Modeling heterogeneity in higher-order moments
while preserving mean and variance:
application to spatio-temporal modeling
Abstract
In this study, we propose a general model capable of addressing heterogeneity in higher-order moments while preserving mean and variance, including the t, Laplace, and skew-normal distributions as special cases. Our model flexibly accommodates variations in tail heaviness and asymmetry at each data point while maintaining interpretability similar to normal distribution models. Notably, it is closed under linear transformations and provides explicit analytical expressions for skewness and kurtosis. The proposed model is applied to spatial and temporal data analysis, demonstrating that its properties vary based on the chosen matrix decomposition approach. To facilitate efficient inference, we develop a Bayesian estimation method using data augmentation, which is particularly effective for temporal models. Simulation studies confirm that accounting for heterogeneity in higher-order moments enhances parameter estimation accuracy and predictive performance. To illustrate real-world applicability, we analyze production functions across U.S. states. The results indicate that our model effectively captures heterogeneity in higher-order moments, leading to superior model fit in empirical data analysis.
keywords:
Heterogeneity in higher-order moments; Spatio-temporal modeling; Efficient Bayesian inference;[label1] organization=The Graduate University for Advanced Studies,addressline=Shonan Village, city=Hayama, postcode=240-0193, state=Kanagawa, country=Japan
[label2] organization=BrainPad inc.,addressline=3-1-1 Roppongi, city=Minato-ku, postcode=108-0071, state=Tokyo, country=Japan
[label3] organization=Institute of Statistical Mathematics,addressline=10-3 Midori-cho, city=Tachikawa, postcode=190-8562, state=Tokyo, country=Japan
1 Introduction
The modeling of higher-order moments, such as skewness and kurtosis, is crucial in many real-world applications (Tagle et al., 2019). For example, infection risk may exhibit a skewed distribution with extremely high values during epidemic periods, and the strength of skewness can vary across different regions and time periods. Therefore, describing the process using a non-Gaussian model that can flexibly handle such heterogeneous skewness and higher-order moments is desirable.
To account for non-Gaussianity, a wide variety of methods have been developed, as reviewed by Yan et al. (2020). A prominent example is the closed-skew normal (CSN) distribution, known for its expressive power (Azzalini, 1985; Azzalini and Capitanio, 1999). However, replacing the normal distribution in a model with a CSN distribution often disrupts the mean and variance properties, which are essential for interpretability. In particular, spatio-temporal models—actively studied in fields such as disease mapping (Best et al., 2005), species distribution modeling (Dormann et al., 2007), and socio-economic analysis (Anselin, 2022) —rely on the mean regression function to interpret the influence of the specified covariates and covariance specified to quantify the strength of spatial and temporal correlations.
Márquez-Urbina and González-Farías (2022) addressed this issue by proposing a flexible subclass of the CSN distribution that maintains the mean and variance. This property enhances the interpretability of parameters such that when the mean is specified by a regression function, the coefficients and variance parameters can be interpreted similarly to those in a conventional Gaussian regression model. Additionally, Tan and Chen (2024) proposed an extended model known as the closed skew normal subclass (CSNS) distribution, which addresses the heterogeneity of higher-order moments. The CSNS distribution still has limitations in the range of achievable skewness and kurtosis, restricting its representational flexibility. Moreover, Tan and Chen (2024) used the CSNS distribution as an approximation in variational inference, rather than as a component of modeling. Notably, although the model’s properties vary depending on the matrix decomposition method used internally, it is restricted to LU decomposition. Similarly, no established Bayesian estimation method is available despite its potential merits for modeling uncertainty in spatio-temporal phenomena (Cressie and Wikle, 2011; Márquez-Urbina and González-Farías, 2022).
To overcome these limitations, we propose a general model that encompasses the CSNS distribution as a special case and accommodates the heterogeneity of higher-order moments while preserving the mean and variance. Subsequently, several properties of the proposed model are presented. In particular, since the characteristics of the model vary depending on the matrix factorization method employed, we explain the specific matrix factorization techniques suitable for adapting to spatio-temporal data. Furthermore, we develop an efficient Bayesian inference method that is particularly effective for temporal data.
The remainder of this paper is organized as follows. Section 2 provides background on the CSN and CSNS distributions. Section 3 introduces the proposed model and its theoretical properties. Section 4 investigates the impact of different matrix factorization methods, particularly in spatio-temporal context. Section 5 develops an efficient Bayesian inference method. Section 6 presents the simulations conducted to the model estimation accuracy, and Section 7 applies the model to the estimation of production functions across U.S. states.
2 CSN and CSNS distribution
The CSN distribution is an extension of the multivariate normal distribution that incorporates higher-order moments. For , the probability density function is given by:
Here, , , and are covariance matrices. and denotes the probability distribution function and cumulative distribution function of an -dimensional normal distribution with mean and covariance , respectively. Finally, represents an -dimensional zero vector.
As a modified version of the CSN distribution, the CSNS distribution ensures that the mean and variance remain consistent with those of a multivariate normal distribution. The CSNS distribution is derived by first defining the following random variable:
where denotes a multivariate normal distribution with mean and covariance , and denotes a normal distribution truncated below . The mean of the above random variable is and the variance is . To standardize the variable, we define , ensuring that has a mean of and a variance of . Setting
| (1) |
guarantees that maintains mean and covariance . Here, , , and is the LU decomposition of . The distribution of can be expressed as the CSN distribution:
where , , , and is the identity matrix.
