figurec
Mining Asymmetric Intertextuality
Abstract
This paper introduces a new task in Natural Language Processing (NLP) and Digital Humanities (DH): Mining Asymmetric Intertextuality. Asymmetric intertextuality refers to one-sided relationships between texts, where one text cites, quotes, or borrows from another without reciprocation. These relationships are common in literature and historical texts, where a later work references aclassical or older text that remain static.
We propose a scalable and adaptive approach for mining asymmetric intertextuality, leveraging a split-normalize-merge paradigm. In this approach, documents are split into smaller chunks, normalized into structured data using LLM-assisted metadata extraction, and merged during querying to detect both explicit and implicit intertextual relationships. Our system handles intertextuality at various levels, from direct quotations to paraphrasing and cross-document influence, using a combination of metadata filtering, vector similarity search, and LLM-based verification.
This method is particularly well-suited for dynamically growing corpora, such as expanding literary archives or historical databases. By enabling the continuous integration of new documents, the system can scale efficiently, making it highly valuable for digital humanities practitioners in literacy studies, historical research and related fields.
Keywords Intertextuality Metadata Hierarchical Chunking information extraction Split-Normalize-Merge Metadata-filtered Vector Search information retrieval historical databases
1 Introduction
As the volume of literary, and historical texts available in digital form continues to grow exponentially, the ability to trace how ideas are referenced, borrowed, or transformed across texts has become ever more vital. Intertextuality—the study of relationships between texts—provides critical insight into intellectual traditions, cultural change, and literary influence. However, the increasing complexity of digital archives poses significant challenges for tracking these relationships, particularly when they are subtle or implicit.
One particularly challenging form of intertextuality is asymmetric intertextuality. In this paper, we define asymmetric intertextuality as a type of relationship between two texts in which they are structurally or semantically non-isomorphic—that is, they do not exhibit a straightforward one-to-one correspondence in their relationship. This occurs when one text references or borrows from another, but the connection between them is non-reciprocal and structurally uneven. While one-way intertextuality refers to a directional flow of influence, asymmetric intertextuality encompasses a broader mismatch in how the texts relate, where the influence cannot be mapped symmetrically or bidirectionally [1].
In contexts such as literature (allusions and thematic borrowing), journalism (quotations), and historical texts (quotations, allusions, borrowings, etc), both one-way and asymmetric intertextual relationships often occur. Despite concerted efforts to build tools and develop techniques to identify intertextuality, these relationships are not easily detected by traditional methods, including token-based n-gram analysis or even recent advancements in semantic search. The detection of such asymmetric relationships requires a more advanced system capable of identifying both explicit and implicit connections, especially when texts transform or paraphrase the original content [2].
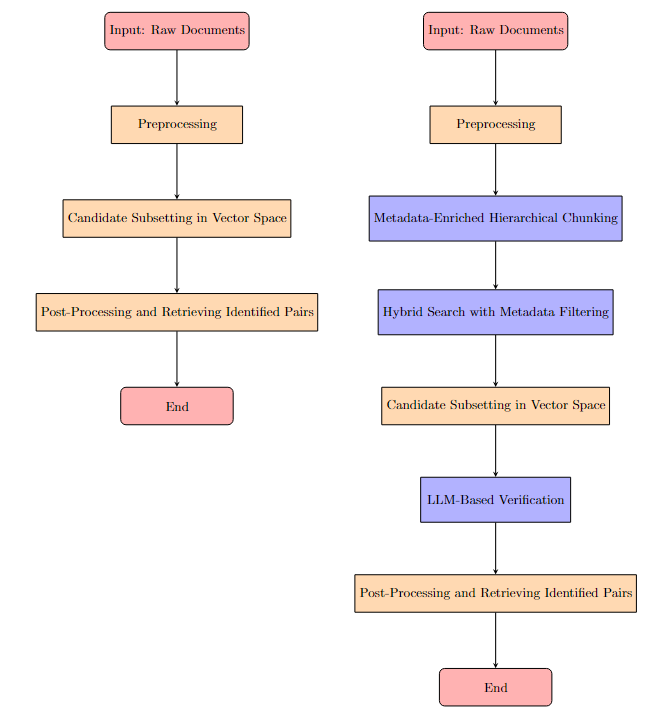
In this paper, we propose to tackle the problem of detecting asymmetric intertextuality using a novel Split-Normalize-Merge paradigm. Our approach breaks documents into smaller chunks (Split), normalizes them using LLM-assisted metadata extraction (Normalize), and reassembles them during querying to detect both explicit and implicit relationships (Merge). By combining large language models (LLMs), vector similarity search, and metadata filtering, we address the limitations of traditional approaches and propose a scalable solution for detecting asymmetric intertextuality across large and dynamically growing corpora.
1.1 Broader Definition of Intertextuality
Intertextuality encompasses a wide range of textual relationships, from direct quotations to more subtle forms of influence like allusion, plagiarism, or thematic borrowing. Scholars have long studied how texts reference one another, but the complexity of intertextuality increases significantly when references are implicit or indirect.
For the purposes of this paper, we focus on explicit forms of intertextuality, such as quotation and citation, but we also acknowledge the broader landscape that includes more implicit forms like allusion, paraphrasing, and thematic borrowing.
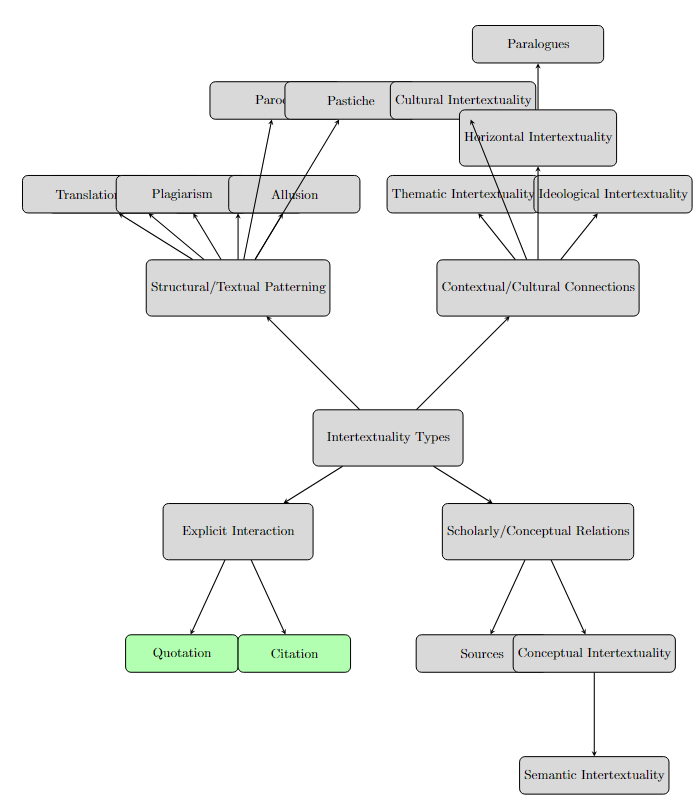
Forms of intertextuality can include:
-
1.
