11email: benwang.cs11@nycu.edu.tw, gdwang.cs10@nycu.edu.tw, sf1638.cs05@nctu.edu.tw, wcpeng@cs.nycu.edu.tw
Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalanced Regression
Abstract
Tabular data serve as a fundamental and ubiquitous representation of structured information in numerous real-world applications, e.g., finance and urban planning. In the realm of tabular imbalanced applications, data imbalance has been investigated in classification tasks with insufficient instances in certain labels, causing the model’s ineffective generalizability. However, the imbalance issue of tabular regression tasks is underexplored, and yet is critical due to unclear boundaries for continuous labels and simplifying assumptions in existing imbalance regression work, which often rely on known and balanced test distributions. Such assumptions may not hold in practice and can lead to performance degradation. To address these issues, we propose MATI: Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalance Regression, featuring two key innovations: (i) the Region-Aware Mixture Expert, which adopts a Gaussian Mixture Model to capture the underlying related regions. The statistical information of each Gaussian component is then used to synthesize and train region-specific experts to capture the unique characteristics of their respective regions. (ii) Test-Time Self-Supervised Expert Aggregation, which dynamically adjusts region expert weights based on test data features to reinforce expert adaptation across varying test distributions. We evaluated MATI on four real-world tabular imbalance regression datasets, including house pricing, bike sharing, and age prediction, covering a range of narrow to wide target distributions. To reflect realistic deployment scenarios, we adopted three types of test distributions: a balanced distribution with uniform target frequencies, a normal distribution that follows the training data, and an inverse distribution that emphasizes rare target regions. On average across these three test distributions, MATI achieved a 7.1% improvement in MAE compared to existing imbalanced regression methods, along with extensive analyses of the effects of each module.
Keywords:
Tabular Regression Imbalanced Regression Test-Time Training.1 Introduction
The exploration of tabular applications has broad applicability across numerous domains. Whether it involves property valuations [11, 25], urban planning [43, 38], or fraud detection [1, 24], these scenarios can be effectively framed as tabular classification/regression tasks characterized by heterogeneous and non-structural relations between samples (rows) and features (columns). Data imbalance has been a significant hurdle in real-world tabular applications, leading to biased predictions and unreliable outcomes. For instance, imbalances occur in human age estimation, where rare instances (e.g., newborn babies) tend to be influenced by the model’s prior knowledge of the majority class (e.g., young adults), resulting in a negative impact on performance [42]. In recent years, the advancements in mitigating data imbalance for tabular data have been investigated for classifications [42, 33, 46] as well as regression tasks [42, 35, 33].
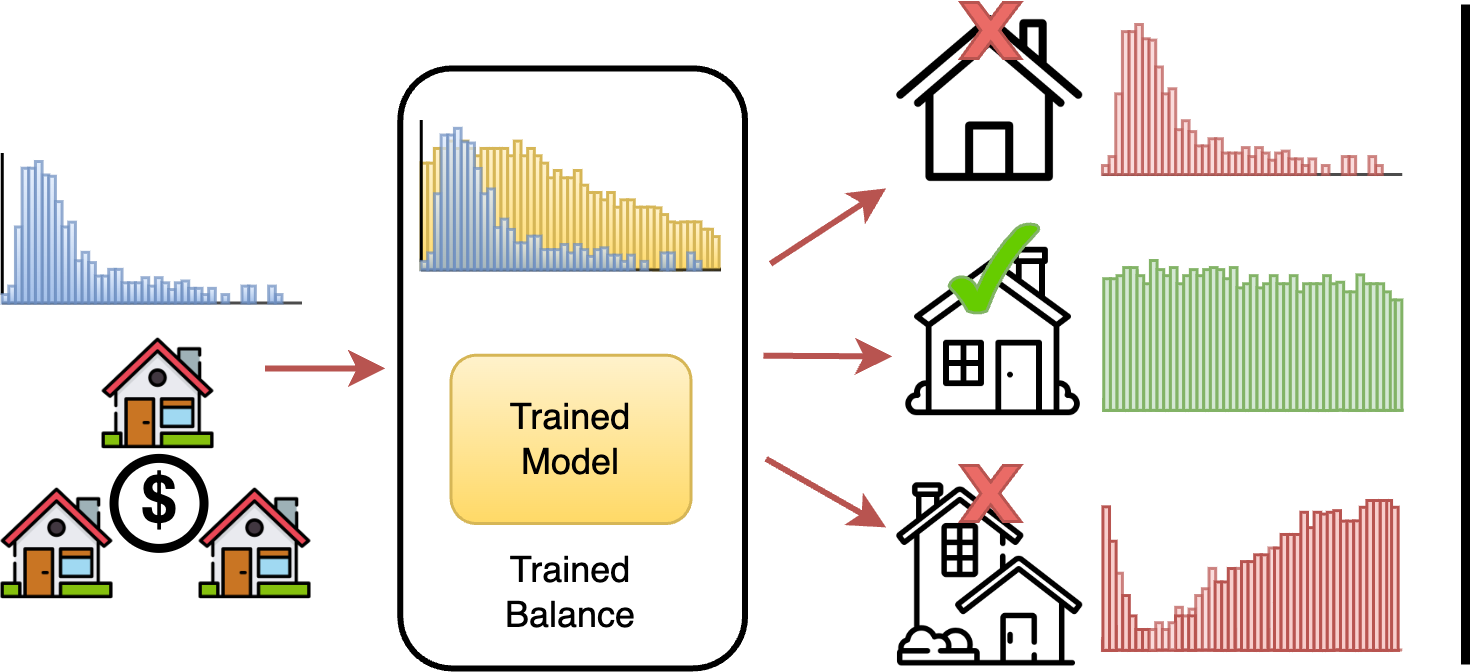
However, these methods fall short in two critical challenges when applied to tabular imbalanced regression tasks: First, regression labels are continuous and often unbounded, which differentiates them from classification labels that are discretized explicitly. This challenge arises from the difficulty in learning the diverse characteristics of certain target regions, especially those that rarely appear. Second, existing imbalanced regression methods often assume that test distributions are known and balanced [42, 33]. In practice, test distributions can vary significantly, and this mismatch between training and test data distributions can result in substantial performance degradation on few-shot regions. A potential approach is to adopt [46] addressing unknown test distributions in imbalanced classification; nonetheless, these classification-focused methods cause ambiguity when transferred to regression tasks due to the dependencies between target indices [42]. This highlights the urgent need to develop approaches for the distinct challenges of imbalanced regression datasets.
