shedding light on their invariance characteristics, relationships to other divergences, and potential applications. Notably, we shall establish that divergence is well-defined even for negative values of the exponent , and examine its special cases which connect to the geometric and harmonic mean divergences. This comprehensive treatment aims to illuminate the role that and its dual can play in advancing both theoretical and applied aspects of statistical inference and machine learning [28].
Let us focus on the -divergence in power divergence measures. We define a power-transformed function as follows:
| (1.12) |
which we refer to as the -expression of , where . Thus, the measure having the RN-derivative belongs to since . We can write
and
These equations directly yield an observation: and are scale-invariant, but only with respect to one of the two arguments.
| (1.13) |
while
The power exponent is usually assumed to be positive. However, we extend to be a real number in this discussion, see [23] for a brief discussion.
Proposition 1.
Proof.
We introduce two generator functions defined as:
| (1.14) |
for . By definition, the divergence can be expressed as:
| (1.15) |
Due to the convexity of in for any , we have
| (1.16) |
with equality if and only if . The right-hand-side of (1.16) can be rewritten as:
The second term identically vanishes since and have both total mass one. Similarly, we observe for any real number that
| (1.17) |
which is equal or greater than and the equality holds if and only if due the convexity of . Therefore, and are both divergence measures for any real number . ∎
We will discuss with a negative power exponent in a context of statistical inferences. The -divergence (1.9) is implicitly assumed to be integrable as well as the KL-divergence, in which the integrability condition for the -divergence with is presented. Let us look into the case of a multinomial distribution Bin defined in (1.3) with the reference measure given by (1.7). An argument similar to that on the -divergence yields
as the -divergence of the log expression in (1.21), where and are cell probability vectors of dimension. The -divergence with the counting measure would also have no closed expression. Therefore, careful consideration is needed when choosing the reference measure for divergence. Let be the RN-derivative of with respect to the Lebesgue measure . Then, the -divergence (1.9) with
where . Our key objective is to identify a that ensures stable and smooth behavior under a given statistical model and dataset.
We discuss a generalization of the -divergence. Let be a convex function. Then, -divergence is defined by
| (1.18) |
where is a normalizing constant satisfying and the function satisfies
| (1.19) |
It is derived from the assumption of the convexity of that
which is equal to
| (1.20) |
up to the proportional factor due to (1.19). By the definition of normalizing constants, the integral in (1.20) vanishes. Hence, becomes a divergence measure. Specifically, for due to the normalizing constant . For example, if as in (1.14), reduces to the -divergence. There are various examples of other than (1.14), for example,
which is related to the -entropy discussed in a physical context [52, 78]. We do not go further into this topic as it is beyond the scope of this paper.
We investigate a notable property of the dual divergence. There exists a strong relationship between the generalized mean of probability measures and the minimization of the average dual divergence. Subsequently, we will explore its applications in active learning.
Proposition 2.
Consider an average of dual -divergence measures as
Let . Then, the Radon-Nikodym (RN) derivative of is uniquely determined as follows:
where and is the normalizing constant.
Proof.
If we write by , then
which is equal to
This expression simplifies to . Therefore, and the equality holds if and only if This is due to the property of as a divergence measure. ∎
The optimal distribution can be viewed as the consensus one integrating committee members’ distributions ’s into the average of divergence measures with importance weights . We adopt a ”query by committee” approach and examine the robustness against variations in committee distributions. Proposition 2 leads to an average version of the Pythagorean relations:
We refer to as the power mean of the set . In general, a generalized mean is defined as
where is a one-to-one function on . We confirm that, if , then that is the arithmetic mean, or the mixture distribution of ’s with mixture proportions ’s. If , then
which is the harmonic mean of ’s with weights ’s. As goes to , the dual -divergence converges to the dual KL-divergence defined by . The minimizer is given by
which is the harmonic mean of ’s with weights ’s. We will discuss divergence measures using the harmonic and geometric means of ratios for RN-derivatives in a later section.
We often utilize the logarithmic expression for the divergence, given by
| (1.21) |
We find a remarkable property such that
for all and , noting the log expression is written by
| (1.22) |
by the use of -expression defined in (1.12). This implies that measures not a departure between ad but an angle between them. When , this is the negative log cosine similarity for and . In effect, the cosine for and are in is defined by
This is closely related to in a discrete space when . which is closely related to on discrete space when . We will discuss an extension of to be defined on a space of all signed measures that comprehensively gives an asymmetry in measuring the angle.
In summary, the exploration of power divergence measures in this section has illuminated their potential as versatile tools for quantifying the divergence between probability distributions. From the foundational Kullback-Leibler divergence to the more specialized , , and divergence measures, we have seen that each type has its own strengths and limitations, making them suited for particular classes of problems. We have also underscored the mathematical properties that make these divergences unique, such as invariance under different conditions and applicability in empirical settings. As the field of statistics and machine learning continues to evolve, it’s evident that these power divergence measures will find even broader applications, providing rigorous ways to compare models, make predictions, and draw inferences from increasingly complex data.
1.5 GM and HM divergence measures
We discuss a situation where a random variable is discrete, taking values in a finite set of non-negative integers denoted by . Let be the space of all probability measures on . In the realm of statistical divergence measures, arithmetic, geometric, and harmonic means for a probability measure of receives less attention despite their mathematical elegance and potential applications. For this, consider the RN-derivative of a probability measure relative to that equals a ratio of probability mass functions (pmfs) and induced by and in . Then, there is well-known inequality between the arithmetic and geometric means:
| (1.23) |
and that between the arithmetic and harmonic means:
| (1.24) |
where is a weight function that is arbitrarily a fixed pmf on . Equality in (1.23) or (1.24) holds if and only if . This well-known inequality relationships among these means serve as the mathematical bedrock for defining new divergence measures. Specifically, the Geometric Mean (GM) and Harmonic Mean (HM) divergences are inspired by inequalities involving these means and ratios of probabilities as follows.
First, we define the GM-divergence as
transforming the expression (1.23), where , and are the pmfs with respect to , and , respectively. Note that is a divergence measure on as defined in Definition 1. We restrict to be a finite discrete set for this discussion; however, our results can be generalized. In effect, the GM-divergence has a general form:
| (1.25) |
For comparison, we have a look at the -divergence
| (1.26) |
by selecting a probability measure as a reference measure.
Proof.
We write the GM-divergence by the difference of the cross and diagonal entropy measures: , where
The GM-divergence has a log expression:
We note that is equal to taking the limit of to . Here we discuss the case of the Poisson distribution family. We choose a Poisson distribution Po as the reference measure. Thus, the GM-divergence of the log-form is given by
Second, we introduce the HM-divergence. Suppose in the inequality (1.24). Then, (1.24) is written as
| (1.28) |
We define the harmonic-mean (HM ) divergence arranging the inequality (1.28) as
Here
is the cross entropy, where and is the pmfs of and , respectively. The (diagonal) entropy is given by the harmonic mean of ’s:
Note that qualifies as a divergence measure on , as defined in Definition 1, due to the inequality (1.28). When , is equal to in (1.9) with the counting measure . The log form is given by
The GM-divergence provides an insightful lens through which we can examine statistical similarity or dissimilarity by leveraging the multiplicative nature of probabilities. The HM-divergence, on the other hand, focuses on rates and ratios, thus providing a complementary perspective to the GM-divergence, particularly useful in scenarios where rate-based analysis is pivotal. By extending the divergence measures to include GM and HM divergence, we gain a nuanced toolkit for quantifying divergence, each with unique advantages and applications. For instance, the GM-divergence could be particularly useful in applications where multiplicative effects are prominent, such as in network science or econometrics. Similarly, the HM-divergence might be beneficial in settings like biostatistics or communications, where rate and proportion are of prime importance. This framework, rooted in the relationships among arithmetic, geometric, and harmonic means, not only expands the class of divergence measures but also elevates our understanding of how different mathematical properties can be tailored to suit the needs of diverse statistical challenges.”
1.6 Concluding remarks
In summary, this chapter has laid the groundwork for understanding the class of power divergence measures in a probabilistic framework. We study that divergence measures quantify the difference between two probability distributions and have applications in statistics and machine learning. It begins with the well-known Kullback-Leibler (KL) divergence, highlighting its advantages and limitations. To address limitations of KL-divergence, three types of power divergence measures are introduced.
Let us look at the , , and -divergence measures for a Poisson distribution model. Let denote a Poisson distribution with the RN-derivative
| (1.29) |
with respect to the reference measure having . Seven examples of power divergence between Poisson distributions and are listed in Table 1.1. Note that this choice of the reference measure enable us to having such an tractable form of the and divergences as well as its variants. Here we use a basic formula to obtain these divergence measures:
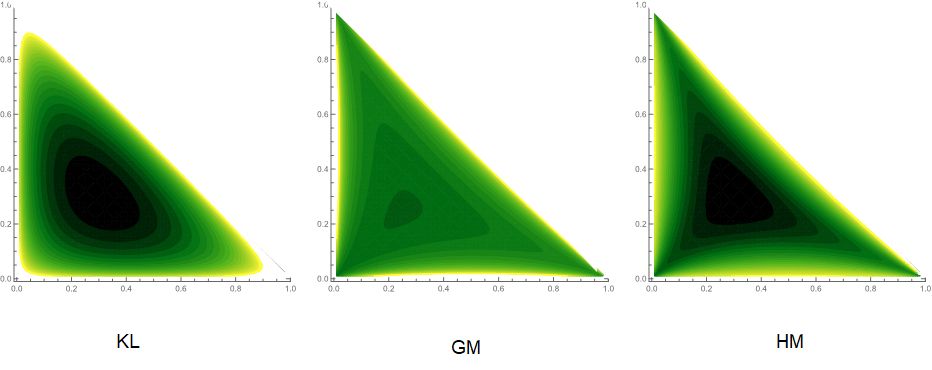
for an exponent of . The contour sets of seven divergences between Poisson distributions are plotted in Figure 1.1. All the divergences attain the unique minimum in the diagonal line . The contour set of GM and HM divergences are flat compared to those of other divergences.
| -divergence | |
|---|---|
| -divergence | |
| -divergence | |
| dual -divergence | |
| log -divergence | |
| GM-divergence | |
| HM-divergence |
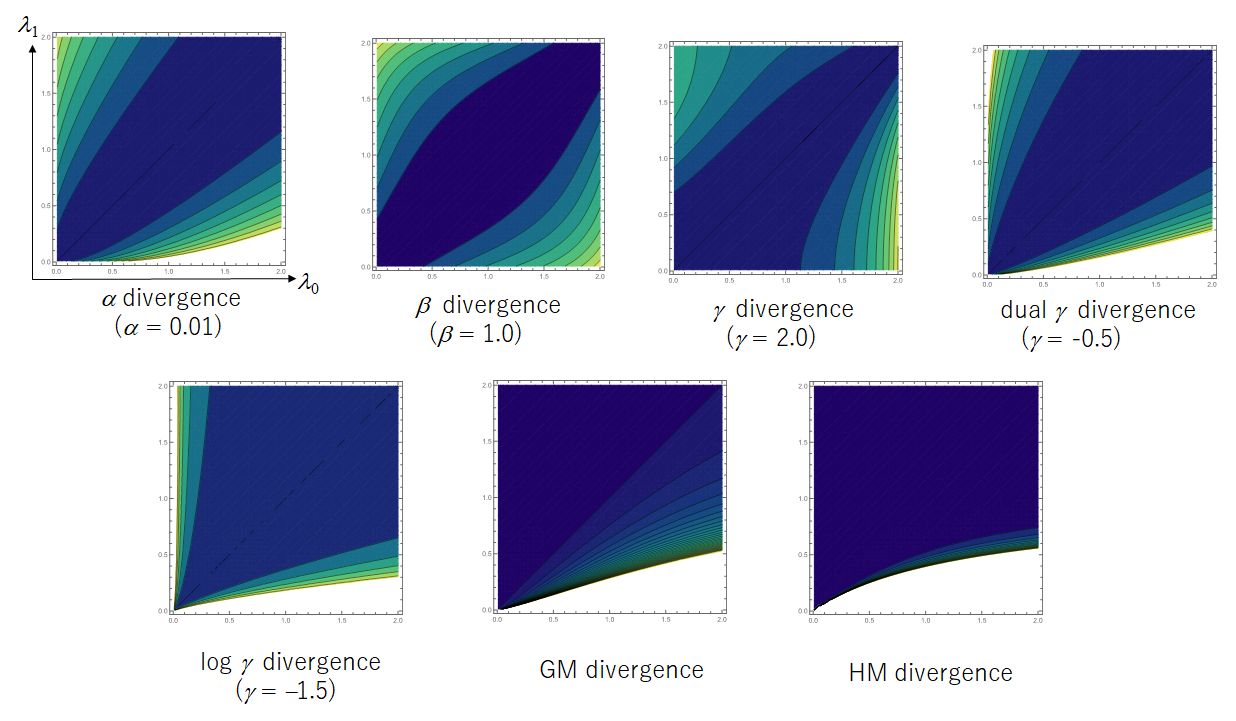
The -divergence is intrinsic to assess the divergence between two probability measures. One of the most important properties is invariance with the choice of the reference measure that expresses the Radon-Nicodym derivatives for the two probability measure . The invariance provides direct understandings for the intrinsic properties beyond properties for the probability density or mass functions. A serious drawback is pointed out that an empirical counterpart is not available for a given data set in most practical situations. This makes difficult for applications for statistical inference for estimation and prediction. In effect, the statistical applications are limited to the curved exponential family that is modeled in an exponential family. See [18] for the statistical curvature characterizing the second order efficiency.
The -divergence and the -divergence are not invariant with the choice of the reference measure. We have to determine the reference measure from the point of the application to statistics and machine learning. Subsequently, we discuss the appropriate selection of the reference measure in both cases of and divergences. Both divergence measures are efficient for applications in areas of statistics and machine learning since the empirical loss function for a parametric model distribution is applicable for any dataset. For example, the -divergence is utilized as a cost function to measure the difference between a data matrix and the factorized matrix in the nonnegative matrix factorization. Such applications the minimum -divergence method is more robust than the maximum likelihood method which can be viewed as the minimum KL-divergence method. In practice, the is not scale invariant in the space of all finite measures that involves that of all the probability measures. We will study that the lack of the scale invariance does not allow simple estimating functions even under a normal distribution model.
Alternatively, the -divergence is scale-invariant with respect to the second argument. The -divergence provides a simple estimating function for the minimum -estimator. This property enables to proposing an efficient learning algorithm for solving the estimating equation. For example, the -divergence is used for the clustering analysis. The cluster centers are determined by local minimums of the empirical loss function defined by the -divergence, see [75, 74] for the learning architecture. A fixed-point type of algorithm is proposed to conduct a fast detection for the local minimums. Such practical properties in applications will be explored in the following section. We consider the dual -divergence that is invariant for the first argument. We will explore the applicability for defining the consensus distribution in a context of active learning. It is confirmed that the -divergence is well defined even for negative value of the exponent . The -divergences with and are reduced to the GM and HM divergences, respectively. In a subsequent discussion, special attentions to the GM and HM divergences are explored for various objectives in applications, see [26] for the application to dynamic treatment regimes in the medical science.
Chapter 2 Minimum divergence for regression model
This chapter explores statistical estimation within regression models. We introduce a comprehensive class of estimators known as Minimum Divergence Estimators (MDEs), along with their empirical loss functions under a parametric framework. Standard properties such as unbiasedness, consistency, and asymptotic normality of these estimators are thoroughly examined. Additionally, the chapter addresses the issue of model misspecification, which can result in biases, inaccurate inferences, and diminished statistical power, and highlights the vulnerability of conventional methods to such misspecifications. Our primary goal is to identify estimators that remain robust against potential biases arising from model misspecification. We place particular emphasis on the -divergence, which underpins the -estimator known for its efficiency and robustness.
2.1 Introduction
We study statistical estimation in a regression model including a generalized linear model. The maximum likelihood (ML) method is widely employed and developed for the estimation problem. This estimation method has been standard on the basis of the solid evidence in which the ML-estimator is asymptotically consistent and efficient when the underlying distribution is correctly specified a regression model. See [16, 62, 7, 39]. The power of parametric inference in regression models is substantial, offering several advantages and capabilities that are essential for effective statistical analysis and decision-making. The ML method has been a cornerstone of parametric inference. This principle yields estimators that are asymptotically unbiased, consistent, and efficient, given that the model is correctly specified. Specifically, generalized linear models (GLMs) extend linear models to accommodate response variables that have error distribution models other than a normal distribution, enabling the use of ML estimation across binomial, Poisson, and other exponential family distributions.
However, we are frequently concerned with model misspecification, which occurs when the statistical model does not accurately represent the data-generating process. This could be due to the omission of important variables, the inclusion of irrelevant variables, incorrect functional forms, and wrong error structures. Such misspecification can lead to biases, inaccurate inferences, and reduced statistical power because of misspecification for the parametric model. See [95] for the critical issue of model misspecification. A misspecified model is more sensitive to outliers, often resulting in more biased estimates. Outliers can also obscure true relationship between variables, making it difficult to detect model misspecification by overshadowing the true relationships between variables. Unfortunately, the performance of the ML-estimator is easily degraded in such difficult situations because of the excessive sensitivities to model misspecification. Such limitations in the face of model misspecification and complex data structures have prompted the development of a broad spectrum of alternative methodologies. In this way, we take the MDE approach other than the maximum likelihood.
We discuss a class of estimating methods through minimization of divergence measure [2, 65, 69, 67, 21, 66, 22, 55, 53, 54, 26]. These are known as minimum divergence estimators (MDEs). The empirical loss functions for a given dataset are discussed in a unified perspective under a parametric model. Thus, we derive a broad class of estimation methods via MDEs. Our primary objective is to find estimators that are robust against potential biases in the presence of model misspecification. MDEs can be applied to a case where the outcome is a continuous variable in a straightforward manner, in which the reference measure to define the divergence is fixed by the Lebesgue measure. Alternatively, more consideration is needed regarding the choice of a reference measure in a discrete variable case for the outcome. In particular, and divergence measures are strongly associated with a specific dependence for the choice of a reference measure. We explore effective choices for the reference measure to ensure that the corresponding divergences are tractable and can be expressed feasibly. We focus on the -divergence as a robust MDE through an effective choice of the reference measure.
