Jianing Qiujianing.qiu17@imperial.ac.uk1,2
\addauthorFrank P.-W. Lopo.lo15@imperial.ac.uk1
\addauthorYingnan Suny.sun16@imperial.ac.uk1,2
\addauthorSiyao Wangs.wang18@imperial.ac.uk1
\addauthorBenny Lobenny.lo@imperial.ac.uk1
\addinstitution
The Hamlyn Centre
Imperial College London
London, UK
\addinstitution
Department of Computing
Imperial College London
London, UK
Mining Discriminative Food Regions
Mining Discriminative Food Regions for Accurate Food Recognition
Abstract
Automatic food recognition is the very first step towards passive dietary monitoring. In this paper, we address the problem of food recognition by mining discriminative food regions. Taking inspiration from Adversarial Erasing, a strategy that progressively discovers discriminative object regions for weakly supervised semantic segmentation, we propose a novel network architecture in which a primary network maintains the base accuracy of classifying an input image, an auxiliary network adversarially mines discriminative food regions, and a region network classifies the resulting mined regions. The global (the original input image) and the local (the mined regions) representations are then integrated for the final prediction. The proposed architecture denoted as PAR-Net is end-to-end trainable, and highlights discriminative regions in an online fashion. In addition, we introduce a new fine-grained food dataset named as Sushi-50, which consists of 50 different sushi categories. Extensive experiments have been conducted to evaluate the proposed approach. On three food datasets chosen (Food-101, Vireo-172, and Sushi-50), our approach performs consistently and achieves state-of-the-art results (top-1 testing accuracy of , , , respectively) compared with other existing approaches. Dataset and code are available at https://github.com/Jianing-Qiu/PARNet
1 Introduction
Diet-induced diseases are becoming increasingly prevalent among populations. One underlying factor is people’s poor management of their daily dietary intake. The other factor is that there is currently no accurate measurement of dietary intake. Dietary measurement in nutritional epidemiology is heavily based on self-reported data that are highly inaccurate and subjective [Shim et al.(2014)Shim, Oh, and Kim], which hinders nutritionists from designing effective dietary guidance. To mitigate the problem of existing dietary measurement techniques that require extensive user input and produce unsatisfactory results, the concept of passive dietary monitoring is proposed [Lo(2017)], which relies on sensors such as cameras to pervasively record eating episodes and automatically perform food recognition, volume estimation, and deduce dietary intake. In realising this concept of passive monitoring, food recognition is the first and a crucial step as any misrecognition will lead to inaccurate measurements afterwards. With recent advances in computer vision, recognising pictured dishes have achieved promising results but still remains as a challenging field of research given that there are enormous varieties of dishes and even the same type of food can have very different appearances. In this work, we aim to achieve accurate food recognition by mining discriminative regions of a food image. This is motivated by the previous work done by Bossard et al\bmvaOneDot [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] that utilises random forests to mine discriminative components from food images. Unlike [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool], we develop a convolutional neural network (CNN) model and utilise a weakly supervised method to discover discriminative food regions. This weakly supervised method used in both network training and inference is based on Adversarial Erasing (AE) [Wei et al.(2017)Wei, Feng, Liang, Cheng, Zhao, and Yan], a strategy developed for weakly supervised semantic segmentation. One prominent feature of AE is that it enables the discriminative region of an object of interest to be discovered progressively, which in our case enables better recognition of food items. Our implementation of AE however differs from [Wei et al.(2017)Wei, Feng, Liang, Cheng, Zhao, and Yan] in that we integrate it into a new network architecture for object recognition (food recognition in particular), and all sub-networks involved are trained jointly, which is more convenient, compared to its original usage in which networks need to be trained independently. Although region mining is performed, the proposed approach still predicts the food class of an input image efficiently in an end-to-end manner, which will be detailed in Sections 3.1 and 3.2.
The contributions of our work are twofold: (i) we propose a new network architecture that is able to mine discriminative food regions in a weakly supervised fashion and be trained end-to-end. The mining strategy is adopted and optimised for food recognition. Comprehensive experiments are performed to validate the proposed approach; (ii) we introduce a new fine-grained food dataset which consists of 50 sub-categories of one common food class, i.e\bmvaOneDot, sushi, in contrast to most existing datasets that only contain coarse food classes.
