Moving Beyond LDA: A Comparison of Unsupervised Topic Modelling Techniques for Qualitative Data Analysis of Online Communities
Abstract.
Social media constitutes a rich and influential source of information for qualitative researchers. Although computational techniques like topic modelling assist with managing the volume and diversity of social media content, qualitative researcher’s lack of programming expertise creates a significant barrier to their adoption. In this paper we explore how BERTopic, an advanced Large Language Model (LLM)-based topic modelling technique, can support qualitative data analysis of social media. We conducted interviews and hands-on evaluations in which qualitative researchers compared topics from three modelling techniques: LDA, NMF, and BERTopic. BERTopic was favoured by 8 of 12 participants for its ability to provide detailed, coherent clusters for deeper understanding and actionable insights. Participants also prioritised topic relevance, logical organisation, and the capacity to reveal unexpected relationships within the data. Our findings underscore the potential of LLM-based techniques for supporting qualitative analysis.
1. Introduction
For qualitative researchers, social media serves as a rich and influential source of information (Andreotta et al., 2019). Reddit, in particular, has emerged as a crucial platform for gathering diverse and localized content; offering opinions, advice, and recommendations from trusted sources (Ryan et al., 2017; Ahn and Shin, 2013; Allen et al., 2014). This geographically specific and up-to-date information is invaluable for aiding research, synthesis, and presentation of data (Dugan et al., 2008; Skeels and Grudin, 2009; Steinfield et al., 2009; Morris et al., 2010). Researchers leverage social media to uncover nuanced insights in fields such as mental health, politics, consumer behavior, health and fitness, technology, gaming, education, and social movements (Andreotta et al., 2019; Ahn and Shin, 2013; Kapoor et al., 2018). For instance, public health researchers use Reddit to study health-related topics and understand community perspectives and communication norms, which aids in developing more effective interventions and policies (Eysenbach, 2005; Heldman et al., 2013; Gauthier et al., 2022; Rotolo et al., 2022; Gauthier et al., 2023).
Despite the availability of social media data, the sheer volume, diversity, noise, dynamic nature, and contextual nuances of this data present significant challenges (Andreotta et al., 2019). Computational techniques like topic modelling are thus necessary to effectively analyze this extensive content (Rana et al., 2016). However, traditional topic modelling methods like Latent Dirichlet Allocation (LDA), Biterm Topic Model (BTM), and Non-Negative Matrix Factorization (NMF) often fail to capture nuanced meanings and contextual usage and require extensive data cleaning and pre-processing, making them labor-intensive (Yan et al., 2013; Mazarura and De Waal, 2016; Zou and Song, 2016). In contrast, Large Language Model (LLM) based techniques like BERTopic, Top2Vec and GPT-3 offer substantial improvements. They provide advanced understanding of text with minimal pre-processing, adapting efficiently to various contexts (Brown et al., 2020; Devlin et al., 2019; Vaswani et al., 2017).
Further, qualitative researchers face significant challenges when integrating computational techniques like topic modelling into their qualitative workflows due to a lack of programming expertise (Lochmiller, 2021; Baden et al., 2022). They also have concerns about losing control over the nuanced aspects of their research and doubts about the accuracy of computer-generated insights (Abram et al., 2020; Jiang et al., 2021; Feuston and Brubaker, 2021). Ethical and privacy concerns further contribute to this reluctance (Siiman et al., 2023).
Nevertheless, AI tools can significantly aid in analyzing large volumes of social media data. These tools efficiently process and analyze data, identifying trends, sentiments, and patterns that would be challenging to uncover manually (Batrinca and Treleaven, 2015). Researchers could utilize AI’s capability for deep data analysis, providing a comprehensive understanding of social media interactions (Fan and Gordon, 2014). In particular, topic modelling is increasingly being integrated into qualitative research to manage and interpret large datasets, offering deeper and more objective insights (Gillies et al., 2022).
Our research is motivated by the desire to assist qualitative researchers who often face challenges with manual, time-consuming, and potentially biased data analysis methods due to limited programming skills. Recognizing these challenges, we aim to explore the potential of Large Language Models (LLMs) for unsupervised topic modelling, offering a more efficient and objective approach to data analysis. By understanding how qualitative researchers currently use topic modelling and identifying the specific difficulties they encounter, we can develop better tools to support their work.
We integrated BERTopic into the Computational Thematic Analysis (CTA) toolkit (Gauthier and Wallace, 2022). Integrating BERTopic into the CTA Toolkit required architectural changes to accommodate the model’s advanced requirements which uses word embeddings as compared to the original bag of words methodology, and leverages transformer-based processing. This included incorporating GPU utilization to meet BERTopic’s high computational demands and ensuring efficient processing of large datasets. Additionally, changes to the data filtering methods were necessary to ensure improved data processing and data integrity.
We then conducted interviews with qualitative researchers to discuss the challenges they face with existing topic modelling tools. Following these discussions, researchers engaged with the CTA toolkit, applying it to their own datasets and models to identify their preferred options. This hands-on exploration allowed them to evaluate the tools in the context of their specific needs. The choices and reasons for their preferences were then collaboratively analyzed, ensuring that the selected topic modelling techniques aligned well with the researchers’ needs and preferences.
Participants prioritized topic relevance, logical organization, and the capacity to reveal unexpected yet significant relationships within the data when evaluating topic modelling techniques. They desired detailed, coherent clusters that clearly separated and grouped significant topics, which facilitated deeper understanding and actionable insights, which were provided by BERTopic. Despite some visualization shortcomings, they valued BERTopic’s ability to uncover hidden connections, emphasizing the need for meaningful, comprehensive analysis tools that support their research objectives and enhance data interpretation. BERTopic was ranked first by 8 out of 12 participants (67%), LDA by 3 out of 12 participants (25%), and NMF by 1 out of 12 participants (8%).
In summary, we make three contributions:
-
(1)
We integrated BERTopic into the Computational Thematic Analysis Toolkit.
-
(2)
We conducted interviews with qualitative researchers to discuss the challenges they face when using topic modelling tools to analyse social media data.
-
(3)
We discuss the findings on researchers’ priorities in topic modelling techniques.
