Movable Antenna-Aided Secure Full-Duplex Multi-User Communications
Abstract
In this paper, we investigate physical layer security (PLS) for full-duplex (FD) multi-user systems. We consider a base station (BS) that operates in FD mode and transmits artificial noise (AN) to simultaneously protect uplink (UL) and downlink (DL) transmissions. Conventional fixed-position antennas (FPAs) at the FD BS struggle to fully exploit spatial degrees of freedom (DoFs) to improve signal reception and suppress interference. To overcome this limitation, we propose a novel FD BS architecture equipped with multiple transmit and receive movable antennas (MAs). The MAs introduce the DoFs in antenna position optimization, which can improve the performance of secure communication systems. To serve users and counter the cooperative interception of multiple eavesdroppers (Eves), we formulate a sum of secrecy rates (SSR) maximization problem to jointly optimize the MA positions, the transmit, receive, and AN beamformers at the BS, and the UL powers. We propose an alternating optimization (AO) algorithm, which decomposes the original problem into three sub-problems, to solve the challenging non-convex optimization problem with highly coupled variables. Specifically, we propose the multi-velocity particle swarm optimization (MVPSO), which is an improved version of the standard particle swarm optimization (PSO), to simultaneously optimize all MA positions. The transmit/AN beamformers and the UL powers are solved by successive convex approximation (SCA). The optimal receive beamformer is derived as a closed-form solution. Simulation results demonstrate the effectiveness of the proposed algorithms and the advantages of MAs over conventional FPAs in enhancing the security of FD multi-user systems.
Index Terms:
Movable antenna (MA), physical layer security (PLS), full-duplex (FD), alternating optimization (AO), particle swarm optimization (PSO).I Introduction
In the era of ubiquitous connectivity, people extensively rely on wireless networks to transmit important and private information. Consequently, security and privacy have become critical concerns for next-generation wireless communications [2]. Over the last few decades, conventional security mechanisms primarily focus on cryptographic encryption/decryption methods [3]. However, as threats evolve and become increasingly sophisticated, the encryption/decryption-based methods will cause heavy computation and key management costs. Thus, relying merely on these solutions is insufficient. This has led to a growing interest in physical layer security (PLS), which is based on information theory fundamentals and emphasizes the secrecy capacity of propagation channels [4, 5].
In particular, a pivotal technique for enhancing PLS is multi-antenna transmission, which leverages spatial degrees of freedom (DoFs) [6]. To improve legitimate channels while degrading eavesdropping channels, significant efforts have been devoted to secure beamforming techniques in various scenarios [7, 8, 9]. By exploiting the spatial diversity offered by multiple antennas, these studies comprehensively validated the efficacy of beamforming in improving security performances.
However, conventional multi-antenna systems typically utilize fixed-position antennas (FPAs), which restrict their abilities to further exploit the channel variations, especially in cases with a limited number of antennas. To overcome this limitation, movable antenna (MA) [10] offers a practical and innovative solution. The MA enables flexible movement within two or three-dimensional region through a driver, such as a step motor along a slide track [11]. Due to continuous movement, the MA can better utilize spatial DoFs than the antenna selection (AS) [12] with discretely arranged antennas. So far, numerous studies have demonstrated the advantages of MA-aided systems over FPA systems. The pioneering work [10] established the field-response channel model for MA-aided communication systems. Under the far-field condition, the authors provided a methodology for calculating the channel responses at various MA positions and analyzed the variations in channel gains under deterministic and statistical channels. Moreover, the authors in [13] investigated the channel capacity of multiple-input multiple-output (MIMO) systems with MAs. Dealing with the challenges in multi-user uplink (UL) communications, the authors in [14, 15] respectively considered the utilization of MAs at the base station (BS) and user ends. Regarding multi-user downlink (DL) communications, the authors in [16] modeled the motions of MAs as discrete movements and jointly optimized the transmit beamformer and the MA positions at the BS to minimize the total transmit power. Furthermore, the authors in [17, 18] investigated the MA array-aided beamforming. The antenna position and weight vectors are jointly optimized to achieve the full array gain and the null steering over the desired and undesired directions, respectively. Moreover, the MA-aided secure communication system has become a hot topic. Specifically, based on the obtained channel state information (CSI) and the previously proposed field-response channel model, the channel responses at any location in a given region, i.e., channel gain map, can be reconstructed. Then, based on the channel gain map, the MAs can move to positions where the channel power gains are advantageous/high for legitimate users but adverse/low for eavesdroppers (Eves), leading to an improved secrecy rate. Reference [19] showed the performance improvements in multiple-input single-output (MISO) systems achieved by the one-dimensional MA array over conventional FPAs. The authors in [20] extended the movements of MAs to two dimensions and studied the secure DL communication in a MISO system with a single-FPA user and a single-FPA Eve. Furthermore, a more general MA-aided secure MIMO DL communication system was investigated in [21]. Besides, without perfect CSI of the Eves, the authors in [22, 23] jointly optimized the transmit beamformer and MA positions to bolster systems’ securities. It is worth noting that accurate CSI is paramount to ensuring the improvements of MA-aided communication systems. Fortunately, recent works [24, 25] have proposed some practical methods with low pilot overhead and computational complexity to achieve satisfactory CSI estimation for MA-aided systems.
In addition, artificial noise (AN) is another effective technique to improve the secrecy rate by interfering with Eves’ receptions [26]. Nevertheless, in half-duplex (HD) mode, the AN transmitted by the BS solely shields the DL users, leaving the UL users entirely vulnerable to the Eves, particularly when each UL user is equipped with only a single FPA. It is noteworthy that the full-duplex (FD) mode, wherein transmit and receive signals are superimposed onto the same time-frequency resource block, naturally addresses this issue while concurrently yielding gains in spectral efficiency [27]. Consequently, the resource allocations for secure FD multi-user systems employing AN have garnered increasing attention. Reference [28] proposed the robust beamforming and jamming methods using AN in a worst case, where an FD BS simultaneously serves multiple UL and DL users with single FPA in the presence of a multi-FPA Eve. The authors in [29] expanded the scenario to include multiple Eves with single FPA. Additionally, the authors in [30] considered a more complex scenario involving multiple UL users, DL users, and multi-FPA Eves and jointly minimized the total transmit powers for achieving secure UL and DL transmissions concurrently.
As previously mentioned, current research on MA-aided secure communication systems is confined to HD mode, which fails to provide comprehensive protection for both UL and DL users. On the other hand, existing secure FD systems have solely considered FPAs, which limit the exploitation of spatial DoFs, and their results are not directly applicable to MA-aided systems with reconfigurable channels by antenna position optimization. We note that the mobility of MA provides remarkable advantages over conventional FPA in signal power enhancement, interference mitigation, and flexible beamforming [11, 31]. Compared to HD mode, FD systems introduce additional self-interference (SI) with much higher power than the signal of interest (SoI) [32]. Therefore, the MAs are supposed to relocate to the positions where the SI channel gain is minimized and the SoI channel gain is maximized to suppress the SI and improve the power of SoI. Meanwhile, the geometry of an MA array can be reshaped to achieve multi-beamforming with high array gains over the target directions and low array gains over the undesired directions [18], which can help to mitigate the multi-user interference and AN interference, thereby leading to enhanced security performance. Currently, there is still a lack of system design for secure FD multi-user systems aided by MAs. As such, in this paper, we present the first exploration of PLS for MA-aided FD systems. Compared to existing HD MA-aided multi-access systems, e.g., [15], the FD system can not only enhance spectral efficiency but also protect both UL and DL transmissions. Thus, we aim to leverage the reconfigurability of MA positions to further improve the security of FD multi-user systems. The main contributions of this paper are summarized as follows.
-
1)
We propose a novel FD BS architecture equipped with separate transmit and receive MAs to simultaneously serve multiple UL and DL users while actively resisting cooperative eavesdropping by multiple Eves. An optimization problem is formulated to maximize the sum of secrecy rates (SSR) by jointly optimizing the MA positions, the transmit, receive, and AN beamformers at the BS, and the UL powers, subject to the constraints of maximum transmit powers of each user and the BS, finite moving regions for MAs, and minimum inter-MA distance.
-
2)
We propose an alternating optimization (AO) algorithm to solve the formulated non-convex optimization problem with highly coupled variables. The AO decomposes the original problem into three sub-problems and iteratively solves them. In particular, we modify the standard particle swarm optimization (PSO) and propose the multi-velocity PSO (MVPSO) for optimizing MA positions to avoid undesired sub-optimal solutions. Then, we reformulate the SSR into a more tractable form and utilize the successive convex approximation (SCA) to optimize the transmit and AN beamformers at the BS and the UL powers. Finally, the closed-form expression for the optimal receive beamformer is derived.
-
3)
We conduct extensive simulations to evaluate the effectiveness of the proposed algorithm and the advantages of the proposed scheme for the MA-aided secure FD multi-user system. Simulation results confirm that the proposed MVPSO algorithm effectively avoids undesired local optimal solutions compared to the standard PSO algorithm and generally outperforms the state-of-the-art antenna position optimization algorithms. Besides, compared to the conventional HD BS with only FPAs, the proposed FD BS equipped with MAs can excellently utilize spatial DoFs to resist the Eves and assist the UL and DL communications. Meanwhile, the reuse of time-frequency resources in FD mode and the AN released by the BS further improve the SSR. Moreover, the derived optimal receive beamformer significantly strengthens the reception of UL signals. Finally, we evaluate the impact of the imperfect field-response information (FRI) on MA positioning.
The rest of this paper is organized as follows. Section II introduces the system model and the optimization problem for the proposed system. In Section III, we propose the AO algorithm to solve the optimization problem. Next, simulation results and discussions are provided in Section IV. Finally, this paper is concluded in Section V.
Notation: , , , and denote a scalar, a vector, a matrix, and a set, respectively. denotes the -th element of the vector . indicates that is a positive semidefinite matrix. , , , , and denote the transpose, conjugate transpose, Euclidean norm, trace, and rank, respectively. represents Hadamard product. stands for . and are the sets for complex and real matrices of dimensions, respectively. is the identity matrix of order . represents the circularly symmetric complex Gaussian (CSCG) distribution with mean zero and covariance matrix . denotes the subtraction of set from set . and stand for “distributed as” and “defined as”, respectively.
