Model Review: A PROMISEing Opportunity
Abstract.
To make models more understandable and correctable, I propose that the PROMISE community pivots to the problem of model review. Over the years, there have been many reports that very simple models can perform exceptionally well. Yet, where are the researchers asking “say, does that mean that we could make software analytics simpler and more comprehensible?” This is an important question, since humans often have difficulty accurately assessing complex models (leading to unreliable and sometimes dangerous results).
Prior PROMISE results have shown that data mining can effectively summarizing large models/ data sets into simpler and smaller ones. Therefore, the PROMISE community has the skills and experience needed to redefine, simplify, and improve the relationship between humans and AI.
1. Introduction
PROMISE will soon enter its third decade. What have we learned from two decades of PROMISE v1.0 that could shape the next decade of PROMISE v2.0?
Over the years, there have been many results where very simple models performed exceptionally well (Holte, 1993; Menzies et al., 2008; Agrawal et al., 2019; Xu et al., 2021; Tawosi et al., 2023; Kohavi and John, 1997). Using those results, PROMISE v2.0 could focus less on model creation, and more on something that requires and demands simpler and more comprehensible models. Specifically, I say PROMISE v2.0 should be about simplifying model review (using data mining).
2. Why Change PROMISE?
PROMISE v1.0 was created one night in 2004 walking around Chicago’s Grant Park. Jelber Sayyad-Shirabad and I had spent the day at a disappointing workshop on data mining and SE. “Must do better”, we said. “Why don’t we do it like in ML? Make conclusions reproducible? Demand that if people publish a paper, they should also publish the data used in that data?"111 In 2023 it is hard to believe that “reproducible SE” was a radical idea. But once upon a time, there was little sharing of data and scripts– so much so that in 2006 Lionel Briand predicted the failure of PROMISE saying “no one will give you data”..
At first, the series got off to a shaky start. But once Elaine Weyuker, Thomas Ostrand, Gary Boetticher, and Guenther Ruhe joined the steering committee, the meeting earned the prestige needed for future growth. And in those early days, it was impressive to see so many researchers taking up the idea of reproducible results. Numerous papers were written that applied an increasing elaborate tool set to data like COC81, JM1, XALAN, DESHARNIS and all the other data sets that were used (and reused) in the first decade of PROMISE.
Many of those papers lead to successful research. In 2018, 20% of the articles listed in Google Scholar Software Metrics for IEEE Transactions on SE used data sets from the first decade of PROMISE. So while other research areas struggled to obtain reproducible results, PROMISE swam (as it were) in an ocean of reproducibility.
The problem was that in the second decade of PROMISE, many researchers still continue that kind of first-decade research. For example, all too often, I must review papers from authors who think it is valid to publish results based on (e.g.) the COC81 data set first published in 1981 (Boehm, 1981); the DESHARNIS data set, first published in 1989 (Desharnais, 1989); the JM1 data, first published in 2004 (Menzies and Di Stefano, 2004); or the XALAN data set, first published in 2010 (Jureczko and Madeyski, 2010)222Just to be clear, there is value in a publicly accessible collection of reference problems. For instance, if a PROMISE author is unable to present results from confidential industrial data, they can use the reference collection to construct a reproducible example of their technique. That said, I am usually tempted to reject papers that are solely based on defect datasets that I contributed to the PROMISE repository in 2005 (e.g. CM1, JM1, KC1, KC2, KC3, KC4, MC1, MC2, MW1, PC1, PC2, PC3, PC4 and PC5) since, in 2023 we have access to much more recent data (e.g. see the 1100+ recent Github projects used by Xia et al. (Xia et al., 2022))..
Meanwhile, AI fever took over SE. As of 2018, it became standard at ASE, FSE, ICSME, ICSE, etc. to see papers that make much use of AI. For example, the MSR conference (which in the early days looked like a sister event to PROMISE) has grown to a large annual A-grade venue. And just as MSR grew, so did PROMISE shrink. In 2008, PROMISE was a two-day event with 70 attendees. PROMISE is now a much smaller and shorter event. Without definitive results or a novel technological position, it became difficult to differentiate PROMISE from dozens of other, somewhat more prominent, venues.