Explicit Interaction involves direct textual references or borrowings:
-
•
Quotation: The verbatim or near-verbatim reuse of text. For example, Herman Melville’s Moby Dick directly quotes biblical passages like the story of Jonah to draw theological parallels [3].
-
•
Citation: While less common in historical and literary texts, citation-like references still appear, such as in Chinese classical texts that reference earlier works [4].
-
•
-
2.
Scholarly/Conceptual Relations focus on intellectual and thematic connections:
-
•
Sources (Implicit citation): The identification of original works that provide foundational content for new texts [5].
-
•
Conceptual Intertextuality: The sharing of themes or ideas across texts without direct textual borrowing. For instance, classical Chinese texts often reference philosophical concepts from earlier works without direct quotation [6].
-
•
-
3.
Structural/Textual Patterning refers to intertextuality driven by structural or stylistic similarities:
-
•
Translation: The transformation of a text from one language to another [7].
-
•
Plagiarism: Unauthorized textual overlap [8].
-
•
Allusion: Indirect references to earlier works, relying on the reader’s knowledge [9].
-
•
Paraphrastic Intertextuality: Rephrasing content while maintaining semantic similarity [10].
- •
-
•
-
4.
Contextual/Cultural Connections explore intertextuality in relation to broader cultural or thematic frameworks:
-
•
Thematic Intertextuality: For example, classical Chinese texts engage in thematic intertextuality through philosophical ideas that transcend specific works [13].
-
•
In this paper, we focus specifically on quotation and citation, while acknowledging that asymmetry in intertextuality is often evident in less explicit forms, such as paraphrasing or thematic borrowing.
1.2 One-Way Intertextuality: A Cross-Domain Phenomenon
While asymmetric intertextuality involves structural or semantic transformations, one-way intertextuality refers more simply to the directional flow of references, communication, or influence between two texts. This phenomenon is widespread across various domains, including literature, journalism, and historical texts.
In one-way intertextuality, a newer text draws from or references an older one, but the reference is not reciprocated. This one-directional flow is common in many contexts and can take several forms, including quotation, paraphrase, and thematic borrowing [14].
1.2.1 Examples Across Domains
-
•
Literature: Many pre-modern novels or poems reference or allude to classical works (e.g., Shakespeare, Homer, or Chinese classics like the Shijing). However, these allusions are one-sided: the original works remain static and unchanged, while the newer texts reinterpret or recontextualize them [4].
-
•
Journalism: News articles frequently quote or paraphrase statements from public figures or historical documents. However, these quotes are often taken out of context or reframed to fit the narrative of the article, making the relationship non-reciprocal and often asymmetric.
1.2.2 Challenges in Detecting One-Way Intertextuality
Detecting one-way intertextuality is challenging because the references are often implicit. Traditional token-based methods (like keyword matching or n-gram analysis) struggle to capture paraphrased or recontextualized references, while semantic search methods often miss subtle thematic or structural borrowings [2].
For example, a modern text may paraphrase an older work without using direct quotations, making it hard for basic search algorithms to detect the connection. Similarly, thematic borrowings, where ideas or concepts are reinterpreted without explicit citation, pose a major challenge for current intertextuality detection tools.
1.2.3 Why One-Way Intertextuality is Usually Asymmetric
Not all one-way relationships are asymmetric, but many are. In cases where a newer text transforms, paraphrases, or recontextualizes an older one, the relationship between the texts becomes structurally non-isomorphic. The newer text may borrow heavily from the older one, but the transformation of the content introduces asymmetry. The two texts are no longer equivalent in their relationship, and the influence is not easily mapped in a bi-directional way.
This is particularly true in cases of paraphrasing or thematic borrowing, where the newer text changes the meaning or application of the original content. The lack of direct quotation or citation makes these connections harder to detect, requiring more advanced systems that can capture the semantic and structural differences between the two texts.
1.3 Common Characteristics and Challenges Across Domains
While one-way and asymmetric intertextuality manifest differently across various domains, they share several common characteristics that make them difficult to detect using traditional methods:
-
•
Unidirectional Influence: Whether in academic writing or literature, the flow of influence is always one-way. A newer text references an older one, but the older text cannot reciprocate.
-
•
Implicitness: Many one-way intertextual links are implicit. A modern text may refract, paraphrase, or borrow thematically from an older work without directly citing it or using recognizable keywords, making detection difficult.
-
•
Paraphrasing and Transformation: One of the biggest challenges in detecting one-way intertextuality is that newer texts often transform or paraphrase the content of the older work. This transformation introduces asymmetry, posing challenges to traditional search methods.
-
•
Cross-Domain Applicability: Whether in academia, literature, journalism, or social media, one-way and asymmetric intertextuality appear across a variety of domains, making the need for a cross-domain detection system more pressing.
1.4 A New Formalism for Detecting Asymmetry in Intertextuality
This paper introduces a novel formalism for detecting asymmetric intertextuality, a type of textual relationship where influence flows in one direction, often through paraphrasing, thematic borrowing, or non-reciprocal citations. Such relationships are difficult to detect using traditional methods.
In Section 2, we provide a review of existing approaches and highlight the gaps that this formalism aims to address. Section 3 delves into the design space of intertextuality detection methods, formalizing the requirements and challenges of detecting asymmetric relationships. Finally, Section 4 demonstrates the proposed formalism in action, outlining the design decisions, illustrating the process through examples.
2 Related Works
2.1 Quotations and Citations Patterns & Datasets
Quotation detection has been explored across various domains, with several key datasets providing annotated text for model training and evaluation. These datasets typically focus on intra-document relationships, where quotes are detected within a single document. However, detecting cross-document relationships, such as paraphrasing or thematic borrowing, remains a challenge. Below is a summary of the most prominent datasets:
| Dataset | Language/Domain | Size | Quote Types |
|---|---|---|---|
| Cornell movie (2023) [15] | Literary (English) | 5,015 quotes | Direct, Indirect |
| Finnish News (2023) [16] | Finnish News | 1,500 articles | Direct, Indirect (linked with coreference chains for speaker attribution) |
| German News (2024) [17] | German News | 998 articles | Direct, Indirect, Reported, Free Indirect, Indirect/Free Indirect (Annotated with speaker roles) |
Several datasets focus on identifying citation intents in academic texts:
| Dataset | Size | Citation Intents |
|---|---|---|
| SciCite (2019)[18] | 11,020 citations | Background, Method, Result Comparison |
| ACL-ARC (2018)[19] | 1,941 citations | Background, Uses, Extends, Motivation, Compare/Contrast, Future Work |
We mention these datasets to highlight the existing standards for quotation detection, but also to point out the gap they leave in detecting more complex, asymmetric relationships across documents. Our task involves detecting these cross-document relationships, such as paraphrasing or thematic borrowing, which these datasets are not designed to address.
2.2 LLM-assisted Structured Data Generation
Recent advances in Large Language Models (LLMs) have enabled significant progress in structured data extraction from unstructured text. These models excel in tasks like entity recognition, relationship extraction, and summarization [20, 21]. Traditional rule-based systems often struggle with the nuances of unstructured data, but LLMs, with their ability to understand context and semantics, have transformed various fields such as legal document analysis, medical report generation, and customer feedback summarization.