II System Model
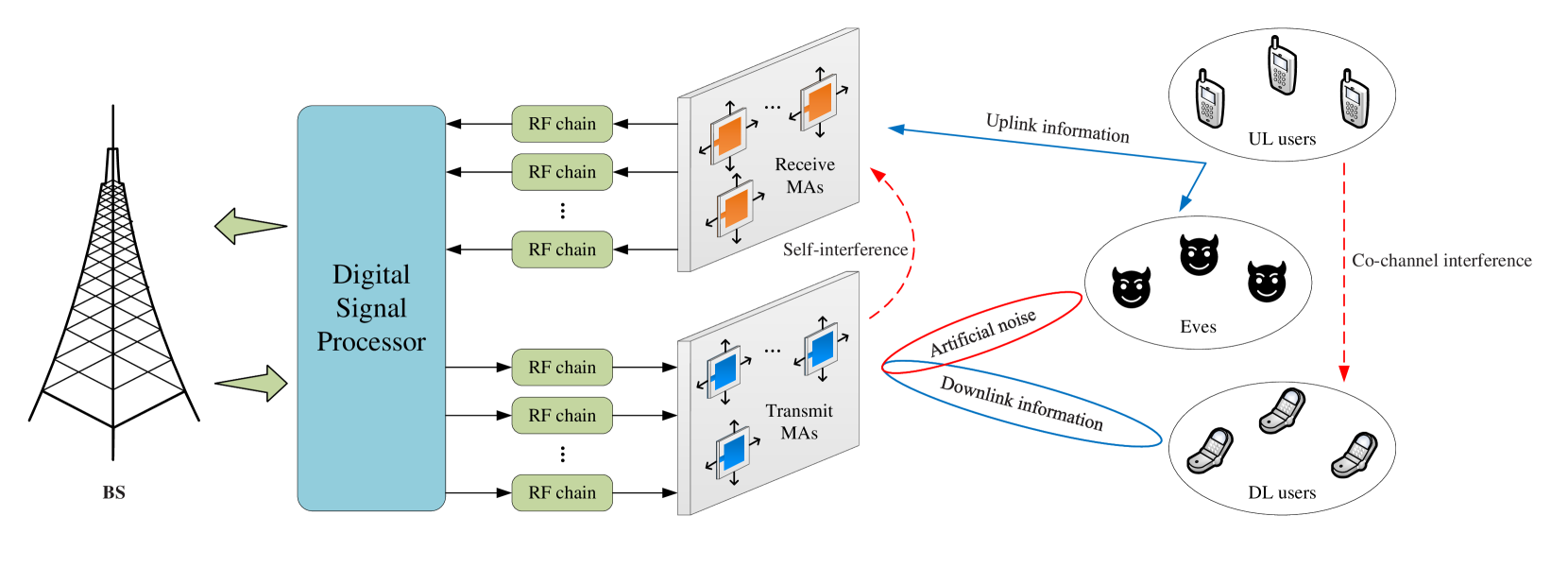
As shown in Fig. 1, we consider a secure FD multi-user system with an MA-aided FD BS to serve HD UL users and HD DL users, in the presence of HD Eves. Each user or Eve is equipped with a single FPA. The BS is equipped with transmit MAs and receive MAs, which can move in the two-dimensional regions for actively reconfiguring the channel conditions111We will consider a quasi-static block-fading channel model with static or low-mobility terminals in Section II-A. Thus, the power consumption for antenna movement is negligible due to infrequent MA position changes. For the scenarios with fast-fading channels, the MA positions can be designed based on the statistical CSI to avoid frequent antenna movements.. The positions of the -th transmit MA and the -th receive MA are described by their Cartesian coordinates, i.e., () and (), where and represent the transmit and receive regions, respectively.
Define the collections of transmit MAs and receive MAs as and , respectively. For MA-aided communication systems, the channel response can be written as the function of MA positions [10]. Thus, the SI channel of the BS, the channel from the BS to DL user (), the channel from the BS to Eve (), and the channel from UL user () to the BS are denoted as , , , and , respectively. Besides, we denote the channel from UL user to DL user as and to Eve as .
In a given time slot, the BS transmits independent information streams to the DL users. For DL user , the information stream can be expressed as , where denote the DL information with normalized power, and is the corresponding beamformer222In DL multiuser communication scenarios, each user may have independent data requirements, . Thus, the BS needs to transmit all users’ data simultaneously and use the corresponding beamformers, , to steer the signals toward the intended receive terminals.. To ensure security, the BS also generates an AN vector and transmits it with DL information to interfere with Eves’ malicious interception333We will optimize the AN beamformer, , in Section III-B to achieve high array gains over Eves’ directions and low array gains over users’ directions, thereby reducing the eavesdropping signal-to-interference-plus-noise ratios (SINRs) in (18) and (19).. Therefore, the DL signals can be expressed as
| (1) |
| (2) | |||
| (3) | |||
| (4) |
Then, the receive signals at the BS, DL user , and Eve are respectively given by (2), (3), and (4) at the bottom of the page, where and are the UL information with normalized power and the transmit power of UL user , respectively. , , and represent the additive white Gaussian noise (AWGN) at the BS, DL user , and Eve with average noise powers , , and , respectively.
II-A Channel Model
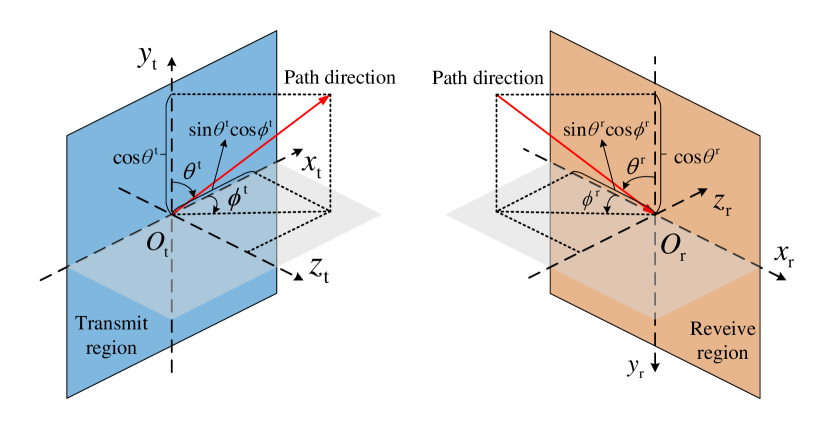
We consider quasi-static block-fading channels and concentrate on one specific fading block with the multi-path channel components at any location in the regions given as fixed [20]. As shown in Fig. 2, define the elevation and azimuth angles of departure (AoDs) and angles of arrival (AoAs) as and , respectively. Based on the field-response channel model [10], we establish the channel responses involving the MA, i.e., SI channel , UL channel , and DL channels and , as follows.
II-A1 SI channel
Let and denote the numbers of transmit and receive paths, respectively. The difference of the signal propagation distance for the -th () transmit path between the MA position and the origin of the transmit region, i.e., in Fig. 2, can be expressed as . Denoting as the carrier wavelength, the phase difference is calculated by . Thus, the transmit field-response vector (FRV), which characterizes the phase differences of transmit paths, are obtained as
| (5) |
Similarly, the receive FRV is given by
| (6) |
which represents the phase differences of receive paths, where () is the difference of the signal propagation distance for the -th receive path between the MA position and the origin of the receive region, i.e., in Fig. 2.
Moreover, define the path-response matrix (PRM) as , where the entry in the -th row and -th column represents the channel response between the -th transmit path and the -th receive path from to . As a result, the SI channel matrix is obtained as
| (7) |
where and are the field-response matrices (FRMs) of transmit MAs and receive MAs, respectively.
II-A2 UL and DL Channels
Since the users and Eves are equipped with FPAs, the FRMs only present at the receive end for UL channel and the transmit end for DL channel. Denote , , and as the numbers of the receive paths from UL user to the BS and the transmit paths from the BS to DL user and to Eve , respectively. Then, the UL and DL channels can be written as
| (8) | ||||
| (9) | ||||
| (10) |
where is the receive FRM for UL channel of UL user , and are the corresponding transmit FRMs for DL channels of DL user and Eve . and , are the path-response vectors (PRVs), which respectively represent the channel responses from UL user to at the BS and from at the BS to DL user and Eve . Since and , have the similar structures as and , we can modify the calculations of and to obtain and , by replacing
| (11) |
with
| (12) |
and replacing
| (13) |
with
| (14) | |||
| (15) |
II-B Problem Formulation
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
The achievable rate of UL user is given by , where is the receive signal-to-interference-plus-noise ratio (SINR) and given by (16) at the bottom of the page. Here, is the receive beamformer of UL user , is the SI loss coefficient representing the path loss and the SI cancellations in analog and digital domains. Besides, the achievable rate of DL user is given by , where is the receive SINR and given by (17) at the bottom of the page.
To ensure secure communications, we consider a worst-case assumption. In particular, we assume that each Eve separately eavesdrops on UL and DL transmissions [29] and can cancel all multi-user interference before decoding the information of a desired user [30]. Furthermore, the Eves aim to collaborate in processing the confidential information [19]. Thus, under these assumptions, the achievable rates of Eves eavesdropping on UL user and DL user are respectively given by and , where and are the receive SINRs and given by (18) and (19) at the bottom of the page. For the convenience of subsequent derivations, we rewrite the receive SINRs by the equalities marked by - in (16)-(19), where
| (20) | |||
| (21) | |||
| (22) | |||
| (23) | |||
| (24) | |||
| (25) | |||
| (26) |
In the paper, we focus on maximizing the SSR444The goal of this paper is to provide a performance upper bound for realistic scenarios and robust designs. Thus, we assume the perfect CSI of all channels is available at the BS for channel response and SSR calculations. Despite the challenges in acquiring perfect CSI, existing works [24, 25, 30] have proposed some practical methods that can achieve satisfactory CSI estimation for MA-aided or FD-based systems. Besides, the impact of imperfect CSI on the considered systems will be evaluated via simulations in Section IV-D. of the users, i.e.,
| (27) |
by jointly optimizing the MA positions, and , the transmit, AN, and receive beamformers at the BS, , , and , and the UL powers, . The corresponding optimization problem is formulated as follows555This paper designs the resource allocation algorithm based on an SSR maximization problem. We note that the derived solutions can also be applied to minimize the total UL and DL transmit powers with appropriate rate constraints due to the duality between rate and power optimization [30]..
| (28) | ||||
Here, constraint C1 normalizes the receive beamformer. and in constraints C2 and C3 are the maximum transmit powers of the BS and UL user , respectively. Constraint C4 limits the ranges of MA movements. Constraints C5 and C6 ensure that minimum inter-MA distance at the BS for practical implementation. The operator has no impact on the optimization and will be omitted in the subsequent derivations.
