MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention
Abstract
Transformers have achieved state-of-the-art performance across various tasks, but suffer from a notable quadratic complexity in sequence length due to the attention mechanism. In this work, we propose MonarchAttention – a novel approach to sub-quadratic attention approximation via Monarch matrices, an expressive class of structured matrices. Based on the variational form of softmax, we describe an efficient optimization-based algorithm to compute an approximate projection of softmax attention onto the class of Monarch matrices with computational complexity and memory/IO complexity. Unlike previous approaches, MonarchAttention is both (1) transferable, yielding minimal performance loss with no additional training, even when replacing every attention layer of the transformer, and (2) hardware-efficient, utilizing the highest-throughput tensor core units on modern GPUs. With optimized kernels, MonarchAttention achieves substantial speed-ups in wall-time over FlashAttention-2: for shorter sequences , for medium-length sequences , and for longer sequences . We demonstrate the quality of MonarchAttention on diverse tasks and architectures in vision and language problems, showing that it flexibly and accurately approximates softmax attention in a variety of contexts. Our code is available at https://github.com/cjyaras/monarch-attention.
1 Introduction
Over the past decade, transformers (Vaswani et al., 2017) have become the dominant architecture for generating and processing various data modalities, such as text (Brown et al., 2020), images (Dosovitskiy et al., 2021), and speech (Radford et al., 2023). Central to the transformer’s success is attention, the mechanism through which complex interactions within sequential data are captured through weighted combinations of embeddings at every position in the sequence. Famously, the attention mechanism has a quadratic-time complexity in the length of the sequence , where is the head dimension, which is a key bottleneck for both training and inference, particularly in long sequence problems. To address this, numerous works have proposed sub-quadratic substitutes for attention. Yet, such approaches either (1) are not transferable, requiring training from scratch or fine-tuning of existing models, or (2) do not yield speed-ups in practice (except on extremely long sequences) due to a gap between theoretical complexity and practical considerations for modern GPUs, especially compared to highly optimized implementations (Dao et al., 2022b).
In this work, we propose MonarchAttention: a novel sub-quadratic attention substitute based on approximating the attention matrix via Monarch matrices (Dao et al., 2022a), a class of expressive structured matrices. At first glance, this is computationally infeasible – for sequence length , computing an exact projection onto the set of Monarch matrices has a super-quadratic -time complexity, not to mention that we need to form the entire attention matrix. Instead, we reframe the computation of the attention matrix as an optimization problem in terms of the variational form of softmax, and exploit low-dimensional structure in the variational objective when constrained to the set of Monarch matrices – this yields a sub-quadratic -time approximation, where is the head dimension.
This approach is analogous to optimization-based approaches for low-rank approximation of a matrix (Chi et al., 2019), where rather than computing a full SVD and truncating to the desired rank, one can more efficiently minimize a Frobenius norm objective constrained to the set of low-rank matrices. We briefly review prior work on structured matrices, including Monarch matrices, as well as existing approaches to efficient attention.

Structured & Monarch Matrices.
We use the phrase “structured matrices” to mean those that admit sub-quadratic storage and matrix-vector multiplication, such as low-rank or sparse matrices. There are many useful classes of structured matrices, such as those with low displacement rank (Kailath et al., 1979), which includes Toeplitz, Hankel, Vandermonde, Cauchy matrices (Pan, 2001); orthogonal polynomial transforms (Chihara, 2014), which includes discrete Fourier/cosine and Hadamard transforms; butterfly factorizations (Dao et al., 2019), which implement fast matrix-vector multiplication via a recursive divide-and-conquer algorithm similar to that of fast Fourier transforms (FFTs); and Monarch matrices, an expressive family of structured matrices (generalizing butterfly matrices and thereby many fast transforms) that overcome unfavorable memory access patterns typical to FFT-like algorithms by implementing matrix products via batched dense matrix multiplications (also called matmuls) on fast tensor cores found in modern GPUs.
Sub-Quadratic Attention.
Nearly all approaches to sub-quadratic attention approximate the attention matrix by a structured matrix, specifically low-rank and/or sparse.
-
Low-Rank. Motivated by Johnson-Lindenstrauss embeddings, Wang et al. (2020) propose sketching the key and value matrices along the sequence dimension via learnable projections. Katharopoulos et al. (2020) introduce linear attention, where the exponential kernel is approximated via inner products of queries and keys lifted via some feature map. Several follow-up works proposed various feature maps, such as the exponential linear unit (ELU) (Katharopoulos et al., 2020), random positive features (Choromanski et al., 2021), rectified linear unit (ReLU) with cosine reweighting (Qin et al., 2022), and learnable single-layer multi-layer perceptrons (MLPs) (Zhang et al., 2024). Xiong et al. (2021) use the Nyström method for computing low-rank approximations by sampling rows and columns.