2. Related Work
The HCI community is increasingly exploring the use of social media to gain insights into human behavior (Gauthier, 2020; Gauthier et al., 2023; Andalibi et al., 2016; Ammari et al., 2018). Topic modelling in particular has been used to support social media analysis by identifying underlying themes and patterns within large datasets, allowing researchers to categorize and summarize vast amounts of unstructured text data efficiently (Jacobi et al., 2018; Curiskis et al., 2020). This facilitates the detection of trends, sentiment analysis, and the extraction of meaningful insights from complex and diverse social media content. Topic modelling has been applied across numerous fields – studies such as those by Jacobi et al. (2018) in journalism, Gauthier (2020); Gauthier et al. (2023); Rotolo et al. (2022); Eysenbach (2005); Han et al. (2021) in public health, Haghighi et al. (2018) in urban planning, Bail et al. (2018) in political science, and Pousti et al. (2021) in information systems illustrate the broad applicability and value of topic modelling in leveraging social media data platforms for research.
One such platform is Reddit, which facilitates extensive online interactions through user-generated communities called subreddits, covering diverse topics (Kumar et al., 2022; Rocha-Silva et al., 2023). Its structure, allowing long comments and user anonymity, encourages open and honest discussions (Alsinet et al., 2021; Ammari et al., 2018). Researchers utilize Reddit’s public data for qualitative and quantitative studies, benefiting from its organized subreddit format that simplifies data collection. This makes Reddit a valuable tool for examining online community interactions and behavior, providing rich datasets and insights into various aspects of online communication (Proferes et al., 2021).
Many studies demonstrate social media’s significant potential for mental health support and community engagement (De Choudhury and De, 2014; Rubya and Yarosh, 2017; Pretorius et al., 2020; Haimson et al., 2015; Wallace et al., 2017). They explore topics like mental health discussions on Reddit, video-mediated peer support, digital interventions, gender transition support, and support for older adults. Gauthier (2020) investigates online sobriety communities, while Arif et al. (2018) and Tsou et al. (2015) highlight social media analytics in crisis management and information operations. These studies collectively underscore social media’s diverse impact, emphasizing the importance of advanced topic modelling for deeper insights.
However, the vast and varied nature of social media data presents significant challenges for qualitative researchers (Stieglitz et al., 2020). Many qualitative researchers lack programming or data science expertise, making the adoption of advanced topic modelling tools particularly challenging. While they find machine learning techniques both empowering and exciting, appreciating the novel insights these tools can provide, they also harbor reservations about the trustworthiness of machine-generated results and the potential for missing nuanced content. Studies such as those by Lochmiller (2021) and Baden et al. (2022) highlight the dual perspectives of excitement and skepticism researchers feel towards integrating computational methods into their workflows. Additionally, research by Burgess and Bruns (2012), Lewis et al. (2013), and DiMaggio et al. (2013) underscores the critical need for intuitive, reliable, and ethically sound computational tools. These tools must address the complexities of social media, bridge the gap for researchers without technical expertise, and respect the methodological foundations of qualitative research.
Traditional topic modelling methods such as LDA (Blei et al., 2003), Biterm (Yan et al., 2013), NMF (Lee and Seung, 1999) often fall short in capturing the nuanced meanings and contextual usage of words, necessitating extensive data cleaning and pre-processing, which makes them labor-intensive (Xu et al., 2015; Hong and Davison, 2010; Yan et al., 2013; Mazarura and De Waal, 2016; Zou and Song, 2016). These methods rely on predefined topic numbers and treat words independently, leading to the loss of important contextual information and challenges with short texts like tweets or Reddit comments. Additionally, their effectiveness can be highly sensitive to hyperparameter settings, and they often require substantial computational resources. Conversely, Large Language Model (LLM) based techniques, such as BERTopic (Grootendorst, 2022), Top2Vec (Angelov, 2020) and GPT-3 (Brown et al., 2020), offer significant improvements. These models provide a more advanced understanding of text with minimal pre-processing and adapt efficiently to various contexts (Devlin et al., 2018; Brown et al., 2020). LLMs are leading in topic modelling due to their user-friendliness and advanced capabilities (Mu et al., 2024). Recent research highlights their effectiveness in zero-shot text summarization, achieving near-human performance, suggesting their potential for generating insightful topics (Zhang et al., 2024).
3. Topic Modelling Techniques
3.1. Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is extensively used in the literature due to its robustness and flexibility in identifying hidden thematic structures within large text corpora (e.g., Jelodar et al. (2019); Cohen et al. (2014); Zhang et al. (2017); Zhao et al. (2011)). Since its introduction by Blei et al. (2003), LDA has become one of the most popular topic modelling techniques in natural language processing and has been applied in diverse fields such as social media analysis, scientific research, and business intelligence.
LDA has been widely used to analyze Reddit data, demonstrating its effectiveness across various research areas. It has been applied to study sentiment and public opinion on topics like the Russo-Ukrainian conflict and COVID-19 vaccines (Guerra and Karakuş, 2023; Melton et al., 2021), as well as health discussions on cystic fibrosis, depression, and the pandemic’s social impacts (Karas et al., 2022; Tadesse et al., 2019). LDA also aids in monitoring public response during crises, such as the COVID-19 pandemic and Jakarta floods (Ma and Kim, 2023; Rahmadan et al., 2020), and exploring niche issues like gender-affirming voice interventions (Mandava et al., 2023). Furthermore, it has been used for analyzing suicidal drivers, vaccine sentiment, and other health-related topics on social media (Donnelly, 2023; Melton et al., 2021; Khan and Ali, 2023).
However, LDA’s performance is constrained by several inherent limitations. It relies on a “bag of words” approach, ignoring the order and structure of words in documents, which can dilute the semantic integrity of the topics generated (Cordeiro, 2012). Furthermore, LDA has been criticized for its inefficiency in handling short texts, common in social media and other contemporary datasets. This inefficiency often leads to less coherent and more general topics, failing to capture the detailed nuances necessary for high-quality insights (Bi et al., 2018). Literature supports these observations, noting LDA’s limitations in topic diversity (Egger and Yu, 2022), coherence, and granularity (Newman et al., 2010; Chang et al., 2009).
3.2. Non-Negative Matrix Factorization (NMF)
Non-negative Matrix Factorization (NMF) is a technique in multivariate analysis and linear algebra where a matrix is factorized into two matrices with non-negative elements, revealing latent structures in the data. Introduced by Paatero and Tapper (1994), NMF gained significant attention after Lee and Seung (1999) research article, which demonstrated its application in learning parts of objects and face recognition. Lee and Seung (1999) highlight that NMF is particularly effective at clustering data into distinct, easily interpretable groups, supporting its utility for thematic analysis.