Note that problem (28) is a highly non-convex optimization problem. Specifically, the non-convexity of the objective function and the minimum inter-MA distance constraints C5 and C6, along with the couplings between the optimization variables, make the optimization problem particularly intractable. To the best of our knowledge, existing optimization tools cannot be directly applied to obtain the globally optimal solution. Thus, we propose an AO algorithm to solve problem (28) in the next section.
III Proposed Solution
In this section, we propose an AO algorithm to address problem (28). Indeed, AO is a widely applicable methodology that decomposes the original problem into several sub-problems and iteratively solves each one while holding the optimization variables in other sub-problems fixed [13, 21, 28, 30]. Specifically, we decompose problem (28) into three sub-problems, i.e., iteratively optimizing , , and .
III-A Sub-Problem 1: Optimize With Given and
With the given and , the SSR can be expressed as a function of and . Therefore, sub-problem 1 can be formulated as
| (29) | ||||
The conventional alternating position optimization (APO) [14], which iteratively fixes the other MAs while moving only one, may converge to an undesired local optimal solution because the given positions of other MAs narrow the optimization space of the current MA to a tiny region [14]. To address this problem, we propose the MVPSO algorithm, which is an effective improvement of the standard PSO [32, 1] by replacing the single velocity of each particle in the iterations with multiple candidate velocities, to simultaneously optimize the positions of all transmit and receive MAs. The details of MVPSO are presented below.
We first randomly initialize the positions and velocities of particles as and , respectively, where each particle’s position represents a possible solution for the antenna position vector, i.e., (). Without loss of generality, we assume that each moving region is a square with size . Each element in obeys the uniform distribution over the real-number interval to ensure that the initial positions of MAs do not exceed the corresponding moving regions, i.e., constraint C4 holds. Then, the personal best position of the -th particle are initialized as and the global best position is selected based on the fitness function. After completing the initialization, the processing procedures of the MVPSO algorithm are summarized in Algorithm 1. Let denote the maximum number of iterations, the introduction of Algorithm 1 is given as follows.
III-A1 Define Fitness Function
Considering constraints C5 and C6 on the minimum inter-MA distance, we first define a penalty function as
| (30) |
where is the position of the -th particle in the -th () iteration. is an indicator function, equaling 1 when the condition within the bracket is true; otherwise, it equals 0. and are the positive penalty factors utilized to regulate the severity of the penalty. Assume that the best position has the largest fitness value. Based on this given penalty function, for maximizing the SSR, the fitness function is defined as
| (31) |
where the values of and consistently maintain . Thus, the penalty function can push the particles to satisfy the minimum inter-MA distance. In other words, with the progression of iterations, will converge to zero.
III-A2 Update Positions and Velocities
The candidate positions of the -th particle in the -th iteration are updated by candidate velocities, i.e.,
| (32) |
where is the -th () candidate velocity, which will be specified later. is a function, that projects each entry of the vector to the nearest boundary if it exceeds the feasible region, to satisfy constraint C4, i.e.,
| (33) |
For standard PSO, the inertia weight in each particle’s velocity decreases with the number of iterations in the interval , i.e.,
| (34) |
Generally, a small leads to local exploitation for optimal solutions within the current region, whereas a large signifies that the particles can globally explore to evade undesired local optimal solutions [33]. Hence, the standard PSO lacks exploitation in the early iterations and exploration in the late iterations. Based on the aforementioned observations, we modify the standard PSO and propose the MVPSO, in which each particle can select the optimal velocity from multiple candidate velocities in each iteration.
The candidate velocities in (32) are generated by the weighted combinations of velocity components, i.e.,
| (35) |
where is a constant vector of the -th particle, which represents the combination weights for generating the -th candidate velocity. is the collection of velocity components for the -th particle and represents the -th () velocity component, which is calculated as
| (36) |
where is the selected optimal velocity in the -th iteration which will be specified later. is the inertia weight of the -th velocity component. and are the personal and global learning factors that push each particle toward the personal and global best positions, respectively. To reduce the possibility of converging to an undesired local optimal solution, two random vectors and , with uniformly distributed entries in the range , are utilized.
In general, the combination weights of different velocity components can be configured to simultaneously accommodate exploitation and exploration. However, the velocity components in may not cover the optimal velocity but contain the velocity components with biased local and biased global search behaviors. In other words, both the velocity components themselves and their weighted combinations can serve as the candidate velocities. Thus, the constant vector is introduced to control the combination of the velocity components. It is worth noting that the standard PSO can be regarded as a special case of the proposed MVPSO by only setting one candidate velocity. Similar multi-candidate approaches have been employed to address optimization problems in wireless communications, e.g., [15].
Finally, the position of the -th particle in the -th iteration is selected from candidate solutions which can achieve the maximum fitness value in (31), i.e.,
| (37) |
The corresponding velocity is updated to the candidate velocity associated with the selected solution, i.e.,
| (38) |
The generation and selection of each particle’s position and velocity are presented in lines 6-12.
III-A3 Update Personal and Global Best Positions
After obtaining the particles’ positions, the personal and global best positions are updated if the fitness value at the current position exceeds the personal and global best fitness values, respectively. The corresponding pseudo-code is shown in lines 13-18. After iterations, an optimized solution for the antenna position vector is obtained by the global best position, i.e., line 21.
III-B Sub-Problem 2: Optimize With Given and
Based on the rule of the logarithmic function, we define and , which are given by (39) and (40) at the bottom of the page, and rewrite the SSR as .
| (39) | ||||
| (40) |
Thus, with given and , sub-problem 2 can be formulated as
| (41) | ||||
| (42) |
Problem (41) is also non-convex due to the objective function and the rank constraint C9. Note that and are concave functions, and thus the objective function in (41) is a difference-of-concave function. Therefore, the SCA [34] is applied to obtain a sub-optimal solution. Specifically, define the maximum number of iterations for SCA as . In the -th () iteration, we construct a global overestimate of for a given feasible point by the first-order Taylor expansion, i.e., , which is given by (III-B) at the bottom of the page, where , , and denote the gradients of function with respect to , , and , respectively.
Subsequently, for a given feasible point in the -th iteration, a lower bound of the maximization problem in (41) can be obtained by solving the following optimization problem.
| (43) | ||||
where is defined as . Note that the persistent non-convexity of problem (43) stems from the rank-one constraint C9. Thus, the semidefinite relaxation (SDR) is adopted to relax constraint C9 by removing it. Then, the relaxed version of problem (43) can be optimally solved with the aid of standard convex solvers such as CVX. Besides, the tightness of the rank relaxation is verified in the following theorem.
Theorem 1
If , the optimal beamforming matrices and , which satisfy and , can always be obtained.
Proof:
Please refer to [34, Appendix A]. ∎
Then, the relaxed version of problem (43) is iteratively solved until the increase of is less than the predefined convergence threshold or the maximum number of iterations is reached. Finally, the optimized UL powers are outputted, and the optimized beamformers and are obtained by performing the eigenvalue decomposition on and , respectively.
III-C Sub-Problem 3: Optimize With Given and
With given and , maximizing the receive SINR of each UL user with beamformer yields the maximization of the SSR. Specifically, let and , we can obtain the optimal receive beamformer by solving the following optimization problem.
| (44) | ||||
where is defined as follows.
| (45) |
The optimal solution of problem (44) is given by [34]
| (46) |
After obtaining the solutions of three sub-problems, the proposed AO algorithm iteratively solves the three sub-problems until the increase of is less than the threshold or the maximum number of iterations for AO is reached.
III-D Convergence and Complexity Analysis
The convergence and computational complexity of the overall AO algorithm are analyzed as follows. Define the index and maximum number of iterations for AO as and , respectively, where . The convergence is ensured by the following inequality
The inequality marked by holds because is the optimal receive beamformer for maximizing the SINR of each UL user. The inequality marked by holds because , , and are the optimized transmit and AN beamformers and UL powers by the SCA. The inequality marked by holds because and are the optimized positions of MAs searched by the proposed MVPSO. As a result, the SSR is non-decreasing during the iterations in the AO algorithm. Meanwhile, due to the finite communication resources, the SSR is always bounded. As such, the convergence of the overall algorithm is guaranteed. Moreover, the convergences are verified by the simulations in Section IV-B.
The computational complexity of the AO mainly arises from the search process of the MVPSO algorithm, the iterations of the AO and SCA algorithms, and the calculation of the receive beamformer. For the MVPSO in Algorithm 1, the complexities of calculating and in (31) are
and , respectively. Thus, the total complexity of Algorithm 1 is . For the SCA algorithm, let denote the number of iterations, the complexity is due to solving the SDR problem iteratively [34]. For calculating the receive beamformer, the complexity is due to the matrix inversion in (46). Based on the above analyses, the computational complexity of the overall algorithm is
, where is the number of iterations for AO.
III-E Implementation Considerations of Proposed System
The above analyses focus on designing the resource allocation strategy for the proposed MA-aided secure FD multi-user system. In this sub-section, we discuss some practical considerations for the implementation of the proposed system.
III-E1 Antenna Movement
The proposed system requires integrating an antenna positioning module with the conventional communication module at the FD BS. For large-scale systems, the motor-based MA system, which utilizes a step motor to facilitate the movement of the antenna along a sliding track, is particularly well-suited because the motor’s driving power and the sliding track’s length can be tailored to accommodate different antenna’s weights and sizes [10]. For small-scale systems, such as millimeter-wave (mmWave) and terahertz (THz) systems, micro-electromechanical systems (MEMS) can be employed to achieve low power consumption and high positioning accuracy [11].
