Mismatched Estimation
in the Distance Geometry Problem
Abstract
We investigate mismatched estimation in the context of the distance geometry problem (DGP). In the DGP, for a set of points, we are given noisy measurements of pairwise distances between the points, and our objective is to determine the geometric locations of the points. A common approach to deal with noisy measurements of pairwise distances is to compute least-squares estimates of the locations of the points. However, these least-squares estimates are likely to be suboptimal, because they do not necessarily maximize the correct likelihood function. In this paper, we argue that more accurate estimates can be obtained when an estimation procedure using the correct likelihood function of noisy measurements is performed. Our numerical results demonstrate that least-squares estimates can be suboptimal by several dB.
I Introduction
The distance geometry problem (DGP) [1, 2, 3] aims to determine the locations of points in Euclidean space given measurements of the distances between these points. The DGP arises in many important applications. In wireless networks with moving devices in two-dimensional (2D) planes, the positions of these devices can be estimated by solving the DGP [4]. In computational biology, solving the DGP can allow us to determine the locations of atoms in molecules [5]. In robotics, a simple robotic movement can be modeled as a pair of rigid bars rotating along a joint. Whether these bars can flex along a joint to reach a specific point in 3D space can be determined by solving the DGP [6].
The main challenge for the DGP is that pairwise distance measurements are noisy [1]. Because of the noise, it is common to find a set of locations of points that minimizes the sum of squared errors (SSE) between the pairwise distances of a target structure and noisy measurements of these pairwise distances [7]. When the noisy measurements of pairwise distances are Gaussian distributed, minimizing the SSE function yields a maximum likelihood (ML) estimate of a structure of points. However, in practice, it is unlikely that the measurements are exactly Gaussian distributed, and so the SSE function is unlikely to yield an ML estimate. In this work, we will provide better estimation quality by performing ML estimation using the correct noise distribution. We call our approach matched DGP estimation. In contrast, much of the prior art performed mismatched DGP estimation (details below).
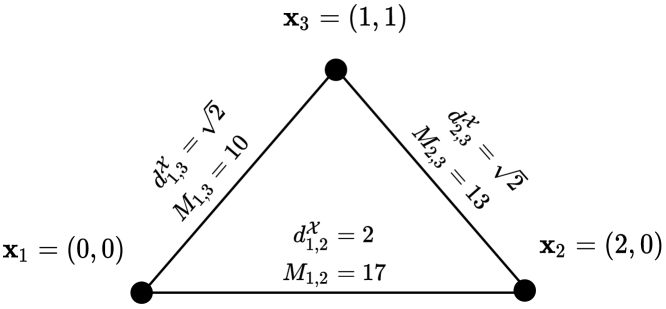
Problem formulation. Let be an unobserved set of locations of points in -dimensional Euclidean space . Additionally, let be the set of edges connecting every pair of points in . Note that , where denotes the cardinality of a set. We define the length of an edge as the norm of , . We define , where is the set of nonnegative integers, as the number of noisy measurements of the length of edge . An example structure is shown in Fig. 1. In the DGP, our objective is to determine given noisy measurements of lengths of edges in .
Estimating the locations of the points. We estimate using the method of ML. Let the random variable represent the th noisy measurement of the length of edge , where a realization of is denoted by . For example, is the th measurement of the length of edge . We assume that for every . Let the set of all be, , where . The sets and are defined similarly for . Our objective is to derive an expression for the likelihood function , where .
Suppose that the measurements for edge are independent of the measurements for edge for every , and that for every . Under these assumptions, the likelihood can be expressed as, . Additionally, suppose that all measurements associated with edge are independent and identically distributed (i.i.d.). The likelihood can be further simplified,
| (1) |
where is the true marginal pdf of . In the rest of the paper, we will use , where is a vector of shape parameters, to denote the marginal pdf for . When a single shape parameter describes this marginal pdf, the scalar version will be used instead.
Given a set of noisy edge length measurements , an ML estimate of can be obtained by maximizing (1). This case will be referred to as matched DGP estimation. In practice, we often do not know what parametric form the marginal pdf of takes. In this case, we would modify (1) by replacing the true marginal pdf of with an assumed version, . If , then we refer to the modified version of the likelihood as the mismatched likelihood. Moreover, an estimate of that is obtained by maximizing the mismatched likelihood will not necessarily be an ML estimate. We refer to this case as mismatched DGP estimation. We are interested in the difference in quality of estimates of in the matched and mismatched cases.
