Modified Galton-Watson processes with immigration under an alternative offspring mechanism
Abstract
We propose a novel class of count time series models alternative to the classic Galton-Watson process with immigration (GWI) and Bernoulli offspring. A new offspring mechanism is developed and its properties are explored. This novel mechanism, called geometric thinning operator, is used to define a class of modified GWI (MGWI) processes, which induces a certain non-linearity to the models. We show that this non-linearity can produce better results in terms of prediction when compared to the linear case commonly considered in the literature. We explore both stationary and non-stationary versions of our MGWI processes. Inference on the model parameters is addressed and the finite-sample behavior of the estimators investigated through Monte Carlo simulations. Two real data sets are analyzed to illustrate the stationary and non-stationary cases and the gain of the non-linearity induced for our method over the existing linear methods. A generalization of the geometric thinning operator and an associated MGWI process are also proposed and motivated for dealing with zero-inflated or zero-deflated count time series data.
Keywords: Autocorrelation; Count time series; Estimation; INAR processes; Galton-Watson processes; Geometric thinning operator.
1 Introduction
The Galton-Watson (GW) or branching process is a simple and well-used model for describing populations evolving in time. It is defined by a sequence of non-negative integer-valued random variables satisfying
| (1) |
with by convention, where is a doubly infinite array of independent and identically distributed (iid) random variables. Write for the offspring distribution, so that for all . In the populational context, the random variable denotes the size of the -th generation. A generalization of this model is obtained by allowing an independent immigration process in (1), which is known as the GW process with immigration (GWI) and given by
| (2) |
where is assumed to be a sequence of iid non-negative integer-valued random variables, with independent of and , for all and for all . If one assumes and , then the conditional expectation of the size of the -th generation given the size of the -th generation, is linear on and given by
| (3) |
An interesting example appears when the offspring is Bernoulli distributed, that is, when . This yields the binomial thinning operator “” by Steutel and van Harn (1979), which is defined by
In this case, the GWI process in (2) is related to the first-order Integer-valued AutoRegressive (INAR) models presented in Alzaid and Al-Osh (1987), McKenzie (1988), and Dion et al. (1995). Conditional least squares estimation for the GWI/INAR models were explored, for instance, by Wei and Winnicki (1990), Ispány et al. (2003), Freeland and McCabe (2005), and Rahimov (2008).
Alternative integer-valued processes based on non-additive innovation through maximum and minimum operations were proposed by Littlejohn (1992), Littlejohn (1996), Kalamkar (1995), Scotto et al. (2016), and Aleksić and Ristić (2021). For the count processes considered in these works, a certain non-linearity is induced in the sense that the conditional expectation is non-linear on (and also the conditional variance) in contrast with (3). We refer to these models as “non-linear” along with this paper. On the other hand, the immigration interpretation in a populational context is lost due to the non-additive innovation assumption.
Our aim in this paper is to introduce an alternative model to the classic GW process with immigration (GWI) and Bernoulli offspring. We develop a modified GWI process (MGWI) based on a new thinning operator/offspring mechanism while preserving the additive innovation, which has a practical interpretation. We show that this new mechanism, called the geometric thinning operator, induces a certain non-linearity when compared to the classic GWI/INAR processes. We now highlight other contributions of the present paper:
-
(i)
development of inferential procedures and numerical experiments, which are not well-explored for the existing non-linear models aforementioned;
-
(ii)
properties of the novel geometric thinning operator are established;
-
(iii)
a particular MGWI process with geometric marginals is investigated in detail, including an explicit expression for the autocorrelation function;
-
(iv)
both stationary and non-stationary cases are explored, being the last important for allowing the inclusion of covariates, a feature not considered by the current non-linear models;
-
(v)
empirical evidences that the non-linearity induced for our MGWI processes can produce better results in terms of prediction when compared to the linear case (commonly considered in the literature);
-
(vi)
a generalization of the geometric thinning operator and an associated MGWI process are also proposed and motivated for dealing with zero-inflated or zero-deflated count time series data.
The paper is organized as follows. In Section 2, we introduce the new geometric thinning operator and explore its properties. Section 3 is devoted to the development of the modified Galton-Watson processes with immigration based on the new operator, with a focus on the case where the marginals are geometrically distributed. Two methods for estimating the model parameters are discussed in Section 4, including Monte Carlo simulations to evaluate the proposed estimators. In Section 5, we introduce a non-stationary MGWI process allowing for the inclusion of covariates and provide some Monte Carlo studies. Section 6 is devoted to two real data applications. Finally, in Section 7, we develop a generalization of the geometric thinning operator and an associated modified GWI model.
2 Geometric thinning operator: definition and properties
In this section, we introduce a new thinning operator and derive its main properties. We begin by introducing some notation. For two random variables and , we write to denote the minimum between and . The probability generating function (pgf) of a non-negative integer-valued random variable is denoted by
for all values of for which the right-hand side converges absolutely. The -th derivative of with respect to and evaluated at is denoted by .
Let be a geometric random variable with parameter and probability function assuming the form
In this case, the pgf of is
| (4) |
and the parameter has the interpretation . The shorthand notation will be used throughout the text. We are ready to introduce the new operator and explore some of its properties.
Definition 1.
(Geometric thinning operator) Let be a non-negative integer-valued random variable, independent of , with . The geometric thinning operator is defined by
| (5) |
Remark 1.
The operator defined in (5) satisfies , like the classic binomial thinning operator . Therefore, is indeed a thinning operator.
In what follows, we present some properties of the proposed geometric thinning operator. We start by obtaining its probability generating function.
Proposition 1.
Let be a non-negative integer-valued random variable with pgf . Then, the pgf of is given by
Proof.
By the independence assumption between and , it holds that
Hence,
The second term on the last equality can be expressed as
The result follows by rearranging the terms. ∎
The next result gives us the moments of , which will be important to discuss prediction and forecasting in what follows.
Proposition 2.
Let be the geometric thinning operator in (5). It holds that the -th factorial moment of is given by
for , where .
Proof.
The result follows by using the pgf given in Proposition 1 and the generalized Leibniz rule for derivatives, namely , with and . ∎
In what follows, the notation means weakly converges to .
Proposition 3.
Let be the geometric thinning operator in (5). Then,
-
(i)
-
(ii)
Proof.
The proof follows immediately from Proposition 1 and the Continuity Theorem for pgf’s. ∎
We now show a property of the operator of own interest.
Proposition 4.
Let be independent geometric random variables with parameters , respectively. Assume that are non-negative integer-valued random variables independent of the ’s, and let . Then,
| (6) |
with , .
Proof.
We prove (6) by induction on . For , it holds that
where . Assume that . Since
the proof is complete. ∎
In the next section, we introduce our class of modified GW processes and provide some of their properties.
3 Modified Galton-Watson processes with immigration
In this section, we introduce modified GW processes with immigration based on the new geometric thinning operator defined in Section 2 and explore a special case when the marginals are geometrically distributed.
Definition 2.
A sequence of random variables is said to be a modified GW process with immigration (in short MGWI) if it satisfies the stochastic equation
| (7) |
with , being a sequence of iid random variables with , being an iid non-negative integer-valued random variables called innovations, where is independent of and , for all , and is some starting value/random variable.
The following theorem is an important result concerning the modified GWI process.
Theorem 5.
The stochastic process in (7) is stationary and ergodic.
Proof.
Consider the process . Since this is a sequence of iid bivariate vectors, it follows that is stationary and ergodic. Now, note that there is a real function , which does not depend on , such that
Hence, the result follows by applying Theorem 36.4 from Billingsley (1995). ∎
From now on, we focus our attention on a special case from our class of MGWI processes when the marginals are geometrically distributed. To do this, let us first discuss the zero-modified geometric (ZMG) distribution, which will play an important role in our model construction.
