Mining Frequent Neighborhood Patterns in Large Labeled Graphs
Abstract
Over the years, frequent subgraphs have been an important sort of targeted patterns in the pattern mining literatures, where most works deal with databases holding a number of graph transactions, e.g., chemical structures of compounds. These methods rely heavily on the downward-closure property (DCP) of the support measure to ensure an efficient pruning of the candidate patterns. When switching to the emerging scenario of single-graph databases such as Google Knowledge Graph and Facebook social graph, the traditional support measure turns out to be trivial (either 0 or 1). However, to the best of our knowledge, all attempts to redefine a single-graph support resulted in measures that either lose DCP, or are no longer semantically intuitive.
This paper targets mining patterns in the single-graph setting. We resolve the “DCP-intuitiveness” dilemma by shifting the mining target from frequent subgraphs to frequent neighborhoods. A neighborhood is a specific topological pattern where a vertex is embedded, and the pattern is frequent if it is shared by a large portion (above a given threshold) of vertices. We show that the new patterns not only maintain DCP, but also have equally significant semantics as subgraph patterns. Experiments on real-life datasets display the feasibility of our algorithms on relatively large graphs, as well as the capability of mining interesting knowledge that is not discovered in prior works.
category:
H.2.8 Database Management Database Applicationskeywords:
Data miningkeywords:
Graph Mining1 Introduction


Since Agrawal et al. introduced the concept of Association Rule Mining[1] in 1993, frequent itemset mining, which is the core subtask of association rule mining, has resulted in fruitful follow-up works. Among the horizontal explorations which target mining substructures more expressive than a subset, including subsequences, subtrees, and subgraphs, the Frequent Subgraph Mining (we denote it as FSM later for short) problem turns out to be the most expressive.
In the typical graph-transaction setting, the database consists of a large number of transactions, e.g., chemical structures of small molecules. The measure of frequency, a.k.a. support, is then naturally defined as how many transactions a given pattern is observed as a subgraph of. This definition provides clear semantics in applications. For example, an atom group commonly found among a set of organic compounds may indicate that they potentially share some properties. Moreover, it also satisfies the downward-closure property (DCP), which requires that the support of a pattern must not exceed that of its sub-patterns. This property is essential to all frequent pattern mining algorithms, as it enables safely pruning a branch of infrequent patterns in the search space for efficiency.
Nevertheless, when switching to the single-graph setting, i.e., the database is itself a large graph and the knowledge inside the single graph is of major concern, the definition of support by counting transactions easily fails because the support of any pattern is simply 0 or 1. In other words, this definition cannot quantify our intuition that a subgraph occurs “frequently” in a large graph.
Indeed, it is not difficult to obtain a support definition based on the count of “distinct” matches. However DCP simply does not hold for any straightforward ones. Consider Figure 1(a) describing the event “author writes paper and ”. When it is matched to a toy database consisting of exactly one author writing papers, the number of different matches for the three vertices is . For the sub-pattern “author writes one paper ”, the count is . Even if we take into consideration the automorphism of the pattern, and regard all matches as identical if they involve the same set of vertices in the database, it is still the case that .
Intuitively, complicated patterns have larger support counts because they tend to reuse elements in the database. Inspired by this observation, Vanetik et al.[17] and Kuramochi et al.[10] redefined the support in the single-graph setting to be the maximum number of edge-disjoint matches, which satisfies DCP. According to them, the support of the “an-author-writes-two-papers” pattern on the toy database should be (), since we can find almost such number of matches without reusing any edge. Besides the problem complexity increased, we argue that they introduces non-determinism to the support computation, which disobeys the human sense that counting is a “one-by-one” procedure.

Since it cannot be avoided that traditional matches reuse elements, it seems to be the fact that DCP and intuitiveness can never be both achieved in any subgraph support that counts matches of the entire pattern. However, if we assign the count operator on a fixed vertex in a pattern, and treat two matches as identical if they match the fixed vertex to the same vertices in the database, we obtain a support measure that both has DCP and is intuitive. Consider Figure 1(a) again, where the author vertex is painted solid and to be counted. On the toy database in Figure 2, though and are both matches for , they only contribute one to the support because they share the same author . Moreover, and may also serve to compose legal matches, so the overall support is 3. Similarly, for Figure 1(b) which is a super-pattern of Figure 1(a), only by matching the author vertex to or can we appropriately arrange the two paper vertices, so the support is 2 (<3). In fact, under our new definition of support, the two patterns describe “authors who have at least two papers” and “authors who once cited their own paper”, respectively. Since this sort of pattern characterizes vertices that are embedded in a given local topology, we denote them as neighborhood patterns, and the corresponding mining problem as Frequent Neighborhood Mining (denoted as FNM for short). By neighborhood we refer to not only other vertices directly linked to the counted vertex as defined in the graph theory terminology, but also the vertices, edges indirectly connected, along with their labels.
Prior to us, [5, 8] have already studied similar problems by defining the number of such “partial matches” as the support of a graph structure. However, only tree-like patterns were addressed as their mining targets. Instead, we try to remove the constraint that cycles are not allowed, and investigate the new type of pattern in a generalized way that the FSM problem was studied. Our contribution lies in that we established rich and deep connections between the two problems from the aspects of basic definitions, problem complexity, solutions, and possible optimizations. By operating on a real-life dataset we also confirm that trading the problem complexity for better expressivity is worthwhile, for patterns with cycles can lead to more informative and interesting discoveries on the data being investigated. E.g., taking both Figure 1(b), 1(a), and the support ratios in their captions into consideration, we can conclude that among all authors who are “able” to cite their own paper (having at least two papers), one out of five will do so.
The rest of this paper is organized as follow. In Section 2 we formalize the FNM problem, where the Pivoted Subgraph Isomorphism problem is identified as the core of FNM, like what subgraph isomorphism is to the FSM problem. Section 3 discusses our basic solution and further optimization for FNM. We prove that the building blocks of FNM are not as trivial as those of FSM, while some optimization for the latter one can still be adapted for ours. In Section 4 we conduct experiments on real datasets to verify the performance of our solution and the utility of the mined neighborhood patterns. After introducing related and future works we finally conclude.