Figure 1 illustrates the probability density function of the CSNS distribution with mean and variance for different values of . When , the CSNS distribution coincides with the normal distribution. As increases, the skewness increases, and the distribution approaches a shifted half-normal distribution.
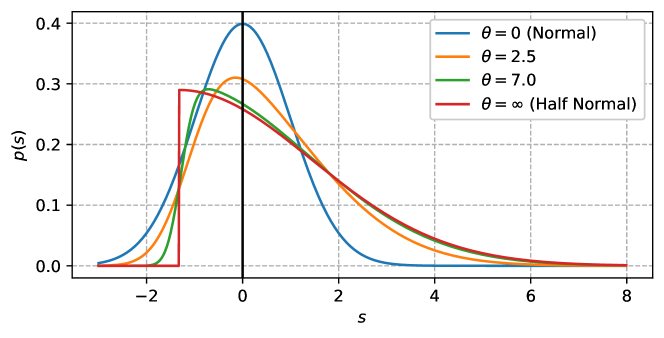
3 Proposed method
In this section, a general model that can handle heterogeneity in higher-order moments while preserving the mean and variance is proposed, based on the idea of the CSNS distribution. In Section 3.1, we provide an overview of the model along with several illustrative examples. Subsequently, in Section 3.2, we discuss the model’s closure under linear transformations as well as skewness and kurtosis.
3.1 A general model for heterogeneous highe-order moments
To derive the proposed model, we first consider an -dimensional random variable defined as:
| (2) |
where is a random variable with independent components of mean and variance , and is any matrix satisfying . The mean and variance of are and , respectively. As observed in Equation (1), the original CSNS distribution considers the LU decomposition. However, since the mean and variance can be preserved regardless of the choice of matrix decomposition, we employ a more general matrix decomposition in the definitions to facilitate subsequent discussions.
There are many possible ways to design . In this study, we consider a random variable that can be expressed as follows:
where is a dimensional random variable independent of , and is a dimensional parameter. The function is the reciprocal of the standard deviation of that ensures standardization. is a random variable with mean . is chosen so that the variance of is positive. We adopted the following notations , , and .
Table 1 summarizes the specific instances of the proposed model. Here, denotes an inverse gamma distribution with parameters and , denotes an exponential distribution with mean , and denotes an inverse Gaussian distribution with parameters and .
| t | ||||||
|---|---|---|---|---|---|---|
| Laplace | ||||||
| NIG | ||||||
| AL | ||||||
| SN | ||||||
| ST |
|
First, a simple example is the t-distribution, which requires for the mean and variance to exist. Similarly, the Laplace distribution can be considered. Both distributions are symmetric with zero skewness. A more generalized class of distributions that allow for non-zero skewness is the family of normal mean-variance mixtures. Examples of such distributions include the normal-inverse Gaussian (NIG) and asymmetric Laplace (AL) distributions. A further generalization of the NIG distribution is the generalized hyperbolic distribution.
The most important example is the skew normal (SN) distribution, because, as discussed in the previous section, follows the CSNS distribution, which is a subclass of the CSN distribution. Moreover, the CSN distribution and its derivative, the unified skew normal distribution, are known to exhibit conjugacy in linear regression, probit, multinomial probit, and Tobit models, making them an active area of research in recent years (Niccolò et al., 2023). Additionally, as a scale mixture of the SN distribution, the skew-t distribution (ST) emerges as a natural extension. An important property of this model is that it is closed under linear transformations of the SN distribution through scale mixtures (Wang et al., 2024).
Furthermore, since the distributions of each do not necessarily have to be identical, more general models, such as combinations of multiple distributions, can also be treated within the same framework.
3.2 Properties of the proposed model
An important property of this model is that it is closed under linear transformations. Specifically, for any matrix , we have , indicating that the model is closed under linear transformations.
Furthermore, if the third and fourth moments of exist, the skewness and kurtosis can be analytically derived as follows;
where is the element in the th row and th column of , and is the element in the th row and th column of ; represents the third moment of ; and denotes its fourth moment. Table 2 presents the third and fourth moments for each model. In the case of the -distribution, the third moment exists only if , and the fourth moment exists only if . Similarly, in the case of the ST distribution, the third moment exists only if , and the fourth moment exists only if .
| Third moment | Fourth moment | |
|---|---|---|
| t | ||
| Laplace | ||
| NIG | ||
| AL | ||
| SN | ||
| ST |
Mardia’s skewness and kurtosis can also be analytically derived, and both are independent of the mean and variance. For two random variables and following the same distribution with mean and covariance matrix , Mardia’s skewness and kurtosis follow the expressions given below:
Since ,
These properties imply that the first, second, and higher-order moments can be designed independently.
4 Application to spatio-temporal modeling
In the proposed model, characteristics vary based on the matrix decomposition method. Although the scope of this model is not necessarily limited to spatial or temporal data, it is well-suited for explaining changes in model properties. Additionally, since spatial and temporal models are often designed based on the mean and variance, preserving these statistical properties. In Section 4.1, we consider applications to spatial models, followed by applications to temporal models in Section 4.2.