2 Related Work
Food Recognition. Existing vision-based approaches for food recognition either use hand-crafted features in conjunction with SVMs, or use CNNs alone. Works in the former such as [Bettadapura et al.(2015)Bettadapura, Thomaz, Parnami, Abowd, and Essa, Chen et al.(2009)Chen, Dhingra, Wu, Yang, Sukthankar, and Yang] resort to color and SIFT based features for food image classification. Pairwise local features are developed in [Yang et al.(2010)Yang, Chen, Pomerleau, and Sukthankar] to capture spatial relationships between the ingredients. In [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool], food recognition is decomposed into two steps: first scoring an image’s superpixels using the component models trained by random forest mined food parts, and then predicting the food class using a multi-class SVM. The results of these approaches are not satisfactory as neither the learned representations nor the models are capable of distinguishing food items with high intra-class variations. Among the latter CNN-based approaches, Chen and Ngo [Chen and Ngo(2016)] designed a series of CNN architectures and utilised multi-task learning to simultaneously recognise the food category and ingredients composition. Based on the observation that certain food dishes have a clear vertical layer structure, Martinel et al\bmvaOneDot [Martinel et al.(2018)Martinel, Foresti, and Micheloni] later proposed a slice convolutional layer to learn such information. Integrated with the wide residual network [Zagoruyko and Komodakis(2016)], the resulting architecture shows promising results on food recognition. Some previous works [Beijbom et al.(2015)Beijbom, Joshi, Morris, Saponas, and Khullar, Bettadapura et al.(2015)Bettadapura, Thomaz, Parnami, Abowd, and Essa, Meyers et al.(2015)Meyers, Johnston, Rathod, Korattikara, Gorban, Silberman, Guadarrama, Papandreou, Huang, and Murphy] also tried to narrow down the number of food categories by using the restaurant context. Food recognition recently has also been proposed as a topic of challenges in the fine-grained visual categorization competition [Cui et al.(2018)Cui, Song, Sun, Howard, and Belongie, Yu et al.(2018)Yu, Wang, Shelhamer, and Darrell].
Adversarial Erasing.
Adversarial Erasing (AE) is initially introduced by Wei et al\bmvaOneDot [Wei et al.(2017)Wei, Feng, Liang, Cheng, Zhao, and Yan] aiming to address the weakly supervised semantic segmentation problem. It is an iterative process that enforces a succeeding classification network to discover a new discriminative region from an image with the more discriminative regions removed by the previous networks. Each discriminative region is obtained by thresholding the associated class activation map (CAM) [Zhou et al.(2016)Zhou, Khosla, Lapedriza, Oliva, and Torralba], which is a visualisation map that highlights the areas in a given image that a classification network relies on for identifying the target class. By merging these mined regions, the object of interest can then be well segmented. To accomplish this, a sequence of networks were needed, and each of them was trained independently. Zhang et al\bmvaOneDot [Zhang et al.(2018)Zhang, Wei, Feng, Yang, and Huang] later employed AE for weakly supervised object localisation, and trained two complementary classifiers jointly with localisation maps being online inferred. AE is adopted in this work to enhance food recognition. To this end, a completely different model from the ones used by the above two approaches is developed. In addition, we calculate CAM in an online manner to enable the end-to-end training. There are several other works sharing the similar idea with AE. For example, Singh and Lee [Singh and Lee(2017)] proposed to hide patches randomly in an input image to boost weakly supervised object localisation. For the same purpose, Kim et al\bmvaOneDot [Kim et al.(2017)Kim, Cho, Yoo, and So Kweon] adopted a two-phase learning strategy of suppressing the second network’s activation conditioned on the outcome of the first network.
3 Method
We use AE to progressively mine discriminative regions from an input food image. The representations of the mined regions and that of the original input image are concatenated as the final representation for food recognition. Our network architecture denoted as PAR-Net has three sub-networks (i.e\bmvaOneDot, a primary network, an auxiliary network and a region network) and an extra fully connected layer. We use CAM in an online fashion to highlight the discriminative region at each mining step, which is described in Section 3.1. The network architecture as well as the training and inference procedures are detailed in Section 3.2.
3.1 Calculating CAM
To calculate CAM [Zhou et al.(2016)Zhou, Khosla, Lapedriza, Oliva, and Torralba], a classification network normally follows the structure of conv-gap-fc-softmax on top. The generic way of producing CAM thus is defined as in Eqn. 1.
| (1) |
where denotes the target class of an image ; is the feature map ( in total) of the last convolutional layer; is the weight in the fully connected layer that represents the contribution of the neuron of the global average pooling (GAP) layer makes for identifying the class for .
We integrate CAM into both network training and inference, and calculate it differently during these two procedures. Specifically, in training, is always adopted as the ground truth label associated with the image . Whereas in inference, is the predicted top-1 class.