III-E2 Adaptability of SI Cancellation Modules
Unlike HD systems, the FD BS incorporates both analog and digital SI cancellation modules within its receive chains. These modules estimate the SI channel and then reconstruct the SI signal for cancellation. In conventional FPA FD systems, the SI channel remains relatively static due to fixed antenna positions. However, the MA-aided FD system faces dynamic changes in the SI channel caused by antenna movements, necessitating the efficient adaptability of the SI cancellation modules. A potential solution is the integration of machine learning algorithms, which can dynamically learn the characteristics of the varying SI channel, thus achieving excellent SI channel estimation [35].
IV Simulation Results
In this section, we present the simulation results to evaluate the performance of the proposed scheme.
IV-A Simulation Setup and Benchmark Schemes
| Parameter | Description | Value |
|---|---|---|
| Number of antennas | 6 | |
| Moving region size | ||
| Minimum inter-MA distance | ||
| Number of channel paths | ||
| SI loss coefficient | -90dB | |
| Path loss at the reference distance | -40dB | |
| Path loss exponent | 2.8 | |
| , , | Average noise powers | -90dBm |
| Maximum DL transmit power | 40dBm | |
| Maximum UL transmit power | 10dBm | |
| , , | Numbers of users/Eves | 4 |
| Number of particles | 100 | |
| , , | Maximum numbers of iterations | 100 |
| , | Penalty factors | 10 |
| , | Personal and global learning factors | 1.4 |
| , | Convergence thresholds |
In the simulation, the UL users, DL users, and Eves are randomly and uniformly distributed in a cell centered on the FD BS with a radius of 600 meters (m). The FD BS is equipped with the same number of transmit and receive antennas, i.e., . We adopt the geometry channel model [10, 13], where the numbers of all transmit and receive paths are identical, i.e., . In this way, the PRM of the SI channel is a diagonal matrix, where each diagonal element follows the CSCG distribution . For UL and DL channels, each element in PRVs follows the CSCG distribution , where represents the path loss at the reference distance of 1 m, is the path loss exponent, and denotes the propagation distance from the BS to DL user/Eve or from UL user to the BS. The AoDs and AoAs are assumed to be the independent and identically distributed random variables within the interval . Unless specified otherwise, the default simulation parameters are set as shown in Table I.
In the simulations, the proposed scheme is termed as “Proposed”. For the MVPSO algorithm, we set candidate velocities, which are derived from the weighted combinations of velocity components. Specifically, the inertia weights for these three velocity components are respectively set as , , and to balance both the exploration and exploitation of the particles [33]. Moreover, the combination weight vectors for all particles in (35) are set as , , and . Besides, to fully demonstrate the advantages of the proposed scheme, we define the following state-of-the-art FPA-based and MA-based benchmark schemes.
IV-A1 FPA-Based Schemes
-
FPA: The BS is equipped with the transmit and receive FPA-based uniform planar arrays (UPAs) with and antennas, respectively. The UPAs and MA moving regions have the same aperture size.
-
AS: The BS is equipped with the transmit and receive FPA-based UPAs with and antennas, respectively. The UPAs and MA moving regions have the same aperture size. In a single AO iteration, transmit antennas and receive antennas are selected via exhaustive searches to maximize the SSR.
IV-A2 MA-Based Schemes With Various Antenna Position Optimization Algorithms
-
Random position (RP) [13]: Randomly generate 100 pairs of and that satisfy constraints C4-C6. For each pair, solve sub-problems 2 and 3, and select the - pair with the largest SSR.
-
APO [14]: The transmit and receive regions are discretized into multiple grids of size . The MA positions are determined by the APO method, i.e., with other MAs fixed, the position of the current MA with the largest SSR, which meets constraints C5 and C6, is selected via exhaustive searches.
-
PSO [32]: This scheme optimizes the MA positions by the standard PSO algorithm.