2 Problem Formulation
In this section, first, we introduce basic notations to describe a labeled graph and a neighborhood pattern. With the notations we then formulate the decision problem of checking whether a neighborhood pattern matches a given vertex in a large graph as the Pivoted Subgraph Isomorphism problem. We prove that, as the name indicates, this problem is np-complete, making our problem as difficult as the FSM one. After defining the support of a neighborhood pattern as the number of vertices in the database it could be matched to, we briefly justify its downward closure property. Finally, more space will be given to some discussions on the expressivity of our problem formulation.
2.1 Labeled Graphs
Definition 1.
A (directed) labeled graph is a 5-tuple , where
-
•
is the set of all vertices;
-
•
and denote label names used to form vertex and edge labels, respectively;
-
•
is the set of all vertex labels;
-
•
is the set of labeled edges;
Note that unlike [7, 19, 9], we allow an arbitrary number of labels on a single vertex. This is a reasonable generalized assumption for possible applications. For example in a knowledge base consisting of objects and their relationship, an object may be a father, a politician, and a vegetarian at the same time. It’s also possible that a vertex has no label, i.e., we know nothing about the object, except its existence. On the other hand, parallel edges carrying distinct label names may link a pair of vertices to model multiple relations simultaneously existing between two objects. We do not allow edges with no label because we do not process the weak relation of “arbitrary” or “universal” relation. Without losing any generality, we do not allow loops, i.e., edges starting and ending with the same vertex. We can use a vertex label with a specially designed name to replace the loop on a vertex. We use “elements” as the joint name of vertex labels and labeled edges, and define , i.e., the number of elements, as the size of a labeled graph.
2.2 Pivoted Subgraph Isomorphism
Definition 2.
A pivoted graph is a tuple , where
-
•
is a labeled graph;
-
•
is called the pivot of .
Actually, neighborhood patterns are essentially pivoted graphs. By introducing the concept “pivot”, we aim to characterize the semantics of fixing a vertex in a subgraph to form a neighborhood pattern, or selecting a vertex in a database to match a pattern to.
Definition 3.
A pivoted graph is pivoted subgraph isomorphic to , denoted as , if and only if there exists an injective such that
-
•
, ;
-
•
, ;
-
•
.
The first two descriptions describe that the isomorphic function preserves both vertex labels and edge labels. In addition, the special isomorphism between pivoted graphs requires that the isomorphic function maps the pivot of to that of . As a subtask of FNM, the problem of deciding whether a pivoted graph is pivoted subgraph isomorphic to another is in np-complete.
Theorem 1
The problem of testing pivoted subgraph isomorphism between two arbitrary pivoted graphs is np-complete.
We prove in the appendix by reducing it to the classical subgraph isomorphism problem.
Property 1
The relation is transitive.
Proof is omited due to the limited space.
2.3 Support Measure and its PCP
Definition 4.
Given a large labeled graph , a neighborhood pattern matches , if . Denoting the set of all vertices in that matches as , we define the support of in as the size of , and call a frequent neighborhood pattern of , if its support is above a given threshold .
With the support measure defined, the frequent neighborhood mining problem is simply finding all frequent neighborhood patterns in a large graph, with respect to a given threshold. To control the problem complexity, we further requires the mined patterns be connected, i.e., paths exists between every vertex and the pivot. In later discussions, sometimes we consider the operation of removing a labeled edge from a pattern. If the removal leads to an isolated vertex, i.e., a vertex without any vertex label or edge associated to it, we further remove the vertex to make the resulted pattern legal. If we adopt to describe the sub-pattern/super-pattern relationship between neighborhood patterns, the fact that a pattern cannot be more frequent than any of its sub-patterns is directly derived via Property 1.
Theorem 2
The support measure defined in Definition 4 satisfies the downward closure property.
Proof.
(Sketch) Given , , and , where . For any , if , according to Property 1 we have . Therefore, and it holds that . ∎
3 Mining Algorithms
In this section, we describe the algorithm for mining frequent neighborhood patterns, which follows the apriori breadth-first search paradigm. We reveal the major technical difference between mining subgraph and neighborhood patterns, that is, the latter task has more complicated “building blocks”. We prove that the building blocks in our task are no longer all frequent size-1 patterns. Instead, they consists of all frequent paths, and require special treatments. Besides, similarities between the solutions and optimizations of FNM and FSM are also discussed.
3.1 Building Blocks
Typically, the traditional FSM algorithm generates subgraph patterns in an increasing-size manner. First, all frequent subgraphs of size 1 are pre-computed as “building blocks”. Then candidates of size are obtained by joining pattern pairs of size that differ by only one vertex or edge, after which false positives are filtered by a verification against the database. We indicate that the join ensures a complete result because every candidate of size is decomposable, that is, we can always find two distinguished elements, after removing either one we obtain a connected, thus legal, sub-pattern of size . They may be isomorphic to each other, but their join takes the candidate into our consideration.
For our neighborhood mining problem, however, it is not the case. Consider the path-like neighborhood patterns in Figure 3. Obviously, to find a connected sub-pattern of size for Figure 3(a), we have only one choice of removing the edge and vertex at the end of the path. Meanwhile, in the case of Figure 3(b), only the vertex label to the right can be removed. Otherwise, the resulted patterns will be illegally unconnected. Since they are not decomposable, it’s impossible to derive them by joining two smaller patterns. Luckily, the following theorem clarifies that these special patterns are only limited to what is described in Figure 3 and Definition 5, which enables us to treat them as building blocks and pre-process them in advance.


Definition 5.
A neighborhood pattern is a path pattern if the following statements holds
-
•
It is a path of labeled edges (directions are ignored) where the pivot is on one end of the path.
-
•
It contains at most one vertex label, which (if exists) must appear on the other end of the path.
Theorem 3
A neighborhood pattern is not decomposable, iff. it is a path pattern.
Proof.