4.1 Application to spatial modeling
Many spatial models, such as the spatial autoregressive (SAR) and the conditional autoregressive (CAR) model, capture spatial correlations by assuming that the random variable of interest follows and designing accordingly, where denotes the number of locations.
When applying the proposed model to spatial data, we substitute the mean and variance of the spatial model into the corresponding parameters of the proposed model. However, the model’s properties can significantly vary depending on the chosen matrix decomposition method. For example, similar to the standard SAR model, consider a model . where is a parameter that determines the strength of the spatial correlation, and is the row-standardized adjacency matrix. Here, we assume that follows the proposed model, that is, it satisfies Equation (2). In this case, follows the model, because of the property of closure under linear transformations. This indicates that using for matrix decomposition is natural, and properties are preserved.
On the other hand, for CAR models, and more generally for data where the column-wise ordering has no inherent meaning, the standard practice is to use the matrix square root. For example, in the Leroux model, which is a type of CAR model, the covariance matrix is specified as follows:
| (3) | ||||
where is the adjacency matrix. The reason for using the matrix square root in the CAR model is that the model constructed using the matrix square root exhibits symmetry with respect to changes in the ordering of the data, whereas the model using the Cholesky decomposition or LU decomposition is not symmetric under permutation. Let the permuted random variable of , which follows the proposed model, be , where is the permutation matrix such that . Consider the randomly permuted variable when using the matrix square root . Since the matrix square root of is given by , we obtain
which implies that the distribution of is identical to that of . On the other hand, for general matrix decompositions such as Cholesky decomposition or LU decomposition, does not satisfy , leading to the loss of symmetry with respect to permutation.
If the symmetry does not hold under permutation, a change in the order of the data can affect the estimation results. To illustrate how the choice of the matrix decomposition method impacts symmetry, Figure 2 shows the skewness at each point on a grid for the model under different matrix decomposition methods. When using Cholesky decomposition, the skewness lacks symmetry, and reordering the data sequence causes random variations in skewness. In contrast, when using the matrix square root, the skewness exhibits symmetry and remains unchanged regardless of the order of points. This property holds not only for skewness but for the entire distribution. Consequently, using the matrix square root is generally preferable to decompose the variance matrix in cases where the ordering of data points is arbitrary.
Notably, when using the CAR model, spatial Markov properties are not preserved, although this is rarely a practical concern. Therefore, it is more appropriate to consider the CAR model merely as one of the design methods in constructing covariance matrices.
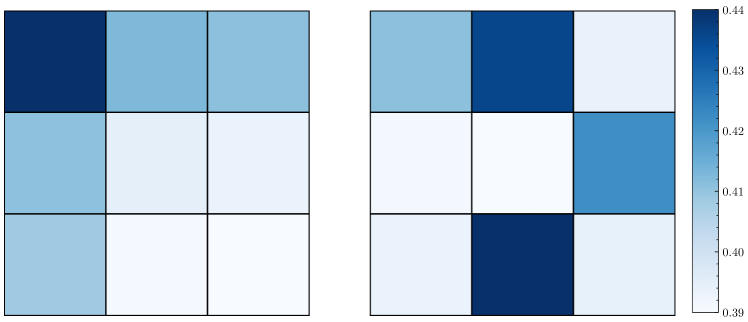
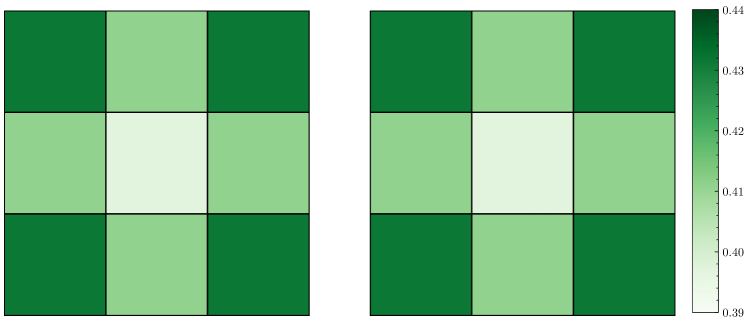
4.2 Application to temporal modeling
To incorporate the proposed model into a time series framework, first, we consider an -order autoregressive (AR) model with the error term following the proposed distribution:
| (4) |
where , , and . Here, we assume that follows Equation (2).
The AR model is closed under the proposed model, and its mean and variance remain the same when assuming multivariate normal distribution is assumed for the error terms. Specifically, the model represented by Equation (4) is equivalent to the model expressed below:
where is length of time; denotes the Kroneker product; , , and . is the Cholesky decompositon of the covariance matrix of the AR model when . Each element of this submatrix is given as follows:
where is the submatrix of , consisting of rows to and columns to , and is the zero matrix.
Unlike spatial models, the appearance of the Cholesky decomposition in the AR model can be explained by the fact that the order of data in the temporal domain carries significant meaning. This distinction can also be understood from the fact that spatial adjacency is represented by an undirected graph, whereas temporal adjacency is represented by a directed graph.