We say that a random variable follows a ZMG distribution with parameters and if its probability function is given by
We denote . The geometric distribution with mean is obtained as a particular case when . For and , the ZMG distribution is zero-deflated or zero-inflated with relation to the geometric distribution, respectively. The associated pgf assumes the form
| (9) |
Now, assume that , with . We have that
which means . From (7), it follows that a MGWI process with geometric marginals is well-defined if the function is a proper pgf, with belonging to some interval containing the value 1, where and are the pgf’s of geometric distributions with means and , respectively. More specifically, we have
| (10) |
which corresponds to the pgf of a zero-modified geometric distribution with parameters and ; see (9). This enables us to define a new geometric process as follows.
Definition 3.
The stationary geometric MGWI (Geo-MGWI) process is defined by assuming that (7) holds with and .
From (10), we have that the mean and variance of the innovations are given by
respectively. Additionally, the third and forth moments of the innovations are
In what follows, we assume that is a Geo-MGWI process and explore some of its properties. We start with the 1-step transition probabilities.
Proposition 6.
The 1-step transition probabilities of the MGWI process, say , assumes the form
| (11) |
for . In particular, we have .
Proof.
For , we have that . For , it follows that
where
This gives the desired transition probabilities in (11). ∎
Proposition 7.
Proof.
We have that
where
| (13) |
Therefore,
∎
Proposition 8.
The 1-step ahead conditional mean and conditional variance are given by
respectively.
Proof.
From the definition of the MGWI process, we obtain that
for all . The conditional expectation above can be obtained from Proposition 2 with being a degenerate random variable at (i.e. ). Then, it follows that
The conditional variance can be derived analogously, so details are omitted. ∎
Remark 2.
Note that the conditional expectation and variance given in Proposition 8 are non-linear on in contrast with the classic GW/INAR processes where they are linear.
Proposition 9.
The autocovariance and autocorrelation functions at lag 1 of the Geo-MGWI process are respectively given by
| (14) |
Proof.
We have that , with
After some algebra, the result follows. ∎
In the following proposition, we obtain an expression for the conditional expectation . This function will be important to find the autocovariance function at lag and to perform prediction and/or forecasting.
Proposition 10.
For , define and , and the real functions
, where and . Finally, let . Then, for all ,
| (15) |
for all integer .
Proof.
Let denote the sigma-field generated by the random variables . By the Markov property it is clear that
| (16) |
for all . The proof proceeds by induction on . Equation (16) and Proposition 8 give us that
with . Using (13), we obtain that
From the definition of , we obtain
Note that
Therefore, , and hence we get the desired expression , which completes the proof. ∎
Proposition 11.
4 Parameter estimation
In this section, we discuss estimation procedures for the geometric MGWI process through conditional least squares (CLS) and maximum likelihood methods. We assume that is a trajectory from the Geo-MGWI model with observed values , where stands for the sample size. We denote the parameter vector by .
For the CLS method, we define the function as
| (21) |
The CLS estimators are obtained as the argument that minimizes , i.e.
| (22) |
Since we do not have an explicit expression for , numerical optimization methods are required to solve (22). This can be done through optimizer packages implemented in softwares such as R (R Core Team, 2021) and MATLAB. The gradient function associated with can be provided for these numerical optimizers and is given by
A strategy to get the standard errors of the CLS estimates based on bootstrap is proposed and illustrated in our empirical illustrations; please see Section 6.
We now discuss the maximum likelihood estimation (MLE) method. Note that our proposed Geo-MGWI process is a Markov chain (by definition) and therefore the likelihood function can be expressed in terms of the 1-step transition probabilities derived in Proposition 6. The MLE estimators are obtained as the argument that maximizes the log-likelihood function, that is, , with
| (23) |