IV-A3 MA-Based Schemes With Various Transmission Strategies
-
ZF: This scheme employs the zero-forcing (ZF) receive beamformer instead of the optimal receive beamformer in (46) used in the proposed scheme.
-
NoAN: This scheme does not transmit the AN introduced in the proposed scheme. The transmit beamformers, , are optimized with the same maximum DL power constraint, .
-
HD: This scheme configures the BS to operate in the time-division HD mode. Thus, the SSR is penalized due to the half communication time compared to FD mode.
IV-B Convergence Evaluations of Proposed Algorithms
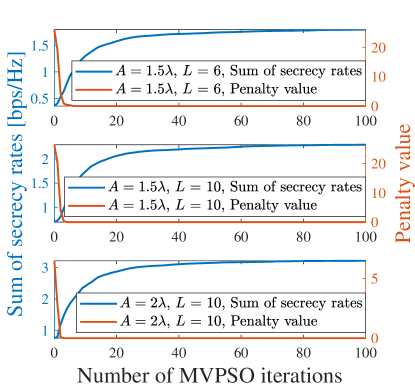
In Fig. 3a, the convergence of the proposed MVPSO is evaluated with different moving region sizes and path numbers. As can be observed, the three SSRs increase with the number of iterations and tend towards stable values within 100 iterations, validating the convergence performance. Additionally, to verify the effectiveness of the proposed penalty function in (III-A1), we also illustrate the variations of the penalty values with the number of iterations. We can observe that the larger the moving region size, the fewer iterations are needed for the penalty value to reach zero. The three penalty values remain zero after 5 iterations, which ensures that the minimum inter-MA distance constraints C5 and C6 are satisfied.
Besides, the convergence evaluation of the overall AO algorithm is shown in Fig. 3b. With different moving region sizes, numbers of paths, and numbers of MAs, the SSRs increase with the number of AO iterations and converge within 20 iterations, substantiating the previous discussions on the convergence of the AO algorithm in Section III-D.
IV-C Channel Power Gains under MVPSO
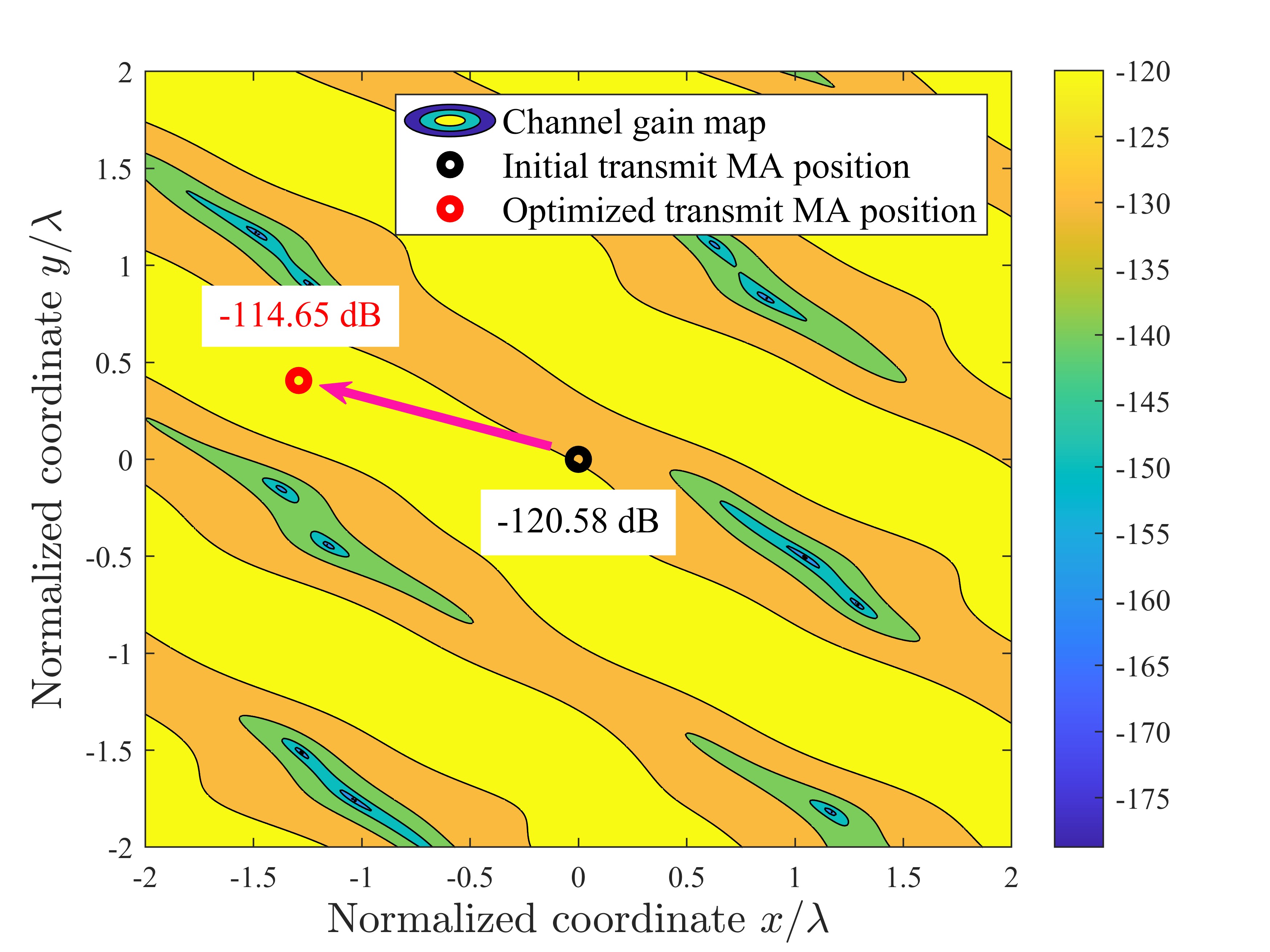
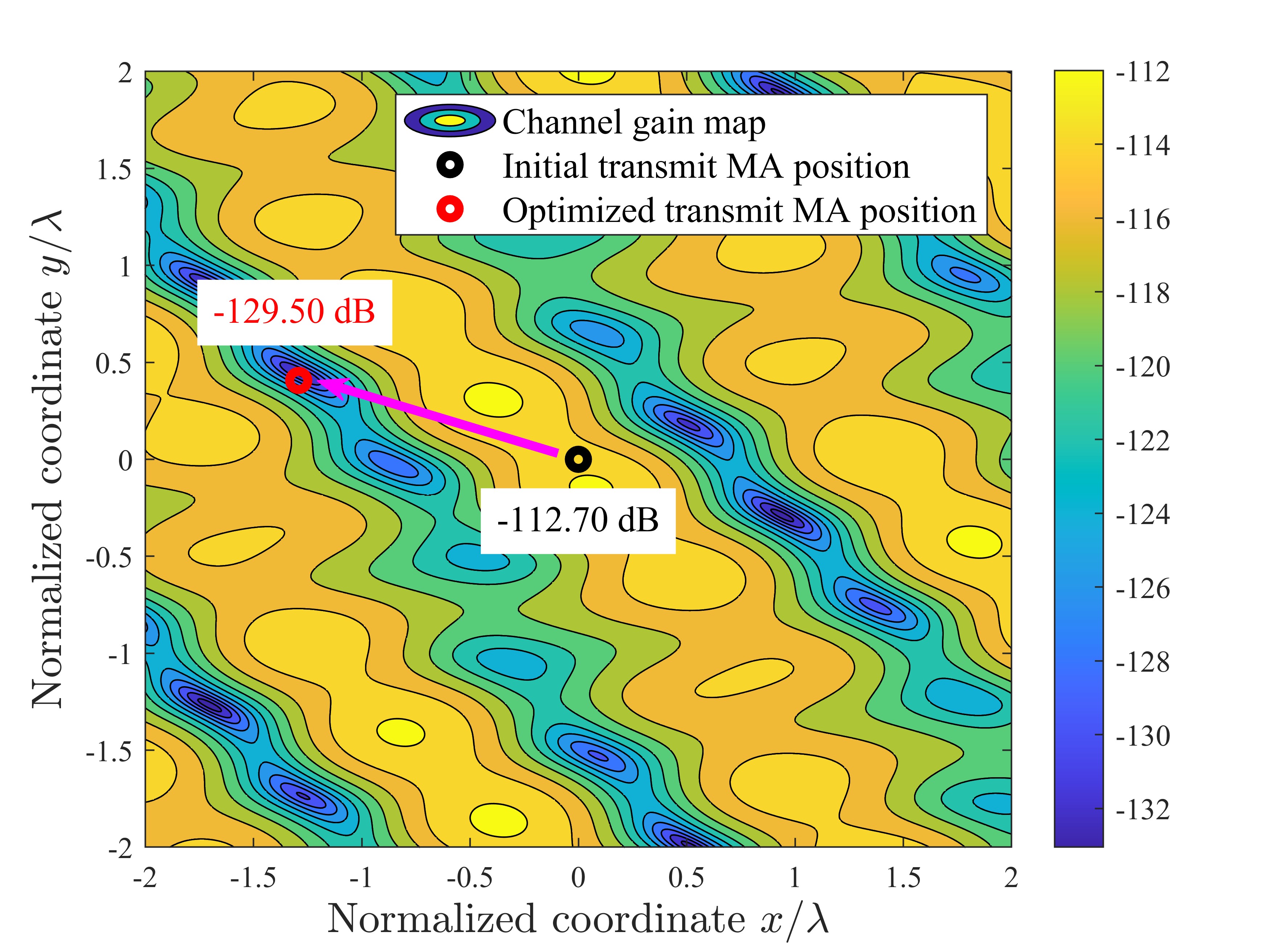
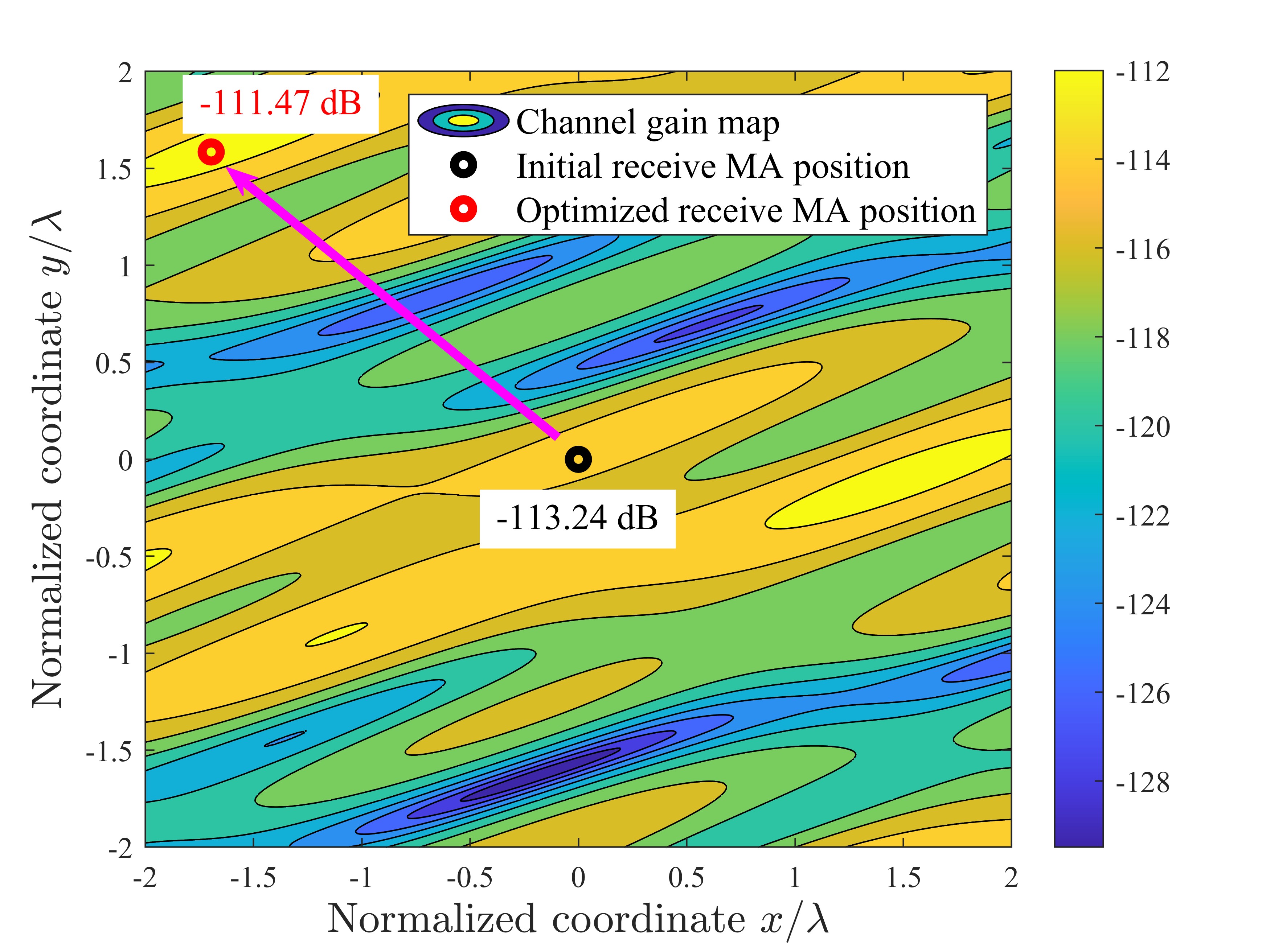
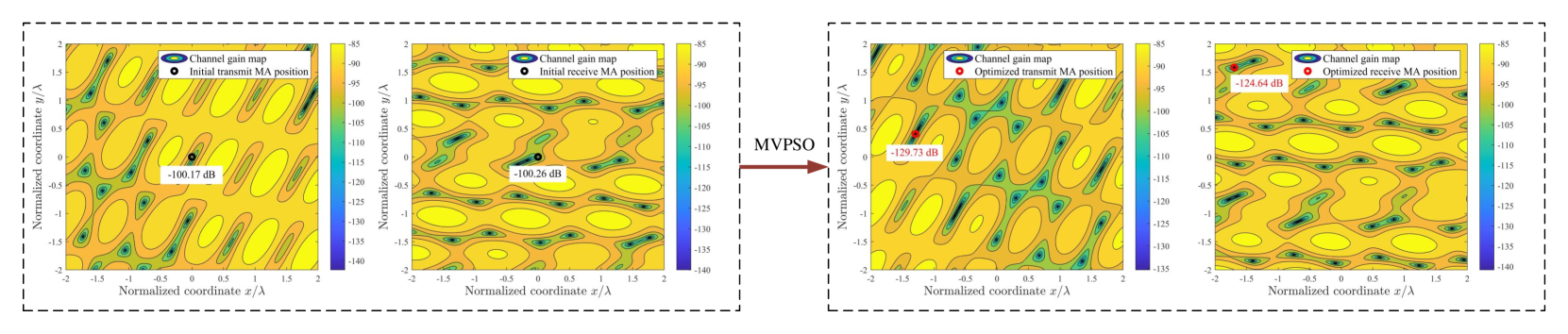
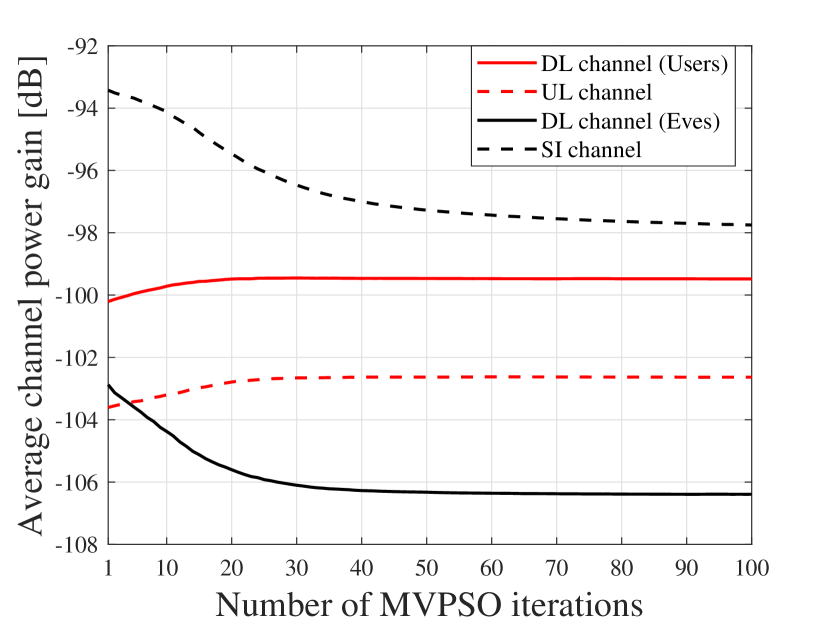
To further investigate the impact of antenna position optimization via the MVPSO on altering channel conditions, one realization of the channel power gains (in dB) versus the MA position is illustrated in Fig. 4. For ease of presentation, the numbers of transmit MA, receive MA, DL user, UL user, and Eve are set as 1, i.e., . It is shown that due to the prominent small-scale fading in the spatial domain, for the DL and UL channels, each user or Eve has its unique channel gain map in the transmit or receive region (see Figs. 4a-4c). For the SI channel, there are also corresponding channel gain maps in the transmit and receive regions before and after antenna position optimization (see Fig. 4d). As can be observed, for transmit MA, its position is initialized at the origin of the transmit region, with the channel power gains for the DL user, Eve, and the receive MA being -120.58 dB, -112.70 dB, and -100.17 dB, respectively. By employing the proposed MVPSO, the channel power gain of the optimized transmit MA’s position for the DL user increases to -114.65 dB, while the channel power gains for the Eve and the receive MA decrease to -129.50 dB and -129.73 dB, respectively. Besides, for the receive MA, the optimized position, compared to the initial position, results in an increase of 1.77 dB in channel power gain for the UL user and a decrease of 24.38 dB in channel power gain for the transmit MA. These results indicate that even small movements of MAs can lead to significant changes in channel responses. Furthermore, antenna position optimization via the MVPSO comprehensively balances maximizing the channel power gains for the UL and DL users while minimizing those for the Eve and SI. These conclusions are also validated in Fig. 5, which illustrates the average channel power gain for the multi-user case under the MA position optimization by MVPSO. We can see that the channel power gains of DL and UL users increase, while those of SI and Eves decrease with the iterations, and the decreases are greater than the increases. This demonstrates that the position optimization of MAs through MVPSO can effectively reconfigure the channels based on multi-user system requirements, degrading performance-harmful channels (SI/Eves channels) while improving performance-beneficial ones (DL/UL users channels) to maximize the SSR.