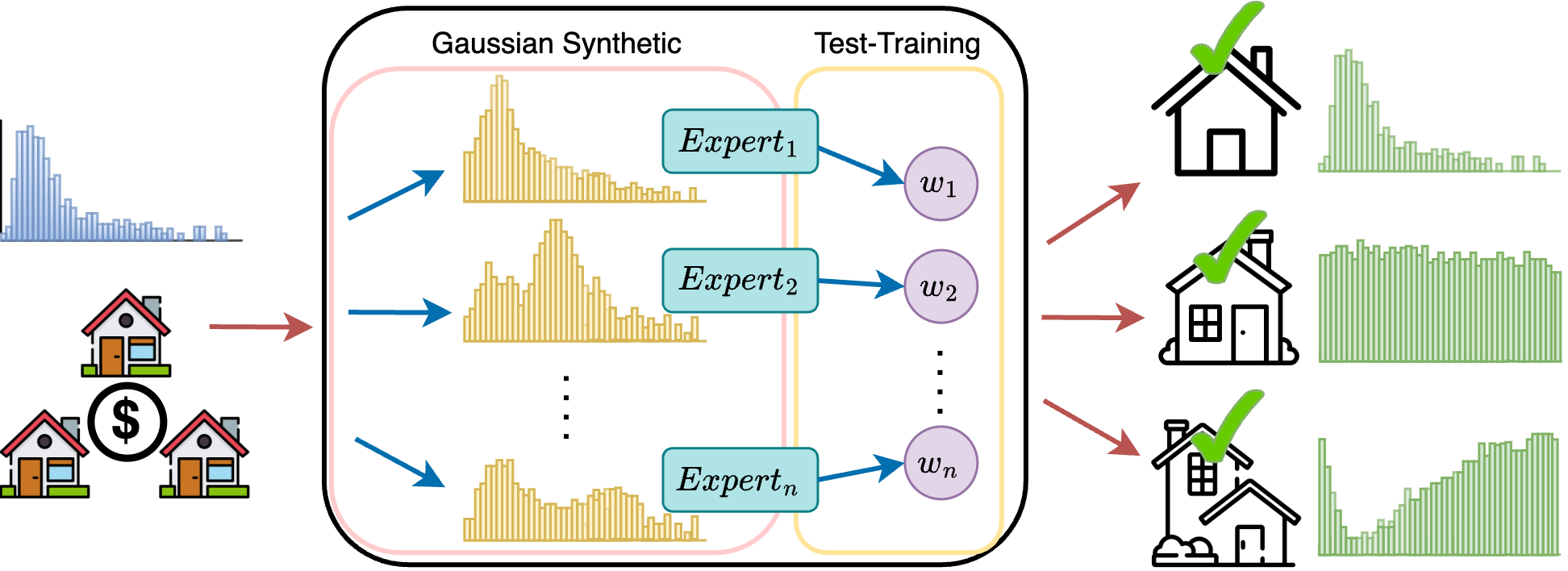
In this paper, we propose Mixture Experts With Self-Supervised Aggregation for Deep Imbalance Regression, MATI, a new approach with two novel techniques: 1) Learning experts from imbalanced data: We introduce the Region-Aware Mixture Expert by first dividing training data into multiple Gaussian components to acquire statistical information on each component generated by employing a regression synthesizer, and then training expert models based on synthesized datasets to focus on characteristics of specific regions. 2) Self-adjusting expert weights at test-time: We introduce Test-Time Self-Supervised Expert Aggregation by perturbing test inputs [44] and adjusting expert weights based on unlabeled test data. By minimizing the prediction gap of expert models on perturbed and unperturbed data, expert models with more expertise receive larger weights. To verify the relation between continuous prediction gap minimization and regression tasks, we extend the theoretical correlation between expert contribution adjustment and prediction stability from classification to regression.
To comprehensively study imbalance performance on each target distribution, we extend the DIR benchmark [42] from balanced distributions to include two additional imbalanced test sets, a normal test set and an inverse test set, as shown in Figure 1. These test sets represent different imbalance levels in regression tasks, with the normal distribution following the training distribution and the inverse distribution following the reciprocal of the normal. We then extensively evaluated our MATI and state-of-the-art baselines on four benchmarks in normal, balanced, and inverse distributions. Our results demonstrate a notable improvement of 7.1% in terms of average MAE scores and illustrate that existing methods significantly degrade their performance on normal and inverse distributions, indicating the critical importance of integrating diverse distributions into the testing data for evaluations. We highlight our main contributions as follows:
-
•
We propose a novel tabular regression model via Mixture Experts with Self-Supervised Aggregation, MATI, for tabular imbalance regression. To the best of our knowledge, this is the first work that tackles varying imbalances across test distributions in regression tasks.
-
•
MATI consists of region-aware mixture experts to enable expert models to focus on corresponding distributions based on synthetic datasets, and test time self-supervised expert aggregation to dynamically adjust expert weights based on the distributions of test data.
-
•
We introduce a novel evaluation approach for tabular imbalanced regression tasks incorporating additional normal and inverse test sets, providing nuanced assessments across diverse imbalanced distributions. Experimental results show that MATI outperforms existing methods with an average MAE improvement of 7.1% across these test distributions.
2 Related Tabular Imbalanced Works
2.1 Imbalanced Classification
Existing techniques for handling imbalanced data mainly focus on imbalanced and long-tailed classification, including rebalancing, logit adjustment, feature enhancement, and ensemble methods. Rebalancing comprises resampling [37, 8, 16, 22, 14, 30] and reweighting [5, 9, 18, 19, 21], both designed to balance classes by the corresponding techniques during the training process. Logit adjustment methods [28, 36, 32, 31, 26] adjust the output logits based on the frequencies of training labels. However, both rebalancing and logit adjustment methods focus on tail classes yet overlook overall class distributions, leading to increased sensitivity to tail classes and consequently, higher model variance [39]. Feature enhancement methods [27, 13] aim to improve the representation of minority classes by integrating features across class distributions, thereby enhancing the model’s ability to recognize underrepresented classes. These methods are tailored for visual data, and thus may not effectively apply to the structured nature of tabular data.