This chapter is organized as follows. Section 2.4 gives an overview of M-estimation in a framework of generalized linear model. In Section 2.3 the -divergence is introduced in a regression model and the -loss function is discussed. In Section 2.4 we focus on the -estimator in a normal linear regression model. A simple numerical example demonstrates a robust property of the -estimator compared to the ML-estimator. Section 2.5 discusses a logistic model for a binary regression. The -loss function is shown to have a robust property where the Euclidean distance of the estimating function to the decision boundary is uniformly bounded when is in a specific range. In Section 2.6 extends the result in the binary case to a multiclass case. Section 2.7 considers a Poisson regression model focusing on a log-linear model. The -divergence is given by a specific choice of the reference measure. The robustness for the -estimator is confirmed for any in the specific range. A simple numerical experiment is conducted. Finally, concluding remarks for geometric understandings are given in 2.8.
2.2 M-estimators in a generalized linear model
Let us establish a probabilistic framework for a -dimensional covariate variable in a subset of , and an outcome with a value of a subset of in a regression model paradigm. The major objective is to estimate the regression function
based on a given dataset. In a paradigm of prediction, is often called a feature vector, where to build a predictor defined by a function from to is one of the most important tasks. Let be a space of conditional probability measures conditioned on . For any event in the conditional probability given is written by
where is the RN-derivative of given with a reference measure . A statistical model embedded in is written as
| (2.1) |
where is a parameter of a parameter space . Then, the Kullback-Leibler (KL) divergence on is given by
with the cross entropy,
Note that the KL-divergence is independent of the choice of reference measure as discussed in Chapter 1. Let be a random sample drawn from a distribution of . The goal is to estimate the parameter in in (2.1). Then, the negative log-likelihood function is defined by
where is the RN-derivative of with respect to . Note that, for any measure equivalent to the negative log-likelihood functions up to a constant. The expectation of under the model distribution of is equal to the cross entropy:
| (2.2) |
where and is the true value of the parameter and is the conditional expectation under the model distribution ’s. Hence,
which can be viewed as an empirical analogue of the Pythagorean equation. Due to the property of the KL-divergence as a divergence measure,
By definition, the ML-estimator is the minimizer of in ; while the true value is the minimizer of in . The continuous mapping theorem reveals the consistency of the ML-estimator for the true parameter, see [61, 94] The estimating function is defined by the gradient of the negative log-likelihood function
Hence, the ML-estimator is a solution of the estimating equation, under regularity conditions. We note that the solution of the expected estimating function under the distribution with the true value is itself, that is,
This implies that the continuous mapping theorem again concludes the consistency of the ML-estimator for the true value .
The framework of a generalized linear model (GLM) is suitable for a wide range of data types other than the ordinary linear regression model, see [62]. While the ordinary linear regression usually assumes that the response variable is normally distributed, GLMs allow for response variables that have different distributions, such as the Bernoulli, categorical, Poisson, negative binomial distributions and exponential families in a unified manner. In this way, GLMs provide excellent applicability for a wide range of data types, including count data, binary data, and other types of skewed or non-continuous data. A GLM consists of three main components:
-
1
Random Component: Specifies the probability distribution of the response variable . This is typically a member of the exponential family of distributions (e.g., normal, exponential, binomial, Poisson, etc.).
-
2
Systematic Component: Represents the linear combination of the predictor variables, similar to ordinary linear regression. It is usually expressed as .
-
3
Link Function: Provides the relationship between the random and systematic components. The expected value of given , or the regression function is one-to-one with the linear combination of predictors through the link function .
In the framework of the GLM, an exponential dispersion model is employed as
with respect to a reference measure , where and is called the canonical and the dispersion parameters, respectively, see [51]. Here we assume that can be defined in . This allows for a linear modeling with a flexible form of the link function . Specifically, if is an identity function, then is referred to as the canonical link function. This formulation involves most of practical models in statistics such as the logistic and the log linear models. In practice, the dispersion parameter is usually estimated separately from , and hence, we assume is known to be for simplicity. This leads to a generalized linear model:
| (2.3) |
with as the conditional RN-derivative of given . The regression function is given by
due to the Bartlett identity.
Let us consider M-estimators for a parameter in the linear model (2.3). Originally, the M-estimator is introduced to cover robust estimators of a location parameter, see [47] for breakthrough ideas for robust statistics, and [83] for robust regression. We define an M-type loss function for the GLM defined in (2.3):
| (2.4) |
for a given dataset and we call
the M-estimator. Here the generator function is assumed to be convex with respect to . If , then the M-estimator is nothing but the ML estimator. Thus, the estimating function is given by
| (2.5) |
where . If we confine the generator function to a form of , then this formulation reduces to the original form of M-estimation [48, 93]. In general, the estimating function is characterized by . Hereafter we assume that
where is the expectation under . This assumption leads to consistency for the estimator . We note that the relationship between the loss function and the estimating function is not one-to-one. Indeed, there exist many choices of the estimating function for obtaining the estimator other than (2.5). We have a geometric discussion for an unbiased estimating function.
We investigate the behavior of the score function of the -estimator. By definition, the -estimator is the solution such that the sample mean of the score function is equated to zero. We write a linear predictor as , where . We call
| (2.6) |
the prediction boundary. Then, the following formula is well-known in the Euclidean geometry.
Proposition 4.
Let and be the Euclidean distance from to the prediction boundary defined in (2.6). Then,
| (2.7) |
Proof.
Let be the projection of onto . Then, , where denotes the Euclidean norm. There exists a non zero scalar such that noting that a normal vector to the hyperplane is given by . Hence, and
| (2.8) |
which concludes (2.7) since due to .
∎
Thus, a covariate vector of is decomposed into the orthogonal and horizontal components as , where
| (2.9) |
We note that and . Due to the orthogonal decomposition (2.9) of , the estimating function is also decomposed into
where
Here we use a property: . Thus, in , and are strongly connected each other; in , and are less connected.
The estimating function (2.5) is decomposed into a sum of the orthogonal and horizontal components,
where
We consider a specific type of contamination in the covariate space .
Proposition 5.
Let and , where with arbitrarily a fixed scalar depending on . Then, , and
Proof.
By definition, and due to . These imply the conclusion. ∎
We observe that and have both no influence with the contamination in . Alternatively, has a substantial influence by scalar multiplication. Hence, we can change the definition of the horizontal component as
choosing as . Then, it has a mild behavior such that
In this way, the estimating function (2.5) of M-estimator can be written as
| (2.10) |
Proposition 6.
Assume there exists a constant such that
Then, the estimating function in (2.10) of the M-estimator is bounded with respect to any dataset .
Proof.
It follows from the assumption such that there exists a constant such that since
Therefore, we observe
which is equal to .
∎
On the other hand, suppose another type of contamination , where with a fixed scalar depending on . Then, and have both strong influences; has no influence.
The ML-estimator is a standard estimator that is defined by maximization of the likelihood for a given data set . In effect, the negative log-likelihood function is defined by
The likelihood estimating function is given by
| (2.11) |
Here the regression parameter is of our main interests. We note that the ML-estimator can be obtained without the nuisance parameter even if it is unknown. In effect, there are some methods for estimating using the deviance and the Pearson divergence in a case where is unknown. The expected value of the negative log-likelihood conditional on is given by
up to a constant since the conditional expectation is given by due to a basic property of the exponential dispersion model (2.3).
2.3 The -loss function and its variants
Let us discuss the the -divergence in the framework of regression model based on the discussion in the general distribution setting of the preceding section. The -divergence is given by
with the cross entropy,
The loss function derived from the -divergence is
where is the -expression of , that is
| (2.12) |
We define the -estimator for the parameter by . By definition, the -estimator reduces to the ML-estimator when is taken a limit to .
Remark 1.
Let us discuss a behavior of the -loss function when becomes larger in which the outcome is finite-discrete in . For simplicity, we define the loss function as
Let and . Then, the -expression satisfies
Similarly,
Hence, is equivalent to the 0-1 loss function ; while
| (2.13) |
This is the number of ’s equal to the worst predictor . If we focus on a case of , then is nothing but the 0-1 loss function since . In principle, the minimization of the 0-1 loss is hard due to the non-differentiability. The -loss function smoothly connects the log-loss and the 0-1 loss without the computational challenge. See [31, 71] for detailed discussion for the 0-1 loss optimization.
In a subsequent discussion, the -expression will play an important role on clarifying the statistical properties of the -estimator. In fact, the -expression function is a counterpart of the log model function: in . Here we have a note as one of the most basic properties that
| (2.14) |
Equation (2.14) yields
and, hence,
| (2.15) |
This implies
Thus, we observe due to the discussion similar to that for the ML-estimator and the KL-divergence that consistent for . The -estimating function is defined by
Then, we have a basic property that the -estimating function should satisfy in general.
Proposition 7.
The true value of the parameter is the solution of the expected -estimating equation under the expectation of the true distribution. That is, if ,
| (2.16) |
where is the conditional expectation under the true distribution ’s given .
Proof.
By definition,
Here we note
up to a proportionality constant. Hence,
If , then this vanishes identically due to the total mass one of . ∎
The -estimator is a solution of the estimating equation; while true value is the solution of the expected estimating equation under the true distribution with . Similarly, this shows the consistency of the -estimator for the true value of the parameter. The -estimating function is said to be unbiased in the sense of (2.16). Such a unbiased property leads to the consistency of the estimator. However, if the underlying distribution is misspecified, then we have to evaluate the expectation in (2.16) under the misspecified distribution other than the true distribution. Thus, the unbiased property is generally broken down, and the Euclidean norm of the estimating function may be divergent at the worst case. We will investigate such behaviors in misspecified situations later.
Now, we consider the MDEs via the GM and HM divergences introduced in Chapter 1. First, consider the loss function defined by the GM-divergence:
where is the reference probability measure in . We define as , which we refer to as the GM-estimator. The -estimating equation is given by
| (2.17) |
where . Secondly, consider the loss function defined by the HM-divergence:
The -model can be viewed as an inverse-weighted probability model on the account of
We define the HM estimator by . The -estimating equation is given by
We note from the discussion in Section 2 that and are equal to and with ; and are equal to and with . We will discuss the dependence on the reference measure , in which we like to elucidate which choice of gives a reasonable performance in the presence of possible model misspecification.
We focus on the GLM framework in which we look into the formula on the -divergence. Then, the choice of the reference measure should be paid attentions to the -divergence. The original reference measure is changed to such that Hence, the model is given by withr respect to . We note that is a probability measure since the RN-derivative is equal to defined in (2.3) when is a zero vector. This makes the model more mathematically tractable and allows us to use standard statistical methods for estimation and inference. Then, the -expression for is given by
| (2.18) |
This property of reflexiveness is convenient the analysis based on the -divergence. First of all, the -loss function is given by
| (2.19) |
due to the -expression (2.18). The -estimating function is given by
| (2.20) | ||||
We note that the change of the reference measure from to is the key for the minimum -divergence estimation. In fact, the -loss function would not have a closed form as (2.19) unless the reference measure is changed. Here, we remark that the -loss function is a specific example of M-type loss function in (2.4) with a relationship of
The expected loss function is given by
where denotes the expectation under the true distribution . This function attains a global minimum at as discussed around (2.15) in the general framework. Similarly, the GM-loss function is written by
where . The HM loss function is written by
since the -expression becomes when . In accordance with these, all the formulas for the loss functions defined in the general model (2.1) are reasonably transported in GLM. Subsequently, we go on the specific model of GLM to discuss deeper properties.
We have discussed the generalization of the -divergence in the preceding section. The generalized divergence defined in (1.18) in Chapter 2 yields the loss function by
where is a normalizing factor satisfying
| (2.21) |
The similar discussion as in the above conducts
The estimating function is written as
due to assumption (1.19). This implies
which vanishes since all ’s have total mass one as in (2.21). Consequently, we can derive the MD estimator based on the generalized divergence with the -divergence as the standard. In Section 3, we will consider another candidate of for estimation under a Poisson point process model.
2.4 Normal linear regression
Linear regression, one of the most familiar and most widely used statistical techniques, dates back to the 19-th century in the mathematical formulation by Carolus F. Gauss [96]. It originally emerged from the eminent observation of Francis Galton on regression towards the mean at the begging of the 20-th century. Thus, the ordinary least squares method is evolved with the advancement of statistical theory and computational methods. As the application of linear regression expanded, statisticians recognized its sensitivity to outliers. Outliers can significantly influence the regression model’s estimates, leading to misleading results. To address these limitations, robust regression methods were developed. These methods aim to provide estimates that are less affected by outliers or violations of model assumptions like normality of errors or homoscedasticity.
Let be an outcome variable in and be a covariate vector in a subset of . Assume the conditional probability density function (pdf) of given as
| (2.22) |
Thus, the normal linear regression model (2.22) is one of the simplest examples of GLM with an identity link function where is a dispersion parameter. Indeed, is a crucial parameter for assessing model fit. We will discuss the estimation for the parameter later. The KL-divergence between normal distributions is given by
For a given dataset , the negative log-likelihood function is as follows:
The estimating function for is
where is assumed to be known. In fact, it is estimated in a practical situation where is unknown. Equating the estimating function to zero gives the likelihood equations in which the ML-estimator is nothing but the least square estimator. This is a well-known element in statistics with a wide range of applications, where several standard tools for assessing model fit and diagnostics have been established.
On the other hand, robust regression robust methods aim to provide estimates that are less affected by outliers or violations of model assumptions like normality of errors. The key is the introduction of M-estimators, which generalize maximum likelihood estimators. They work by minimizing a sum of a loss function applied to the residuals. The choice of the loss function (such as Huber’s winsorized loss or Tukey’s biweight loss [3]) determines the robustness and efficiency of the estimator. The M-estimator, , of a parameter is obtained by minimizing an objective function, typically defined by a sum of ’s applied to the adjusted residuals:
| (2.23) |
The estimating equation is given by
where .
Here are typical examples:
(1). Quadratic loss: , which is equivalent to the log-likelihood function
(2). Huber’s loss:
(3). Tukey’s loss:
where and are hyper parameters.
We return the discussion for the -estimator. The -divergence is given by
where . The -expression of the normal linear model is given by
where is a normal density function with mean and variance . Hence, the -loss function is given by
which is written as
| (2.24) |
up to a scalar multiplication. Consequently, the -loss function is a specific example of -loss function in (2.23) viewing as . We note that the -estimator is one of M-estimators. The -estimating function is defined as where the score function is defined by
| (2.25) |
The generator function is given as as an M-estimator.
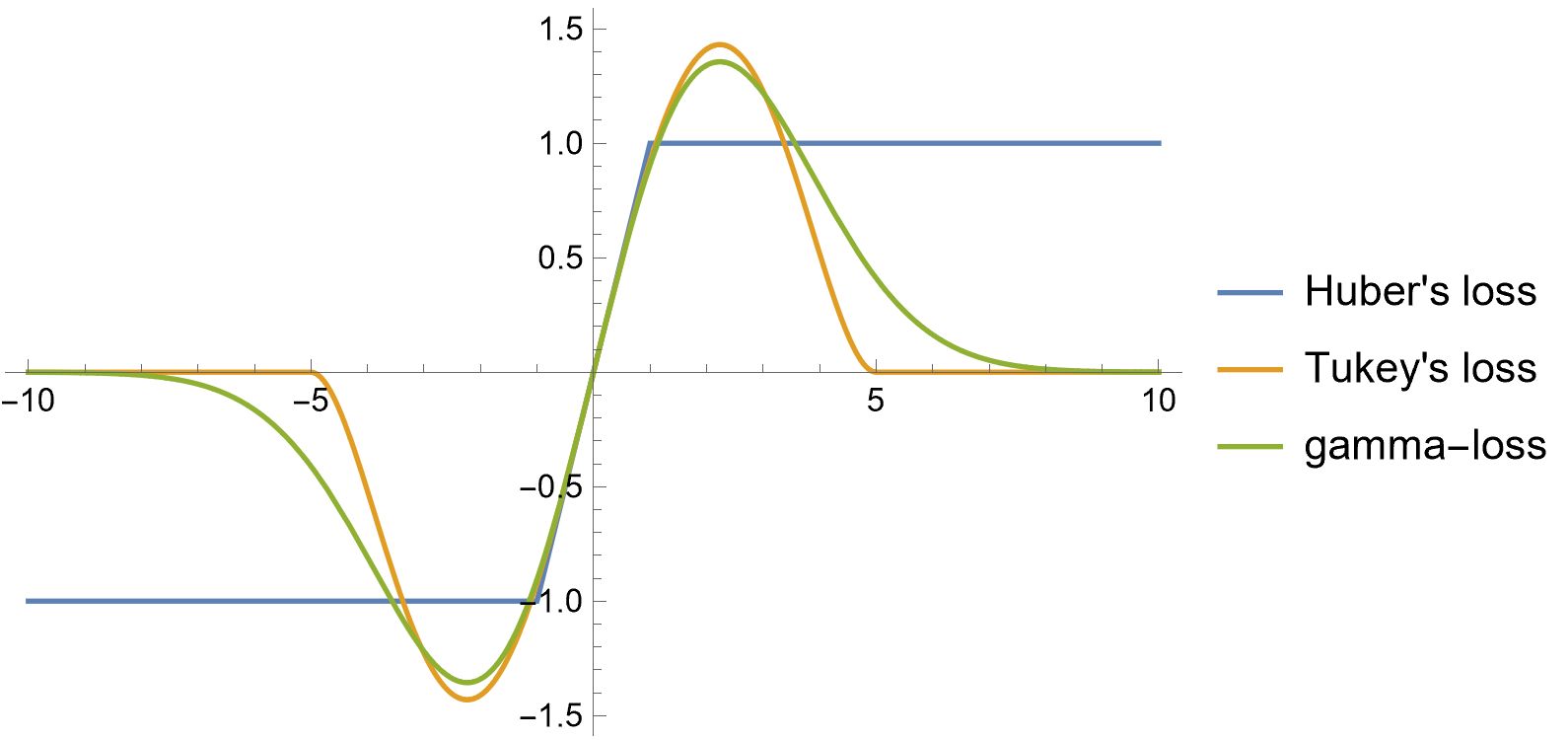
Fig 2.1 displays the plots of the generator functions:
(1). -loss, ,
(2). Huber’s loss,
(3). Tukey’s loss, .
It is observed the generator functions of the -loss and Tukey’s loss are both redescending. This means the influence of each data point on the estimation decreases to zero beyond a certain threshold, effectively eliminating the impact of extreme outliers.
Unlike the quadratic loss and Huber’s loss functions, such redescending loss functions are non-convex. This characteristic makes it more robust but also introduces challenges in optimization, as it can lead to multiple local minimums.
The variance parameter in the normal regression model is referred to as a dispersion parameter in GLM. In a situation where is unknown the likelihood method is similar to the known case. The ML-estimator for is derived by
plugging in . Alternatively, the -estimator for is is derived by the solution of the joint estimating equation combining
with the estimating equation for . Similarly, we can find that the boundedness property for the -score function for holds.