5 Bayesian inference
This section proposes a Bayesian estimation method for the parameters of the proposed model. Section 5.1 describes a Bayesian inference approach using the data augmentation method for general models, including spatial models. Since the data augmentation method is particularly effective for time series models, its application is detailed in Section 5.2.
5.1 Bayesian inference for the proposed model
To efficiently perform Bayesian inference for the posterior distribution of the proposed model, we propose a sampling method that combines data augmentation and Gibbs sampling. Firstly, follows a multivariate normal distribution:
where , , , with the elements depending on and (see Table 1). Therefore, conditioned on can be treated in the same manner as in models with a standard normal prior distribution. For example, given the observation model
the posterior distribution of can be expressed analytically as follows:
where and . Similarly, if the prior for is a multivariate normal distribution, then also follows a multivariate normal distribution. This property is useful for deriving coefficients in linear regression and other related models. The variables influences only through . Using this property, the elements of may be sampled individually from instead of after sampling . Therefore, the sampling from the posterior distribution and can be implemented in parallel. Additionally, in some distributions, such as the t, Laplace, CSN distributions, is represented analytically. For example, in a CSNS distribution,
This method significantly reduces computational costs. Sampling from an -dimensional CSN distribution requires a computational complexity of when sampling from an -dimensional multivariate truncated normal distribution (Botev, 2017). In contrast, the sampling method described above only requires sampling from independently distributed truncated normal distributions, resulting in a computational complexity of .
5.2 Bayesian inference for temporal model
As the AR model is closed under the proposed framework, the aforementioned data augmentation method can also be applied to the AR model. Furthermore, because the transitions of form a linear Gaussian state-space model, a more efficient method known as forward filtering backward sampling (FFBS) method can be applied (Carter and Kohn, 1994; Frühwirth-Schnatter, 1994). For simplicity, we consider only the first-order AR here; however, the following techniques can generally be applied to higher-order models as well. The model with observation noise is expresed as follows:
| (5) | ||||
Regarding the posterior distribution of , conditioned on , it becomes a normal distribution allowing the use of the FFBS method. Let and be the mean and the variance of , then
where is , and variance is . By using the above formulation iteratively, the distribution of can be calculated for . After calculation, can be sequentially backward sampled:
where is a sample of .
6 Simulation studies
This study investigated the inverse estimation performance for spatio-temporal data through simulations. Specifically, using the case of the CSNS distribution as an example, we examined whether the estimation performance improves by properly modeling heterogeneity in higher-order moments. To this end, four types of heterogeneity were investigated. The models are defined as follows: the model with for is referred to as the zero theta (ZT) model, corresponding to the Gaussian regression model; the model with for is referred to as the fixed theta (FT) model; the model with for is referred to as the temporal varying theta (TT) model; and the model with for is referred to as the spatial varying theta (ST) model.
The observation model is as follows:
where follows a CSNS distribution, depending on the parameter, using the matrix square root. The covariance matrix , which models spatial correlation, is assumed to follow Equation (3). The time length for parameter estimation was set to , whereas the time length for evaluating prediction accuracy, , was set to . The location is represented by a grid. The adjacency matrix is defined by assigning a value of to the neighboring pairs that share a border with separating grids, and to all others. The features is generated as a random sample from the standard normal distribution.
The true values for the simulation model for each case are as follows: in Case 1, we used the ZT model; in Case 2, the FT model with ; in Case 3, the TT model with , where were generated as random variables; and in Case 4, the ST model with , where is generated as random variables. For the remaining parameters, the coefficient for randomly generated features was set to , intercept to , standard deviation of the observation noise to , coefficient of the temporal AR model to , parameter , which determines the variability of , to , and parameter , which controls the strength of spatial correlation, to .
The prior distributions for the estimation model were shared across all four models, following Lee et al. (2018). We employ a hierarchical distribution as the prior distributions for . The priors are as follows:
where denotes the uniform distribution from to .
Using the sampling method described in Section 4.3, we obtained 1,000 samples from the posterior distribution for each simulation to evaluate estimation performance. During the sampling process, more than 50,000 samples were discarded corresponding to the burn-in period based on the results of trace plots, and thinning was applied to ensure that the autocorrelation was below 0.3. Figure 3 presents an example of a trace plot for several parameters of the FT model in Case 1, after discarding burn-in samples and applying thinning. The plot confirms that convergence was sufficient.