where the conditional probabilities in are given by (11) and is the probability function of a geometric distribution with mean . There is no closed-form expression available for . The maximization of (23) can be accomplished through numerical methods such as the Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm implemented in the R package optim. The standard errors of the maximum likelihood estimates can be obtained by using the Hessian matrix associated with (23), which can be evaluated numerically.
In the remaining of this section, we examine and compare the finite-sample behavior of the CLS and MLE methods via Monte Carlo (MC) simulation with 1000 replications per set of parameter configurations, with the parameter estimates computed under both approaches. All the numerical experiments presented in this paper were carried out using the R programming language.
| Scenario I: | ||||
|---|---|---|---|---|
| 100 | 1.996 (0.281) | 0.957 (0.425) | 1.999 (0.282) | 0.962 (0.698) |
| 200 | 1.995 (0.197) | 1.021 (0.290) | 1.998 (0.197) | 1.059 (0.536) |
| 500 | 2.013 (0.124) | 0.987 (0.177) | 2.014 (0.125) | 0.991 (0.339) |
| 1000 | 1.998 (0.088) | 0.998 (0.128) | 1.998 (0.088) | 0.988 (0.238) |
| Scenario II: | ||||
| 100 | 1.206 (0.181) | 0.486 (0.289) | 1.208 (0.182) | 0.556 (0.482) |
| 200 | 1.197 (0.128) | 0.491 (0.205) | 1.198 (0.129) | 0.495 (0.327) |
| 500 | 1.196 (0.082) | 0.498 (0.119) | 1.196 (0.082) | 0.490 (0.197) |
| 1000 | 1.200 (0.058) | 0.506 (0.090) | 1.200 (0.058) | 0.494 (0.143) |
| Scenario III: | ||||
| 100 | 0.499 (0.130) | 1.515 (0.523) | 0.498 (0.132) | 1.487 (0.831) |
| 200 | 0.499 (0.091) | 1.514 (0.387) | 0.498 (0.093) | 1.495 (0.595) |
| 500 | 0.496 (0.058) | 1.490 (0.236) | 0.496 (0.059) | 1.472 (0.356) |
| 1000 | 0.500 (0.042) | 1.502 (0.174) | 0.500 (0.044) | 1.524 (0.299) |
| Scenario IV: | ||||
| 100 | 0.298 (0.078) | 0.506 (0.271) | 0.298 (0.078) | 0.504 (0.340) |
| 200 | 0.296 (0.057) | 0.491 (0.186) | 0.297 (0.057) | 0.492 (0.244) |
| 500 | 0.299 (0.037) | 0.496 (0.120) | 0.300 (0.037) | 0.504 (0.157) |
| 1000 | 0.299 (0.026) | 0.499 (0.087) | 0.299 (0.026) | 0.500 (0.110) |
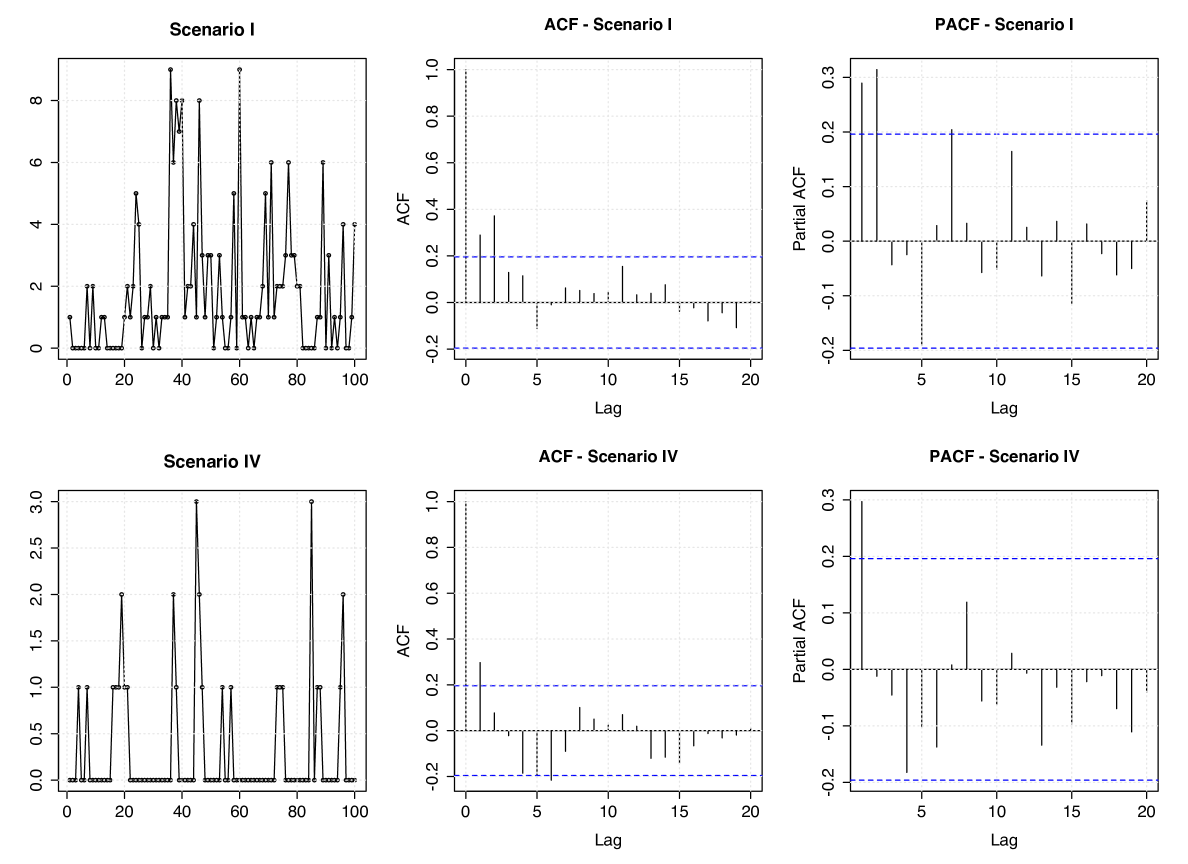
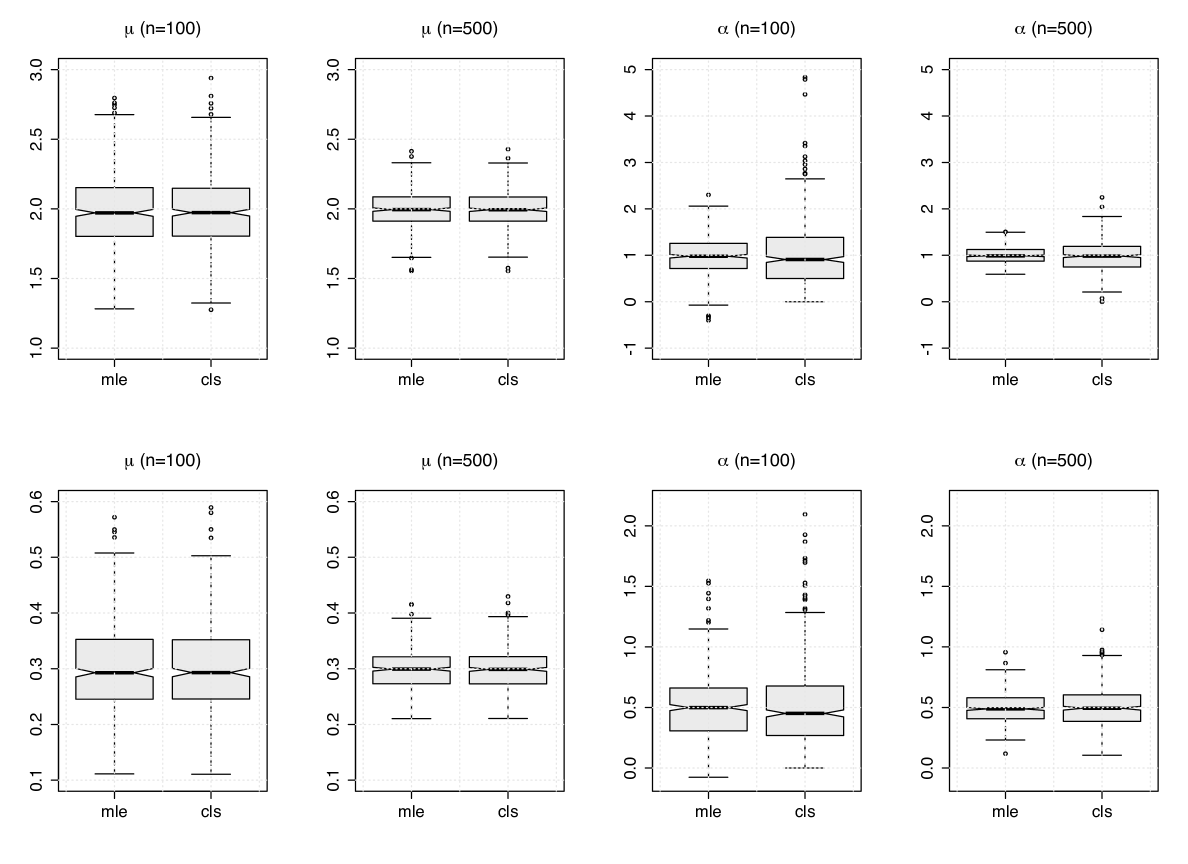
We consider four simulation scenarios with different values for , namely: (I) , (II) , (III) , and (IV) . To illustrate these configurations, we display in Figure 1 simulated trajectories from the Geo-MGWI process and their associated ACF and PACF under Scenarios I and IV. In Table 1, we report the empirical mean and root mean squared error (RMSE) of the parameter estimates obtained from the MC simulation based on the MLE and CLS methods. We can observe that both approaches produce satisfactory results and also a slight advantage of the MLE estimators over the CLS for estimating , mainly in terms of RMSE, which is already expected. This advantage can also be seen from Figure 2, which presents boxplots of the parameter estimates for and under the Scenarios I and IV with sample sizes and . In general, the estimation procedures considered here produce estimates with bias and RMSE decreasing towards zero as the sample size increases, therefore giving evidence of consistency.
5 Dealing with non-stationarity
In many practical situations, stationarity can be a non-realistic assumption; for instance, see Brännäs (1995), Enciso-Mora et al. (2009), and Wang (2020) for works that investigate non-stationary Poisson INAR process. Motivated by that, in this section, we propose a non-stationary version of the Geo-MGWI process allowing for time-varying parameters. Consider
where and are and covariate vectors for , and and are and vectors of associated regression coefficients.
We define a time-varying or non-stationary Geo-MGWI process by
| (24) |
and , where , is an independent sequence with , are independent random variables with , for . It is also assumed that is independent of and , for all . Under these assumptions, the marginals of the process (24) are distributed, for .
We consider two estimation methods for the parameter vector . The first one is based on the conditional least squares. The CLS estimator of is obtained by minimizing (21) with and instead of and , respectively. According to Wang (2020), this procedure might not be accurate in the sense that non-significant covariates can be included in the model. In that paper, a penalized CLS (PCLS) method is considered. Hence, a more accurate estimator is obtained by minimizing , where is a penalty function and is a tuning parameter. See Wang (2020) for possible choices of penalty function. This can be used as a selection criterion and we hope to explore it in a future paper. A second method for estimating the parameters is the maximum likelihood method. The log-likelihood function assumes the form (23) with and replaced by and , respectively.
