propositiontheorem\aliascntresettheproposition \newaliascntcorollarytheorem\aliascntresetthecorollary \newaliascntlemmatheorem\aliascntresetthelemma
Model-adapted Fourier sampling for generative compressed sensing
Abstract
We study generative compressed sensing when the measurement matrix is randomly subsampled from a unitary matrix (with the DFT as an important special case). It was recently shown that uniformly random Fourier measurements are sufficient to recover signals in the range of a neural network of depth , where each component of the so-called local coherence vector quantifies the alignment of a corresponding Fourier vector with the range of . We construct a model-adapted sampling strategy with an improved sample complexity of measurements. This is enabled by: (1) new theoretical recovery guarantees that we develop for nonuniformly random sampling distributions and then (2) optimizing the sampling distribution to minimize the number of measurements needed for these guarantees. This development offers a sample complexity applicable to natural signal classes, which are often almost maximally coherent with low Fourier frequencies. Finally, we consider a surrogate sampling scheme, and validate its performance in recovery experiments using the CelebA dataset.
1 Introduction
Compressed sensing considers signals with high ambient dimension that belong to (or can be well-approximated by elements of) a prior set with lower “complexity” than the ambient space. The aim is to recover (an approximation to) such signals with provable accuracy guarantees from the linear, typically noisy, measurements , where denotes noise and with is an appropriately chosen (possibly random) measurement matrix. The signal is to be recovered by means of a computationally feasible method that utilizes the structure of and has access to only and . In classical compressed sensing, is the set of sparse vectors. In generative compressed sensing, the prior set is chosen to be the range of a generative neural network , an idea that was first explored in [5]. Our results will hold for ReLU-activated neural networks as defined in [4, Definition I.2]. Here we denote the ReLU (Rectified Linear Unit) activation as , applied component-wise to a real vector .
Definition 1.1 (-Generative Network).
With , fix the integers , and for , let . A -generative network is a function of the form
In the same work [5], the authors provided a theoretical framework for generative compressed sensing with having independent identically distributed (i.i.d.) Gaussian entries. However, the assumption of Gaussian measurements is unrealistic for applications like MRI, where measurements are spatial Fourier transforms. Limitations of the hardware in such an application restrict the set of possible measurements to the rows of a fixed unitary matrix (or approximately so, up to discretization of the measurements). Hence we consider the more realistic subsampled unitary measurement matrices, i.e., matrices with rows randomly subsampled from the rows of a unitary matrix .
A first result in the generative setting with subsampled unitary measurements [4] shows that for well-behaved networks, (up to log factors) measurements is sufficient for recovery with high probability. However, sampling uniformly is not efficient; sampling more informative measurements at a higher rate is known to improve performance in compressed sensing (e.g., low Fourier frequencies have strong correlation with natural images, they will therefore tend to be more informative) [3]. This idea is mirrored in the radial sampling strategy used in MRI scans, which takes a disproportionate number of low-frequency measurements [15]. We address this limitation by generalizing the theory to any measurement matrix of the form where is a unitary matrix and is a sampling matrix, which we now define. We adopt the convention that denotes a canonical basis vector and that is the simplex in . See Section 1 for the definition of symbols throughout this paper.
Definition 1.2 (Sampling Matrix).
We define a sampling matrix to be any matrix composed of i.i.d. row vectors such that for all , for some fixed probability vector .
We will further show, similarly to [18], that picking the sampling probabilities in a manner informed by the geometry of the problem yields improved recovery guarantees relative to the uniform case. Specifically, we provide a bound on the measurement complexity of even for models which are highly aligned with a small subset of the rows of . To find good sampling probabilities, we must understand that measurements (i.e. the rows of the measurement matrix) are effective for a prior set if they help differentiate between signals in . Therefore, we consider the alignment of rows of with the set (where the difference is in the sense of a Minkowski sum, see Section 1). We will sample rows of that have a high degree of alignment with at a higher rate. For technical reasons, we consider alignments with a slightly larger set, given by the following set operator previously introduced in [4, Definition 2.1].
Definition 1.3 (Piecewise Linear Expansion).
Let be the union of convex cones: . Define the piecewise linear expansion
The piecewise linear expansion is a well-defined set operator as shown in [4, Remark A.2]. Specifically, it is independent of the choice of convex cones .
We require the following quantity to quantify the alignment of the individual vectors with the prior set.
Definition 1.4 (local coherence).