For topic modelling and short-text analysis in Reddit, NMF effectively decomposes text data into meaningful topics using term-document matrices (Egger and Yu, 2022; Albalawi et al., 2020). It handles emotion and sentiment analysis well, comparing favorably with traditional LDA methods, and is used to detect and analyze communities by integrating sentiment analysis (Curiskis et al., 2020). In semantic and social analysis, NMF models user participation and content data effectively and extends to analyze multiplex networks, integrating information from multiple Reddit communities (Wu et al., 2008). NMF is also used in climate change discussions on Reddit, effectively handling the diverse and dynamic nature of social media posts to extract meaningful insights (Parsa et al., 2022). Additionally, NMF has been applied to mental health analysis, identifying latent structures in text data to understand issues like depression, stress, and suicide risk on social media platforms (Garg, 2023).
3.3. BERTopic
BERTopic, introduced by Maarten Grootendorst (Grootendorst, 2022), is a state-of-the-art topic modelling technique that leverages transformers and class-based term frequency-inverse document frequency (c-TF-IDF) to create dense embeddings and hierarchical topic representations. This integration allows for more nuanced and contextually aware topic modelling, which is particularly beneficial for analyzing complex and large-scale datasets (Reimers and Gurevych, 2019). This method benefits from BERT’s advanced capabilities in capturing contextual information through deep bidirectional transformers, providing more accurate and nuanced topic modelling compared to traditional models like LDA and NMF (Devlin et al., 2019). The foundational advancements of the Transformer model (Vaswani et al., 2017) further enhance BERTopic’s effectiveness in providing refined and contextually aware topic modelling.
The implementation leverages advanced techniques in natural language processing and machine learning, including the Sentence-BERT model, UMAP for dimensionality reduction, HDBSCAN for clustering, and cTF-IDF for topic extraction. The token sets are prepared by converting them into a text format suitable for the BERTopic model, and then generating dense vector embeddings.
4. Summary
LDA and NMF are widely used for topic modelling in social media data analysis, but they have several limitations. LDA assumes a known number of topics and that words are generated independently given the topic, which can lead to loss of context and struggles with short texts like tweets or Reddit comments (Blei et al., 2003; O’Callaghan et al., 2015). Additionally, LDA’s performance is sensitive to hyperparameters and requires substantial computational resources (Wallach et al., 2009). NMF, while useful for producing sparse, interpretable results, is sensitive to matrix initialization and requires careful tuning, and it does not inherently capture probabilistic topic distributions (Lee and Seung, 1999, 2001). Studies show mixed results for these methods on social media data, highlighting the need for better algorithms to gain more accurate and insightful analyses (O’Callaghan et al., 2015).
Comparative studies, such as those by Egger and Yu (2022) demonstrated that BERTopic outperforms LDA, NMF, and Top2Vec in capturing semantic nuances and contextual information particularly on Twitter. Consequently, we incorporated BERTopic into our study to validate its effectiveness in enhancing our ability to extract nuanced insights and understand the complexities of social media data, specifically on Reddit. This approach is particularly beneficial for qualitative researchers from a Human-Computer Interaction (HCI) perspective, as it addresses the need for more intuitive and contextually rich analysis tools.
5. The Computational Thematic Analysis Toolkit
The Computational Thematic Analysis (CTA) Toolkit, developed by Gauthier and Wallace (2022), integrates qualitative thematic analysis and computational methods. We chose the CTA Toolkit as our experimental platform because its functionality aligned well with our research requirements; it provides a visual interface for qualitative analysis of social media data using computational techniques like topic modelling. We extended the toolkit by adding BERTopic as a topic modelling option, which allowed us to directly compare it to LDA and NMF under a single interface. We now provide a brief overview of the CTA toolkit’s key features for data collection, data cleaning and filtering, and modelling before describing how we integrated BERTopic.
The data collection module automates the retrieval and organization of data from online platforms like Twitter and Reddit. Researchers import data by defining parameters such as time periods and specific communities. The toolkit groups submissions and their corresponding comments into cohesive discussions, ensuring that the data is organized and ready for subsequent analysis. To address the ethical complexities inherent in online data collection, the toolkit prompts researchers to consider the ethical implications of their work before data is imported for analysis. These prompts guide researchers through considerations such as community consent and the handling of deleted posts.
The data cleaning and filtering module then employs natural language processing (NLP) tools, including NLTK and spaCy, to tokenize, stem, and lemmatize the text as it is imported. It also tags parts of speech and identifies stop words, facilitating a detailed and precise cleaning process. The toolkit enhances transparency by displaying a summary of the tokens and filtering rules applied, allowing researchers to see the impact of these steps on their data. This feature is essential for maintaining the integrity and reproducibility of the research.
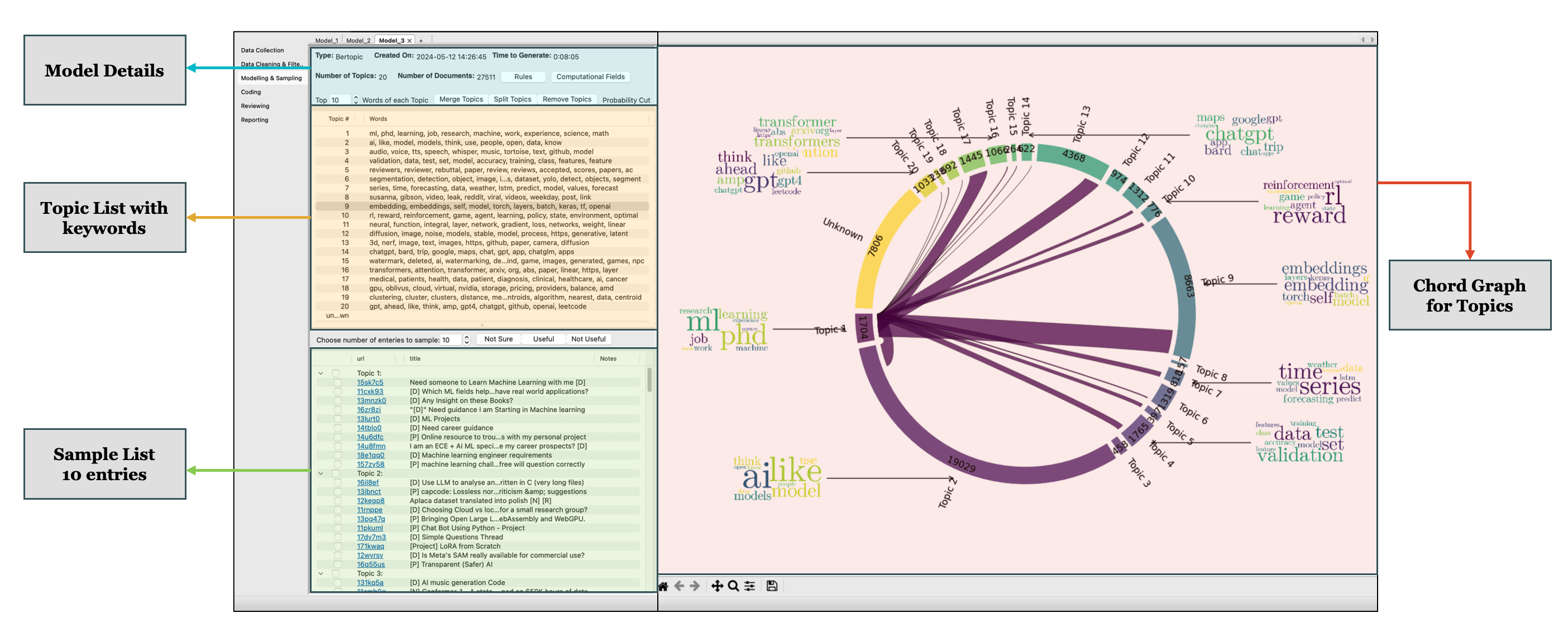
The modeling and sampling module (Figure 1) allows researchers to interactively select and review data models, ensuring that the most relevant and representative data is used in the thematic analysis. This interactive approach supports the iterative nature of qualitative research, allowing researchers to refine their models based on emerging insights. To identify latent patterns within large datasets the CTA toolkit uses unsupervised topic modeling techniques — LDA (Blei et al., 2003), biterm (Yan et al., 2013), NMF (Lee and Seung, 1999). The toolkit’s visual interface includes a chord diagram visualization of generated topic models. The outer ring represents the different topics identified in the dataset. Each segment is labeled with a topic number (e.g., Topic 1, Topic 2, etc.). Alongside each topic label, there are word clouds showing the most relevant terms for each topic. The inner lines connecting different segments represent the number of overlapping documents between topics. Thicker lines imply more shared documents between the connected topics.