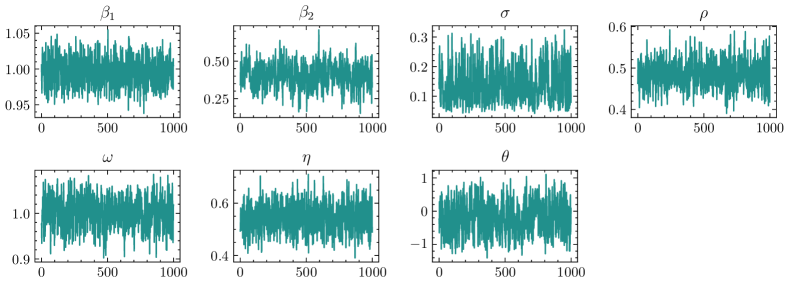
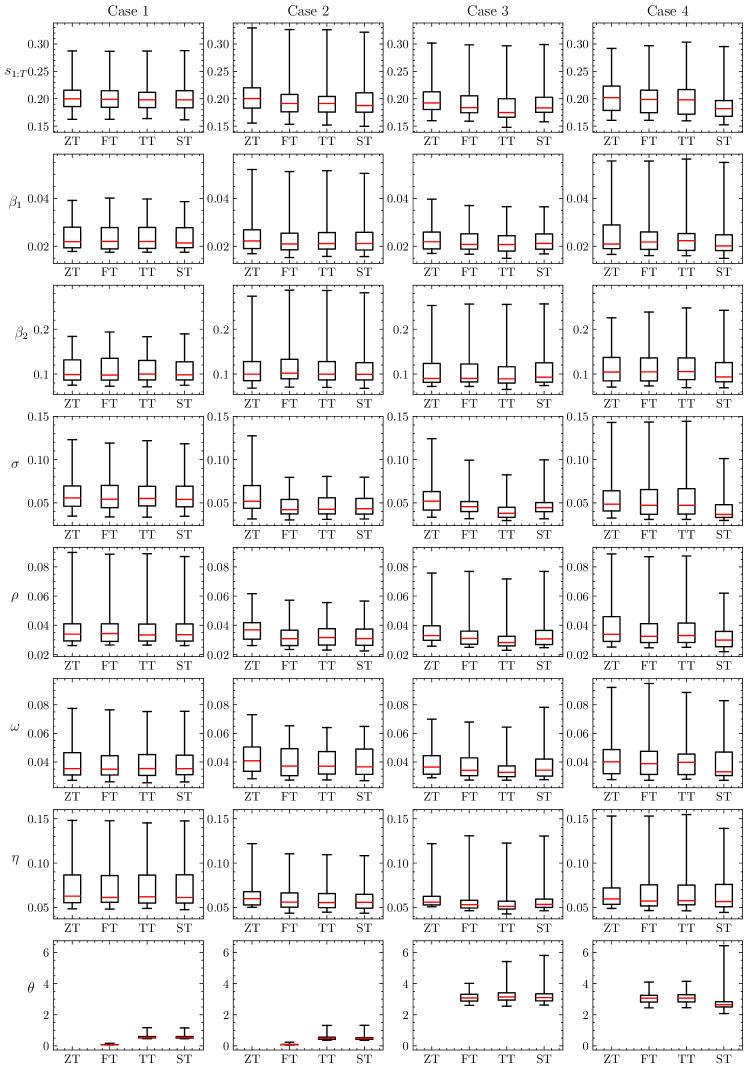
Figure 4 presents the root mean squared errors (RMSE) of each parameter for the four cases and four estimation models that were simulated 50 times. Box plots are used to illustrate each case. In the ZT model, was fixed to and not estimated; therefore, the RMSE plot for is left blank for the ZT model.
First, for Case 1, assuming normally distributed latent variables, the estimation performance is nearly identical across all four models. This indicates that even when the true model follows a normal distribution, accounting for higher-order moments does not degrade estimation performance. For Case 2, the estimation performance of the ZT model is generally poor; however no significant difference in performance is observed for the other three models. This suggests that when is fixed to a single value, consideration of heterogeneity in higher-order moments does not impair estimation performance. Finally, in Cases 3 and 4, the true models (TT and ST) demonstrate improved estimation performance for most parameters. Notably, the improvements are significant for the standard deviation of observational noise (), time-series coefficient (), and variability of random effects (). These results suggest that modeling heterogeneity in higher-order moments enhances parameter estimation performance. For , the FT model performed well in Cases 1 and 2, whereas in Case 3, the variation is slightly different with no notable differences among the three models. In Case 4, despite increased variation, the ST model improved estimation performance.
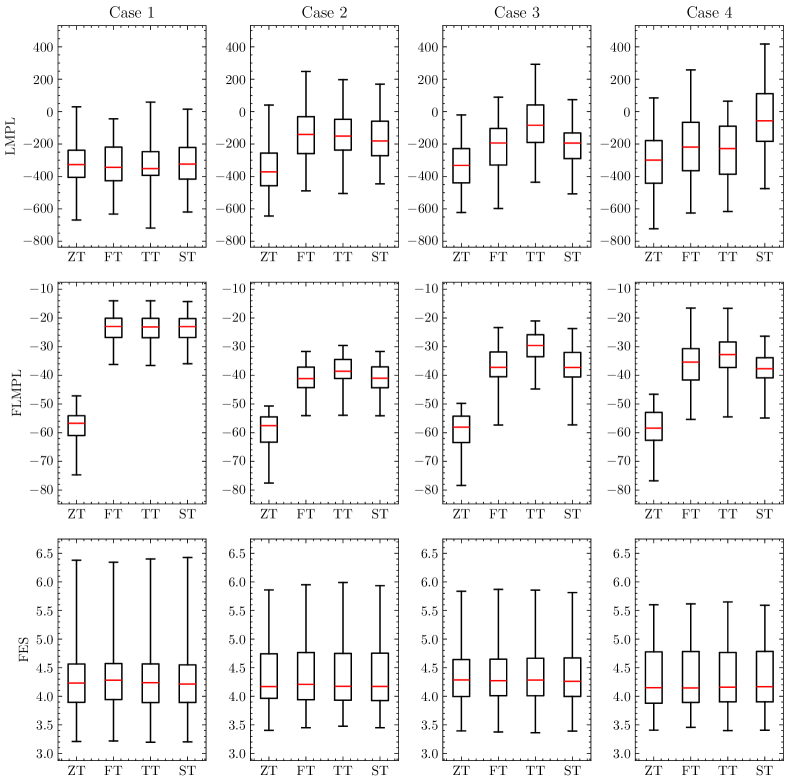
Similarly, Figure 5 displays predictive accuracy, which was evaluated using log marginal predictive likelihood (LMPL), LMPL in the future data (FLMPL), and RMSE of in the future data (FRMSE). The calculation method for LMPL followed that used in the CarBayesST package (Lee et al., 2018). FLMPL is an estimator of LMPL for the future data conditioned on the learning data , specifically . FLMPL is calculated from samples of the posterior distribution as follows:
where is a sample of parameters from the posterior distribution conditioned on , and is the number of samples. Similarly, FRMSE is the RMSE of and is numerically calculated as follows:
where is a sample drawn from , and is the Euclidean norm.
