Modern Multiple Imputation with Functional Data
Abstract
This work considers the problem of fitting functional models with sparsely and irregularly sampled functional data. It overcomes the limitations of the state-of-the-art methods, which face major challenges in the fitting of more complex non-linear models. Currently, many of these models cannot be consistently estimated unless the number of observed points per curve grows sufficiently quickly with the sample size, whereas, we show numerically that a modified approach with more modern multiple imputation methods can produce better estimates in general. We also propose a new imputation approach that combines the ideas of MissForest with Local Linear Forest and compare their performance with PACE and several other multivariate multiple imputation methods. This work is motivated by a longitudinal study on smoking cessation, in which the Electronic Health Records (EHR) from Penn State PaTH to Health allow for the collection of a great deal of data, with highly variable sampling. To illustrate our approach, we explore the relation between relapse and diastolic blood pressure. We also consider a variety of simulation schemes with varying levels of sparsity to validate our methods.
Keywords: Functional Data Analysis, Multiple Imputation, Functional Regression, Missing Data.
1 Introduction
Functional Data Analysis (FDA) is a branch of statistics that models the relationship between functions measured over a particular domain, such as time or space (Kokoszka and Reimherr,, 2018; Horváth and Kokoszka,, 2012; Ferraty and Romain,, 2011; Ferraty and Vieu,, 2006; Ramsay and Silverman,, 1997). There is a rich literature on modeling functions that are densely observed but comparatively less literature on modeling functions that are sparsely observed, which introduce new challenges. Currently, there are very few imputation methods designed for functional data (James et al.,, 2000; Rice and Wu,, 2001; He et al.,, 2011), with a mean imputation procedure, commonly known as PACE (Yao et al.,, 2005), being the most common.
Single imputation procedures (like mean imputation or PACE) are useful in general but can’t account for the uncertainty induced from the imputation procedure; once the imputation is done, analyses then typically proceeds as if the imputed values were the truth. This leads to overly optimistic measures of uncertainty and the potential for substantial bias (Petrovich et al.,, 2018). To deal with this and other problems associated with single imputation methods, we consider multiple imputation methods. Multiple imputation involves filling in the missing values multiple times, which creates multiple “complete” data sets. The variability between these complete data sets reflects the uncertainty introduced in the imputation method. Multiple imputation procedures are very versatile, flexible and can be used in a wide range of settings. As multiple imputation involves creating multiple predictions for each missing value, the corresponding statistical analysis takes into account the uncertainty in the imputations and hence, yields a more reliable standard error. In simple terms, if there is less information in the observed data regarding the missing values, the imputations will be more variable, leading to higher standard errors in the analysis. In contrast, if the observed data is highly predictive of the missing values, the imputations will be more consistent across the multiple imputed data sets, resulting in smaller and reliable standard errors (Greenland and Finkle,, 1995).
Longitudinal studies are amenable to Functional Data Analysis (FDA), often contain sparse and irregular samples. Such data can be considered as having missing values making imputation a natural consideration. Many FDA methods analyze fully or densely observed data sets without any appreciable missing values. However, this is often not the case when dealing with large medical and biological data. Hence, in such cases, we can either apply Sparse FDA methods (Yao et al.,, 2005; Kokoszka and Reimherr,, 2018) or use imputation to apply more traditional FDA techniques. Several multiple imputation techniques have been proposed to impute incomplete multivariate data, including Multivariate Imputation by Chained Equations (MICE) (van Buuren,, 2007) and MissForest (MF) (Stekhoven and Bühlmann,, 2011). Though these methods have not been directly applied to functional data, they have worked well in general. MICE builds a separate model for each variable (that contains missing values), conditioned on the others, which can be specified based on the data type (continuous, binary, etc.). MF is similar to MICE but uses random forests for building the conditional models. In both cases, variables are sequentially imputed until convergence is reached. We use the MICE (Buuren and Groothuis-Oudshoorn,, 2011) and missForest (Stekhoven,, 2013) packages in R to implement these methods. Also, Local Linear Forest (LLF) (Friedberg et al.,, 2018) which is a modification of Random Forest, is a powerful Regression method. Functional Data is naturally smooth and LLF is equipped to model signals. Taking advantage of this interesting property of LLF, we propose another imputation method similar to that of MF and MICE using LLF.
Several other imputation methods include K-nearest-neighbor (KNN) (Acuna and Rodriguez,, 2004), Nonparametric imputation by data depth (Mozharovskyi et al.,, 2017), substantive model compatible fully conditional specification (Bartlett et al.,, 2015), and many more. There have also been studies comparing imputation methods (Ding and Ross,, 2012; Waljee et al.,, 2013; Liao et al.,, 2014; Ning and Cheng,, 2012) under different scenarios and data types, but for functional data, PACE has become the “gold standard”. Unfortunately, current methods for imputation in FDA are not designed to handle complex models and do not allow for consistent estimation unless one assumes that the number of observed points per curve grows sufficiently quick with the sample size. Though this is mathematically convenient, it highlights a serious concern when handling sparse functional data. Most of the methods impute while ignoring the response and subsequent modeling that is to be done with the reconstructed curves, a notable exception being Bayesian methods (Kowal et al.,, 2019; Thompson and Rosen,, 2008). This leads to biased estimates with unreliable standard errors and misleading p-values. For these reasons, PACE which is executed using fdapace package (Chen et al.,, 2019), uses an alternative approach to produce consistent estimates for functional linear models that do not generalize to non-linear models.
Missing data as described by Rubin, (2004), can be divided into three categories: 1. Missing Completely at Random (MCAR), in which the missing values are independent of the observed data. 2. Missing at Random (MAR), in which the missing value patterns depend only on the observed data and are conditionally independent of the unobserved data. 3. Missing Not at Random (MNAR) also known as non-ignorable missing data or structural missing data, in which the missing data patterns depend on the observed and unobserved data. Usually, it is assumed that one is either working with MCAR or MAR, to make the problem tractable. We make a similar assumption in our procedure, without formally defining the missing data mechanism. Many of the recent works in Functional Data imputation (Preda et al.,, 2010; Ferraty et al.,, 2012; Crambes and Henchiri,, 2018; He et al.,, 2011) have built upon these ideas and adopted a missing data perspective to tackle various forms of sparsity in functional models. But all these approaches consider either a linear relationship or sparsity in the response, whereas we work with a completely observed response and sparsely observed covariates, where we can have a non-linear relation between them.
In this work, we explore the performance of several modern imputation procedures with functional data. Also, we propose another imputation method using LLF. We demonstrate how a simple modification using binning alongside careful initialization can dramatically improve the imputation and subsequent estimation for both linear and non-linear models. From a missing data perspective, the goal is to do imputation of the missing data in a way that retains the performance of subsequent statistical modeling.
1.1 PaTH To Health
Electronic Health Record (EHR) or Clinical Data often require longitudinal statistical methods, which account for the correlation between repeated measurements on the same subject. If one also assumes that these are taken from a smooth curve or data generating process, then we can exploit tools from FDA, which can produce gains in terms of flexibility and statistical power (He et al.,, 2011; Carnahan-Craig et al.,, 2018; Goldsmith and Schwartz,, 2017). Since hospital visits can occur both infrequently and irregularly, we can’t directly apply many FDA techniques to them. They pose a challenge to the current methods as well as for imputation. To address these challenges and illustrate the effectiveness of our approach over the current methods, we wish to apply them to an EHR data set where we predict if a smoker will relapse or not based on their Blood Pressure (BP) recordings over a span of 18 months.
The data provided by the Penn State PaTH to Health, assists research that uses patient data from multiple sources to further scientific discoveries. The data set describes patient-level data variables in a standardized manner (i.e., with the same variable name, attributes, and other metadata) along with information on demographics, encounters, diagnoses, and procedures. More information can be found on their website.
While there is a wealth of research related to smoking and blood pressure (BP) (Wang et al.,, 2018; Hansson et al.,, 1996; Primatesta et al.,, 2001), our goal here is not to make deep scientific statements, but rather to illustrate the utility of our methods, which we hope will prove useful to practitioners. The highest risk of relapse for smokers is during the end of their first and second year after quitting (Herd et al.,, 2009; García-Rodríguez et al.,, 2013). We, therefore, focus on modeling the relapse of the patients based on monitoring their BP within the first two years, which may be useful to the practitioners designing interventions for patients at risk of relapse.