Let us apply the geometric discussion associated with the decision boundary in (2.6) to the normal regression model. We write the estimating function of M-estimator in (2.23) as
for a given dataset . Due to the orthogonal decomposition of , the estimating function is also decomposed into a sum of the orthogonal and horizontal components, , where
We note that this decomposition is the same as that for the GLM in Section . We consider a specific type of contamination in the covariate space such that , where with a fixed scalar depending on . As in the discussion for the general setting of the GLM, and have both strong influences; has no influence. Let us investigate a preferable property for the -estimator applying the decomposition formula above.
Proposition 8.
Let be the -score function defined in (2.25). Then,
| (2.26) |
for any fixed of and any , where is the Euclidean distance.
Proof.
It is written that
where . Therefore,
which is bounded by
This is simplified as
Therefore, (2.26) is concluded for the fixed . ∎
It follows from Proposition 8 that all the estimating scores of the -estimator appropriately lies in a tubular neighborhood
| (2.27) |
surrounding . As a result, the distance from the estimating function to the boundary is bounded, that is,
However, in the limit case of or the ML-estimator, this boundedness property for covariate outlying is broken down. Tukey’s biweight loss estimating function satisfies the boundedness; Huber’s loss estimating function does not satisfy that.
We have a brief study for numerical experiments. Assume that covariate vectors ’s are generated from a bivariate normal distribution , where denotes a 3-dimensional identity matrix. This simulation was designed based on a scenario about the conditional distribution of the response variables ’s as follows.
- Specified model
-
- Misspecified model
-
Here parameters were set as , and with ; with .
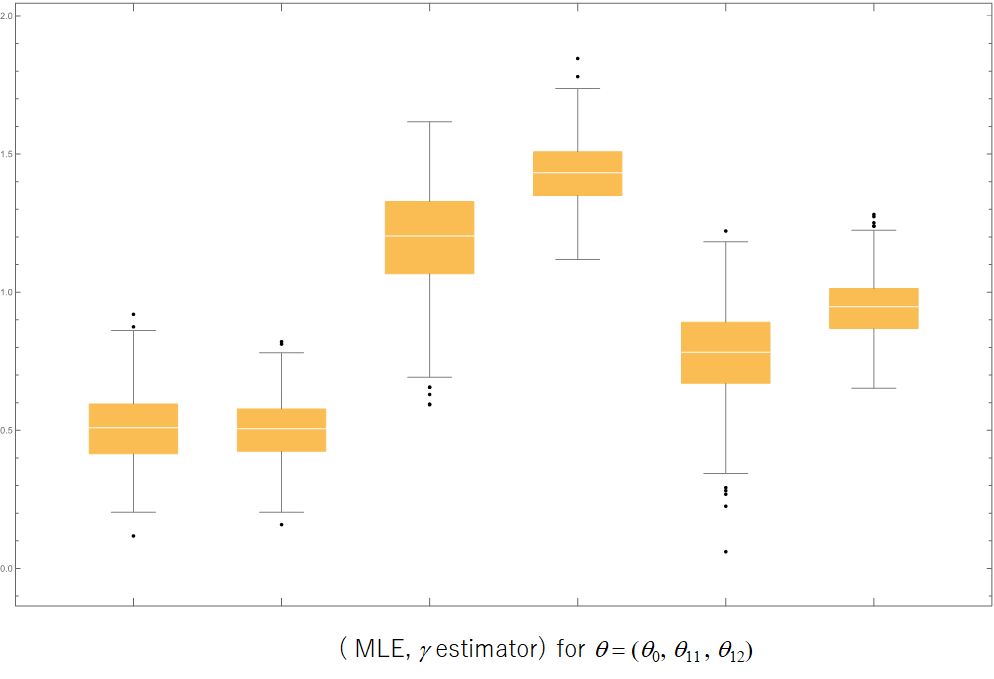
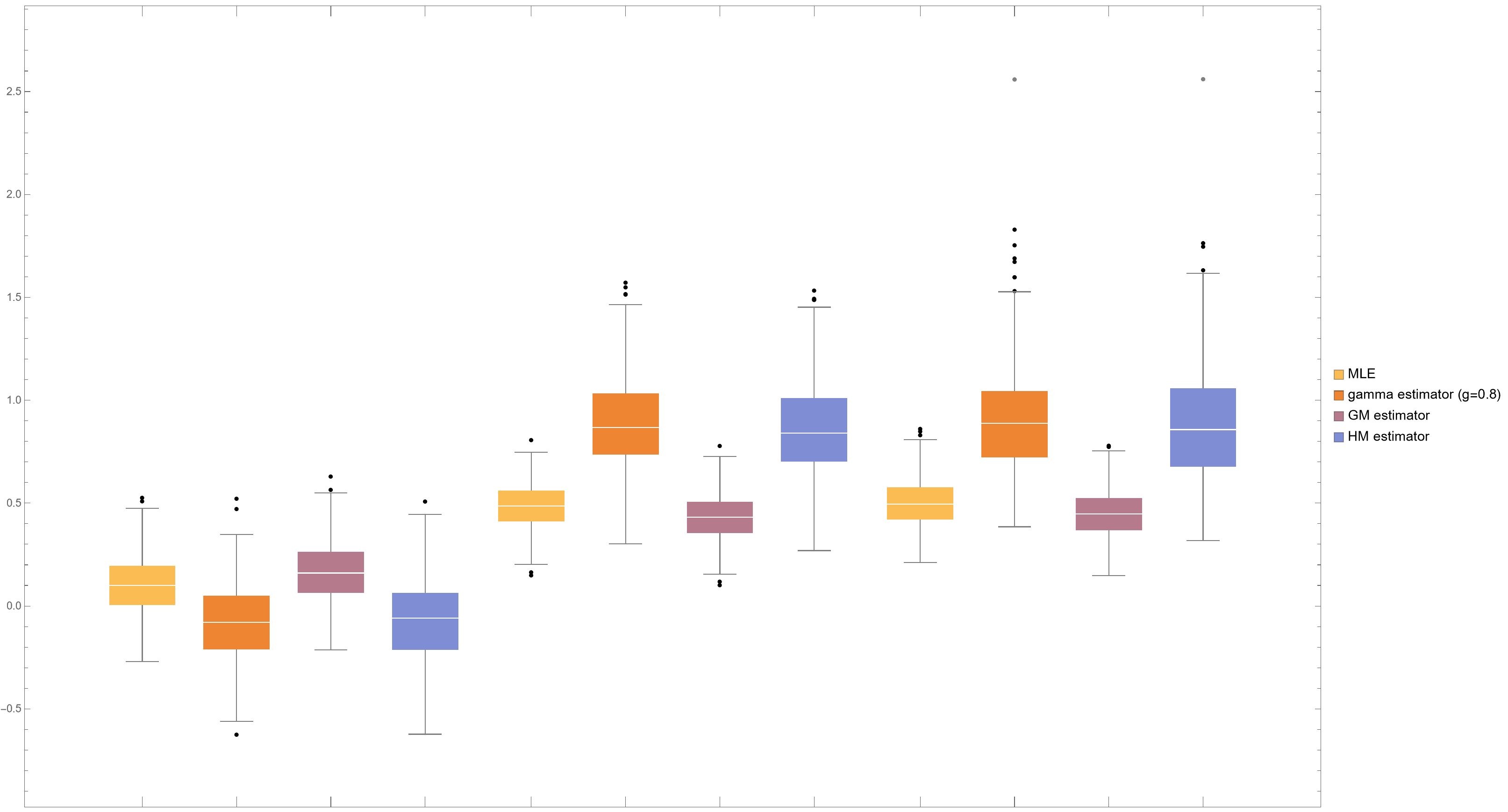
We compared the estimates the ML-estimator and the -estimator with , where the simulation was conducted by 300 replications. In the the case of specified model, the ML-estimator was slightly superior to the -estimator in a point of the root means square estimate (rmse), however the superiority is almost negligible. Next, we suppose a mixture distribution of two normal regression modes in which one was the same model as the above with the mixing probability ; the other was still a normal regression model but the the minus slope vector with the mixing probability . Under such a misspecified setting, -estimator was crucially superior to the ML-estimator, where the rmse of the ML-estimator is more than double that of the -estimator. Thus, the ML-estimator is sensitive to the presence of such a heterogeneous subgroup; the -estimator is robust. Proposition 8 suggests that the effect of the subgroup is substantially suppressed in the estimating function of the -estimator. See Table 2.1 and Figure 2.2 for details.
(a). The case of specified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimate | ||
| -estimate |
(b). The case of misspecified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimate | ||
| -estimate |
2.5 Binary logistic regression
We consider a binary outcome with a value in and a covariate in a subset of . The probability distribution is characterized by a probability mass function (pmf) or the RN-derivative with respect to a counting measure :
which is referred to as the Bernoulli distribution , where is the probability of . A binary regression model is defined by a link function of the systematic component into the random component: so that the conditional pmf given with a linear model is given by
| (2.28) |
The KL-divergence between Bernoulli distributions is given by
For a given dataset , the negative log-likelihood function is given by
and the likelihood equation is written by
| (2.29) |
On the other hand, the -divergence is given by
where is the counting measure on . Note that this depends on the choice of as the reference measure on . The -expression of the logistic model (2.28) is given by
Hence, the -loss function is written by
| (2.30) |
and the -estimating function is written as
where
| (2.31) |
see [49] for the discussion for robust mislabel. See [24, 69, 90, 92, 91, 55] for other type of MDE approaches than the estimation.
The -divergence on the space of Bernoulli distributions is well defined for all real number . Let us fix as , and thus the GM-divergence between Bernoulli distributions is given by
where the reference measure is chosen by . Hence, the GM-loss function is given by
The GM-loss function with the reference measure is equal to the exponential loss function for AdaBoost algorithm discussed for an ensemble learning [30]. The integrated discrimination improvement index via odds [40] is based on the GM-loss function to assess prediction performance. We will give a further discussion in a subsequent chapter. The GM-estimating function is written by
due to for . Therefore, this estimating function is unbiased for any , that is, the expected estimating function conditional on under the logistic model (2.28) is equal to a zero vector.
We discuss which is effective for practical problems in logistic regression applications. In particular, we focus on a problem of imbalanced samples that is an important issue in the binary regression. An imbalanced dataset is one where the distribution of samples across these two classes is not equal. For example, in a medical diagnosis dataset, the number of patients with a rare disease (class 1) may be significantly lower than those without it (class 0). In this way, it is characterized as
There are difficult issues for the model bias, the poor generalization and the inaccurate performance metrics for the prediction. Imbalanced samples can lead to biased or inconsistent estimators, affecting hypothesis tests and confidence intervals. For these problem resampling techniques have been exploited by oversampling the minority class or undersampling the majority class can balance the dataset. Also, the cost-sensitive Learning introduces a cost matrix to penalize misclassification of the minority class more heavily. The asymmetric logistic regression is proposed introducing a new parameter to account for data complexity [55]. They observe that this parameter controls the influence from imbalanced sampling. Here we tackle with this problem by the GM-estimator choosing an appropriate reference distribution in the GM-loss function. We select as the reference measure, where is the proportion of the negative sample, namely . Then, the resultant loss function is given by
| (2.32) |
We refer this to as the inverse-weighted GM-loss function since the weight
Hence, the estimating function is given by
Equating the estimating function to zero gives the equality between two sums of positive and negative samples:
Alternatively, the likelihood estimating equation is written as
Both of estimating equations are unbiased, however the weightings are contrast each other.
We conduct a brief study for numerical experiments. Assume that covariate vectors are generated from a mixture of bivariate normal distributions as
where denotes a 2-dimensional identity matrix. Here, we set as , and the mixture ratio will be taken by some fixed values. The outcome variables are generated from Bernoulli distributions as , where
where we set as and This simulation is designed to have imbalanced samples such that the positive sample proportion approximately becomes near .
We compared the ML-estimator with the inverse-weighted GM estimator with 30 replications. Thus, we observe that the GM estimator have a better performance over the ML-estimator in the sense of true positive rate. Table LABEL:TPRTNR is the list of the true positive and negative rates based on test samples with size . Note that two label conditional distributions are are . These are set to be sufficiently separated from each other. Hence, the classification problem becomes extremely an easy task when is a moderate value. Both ML-estimator and GM estimator have good performance in cases of . Alternatively, we observe that the true positive rate for GM estimator is considerably higher than that of ML-estimator in a situation of imbalance samples as in either case of .
| MLE | GME | |
|---|---|---|
denotes a pair of the true positive and negative rates and .
We next focus on the HM-divergence (-divergence, ):
where the reference measure is determined by . The HM-loss function is derived as
for the logistic model (2.28). Note that the HM-loss function is the -loss function with , which the -expression is reduced to
Hence, the HM-estimating function is written as
This is a weighted likelihood score function with the conditional variance of as the weight function. We will observe that this weighting has an effective key for the HM estimator to be robust for covariate outliers.
Let us investigate the behavior of the estimating function of the -estimator. In general, is unbiased, that is, under the conditional expectation with the true distribution with the pmf . However, this property easily violated if the expectation is taken by a misspecified distribution with the pmf other than the true distribution [12, 13, 53]. Hence, we look into the expected estimating function under the misspecified model.
Proposition 9.
Proof.
It is written from (2.31) that
| (2.34) |
Hence, if , then
where
| (2.35) |
We observe that, if or , then
This concludes (2.33).
∎
.
We note that Proposition 9 focuses only on the logistic model (2.28), however such a boundedness property holds in both the probit model and the complementary log-log model.
We consider a geometric understanding for the bounded property in (2.33). In GLM, the linear predictor is written by , where and are referred to as a slope vector and intercept term, respectively. The decision boundary is defined as as in (2.6). The Euclidean distance of into ,
is referred to as the margin of from the decision boundary , which plays.a central role on the support vector machine [14]. Let
| (2.36) |
This is the -tubular neighborhood including . In this perspective, Proposition 9 states for any that the conditional expectation of -estimating function is in the tubular neighborhood with probability one even under the misspecified distribution outside the parametric model (2.28). On the other hands, the likelihood estimating function does not satisfy such a stable property because the margin of the conditional expectation becomes unbounded. Therefore, we result that the -estimator is robust for misspecification for the model for or ; while the ML-estimator is not robust.
We observe in the Euclidean geometric view that, for a feature vector of , the decision hyperplane decompose into orthogonal and tangential components as , where and . Note and . In accordance with this geometric view, we give more insights on the robust performance for the -estimator class. We write the -estimating function (2.31) by . Then,
| (2.37) |
Therefore, we conclude that
| (2.38) |
Thus, we observe a robust property of the -estimator in a more direct perspective.
Proposition 10.
Assume or . Then, the -estimating function based on a dataset satisfies
| (2.39) |
Proof.
The log-likelihood estimating function is given by
| (2.41) |
Hence, is unbounded in since either of two terms in (2.41) diverges to infinity as goes to infinity. The GM-estimating function is written by
This implies that is unbounded.
We have a brief study for numerical experiments in two types of sampling. One is based on the covariate distribution conditional on the outcome , which is widely analyzed in case-control studies. The other is based on the conditional distribution of given the covariate vector , which is common in cohort-control studies. First, we consider a model of an outcome-conditional distribution. Assume that the conditional distribution of given is a bivariate normal distribution , where is a 2-dimensional identity matrix. Then, the marginal distribution of is written as , where . The the conditional pmf of given is given by
due to the Bayes formula, where and . Let The simulation was conducted based on a scenario about the positive and negative samples with and , respectively, as follows.
(a). Specified model: and
(b). Misspecified model:
and
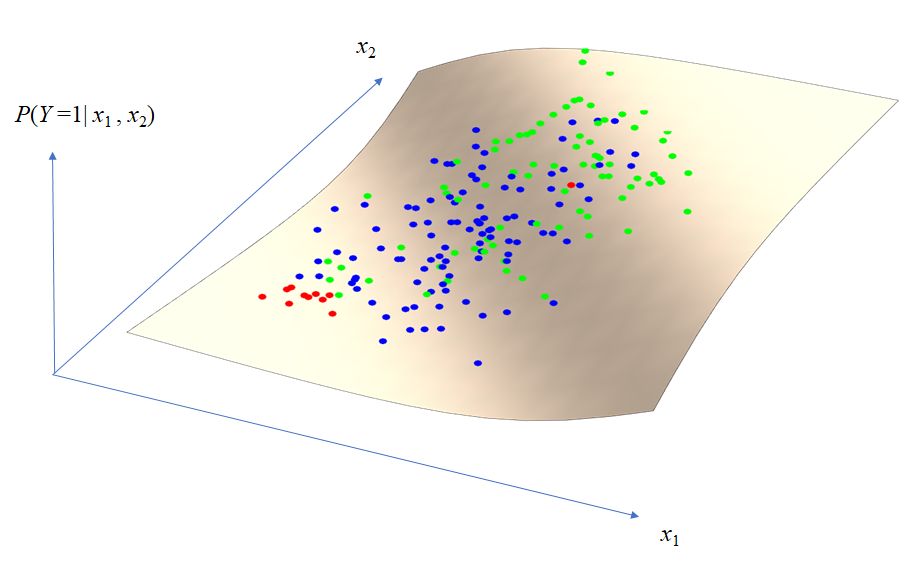
Here parameters were set as , , and , so that . Figure 2.3 shows the plot of 103 negative samples (Blue), 87 negative samples (Green), 10 negative outliers (Red) on the logistic model surface . Thus, 10 negative outliers are away from the hull of 87 negative samples.
We compared the estimates the ML-estimator , the -estimator with , the GM-estimator and -estimator , where the simulation was conducted by 300 replications. See Table 2.3 for the performance of four estimators in case (a) and (b) and Figure 2.4 for the box-whisker plot in case (b). In the case (a) of specified model, the ML-estimator was superior to other estimators in a point of the root means square estimate (rmse), however the superiority is subtle. Next, we observe for case (b) of misspecified model in which the conditional distribution given is contaminated with a normal distribution with mixing ratio . Under this setting, -estimator and the HM -estimator were substantially robust; the ML-estimator and GM-estimator were sensitive to the misspecification. Upon closer observation, it becomes apparent that -estimator and the HM -estimator were superior to the ML-estimator and GM-estimator in the bias behaviors rather than the variance ones as shown in Figure 2.4. This observation is consistent with what Proposition (10) asserts: The estimator has a boundedness property if or . Because the ML-estimator, the GM-estimator and the HM-estimator equal the -estimators with , respectively.