3. Why Switch to Model Review?
Reducing the size of the model is an important part of model review. According to psychological theory (Czerlinski et al., 1999; Gigerenzer et al., 1999; Martignon et al., 2003; Brighton, 2006; Martignon et al., 2008; Gigerenzer, 2008; Phillips et al., 2017; Gigerenzer and Gaissmaier, 2011; Neth and Gigerenzer, 2015), humans can best review a system when it “fits” it into their memory; i.e., when that it comprises many small model fragments. Larkin et al. (Larkin et al., 1980) characterize human expertise by a very large long-term memory (LTM) and a very small short-term memory (STM) that contains as few as four to seven items333Ma et al. (Ma et al., 2014) have used evidence from neuroscience and functional MRIs to argue that the capacity of the STM could be better measured using other factors than “number of items “”. But even they conceded that “the concept of limited (STM) has considerable explanatory power for behavioral data”.. The LTM contains many tiny rule fragments that explore the contents of the STM to say “when you see THIS, do THAT”. When an LTM rule triggers, can rewrite the STM content, which, in turn, can trigger other rules. Experts are experts, says Larkin et al. (Larkin et al., 1980) because LTM patterns dictate what to do, without having to pause for reflection. Novices perform worse than experts, says Larkin et al., when they fill up their STM with too many to-do’s where they plan to pause and reflect on what to do next. This theory is widely endorsed. Phillips et al. (Phillips et al., 2017) discuss how models with tiny fragments can be quickly comprehended by emergency room physicians making rapid decisions; or by guard soldiers making snap decisions about whether to fire or not on a potential enemy; or by stockbrokers making instant decisions about buying or selling stock.
Complex models cannot fit into STM, leading to problems with model review. Green (Green, 2022) comments that when faced with large and complex problems, cognitive theory (Simon, 1956) tells us that humans use heuristic “cues” to lead them to the most important parts of a model. Such cues are essential if humans are to reason about large problems. That said, using cues can introduce their own errors: …people (including experts) are susceptible to “automation bias” (involving) omission errors - failing to take action because the automated system did not provide an alert - and commission error (Green, 2022). This means that oversight can lead to the opposite desired effect by “legitimizing the use of faulty and controversial (models) without addressing (their fundamental issues”) (Green, 2022).
By “faulty and controversial models”, Green refers to the long list of examples where detrimental models were learned via algorithmic means. For example, Cruz et al. (Cruz et al., 2021) lists examples where:
-
•
Proposals from low-income groups are are five times more likely to be incorrectly ignored by donation groups;
-
•
Woman can be five times more likely to be incorrectly classified as low income;
-
•
African Americans are five times more likely to languish in prison until trial, rather given the bail they deserve.
These are just a few of the many reported examples(Rudin, 2019)444See also http://tiny.cc/bad23a, http://tiny.cc/bad23b, http://tiny.cc/bad23c of algorithmic discrimination. For another example, the last chapter of Noble (Noble, 2018) describes how a successful hair salon went bankrupt due to internal choices within the YELP recommendation algorithm.
Like Mathews (Johnson and Menzies, 2023), I am not surprised that so many models are unfair. Mathews argues that everyone seeks ways to exploit some advantage for themselves. Hence, we should expect that the software we build to discriminate against some social groupings;
“People often think of their own hard work or a good decision they made. However, it is often more accurate to look at advantages like the ability to borrow money from family and friends when you are in trouble, deep network connections so that you hear about opportunities or have a human look at your application, the ability to move on from a mistake that might send someone else to jail, help at home to care for children, etc. The narrative that success comes from hard work misses that many people work hard and never succeed. Success often comes from exploiting a playing field that is far from level and when push comes to shove, we often want those advantages for our children, our family, our friends, our community, our organizations.”
Hence I assert that unfairness is a widespread issue that needs to be addressed and managed. Specifically, we need to ensure that a software system created by one group, , can be critiqued and modified by another group, . There are many ways to do this and at PROMISE’23, it is appropriate to focus on the data mining methods issues (see next section).
But first, we take care to stress that technical methods like data mining should not be used in isolation. PROMISE v2.0 should acknowledge its relationship and responsibilities to those affected by the tools we deliver. We must stop “flattening”, which is the trivialization and even ignoring of legitimate complaints that our institutions discriminate against certain social groups (Coaston, 2019). Bowleg (Bowleg, 2021) warns that flattening “depoliticized and stripped (its) attention to power, social justice, and (how we do things wrongly)”.