One key advantage of LLMs is their ability to handle diverse formats and long documents. Techniques such as sparse attention mechanisms (e.g., Longformer) [22] and divide-and-conquer models [23] allow for efficient handling of large texts, ensuring that important information is extracted without exceeding token limits. These advances have greatly improved the scalability of LLMs in domains requiring the processing of large, complex documents.
LLMs have also demonstrated robustness in extracting structured tables, knowledge graphs, and metadata from varied text formats, including visually rich documents [20]. This versatility highlights their potential to be adapted for a wide range of applications requiring structured data generation.
2.3 Intertextuality Detection with Advanced Models
Advanced models, particularly those leveraging LLMs, are becoming increasingly crucial for detecting complex intertextual relationships. The introduction of techniques like split-normalize-merge and discourse-aware chunking has enabled tools to go beyond simple citation or quotation detection. These models, which can process large, multi-page documents, are now capable of detecting paraphrasing, thematic borrowing, and asymmetric influences across documents.
Wang et al. [24] introduced a document-centric LLM for information extraction, framing the task as a question-answering one, which allows for zero-shot extraction. Similarly, Huang et al. [25] proposed visual-language models that integrate layout and text to improve the detection of complex document structures. However, these models still fall short in cases where paraphrasing or thematic borrowing occurs without explicit markers.
Our work extends these approaches by leveraging LLM-assisted metadata extraction and semantic similarity searches, which allow for the detection of both explicit and implicit cross-document relationships. This methodology, combined with the ability to process long, complex documents, provides a more comprehensive understanding of how texts influence one another, even when traditional citation or quotation markers are absent.
3 Formalizing the Design Space of Creating Asymmetric Intertextuality Solutions
Mining asymmetric intertextuality requires a system that can handle the complexity of various intertextual relationships, ranging from explicit citations to more implicit thematic borrowings. This section discusses the design space and requirements necessary to build such a system, emphasizing the need for flexibility in decomposing text into its core components, such as cue words, quotation markers, and citation markers. By doing so, we can effectively detect both explicit and implicit intertextuality across dynamically growing corpora.
3.1 Split: Handling Asymmetricity
To address the asymmetric nature of intertextuality, where one text references or borrows from another without reciprocation, the system must decompose sentences into granular components. These components include cue words (e.g., "according to"), quotation markers (e.g., quotation marks or speaker attributions), and citation markers (e.g., "(Smith, 2022)" or "[1]"). Each of these elements plays a critical role in identifying different types of intertextual relationships.
The key requirement of such a system is its ability to normalize texts by separating these external markers from the core content, enabling both explicit (direct quotation or citation) and implicit (paraphrasing, thematic borrowing) intertextual relationships to be detected. This decomposition allows for precise semantic comparison across texts, helping to uncover subtle and asymmetric influences that traditional methods often overlook.
The following subsections define specific types of asymmetric intertextuality and the role of external cues in detecting them.
3.1.1 Types of Asymmetric Intertextuality
Asymmetric intertextuality can manifest in various forms, each requiring different detection strategies. These intertextual relationships can be classified into three broad categories—Quotation, Citation, and Implicit Intertextuality—each reflecting a different type of textual borrowing or influence.
| Type | Description |
|---|---|
| Direct Quote (DQ) [17] | Verbatim reuse of text from one document to another. Example: A paper quoting a passage from an earlier work word-for-word. |
| Indirect Quote (IQ) [17] | Paraphrased or summarized content from a source document. Example: A paper rephrasing an argument from an older source without quoting it directly. |
| Reported Quote (RQ) [17] | A third-party mention of a quotation, often seen in reviews or news reports. Example: A review article mentioning quotes from multiple research papers without quoting them verbatim. |
| Background Citation (BC) [18] | Citing a work for context or background information. Example: A research paper citing a foundational theory as background for its own research. |
| Method Citation (MC) [18] | Citing a work for its methodology or tools in a sentence-to-document comparison. Example: A research paper adopting an experimental protocol from an earlier study. |
| Result Comparison (RC) [18] | Citing a work to compare results in a sentence-to-document comparison. Example: A research paper comparing its findings with those from an earlier study. |
| Implicit Quotation (IQT) | Paraphrased or transformed versions of a quotation without explicit markers, making the source harder to trace. Example: A subtle transformation of a famous quote that retains its meaning but avoids recognizable phrasing. |
| Implicit Citation (ICT) | Reference to ideas or methods without explicit citation, often seen in paraphrased or reinterpreted form. Example: A paper borrowing ideas or methods from another without direct citation, possibly as a paraphrase. |
This classification highlights the different ways in which intertextuality can manifest. Identifying and processing these relationships requires the ability to break down sentences into their core elements, as discussed further in the next section.
3.1.2 Intertextuality-Type Related Re-equippable Elements
In detecting asymmetric intertextuality, the system uses various external cues—such as quotation marks, citation markers, and paraphrasing cues—that signal different types of intertextual references. These external elements are unequipped during preprocessing but are stored as metadata. They are crucial for both metadata-filtered vector search and deep search, helping to refine candidate matches and ultimately re-equipping elements when necessary.
Below, we outline the specific unequippable elements and associated metadata for each intertextuality type. Both the vector search and deep search stages utilize these elements to identify asymmetric relationships such as matching similar author names or paraphrased ideas across documents.
| Intertextuality Type | Re-equippable Elements | Associated Metadata |
|---|---|---|
| Direct Quote (DQ) |
- Quotation marks
- Speaker attribution (e.g., "said by X") - Citation markers (e.g., (Author, Year)) - Punctuation related to the quote |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, discourse role
- Document Metadata: Title, author, publication year, author names (useful for asymmetric pairing, e.g., "John writes XYZ"), OCLC number |
| Indirect Quote (IQ) |
- Paraphrasing cues (e.g., "according to X", "as mentioned by Y")
- Speaker attribution (e.g., "X argues that…") - Citation markers - Reported speech verbs (e.g., "claims", "asserts") |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, discourse role
- Document Metadata: Title, author, publication year, author names, OCLC number |
| Reported Quote (RQ) |
- Reported speech attribution (e.g., "X said in an interview")
- Quotation marks (if present) - Speaker attribution - Citation markers |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, discourse role
- Document Metadata: Title, author, publication year, OCLC number - Speaker Information: The original speaker’s name, if available |
| Background Citation (BC) |
- Citation markers
- Paraphrasing cues (e.g., "based on the work of X") - Methodology references (e.g., "following X’s theory") |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, citation intent
- Document Metadata: Title, author, publication year, OCLC number |
| Method Citation (MC) |
- Citation markers
- Methodology attribution (e.g., "Using Y’s approach") - Methodological cues (e.g., "as demonstrated by") |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, citation intent
- Document Metadata: Title, author, publication year, OCLC number |
| Result Comparison (RC) |
- Citation markers
- Comparison cues (e.g., "compared to X’s result") - Specific study names |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, citation intent
- Document Metadata: Title, author, publication year, OCLC number - Study Name: The name of the study being compared |
| Implicit Quotation (IQT) | - None |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, discourse role
- Document Metadata: Title, author, publication year, OCLC number |
| Implicit Citation (ICT) | - None |
- Sentence Metadata: Document ID, sentence ID, sentence embedding, discourse role
- Document Metadata: Title, author, publication year, OCLC number |
The system unequips these external cues during preprocessing and stores them in metadata. These elements are used during both metadata-filtered vector search and deep search to guide the search, refine candidate matches, and ultimately reintroduce these elements when necessary.
