Mixed-integer linear programming for computing optimal experimental designs
Abstract
The problem of computing an exact experimental design that is optimal for the least-squares estimation of the parameters of a regression model is considered. We show that this problem can be solved via mixed-integer linear programming (MILP) for a wide class of optimality criteria, including the criteria of A-, I-, G- and MV-optimality. This approach improves upon the current state-of-the-art mathematical programming formulation, which uses mixed-integer second-order cone programming. The key idea underlying the MILP formulation is McCormick relaxation, which critically depends on finite interval bounds for the elements of the covariance matrix of the least-squares estimator corresponding to an optimal exact design. We provide both analytic and algorithmic methods for constructing these bounds. We also demonstrate the unique advantages of the MILP approach, such as the possibility of incorporating multiple design constraints into the optimization problem, including constraints on the variances and covariances of the least-squares estimator.
keywords:
Optimal design , Exact design , Mixed-integer linear programming , A-optimality , G-optimality[label1]organization=Comenius University Bratislava, city=Bratislava, country=Slovakia
1 Introduction
The optimal design of experiments is an important part of theoretical and applied statistics (e.g., Fedorov (1972), Pázman (1986), Pukelsheim (1993), Atkinson et al. (2007), Goos and Jones (2011)) that overlaps with various areas of general optimization (Vandenberghe and Boyd (1999), Ghosh et al. (2008), Todd (2016), and others). From the statistical perspective, the typical problem in optimal experimental design is the selection of trials to maximize the information obtained about the parameters of an underlying model.
In this research, we focus on optimal exact designs, which are technically solutions to a special class of discrete optimization problems; in contrast, approximate designs are continuous relaxations of exact designs. Precise formulations of both design classes are provided in Section 1.2. In the remainder of this paper, we use the term “design” specifically to refer to an exact design.
Analytical forms of optimal designs are difficult to derive; they have only been found for some special cases (e.g., Gaffke (1986), Neubauer et al. (2000), Bailey (2007)). Therefore, much attention is given to numerical computations. There are two general classes of algorithms for solving optimal design problems: heuristics and enumeration methods.
Heuristics aim to rapidly generate a reasonably efficient design but often fail to converge to an optimal one. Some of the most popular heuristics include various exchange methods (see, e.g., Chapter 12 in Atkinson et al. (2007) for a review of classical algorithms or Huang et al. (2019) for more recent developments) and methods inspired by physics or the natural world (Haines (1987), Lin et al. (2015), Chen et al. (2022) and others). Another approach is based on a quadratic approximation of the criterion (Harman and Filová (2014), Filová and Harman (2020)).
A separate approach consists of first computing optimal approximate designs and subsequently rounding them. The advantage of this approach is that the optimal approximate design problem is continuous and typically convex. From the perspective of mathematical programming, this means that this problem can be handled through various powerful methods of convex optimization, such as general convex programming (e.g., Wong and Zhou (2019), Wong and Zhou (2023)), semidefinite programming (e.g., Vandenberghe and Boyd (1999)), second-order cone programming (Sagnol (2011), Sagnol and Harman (2015)) and linear programming (e.g., Harman and Jurík (2008)). The disadvantage is that for practical applications, the resulting optimal approximate designs need to be converted into exact designs via a rounding procedure (e.g., Pukelsheim and Rieder (1992)), which often leads to a suboptimal exact design. That is, the two-step approach—first computing optimal approximate designs and then rounding them to exact designs—can also be considered a heuristic.
Compared to heuristics, enumeration methods are typically slower, but they ultimately find optimal designs with a proof of optimality. Enumeration methods include algorithms for solving integer programs because optimal design problems are, trivially, special instances of a general integer program. As such, very small optimal design problems can be solved through the complete enumeration of all permissible designs (e.g., Haines and Clark (2014)), but a more economical integer or mixed-integer programming method is usually needed, such as branch and bound (e.g., Welch (1982), Duarte et al. (2020), Ahipasaoglu (2021)). For problems that are shown to have a special structure, specialized and, thus, typically better-performing solvers can be employed. In particular, a mixed-integer second-order cone programming (MISOCP) formulation of the optimal design problem for the most popular design criteria presented by Sagnol and Harman (2015) permits the use of efficient branch and cut algorithms.
In this paper, we show that a large class of optimal design problems can be solved by means of an even more specialized mixed-integer linear programming (MILP) approach. More precisely, we show that the classical exact optimal design problem can be expressed as an MILP problem for a rich class of minimax optimality criteria, including the fundamental criteria of -, -, - and -optimality.
This result is theoretically important, but it also has practical advantages. Most obviously, in contrast to MISOCP solvers, MILP solvers are more readily available. Moreover, our MILP formulation allows one to introduce additional constraints on the designs corresponding to practical requirements—these could be not only linear constraints on the experimental resources, but also limits on the variances and covariances of the least-squares estimator (more details are provided in Section 4). In contrast, heuristics cannot handle such additional design constraints (with some exceptions; see, e.g., Harman et al. (2016)), and even the existing enumeration methods (such as those of Ahipasaoglu (2021) and Sagnol and Harman (2015)) typically do not directly allow such a wide range of constraints (and it would be nontrivial to modify them to do so). Another advantage of the MILP formulation is that it covers criteria such as -optimality, for which an MISOCP formulation is currently unavailable.
Integer linear programming (ILP) and MILP have already been used in the field of experimental design for various purposes, albeit in a substantially different way than the one proposed in this paper. For instance, ILP has been used for the classification of orthogonal arrays and for the generation of minimum-size orthogonal fractional factorial designs (e.g., Bulutoglu and Margot (2008), Fontana (2013)), and MILP has been used for optimal arrangements of orthogonal designs (e.g., Sartono et al. (2015a), Sartono et al. (2015b), Vo-Thanh et al. (2018)). However, the above applications utilize specific (linear) characteristics of the studied models or of the studied classes of designs, whereas we provide an MILP formulation for arbitrary models, i.e., for problems that are not inherently linear (although we utilize certain indirect linear aspects of the considered optimality criteria, as detailed in Section 1.2).
The key idea underlying our formulation is McCormick relaxation (McCormick (1976)), which critically depends on finite interval bounds for all elements of a certain matrix. In the context of the optimal design of experiments, this matrix is the covariance matrix of the least-squares estimator of the model parameters under the optimal design; for brevity, we call such constraints covariance bounds. It would be trivial to construct covariance bounds for the MILP problem provided that we knew the optimal design. However, the optimal design is the final aim of the MILP computation itself; therefore, it is not known beforehand. The situation is also complicated by the fact that the covariance matrix depends on the experimental design in a nonlinear way. Therefore, the construction of covariance bounds is a major challenge in the application of the MILP approach, and we provide both analytical and numerical constructions of such bounds.
MILP formulations based on McCormick relaxation were recently proposed by Bhela et al. (2019) in the network topology context and, independently, by Okasaki et al. (2023) in the context of -optimal Bayesian sampling designs. Bhela et al. (2019) sought an optimal placement of edges in a graph so as to minimize a given function of the eigenvalues of the (weighted) Laplacian. This problem corresponds to -optimality in a specific statistical model (for more details on the connection between optimal designs and optimizing graph Laplacians, see Cheng (1981) and Bailey and Cameron (2009)). Thus, the problems addressed by Bhela et al. (2019) and Okasaki et al. (2023) can mathematically be viewed as special instances of the optimal design problem. In this paper, we extend their approaches to general problems of experimental design and to a broad class of minimax criteria. Importantly, to this end, we provide the covariance bounds for such general problems.