We integrated BERTopic within the CTA Toolkit’s pipeline. This work posed several challenges, primarily due to the inherent differences between BERTopic’s LLM-based processing requirements and the existing bag-of-words architecture. Additionally, BERTopic’s reliance on transformer models demands higher computational resources, including increased memory and processing power. For BERTopic, we leveraged the device’s built-in GPU to enhance processing efficiency. Moreover, the toolkit included filters and preprocessing steps tailored for bag-of-words models, which were not suitable for BERTopic’s needs. The preprocessing step involved default filters which eliminate terms with TF-IDF values less than 75%. This approach aimed to retain only the most significant terms; however, it led to the loss of almost 80% of the data, which proved to be detrimental to the analysis. Therefore, we decided to eliminate this filtering step for BERTopic to preserve the integrity and comprehensiveness of the data.
6. Interviews with Qualitative Researchers
To understand the specific needs and challenges faced by qualitative researchers, we conducted a series of interviews with experts. We conducted interviews to identify researchers’ requirements and gather insights into their experiences with traditional topic modelling techniques, including manual coding methods, or using proprietary software, and their impressions of modern unsupervised topic modelling techniques like BERTopic.
We interviewed 12 participants, each an expert in qualitative research with distinct interests and varying levels of experience in their respective fields. We asked each participant to identify a subreddit of interest, downloaded the archived data, and loaded it into the Computational Thematic Analysis Toolkit. The datasets spanned a wide range of domains, including gaming, technology, COVID-19, health, environment, and politics.
We then asked participants to reflect on their data set through three unsupervised topic models: LDA, NMF, and BERTopic. The three topic modelling techniques were selected to reflect different conceptual approaches. LDA is a probabilistic approach which is widely used in the literature (e.g. (Grimmer, 2010; Hoffman et al., 2010; Teh et al., 2006)). NMF offers computational efficiency and a matrix-based perspective that is fast and effective for large datasets (Wu et al., 2008). BERTopic leverages cutting-edge capabilities of language models to provide deep, contextually rich topic modelling (Grootendorst, 2022). We asked participants to examine their data to help explain how the topic models might be useful.
This study has undergone a thorough review process and received ethics clearance from our Research Ethics Board (REB #46062) from University. The review process involved a detailed examination of the study’s methodology, participant recruitment procedures, data collection methods, and potential risks to ensure compliance with ethical standards.
6.0.1. Participants
Participants were selected through purposive sampling to ensure that they had relevant experience and expertise in the fields under investigation. The selection criteria included a minimum level of experience in qualitative research and active involvement conducting content analysis in their work. The demographic composition of the participants included a balanced representation of gender, age, and occupational backgrounds. This diversity ensured that the study captured a wide range of perspectives and insights, enhancing the richness and depth of the analysis.
Participants were recruited through direct invitations sent via email, leveraging professional networks and academic contacts. This recruitment method ensured that the participants were highly motivated and well-qualified to contribute to the study. Their diverse backgrounds and research interests provided a comprehensive understanding of the various topics discussed on the selected subreddits. Table 1 summarizes participant information, detailing the subreddit they analyzed, their research area and years of experience.
| Reddit Dataset | PID | Research Area | Years Experience |
|---|---|---|---|
| r/disabledgamers | P1 | Accessibility/disability research | 10 years |
| r/MachineLearning | P2 | eXplainable AI in LLMs | 3 years |
| r/HermanCainAward | P3 | Sentimental analysis on social media | 3 years |
| r/cybersecurity | P4 | Cyber security and privacy risk in social robot | 6 months |
| r/emergencymedicine | P5 | Health policy and emergency care | 12 years |
| r/SustainableFashion | P6 | Fashion and sustainability management | 10 years |
| r/LanguageTechnology | P7 | Large Language Models for GenAI | 8 years |
| r/nutrition | P8 | Nutrition and Diet quality | 2 years |
| r/uwaterloo | P9 | Machine Learning | 4 years |
| r/Coronavirus | P10 | Covid 19 vaccine hesitancy | 2 years |
| r/bipolar | P11 | Care quality for bipolar disorder | 6 years |
| r/CoronavirusCanada | P12 | STEM and medicine | 5 years |
6.0.2. Procedure
We directly emailed researchers to explain the study’s aims and invite their participation. Upon indicating their interest in participation, we identified an appropriate subreddit for analysis based on their research interests, obtained signed consent letters, and scheduled a mutually convenient date and time for the interview, which could be conducted either online or in-person meeting.
On the day of the study, we initiated the session with a presentation of approximately five minutes. This presentation provided a comprehensive overview of the project, outlining its objectives and the significance of the research. We also addressed any questions or clarifications raised by the participants, ensuring they had a thorough understanding of the study’s context.