On the other hand, ensemble methods [46, 4, 39] are designed to capture diverse information (e.g., facial characteristics of ages) from imbalanced datasets and effectively aggregate this information through multi-expert approaches. These methods leverage multiple specialized models to address various aspects of the data. Regarding ensemble approaches that are designed to be test-agnostic, LADE [17] utilizes test data distribution as available information to post-adjust model outputs, while SADE [46] introduces a test-time training method for imbalanced classification that adjusts expert weights based on the assumption of discrete target space. However, LADE and SADE were both designed for categorical indices, which cannot be directly adapted to imbalanced regression. On the flip side, our method adopts a region-aware training technique with a regression synthesizer and a self-supervised method to dynamically aggregate models for imbalanced regression. We enhance the representation of few-shot regions through multiple experts and adjust expert contributions through test-time training based on varying test distributions.
2.2 Imbalanced Regression
Imbalanced regression is less explored compared to classification due to the unclear boundaries of regression targets, which leads to fewer benchmark datasets for imbalanced regression. Existing works on imbalance regression resample data by interpolating features and labels [37] or adding Gaussian noise [3]. These methods of imbalanced regression are directly or indirectly related to SMOTE [6] which was developed for classification tasks that generate synthetic samples for the minority class to balance the dataset. These approaches suffer from a lack of context awareness, and the fact that resampling methods highly rely on statistical properties for synthesizing [34].
[42] curated a deep imbalanced regression (DIR) benchmark and proposed label smoothing using kernel density estimation to smooth and estimate label frequencies for reweighting techniques. [40] improved imbalanced regression by introducing probabilistic smoothing combined with variational inference, which enhances accuracy across underrepresented regions in the image data distribution. For logit adjustment, [33] adjusted the mean squared error (MSE) loss function by incorporating a balancing term, which modifies the standard MSE loss to give more weight to errors from underrepresented (minority) classes or regions in the data distribution. However, these imbalanced regression methods assume balanced test distributions, making them inadequate for addressing test-agnostic evaluation (e.g., imbalanced distributions at test time).
3 Methodology
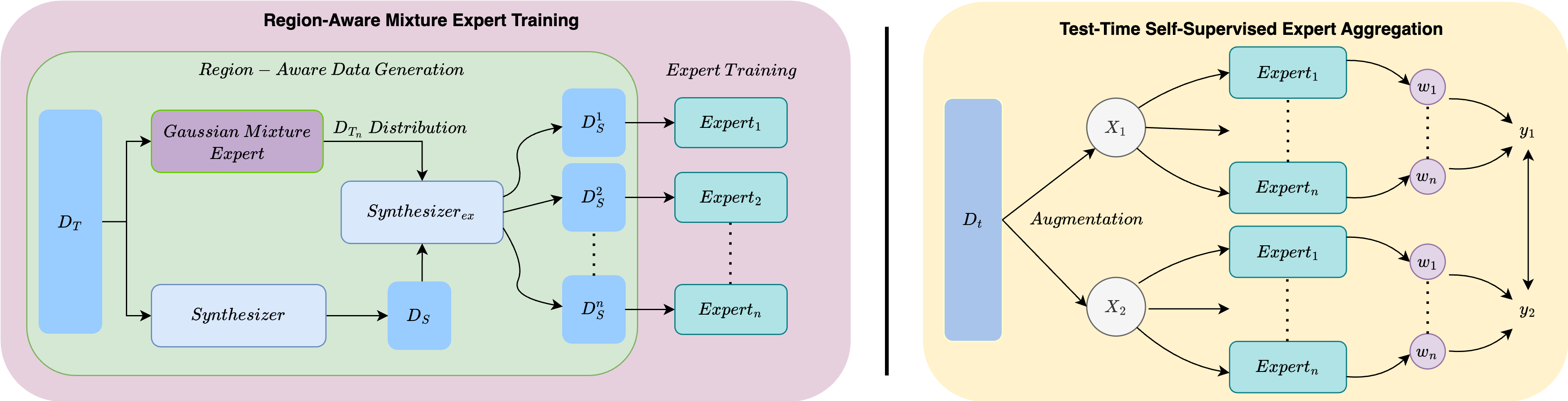
In this section, we introduce the problem setting, evaluation protocols, and details of MATI’s two novel designs as illustrated in Figure 2: Region-Aware Mixture Expert Training and Test-Time Self-Supervised Expert Aggregation.
3.1 Problem Formulation
We focus on tabular imbalance regression tasks: consider a dataset , where each denotes the input features, and represents the associated continuous target. To address the challenge of imbalanced regression, we follow the definition of [42] to define the label space as a partitioned set of non-overlapping intervals or bins, such that . Note that is a finite set of indices corresponding to these bins, and defines the resolution of interest within the target variable.
3.1.1 Evaluation Protocol
Previous methods use either a balanced evaluation metric or a balanced test set to assess performance across samples with varying rarities [33]. However, we argue that assuming the test distribution to be balanced is inappropriate in practice; actual test distribution in regression might be shifted and possess different levels of imbalance [46]. To address this issue, we propose a new evaluation protocol for imbalanced performance by sampling test sets with different weights for each target bin, resulting in three kinds of test sets: balanced, normal, and inverse. These test sets are drawn from an imbalanced training distribution , which is skewed towards certain regions of . The balanced test set is uniformly distributed [42], the normal test set follows the target bin frequency of , and the inverse test set follows the reciprocal distribution of the normal test set. Our goal is to learn a model from training data with a distribution to predict effective results under balanced, normal, and inverse distribution scenarios.
3.2 Region-Aware Mixture Expert Training
Inspired by the successful advancements of utilizing the multi-expert techniques in vision [17, 4, 46, 7] and language [15, 20] applications, where each expert model is specifically skilled in handling certain classes or target regions, we introduced region-aware mixture experts by extending expert models dedicated to specific distributions of imbalanced regression tasks. Specifically, we train our region experts by synthesizing different regions of data based on the distribution information from .