For LMPL, in Case 1, there is no significant difference among the four models, whereas in Cases 2, 3, and 4, the true model shows higher values. This indicates that selecting the true model improves the fit to the observed data. In contrast, for FLMPL, the ZT model performs poorly across all cases, with the TT model consistently performing slightly better than the FT and ST models. In this scenario, the standard deviation of the observational noise is 0.1, whereas the FRMSE ranges from approximately 1.1 to 1.5. This can be attributed to the assumption that varies over time, causing the model to exhibit heavier tails, which influences prediction. Finally, for FRMSE, there is little variation across the cases. This can be interpreted as the CSNS distribution maintaining the mean and variance, resulting in minimal differences in squared errors of the observations.
7 Application
This study focuses on identifying the production functions for 48 states in the United States, using annual data from 1970 to 1986, following the model outlined in Baltagi (2021). A production function represents how capital and labor affect output. We assumed a Cobb-Douglas type production function, where output is expressed as the product of capital and labor raised to respective exponents. By taking the logarithm of the Cobb-Douglas production function and rewriting it in a form that allows for coefficient estimation from observed data, it can be expressd as follows:
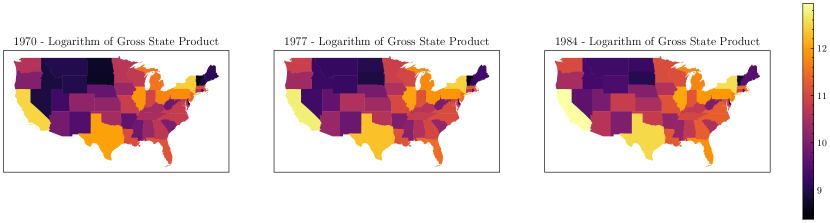
Here, represents the logarithm of the gross state product, with the features including private capital stock (), highways and streets (), water and sewer facilities (), other public buildings and structures (), nonagricultural payroll employment (), and the state unemployment rate (). All features, except the unemployment rate, are expressed in natural logarithms. The data spanning from 1970 to 1984 were utilized as the training dataset, whereas the data from 1985 to 1986 were used to validate the predictive accuracy of the models. Figure 6 displays the value of , the logarithm of the gross state product for each state. Data from the first (1970), middle (1977), and final year (1984) are plotted.
For the models, we compared the estimation results of ZT, FT, TT, and ST, using the same approach and priors as that of the simulation study. We set sufficiently long burn-in and thinning periods and obtained samples from the posterior distribution to evaluate the estimation results.
Table 3 displays the median and 90% credible interval of samples drawn from the posterior distributions of parameters for each model. The medians of the posterior distributions of the all parameters exhibit similar patterns, although a slight variation is observed in the estimates of the regression coefficients. This variation can be attributed to the proposed model, which preserves both the mean and variance.