3.2 PAR-Net
The network structure consists of four major parts: (i) a primary network (P-Net) which classifies the original full input image; (ii) an auxiliary network (A-Net) which classifies images with discriminative region(s) erased; (iii) a region network (R-Net) which classifies the cropped and upsampled discriminative regions; (iv) an extra fully connected layer which classifies the concatenated representations of the input full image and the mined regions. An overview of the network architecture is shown in Figure 1. The training and inference procedures are designed as follows:
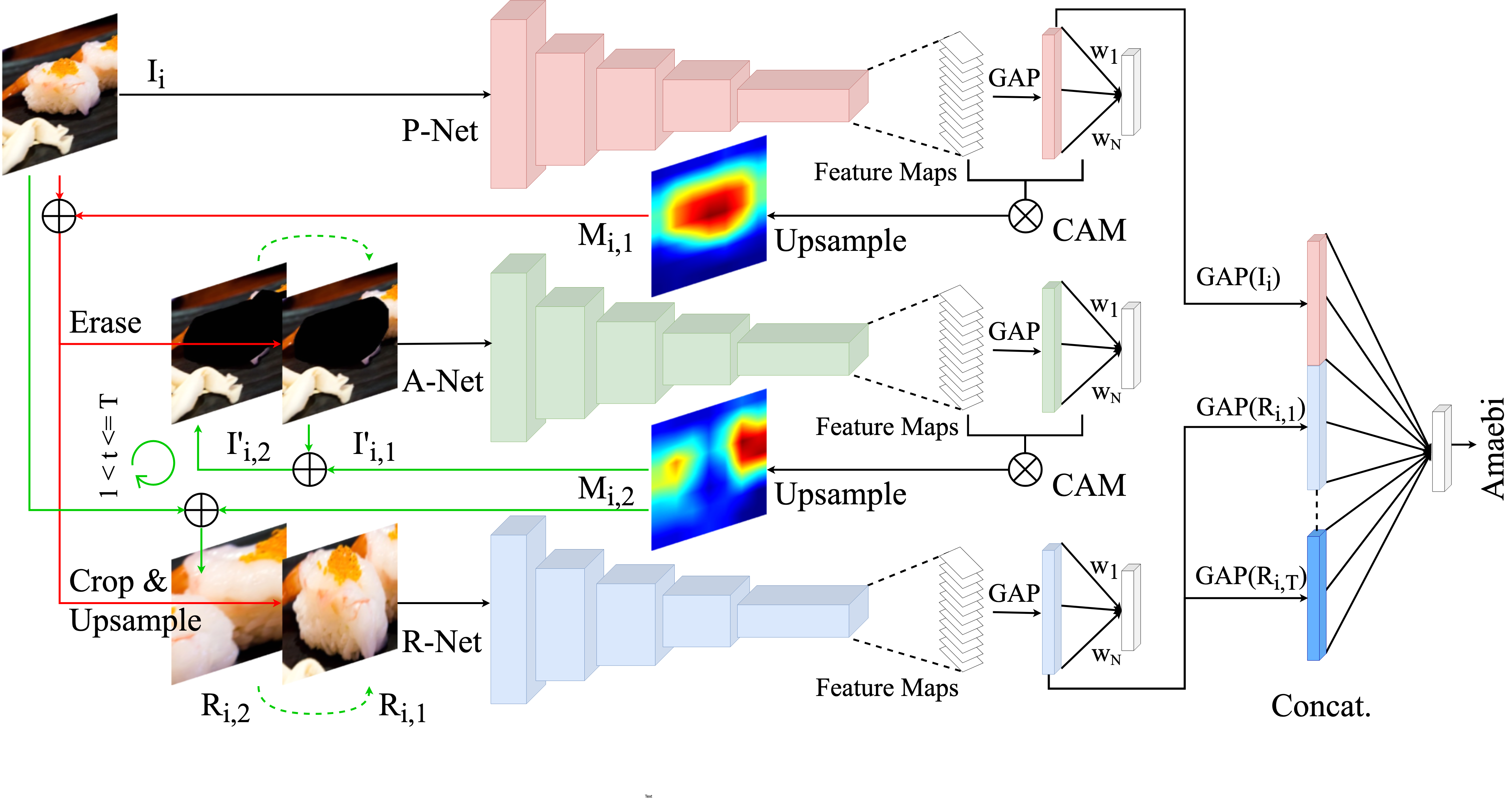
Training. We adopt the standard cross-entropy loss for all the classification involved during training. Concretely, given an image-label pair as the input, and the number of times of region mining , we first feed into the P-Net for classification and denote the resulting loss as . In the meantime, the corresponding class activation map is calculated based on Eqn. 1, and upsampled to obtain a heatmap indicating the discriminative region. In the following, we use , and to denote the CAM-based heatmap, the mined region, and the image with the discriminative region(s) erased at mining step (). All the and inherit the ground truth label from the input image .
