MirrorAlign: A Super Lightweight Unsupervised Word Alignment Model
via Cross-Lingual Contrastive Learning
Abstract
Word alignment is essential for the downstream cross-lingual language understanding and generation tasks. Recently, the performance of the neural word alignment models Garg et al. (2019); Ding et al. (2019); Zenkel et al. (2020) has exceeded that of statistical models. However, they heavily rely on sophisticated translation models. In this study, we propose a super lightweight unsupervised word alignment model named MirrorAlign, in which a bidirectional symmetric attention trained with a contrastive learning objective is introduced, and an agreement loss is employed to bind the attention maps, such that the alignments follow mirror-like symmetry hypothesis. Experimental results on several public benchmarks demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in word alignment while significantly reducing the training and decoding time on average. Further ablation analysis and case studies show the superiority of our proposed MirrorAlign. Notably, we recognize our model as a pioneer attempt to unify bilingual word embedding and word alignments. Encouragingly, our approach achieves 16.4 speedup against GIZA++, and 50 parameter compression compared with the Transformer-based alignment methods. We release our code to facilitate the community111https://github.com/moore3930/MirrorAlign.
1 Introduction
Word alignment, aiming to find the word-level correspondence between a pair of parallel sentences, is a core component of the statistical machine translation (Brown et al., 1993, SMT). It also has benefited several downstream tasks, e.g., computer-aided translation Dagan et al. (1993), semantic role labeling Kozhevnikov and Titov (2013), cross-lingual dataset creation Yarowsky et al. (2001), cross-lingual modeling Ding et al. (2020a), and cross-lingual text generation Zan et al. (2022).
Recently, in the era of neural machine translation (Bahdanau et al., 2015; Vaswani et al., 2017, NMT), the attention mechanism plays the role of the alignment model in translation system. Unfortunately, Koehn and Knowles (2017) show that attention mechanism may in fact dramatically diverge with word alignment. The works of Ghader and Monz (2017); Li et al. (2019) also confirm this finding.
Although there are some studies attempt to mitigate this problem, most of them are rely on a sophisticated translation architecture Garg et al. (2019); Zenkel et al. (2020). These methods are trained with a translation objective, which computes the probability of each target token conditioned on source tokens and previous target tokens. This will bring tremendous parameters and noisy alignments. Most recent work avoids the noisy alignment of translation models but employed too much expensive human-annotated alignments Stengel-Eskin et al. (2019). Given these disadvantages, simple statistical alignment tools, e.g., FastAlign Dyer et al. (2013) and GIZA++ Och and Ney (2003)222GIZA++ employs the IBM Model 4 as default setting., are still the most representative solutions due to their efficiency and unsupervised fashion. We argue that the word alignment task, intuitively, is much simpler than translation, and thus should be performed before translation rather than inducing alignment matrix with heavy neural machine translation models. For example, the IBM word alignment model, e.g., FastAlign, is the prerequisite of SMT. However, related research about lightweight neural word alignment without NMT is currently very scarce.
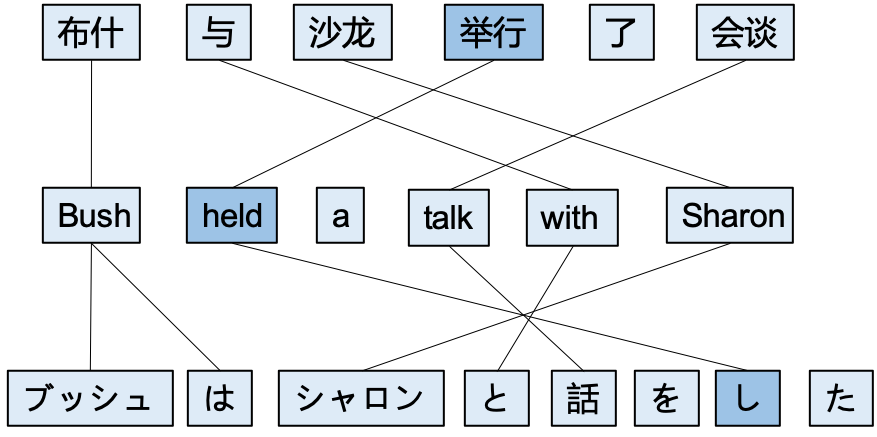
Inspired by cross-lingual word embeddings (Luong et al., 2015b, CLWEs), we propose to implement a super lightweight unsupervised word alignment model in Section 3, named MirrorAlign, which encourages the embedding distance between aligned words to be closer. We also provide the theoretical justification from mutual information perspective for our proposed contrastive learning objective in Section 3.4, demonstrating the reasonableness of our method. Figure 1 shows an English sentence, and its corresponding Chinese and Japanese sentences, and their word alignments. The links indicate the correspondence between EnglishChinese and EnglishJapanese words. If the Chinese word “举行” can be aligned to English word “held”, the reverse mapping should also hold. Specifically, a bidirectional attention mechanism with contrastive estimation is proposed to capture the alignment between parallel sentences. In addition, we employ an agreement loss to constrain the attention maps such that the alignments follow symmetry hypothesis Liang et al. (2006).