Limitations of least-squares. Suppose that follows a Gaussian distribution with mean and variance , namely,
Then, maximizing the likelihood with respect to (w.r.t.) is equivalent to minimizing the SSE w.r.t. . Several approaches to solve the DGP in the case of noisy measurements use variants of the SSE function [3, 8, 9]. A survey of prior art appears in Sec. II.
The aforementioned equivalence between minimizing the SSE function and maximizing the likelihood derived in (1) is only true when is Gaussian. In practice, depending on the measurement technique, it is unlikely that the noisy measurement is Gaussian distributed. Therefore, it is unlikely that minimizing the SSE function will yield an ML estimate of a structure.
Contributions. In this paper, we empirically show that, compared to mismatched DGP estimation, matched DGP estimation can offer an improvement of several dB. Moreover, our contribution is that, to the best of our knowledge, and in the context of the DGP, we are the first to focus on ML estimation beyond Gaussian-distributed measurements. The rest of the paper is structured as follows: we review the prior art in Sec. II. The different marginal pdfs of that will be considered, and how estimates of will be evaluated, are discussed in Sec. III. Experimental results are presented in Sec. IV. Finally, we summarize our results and describe future work in Sec. V.
II Related Work
One of the earliest discussions of cost functions related to the solution of the DGP was due to Crippen and Havel [3]. In their work, they used a variant of the SSE function, which we refer to as SSE-CH, to estimate molecular structures with physical constraints. Although others have empirically shown that SSE-CH yields acceptable results [3], the resulting estimate of a structure need not be an ML estimate.
Subsequent papers implement modifications to the SSE-CH cost function. For example, Moré and Wu [9] adopted a continuation approach: the SSE-CH cost function is repeatedly smoothed via a convolution with a Gaussian kernel. After each successive smoothing stage, a minimizer of the smoothed SSE-CH is obtained. Eventually, the minimizers are traced back to the original function [9, p. 827]. Although this approach yielded promising results, the underlying cost function that is smoothed is still the SSE function. Moreover, there is no guarantee that the resulting estimate of is an ML estimate.
Souza et al. [10] attempt to make SSE-CH differentiable by approximating certain parts using hyperbolic functions. Souza et al. [11] made further improvements by applying these approximations to the geometric buildup algorithm proposed by Luo and Wu [12]. However, the underlying cost function is still a variant of the SSE function, and so there is no guarantee of obtaining ML estimates. For a detailed review of approaches to solve the DGP, see [7]. More recently, Gopalkrishnan et al. [13] optimize a variation of SSE-CH to reconstruct DNA molecules from pairwise distance measurements. Giamou et al. [14] also optimize a variation of SSE-CH to determine the joint angles of a robot given the robot’s forward kinematics and desired poses. However, because variations of SSE-CH are used, it is unlikely that estimates obtained in these applications are ML estimates.
III Noise Distributions and Evaluation
We will consider different forms of the marginal pdf of , as included in (1), that result in a likelihood that, when maximized w.r.t. , yields ML estimates. It was previously shown that if follows a Gaussian distribution, then minimizing the SSE function is equivalent to maximizing the likelihood in (1). We consider the cases when follows either a Laplace or non-standardized Student’s (NSST) distribution.
If follows a Laplace distribution with mean and variance , then
| (2) |
If follows an NSST distribution with mean and variance , assuming , then an expression for the marginal pdf of can be derived as follows. Let follow a Student’s distribution with parameter , which is a positive integer. The pdf of is
where for every . If , then
| (3) |
where .
Evaluation. Given an estimate of , if we rotate, reflect, and/or translate the points in by an equal amount, then will still have the same edge lengths as . Therefore, a unique solution to the DGP cannot exist without additional constraints. Moreover, the proximity of to will need to be evaluated up to rotation, translation, and reflection. Let and be matrices, where the th columns of and correspond to the th points in and , respectively. We first translate the column vectors in and so that they are centered at the origin by computing and , where is an matrix of ones.
Next, how close is to is equivalent to the solution of the orthogonal Procrustes problem (OPP) [15],
| (4) | ||||
| s.t. |
where is the Frobenius norm, which for a matrix, , is defined as, . The objective of the OPP is to determine the orthonormal matrix that most closely maps to . We will refer to the value obtained by solving the OPP for an estimate , divided by the number of points , as the OPP loss associated with . As our objective is to show that an ML estimate of more closely approximates than a non-ML estimate , we will compare the OPP losses of and .