The process of training target region experts is depicted in the left part of Figure 2. To mitigate the imbalance by generating synthetic samples in underrepresented regions, the training set undergoes a synthesizer designed based on SMOGN [3], which includes a minority oversampling technique tailored for tabular regression. The synthesizer automatically defines rare regions for over-sampling within the entire target space of . This results in a dataset, denoted as , which is more balanced compared to the original data :
| (1) |
The original data with imbalance distribution may consist of multiple complex distributions where a single model might be biased towards the nearest majority regions [10]. To capture this distributional information and enable multiple models to correspond accordingly, a Gaussian Mixture Model (GMM) is applied to to capture the distinct distributions within the original training data. We divide the dataset with its labels into multiple datasets by fitting GMM on the original dataset and its label. Formally, the GMM is defined as:
| (2) |
where is the number of Gaussian components, are the mixture weights, and is the Gaussian distribution with mean and variance .
Afterwards, each data point is assigned to a cluster based on the posterior probability:
| (3) |
Generally, the original dataset can be divided into subsets , where each subset contains data points assigned to the -th Gaussian component:
| (4) |
GMM provides a statistical approach to model the complex underlying structure of , while it fits by its label into sets of data, each denoted as , where is decided by the Akaike Information Criterion score [23] for better training and generalization results. With the Gaussian components, we utilize a second synthesizing on based on the statistical information of each , denoted as as in Figure 2. synthesizes data in the same manner as Synthesizer, except that the over-sampled regions are replaced with statistical information. Specifically, we over-sample on a specified target range of , and the range is decided by the label mean and standard deviation of each component with an adjustable hyperparameter multiplied on :
| (5) |
The outcome of this training step is a collection of datasets after over-sampling a specified target range of , denoted as . The final phase involves the development of multiple expert models, represented as . Each expert is trained on its corresponding training data with the MSE loss, ensuring that every model develops a specialized understanding of a particular target region.
3.3 Test-Time Self-Supervised Expert Aggregation for Regression
After training region-specific experts, our next objective is to aggregate these expert models without prior knowledge of the test distribution and labels, allowing for effective adaptation to test distributions with varying degrees of imbalance. To that end, our intuitions are that 1) there exists a positive correlation between expertise and prediction stability, i.e., when predicting different views of samples, experts have higher prediction similarity of samples from their favorable regions, and 2) the principle that a model with more expertise in a particular area should assume a more significant role and consequently carry greater weight after the aggregation.
As shown in algorithm 1, we aggregate the trained region experts by minimizing the continuous output gap of different views of a test sample since experts proficient in specific regions should demonstrate enhanced stability in their predictions. Hence, Continuous Prediction Gap Minimization is proposed to ensure that the contribution of experts is effectively adapted to test distributions with varying degrees of imbalance.
3.3.1 Continuous Prediction Gap Minimization
To tackle varying test distributions, we dynamically adjust region expert contributions by learning aggregation weights for frozen parameter experts by minimizing the model output gap between two similar unlabeled test samples, which is generated by adding slight perturbation on the other one. Let denote a mini-batch of test samples used for test-time adaptation. As shown in the right part of Figure 2, the method involves three steps:
-
1.
Perturbation. For each test sample , we generate two perturbed views and using VIME [44], a simple yet effective tabular augmenting approach.
-
2.
Expert Inference.The parameters of all region experts are frozen. Each expert produces a logit output , and we assign a learnable weight to each expert. Only the weights are updated during test-time training.
-
3.
Prediction Aggregation. The weights are normalized using a softmax function , and the final prediction is computed as a weighted sum of expert outputs:
Applying this to both views and , we obtain corresponding outputs and . The goal is to minimize the prediction difference between these two views, thereby encouraging stable expert combinations for each test input.
The objective function of minimizing the prediction gap in regression is defined as:
| (6) |
Optimizing the prediction gap assigns greater weights to more proficient experts, adapting to the unknown test distribution. This self-supervised aggregation approach facilitates expert weight adjustment without relying on test labels.
3.3.2 Theoretical Analysis
We theoretically adapt the prediction stability maximization strategy to a regression context. Given random variables predictions and labels defined as and , our goal is to adjust the weights of experts to produce predictions that better align with . This can be achieved through the maximization of mutual information between the predicted distribution and the true label distribution [41]. For regression, prediction gap is proportional to the mutual information between the predicted distribution and the test distribution . This relationship is formally stated as follows:
Theorem 1. The prediction gap is positively proportional to the mutual information between the predicted distribution and the test distribution :
To prove this theorem, we introduce the concept of center loss, which minimizes the distance between features and their respective class centers. Center loss has a demonstrated proportional relationship with mutual information in classification tasks [46, 41]. We link prediction gap with mutual information by utilizing center loss in the regression context [46, 45]. By categorizing the continuous target space into bins [42, 45], we can relate the MSE of prediction gap (cf. Eq. 6) and center loss of these bins in regression tasks:
| (7) |
where denotes the number of samples in bin , represents the hard mean of all predictions of samples from bin , where , for the equations to indicate equality up to a multiplicative and/or additive constant. By introducing the strategy of Continuous Prediction Gap Minimization to the regression scenario, we show that minimization of is proportional to the maximization of mutual information between prediction and the true label; this adjusts the weights of experts to the output prediction that better fits .