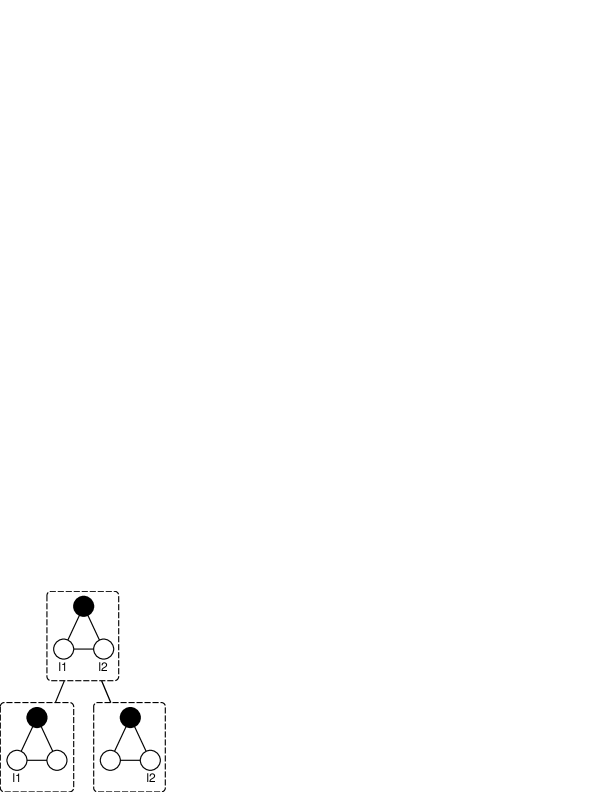

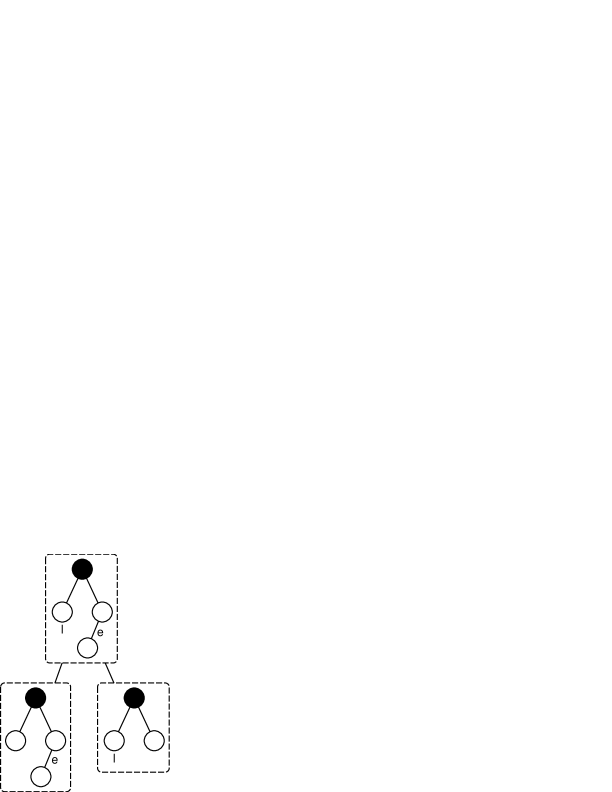
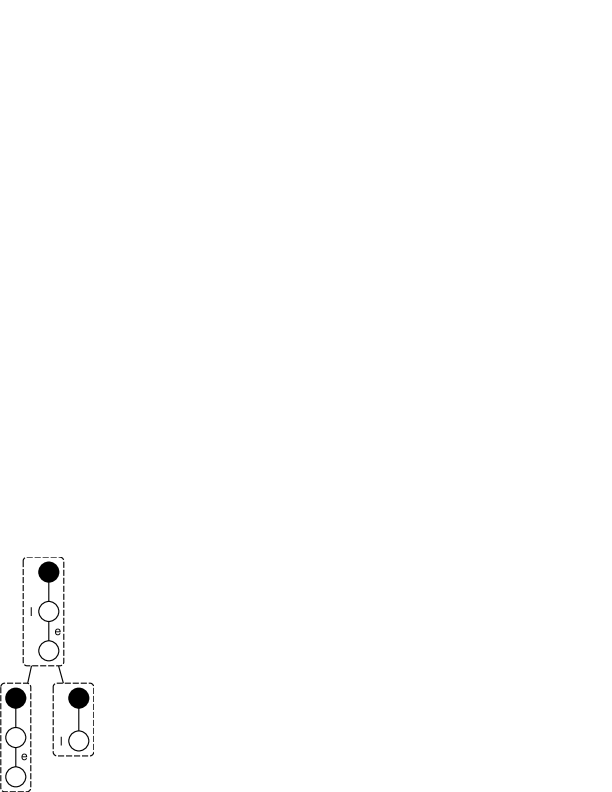
The sufficiency of the theorem is apparent and has been briefly discussed above. Therefore we only concentrate on proving the necessity.
If a neighborhood pattern is not decomposable, it must have at most one vertex label. Otherwise, we can arbitrarily choose two of them as and , and decompose the pattern as and , as is illustrated in Figure 4(a). Moreover, it must not contain cycles. Otherwise, we arbitrarily choose two edges on the cycle as and , and decompose it as and (Figure 4(b)). Note that this does not harm the connectivity of the patterns since edges on a cycle are not cutting-edges.
So far, the shape of has been limited to be a tree with at most one label. We transform it to a rooted one, where the root is the pivot of the pattern. This tree must have only one leaf. If two, we can again remove them with associated edges respectively (in the case where the leaf possesses the only vertex label, we only remove the label instead) to decompose the pattern (Figure 4(c)).
Now the tree with only one leaf is actually a path. But we still have to prove that if the tree contains a vertex label, it must be on the only leaf: if any vertex other than the leaf carries the label, removing the label and removing the leaf with associated edge respectively will get the pattern decomposed (Figure 4(d)). ∎
3.2 Constructing Building Blocks
Being a special case of the general neighborhood patterns, path patterns can still be organized into a level-wise structure, or more exactly, a hierarchical one, which preserves the downward closure property. The parent of each path pattern is uniquely found, by removing the vertex label or the vertex on the other end of the path than the pivot. Thus, the level-wise search algorithm on such a structure deserves an “extending” approach to generate larger patterns from small ones, rather than the “joining” one used for non-building-blocks.
In Algorithm 1, we describe the basic algorithm for finding frequent paths. First, a queue used for the bread-first search is initialized with an empty path . When extending a path on the front of the queue, we traverse according to the pattern, each time with one vertex in as the starting point. Note that for each starting point, we should not visit a vertex more than once. Each traversal returns all possible moves when we arrive at the ending point(s) and try to take a next step. E.g., we traverse along a “” path starting from vertex “Jiawei Han”, and stop at the vertex of paper [10] (it cites [19] of Jiawei Han), then possible next-steps on [10] may be following an “cites” edge to another unvisited paper it cites (such as paper [7]) to produce Figure 3(a), or terminate the path with a vertex label “Paper” to end up with Figure 3(b). Each time a new next-step for the current starting point is discovered, it increases its counter by 1. When all traversals are over, those next-steps with a count of more than are used to extend the path. After saving all extended paths to the result set, non-terminated paths, i.e., new paths obtained by appending an edge rather than a vertex label such as Figure 3(a), are added to the queue for further expansion. The algorithm terminates when all extendable paths in the queue are consumed.