For the non-stationary case, we carry out a second set of Monte Carlo simulations by considering trend and seasonal covariates in the model as follows:
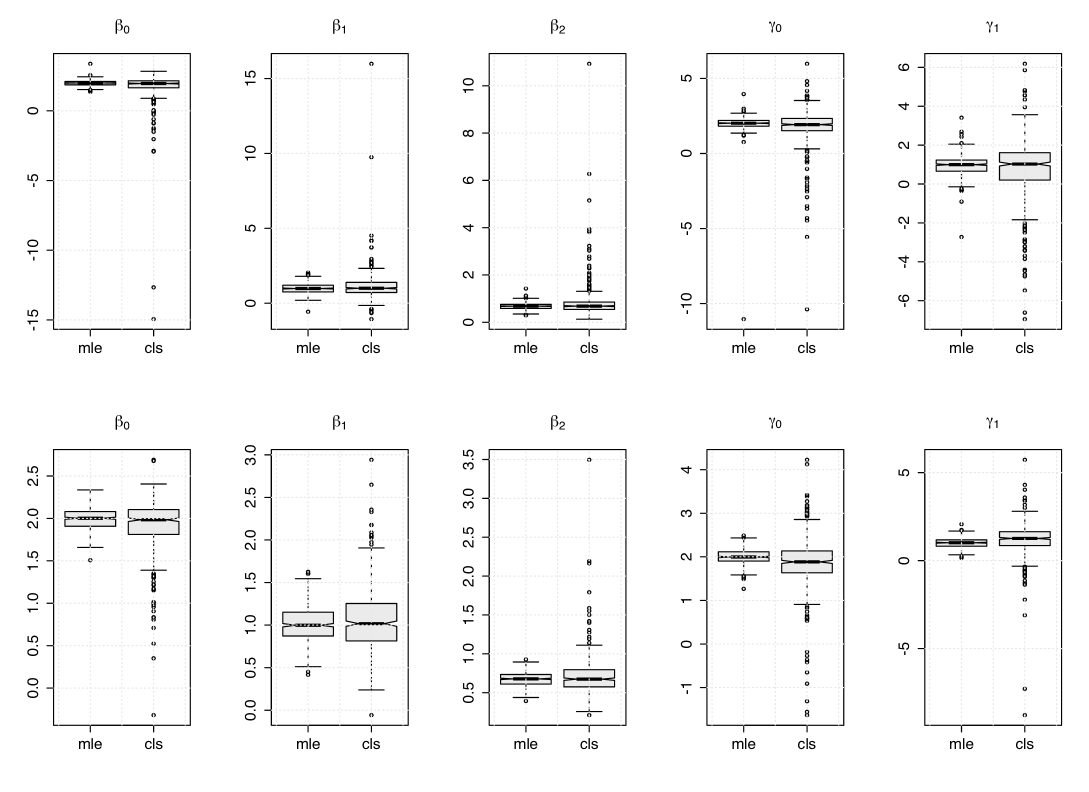
for . The above structure aims to mimic realistic situations when dealing with epidemic diseases. We here set the following scenarios: (V) and (VI) . We consider 500 Monte Carlo replications and the sample sizes . Table 2 reports the empirical mean and the RMSE (within parentheses) of the parameter estimates based on the MLE and CLS methods. We can observed that the MLE method outperforms the CLS method for all configurations considered, as expected since we are generating time series data from the “true” model. This can be also seen from Figure 3, which presents the boxplots of MLE and CLS estimates under the Scenarios V with sample sizes . Regardless, note that the bias and RMSE of the CLS estimates decrease as the sample size increases.
| Scenario V | ||||||||||||
| MLE | 1.969 (0.278) | 1.006 (0.473) | 0.662 (0.209) | 1.939 (0.635) | 1.027 (0.741) | |||||||
| CLS | 1.398 (2.425) | 1.373 (1.997) | 0.914 (1.317) | 1.777 (1.649) | 0.469 (2.531) | |||||||
| MLE | 1.984 (0.206) | 0.987 (0.337) | 0.677 (0.138) | 1.986 (0.453) | 0.963 (0.503) | |||||||
| CLS | 1.743 (1.212) | 1.117 (1.005) | 0.813 (0.725) | 1.783 (1.295) | 0.732 (1.557) | |||||||
| MLE | 1.993 (0.126) | 1.007 (0.209) | 0.673 (0.091) | 2.005 (0.168) | 1.003 (0.272) | |||||||
| CLS | 1.923 (0.317) | 1.059 (0.376) | 0.706 (0.241) | 1.864 (0.622) | 1.184 (1.000) | |||||||
| MLE | 1.996 (0.083) | 1.006 (0.136) | 0.674 (0.064) | 2.012 (0.116) | 0.999 (0.200) | |||||||
| CLS | 1.929 (0.265) | 1.061 (0.284) | 0.696 (0.205) | 1.869 (0.461) | 1.230 (0.665) | |||||||
| Scenario VI | ||||||||||||
| MLE | 2.967 (0.296) | 0.965 (0.554) | 0.506 (0.221) | 2.935 (0.376) | 2.049 (0.629) | |||||||
| CLS | 2.283 (1.732) | 1.264 (1.960) | 0.704 (1.098) | 3.231 (1.290) | 1.291 (2.048) | |||||||
| MLE | 2.981 (0.198) | 0.995 (0.363) | 0.484 (0.152) | 2.996 (0.249) | 1.998 (0.435) | |||||||
| CLS | 2.357 (1.390) | 1.310 (1.410) | 0.601 (0.884) | 3.561 (1.165) | 1.106 (1.855) | |||||||
| MLE | 2.996 (0.121) | 0.988 (0.226) | 0.484 (0.093) | 3.008 (0.147) | 1.980 (0.264) | |||||||
| CLS | 2.570 (0.950) | 1.279 (0.912) | 0.641 (0.526) | 3.370 (0.886) | 1.481 (1.354) | |||||||
| MLE | 2.998 (0.083) | 1.004 (0.156) | 0.477 (0.067) | 2.999 (0.099) | 2.009 (0.184) | |||||||
| CLS | 2.697 (0.623) | 1.192 (0.597) | 0.601 (0.452) | 3.244 (0.714) | 1.737 (1.026) | |||||||
6 Real data applications
In this section, we discuss the usefulness of our methodology under stationary and non-stationary conditions. In the first empirical example, we consider the monthly number of polio cases reported to the U.S. Centers for Disease Control and Prevention from January 1970 to December 1983, with 168 observations. The data were obtained through the gamlss package in R. Polio (or poliomyelitis) is a disease caused by poliovirus. Symptoms associated with polio can vary from mild flu-like symptoms to paralysis and possibly death, mainly affecting children under 5 years of age. The second example concerns the monthly number of Hansen’s disease cases in the state of Paraíba, Brazil, reported by DATASUS - Information Technology Department of the Brazilian Public Health Care System (SUS), from January 2001 to December 2020, totalizing 240 observations. Hansen’s disease (or leprosy) is a curable infectious disease that is caused by M. leprae. It mainly affects the skin, the peripheral nerves mucosa of the upper respiratory tract, and the eyes. According to the World Health Organization, about 208000 people worldwide are infected with Hansen’s disease. The data are displayed in Table 3.