4 Experiments
4.1 Experimental Settings
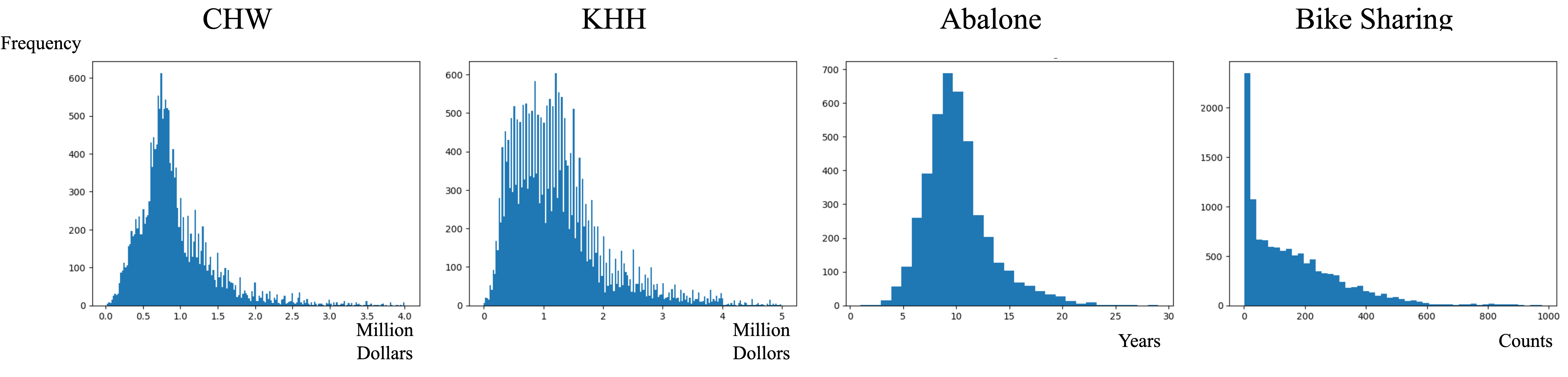
Datasets. We curated four real-world tabular imbalance regression benchmarks across diverse domains, as shown in 3, including pricing, aging, and counts, and constructed three distinct test data distributions: balanced, normal, and inverse. 1) Taiwan House [25] focuses on house price appraisal for two Taiwanese regions, CHW and KHH, both exhibiting long-tail distributions with extremely high-price bins. CHW represents a smaller city with lower prices, while KHH corresponds to a larger city with higher average prices. We set a bin range of 1 million and appended few-shot bins with extreme values to the last bin. The task involves predicting house prices using metadata, with three components determined via AIC. 2) Abalone [29] predicts abalone age from physical measurements, characterized by an imbalanced target range lacking both low and high ages. The bin size was set to 1, and two components were identified. 3) Bike Sharing [12] estimates bike rental counts based on weather, date, and weekday data, with a bin range of 5 to account for few-shot bins with extreme values. Three components were used. Evaluation metrics included MAE and MAPE for the CHW and KHH datasets, leveraging MAPE’s suitability for large-range targets, and RMSE and MAE for Abalone and Bike Sharing to assess regression performance. These datasets provide a robust foundation for testing under diverse imbalanced conditions.
Baselines and Implementation Details. To validate the effectiveness of MATI, we benchmarked it against several state-of-the-art baselines: 1) Vanilla, a simple approach without imbalanced regression techniques, trains TabNetRegressor using the same settings as our expert models. 2) SMOGN [3], which applies MATI’s synthetic process across the entire target space, identifies minority regions and synthesizes data with Gaussian noise before training TabNetRegressor. 3) RRT [42], which retrains only the final layer using inverse reweighting after initial full-model training. 4) RRT+LDS, an extension of RRT incorporating Label Distribution Smoothing (LDS) with kernel density estimation for refined weighting. 5) BMC [33], which replaces standard MSE loss with Balanced MSE Correction, leveraging label distribution priors for balanced predictions. These baselines provide rigorous evaluation for MATI’s performance.
For the baseline methods and MATI, we used TabNetRegressor [2] as our base model for fair comparisons. We trained each method for a maximum of 200 epochs, with an early stopping set of 20 epochs. The model size ranged from 3 to 5 for each method, and the results are the average of three different seeds. For some detailed hyperparameters, we set from 1 to 2 for the synthesizer. To ensure fairness, we fix the number of epochs and the corruption ratio for test-time training in MATI. The number of epochs is set between 20 and 50, depending on the test set size, while the corruption ratio is fixed at 0.1.
4.2 Quantitative Results on Varying Test Distributions
Tables 1 and 2 present the performance of MATI and the baselines on the four datasets. We summarize the observations as follows: 1) Superior MATI Performance on Balanced Test Set: Quantitatively, MATI outperforms all baselines on the balanced test set, achieving at least 0.339 and 1.021 lower MAPE in the CHW and KHH house price datasets, respectively. It also surpasses baselines by at least 1.05% and 8.71% in RMSE on the Abalone and Bike Sharing datasets. Despite these baselines focusing on the performance of balanced test distributions, the comparisons with our MATI not only illustrate the need for evaluating various distributions but also reveal the importance of considering different distributions via the corresponding experts. 2) The Advantage of Test-Time Aggregation: We can observe that imbalanced regression baselines (i.e., RRT+LDS) perform well only on balanced evaluation protocols, while MATI excels across different distributions. Vanilla is only superior in many-shot regions which share the same distribution as the training sets, but is deleterious in few-shot regions due to the lack of imbalanced techniques. In contrast, MATI equipped with Test-Time Self-Supervised Expert Aggregation adjusts expert weights for adapting to test distributions. This allows MATI to perform slightly worse than Vanilla on the normal test set, but to achieve optimal results on both the balanced and inverse test sets. This highlights the effectiveness of MATI’s test-time aggregation in handling to varying test distribution.