(a). The case of specified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| GM-estimate | ||
| HM-estimate |
(b). The case of misspecified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| GM-estimate | ||
| HM-estimate |
Second, we consider a model of a covariate-conditional distribution of . Assume that follows a standard normal distribution and a conditional distribution of given follows a logistic model
The simulation was conducted based on a scenario as follows.
(a). Specified model:
(b). Misspecified model:
Here parameters were set as . Figure 2.3 shows the plot of 103 negative samples (Blue), 87 negative samples (Green), 10 negative outliers (Red) on the logistic model surface . Thus, 10 negative outliers are away from the hull of 87 negative samples.
Similarly, a comparison among the ML-estimator , the -estimator with , the GM-estimator and -estimator with replications. See Table 2.4. In the case (a), the ML-estimator was slightly superior to other estimators. For case (b), -estimator and the HM -estimator were more robust; the ML-estimator and GM-estimator, which was the same tendency as the case of the outcome-conditional model.
(a). The case of specified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| GM-estimate | ||
| HM-estimate |
(b). The case of misspecified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| GM-estimate | ||
| HM-estimate |
2.6 Multiclass logistic regression
We consider a situation where an outcome variable has a value in and a covariate with a value in a subset of . The probability distribution is given by a probability mass function (pmf)
which is referred to as the categorical distribution , where is the probability vector, with being .
Remark 2.
We begin with a simple case of estimating without any covariates. Let be a random sample drawn from . Then, the estimators discussed here equal the observed frequency vector as follows. First of all, the ML-estimator is the observed frequency vector with components , where . Next, the -loss function
is written as . We observe
up to a constant. Therefore, the -estimator for is equal to for all . Similarly, the -estimator is equal to for all . However the -estimator does not satisfy that except for the limit case of to , or the ML-estimator.
We return the discussion for the regression model with a covariate vector . A multiclass logistic regression model is defined by a soft max function as a link function of the systematic component into the random component. The conditional pmf given is given by
| (2.44) |
which is referred as a multinomial logistic model, where and . The KL-divergence between categorical distributions is given by
For a given dataset , the negative log-likelihood function is given by
where we set if . The likelihood equation is written by the -th component:
for . The -divergence is given by
We remark that the -expression defined in (2.12) is given by
where is in the multi logistic model (2.44). Hence, the -loss function is given by
and the -estimating equation is written as
where is defined by
| (2.45) |
The GM-divergence between categorical distributions:
where the reference distribution is chosen by . Hence, the GM-loss function is given by
where . We will have a further discussion later such that the GM-loss is closely related to the exponential loss for Multiclass AdaBoost algorithm. The GM-estimating function is given by
Finally, the HM-divergence is
The HM-loss function is derived as
for the logistic model (2.44) noting . This is the sum of squared probabilities of the inverse label. Hence, the HM-estimating function is written as
Let us have a brief look at the behavior of the -estimating function in the presence of misspecification of the parametric model in the multiclass logistic distribution (2.44). Basically, most of properties are similar to those in the Bernoulli logistic model.
Proposition 11.
Consider the -estimating function under a multiclass logistic model (2.44). Assume or . Then,
| (2.46) |
where
| (2.47) |
with
Proof.
The -th linear predictor is written by with the slope vector and the intercept . The -th decision boundary is given by
| (2.49) |
In a context of prediction, a predictor for the label based on a given feature vector is give by
which is equal to the Bayes rule under the multiclass logistic model, where in the parametrization as in (2.44). We observe through the discussion similar to Proposition 9 in the situation of the Bernoulli logistic model that is uniformly bounded in even under any misspecified distribution outside the parametric model. Therefore, we result that the -estimator has such a stable behavior for all the sample if is in a range . The ML-estimator and the GM-estimators equals -estimators with and , respectively. Therefore, both ’s are outside the range, which suggests they are suffered from the unboundedness.
We next study ordinal regression, also known as ordinal classification. Consider an ordinal outcome having values in . The probability of falling into a certain category or lower is modeled as
| (2.50) |
for , where . The model (2.50) is referred to as ordinal logistic model noting with a logistic distribution . Here, the thresholds are assumed to ensure that the probability statement (2.50) makes sense. Each threshold effectively sets a boundary point on the latent continuous scale, beyond which the likelihood of higher category outcomes increases. The difference between consecutive thresholds also gives insight into the ”distance” or discrimination between adjacent categories on the latent scale, governed by the predictors.
For a given observations the negative log-likelihood function
where . Similarly, the -loss function can be given in a straightforward manner. However, these loss functions seem complicated since the conditional probability is introduced indirectly as a difference between the cumulative distribution functions ’s.
To address this issue, it is treated that each threshold as a separate binarized response, effectively turning the ordinal regression problem into multiple binary regression problems. Let and be cumulative distribution functions on . We define a dichotomized cross entropy
This is a sum of the cross entropys between a Bernoulli distributions and . The KL divergence is given as . Thus, the dichotomized log-likelihood function is given by
where . Note , where denotes the expectation under the distribution and . Under the ordinal logistic model (2.50),
On the other hand, the dichotomized -loss function is given by
where is the -expression for , that is,
Under the ordinary logistic model (2.50),
If is taken a limit to , then it is reduced the GM-loss function
if , then it is reduced the HM-loss function
Remark 3.
Let us discuss an extension for dichotomized loss functions to a setting where the outcome space is a subset of . Consider a partition of such that . Then, the model is reduced to a categorical distribution , where with . The cross entropy is reduced to
and the negative log-likelihood function is reduced to
Similarly, the -cross entropy is reduced to
and the -loss function is reduced to
There are some parametric models similar to the present model including ordered probit models, continuation ratio model and adjacent categories logit model. The coefficients in ordinal regression models tell us about the change in the odds of being in a higher ordered category as the predictor increases. Importantly, because of the ordered nature of the outcomes, the interpretation of these coefficients gets tied not just to changes between specific categories but to changes across the order of categories. Ordinal regression is useful in fields like social sciences, marketing, and health sciences, where rating scales (like agreement, satisfaction, pain scales) are common and the assumption of equidistant categories is not reasonable. This method respects the order within the categories, which could be ignored in standard multiclass approaches.
2.7 Poisson regression model
The Poisson regression model is a member of generalized linear model (GLM), which is typically used for count data. When the outcome variable is a count (i.e., number of times an event occurs), the Poisson regression model is a suitable approach to analyze the relationship between the count and explanatory variables. The key assumptions behind the Poisson regression model are that the mean and variance of the outcome variable are equal, and the observations are independent of each other. The primary objective of Poisson regression is to model the expected count of an event occurring, given a set of explanatory variables. The model provides a framework to estimate the log rate of events occurring, which can be back-transformed to provide an estimate of the event count at different levels of the explanatory variables.
Let be a response variable having a value in and be a covariate variable with a value in a subset of . A Poisson distribution with an intensity parameter has a probability mass function (pmf) given by
for of . A Poisson regression model to a count given is defined by the probability distribution with pmf
| (2.51) |
The link function of the regression function to the canonical variable is a logarithmic function, , in which (2.51) is referred to as a log-linear model. The likelihood principle gives the negative log-likelihood function by
for a given dataset . Here the term can be neglected since it is a constant in . In effect, the estimating function is give by
We see from the general theory for the likelihood method that the ML-estimator for is consistent with .
Next, we consider the -divergence and its applications to the Poisson model. For this, we fix a reference measure as . Then, the RN-derivative of a conditional probability measure with respect to is given by
and hence the -expression for this is given by
The -cross entropy between Poisson distribution is given by
where is the reference measure defined by for . Note that this choice of enable us to having such an tractable form of this entropy. Hence, the -loss function is given by
The estimating function is given by
where
| (2.52) |
where
We investigate the unbiased property for the estimating function.
Proposition 12.
Proof.
By definition, we have
where . The following limit holds for positive constants :
| (2.53) |
Thus, we immediately observe
due to (2.53). This concludes that is a bounded function in for any . ∎
It is noted that the function in (2.53) has a mild shape as in Figure 2.6. Thus, the property of redescending is characteristic in the -estimating function. The graph is rapidly approaching to when the absolute value of the canonical value increases.
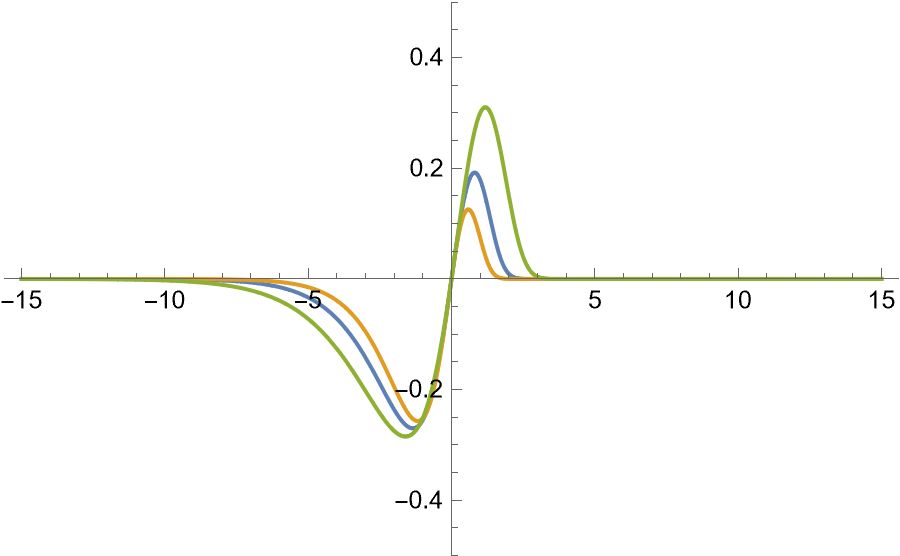
We remark that denotes the margin of the estimating function to the boundary . The margin is bounded in but unbounded in , in which the behavior is delicate as seen in Figure 2.7. When , the boundedness is almost broken down in a practical numerical sense. The green lines are plotted for a curve In this way, the margin becomes a zero on the green line. The behavior is found mild in a region away from the green line when is a small positive value; that is found unbounded there when equals a zero, or the likelihood case. This suggests a robust and efficient property for the -estimator with a positive small . To check this, we consider conduct a numerical experiment where there occurs a misspecification for the Poisson log-linear model in (2.51). The synthetic dataset is generated from a mixture distribution, in which a heterogeneous subgroup is generated from a Poisson distribution with a small proportion in addition to a normal group from with the proportion . Here is determined from plausible scenarios. We generate ’s from a trivariate normal distribution and ’s from
Here the intercept is set as and the slope vector is as in the normal group; while the slope vector is set as either or a zero vector in the minor group. It is suggested that the minor group has a reverse association to the normal group, or no reaction to the covariate. If there is no misspecification above, or equivalently , then the ML-estimator performs better than the -estimator. However, the ML-estimator is sensitive to such misspecification; the -estimator has robust performance, see Table 2.5. Here, the sample size is set as and the replication number is as . The is selected as , in which larger values of yield unreasonable estimates. This is because the the margin of the -estimator has extreme behavior as noted around Figure 2.7.
(a). The case of
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate |
(b). The case of and
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate |
(c). The case of and
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate |
In this section, we focus on the -divergence, within the framework of the Poisson regression model. The -divergence provides a robust alternative to the traditional ML estimator, which are sensitive to model misspecification and outliers. The robustness of the estimator was examined from a geometric viewpoint, highlighting the behavior of the estimating function in the feature space and its relationship with the prediction level set. The potential of -divergence in enhancing model robustness is emphasized, with suggestions for future research exploring its application in high-dimensional data scenarios and machine learning contexts, such as deep learning and transfer learning. This work not only contributes to the theoretical understanding of statistical estimation methods but also offers practical insights for their application in various fields, ranging from biostatistics to machine learning. For future work, it would be beneficial to further investigate the theoretical underpinnings of -divergence in a wider range of statistical models and to explore its application in more complex and high-dimensional data scenarios, including machine learning contexts like multi-task learning and meta-learning .
2.8 Concluding remarks
In this chapter we provide a comprehensive exploration of MDEs, particularly -divergence, within regression models, see [70, 74, 76] for other applications of unsupervised learning. This addresses the challenges posed by model misspecification, which can lead to biased estimates and inaccuracies, and proposes MDEs as a robust solution. We have discussed various regression models, including normal, logistic, and Poisson, demonstrating the efficacy of -divergence in handling outliers and model inconsistencies. In particular, the robustness for the estimator is pursued in a geometric perspective for the estimation function in the feature space. This elucidates the intrinsic relationship between the feature space outcome space such that the behavior of the estimating function in the product space of the feature and outcome spaces is characterized the projection length to the prediction level set. It concludes with numerical experiments, showcasing the superiority of -estimators over traditional maximum likelihood estimators in certain misspecified models, thereby highlighting the practical benefits of MDEs in statistical estimation and inference. For a detailed conclusion, it is important to recognize the significant role of -divergence in enhancing model robustness against biases and misspecifications. Emphasizing its applicability across different statistical models, the chapter underscores the potential of MDEs to improve the reliability and accuracy of statistical inferences, particularly in complex or imperfect real-world data scenarios. This work will not only contribute to the theoretical understanding of statistical estimation methods but also offer practical insights for their application in diverse fields, ranging from biostatistics to machine learning.
For future work, considering the promising results of -divergence in regression models, it could be beneficial to explore its application in more complex and high-dimensional data scenarios. This includes delving into machine learning contexts, such as deep learning or neural networks, where robustness against data imperfections is crucial. The machine learning is rapidly developing activity areas towards generative models for documents, images and movies, in which the architecture is in a huge scale for high-dimensional vector and matrix computations to establish pre-trained models such as large language models. There is a challenging direction to incorporate the -divergence approach into such areas including multi-task leaning, transfer leaning, meta leaning and so forth. For example, transfer learning is important to strengthen the empirical knowledge for target source. Few-shot learning is deeply intertwined with transfer learning. In fact, most few-shot learning approaches are based on the principles of transfer learning. The idea is to pre-train a model on a related task with ample data (source domain) and then fine-tune or adapt this model to the new task (target domain) with limited data. This approach leverages the knowledge (features, representations) acquired during the pre-training phase to make accurate predictions in the few-shot scenario. Additionally, investigating the theoretical underpinnings of -divergence in a wider range of statistical models could further solidify its role as a versatile and robust tool in statistical estimation and inference.
In transfer learning, the goal is to leverage knowledge from a source domain to improve learning in a target domain. The -divergence can be used to ensure robust parameter estimation during this process. Let be the source domain with distribution and parameter , and be the target domain with distribution and parameter . The objective is to minimize a loss function that incorporates both source and target domains:
where is a regularization parameter balancing the influence of the source model on the target model. Using -divergence, the loss functions and are defined as:
where is the empirical distribution in the source domain, and denotes the -divergence. The gradients for updating the parameters are given by:
These gradients take into account the robustness properties of the -divergence, reducing sensitivity to outliers and model misspecifications.
In multi-task learning, the aim is to learn multiple related tasks simultaneously, sharing knowledge among them to improve overall performance. The -divergence helps in creating a robust shared representation. Let denote the -th task with parameter , and let be the shared parameter space. The combined loss function for multiple tasks is:
where are weights for each task, and is the loss for task . The task-specific losses are defined using -divergence:
where is the empirical distribution for task . The gradients for updating the shared parameters and task-specific parameters are:
The -divergence ensures that the updates are robust to outliers and anomalies within each task’s data. By using a divergence measure that penalizes discrepancies between distributions, the model learns shared features that are less sensitive to noise and specific to individual tasks.
Efficiently optimizing the -divergence in high-dimensional parameter spaces remains challenging. Developing scalable algorithms that maintain robustness properties is crucial. Further theoretical exploration of the convergence properties and bounds of -divergence-based estimators in transfer and multi-task learning scenarios. Applying these robust methods to diverse real-world datasets in fields like healthcare, finance, and natural language processing to validate their practical effectiveness and robustness. By integrating -divergence into transfer and multi-task learning frameworks, we can enhance the robustness and adaptability of machine learning models, making them more reliable in varied and complex data environments.
Chapter 3 Minimum divergence for Poisson point process
This study introduces a robust alternative to traditional species distribution models (SDMs) using Poisson Point Processes (PPP) and new divergence measures. We propose the -estimator, a method grounded in cumulative distribution functions, offering enhanced accuracy and robustness over maximum likelihood (ML) estimation, especially under model misspecification. Our simulations highlight its superior performance and practical applicability in ecological studies, marking a significant step forward in ecological modeling for biodiversity conservation.
3.1 Introduction
Species distribution models (SDMs) are crucial in ecology for mapping the distribution of species across various habitats and geographical areas [37, 29, 63, 88, 68]. These models play an essential role in enhancing our understanding of biodiversity patterns, predicting changes in species distributions due to climate change, and guiding conservation and management efforts [60]. The MaxEnt (Maximum Entropy) approach to species distribution modeling represents a pivotal methodology in ecology, especially in the context of predicting species distributions under various environmental conditions [77]. This approach is particularly favored for its ability to handle presence-only data, a common scenario in ecological studies where the absence of a species is often unrecorded or unknown [26]. Alternatively, the approach based on Poisson Point Process (PPP) gives more comprehensive understandings for random events scattered across a certain space or time [81]. It is particularly powerful in various fields including ecology, seismology, telecommunications, and spatial statistics. We review quickly the framework for a PPP, cf. [89] for practical applications focusing on ecological studies and [57, 45] for statistical learning perspectives. The close relation between the MaxEnt and PPP approaches are rigorously discussed in [82].
In this chapter, we introduce an innovative approach that employs Poisson Point Processes (PPP) along with alternative divergence measures to enhance the robustness and efficiency of SDMs [84]. We propose the use of the -estimator, a novel method based on cumulative distribution functions, which offers a promising alternative to ML-estimator, particularly in the presence of model misspecification. Traditional approaches, such as ML estimation, often grapple with issues of model misspecification, leading to inaccurate predictions. Our approach is evaluated through a series of simulations, demonstrating its superiority over traditional methods in terms of accuracy and robustness. The paper also explores the computational aspects of these estimators, providing insights into their practical application in ecological studies. By addressing key challenges in SDM estimation, our methodology paves the way for more reliable and effective ecological modeling, essential for biodiversity conservation and ecological research.
Let be a subset of to be provided observed points. Then the event space is given by the collection of all possible finite subsets of as a union of pairs in addition to , where denotes an empty set. Thus, the event space comprises pairs of the set of observed points and the number . Let be a positive function on that is called an intensity function. A PPP defined on is described by the intensity function in a two-step procedure for any realization of .