6.0.3. Background Interview
In the background interview phase, we aimed to gather comprehensive information about the participants’ research background and their application of content analysis techniques. The interview commenced with questions about their main area of research and expertise, as well as the duration of their involvement in their respective fields. We then explored the relevance of content analysis in their research by inquiring where and how they utilize these techniques, supplemented by requests for specific use cases. The discussion progressed to understanding the types of data typically used for content analysis, including the nature and sources of these data—whether public, private, or institutional. Participants were asked to detail the methods and tools they currently employ for content analysis, including any specific software or libraries. This was followed by a focus on the challenges they encounter with existing tools and their suggestions for improvements. To conclude this phase, we sought their insights on the potential benefits of integrating modern technologies such as AI, Large Language Models (LLMs), and Machine Learning into their research practices.
Following this preliminary discussion, we proceeded to demonstrate the CTA toolkit. Initially, we presented statistical information pertinent to the selected subreddit and outlined the specific tasks the participants would undertake. We then demonstrated the key features of the toolkit, describing how it integrates various topic modelling techniques, including BERTopic, LDA, and NMF. Participants were then provided access to the software, with a 10-20 minute period allocated for them to explore its functionalities. During this time, they examined the three models in depth, comparing the topics generated by each.
6.0.4. Interview on Topic Models
In Interview on Topic Models phase, conducted after participants had experimented with the CTA toolkit, we focused on gathering their detailed feedback on its efficacy and relevance to their work. Initially, we asked participants to use the Microsoft Desirability Toolkit to select words that best described our method, with specific focus areas for the overall visualization experience, LDA, NMF, and BERTopic models. Participants were then requested to rank the three models (LDA, NMF, BERTopic) based on their usefulness, explaining the factors influencing their rankings. We sought comparisons between our proposed method and existing tools that the participants had previously used, asking them to highlight specific features they liked or disliked and to suggest areas for improvement.
Additionally, we investigated the relevance of the three models to their research, asking which model suited their work the best and why. We explored the potential integration of our methodology into their work, including any anticipated challenges. Finally, participants were asked to rate the likelihood of incorporating our model into their working pipeline on a scale of 1-10 and to share any additional insights about the proposed methodology and the interview process. This phase aimed to comprehensively understand the practical utility and potential improvements for our approach based on direct user feedback.
6.1. Equipment
Model training was conducted on a MacBook Air with an Apple M1 chip, featuring an 8-core CPU (4 performance and 4 efficiency cores), a 7-core GPU, and 16GB of RAM for efficient processing of large datasets and complex computations. The setup also included a Philip’s 4K Ultra HD LCD monitor (28” inch) to facilitate detailed visualization of results and model performance.
6.2. Participant Data Sets
We gathered data from 12 subreddits covering six broad topics: gaming, technology, COVID-19, health, and the environment (Table 2). The data from PushShift.io (Baumgartner et al., 2020) was decompressed from the .zst (Zstandard) file format to .json format and organized into a structured month-year format for ease of access and analysis. Processing times varied based on dataset size, ranging from approximately 10 minutes to 2 hours.
During these discussions, we consulted with the participants to determine if they had specific dates or years in mind for analysis. If they did, we collected data for that specified duration. Otherwise, we utilized the entire dataset available on the subreddit.
| Subreddit | ID | Number of Documents | Start Date | End Date | Description | Rank by Size * |
|---|---|---|---|---|---|---|
| r/disabledgamers | P1 | 4,403 | 01/01/2015 | 31/12/2023 | A community for gamers with disabilities to discuss accessibility options, adaptive controls, and gaming experiences. | Top 7% |
| r/MachineLearning | P2 | 27,506 | 01/01/2023 | 31/12/2023 | A vibrant community dedicated to discussions on machine learning, AI, and data science. | Top 1% |
| r/HermanCainAward | P3 | 35,013 | 01/09/2021 | 31/12/2023 | A subreddit documenting and discussing cases of COVID-19 skepticism and its consequences. | Top 1% |
| r/cybersecurity | P4 | 26,692 | 01/01/2023 | 31/12/2023 | A resource for cybersecurity topics including threat analysis, security breaches, and industry best practices. | Top 1% |
| r/emergencymedicine | P5 | 14,117 | 01/04/2012 | 31/12/2023 | A community focused on discussions about emergency medical care, including case studies and clinical guidelines. | Top 10% |
| r/SustainableFashion | P6 | 5,845 | 01/05/2017 | 31/12/2023 | A platform for discussing sustainable fashion practices, upcycling, and eco-friendly brands. | Top 3% |
| r/LanguageTechnology | P7 | 13,420 | 01/10/2011 | 31/12/2023 | A subreddit focusing on advancements in NLP, computational linguistics, and language-based AI. | Top 3% |
| r/nutrition | P8 | 14,313 | 01/01/2023 | 31/12/2023 | A community discussing various topics related to nutrition, diet plans, and health outcomes. | Top 1% |
| r/uwaterloo | P9 | 15,793 | 01/01/2023 | 31/12/2023 | A community for discussions related to academic life, programs, and events at the University of Waterloo. | Top 10% |
| r/Coronavirus | P10 | 23,906 | 01/11/2020 | 01/02/2021 | A large community dedicated to global news, scientific research, and public health guidelines related to COVID-19. | Top 1% |
| r/bipolar | P11 | 24,512 | 01/06/2023 | 31/12/2023 | A supportive community for individuals affected by bipolar disorder, offering personal experiences and coping strategies. | Top 5% |
| r/CoronavirusCanada | P12 | 26,862 | 01/03/2020 | 31/12/2023 | A subreddit focusing on COVID-19 discussions within Canada, including local news and government policies. | Top 5% |
7. Topic Modelling
We used a standard procedure to create models for each subreddit, following the same protocol for LDA, NMF, and BERTopic. This process involved performing tokenization, which were then converted into formats suitable for each model: a bag-of-words corpus for LDA, a TF-IDF matrix for NMF, and dense vector embeddings for BERTopic. Each model was configured according to its specific requirements, with hyperparameters and settings tailored to optimize performance, and kept to default settings, as detailed in the following sections.
We began by merging submissions and comments from JSON files (RS_<filename>.json and RC_<filename>.json) in a specified subreddit directory. Submissions and comments are merged into threads using their IDs, creating a cohesive narrative for each discussion. Threads are saved as JSON for analysis. We then tokenized each thread with gensim’s simple_preprocess, and stored tokens in a dictionary. Stopwords and irrelevant terms are removed using NLTK, while bigrams are identified with gensim.