| CHW | KHH | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | MAPE ↓ | MAE ↓ | MAPE ↓ | MAE ↓ | ||||||||
| Balanced | Normal | Inverse | Balanced | Normal | Inverse | Balanced | Normal | Inverse | Balanced | Normal | Inverse | |
| Vanilla | 26.221 | 21.714 | 30.362 | 0.296 | 0.334 | 0.339 | 27.556 | 21.111 | 32.333 | 0.301 | 0.343 | 0.378 |
| SMOGN | 28.252 | 24.601 | 30.361 | 0.334 | 0.285 | 0.360 | 29.454 | 25.563 | 32.322 | 0.356 | 0.297 | 0.366 |
| RRT | 36.244 | 25.344 | 38.762 | 0.35 | 0.311 | 0.389 | 36.236 | 25.331 | 35.224 | 0.361 | 0.323 | 0.397 |
| RRT+LDS | 25.563 | 27.563 | 32.555 | 0.321 | 0.298 | 0.365 | 25.354 | 28.231 | 33.456 | 0.294 | 0.314 | 0.359 |
| BMC | 32.051 | 29.231 | 35.983 | 0.296 | 0.239 | 0.337 | 33.989 | 28.999 | 36.932 | 0.337 | 0.232 | 0.355 |
| MATI | 25.224 | 22.793 | 28.227 | 0.293 | 0.254 | 0.333 | 24.333 | 22.896 | 29.348 | 0.286 | 0.251 | 0.342 |
| Abalone | Bike Sharing | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | RMSE ↓ | MAE ↓ | RMSE ↓ | MAE ↓ | ||||||||
| Balanced | Normal | Inverse | Balanced | Normal | Inverse | Balanced | Normal | Inverse | Balanced | Normal | Inverse | |
| Vanilla | 3.756 | 2.614 | 4.955 | 2.787 | 1.947 | 4.093 | 92.231 | 49.382 | 92.325 | 67.454 | 36.421 | 78.655 |
| SMOGN | 3.561 | 2.625 | 4.588 | 2.876 | 2.099 | 3.944 | 102.413 | 61.428 | 119.937 | 73.711 | 43.564 | 91.823 |
| RRT | 3.332 | 2.669 | 4.234 | 2.662 | 2.101 | 3.467 | 93.107 | 49.664 | 100.567 | 66.377 | 37.537 | 79.661 |
| RRT+LDS | 3.831 | 2.911 | 4.885 | 2.892 | 2.204 | 3.998 | 92.264 | 49.909 | 100.916 | 66.138 | 37.507 | 80.477 |
| BMC | 3.541 | 2.919 | 4.263 | 2.878 | 2.333 | 3.629 | 87.783 | 48.451 | 86.672 | 63.689 | 37.834 | 71.781 |
| MATI | 3.297 | 2.622 | 3.855 | 2.641 | 2.079 | 3.131 | 86.989 | 56.201 | 81.785 | 62.140 | 37.982 | 65.310 |
| Bike Sharing | CHW | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Expert | RMSE ↓ | MAE ↓ | MAPE ↓ | MAE ↓ | ||||||||
| Region 1 | Region 2 | Region 3 | Region 1 | Region 2 | Region 3 | Region 1 | Region 2 | Region 3 | Region 1 | Region 2 | Region 3 | |
| 18.121 | 119.814 | 166.433 | 11.776 | 91.945 | 133.471 | 29.213 | 28.9321 | 37.122 | 0.288 | 0.239 | 0.298 | |
| 20.781 | 94.745 | 168.383 | 16.174 | 72.602 | 138.161 | 29.789 | 27.973 | 36.464 | 0.334 | 0.233 | 0.290 | |
| 29.870 | 105.482 | 160.133 | 20.716 | 82.391 | 128.923 | 31.213 | 32.245 | 35.744 | 0.328 | 0.273 | 0.282 | |
4.3 Ablation Studies on varying skewed test data distribution
To assess the proficiency of region experts and validate the test-time aggregation mechanism of MATI, we conducted experiments on the Bike Sharing and CHW datasets, both of which exhibit highly right-skewed distributions. For these datasets, we employed three Gaussian components, sorting experts by their means to define Region 1, Region 2, and Region 3, handled by , , and , respectively. Region-specific test sets were created by sampling based on Gaussian means and standard deviations, enabling performance evaluation of each expert in its corresponding region.Table 3 confirms that each expert excels within its designated region, validating the effectiveness of Gaussian Mixture Synthesizing in modeling region-specific characteristics. Furthermore, MATI’s dynamic weight adjustment during test-time aggregation effectively aligns expert contributions to the test distribution. Table 4 illustrates that , optimized for Region 1, dominates on right-skewed normal test sets; , representing Region 2, is weighted higher on balanced test sets; and , trained for Region 3, is prioritized on left-skewed inverse test sets. These findings demonstrate MATI’s ability to adaptively allocate expert weights, ensuring optimal performance across diverse test scenarios.
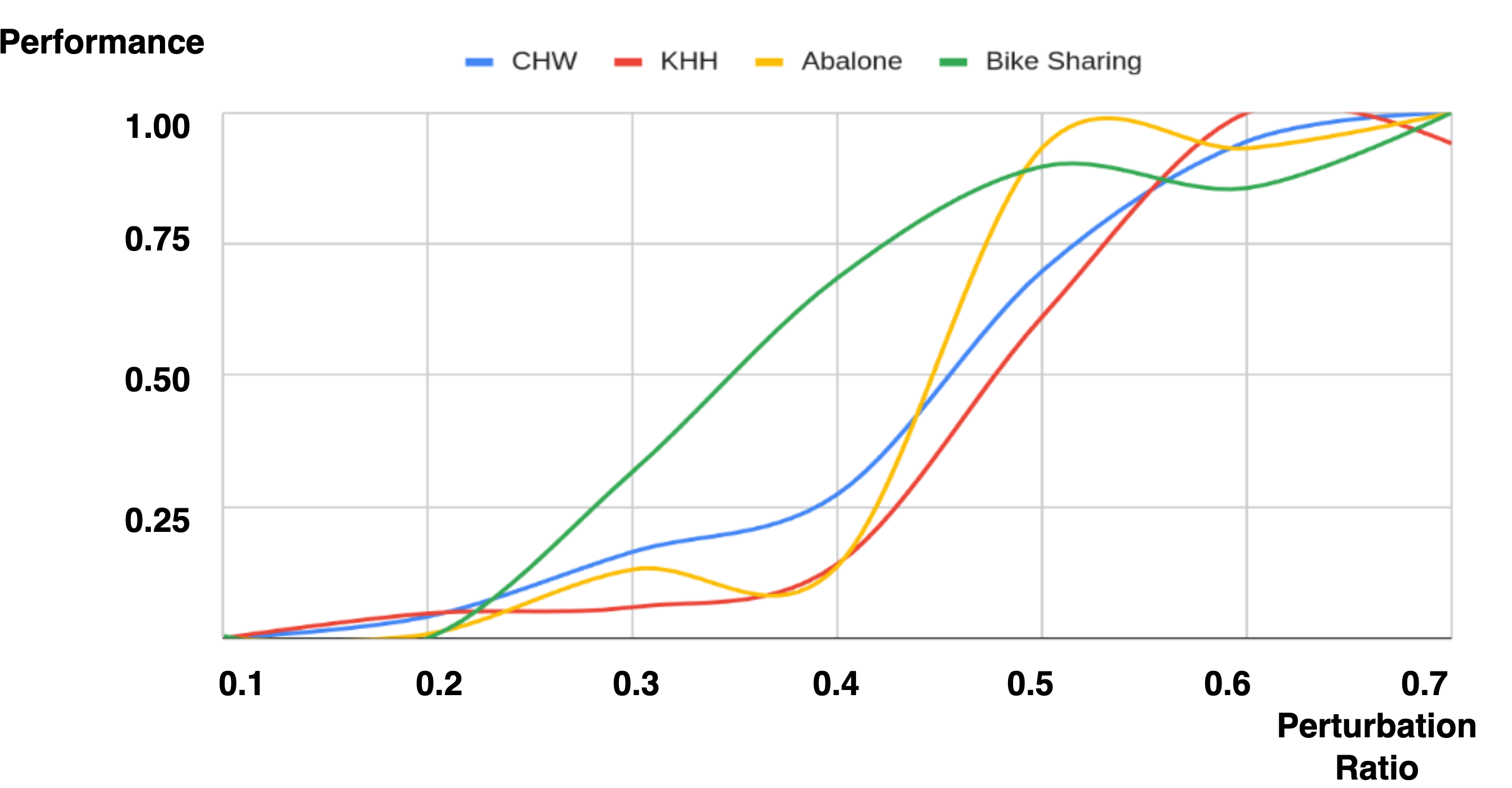
4.4 Effects of Perturbation Ratio
To verify that the perturbation method does not generate excessively large or dissimilar samples, thereby affecting the performance, we closely examined the changes in performance with varying perturbation ratios (Algorithm 1, line 5) from 0.1 to 0.7. As illustrated in Figure 4, the performance curves for the four datasets remain relatively flat and stable at lower perturbation ratios. However, when the ratio exceeds 0.4, there is a noticeable and abrupt increase in the curves. This finding indicates that a slight perturbation of the input features allows the perturbation method to generate proper and similar samples for aggregation.