Therefore, after upsampling to the same size as , the first heatmap is obtained. We threshold to keep the values that are above , and then find the connected components. For each connected component, we sum all values inside. The one with the largest sum is used to indicate the most discriminative region in . This operation for finding the discriminative region is slightly different from the original CAM implementation for object localisation [Zhou et al.(2016)Zhou, Khosla, Lapedriza, Oliva, and Torralba] since we are more interested in the discriminativeness than the localisation accuracy. We denote the most discriminative region highlighted by in as , which could be of any shape. A tight bounding box covering is then used to crop it out. We upsample the cropped patch using bilinear interpolation to the same size as , and feed it into the R-Net for recognition. Simultaneously, we replace the pixels inside in with zeros (as the first erasing operation), resulting in the first discriminative-region-erased image which is then fed into the A-Net for classification. Note that the P-Net is only responsible for classifying the original full image and finding the first discriminative region. The remaining regions are mined by the A-Net. This is mainly to ensure that the accuracy of classifying a full input image can be preserved such that the input image’s extracted representation is of high discriminativeness.
If , the A-Net then continues to discover the next discriminative region by calculating while classifying (the A-Net classifies in an adversarial manner as increases, the will have less discriminative regions left for the A-Net to rely on for identifying the correct class), and the R-Net keeps recognising the new discriminative region fed from the A-Net. It is worth noting that is always cropped from the original input image based on and the same ratio for calculating the threshold , and is always obtained by erasing from . For each classification of the A-Net and the R-Net at each mining step , we denote their losses as and , respectively. We extract the representation of the input image and each region from the GAP layer of the P-Net and the R-Net, respectively. These representations are concatenated and input into the additional fully connected layer for classification. We use to calculate the loss, and denote it as . Thus, depending on the number of times of region mining , the total loss of the whole model is defined as in Eqn. 2.
| (2) |
Notice that when , the overall loss is equivalent to the loss (i.e\bmvaOneDot, classify the input image only by the P-Net), and when , the A-Net’s loss is not counted. As a matter of fact, loss is accumulated only if a discriminative region is mined from . The PAR-Net as a whole is then trained end-to-end.
Inference. In inference, since only an image is provided as the input, the calculation of CAM is different from that in training as mentioned in Section 3.1. The other parts however remain the same. To be more specific, when , the P-Net still mines the first discriminative region but instead uses where is the predicted top-1 class of the input image by the P-Net, and the A-Net mines the rest discriminative regions with where is the estimated top-1 class of the image by the A-Net. All mined regions are fed into the R-Net to obtain their representations. The output of the additional fully connected layer is used as the final prediction for the input food image .
4 Experiments
In this section, we first introduce the datasets used to validate the proposed approach, and then describe the implementation details. The results are then presented followed by the comparison between our approach and other state-of-the-arts. The ablation studies are reported at the end.
4.1 Datasets
The proposed method was evaluated on the following three food datasets:
Food-101. Food-101 [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] contains 101 food classes and each class has 1,000 images. The whole dataset is split into 75,750 images for training and 25,250 images for testing.
Vireo-172. Vireo-172 [Chen and Ngo(2016)] is a large scale Chinese food dataset with 172 food classes and 110,241 food images in total. The dataset is divided into training, validation, and test sets. Each class assigns of its images for training, for validation, and the rest for testing.