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2001 | 60 | 58 | 91 | 72 | 94 | 52 | 54 | 78 | 64 | 111 | 81 | 70 |
| 2002 | 55 | 72 | 71 | 70 | 61 | 51 | 80 | 82 | 97 | 107 | 142 | 81 |
| 2003 | 92 | 106 | 126 | 78 | 86 | 69 | 91 | 91 | 64 | 83 | 83 | 55 |
| 2004 | 67 | 82 | 121 | 84 | 102 | 77 | 83 | 102 | 77 | 59 | 86 | 67 |
| 2005 | 59 | 86 | 84 | 102 | 75 | 57 | 82 | 126 | 107 | 123 | 138 | 94 |
| 2006 | 88 | 78 | 105 | 91 | 106 | 68 | 85 | 106 | 95 | 80 | 101 | 67 |
| 2007 | 78 | 81 | 96 | 68 | 94 | 67 | 66 | 88 | 71 | 84 | 74 | 64 |
| 2008 | 79 | 75 | 66 | 81 | 74 | 45 | 82 | 91 | 85 | 74 | 77 | 61 |
| 2009 | 53 | 79 | 105 | 81 | 68 | 67 | 64 | 73 | 75 | 76 | 85 | 48 |
| 2010 | 51 | 74 | 94 | 64 | 60 | 51 | 54 | 70 | 69 | 68 | 64 | 43 |
| 2011 | 66 | 67 | 83 | 77 | 71 | 67 | 58 | 90 | 73 | 59 | 78 | 72 |
| 2012 | 71 | 82 | 80 | 64 | 82 | 60 | 83 | 77 | 76 | 60 | 49 | 52 |
| 2013 | 54 | 53 | 80 | 83 | 52 | 52 | 79 | 61 | 71 | 61 | 78 | 47 |
| 2014 | 61 | 79 | 51 | 63 | 51 | 45 | 61 | 63 | 83 | 63 | 60 | 40 |
| 2015 | 64 | 53 | 79 | 43 | 55 | 47 | 48 | 66 | 48 | 48 | 46 | 48 |
| 2016 | 39 | 43 | 54 | 34 | 50 | 38 | 38 | 67 | 35 | 44 | 48 | 41 |
| 2017 | 40 | 46 | 54 | 43 | 43 | 53 | 45 | 68 | 65 | 44 | 58 | 47 |
| 2018 | 64 | 42 | 72 | 62 | 51 | 42 | 43 | 64 | 47 | 48 | 76 | 40 |
| 2019 | 63 | 70 | 56 | 54 | 59 | 51 | 60 | 65 | 80 | 85 | 65 | 49 |
| 2020 | 57 | 62 | 61 | 16 | 21 | 19 | 35 | 25 | 60 | 63 | 51 | 30 |
| 2021 | 35 | 53 | 56 | 41 | 44 | 41 | 32 | 33 | 17 | 5 | 5 | 5 |
6.1 Polio data analysis
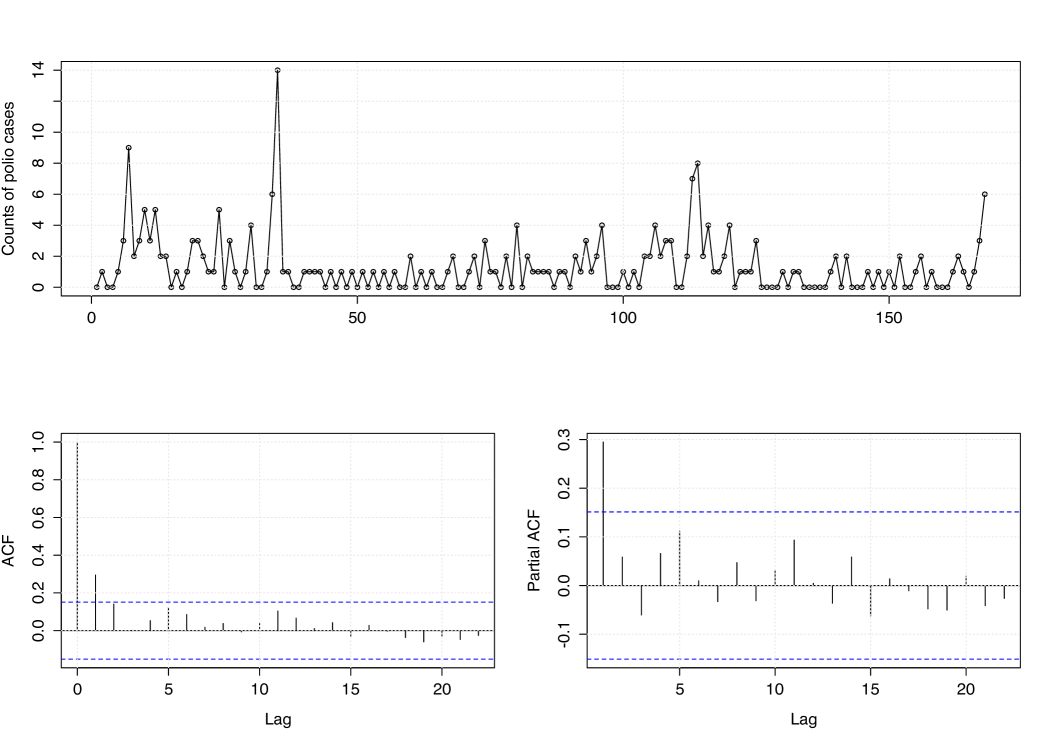
We begin the analysis of the polio data by providing plots of the observed time series and the corresponding sample ACF and PACF plots in Figure 4. These plots give us evidence that the count time series is stationary. Table 4 provides a summary of the polio data with descriptive statistics, including mean, median, variance, skewness, and kurtosis. From the results in Table 4, we can observe that counts vary between 0 and 14, with the sample mean and variance equal to 1.333 and 3.505, respectively, which suggests overdispersion of the data.
| Minimum | Maximum | Mean | Median | Variance | Skewness | Kurtosis | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 1.333 | 1.000 | 3.505 | 3.052 | 16.818 |
For comparison purposes, we consider the classic first-order GWI/INAR process with . This linear conditional expectation on holds for the classic stationary INAR processes such as the binomial thinning-based ones, in particular, the Poisson INAR(1) model by Alzaid and Al-Osh (1987). The aim is to evaluate the effect of the nonlinearity of our proposed models on the prediction in comparison to the classic GWI/INAR(1) processes.
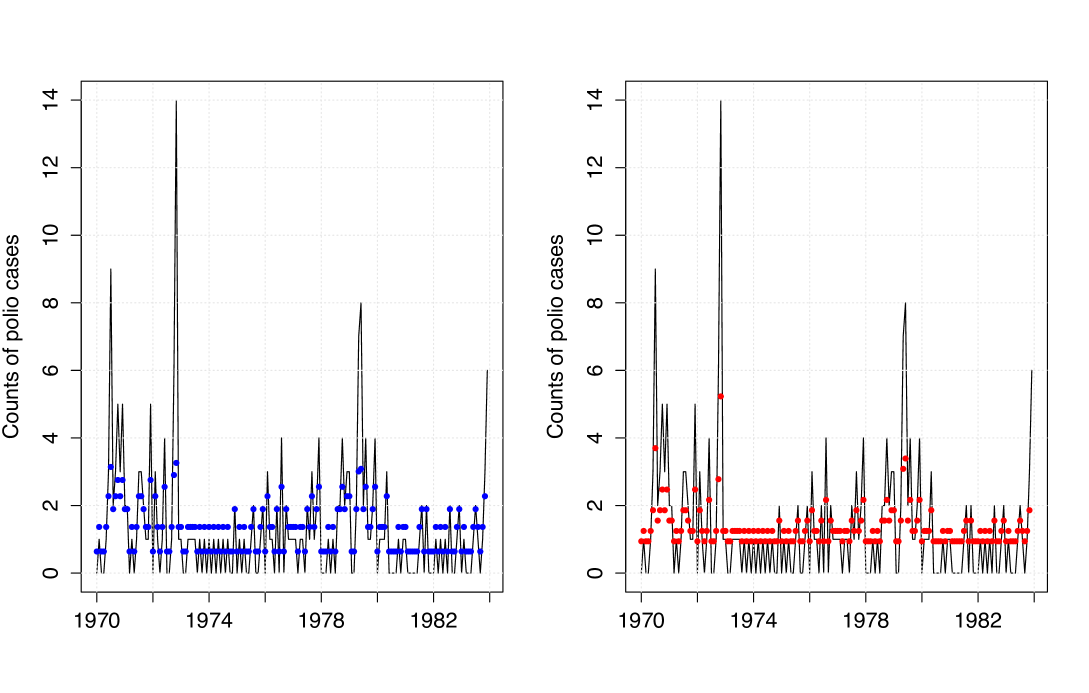
We consider the CLS estimation procedure, where just the conditional expectation is considered. This allows for a more flexible approach since no further assumptions are required. To obtain the standard errors of the CLS estimates, we consider a parametric bootstrap where some model satisfying the specific form for the conditional expectation holds. In this first application, for our MGWI process, we consider the geometric model derived in Section 3. For the classic INAR, the Poisson model by Alzaid and Al-Osh (1987) is considered in the bootstrap approach. This strategy to get standard errors has been considered, for example, by Maia et al. (2021) for a class of semiparametric time series models driven by a latent factor. In order to compare the predictive performance of the competing models, we compute the sum of squared prediction errors (SSPE) defined by , where is the predicted mean at time , for . Table 5 summarizes the fitted models by providing CLS estimates and their respective standard errors, and the SSPE values. The SSPE results in Table 5 show the superior performance of the MGWI process over the classic GWI/INAR process in terms of prediction. This can also be observed from Figure 5, where the MGWI process shows a better agreement between the observed and predicted values.