IV-D Performance Comparison with Benchmark Schemes
In this sub-section, we compare the performance of the proposed scheme with benchmark schemes.
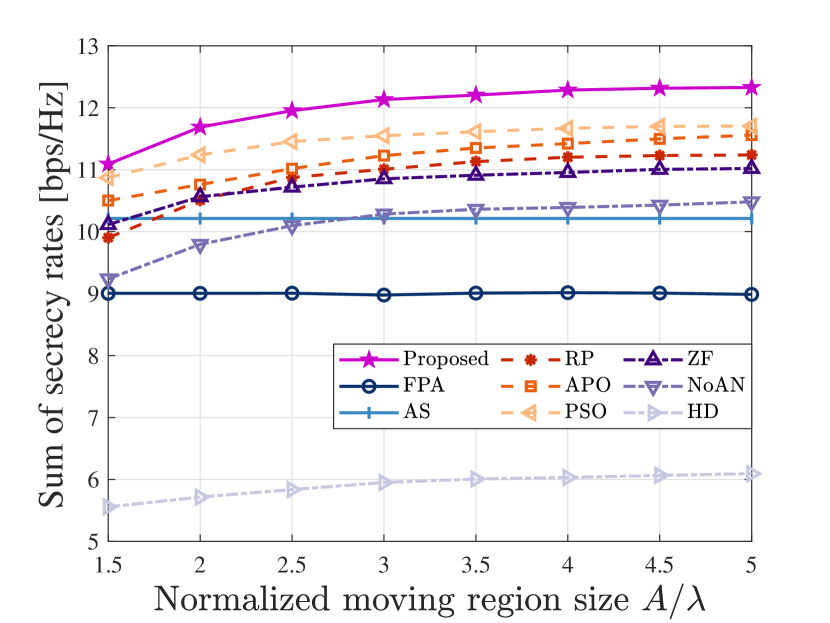
Fig. 6 illustrates the SSR versus the normalized size of moving region for MAs. It can be observed that, the SSRs of all MA-based schemes increase with the normalized moving region size and gradually converge to stable values. This is because a larger moving region allows the MA to further explore spatial DoFs, but the limited number of paths restricts the diversity gains from increasing indefinitely. The fixed antenna configurations in the AS and FPA schemes render their performances unaffected by the moving region size, and the AS scheme can leverage spatial DoFs to some extent to improve the SSR compared to the FPA scheme. Furthermore, the proposed MVPSO outperforms the standard PSO, which in turn surpasses the conventional APO scheme. As the moving region size increases, the performance gap between the MVPSO and the PSO widens, while the gap between the PSO and the APO narrows. This is because the APO scheme maintains the fixed positions for other MAs while optimizing the current MA position, thereby disregarding the interdependencies among the MA positions. The standard PSO overcomes this limitation by optimizing all MA positions concurrently to prevent undesired sub-optimal solutions. However, its inability to balance exploitation and exploration hampers its effectiveness in discovering the optimal MA positions for the larger moving regions. Therefore, the MVPSO scheme stands out for its capability to simultaneously explore and exploit throughout the entire iteration process. In addition, the RP scheme performs the worst among all the considered antenna position optimization algorithms because it randomly initializes the MA positions without taking the actual channel conditions into account. Moreover, the results demonstrate that the AN and the FD mode effectively enhance the system’s PLS performance. Unlike the HD systems, in FD mode, the transmission of AN can simultaneously safeguard both UL and DL users, and the reuse of spectrum further augments the SSR.
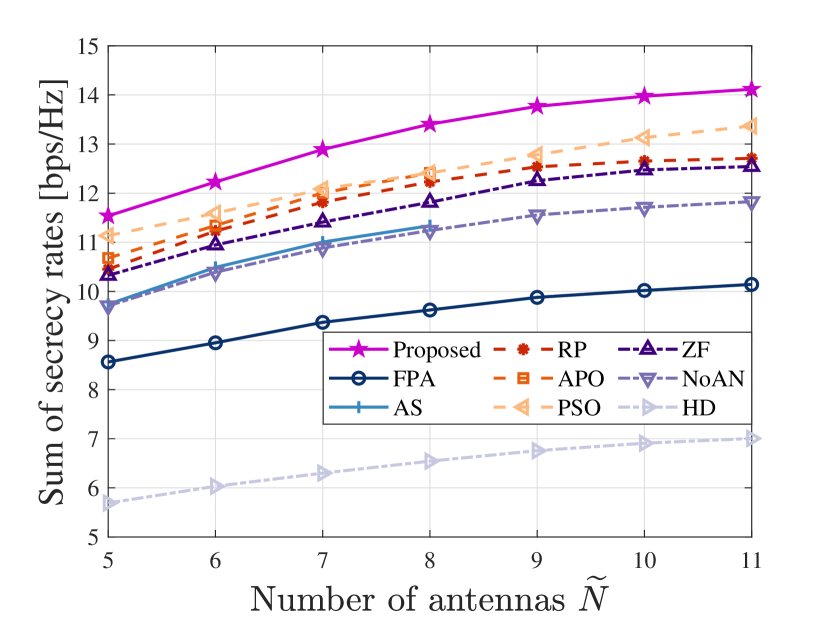
In Fig. 7, the SSRs of different schemes are compared versus the number of antennas. The APO and AS schemes are omitted when due to high computational complexities. For example, considering MAs in the transmit and receive regions, the APO scheme necessitates calculating channel responses in a single AO iteration, and the number of total selections for the AS scheme is , which are hard to undertake. As the number of antennas increases, all schemes exhibit increases in the SSRs due to the enhanced spatial diversity gain and beamforming gain. We can find that the SSR growth in the FPA scheme is slower compared to the MA-based schemes. Specifically, the increase in the number of antennas from 5 to 11 brings the 18.44% and 22.34% increases in the SSRs for the FPA and the proposed MA-based scheme, respectively. This is because for the MA-based schemes, increasing the number of antennas allows for better exploitation of spatial DoFs by extensive movements within the designated regions. Consistently, the proposed scheme maintains optimal performance with varying numbers of antennas. Besides, we note that as the number of antennas increases, the APO scheme gradually approaches the SSR level nearly equivalent to that of the PSO scheme. This reveals that the standard PSO with a single velocity fails to fully search for the optimal solutions when the dimensions of the optimization variables, i.e., the number of antennas, are large, thus underscoring the necessity and effectiveness of the proposed MVPSO.
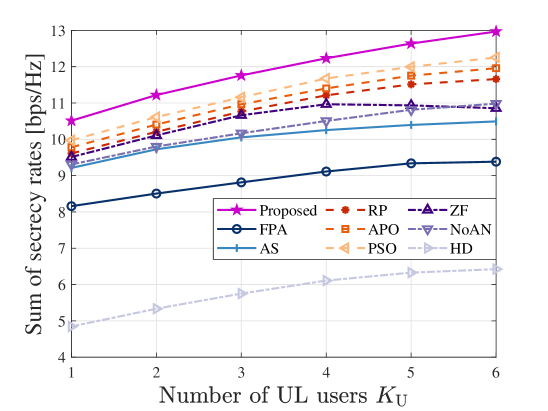
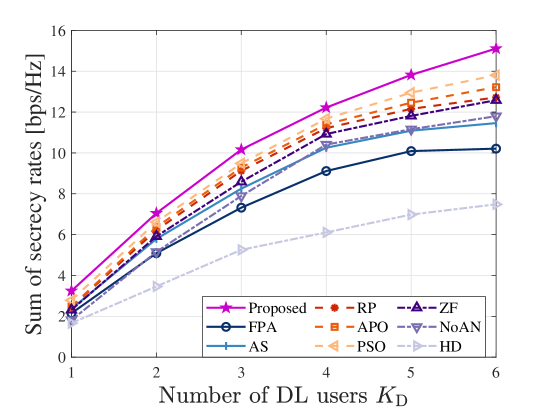
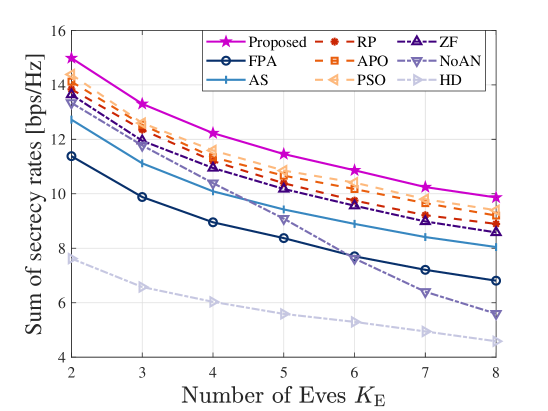
To gain more insight, we present in Fig. 8 the SSR for each scheme versus numbers of UL users, DL users, and Eves. As shown in Figs. 8a and 8b, the SSRs of the MA-based schemes (excluding the ZF scheme in Fig. 8a) consistently improve as the numbers of users increase, while the FPA-based schemes struggle when handling multiple users. This is because the flexible adjustment of the MA array can realize multi-beamforming with much less loss of the individual array gains in different directions. Besides, we note that the noise amplification caused by the ZF beamforming may deteriorate the SINRs of the UL users. Thus, the ZF scheme in Fig. 8a shows an SSR degradation with more UL users compared to the proposed optimal receive beamformer. Moreover, considering the worst-case scenario of the cooperative eavesdropping by multiple Eves who can completely cancel multi-user interference, the relationships between the performances of different systems and the number of Eves are depicted in Fig. 8c. Intuitively, the SSRs of all schemes decrease as the number of Eves increases. The reasons are as follows. With more Eves, the SINRs of cooperative UL and DL eavesdropping (as seen in the summation terms of (18) and (19)) increase. This coordinated effort undermines the systems’ abilities to maintain secure communications, thereby diminishing the SSRs of all schemes. Fortunately, the proposed scheme still surpasses other benchmark schemes. However, the SSR of the NoAN scheme experiences a steep decline with an increasing number of Eves, approaching the performance of the HD scheme even at . This demonstrates that due to the reuse of time-frequency resources in FD systems, the AN with effective beamforming can interfere with Eves’ receptions while simultaneously protecting the UL and DL transmissions. Thus, AN is indispensable for secure FD transmission.