In the remainder of this section, we introduce the notation used in this paper and discuss the optimal design problem in more detail. In Section 2, we derive the MILP formulation, and in Section 3, we provide covariance bounds that can be used for this formulation. Various extensions are discussed in Section 4. The proposed formulation is applied in multiple experimental settings and compared with the MISOCP approach in Section 5. Finally, Section 6 presents a short discussion.
1.1 Notation
Throughout the paper, we use the following standard mathematical notation: is the identity matrix; is the matrix of zeros; is the all-ones vector; and is the vector of zeros. Indices are suppressed where they are evident. The symbol denotes the -th elementary unit vector (i.e., its -th element is one, and all other elements are zero); is the set of all real vectors; and , and are the sets of all symmetric, (symmetric) nonnegative definite and (symmetric) positive definite matrices, respectively. For , denotes the maximum eigenvalue, is the trace, is the square-root matrix, and if is nonsingular, denotes the inverse of . For any matrix , we denote its transpose by and its Moore–Penrose pseudoinverse by ; is the column space (the range) of . The notation represents the element of with coordinates . The symbol denotes the Euclidean norm of a vector or the Frobenius norm of a matrix. The symbol represents the set of all nonnegative integers, and is an abbreviated form of the set .
1.2 Optimal designs
For clarity, we explain the main message of this paper in the context of the standard optimal experimental design on a finite design space . That is, suppose that under the -th experimental conditions (“at design point ”), the real-valued observation satisfies the regression model , where is the vector of unknown parameters and the , , are known vectors, sometimes called regressors. An actual experiment then consists of trials performed at design points selected from . We assume that , , and that the observations from distinct trials are uncorrelated. The assumption can be made without loss of generality and is therefore commonly adopted in the optimal design of experiments. In Section 4, we show that our results can be easily extended to more general settings, such as nonlinear models, continuous design spaces and diverse design constraints. We note, however, that they do not extend to the case of correlated observations because for such problems, the information matrix does not have a desirable (additive) form.
We also initially restrict ourselves to binary (i.e., replication-free) exact designs, as the corresponding optimal design problems naturally lend themselves to our MILP reformulation. Optimal binary designs are of interest by themselves (see, e.g., Rasch et al. (1997)); however, we show in Section 4 that our results also extend to exact designs with replications. A binary design of size on is a selection of distinct elements of . This can be formalized by representing a binary design as a vector such that , where denotes the number of trials at design point . The set of all such designs is denoted by . In contrast, a general design satisfies such that . As we focus on binary designs in our presentation, by a “design” we mean a binary design.
The amount of information provided by a design is measured by its information matrix , which, if nonsingular, is the inverse of the covariance matrix of the least-squares estimator of . Moreover, if the errors are normal, is exactly the Fisher information matrix for . We also suppose that and that the linear span of is the full , which guarantees that there exists at least one with a nonsingular information matrix.
In some of our results, approximate designs will also play a minor role. Instead of integer numbers of trials, such designs represent the proportions of trials at individual design points for . An approximate design for a model , , can be formally represented by a vector such that for all and . The information matrix of is then . We will always use the qualifier “approximate” when referring to an approximate design.
The “loss” associated with an information matrix is measured by a so-called optimality criterion , selected in accordance with the aim of the experiment; in our case, the optimality criterion is formally a function mapping from to . A -optimal design then minimizes over all designs of size with a nonsingular information matrix . Examples include -optimality, for which ; -optimality, for which ; -optimality,111-optimality is sometimes also called -optimality or -optimality because it can be interpreted as an integrated prediction variance. for which ; -optimality, for which ; -optimality, for which ; -optimality, for which ; and -optimality, for which for a selected . For statistical interpretations of these criteria, see, e.g., Chapter 10 in Atkinson et al. (2007) and Chapter 5 in Pronzato and Pázman (2013).
In this paper, we focus on a broad class of criteria, which we now define. For , let be a given matrix. We use to denote the sequence and to denote the matrix . We assume that and that no column of is equal to . We consider the following criterion:
which belongs to the family of minimax criteria discussed by Wong (1992). The expression represents the variance matrix of the least-squares estimator of , which implies that seeks to minimize the maximum of the -optimality criterion values over all linear parameter systems , . Clearly, all the s are estimable under a design if and only if is nonsingular. As special cases of , we can obtain the criteria of -optimality (, ), -optimality222The -optimal design can also be found by computing the -optimal design for a transformed model (see, e.g., Appendix A.3 in Sagnol and Harman (2015)). In particular, the -optimal design for a model with regressors , , where , is -optimal for the original model. However, in this paper, we consider -optimality as a standalone criterion. Note that so-called weighted -optimality ( for given positive weights ) also belongs to the class and it can be addressed in a similar manner. (, ), -optimality (, for ), and -optimality (, for ).
criteria are crucial for our MILP formulation, as they involve terms that are linear in the covariance matrix of the least-squares estimator . We explicitly reformulate these criteria in terms of the covariance matrix as , where , which can be extended to the entire linear space by simply setting for any . This reformulation allows for an optimal design problem formulation that is linear in the covariance matrix . However, this is not sufficient to make the problem linear: it merely moves the nonlinearity from the objective function to the constraints of the optimization problem because of the nonlinear relationship . Nevertheless, by applying McCormick relaxation, we can address the newly introduced nonlinearity in the constraints, thus ultimately arriving at a linear program, as detailed in Section 2. This also explains why our approach cannot be extended to -optimality: the problem of -optimal design apparently cannot be recast to involve only the aforementioned specific type of nonlinearity.
In the remainder of this paper, we denote the elements of a covariance matrix by and the elements of a -optimal covariance matrix by .
2 MILP formulation
The problem of -optimal design described in the previous section can be formulated as
Note that we assume that the set of feasible solutions is nonempty. Clearly, this problem can be rewritten in the following form:
| (1) | ||||
Since the objective function in (1) is the maximum of linear functions of , the only nonlinear part of problem (1) is . However, this condition can be reformulated using the relaxation method proposed by McCormick (1976), analogously to Bhela et al. (2019). The trick, and the key difficulty, lies in finding a priori bounds and for each element of any optimal :
| (2) |
and then constructing new variables
| (3) |
The condition can then be expressed as a set of linear equations for the s by applying the substitution . This condition is linear in the -dimensional real vector composed of all variables , and we can express it as for an appropriately chosen and .333It does not seem that there is a simple formula for and as a function of the elements of ; see Appendix A for the detailed formulation of .
However, in this process, the nonlinear conditions are introduced. Note that without altering the set of optimal solutions, we can add the following inequalities:
which can be expressed using the variables as
| (4) | |||
| (5) | |||
| (6) | |||
| (7) |
for all and . These inequalities hold for any optimal and because and ; thus, they can be added to (1). Interestingly, by adding the linear conditions expressed in (4)-(7), one can actually replace the nonlinear conditions (3) in (1) (as observed by Bhela et al. (2019) in the network topology context): because of the binary nature of , conditions (4)-(7) imply (3). In particular, if , then (4) and (6) imply that , and if , then (5) and (7) imply that . In each case, , and thus, (3) is unnecessary.
Therefore, we obtain an equivalent444In the sense of having the same set of optimal solutions . formulation of (1):
| (8) | ||||
where all the constraints are linear in the variables . This is then equivalent to
| (9) | ||||
where even the objective function is linear. Since all the constraints in (9) are linear or binary,555Recall that is a set of binary vectors subject to a linear constraint . problem (9) is a mixed-integer linear program. Therefore, we have expressed the -optimal binary design problem in the form of an MILP problem. As special cases, we can obtain the MILP formulations for -, -, - and -optimal binary design by choosing the corresponding optimality criteria . In Appendix A, we provide a precise formulation of (9) in vector form, which can therefore be used as input for MILP solvers. Nonetheless, to use the reformulation (9), we still need to determine the coefficients and , which appear in constraints (4)-(7).