-
Sparse. Child et al. (2019) introduce sparsity by applying fixed, structured sparse masks on the attention matrix. In particular, Chen et al. (2022) propose a particular block butterfly matrix for the sparse mask, which is more hardware-friendly at the cost of reduced expressiveness. Those that do not enforce a structure on the sparsity pattern include Kitaev et al. (2020); Daras et al. (2020) where they utilize locality-sensitive hashing (LSH) on shared query/key vectors to only compute attention within clusters of similar tokens.
-
Low-Rank + Sparse. Inspired by robust PCA, Chen et al. (2021) decompose the attention matrix into a sum of two matrices: an unstructured sparse component using LSH and a low-rank component that is constructed via linear attention. Han et al. (2024) propose to subsample columns of the non-normalized attention matrix based on row norms of the value matrix, while estimating the softmax normalization factors from a few large elements via LSH.
We note that there are significant drawbacks to the approaches described above. Pure low-rank methods are often fast and hardware-friendly, but are not typically suitable as drop-in replacements for attention in pre-trained transformers due to the prevalence of “strongly diagonal”, high-rank attention matrices where attention weights are concentrated locally in a sequence. Making up for this with a fixed sparsity pattern does not allow for data-dependent support of the attention matrix, necessary for zero-shot conversion. Finally, sparsity/LSH-based approaches that do not have a fixed sparsity pattern, improve on accuracy over low-rank approximations but suffer from significant overhead due to GPU incompatibility. MonarchAttention, on the other hand,
achieves the best of both worlds: it is fast and hardware-friendly due to utilization of tensor cores for batched matmuls, while computing highly accurate approximations to the extent that it can directly replace softmax attention with no additional training.
We conclude this section by discussing closely related works. Dao et al. (2022b) propose FlashAttention, an IO-aware streaming algorithm for computing exact softmax attention.
We show in Section 3 that each step of MonarchAttention can be written as a FlashAttention-like computation, allowing for similar IO savings to FlashAttention – in fact, we demonstrate that MonarchAttention achieves a strictly better worst-case IO complexity compared to FlashAttention.
We also note that Dao et al. (2022b) propose to further accelerate FlashAttention using block butterfly attention masks, so MonarchAttention can be viewed as a generalization of block-sparse FlashAttention to more general Monarch matrices.
Finally, MonarchAttention is closely related to Monarch Mixer (Fu et al., 2023), a mixer-type architecture (Tolstikhin et al., 2021) that utilizes Monarch instead of dense matrices for token and channel mixing. MonarchAttention also uses Monarch matrices for mixing tokens – however, it is based on the attention operation which is data-dependent, unlike Monarch Mixer.
Organization.
In Section 2, we discuss preliminaries on (softmax) attention, and Monarch matrices. In Section 3, we describe the MonarchAttention algorithm and implementation. In Section 4, we evaluate MonarchAttention in a variety of settings for zero-shot conversion to sub-quadratic attention and benchmark its implementation. In Section 5, we discuss limitations and future directions.
2 Preliminaries
Notation.
We use to denote the index set . We use to denote the dimensional unit simplex, given by . We denote the identity matrix by . We use the notation to denote an element of a 3-way tensor, and to denote a slice. We use to denote the Kronecker delta that is if and otherwise 0.
Softmax.
The softmax function maps real numbers to the -dimensional unit simplex, and is defined as
| (1) |
An alternative definition (Blondel et al., 2019) is given by the following variational form:
| (2) |
where is Shannon entropy. See Appendix A for equivalence of (1) and (2).
Attention.
Given query, key, value matrices , where is the sequence length and is the head dimension, a single head of standard softmax attention111Typically, the matrix is scaled by a factor of , but this can be absorbed into . computes
| (3) |
where the softmax function is applied across rows. The computational complexity of attention is for each forward pass, because the matrices are data-dependent.
Monarch Matrices.
Given for integers , we define a block rank-one matrix as
for some for and . It follows that
where for and for , and is a “transpose”222 corresponds to row-major reshaping to , transposing to , then row-major flattening back to . See Appendix B for an example. permutation matrix whose th row is given by where
Given the above, a Monarch matrix is given by – in other words, it is a row-permuted block rank-one matrix. When , storing such a matrix requires only space, while matrix multiplication (matmul) with a matrix can be computed efficiently in operations (as opposed to for dense matrices) with batched matmuls and transposes:
| (4) |
for . A useful characterization of is in block form:
| (5) |
where .
3 MonarchAttention
The main goal of MonarchAttention is to find a Monarch matrix in time such that . Then, we can approximately compute the output using efficient matmul. We can do this by viewing the softmax operation as an optimization problem via its variational form (2), whose objective can be efficiently maximized with exact alternating steps when constrained to Monarch matrices. As shown in Figure 1, this yields highly accurate approximations to the softmax attention matrix.