IV Numerical Results
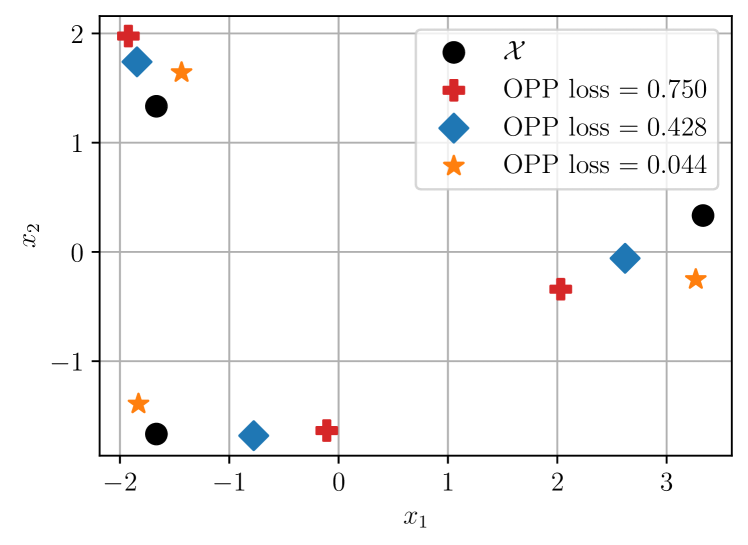
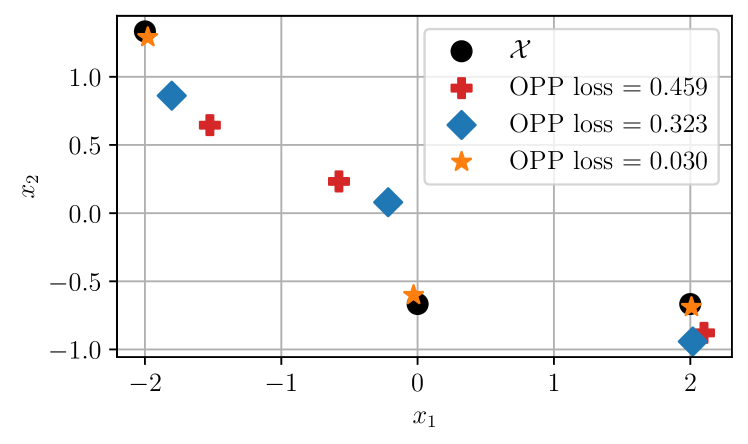
We begin our discussion with numerical results on triangles, which are structures consisting of 3 points (see Fig. 2). Later, we demonstrate analogous numerical results for structures with 10 points (see Fig. 5). In our experiments, we let follow either a Laplace (2) or NSST (3) distribution. If follows a Laplace (respectively, NSST) distribution, then the marginal pdf of in the likelihood (1) is varied between the Laplace (respectively, NSST) pdf in the matched case and the Gaussian pdf in the mismatched case.
The variance of the noisy measurements was changed as a function of different signal-to-noise ratio (SNR) values. If the distribution from which the i.i.d. noisy measurements associated with edge were obtained has variance , and if we let be the average edge length of a structure , then , where SNR is quantified in decibel (dB) units. We leave the case where depends on edge for future work. The SNR was varied from –20 dB to 20 dB in steps of 5 dB. For each SNR value, we sample a set of noisy measurements, maximize the likelihood111An implementation of the L-BFGS algorithm [16] that is available in PyTorch [17] was used to maximize the likelihood. in (1) for the Laplace (or NSST) cases, and then report the OPP loss associated with an estimated structure for each case.