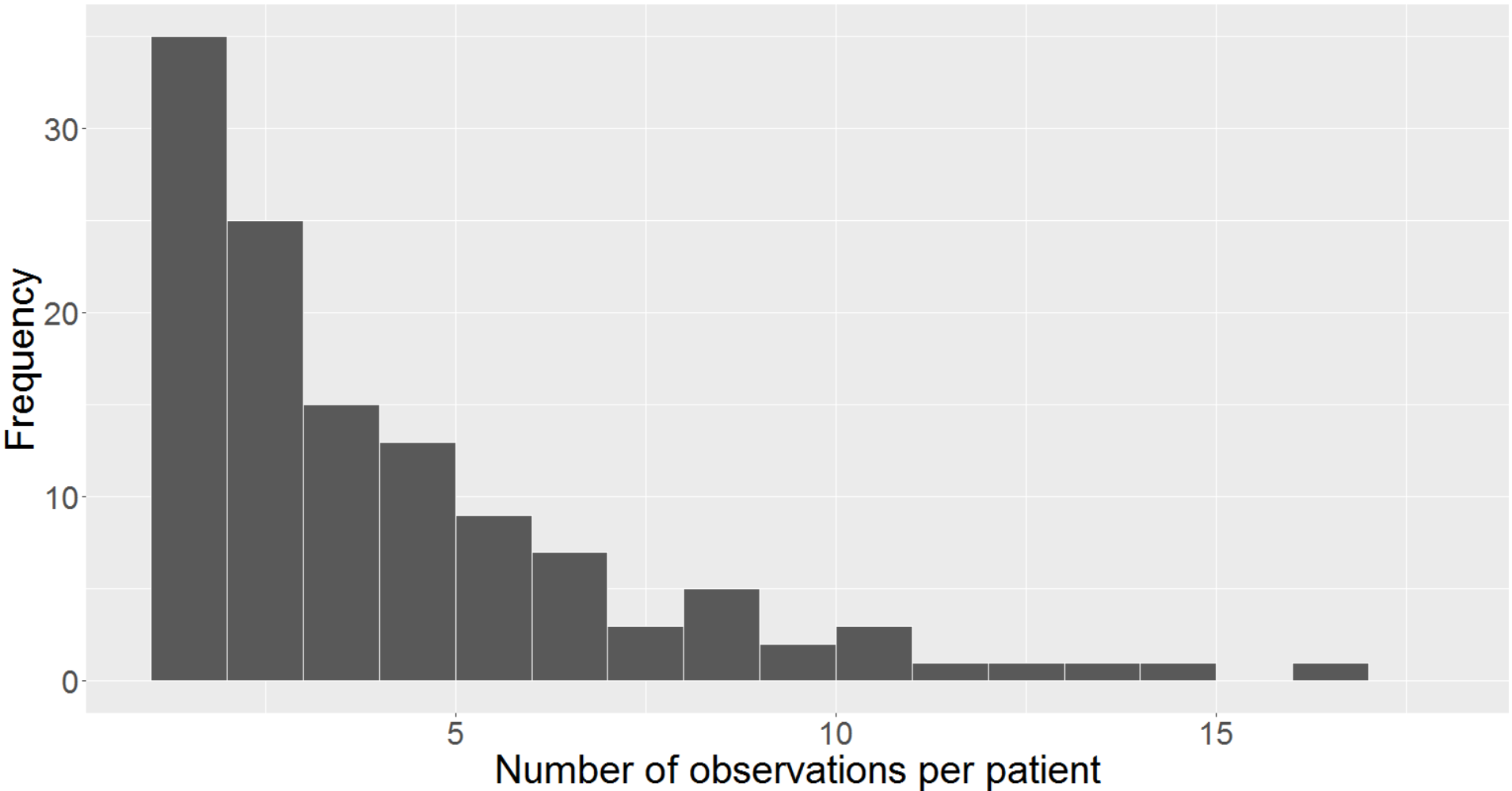
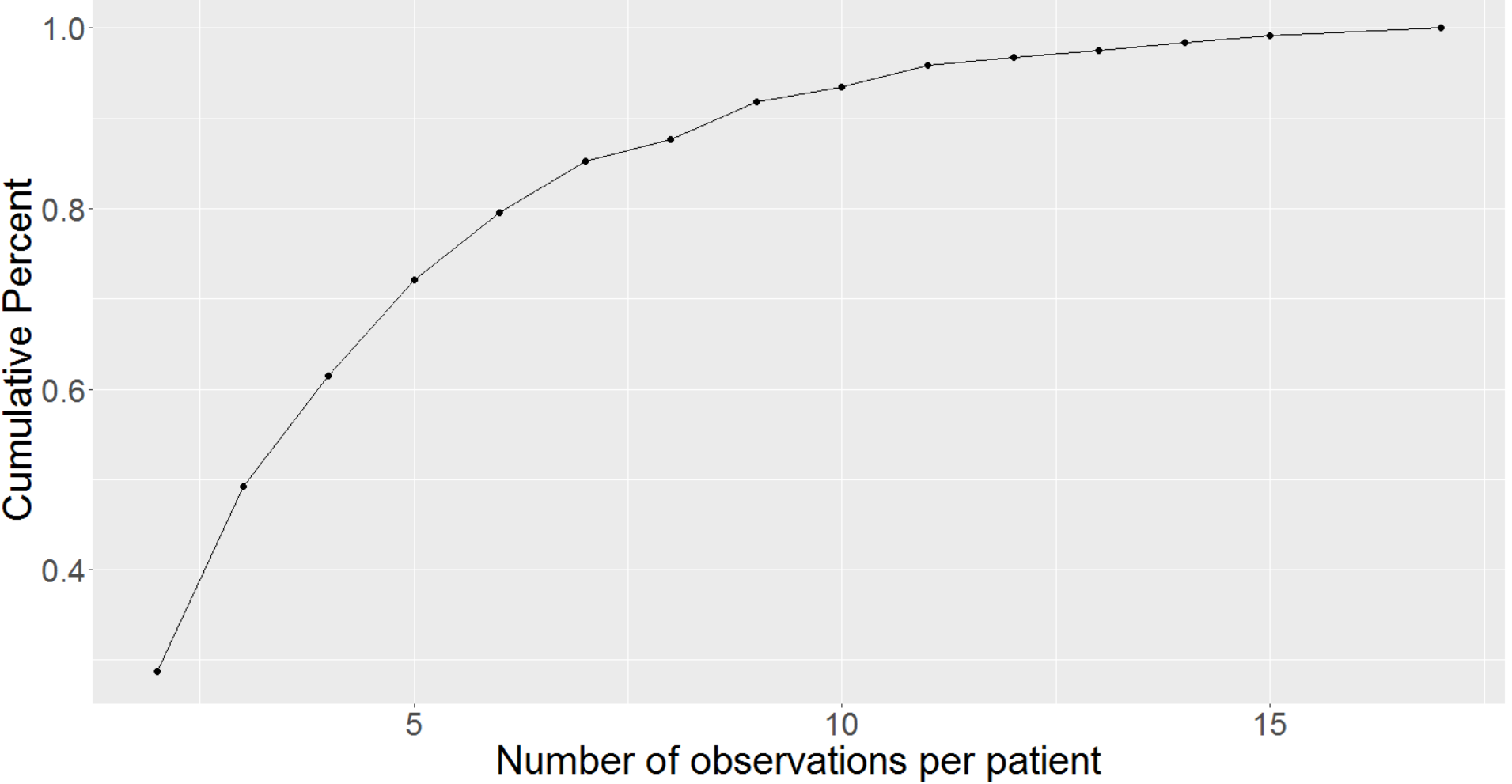
In general, EHR data sets vary significantly with the timing and regularity of the appointments, and clinical measurements are affected by errors of varying types and degrees (Daymont et al.,, 2017). Similar challenges apply to measurements in the PaTH data set where we have various kinds of clinical measurements and information recorded. The ability to characterize trajectories of sparse irregular data has potential applicability to many clinical questions. Though the term sparsity is somewhat subjective in the context of functional/longitudinal data, many of the patients in the Path data set have just 2 measurements, while the most number of measurements for any patient is 17 (after cleaning and implementing the exclusion criteria). We can see from Figure 1 the modal number of measurements is 2, while relatively few patients had more than 7 clinical visits and almost none had more than 11. Also, from the cumulative observation Figure (appendix Figure 6), we observe that 94% of the patients had 10 or fewer measurements, 72% had at most 5 measurements, and 28% had no more than 2 measurements. On an average, we have around 4 measurements per patient. Sparsity arises due to many reasons in an EHR setting. Some patients never come back, some patients are not observed with any uniformity or regularity, etc. Having identified the BP trajectories as both sparse and irregular, we move to introduce the imputation methods that account for these conditions in a Functional framework before revisiting this data in Section 3.
1.2 Organization
The rest of the paper is organized as follows. In Section 2, we briefly go through PACE and Multivariate Imputation methods (MICE and MF) before introducing our proposed method using LLF, and modifications to the Multivariate Imputation methods using bins and careful initialization, to better deal with Functional Data. We present multiple simulations for the linear and non-linear cases under different values of sparsity in Section 3. This section also includes the EHR data, where we fit a scalar-on-function regression model to determine if a patient (smoker) will relapse or not at the end of 18 months using BP as the functional predictor. These examples help us to illustrate the limitations of previous approaches and demonstrate the usefulness of our methodology, which overcomes many of the issues discussed earlier. In the final section, we present our concluding remarks and future research directions, which pertain to better understanding of the bins and deeper statistical theory.
2 Methods
In this section, we give details of the current imputation methods for the scalar-on-function regression model. In subsection 2.1 we define the necessary notation used in the paper. In subsection 2.2, we briefly discuss scalar-on-function regression models. Subsection 2.3 gives an overview of PACE and the multivariate imputation method MICE in detail along with their shortcomings. In subsection 2.4, we discuss LLF and the multivariate imputation method MF. We present our new imputation procedure that extends the ideas of MF to LLF, as well as discuss how to use careful binning and initialization to improve performance.