Softmax Objective.
First, from (2) we can write
| (6) |
where denotes a matrix whose rows lie on , and . For a dense matrix , computing requires operations, which is the same as computing directly. However, we are interested in the case where is a Monarch matrix :
where , and are the th and th block of rows of respectively. Then, for each we evaluate on the rank-one matrix :
Thus, for each we only need operations to compute due to and . We emphasize that the rank-one structure implies separability of the entropy term, meaning we can compute the entropy on and individually and avoid the need to materialize , which would incur cost as opposed to . Since there are many matrices, we have in total operations to compute , which for is , improving on the dense computation by a factor of .
Alternating Maximization with Constraints.
We will now explain the alternating maximization approach for optimizing . When is fixed, the objective is concave in , and vice-versa – therefore, we can derive closed form expressions via KKT conditions for and that maximize with one of or fixed, which will constitute a single update step. Evaluating (and therefore differentiating) w.r.t. and can be done in time, which will be the same complexity as one of these steps. For steps, this will require computation; provided that , this will still be sub-quadratic. However, the constraint presents a challenge in its current form, since this requires materializing to check that each entry is non-negative. Instead, we use the fact that
i.e., slices of individually lying on the unit simplex is sufficient to enforce the constraint on . This is easily seen from (5) – obviously if , then . Moreover, this also enforces the sum-to-one constraint, as rows of sum as
We now present the updates for . Initializing as block identity, we have
| (7) | ||||
| (8) |
for , where are applied along and index dimensions respectively, and
| (9) | ||||
| (10) |
where are the th and th row of and respectively. The full derivation is provided in Section C.1. After steps, we obtain the final Monarch approximation with factors and , from which we output using (4). A naïve implementation of the full algorithm is provided in Section C.2. We discuss in Section C.3 how padding can be incorporated into MonarchAttention for when is not divisible by .
Implementation.
To minimize data movement and memory usage on GPU, we do not materialize or in high-bandwidth memory (HBM). In addition to , we only need to maintain states333The and variables can share the same memory location as those corresponding to can be derived from (and vice-versa). from (9) and (10), resulting in additional memory. All other intermediate values are only materialized in on-chip SRAM, fusing all operations between the (and similarly ) variables. For instance, from the above update equations, the computation of from is given by
which can be seen as a batched attention computation, meaning we can implement a FlashAttention-like kernel to reduce IO between HBM and on-chip SRAM. However, several aspects of this computation make it particularly IO-efficient. Besides the fact that acts as both the and matrices in (3), the effective sequence length is . This eliminates the need for tiling along the sequence length, except for very long sequences having , where is the size of on-chip SRAM. This means that we have an optimal IO complexity of for a single call, as opposed to the worst-case complexity of FlashAttention. The computation of from , as well as the Monarch matmul, can be written in a similar fashion. Based on this, MonarchAttention not only achieves significant speed-up over FlashAttention for longer sequences, but also for shorter ones. Python-like code for MonarchAttention is given in Figure 4.
4 Experiments


In this section, we evaluate the zero-shot performance (no additional training) of MonarchAttention for converting pre-trained/fine-tuned transformer attention layers to sub-quadratic attention in four different model/task settings. We compare with previous low-rank attention methods (Katharopoulos et al., 2020; Choromanski et al., 2021; Xiong et al., 2021; Qin et al., 2022); see Section D.1 for more details on the baselines. We specifically exclude low-rank methods with learnable components (Wang et al., 2020; Zhang et al., 2024), since we are focused on the zero-shot setting, as well as sparsity/LSH-based approaches (Kitaev et al., 2020; Daras et al., 2020; Chen et al., 2021; Han et al., 2024), since these do not admit efficient implementations on current GPUs. We also benchmark our fast implementation of MonarchAttention, comparing with FlashAttention-2 (Dao, 2023).
Image Classification with Vision Transformer.