To address these issues, organizations should review their hiring practices to diversify the range of perspectives seen in design teams. Requirements engineering practices should be improved to include extensive communication with the stakeholders of the software. Software testing teams should extend their tests to cover issues such as discrimination against specific social groups (Cruz et al., 2021; Majumder et al., 2023; Chakraborty et al., 2021).
Further, on the legal front, Canellas (Canellas, 2021) and Mathews et al. (Matthews, 2023) suggest a tiered process in which the most potentially discriminatory projects are routinely reviewed by an independent external review team (as done in the IEEE 1012 independent V&V standard). Ben Green (Green, 2022) notes that reviewing software systems and AI systems is becoming a legislative necessity and that human-in-the-loop auditing of decisions made by software is often mandatory. Such legislation is necessary to move away from the internal application of voluntary industrial standards (since, as seen in the Volkswagen emissions scandal (see http://tiny.cc/scandalvw), companies cannot always be trusted to voluntarily apply reasonable standards.
4. How To Make Smaller Models?
How to make models smaller, more comprehensible, and easier to review? Enter all the data mining tools explored at PROMISE. In those explorations, often it was seen that
A small number of key variables control the rest.
Just to state the obvious, there is a clear connection between keys and the cognitive effort needed better review methods. Specifically: for a system with keys, we only need to look at a few keys to understanding and/or critique and/or control that system.
Outside of SE, I have seen keys in hospital nutrition analysis (Partington et al., 2015) and avionic control systems (Gay et al., 2010). Within SE, I have seen keys in:
-
•
Defect prediction datasets (Menzies et al., 2006) where two to three attributes were enough to predict for defects
-
•
Effort estimation models (Chen et al., 2005) where four to eight attributes where enough to predict for defects;
-
•
Requirements models for NASA deep space missions (Jalali et al., 2008) where two-thirds of the decision attributes could be ignored while still finding effective optimizations;
-
•
11 Github issue close time data sets (Rees-Jones et al., 2017) where only 3 attributes (median) were needed for effective prediction.
One way to see how many keys are in a system is to ask how many prototypes (minimum number of examples) are required to explore that system. At PROMISE"08, the keys were found in 50 examples (selected at random) since the models built from this small sample performed no worse than the models learned from thousands of additional examples (Menzies et al., 2008). In 2023 we made a similar observation. In a study that explored 20 years of data from 250 Github projects with 6000 commits per project (average). In that study, the defect models learned from only the first 150 commits were predicted, as well as the models learned from much larger samples (N.C. and Menzies, 2023).
| My preferred recursive bi-clustering procedure is based on the FASTMAP Nyström algorithm (Faloutsos and Lin, 1995; Platt, 2005; Papakroni, 2013). |
| This method maps points to the dimension of greatest variance, computed as follows. Find any point. Finds its furthest neighbor , then finds ’s furthest neighbor . Map all other points to the line using where =. After mapping, we divide the data on the median value. |
| The generation of contrast rules can then be used to report the minimal differences that most distinguish the desired and current leaf clusters. Specifically, treat two leaf clusters current and the desired as a two-class system. Using data just from those two clusters, apply supervised discretization based on entropy to convert all attributes into ranges. For ranges that appear at frequency in the desired, rank them according to their frequency in the current using . Build rules by exploring all combinations of the (say) top-ranked ranges. |
| Pruning heuristics can be used to report only the essential differences in the data. In greedy pruning , the distant points are evaluated, and we only recurse on the data nearest the best point. In non-greedy pruning, the whole tree is generated (without evaluations). evaluation and pruning is then applied to the largest subtrees with the fewest differences within the most variable attributes. This is repeated to generate survivors , which are then explored with the greedy approach (Lustosa and Menzies, 2023). |
Of course, not all data sets can be explored by a few dozen keys. Recently, we have successfully modeled security violations in 28,750 Mozilla functions with 271 exemplars and 6000 Github commits using just 300 exemplars (Yu et al., 2019)555Specifically, after incremental active learning, the SVM had under 300 support vectors.. Although 300 is not an especially small number, it is small enough so that, given (say) two analysts and a month, it would be possible to review them all.