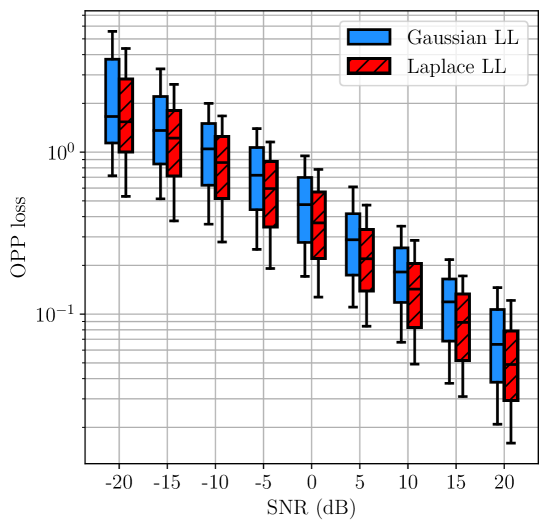
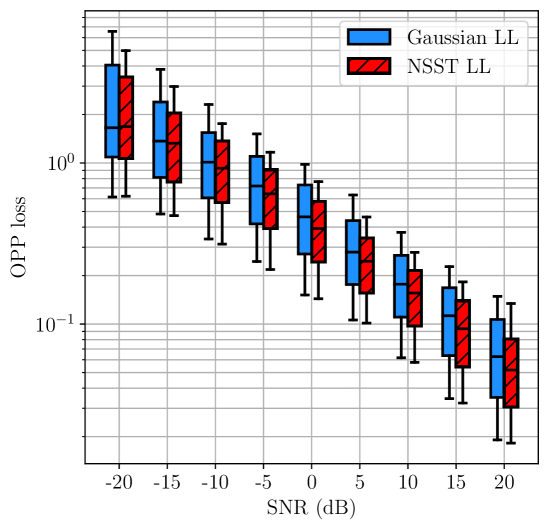
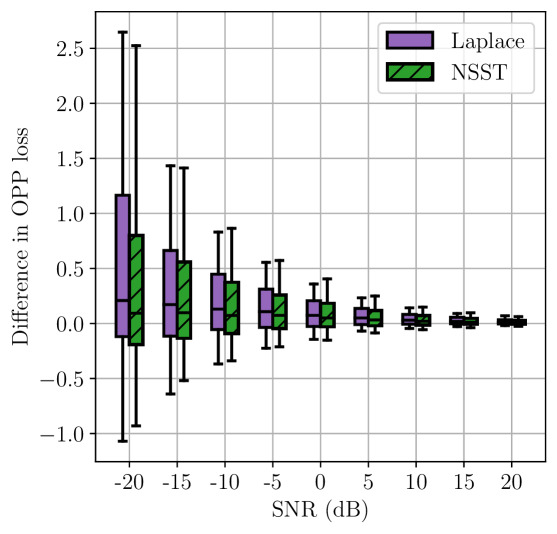
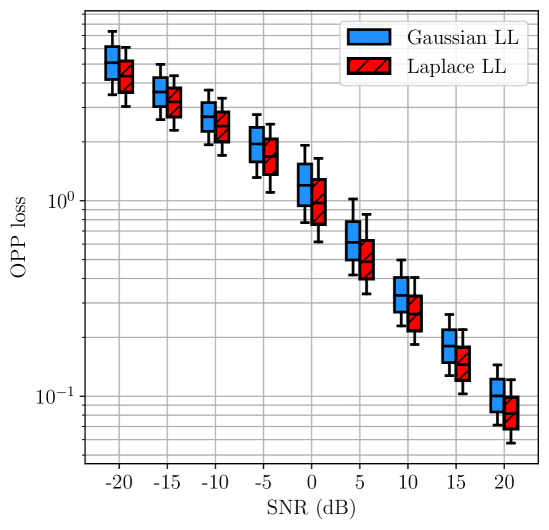
Triangles. We first considered 8 triangles in 2D. Two of these triangles, together with example estimates and their associated OPP losses, are shown in Fig. 2. For each SNR value, and for each triangle, we sampled noisy measurements per edge 100 times. For each sample, we computed an estimate using different likelihoods and then computed the OPP loss associated with . The distributions of these OPP losses are shown in Fig. 3(a) and Fig. 3(b). We also computed the pairwise difference in OPP losses resulting from mismatched and matched estimation. The distributions of these differences are shown in Fig. 3(c).
We observe that, in general, the distribution of OPP losses associated with the likelihood that is matched to the noise distribution is shifted lower than the distribution associated with the likelihood that is not matched to the noise distribution. Moreover, in several instances, the increase in median OPP loss due to a 3–4 dB decrease in SNR can approximately be compensated for by choosing to use the likelihood that is matched to the noise distribution.