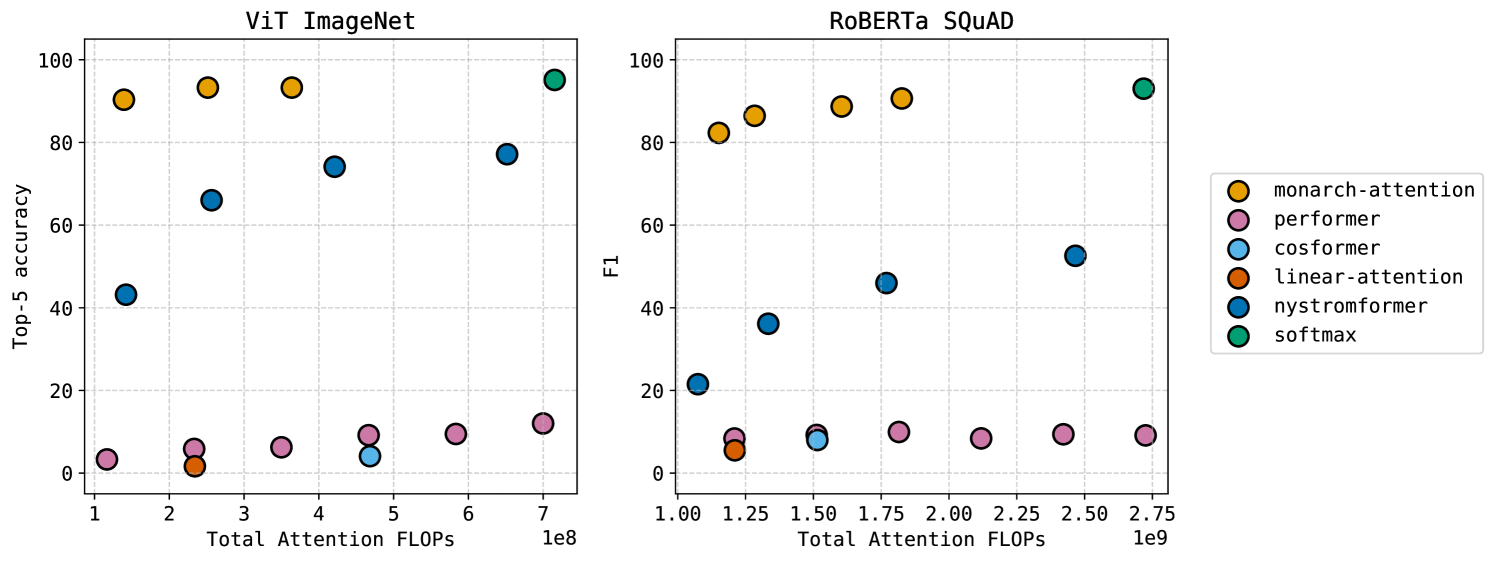
We convert all 12 attention layers, each having 12 heads with sequence length and head dimension , of the 87M parameter ViT-B (Dosovitskiy et al., 2021) that has been pre-trained on ImageNet-21K (Deng et al., 2009) and fine-tuned on ImageNet-1K (Russakovsky et al., 2015) for image classification. To evaluate the performance at different FLOP counts, we vary the number of steps for MonarchAttention, and vary the rank for Performer and Nyströmformer; see Section D.2 for more details on the set-up. The results are shown in the left panel of Figure 2. MonarchAttention achieves significant improvement over other baselines – compared to the original softmax attention, MonarchAttention loses only 5% accuracy to reduce attention FLOPs by 80%, or matches the performance to reduce attention FLOPs by 50%.
Question Answering with Encoder-Only Transformer.
We convert the initial 4 and final 4 layers of the 12 attention layers, each having 12 heads with sequence length and head dimension , of the 125M parameter RoBERTa-B (Liu et al., 2019) that has been pre-trained on a large English corpus and fine-tuned on SQuAD1.1 (Rajpurkar et al., 2016) for question answering. As before, to evaluate the performance at different FLOP counts, we vary the block size for MonarchAttention, and vary the rank for Performer and Nyströmformer; see Section D.3 for more details on the set-up. The results are shown in the right panel of Figure 2. Once again, MonarchAttention achieves significant improvement over other baselines – compared to the original softmax attention, MonarchAttention loses only 10 points in F1 score to reduce attention FLOPs by 60%, or matches the performance to reduce attention FLOPs by 35%.
Summarization with Encoder-Decoder Transformer.