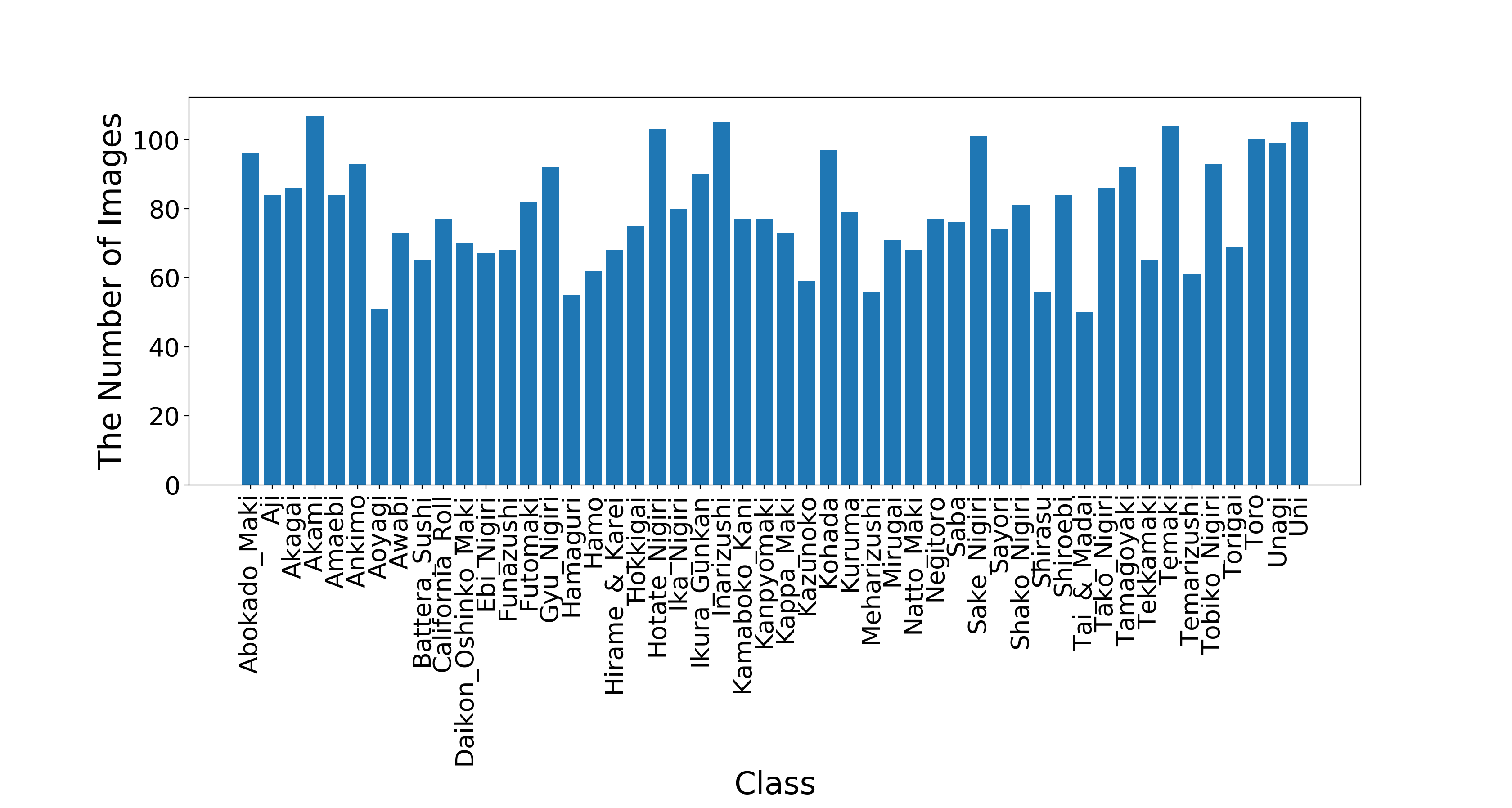
Sushi-50. We built Sushi-50 111http://www.doc.ic.ac.uk/~jq916/Sushi-50.zip as a fine-grained food dataset, which has 50 different sushi classes. These classes are selected based on a sushi guide 222https://www.japan-talk.com/jt/new/sushi-list with those not having sufficient images excluded. All images were downloaded from google and duplicates were removed. This new dataset has 3,963 images. Each class has of its images assigned for training and another retained for testing. Figure 3 shows one sushi sample for each class and Figure 3 shows the number of images of each class.

4.2 Implementation Details
Each sub-network within the PAR-Net is based on the ResNet [He et al.(2016)He, Zhang, Ren, and Sun]. We attempt various combinations of the sub-networks by using ResNets with different depth. In training, a crop is randomly sampled from the original image and resized to with scale and aspect ratio augmentation [Szegedy et al.(2015)Szegedy, Liu, Jia, Sermanet, Reed, Anguelov, Erhan, Vanhoucke, and Rabinovich] as the input, or its horizontal flip. No any further data augmentation technique is used. In inference, we use the center crop (1-crop) of size from the original image (resized to ). Following the practice in [Martinel et al.(2018)Martinel, Foresti, and Micheloni], we also test our approach with the standard ten crops (10-crop). The PAR-Net is implemented with PyTorch. We initialise each sub-network with the weights of the corresponding ResNet model pretrained on ImageNet [Deng et al.(2009)Deng, Dong, Socher, Li, Li, and Fei-Fei] and fine-tune all layers afterwards. We train the PAR-Net for up to 35 epochs using stochastic gradient descent (SGD) with a momentum of 0.9, and a mini-batch size of 16. The initial learning rate is set to and divided by 10 every 7 epochs. A weight decay of is adopted. We set the ratio to 0.5 and the number of times of region mining to 3. More detailed analysis about the choice of and is given in Section 4.4.