| ZT | FT | |
|---|---|---|
| 1.197 (1.033–1.322) | 1.317 (1.144–1.451) | |
| 0.404 (0.371–0.429) | 0.386 (0.352–0.413) | |
| 0.143 (0.101–0.175) | 0.120 (0.079–0.152) | |
| 0.080 (0.054–0.099) | 0.080 (0.054–0.101) | |
| -0.007 (-0.037–0.016) | -0.018 (-0.048–0.007) | |
| 0.470 (0.431–0.501) | 0.513 (0.468–0.547) | |
| -0.007 (-0.010– -0.005) | -0.006 (-0.009– -0.004) | |
| 0.015 (0.014–0.016) | 0.015 (0.014–0.016) | |
| 0.953 (0.929–0.973) | 0.953 (0.927–0.972) | |
| 0.050 (0.047–0.052) | 0.049 (0.046–0.052) | |
| 0.756 (0.640–0.830) | 0.742 (0.627–0.822) |
| TT | ST | |
|---|---|---|
| 1.431 (1.253–1.566) | 1.378 (1.211–1.522) | |
| 0.366 (0.331–0.394) | 0.328 (0.293–0.356) | |
| 0.114 (0.072–0.148) | 0.179 (0.134–0.212) | |
| 0.081 (0.054–0.102) | 0.081 (0.055–0.102) | |
| -0.025 (-0.056– -0.001) | -0.021 (-0.053–0.004) | |
| 0.538 (0.495–0.572) | 0.527 (0.486–0.560) | |
| -0.004 (-0.007– -0.002) | -0.007 (-0.010– -0.005) | |
| 0.015 (0.014–0.016) | 0.014 (0.013–0.015) | |
| 0.947 (0.924–0.964) | 0.960 (0.939–0.975) | |
| 0.047 (0.044–0.049) | 0.043 (0.041–0.046) | |
| 0.569 (0.447–0.662) | 0.697 (0.565–0.785) |
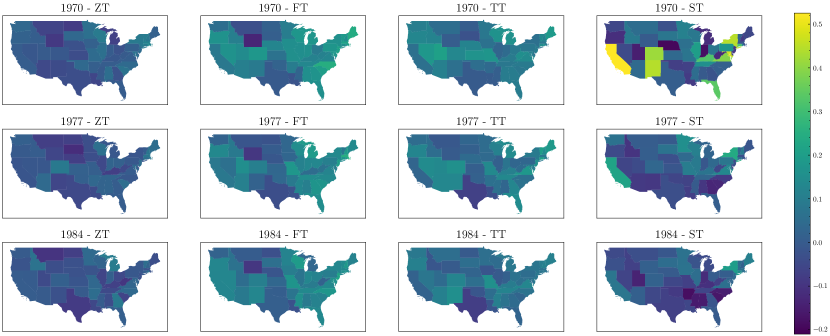
Figure 7 displays the median of the posterior distribution of for each state in 1970, 1977, and 1984 under each model. The figure reveals that, while the trends in the estimates of are similar across the four models, the actual values differ significantly. For example, the posterior median of for Wyoming in 1970 under the ZT model is approximately , whereas it is under the TT model. Certain states appear in much brighter colors under the CSNS model. For instance, Wyoming around 1970 is depicted in a brighter color, indicating higher productivity than expected based on its capital and infrastructure. In 1970, Wyoming was the second least populous state (United States Census Bureau, 1973), exhibiting low feature values, with being the smallest. However, owing to its abundant resources such as coal, crude oil, and natural gas (U.S. Energy Information Administration, 2023), Wyoming demonstrated a total production that surpassed predictions based on its features. The states appearing in brighter colors under the CSNS model suggest that this model assigns greater probability to positive values than the normal model, because is positive. Additionally, in the ST model, differences in shading intensity are more distinct separated than in the FT and TT models.
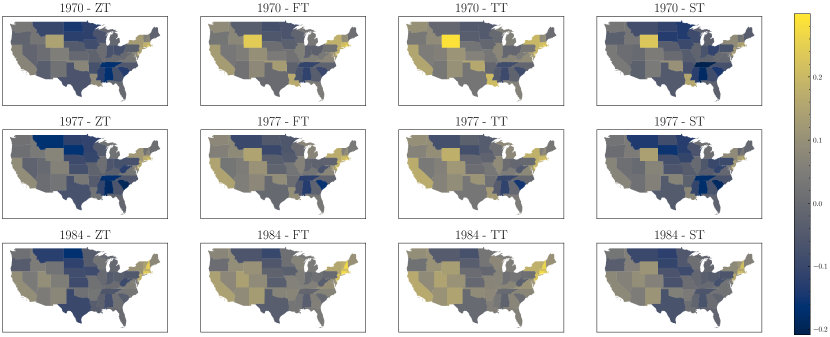
Figure 8 depicts the skewness of the posterior distributions in each model. In this figure, in the ST model for 1970, the differences in skewness are more distinct than in the other models. This is attributed to the ST model’s ability to capture the spatial heterogeneity of higher-order moments. In 1977 and 1984, these differences in skewness are less pronounced, presumably because the variance increases over time, making it more difficult for the skewness to become substantially larger.
Finally, Table 4 presents the evaluation of predictive accuracy. Compared with the ZT model, the FT, TT and ST model show improvements in all evaluated metrics. Even though has undergone a logarithmic transformation, considering the heterogeneity of higher-order moments leads to enhanced estimation performance. In particular, the TT and ST models outperform the FT model, suggesting that incorporating both temporal and spatial heterogeneity in higher-order moments improves model fit and predictive accuracy.
| LMPL | FLMPL | FRMSE | |
|---|---|---|---|
| ZT | 1908.433 | 203.602 | 5.945 |
| FT | 1920.203 | 254.741 | 5.875 |
| TT | 1947.617 | 268.959 | 5.680 |
| ST | 1945.871 | 255.556 | 5.302 |
8 Conclusion
In this study, we propose a method that enables the treatment of the heterogeneity of the higher order moments while preserving the mean and variance, crucial for maintaining parameter interpretability (see Section 1). After demonstrating closure under linear transformations of the proposed model, we analytically derived its skewness and kurtosis. In addition, applying it to spatio-temporal data, we examined how the properties of the model change depending on the chosen matrix decomposition method. In particular, using the matrix square root preserves symmetry with respect to ordering, making it suitable for data with inherent symmetry. For time-series data, we showed that the Cholesky decomposition corresponds to the AR model representation. We then proposed an efficient Bayesian inference method employing data augmentation and the FFBS algorithm.