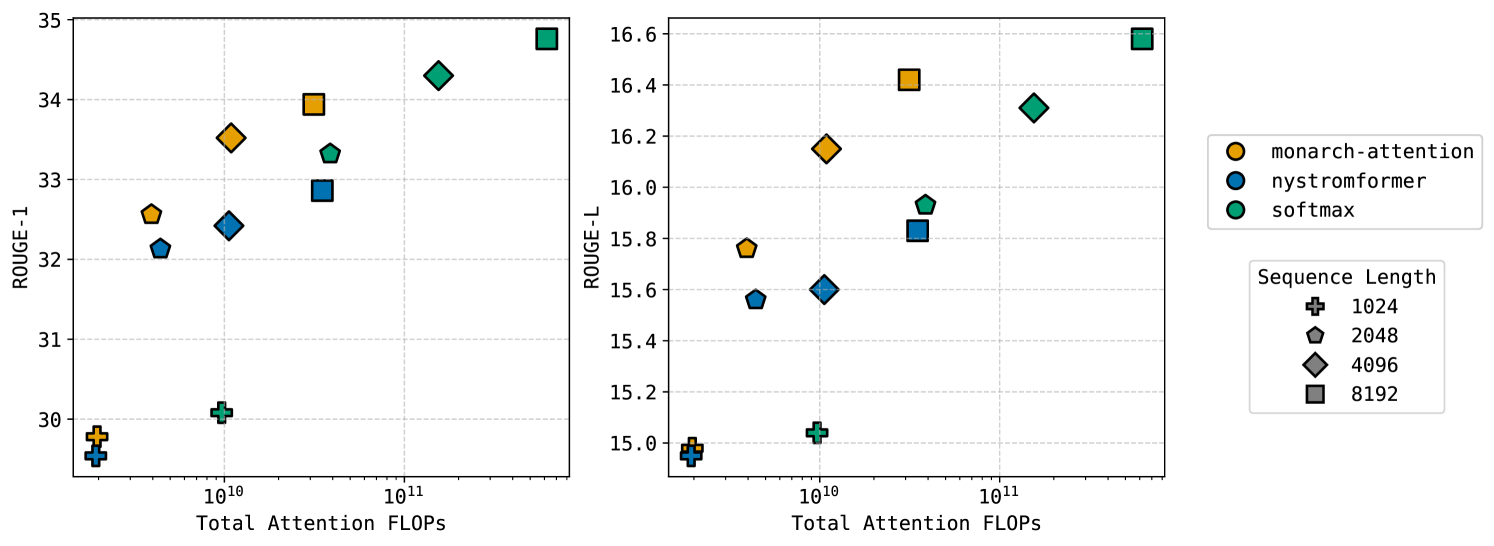
We convert all 6 attention layers, each having 12 heads with head dimension , in the encoder of the 139M parameter BART-B (Lewis et al., 2020) that has been pre-trained on a large English corpus and fine-tuned on BookSum-chapters (Kryściński et al., 2022) for summarization. We only convert the encoder model and leave the decoder intact. To evaluate the benefits of sub-quadratic attention for processing longer sequences, we truncate the text to be summarized to various sequence lengths for each method; see Section D.4 for more details on the set-up. The results are shown in Figure 3. We see that MonarchAttention achieves a strictly better ROUGE score (Lin, 2004) vs. FLOPs tradeoff than even softmax attention, due to accurate and efficient processing of longer sequences. In particular, the MonarchAttention model improves on the softmax attention model by on ROUGE-1 and on ROUGE-L with slightly fewer FLOPs, while the Nyströmformer model with similar FLOPs does strictly worse than softmax.
| Layers Replaced | Method | Total Attention FLOPs () | FID () | sFID () |
|---|---|---|---|---|
| – | Softmax | 8.46 | – | – |
| All | Nyströmformer | 3.30 | 5.97 | 13.47 |
| MonarchAttention | 3.44 | 2.82 | 5.09 | |
| First Half | Nyströmformer | 5.88 | 8.17 | 19.01 |
| MonarchAttention | 5.95 | 0.39 | 0.66 | |
| Second Half | Nyströmformer | 5.88 | 6.76 | 13.58 |
| MonarchAttention | 5.95 | 1.98 | 3.36 |
Image Generation with Diffusion Transformer.
We convert a subset of the 28 attention layers, each having 16 heads with sequence length and head dimension , of the 675M parameter DiT-XL (Peebles and Xie, 2023) that has been trained on ImageNet (Deng et al., 2009). We consider replacing either all layers, the first layers, or the last layers; see Section D.5 for more details on the set-up. Examples of generated images with each method for replacing the first 14 layers are shown in Figure 5, where MonarchAttention produces clear images resembling those of softmax attention, while the Nyströmformer ones are extremely noisy. We also quantitatively evaluate the (s)FID scores (Heusel et al., 2017) of MonarchAttention compared with Nyströmformer, using images generated with the original softmax attention model as reference – the results are reported in Table 1. MonarchAttention noticeably outperforms Nyströmformer with similar FLOP count. In particular, using MonarchAttention in the first half of the DiT layers results in extremely small FID and sFID from the softmax attention model’s images, while reducing FLOPs by nearly .
Benchmarking MonarchAttention.