3 Covariance bounds
The MILP formulation (9) requires interval bounds (2) on the elements of , which we call covariance bounds. The construction of such bounds is a rich problem, interesting not only for the computation of optimal designs but also in and of itself as a potentially useful characteristic of an experimental design problem. In this section, we describe selected strategies for constructing such interval bounds.
3.1 General -optimality
Our construction of the covariance bounds relies on knowledge of a design that has a nonsingular information matrix. Therefore, let have a nonsingular information matrix , and let . The more -efficient is, the stronger are the bounds we obtain; thus, in applications, we recommend computing via a -optimization heuristic (e.g., some exchange algorithm; see Chapter 12 in Atkinson et al. (2007)).
Let . Clearly, , that is,
| (10) |
We will show that the constraints (10) are sufficient to provide finite bounds on all the elements of .
3.1.1 Computational construction
Recall the notation for . A direct approach to finding the covariance bounds is a computational one: apply mathematical programming to find the smallest/largest value of over all matrices that satisfy (10). Then, must be bounded by these values. Formally, for any ,
| (11) | |||||
| (12) | |||||
Optimization problems (11) and (12) are (continuous, not discrete) semidefinite programming (SDP) problems; that is, they are easy to solve using readily available and efficient SDP solvers. Moreover, the above bounds are, by definition, the strongest ones that can be constructed using only the inequalities (10).
In the case of the lower diagonal bounds, problem (12) can be analytically solved to arrive at the simple bound . This is because for any , and the objective function value is attained for the feasible solution . On the other hand, the upper bounds on the diagonal elements of as well as the lower and upper bounds on the nondiagonal elements of generally depend on the optimality criterion and the value of .
To find bounds for the entire , a distinct pair of problems (11) and (12) must be solved for each . This therefore requires solving semidefinite programs666More precisely, programs, because the lower diagonal bounds have analytical solutions., which in some cases may be inconvenient. In addition, the finiteness of the optimal values of (11) and (12) is not immediately apparent; however, these values must be finite to be of any utility. We therefore also provide analytical bounds on the s that guarantee the finiteness of (11) and (12) (see Theorem 3) and do not require the numerical solution of auxiliary optimization problems.
3.1.2 Analytical construction
First, we provide two simple constructions of the bounds on the nondiagonal covariances based on the bounds on the variances . Because is positive semidefinite, Sylvester’s criterion for positive semidefinite matrices implies that and , i.e.,
| (13) |
Furthermore, the inequality of the geometric and arithmetic means provides weaker but linear bounds, which can also be useful:
| (14) |
Therefore, to find both lower and upper bounds on the s for all , we need only to construct finite upper bounds on the variances for all or on the sums for all .
The key mathematical result for the analytical bounds is the following lemma. The proof of Lemma 1 and all other nontrivial proofs are deferred to Appendix B.
Lemma 1
Let be any nonnegative definite matrix such that for all . Let be a vector with nonnegative components summing to , and let . Assume that is an matrix such that . Then,
| (15) |
Because for all , we can use Lemma 1 with various choices for and to obtain bounds on the elements of . Let , . Among the large variety of possibilities, we will use only the matrices , which directly provide bounds on , and , which provide bounds on due to inequality (14). For such , any that satisfies , , and can be used.
It is then of interest to examine choices for . Interestingly, such a vector can be viewed as an approximate design for the artificial model , with -dimensional observations , design space and elementary information matrices . The corresponding information matrix of is then , which is exactly . Therefore, we refer to such vectors as (approximate) designs. In particular, we consider the following choices:
-
1.
The uniform design ; note that .
-
2.
The design with components for all , where are vectors of dimensions such that
and . We call the Moore–Penrose approximate design for for the artificial model.
-
3.
The design that minimizes in the class of all approximate designs (i.e., , ) satisfying . We call the -optimal approximate design for the artificial model.
-
4.
and .
The uniform design is the most straightforward choice. A more refined choice is the Moore–Penrose approximate design, which accounts for the desirability of having a “small” matrix . The -optimal approximate design actually optimizes the right-hand side of (15) for to make it as small as possible; such designs are theoretically interesting but not necessarily practically desirable. Finally, the designs and are constructed such that satisfies . Note that although we use approximate designs as an auxiliary tool for computing covariance bounds, optimal approximate designs are needed only for the computation of and .
Lemma 2
Let . The column space of each of the matrices , , and contains . Let , . The column space of each of the matrices , , and contains the column space of the matrix .
According to Lemma 2, for , we can use Lemma 1 with , , and and with and apply bound (13) to obtain the following theorem:
Theorem 1 (Type I covariance bounds)
For any , we have
| (16) | |||||
| (17) | |||||
| (18) |
where and represent the elements of matrices and with coordinates , respectively.
Similarly, for , , we can use Lemma 1 with , , , and and apply bound (14). We thus obtain the following theorem.
Theorem 2 (Type II covariance bounds)
For any , , we have
| (19) | |||||
| (20) | |||||
| (21) |
The bounds provided by the above theorems can be computed analytically or by means of standard numerical linear algebra and relatively simple optimization. They also guarantee the finiteness of the SDP-based bounds (e.g., using (16) and (19)):
Theorem 3 (Finiteness of the SDP-based bounds)
3.2 -, -, -, and -optimality
As shown in Section 3.1.1, we have for . We therefore further examine only the remaining bounds. Table 1 provides an overview of the results for -, -, -, and -optimality, and the following subsections give detailed explanations of these bounds.
| diagonal: | nondiagonal: | |||
| computational | analytical | computational | analytical | |
| Section 3.2.4 | Section 3.2.4 | |||
3.2.1 -optimality
For -optimality (, ), , and , bounds (16)-(18) and (19)-(21) reduce to
| (22) | |||||
| (23) |
By solving the SDP formulations (11) and (12), we again obtain only (22) and (23); for the diagonal elements, we have already proven that , so it is sufficient to find a with and . These conditions are satisfied for . For the nondiagonal elements, the maximum is attained for , and the minimum is attained for .
3.2.2 -optimality
3.2.3 -optimality
3.2.4 -optimality
For -optimality (, , , ), the situation becomes more complex and more interesting. Let .777It may be efficient to compute via a heuristic for -optimality, as these algorithms are typically faster and more readily available than those for -optimality. We note that - and -optimal designs tend to be close because they coincide in approximate design theory. Note that for -optimality, the primary (original) and the artificial models coincide; thus, the auxiliary approximate design on is in fact the approximate design on the original design space , and is exactly the standard information matrix of an approximate design . Then,
- 1.
- 2.
- 3.
3.3 Further improvements
Let . A general strategy for the construction of interval bounds for the optimal is as follows. First, find appropriate matrices and numbers for , where is an index set, such that we can be sure that satisfies the constraints
| (27) |
Second, construct and such that contains the values for any satisfying (27). In Section 3.1, we applied this strategy with , , and . However, constraints of the type (27) can be added to those from Section 3.1 to obtain better theoretical covariance bounds. They can also be added to the SDP formulations (11) and (12) to algorithmically provide better bounds.
For instance, a stronger lower bound for , , can be found by computing the -optimal approximate design for the primary model, i.e., by minimizing under the constraint , where ( for all and ) is an approximate design for the original model. Let be the minimal value of . Clearly, for any with a nonsingular information matrix, we then have . It follows that , which is always stronger than our standard bound . However, unlike , obtaining these bounds requires solving -optimal approximate design problems by means of, e.g., linear programming (Harman and Jurík (2008)). A similar approach can be applied to the nondiagonal elements. Nevertheless, we have decided not to explore these possibilities in this paper and instead leave them for further research.