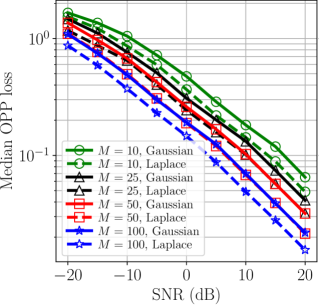
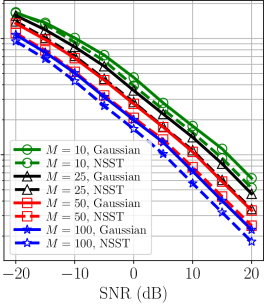
We then repeated this experiment for different values of , the number of noisy measurements per edge. The median OPP losses for are shown in Fig. 4. We observe that, in general, maximizing the likelihood that is matched to the noise distribution offers an improvement over mismatched DGP estimation comparable to the improvement obtained by doubling the number of noisy measurements per edge.
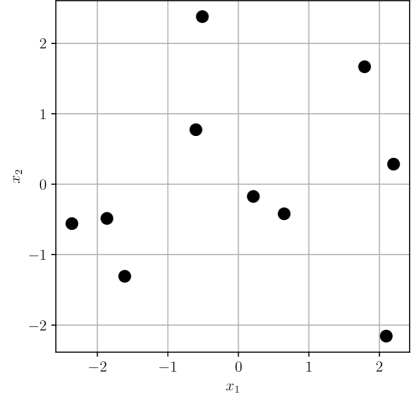
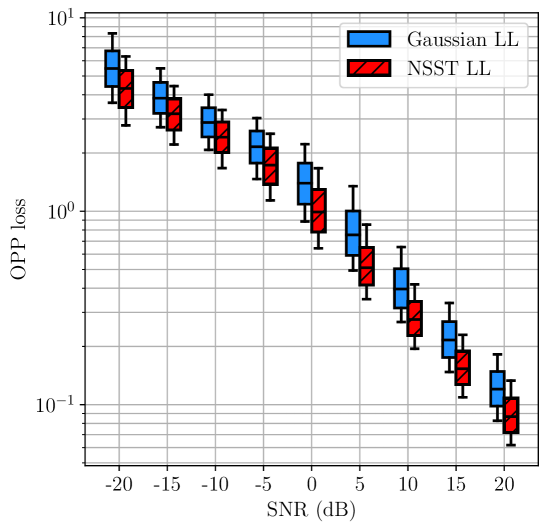
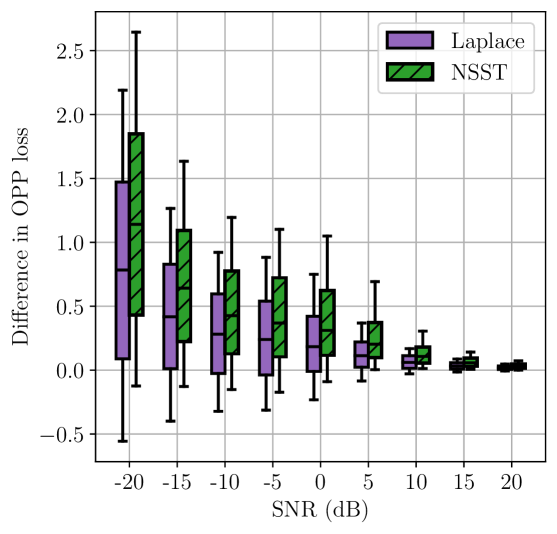
10 points. To further support our results, we repeated our experiments for 30 10-point structures in 2D. One of these structures is shown in Fig. 5. The distributions of OPP losses are shown in Fig. 6(a) and Fig. 6(b), and the distributions of pairwise differences in OPP losses for the mismatched and matched cases are shown in Fig. 6(c). Similar to the case of triangles, we observe that, in general, the distribution of OPP losses associated with the likelihood that is matched to the noise distribution is lower than the distribution associated with the likelihood that is not matched to the noise distribution.
V Conclusions and Future Work
In this paper, we have explored the impact of matching the likelihood function to the noise distribution on estimation accuracy in the context of the distance geometry problem (DGP). We have empirically found that matching the likelihood function to the noise distribution can offer a 3–4 dB compensation for the loss in estimation accuracy due to noisier measurements and smaller sample sizes. Moreover, matched estimation can be helpful in these scenarios, which often arise in practice.
There are several directions for future work that can be explored. For example, in practice, measurements may not be available for some edges, so the case where the numbers of edge measurements are unequal may also be considered. We may also explore the application of our approach to real-world measurements. Finally, a theoretical evaluation of the mismatch between the likelihood function and the noise distribution would be an insightful endeavor.