The local coherence of a vector with respect to a cone is defined as
The local coherences of a unitary matrix with respect to a cone are collected in the vector with entries , where is the row of .
By using the local coherences of to inform sampling probabilities, we will show that recovery occurs from only (up to log factors) measurements with high probability.

Prior Work
Sampling with non-uniform probabilities was the subject of a line of research in classical compressed sensing. Seminal works involving the notion of local coherence in classical compressed sensing are [10, 11, 18, 19]. There have been quantities analogous to the local coherence appearing in the literature, such as Christoffel functions [16] and leverage scores [7, 14], which were recently introduced in machine learning in the context of, e.g., kernel-based methods [8] and deep learning [1].
While writing this manuscript, we became aware of the recent paper [2]. This work presents a framework for optimizing sampling in general scenarios based on the so-called generalized Christoffel function, a quantity that admits the (squared) local coherence considered here as a particular case. Furthermore, the method we use to numerically approximate the coherence in Section 3 can be seen as a special case of that proposed in [2]. However, the results in [2] assume that is a union of low-dimensional subspaces. Hence, they are not directly applicable to the case of generative compressed sensing with ReLU networks, for which is in general only contained in a union of low-dimensional subspaces. On the other hand, our theory explicitly covers the case of generative compressed sensing, and illustrates how sufficient conditions on leading to successful signal recovery depend on the generative network’s parameters . Second, we provide recovery guarantees that hold with high probability, as opposed to expectation.
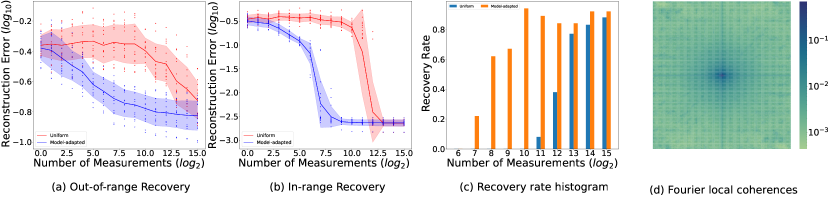
The present work directly improves on results from [4] by improving the sample complexity from to when the sampling probabilities are adapted to the generative model used. This is a sizable improvement in performance guarantees for a significant class of realistic generative models. It can be understood as extending the theory of generative compressed sensing with Fourier measurements to many realistic settings where we provide nearly order-optimal bounds on the sampling complexity. Indeed, in the context of the main result from [4], “favourable coherence” corresponds to where is an absolute constant. Despite the fact that the prior generated by a neural network with Gaussian weights will have such a coherence [4], we observe empirically in Figure 2d) that for a trained generative model, a small number of Fourier coefficients have values close to one. In such cases, the main result from [4] becomes vacuous while Theorem 2.1 remains meaningful.
Notation
For any map , we denote to be the range of . We define the simplex , and the sphere . For any matrix , we denote its pseudo-inverse by . For a set we denote its self-difference . We define to be the orthogonal projection on to a set in the sense that is a single element from the set . We let . We denote to be the the canonical inner product in or depending on the context.
2 Main Result
We now state the main result of this paper, where we give an upper bound on the sample complexity required for signal recovery. The accuracy of the recovery is dependent on the measurement noise, the modelling error (how far the signal is from the prior), and imperfect optimization. These are denoted, respectively, by and below.
Theorem 2.1.
Fix a -generative network , the cone , the unitary matrix . Let be the vector of local coherences of with respect to . Let with the corresponding random sampling matrix. Let be the diagonal matrix with entries . Let . Let . If
for an absolute constant, then with probability at least over the realization of the following statement holds.
Statement 2.1.
For any choice of and , let and , and any satisfying . We have that
Remark 2.1.
The matrix has a vector of diagonal entries satisfying . ∎
Remark 2.2.
We give a generalization of this result to arbitrary sampling probability vectors in Theorem A3.1. ∎
3 Numerics
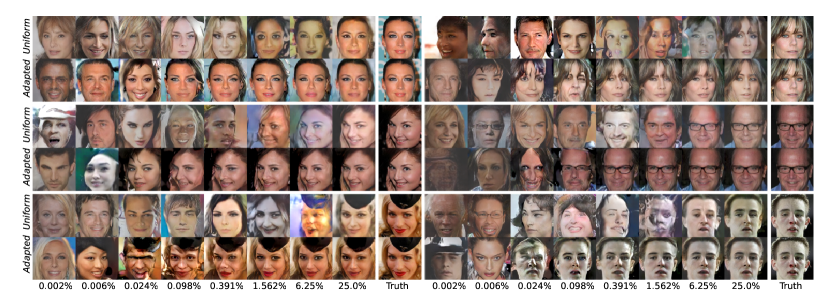
In this section, we provide empirical evidence of the connection between coherence-based non-uniform sampling and recovery error. By presenting visual (Figure 1) and quantitative (Figure 2) evidence, we validate that model-adapted sampling using a coherence-informed probability vector can outperform a uniform sampling scheme — requiring fewer measurements for successful recovery.