3.3 Joining and Verifying
As is stated above, what distinguishes our problem from the traditional ones solved by a “join-verify-join-…” scheme is the fact that, large path patterns cannot be derived by joining smaller patterns, no matter these smaller ones are paths, trees, or else. Therefore, the working flow of Algorithm 2 differs from other apriori-based subgraph mining algorithm only by Line 15. This line adds path patterns of the current size to , the frequent non-building-block ones of the same size, to ensure that larger patterns relying on them are not lost due to their absence.
Besides, our join operation at Line 8 is also worth an detailed explanation. Roughly speaking, we determine whether two patterns should be joined via deleting one element from the first, and check whether the remaining structure is pivoted subgraph isomorphic to the second. Notice that there may be multiple isomorphic mappings so the number of results produced by a single join may be more than one. For each mapping, the deleted element is mapped to the right position in the second pattern, and inserted to produce a joining result. If the removed element is a vertex label, the join is relatively easy. But if it is an edge, the operation is a bit tricky.
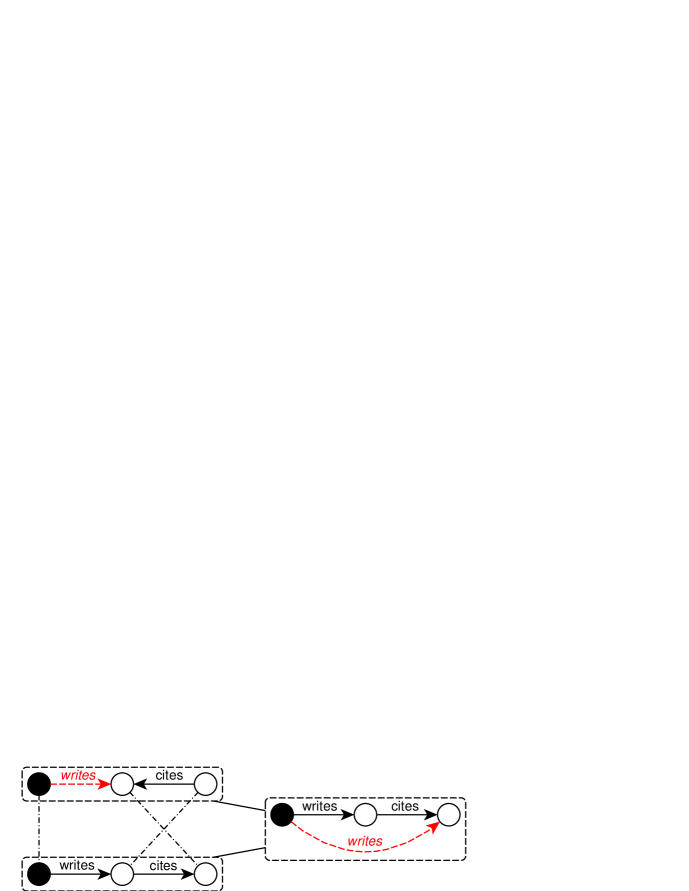

On the one hand, the remaining structure is not necessarily connected after the deletion of an edge. Consider Figure 5(a), where we are going to join the patterns “authors having a cited paper” and “authors having a paper citing another”. For the sake of the example and w.l.o.g., we assume that this join is in a branch of the search space where vertex labels are not introduced yet, while readers can still infer by the context that the pivots are author vertices, and the non-pivot vertices represent papers. After deleting the edge marked with dotted line and italic label in the first pattern we obtain an unconnected structure. The remaining structure is pivoted subgraph isomorphic to the second pattern, where the mapping is illustrated by dotted lines. Since the paper vertex in the first pattern that the deleted edge points to is mapped to the second paper vertex in the second pattern, we restore the mapped edge between the author vertex and the second paper vertex to generate the result on the right. Obviously, this pattern is the skeleton of that illustrated in Figure 1(b).
On the other hand, new vertices may be introduced when handling dangling edges. In Figure 5(b) we again try joining the same patterns as in Figure 5(a), but this time we delete the edge. As is required in Section 2.3, this deletion isolates the second paper vertex, so the vertex is also removed. When the pivoted subgraph isomorphism from the remaining structure to the second pattern is established, the vertex that the deleted edge was associated to is mapped to the first paper vertex in the second pattern, which is the new ending point of the restored edge. But be aware that the new starting point may be the other unmatched paper vertex, as well as a additionally introduced vertex. Neglecting this case will cause the bottom-right pattern to be lost, which is the representative of all tree-like patterns.
Moreover, it should be noted that Line 12 actually embeds a procedure of checking for duplicated patterns. If neglected, they will cause more duplicated patterns, joins, and support computations in later computations. To efficiently check for duplicates, we can hash each produced patterns with the vertex labels on, and associated edges of the pivot. When a new pattern is produced, we first use the hash table to find potential duplicates, and further verify them with a series of isomorphism checks.
Finally, the last performance overhead of this algorithm lies in the pivoted subgraph isomorphism checker at Line 11 and 12. At this stage, we have not considered adapting any advanced heuristic optimizations of the original subgraph isomorphism problem to ours. In the experiments we simply implemented a depth-first search checker, utilizing an index built on all label names of the large graph .
3.4 Optimization via VID-Lists
In [9], Kuramochi et al. used TID (Transaction Identifier) lists to optimize their FSM algorithm under the graph transaction setting. Analogously, we propose VID (Vertex Identifier) lists to improve our efficiency both in the building block construction phase and the joining phase. Both of our optimizations origin from the fact that for any patterns , the set of vertices (transactions in Kuramochi’s cases) matching , i.e., , must be a superset of . This is essentially a reinforced version of the DCP, which enable us to reduce the number of vertices considered when counting the support of a candidate. To utilize it, we have to maintain the IDs of all vertices in as an ordered list for any , instead of recording only its size.
Specifically, at Line 7 in Algorithm 1, when extending , we only need to consider instead of all vertices in . In Algorithm 2, for each enumerated pair of patterns at Line 7, we first intersect and in linear time. If the number of results is below , they need not be joined because vertices matching their shared super-patterns must be within the intersection. If they pass the test, is saved, and at Line 11 we only need to verify the intersection instead of the whole to count the support of the size- patterns. Let’s take the join in Figure 5(a) on the toy database in Figure 2 for example. The upper left pattern matches author ,, and , and the lower left one matches ,,, and . Since does not appear in the intersection, it will not be checked when computing the support of the joined pattern. Vertices matching the pattern under consideration are stored again in VID lists at Line 9 of Algorithm 1 and Line 11 of Algorithm 2 for larger patterns’ use.