Acknowledgments
We thank Vaibhav Choudhary and Nikhil Gopalkrishnan for informative discussions.
References
- [1] Leo Liberti and Carlile Lavor “The Distance Geometry Problem” In Euclidean Distance Geometry: An Introduction Cham: Springer International Publishing, 2017, pp. 9–18 DOI: 10.1007/978-3-319-60792-4˙2
- [2] Zachary Voller and Zhijun Wu “Distance Geometry Methods for Protein Structure Determination” In Distance Geometry: Theory, Methods, and Applications New York, NY: Springer, 2013, pp. 139–159 DOI: 10.1007/978-1-4614-5128-0˙8
- [3] G.. Crippen and Timothy F. Havel “Distance Geometry and Molecular Conformation” Research Studies Press, 1988 GOOGLEBOOKS: 5CPwAAAAMAAJ
- [4] T. Eren et al. “Rigidity, Computation, and Randomization in Network Localization” In IEEE INFOCOM 4, 2004, pp. 2673–2684 DOI: 10.1109/INFCOM.2004.1354686
- [5] T.. Havel “An Evaluation of Computational Strategies for Use in the Determination of Protein Structure from Distance Constraints Obtained by Nuclear Magnetic Resonance” In Prog. Biophys. Mol. Biol. 56.1, 1991, pp. 43–78 DOI: 10.1016/0079-6107(91)90007-F
- [6] Leo Liberti and Carlile Lavor “Open Research Areas in Distance Geometry” In Open Problems in Optimization and Data Analysis Springer, 2018, pp. 183–223
- [7] Carlile Lavor, Leo Liberti and Nelson Maculan “An Overview of Distinct Approaches for the Molecular Distance Geometry Problem” In Encyclopedia of Optimization Boston, MA: Springer US, 2009, pp. 2304–2311 DOI: 10.1007/978-0-387-74759-0˙400
- [8] Bruce Hendrickson “The Molecule Problem: Exploiting Structure in Global Optimization” In SIAM J. Optim. 5.4 Society for Industrial and Applied Mathematics, 1995, pp. 835–857 DOI: 10.1137/0805040
- [9] Jorge J. Moré and Zhijun Wu “Global Continuation for Distance Geometry Problems” In SIAM J. Optim. 7.3 Society for Industrial and Applied Mathematics, 1997, pp. 814–836 DOI: 10.1137/S1052623495283024
- [10] Michael Souza, Adilson Elias Xavier, Carlile Lavor and Nelson Maculan “Hyperbolic Smoothing and Penalty Techniques Applied to Molecular Structure Determination” In Operations Research Letters 39.6, 2011, pp. 461–465 DOI: 10.1016/j.orl.2011.07.007
- [11] Michael Souza, Carlile Lavor, Albert Muritiba and Nelson Maculan “Solving the Molecular Distance Geometry Problem with Inaccurate Distance Data” In BMC Bioinform. 14, 2013, pp. S7 DOI: 10.1186/1471-2105-14-S9-S7
- [12] Xin-Long Luo and Zhi-Jun Wu “Least-Squares Approximations in Geometric Buildup for Solving Distance Geometry Problems” In J. Optim. Theory Appl. 149.3, 2011, pp. 580–598 DOI: 10.1007/s10957-011-9806-6
- [13] Nikhil Gopalkrishnan, Sukanya Punthambaker, Thomas E Schaus, George M Church and Peng Yin “A DNA nanoscope that identifies and precisely localizes over a hundred unique molecular features with nanometer accuracy” In bioRxiv, 2020
- [14] Matthew Giamou et al. “Convex Iteration for Distance-Geometric Inverse Kinematics” In IEEE Robot. Autom. Lett. 7.2, 2022, pp. 1952–1959 DOI: 10.1109/LRA.2022.3141763
- [15] Peter H. Schönemann “A Generalized Solution of the Orthogonal Procrustes Problem” In Psychometrika 31.1, 1996, pp. 1–10 DOI: 10.1007/BF02289451
- [16] “Quasi-Newton Methods” In Numerical Optimization, Springer Series in Operations Research and Financial Engineering New York, NY: Springer, 2006, pp. 135–163 DOI: 10.1007/978-0-387-40065-5˙6
- [17] Adam Paszke et al. “Pytorch: An imperative style, high-performance deep learning library” In Advances in Neural Information Processing Systems 32, 2019