-
(i)
The number is non-negative and generated from a Poisson distribution. This distribution, denoted as , has a probability mass function (pmf) given by
where with an intensity function on .
-
(ii)
The sequence in is obtained by independent and identically distributed sample of a random variable on with probability density function (pdf) given by
for .
This description covers the basic statistical structure of the Poison point process. The joint random variable has a pdf written as
| (3.1) |
where . Thus, the intensity function characterizes the pdf of the PPP. The set of all the intensity function has a one-to-one correspondence with the set of all the distributions of the PPPs. Subsequently, we will discuss divergence measures on intensity functions rather than pdfs.
3.2 Species distribution model
Species Distribution Models (SDMs) are crucial tools in ecology for understanding and predicting species distributions across spatial landscapes. The inhomogeneous PPP plays a significant role in enhancing the functionality and accuracy of these models due to its ability to handle spatial heterogeneity, which is often a characteristic of ecological data. Ecological landscapes are inherently heterogeneous with varying attributes such as vegetation, soil types, and climatic conditions. The inhomogeneous PPP accommodates this spatial heterogeneity by allowing the event rate to vary across space, thereby enabling a more realistic modeling of species distributions. This can incorporate environmental covariates to model the intensity function of the point process, which in turn helps in understanding how different environmental factors influence species distribution. This is crucial for both theoretical ecological studies and practical conservation planning [56].
If presence and absence data are available, we can employ familiar statistical method such as the logistic model, the random forest and other binary classification algorithms. However, ecological datasets often consist of presence-only records, which can be a challenge for traditional statistical models. We focus on a statistical analysis for presence-only-data, in which the inhomogeneous modeling for PPPs can effectively handle presence-only data, making it a powerful tool for species distribution model in data-scarce scenarios.
Let us introduce a SDM in the framework of PPP discussed above. Suppose that we get a presence dataset, say , or a set of observed points for a species in a study area . Then, we build a statistical model of an intensity function driving a PPP on , in which a parametric model is given by
| (3.2) |
called a species distribution model (SDM), where is an unknown parameter in the space . The pdf of the joint random variable is written as
due to (3.1), where and . In ecological terms, this can be understood as recording the locations (e.g., GPS coordinates) where a particular species has been observed. The pdf here helps in modeling the likelihood of finding the species at different locations within the study area, considering various environmental factors. Typically, we shall consider a log-linear model
| (3.3) |
with , a feature vector , a slope vector and an intercept . Here consists environmental characteristics such as geographical, climatic and other factors influencing the habitation of the species. Then, parameter estimation is key in SDMs to understand the relationships between species distributions and environmental covariates. The ML-estimator is a common approach used in PPP to estimate these parameters, which in turn, refines the SDM.
The negative log-likelihood function based on an observation sequence is given by
| (3.4) |
Here the cumulative intensity is usually approximated as
| (3.5) |
by Gaussian quadrature, where are the centers of the grid cells containing no presence location and is a quadrature weight for a grid cell area. The approximated estimating equation is given by
| (3.6) |
where is an indicator for presence, that is, if and otherwise.
Let and be probability density functions (pdf) of two PPPs, where is a realization. Due to the discussion above, the pdfs are written as
| (3.7) |
in which and have a one-to-one correspondence, and and have also the same property. The Kullback-Leibler (KL) divergence between and is defined by the difference between the cross entropy and the diagonal entropy as , where the cross entropy is defined by
with the expectation with the pdf . This is written as
| (3.8) |
Thus, the KL-divergence is
| (3.9) |
see [57] for detailed derivations. This can be seen as a way to assess the effectiveness of an ecological model. For instance, how well does our model predict where a species will be found, based on environmental factors like climate, soil type, or vegetation? The closer our model’s predictions are to the actual observations, the better it is at explaining the species’ distribution. In effect, coincides with the extended KL-divergence between intensity functions and . Here, the term in the integrand of (3.9) should be added to the standard form since both and in general do not have total mass one.
Let be an observations having a pdf . We consider the expected value under the true pdf that is given by
noting a familiar formula for a random sum in PPP:
| (3.10) |
where denotes the expectation with the pdf . This is nothing but the cross entropy between intensity functions and . In accordance, we observe a close relationship between the log-likelihood and the KL-divergence that is parallel to the discussion around (2.2) in chapter 3. In effect,
This relation concludes the consistency of the ML-estimator for the true value noting . This suggests that the method used to estimate the impact of environmental factors on species distribution is dependable. In practical terms, this means ecologists can trust the model to make accurate predictions about where a species might be found, based on environmental data.
3.3 Divergence measures on intensity functions
We would like to extend the minimum divergence method for estimating to estimating a SDM. The main objective is to propose an alternative to the maximum likelihood method, aiming to enhance robustness and expedite computation. We have observed the close relationship between the log-likelihood and the KL-divergence in the previous section. Fortunately, the empirical form of the KL-divergence is matched with the log-likelihood function in the framework of the SDM. We remark that a fact that the KL-divergence between PPPs is equal to the KL-divergence between its intensity functions is essential for ensuring this property. However, this key relation does not hold in the situation for the power divergence.
First, we review a formula for random sum and product in PPP, which is gently and comprehensively discussed in [89].
Proposition 13.
Let be a realization of PPP with an intensity function on an area . Then, for any integrable function ,
| (3.11) |
and
Proof.
By definition,
Similarly,
∎
Proposition 13 gives interesting properties of the random sum with the random product, see section 2.6 in [89] for further discussion and historical backgrounds. In ecology, this can be interpreted as predicting the total impact or effect of a particular environmental factor (represented by ) across all locations where a species is observed within a study area . For example, could represent the level of a specific nutrient or habitat quality at each observation point . The integral then sums up these effects across the entire habitat, providing a comprehensive view of how the environmental factor influences the species across its distribution. This formula can be used in SDMs to quantify the cumulative effect of environmental variables on species presence. For instance, it could help in assessing how total food availability or habitat suitability across a landscape influences the likelihood of species presence. By integrating such ecological factors into the SDM, researchers can gain insights into the species’ habitat preferences and distribution patterns. Understanding the cumulative impact of environmental factors is crucial for conservation planning and management. This approach helps identify critical areas that contribute significantly to species survival and can guide habitat restoration or protection efforts. For instance, if the model shows that certain areas have a high cumulative impact on species presence, these areas might be prioritized for conservation.
Second, we introduce divergence measures to apply the estimation for a species distributional model employing the formula introduced in Proposition 13. The -divergence between probability measures and of PPPs with RN-derivatives and in (3.7) is given by
Here the cross -entropy is defined by
where denote the expectation with respect to . Accordingly, the -cross entropy between probability distributions and having the intensity functions and , respectively, is written as
since
| (3.12) |
due to Proposition 13. However, it is difficult to give an empirical expression of for a given realization generated from . In accordance, we consider another type of divergence.
Consider the log -divergence between and that is defined by
This is written as
| (3.13) |
Therefore, the loss function is induced as
for a SDM (3.2). This loss function has totally different from the negative log-likelihood. In a regression model, and yield the same loss function; while in a PPP model only yield the loss functions .
We observe that the property about random sum and product leads to delicate differences among one-to-one transformed divergence measures. So, we consider a divergence measure directly defined on the space of intensity functions other than on that of probability distributions of PPPs. The -divergence is given by
| (3.14) |
The -divergence is given by
The loss functions corresponding to these are given by
| (3.15) |
and
| (3.16) |
And, the estimating functions corresponding to these are given by
and
| (3.17) |
A divergence measure between two PPPs is written by a functional with respect to intensity functions induced by them. We observe an interesting relationship from this viewpoint.
Proposition 14.
Proof is immediate by definition.
Essentially, satisfies the scale invariance which expresses an angle between an rather than a distance between them; does not satisfy such invariance in the intensity function space. Thus, they are totally different characteristics, however the connection of probability distributions and their intensity functions for PPPs entails this coincidence. It follows from Proposition 14 that the GM-divergence equals the Itakura-Saito divergence, that is
Hence, the GM-loss function is given by
and the estimating function is
| (3.18) |
Proposition 15.
Assume a log-linear model with a feature vector . Then, the estimating function of the -estimator is given by
| (3.19) |
where .
Equating to zero satisfies
| (3.20) |
by the quadrature approximation. This implies that the inverse intensity weighted mean for presence data is equal to the region mean for . The learning algorithm to solve the estimating equation (3.20) to get the GM-estimator needs only the update of the inverse intensity mean for the presence during without any updates for the region mean during the iteration process. In this regard, the computational cost for the -estimator frequently becomes huge for a large set of quadrature points. For example, it needs to evaluate the quadrature approximation in the likelihood equation (3.6) during iteration process for obtaining the ML-estimator. On the other hand, such evaluation step is free in the algorithm for obtaining the GM-estimator.
Finally, we look into an approach to the minimum divergence defined on the space of pdf’s. A intensity function determines the pdf for an occurrence of a point by . From a point of this, we can consider the divergence class of pdfs, which has been discussed in Chapter 2. However, this approach has a weak point such that, in a log-linear model , such a pdf transformation cancels the intercept parameter as found in
Therefore, the maximum entropy method is based on such an approach, so that the intercept parameter cannot be consistently estimated. See [82] for the detailed discussion in a rigorous framework. Here we note that the -divergence between and is essentially equal to that between and , that is
This implies that the intercept is not estimable in the estimating function (3.17). In deed, the -loss function (3.16) for the log-linear model is reduced to
which is constant in . From the scale invariance of the log divergence, noting and equals and up to a scale factor. Similarly, the intercept parameter is not identifiable. On the other hand, the -loss function (3.15) is written down as
in which is estimable.
3.4 Robust divergence method
We discuss robustness for estimating the SDM defined by a parametric intensity function . In particular, a log-linear model , where and is environmental feature vector influencing on a habitat of a target species. In Section 3.3 we discuss the minimum divergence estimation for the SDM in which power divergence measures are explored on the space of the PPP distributions, on that of intensity functions, or on that of pdfs in exhaustive manner. In the examination, the minimum -divergence method defined on the space of intensity functions is recommended for its reasonable property for the consistency of estimation.
We look at the -estimating function for a given dataset that is defined as
| (3.21) |
where , is a quadrature weight on the set combined with presence and background grid centers, and is an indicator for presence, that is, if and otherwise. Note that taking as a specific choice yields the likelihood equation (3.6). Alternatively, taking a limit of to entails the GM-estimating function as
| (3.22) | ||||
| (3.23) |
where . This leads to a remarkable cost reduction for the computation in the learning algorithm as discussed after Proposition 15. Here the computation in (3.22) is only for the first term of presence data with one evaluation using background data. For any , the -estimating function is unbiased. Because
which is equal to a zero vector if the the quadrature approximation is proper, where denote expectation under the log-linear model . This unbiasedness property guarantees the consistency of the -estimator for . In accordance with this, we would like to select the most robust estimator for model misspecification in the class of -estimators. The difference of the -estimator with the ML-estimator is focused only on the estimating weight in (3.24). We contemplate that the estimating weight would be not effective for any data situation regardless of whether is positive or negative. Indeed, the estimating weight becomes unbounded and has no comprehensive understanding for misspecification.
We consider another estimator rather than the -estimator for seeking robustness of misspecification based on the discussion above [84]. A main objective is to change the estimating weight for the -estimator into a more comprehensive form. Let be a cumulative distribution function defined on . Then, we define an estimating function
| (3.24) |
where is a hyper parameter. We call the -estimator by defined by a solution for the equation . Immediately, the unbiasedness for can be confirmed. In this definition, the estimating weight is given as . For example, we will use a Pareto cumulative distribution function
where a shape parameter is fixed to be in a subsequent experiment. We envisage that expresses the existence probability of the intensity for the presence of the target species. Hence, a low value of the weight implies a low probability of the presence. The plot of the estimating weights for would be helpful if we knew the true value.
Suppose that the log-linear model for the given data would be misspecified. We consider a specific situation for misspecification such that
| (3.25) |
This implies there is a contamination of a subgroup with a probability in a major group with the intensity function correctly specified. Here the subgroup has the intensity function that is far away from the log-linear model . Geometrically speaking, the underlying intensity function in (3.25) is a tubular neighborhood surrounding the model with a radius in the space of all intensity functions. In this misspecification, we expect that the estimating wights for the subgroup should be suppressed than those for the major group. It cannot be denied in practical situations that there is always a risk of model misspecification. it is comparatively easy to find outliers for presence records or background data cause by mechanical errors. Standard data preprocessing procedures helpful for data cleaning, however it is difficult to find outliers under such a latent structure for misspecification. In this regard, the approach by the -estimator is promising to solve the problem for such difficult situations. The hyper parameter should be selected by a cross validation method to give its effective impact on the estimation process. We will discuss on enhancing the clarity and practical applicability of the concepts in this approach as a future work.
We have a brief study for numerical experiments. Assume that a feature vector set on presence and background grids is generated from a bivariate normal distribution , where denotes a 2-dimensional identity matrix. Our simulation scenarios for the intensity function was organized as follows.
(a). Specified model: , where
(b). Misspecified model: , where
Here parameters were set as , , and . In case (b), is a specific example of in (3.25), which implies that the subgroup has the intensity function with the negative parameter to the major group. In ecological studies, a major group in the species might thrive under conditions where a few others do not, and vice versa. Using a negative parameter could imitate this kind of inverse relationship. See Figure 3.1 for the plot of presence numbers against two dimensional feature vectors. The presence numbers were generated from the misspecified model (b) with the simulation number .
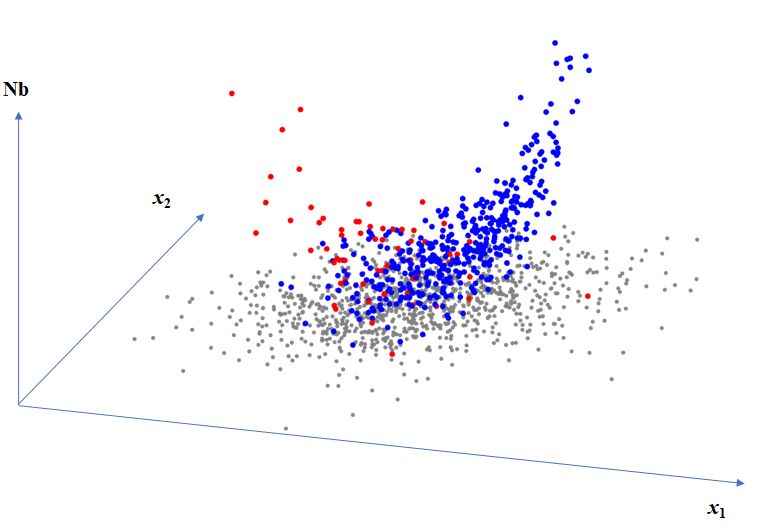
We compared the estimates the ML-estimator , the -estimator and the -estimator , where the simulation was conducted by 300 replications. In the the case of specified model, the ML-estimator was slightly superior to the -estimator and -estimator in a point of the root means square estimate (rmse), however the superiority over the -estimator is just little. Next, we suppose a mixture model of two intensity functions in which one was the log-linear model as the above with the mixing ratio ; the other was still a log-linear model but the the slope vector was the minus one with the mixing ratio . Under this setting, -estimator was especially superior to the ML-estimator and the -estimator, where the rmse of the ML-estimator is more than double that of the -estimator. The -estimator shows less robust for this misspecification. Thus, the ML-estimator is sensitive to the presence of such a heterogeneous subgroup; the -estimator is robust. It is considered that the estimating weight effectively performs to suppress the influence of the subgroup in the estimating function of the -estimator. See Table 3.1 for details and and Figure 3.2 for the plot of three estimators in the case (b). We observe in the numerical experiment that the -estimator has almost the same performance as that of the ML-estimator when the model is correctly specified; the -estimator has more robust performance than the ML-estimator when the model is partially misspecified in a numerical example.
(a). The case of specified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| -estimate |
(b). The case of misspecified model
| Method | estimate | rmse |
|---|---|---|
| ML-estimator | ||
| -estimate | ||
| -estimate |
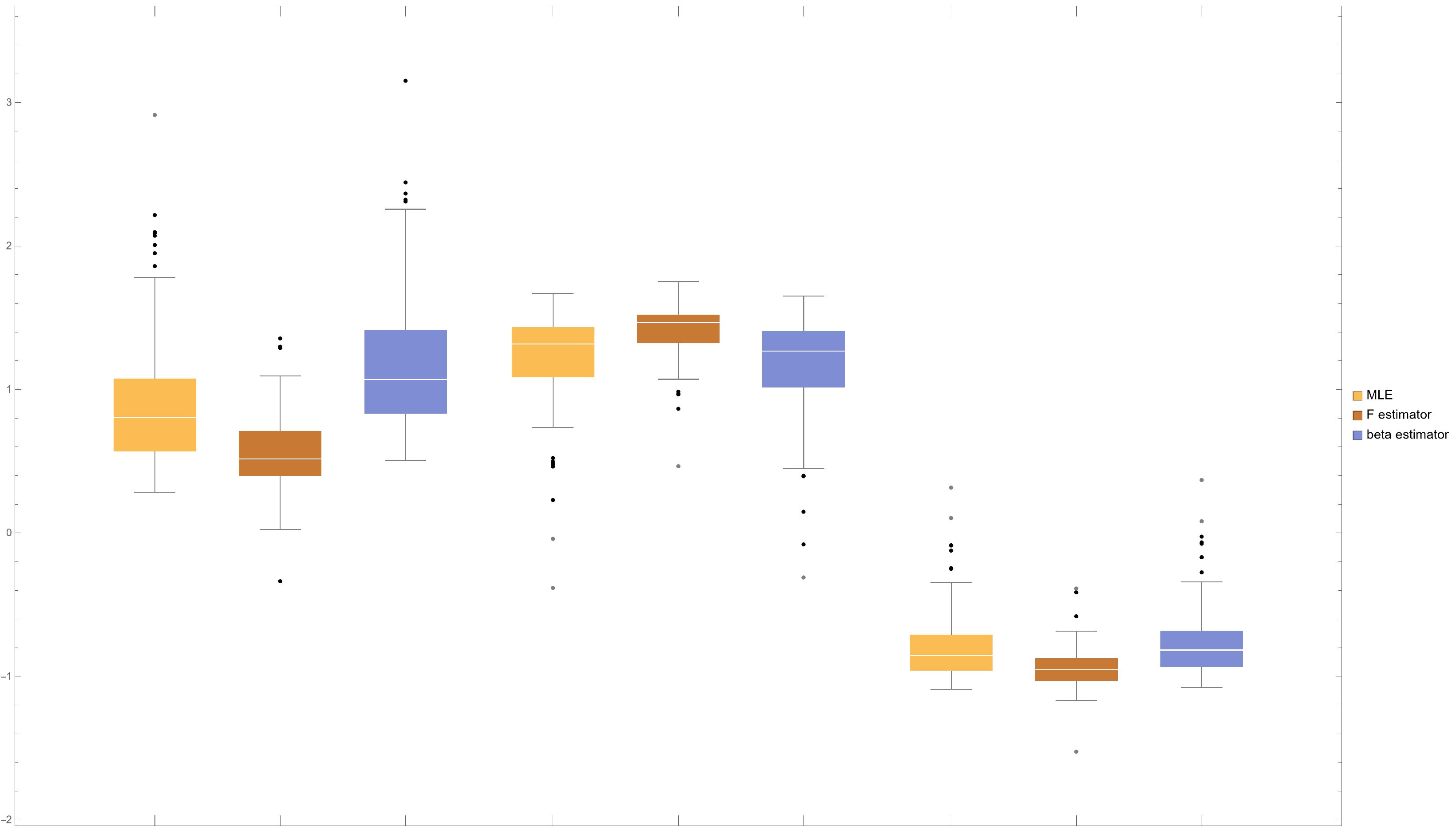
We discuss a problem that the -estimator is defined by the solution of the equation ; while the objective function is not given. However, it follows from Poincaré lemma that there is a unique objective function such that . See [4] for geometric insights in the Poincaré lemma. Because is integrable since the Jacobian matrix of is symmetric. In effect, we have the solution as follows.