3.1.3 Universal Re-equippable Elements
In addition to the intertextuality-type-specific elements, there are universal elements that apply across different types of intertextuality. These elements are potentially useful for defining more nuanced asymmetric intertextuality patterns in future research and are particularly useful during deep search for refining matches and understanding the context. While universal re-equippable elements may not always directly indicate a specific intertextuality type, they help to enhance the search and provide additional context for implicit and asymmetric intertextuality patterns.
Below is a comprehensive list of universal re-equippable elements, along with their associated metadata, which is used to reintroduce them during the deep search phase.
| Category | Unequippable Elements | Metadata to Re-Equip |
|---|---|---|
| Stylistic Markers | - Punctuation (e.g., parentheses, dashes, ellipses) - Formatting (e.g., italics, bold, underlined text) | - Text formatting type - Position in sentence |
| Discourse Cues | - Transitional phrases (e.g., "however", "therefore") - Sentence starters (e.g., "According to…") | - Discourse role - Position in text (e.g., beginning of paragraph) |
| Attribution Markers | - Speaker identification (e.g., "John said") - Reported speech (e.g., "He said", "She claimed") | - Speaker name - Reported speech markers (direct/indirect) |
| Content Markers | - Attribution verbs (e.g., "suggests", "claims", "argues") - Passive reporting (e.g., "it is believed", "it was suggested") | - Attribution verb - Sentence structure - Voice (active/passive) |
| Sentence Structure | - Parentheticals - Subordinate clauses (e.g., "which", "that", "when") | - Parenthetical content - Clause structure (main/subordinate) |
| Citation Formats | - Inline citations (e.g., "(Author, Year)") - Digital references (e.g., hyperlinks) | - Citation format - Source document ID |
| Numerical Data | - Dates and numbers (e.g., years, percentages) - Statistical results (percentages, figures) | - Numerical value - Context (e.g., results, methods) |
| Figures and Tables | - Mentions of figures/tables (e.g., "see Fig. 3") | - Figure/table reference - Caption or description |
By storing these unequipped elements as metadata, we ensure that the original structure is accurately restored during deep search, allowing for a more nuanced understanding of intertextual relationships. These elements play a crucial role in refining the results and improving the detection of both explicit and implicit intertextuality.
3.2 Normalize: Structuring Data for Hybrid Search
The normalization step in the split-normalize-merge paradigm is critical for transforming fragmented text elements into a structured, searchable representation that enables both explicit and implicit intertextuality detection. This transformation is necessary to manage the complexity of documents that exhibit asymmetric intertextual relationships, where connections between texts may be non-reciprocal or structurally uneven [26].
Normalization must prepare the data not only for semantic comparison across texts but also ensure that the database and indexing system can efficiently support the hybrid search in the next step [27]. This requires meticulous attention to how documents and sentences are decomposed, vectorized, and stored [28].
3.2.1 Document-Level Normalization: Discourse and Structural Layers
At the document level, the system must account for the multi-layered structure of texts by identifying and tagging discourse roles (e.g., introduction, methods, results). This process helps capture the broader context in which citations, quotations, and paraphrases occur [29, 30].
The following strategies could be employed:
-
•
Discourse Tagging: Each section of the document is assigned a specific discourse role (e.g., background, methodology, or conclusion). This helps in contextualizing the nature of intertextual relationships, such as whether a citation in the methodology section indicates a methodological borrowing or whether a quotation in the discussion section suggests a result comparison [29, 30].
-
•
Hierarchical Decomposition: Documents are broken down into sections, paragraphs, and sentences, while preserving their hierarchical structure. This decomposition is crucial for detecting cross-document influences, where intertextual relationships may span entire sections or even whole documents, rather than being restricted to sentence-level interactions [5].
3.2.2 Sentence-Level Normalization: Semantic Decomposition
At the sentence level, the system transforms each sentence into a structured, vectorized representation that captures its semantic meaning independently of surface-level markers like quotation marks or citation tags. This is particularly important for detecting implicit intertextuality, where paraphrasing or indirect references obscure the direct connection between texts [31].
-
•
Sentence Embeddings: Sentences are encoded into vector embeddings (e.g., using Sentence-BERT [32]) to capture their semantic content. These embeddings support semantic similarity searches in the merge/hybrid search phase, allowing the system to detect paraphrased or reworded intertextual connections that lack lexical overlap with the source text [33].
-
•
Contextual Metadata: Each sentence is enriched with metadata such as discourse role, citation context, and document-level identifiers. This metadata is essential for the next step, enabling the system to filter and refine the search based on specific types of intertextual relationships (e.g., direct quotations, paraphrasing, or implicit citations) [5].
3.2.3 Connecting Local and Global Layers
While sentence-level analysis provides fine-grained detection of intertextuality, it is often insufficient when dealing with implicit citations or thematic borrowing across larger sections or whole documents. To address this, the system must establish cross-document links at both the sentence and section levels [31].
-
•
Linking Documents for Implicit Citations: Many intertextual connections, especially in academic writing, involve implicit references where one document builds upon another without explicitly citing it. By linking documents based on semantic similarity and discourse roles, the system can detect such implicit relationships [5, 31].
-
•
Cross-Sentence Dependencies: Some intertextual relationships, such as implicit quotations, may require analyzing surrounding sentences or even entire sections. By preserving the hierarchical structure of documents, the system allows for cross-sentence and cross-section comparisons during the merge phase, which is critical for detecting complex intertextual influences [29].
3.2.4 Vectorization and Metadata
To support the hybrid search in the next step, the normalized data must be stored in a database that allows for efficient querying and retrieval. This involves two key steps:
-
•
Vectorization: Each sentence and section is vectorized (such as Cohere-embed-english-v3.0) and stored in a vector database (e.g., FAISS or Milvus), which allows for fast nearest-neighbor searches during the merge phase [34]. These vectors enable the system to perform semantic comparisons across documents with minimal computational overhead, even in large corpora [33].
-
•
Metadata Storage: In addition to vectorized representations, each document and sentence is stored alongside its corresponding metadata, including discourse role, citation type, and quotation markers [29, 5]. This metadata is crucial for hybrid search filtering, where the system can refine its results based on the type of intertextual relationship being queried (e.g., direct quotation, method citation, paraphrase).
By organizing the normalized data in this way, the system ensures that the subsequent merge phase can leverage both semantic similarity and metadata filtering to detect asymmetric intertextual relationships across documents [27].
3.2.5 Connecting Sentences to Documents
Each sentence in the Sentence Collection is linked to its parent document using the document_id field. Additionally, each sentence is linked to a specific section within the document using the section_id field, ensuring that the context of the sentence is preserved.