2.1 Setup and Notation
We assume the data is collected from trajectories that are independent realizations of a smooth random function, with unknown mean function = and covariance function . We define the underlying functional covariates as where denotes the argument of the functions, usually time, and denotes the subject or unit. We assume that these curves are only observed at times () with some error:
Let denote the vector of observed values on the function Let , be the outcome, which is a function of and some error. Examples of such relations can be found in the next subsection.
Generally, when integration is written without limits, it is implied to be over the entire domain, usually standardized to for simplicity. The main focus of this work is to develop tools for consistently estimating the parameters in functional regression models.
2.2 Functional models
The scalar-on-function regression model in the linear case is defined as:
| (1) |
A common way of estimating the model components is by Basis or Functional Principal Component (FPC) expansions, where we simplify the problem of estimating the parameters by projecting the functions to a finite dimension and then using multiple regression and least squares (Kokoszka and Reimherr,, 2018; Ramsay and Silverman,, 1997).
Non-linear modeling becomes very challenging with functional data due to the curse of dimensionality. One popular way of simplifying the problem is by using the generalized additive model, also known as continuously additive model (McLean et al.,, 2014; Müller et al.,, 2013; Wang and Ruppert,, 2013; Fan et al.,, 2015; Ma and Zhu,, 2016):
| (2) |
where the bivariate function is smooth, but unknown. It is commonly estimated using either basis expansions (Yao et al.,, 2005; Greven et al.,, 2010) (often with a tensor product basis) or using Reproducing Kernel Hilbert Spaces (Wang and Ruppert,, 2013; Reimherr et al.,, 2017). McLean et al., (2014) developed Functional Generalized Additive Models that enabled non-scalar response mapping.
Most methods for fitting the models discussed above require densely sampled functional data. For irregular and sparsely sampled data that are observed with error, estimating the modeling parameters becomes much more challenging. Directly smoothing the to plug into a dense estimation framework seems like a straightforward idea but can result in substantial bias.
2.3 Imputation Methods
PACE (Yao et al.,, 2005) uses functional principal components (FPC) analysis, in which the FPC scores are imputed using conditional expectations. In addition to the requirements discussed previously, PACE also relies heavily on the data being Gaussian. The Karhunen-Loève or Principal Component expansion of is given by:
| (3) |
where are the eigenfunctions of with eigenvalues . The scores are computed as:
| (4) |
PACE proceeds by computing the conditional expectation of the scores given the observed data. This conditioning method is straightforward and tends to work much better than direct smoothing of . It provides the Best Linear Unbiased Predictors (BLUPs) under Gaussian assumptions and works in the presence of both measurement errors and sparsity. We can plug in the BLUPs values into a dense estimation framework to model the response.
PACE still suffers from a few major problems. One issue is that the imputation procedure of PACE does not consider the response nor does it have any consideration for subsequent models that will be fit. This results in a bias while estimating model parameters (Petrovich et al.,, 2018). In addition, PACE is just a single imputation method and hence the uncertainty in the imputation is not properly propagated when forming confidence intervals, prediction intervals, or p-values. For this reason, the PACE software (Chen et al.,, 2019) uses an alternative approach for fitting linear models, which does not extend to non-linear models.
After understanding PACE, we now look into some of the standard methods used for imputation in the multivariate case. All of these methods have proven to work well in the multivariate setting but have never been tested in the functional setting, where the sample sparsity can be very high.
Multivariate Imputation by Chained Equations (MICE) (van Buuren,, 2007), also known as “fully conditional specification” or “sequential regression multiple imputation”, has emerged in the statistical literature as one of the principal methods for addressing missing data. MICE performs multiple imputations rather than single imputation and hence, it can account for the statistical uncertainty. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g. continuous or categorical) as well as complexities such as bounds or survey skip patterns. At a high level, the MICE procedure is a series of models whereby each variable with missing data is modeled conditional upon the other variables in the data. The MICE procedure is as follows: 1. We start by initialization, wherein we fill in all the missing values with mean imputation. 2. Next, we select the first variable with missing entries. A model is fit with this variable as the outcome and the other variables as predictors. 3. The missing values of the current variable are then replaced with predicted (imputed) values from the model in step 2. 4. Step 2 and step 3 are repeated while rotating through the variables with missing values sequentially. The cycling through each of the variables constitutes one iteration or cycle. 5. At the end of one cycle, all of the missing values have been replaced with predictions from the model that reflect the relationships observed in the data. The cycles are repeated a few times and after each cycle the imputed values are updated.
The number of cycles to be performed is pre-specified and after the last cycle, the final imputations are retained, resulting in one imputed data set. Generally, 10-15 cycles are performed. The idea is that, by the end of the cycles, the distribution of the parameters governing the imputations (e.g. the coefficients in the regression models) should have converged, in the sense of becoming stable. Different MICE software packages vary somewhat in their exact implementation of this algorithm (e.g. in the order in which the variables are imputed), but the general strategy is the same. Here, we have used the MICE (Buuren and Groothuis-Oudshoorn,, 2011) package in R.
A key advantage of MICE is its flexibility in using different models. Generally, the modeling techniques included in MICE are Predictive Mean Matching, Linear Regression, Generalized Linear Models, Bayesian Methods, Random Forest, Linear Discriminant Analysis, and many more. Its primary disadvantage is that it does not have the same theoretical justification as other imputation methods. In particular, fitting a series of conditional distributions, as is done using the series of regression models, may not be consistent with proper joint distribution, though some research suggests that this may not be a large issue in applied settings (Schafer and Graham,, 2002).
2.4 Our Approach
2.4.1 MissForest and Local Linear Forest
MissForest (MF) (Stekhoven and Bühlmann,, 2011) is a multiple imputation method, which proceeds by training a Random Forest (RF) on the observed parts of the data. Random forest (Breiman,, 2001) is a non-parametric method that is able to deal with mixed data types as well as allow for interactive and non-linear effects. MF addresses the missing data problem using an iterative imputation scheme by training a RF on observed values in the first step, followed by predicting the missing values in the next step and then proceeding iteratively. RF works well in High dimensional cases with good accuracy and robustness. Though the idea of MF is similar to MICE, they differ in the ordering scheme of the columns to be imputed, and MICE requires certain assumptions about the distribution of the data or subsets of the variables, which may or may not be true.
For an arbitrary variable in including missing values at entries , we can separate the data set into four parts: The observed values for variable , denoted by , the missing values for variable , denoted by , the variables other than with observations at / denoted by and the variables other than with observations at denoted by .
The approach is as follows: We initialize for the missing values in using mean imputation or another imputation method. We then sort the variables in () in ascending order of the missing values. For each variable , the missing values are imputed by first fitting an Random Forest with response and predictors ; then, predicting the missing values by applying the trained RF to . We sequentially do this for all variables with missing values, that is one cycle. The imputation procedure is repeated for multiple cycles until a stopping criterion is met.
The advantage of MF is that it can deal with any kind of data. Also, MF is straightforward, as it does not need any tuning of parameters nor does it require any assumption about distributional aspects of the data. The full potential of MF is deployed when the data includes complex interactions or non-linear relations between variables of different types, which is not possible with PACE. Furthermore, MF can be applied to high-dimensional data sets with a low sample size and still provide excellent results. MF often outperforms other methods in terms of imputation (Stekhoven and Bühlmann,, 2011), but the method has no smoothing mechanism and hence the imputed values of the curves are not smooth. To deal with this and to increase model accuracy, we integrate binning into the method as explained in the next subsection.
Local Linear Forest (Friedberg et al.,, 2018) uses a RF to generate weights that are used as a kernel for local linear regression, i.e., Local Linear Forest takes the RF weights and uses them to solve:
| (5) |
The RF weights are found with the help of the leaf in each tree in a forest of trees as follows:
| (6) |
where and for each Athey et al., (2016) used this perspective to harness RF for solving weighted estimating equations, and gave asymptotic guarantees on the resulting predictions. With the help of the above weights, LLF solves the locally weighted least squares problem.
LLF is a modification of Local Linear Regression with the help of RF, equipped to model signals and fix bias issues. We use this to our advantage and propose a modification to the MF method, where we replace the RF with LLF. We refer to this as Miss Local Linear Forest (MLLF). This new approach using LLF for imputation follows the same steps as MF but instead of using RF as the modeling technique to impute the missing values, we will now use LLF. Since LLF does not inherit the multiple imputation like MF, we generate multiple imputed sets and take an average like in the case of MICE. MLLF has similar benefits to MF. We update the MissForest code (Stekhoven,, 2013) in R using grf package (Tibshirani et al.,, 2020) to implement MLLF.
2.4.2 Adapting methods to Functional data
One of the key features of Functional Data is the smoothness of the underlying curves. MF and MLLF produce well-imputed curves but are not smooth. We overcome this problem with the help of binning and careful initialization. We improve the initialization by using PACE instead of simple mean imputation. These boosted methods using PACE are denoted as MFP for MissForest and MLLFP for Local Linear Forest. While this leads to higher performance in general with slightly smoother imputed curves, it does not directly smooth the imputed curves or resulting model parameters. Also, this initialization comes with a computational burden as PACE itself is computationally heavy. Another restriction which all of these imputation methods have, except PACE, is that they need to pass through the observed points, which need not be optimal, especially in the presence of observation noise.