4.3 Results
| Method | Food-101 (Top-1) | Vireo-172 (Top-1) | Sushi-50 (Top-1) | |||
|---|---|---|---|---|---|---|
| 1-crop | 10-crop | 1-crop | 10-crop | 1-crop | 10-crop | |
| ResNet-50 | 87.1 | 88.2 | 87.0 | 87.7 | 88.9 | 89.0 |
| ResNet-101 | 88.1 | 89.0 | 87.5 | 88.3 | 89.7 | 90.0 |
| PAR-Net (P50+A34+R50) | 88.5 | 89.5 | 88.8 | 89.3 | 91.2 | 91.0 |
| PAR-Net (P101+A34+R50) | 89.3 | 90.2 | 89.2 | 89.7 | 92.3 | 91.9 |
| PAR-Net (P101+A101+R101)* | 89.3 | 90.4 | 89.6 | 90.2 | 91.8 | 92.0 |
The overall results on the test sets are shown in Table 1. The accuracy of the PAR-Net is the accuracy of classifying the concatenated representation. The PAR-Net with its P-Net and R-Net being two individual ResNet-50s and its A-Net being a ResNet-34 (represented as P50+A34+R50 in Table 1) improves the 1-crop testing accuracy by 1.4%, 1.8%, 2.3% on Food-101, Vireo-172, and Sushi-50, respectively, compared to the baseline results of using a single ResNet-50. Similar improvements can also be observed in the 10-crop testing. When the P-Net is instantiated with a ResNet-101, the accuracy on all the three datasets further increases. We achieve the best 10-crop accuracy on all the datasets when using ResNet-101 for each sub-network.
| Method | Top-1 |
|---|---|
| RFDC [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] | 50.76 |
| DCNN-FOOD [Yanai and Kawano(2015)] | 70.41 |
| DeepFood [Liu et al.(2016)Liu, Cao, Luo, Chen, Vokkarane, and Ma] | 77.4 |
| Inception V3 [Hassannejad et al.(2016)Hassannejad, Matrella, Ciampolini, De Munari, Mordonini, and Cagnoni] | 88.28 |
| DLA (CVPR2018) [Yu et al.(2018)Yu, Wang, Shelhamer, and Darrell] | 90.0 |
| WISeR (WACV2018) [Martinel et al.(2018)Martinel, Foresti, and Micheloni] | 90.27 |
| DSTL (CVPR2018) [Cui et al.(2018)Cui, Song, Sun, Howard, and Belongie] | 90.4 |
| PAR-Net (Ours) | 90.4 |
| Method | Top-1 |
|---|---|
| VGG [Simonyan and Zisserman(2015)] | 80.41 |
| Arch-D (ACMMM2016) [Chen and Ngo(2016)] | 82.06 |
| PAR-Net (Ours) | 90.2 |
| Method | Top-1 |
|---|---|
| ResNet-101 [He et al.(2016)He, Zhang, Ren, and Sun] | 90.0 |
| PAR-Net (Ours) | 92.0 |
We then compare our approach with other state-of-the-arts. The result achieved by our approach on Food-101 (see Table 4) outperforms [Martinel et al.(2018)Martinel, Foresti, and Micheloni] in which more data augmentation techniques are used, and matches [Cui et al.(2018)Cui, Song, Sun, Howard, and Belongie] whereas in [Cui et al.(2018)Cui, Song, Sun, Howard, and Belongie] higher image resolution and a more sophisticated transfer learning approach are adopted. On Vireo-172, our approach achieves the current best accuracy (see Table 4), and on Sushi-50, compared to a baseline method, the proposed approach yields better performance (see Table 4). We visualise some predicted results of the PAR-Net on the test sets (two examples for each dataset) in Figure 4. In the first four rows, the input food image is incorrectly recognised by the P-Net. However, the following mined discriminative regions are successfully classified by the R-Net. The final predication based on the concatenated representation therefore is correct. In the bottom two rows, the input as well as the mined regions are correctly recognised by the P-Net and the R-Net, respectively, which leads to the desired prediction after concatenating representations. Diversity of the mined discriminative regions within each image can also be observed in Figure 4, which is beneficial for the more accurate final prediction. The results obtained demonstrate the effectiveness of using mined discriminative regions to improve food recognition and show consistent performance of our method across multiple food datasets.