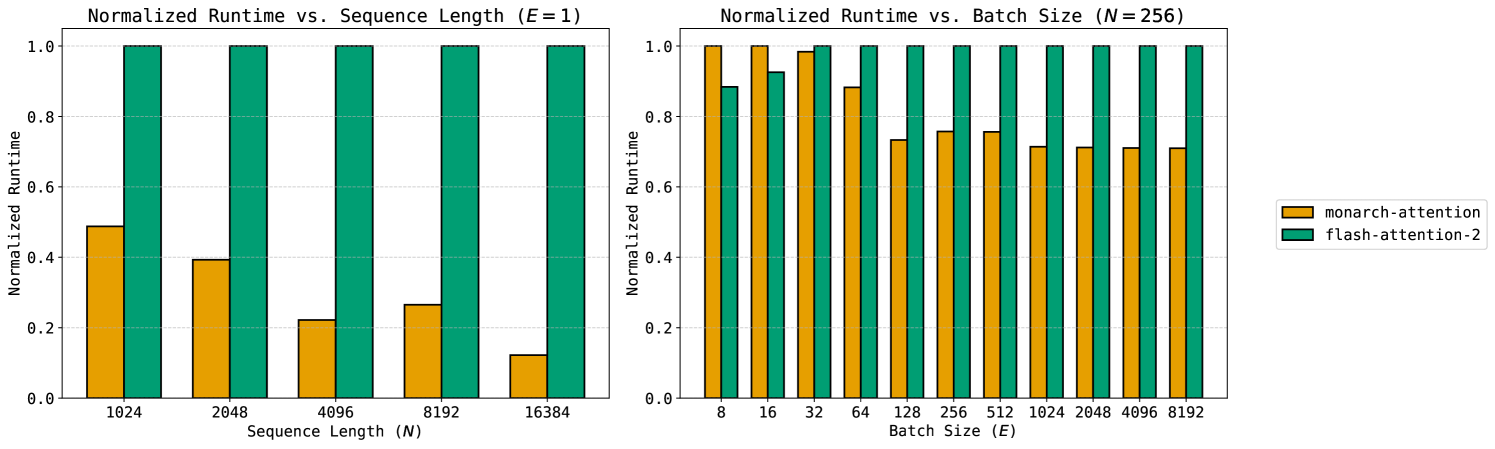
Finally, we validate that the computational/IO complexity reduction achieved by MonarchAttention translates into actual speed-ups on the NVIDIA A40, a modern GPU. We implement the pseudo-code described in Section 3 as four separate Triton kernels and compare it against the fastest available implementations of FlashAttention-2 – either the Triton implementation or PyTorch’s scaled_dot_product_attention, which calls the CUDA backend for FlashAttention-2. Using a fixed batch size , number of heads , and head dimension , we sweep the input sequence length and compare the run-times of FlashAttention-2 and MonarchAttention (with and ) in Figure 6 (left). As sequence length increases, MonarchAttention consistently outperforms FlashAttention-2, notably achieving up to speed-up with . To highlight gains for shorter sequences, we implement MonarchAttention as a single fully-fused Triton kernel, with a single thread block computing a single head. For fixed sequence length , number of heads , and head dimension , we sweep the batch size and compare the run-time of the fully-fused MonarchAttention kernel against FlashAttention-2 in Figure 6 (right). With smaller batch sizes, we have low utilization of hardware, since we compute a single head with a single thread block. However, as we increase the batch size, MonarchAttention achieves up to speed-up over FlashAttention-2.
5 Conclusion
To conclude, we discuss several limitations and future directions for this work. First, the implementation of MonarchAttention can be improved, particularly with more recent GPUs having expanded capabilities such as distributed shared memory found on Hopper architectures. Next, while we have presented MonarchAttention as a direct replacement for softmax attention with no additional training, in theory it can also accelerate training from scratch or achieve better results by converting existing models with some fine-tuning. Moreover, MonarchAttention currently does not support causal masking, which could accelerate training of language models trained with next-token prediction. Finally, we believe that viewing fundamental operations such as softmax through their variational form is a powerful idea that can be generalized, allowing for more generic structured approximations beyond Monarch approximations to softmax attention.
Acknowledgement
LB and CY were supported in part by NSF CAREER award CCF-1845076 and an Intel Early Career award. LB was also supported by the University of Michigan Crosby award. CY and AX were supported by NSF CCF 312842. PA and CL were supported in part by COGNISENSE, one of seven centers in JUMP 2.0, a Semiconductor Research Corporation (SRC) program sponsored by DARPA. We thank Samet Oymak (University of Michigan) for discussion and use of computational resources provided by an Amazon Research Award on Foundation Model Development.
References
- Blondel et al. (2019) Mathieu Blondel, Andre Martins, and Vlad Niculae. Learning classifiers with fenchel-young losses: Generalized entropies, margins, and algorithms. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 606–615. PMLR, 2019.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Chen et al. (2021) Beidi Chen, Tri Dao, Eric Winsor, Zhao Song, Atri Rudra, and Christopher Ré. Scatterbrain: Unifying sparse and low-rank attention. Advances in Neural Information Processing Systems, 34:17413–17426, 2021.
- Chen et al. (2022) Beidi Chen, Tri Dao, Kaizhao Liang, Jiaming Yang, Zhao Song, Atri Rudra, and Christopher Re. Pixelated butterfly: Simple and efficient sparse training for neural network models. International Conference on Learning Representations, 2022.