| Bike Sharing | CHW | |||||
|---|---|---|---|---|---|---|
| Distribution | Expert 1 | Expert 2 | Expert 3 | Expert 1 | Expert 2 | Expert 3 |
| Right-Skewed | 0.372 | 0.334 | 0.294 | 0.400 | 0.270 | 0.330 |
| Balanced | 0.312 | 0.443 | 0.275 | 0.310 | 0.410 | 0.280 |
| Left-Skewed | 0.310 | 0.345 | 0.345 | 0.293 | 0.324 | 0.383 |
5 Conclusion
In this paper, we present MATI, an innovative method that combines Mixture Experts with Test-Time Self-Supervised Aggregation to address Tabular Imbalance Regression. MATI targets the two challenges of learning from imbalanced data and adapting to varying test distributions in regression tasks. By employing Gaussian Mixture Synthesizing for region-specific expert training and Continuous Prediction Gap Minimization for test-time aggregation, MATI enhances the representation of few-shot regions and boosts model robustness against diverse test distributions. Distinct from existing works that only focused on balanced set evaluation, we included normal and inverse test sets for evaluations, allowing comprehensive evaluations on the capability of tackling imbalanced distributions. Extensive evaluations of 4 real-world benchmarks show that MATI significantly outperforms state-of-the-art baselines by 7.1% in terms of the average of various distribution and application scenarios. We believe our MATI serves as a general framework for tabular regression applications due to the generic design for modeling imbalanced distributions as well as for the test-time aggregation technique, and multiple interesting directions could be further explored such as a unified approach for tabular imbalanced regression as well as classification applications, multi-modal features for few-shot regions, etc.
References
- [1] Alfaiz, N.S., Fati, S.M.: Enhanced credit card fraud detection model using machine learning. Electronics 11(4), 662 (2022)
- [2] Arik, S.Ö., Pfister, T.: Tabnet: Attentive interpretable tabular learning. In: Proceedings of the AAAI conference on artificial intelligence. vol. 35, pp. 6679–6687 (2021)
- [3] Branco, P., Torgo, L., Ribeiro, R.P.: Smogn: a pre-processing approach for imbalanced regression. In: First international workshop on learning with imbalanced domains: Theory and applications. pp. 36–50. PMLR (2017)
- [4] Cai, J., Wang, Y., Hwang, J.N.: Ace: Ally complementary experts for solving long-tailed recognition in one-shot. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 112–121 (October 2021)
- [5] Cao, K., Wei, C., Gaidon, A., Arechiga, N., Ma, T.: Learning imbalanced datasets with label-distribution-aware margin loss. Advances in neural information processing systems 32 (2019)
- [6] Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research 16, 321–357 (2002)
- [7] Chen, Z., Chen, J., Xie, Z., Xu, E., Feng, Y., Liu, S.: Multi-expert attention network with unsupervised aggregation for long-tailed fault diagnosis under speed variation. Knowledge-Based Systems 252, 109393 (2022)
- [8] Chu, P., Bian, X., Liu, S., Ling, H.: Feature space augmentation for long-tailed data. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16. pp. 694–710. Springer (2020)
- [9] Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9268–9277 (2019)
- [10] Dong, Q., Gong, S., Zhu, X.: Imbalanced deep learning by minority class incremental rectification. IEEE transactions on pattern analysis and machine intelligence 41(6), 1367–1381 (2018)
- [11] Du, W., Wang, W., Peng, W.: Dora: Domain-based self-supervised learning framework for low-resource real estate appraisal. In: CIKM. pp. 4552–4558. ACM (2023)
- [12] Fanaee-T, H.: Bike Sharing. UCI Machine Learning Repository (2013), DOI: https://doi.org/10.24432/C5W894
- [13] Gao, J., Zhao, H., Li, Z., Guo, D.: Enhancing minority classes by mixing: an adaptative optimal transport approach for long-tailed classification. Advances in Neural Information Processing Systems 36 (2024)
- [14] Guo, H., Wang, S.: Long-tailed multi-label visual recognition by collaborative training on uniform and re-balanced samplings. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15089–15098 (2021)
- [15] Guo, T., Chen, X., Wang, Y., Chang, R., Pei, S., Chawla, N.V., Wiest, O., Zhang, X.: Large language model based multi-agents: A survey of progress and challenges (2024), https://arxiv.org/abs/2402.01680
- [16] He, H., Garcia, E.A.: Learning from imbalanced data. IEEE Transactions on knowledge and data engineering 21(9), 1263–1284 (2009)
- [17] Hong, Y., Han, S., Choi, K., Seo, S., Kim, B., Chang, B.: Disentangling label distribution for long-tailed visual recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6626–6636 (2021)
- [18] Huang, C., Li, Y., Loy, C.C., Tang, X.: Learning deep representation for imbalanced classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5375–5384 (2016)
- [19] Jamal, M.A., Brown, M., Yang, M.H., Wang, L., Gong, B.: Rethinking class-balanced methods for long-tailed visual recognition from a domain adaptation perspective. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7610–7619 (2020)