Proposition 16.
Let be a cumulative distribution function on . Consider a loss function for a model defined by
where and Then, if the the model is a log-linear model , the estimating function is given by in (3.24).
Proof.
The gradient vector of is given by
This is written as
| (3.26) |
where is the presence indicator. Hence, we conclude that is equal to that given in (3.24) under a log-linear model. ∎
The -estimator is derived by minimization of this loss function . Hence, we have a question whether there is a divergence measure that induces to .
Remark 4.
We have a quick review of the Bregman divergence that is defined by
where is a convex function. The loss function is given by
and the estimating function is
Therefore, we observe that, if , then , where is defined in (3.26). This implies that the divergence, , associated with is equal to the Bregman divergence with the generator satisfying . That is,
where and are defined in Proposition 16 and .
3.5 Conclusion and Future Work
Our study marks a significant advance in the field of species distribution modeling by introducing a novel approach that leverages Poisson Point Processes (PPP) and alternative divergence measures. The key contribution of this work is the development of the -estimator, a robust and efficient tool designed to overcome the limitations of traditional ML-methods, particularly in cases of model misspecification.
The -estimator, based on cumulative distribution functions, demonstrates superior performance in our simulations. This robustness is particularly notable in handling model misspecification, a common challenge in ecological data analysis. Our approach provides ecologists and conservationists with a more reliable tool for predicting species distributions, which is crucial for biodiversity conservation efforts and ecological planning. We also explored the computational aspects of the -estimator, finding it to be computationally feasible for practical applications, despite its advanced statistical underpinnings. While our study offers significant contributions, it also opens up several avenues for future research: Further validation of the -estimator in diverse ecological settings and with different species is necessary to establish its generalizability and practical utility. The integration of the -estimator with other types of ecological data, such as presence-only data, would enhance its applicability. There is scope for further refining the computational algorithms to enhance the efficiency of the -estimator, making it more accessible for large-scale ecological studies. Exploring the applicability of this method in other scientific disciplines, such as environmental science and geography, could be a fruitful area of research. In conclusion, our work not only contributes to the theoretical underpinnings of species distribution modeling but also has significant practical implications for ecological research and conservation strategies.
The intensity function is modeled based on environmental variables, reflecting habitat preferences. This process typically involves a dataset of locations where species and environmental information have been observed, along with accurate and high-quality background data. With precise training on these datasets, reliable predictions can be derived using maximum likelihood methods in Poisson point process modeling. These predictions are easily applied using predictors integrated into the maximum likelihood estimators. While Poisson point process modeling and the maximum likelihood method can derive reliable predictions from observed data, predicting for ‘unsampled‘ areas that differ significantly from the observed regions poses a significant challenge [97, 64].
The ability to predict the occurrence of target species in unobserved areas using datasets of observed locations, environmental information, and background data is a pivotal issue in species distribution modeling (SDM) and ecological research. Applying these models to regions that differ significantly from those included in the training dataset introduces several technical and methodological challenges. When unobserved areas differ substantially from the observed regions, predicting the occurrence of target species in unobserved areas remains a critical issue. To address this issue, exploring predictions based on the similarity of environmental variables is essential. One promising approach relies on ecological similarity rather than geographical proximity, making it particularly effective for species with wide distributions or fragmented habitats. Additionally, by adopting a weighted likelihood approach and linking Poisson point processes through a probability kernel function between observed and unobserved areas, it becomes possible to efficiently predict the probability of species occurrence in unobserved areas. We believe that the methodologies developed in this study will inspire further innovations in statistical ecology and beyond.
Chapter 4 Minimum divergence in machine leaning
We discuss divergence measures and applications encompassing some areas of machine learning, Boltzmann machines, gradient boosting, active leaning and cosine similarity. Boltzmann machines have wide developments for generative models by the help of statistical dynamics. The ML-estimator is a basic device for data learning, but the computation is challenging for evaluating the partition functions. We introduce the GM divergence and the GM estimator for the Boltzmann machines. The GM estimator is shown a fast computation thanks to free evaluation of the partition function. Next, we focus on on active learning, particularly the Query by Committee method. It highlights how divergence measures can be used to select informative data points, integrating statistical and machine learning concepts. Finally, we extend the -divergence on a space of real-valued functions. This yields a natural extension of the cosine similarities, called -cosine similarities. The basic properties are explored and demonstrated in numerical experiments compared to traditional cosine similarity.
4.1 Boltzmann machine
Boltzmann Machines (BMs) are a class of stochastic recurrent neural networks that were introduced in the early 1980s, crucial in bridging the realms of statistical physics and machine learning, see [44, 43] for the mechanics of BMs, and [35] for comprehensive foundations in the theory underlying neural networks and deep learning. They have become fundamental for understanding and developing more advanced generative models. Thus, BMs are statistical models that learn to represent the underlying probability distributions of a dataset. They consist of visible and hidden units, where the visible units correspond to the observed data and the hidden units capture the latent features. Usually, the connections between these units are symmetrical, which means the weight matrix is symmetric. The energy of a configuration in a BM is calculated using an energy function, typically defined by the biases of units and the weights of the connection between units. The partition function is a normalizing factor used to ensure that the probabilities sum to 1 summing exponentiated negative energy over all possible configurations of the units [35].
Training a BM involves adjusting the parameters (weights and biases) to maximize the likelihood of the observed data. This is often done via stochastic maximum likelihood or contrastive divergence. The log-likelihood gradient has a simple form, but computing it exactly is intractable due to the partition function. Thus, approximations or sampling methods like Markov chain Monte Carlo are used. BMs have been extended to more complex and efficient models like Restricted BMs and deep belief networks. They have found applications in dimensionality reduction, topic modeling, and collaborative filtering among others. We overview the principles and applications of BMs, especially in exploring the landscape of energy-based models and the geometrical insights into the learning dynamics of such models. The exploration of divergence, cross-entropy, and entropy in the context of BMs might yield profound understandings, potentially propelling advancements in both theoretical and practical domains of machine learning and artificial intelligence.
Let be the space of all probability mass functions defined on a finite discrete set , that is
in which is called a -variate Boltzmann distribution. A standard BM in is introduced as
for , where is the energy function defined by
with a parameter . Here is the partition function defied by
The Kullback-Leibler (KL) divergence is written as
which involves the partition function . The negative log-likelihood function for a given dataset is written as
and the estimating function is given by
where denotes the expectation with respect to . In practice, the likelihood computation is known as an infeasible problem because of a sequential procedure with large summation including or . There is much literature to discuss approximate computations such as variational approximations and Markov-chain Monte Carlo simulations [42].
On the other hand, we observe that the computation for the GM-divergence does not need to have any evaluation for the partition function as follows: the GM-divergence is defined by
| (4.1) |
This is written as
where is an averaged energy given by Note that the averaged energy is written as
| (4.2) |
where and . We observe that is free from the partition term due to the cancellation of in multiplying the two terms in the right-hand-side of (4.1).
For a given dataset , the GM-loss function for is defined by
and the minimizer is called the GM-estimator. The estimating function is given by
In accordance, the computation for finding is drastically lighter than that for the ML-estimator. For example, a stochastic gradient algorithm can be applied in feasible manner. In some cases, a Newton-type algorithm may still be applicable, which is suggested as
where
This discussion is applicable for the deep BMs with restricted BMs.
Here we have a small simulation study to demonstrate the fast computation for the GM estimator compared to the ML-estimator.
Basically, the computation time can vary based on the hardware specifications and other running processes.
This simulation is done by Python program on the Google Colaboratory
(https://research.google.com/colaboratory).
Keep in mind that the computation of the partition function can be extremely challenging for large dimensions due to the exponential number of terms.
For simplicity, this implementation will not optimize this calculation and might not be feasible for very large dimensions.
It is notable that the computation time for the log-likelihood increased significantly with the higher dimension, which is expected due to the exponential increase in the number of states that need to be summed over in the partition function.
On the other hand, the computation time for the GM loss remains relatively low, which reinforces its computational efficiency, particularly in higher dimensions.
it is not feasible to directly compute the log-likelihood times for dimensions up to 20 within a reasonable time frame using the current method.
As shown, the computation time for the log-likelihood increases significantly with the dimension, reflecting the computational complexity due to the partition function.
On the other hand, the GM loss computation time remains relatively low and stable across these dimensions.
This trend suggests that while the GM estimator maintains its computational efficiency in higher dimensions, the ML-estimator becomes increasingly impractical due to the exponential growth in computation time. For dimensions beyond this range, especially approaching , one might expect the computation time for the log-likelihood to become prohibitively long, further emphasizing the advantage of the GM loss method in high-dimensional settings.
Figure 4.1 focuses on computing and plotting the computation times for log-likelihood and GM loss across dimensions of the BM, where the sample size is fixed as .
This result is consistent with our observation that the GM loss might offer a more computationally efficient alternative to the ML-estimator, especially as the dimensionality of the problem increases.
For a case of the higher dimension mare than , the naive gradient algorithm for the ML-estimator cannot converge in the limited time; that for the GM estimator works well if .
When and , the computation time is approximately 0.811 seconds.
Consider a Boltzmann distribution with visible and hidden units
for , where , and is the energy function defined by
with a parameter . Here is the partition function defied by
The marginal distribution is given by
and the GM-divergence is given by
| (4.3) |
where and
Note that the bias term is not written by the sufficient statistics as in (4.2). For a given dataset , the GM-loss function for is defined by
| (4.4) |
The estimating function is given by
| (4.5) |
where
| (4.6) |
and
For , the conditional distributions of ’s given are conditional independent as seen in
| (4.7) | ||||
and hence,
and
where .
Note that the conditional expectation in the estimating function (4.5) can be evaluated by in (4.7) that is free from the partition function . A stochastic gradient algorithm is easily implemented in a fast computation.
Next, consider a Boltzmann distribution connecting visible and hidden units to an output variable as
for , where is the energy function defined by
with for and a parameter . Here is the partition function defied by
The marginal distribution is given by
Similarly, for a given dataset , the GM-loss function for is defined by
where
and
with the cardinal number of . In accordance with this, we can apply the GM-loss function for the Boltzmann distribution with supervised outcomes, and for that with the multiple hidden variables. In accordance with these, we point that the GM divergence and the GM estimator has advantageous property over the KL divergence and the ML-estimator in theoretical formulation. A numerical example shows the advantage in a small scale of experiment. However, we have not discussed sufficient experiments and practical applications to confirm the advantage. For this, it needs further investigation for comparing the GM method with the current methods discussed for the deep brief network [99].
4.2 Multiclass AdaBoost
AdaBoost is a part of ensemble learning algorithms that combine the decisions of multiple base learners, or weak learners to produce a strong learner. The core premise is that a group of ”weak” models can be combined to form a ”strong” model. AdaBoost [30] and its variants have found applications across various domains, including bioinformatics and statistical ecology, where they help in creating robust predictive models from noisy or incomplete data. AdaBoost has been extended to handle multiclass classification problems.
An example is Multiclass AdaBoost or AdaBoost.M1, an extension adapting the algorithm to handle more than two classes. There are also other variants like SAMME (Stagewise Additive Modeling using a Multiclass Exponential loss function) which further extends AdaBoost to multiclass scenarios [38]. Random forests and gradient boosting machines (GBM) can be mentioned as popular and efficient methods of ensemble learning [5, 32]. Random forests exhibit a good balance between bias and variance, primarily due to the averaging of uncorrelated decision trees. GBMs are highly flexible and can be used with various loss functions and types of weak learners, though trees are standard. AdaBoost excels in situations where bias reduction is crucial, while Random Forests are a robust, all-rounder solution. GBMs offer high flexibility and can achieve superior performance with careful tuning, especially in complex datasets. Interestingly, there is a connection between AdaBoost and information geometry [69]. The process of re-weighting the data points can be seen as a form of geometrically moving along the manifold of probability distributions over the data. This geometric interpretation might tie back to concepts of divergence and entropy, which are core to information geometry. We focus on discussing various loss functions that are derived from the class of power divergence.
We discuss a setting of a binary class label. Let be a covariate with a value in a subset of , and be an outcome with a value in . Let be a predictor such that the prediction rule is given by . The exponential loss is proposed for the Adaboost [30, 85]. As one of the most characteristic points, the optimization is conducted in the function space of a set of weak classifiers. The exponential loss functional plays a central role as a key ingredient, which is defined on a space of predictors as
where is a predictor on . If we take expectation under a conditional distribution
then the expected exponential loss is
which is greater than or equal to . The equality holds if and only if . This implies that the minimizer of the expected GM loss is equal to the true predictor , namely,
The functional optimization is practically implemented by a simple algorithm. The stagewise learning algorithm is given as follows (Freund & Schapire, 1995):
(1). Provide . Set as and .
(2). For step
(2.a). , where .
(2.b). , where .
(2.c).
(3). Set
Note that substep (2.b) is calculated as a comprehensive form: the half log odds of error rate,
where . The algorithm is an elegant and simple form, in which the mathematical operation is just defined by elementary functions of and . On the other hand, the iteratively reweighted least square algorithm needs the operation of matrix inverse even for a linear logistic model. Let us apply the -loss functional for the boosting algorithm, cf. Chapert 2 for a general form of the -loss. First of all, confirm
as the -expression. Hence, the -loss functional is written by
Let us discuss the gradient boosting algorithm based on the -loss functional. The stagewise learning algorithm for is given as follows:
where is an initial guess and is determined by an appropriate stopping rule. However, the joint minimization is expensive in the light of the computation. For this, we use the gradient as
which is written as
where is a constant in , and
In accordance, the -boosting algorithm is parallel to AdaBoost as:
(1). Provide . Set as .
(2). For step
(2.a). , where .
(2.b). , where .
(2.c).
(3). Set
The-GM functional, , and the HM-loss functional, , are derived by setting to and , respectively. It can be observed that the exponential loss functional is nothing but the GM-loss functional. We consider a situation of an imbalanced sample, where for the probability of . We adopt the adjusted exponential (GM) loss functional in (2.32) as
The learning algorithm is given by replacing substeps (2.b) and (2.c) to
(2.b∗). , where .
(2.c∗).
We observe in (2.b∗):
where
We discuss a setting of a multiclass label. Let be a feature vector in a subset of and be a label in . The major objective is to predict given , in which there are spaces of classifiers and predictors, namely, and
A classifier is introduced by a predictor as
a predictor is introduced by a predictor as
| (4.8) |
Note that ; while is a subset of . In the learning algorithm discussed below, the predictor is updated by the linear span of predictors embedded by selected classifiers in a sequential manner. The conditional probability mass function (pmf) of given is assumed as a soft-max function
where is a predictor of . We notice that and are one-to-one as a function of . Indeed, they are connected as . We note that this assumption is in the framework of the GLM as in the conditional pmf (2.44) with a different parametrization discussed in Section 2.6 if is a linear predictor. However, the formulation is nonparametic, in which the model is written by . Similarly, the -loss functional for is
The minimum of the expected the -loss functional for is attained at taking expectation under a conditional distribution
Thus, we conclude that the minimizer of the expected -loss in is equal to the true predictor , namely,
Thus, the minimization of the -loss functional on the predictor space yields non-parametric consistency. Similarly, the stagewise learning algorithm for is given as follows:
where is an initial guess and is defined in (4.8). For any fixed , we observe
where
(1). Provide . Set as and .
(2). For step
(2.a). , where .
(2.b). , where with the
embedded predictor defined in (4.8).
(2.c).
(3). Set
The GM-loss functional is given by
due to the normalizing condition This is essentially the same as the exponential loss [38], in which the class label is coded as similar to (4.8). Thus, the equivalence of the GM-loss and the exponential loss also holds for a multiclass classification. We can discuss the problem of imbalanced samples similarly as given for a binary classification. Let and
The adjusted exponential (GM) loss functional in (2.32) as
The learning algorithm is given by a minor change for substeps (2.b) and (2.c). The HM-loss functional is given by
GBMs are highly flexible and can be adapted to various loss functions and types of weak learners, although decision trees are commonly used as the base learners. This flexibility is one of the key strengths of GBM, allowing it to be tailored to a wide range of problems and data types. The loss functions discussed above can be applied to GBMs. Its require careful tuning of several parameters (e.g., number of trees, learning rate, depth of trees), which can be time-consuming. This discussion primarily focuses on the minimum divergence principle from a theoretical perspective. In future projects, we aim to extend our discussion to develop effective GBM applications for a wide range of datasets.
4.3 Active learning
Active learning is a subfield of machine learning that focuses on building efficient training datasets, see [86] for a comprehensive survey. Unlike traditional supervised learning, where all labels are provided upfront, active learning aims to select the most informative examples for labeling, thereby potentially reducing the number of labeled examples needed to achieve a certain level of performance, cf. [10] for understanding how statistical methods are integrated into active learning algorithms. Active learning is a fascinating area where statistical machine learning and information geometry can intersect, offering deep insights into the learning process. One of the primary goals is to reduce the number of labeled instances required to train a model effectively. Annotation can be expensive, especially for tasks like medical image labeling, natural language processing, or any domain-specific task requiring expert knowledge. In scenarios where data collection is expensive or time-consuming, active learning aims to make the most out of a small dataset. By focusing on ambiguous or difficult instances, active learning improves the model’s performance faster than random sampling would. In this way, the active learning has been attracted attentions in a situation relevant in today’s data-rich but label-scarce environments. This could set the stage for the technical details that follow.
