Monotonous Parameter Estimation of One Class of Nonlinearly Parameterized Regressions without Overparameterization
Abstract
The estimation law of unknown parameters vector is proposed for one class of nonlinearly parametrized regression equations . We restrict our attention to parametrizations that are widely obtained in practical scenarios when polynomials in are used to form . For them we introduce a new “linearizability” assumption that a mapping from overparametrized vector of parameters to original one exists in terms of standard algebraic functions. Under such assumption and weak requirement of the regressor finite excitation, on the basis of dynamic regressor extension and mixing technique we propose a procedure to reduce the nonlinear regression equation to the linear parameterization without application of singularity causing operations and the need to identify the overparametrized parameters vector. As a result, an estimation law with exponential convergence rate is derived, which, unlike known solutions, (i) does not require a strict P-monotonicity condition to be met and a priori information about to be known, (ii) ensures elementwise monotonicity for the parameter error vector. The effectiveness of our approach is illustrated with both academic example and 2-DOF robot manipulator control problem.
keywords:
parameter estimation; nonlinear regression model; overparametrization; finite excitation; adaptive control.,
1 Introduction
In the majority of applications real technical systems have a limited number of significant physical parameters. At the same time, mathematical models of these systems, written in the state space or Euler-Lagrange form, are described by equations with overparameterization, i.e. with a large number of new virtual parameters that are nonlinearly related to the original ones [6], [12].
As far as classic methods of identification theory and adaptive control are concerned, each parameter of a mathematical model is considered to be unique and independent (decoupled) from the others. With increasing the system order and, as a result, the number of the above-mentioned virtual parameters, this leads to the well-known [6] shortcomings, which make it difficult to apply the basic estimation laws:
-
S1.
Slower convergence and stringent excitation conditions due to the need to solve the identification problem in a larger parameter space.
-
S2.
Necessity to apply projection operators for online estimation of the system physical parameters.
To overcome these problems, it has been proposed [1], [8], [9], [10] to take into account the relationship between the unknown parameters to design the estimation law. In [1] the dynamic regressor extension and mixing (DREM) technique is applied to “isolate the good mappings” from virtual to physical parameters and utilize the strong P-monotonicity property [11] to achieve consistent parameter estimation for nonlinearly parameterized regressions. In case the regressor is non-square integrable, the solution [1] ensures asymptotic convergence of the parameter identification error. The requirement of strong P-monotonicity has turned out to be strict enough for some applications, e.g. composite control of Euler-Lagrange systems [9], [12], adaptive observation of windmill power coefficient [2]. For some, mainly polynomial mappings, it is possible to relax this condition using a special monotonizability assumption [2], [8], [9]. The relaxation mechanism is based on the search for a bijective substitution such that the new nonlinear mapping satisfies the strong P-monotonicity condition. However, the solution from [8], [9] has several key problems:
-
P1.
The convergence of the parametric error is guaranteed only for hardly validated non-square integrable regressors (Proposition 4 in [9]);
-
P2.
Weak property of non-increasing norm of the parameter error vector is guaranteed, but not the elementwise monotonicity (Remark 8 in [9]).
-
P3.
The estimation law requires a priori information about uncertainty parameters (for example, Lemma 2 in [9]).
-
P4.
The calculation of the system physical parameters from the obtained estimates can lead to singularities and sometimes requires application of projection operator (for example, see definition in Lemma 2 of [9]).
-
P5.
Due to P2 and P4 the transient behavior of parametric error is unpredictable, singularity may occur if we want to use .
In a recent paper [10] a new estimation law has been proposed that solves P1 and ensures exponential convergence of the parametric error when a more realistic for some practical scenarios condition of regressor finite excitation is satisfied.
The motivation for this study is to solve all problems P1-P5 for one class of nonlinearly parametrized regression equations (NLPRE).
Notation and Definitions. Further the following notation is used: is the absolute value, is the suitable norm of , is an identity matrix, is a zero matrix, stands for a zero vector of length , stands for a matrix determinant, represents an adjoint matrix. Denote as a stable operator ( and ). For a mapping we denote its Jacobian by . We also use the fact that for all (possibly singular) matrices the following holds: .
Definition. A regressor is finitely exciting over a time range if there exist , and such that the following inequality holds:
| (1) |
where is the excitation level.
2 Problem Statement
The following NLPRE is considered:
| (2) |
where , are measurable regressand and regressor, respectively, is a vector of unknown time-invariant parameters, is a known mapping and . The problem is to estimate parameters using and such that:
| (3a) | |||
| (3b) |
where is an estimate of the unknown parameters, is an estimation error of the ith parameter from , is an abbreviation for exponential rate of convergence.
The feasibility conditions for the problem (3a) are
-
FC1.
, i.e. condition of identifiability of an overparametrized parameters .
-
FC2.
, where i.e. existence of inverse mapping that reconstructs the unknown parameters from a ”good” elements handpicked by from .