4.4 Ablation Studies
| Dataset | T | Network Structure | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 0.3 | 0.5 | 0.7 | No weights sharing | P&R share weights | P&A&R share weights | |
| Vireo-172 | 88.5 | 88.8 | 89.0 | 88.7 | 88.8 | 87.8 | 88.8 | 88.1 | 87.3 |
| Sushi-50 | 90.5 | 91.2 | 91.0 | 90.3 | 91.2 | 91.1 | 91.2 | 90.6 | 89.8 |
| Dataset | PAR-Net (P50+A34+R50) | PAR-Net (P101+A101+R101) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Food-101 | 87.1 | 86.8 | 84.0 | 80.4 | 65.6 | 50.7 | 88.5 | 87.8 | 87.4 | 82.3 | 73.8 | 79.1 | 68.1 | 89.3 |
| Vireo-172 | 87.0 | 87.6 | 85.0 | 81.1 | 60.5 | 37.2 | 88.8 | 88.0 | 87.6 | 82.7 | 74.9 | 77.1 | 60.4 | 89.6 |
| Sushi-50 | 88.9 | 90.6 | 87.1 | 81.7 | 42.2 | 20.6 | 91.2 | 89.0 | 90.2 | 83.2 | 75.2 | 52.8 | 27.0 | 91.8 |
Impact of the number of times of region mining. To study how many regions should be mined so as to achieve the optimal result, we conducted experiments with the PAR-Net (P50+A34+R50) on Vireo-172 and Sushi-50. As shown in the left of Table 5, mining 3 discriminative regions in general is sufficient for achieving satisfactory performance. The accuracy drops when less regions are mined. Although the accuracy is slightly higher on Vireo-172 when the number of mined regions increases to 4, it inevitably requires more overhead in training and inference. Therefore, we adopt for most of our experiments.
Impact of the ratio used to calculate the threshold. We threshold a CAM-based heatmap by using a ratio multiplied with the maximum value of the heatmap, after which we use the connected component with the largest sum to indicate the most discriminative region. The therefore determines the size of the discriminative region, the smaller the , the larger the size. We show the impact of the value of on the accuracy of food recognition in the middle of Table 5. The experiments are based on using the PAR-Net (P50+A34+R50) and a fixed . In general, works well on both Vireo-172 and Sushi-50. However, the results suggest that the choice of could be dataset-dependent as is only marginally worse than whereas causes a clear drop in the accuracy on Vireo-172. An opposite trend can be observed on Sushi-50.
Impact of the network structure. So far, the accuracy reported of the PAR-Net is based on using three individual sub-networks. As both P-Net and R-Net learn food representations (global and local, respectively), an intuition is that they could share weights. Therefore, we used a single network (ResNet-50) to replace the P-Net and R-Net, and still kept the A-Net (ResNet-34). This modified structure was trained with the same setup as in Section 4.2. It can be observed from the right of Table 5 that this structure is of inferior performance compared to the original PAR-Net (P50+A34+R50). When we forced all three sub-networks to share weights, i.e\bmvaOneDot, replacing them with a single ResNet-50, the accuracy further decreases. This can be interpreted as a limitation of the PAR-Net that it is necessary to have independent sub-networks to conduct different tasks in order to achieve good performance.
Accuracy of each sub-network. As classification occurs in each sub-network (the P-Net classifies the input image, the R-Net classifies the mined regions, and the A-Net classifies discriminative-region-erased images), we show each sub-network’s classification accuracy on the corresponding target, which is summarised in Table 6. As mining continues, the accuracy of classifying the mined region decreases as expected (), because the later mined region is less discriminative than the earlier ones. This is also true for the images with discriminative region(s) erased, the accuracy degrades () as the later image have less discriminative regions left compared to the previous one. It is worth noting that the accuracy based on the concatenated representation is always higher than that of the input image and the mined regions, which verifies that the integration of global and local representations contributes to better food recognition.
5 Conclusions
We introduced a novel model for food recognition, which progressively mines discriminative food regions and merges their representations with the full input image’s to make an accurate prediction. The model has been validated on multiple food datasets including a new fine-grained one introduced by this paper, and yields state-of-the-art performance. By providing more accurate recognition results, the proposed model is expected to facilitate the development of passive dietary monitoring. Investigating vision-based approaches for food ingredient level analysis is planned in future work.
Acknowledgements. This work is supported by the Innovative Passive Dietary Monitoring Project funded by the Bill & Melinda Gates Foundation (Opportunity ID: OPP1171395).
References
- [Beijbom et al.(2015)Beijbom, Joshi, Morris, Saponas, and Khullar] Oscar Beijbom, Neel Joshi, Dan Morris, Scott Saponas, and Siddharth Khullar. Menu-match: Restaurant-specific food logging from images. In WACV, 2015.
- [Bettadapura et al.(2015)Bettadapura, Thomaz, Parnami, Abowd, and Essa] Vinay Bettadapura, Edison Thomaz, Aman Parnami, Gregory D Abowd, and Irfan Essa. Leveraging context to support automated food recognition in restaurants. In WACV, 2015.
- [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. In ECCV, 2014.