In experiments, the VID-optimization reduces the running time by up to two orders of magnitude. In Section 4 we will discuss in detail the experimental results and the feasibility of this optimization.
4 Experiments
Our experiments were performed on two real datasets: EntityCube111http://entitycube.research.microsoft.com/ and ArnetMiner Citation Network222http://arnetminer.org/citation [14, 16, 13, 15], the statistics of which as labeled graphs are presented in Table 1. Due to the intrinsic characteristics of them, the efficiency of our algorithm was mainly tested on the first one, while the second was used to showcase the distinctive form of knowledge our method is able to discover. The algorithm was implemented in C# and run on a 2.4G 16-core Intel Xeon PC with 72GB main memory. The code optimization option was turned on in the compiler. All reported time was in seconds.
| Dataset | |||||
|---|---|---|---|---|---|
| EntityCube | 4,685,439 | 165,533 | 75,831 | 288 | 207 |
| ArnetMiner | 2,495,972 | 0 | 7,791,406 | 0 | 3 |
4.1 Datasets
The EntityCube system is a research prototype for exploring object-level search technologies, which automatically summarizes the Web for entities (such as people, locations and organizations). We utilized the relationship network between person entities extracted by the system. Specifically, with a list of people names as seeds, we queried the system using one name each time, and got related persons and the corresponding relationship names as return. On the one hand, the seed persons and returned persons were used to form the vertex set . On the other hand, the system returns two types of relationship. The name of one is in a plural form, such as “politicians(Barack Obama, Bill Cliton)”, indicating the connection that they’re both politicians. Thus, the relationship name naturally served as vertex labels for the two associated entities. The other type of relationship appears in a singular form, e.g., “wife(Michelle Obama, Barack Obama)”. They were interpreted as labeled edges between the corresponding vertices.
The ArnetMiner Citation Network dataset contains many papers with associated attribute information, as well as their citation relationship. The dataset consists of five versions, while we use the fifth one. We extracted all papers, authors, and conferences appearing in the data, and construct the vertex set with them. Conferences of the same series and on different years are treated as identical. There are only three types of labeled edges, i.e., “writes” between an author and a paper, “accepts” between a conference and a paper, and “cites” between a paper and another. Because these edge label names actually implies the type of both the starting and ending vertices of an edge, we didn’t employ any vertex label to avoid redundancy. In the data, IDs are provided to uniquely denote papers and form citations, which were adopted by us. However in the author and conference sections of each paper, only texts are presented. Therefore, when converting them to the IDs in our algorithm, we required exact text-match and didn’t perform any cleaning operation involving external data.