Coherence heuristic
Ideally, we would compute the local coherence using Definition 1.4, but to our knowledge computing local coherence is intractable for generative models relevant to practical settings [4]. Thus, we approximate the quantity by sampling points from the range of the generative model and computing the local coherence from the sampled points instead. Specifically, we sample codes from the latent space of the generative model to generate a batch of images with shape , where stand for batch size, number of channels, image height and image width respectively. Then, we compute the set self-difference of the image batch, and normalize each difference vector. This gives a tensor of shape . We perform a channel-wise two-dimensional Discrete Fourier Transform (DFT) on the tensor, take the element-wise modulus, and then maximize over the batch dimension. This results in a coherence tensor with shape To obtain the coherence-informed probability vector of each channel, we first square element-wise, then we normalize channel-wise. To estimate the local coherences of our generative model we use a batch size of 5000 and employ the DFT from PyTorch [17].
In-Range vs Out-of-Range Signals
We run signal recovery experiments for two kinds of images: when the signals are conditioned to be in the range of the generative model (in-range signals), and when they are directly picked from the validation set (out-of-range signals). The in-range signals are randomly generated (with Gaussian codes) by the same generative network that we use for recovery. This ensures that these signals lie within the prior set. In the out-of-range setting, a residual recovery error can be observed even with large numbers of measurements Figure 2. This error occurs because of the so-called model mismatch; there is some distance between the prior set and the signals.
Procedure for Signal Recovery
The way we perform signal recovery goes as follows. For a given image , we create a mask by randomly sampling with replacement times for each channel according to the probability vector. Let be the channel-wise DFT operator and be the generative neural network (where we omit the batch dimension for simplicity). We denote to be the element-wise tensor multiplication and to be the Frobenius norm. We approximately solve the optimization program by running AdamW [13] with and for 20000 iterations on four different random initializations, and pick the code that achieves the lowest loss. The recovered signal is then . We measure the quality of the signal recovery by using the relative recovery error (rre),
Observe that Figure 2b) demonstrates the efficiency of model-adapted sampling. Signal recovery with adapted sampling occurs with times fewer measurements than when using uniform sampling. Similar performance gains can be observed visually in Figure 1 and Figure 3. Comparing the number of measurements to the ambient dimension, we see from Figure 2d) that signal recovery occurs with .
There are a few ways these numerical experiments do not directly match our theory. The sampling is done channel wise, which is technically block sampling [3]. Also, the signal recovery is performed without the preconditioning factor that appears in Theorem 2.1.
4 Conclusion
In this paper we bring together the ideas used to quantify the compatibility of generative models with subsampled unitary measurements, which were first explored in [4], with ideas of non-uniform sampling from classical compressed sensing. We present the first theoretical result applying coherence-based sampling (similar to leverage score sampling, or Christoffel function sampling) to the setting where the prior is a ReLU generative neural network. We find that adapting the sampling scheme to the geometry of the problem yields substantially improved sampling complexities for many realistic generative networks, and that this improvement is significant in empirical experiments.
Possible avenues for future research include extending the theory presented in [2] to ReLU nets by using methods introduced in the present work. This would yield the benefit of extending the theory from this paper to a number of realistic sampling schemes. A second research direction consists of investigating the optimality of the sample complexity bound that we present in this paper. The sample complexity that we guarantee includes a factor of when the generative model is well-behaved. Whether this dependence can be reduced to , as is the case when the measurement matrix is Gaussian, is an interesting problem that remains open. Finally, the class of neural networks considered in this work could be expanded to include more realistic ones.