Our contributions can be summarized as follows:
-
•
We propose a super lightweight unsupervised alignment model (MirrorAlign), even merely updating the embedding matrices, achieves better alignment quality on several public benchmark datasets compare to baseline models while preserving comparable training efficiency with FastAlign.
-
•
To boost the performance of our model, we design a theoretically and empirically proved bidirectional symmetric attention with contrastive learning objective for word alignment task, in which we introduce extra objective to follow the mirror-like symmetry hypothesis.
-
•
Further analysis show that the by-product of our model in training phase has the ability to learn bilingual word representations, which endows the possibility to unify these two tasks in the future.
2 Related Work
Word alignment studies can be divided into two classes:
Statistical Models
Statistical alignment models directly build on the lexical translation models of Brown et al. (1993), also known as IBM models. The most popular implementation of this statistical alignment model is FastAlign Dyer et al. (2013) and GIZA++ Och and Ney (2000, 2003). For optimal performance, the training pipeline of GIZA++ relies on multiple iterations of IBM Model 1, Model 3, Model 4 and the HMM alignment model Vogel et al. (1996). Initialized with parameters from previous models, each subsequent model adds more assumptions about word alignments. Model 2 introduces non-uniform distortion, and Model 3 introduces fertility. Model 4 and the HMM alignment model introduce relative distortion, where the likelihood of the position of each alignment link is conditioned on the position of the previous alignment link. FastAlign Dyer et al. (2013), which is based on a reparametrization of IBM Model 2, is almost the existing fastest word aligner, while keeping the quality of alignment.
In contrast to GIZA++, our model achieves nearly 15 speedup during training, while achieving the comparable performance. Encouragingly, our model is at least 1.5 faster to train than FastAlign and consistently outperforms it.
Neural Models
Most neural alignment approaches in the literature, such as Alkhouli et al. 2018, rely on alignments generated by statistical systems that are used as supervision for training the neural systems. These approaches tend to learn to copy the alignment errors from the supervising statistical models. Zenkel et al. (2019) use attention to extract alignments from a dedicated alignment layer of a neural model without using any output from a statistical aligner, but fail to match the quality of GIZA++. Garg et al. (2019) represents the current state of the art in word alignment, outperforming GIZA++ by training a single model that is able to both translate and align. This model is supervised with a guided alignment loss, and existing word alignments must be provided to the model during training. Garg et al. (2019) can produce alignments using an end-to-end neural training pipeline guided by attention activations, but this approach underperforms GIZA++. The performance of GIZA++ is only surpassed by training the guided alignment loss using GIZA++ output. Stengel-Eskin et al. (2019) introduce a discriminative neural alignment model that uses a dot-product-based distance measure between learned source and target representation to predict if a given source-target pair should be aligned. Alignment decisions are conditioned on the neighboring decisions using convolution. The model is trained using gold alignments. Zenkel et al. (2020) uses guided alignment training, but with large number of modules and parameters, they can surpass the alignment quality of GIZA++.
They either use translation models for alignment task, which introduces a extremely huge number of parameters (compared to ours), making the training and deployment of the model cumbersome. Or they train the model with the alignment supervision, however, these alignment data is scarce in practice especially for low resource languages. These settings make above approaches less versatile.
Instead, our approach is fully unsupervised at word level, that is, it does not require gold alignments generated by human annotators during training. Moreover, our model achieves comparable performance and is at least 50 times smaller than theirs, i.e., #Parameters: 4M (ours) vs. 200M (above).