Note that keys have obvious implications for software testing. Ling (Ling and Menzies, 2023) generates test suites for cyberphysical systems by first finding prototypes. In that work, candidate tests are recursively bi-clustered to leaves of size (using the methods of Table 1). Test suites generated from the mode of each cluster are orders of magnitude faster to generate and just as effective as tests generated by more complex (and slower) methods.
This recursive bi-clustering method has also been applied to multi-objective optimization (Agrawal et al., 2020). Given a large enough initial population (e.g. ), recursive bi-clustering is faster and finds better solutions than state-of-the-art genetic algorithms and sequential model optimization methods (Chen et al., 2019; Lustosa and Menzies, 2023) (even though it only evaluates examples while other methods might evaluate 100s to 1000s of examples).
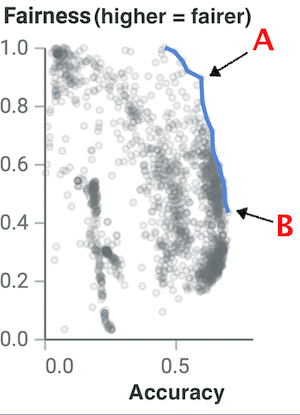
Once we have a keys-based multi-objective optimizer, we can offer much support for reviewing models with respect to their fairness. Figure 1 comes from Cruz et al. (Cruz et al., 2021). That figure shows the effects of 10,000 different hyperparameter options applied to five machine learning algorithms (random forest; LinReg; boosted trees; decision trees; feed-forward NN)666The hyperparameters of Random Forests, learners include (a) how many trees to build (e.g., ); (b) how many features to use in each tree (e.g., ); (c) how to poll the whole forest (e.g., majority or weighted majority); (d) what impurity measures (e.g., gini or entropy or log.loss); (e) what is the minimum examples needed to branch a sub-tree (e.g., min; (f) should branches be binary or n-arty. In all, this gives us different ways, just to configure a learner in Figure 1. . Adjusting tunings can change learners from low to high accuracies and fairness (measured here as the ratio of false positives between different social groups, such as men and women). But with the search methods of the Table 1, reviewing all those points would require just 20 evaluations– a number so small that (potentially) it could happen between coffee breaks of a stakeholder review session.
5. What to Publish at PROMISE v2.0?
Having presented the methods of the last section, I rush to add that they are hardly complete. There is much here that could be better defined/ refined/ improved/ replaced by further research in PROMISE v2.0.
In my view, the goal of a PROMISE v2.0 paper could be “less is more”; that is, achieve faster, simpler, better results using some simplification of the existing technique. There are many ways this could be done; e.g. with:
- •
- •
- •
-
•
Variance studies that tests if the improvement of a complex method over a simpler one are statistically insignificant;
-
•
Ablation studies (Yedida et al., 2023) to see how much can be thrown away (of the modeling method, of parts of the training data) while preserving model performance.
-
•
Studies showing that (say) a 10% implementation can perform nearly as well as 100% of an entire system.
-
•
Some kind of keys-based approach (e.g. see last section).
Human-in-the-loop studies would also be strongly encouraged in PROMISE v2.0, to test if the smaller models are still acceptable and useful for people. But in line with PROMISE’s long and admirable history of reproducibility, these experiments should include human surrogates (developed perhaps via data mining) that can model the strengths and weaknesses of subject matter experts (and surrogates should be shared as part of the reproducibility package of a paper).
Also encouraged would be a broader range of performance criteria than just (e.g.) accuracy, Performance should be measured in a multidimensional manner and include much more than mere predictive performance, but also runtime, energy usage, discrimination measures, model development cost, etc.
6. A Counter Argument (More is More)
My “less is more” proposal is antithetical to much current research in SE and AI. Data-hungry researchers in SE assume that “more is more”; i.e. if some data are useful, then even more data is even more useful. For example “Long- term JIT models should be trained using a cache of many changes” (Amasaki, 2020); and “..as long as it is large; the resulting prediction performance is likely to be boosted more by the size of the sample’” (Rahman et al., 2014).
A common problem with “more is more“ is that researchers often make that assumption without actually testing it. For example, a recent systematic review (Hou et al., 2023) of the literature on large language models in SE reported 229 research articles from 2017 to 2023. We asked the authors of that review, “how many articles compared their approach to something simpler non-neural approach?” and “in how many of those comparisons was there any hyperparameter optimization?”. They responded with a list of 13 papers () which, when read, contain some questionable methodological choices. For example, one of those 13 articles reported that LLMs perform better than a text mining methods called LDA. But that article used LDA in its “off-the-shelf” configuration even though we have seen dramatic improvements in LDA performance with hyperparameter optimization (Agrawal et al., 2019, 2018).