When FC1-FC2111It should be understood that, if the inverse function does not exist, then there is no way to obtain from .are met, then the parameters can be obtained and recalculated into (possibly, only asymptotically). However the main contribution of this paper is to solve all problems P1-P5 and shortcomings S1-S2 of existing solutions and consequently ensure elementwise monotonicity (3b) and obtain without estimation of and substitution .
3 Main Result
To facilitate the proposed estimation design, in addition to FC1-FC2 a class of mappings and respective inverse functions , to which we restrict our attention, is defined in the following linearizing assumption.
Assumption 1.There exist , , such that for all the following holds:
| (4) |
where
and all above mentioned mappings are known222Assumption 1 is not restrictive and can be easily verified via direct inspection of mapping ..
Assumption 1 is met in case when polynomials in are used to form and consequently the inverse transform function can be computed using algebraic functions.
Example. For vector the mappings from (4) take the form:
| (5) |
Assumption 1 sets the conditions to obtain the following linearly parameterized regression equation from :
| (6) |
Taking into consideration that the following equalities hold in accordance with Assumption 1:
| (7) |
equation (6) is rewritten as:
| (8) |
where is the unmeasurable linear regression equation with respect to .
Example (remainder). For the mappings from (8) take the form:
Thus, if Assumption 1 is satisfied, having equation for and the known mappings from (4) at hand, the regression equation with nonlinear parameterization (2) can be transformed into the new one with linear parameterization (8). That is the reason why Assumption 1 is called “linearizing”.
Using (2), the regression equation with measurable could be obtained with the help of DREM procedure [1]. Towards this end, we introduce the following dynamic extension:
| (9) |
and apply a mixing procedure to :
| (10) |
The following proposition has been proved in [4], [5] for the scalar regressor obtained by (9) and (10).
Proposition 1. If , then for all
So, the signals can be computed through equations (9) and (10). Then the mixing procedure is applied a novo:
| (11) |
Having the linear regression equation (11) at hand, the estimation law to identify the unknown parameters is introduced based on standard gradient descent method:
| (12) |
where is an adaptive gain, is an initial condition.
The properties of the law (12) are considered in the following theorem.
Following Assumption 1, it holds that , and also holds owing to Proposition 1, then for all we can write the following expression for :
| (14) |
which, in its turn, allows one to rewrite the solution (13) for all as:
| (15) |
from which it follows that .
This completes the proof of Theorem 1.
Therefore, if the mapping satisfy the premises of Assumption 1, then, in accordance with the extension (9) and mixing procedures (10) and (11), the estimation law (12) can be designed ensuring that the goals (3a) and (3b) are achieved. Note that, in contrast to [10], in addition to properties (3a) and (3b) the proposed law does not use a priori information about low and upper bounds of parameters (P3) in design procedure333It should be noted that the proposed law requires only knowledge that lies in the safe domain from FC2. and does not include singularity causing division operations (P4-P5).
4 Numerical Experiment
4.1 Academic example
Using an academic example, the proposed identification method has been compared with the gradient law and the one proposed in [9]. The regressor and the mapping were defined as follows:
| (16) |
where the FC1 was met, and the premises of FC2 were satisfied in case .
According to the proposed approach, the matrix to implement the mixing procedure (10) was introduced, and the mappings from Assumption 1 that were necessary to implement (12) were defined as in the above-given example (see (5)).
In accordance with the “monotonizability Assumption”, the following change of variables was introduced to implement the estimation law from [9]:
| (17) |
which allowed one to rewrite as and ensure that there existed such that the strong P-monotonicity condition [11] for mapping :
| (18) |
was met for .
According to [9] and using (10), the parameter estimation law was rewritten as:
| (19) |
The classic gradient-based estimation law was defined as:
| (20) |
It should be noted that in contrast to (12), the law (19) required information about the low bounds , while the law (20) included the division operation. To conduct the experiment, the unknown parameters , parameters of filters (9) and laws (12), (19), (20) were set as follows:
| (21) |
The initial conditions for (20) were chosen by trial and error so that to meet the condition . Figure 1 depicts the transients of the estimates obtained with the help of (12), (19), and (20).

Estimates obtained with the laws (12) and (19) exponentially converged to the true values, since the condition was met. At the same time, the estimates by (20) did not converge to true values since . The simulation result confirmed that the goal (3a) and (3b) was achieved and demonstrated the advantages of the proposed solution in comparison with both the classic gradient identifier with overparameterization (20) and the law (19) from [9].
4.2 2-DOF robot manipulator
A problem of adaptive control of a 2-DOF robot manipulator with uncertainty has been considered:
| (22) |
where is the vector of generalized coordinates, is the control vector, is the generalized inertia matrix, which is positive definite and assumed to be bounded, represents the Coriolis and centrifugal forces matrix, is the potential energy function.
The goal was stated as where is state tracking error, and is a reference trajectory. Certainty equivalence Slotine-Li controller [13] that ensured achievement of the above-mentioned goal had the form [9]:
| (23) |
with where .