3 Our Approach
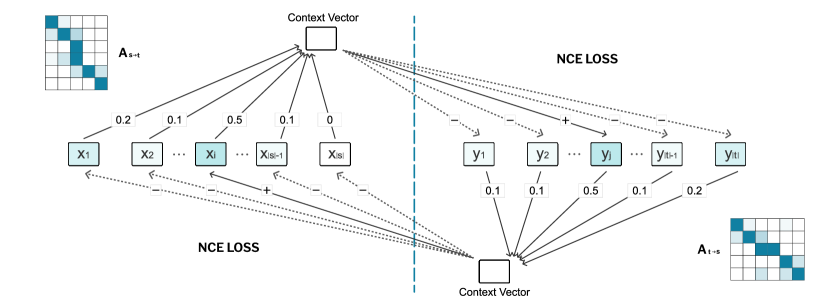
Our model trains in an unsupervised fashion, where the word level alignments are not provided. Therefore, we need to leverage sentence-level supervision of the parallel corpus. To achieve this, we introduce negative sampling strategy with contrastive learning to fully exploit the corpus. Besides, inspired by the concept of cross-lingual word embedding, we design the model under the following assumption: If a target token can be aligned to a source token, then the dot product of their embedding vectors should be large. Figure 2 shows the schema of our approach MirrorAlign.
3.1 Sentence Representation
For a given source-target sentence pair , represent the -th and -th word embeddings for the source and target sentences, respectively. Luong et al. (2015a); Ding et al. (2020b) illustrate that modelling the neighbour words within the local window helps to understand the current words. Inspired by this, we perform a extremely simple but effective mean pooling operation with the representations of its surrounding words to capture the contextualized information. Padding operation is used to ensure the sequence length. As a result, the final representation of each word can be calculated by element-wisely adding the mean pooling embedding and its original embedding:
| (1) |
where is the pooling window size. We can therefore derive the sentence level representations for and . In addition to modeling words, modeling structured information (such as syntactic information) may be helpful to enhance the sentence representation Li et al. (2017); Marcheggiani and Titov (2017); Ding and Tao (2019), thus improving the word alignment. We leave this exploration for future work.
3.2 Bidirectional Symmetric Attention
Bidirectional symmetric attention is the basic component of our proposed model. The aim of this module is to generate the source-to-target (aka. s2t) and target-to-source (aka. t2s) soft attention maps. The details of the attention mechanism: given a source side word representation as query and pack all the target tokens together into a matrix . The attention context can be calculated as:
| (2) |
where the vector represents the attention probabilities for in source sentence over all the target tokens, in which each element signifies the relevance to the query, and can be derived from:
| (3) |
For simplicity, we denote the attention context of in the target side as . s2t attention map is constructed by stacking the probability vectors corresponding to all the source tokens.
Reversely, we can obtain t2s attention map in a symmetric way. Then, these two attention matrices and will be used to decode alignment links. Take s2t for example, given a target token, the source token with the highest attention weight is viewed as the aligned word.
3.3 Agreement Mechanism
Intuitively, the two attention matrices and should be very close. However, the attention mechanism suffers from symmetry error in different direction Koehn and Knowles (2017).
To bridge this discrepancy, we introduce agreement mechanism Liang et al. (2006), acting like a mirror that precisely reflects the matching degree between and , which is also empirically confirmed in machine translation Levinboim et al. (2015). In particular, we use an agreement loss to bind above two matrices:
| (4) |
In Section 4.6, we empirically show this agreement can be complementary to the bidirectional symmetric constraint, demonstrating the effectiveness of this component.
| Method | EN-FR | FR-EN | sym | RO-EN | EN-RO | sym | DE-EN | EN-DE | sym |
|---|---|---|---|---|---|---|---|---|---|
| NNSA | 22.2 | 24.2 | 15.7 | 47.0 | 45.5 | 40.3 | 36.9 | 36.3 | 29.5 |
| FastAlign | 16.4 | 15.9 | 10.5 | 33.8 | 35.5 | 32.1 | 28.4 | 32.0 | 27.0 |
| MirrorAlign | 15.3 | 15.6 | 9.2 | 34.3 | 35.2 | 31.6 | 31.1 | 28.0 | 24.8 |
3.4 Training Objective and Theoretical Justification
Suppose that is a pair of s2t word representation and corresponding attention context sampled from the joint distribution (hereinafter we call it a positive pair), the primary objective of the s2t training is to maximize the alignment degree between the elements within a positive pair. Thus, we first define an alignment function by using the inner product as:
| (5) |
where denotes the function and is the inner product operation. However, merely optimizing the alignment of positive pairs ignores important positive-negative relation knowledge Mikolov et al. (2013).