To be clear, I firmly believe that deep learning and generative AI methods such as “chain of thought”777https://github.com/Timothyxxx/Chain-of-ThoughtsPapers will dramatically change the nature of science (in general) and SE (in particular). But moving away from generative tasks to classification, regression, and optimization tasks, my experimental results strongly suggest that other non-neural methods can be just as effective, particularly when combined with hyperparameter optimization. This is an important point since the non-neural methods can yield the succinct symbolic models that humans need to review and understand a model.
But rather than stating all this in an adversarial manner, it might be more useful to ask how “less is more” can be beneficial for more elaborate approaches. Lustosa (work in progress) has explored the hyperparameters of some deep learners using the recursive bi-clustering method described in the Introduction, and found that it was able to configure the deep learners more effectively than other state-of-the-art optimizers, and do so much faster.
7. A Final Thought
Despite all my papers on the topic, “less is more” is mostly ignored. Perhaps this is my own fault. Initially, I argued this with simulation studies on artificially created examples, which some people find unconvincing (Menzies et al., 2000; Menzies and Singh, 2004). However, subsequent work reported results from real-world data (Menzies et al., 2007, 2008; Chen et al., 2005; Menzies et al., 2006; Partington et al., 2015; Jalali et al., 2008; Chen et al., 2019; Lustosa and Menzies, 2023; Agrawal et al., 2020; Ling and Menzies, 2023; Yu et al., 2019; N.C. and Menzies, 2023). Furthermore, the latter work included numerous studies that demonstrate that this “less is more” approach produces smaller and better models than the current state-of-the-art.
Perhaps there is something deeply embedded in our research culture that encourages and rewards complexity. Perhaps our research is driven by the concerns of large software organizations that prefer complexity (since only those large organizations have the resources to build and maintain complex solutions).
Perhaps also, in a publication-oriented environment, researchers tend to rush out reports of complex mashups of tools, rather than refactor and reduce the size of their toolkits.
Perhaps what we need is a space where we can revisit and reflect on old results, looking for some synthesis that significantly simplifies and improves those results. To create a journal venue for such papers, I invite submissions to the “Less is More” section of the Automated Software Engineering journal888See https://ause-journal.github.io/simpler.html.
And as to an associated conference venue, perhaps that venue could be PROMISE v2.0?
Acknowledgements
Thanks to Hou et al. for quickly responding to a query on LLMs. Also, thanks to all the grad students and coauthors who helped mature, refine, and simplify the ideas that led to this paper.
References
- (1)
- Agrawal et al. (2019) Amritanshu Agrawal, Wei Fu, Di Chen, Xipeng Shen, and Tim Menzies. 2019. How to “dodge” complex software analytics. IEEE TSE 47, 10 (2019), 2182–2194.
- Agrawal et al. (2018) Amritanshu Agrawal, Wei Fu, and Tim Menzies. 2018. What is Wrong with Topic Modeling?(and How to Fix it Using Search-based Software Engineering). Information and Software Technology (2018).
- Agrawal et al. (2020) Amritanshu Agrawal, Tim Menzies, Leandro L Minku, Markus Wagner, and Zhe Yu. 2020. Better software analytics via “DUO”: Data mining algorithms using/used-by optimizers. Empirical Software Engineering 25 (2020), 2099–2136.
- Amasaki (2020) Sousuke Amasaki. 2020. Cross-version defect prediction: use historical data, cross-project data, or both? Empirical Software Engineering (2020), 1–23.
- Biswas and Rajan (2023) Sumon Biswas and Hridesh Rajan. 2023. Fairify: Fairness Verification of Neural Networks. In ICSE’23. 1546–1558. https://doi.org/10.1109/ICSE48619.2023.00134
- Boehm (1981) B.W. Boehm. 1981. Software Engineering Economics. Prentice Hall.
- Bowleg (2021) Lisa Bowleg. 2021. Evolving Intersectionality Within Public Health: From Analysis to Action. American Journal of Public Health 111, 1 (2021), 88–90. https://doi.org/10.2105/AJPH.2020.306031 PMID: 33326269.