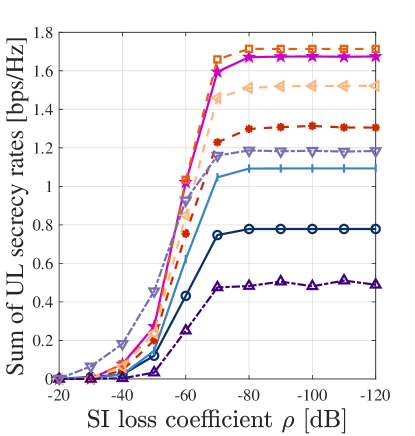
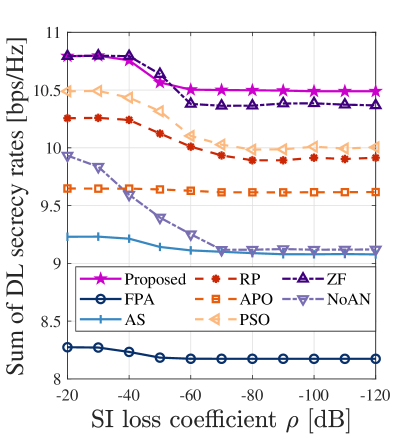
Subsequently, we investigate the impact of the SI loss coefficient on system performance. Figs. 9a and 9b respectively present the sums of UL and DL secrecy rates versus SI loss coefficient without the HD scheme. For the SI loss coefficient , a smaller value in dB indicates a more powerful capability for SI cancellation. It can be observed that as decreases, the sums of UL and DL secrecy rates of all FD-based schemes increase and decrease, respectively. This is because, with the improved SI cancellation, the FD BS can reliably demodulate the UL users’ information. Thus, the user scheduling policy allows for UL transmissions, resulting in an increased UL secrecy rate. However, for DL users, the undesired co-channel interference introduced by UL transmissions decreases their received SINRs, thus reducing the DL secrecy rate. Additionally, in case of weak SI cancellation, i.e., , we observe the dominance of DL transmissions due to the severe SI affecting the reception of UL signals. Consequently, without UL transmissions, the performance of the ZF scheme closely mirrors that of the proposed scheme. On the contrary, when SI cancellation is robust, i.e., , both UL and DL secrecy rates approach saturation. This is because the power of the residual SI becomes negligible compared to other interference perceived at the BS, rendering further improvements in SI cancellation ineffective in yielding significant gains. Besides, we notice that the UL secrecy rate of the APO scheme slightly surpasses that of the proposed scheme, but this improvement comes at the sacrifice of the DL secrecy rate. This indicates that, compared to the APO scheme, the proposed scheme more effectively leverages the DL transmission capability to maximize the sum of UL and DL secrecy rates. Moreover, the DL secrecy rate of the NoAN scheme in Fig. 9b underperforms that of the APO scheme when . This is because the discrete adaptation of the APO scheme to spatial channel variations results in its DL secrecy rate remaining relatively stable as the SI conditions change, a trend also seen in the FPA and AS schemes with discretely arranged antennas. In contrast, the continuous antenna movement in the NoAN scheme leads to a marked decline in secure DL communication performance as SI suppression improves. Furthermore, due to the absence of AN protection, the steady-state DL secrecy rate of the NoAN scheme is ultimately lower than that of the APO scheme.
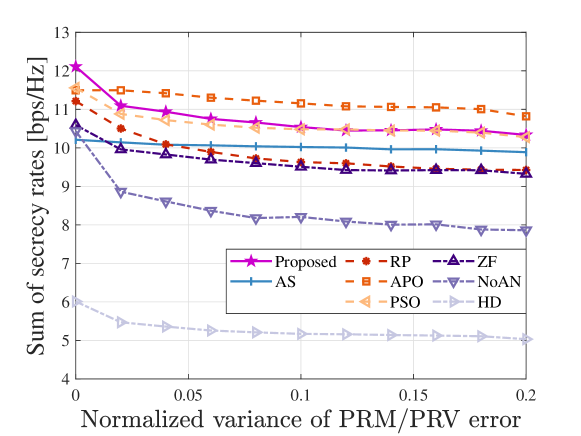
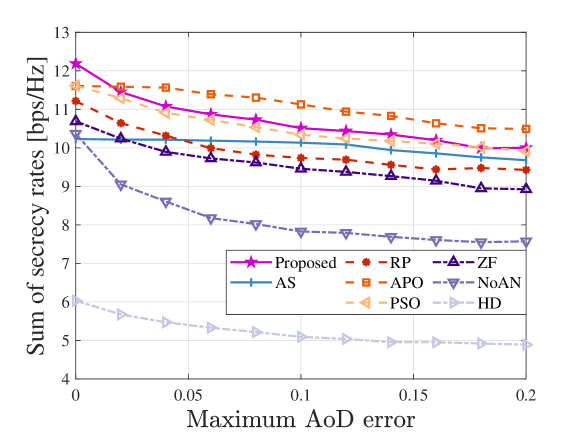
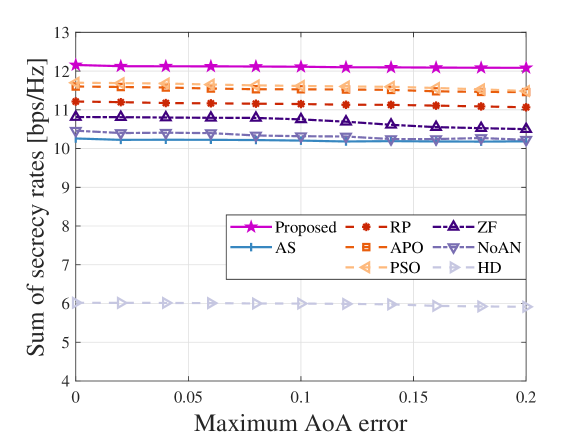
In the above discussions, we assume that the BS possesses the perfect knowledge of the FRIs, i.e., the PRMs/PRVs of UL, DL, and SI channels, the AoDs of DL and SI channels, and the AoAs of UL and SI channels. Due to noise, limited training overhead, and multiple Eves, obtaining perfect FRIs is challenging in practice. Therefore, Fig. 10 separately evaluates the impact of PRM/PRV, AoD, and AoA errors on system performances. The descriptions of the FRI errors reference [14, 15, 21]. In each sub-figure, the remaining two types of FRIs are assumed to be perfectly known. To focus on the impact of imperfect FRIs on MA position optimization, the MA positions are determined by the estimated FRIs, while the calculations of the beamformers and UL powers are based on the actual channel responses [15]. We neglect the FPA scheme because it does not involve antenna position optimization. From Fig. 10, it can be observed that the SSRs decrease with the normalized variance of PRM/PRV error and maximum AoD and AoA errors. Specifically, the proposed scheme experiences the performance losses of 14.65%, 17.93%, and 0.61% due to PRM/PRV, AoD, and AoA errors, respectively. Compared to PRM/PRV and AoD errors, AoA error has a less detrimental effect on performances. The reasons are as follows. Because the AoA error only affects the calculations of UL and SI channels, the low UL powers make the deviations between the estimated and actual AoAs have an insignificant impact on UL transmissions. Thus, the MA position optimization based on the estimated AoA can still maintain excellent performance. Besides, we find that the APO scheme is less sensitive to PRM/PRV and AoD errors compared to the proposed scheme. This is because the APO scheme discretizes the moving regions into multiple grids, where the center of each grid serves as a candidate position. This discretization restricts MAs to discerning channel variations solely between different grids. In addition, the small PRM/PRV and AoD errors do not significantly impact the relative channel gains between different grids. Ultimately, the PRM/PRV and AoD errors have a minor impact on the APO scheme, yet the discretized movements fail to fully utilize spatial DoFs. Hence, in practical applications, we can strike a balance between fully exploiting spatial DoFs and mitigating the sensitivity to imperfect FRIs based on the SINR conditions. Specifically, in high SINR scenarios, the system does not need to rely heavily on MA movement to achieve higher spatial diversity gains, as the communication requirements can be easily met. Therefore, a discrete antenna positioning strategy [16] can be adopted to enhance robustness against imperfect FRIs. Conversely, in low SINR scenarios, continuous MA movement is required to fully exploit the spatial DoFs and ensure reliable communications. In such cases, efficient FRI estimation techniques [24, 25] are essential to minimize system performance losses.