pages1 Rpages1 Rpages10 Rpages21 Rpages15 Rpages14 Rpages11 Rpages9 Rpages1 Rpages165 Rpages12 Rpages4 Rpages17
References
- [1] Ben Adcock, Juan M Cardenas and Nick Dexter “CAS4DL: Christoffel adaptive sampling for function approximation via deep learning” In Sampling Theory, Signal Processing, and Data Analysis 20.2 Springer, 2022, pp. 21
- [2] Ben Adcock, Juan M. Cardenas and Nick Dexter “CS4ML: A General Framework for Active Learning with Arbitrary Data Based on Christoffel Functions” arXiv, 2023 arXiv:2306.00945 [cs, math]
- [3] Ben Adcock and Anders C. Hansen “Compressive Imaging: Structure, Sampling, Learning” Cambridge: Cambridge University Press, 2021 DOI: 10.1017/9781108377447
- [4] Aaron Berk et al. “A Coherence Parameter Characterizing Generative Compressed Sensing with Fourier Measurements” In IEEE Journal on Selected Areas in Information Theory, 2022, pp. 1–1 DOI: 10.1109/JSAIT.2022.3220196
- [5] Ashish Bora, Ajil Jalal, Eric Price and Alexandros G. Dimakis “Compressed Sensing Using Generative Models” In Proceedings of the 34th International Conference on Machine Learning PMLR, 2017, pp. 537–546
- [6] E.J. Candes, J. Romberg and T. Tao “Robust Uncertainty Principles: Exact Signal Reconstruction from Highly Incomplete Frequency Information” In IEEE Transactions on Information Theory 52.2, 2006, pp. 489–509 DOI: 10.1109/TIT.2005.862083
- [7] Samprit Chatterjee and Ali S Hadi “Influential observations, high leverage points, and outliers in linear regression” In Statistical science JSTOR, 1986, pp. 379–393
- [8] Tamás Erdélyi, Cameron Musco and Christopher Musco “Fourier sparse leverage scores and approximate kernel learning” In Advances in Neural Information Processing Systems 33, 2020, pp. 109–122
- [9] Simon Foucart and Holger Rauhut “A Mathematical Introduction to Compressive Sensing” Springer New York, 2013
- [10] Felix Krahmer, Holger Rauhut and Rachel Ward “Local Coherence Sampling in Compressed Sensing” In Proceedings of the 10th International Conference on Sampling Theory and Applications
- [11] Felix Krahmer and Rachel Ward “Stable and Robust Sampling Strategies for Compressive Imaging” In IEEE Transactions on Image Processing 23.2, 2014, pp. 612–622 DOI: 10.1109/TIP.2013.2288004
- [12] Ziwei Liu, Ping Luo, Xiaogang Wang and Xiaoou Tang “Deep Learning Face Attributes in the Wild” In Proceedings of International Conference on Computer Vision (ICCV), 2015
- [13] Ilya Loshchilov and Frank Hutter “Decoupled Weight Decay Regularization”, 2019 arXiv:1711.05101 [cs.LG]
- [14] Ping Ma, Michael Mahoney and Bin Yu “A statistical perspective on algorithmic leveraging” In International conference on machine learning, 2014, pp. 91–99 PMLR
- [15] Maria Murad et al. “Radial Undersampling-Based Interpolation Scheme for Multislice CSMRI Reconstruction Techniques” In BioMed Research International 2021, 2021, pp. 6638588 DOI: 10.1155/2021/6638588
- [16] Paul Nevai “Géza Freud, orthogonal polynomials and Christoffel functions. A case study” In Journal of Approximation Theory 48.1, 1986, pp. 3–167 DOI: https://doi.org/10.1016/0021-9045(86)90016-X
- [17] Adam Paszke et al. “PyTorch: An Imperative Style, High-Performance Deep Learning Library” In Advances in Neural Information Processing Systems 32 Curran Associates, Inc., 2019, pp. 8024–8035 URL: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- [18] Gilles Puy, Pierre Vandergheynst and Yves Wiaux “On Variable Density Compressive Sampling” In IEEE Signal Processing Letters 18.10, 2011, pp. 595–598 DOI: 10.1109/LSP.2011.2163712
- [19] Holger Rauhut and Rachel Ward “Sparse Legendre Expansions via 1-Minimization” In Journal of Approximation Theory 164.5, 2012, pp. 517–533 DOI: 10.1016/j.jat.2012.01.008
- [20] Roman Vershynin “High-Dimensional Probability: An Introduction with Applications in Data Science” Cambridge University Press, 2018
- [21] Yuanbo Xiangli et al. “Real or Not Real, that is the Question” In International Conference on Learning Representations, 2020
This supplementary material contains acknowledgements, a generalization of Theorem 2.1, the proof of said generalization, properties of the piecewise linear expansion, and additional image recoveries both in-range and out-of-range.