To make the training process more informative, we reform the overall objective in the contrastive learning manner Oord et al. (2018); Saunshi et al. (2019) with Noise Contrastive Estimation (NCE) loss Mikolov et al. (2013), which has been widely used in many NLP tasks Xiong et al. (2021); Gao et al. (2021); Wang et al. (2022). Specifically, we first sample negative word representations 333In the contrastive learning setting, and can be sampled from different sentences. If and are from the same sentence, ; otherwise, can be a random index within the sentence length. For simplicity, in this paper, we use where to denote the negative samples, although with a little bit ambiguity. from the margin . Then, we can formulate the overall NCE objective as following:
| (6) | ||||
It is evident that the objective in Eq. (6) explicitly encourages the alignment of positive pair while simultaneously separates the negative pairs .
Moreover, a direct consequence of minimizing Eq. (6) is that the optimal estimation of the alignment between the representation and attention context is proportional to the ratio of joint distribution and the product of margins which is the point-wise mutual information, and we can further have the following proposition with repect to the mutual information:
Proposition 1.
The mutual information between the word representation and its corresponding attention context is lower-bounded by the negative in Eq. (6) as:
| (7) |
where is the number of the negative samples.
The detailed proof can be found in Oord et al. (2018). Proposition 1 indicates that the lower bound of the mutual information can be maximized by achieving the optimal NCE loss, which provides theoretical guarantee for our proposed method.
Our training schema over parallel sentences is mainly inspired by the bilingual skip-gram model Luong et al. (2015b) and invertibility modeling Levinboim et al. (2015). Therefore, the ultimate training objective should consider both forward () and backward () direction, combined with the mirror agreement loss. Technically, the final training objective is:
| (8) | ||||
where and are symmetrical and is a loss weight to balance the likelihood and disagreement loss.
| Model | EN-FR | RO-EN | DE-EN |
|---|---|---|---|
| Naive Attention | 31.4 | 39.8 | 50.9 |
| NNSA | 15.7 | 40.3 | - |
| FastAlign | 10.5 | 32.1 | 27.0 |
| MirrorAlign | 9.2 | 31.6 | 24.8 |
| Zenkel et al. (2020) | 8.4 | 24.1 | 17.9 |
| Garg et al. (2019) | 7.7 | 26.0 | 20.2 |
| GIZA++ | 5.5 | 26.5 | 18.7 |

4 Experiments
4.1 Datasets and Evaluation Metrics
We perform our method on three widely used datasets: English-French (EN-FR), Romanian-English (RO-EN) and German-English (DE-EN). Training and test data for EN-FR and RO-EN are from NAACL 2003 share tasks Mihalcea and Pedersen (2003). For RO-EN, we add Europarl v8 corpus, increasing the amount of training data from 49K to 0.4M. For DE-EN, we use the Europarl v7 corpus as training data and test on the gold alignments. All above data are lowercased and tokenized by Moses. The evaluation metrics are Precision, Recall, F-score (F1) and Alignment Error Rate (AER).
4.2 Baseline Methods
Besides two strong statistical alignment models, i.e. FastAlign and GIZA++, we also compare our approach with neural alignment models where they induce alignments either from the attention weights or through feature importance measures.
FastAlign
One of the most popular statistical method which log-linearly reparameterize the IBM model 2 proposed by Dyer et al. (2013).
GIZA++
A statistical generative model Och and Ney (2003), in which parameters are estimated using the Expectation-Maximization (EM) algorithm, allowing it to automatically extract bilingual lexicon from parallel corpus.
NNSA
A unsupervised neural alignment model proposed by Legrand et al. (2016), which applies an aggregation operation borrowed from the computer vision to design sentence-level matching loss. In addition to the raw word indices, following three extra features are introduced: distance to the diagonal, part-of-speech and unigram character position. To make a fair comparison, we report the result of raw feature in NNSA.
Naive Attention
Averaging all attention matrices in the Transformer architecture, and selecting the source unit with the maximal attention value for each target unit as alignments. We borrow the results reported in Zenkel et al. (2019) to highlight the weakness of such naive version, where significant improvement are achieved after introducing an extra alignment layer.