LDA Implementation: The LDA model was implemented using the gensim library. For tokenization and preprocessing, gensim handled tokenization and bigrams, NLTK removed stopwords, and spaCy performed lemmatization. A dictionary mapped unique words to IDs, and token sets were converted to a bag-of-words corpus. Hyperparameters (symmetric) and (auto) were chosen to balance topic distribution.
NMF Implementation: The NMF model was implemented using the scikit-learn library. Token sets were converted into space-separated strings for the TF-IDF vectorizer. The vectorizer transformed text into a TF-IDF matrix, which was saved and fitted to the NMF model, with a set random state for reproducibility.
BERTopic Implementation: BERTopic used the sentence-transformers library for embeddings, umap-learn for dimensionality reduction, and hdbscan for clustering. The bertopic library integrated these components, facilitating effective topic modelling analysis.
The number of topics (num_topics) for LDA and NMF were chosen based on the maximum topic coherence value observed from generating topic models ranging from 5 to 50 topics, in increments of 5. To determine an optimal value BERTopic, we generated 11 topic models and chose the median value. In doing so, we observed that the mean and median values for nr_topics were almost in conjunction, differing by average standard deviation between the median and average values being across 12 datasets.
7.1. Data Collection and Analysis
During our study, we offered participants the option to conduct interviews through video chat or in person at the university campus. All participants chose the online format, conducted through Microsoft Teams, a trusted platform with end-to-end encryption. Each interview lasted between 1 - 1.5 hours. With participants’ consent, we recorded the audio for transcription using the platform’s built-in feature, and recordings were deleted within 24 hours to ensure privacy. The transcriptions included responses to the phase 1 and 2 questionnaires. For analysis, we systematically reviewed the transcriptions, identifying themes and key aspects that reflected participants’ interactions with the topic models, thereby capturing the nuances of their experiences.
In our analysis comparing the ranking given by the participants for the three topic modelling methods, we utilized the Friedman test and the Nemenyi post-hoc test for statistical inference. The Friedman test was suitable for comparing the ranks of multiple models on the same datasets, revealing overall significant differences without assuming normal distribution. The Nemenyi post-hoc test complemented this by identifying specific pairs of models with statistically significant differences, adjusting for multiple comparisons.
Additionally, we employed the ANOVA (Analysis of Variance) and Tukey’s Honest Significant Difference (HSD) tests for statistical inference. ANOVA was chosen because it is ideal for comparing the means of multiple groups and determining if statistically significant differences exist among the models. This flexibility makes ANOVA applicable to various metrics, including Number of Topics, Topic Coherence, Topic Diversity, KL-Divergence, Perplexity, and Execution Time. ANOVA combined with post-hoc test Tukey’s HSD provides a consistent and thorough method for comparative performance analysis, determining which specific group means are different. It controls the Type I error rate and provides confidence intervals for the differences between means.
8. Results
BERTopic consistently outperformed LDA and NMF in terms of quantitative metrics, including topic coherence, topic diversity, and KL divergence. On the other hand, and as expected, NMF was the least computationally-demanding model and required the lowest amount of time to compute. LDA tended to lay in-between the other two models across measures. Participant preferences closely align with these findings. BERTopic was ranked first by 8 out of 12 participants (67%), LDA by 3 out of 12 participants (25%), and NMF by 1 out of 12 participants (8%). A Friedman test revealed that these differences were statistically significant, , . Post-hoc analysis using the Nemenyi test showed significant differences between BERTopic and LDA (), BERTopic and NMF (), but not between LDA and NMF ().
We first present these quantitative results in detail. Then, in presenting our analysis of interviews with researchers, we highlight rationale for these preferences alongside practical concerns for each topic modelling technique.
8.1. Number of Topics
| Reddit Dataset | LDA | NMF | BERTopic |
| r/disabledgamers | 10 | 5 | 22 |
| r/MachineLearning | 10 | 5 | 56 |
| r/HermanCainAward | 40 | 40 | 131 |
| r/cybersecurity | 35 | 5 | 142 |
| r/emergencymedicine | 30 | 50 | 20 |
| r/SustainableFashion | 15 | 10 | 35 |
| r/LanguageTechnology | 30 | 20 | 78 |
| r/nutrition | 10 | 5 | 27 |
| r/uwaterloo | 15 | 10 | 43 |
| r/Coronavirus | 10 | 10 | 133 |
| r/bipolar | 45 | 10 | 56 |
| r/CoronavirusCanada | 10 | 15 | 62 |
| Mean | 22 | 15 | 67 |
| Minimum | 10 | 5 | 20 |
| Maximum | 45 | 50 | 142 |
BERTopic consistently identified the largest number of distinct topics across the datasets, with a mean of 67 topics, ranging from 20 to 142. LDA follows with a mean of 22 topics, with a minimum of 10 and a maximum of 45. NMF identifies the fewest topics on average, with a mean of 15, a minimum of 5, and a maximum of 50. Table 3 compares the topic coherence scores of these three topic modelling methods.
A one-way ANOVA revealed a significant effect of the topic modelling method on the number of topics identified, , , . To explore these differences further, a Tukey HSD post hoc test was conducted. The Tukey HSD test indicated that the mean number of topics for LDA () was significantly lower than BERTopic (), with a mean difference of 45.41 (95% CI, 17.16 to 73.66), . Additionally, NMF () was also significantly lower than BERTopic (), with a mean difference of 51.66 (95% CI, 23.41 to 79.9), . However, NMF did not significantly differ from LDA ().
8.2. Topic Coherence
| Reddit Dataset | LDA | NMF | BERTopic |
| r/disabledgamers | 0.494 | 0.667 | 0.639 |
| r/MachineLearning | 0.475 | 0.721 | 0.649 |
| r/HermanCainAward | 0.456 | 0.544 | 0.575 |
| r/cybersecurity | 0.520 | 0.714 | 0.687 |
| r/emergencymedicine | 0.460 | 0.527 | 0.623 |
| r/SustainableFashion | 0.386 | 0.573 | 0.685 |
| r/LanguageTechnology | 0.474 | 0.599 | 0.596 |
| r/nutrition | 0.543 | 0.849 | 0.683 |
| r/uwaterloo | 0.507 | 0.706 | 0.695 |
| r/Coronavirus | 0.564 | 0.748 | 0.683 |
| r/bipolar | 0.543 | 0.819 | 0.573 |
| r/CoronavirusCanada | 0.584 | 0.746 | 0.670 |
| Mean | 0.500 | 0.684 | 0.647 |
| Minimum | 0.386 | 0.527 | 0.573 |
| Maximum | 0.584 | 0.849 | 0.695 |
LDA exhibits coherence scores ranging from a minimum of 0.386 to a maximum of 0.584, with a mean score of 0.500. NMF shows a broader range of coherence scores, from 0.527 to 0.849, with a higher mean score of 0.684. BERTopic, meanwhile, has a relatively consistent range of coherence scores, between 0.573 and 0.695, with a mean score of 0.647. Table 4 compares the topic coherence scores of these three topic modelling methods.