3.3 Merge: Reintroducing Unequipped Elements
After detecting potential intertextual relationships through vector similarity and metadata-filtered search, the next step is to reintroduce the external elements that were removed during the normalization phase. These elements include quotation marks, citation markers, paraphrasing cues, and other surface-level markers that help contextualize the detected intertextuality. Additionally, LLM-based verification (as a baseline method, deep learning methods also possible) is employed to confirm the validity of the detected relationships by re-equipping these elements in context.
3.3.1 Overview of Searching Process
Once a potential intertextual match is detected, the system re-equips the external cues that were stripped during preprocessing. These unequippable elements, stored as metadata, are critical for refining the detected relationship and ensuring that the intertextual connection is valid. The re-equipped elements are reintroduced in two stages:
-
•
Stage 1 - Metadata-filtered Vector Search: Elements stored as metadata are reintroduced based on the type of intertextuality detected (e.g., direct quote, paraphrase, citation). This ensures that the original structure of the text is restored and that the relationship is presented in its full context.
-
•
Stage 2 - Deep Search: The system uses a large language model (LLM) to process the re-equipped elements in context, ensuring that the final output is coherent and semantically aligned with the original text. The LLM also verifies the relationship by cross-referencing the re-equipped elements with both the source and target documents.
The specific elements that are re-equipped include:
-
•
Quotation Marks : Reintroduced for sentences identified as direct quotes to distinguish verbatim reuse of text. These are essential for identifying Direct Quotes (DQ) and Reported Quotes (RQ).
-
•
Citation Markers : Restored for both explicit and implicit citations, marking the source of the referenced material. Citation markers are critical for identifying Method Citations (MC), Result Comparisons (RC), and Background Citations (BC).
-
•
Paraphrasing Cues : Phrases like "according to" or "as mentioned by" are restored to clarify paraphrased content. These are especially important for detecting Indirect Quotes (IQ) and Implicit Citations (ICT).
-
•
Speaker Attribution : Re-applied for reported quotes, indicating the original speaker or source of the information. This is important for Reported Quotes (RQ) and cases where the original speaker is referenced but not directly quoted.
-
•
Discourse Cues : Transitional phrases and sentence starters (e.g., "however", "therefore", "according to") are restored to provide the rhetorical structure of the text, which is useful for Indirect Quotes (IQ) and Implicit Citations (ICT).
-
•
Figures and Tables : Mentions of figures or tables (e.g., "see Fig. 3") and their captions are restored when they play a role in the intertextual relationship, particularly in Result Comparisons (RC).
-
•
Numerical Data : Relevant dates, numbers, and statistical results are reintroduced to provide factual context, especially in citations involving data or analysis, such as Method Citations (MC) or Result Comparisons (RC).
These re-equipped elements are represented by indicator functions in the mathematical formalism, which adjust the similarity score based on whether these external cues were present in the original sentence. The indicator functions represent the presence of each element, where can be any unequippable element (e.g., for quotation marks, for citation markers, etc.).
The re-equipping process ensures that the semantic meaning of the text is maintained while providing the necessary context to validate the intertextual relationship. The following mathematical formalism describes how these elements are used to modify the similarity score:
3.3.2 Mathematical Formalism for Metadata-filtered Vector Search
In this section, we formalize the process of re-equipping external elements such as quotation marks, citation markers, and paraphrasing cues when detecting intertextual relationships. The general equation below adjusts the similarity score between a source chunk and a target document by accounting for the presence of these external elements.
In the candidate subsetting stage, we compute the cosine similarity between vectorized chunks or documents. We define two equations for the vector search process:
-
•
Quotation Types (Direct Quote, Indirect Quote, Reported Quote): This involves comparing two chunks of text, typically at the sentence-to-sentence level:
Where and are chunks of text, and represents the cosine similarity between their vector embeddings.
-
•
Citation Types (Method Citation, Result Comparison, Background Citation): This involves comparing a chunk to a document, typically at the sentence-to-document level:
Where is a chunk of text and is a document or a section of the document. The equation computes the cosine similarity between the chunk and the document.
The adjusted similarity between a chunk from the source document and a document from the target corpus is given by:
Where:
-
•
is the base cosine similarity between the vector embeddings of chunk and document .
-
•
is the weight associated with the external element (e.g., quotation marks, citation markers).
-
•
is an indicator function that equals 1 if the external element is present in the chunk , and 0 otherwise.
This formalism helps prioritize different types of intertextuality by adjusting the similarity score based on the presence of specific re-equippable elements.
3.3.3 Mathematical Formalism for Deep Search
The deep search phase refines the results by reintroducing the universal re-equippable elements and applying LLM (Large Language Model) processing to enhance the search. We split the deep search into two stages:
Stage 1: Plain Vector Matching
This stage involves plain vector similarity between the source chunk and the target chunk or document or .
Where:
-
•
is the cosine similarity between the vector embeddings of chunk and document .
Stage 2: LLM-Based Re-equipping
In this stage, the LLM takes the universal re-equippable elements (such as quotation marks, paraphrasing cues, and citation markers) from the metadata and re-equips them in the search process.
Where:
-
•
is the score adjustment provided by the LLM based on the re-equippable elements (from metadata and ).
The LLM takes into account the presence of universal re-equippable elements to refine the similarity score.
3.4 Scalability and Performance Optimization
As the system handles large and dynamically growing document corpora, ensuring scalability and optimizing performance becomes crucial. This section outlines the strategies employed to enhance the system’s efficiency while maintaining accuracy in detecting intertextual relationships.
3.4.1 Efficient Querying with Vector Databases
-
•
Using Vector Databases: The system employs specialized vector databases, such as FAISS or Milvus [34, 35], designed to handle high-dimensional similarity searches efficiently. These databases are optimized for fast nearest-neighbor searches, allowing quick retrieval of semantically similar text chunks from large corpora.
-
•
High-Dimensional Space Optimization: The system should be able to performs efficient vector comparisons in high-dimensional space, facilitating rapid searches across vast document collections without performance degradation.
-
•
Real-Time Retrieval: As new documents are added to the corpus, the system utilizes the vector database to perform real-time retrieval of semantically similar text. This ensures that the system can scale effectively while maintaining low query latency [34].
3.4.2 Dynamic Corpus Updates
-
•
Incremental Vectorization: New documents are vectorized incrementally as they are introduced, eliminating the need to reprocess the entire corpus, which enhances the system’s responsiveness and scalability [27].
-
•
Seamless Integration of New Documents: The system dynamically integrates new documents into the search space, allowing continuous indexing and querying without disrupting the existing structure.
-
•
Avoiding Full Reprocessing: By vectorizing new documents dynamically, the system avoids the significant computational overhead typically associated with full corpus reprocessing. This is especially important for handling large, continuously growing datasets [33].
3.4.3 Handling Large Corpora
-
•
Sparse Attention Models: To handle large datasets efficiently, sparse attention models [36] are used to reduce the computational complexity of similarity searches, ensuring high accuracy while minimizing resource usage.