We overcome the non-smoothness issue and computational problem by the use of bins. Binning (also known as Discrete binning or bucketing) is a data pre-processing method that is used to reduce the effects of minor observation errors and smooth the data. The original data values which fall in a given small interval, a bin, are replaced by a value representative for that interval, usually the mean value. Binning aggregates the values into a fixed range. So, we divide the desired grid of the time points into bins and impute over the points before interpolating back to time points using b-splines. Here, is a tuning parameter that acts much like a bandwidth in kernel smoothing. This not only leads to smoother imputation results but also improves the subsequent modeling as well. As binning helps in reducing the number of time points (), the overall process becomes way more computational friendly. The way bins are defined is as follows:
-
•
The first bin is the first time point of the data.
-
•
The last bin is the last time point of the data.
-
•
The middle - bins are divided into equal parts and are represented by the mean of all values in that bin.
We denote the methods with the binning as MF_B for MissForest and MLLF_B for Local Linear Forest. If we add PACE initialization to it then we denote the methods as MFP_B for MissForest and MLLFP_B for Local Linear Forest. We can see in the next section that, this not only leads to much smoother results but also improves imputations and modeling performance.
3 Simulation and Results
Throughout this section, we refer to MissForest as MF, MissForest with PACE initialization as MFP, binning without PACE as MF_B and with PACE as MFP_B. Miss Local Linear Forest (MLLF) uses an analogous naming scheme. In addition to comparing all the methods in simulations, we will compare the results for the EHR data as well. In the simulation, we compare them in both Linear and Non-Linear scalar-on-function regression settings with a scalar and binary response, investigating the imputation accuracy, model fit (prediction accuracy), and estimates (only for the Linear case). We compare across multiple simulated data sets with varying time points observed , sample sizes and sparsity .
3.1 Simulation
Linear case:
For the Linear case, we simulate iid random curves from a Gaussian process with mean 0 and covariance
which is the Matérn covariance function and is the modified Bessel function of the second kind. We set and These curves are evaluated at equally-spaced time points from . We assume that each observed point contains a normal measurement error with mean zero and variance We set where is a weight coefficient used to adjust the signal. The response, is computed using the model in Equation (1), where and In the binary response case, we define using Bernoulli and logit link function in Equation (1). Finally, for each curve, we assume a percentage () of the time points are unobserved. After the scores are imputed, we fit a scalar-on-function regression model using these imputed curves.
For the linear case, we simulate the data sets of different sample sizes, (results for n=200 and n=1000 are included in the appendix); different number of observations per curve, ; and with different sparsity level, . For sparsity levels, Medium means of the points are missing for each curve and High means more than of the points are missing for each curve. Also, the values of are taken such that it helps with the process of binning. Each of these settings is simulated 10 times. Since we are primarily interested in the accuracy of the final estimates , and we report the Root Mean Square Error (RMSE) or Prediction Error for each of them.
| Method | n=500, s=Medium | n=500, s=High | ||||||||||
| m=32, b=17 | m=52, b=27 | m=32, b=8 | m=52, b=12 | |||||||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |||||
| MF | 0.136 | 0.155 | 0.108 | 0.227 | 0.241 | 0.077 | 0.267 | 0.422 | 0.470 | 0.177 | 0.307 | 0.390 |
| PACE | 0.170 | 0.208 | 0.199 | 0.484 | 0.595 | 1.910 | 0.376 | 0.432 | 0.369 | 0.350 | 0.388 | 0.308 |
| MLLF | 0.142 | 0.149 | 0.070 | 0.234 | 0.242 | 0.023 | 58.010 | 43.721 | 0.601 | 69.24 | 55.43 | 0.508 |
| MICE | 3.611 | 3.612 | 0.090 | 0.237 | 0.253 | 0.089 | 9.840 | 5.950 | 0.910 | 3.162 | 2.390 | 1.073 |
| MFP | 0.122 | 0.144 | 0.105 | 0.228 | 0.250 | 0.130 | 0.141 | 0.289 | 0.398 | 0.232 | 0.310 | 0.328 |
| MLLFP | 0.132 | 0.153 | 0.144 | 0.232 | 0.246 | 0.100 | 0.376 | 0.432 | 0.364 | 0.384 | 0.386 | 0.302 |
| MF_B | 0.122 | 0.136 | 0.079 | 0.173 | 0.180 | 0.052 | 0.117 | 0.264 | 0.334 | 0.152 | 0.217 | 0.261 |
| MLLF_B | 0.126 | 0.137 | 0.082 | 0.174 | 0.177 | 0.053 | 0.097 | 0.291 | 0.338 | 0.132 | 0.203 | 0.267 |
| MFP_B | 0.122 | 0.138 | 0.053 | 0.176 | 0.182 | 0.023 | 0.101 | 0.263 | 0.339 | 0.146 | 0.219 | 0.275 |
| MLLFP_B | 0.128 | 0.143 | 0.059 | 0.179 | 0.178 | 0.023 | 0.091 | 0.817 | 0.614 | 0.129 | 0.214 | 0.307 |
under Linear case when n=500 for different time points and sparsity settings.
| Method | n=500, s=Medium | n=500, s=High | ||||||||||
| m=32, b=17 | m=52, b=7 | m=32, b=17 | m=52, b=12 | |||||||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |||||
| MF | 0.268 | 0.409 | 0.043 | 0.280 | 0.391 | 0.155 | 0.317 | 0.383 | 0.187 | 0.251 | 0.347 | 0.307 |
| PACE | 0.270 | 0.508 | 0.199 | 0.431 | 0.426 | 1.910 | 0.348 | 0.463 | 0.369 | 0.466 | 0.687 | 0.308 |
| MLLF | 0.364 | 0.453 | 0.040 | 0.532 | 1.376 | 0.212 | 0.282 | 0.490 | 0.309 | 0.374 | 2.768 | 1.715 |
| MICE | 0.459 | 1.282 | 0.284 | 0.589 | 0.385 | 0.934 | 0.543 | 4.828 | 1.115 | 0.672 | 1.814 | 1.050 |
| MFP | 0.260 | 0.385 | 0.198 | 0.282 | 0.340 | 0.198 | 0.258 | 0.356 | 0.185 | 0.260 | 0.360 | 0.282 |
| MLLFP | 0.274 | 0.417 | 0.038 | 0.364 | 0.379 | 0.213 | 0.360 | 0.462 | 0.307 | 0.366 | 0.372 | 0.651 |
| MF_B | 0.160 | 0.262 | 0.036 | 0.276 | 0.322 | 0.132 | 0.214 | 0.329 | 0.174 | 0.250 | 0.290 | 0.261 |
| MLLF_B | 0.161 | 0.235 | 0.037 | 0.264 | 0.378 | 0.132 | 0.232 | 0.346 | 0.169 | 0.246 | 0.271 | 0.274 |
| MFP_B | 0.161 | 0.249 | 0.037 | 0.266 | 0.321 | 0.121 | 0.220 | 0.309 | 0.179 | 0.244 | 0.296 | 0.275 |
| MLLFP_B | 0.169 | 0.270 | 0.036 | 0.274 | 0.357 | 0.121 | 0.236 | 0.467 | 0.250 | 0.252 | 0.281 | 0.304 |
under Linear case with Binary response when n=500 for different time points and sparsity settings.
(n)=500, time points (m)=52, sparsity (s)=High and scalar response.
Table 1 and Table 2 indicates that, in general, irrespective of the number of points, all the binned methods perform better compared to other methods for Prediction Error or RMSE of Prediction, coefficients and Imputation when the sparsity is Medium and the sample size is 500. Also, we can see that the RMSE of imputation for PACE is the same for both the tables. This is because we are using the same sample curves to generate scalar and binary response. There is no clear winner between MF and MLLF within the binned methods with or without PACE initialization. Again, for High sparsity, we notice a similar behavior as before, irrespective of the number of points, all the binned methods perform better. As we increase the sparsity, it seems like MICE and MLLF perform worse. This happens mainly because they do a poor job of imputing the curves, the effects of which get compounded when estimating the parameters and modeling. Again, binned methods are the best with no clear winner. The results for the other cases with different sample sizes and scalar response yield similar performance to these tables and can be found in the appendix Table 6 for and appendix Table 7 for .
