MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Abstract.
Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users’ creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
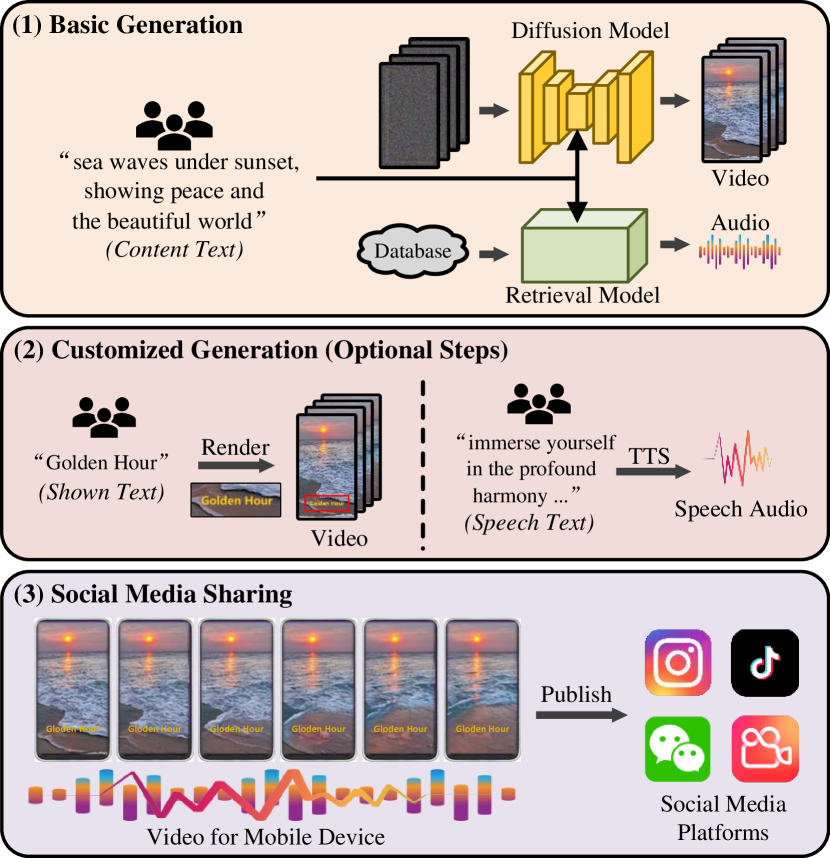
1. Introduction
The rise of mobile devices, e.g., smartphones, and the exponential growth in social media has revolutionized the way we consume video content. A prominent shift in viewing habits has occurred, with vertical videos gaining significant traction among mobile users. This paper investigates the landscape of vertical mobile video generation, focusing on the distinct challenges, opportunities, and implications it presents for content creators and consumers alike. By exploring this evolving form of visual storytelling, we uncover the transformative potential it holds for the future of content consumption. However, creating such videos is not easy for everyone, as professional skills are always required from shooting to editing.
In this paper, we present a novel system MobileVidFactory to elegantly help users create their own videos for mobile devices. In summary, our system is leading in the following aspects:
-
1)
Our system is the first automatic mobile-device video generation framework to the best of our knowledge, which can be used to generate high-quality, sounding, and vertical videos with simple text from users.
-
2)
Our system contains both deep networks to generate the basic visual and auditory content, and fixed modules to add customized content for users, where all components are controlled by text mainly. This makes our system meet different needs of users as much as possible and operate easily.
-
3)
Our system is able to learn to synthesize open-domain high-quality vertical videos after finetuning with a few vertical video data, as we design an efficient training strategy to learn motion information from large-scale horizontal video datasets and migrate it losslessly to vertical video.
2. System
We aim to automatically generate vertical videos that can be directly used on mobile devices and can be easily controlled by simple texts from users. As shown in Fig.1, our system contains two generation processes: basic generation, which produces the elemental video and audio, and customized generation, which offers the option to add screen text and dubbing.