4 Extensions
In this section, we provide guidelines for more complex optimal design problems that can be solved in a straightforward way via the proposed MILP approach.
4.1 Designs with replications
If we have a -optimal design problem in which we allow for up to replicated observations at the design point , an MILP formulation can be obtained by replicating the regressor exactly times and then using (9). Setting for each allows us to compute optimal designs for the classical problem, i.e., with a single constraint representing the total number of replications at all design points combined, which is demonstrated in Section 5.1.
4.2 Multiple design constraints
In some applications, we need to restrict the set of permissible designs to a set smaller than . Such additional constraints on can correspond to safety, logistical or resource restrictions. Many such constraints are linear (see, e.g., Harman (2014), Sagnol and Harman (2015) and Harman et al. (2016) for examples), and they can be directly included in (9). Another class of linear constraints corresponds to the problem of optimal design augmentation, which entails finding an optimal design when specified trials must be performed or have already been performed (see Chapter 19 in Atkinson et al. (2007)). Constraints of this kind can also be incorporated into the MILP formulation in a straightforward way (, where is the number of trials already performed at point ), but a design satisfying the required constraints must be used to construct the covariance bounds. However, the practical nature of the constraints usually allows for simple selection of such an initial . MILP with additional design constraints is used in Section 5.1 to obtain a “space-filling” optimal design and in Section 5.2 to find a cost-constrained optimal design (see Sections 5.1 and 5.2 for the formal definitions of such designs).
4.3 Optimal designs under covariance constraints
A unique feature of the proposed approach is that we can add to (9) any linear constraints on the elements of the variance matrix , and the resulting problem will still be a mixed-integer linear program, whereas the available heuristics for computing optimal designs do not allow for such variance–covariance constraints. For instance, we can specify that the absolute values of all covariances should be less than a selected threshold ( for ), with the aim of finding a design that is optimal among those that are “close” to orthogonal (or even exactly orthogonal). Similarly, we can add the condition that the sum of all variances of the least-squares estimators should be less than some number (), with the aim of, e.g., finding the -optimal design among all designs that attain at most a given value of -optimality. More generally, we can compute a -optimal design that attains at most a selected value of a different criterion from the same class.
As in Section 4.2, a design that satisfies the required constraints must be used to construct the covariance bounds—which may not be easy to find for constraints such as . Fortunately, one class of constraints has such designs readily available: those that require the design to attain a certain value of a different optimality criterion from the class. For instance, we can find the -optimal design among all the designs that satisfy (i.e., : a limit on the value of -optimality). Here, can be chosen as either the -optimal design or a design obtained via a heuristic for -optimality. Such then allows for any such that , which captures all reasonable choices for .888A lower would mean that we seek a design that is better with respect to -optimality than either the -optimal design itself or some best known design. The applicability of this approach is also demonstrated in Section 5.1.
4.4 Infinite design spaces
We focus on finite design spaces because integer programming approaches are unsuitable for continuous design spaces (as there would be an infinite number of variables in the latter case). Finiteness of the design set is common in both experimental design and related disciplines (e.g., Mitchell (1974), Atkinson and Donev (1996), Ghosh et al. (2008), Bailey and Cameron (2009), Todd (2016)). Moreover, even if the theoretical design space is infinite, it can be discretized, which is a typical technique in design algorithms (e.g., Fedorov (1989), Meyer and Nachtsheim (1995)). This often results in only a negligible loss in the efficiency of the achievable design. Although some heuristics can handle continuous design spaces directly, they are still only heuristics and, as such, risk providing a design that is worse than one obtained by applying a discrete optimizer to a discretized design space (cf. Harman et al. (2021)).
4.5 Nonlinear models
Because our results rely on the additive form of the information matrix, they can be straightforwardly extended to the usual generalizations by simply adapting the formula for the information matrix. For a nonlinear regression with Gaussian errors, the usual local optimality method can be used (see, e.g., Pronzato and Pázman (2013), Chapter 5), resulting in the information matrix
where is a nominal parameter that is assumed to be close to the true value of . This approach is demonstrated in Section 5.2. Generalized linear models can be dealt with in a similar manner; see Khuri et al. (2006) and Atkinson and Woods (2015). In other words, if we use the so-called approach of locally optimal design for nonlinear models, the computational methods are equivalent to those of standard optimal design for linear models.
5 Numerical study
All computations reported in this section were performed on a personal computer with the 64-bit Windows 10 operating system and an Intel i5-6400 processor with 8 GB of RAM. Our algorithm was implemented in the statistical software R, the mixed-integer linear programs were solved using the R implementation of the Gurobi software (Gurobi Optimization, LLC (2023)), and the MISOCP computations of the optimal designs were performed using the OptimalDesign package (Harman and Filová (2019)), ultimately also calling the Gurobi solver. The SDP-based bounds (11) and (12) were solved for via convex programming using the CVXR package (Fu et al. (2020)). The R codes for applying our MILP approach are available at http://www.iam.fmph.uniba.sk/ospm/Harman/design/, and the authors also plan to implement the MILP algorithm in the OptimalDesign package to make it available in a more user-friendly manner.
Naturally, all the reported running times of the MILP approach include the time it took to compute the relevant bounds via the SDP formulations (11) and (12) or via the analytical formulas in Section 3.1.2. We also note that in all the following applications of our MILP formulation, we used the analytical bounds (22), (23) and (26) for - and -optimality because they are equivalent to the SDP bounds (11) and (12) but less time consuming to compute. For - and -optimality, we considered both approaches, and we selected the one that tended to result in faster computation of the entire MILP algorithm: the SDP bounds for -optimality and the analytical bounds for -optimality. Note that although the SDP bounds for -optimality tend to result in shorter total computation times for larger models, the analytical version enabled overall faster MILP computations for the models considered in this paper. The initial designs in the case of -optimality were computed using the KL exchange algorithm (see Chapter 12 of Atkinson et al. (2007)) for -optimality; for all other criteria, the KL exchange algorithm for -optimality was used.
5.1 Quadratic regression
Let us demonstrate the MILP algorithm on the quadratic regression model
| (28) |
where the values lie in the domain equidistantly discretized to points, i.e., . The exact optimal designs for model (28) have been extensively studied in the past (e.g., Gaffke and Krafft (1982), Chang and Yeh (1998), Imhof (2000), Imhof (2014)), but for some criteria, sample sizes and design spaces, there are still no known analytical solutions.