-
•
Divide-and-Conquer Approaches: The system employs divide-and-conquer strategies, breaking large corpora into smaller chunks for independent processing. This modular approach helps the system manage large datasets more efficiently without sacrificing accuracy.
- •
In summary, by leveraging vector databases, dynamic updates, and efficient handling of large datasets, the system is designed to scale while maintaining its accuracy and performance. The next section will focus on a specific design implementation chosen for its balance of scalability, accuracy, and computational efficiency.
4 Exploring Design Spaces for Asymmetric Intertextuality Detection
In this section, we demonstrate the functionality of the Split-Normalize-Merge paradigm using a basic setup and a simple dataset.
4.1 Dataset for Demonstration
For the purposes of this demonstration, we use the Contract Understanding Atticus Dataset (CUAD) [37], a specialized dataset designed to facilitate legal contract review. CUAD consists of 510 contracts and over 13,000 annotated clauses, specifically selected to highlight a range of key clauses that are important for legal professionals to review.
Dataset Details:
-
•
Size: The dataset contains 510 contracts and over 13,000 annotated clauses.
-
•
Source: The dataset is constructed from legal contracts filed with the U.S. Securities and Exchange Commission (SEC) through the EDGAR system, which are publicly available.
-
•
Intertextuality Types: The dataset includes 41 different categories of contract clauses, such as governing law, non-compete clauses, exclusivity, and termination for convenience. These were specifically chosen to demonstrate the system’s ability to detect key legal obligations, restrictions, and risks in contracts.
-
•
Simplifications: For simplicity, the dataset focuses on contracts across 25 different types, but legal experts annotated only the most salient portions of each contract. Only important clauses, which make up about 10
This dataset is intended as a proof-of-concept to demonstrate the potential of the Split-Normalize-Merge paradigm, with its success indicating promising applications for future large-scale scenarios. A simplified example is used here to ensure that it can be fully explained within the context of this paper.
4.2 Demonstration of the Split-Normalize-Merge Paradigm
To illustrate how the Split-Normalize-Merge paradigm works, we provide a step-by-step demonstration using a basic example. This example consists of two text pairs that exhibit asymmetric intertextuality, such as paraphrasing or thematic borrowing.
4.2.1 Step 1: Split
In this step, we split the legal documents into smaller chunks, such as sentences or sections. This process allows the system to analyze content at a finer granularity, which is essential for detecting paraphrasing, thematic borrowing, or other intertextual relationships, especially in legal texts.
For this demonstration, we use the Contract Understanding Atticus Dataset (CUAD), a specialized dataset designed to facilitate legal contract review. CUAD consists of 510 contracts and over 13,000 annotated clauses, specifically selected to highlight key clauses that are important for legal professionals.
Let’s consider a document with the following chunk:
"EXHIBIT 4.25 INFORMATION IN THIS EXHIBIT IDENTIFIED BY [ * * * ]"
Using a sentence or section tokenizer, the document would be split into smaller chunks, preserving meaningful units of analysis. For example:
-
•
Chunk 1: "EXHIBIT 4.25 INFORMATION IN THIS EXHIBIT IDENTIFIED BY [ * * * ]"
-
•
Chunk 2: "This Agreement shall commence on the Effective Date and remain in effect until terminated as provided herein."
Each chunk is stored as a separate record in the database. Here’s an example of how the first chunk is stored:
{
"_id": {
"$oid": "670f89c9c6abf22788e288f5"
},
"doc_id": "670f881e870d0cb83f7e67ed",
"filename": "ABILITYINC_06_15_2020-EX-4.25-SERVICES AGREEMENT.txt",
"chunk_number": 1,
"chunk_text": "EXHIBIT 4.25 INFORMATION IN THIS EXHIBIT IDENTIFIED BY [ * * * ]"
}
This splitting process enables finer-grained analysis, crucial for detecting intertextual relationships in legal contracts.
Next, we implement two runs of mining with a Large Language Model (LLM), utilizing few-shot prompting to guide the model in identifying relevant relationships and metadata:
-
•
Run 1: Intertextuality-related items. This run focuses on identifying intertextual relationships, such as direct quotations, paraphrasing, or thematic borrowing. The model uses a few-shot prompt to identify paraphrasing or thematic borrowing between chunks. See Appendix A.1 for the detailed prompt.
-
•
Run 2: Universal-related items. This run focuses on unequippable elements that apply across documents, such as citation markers, quotation marks, or discourse cues. The model uses a few-shot prompt to extract universal metadata, such as discourse roles and references. See Appendix A.2 for the detailed prompt.
By running these two passes with LLM-based few-shot prompting, we capture both specific intertextuality-related relationships and broader document structure elements, enabling a comprehensive analysis of legal documents.
4.2.2 Step 2: Normalize
After the splitting and enrichment of legal contract data (as discussed in Step 1), the next critical step is migrating the data from MongoDB to Elasticsearch and preparing it for hybrid search. This process involves deciding which fields require vector embeddings and which can be directly indexed for metadata-based filtering. The primary criterion for this decision is whether capturing the semantic meaning of the text is essential for improving search accuracy.
1. Decision Criteria for Embedding-Based Search
The key principle for deciding whether a field requires embeddings is whether semantic meaning plays a critical role in the search process. Fields that benefit from semantic similarity search are usually unstructured text fields, where the meaning of the text can vary even when the wording differs (e.g., paraphrasing). By contrast, fields that contain structured or categorical data (like names or IDs) are better suited for direct indexing without embeddings.
-
•
Fields requiring embeddings: These are typically fields containing unstructured, semantically rich text, such as normalized sentences or discourse-level summaries. Embeddings help capture the underlying meaning of these fields, allowing for similarity search even when the exact wording differs. For example:
-
–
chunk_text: The main clause text, where paraphrasing or rewording may occur, benefits from embeddings to capture the semantic meaning.
-
–
section_title: If present, this can help provide context for the clauses within a section.
-
–
-
•
Fields not requiring embeddings: These are fields where the semantic meaning is less relevant or unnecessary for search purposes. In such cases, exact matches or keyword searches are more appropriate. Examples include:
-
–
person_name, doc_id, or clause_type: These fields contain structured or categorical data, where embeddings would not add value. For instance, searching for a specific person’s name doesn’t benefit from capturing semantic meaning.
-
–
This approach aligns with the formalism discussed in Section 3.3.2, where re-equippable elements (such as quotation marks or paraphrasing cues) are reintroduced based on whether the semantic meaning of the text is crucial to the intertextual relationship. Similarly, we use embeddings only when the field’s meaning can vary semantically and contribute to the overall search.
For detailed schema information regarding which fields are indexed directly and which require embeddings, please refer to Appendix B.
2. Embedding Generation Using Cohere-embed-english-v3.0
For fields requiring embeddings (such as chunk_text), we generate vector embeddings using the Cohere-embed-english-v3.0 model. This model outputs 768-dimensional vectors that capture the semantic content of the text, which is essential for similarity search in cases where the wording of clauses may differ, but the meaning is the same.
For more details on the embedding generation process using this model, see Appendix C.