V Conclusion
In this paper, we proposed a new paradigm for secure FD multi-user systems, where an FD BS equipped with MAs simultaneously serves multiple UL and DL users while protecting their private information against multiple cooperative Eves. We formulated an optimization problem to maximize the SSR by jointly optimizing the MA positions, the transmit, receive, and AN beamformers at the BS, and the UL powers. To tackle this non-convex problem, an AO algorithm was proposed to decompose the original problem into three sub-problems and iteratively solve them. Specifically, the MA positions are updated by the proposed MVPSO, which applies multiple candidate velocities instead of the single velocity used in the standard PSO algorithm to determine the superior MA positions. Additionally, the SSR is reformulated as a difference-of-concave function to optimize the transmit/AN beamformers and the UL powers via the SCA algorithm. Moreover, the optimal receive beamformer is derived as a closed-form solution. Simulation results revealed the effectiveness of the proposed MVPSO in determining the MA positions compared to the standard PSO and other state-of-the-art antenna position optimization algorithms. Besides, the results showed that the additional DoFs in antenna movement provided by MAs benefit the enhancement of signal power, the mitigation of various interferences, and the flexibility of multi-beamforming in the proposed system, thereby leading to excellent security performance. In addition, the results demonstrated that the AN transmitted by the FD BS can protect both UL and DL users simultaneously, a capability that cannot be achieved with an HD BS. Furthermore, we evaluated the impact of the discrepancies between the estimated and actual FRIs on system performance, which provides valuable references for the applications of the proposed scheme in practice.
References
- [1] J. Ding, Z. Zhou, C. Wang, W. Li, L. Lin, and B. Jiao, “Secure full-duplex communication via movable antennas,” arXiv preprint arXiv:2403.20025, 2024.
- [2] J. M. Hamamreh, H. M. Furqan, and H. Arslan, “Classifications and applications of physical layer security techniques for confidentiality: a comprehensive survey,” IEEE Commun. Surv. Tutor., vol. 21, no. 2, pp. 1773-1828, Oct. 2018.
- [3] W. Stallings, Cryptography and Network Security: Principles and Practice. New York, NY, USA: Prentice Hall Press, 2010.
- [4] A. Mukherjee, S. A. A. Fakoorian, J. Huang, and A. L. Swindlehurst, “Principles of physical layer security in multiuser wireless networks: a survey,” IEEE Commun. Surv. Tutor., vol. 16, no. 3, pp. 1550-1573, Feb. 2014.
- [5] Y. Wu, A. Khisti, C. Xiao, G. Caire, K. -K. Wong, and X. Gao, “A survey of physical layer security techniques for 5G wireless networks and challenges ahead,” IEEE J. Sel. Areas Commun., vol. 36, no. 4, pp. 679-695, Apr. 2018.
- [6] X. Chen, D. W. K. Ng, W. H. Gerstacker, and H. -H. Chen, “A survey on multiple-antenna techniques for physical layer security,” IEEE Commun. Surv. Tutor., vol. 19, no. 2, pp. 1027-1053, Nov. 2016.
- [7] R. Feng, Q. Li, Q. Zhang, and J. Qin, “Robust secure beamforming in MISO full-duplex two-way secure communications,” IEEE Trans. Veh. Technol., vol. 65, no. 1, pp. 408-414, Jan. 2016.
- [8] Z. Lin, M. Lin, B. Champagne, W. -P. Zhu, and N. Al-Dhahir, “Secrecy-energy efficient hybrid beamforming for satellite-terrestrial integrated networks,” IEEE Trans. Commun., vol. 69, no. 9, pp. 6345-6360, Sep. 2021.
- [9] M. Cui, G. Zhang, and R. Zhang, “Secure wireless communication via intelligent reflecting surface,” IEEE Wireless Commun. Lett., vol. 8, no. 5, pp. 1410-1414, Oct. 2019.
- [10] L. Zhu, W. Ma, and R. Zhang, ”Modeling and performance analysis for movable antenna enabled wireless communications,” IEEE Trans. Wireless Commun., vol. 23, no. 6, pp. 6234-6250, Jun. 2024.
- [11] L. Zhu, W. Ma, and R. Zhang, “Movable antennas for wireless communication: opportunities and challenges,” IEEE Commun. Mag., vol. 62, no. 6, pp. 114-120, Jun. 2024.
- [12] S. Sanayei and A. Nosratinia, “Antenna selection in MIMO systems,” IEEE Commun. Mag., vol. 42, no. 10, pp. 68-73, Oct. 2004.
- [13] W. Ma, L. Zhu, and R. Zhang, “MIMO capacity characterization for movable antenna systems,” IEEE Trans. Wireless Commun., vol. 23, no. 4, pp. 3392-3407, Apr. 2024.
- [14] Z. Xiao, X. Pi, L. Zhu, X. Xia, and R. Zhang, “Multiuser communications with movable-antenna base station: joint antenna positioning, receive combining, and power control,” arXiv preprint arXiv:2308.09512, 2023.
- [15] L. Zhu, W. Ma, B. Ning, and R. Zhang, “Movable-antenna enhanced multiuser communication via antenna position optimization,” IEEE Trans. Wireless Commun., vol. 23, no. 7, pp. 7214-7229, Jul. 2024.
- [16] Y. Wu, D. Xu, D. W. K. Ng, W. Gerstacker, and R. Schober, “Movable antenna-enhanced multiuser communication: jointly optimal discrete antenna positioning and beamforming,” in Proc. IEEE Globecom, Kuala Lumpur, Malaysia, 2023, pp. 7508-7513.
- [17] L. Zhu, W. Ma, and R. Zhang, “Movable-antenna array enhanced beamforming: achieving full array gain with null steering,” IEEE Commun. Lett., vol. 27, no. 12, pp. 3340-3344, Dec. 2023.
- [18] W. Ma, L. Zhu, and R. Zhang, “Multi-beam forming with movable-antenna array,” IEEE Commun. Lett., vol. 28, no. 3, pp. 697-701, Mar. 2024.
- [19] G. Hu, Q. Wu, K. Xu, J. Si, and N. Al-Dhahir, “Secure wireless communication via movable-antenna array,” IEEE Signal Process. Lett.,vol. 31, pp. 516–520, Feb. 2024.
- [20] Z. Cheng, N. Li, J. Zhu, X. She, C. Ouyang, and P. Chen, “Enabling secure wireless communications via movable antennas,” in Proc. ICASSP, Seoul, Korea, Apr. 2024, pp.14-19.
- [21] J. Tang, C. Pan, Y. Zhang, H. Ren, and K. Wang, “Secure MIMO communication relying on movable antennas,” IEEE Trans. Wireless Commun., Sep. 20, 2024, early access, DOI: 10.1109/TCOMM.2024.3465369.
- [22] Z. Feng, Y. Zhao, K. Yu, and D. Li, “Movable antenna empowered physical layer security without eve’s CSI: joint optimization of beamforming and antenna positions,” arXiv preprint arXiv:2405.16062, 2024.
- [23] G. Hu, Q. Wu, D. Xu, K. Xu, J. Si, Y. Cai, and N. Al-Dhahir, “Movable antennas-assisted secure transmission without eavesdroppers’ instantaneous CSI,” IEEE. Trans. Mob. Comput., Aug. 6, 2024, early access, DOI: 10.1109/TMC.2024.3438795.
- [24] W. Ma, L. Zhu, and R. Zhang, “Compressed sensing based channel estimation for movable antenna communications,” IEEE Commun. Lett.,vol. 27, no. 10, pp. 2747-2751, Oct. 2023.
- [25] Z. Xiao, S. Cao, L. Zhu, Y. Liu, B. Ning, X. Xia, and R. Zhang, “Channel estimation for movable antenna communication systems: a framework based on compressed sensing,” IEEE Trans. Wireless Commun., vol. 23, no. 9, pp. 11814-11830, Sep. 2024.
- [26] X. Guan, Q. Wu, and R. Zhang, “Intelligent reflecting surface assisted secrecy communication: is artificial noise helpful or not?,” IEEE Wireless Commun. Lett., vol. 9, no. 6, pp. 778-782, Jun. 2020.
- [27] L. Lin, D. Zheng, J. Ding, B. Jiao, and H. V. Poor, “Lightweight digital self-interference cancellation,” in Proc. IEEE/CIC ICCC, Hangzhou, China, Sep. 2024, pp. 2095-2100.
- [28] Y. Sun, D. W. K. Ng, and R. Schober, “Resource allocation for secure full-duplex radio systems,” in Proc. WSA, Berlin, Germany, Mar. 2017, pp. 1-6.
- [29] F. Zhu, F. Gao, T. Zhang, K. Sun, and M. Yao, “Physical-layer security for full duplex communications with self-interference mitigation,” IEEE Trans. Wireless Commun., vol. 15, no. 1, pp. 329-340, Jan. 2016.
- [30] Y. Sun, D. W. K. Ng, J. Zhu, and R. Schober, “Multi-objective optimization for robust power efficient and secure full-duplex wireless communication systems,” IEEE Trans. Wireless Commun., vol. 15, no. 8, pp. 5511-5526, Aug. 2016.
- [31] L. Lin, J. Ding, Z. Zhou, and B. Jiao, “Power-efficient full-duplex satellite communications aided by movable antennas,” arXiv preprint arXiv:2409.06502, 2024.
- [32] J. Ding, Z. Zhou, W. Li, C. Wang, L. Lin, and B. Jiao, “Movable antenna enabled co-frequency co-time full-duplex wireless communication,” IEEE Commun. Lett., vol. 28, no. 10, pp. 2412-2416, Oct. 2024.
- [33] N. Lynn and P. N. Suganthan, “Heterogeneous comprehensive learning particle swarm optimization with enhanced exploration and exploitation,” Swarm Evol. Comput., vol. 24, pp. 11-24, Aug. 2015.
- [34] D. Xu, X. Yu, Y. Sun, D. W. K. Ng, and R. Schober, “Resource allocation for IRS-assisted full-duplex cognitive radio systems,” IEEE Trans. Commun., vol. 68, no. 12, pp. 7376-7394, Dec. 2020.
- [35] A. Mohammadian, C. Tellambura and G. Y. Li, “Deep learning LMMSE joint channel, PN, and IQ imbalance estimator for multicarrier MIMO full-duplex systems,” IEEE Wireless Commun. Lett., vol. 11, no. 1, pp. 111-115, Jan. 2022.