To illustrate the MILP computational approach, we select design points and observations, and we compute the -, -, - and -optimal designs. The running times of these computations are given in the first row of Table 2, and the resulting designs are illustrated in Figure 1 (left). The running times show that the optimal design calculations using MILP strongly depend on the selected optimality criterion.
| Criterion | A | I | MV | G |
| Binary | 3.99 (0.26) | 11.75 (1.18) | 2.59 (0.33) | 36.62 (0.90) |
| Replicated | 74.98 (2.67) | 214.57 (13.66) | 64.44 (4.00) | 487.56 (61.59) |
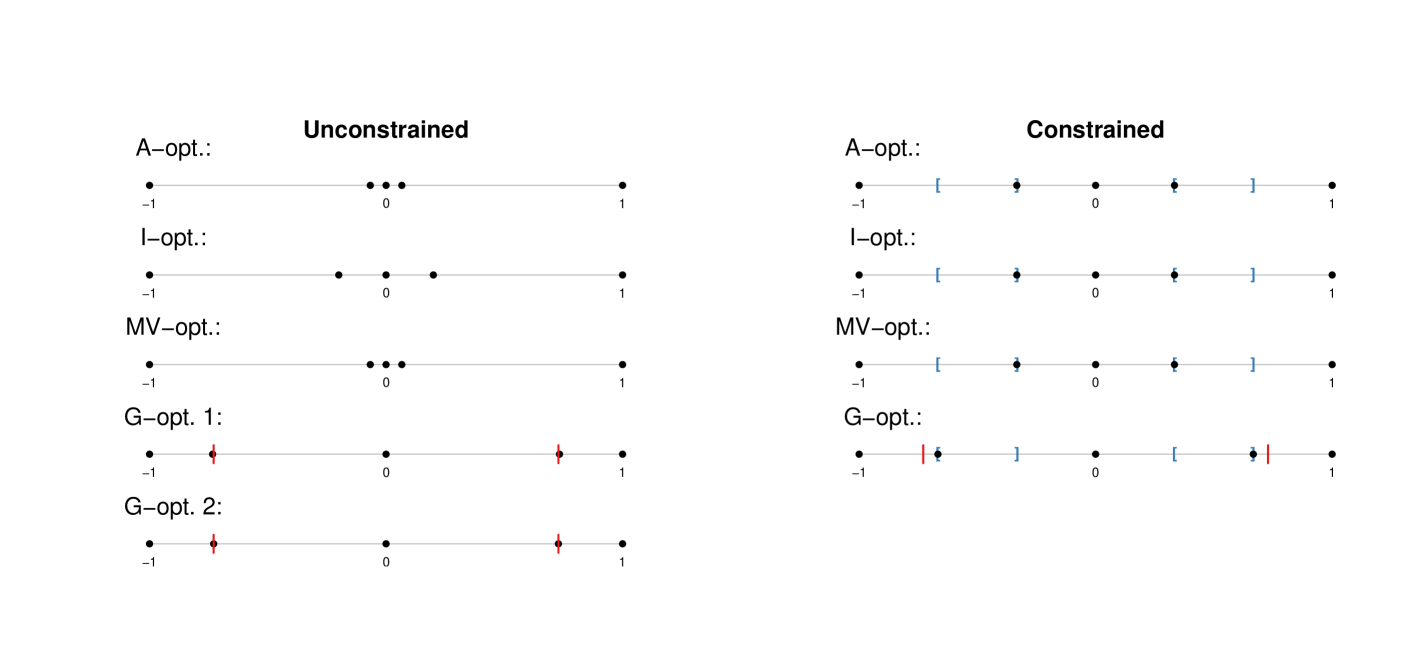
The above results can be used to support a conjecture presented by Imhof (2014), who stated that a -optimal design for quadratic regression on the (continuous, not discretized) domain should satisfy Theorem 1 of Imhof (2014) even for , although he did not prove this conjecture. That is, such a design should specify one trial to be performed at each of the points , where is the solution to . By plotting the corresponding value (Figure 1), we see that the -optimal design indeed satisfies Theorem 1 of Imhof (2014) (up to the considered discretization). If we add the points to the set of permissible s, then the -optimal design on the discrete set selects these points and thus exactly corresponds to the -optimal design hypothesized by Imhof (2014); see the design labeled “G-opt. 2” in Figure 1 (left).
Design constraints
As mentioned in Sections 4.2 and 4.3, a beneficial property of the MILP formulation is that it can easily accommodate any constraint that is linear in the design values and in the elements of the covariance matrix . For instance, the designs in Figure 1 (left) are focused on the regions around , and , but one can naturally require a design that is more space-filling. In the present model, we formulate this by introducing the additional constraints
| (29) |
These constraints enforce that at least one trial should be performed for between and and also for between and . Such constraints can be included in the linear program, and all the computations can proceed as usual. One exception is that a design that satisfies the constraints (29) must be used to construct the relevant covariance bounds. For this purpose, we used a design that assigns one trial to each of the design points , which satisfies (29). The resulting constrained optimal designs obtained via MILP are depicted in Figure 1 (right).
Covariance constraints
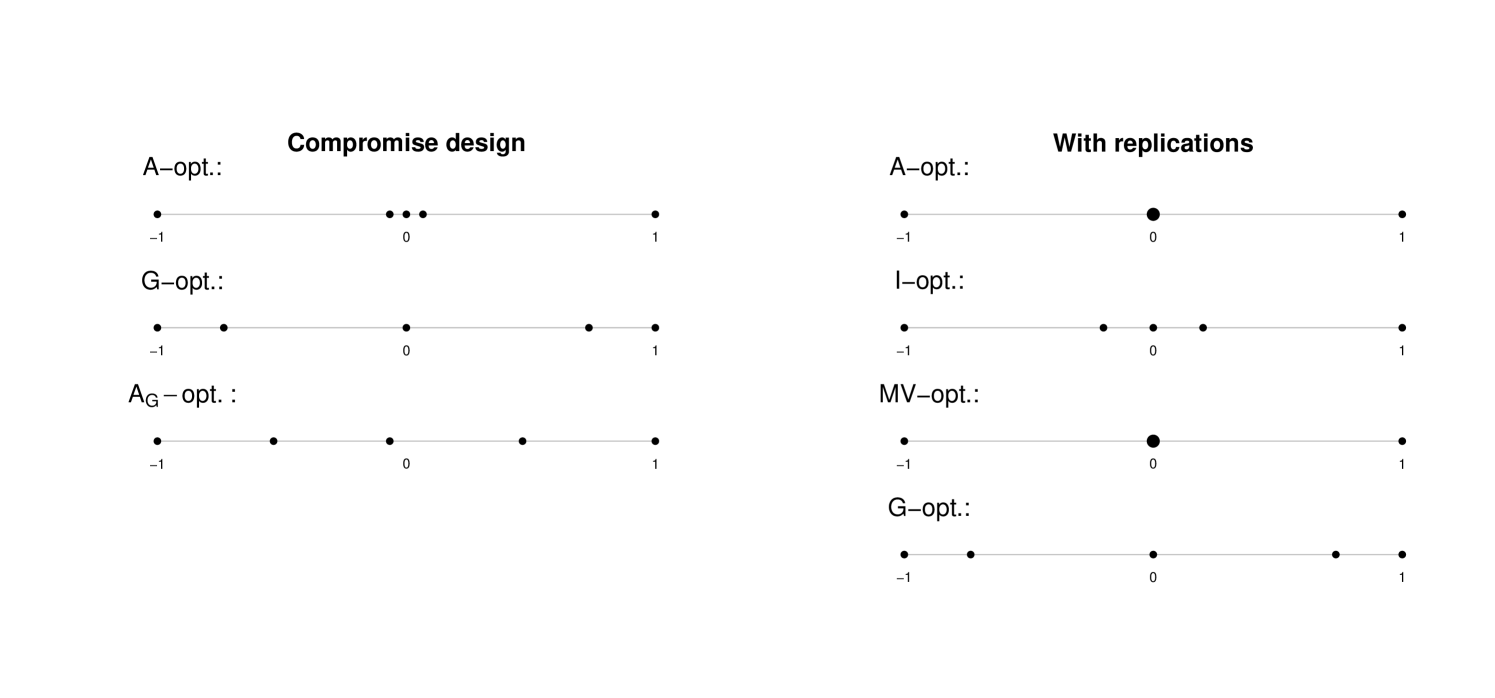
The - and -optimal designs for (28) differ quite significantly, so we might be interested in finding a “compromise” design. This can be achieved by, e.g., finding the -optimal design among all the designs that attain at most a specified value of the -optimality criterion. In particular, we have and , where and are the - and -optimal designs, respectively, and we wish to construct the design that is -optimal among all designs that have (i.e., such designs have a maximum variance of , , of at most 0.9). The constraints are linear in , which means that they can be incorporated into the MILP formulation. To construct the covariance bounds, a design that satisfies must be chosen. As discussed in Section 4.3, a natural choice is the -optimal design, i.e., . The optimal constrained design obtained via MILP is depicted in Figure 2 (left), together with and . This figure illustrates that is indeed a compromise between and .