- Chi et al. (2019) Yuejie Chi, Yue M Lu, and Yuxin Chen. Nonconvex optimization meets low-rank matrix factorization: An overview. IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019.
- Chihara (2014) Theodore S Chihara. An Introduction to Orthogonal Polynomials. Courier Corporation, 2014.
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- Choromanski et al. (2021) Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. International Conference on Learning Representations, 2021.
- Dao (2023) Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- Dao et al. (2019) Tri Dao, Albert Gu, Matthew Eichhorn, Atri Rudra, and Christopher Ré. Learning fast algorithms for linear transforms using butterfly factorizations. In International conference on machine learning, pages 1517–1527. PMLR, 2019.
- Dao et al. (2022a) Tri Dao, Beidi Chen, Nimit S Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher Ré. Monarch: Expressive structured matrices for efficient and accurate training. In International Conference on Machine Learning, pages 4690–4721. PMLR, 2022a.
- Dao et al. (2022b) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35:16344–16359, 2022b.
- Daras et al. (2020) Giannis Daras, Nikita Kitaev, Augustus Odena, and Alexandros G Dimakis. Smyrf-efficient attention using asymmetric clustering. Advances in Neural Information Processing Systems, 33:6476–6489, 2020.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. International Conference on Learning Representations, 2021.
- Fu et al. (2023) Dan Fu, Simran Arora, Jessica Grogan, Isys Johnson, Evan Sabri Eyuboglu, Armin Thomas, Benjamin Spector, Michael Poli, Atri Rudra, and Christopher Ré. Monarch mixer: A simple sub-quadratic gemm-based architecture. Advances in Neural Information Processing Systems, 36:77546–77603, 2023.
- Han et al. (2024) Insu Han, R Jayaram, A Karbasi, V Mirrokno, D Woodruff, and A Zandieh. Hyperattention: Long-context attention in near-linear time. International Conference on Learning Representations, 2024.
- Heusel et al. (2017) Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Kailath et al. (1979) Thomas Kailath, Sun-Yuan Kung, and Martin Morf. Displacement ranks of matrices and linear equations. Journal of Mathematical Analysis and Applications, 68(2):395–407, 1979.
- Katharopoulos et al. (2020) Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR, 2020.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kitaev et al. (2020) Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. International Conference on Learning Representations, 2020.
- Kryściński et al. (2022) Wojciech Kryściński, Nazneen Rajani, Divyansh Agarwal, Caiming Xiong, and Dragomir Radev. Booksum: A collection of datasets for long-form narrative summarization. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 6536–6558, 2022.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, 2020.
- Lhoest et al. (2021) Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, et al. Datasets: A community library for natural language processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 175–184, 2021.
- Lin (2004) Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Pan (2001) Victor Pan. Structured matrices and polynomials: unified superfast algorithms. Springer Science & Business Media, 2001.
- Peebles and Xie (2023) William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023.
- Qin et al. (2022) Zhen Qin, Weixuan Sun, Hui Deng, Dongxu Li, Yunshen Wei, Baohong Lv, Junjie Yan, Lingpeng Kong, and Yiran Zhong. cosformer: Rethinking softmax in attention. International Conference on Learning Representations, 2022.
- Radford et al. (2023) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, 2016.
- Russakovsky et al. (2015) Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015. doi: 10.1007/s11263-015-0816-y.
- Tolstikhin et al. (2021) Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. Advances in neural information processing systems, 34:24261–24272, 2021.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. (2020) Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019.
- Xiong et al. (2021) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 14138–14148, 2021.
- Zhang et al. (2024) Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Re. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry. International Conference on Learning Representations, 2024.
Appendix A Equivalence of Softmax Definitions
Appendix B Monarch Background
We provide an example of the transpose permutation in Section 2. Recall that applying to a vector corresponds to row-major reshaping to , transposing to , then row-major flattening back to . This is equivalent to applying a permutation matrix whose th row is given by where
As an illustrative example, let , , and . The action of is given by the following steps:
In matrix form, we have
Appendix C Details for MonarchAttention
C.1 Updates
Derivatives.
We evaluate with as a Monarch matrix. Using (5), we have
The derivatives of w.r.t. each factor are given by
| (11) | ||||
| (12) |
where
We derive updates for each factor based on maximizing with the other factor fixed.
update.
First, we fix and consider
From the KKT stationarity condition, we have
where are dual variables. Along with (11), we have
Now, from complementary slackness and the fact that is not defined for , we must have . Moreover, since , we have . Altogether, we have
Finally, from the constraint , we must have , which gives the final closed form update:
where is applied along the index dimension.
update.
Similarly, we fix and consider
From the KKT stationarity condition, we have
where are dual variables. Along with (12), we have
As before, from complementary slackness and the fact that is not defined for , we must have . Altogether, we have
Finally, from the constraint , we must have , which gives the final closed form update:
where is applied along the index dimension.