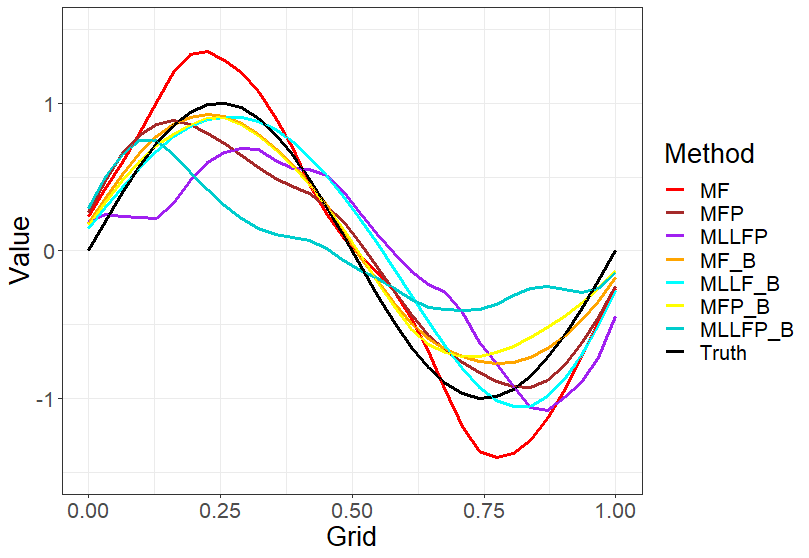
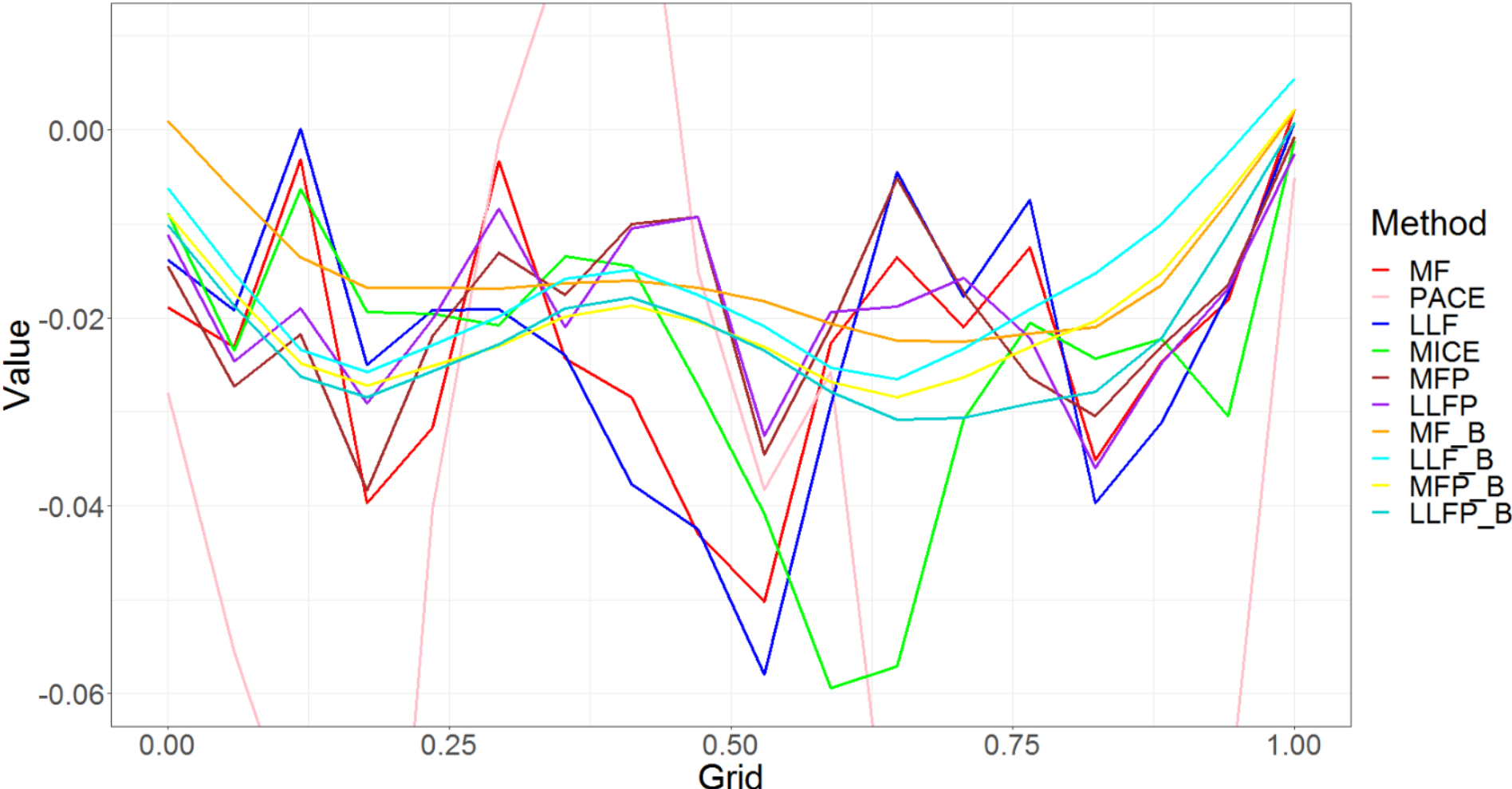
We can see from Figure 2, how each method does in estimating the coefficient. We can observe that most of the MissForest extensions are catching the right shape and doing a good job. The plot does not contain PACE, MICE and MLLF as their estimates were very poor, which is also reflected in the RMSE for the coefficients from Table 1.
Figure 3 shows an example of imputed curves under different methods for one random sample curve. Here, the main focus is to see how binning helps in not only doing better imputation as seen from Table 1 but also the fact that it gives much smoother results as compared to the MissForest methods without the binning. The same effect can be seen with Local Linear Forest methods as well. This plot is included in the appendix Figure 7.
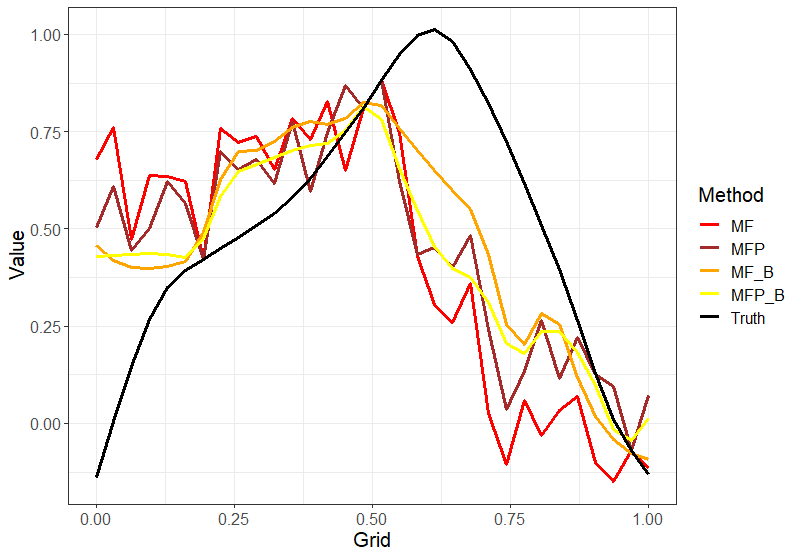
for one random sample curve with time points (m)=52 and sparsity (s)=High.
Non-Linear case:
All simulations parameters are the same as before, except the response is computed using the model in Equation (2), where . For the Non-linear case, we also simulate data sets of sample size as 500 with different number of observations per curve, ; and with different sparsity, Each of these settings is simulated 10 times. Since we are primarily interested in the accuracy of the final output and we report the Root Mean Square Error (RMSE) or Prediction Error for each of them. Another Non-Linear model result can be found in the appendix Table8.
| Method | n=500, s=Medium | n=500, s=High | ||||||
| m=32, b=17 | m=52, b=27 | m=32, b=8 | m=52, b=12 | |||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |
| MF | 0.236 | 0.102 | 0.223 | 0.078 | 0.303 | 0.428 | 0.355 | 0.381 |
| PACE | 0.328 | 0.238 | 0.214 | 1.253 | 0.431 | 0.659 | 0.386 | 0.551 |
| MLLF | 0.230 | 0.066 | 0.209 | 0.064 | 0.419 | 0.592 | 0.351 | 0.482 |
| MICE | 0.334 | 0.812 | 0.214 | 0.680 | 0.652 | 0.892 | 0.644 | 1.020 |
| MFP | 0.235 | 0.980 | 0.210 | 0.075 | 0.334 | 0.379 | 0.351 | 0.324 |
| MLLFP | 0.276 | 0.044 | 0.560 | 0.027 | 0.427 | 0.357 | 0.342 | 0.259 |
| MF_B | 0.174 | 0.045 | 0.161 | 0.053 | 0.293 | 0.257 | 0.318 | 0.275 |
| MLLF_B | 0.183 | 0.045 | 0.163 | 0.054 | 0.335 | 0.364 | 0.312 | 0.282 |
| MFP_B | 0.176 | 0.031 | 0.160 | 0.026 | 0.290 | 0.257 | 0.311 | 0.251 |
| MLLFP_B | 0.174 | 0.031 | 0.163 | 0.028 | 0.328 | 0.385 | 0.329 | 0.308 |
| Method | n=500, s=Medium | n=500, s=High | ||||||
| m=32, b=17 | m=52, b=12 | m=32, b=17 | m=52, b=12 | |||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |
| MF | 0.388 | 0.157 | 0.390 | 0.296 | 0.478 | 0.522 | 0.306 | 0.402 |
| PACE | 0.405 | 0.238 | 0.356 | 1.253 | 0.589 | 0.659 | 0.411 | 0.551 |
| MLLF | 0.386 | 0.144 | 0.392 | 0.274 | 0.486 | 2.790 | 0.382 | 1.490 |
| MICE | 0.451 | 0.154 | 0.388 | 0.282 | 0.641 | 1.262 | 0.712 | 2.139 |
| MFP | 0.388 | 0.213 | 0.292 | 0.238 | 0.492 | 0.573 | 0.300 | 0.708 |
| MLLFP | 0.382 | 0.268 | 0.288 | 0.276 | 0.290 | 0.413 | 0.402 | 1.401 |
| MF_B | 0.296 | 0.112 | 0.262 | 0.232 | 0.308 | 0.374 | 0.288 | 0.372 |
| MLLF_B | 0.294 | 0.113 | 0.262 | 0.232 | 0.294 | 0.369 | 0.292 | 0.372 |
| MFP_B | 0.294 | 0.091 | 0.262 | 0.221 | 0.302 | 0.379 | 0.290 | 0.366 |
| MLLFP_B | 0.294 | 0.090 | 0.262 | 0.221 | 0.280 | 0.550 | 0.292 | 0.370 |
Binary response when n=500 for different time points and sparsity settings.