The estimates of the unknown parameters with exponential or asymptotic rate of convergence were required to implement (23). Using measurable signals and and the results of Proposition 7 from [9], the regression model (2) was parametrized as follows:
| (24) |
and . In accordance with the “monotonizability Assumption”, the following change of variables was introduced to implement the identification law from [9]:
| (25) |
which allowed one to rewrite as and ensure that there existed a constant such that the strong P-monotonicity condition [11] for mapping :
| (26) |
was met for
According to [9] and using (9), the estimation law was defined as:
| (27) |
Following the proposed method of identification, the vector from FC2 and the mappings from Assumption 1 took the form:
| (28) |
Note that, unlike (12), the law (27) requires information about the bounds and uses the singularity burden division operation in the mapping . To conduct the experiment, the unknown parameters , parameters of the control law (23), filters (9) and laws (12), (27) were set as follows:
| (29) |
It is worth mentioning that the applicability and safety of use of time-varying adaptive gain in certainty equivalence indirect control problem was shown in, for instance, Proposition 6 from [9]. So the above-presented proof of Theorem is correct mutatis mutandis for this simulation example.
Figure 2 presents the transients of both estimates obtained with the help of the laws (12), (27) and errors for implementations (23) with (14), (23) with (27).
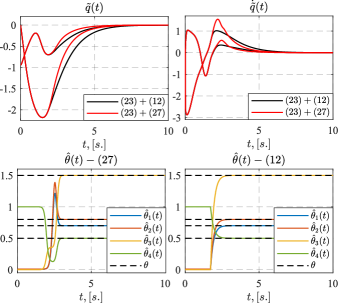
5 Conclusion
The unknown parameters estimation law for one class of NLPRE was proposed. In contrast to existing solutions, elementwise monotonicity of the parametric error was ensured. Necessary and sufficient implementability conditions for the developed law were: (i) the regressor finite excitation requirement, (ii) existence of inverse function from overparameterized parameters to physical ones, (iii) that only polynomials functions in were used to form overparametrization. The results can be applied to improve the solutions quality of adaptive control and observation problems from recent studies [2], [3], [7], [9].
References
- [1] S. Aranovskiy, A. Bobtsov, R. Ortega, and A. Pyrkin. Parameters estimation via dynamic regressor extension and mixing. In Proc. Amer. Control Conf., pages 6971–6976, 2016.
- [2] A. Bobtsov, R. Ortega, S. Aranovskiy, and R. Cisneros. On-line estimation of the parameters of the windmill power coefficient. Systems & Control Letters, 164:105242, 2022.
- [3] R. Cisneros and R. Ortega. Identification of nonlinearly parameterized nonlinear dissipative systems. IFAC-PapersOnLine, 55(12):79–84, 2022.
- [4] A.I. Glushchenko and K.A. Lastochkin. Unknown piecewise constant parameters identification with exponential rate of convergence. Int. J. of Adaptive Control and Signal Proc., 37(1):315–346, 2023.
- [5] A.I. Glushchenko, K.A. Lastochkin, and V.A. Petrov. Exponentially stable adaptive control. Part I. Time-invariant plants. Autom. and Remote Control, 83(4):548–578, 2022.
- [6] L. Ljung. System Identification: Theory for the User. Prentice Hall, New Jersey, 1987.
- [7] R. Ortega, A. Bobtsov, R. Costa-Castello, and N. Nikolaev. Parameter estimation of two classes of nonlinear systems with non-separable nonlinear parameterizations. 2022. arXiv preprint arXiv:2211.06455, https://arxiv.org/abs/2211.06455.
- [8] R. Ortega, V. Gromov, E. Nuño, A. Pyrkin, and J.G. Romero. Parameter estimation of nonlinearly parameterized regressions: application to system identification and adaptive control. IFAC-PapersOnLine, 53(2):1206–1212, 2020.
- [9] R. Ortega, V. Gromov, E. Nuño, A. Pyrkin, and J.G. Romero. Parameter estimation of nonlinearly parameterized regressions without overparameterization: application to adaptive control. Automatica, 127:109544, 2021.
- [10] R. Ortega, J.G. Romero, and S. Aranovskiy. A new least squares parameter estimator for nonlinear regression equations with relaxed excitation conditions and forgetting factor. Systems & Control Letters, 169:105377, 2022.
- [11] A. Pavlov, A. Pogromsky, N. van de Wouw, and H. Nijmeijer. Convergent dynamics, a tribute to Boris Pavlovich Demidovich. Systems & Control Letters, 52(3):257–261, 2004.
- [12] J.G. Romero, R. Ortega, and A. Bobtsov. Parameter estimation and adaptive control of euler–lagrange systems using the power balance equation parameterisation. Int. J. of Control, pages 1–13, 2021.
- [13] J.E. Slotine and L. Weiping. Adaptive manipulator control: A case study. IEEE Trans. on Automatic control, 33(11):995–1003, 1988.