Replicated observations
All the designs discussed above are binary, i.e., without replications. To allow for any number of replications, we can simply repeat each regressor times and apply the MILP algorithm, as outlined in Section 4.1. The resulting designs for (28) with are illustrated in Figure 2 (right), and the computation times are given in Table 2. In the - and -optimal designs, the design point is replicated three times, while the - and -optimal designs are still binary even when replications are allowed. The observed computation times demonstrate that allowing for replications can result in a significantly increased running time.
5.2 Nonlinear regression
Nonlinear models, continuous design spaces
In this section, we demonstrate the usefulness of the MILP approach for nonlinear models and for infinite design spaces. Consider the following model given by Pronzato and Zhigljavsky (2014) (Problem 10 therein):
| (30) |
localized at , where and follows the Gaussian distribution . Let us seek a -optimal design for trials. Since the design space is continuous, we cannot apply MILP directly. Instead, we first apply the approximate design algorithm GEX proposed by Harman et al. (2021) to find the -optimal approximate design (because - and -optimality coincide in the approximate design case, we use the GEX algorithm for -optimality), and we consider the points that support the -optimal approximate design (i.e., such that ); see Figure 3 (left). We then find the exact design that is -optimal on these nine “candidate” support points using our MILP approach; see Figure 3 (middle). This design is highly efficient among the designs on the entire design space ; for instance, it coincides with the design obtained via the KL exchange algorithm for -optimality applied on a densely discretized version of .

Whereas the GEX algorithm took a few seconds and the subsequent MILP computations required less than one second, the KL exchange algorithm required 10 minutes to arrive at the same design. Consequently, for a model with multiple continuous factors, the direct application of an exchange heuristic would be unfeasible; the current relatively simple model was chosen only so that the efficiency of the proposed approach could be easily demonstrated. Note also that the GEX algorithm works by using a dense discretization of the design space (in particular, we considered a grid of more than 20 million points), but any approximate design algorithm for continuous spaces can be used instead, such as particle swarm optimization (cf. Chen et al. (2022)). In addition, one may employ any nonlinear programming approach for a continuous domain to fine-tune the positions of the support points of the exact design determined by our approach.
Cost constraints
Because the MILP formulation allows for the inclusion of extra constraints, we can consider a cost constraint of the form
| (31) |
where and represent the costs of factors 1 and 2, respectively; is the total budget; and are the nine candidate points, with . We then use the MILP approach to find the design that is -optimal among all the designs supported on the candidate points satisfying (31) with , and . To construct the covariance bounds for the MILP formulation, we select the design in which all 6 trials are assigned to the 6 candidate points that satisfy . The optimal cost-constrained design given by the MILP algorithm is depicted in Figure 3 (right).
5.3 Time complexity
To estimate the typical running time of the MILP computation, we consider an (artificial) “Gaussian” model
| (32) |
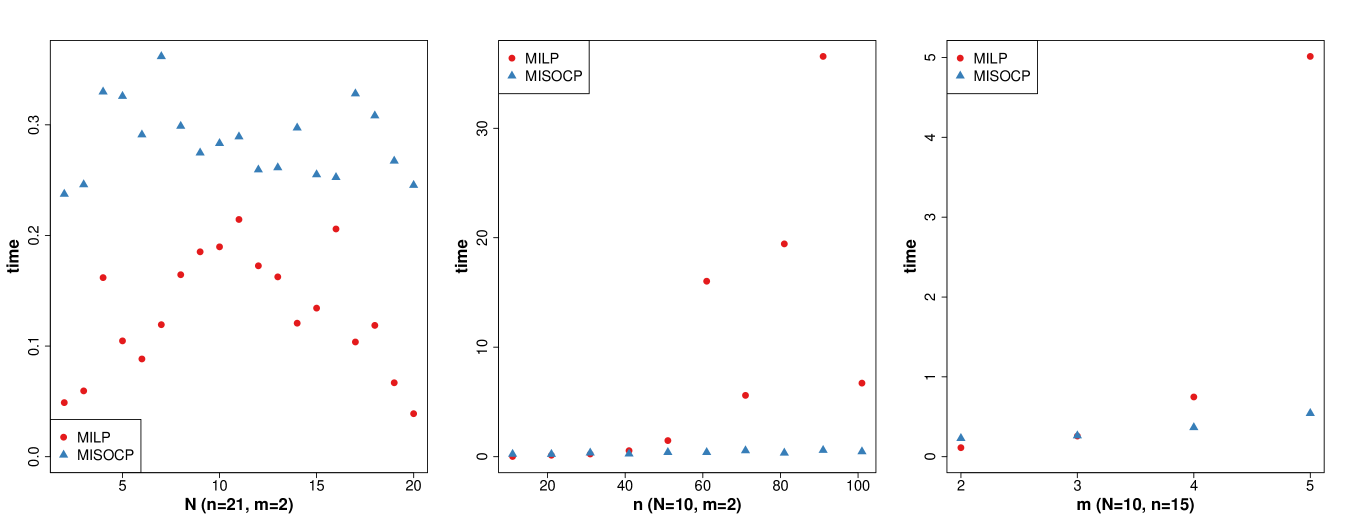
where the vectors are independently generated from the -dimensional standardized Gaussian distribution . Figure 4 shows the mean running times based on 10 runs of MILP computations of the -optimal designs for various values of , and . To compare the MILP approach with its most natural competitor, the mean running times of ten runs of the MISOCP approach proposed by Sagnol and Harman (2015) are also included in this plot. Overall, the MILP algorithm is often faster than the MISOCP algorithm for smaller models, but it tends to fall behind in performance as and increase. Note that the two algorithms always returned designs with the same value of the optimality criterion, so we report only their respective computation times.
We also consider three more realistic models: a basic linear regression model
| (33) |
with design points and parameters; the quadratic regression model (28) with and ; and a factorial main-effects model
| (34) |
with and . We compare the MILP and MISOCP computations of the - and -optimal designs for these models for selected numbers of observations ; the results are reported in Table 3.
| Model | A-opt. | I-opt. | ||
|---|---|---|---|---|
| (33), , , | 0.20 (0.02) | 0.26 (0.02) | 1.05 (0.06) | 0.25 (0.02) |
| (28), , , | 24.31 (2.12) | 0.32 (0.07) | 137.69 (7.17) | 1.07 (0.06) |
| (34), , , | 2.67 (0.30) | 20.49 (0.94) | 2.84 (0.12) | 20.46 (1.17) |
The above examples suggest that the MILP approach is often slower than the MISOCP approach for larger and , but not always. Moreover, even in situations where MILP is currently slower than MISOCP, this may change in the future, e.g., with new developments in MILP solvers (see the Discussion). It should also be noted that the comparisons were performed only for problems with an existing MISOCP formulation. For certain problems that can be solved via our MILP-based approach, such as -optimality problems and problems with covariance or design constraints, we are unaware of available MISOCP implementations; hence, corresponding comparisons were not feasible.