3. Migrating Data to Elasticsearch
Once the data is enriched with metadata and embeddings, it is migrated from MongoDB to Elasticsearch. This process involves:
-
•
Indexing metadata fields for direct search (e.g., doc_id, clause_type, and named_entities), which allows for efficient keyword or exact match search.
-
•
Indexing embeddings for semantic search on fields like chunk_text, enabling similarity search based on the meaning of the text.
The Elasticsearch schema for both document-level and clause-level indices is provided in Appendix B.
In summary, the normalization step involves migrating legal contract data from MongoDB to Elasticsearch, using embeddings for semantically rich fields and direct indexing for structured or categorical fields. This prepares the system for hybrid search, combining metadata filtering and semantic similarity search to retrieve relevant legal clauses efficiently.
4.2.3 Step 3: Merge
The Merge phase finalizes the intertextuality detection process by leveraging the Elasticsearch index created during the Normalize step. Here, we perform a metadata-filtered search to reintroduce unequipped elements and optionally carry out a deep search with LLM verification.
1. Using the Elasticsearch Index
We begin by querying the Elasticsearch index that stores the document chunks and their associated metadata, including fields such as quotation type and discourse type. These fields help us identify the nature of each chunk—for example, whether it contains a Direct Quote, Paraphrase, or Citation, and its role within the larger document (e.g., Introduction or Conclusion).
2. Metadata-Filtered Search
Using the quotation type and discourse type fields, we filter the chunks to focus on specific intertextuality types. For example:
-
•
Direct Quotes: We restore quotation marks and speaker attributions.
-
•
Paraphrased Content: We add paraphrasing cues like "according to" or "as mentioned by".
-
•
Citations: We reintroduce citation markers (e.g., "(Author, Year)").
This metadata-filtered search allows us to prioritize matches based on their intertextuality type, ensuring that the detected relationships are properly contextualized.
3. Optional: Deep Search
If further refinement is required, we perform a deep search by analyzing the chunks in greater detail. During this step, the system searches for more subtle relationships, such as thematic borrowing or heavily paraphrased content, which may not be captured by the initial metadata search.
LLM-Based Verification
For both the metadata-filtered search and deep search, we use LLAMA 3.1 405B to verify the detected relationships. The LLM checks whether the re-equipped elements (e.g., quotation marks, paraphrasing cues) align with the semantic meaning of the source and target chunks. or the complete few-shot prompt used to guide the verification process, see Appendix D.
5 Conclusion
In this paper, we introduced a novel methodology for detecting asymmetric intertextuality, a task that has not been previously formalized in the Natural Language Processing (NLP) and Digital Humanities (DH) domains. Our approach, based on the split-normalize-merge paradigm, offers a flexible and scalable solution to identify subtle, one-sided relationships between texts, such as paraphrasing and thematic borrowing, where traditional methods often fall short.
The split-normalize-merge paradigm extends the capacity of intertextuality detection by leveraging large language models (LLMs) and vector similarity searches. By breaking down documents into manageable chunks, normalizing them using metadata extraction and LLM-based semantic encoding, and merging these chunks during querying, our system can efficiently handle dynamically growing corpora. This enables the detection of both explicit and implicit intertextual connections, making the approach adaptable across various domains, including academic research, journalism, and literary studies.
The novelty of our approach lies in its ability to uncover complex intertextual relationships, even in the absence of direct quotations or citations. This capability is particularly important for identifying paraphrased, thematic, or cross-document influences that are not easily captured by traditional methods.
As the field of intertextuality detection continues to evolve, we anticipate that our methodology will serve as a foundation for further research. Future work could explore the development of benchmark datasets specifically tailored to asymmetric intertextuality or alternative evaluation strategies that enhance the robustness of the system. As new datasets and evaluation frameworks emerge, the split-normalize-merge paradigm can be refined and adapted to meet the needs of a growing number of applications in both NLP and DH.
In conclusion, our work represents an important step towards advancing the detection of asymmetric intertextuality. We believe it opens up new opportunities for interdisciplinary research, enabling more nuanced understanding of how texts interact across time, genre, and discourse.
References
- Genette [1997] Gérard Genette. Palimpsests: Literature in the Second Degree. University of Nebraska Press, 1997.
- Allen [2011] Graham Allen. Intertextuality. Routledge, 2011.
- Melville [1851] Herman Melville. Moby Dick. Harper & Brothers, 1851.
- Sturgeon [2018] Donald Sturgeon. Digital approaches to text reuse in the early chinese corpus. Journal of Chinese Literature and Culture, 5(2):186–213, 2018. doi:10.1215/23290048-7256963.
- Romanello [2016] Matteo Romanello. Citation: Intertextuality in the digital age. Journal of Digital Humanities, 5(1):45–68, 2016.
- Vierthaler and Gelein [2019] P. Vierthaler and M. Gelein. A blast-based, language-agnostic text reuse algorithm with a markus implementation and sequence alignment optimized for large chinese corpora. Journal of Cultural Analytics, 4(2), 2019. doi:10.22148/16.034.
- Bahdanau et al. [2014] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), 2014.
- Ghiban and Trausan-Matu [2013] Dorinel Ghiban and Stefan Trausan-Matu. Detecting plagiarism using word embeddings and machine learning. Journal of Computational Linguistics, 39(2):321–345, 2013.
- Henrichs [2020] Amanda Henrichs. Allusions in the age of the digital: Four ways of looking at a corpus. Women Writers in Context, 2020.
- Newell and Cowlishaw [2018] Nicholas Newell and Tom Cowlishaw. Automatic machine translation evaluation in many languages via zero-shot paraphrasing. In Proceedings of the 2018 Conference on Machine Translation (WMT), pages 781–789, 2018.
- Miola [2004] Robert S. Miola. Seven types of intertextuality, pages 13–25. Manchester University Press, 2004.
- Kabbara and Cheung [2016] Jad Kabbara and Jackie Chi Kit Cheung. Stylistic transfer in natural language generation systems using recurrent neural networks. In Proceedings of the Workshop on Uphill Battles in Language Processing: Scaling Early Achievements to Robust Methods, pages 43–47, 2016.
- Tharsen and Gladstone [2022] John Tharsen and Christopher Gladstone. Textpair viewer (tpv) 1.0: An interactive visual toolkit for exploring networks of textual alignments and text reuse. Shuzi renwen, (2), 2022. URL https://www.dhcn.cn/site/works/dhjournal/20452.html.
- Standage [2013] Tom Standage. Writing on the Wall: Social Media–The First 2,000 Years. Bloomsbury Publishing, 2013.
- Tekir et al. [2023] Selman Tekir, Akarsha Pappu, Emine Yilmaz, and Evangelos Kanoulas. Quote attribution in news articles. In Proceedings of the 2023 ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2345–2349, 2023.
- Janicki et al. [2023] Maciej Janicki et al. Detection of quotation structures in finnish news data. arXiv preprint arXiv:2306.15412, 2023.
- Frey et al. [2024] Philipp Frey, Dirk Müller, and Hinrich Schütze. Fine-grained quotation detection and attribution in german news articles. Journal of Computational Linguistics, 2024.
- Cohan et al. [2019] Arman Cohan, Sergey Feldman, Doug Downey, and Daniel S. Weld. Structural scaffolds for citation intent classification in scientific publications. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1:3586–3596, 2019.