A one-way ANOVA revealed a significant effect of the topic modelling method on topic coherence, , , . To explore these differences further, a Tukey HSD post hoc test was conducted. The Tukey HSD test indicated that the mean topic coherence for LDA () was significantly lower than BERTopic (), with a mean difference of 0.147 (95% CI, 0.038 to 0.256), . Additionally, LDA was also significantly lower than NMF (), with a mean difference of 0.184 (95% CI, 0.076 to 0.293), . However, NMF did not significantly differ from BERTopic, with a mean difference of -0.037 (95% CI, -0.146 to 0.071), .
8.3. Topic Diversity
| Reddit Dataset | LDA | NMF | BERTopic |
| r/disabledgamers | 0.680 | 0.920 | 0.967 |
| r/MachineLearning | 0.770 | 0.880 | 1.000 |
| r/HermanCainAward | 0.723 | 0.828 | 0.990 |
| r/cybersecurity | 0.751 | 0.900 | 1.000 |
| r/emergencymedicine | 0.673 | 0.796 | 1.000 |
| r/SustainableFashion | 0.653 | 0.880 | 1.000 |
| r/LanguageTechnology | 0.700 | 0.900 | 1.000 |
| r/nutrition | 0.800 | 0.900 | 1.000 |
| r/uwaterloo | 0.773 | 0.870 | 1.000 |
| r/Coronavirus | 0.750 | 0.920 | 1.000 |
| r/bipolar | 0.727 | 0.920 | 0.992 |
| r/CoronavirusCanada | 0.800 | 0.920 | 1.000 |
| Mean | 0.733 | 0.866 | 0.995 |
| Minimum | 0.653 | 0.796 | 0.967 |
| Maximum | 0.800 | 0.920 | 1.000 |
LDA exhibits diversity scores ranging from a minimum of 0.653 to a maximum of 0.800, with a mean score of 0.733. NMF shows a range of diversity scores from 0.796 to 0.920, with a mean score of 0.866. BERTopic, meanwhile, has a high and consistent range of diversity scores, between 0.967 and 1.000, with a mean score of 0.995. Table 5 compares the topic diversity scores of these three topic modelling methods.
A one-way ANOVA revealed a significant effect of the topic modelling method on topic diversity, , , . To explore these differences further, a Tukey HSD post hoc test was conducted. The Tukey HSD test indicated that the mean topic diversity for LDA () was significantly lower than BERTopic (), with a mean difference of 0.262 (95% CI, 0.226 to 0.299), . Additionally, NMF () was also significantly lower than BERTopic, with a mean difference of 0.1096 (95% CI, 0.072 to 0.146), . NMF also significantly differed from LDA, with a mean difference of 0.152 (95% CI, 0.115 to 0.189), .
8.4. KL Divergence
| Reddit Dataset | LDA | NMF | BERTopic |
| r/disabledgamers | 0.020 | 7.956 | 0.004 |
| r/MachineLearning | 0.095 | 8.397 | 0.003 |
| r/HermanCainAward | 0.109 | 10.166 | 0.027 |
| r/cybersecurity | 0.093 | 9.479 | 0.002 |
| r/emergencymedicine | 0.048 | 11.766 | 0.014 |
| r/SustainableFashion | 0.125 | 11.042 | 0.012 |
| r/LanguageTechnology | 0.144 | 9.607 | 0.001 |
| r/nutrition | 0.027 | 7.298 | 0.003 |
| r/uwaterloo | 0.194 | 8.856 | 0.013 |
| r/Coronavirus | 0.032 | 9.981 | 0.002 |
| r/bipolar | 0.066 | 10.475 | 0.001 |
| r/CoronavirusCanada | 0.136 | 9.277 | 0.004 |
| Mean | 0.090 | 9.52 | 0.007 |
| Minimum | 0.020 | 7.298 | 0.001 |
| Maximum | 0.194 | 11.766 | 0.027 |
LDA exhibits KL divergence scores ranging from a minimum of 0.0199 to a maximum of 0.1943, with a mean score of 0.090. NMF shows a much broader range of KL divergence scores from 7.2976 to 11.7661, with a mean score of 9.52. BERTopic, meanwhile, has a relatively low and consistent range of KL divergence scores, between 0.0006 and 0.0265, with a mean score of 0.007. Table 6 compares the KL divergence scores of these three topic modelling methods.
A one-way ANOVA revealed a significant effect of the topic modelling method on KL-Divergence, , , . To explore these differences further, a Tukey HSD post hoc test was conducted. The Tukey HSD test indicated that the mean KL-Divergence for LDA () was not significantly higher than BERTopic (), with a mean difference of 0.083 (95% CI, -0.658 to 0.825), . Additionally, LDA was significantly lower than NMF (), with a mean difference of 9.43 (95% CI, 8.69 to 10.175), . Furthermore, NMF was significantly higher than BERTopic, with a mean difference of 9.5179 (95% CI, 8.776 to 10.25), .
| Reddit Dataset | LDA | NMF | BERTopic |
| r/disabledgamers | 280 | 51 | 173 |
| r/MachineLearning | 1329 | 74 | 701 |
| r/HermanCainAward | 3178 | 836 | 2891 |
| r/cybersecurity | 933 | 136 | 1190 |
| r/emergencymedicine | 452 | 101 | 274 |
| r/SustainableFashion | 200 | 53 | 153 |
| r/LanguageTechnology | 1034 | 62 | 408 |
| r/nutrition | 333 | 68 | 599 |
| r/uwaterloo | 531 | 56 | 262 |
| r/Coronavirus | 1575 | 91 | 767 |
| r/bipolar | 730 | 88 | 653 |
| r/CoronavirusCanada | 1587 | 180 | 1178 |
| Mean | 1013 | 149 | 771 |
| Minimum | 200 | 51 | 153 |
| Maximum | 3178 | 836 | 2891 |
9. Execution Time
For LDA, the execution times range from a minimum of 200 seconds to a maximum of 3178 seconds, with a mean time of 1013 seconds. NMF exhibits a much lower range of execution times from 51 seconds to 836 seconds, with a mean time of 149 seconds. BERTopic shows a range of execution times between 153 seconds and 2891 seconds, with a mean time of 771 seconds. Table 7 compares the execution time of these three topic modelling methods.