- Brighton (2006) Henry Brighton. 2006. Robust Inference with Simple Cognitive Models.. In AAAI spring symposium: Between a rock and a hard place: Cognitive science principles meet AI-hard problems. 17–22.
- Canellas (2021) Marc Canellas. 2021. Defending IEEE Software Standards in Federal Criminal Court. Computer 54, 6 (2021), 14–23. https://doi.org/10.1109/MC.2020.3038630
- Chakraborty et al. (2021) Joymallya Chakraborty, Suvodeep Majumder, and Tim Menzies. 2021. Bias in Machine Learning Software: Why? How? What to Do?. In FSE’21. New York, NY, USA, 429–440. https://doi.org/10.1145/3468264.3468537
- Chen et al. (2019) Jianfeng Chen, Vivek Nair, Rahul Krishna, and Tim Menzies. 2019. “Sampling” as a Baseline Optimizer for Search-Based Software Engineering. IEEE TSE 45, 6 (2019), 597–614.
- Chen et al. (2005) Zhihao Chen, Tim Menzies, Daniel Port, and D Boehm. 2005. Finding the right data for software cost modeling. IEEE software 22, 6 (2005), 38–46.
- Coaston (2019) Jane Coaston. 2019. VOX, May 28. On-line at https://www.vox.com/the-highlight/2019/5/20/18542843/intersectionality-conservatism-law-race-gender-discrimination.
- Cruz et al. (2021) André F Cruz, Pedro Saleiro, Catarina Belém, Carlos Soares, and Pedro Bizarro. 2021. Promoting fairness through hyperparameter optimization. In 2021 IEEE International Conference on Data Mining (ICDM). IEEE, 1036–1041.
- Czerlinski et al. (1999) Jean Czerlinski, Gerd Gigerenzer, and Daniel G Goldstein. 1999. How good are simple heuristics?. In Simple Heuristics That Make Us Smart. Oxford University Press.
- Desharnais (1989) JM Desharnais. 1989. Analyse statistique de la productivitie des projets informatique a partie de la technique des point des function. Masters Thesis, University of Montreal (1989).
- Faloutsos and Lin (1995) Christos Faloutsos and King-Ip Lin. 1995. FastMap: A fast algorithm for indexing, data-mining and visualization of traditional and multimedia datasets. In Proceedings of the 1995 ACM SIGMOD international conference on Management of data. 163–174.
- Gay et al. (2010) Gregory Gay, Tim Menzies, Misty Davies, and Karen Gundy-Burlet. 2010. Automatically finding the control variables for complex system behavior. Automated Software Engineering 17 (2010), 439–468.
- Gigerenzer (2008) Gerd Gigerenzer. 2008. Why heuristics work. Perspectives on psychological science 3, 1 (2008), 20–29.
- Gigerenzer et al. (1999) Gerd Gigerenzer, Jean Czerlinski, and Laura Martignon. 1999. How good are fast and frugal heuristics. Decision science and technology: Reflections on the contributions of Ward Edwards (1999), 81–103.
- Gigerenzer and Gaissmaier (2011) Gerd Gigerenzer and Wolfgang Gaissmaier. 2011. Heuristic decision making. Annual review of psychology 62 (2011), 451–482.
- Green (2022) Ben Green. 2022. The flaws of policies requiring human oversight of government algorithms. Computer Law & Security Review 45 (2022), 105681.
- Holte (1993) Robert C. Holte. 1993. Very Simple Classification Rules Perform Well on Most Commonly Used Datasets. Machine Learning 11 (1993), 63–90. https://api.semanticscholar.org/CorpusID:6596
- Hou et al. (2023) Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2023. Large Language Models for Software Engineering: A Systematic Literature Review. arXiv:2308.10620 [cs.SE]
- Jalali et al. (2008) Omid Jalali, Tim Menzies, and Martin Feather. 2008. Optimizing requirements decisions with keys. In Proceedings of the 4th international workshop on Predictor models in software engineering. 79–86.
- Johnson and Menzies (2023) Brittany Johnson and Tim Menzies. 2023. Unfairness is everywhere. So what to do? An interview with Jeanna Matthews. IEEE Software (2023). Issue Nov/Dev.
- Jureczko and Madeyski (2010) Marian Jureczko and Lech Madeyski. 2010. Towards identifying software project clusters with regard to defect prediction. In Proceedings of the 6th international conference on predictive models in software engineering. 1–10.