| Models | Parameters | Estimates | Stand. Errors | SSPE | ||||
|---|---|---|---|---|---|---|---|---|
| MGWI | 1.3585 | 0.2047 | 522.8987 | |||||
| 2.6514 | 1.2230 | |||||||
| GWI/INAR | 1.3572 | 0.1627 | 530.6749 | |||||
| 0.3063 | 0.0772 |
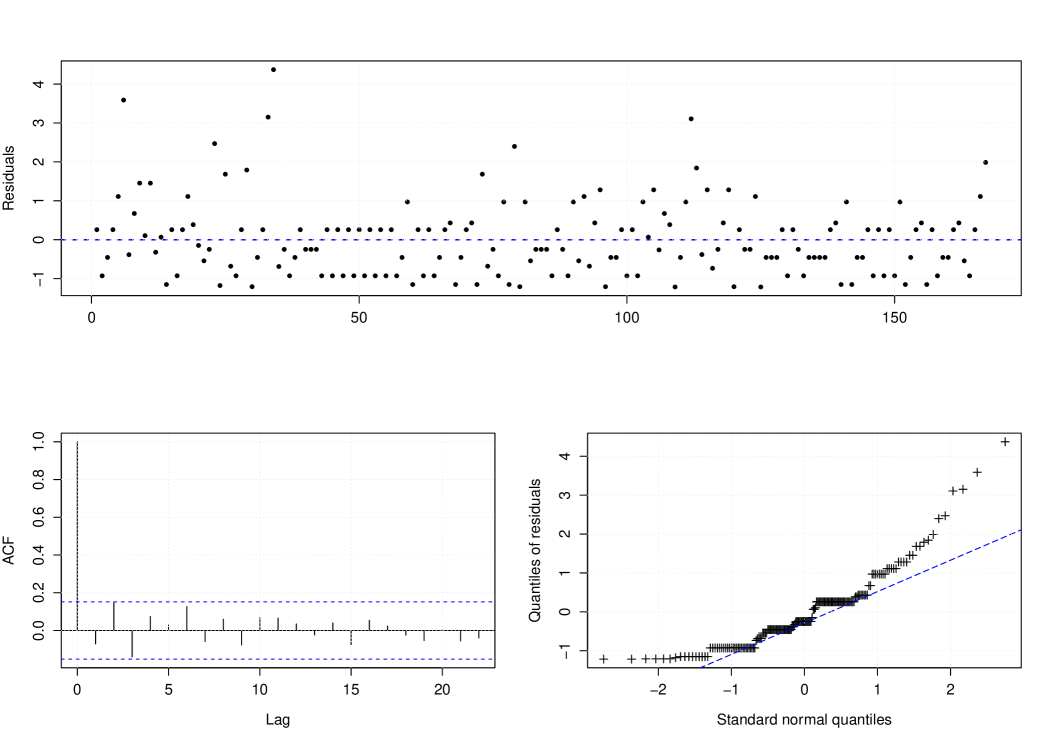
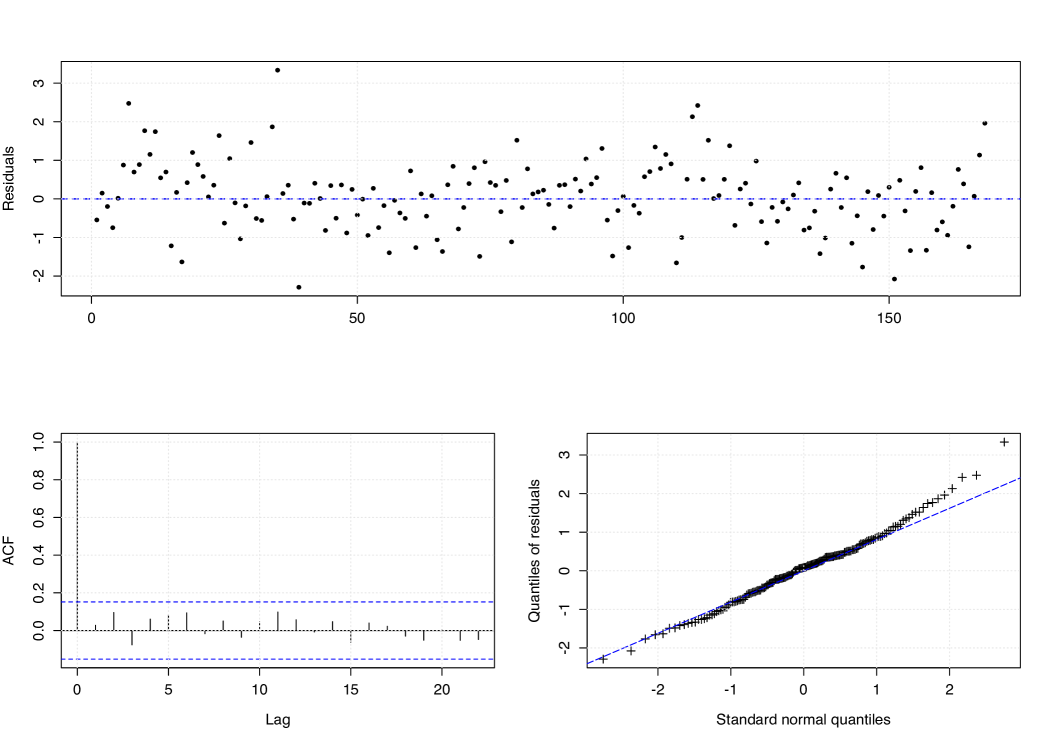
To evaluate the adequacy of our proposed MGWI process, we consider the Pearson residuals defined by , where , for , where we assume that the conditional variance takes the form given in Proposition 8. Figure 6 presents the Pearson residuals against the time, its ACF, and the qq-plot against the normal quantiles. These plots show that the data correlation was well-captured. On the other hand, the qq-plot suggests that the Pearson residuals are not normally distributed. Actually, this discrepancy is not unusual especially when dealing with low counts; for instance, see Zhu (2011) and Silva and Barreto-Souza (2019). As an alternative way to check the adequacy, we use the normal pseudo-residuals introduced by Dunn and Smyth (1996), which is defined by , where is the standard normal distribution function and is uniformly distributed on the interval , where is the fitted predictive cumulative distribution function of the MGWI process. Figure 7 shows the pseudo residuals against the time, its ACF, and qq-plot. We can observe that the pseudo-residuals are not correlated and are approximately normally distributed. Therefore, we conclude that the MGWI process provides an adequate fit to the polio count time series data.