The query by committee (QBC) method is a popular method in active learning in which there are another approaches the uncertainty sampling, the expected model change and Bayesian Optimization, see [87] for the theoretical underpinnings of the QBC approach. We focus on the QBC approach, a ”committee” of models is trained on the current labeled dataset. When it comes to selecting the next data point to label, the committee ”votes” on the labels for the unlabeled data points. The data point for which there is the most disagreement among the committee members is then selected for labeling. The idea is that this point lies in a region of high uncertainty and therefore would provide the most information if labeled. From an information geometry perspective, one could consider the divergence or distance between the probability distributions predicted by each model in the committee for a given data point. The point that maximizes this divergence could be considered the most informative.
Let be a feature vector in a subset of and be a label in . The conditional probability mass function (pmf) of given is assumed as a soft-max function
where is a predictor vector with components satisfying The prediction is conducted by
noting and are one-to-one as a function of . In effect, they are connected as . We note that this assumption is in the framework of the GLM as in the conditional pmf (2.44) with a different parametrization discussed in Section 2.6 if is a linear predictor.
We aim to design a sequential family of datasets such that the -th dataset is updated as
for , where is an appropriately chosen datasets. Given , we conduct an experiment to get in which is explored to improve the performance of the prediction of the label , and the outcome is sampled from the conditional distribution given . Thus, the active leaning proposes such a good update pair that encourages the -th prediction result to strengthen the performance in a universal manner. The key of the active leaning is to build the efficient method to get the feature vector that compensates for the weakness of the prediction based on . For this, it is preferable that the distribution of given is separate from that given . Here, let us take the QBC approach in which an acquisition function plays a central role.
Assume that there are committee members or machines such that the -th member employs a predictor for a feature vector and a label based on the dataset , and thus the prediction for given is performed by . We define an acquisition function defined on a feature vector of
| (4.9) |
adopting a divergence measure , where is the predictor vector learned by the -th member at stage ; is the consensus predictor vector combining among . The consensus predictor is given by
where is the set of all the predictor vectors. Such an optimization problem is discussed around Proposition 2 associated with the generalized mean [41]. In accordance, the new feature vector is selected as
| (4.10) |
where is a subset of possible candidates of at stage .
The standard choice of for (4.9) is the KL-divergence in (1.1), which yields the consensus distribution with the pmf
or equivalently as the consensus predictor. Alternatively, we adopt the dual -divergence defined in (1.11) and thus,
where
Here, is the -expression defined in (1.12), or
This yields
as the pmf of the consensus distribution and
as the consensus predictor up to a constant in . We note that the consensus predictor has a form of log-sum-exp mean. This has the extreme forms as
Let us look at the decision boundary of the consensus predictors and combining two linear predictors in a two dimensional space, see Figure 4.2.
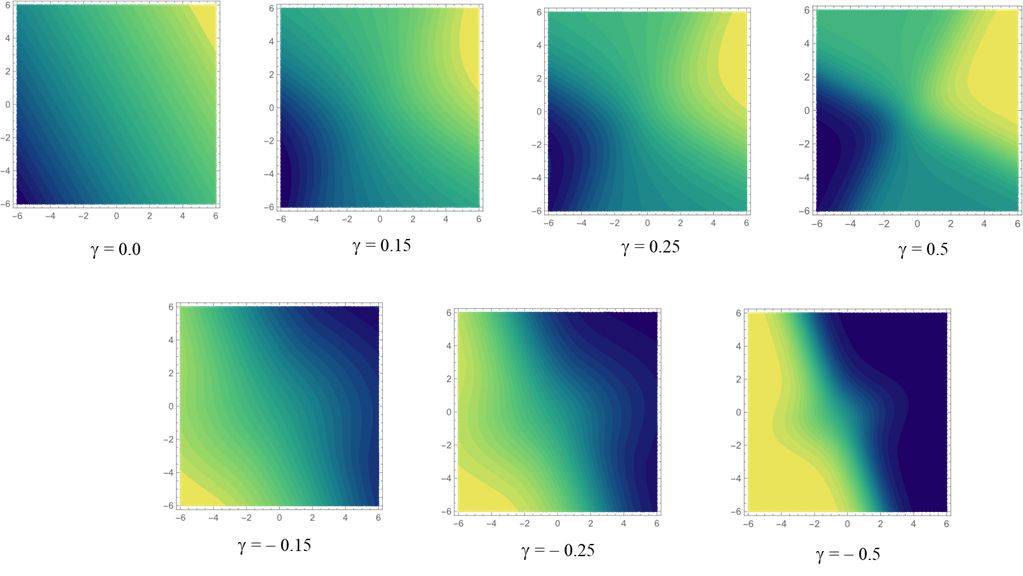
.
If all the committee machines have linear predictors, then the consensus predictor is still a linear predictor, but the -consensus predictor is a nonlinear predictor according to the value of as in Figure 4.2. Hence, we can explore the nonlinearity at every stage learning an appropriate value of . Needless to say, the objective is to find a good feature vector in (4.10), and hence we have to pay attentions to the leaning procedure conducted by a minimax process
It is possible to monitor the minimax value each stage, which can evaluate the learning performance. In effect, the minimax game of the cross entropy with Nature and a decision maker is nicely discussed [36]. The mini-maxity is solved in the zero sum game: Nature wants to maximize the cross entropy under a constrain with a fixed expectation; the decision maker wants to minimize one o the full space. However, our minimax process is not relevant to this observation straightforward. It is necessary to make further discussion to propose a selection of the optimal value of based on .
4.4 The -cosine similarity
The -divergence is defined on the probability measures dominated by a reference measure. We have studied statistical applications focusing on regression and classification. We would like to extend that the -divergence can be defined on the Lebesgue -space, for an exponent , , where the -norm is defined by
| (4.11) |
where is a -finite measure. There is a challenge for the extension: a function can take a negative value. If we adopt a usual power transformation , it indeed poses a problem. When as raising a negative number to a fractional power can lead to complex values, which would not be meaningful in this context. For this, we introduce a sign-preserved power transformation as
The log -divergence (1.21) is extended as
for and of , where . This still satisfies the scale invariance. There would be potential developments to utilize in a field of statistics and machine learning, by which singed functions like a predictor function or functional data can be directed evaluated. In particular, we explore this idea to a context of cosine similarity.
Cosine similarity is a measure used to determine the similarity between two non-zero vectors in an inner product space, which includes Hilbert spaces. This measure is particularly important in many applications, such as information retrieval, text analysis, and pattern recognition. In a Hilbert space, which is a complete inner product space, cosine similarity can be defined in a way that generalizes the concept from Euclidean spaces:
| (4.12) |
where and is the inner product, namely, . Thus, in the Hilbert space, , for any scalars and . The Cauchy-Schwartz inequality yields , and if and only if there exists a scalar such that for almost everywhere.
We extend the cosine measure (4.12) on the Lp-space by analogy with the extension of the log -divergence, see [59, 11] for foundations for function analysis. For this, we observe the Hölder inequality implies , where
| (4.13) |
for and , where is the conjugate exponent to satisfying . The dual space (the Banach space of all continuous linear functionals) of the Lp-space for has a natural isomorphism with Lq-space. The isomorphism associates with the functional defined by . Thus, the the Hölder inequality guarantees that is well defined and continuous, and hence is said to be the continuous dual space of . Apparently, seems a surrogate for . However, the domain of is ; that of is . Further, means ; means . Thus, the functional has inappropriate characters as a cosine functional to measure an angle between vectors in a function space. For this, consider a transform from to by noting . Then, we can define for and in Consequently, we define a cosine measure defined on as
| (4.14) |
linking to as , where is the conjugate exponent to . A close connection with the log -divergence is noted as
This implies , in which both express quantities when and are the most distinct. In this formulation, , called the -cosine, ensures mathematical consistency across all real values of , which is vital for the measure’s applicability in a wide range of contexts. Note that, if , then , in which reduces to . Further, a basic property is summarized as follows:
Proposition 17.
Let and be in . Then, , and equality holds if and only is proportional to .
Proof.
By definition, , where is defined in (4.13). This implies . The equality holds if and only if , that is, there exists a scalar such that for everywhere . ∎
In this way, the -cosine is defined by the isomorphism between and . We note that
Accordingly, is a natural extension of the cosine functional . As a special character, is asymmetric in and if . The asymmetry remains, akin to divergence measures, providing a directional similarity measure between two functions. We have discussed the cosine measure extended on relating to the log -divergence. In effect, the divergence is defined for the applicability of any empirical probability measure for a given dataset. However, such a constraint is not required in this context. Hence we can define a generalized variants
| (4.15) |
for and in , called the -cosine measure, with tuning parameters and Specifically, it is noted . We note that the information divergence associated with is given by
In statistical machine learning, this measure could be used to compare probability density functions, regression functions, or other functional forms, especially when dealing with asymmetric relationships. It might be particularly relevant in scenarios where the sign of the function values carries important information, such as in economic data, signal processing, or environmental modeling.
The formulation defined on the function space is easily reduced on a Euclidean space as follows. Let and be in . Then, the cosine similarity is defined by
| (4.16) |
where and and denote the Euclidean inner product and norm on . The -cosine function in is introduced as
| (4.17) |
for a power parameter . We can view the plot of the sign-preserving power transformation for in Fig. 4.3:
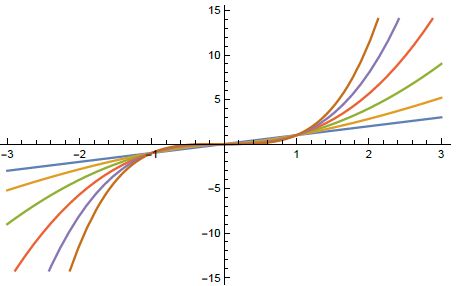
We investigate properties of the -cosine and cosine comparing to the standard cosine. Let and . Then, the -cosine is written as
We observe the following behaviors where has an extreme value.
Proposition 18.
Let and be in .
Then,
(a).
where . Further,
(b).
where the -th component of denotes for with .
Proof.
By definition, . This implies (a). Next, if we divide both the numerator and the denominator of by , then
Hence, for
Consequently, we conclude (b). ∎
We remark that
Alternatively, the order of taking limits of and to with respect to results in different outcomes:
Note that is a sparse vector as it has only at the components with the maximum absolute value with 0’s elsewhere . Thus, is proportional to the Euclidean inner product between and the sparse vector . This is contrast with the standard cosine similarity, in which the orthogonality with is totally different from that with . In effect, ; . The orthogonality with is reduced to the inner product of the -dimensional Euclidean space, where is the cardinal number of . Note that the equality condition in the limit case of is totally different from that when is finite. Indeed, if and only if , where can be viewed the arithmetic mean of relative ratios in . It is pointed that the cosine similarity has poor performance in a high-dimensional data. Then, values of the cosine similarity becomes small numbers near a zero, and hence they cannot extract important characteristics of vectors. It is frequently observed in the case of high-dimensional data that only a small part of components involves important information for a target analysis; the remaining components are non-informative. The standard cosine similarity equally measures all components; while the power-transformed cosine (-cos) can focus on only the small part of essential components. Thus, the -cos neglects unnecessary information with the majority components, so that the -cos can extract essential information involving with principal components. In this sense, the -cos does not need any preprocessing procedures for dimension reduction such as principal component analysis.
Proposition 19.
Let and , respectively, where ; with . If and , then,
| (4.18) |
Proof.
From the assumption, and . This implies
| (4.19) |
which is nothing but since all the summands are zeros in the summation of from to in (4.19). ∎
In Proposition 19, the infinite-power cosine similarity is viewed as a robust measure in the sense that for any minor components and . However, we observe that the robustness looks extreme as seen in the following.
Proposition 20.
Consider a function of as
Then, if , is not continuous at .
Proof.
It follows from Proposition 2 that, if , then
where is the dimension of . On the other hand,
This implies the discontinuity of at .
∎
We investigate statistical properties of the power cosine measure in comparison with the conventional cosine similarity. For this we have scenarios to generate realized vectors ’s and ’s in as follows. Assume that the -th replications and are given by
where ’s are identically and independently distributed as . We conduct a numerical experiment with replications setting and with fixed later for some ’s.
First, fix as as a proportional case. Then, the value of the cosine measure is expected to be if the error terms are negligible. When , then has not a consistent mean even with small erros; when , then has a consistent mean near with resonable errors. Table 4.1 shows detailed outcomes with the variance , where Mean and Std denote the mean and standard deviations for ’s with 2000 replications . Second, fix as
where . Note . This means and are orthogonal in the L2-sence. Then, the value of the cosine measure should be near if the error terms are negligible. For all the cases ’s, the mean of is reasonably near with small standard deviations, see Table 4.2 for details.
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
| Mean | Std | |
|---|---|---|
We applied these similarity measures to hierarchical clustering using a Python package. Synthetic data were generated in a setting of 8 clusters, each with 15 data points, in a 1000-dimensional Euclidean space. The distance functions used were and , to compare performance in high-dimensional data clustering. The clustering criterion was set to maxclust in fcluster from the scipy.cluster.hierarchy module. The silhouette score, ranging from -1 to +1, served as a measure of the clustering quality. The clustering was conducted with 10 replications.
For case (a), using the distance based on , the 10 silhouette scores had a mean of -0.038 with a standard deviation of 0.001, indicating poor clustering quality. Alternatively, for case (b), with the distance based on , the scores had a mean of 0.833 and a standard deviation of 0.015, suggesting good clustering quality. Thus, the hierarchical clustering performance using -cosine similarity was significantly better than that using standard cosine similarity, as illustrated in typical dendrograms (Fig. 4.4).
Let be a -variate variable with a covariance matrix , which is a -dimensional symmetric, positive definite matrix. Suppose the eigenvalues of are restricted as . Given -random sample from , the standard PCA is given by solving the -principal vectors , and . Suppose that is generated from , where
| (4.20) |
Here is a positive-definite matrix of size -matrix whose eigenvalues are and is a zero matrix of size We set as
Thus, the scenario is envisaged a situation where the signal is just of dimension with the rest of -dimensional noise.
For this, the sample covariance matrix is defined by
and and are obtained as the -th eigenvalue and eigenvector of , where is the sample mean vector. We propose the -sample covariance matrix as
where the -transform for a -vector is given by and
Thus, the -PCA is derived by solving the eigenvalues and eigenvectors of .
To implement the PCA modification in Python, especially given the specific requirements for generating the sample data following these steps:
-
•
Generate Sample Data: Create a 1000-dimensional dataset where the first 10 dimensions are drawn from a normal distribution with a specific covariance matrix , and the remaining dimensions have a much smaller variance.
-
•
Compute the -Sample Covariance Matrix: Apply the transformation to the covariance matrix computation.
-
•
Eigenvalue and Eigenvector Computation: Compute the eigenvalues and eigenvectors of the -sample covariance matrix.
We conducted a numerical experiment according to these steps. The cumulative contribution ratios are plotted in Fig 4.5. It was observed that the standard PCA ) had poor performance for the synthetic dataset, in which the cumulative contribution to dimensions was lower than . Alternatively, the -PCA effectively improves the performance as the cumulative contribution to dimensions was higher than for . We remark that this efficient property for the -PCA depends on the simulation setting where the signal vector of dimension and the no-signal vector of dimension are independent as in (4.20), where is decomposed as . If the independence is not assumed, then the good recovery by the -PCA is not observed. In reality, there would not be a strong evidence whether the independence holds or not. To address this issue we need more discussion with real data analysis. Additionally, combining PCA with other techniques like independent component analysis or machine learning algorithms can further enhance its performance in complex data environments. This broader perspective should enrich the discussion in your draft, especially concerning the real-world applicability and limitations of PCA modifications.
We have discussed the extension of the -divergence to the Lebesgue Lp-space and introduces the concept of -cosine similarity, a novel measure for comparing functions or vectors in a function space. This measure is particularly relevant in statistics and machine learning, especially when dealing with signed functions or functional data.
The -divergence, previously studied in the context of regression and classification, is extended to the Lebesgue Lp-space. To address the issue of functions taking negative values, a sign-preserved power transformation is introduced. This transformation is crucial for extending the log -divergence to functions that can take negative values. The concept of cosine similarity, commonly used in Hilbert spaces, is extended to the Lp-space. The -cosine similarity is defined as , where and is the conjugate exponent to . This measure maintains mathematical consistency across all real values of . Basic properties of -cosine similarity are explored: , with equality holding if and only if is proportional to . It is also noted that if and only if , indicating maximum distinctness between and . Generalized -cosine measure is given as a more general form of the cosine measure is introduced for space, providing additional flexibility with tuning parameters and . An application of these similarity measures in hierarchical clustering is demonstrated using Python. The -cosine similarity shows better performance in clustering high-dimensional data compared to the standard cosine similarity. It can focus on essential components of the data, potentially reducing the need for preprocessing steps like principal component analysis. The -PCA is defined, parallel to the -cosine, and demonstrated for a good performance in high-dimensional situations. Therefore, the -cosine and -cosine measures could be particularly useful in statistical machine learning for comparing probability density functions, regression functions, or other functional forms, especially in scenarios where the sign of function values is significant.
In conclusion, the -cosine similarity and its generalized form, the -cosine measure, represent significant advancements in the field of statistical mathematics, particularly in the analysis of high-dimensional data and functional data analysis. These measures offer a more flexible and robust way to compare functions or vectors in various spaces, which is crucial for many applications in statistics and machine learning.
4.5 Concluding remarks
The concepts introduced in this chapter, particularly the GM divergence, -divergence, and -cosine similarity, offer promising avenues for advancing machine learning techniques, especially in high-dimensional settings. However, several areas warrant further exploration to fully understand and leverage these methodologies.
While the computational advantages of the GM divergence and -cosine similarity are demonstrated through simulations, real-world applications in domains such as bioinformatics, natural language processing, and image analysis could benefit from a deeper investigation. The scalability of these methods in extremely high-dimensional datasets, particularly those encountered in genomics or deep learning models, remains an open question. Future research should focus on implementing these methods in large-scale machine learning pipelines to assess their performance and robustness compared to traditional methods. This could include exploring parallel computing strategies or GPU acceleration to handle the increased computational demands in practical applications.