4.2 Performance
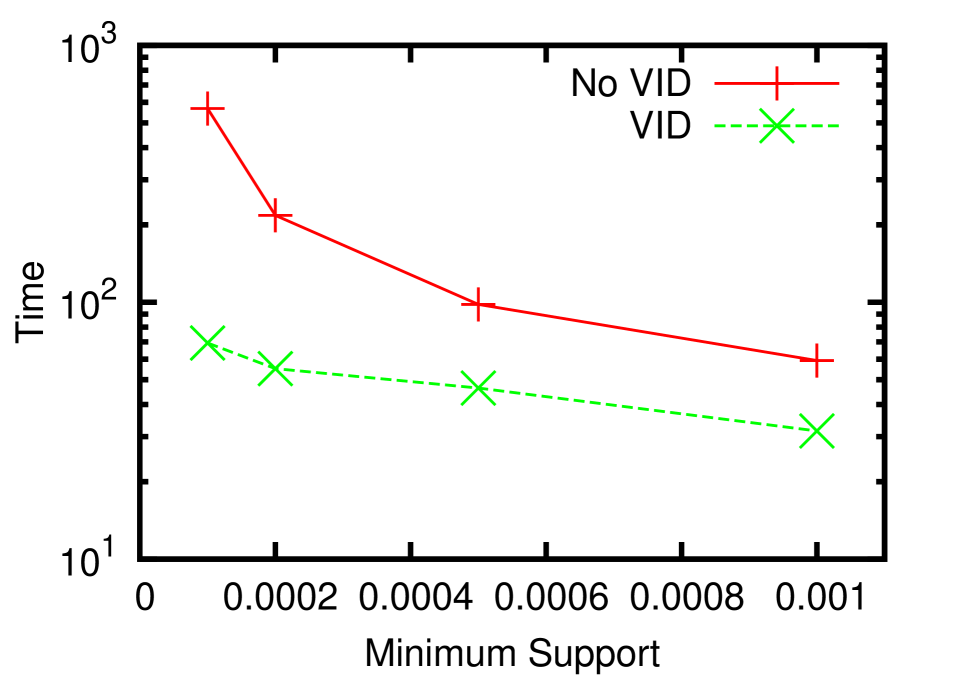
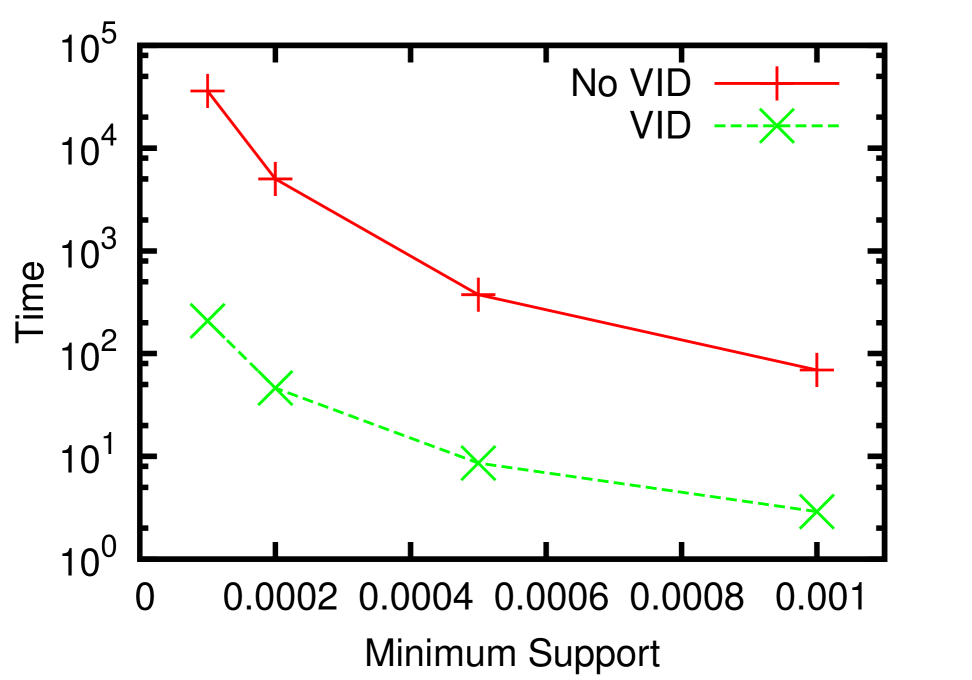
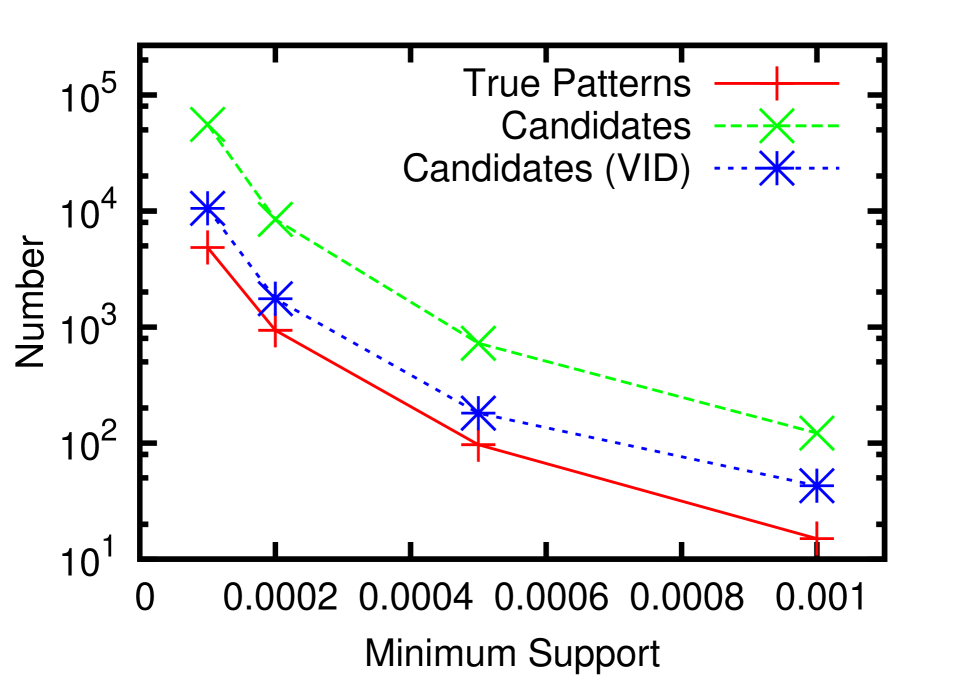
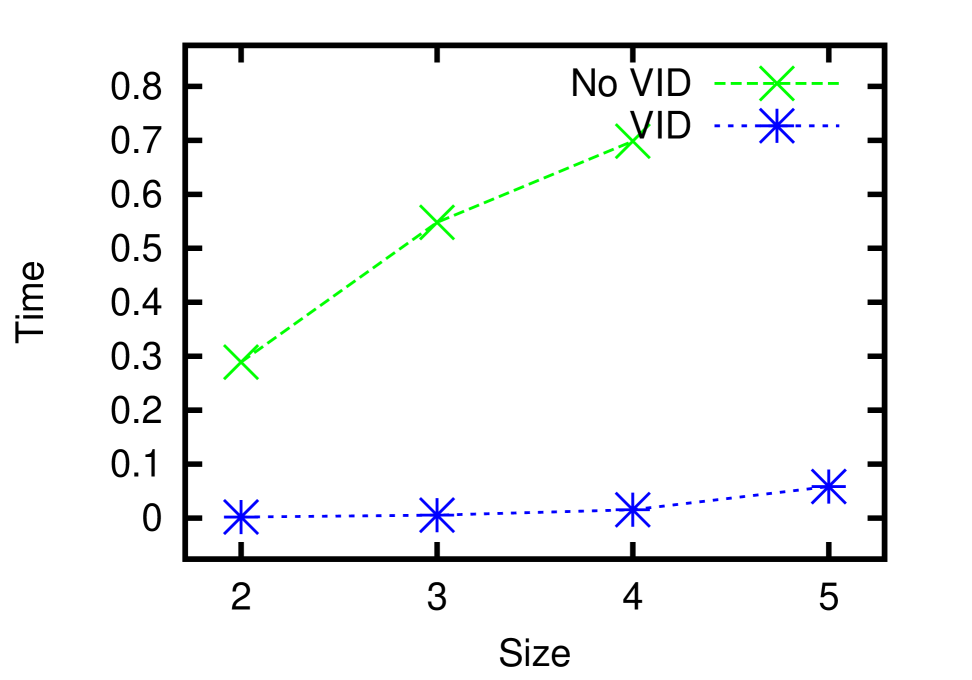
In this section, we report the performance of our algorithms for frequent neighborhood mining. Since no previous work has addressed exactly the same problem, our experiments were dedicated to validating the feasibility of our VID optimization. In practice, the running time of such a pattern mining algorithm is heavily influenced by the size of the result set. Therefore, we decided to conduct the experiments on the EntityCube data with rich label names, for it has a potentially larger result set and the running time is more sensitive to parameters such as the minimum support . In all experiments, was chosen from and all reported time was an average of five consecutive runs.
In Figure 6(a) and 6(b), we terminated the search after all frequent patterns of size below 4 were discovered. It is clear that our VID optimization successfully accelerates both the building block construction and the join-verify phases by up to one and two orders of magnitude, respectively. Analogous to the TID optimization [9] for FSM, the advantages of the VID optimization are two-fold. First, two patterns will not be joined if the intersection of their VID lists is smaller than . Therefore, the algorithm successfully avoids verifying false positives caused by joining unpromising pattern pairs, which is a vital overhead to the overall performance. In Figure 6(c), the number of candidates with/without the VID-list-pruning, and the number of true patterns are illustrated. This figure shows that the pruning helps narrow down the number of candidates by several times. Second, for each pair of patterns that passes the pruning, the time spent on counting the support of the joining results is also reduced because vertices not in the intersection won’t contribute to the count, thus are not checked. Figure 6(d) presents the average verification time for each non-path candidate where . The x-axis denotes different stages of the search procedure, where candidates of size 2 to 5 are verified. Obviously the VID optimization is significantly effective for verifying candidates of all sizes. Particularly, without the optimization, the algorithm didn’t finish the verification of size 5 in reasonable time.