- Kohavi and John (1997) Ron Kohavi and George H. John. 1997. Wrappers for Feature Subset Selection. Artificial Intelligence 97, 1-2 (1997), 273–324.
- Larkin et al. (1980) Jill Larkin, John McDermott, Dorothea P. Simon, and Herbert A. Simon. 1980. Expert and Novice Performance in Solving Physics Problems. Science 208, 4450 (1980), 1335–1342. https://doi.org/10.1126/science.208.4450.1335 arXiv:http://science.sciencemag.org/content/208/4450/1335.full.pdf
- Ling and Menzies (2023) Xiao Ling and Tim Menzies. 2023. On the Benefits of Semi-Supervised Test Case Generation for Cyber-Physical Systems. arXiv:2305.03714 [cs.SE]
- Lustosa and Menzies (2023) Andre Lustosa and Tim Menzies. 2023. Optimizing Predictions for Very Small Data Sets: a case study on Open-Source Project Health Prediction. arXiv preprint arXiv:2301.06577 (2023).
- Ma et al. (2014) Wei Ji Ma, Masud Husain, and Paul M Bays. 2014. Changing concepts of working memory. Nature neuroscience 17, 3 (2014), 347–356.
- Majumder et al. (2023) Suvodeep Majumder, Joymallya Chakraborty, Gina R. Bai, Kathryn T. Stolee, and Tim Menzies. 2023. Fair Enough: Searching for Sufficient Measures of Fairness. ACM Trans. Softw. Eng. Methodol. (mar 2023). https://doi.org/10.1145/3585006 Just Accepted.
- Martignon et al. (2008) Laura Martignon, Konstantinos V Katsikopoulos, and Jan K Woike. 2008. Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology 52, 6 (2008), 352–361.
- Martignon et al. (2003) Laura Martignon, Oliver Vitouch, Masanori Takezawa, and Malcolm R Forster. 2003. Naive and yet enlightened: From natural frequencies to fast and frugal decision trees. Thinking: Psychological perspective on reasoning, judgment, and decision making (2003), 189–211.
- Matthews (2023) Jeanna Matthews. 2023. How should we regulate AI? Practical Strategies for Regulation and Risk Management from the IEEE1012 Standard for System, Software, and Hardware Verification and Validation. (2023). https://ieeeusa.org/assets/public-policy/committees/aipc/How-Should-We-Regulate-AI.pdf.
- Menzies et al. (2000) Tim Menzies, Bojan Cukic, Harshinder Singh, and John Powell. 2000. Testing nondeterminate systems. In Proceedings 11th International Symposium on Software Reliability Engineering. ISSRE 2000. IEEE, 222–231.
- Menzies and Di Stefano (2004) Tim Menzies and Justin S Di Stefano. 2004. How good is your blind spot sampling policy. In Eighth IEEE International Symposium on High Assurance Systems Engineering, 2004. Proceedings. IEEE, 129–138.
- Menzies et al. (2006) Tim Menzies, Jeremy Greenwald, and Art Frank. 2006. Data mining static code attributes to learn defect predictors. IEEE transactions on software engineering 33, 1 (2006), 2–13.
- Menzies et al. (2007) Tim Menzies, David Owen, and Julian Richardson. 2007. The Strangest Thing About Software. Computer 40, 1 (2007), 54–60. https://doi.org/10.1109/MC.2007.37
- Menzies and Singh (2004) Tim Menzies and Harhsinder Singh. 2004. Many maybes mean (mostly) the same thing. Soft Computing in Software Engineering (2004), 125–150.
- Menzies et al. (2008) Tim Menzies, Burak Turhan, Ayse Bener, Gregory Gay, Bojan Cukic, and Yue Jiang. 2008. Implications of ceiling effects in defect predictors. In Proceedings of the 4th international workshop on Predictor models in software engineering. 47–54.
- N.C. and Menzies (2023) Shrikanth N.C. and Tim Menzies. 2023. Assessing the Early Bird Heuristic (for Predicting Project Quality). ACM Trans. Softw. Eng. Methodol. 32, 5, Article 116 (jul 2023), 39 pages. https://doi.org/10.1145/3583565
- Neth and Gigerenzer (2015) Hansjörg Neth and Gerd Gigerenzer. 2015. Heuristics: Tools for an uncertain world. Emerging trends in the social and behavioral sciences: An interdisciplinary, searchable, and linkable resource (2015).