Appendix A1 Acknowledgements
The authors acknowledge Ben Adcock for providing feedback on a preliminary version of this paper. S. Brugiapaglia acknowledges the support of the Natural Sciences and Engineering Research Council of Canada (NSERC) through grant RGPIN-2020- 06766 and the Fonds de Recherche du Québec Nature et Technologies (FRQNT) through grant 313276. Y. Plan is partially supported by an NSERC Discovery Grant (GR009284), an NSERC Discovery Accelerator Supplement (GR007657), and a Tier II Canada Research Chair in Data Science (GR009243). O. Yilmaz was supported by an NSERC Discovery Grant (22R82411) O. Yilmaz also acknowledges support by the Pacific Institute for the Mathematical Sciences (PIMS).
Appendix A2 Additional Notation
In this work we make use of absolute constants which we always label . Any constant labelled is implicitly understood to be absolute and has a value that may differ from one appearance to the next. We write to mean . We denote by the operator norm, and by the euclidean norm. We use capital letters for matrices and boldface lowercase letters for vectors. For some matrix , we denote by (lowercase of the letter symbolizing the matrix) the row vector of , meaning that . For a vector , we denote by its entry. We let be the canonical basis of .
Appendix A3 Generalized Main Result
We present a generalization of Theorem 2.1 which provides recovery guarantees for arbitrary sampling probabilities. To quantify the quality of the interaction between the generative model , the unitary matrix , and the sampling probability vector , we introduce the following quantity.
Definition A3.1.
Let be a cone. Let be a unitary matrix and . Let the local coherences of with respect to . Then define the quanity
We can now state the following.
Theorem A3.1 (Generalized Main Result).
Fix the -generative network , the cone , the unitary matrix , the probability vector , and the corresponding random sampling matrix . Let be a diagonal matrix with entries . Let . Let be the vector of local coherences of with respect to . Let .
Suppose that
Furthermore, if we pick the sampling probability vector
we only require that
Then with probability at least over the realization of , Statement 2.1 holds.
This theorem is strictly more general than Theorem 2.1. It is therefore sufficient to prove the generalized version, which we do in the next section.
Remark A3.1.
The result [4, Theorem 2.1] is a corollary of Theorem 2.1; it follows from taking as the uniform probability vector. ∎
Appendix A4 Proof of Theorem A3.1
Definition A4.1 (Restricted Isometry Property).
Let be a cone and a matrix. We say that satisfies the Restricted Isometry Property (RIP) when
Note that the constant is a specific choice made in order to simplify the presentation of this proof. It could be replaced by any generic absolute constant in .
The following lemma says that if, conditioning on , has the RIP on , then we have signal recovery.
Lemma \thelemma (RIP of a Subsampled and Preconditioned Matrix Yields Recovery).
Let be a cone, be a unitary matrix, a matrix with all rows in the canonical basis of . Let be a diagonal matrix. Let .
If has the RIP on the cone , then Statement 2.1 holds.
See the proof in Appendix Appendix A5.
We now proceed to prove a slightly stronger statement than what is required by Appendix A4; that the RIP holds on the piecewise linear expansion .
To control the complexity of , we count the number of affine pieces that it comprises. We do this with the result [4, Lemma A.6], which we re-write below for convenience.
Lemma \thelemma (Containing the Range of a ReLU Network in a Union of Subspaces).
Let be a -generative network with layer widths where and . Then is a union of no more than at-most -dimensional polyhedral cones where
From this result, we see that is contained in a union of no more than affine pieces each of dimension no more than . Then from Remark A6.1 (for the proof, see [4, Remark A.2]), the cone is a union of no more than subspaces each of dimension at-most (the factor of two will be absorbed into the absolute constant of the statement.) Fix to be any one of these subspaces. Then the following lemma implies that the matrix has the RIP on with high probability.
Lemma \thelemma (Deviation of Subsampled Preconditioned Unitary Matrix on a Subspace).
Let be a unitary matrix, and a random sampling matrix associated with the probability vector . Let be a diagonal pre-conditioning matrix with entries . Let . Let be a subspace of dimension . Then
| (1) |
with probability at least .
See the proof in Appendix A5.
Since we have that . Using this fact to upper-bound the r.h.s. of Equation 1, we find an identical concentration inequality that applies to each of the subspaces constituting . By using Appendix A4 to bound the number of subspaces, we control the deviation of uniformly over all the subspaces constituting with a union bound. We find that, with probability at least ,
For the method by which we applied the union bound, see [4, Lemma A.2]. In the r.h.s. of the equation above, the second term dominates the first, so the expression simplifies to
| (2) |
By fixing we find that the RIP holds with probability at least on when
| (3) |
Then we find that the first part of Theorem A3.1 follows from Appendix A4.