- [20] Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., de las Casas, D., Hanna, E.B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L.R., Saulnier, L., Lachaux, M.A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T.L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mixtral of experts (2024), https://arxiv.org/abs/2401.04088
- [21] Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: Decoupling representation and classifier for long-tailed recognition. arXiv preprint arXiv:1910.09217 (2019)
- [22] Kim, J., Jeong, J., Shin, J.: M2m: Imbalanced classification via major-to-minor translation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13896–13905 (2020)
- [23] Kuha, J.: Aic and bic: Comparisons of assumptions and performance. Sociological methods & research 33(2), 188–229 (2004)
- [24] Lebichot, B., Paldino, G.M., Siblini, W., He-Guelton, L., Oblé, F., Bontempi, G.: Incremental learning strategies for credit cards fraud detection. International Journal of Data Science and Analytics 12(2), 165–174 (2021)
- [25] Li, C., Wang, W., Du, W., Peng, W.: Look around! A neighbor relation graph learning framework for real estate appraisal. In: PKDD (4). Lecture Notes in Computer Science, vol. 14648, pp. 3–16. Springer (2024)
- [26] Li, M., Cheung, Y.m., Lu, Y.: Long-tailed visual recognition via gaussian clouded logit adjustment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6929–6938 (2022)
- [27] Li, M., Zhikai, H., Lu, Y., Lan, W., Cheung, Y.m., Huang, H.: Feature fusion from head to tail for long-tailed visual recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 13581–13589 (2024)
- [28] Menon, A.K., Jayasumana, S., Rawat, A.S., Jain, H., Veit, A., Kumar, S.: Long-tail learning via logit adjustment. arXiv preprint arXiv:2007.07314 (2020)
- [29] Nash, W., Sellers, T., Talbot, S., Cawthorn, A., Ford, W.: Uci machine learning repository: Abalone data set (1994), https://archive.ics.uci.edu/ml/datasets/abalone, accessed: 2024-07-30
- [30] Park, S., Hong, Y., Heo, B., Yun, S., Choi, J.Y.: The majority can help the minority: Context-rich minority oversampling for long-tailed classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6887–6896 (2022)
- [31] Peng, H., Sun, M., Li, P.: Optimal transport for long-tailed recognition with learnable cost matrix. In: International conference on learning representations (2021)
- [32] Ren, J., Yu, C., Ma, X., Zhao, H., Yi, S., et al.: Balanced meta-softmax for long-tailed visual recognition. Advances in neural information processing systems 33, 4175–4186 (2020)
- [33] Ren, J., Zhang, M., Yu, C., Liu, Z.: Balanced mse for imbalanced visual regression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7926–7935 (2022)
- [34] Ribeiro, R.P., Moniz, N.: Imbalanced regression and extreme value prediction. Machine Learning 109, 1803–1835 (2020)
- [35] Steininger, M., Kobs, K., Davidson, P., Krause, A., Hotho, A.: Density-based weighting for imbalanced regression. Machine Learning 110, 2187–2211 (2021)
- [36] Tian, J., Liu, Y.C., Glaser, N., Hsu, Y.C., Kira, Z.: Posterior re-calibration for imbalanced datasets. Advances in neural information processing systems 33, 8101–8113 (2020)
- [37] Torgo, L., Ribeiro, R.P., Pfahringer, B., Branco, P.: Smote for regression. In: Portuguese conference on artificial intelligence. pp. 378–389. Springer (2013)
- [38] Wang, D., Fu, Y., Liu, K., Chen, F., Wang, P., Lu, C.T.: Automated urban planning for reimagining city configuration via adversarial learning: quantification, generation, and evaluation. ACM Transactions on Spatial Algorithms and Systems 9(1), 1–24 (2023)
- [39] Wang, X., Lian, L., Miao, Z., Liu, Z., Yu, S.X.: Long-tailed recognition by routing diverse distribution-aware experts. arXiv preprint arXiv:2010.01809 (2020)
- [40] Wang, Z., Wang, H.: Variational imbalanced regression: Fair uncertainty quantification via probabilistic smoothing. Advances in Neural Information Processing Systems 36 (2024)
- [41] Wen, Y., Zhang, K., Li, Z., Qiao, Y.: A discriminative feature learning approach for deep face recognition. In: Computer vision–ECCV 2016: 14th European conference, amsterdam, the netherlands, October 11–14, 2016, proceedings, part VII 14. pp. 499–515. Springer (2016)
- [42] Yang, Y., Zha, K., Chen, Y., Wang, H., Katabi, D.: Delving into deep imbalanced regression. In: International conference on machine learning. pp. 11842–11851. PMLR (2021)
- [43] Yigitcanlar, T., Kankanamge, N., Regona, M., Ruiz Maldonado, A., Rowan, B., Ryu, A., Desouza, K.C., Corchado, J.M., Mehmood, R., Li, R.Y.M.: Artificial intelligence technologies and related urban planning and development concepts: How are they perceived and utilized in australia? Journal of Open Innovation: Technology, Market, and Complexity 6(4), 187 (2020)
- [44] Yoon, J., Zhang, Y., Jordon, J., Van der Schaar, M.: Vime: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems 33, 11033–11043 (2020)
- [45] Zhang, S., Yang, L., Mi, M.B., Zheng, X., Yao, A.: Improving deep regression with ordinal entropy. arXiv preprint arXiv:2301.08915 (2023)
- [46] Zhang, Y., Hooi, B., Hong, L., Feng, J.: Self-supervised aggregation of diverse experts for test-agnostic long-tailed recognition. Advances in Neural Information Processing Systems 35, 34077–34090 (2022)