6.2 Hansen’s disease data analysis
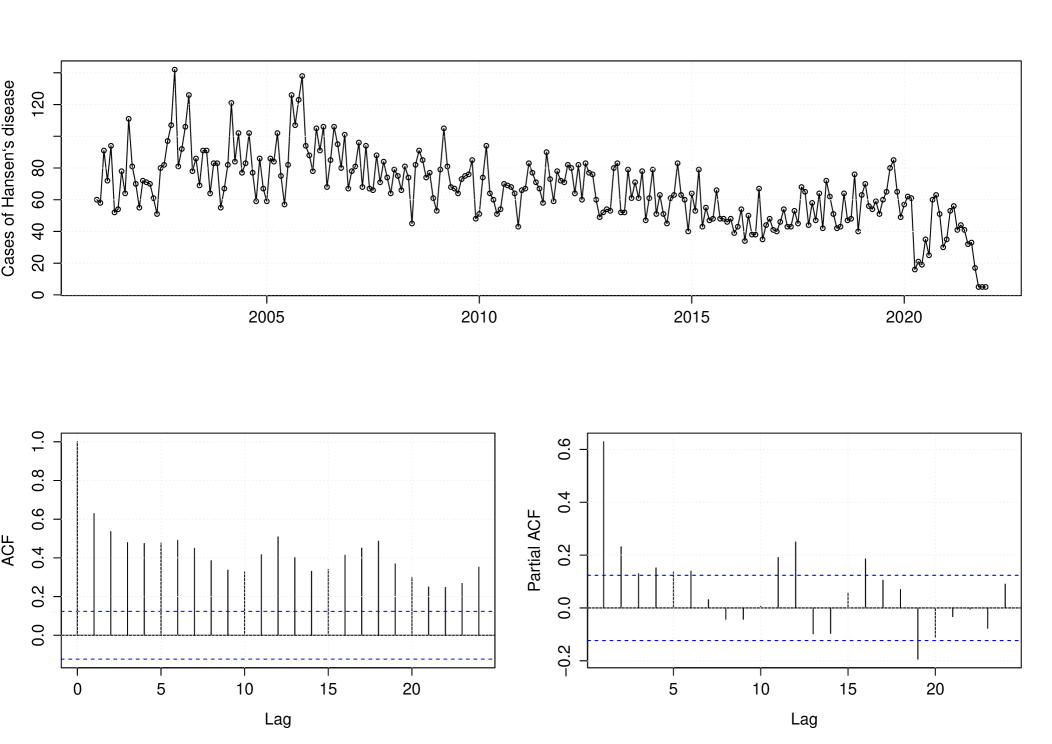
We now analyze Hansen’s disease data. A descriptive data analysis is provided in Table 6. Figure 8 presents the Hansen’s count data and its corresponding sample ACF and PACF plots. This figure provides evidence that the count time series is non-stationary. In particular, we can observe a negative trend. This motivates us to use non-stationarity approaches to handle this data. We consider our non-stationary MGWI process with conditional mean
| (25) |
where the following regression structure is assumed:
with the term being a linear trend. For comparison purposes, we also consider the Poisson INAR(1) process allowing for covariates (Brännäs, 1995) with conditional expectation , where
| Minimum | Maximum | Mean | Median | Variance | Skewness | Kurtosis | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 142 | 66.63 | 66 | 481.103 | 0.250 | 3.937 |
We consider the CLS estimation procedure for both approaches considered here. Table 7 gives us the parameter estimates under the MGWI and PINAR(1) processes, standard errors obtained via bootstrap, and the SSPE values. To get the standard errors for the parameter estimates, we proceed similarly as done in the first application with a slight difference. Since here the counts are high, the geometric assumption cannot be valid. Therefore, we consider a non-stationary MGWI process with innovations following a Poisson distribution with mean in our bootstrap scheme. This ensures that the conditional mean is the same as in (25). From Table 7, we have that the trend is significant (using, for example, a significance level at 5%) to explain the marginal mean , but not for the parameter , under the MGWI model. Furthermore, we note that the sign of the estimate of is negative, which is in agreement with the observed negative trend. We highlight that the parameter also appears in the autocorrelation structure under our approach, therefore the trend is also significant to explain the autocorrelation of the MGWI process. By looking at the results from the PINAR fitting, we see that the trend is significant to explain (parameter related to the autocorrelation) but not the marginal mean . Once again, we have that the model producing the smallest SSPE is the MGWI process. So, our proposed methodology is performing better than the classic PINAR model in terms of prediction. The predictive values according to both models along with the observed counts are exhibited in Figure 9.
| Models | Parameters | Estimates | Stand. Errors | SSPE | ||||
|---|---|---|---|---|---|---|---|---|
| MGWI | 4.3538 | 0.0671 | 58742.31 | |||||
| 0.1178 | ||||||||
| 4.5297 | 0.6303 | |||||||
| 0.9399 | ||||||||
| PINAR | 0.5332 | 59919.40 | ||||||
| 0.7997 | 0.8876 | |||||||
| 4.5290 | 0.0212 | |||||||
| 0.0433 |
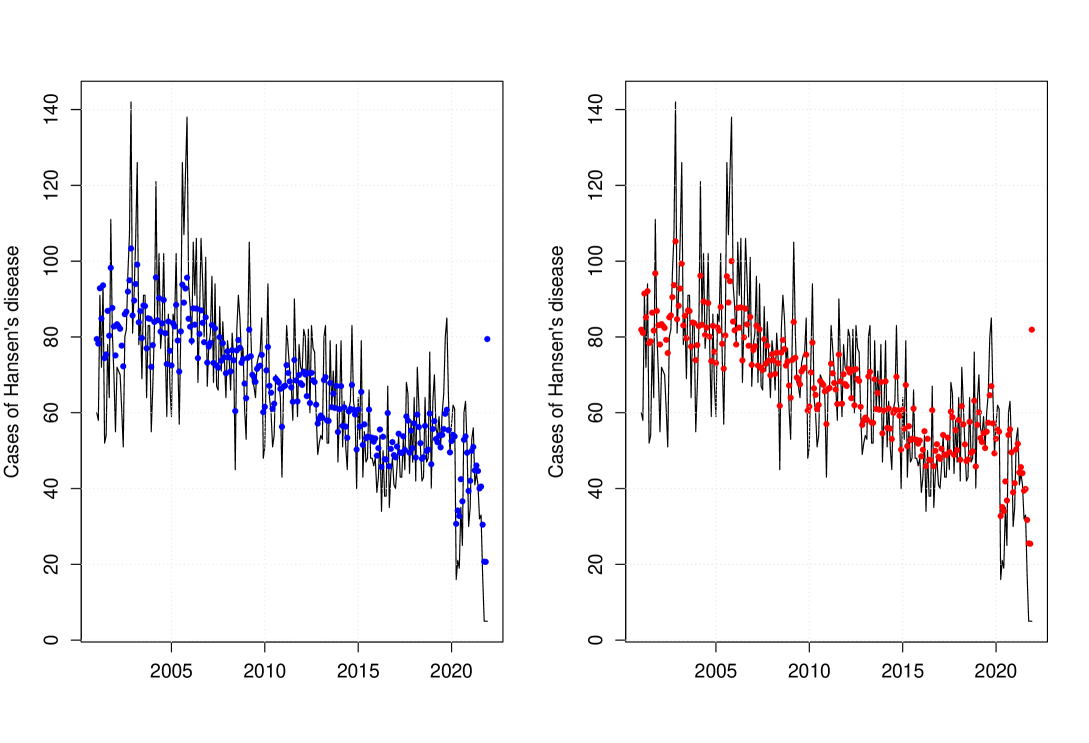
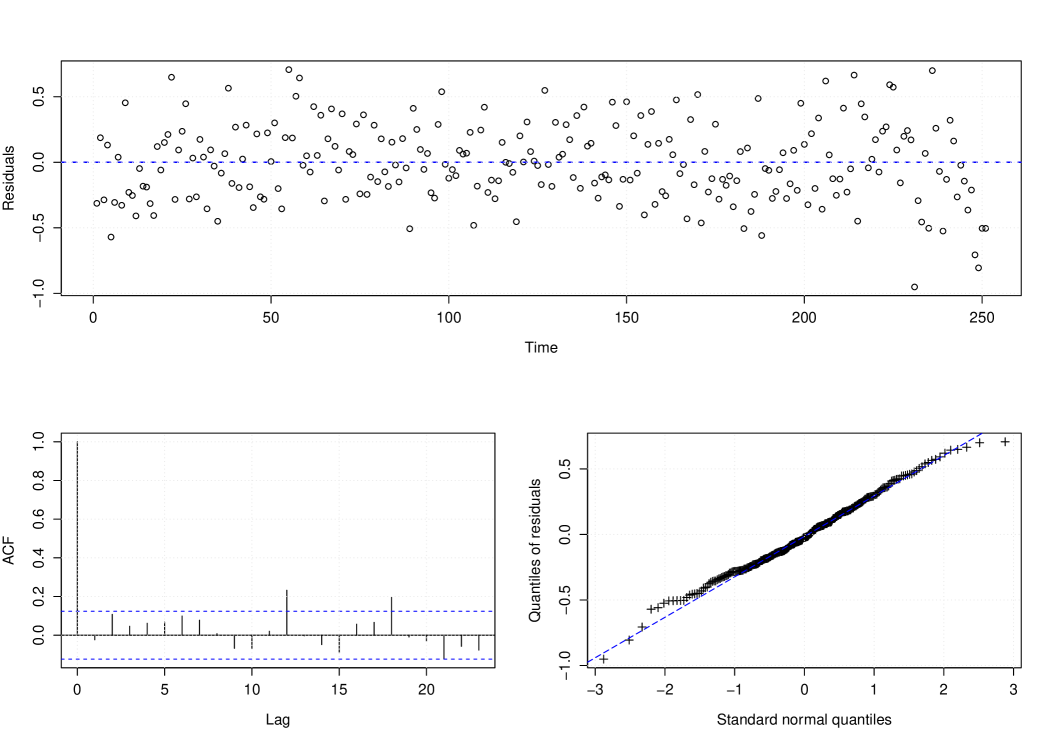
We now conclude this data analysis by checking if the non-stationary MGWI process fits well the data. Figure 10 provides the Pearson residuals against time, its ACF plot, and the qq-plot of the residuals. By looking at this figure, we have evidence of the adequacy of the MGWI process to fit Hansen’s disease data.