Others
Garg et al. (2019) and Zenkel et al. (2020) represent the current developments in word alignment, which both outperform GIZA++. However, They both implement the alignment model based on a sophisticated translation model. Further more, the former uses the output of GIZA++ as supervision, and the latter introduces a pre-trained state-of-the-art neural translation model. It is unfair to compare our results directly with them. We report them in Table 2 as references.
4.3 Setup
For our method (MirrorAlign), all the source and target embeddings are initialized by Xavier method Glorot and Bengio (2010). The embedding size and pooling window size are set to 256 and 3, respectively. The hyper-parameters
is tested by grid search from 0.0 to 1.0 at 0.1 intervals.
For FastAlign, we train it from scratch by the open-source pipeline444https://github.com/lilt/alignment-scripts. Also, we report the results of NNSA and machine translation based model (Section 4.2).
All experiments of MirrorAlign are run on 1 Nvidia P40 GPU. The CPU model is Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz. Both FastAlign and MirrorAlign take nearly half a hour to train one million samples.
4.4 Main Results
Table 2 summarizes the AER of our method over several language pairs. Our model outperforms all other baseline models. Comparing to FastAlign, we achieve 1.3, 0.5 and 2.2 AER improvements on EN-FR, RO-EN, DE-EN respectively.
Notably, our model exceeds the naive attention model in a big margin in terms of AER (ranging from 8.2 to 26.1) over all language pairs. We attribute the poor performance of the straightforward attention model (translation model) to its contextualized word representation. For instance, when translating a verb, contextual information will be paid attention to determine the form (e.g., tense) of the word, that may interfere the word alignment.
Experiment results in different alignment directions can be found in Table 1. The grow-diag symmetrization benifits all the models.
4.5 Speed Comparison
Take the experiment on EN-FR dataset as an example, MirrorAlign converges to the best performance after running 3 epochs and taking 14 minutes totally, where FastAlign and GIZA++ cost 21 and 230 minutes, respectively, to achieve the best results. Notably, the time consumption will rise dozens of times in neural translation fashion.
4.6 Ablation Study
To further explore the effects of several components (i.e., bidirectional symmetric attention, agreement loss) in our MirrorAlign, we conduct an ablation study. Table 3 shows the results on EN-FR dataset. When the model is trained using only or as loss functions, the AER of them are quite high (20.9 and 23.3). As expected, combined loss function improves the alignment quality significantly (14.1 AER). It is noteworthy that with the rectification of agreement mechanism, the final combination achieves the best result (9.2 AER), indicating that the agreement mechanism is the most important component in MirrorAlign.
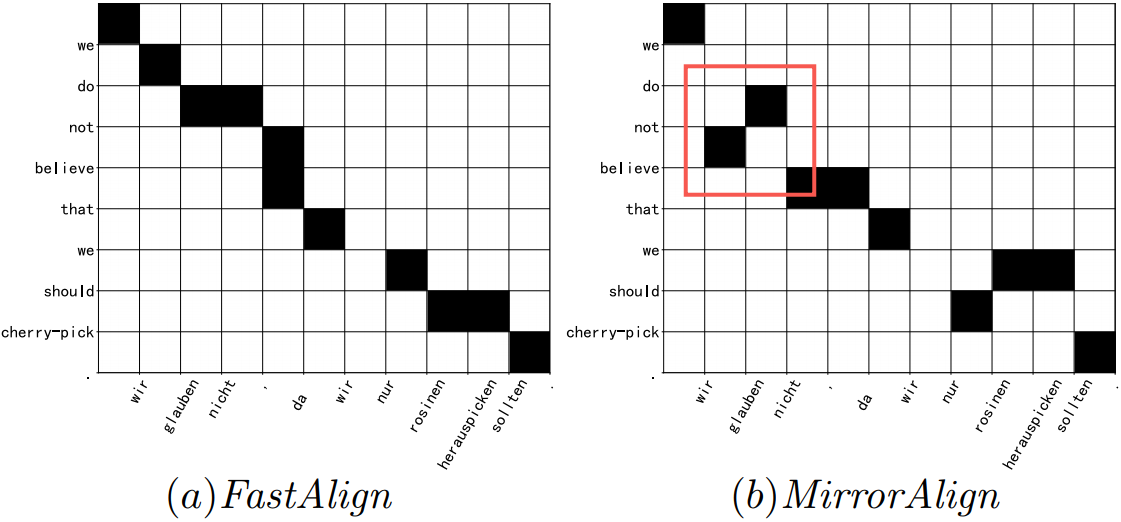
To better present the improvements brought by adding each component, we visualize the alignment case in Figure 3. As we can see, each component is complementary to others, that is, the attention map becomes more diagonally concentrated after adding the bidirectional symmetric attention and the agreement constraint.