6 Discussion
We have shown that a large class of optimal exact design problems can be formulated as mixed-integer linear programs. Although our implementation of the MILP computation of exact designs is generally comparable to the existing MISOCP approach, there are several important advantages of the MILP approach:
-
1.
The MILP formulation is important from a theoretical perspective—it shows that many optimal design problems can be solved using solvers that are even more specialized than MISOCP solvers, continuing the “increasing specialization” trend of mixed-integer programming mixed-integer second-order cone programming mixed-integer linear programming.
-
2.
We provide an MILP formulation for criteria and design problems for which, to our knowledge, no MISOCP formulation has been published—for example, -optimality and optimal designs under constraints on the (co)variances of the least-squares estimator.
-
3.
MILP solvers are more readily available than MISOCP solvers. For example, there are freely available solvers for MILP (e.g., the package lpSolve) in R, whereas the MISOCP solvers in R all seem to be dependent on commercial software (such as gurobi), although currently with free licenses for academics.
-
4.
It is possible that the MILP algorithm may become a faster means of computing optimal designs than the MISOCP algorithm, with either further developments in MILP solvers, the use of different solvers, the application of particular tricks such as “symmetry breaking”, or perhaps a different MILP formulation. Moreover, in this study, we used only the default settings, as our aim was not to fine-tune the solver for particular problems but rather to examine its expected behavior—as such, it may be possible to increase the speed of the MILP computations by using customized solver settings.
It is therefore important to know that the considered optimal design problems can be expressed in MILP form at all so that, starting from this foundation, the formulation and implementation can be further improved.
It is also worth noting that methods with a guarantee of optimality (such as MILP and MISOCP) are generally limited to either small or medium-sized problems due to their time complexity, unlike various exchange-type heuristics. However, in classical statistical applications, the problem size is often not too large (e.g., the number of variables is usually less than ). In practice, therefore, we would recommend first attempting to use an “exact” method such as MILP or MISOCP for a given problem and applying a heuristic method only if the exact method takes too long to find a solution or if the problem is clearly too large. Moreover, the MILP and MISOCP formulations can accommodate additional constraints that are beyond the capabilities of available heuristic methods.
We also emphasize that the MILP approach, similarly to other algorithms for discrete design spaces, can also be used for solving relevant subproblems even for continuous design spaces, as demonstrated in Section 5.2.
Finally, we note that the provided MILP formulation opens up interesting research avenues: e.g., the analytical and computational construction of better covariance bounds, and the construction of designs for arbitrary design or covariance constraints.
Declarations
Declarations of interest: none.
Acknowledgments
This work was supported by the Slovak Scientific Grant Agency [grant VEGA 1/0362/22].
Appendix A MILP formulation
Here, we give the exact mathematical form of the MILP formulation (9) that can be used as an input to MILP solvers. Note that we use the operator (the vectorization of a matrix obtained by stacking its columns), but due to symmetry, the more efficient formulation with (the vector-half operator for symmetric matrices) for both and can be used instead. However, the version seems too complicated to describe concisely here.
For simplicity, we first consider -optimality, i.e., . For -optimality, formulation (8) is still linear and simpler than (9), so we actually describe (8) here. Let , , , (for ), , and . Overall, we have the vector of variables , where , and . Below, we express the constraints and the objective function in (8) using .
1. : The left-hand side can be expressed as
By applying the operator, we obtain because . It follows that can be expressed as
(the matrices of zeros correspond to and in ).
2. : For each , this can be expressed as , where . It follows that for all is equivalent to
4. : This is clearly equivalent to .
5. The objective function for -optimality is , where .
Constraints 1-4 and objective function 5 above form the MILP formulation for -optimality. For a general criterion, we have for in the more general formulation (9). The vector is then redefined as , and the objective function in item 5 above becomes , where , and a column of zeros representing is added to each left-hand-side matrix in constraints 1-4.
6. An additional set of constraints, representing , also needs to be included. These constraints can be expressed by setting ():
which means that the constraints are
Appendix B Proofs
Here, we provide the nontrivial proofs of the lemmas and theorems presented in the paper.
Proof 1 (Lemma 1)
Let be such that for all . Let be a vector with nonnegative components summing to , and let . First, since , we have
| (35) |
Consider an matrix such that . We have
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) |
where (37) follows from , (38) is a basic property of the trace, (39) follows from for any , and (40) is valid because of (35), for any matrix , and (e.g., Example 7.54 (c) in Seber (2008)).
Proof 2 (Lemma 2)
We need only to prove that for any ; all other claims of the lemma are then trivial. We fix and adopt the notations , , where , and . Because , we have
where and . That is, . However, .
References
- Ahipasaoglu (2021) Ahipasaoglu, S.D., 2021. A branch-and-bound algorithm for the exact optimal experimental design problem. Statistics and Computing 31, 1–11.
- Atkinson et al. (2007) Atkinson, A.C., Donev, A., Tobias, R., 2007. Optimum experimental designs, with SAS. Oxford University Press, New York.
- Atkinson and Donev (1996) Atkinson, A.C., Donev, A.N., 1996. Experimental design optimally balanced for trend. Technometrics 38, 333–341.
- Atkinson and Woods (2015) Atkinson, A.C., Woods, D.C., 2015. Designs for generalized linear models, in: Dean, A., Morris, M., Stufken, J., Bingham, D. (Eds.), Handbook of design and analysis of experiments. Chapman and Hall/CRC, New York, pp. 471–514.
- Bailey (2007) Bailey, R.A., 2007. Designs for two-colour microarray experiments. Journal of the Royal Statistical Society: Series C 56, 365–394.
- Bailey and Cameron (2009) Bailey, R.A., Cameron, P.J., 2009. Combinatorics of optimal designs. Surveys in Combinatorics 365, 19–73.
- Bhela et al. (2019) Bhela, S., Deka, D., Nagarajan, H., Kekatos, V., 2019. Designing power grid topologies for minimizing network disturbances: An exact MILP formulation, in: 2019 American Control Conference, IEEE. pp. 1949–1956.
- Bulutoglu and Margot (2008) Bulutoglu, D.A., Margot, F., 2008. Classification of orthogonal arrays by integer programming. Journal of Statistical Planning and Inference 138, 654–666.
- Chang and Yeh (1998) Chang, F.C., Yeh, Y.R., 1998. Exact A-optimal designs for quadratic regression. Statistica Sinica 8, 527–533.
- Chen et al. (2022) Chen, P.Y., Chen, R.B., Wong, W.K., 2022. Particle swarm optimization for searching efficient experimental designs: A review. Wiley Interdisciplinary Reviews: Computational Statistics 14, e1578.
- Cheng (1981) Cheng, C.S., 1981. Maximizing the total number of spanning trees in a graph: Two related problems in graph theory and optimum design theory. Journal of Combinatorial Theory, Series B 31, 240–248.
- Duarte et al. (2020) Duarte, B.P., Granjo, J.F., Wong, W.K., 2020. Optimal exact designs of experiments via mixed integer nonlinear programming. Statistics and Computing 30, 93–112.
- Fedorov (1972) Fedorov, V.V., 1972. Theory of optimal experiments. Academic Press, New York.
- Fedorov (1989) Fedorov, V.V., 1989. Optimal design with bounded density: optimization algorithms of the exchange type. Journal of Statistical Planning and Inference 22, 1–13.
- Filová and Harman (2020) Filová, L., Harman, R., 2020. Ascent with quadratic assistance for the construction of exact experimental designs. Computational Statistics 35, 775–801.
- Fontana (2013) Fontana, R., 2013. Algebraic generation of minimum size orthogonal fractional factorial designs: an approach based on integer linear programming. Computational Statistics 28, 241–253.