From Table 3 and Table 4, we observe that our proposed approaches are outperforming PACE and MICE for Imputation irrespective of the number of points and sparsity. When it comes to prediction, our methods are still better than PACE and MICE but the gap is not as large compared to the linear case. Overall, we see the same trend as in the Linear case, with the binned methods outperforming every other method under various simulation settings.
The major takeaway from all the simulations is that our methods perform the best under various settings. This is because our methods impute smoother curves resulting in better modeling and smoother estimates of the beta coefficients irrespective of the relation between the response and the functional predictors.
3.2 EHR
New statistical tools are vital for data such as PATH, which are very large and have a great deal of underlying structure. We see the performance of the developed tools for imputation with this longitudinal/functional data. The electronic medical records contain information about smokers (patients) who irregularly come for a check-up at the hospital. We have the blood pressure (BP) readings along with some other measurement values at each check-up of the patients. From previous studies, we know that majority of the relapse among smokers occur within the first two years. For cleaning the data, the exclusion criteria were based on the number of longitudinal measurements (time points). Patients who had a smoking history (at least smoked for a year) with less than 2 measurements were excluded. After cleaning, we are left with 122 patients, of which 61 smokers relapsed and 61 smokers didn’t, where each smoker is under observation for 18 months. Hence, here the sample size (n) is 122 and the number of time points (m) is 18. The data is sparse naturally as the patients don’t come in for check-up regularly and sometimes the measurements are missing even though there was a visit due to unknown reasons. We build a model to predict if a patient will relapse or not using the Blood Pressure (BP) measurement over an 18 month period.
| Method | MF | PACE | MLLF | MICE | MFP | MLLFP | MF_B | MLLF_B | MFP_B | MLLFP_B |
| Linear Model | 0.39 | 0.42 | 0.39 | 0.39 | 0.36 | 0.37 | 0.33 | 0.35 | 0.32 | 0.35 |
| CAM | 0.36 | 0.39 | 0.36 | 0.38 | 0.35 | 0.36 | 0.28 | 0.32 | 0.28 | 0.31 |
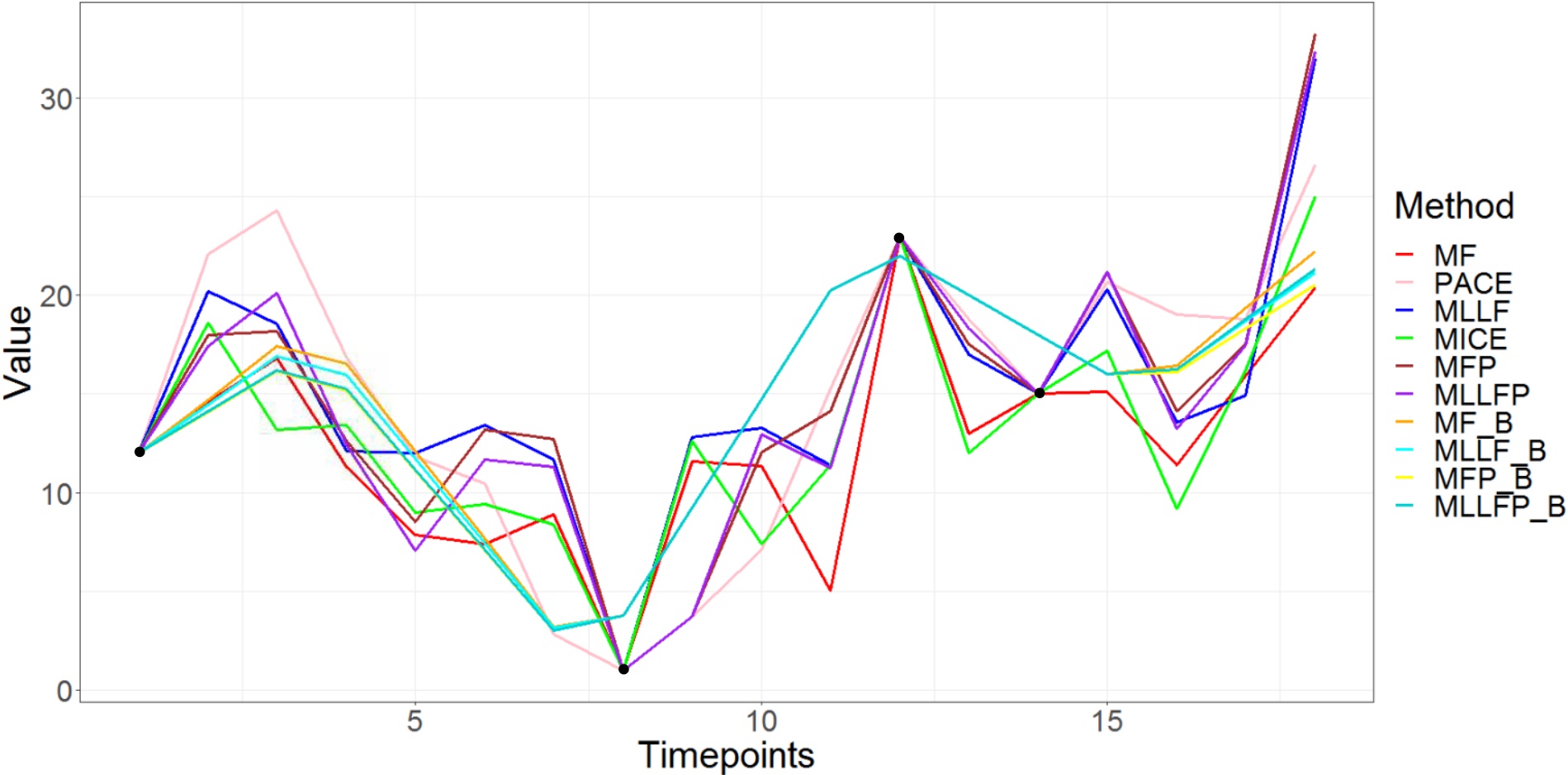
We can infer from Table 5 that the binned methods again are outperforming the other methods in prediction irrespective of linear or non-linear modeling. Also, since both the model results are so close, the true relation looks linear. This is further supported by Figure 4, where we see only the binned methods have smooth imputed curves with the black points denoting the observed values for that patient. Although all the estimated coefficients seem to follow the same trend in Figure 5, the methods with binning have much smoother results, leading to better interpretability. Smoothness is inherent to functional data and that is why binned methods are able to perform so well.
Also, Figure 5 suggests that patients with low BP or sudden changes in their BP have a higher risk of relapse. Also, the curve isn’t constant suggesting that acceleration/velocity of the BP curve is important. We did check and found out that the average BP was higher in the control group (no relapse) than for the cases (relapse). We feel there might be confounding variables and further analysis is needed, which is out of the scope of the project as we are only interested in demonstrating the efficacy of our methods for imputation and training the model, which results in better analysis and interpretation.
linear scalar-on-function regression.
4 Discussion and Conclusions
In this project, we explored different multivariate imputation methods under sparse and irregular functional data setting. We have proposed a new imputation method Missing Local Linear Forest (MLLF) which is a mixture of MissForest (MF) and MICE. Also, we modified this method along with MF to deal with Functional Data in a systematic fashion by careful initialization using PACE and smoothing out the results using Bins. Our proposed approaches overcome a lot of the challenges faced by the current methods (like PACE and MICE) to give consistent estimates. They incorporate the response as well as deal with complex non-linear relations with multiple imputations. Results under multiple simulation settings also illustrated the value of our approach over existing methods for fitting scalar-on-function regression models when the functional predictors are irregularly and sparsely sampled irrespective of the sparsity level, number of points in the curve and sample size. All the binned methods work equally well with slight variations in some cases; though there is no clear winner, MissForest with binning (MF_B) was the most consistent performer.
Our approach is sensitive to the subdivision of the time points into the bins. Different binning strategies were not explored in depth but are one of the directions for further investigation. Another interesting avenue is defining a relationship between time points () and the number of bins (), to ease the search for the optimum bin number. Also, even though it looks like the extension of MissForest (MF) performs better than Local Linear Forest imputation (MLLF), further analysis is required to differentiate between the methods. Deep learning has become a major research area in multiple fields and the application of Neural Networks into the imputation setting might be very interesting though our initial efforts did not bear strong results.