| Setup | P | R | F1 | AER |
|---|---|---|---|---|
| 74.9 | 86.0 | 80.4 | 20.9 | |
| 71.9 | 85.3 | 77.3 | 23.3 | |
| 81.5 | 90.1 | 86.1 | 14.1 | |
| MirrorAlign | 91.8 | 89.1 | 90.8 | 9.2 |
5 Analysis
Alignment Case Study
Figure 4 shows an alignment example. Our model correctly aligns “do not believe” in English to “glauben nicht” in German. Our model, based on word representation, makes better use of semantics to accomplish alignment such that inverted phrase like “glauben nicht” can be well handled. Instead, FastAlign, relied on the positional assumption555A feature of position is introduced in FastAlign to encourage alignments to occur around the diagonal. , and are source and target indices and and are the length of sentences pair., fails here.
Word Embedding Clustering
To further investigate the effectiveness of our model, we also analyze the word embeddings learned by our model. In particular, following Collobert et al. (2011), we show some words together with its nearest neighbors using the Euclidean distance between their embeddings. Table 4 shows some examples to demonstrates that our learned representations possess a clearly clustering structure bilingually and monolingually. We attribute the better alignment results to the ability of our model that could learn bilingual word representation.
| china | distinctive | ||
|---|---|---|---|
| EN | DE | EN | DE |
| china | chinas | distinctive | unverwechselbaren |
| chinese | china | distinct | besonderheiten |
| china’s | chinesische | peculiar | markante |
| republic | chinesischer | differences | charakteristische |
| china’ | chinesischem | diverse | einzelnen |
| cat | love | ||
| EN | DE | EN | DE |
| cat | hundefelle | love | liebe |
| dog | katzenfell | affection | liebt |
| toys | hundefellen | loved | liebe |
| cats | kuchen | loves | lieben |
| dogs | schlafen | passion | lieb |
6 Conclusion and Future Work
In this paper, we presented a super lightweight neural alignment model, named MirrorAlign, that has achieved better alignment performance compared to FastAlign and other existing neural alignment models while preserving training efficiency. We empirically and theoretically show its effectiveness over several language pairs. In the future, we would further explore the relationship between CLWEs and word alignments. A promising attempt is using our model as a bridge to unify cross-lingual embeddings and word alignment tasks.
References
- Alkhouli et al. (2018) Tamer Alkhouli, Gabriel Bretschner, and Hermann Ney. 2018. On the alignment problem in multi-head attention-based neural machine translation. In WMT.
- Bahdanau et al. (2015) Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In ICLR.
- Brown et al. (1993) Peter F Brown, Vincent J Della Pietra, Stephen A Della Pietra, and Robert L Mercer. 1993. The mathematics of statistical machine translation: Parameter estimation. Computational linguistics.
- Collobert et al. (2011) Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. Journal of machine learning research.
- Dagan et al. (1993) Ido Dagan, Kenneth Church, and Willian Gale. 1993. Robust bilingual word alignment for machine aided translation. In Very Large Corpora: Academic and Industrial Perspectives.
- Ding and Tao (2019) Liang Ding and Dacheng Tao. 2019. Recurrent graph syntax encoder for neural machine translation. arXiv.
- Ding et al. (2020a) Liang Ding, Longyue Wang, and Dacheng Tao. 2020a. Self-attention with cross-lingual position representation. In ACL.
- Ding et al. (2020b) Liang Ding, Longyue Wang, Di Wu, Dacheng Tao, and Zhaopeng Tu. 2020b. Context-aware cross-attention for non-autoregressive translation. In COLING.
- Ding et al. (2019) Shuoyang Ding, Hainan Xu, and Philipp Koehn. 2019. Saliency-driven word alignment interpretation for neural machine translation. In WMT.
- Dyer et al. (2013) Chris Dyer, Victor Chahuneau, and Noah A Smith. 2013. A simple, fast, and effective reparameterization of ibm model 2. In NAACL.