- Fu et al. (2020) Fu, A., Narasimhan, B., Boyd, S., 2020. CVXR: An R package for disciplined convex optimization. Journal of Statistical Software 94, 1–34.
- Gaffke (1986) Gaffke, N., 1986. On D-optimality of exact linear regression designs with minimum support. Journal of Statistical Planning and Inference 15, 189–204.
- Gaffke and Krafft (1982) Gaffke, N., Krafft, O., 1982. Exact D-optimum designs for quadratic regression. Journal of the Royal Statistical Society: Series B 44, 394–397.
- Ghosh et al. (2008) Ghosh, A., Boyd, S., Saberi, A., 2008. Minimizing effective resistance of a graph. SIAM Review 50, 37–66.
- Goos and Jones (2011) Goos, P., Jones, B., 2011. Optimal design of experiments: a case study approach. Wiley, Chichester.
- Gurobi Optimization, LLC (2023) Gurobi Optimization, LLC, 2023. Gurobi Optimizer Reference Manual. URL: https://www.gurobi.com.
- Haines (1987) Haines, L.M., 1987. The application of the annealing algorithm to the construction of exact optimal designs for linear-regression models. Technometrics 29, 439–447.
- Haines and Clark (2014) Haines, L.M., Clark, A.E., 2014. The construction of optimal designs for dose-escalation studies. Statistics and Computing 24, 101–109.
- Harman (2014) Harman, R., 2014. Multiplicative methods for computing D-optimal stratified designs of experiments. Journal of Statistical Planning and Inference 146, 82–94.
- Harman et al. (2016) Harman, R., Bachratá, A., Filová, L., 2016. Construction of efficient experimental designs under multiple resource constraints. Applied Stochastic Models in Business and Industry 32, 3–17.
- Harman and Filová (2014) Harman, R., Filová, L., 2014. Computing efficient exact designs of experiments using integer quadratic programming. Computational Statistics and Data Analysis 71, 1159–1167.
- Harman and Filová (2019) Harman, R., Filová, L., 2019. OptimalDesign: A Toolbox for Computing Efficient Designs of Experiments. R package version 1.0.1.
- Harman et al. (2021) Harman, R., Filová, L., Rosa, S., 2021. Optimal design of multifactor experiments via grid exploration. Statistics and Computing 31, 70.
- Harman and Jurík (2008) Harman, R., Jurík, T., 2008. Computing c-optimal experimental designs using the simplex method of linear programming. Computational Statistics and Data Analysis 53, 247–254.
- Huang et al. (2019) Huang, Y., Gilmour, S.G., Mylona, K., Goos, P., 2019. Optimal design of experiments for non-linear response surface models. Journal of the Royal Statistical Society: Series C 68, 623–640.
- Imhof (2000) Imhof, L., 2000. Exact designs minimising the integrated variance in quadratic regression. Statistics 34, 103–115.
- Imhof (2014) Imhof, L.A., 2014. G-optimal exact designs for quadratic regression. Journal of Statistical Planning and Inference 154, 133–140.
- Khuri et al. (2006) Khuri, A.I., Mukherjee, B., Sinha, B.K., Ghosh, M., 2006. Design issues for generalized linear models: A review. Statistical Science 21, 376–399.
- Lin et al. (2015) Lin, C.D., Anderson-Cook, C.M., Hamada, M.S., Moore, L.M., Sitter, R.R., 2015. Using genetic algorithms to design experiments: A review. Quality and Reliability Engineering International 31, 155–167.
- McCormick (1976) McCormick, G.P., 1976. Computability of global solutions to factorable nonconvex programs: Part I – convex underestimating problems. Mathematical Programming 10, 147–175.
- Meyer and Nachtsheim (1995) Meyer, R.K., Nachtsheim, C.J., 1995. The coordinate-exchange algorithm for constructing exact optimal experimental designs. Technometrics 37, 60–69.
- Mitchell (1974) Mitchell, T.J., 1974. An algorithm for the construction of D-optimal experimental designs. Technometrics 16, 203–210.
- Neubauer et al. (2000) Neubauer, M., Watkins, W., Zeitlin, J., 2000. D-optimal weighing designs for six objects. Metrika 52, 185–211.
- Okasaki et al. (2023) Okasaki, C., Tóth, S.F., Berdahl, A.M., 2023. Optimal sampling design under logistical constraints with mixed integer programming. arXiv:2302.05553 [stat.ME].
- Pázman (1986) Pázman, A., 1986. Foundation of Optimum Experimental Design. Reidel Publ., Dordrecht.
- Pronzato and Pázman (2013) Pronzato, L., Pázman, A., 2013. Design of Experiments in Nonlinear Models. Springer, New York.
- Pronzato and Zhigljavsky (2014) Pronzato, L., Zhigljavsky, A.A., 2014. Algorithmic construction of optimal designs on compact sets for concave and differentiable criteria. Journal of Statistical Planning and Inference 154, 141–155.
- Pukelsheim (1993) Pukelsheim, F., 1993. Optimal design of experiments. Wiley, New York.
- Pukelsheim and Rieder (1992) Pukelsheim, F., Rieder, S., 1992. Efficient rounding of approximate designs. Biometrika 79, 763–770.
- Rasch et al. (1997) Rasch, D.A.M.K., Hendrix, E.M.T., Boer, E.P.J., 1997. Replication-free optimal designs in regression analysis. Computational Statistics 12, 19–52.
- Sagnol (2011) Sagnol, G., 2011. Computing optimal designs of multiresponse experiments reduces to second-order cone programming. Journal of Statistical Planning and Inference 141, 1684–1708.
- Sagnol and Harman (2015) Sagnol, G., Harman, R., 2015. Computing exact D-optimal designs by mixed integer second-order cone programming. The Annals of Statistics 43, 2198–2224.
- Sartono et al. (2015a) Sartono, B., Goos, P., Schoen, E., 2015a. Constructing general orthogonal fractional factorial split-plot designs. Technometrics 57, 488–502.
- Sartono et al. (2015b) Sartono, B., Schoen, E., Goos, P., 2015b. Blocking orthogonal designs with mixed integer linear programming. Technometrics 57, 428–439.
- Seber (2008) Seber, G.A., 2008. A Matrix Handbook for Statisticians. John Wiley & Sons, New Jersey.
- Todd (2016) Todd, M.J., 2016. Minimum-Volume Ellipsoids: Theory and Algorithms. SIAM, Philadelphia.
- Vandenberghe and Boyd (1999) Vandenberghe, L., Boyd, S., 1999. Applications of semidefinite programming. Applied Numerical Mathematics 29, 283–299.
- Vo-Thanh et al. (2018) Vo-Thanh, N., Jans, R., Schoen, E.D., Goos, P., 2018. Symmetry breaking in mixed integer linear programming formulations for blocking two-level orthogonal experimental designs. Computers & Operations Research 97, 96–110.
- Welch (1982) Welch, W.J., 1982. Branch-and-bound search for experimental designs based on D-optimality and other criteria. Technometrics 24, 41–48.
- Wong (1992) Wong, W.K., 1992. A unified approach to the construction of minimax designs. Biometrika 79, 611–619.
- Wong and Zhou (2019) Wong, W.K., Zhou, J., 2019. CVX-based algorithms for constructing various optimal regression designs. Canadian Journal of Statistics 47, 374–391.
- Wong and Zhou (2023) Wong, W.K., Zhou, J., 2023. Using CVX to construct optimal designs for biomedical studies with multiple objectives. Journal of Computational and Graphical Statistics 32, 744–753.