In the simulation study, we compared the estimation performance of the four models that incorporated heterogeneity in higher-order moments. The results demonstrated that appropriately accounting for higher-order moment heterogeneity improves parameter estimation performance, model fit, and predictive accuracy.
For a real-data application, we applied the CSNS model to identify production functions across the United States. Although parameters other than generally exhibited similar trends, the posterior distribution of revealed that skewness varies substantially by location, particularly when spatial heterogeneity in higher-order moments is considered. Furthermore, both the TT and ST models showed improvements in terms of model fit and predictive performance metrics, indicating that even when the response variable is log-transformed, accounting for higher-order moment heterogeneity enhances estimation performance.
An open question for future research is the development of a model that simultaneously preserves the mean and variance, maintains spatial conditional independence, and accommodates heterogeneity in higher-order moments. Furthermore, as the proposed model encompasses a broad class of models, a potential extension may explore more complex structures where each dimension follows a different distribution, which remains unaddressed in this study.
The Julia implementation of CSNS model is available on GitHub:
(https://github.com/Kuno3/CsnSubclass).
Acknowledgments
This work was supported by JSPS KAKENHI Grant Number 24K00175.
References
- Anselin (2022) Anselin, L., 2022. Spatial econometrics, in: Rey, S.J., Franklin, R.S. (Eds.), Handbook of Spatial Analysis in the Social Sciences. Edward Elgar Publishing, Cheltenham, pp. 101–122.
- Azzalini (1985) Azzalini, A., 1985. A class of distributions which includes the normal ones. Scand. J. Stat. 12, 171–178.
- Azzalini and Capitanio (1999) Azzalini, A., Capitanio, A., 1999. Statistical applications of the multivariate skew normal distribution. J. R. Stat. Soc. Ser. B Stat. Methodol. 61, 579–602.
- Baltagi (2021) Baltagi, B.H., 2021. Econometric Analysis of Panel Data. 6th ed., Springer, Berlin.
- Best et al. (2005) Best, N., Richardson, S., Thomson, A., 2005. A comparison of bayesian spatial models for disease mapping. Stat. Methods Med. Res. 14, 35–59.
- Botev (2017) Botev, Z.I., 2017. The normal law under linear restrictions: Simulation and estimation via minimax tilting. J. R. Stat. Soc. Ser. B Stat. Methodol. 79, 125–148.
- Carter and Kohn (1994) Carter, C.K., Kohn, R., 1994. On gibbs sampling for state space models. Biometrika 81, 541–553.
- Cressie and Wikle (2011) Cressie, N., Wikle, C.K., 2011. Statistics for spatio-temporal data. John Wiley & Sons.
- Dormann et al. (2007) Dormann, C.F., McPherson, J.M., Araújo, M.B., Bivand, R., Bolliger, J., Carl, G., Davies, R.G., Hirzel, A., Jetz, W., Daniel Kissling, W., et al., 2007. Methods to account for spatial autocorrelation in the analysis of species distributional data: a review. Ecography 30, 609–628.
- Frühwirth-Schnatter (1994) Frühwirth-Schnatter, S., 1994. Data augmentation and dynamic linear models. J. Time Ser. Anal. 15, 183–202.
- Lee et al. (2018) Lee, D., Rushworth, A., Napier, G., 2018. Spatio-temporal areal unit modeling in r with conditional autoregressive priors using the CARBayesST package. J. Stat. Softw. 84, 1–39.
- Márquez-Urbina and González-Farías (2022) Márquez-Urbina, J.U., González-Farías, G., 2022. A flexible special case of the CSN for spatial modeling and prediction. Spatial Stat. 47, 100556.
- Niccolò et al. (2023) Niccolò, A., Augusto, F., Daniele, D., Giacomo, Z., 2023. Bayesian conjugacy in probit, tobit, multinomial probit and extensions: A review and new results. J. Amer. Statist. Assoc. 118, 1451–1469.
- Tagle et al. (2019) Tagle, F., Castruccio, S., Crippa, P., Genton, M.G., 2019. A non-gaussian spatio-temporal model for daily wind speeds based on a multi-variate skew-t distribution. J. Time Ser. Anal. 40, 312–326.
- Tan and Chen (2024) Tan, L.S.L., Chen, A., 2024. Variational inference based on a subclass of closed skew normals. J. of Comput. and Graph. Stat. 0, 1–15.
- United States Census Bureau (1973) United States Census Bureau, 1973. 1970 census of population: Characteristics of the population. https://www.census.gov/library/publications/1973/dec/population-volume-1.html. (accessed 25 May 2024).
- U.S. Energy Information Administration (2023) U.S. Energy Information Administration, 2023. Production - state energy data system (seds). https://www.eia.gov/state/seds/seds-data-complete.php. (accessed 25 May 2024).
- Wang et al. (2024) Wang, K., Karling, M.J., Arellano-Valle, R.B., Genton, M.G., 2024. Multivariate unified skew-t distributions and their properties. J. of Multivar. Analysis 203, 105322.
- Yan et al. (2020) Yan, Y., Jeong, J., Genton, M.G., 2020. Multivariate transformed gaussian processes. Jpn. J. Stat. Data Sci. 3, 129–152.