The chapter primarily discusses the GM divergence and -divergence, but the potential to extend these ideas to other divergence measures, such as Jensen-Shannon divergence or Renyi divergence, could be fruitful. Investigating how these alternative measures interact with the GM estimator or can be integrated into ensemble learning frameworks like AdaBoost might yield novel insights and improved algorithms. Moreover, a systematic comparison of these divergence measures across different machine learning tasks could provide clarity on their relative strengths and weaknesses.
While the -cosine similarity provides a novel way to compare vectors in function spaces, its theoretical underpinnings require further formalization. For instance, exploring its properties in different types of function spaces, such as Sobolev spaces or Besov spaces, might reveal new insights into its behavior and applications. Additionally, the interpretability of the -cosine similarity in practical settings is a key aspect that should be addressed. How does this measure correlate with traditional metrics used in machine learning, such as accuracy, precision, and recall? Can it be used to enhance the interpretability of models, particularly in domains requiring high levels of transparency, such as healthcare or finance?
The methods discussed in this chapter are largely grounded in parametric models, particularly in the context of Boltzmann machines and AdaBoost. However, extending these divergence-based methods to non-parametric or semi-parametric models could open up new applications, particularly in statistical machine learning. For example, exploring the use of GM divergence in the context of kernel methods, Gaussian processes, or non-parametric Bayesian models could provide new avenues for research. Similarly, semi-parametric approaches that combine the flexibility of non-parametric methods with the interpretability of parametric models could benefit from the computational advantages of the GM estimator.
To solidify the practical utility of the proposed methods, extensive empirical validation across a variety of datasets and machine learning tasks is essential. This includes benchmarking against state-of-the-art algorithms to evaluate performance in terms of accuracy, computational efficiency, and robustness. Establishing a comprehensive suite of benchmarks, possibly in collaboration with the broader research community, could facilitate the adoption of these methods. Such benchmarks should include both synthetic datasets, to explore the behavior of these methods under controlled conditions, and real-world datasets, to demonstrate their applicability in practical scenarios. 6. Exploration of Hyperparameter Sensitivity The introduction of and parameters in the -cosine and -cosine measures adds a layer of flexibility, but also complexity. Understanding how sensitive these methods are to the choice of these parameters, and developing guidelines or heuristics for their selection, would be a valuable addition to the methodology. Future work could explore automatic or adaptive methods for tuning these parameters, possibly integrating them with cross-validation techniques or Bayesian optimization to improve the ease of use and performance of the algorithms. Conclusion The introduction of GM divergence, -divergence, and-cosine similarity offers exciting opportunities for advancing machine learning and statistical modeling. However, their full potential will only be realized through continued research and development. By addressing the challenges outlined above, the field can better understand the theoretical implications, enhance practical applications, and ultimately, integrate these methods into mainstream machine learning practice.
Acknowledgements
I also would like to acknowledge the assistance provided by ChatGPT, an AI language model developed by OpenAI. Its ability to answer questions, provide suggestions, and assist in the drafting process has been a remarkable aid in organizing and refining the content of this book. While any errors or omissions are my own, the contributions of ChatGPT have certainly made the writing process more efficient and enjoyable.
Bibliography
- [1] Shun-Ichi Amari. Differential geometry of curved exponential families-curvatures and information loss. The Annals of Statistics, 10(2):357–385, 1982.
- [2] Ayanendranath Basu, Ian R Harris, Nils L Hjort, and MC Jones. Robust and efficient estimation by minimising a density power divergence. Biometrika, 85(3):549–559, 1998.
- [3] Albert E Beaton and John W Tukey. The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data. Technometrics, 16(2):147–185, 1974.
- [4] Raoul Bott, Loring W Tu, et al. Differential forms in algebraic topology, volume 82. Springer, 1982.
- [5] Leo Breiman. Random forests. Machine learning, 45:5–32, 2001.
- [6] Jacob Burbea and C Rao. On the convexity of some divergence measures based on entropy functions. IEEE Transactions on Information Theory, 28(3):489–495, 1982.
- [7] George Casella and Roger Berger. Statistical inference. CRC Press, 2024.
- [8] Herman Chernoff. A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. The Annals of Mathematical Statistics, pages 493–507, 1952.
- [9] Andrzej Cichocki and Shun-ichi Amari. Families of alpha-beta-and gamma-divergences: Flexible and robust measures of similarities. Entropy, 12(6):1532–1568, 2010.
- [10] David A Cohn, Zoubin Ghahramani, and Michael I Jordan. Active learning with statistical models. Journal of artificial intelligence research, 4:129–145, 1996.
- [11] John B Conway. A course in functional analysis, volume 96. Springer, 2019.
- [12] John Copas. Binary regression models for contaminated data. Journal of the Royal Statistical Society: Series B., 50:225–265, 1988.
- [13] John Copas and Shinto Eguchi. Local model uncertainty and incomplete-data bias (with discussion). Journal of the Royal Statistical Society: Series B., 67:459–513, 2005.
- [14] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning, 20:273–297, 1995.
- [15] David R Cox. Some problems connected with statistical inference. Annals of Mathematical Statistics, 29(2):357–372, 1958.
- [16] David Roxbee Cox and David Victor Hinkley. Theoretical statistics. CRC Press, 1979.
- [17] Imre Csiszár, Paul C Shields, et al. Information theory and statistics: A tutorial. Foundations and Trends® in Communications and Information Theory, 1(4):417–528, 2004.
- [18] Bradley Efron. Defining the curvature of a statistical problem (with applications to second order efficiency). The Annals of Statistics, pages 1189–1242, 1975.
- [19] Shinto Eguchi. A differential geometric approach to statistical inference on the basis of contrast functionals. Hiroshima mathematical journal, 15(2):341–391, 1985.
- [20] Shinto Eguchi. Geometry of minimum contrast. Hiroshima Mathematical Journal, 22(3):631–647, 1992.
- [21] Shinto Eguchi. Information geometry and statistical pattern recognition. Sugaku Expositions, 19:197–216, 2006.
- [22] Shinto Eguchi. Information Divergence Geometry and the Application to Statistical Machine Learning, pages 309–332. Springer US, Boston, MA, 2009.
- [23] Shinto Eguchi. Minimum information divergence of q-functions for dynamic treatment resumes. Information Geometry, 7(Suppl 1):229–249, 2024.
- [24] Shinto Eguchi and John Copas. A class of logistic-type discriminant functions. Biometrika, 89:1–22, 2002.
- [25] Shinto Eguchi and John Copas. Interpreting kullback–leibler divergence with the neyman–pearson lemma. Journal of Multivariate Analysis, 97(9):2034–2040, 2006.
- [26] Shinto Eguchi and Osamu Komori. Minimum divergence methods in statistical machine learning. (No Title), 2022.
- [27] Shinto Eguchi, Osamu Komori, and Shogo Kato. Projective power entropy and maximum tsallis entropy distributions. Entropy, 13(10):1746–1764, 2011.
- [28] Shinto Eguchi, Osamu Komori, and Atsumi Ohara. Duality of maximum entropy and minimum divergence. Entropy, 16(7):3552–3572, 2014.
- [29] Jane Elith and John R Leathwick. Species distribution models: ecological explanation and prediction across space and time. Annual review of ecology, evolution, and systematics, 40(1):677–697, 2009.
- [30] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1):119–139, 1997.
- [31] Jerome H Friedman. On bias, variance, 0/1 loss, and the curse-of-dimensionality. Data mining and knowledge discovery, 1:55–77, 1997.
- [32] Jerome H Friedman. Greedy function approximation: a gradient boosting machine. Annals of statistics, pages 1189–1232, 2001.
- [33] Hironori Fujisawa and Shinto Eguchi. Robust parameter estimation with a small bias against heavy contamination. Journal of Multivariate Analysis, 99:2053–2081, 2008.
- [34] Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007.
- [35] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
- [36] Peter D Grünwald and A Philip Dawid. Game theory, maximum entropy, minimum discrepancy and robust bayesian decision theory. 2004.
- [37] Antoine Guisan and Wilfried Thuiller. Predicting species distribution: offering more than simple habitat models. Ecology letters, 8(9):993–1009, 2005.
- [38] Trevor Hastie, Saharon Rosset, Ji Zhu, and Hui Zou. Multi-class adaboost. Statistics and its Interface, 2(3):349–360, 2009.
- [39] Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman. The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer, 2009.
- [40] Kenichi Hayashi and Shinto Eguchi. A new integrated discrimination improvement index via odds. Statistical Papers, pages 1–20, 2024.
- [41] Hideitsu Hino and Shinto Eguchi. Active learning by query by committee with robust divergences. Information Geometry, 6(1):81–106, 2023.
- [42] Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence. Neural computation, 14(8):1771–1800, 2002.
- [43] Geoffrey E Hinton. A practical guide to training restricted boltzmann machines. In Neural Networks: Tricks of the Trade: Second Edition, pages 599–619. Springer, 2012.
- [44] Geoffrey E Hinton, Terrence J Sejnowski, et al. Learning and relearning in boltzmann machines. Parallel distributed processing: Explorations in the microstructure of cognition, 1(282-317):2, 1986.
- [45] Hung Gia Hoang, Ba-Ngu Vo, Ba-Tuong Vo, and Ronald Mahler. The cauchy–schwarz divergence for poisson point processes. IEEE Transactions on Information Theory, 61(8):4475–4485, 2015.
- [46] David W Hosmer Jr, Stanley Lemeshow, and Rodney X Sturdivant. Applied logistic regression. John Wiley & Sons, 2013.
- [47] Peter J Huber. Robust estimation of a location parameter. In Breakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992.
- [48] Peter J Huber and Elvezio M Ronchetti. Robust statistics. John Wiley & Sons, 2011.
- [49] Hung Hung, Zhi-Yu Jou, and Su-Yun Huang. Robust mislabel logistic regression without modeling mislabel probabilities. Biometrics, 74(1):145–154, 2018.
- [50] Jack Jewson, Jim Q Smith, and Chris Holmes. Principles of bayesian inference using general divergence criteria. Entropy, 20(6):442, 2018.
- [51] Bent Jørgensen. Exponential dispersion models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 49(2):127–145, 1987.
- [52] Giorgio Kaniadakis. Non-linear kinetics underlying generalized statistics. Physica A: Statistical mechanics and its applications, 296(3-4):405–425, 2001.
- [53] Osamu Komori and Shinto Eguchi. Statistical Methods for Imbalanced Data in Ecological and Biological Studies. Springer, Tokyo, 2019.
- [54] Osamu Komori and Shinto Eguchi. A unified formulation of k-means, fuzzy c-means and gaussian mixture model by the kolmogorov-nagumo average. Entropy, 23:518, 2021.
- [55] Osamu Komori, Shinto Eguchi, Shiro Ikeda, Hiroshi Okamura, Momoko Ichinokawa, and Shinichiro Nakayama. An asymmetric logistic regression model for ecological data. Methods in Ecology and Evolution, 7(2):249–260, 2016.
- [56] Osamu Komori, Shinto Eguchi, Yusuke Saigusa, Buntarou Kusumoto, and Yasuhiro Kubota. Sampling bias correction in species distribution models by quasi-linear poisson point process. Ecological Informatics, 55:1–11, 2020.
- [57] Osamu Komori, Yusuke Saigusa, and Shinto Eguchi. Statistical learning for species distribution models in ecological studies. Japanese Journal of Statistics and Data Science, 6(2):803–826, 2023.
- [58] Friedrich Liese and Igor Vajda. On divergences and informations in statistics and information theory. IEEE Transactions on Information Theory, 52(10):4394–4412, 2006.
- [59] David G Luenberger. Optimization by vector space methods. John Wiley & Sons, 1997.
- [60] Kumar P Mainali, Dan L Warren, Kunjithapatham Dhileepan, Andrew McConnachie, Lorraine Strathie, Gul Hassan, Debendra Karki, Bharat B Shrestha, and Camille Parmesan. Projecting future expansion of invasive species: comparing and improving methodologies for species distribution modeling. Global change biology, 21(12):4464–4480, 2015.
- [61] Henry B Mann and Abraham Wald. On the statistical treatment of linear stochastic difference equations. Econometrica, Journal of the Econometric Society, pages 173–220, 1943.
- [62] P. McCullagh and J.A. Nelder. Generalized Linear Models. Chapman & Hall, New York, 1989.
- [63] Cory Merow, Adam M Wilson, and Walter Jetz. Integrating occurrence data and expert maps for improved species range predictions. Global Ecology and Biogeography, 26(2):243–258, 2017.
- [64] Hanna Meyer and Edzer Pebesma. Predicting into unknown space? estimating the area of applicability of spatial prediction models. Methods in Ecology and Evolution, 12(9):1620–1633, 2021.
- [65] Mihoko Minami and Shinto Eguchi. Robust blind source separation by beta divergence. Neural Computation, 14:1859–1886, 2002.
- [66] Md Nurul Haque Mollah, Shinto Eguchi, and Mihoko Minami. Robust prewhitening for ica by minimizing -divergence and its application to fastica. Neural Processing Letters, 25:91–110, 2007.
- [67] Md Nurul Haque Mollah, Mihoko Minami, and Shinto Eguchi. Exploring latent structure of mixture ICA models by the minimum beta-divergence method. Neural Computation, 18:166–190, 2006.
- [68] Victoria Diane Monette. Ecological factors associated with habitat use of baird’s tapirs (tapirus bairdii). 2019.
- [69] Noboru Murata, Takashi Takenouchi, Takafumi Kanamori, and Shinto Eguchi. Information geometry of -boost and bregman divergence. Neural Computation, 16:1437–1481, 2004.
- [70] Kanta Naito and Shinto Eguchi. Density estimation with minimization of -divergence. Machine Learning, 90:29–57, 2013.
- [71] Tan Nguyen and Scott Sanner. Algorithms for direct 0–1 loss optimization in binary classification. In International conference on machine learning, pages 1085–1093. PMLR, 2013.
- [72] XuanLong Nguyen, Martin J Wainwright, and Michael I Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory, 56(11):5847–5861, 2010.
- [73] Frank Nielsen. On geodesic triangles with right angles in a dually flat space. In Progress in Information Geometry: Theory and Applications, pages 153–190. Springer, 2021.
- [74] Akifumi Notsu and Shinto Eguchi. Robust clustering method in the presence of scattered observations. Neural Computation, 28:1141–1162, 2016.
- [75] Akifumi Notsu, Osamu Komori, and Shinto Eguchi. Spontaneous clustering via minimum gamma-divergence. Neural computation, 26(2):421–448, 2014.
- [76] Katsuhiro Omae, Osamu Komori, and Shinto Eguchi. Quasi-linear score for capturing heterogeneous structure in biomarkers. BMC Bioinformatics, 18:308, 2017.
- [77] Steven J Phillips, Miroslav Dudík, and Robert E Schapire. A maximum entropy approach to species distribution modeling. In Proceedings of the twenty-first international conference on Machine learning, page 83, 2004.
- [78] Giovanni Pistone. -exponential models from the geometrical viewpoint. The European Physical Journal B, 70:29–37, 2009.
- [79] C Radakrishna Rao. Differential metrics in probability spaces. Differential geometry in statistical inference, 10:217–240, 1987.
- [80] Mark D Reid and Robert C Williamson. Information, divergence and risk for binary experiments. Journal of Machine Learning Research, 12(3), 2011.
- [81] Ian W Renner, Jane Elith, Adrian Baddeley, William Fithian, Trevor Hastie, Steven J Phillips, Gordana Popovic, and David I Warton. Point process models for presence-only analysis. Methods in Ecology and Evolution, 6(4):366–379, 2015.
- [82] Ian W Renner and David I Warton. Equivalence of maxent and poisson point process models for species distribution modeling in ecology. Biometrics, 69(1):274–281, 2013.
- [83] Peter J Rousseeuw and Annick M Leroy. Robust regression and outlier detection. John wiley & sons, 2005.
- [84] Yusuke Saigusa, Shinto Eguchi, and Osamu Komori. Robust minimum divergence estimation in a spatial poisson point process. Ecological Informatics, 81:102569, 2024.
- [85] Robert E Schapire and Yoav Freund. Boosting: Foundations and algorithms. Kybernetes, 42(1):164–166, 2013.
- [86] Burr Settles. Active learning literature survey. 2009.
- [87] H Sebastian Seung, Manfred Opper, and Haim Sompolinsky. Query by committee. In Proceedings of the fifth annual workshop on Computational learning theory, pages 287–294, 1992.
- [88] Helen R Sofaer, Catherine S Jarnevich, Ian S Pearse, Regan L Smyth, Stephanie Auer, Gericke L Cook, Thomas C Edwards Jr, Gerald F Guala, Timothy G Howard, Jeffrey T Morisette, et al. Development and delivery of species distribution models to inform decision-making. BioScience, 69(7):544–557, 2019.
- [89] Roy L Streit and Roy L Streit. The poisson point process. Springer, 2010.
- [90] Takashi Takenouchi and Shinto Eguchi. Robustifying AdaBoost by adding the naive error rate. Neural Computation, 16:767–787, 2004.
- [91] Takashi Takenouchi, Osamu Komori, and Shinto Eguchi. Extension of receiver operating characteristic curve and auc-optimal classification. Neural Computation, 24:2789–2824, 2012.
- [92] Takashi Takenouchi2, Shinto Eguchi, Noboru Murata, and Takafumi Kanamori. Robust boosting algorithm against mislabeling in multiclass problems. Neural Computation, 20:1596–1630, 2008.
- [93] Marina Valdora and Víctor J Yohai. Robust estimators for generalized linear models. Journal of Statistical Planning and Inference, 146:31–48, 2014.
- [94] Aad W Van der Vaart. Asymptotic statistics, volume 3. Cambridge university press, 2000.
- [95] Halbert White. Maximum likelihood estimation of misspecified models. Econometrica: Journal of the econometric society, pages 1–25, 1982.
- [96] Christopher KI Williams. Prediction with gaussian processes: From linear regression to linear prediction and beyond. In Learning in graphical models, pages 599–621. Springer, 1998.
- [97] Katherine L Yates, Phil J Bouchet, M Julian Caley, Kerrie Mengersen, Christophe F Randin, Stephen Parnell, Alan H Fielding, Andrew J Bamford, Stephen Ban, A Márcia Barbosa, et al. Outstanding challenges in the transferability of ecological models. Trends in ecology & evolution, 33(10):790–802, 2018.
- [98] Jun Zhang. Divergence function, duality, and convex analysis. Neural computation, 16(1):159–195, 2004.
- [99] Huimin Zhao, Jie Liu, Huayue Chen, Jie Chen, Yang Li, Junjie Xu, and Wu Deng. Intelligent diagnosis using continuous wavelet transform and gauss convolutional deep belief network. IEEE Transactions on Reliability, 72(2):692–702, 2022.