4.3 Interpretation of Mined Patterns












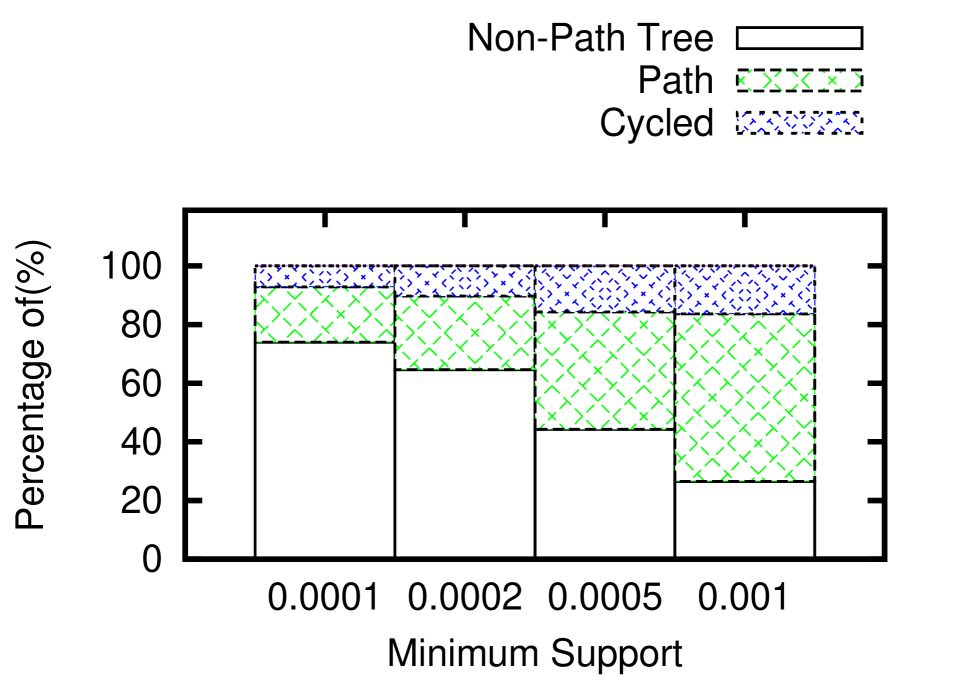
As is mentioned above, the major superiority of FNM over other graph pattern mining methods is that it discovers patterns with cycles, which is not targeted by others. With the hands-on experiences of experimenting on both datasets, we realize that a cycled pattern can be viewed as a set of constraints with lower degree of freedom than a tree-like one of the same size. Figure 6(e) shows the constitution of all patterns in EntityCube data, whose size are below 5. Patterns with cycles actually make up around 10% among all three types. The trend also shows that when we decrease the support ratio and specify a pattern into its super-patterns, it is more difficult for a cycle to form, than a fork to appear.
However, once formed, patterns with cycles serve as a good complement to tree-like patterns. Introducing them does not linearly increase our knowledge about the data being investigated, but actually makes a mutual reinforcement with tree-like ones. As patterns from the ArnetMiner dataset have better interpretability, we selected some interesting neighborhood patterns mined from this dataset to demonstrate our points. Besides the example given in Figure 1, more patterns are displayed in Figure 7. By combining two or more of them, we can make very interesting discoveries about the academia.
For example, the support ratio of Figure 7(g) is lower than that of Figure 1(a) and 7(f), which reflects the common sense that it is more difficult to get one’s paper cited than to write more papers. Besides, the small gap between the ratios of Figure 1(a) and 7(e) reveals the fact that most writers are willing to maintain a co-authoring relationship. On the other hand, the ratios of Figure 1(a) and 7(h) together prove that an average author relatively favors a conference which once accepted his paper. Moreover, Figure 7(c) alone points out that most of us (assuming that we all have papers) have a paper with no less than three authors. Surprisingly, as Figure 7(l) indicates, there are even papers citing each other! By checking the data we find two cases of such a phenomenon. One is caused by the dataset itself. The data treats books as conferences, and their chapters as papers. Of course, chapters from the same book can cite each other. This case is rare. The other case is more often: an author simultaneously submitted two papers to the same conference and got them both accepted. When preparing the camera-ready versions, he made them citing each other.
| Vertex Type | Number | Time | Patterns | Cycled |
|---|---|---|---|---|
| Conference | 6,713 | 3,354 | 135 | 30 |
| Author | 916,979 | 9,469 | 163 | 24 |
| Paper (sampled) | 500,000 | 53,422 | 796 | 147 |
For all patterns presented in this paper, we use support ratios w.r.t. vertices with a specified label, instead of the absolute count mentioned in the problem statement. It’s easy to implement, which only involves a small modification to the algorithm. Suppose we want facts about all authors with a minimum support ratio of 10%. In Algorithm 1 and 2, when a scan on the entire is required for support counting, we only scan those author vertices by accessing an index on the label names. Moreover, when calling the modified algorithms, should be assigned with 10% the number of all author vertices. When mining patterns about authors, conferences, and papers, the support ratios were set to 1%. As the number of paper vertices is huge (over 1.5 million), the support calculation was performed on a subset of 0.5 million papers we sampled. We didn’t explore path patterns of size 4, or any pattern whose size exceeds 4. Readers may refer to Table 2 for more running details.
5 Related Work
5.1 Frequent Subgraph Mining
The frequent subgraph mining problem is well-investigated by the literatures under the graph-transaction setting. Among them, the most influential methods are AGM[7], FSG[9], and gSpan[18]. The first and second adopts the apriori-based BFS scheme, and feature the vertex-incremental and edge-incremental approaches, respectively. The last one falls into a pattern-growth-based DFS category. Optimizations they utilized, such as canonical labeling and vertex invariants, are inspiring and potentially employable to our work. The single-graph setting, however, is not so fully explored due to reasons we mentioned above. Among the few support measures proposed, the Maximum Independent Set support and corresponding mining algorithms are studied in [10, 17]. [2] also defines a single-graph support called Minimum Image Support, which still doesn’t make a intuitive one and has yet to be tested for easiness of handling.