- Noble (2018) Safiya Umoja Noble. 2018. Algorithms of oppression. How search engines reinforce racism. New York University Press, New York. http://algorithmsofoppression.com/
- Olvera-López et al. (2010) J Arturo Olvera-López, J Ariel Carrasco-Ochoa, J Francisco Martínez-Trinidad, and Josef Kittler. 2010. A review of instance selection methods. Artificial Intelligence Review 34 (2010), 133–143.
- Papakroni (2013) Vasil Papakroni. 2013. Data carving: Identifying and removing irrelevancies in the data. West Virginia University.
- Partington et al. (2015) Susan N Partington, Tim J Menzies, Trina A Colburn, Brian E Saelens, and Karen Glanz. 2015. Reduced-item food audits based on the nutrition environment measures surveys. American Journal of Preventive Medicine 49, 4 (2015), e23–e33.
- Phillips et al. (2017) Nathaniel D Phillips, Hansjoerg Neth, Jan K Woike, and Wolfgang Gaissmaier. 2017. FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgment and Decision Making 12, 4 (2017), 344–368.
- Platt (2005) John Platt. 2005. Fastmap, metricmap, and landmark mds are all nyström algorithms. In International Workshop on Artificial Intelligence and Statistics. PMLR, 261–268.
- Rahman et al. (2014) Foyzur Rahman, Sameer Khatri, Earl T Barr, and Premkumar Devanbu. 2014. Comparing static bug finders and statistical prediction. In ICSE’14.
- Rees-Jones et al. (2017) Mitch Rees-Jones, Matthew Martin, and Tim Menzies. 2017. Better predictors for issue lifetime. arXiv preprint arXiv:1702.07735 (2017).
- Rudin (2019) Cynthia Rudin. 2019. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence 1, 5 (2019), 206–215. https://doi.org/10.1038/s42256-019-0048-x
- Shi et al. (2023) Jieke Shi, Zhou Yang, Bowen Xu, Hong Jin Kang, and David Lo. 2023. Compressing Pre-Trained Models of Code into 3 MB. In ASE’22. Article 24, 12 pages. https://doi.org/10.1145/3551349.3556964
- Simon (1956) Herbert A. Simon. 1956. Rational choice and the structure of the environment. Psychological Review 63, 2 (1956), 129–138.
- Tawosi et al. (2023) Vali Tawosi, Rebecca Moussa, and Federica Sarro. 2023. Agile Effort Estimation: Have We Solved the Problem Yet? Insights From a Replication Study. IEEE Transactions on Software Engineering 49, 4 (2023), 2677–2697. https://doi.org/10.1109/TSE.2022.3228739
- Tu and Menzies (2021) Huy Tu and Tim Menzies. 2021. FRUGAL: unlocking semi-supervised learning for software analytics. In 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 394–406.
- Xia et al. (2022) Tianpei Xia, Rui Shu, Xipeng Shen, and Tim Menzies. 2022. Sequential Model Optimization for Software Effort Estimation. IEEE Transactions on Software Engineering 48, 6 (2022), 1994–2009. https://doi.org/10.1109/TSE.2020.3047072
- Xu et al. (2021) Zhou Xu, Li Li, Meng Yan, Jin Liu, Xiapu Luo, John Grundy, Yifeng Zhang, and Xiaohong Zhang. 2021. A comprehensive comparative study of clustering-based unsupervised defect prediction models. Journal of Systems and Software 172 (2021), 110862. https://doi.org/10.1016/j.jss.2020.110862
- Yedida et al. (2023) Rahul Yedida, Hong Jin Kang, Huy Tu, Xueqi Yang, David Lo, and Tim Menzies. 2023. How to find actionable static analysis warnings: A case study with FindBugs. IEEE Transactions on Software Engineering (2023).
- Yu et al. (2019) Zhe Yu, Christopher Theisen, Laurie Williams, and Tim Menzies. 2019. Improving vulnerability inspection efficiency using active learning. IEEE Transactions on Software Engineering 47, 11 (2019), 2401–2420.
- Zhu (2005) Xiaojin Jerry Zhu. 2005. Semi-supervised learning literature survey. (2005).