- [Chen and Ngo(2016)] Jingjing Chen and Chong-Wah Ngo. Deep-based ingredient recognition for cooking recipe retrieval. In ACM Multimedia, 2016.
- [Chen et al.(2009)Chen, Dhingra, Wu, Yang, Sukthankar, and Yang] Mei Chen, Kapil Dhingra, Wen Wu, Lei Yang, Rahul Sukthankar, and Jie Yang. Pfid: Pittsburgh fast-food image dataset. In ICIP, 2009.
- [Cui et al.(2018)Cui, Song, Sun, Howard, and Belongie] Yin Cui, Yang Song, Chen Sun, Andrew Howard, and Serge Belongie. Large scale fine-grained categorization and domain-specific transfer learning. In CVPR, 2018.
- [Deng et al.(2009)Deng, Dong, Socher, Li, Li, and Fei-Fei] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- [Hassannejad et al.(2016)Hassannejad, Matrella, Ciampolini, De Munari, Mordonini, and Cagnoni] Hamid Hassannejad, Guido Matrella, Paolo Ciampolini, Ilaria De Munari, Monica Mordonini, and Stefano Cagnoni. Food image recognition using very deep convolutional networks. In MADiMa. ACM, 2016.
- [He et al.(2016)He, Zhang, Ren, and Sun] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [Kim et al.(2017)Kim, Cho, Yoo, and So Kweon] Dahun Kim, Donghyeon Cho, Donggeun Yoo, and In So Kweon. Two-phase learning for weakly supervised object localization. In ICCV, 2017.
- [Liu et al.(2016)Liu, Cao, Luo, Chen, Vokkarane, and Ma] Chang Liu, Yu Cao, Yan Luo, Guanling Chen, Vinod Vokkarane, and Yunsheng Ma. Deepfood: Deep learning-based food image recognition for computer-aided dietary assessment. In ICOST, 2016.
- [Lo(2017)] Benny Lo. An innovative passive dietary monitoring system. http://dietaryintake.org/index.php?id=1, 2017.
- [Martinel et al.(2018)Martinel, Foresti, and Micheloni] Niki Martinel, Gian Luca Foresti, and Christian Micheloni. Wide-slice residual networks for food recognition. In WACV, 2018.
- [Meyers et al.(2015)Meyers, Johnston, Rathod, Korattikara, Gorban, Silberman, Guadarrama, Papandreou, Huang, and Murphy] Austin Meyers, Nick Johnston, Vivek Rathod, Anoop Korattikara, Alex Gorban, Nathan Silberman, Sergio Guadarrama, George Papandreou, Jonathan Huang, and Kevin P Murphy. Im2calories: towards an automated mobile vision food diary. In ICCV, 2015.
- [Shim et al.(2014)Shim, Oh, and Kim] Jee-Seon Shim, Kyungwon Oh, and Hyeon Chang Kim. Dietary assessment methods in epidemiologic studies. Epidemiology and health, 36, 2014.
- [Simonyan and Zisserman(2015)] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [Singh and Lee(2017)] Krishna Kumar Singh and Yong Jae Lee. Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization. In ICCV, 2017.
- [Szegedy et al.(2015)Szegedy, Liu, Jia, Sermanet, Reed, Anguelov, Erhan, Vanhoucke, and Rabinovich] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In CVPR, 2015.
- [Wei et al.(2017)Wei, Feng, Liang, Cheng, Zhao, and Yan] Yunchao Wei, Jiashi Feng, Xiaodan Liang, Ming-Ming Cheng, Yao Zhao, and Shuicheng Yan. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In CVPR, 2017.
- [Yanai and Kawano(2015)] Keiji Yanai and Yoshiyuki Kawano. Food image recognition using deep convolutional network with pre-training and fine-tuning. In ICMEW, 2015.
- [Yang et al.(2010)Yang, Chen, Pomerleau, and Sukthankar] Shulin Yang, Mei Chen, Dean Pomerleau, and Rahul Sukthankar. Food recognition using statistics of pairwise local features. In CVPR, 2010.
- [Yu et al.(2018)Yu, Wang, Shelhamer, and Darrell] Fisher Yu, Dequan Wang, Evan Shelhamer, and Trevor Darrell. Deep layer aggregation. In CVPR, 2018.
- [Zagoruyko and Komodakis(2016)] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In BMVC, 2016.
- [Zhang et al.(2018)Zhang, Wei, Feng, Yang, and Huang] Xiaolin Zhang, Yunchao Wei, Jiashi Feng, Yi Yang, and Thomas S Huang. Adversarial complementary learning for weakly supervised object localization. In CVPR, 2018.
- [Zhou et al.(2016)Zhou, Khosla, Lapedriza, Oliva, and Torralba] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, 2016.