- Jurgens et al. [2018] David Jurgens, Srijan Kumar, Brendan Hoover, Daniel McFarland, and Dan Jurafsky. Measuring the evolution of a scientific field through citation frames. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 3550–3564, 2018.
- Perot et al. [2023] Vincent Perot, Kai Kang, Florian Luisier, et al. Lmdx: Language model-based document information extraction and localization. arXiv preprint arXiv:2309.10952, 2023.
- Biswas and Talukdar [2024] Anjanava Biswas and Wrick Talukdar. Robustness of structured data extraction from in-plane rotated documents using multi-modal large language models (llm). Journal of Artificial Intelligence Research, 2024.
- Beltagy et al. [2020] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Gidiotis and Tsoumakas [2020] Alexios Gidiotis and Grigorios Tsoumakas. Divide and conquer: Summarization of long documents. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 10371–10381, 2020.
- Wang et al. [2023] Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. Docllm: A layout-aware generative language model for multimodal document understanding, 2023. URL https://arxiv.org/abs/2401.00908.
- Huang et al. [2023] Zhiyu Huang et al. Layoutlmv3: Pretraining for document ai with unified text and image masked modeling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2023.
- Foucault [2013] Michel Foucault. The Archaeology of Knowledge. Routledge, 2013.
- Manning et al. [2008] Christopher D Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019.
- Dong et al. [2021] Yue Dong, Lamis Alsaidi, and Mirella Lapata. Discourse-aware neural extractive text summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1419–1436, 2021.
- Teufel and Moens [2010] Simone Teufel and Marc Moens. The annotation of argumentative zoning for academic discourse. In Proceedings of the 7th Conference on International Language Resources and Evaluation (LREC’10). European Language Resources Association (ELRA), 2010.
- Mihalcea et al. [2006] Rada Mihalcea, Courtney Corley, and Carlo Strapparava. Corpus-based and knowledge-based measures of text semantic similarity. AAAI, 6:775–780, 2006.
- Reimers and Gurevych [2019] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084, 2019.
- Cer et al. [2018] Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, et al. Universal sentence encoder. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 169–174, 2018.
- Johnson et al. [2019] Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus. In IEEE Transactions on Big Data, pages 1–12, 2019.
- Milvus [2020] Milvus. Milvus: A vector database for scalable similarity search. https://milvus.io/, 2020.
- Child et al. [2019] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. Cuad: An expert-annotated nlp dataset for legal contract review. arXiv preprint arXiv:2103.06268, 2021.
Appendix A Few-shot Prompts
A.1 Few-shot Prompt for Intertextuality-related Items
The following prompt is used in the first run to detect intertextual relationships, such as paraphrasing or thematic borrowing:
User:
Extract intertextuality relations from the following text:
Chunk A: "EXHIBIT 4.25 INFORMATION IN THIS EXHIBIT IDENTIFIED BY [ * * * ]"
Chunk B: "EXHIBIT 4.25 contains confidential information."
Assistant:
{
"chunk_A": "EXHIBIT 4.25 INFORMATION IN THIS EXHIBIT IDENTIFIED BY [ * * * ]",
"chunk_B": "EXHIBIT 4.25 contains confidential information.",
"relationship": "paraphrase",
"confidence": 0.95
}
User:
Extract intertextuality relations from the following text:
Chunk A: "This Agreement shall commence on the Effective Date..."
Chunk B: "This Agreement will start from the Effective Date..."
Assistant:
{
"chunk_A": "This Agreement shall commence on the Effective Date...",
"chunk_B": "This Agreement will start from the Effective Date...",
"relationship": "paraphrase",
"confidence": 0.98
}
A.2 Few-shot Prompt for Universal-related Items
The following prompt is used in the second run to extract universal metadata related to discourse roles, citation markers, and other unequippable elements:
User:
Extract universal metadata from the following chunk:
Chunk: "This Agreement shall commence on the Effective Date and remain in effect..."
Assistant:
{
"chunk": "This Agreement shall commence on the Effective Date and remain in effect...",
"discourse_role": "introduction",
"quotation_type": "none",
"citation_marker": "none"
}
User:
Extract universal metadata from the following chunk:
Chunk: "The pricing for services is outlined in Exhibit A..."
Assistant:
{
"chunk": "The pricing for services is outlined in Exhibit A...",
"discourse_role": "body",
"quotation_type": "none",
"citation_marker": "exhibit_reference"
}
Appendix B Elasticsearch Schema
The following schema is used to set up the Elasticsearch indices for both document-level and clause-level data:
B.1 Document Index Schema
PUT /document_index
{
"mappings": {
"properties": {
"doc_id": { "type": "keyword" },
"filename": { "type": "text" },
"document_embedding": { "type": "dense_vector", "dims": 768 },
"sections": {
"type": "nested",
"properties": {
"section_title": { "type": "text" },
"section_embedding": { "type": "dense_vector", "dims": 768 }
}
}
}
}
}
B.2 Clause Index Schema
PUT /sentence_index
{
"mappings": {
"properties": {
"doc_id": { "type": "keyword" },
"chunk_number": { "type": "integer" },
"chunk_text": { "type": "text" },
"clause_type": { "type": "keyword" },
"named_entities": { "type": "text" },
"discourse_role": { "type": "keyword" },
"sentence_embedding": { "type": "dense_vector", "dims": 768 },
"re_equippable_elements": {
"properties": {
"quotation_marks": { "type": "boolean" },
"citation_marker": { "type": "boolean" },
"paraphrasing_cues": { "type": "boolean" },
"speaker_attribution": { "type": "boolean" }
}
}
}
}
}
Appendix C Embedding Generation Using the Cohere-embed-english-v3.0 Model
Embeddings are generated using the Cohere-embed-english-v3.0 model. This model produces 768-dimensional embeddings, which are indexed in Elasticsearch for vector similarity search.
-
•
Chunk Text Embeddings: The chunk_text field is transformed into a 768-dimensional vector using the Cohere model.
-
•
Section Title Embeddings: If present, the section_title field is also embedded to provide additional context for clauses within the section.
For more information on the Cohere-embed-english-v3.0 model, please refer to the official Cohere documentation.
Appendix D Few-Shot Prompting for LLM Verification
Below is the few-shot prompt used to guide the LLAMA 3.1 405B model in verifying the intertextual relationships:
User:
Verify the relationship between these two chunks:
Chunk A: "The quick brown fox jumps over the lazy dog."
Chunk B: "The fast animal leaps over the sluggish canine."
Assistant:
{
"relationship": "paraphrase",
"confidence": 0.91,
"reasoning": "Both chunks describe the same event with different wording, indicating paraphrasing."
}
User:
Verify the relationship between these two chunks:
Chunk A: "This method was used to determine X (Smith, 2020)."
Chunk B: "A similar methodology was applied (see Smith, 2020)."
Assistant:
{
"relationship": "citation",
"confidence": 0.95,
"reasoning": "Both chunks cite the same method and reference the same source."
}
This prompt helps the model classify the intertextual relationship and provides a confidence score for the result.