2.1. Basic Generation
In the basic generation, not like prior works (Ruan et al., 2023; Liu et al., 2023), we independently produce the visual and auditory content. The video is synthesized using a diffusion model, and the audio is obtained through a retrieval model. To generate high-quality vertical videos, we pretrain our model on a large-scale horizontal video dataset (Bain et al., 2021; Wang et al., 2023b), and adapt it to the vertical generation using a few vertical data. Specifically, we firstly extend a pretrained image diffusion model (Rombach et al., 2022; Stability-AI, 2022) to fit the spatial distribution (e.g., new aspect ratio and picture style) of the video dataset by adding learnable blocks in each level of the U-Net (Ronneberger et al., 2015) network, and only train these blocks while fixing all pretrained layers. Then, building upon previous works (Singer et al., 2022; Blattmann et al., 2023), we add new temporal layers, including temporal 1D residual blocks and transformer blocks (Vaswani et al., 2017), and utilize the video dataset to train these additional layers (Zhu et al., 2023). After pretraining, we fix all layers except for the ones added to adjust the spatial distribution. We then finetune these spatial blocks to adapt to the vertical screens of mobile devices using some collected data. Additionally, we provide a frame interpolation module (Li et al., 2023; Liu et al., 2022) to achieve smoother motion in certain cases. To match vivid audio to the visual content, we adopt the previous work (Oncescu et al., 2021; Koepke et al., 2022) as our retrieval model. The network employs a text encoder and an audio encoder to encode text and audio data, respectively. It then evaluates the distance between the encoded features of multiple pairs to search for the most relevant sample. This retrieval model is trained using a contrastive ranking loss. In our scenario, we directly use the textual content provided by users to retrieve the top 3 matching audios from the database. Users can then choose their favorite audio and select the most appropriate section to add to the video.
2.2. Customized Generation
In our system, we design two optional customized functions for users. First, we support adding customized screen text to the video, as the addition of text to short mobile videos can provide context, clarify concepts, and enhance viewer engagement. Text overlays also promote accessibility for individuals with hearing impairments and cater to diverse audiences. With the provided text to be shown, the specified font size and font color to use, and the designated position to place, our system directly overlays the text on top of the video for rendering. Second, to add a personal touch, enhance storytelling, provide explanations, and foster a sense of authenticity, our system allows users to add dubbing to their videos. Using sentences from users, we utilize bark (Wang et al., 2023a) to transform the text into dubbing, known as text-to-speech (TTS). In this process, users can choose the voice they prefer, and various languages, such as English and Chinese, are well supported.

2.3. Demonstration
We demonstrate some generated videos in Fig.2. Focusing on the vertical videos for mobile devices, our system can synthesize frames with abundant details and create compositions that highlight the subject. Additionally, smooth motion can be captured to describe vivid scenes. More samples are included in our video.
3. Conclusion
In this paper, we present MobileVidFactory, a system that automatically generates vertical videos for mobile devices using text inputs. The system consists of a visual generator that creates high-quality videos by leveraging a pretrained image diffusion model and a finetuning process. Users can enrich visual expression by adding specified texts. The audio generator matches suitable background sounds from a database and provides optional text-to-speech narration.
References
- (1)
- Bain et al. (2021) Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. 2021. Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval. In ICCV.
- Blattmann et al. (2023) Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023. Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models. In CVPR.
- Koepke et al. (2022) A. Sophia Koepke, Andreea-Maria Oncescu, João F. Henriques, Zeynep Akata, and Samuel Albanie. 2022. Audio Retrieval with Natural Language Queries: A Benchmark Study. IEEE TMM (2022).
- Li et al. (2023) Zhen Li, Zuo-Liang Zhu, Linghao Han, Qibin Hou, Chun-Le Guo, and Ming-Ming Cheng. 2023. AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation. In CVPR.
- Liu et al. (2022) Chengxu Liu, Huan Yang, Jianlong Fu, and Xueming Qian. 2022. TTVFI: Learning Trajectory-Aware Transformer for Video Frame Interpolation. CoRR arXiv (2022).
- Liu et al. (2023) Jiawei Liu, Weining Wang, Sihan Chen, Xinxin Zhu, and Jing Liu. 2023. Sounding Video Generator: A Unified Framework for Text-guided Sounding Video Generation. arXiv (2023).
- Oncescu et al. (2021) Andreea-Maria Oncescu, A. Sophia Koepke, João F. Henriques, Zeynep Akata, and Samuel Albanie. 2021. Audio Retrieval with Natural Language Queries. In Interspeech.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In CVPR.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI.
- Ruan et al. (2023) Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. 2023. MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation. (2023).
- Singer et al. (2022) Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. 2022. Make-A-Video: Text-to-video generation without text-video data. arXiv (2022).
- Stability-AI (2022) Stability-AI. 2022. Stable Diffusion. https://github.com/Stability-AI/StableDiffusion.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In NeurIPS.
- Wang et al. (2023a) Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. 2023a. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv (2023).
- Wang et al. (2023b) Wenjing Wang, Huan Yang, Zixi Tuo, Huiguo He, Junchen Zhu, Jianlong Fu, and Jiaying Liu. 2023b. VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation. arXiv (2023).
- Zhu et al. (2023) Junchen Zhu, Huan Yang, Huiguo He, Wenjing Wang, Zixi Tuo, Wen-Huang Cheng, Lianli Gao, Jingkuan Song, and Jianlong Fu. 2023. MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images. In ACM MM BNI.