- Gao et al. (2021) Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. In EMNLP.
- Garg et al. (2019) Sarthak Garg, Stephan Peitz, Udhyakumar Nallasamy, and Matthias Paulik. 2019. Jointly learning to align and translate with transformer models. In EMNLP.
- Ghader and Monz (2017) Hamidreza Ghader and Christof Monz. 2017. What does attention in neural machine translation pay attention to? In IJCNLP.
- Glorot and Bengio (2010) Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In ICML.
- Koehn and Knowles (2017) Philipp Koehn and Rebecca Knowles. 2017. Six challenges for neural machine translation. In WNMT.
- Kozhevnikov and Titov (2013) Mikhail Kozhevnikov and Ivan Titov. 2013. Cross-lingual transfer of semantic role labeling models. In ACL.
- Legrand et al. (2016) Joël Legrand, Michael Auli, and Ronan Collobert. 2016. Neural network-based word alignment through score aggregation. In WMT.
- Levinboim et al. (2015) Tomer Levinboim, Ashish Vaswani, and David Chiang. 2015. Model invertibility regularization: Sequence alignment with or without parallel data. In NAACL.
- Li et al. (2017) Junhui Li, Deyi Xiong, Zhaopeng Tu, Muhua Zhu, Min Zhang, and Guodong Zhou. 2017. Modeling source syntax for neural machine translation. In ACL.
- Li et al. (2019) Xintong Li, Guanlin Li, Lemao Liu, Max Meng, and Shuming Shi. 2019. On the word alignment from neural machine translation. In ACL.
- Liang et al. (2006) Percy Liang, Ben Taskar, and Dan Klein. 2006. Alignment by agreement. In NAACL.
- Luong et al. (2015a) Minh-Thang Luong, Hieu Pham, and Christopher D Manning. 2015a. Effective approaches to attention-based neural machine translation. In EMNLP.
- Luong et al. (2015b) Thang Luong, Hieu Pham, and Christopher D Manning. 2015b. Bilingual word representations with monolingual quality in mind. In NAACL Workshop.
- Marcheggiani and Titov (2017) Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for semantic role labeling. In EMNLP.
- Mihalcea and Pedersen (2003) Rada Mihalcea and Ted Pedersen. 2003. An evaluation exercise for word alignment. In NAACL.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In NeurIPS.
- Och and Ney (2000) Franz Josef Och and Hermann Ney. 2000. Improved statistical alignment models. In ACL.
- Och and Ney (2003) Franz Josef Och and Hermann Ney. 2003. A systematic comparison of various statistical alignment models. Computational linguistics.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. arXiv.
- Saunshi et al. (2019) Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khandeparkar. 2019. A theoretical analysis of contrastive unsupervised representation learning. In ICML.
- Stengel-Eskin et al. (2019) Elias Stengel-Eskin, Tzu-Ray Su, Matt Post, and Benjamin Van Durme. 2019. A discriminative neural model for cross-lingual word alignment. In EMNLP.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS.
- Vogel et al. (1996) Stephan Vogel, Hermann Ney, and Christoph Tillmann. 1996. HMM-based word alignment in statistical translation. In COLING.
- Wang et al. (2022) Bing Wang, Liang Ding, Qihuang Zhong, Ximing Li, and Dacheng Tao. 2022. A contrastive cross-channel data augmentation framework for aspect-based sentiment analysis. In ArXiv.
- Xiong et al. (2021) Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate nearest neighbor negative contrastive learning for dense text retrieval. In ICLR.
- Yarowsky et al. (2001) David Yarowsky, Grace Ngai, and Richard Wicentowski. 2001. Inducing multilingual text analysis tools via robust projection across aligned corpora. In HLT.
- Zan et al. (2022) Changtong Zan, Liang Ding, Li Shen, Yu Cao, Weifeng Liu, and Dacheng Tao. 2022. Bridging cross-lingual gaps during leveraging the multilingual sequence-to-sequence pretraining for text generation. In ArXiv.
- Zenkel et al. (2019) Thomas Zenkel, Joern Wuebker, and John DeNero. 2019. Adding interpretable attention to neural translation models improves word alignment. In arXiv.
- Zenkel et al. (2020) Thomas Zenkel, Joern Wuebker, and John DeNero. 2020. End-to-end neural word alignment outperforms GIZA++. In ACL.