7 Generalization
In this section, we provide an extension of the geometric thinning operator and propose a modified GWI process based on such generalization. As we will see, alternative distributions rather than geometric for the operation in (5) can provide flexible approaches for dealing with different features on count time series. We also discuss how to handle zero-inflation or zero-deflation with respect to the geometric model.
Definition 4.
(Zero-modified geometric (ZMG) thinning operator) Assume that is a non-negative integer-valued random variable, independent of , with and . We define the zero-modified geometric thinning operator by
| (26) |
Remark 3.
Note that the ZMG operator given in (26) has the geometric thinning operator as a special case when since . Further, we stress that the parameterization of the ZMG distribution in terms of instead of will be convenient in what follows. Also, we will omit the dependence of on to simplify the notation.
Based on the ZMG operator, we can define a modified GWI process (similarly as done in Section 3) by
| (27) |
where , with , is a sequence of iid non-negative integer-valued random variables, called innovations, with independent of and , for all , with being some starting value/random variable. This is basically the same idea as before; we are just replacing the geometric assumption by the zero-modified geometric law in the thinning operation.
We now show that it is possible to construct a stationary Markov chain satisfying (27) and having marginals ZMG-distributed; this could be seen as an alternative model to the zero-modified geometric INAR(1) process proposed by Barreto-Souza (2015). Furthermore, we argue that such construction is not possible under the geometric thinning operator defined in Section 2 (see Remark 4 below), which motivates the ZMG thinning introduced here.
Let with and . For , it holds that
In other words, . Writing , we obtain
| (28) | |||||
for all such that , where denotes the pgf of a distribution. In addition to the restrictions on and above, assume that , , and . Under these conditions, is the pgf of a distribution. This implies that is a proper pgf associated to a convolution between two independent ZMG random variables. Hence, we are able to introduce a MGWI process with ZMG marginals as follows.
Definition 5.
Remark 4.
Note that we are excluding the case (which corresponds to the geometric thinning operator) since the required inequality does not hold in this case (). This shows that an MGWI process with ZMG marginals cannot be constructed based on the geometric thinning operator defined previously and therefore motivates the ZMG operator.
Acknowledgments
W. Barreto-Souza would like to acknowledge support from KAUST Research Fund. Roger Silva was partially supported by FAPEMIG, grant APQ-00774-21.
References
- Aleksić and Ristić (2021) Aleksić, M.S., Ristić, M.M. (2021). A geometric minification integer-valued autoregressive model. Applied Mathematical Modelling. 90, 265–280.
- Alzaid and Al-Osh (1987) Alzaid, A.A., Al-Osh, M.A. (1987). First-order integer-valued autoregressive (INAR(1)) process. Journal of Time Series Analysis. 8, 261–275.
- Barreto-Souza (2015) Barreto-Souza, W. (2015). Zero-modified geometric INAR(1) process for modelling count time series with deflation or inflation of zeros. Journal of Time Series Analysis. 36, 839–852.
- Billingsley (1995) Billingsley, P. (1995). Probability and Measure, 3rd edition. Wiley & Sons, New York.
- Brännäs (1995) Brännäs, K. (1995). Explanatory variables in the AR(1) count data model. Umeå Economic Studies. 381.
- Dion et al. (1995) Dion, J.P., Gauthier, G., Latour, A. (1995). Branching processes with immigration and integer-valued time series. Serdica Mathematical Journal. 21, 123–136.
- Dunn and Smyth (1996) Dunn, P.K., Smyth, G.K. (1996). Randomized quantile residuals. Journal of Computational and Graphical Statistics. 5, 236–244.
- Enciso-Mora et al. (2009) Enciso-Mora, V., Neal, P., Rao, T.S. (2009). Integer valued AR processes with explanatory variables. Sankhyā – Series B. 71, 248–263.
- Freeland and McCabe (2005) Freeland, R.M., McCabe, B.P.M. (2005). Asymptotic properties of CLS estimators in the Poisson AR(1) model. Statistics and Probability Letters. 73, 147–153.
- Kalamkar (1995) Kalamkar, V.A. (1995). Minification processes with discrete marginals. Journal of Applied Probability. 32, 692–706.
- Littlejohn (1992) Littlejohn, R.P. (1992). Discrete minification processes and reversibility. Journal of Applied Probability. 29, 82–91.
- Littlejohn (1996) Littlejohn, R.P. (1996). A reversibility relationship for two Markovian time series models with stationary geometric tailed distribution. Stochastic Processes and their Applications. 64, 127–133.
- Ispány et al. (2003) Ispány, M., Pap, G., Van Zuijlen, M.C.A. (2003). Asymptotic inference for nearly unstable INAR(1) models. Journal of Applied Probability. 40, 750–765.
- Maia et al. (2021) Maia, G.O., Barreto-Souza, W, Bastos, F.S., Ombao, H. (2021). Semiparametric time series models driven by latent factor. International Journal of Forecasting. 37, 1463–1479.
- McKenzie (1988) McKenzie, E. (1988). Some ARMA models for dependent sequences of Poisson counts. Advances in Applied Probability. 20, 822–835.
- R Core Team (2021) R Core Team (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
- Rahimov (2008) Rahimov, I. (2008). Asymptotic distribution of the CLSE in a critical process with immigration. Stochastic Processes and their Applications. 118, 1892–1908.
- Scotto et al. (2016) Scotto, M.G., Weiß, C.H., Möller, T.A., Gouveia, S. (2016). The max-INAR(1) model for count processes. Test. 27, 850–870.
- Silva and Barreto-Souza (2019) Silva, R.B., Barreto-Souza, W. (2019). Flexible and robust mixed Poisson INGARCH models. Journal of Time Series Analysis. 40, 788–814.
- Steutel and van Harn (1979) Steutel, F.W., van Harn, K. (1979). Discrete analogues of self-decomposability and stability. Annals of Probability. 7, 893–899.
- Wang (2020) Wang, X. (2020). Variable selection for first-order Poisson integer-valued autoregressive model with covariables. Australian and New Zealand Journal of Statistics. 62, 278–295.
- Wei and Winnicki (1990) Wei, C.Z., Winnicki, J. (1990). Estimation of the mean in the branching process with immigration. Annals of Statistics. 18, 1757–1773.
- Zhu (2011) Zhu, F. (2011). A negative binomial integer-valued GARCH model. Journal of Time Series Analysis. 32, 54–67.