C.2 Naïve Algorithm
We provide pseudo-code for the naive version of MonarchAttention in Figure 7. This is a direct implementation of alternating maximization for finding the Monarch factors, ignoring concerns about memory and IO. We alternate between updating and as described above for iterations. Specifically, we highlight the choices to (1) initialize to be block identity, and (2) update before in each iteration.
C.3 Padding and Masking
In practice, the sequence length may not be divisible by the desired block size . In such cases, we round the number of blocks to , and set the new sequence length , post-padding to have rows. However, we need to take special care that the final columns of the padded Monarch attention matrix are zero, since these correspond to padded rows of . This is also an issue when batched sequences of different lengths are padded to a maximum length to avoid dynamic resizing.
From (5), it is clear that to set all columns of beyond the th column to zero, it is sufficient to set to zero whenever . Thus, we simply form the mask given by
which we then add to before softmax in (7). We can also pre-pad the sequence, which would be change the above condition to .
Appendix D Experimental Details
D.1 Baselines
We describe the baselines used in Section 4.
- •
-
•
performer (Choromanski et al., 2021) is a linear attention method using the fact that
to construct a random kernel feature map
where .
-
•
cosformer (Qin et al., 2022) is a linear attention method utilizing position-dependent kernel feature maps of the form
which produces a rank approximation.
-
•
nystromformer (Xiong et al., 2021) computes landmark from by averaging consecutive spans of rows, which are used to approximate softmax attention via the quadrature method:
where denotes the pseudoinverse of , producing a rank approximation.
D.2 Image Classification with ViT
The ViT-B model fine-tuned on ImageNet-21K is retrieved from the Hugging Face transformers library (Wolf et al., 2019) as google/vit-base-patch16-224. The ImageNet-1K evaluation dataset is retrieved from the Hugging Face datasets library (Lhoest et al., 2021) as imagenet-1k using the validation split. We vary the following hyperparameters:
-
•
monarch-attention: and
-
•
performer:
-
•
nystromformer:
D.3 Question Answering with RoBERTa
The RoBERTa-B model fine-tuned on SQuAD1.1 is retrieved from the Hugging Face transformers library as csarron/roberta-base-squad-v1. The SQuAD1.1 evaluation dataset is retrieved from the Hugging Face datasets library as squad using the validation split. For evaluation, we truncate and pad to sequence length of 384. We vary the following hyperparameters:
-
•
monarch-attention: and
-
•
performer:
-
•
nystromformer:
D.4 Summarization with BART
The pre-trained BART-B model is retrieved from the Hugging Face transformers library as facebook/bart-base. The BookSum-chapters training/evaluation dataset is retrieved from the Hugging Face datasets library as kmfoda/booksum using the train and validation splits respectively. BART employs learned positional embeddings up to 1024 sequence length, and since we are interested in long-sequence summarization up to 8192 tokens, we linearly interpolate the encoder positional embeddings up to 8192 tokens, before fine-tuning on BookSum-chapters – we leave the decoder positional embeddings intact. We fine-tune for 5 epochs with batch size of 32 and learning rate of using the Adam optimizer (Kingma and Ba, 2014) without weight decay, with the input and summary sequences truncated and padded to 8192 and 512 tokens respectively. For evaluation, we truncate the input sequence to the corresponding sequence length in Figure 3. The hyperparameters for each method across sequence lengths are shown in Table 2.
| Sequence Length | Method | (, ) | Total Attention FLOPs () | |
|---|---|---|---|---|
| 1024 | Softmax | – | – | 9.66 |
| Nyströmformer | – | 64 | 1.93 | |
| MonarchAttention | (32, 3) | – | 1.96 | |
| 2048 | Softmax | – | – | 38.7 |
| Nyströmformer | – | 80 | 4.41 | |
| MonarchAttention | (32, 2) | – | 3.93 | |
| 4096 | Softmax | – | – | 155. |
| Nyströmformer | – | 112 | 10.6 | |
| MonarchAttention | (64, 2) | – | 10.9 | |
| 8192 | Softmax | – | – | 619. |
| Nyströmformer | – | 160 | 35.0 | |
| MonarchAttention | (64, 2) | – | 31.4 |
D.5 Image Generation with DiT
The pre-trained model DiT-XL is retrieved from the Hugging Face transformers library as facebook/DiT-XL-2-256. Following Peebles and Xie (2023), we generate images using 32 sampling steps, a patch size, and a classifier-free guidance scale of 1.5. We use the following hyperparameters:
-
•
monarch-attention: and
-
•
nystromformer:
To create the images in Figure 5, we used a random seed of input the same random Gaussian samples into all three models. To obtain the results in Table 1, we again used a random seed of , and generated images from each type of model, again using the same random samples across all models.