Finally, at a high level, there are still many remaining challenges with the imputation of functional data. When evaluating the performance of future methods, we suggest considering at least three critical points: (1) does the imputations improve subsequent modeling, (2) can the imputations incorporate the assumed underlying smoothness of the curves or at least domain information, and (3) can the imputations handle measurement noise in the observed points? A multiple imputation approach seems to be critical for the first point, while the latter two are still quite open. Our binning approach, while simple, helped a great deal with the second point. However, the third point was basically untouched in this work. When using methods such as PACE, incorporating observation error is straightforward, but it is unclear how to incorporate it into more complicated imputation procedures.
Acknowledgement
This research was supported in part by the following grant to Pennsylvania State University: NSF SES-1853209
References
- Acuna and Rodriguez, (2004) Acuna, E. and Rodriguez, C. (2004). The treatment of missing values and its effect on classifier accuracy. Journal of Classification, pages 639–647.
- Athey et al., (2016) Athey, S., Tibshirani, J., and Wager, S. (2016). Generalized random forests.
- Bartlett et al., (2015) Bartlett, J. W., Seaman, S. R., White, I. R., Carpenter, J. R., and for the Alzheimer’s Disease Neuroimaging Initiative* (2015). Multiple imputation of covariates by fully conditional specification: Accommodating the substantive model. Statistical Methods in Medical Research, 24(4):462–487. PMID: 24525487.
- Breiman, (2001) Breiman, L. (2001). Random forests. Mach. Learn., 45(1):5–32.
- Buuren and Groothuis-Oudshoorn, (2011) Buuren, S. and Groothuis-Oudshoorn, C. (2011). Mice: Multivariate imputation by chained equations in r. Journal of Statistical Software, 45.
- Carnahan-Craig et al., (2018) Carnahan-Craig, S., Blankenberg, D., Parodi, A., Paul, I., Birch, L., Savage, J., Marini, M., Stokes, J., Nekrutenko, A., Reimherr, M., Chiaromonte, F., and Makova, K. (2018). Child weight gain trajectories linked to oral microbiota composition. Scientific Reports, 8.
- Chen et al., (2019) Chen, Y., Carroll, C., Dai, X., Fan, J., Hadjipantelis, P. Z., Han, K., Ji, H., Mueller, H.-G., and Wang, J.-L. (2019). fdapace: Functional Data Analysis and Empirical Dynamics. R package version 0.5.1.
- Crambes and Henchiri, (2018) Crambes, C. and Henchiri, Y. (2018). Regression imputation in the functional linear model with missing values in the response. Journal of Statistical Planning and Inference, 201.
- Daymont et al., (2017) Daymont, C., Ross, M. E., Russell Localio, A., Fiks, A. G., Wasserman, R. C., and Grundmeier, R. W. (2017). Automated identification of implausible values in growth data from pediatric electronic health records. Journal of the American Medical Informatics Association, 24(6):1080–1087.
- Ding and Ross, (2012) Ding, Y. and Ross, A. (2012). A comparison of imputation methods for handling missing scores in biometric fusion. Pattern Recognition, 45(3):919 – 933.
- Fan et al., (2015) Fan, Y., James, G. M., and Radchenko, P. (2015). Functional additive regression. Ann. Statist., 43(5):2296–2325.
- Ferraty and Romain, (2011) Ferraty, F. and Romain, Y. (2011). The Oxford Handbook of Functional Data Analysis. Oxford University Press.
- Ferraty et al., (2012) Ferraty, F., Sued, M., and Vieu, P. (2012). Mean estimation with data missing at random for functional covariables. Statistics, iFirst.
- Ferraty and Vieu, (2006) Ferraty, F. and Vieu, P. (2006). Nonparametric Functional Data Analysis: Theory and Practice (Springer Series in Statistics). Springer-Verlag, Berlin, Heidelberg.
- Friedberg et al., (2018) Friedberg, R., Tibshirani, J., Athey, S., and Wager, S. (2018). Local linear forests.
- García-Rodríguez et al., (2013) García-Rodríguez, O., Secades-Villa, R., Florez-Salamanca, L., Okuda, M., Liu, S.-M., and Blanco, C. (2013). Probability and predictors of relapse to smoking: Results of the national epidemiologic survey on alcohol and related conditions (nesarc). Drug and alcohol dependence, 132.
- Goldsmith and Schwartz, (2017) Goldsmith, J. and Schwartz, J. (2017). Variable selection in the functional linear concurrent model. Statistics in medicine, 36.
- Greenland and Finkle, (1995) Greenland, S. and Finkle, W. D. (1995). A Critical Look at Methods for Handling Missing Covariates in Epidemiologic Regression Analyses. American Journal of Epidemiology, 142(12):1255–1264.
- Greven et al., (2010) Greven, S., Crainiceanu, C., Caffo, B., and Reich, D. (2010). Longitudinal functional principal component analysis. Electronic journal of statistics, 4:1022–1054.
- Hansson et al., (1996) Hansson, L., Hedner, T., and Jern, S. (1996). Smoking affects blood pressure. Blood pressure, 5:68.
- He et al., (2011) He, Y., Yucel, R. M., and Raghunathan, T. E. (2011). A functional multiple imputation approach to incomplete longitudinal data. Statistics in medicine, 30 10:1137–56.
- Herd et al., (2009) Herd, N., Borland, R., and Hyland, A. (2009). Predictors of smoking relapse by duration of abstinence: findings from the international tobacco control (itc) four country survey. Addiction (Abingdon, England), 104:2088–99.
- Horváth and Kokoszka, (2012) Horváth, L. and Kokoszka, P. (2012). Inference for Functional Data with Applications. Springer Series in Statistics. Springer New York.
- James et al., (2000) James, G., Hastie, T., and Sugar, C. (2000). Principal component models for sparse functional data. Biometrika, 87(3):587–602.
- Kokoszka and Reimherr, (2018) Kokoszka, P. and Reimherr, M. (2018). Introduction to Functional Data Analysis. New York: Chapman and Hall/CRC.
- Kowal et al., (2019) Kowal, D. R., Matteson, D. S., and Ruppert, D. (2019). Functional autoregression for sparsely sampled data. Journal of Business & Economic Statistics, 37(1):97–109.
- Liao et al., (2014) Liao, S., Lin, Y., Kang, D., Chandra, D., Bon, J., Kaminski, N., Sciurba, F., and Tseng, G. (2014). Missing value imputation in high-dimensional phenomic data: Imputable or not, and how? BMC bioinformatics, 15:346.
- Ma and Zhu, (2016) Ma, H. and Zhu, Z. (2016). Continuously dynamic additive models for functional data. Journal of Multivariate Analysis, 150:1 – 13.
- McLean et al., (2014) McLean, M. W., Hooker, G., Staicu, A.-M., Scheipl, F., and Ruppert, D. (2014). Functional generalized additive models. Journal of Computational and Graphical Statistics, 23(1):249–269.
- Mozharovskyi et al., (2017) Mozharovskyi, P., Josse, J., and Husson, F. (2017). Nonparametric imputation by data depth.
- Müller et al., (2013) Müller, H.-G., Wu, Y., and Yao, F. (2013). Continuously additive models for nonlinear functional regression. Biometrika, 100(3):607–622.
- Ning and Cheng, (2012) Ning, J. and Cheng, P. E. (2012). A comparison study of nonparametric imputation methods. Statistics and Computing, 22:273–285.
- Petrovich et al., (2018) Petrovich, J., Reimherr, M., and Daymont, C. (2018). Highly irregular functional generalized linear regression with electronic health records.
- Preda et al., (2010) Preda, C., Saporta, G., and Mbarek, M. (2010). The nipals algorithm for missing functional data. Revue Roumaine de Mathématiques Pures et Appliquées, 55.
- Primatesta et al., (2001) Primatesta, P., Falaschetti, E., Gupta, S., Marmot, M., and Poulter, N. (2001). Association between smoking and blood pressure : Evidence from the health survey for england. Hypertension, 37:187–93.
- Ramsay and Silverman, (1997) Ramsay, J. and Silverman, B. (1997). Functional Data Analysis. Springer series in statistics. Springer.
- Reimherr et al., (2017) Reimherr, M., Sriperumbudur, B., and Taoufik, B. (2017). Optimal prediction for additive function-on-function regression.
- Rice and Wu, (2001) Rice, J. and Wu, C. (2001). Nonparametric mixed effects models for unequally sampled noisy curves. Biometrics, 57(1):253—259.
- Rubin, (2004) Rubin, D. (2004). Multiple imputation for nonresponse in surveys. Wiley classics library edition. Wiley, Hoboken, NJ. [u.a.].
- Schafer and Graham, (2002) Schafer, J. and Graham, J. (2002). Missing data: Our view of the state of the art. Psychological Methods, 7:147–177.
- Stekhoven, (2013) Stekhoven, D. J. (2013). missForest: Nonparametric Missing Value Imputation using Random Forest. R package version 1.4.