5.2 Frequent Tree Query Mining in Graphs
In [5, 6, 8], the authors attempt to mine tree patterns in graphs, whose support measure resembles ours in the way that distinct matches of some vertices are counted, while the match conditions on the others are only existential. They do not target patterns with cycles, which add much to the users’ understand of the data. Moreover, because [5, 6] allow multiple vertices to be counted (in other words, as our “pivots”), their problems are more complicated and thus do not completely follow and benefit from the well-solved apriori pattern mining scheme. We argue that, patterns with more than three pivots may explode in the number, while bringing about some knowledge that is hard to explain and utilize. Finally, these works both claimed that their mining algorithms support constants in the patterns, e.g., “x% of the authors once cited a paper published in KDD”. Our problem setting supports multiple labels on a vertex. Therefore, we can achieve it by simply adding the name of each vertex to its label set. We can also modify our algorithm to implicitly perform such a data transformation.
5.3 ILP Related Works
In [3], Dehaspe et al. introduced an inductive logic programming system for mining frequent patterns in a datalog database. Their final products are rules, which are more advanced than ours. However, they require language biases as additional inputs to bound the search space. In contrast, our method is completely unsupervised. Methods learning horn clauses from knowledge bases such as [12, 11, 4] also resemble the Inductive Logic Programming category. These works are characterized by a variety of metrics to evaluate the utility of a rule. Since noise and scalability issues in real data are their main concerns, they adopt stricter language biases and the rules mined are of more limited forms.
6 Future Work
Under the current problem setting and solution, encouraging results have been achieved in terms of performance and result utility. However, our work can still be further extended from the following aspects. First, the definition of closed neighborhood patterns may be introduced in a similar way as [19]. A pattern is closed, if there exists no proper super-pattern with the same support as it. This definition is expected to significantly reduce the size of results, while preserving the most meaningful ones. Second, the pivots may be allowed to be an edge to enable characterizing the “neighborhood” of an edge. This generalized pattern introduces new semantics, e.g., “x% of all citations are made between papers from the same institutes.” Third, according to [18], the depth-first search approach outperforms the apriori-based (breadth-first) approach by an order of magnitude in the FSM task. Therefore, it is interesting to explore its feasibility in our neighborhood mining task, which has been proved by us to share much in common with the subgraph mining one.
7 Conclusion
In this paper, we addressed mining single-graph databases and introduced the new neighborhood patterns as mining targets. They have clear semantics and are not limited to tree-like shapes. We formally defined the frequent neighborhood mining problem, and proved that it is as difficult as the frequent subgraph mining problem. We indicated that the major difference between FNM and FSM in terms of solution is that our patterns have non-trivial building blocks, which are clearly separated by us via a theorem and proof. After discussing possible optimizations, we conducted experiments on two real datasets to validate the efficiency and effectiveness of our method. The algorithm is proved to be feasible, and shows an unique ability to provide users with especially interesting insights on the analyzed data.
References
- [1] R. Agrawal, T. Imielinski, and A. N. Swami. Mining association rules between sets of items in large databases. In SIGMOD Conference, pages 207–216, 1993.
- [2] B. Bringmann and S. Nijssen. What is frequent in a single graph?. In PAKDD, pages 858–863, 2008.
- [3] L. Dehaspe and H. Toivonen. Discovery of frequent datalog patterns. pages 7–36, 1999.
- [4] L. Galarraga, C. Teflioudi, K. Hose, and F. M.Suchanek. Amie: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22th international conference on World Wide Web, WWW ’13, 2013.
- [5] B. Goethals, E. Hoekx, and J. V. den Bussche. Mining tree queries in a graph. In KDD, pages 61–69, 2005.
- [6] E. Hoekx and J. V. den Bussche. Mining for tree-query associations in a graph. In ICDM, pages 254–264, 2006.
- [7] A. Inokuchi, T. Washio, and H. Motoda. An apriori-based algorithm for mining frequent substructures from graph data. In PKDD, pages 13–23, 2000.
- [8] G. Jeh and J. Widom. Mining the space of graph properties. In KDD, pages 187–196, 2004.
- [9] M. Kuramochi and G. Karypis. An efficient algorithm for discovering frequent subgraphs. pages 1038–1051, 2004.
- [10] M. Kuramochi and G. Karypis. Finding frequent patterns in a large sparse graph. pages 243–271, 2005.
- [11] N. Lao, T. M. Mitchell, and W. W. Cohen. Random walk inference and learning in a large scale knowledge base. In EMNLP, pages 529–539, 2011.
- [12] S. Schoenmackers, J. Davis, O. Etzioni, and D. S. Weld. Learning first-order horn clauses from web text. In EMNLP, pages 1088–1098, 2010.
- [13] J. Tang, L. Yao, D. Zhang, and J. Zhang. A combination approach to web user profiling. ACM TKDD, 5(1):1–44, 2010.
- [14] J. Tang, D. Zhang, and L. Yao. Social network extraction of academic researchers. In ICDM’07, pages 292–301, 2007.
- [15] J. Tang, J. Zhang, R. Jin, Z. Yang, K. Cai, L. Zhang, and Z. Su. Topic level expertise search over heterogeneous networks. Machine Learning Journal, 82(2):211–237, 2011.
- [16] J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su. Arnetminer: Extraction and mining of academic social networks. In KDD’08, pages 990–998, 2008.
- [17] N. Vanetik, E. Gudes, and S. E. Shimony. Computing frequent graph patterns from semistructured data. In ICDM, pages 458–465, 2002.
- [18] X. Yan and J. Han. gspan: Graph-based substructure pattern mining. In ICDM, pages 721–724, 2002.
- [19] X. Yan and J. Han. Closegraph: mining closed frequent graph patterns. In KDD, pages 286–295, 2003.
Proof of Theorem 1. We prove it by reducing from the subgraph isomorphism problem. Labels are ignored because it is a generalization of, thus reducible from, the non-label case.
Given an instance of the subgraph isomorphism problem, we add a new vertex to , and to , respectively. They are marked as pivots and edges are created from them to all vertices of the same graph. Obviously, iff. . By solving the pivoted subgraph isomorphism problem we are able to answer whether . So our problem is np-hard. The solution of an instance of our problem is verified in polynomial time. Therefore, our problem is np-complete.