The second sufficient condition on follows from picking so as to minimize the factor in Equation 3.
Lemma \thelemma (Adapting the Sampling Scheme to the Model).
Let be a unitary matrix, and a random sampling matrix associated with the probability vector . Let be the local coherences of with respect to a cone .
It achieves a value of
See the proof.
Applying Appendix A4 to Equation 3 concludes the proof of Theorem A3.1.
Appendix A5 Proof of the Lemmas
Proof of Appendix A4.
Let be a unitary matrix, and a random sampling matrix associated with the probability vector . Let be a diagonal matrix with entries . Let .
We let and . By left-multiplying the equation by we get . Notice that the linear operator has the RIP by assumption.
By triangle inequality and the observation that ,
Since , with the RIP property we find that
Assembling the two inequalities gives
Finally, we apply triangle inequality to get
∎
Proof of Appendix A4.
In what follows, we will use that , where is the matrix with rows chosen to be any fixed orthonormal basis of . Indeed, notice that , the orthonormal projection on to . Now consider
The second equality above follows from a change of variables . Since the matrix within the square bracket is symmetric, the last expression we find above corresponds to an operator norm.
| (4) | ||||
| (5) |
This is a sum of independent random matrices because the sampling matrix matrix is random and has independent rows. We now consider what will be the central ingredient of this proof: the Matrix Bernstein concentration bound [20, Theorem 5.4.1]. We will use it to bound Equation 5.
Lemma \thelemma (Matrix Bernstein).
Let be independent, mean zero, symmetric random matrices, such that almost surely for all i. Then, for every , we have
where .
To compute and , we notice that we can write
for the random vectors . These vectors have two key properties. First, they are isotropic; this is the property that
The isotropic property gives us immediately that, as required, the matrices are mean-zero.
The second property of the vectors is that they have bounded magnitude almost surely.
Let for conciseness. We proceed to compute a value for . By triangle inequality and property of the operator norm of rank one matrices, we see that
The last inequality holds because of the lower bound , which we now justify. Consider that from Appendix A4 we have that , and furthermore that for any fixed one-dimensional subspace , we have that for a unit vector . This gives us the desired lower bound by monotonicity of over set containment.
We now compute similarly [3, Lemma 12.21]: Then
The second equality holds because the matrix is symmetric non-negative definite, and the last inequality is obtained by dropping the second negative term.
Then applying the Matrix Bernstein yields
Substituting with Equation 5, we get
We would like to get our result in terms of the norm without the square. For this purpose we make use of the “square-root trick” that can be found in [20, Theorem 3.1.1]. We re-write the above as
We make the substitution , which yields
With the restricted inequality , we infer that
Finally, with another substitution we write that
with probability at least . ∎
Proof of Appendix A4.
It suffices to show that satisfies
The vector achieves a value of
which is the minimum. Indeed, for any fixed vector ,
The inequality above holds because the r.h.s. is a convex combination of the terms , and is therefore upper-bounded by the maximum element of the combination. By letting , we get
Therefore, . ∎
Appendix A6 Properties of the Piecewise Linear Expansion
The following is a subset of the elements in remark [4, Remark A.2], to which we refer the reader for the proof.
Remark A6.1 (Properties of the Piecewise Linear Expansion).
Below we list several properties about . Let be the union of convex cones .
-
1.
The set is uniquely defined. In particular, it is independent of the (finite) decomposition of into convex cones.
-
2.
If , then is a union of no more than at-most -dimensional linear subspaces.
-
3.
The set satisfies .
-
4.
There are choices of for which (for instance, refer to the example at the end of this section).
∎
Appendix A7 Experimental Specifications
CelebA with RealnessGAN
CelebFaces Attributes Dataset (CelebA) is a dataset with over 200,000 celebrity face images [12]. We train a model on most images of the CelebA dataset, leaving out 2000 images to comprise a validation set. We crop the colour images to 256 by 256, leading to 256 256 3 = 196608 pixels per image. On this dataset, we train a RealnessGAN with the same training setup as described in [21], substituting the last Tanh layer with HardTanh, a linearized version of Tanh, to fit in our theoretical framework. See [21] for more training and architecture details.
Appendix A8 Additional Image Recoveries