- Stekhoven and Bühlmann, (2011) Stekhoven, D. J. and Bühlmann, P. (2011). Missforest-non-parametric missing value imputation for mixed-type data. Bioinformatics, 28(1):112–118.
- Thompson and Rosen, (2008) Thompson, W. and Rosen, O. (2008). A bayesian model for sparse functional data. Biometrics, 64:54–63.
- Tibshirani et al., (2020) Tibshirani, J., Athey, S., and Wager, S. (2020). grf: Generalized Random Forests. R package version 1.1.0.
- van Buuren, (2007) van Buuren, S. (2007). Multiple imputation of discrete and continuous data by fully conditional specification. Statistical Methods in Medical Research, 16(3):219–242. PMID: 17621469.
- Waljee et al., (2013) Waljee, A. K., Mukherjee, A., Singal, A. G., Zhang, Y., Warren, J., Balis, U., Marrero, J., Zhu, J., and Higgins, P. D. (2013). Comparison of imputation methods for missing laboratory data in medicine. BMJ Open, 3(8).
- Wang and Ruppert, (2013) Wang, X. and Ruppert, D. (2013). Optimal prediction in an additive functional model. Statistica Sinica, 25.
- Wang et al., (2018) Wang, Y., Zheng, X., Zhang, C., Yang, Y., Liu, L., Qi, Y., and Bu, P. (2018). A12426 association between smoking and blood pressure in elderly male patients with essential hypertension. Journal of Hypertension, 36:e321.
- Yao et al., (2005) Yao, F., Müller, H.-G., and Wang, J.-L. (2005). Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association, 100(470):577–590.
5 Appendix
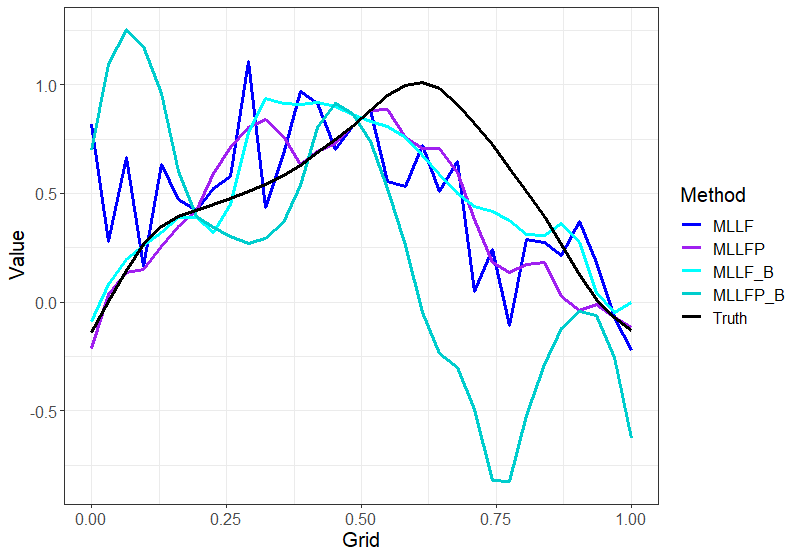
for one random sample curve with time points (m)=52 and sparsity (s)=High.
| Method | n=200, s=Medium | n=200, s=High | ||||||||||
| m=32, b=17 | m=52, b=27 | m=32, b=8 | m=52, b=12 | |||||||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |||||
| MF | 0.149 | 0.1656 | 0.141 | 0.476 | 0.459 | 0.117 | 1.290 | 1.272 | 0.573 | 0.349 | 0.476 | 0.529 |
| PACE | 0.221 | 0.332 | 0.393 | 0.700 | 0.667 | 1.863 | 0.433 | 0.461 | 0.434 | 0.449 | 0.456 | 0.362 |
| MLLF | 0.140 | 0.144 | 0.085 | 0.515 | 0.491 | 0.025 | 30.871 | 20.224 | 0.663 | 26.841 | 20.301 | 0.583 |
| MICE | 0.148 | 0.191 | 0.204 | 0.462 | 0.452 | 0.172 | 0.400 | 0.704 | 0.939 | 0.440 | 0.649 | 0.961 |
| MFP | 0.140 | 0.158 | 0.165 | 0.468 | 0.455 | 0.225 | 0.340 | 0.483 | 0.509 | 0.220 | 0.354 | 0.451 |
| MLLFP | 0.170 | 0.188 | 0.186 | 0.493 | 0.472 | 0.196 | 0.434 | 0.461 | 0.427 | 0.454 | 0.459 | 0.354 |
| MF_B | 0.124 | 0.135 | 0.89 | 0.264 | 0.258 | 0.078 | 0.285 | 0.340 | 0.395 | 0.191 | 0.255 | 0.312 |
| MLLF_B | 0.124 | 0.132 | 0.091 | 0.266 | 0.260 | 0.077 | 0.286 | 0.313 | 0.434 | 0.178 | 0.283 | 0.301 |
| MFP_B | 0.126 | 0.133 | 0.071 | 0.266 | 0.269 | 0.037 | 0.411 | 0.434 | 0.450 | 0.211 | 0.262 | 0.293 |
| MLLFP_B | 0.124 | 0.135 | 0.088 | 0.268 | 0.265 | 0.030 | 0.423 | 0.662 | 0.652 | 0.197 | 0.273 | 0.345 |
Linear case when under different time points and sparsity settings.
| Method | n=1000, s=Medium | n=1000, s=High | ||||||||||
| m=32, b=17 | m=52, b=27 | m=32, b=7 | m=52, b=27 | |||||||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |||||
| MF | 0.155 | 0.163 | 0.085 | 0.259 | 0.265 | 0.061 | 3.137 | 3.070 | 0.404 | 0.395 | 0.455 | 0.328 |
| PACE | 0.176 | 0.242 | 0.192 | 0.125 | 0.583 | 0.868 | 0.412 | 0.441 | 0.389 | 0.326 | 0.354 | 0.281 |
| MLLF | 0.140 | 0.144 | 0.061 | 0.265 | 0.272 | 0.027 | 51.947 | 41.243 | 0.545 | 61.500 | 51.082 | 0.476 |
| MICE | 0.152 | 0.168 | 0.118 | 0.254 | 0.262 | 0.092 | 0.365 | 0.660 | 0.873 | 0.911 | 0.838 | 0.856 |
| MFP | 0.151 | 0.164 | 0.085 | 0.251 | 0.278 | 0.110 | 0.198 | 0.296 | 0.353 | 0.288 | 0.338 | 0.274 |
| MLLFP | 0.167 | 0.198 | 0.134 | 0.0.255 | 0.284 | 0.099 | 0.412 | 0.441 | 0.339 | 0.324 | 0.357 | 0.244 |
| MF_B | 0.143 | 0.168 | 0.071 | 0.116 | 0.220 | 0.046 | 0.149 | 0.267 | 0.357 | 0.104 | 0.194 | 0.263 |
| MLLF_B | 0.147 | 0.153 | 0.072 | 0.113 | 0.208 | 0.046 | 0.123 | 0.293 | 0.373 | 0.111 | 0.265 | 0.295 |
| MFP_B | 0.144 | 0.165 | 0.048 | 0.116 | 0.221 | 0.026 | 0.145 | 0.273 | 0.348 | 0.128 | 0.219 | 0.366 |
| MLLFP_B | 0.143 | 0.160 | 0.051 | 0.113 | 0.211 | 0.031 | 0.127 | 0.802 | 0.644 | 0.138 | 0.354 | 0.475 |
Linear case when under different time points and sparsity settings.
| Method | n=500, s=Medium | n=500, s=High | ||||||
| m=32, b=17 | m=52, b=12 | m=32, b=7 | m=52, b=27 | |||||
| Pred | Imp | Pred | Imp | Pred | Imp | Pred | Imp | |
| MF | 0.180 | 0.189 | 0.292 | 0.112 | 0.682 | 0.541 | 0.832 | 0.468 |
| PACE | 0.147 | 1.912 | 0.253 | 0.549 | 0.598 | 0.393 | 0.557 | 0.292 |
| MLLF | 0.138 | 0.104 | 0.239 | 0.093 | 25.376 | 2.586 | 18.231 | 1.581 |
| MICE | 0.199 | 0.275 | 0.448 | 0.267 | 0.712 | 0.837 | 0.802 | 1.007 |
| MFP | 0.178 | 0.177 | 0.237 | 0.102 | 0.630 | 0.434 | 0.842 | 0.431 |
| MLLFP | 0.320 | 0.060 | 0.212 | 0.091 | 0.483 | 0.320 | 0.570 | 0.160 |
| MF_B | 0.155 | 0.054 | 0.189 | 0.032 | 0.458 | 0.178 | 0.502 | 0.155 |
| MLLF_B | 0.156 | 0.053 | 0.184 | 0.032 | 0.459 | 0.179 | 0.524 | 0.159 |
| MFP_B | 0.154 | 0.055 | 0.191 | 0.030 | 0.455 | 0.179 | 0.502 | 0.156 |
| MLLFP_B | 0.155 | 0.055 | 0.183 | 0.031 | 0.468 | 0.206 | 0.550 | 0.207 |