A one-way ANOVA revealed a significant effect of the topic modelling method on execution time, , , . To explore these differences further, a Tukey HSD post hoc test was conducted. The Tukey HSD test indicated that the mean execution time for LDA () was significantly higher than NMF (), with a mean difference of 863.88 (95% CI, 199.46 to 1528.29), . Additionally, NMF was significantly lower than BERTopic (), with a mean difference of 621.200 (95% CI, -43.214 to 1285.61), . However, there was no significant difference between LDA and BERTopic, with a mean difference of 242.68 (95% CI, -421.73 to 907.095), .
9.1. Microsoft Desirability Toolkit
During the Interview on Topic Models phase, participants were asked to use the Microsoft Desirability Toolkit to select the top 5 words that described each topic modelling technique. Out of 118 words, 64 unique words were chosen by participants: 39 positive (Table 8), and 25 negative (Table 9).
| LDA | NMF | BERTopic |
|---|---|---|
| Clear (3) | Clean (4) | Useful (3) |
| Relevant (3) | Usable (4) | Meaningful (3) |
| Easy to use (2) | Organized (3) | Effective (3) |
| Useful (2) | Helpful (2) | Valuable (3) |
| Usable (2) | Relevant (2) | Relevant (3) |
| Attractive (1) | Useful (2) | Easy to use (2) |
| Compelling (1) | Straightforward (2) | Satisfying (2) |
| Clean (1) | Expected (2) | Helpful (2) |
| Intuitive (1) | Flexible (1) | Comprehensive (2) |
| Convenient (1) | Connected (1) | Usable (1) |
| Integrated (1) | Comprehensive (1) | Clear (1) |
| Essential (1) | Compatible (1) | Understandable (1) |
| Expected (1) | Accessible (1) | Appealing (1) |
| Advanced (1) | Easy to use (1) | Personal (1) |
| Stimulating (1) | Intuitive (1) | Impressive (1) |
| Innovative (1) | Inspiring (1) | Sophisticated (1) |
| Understandable (1) | Advanced (1) | Engaging (1) |
| Approachable (1) | Stimulating (1) | High quality (1) |
| Organized (1) | Innovative (1) | Advanced (1) |
| Accessible (1) | Consistent (1) | Stimulating (1) |
| Helpful (1) | Inviting (1) | Innovative (1) |
| Approachable (1) | Detail (1) | |
| Understandable (1) | Trustworthy (1) | |
| Convenient (1) | Unconventional (1) | |
| Efficient (1) | ||
| Attractive (1) | ||
| Compelling (1) | ||
| Clear (1) | ||
| Essential (1) |
| LDA | NMF | BERTopic |
|---|---|---|
| Simplistic (5) | Simplistic (5) | Complex (4) |
| Disconnected (4) | Unrefined (3) | Overwhelming (3) |
| Confusing (3) | Uncontrollable (1) | Unrefined (2) |
| Unrefined (2) | Poor quality (1) | Poor quality (1) |
| Not valuable (2) | Busy (1) | Busy (1) |
| Complex (2) | Rigid (1) | Not secure (1) |
| Irrelevant (2) | Complex (1) | Simplistic (1) |
| Limiting (1) | Hard to use (1) | Time-consuming (1) |
| Inconsistent (1) | Confusing (1) | Confusing (1) |
| Undesirable (1) | Time-consuming (1) | Overbearing (1) |
| Rigid (1) | Difficult (1) | Distracting (1) |
| Old (1) | Limiting (1) | Rigid (1) |
| Unpredictable (1) | Not valuable (1) | |
| Poor quality (1) | Frustrating (1) | |
| Difficult (1) | Impersonal (1) | |
| Uncontrollable (1) | ||
| Slow (1) |
9.2. Qualitative results
When asked about incorporating topic modelling into their workflows, 10 out of 12 participants (83%) were willing and happy to include and/or use it as a supplementary tool in their future work, while two participants (17%) indicated that their research involves less data, making it less applicable for their needs. This feedback underscores a general sense of enthusiasm towards the techniques and potential for broader adoption. Importantly, they also provided feedback on each model independently, with varying opinions about the suitability of each model for their work. We now summarize these comments.
9.2.1. LDA
Researchers provided mixed feedback on the LDA models, appreciating its simplicity and ease of use while acknowledging its limited detail and relevance. A few participants preferred LDA for its familiarity and straightforward results, 3 participants ranking it as their top choice due to ease of access and clarity. LDA was valued for producing clear, organized outputs, making topic keywords accessible for those seeking quick and easy-to-understand results. However, its lack of depth and tendency to generate broad or sometimes irrelevant topics were noted drawbacks.
3 participants perceived LDA as relevant, accessible, and clear. P3 highlighted its relevance and ease of use, stating, “[For] LDA [I put] ‘relevant’ because I think those topics feel relevant and easy to combine into higher level themes. It’s very easy to find information about LDA online and it’s pretty easy to learn it.” P11 appreciated the meaningful groupings created by LDA, noting, “This model has created groupings that are more meaningful than NMF. There is a common thread across the keywords and there wasn’t any random noise blocking the signal of understanding.” They also mentioned the advantage of LDA producing fewer topics, making it easier to focus on each one equally: “The LDA had the least amount of topics, so it was easier from a user design perspective to pay attention to all of them equally as opposed to the third model [BERTopic] like 56.”
Participants also noted several limitations of LDA: issues of disconnection between the keywords in the topic clusters, lack of meaningful topics, and confusing clusters. P2 found the topics generated by LDA not semantically meaningful: “The topics themselves are not really semantically meaningful… if there’s just like a word like meaningless, that would describe it.” P6 felt LDA lacked depth, making it hard to understand topic connections: “LDA tells you about hey, this is sustainable fashion, but that’s it. Some of the words in clusters don’t make sense. Like topic six, it has flip flops [and] textiles. I’m not sure how they’re relevant.”
P7 observed irrelevant content and rogue keywords, leading to unpredictability: “There was a lot of irrelevant content. There were a bunch of clusters in LDA with rogue keywords. So I wouldn’t call it understandable. Unpredictable, I think.” P8 described LDA as disconnected and rigid, with arbitrarily grouped topics: “Numerous clustering words could have been in any of the other clusters. It just felt like it was thrown together. Why would increased water intake improve diet quality? Its [clusters] didn’t relate to me.” Additionally, some participants displayed biases towards certain modelling techniques. For instance, P3 stated that “[I would rank] LDA 1, just because I know it and I’m most familiar with it, I would either choose LDA because I know LDA and that’s just what I’ve always used Or probably bertopic one because it does give me the most option”, as displayed in Figure 2.
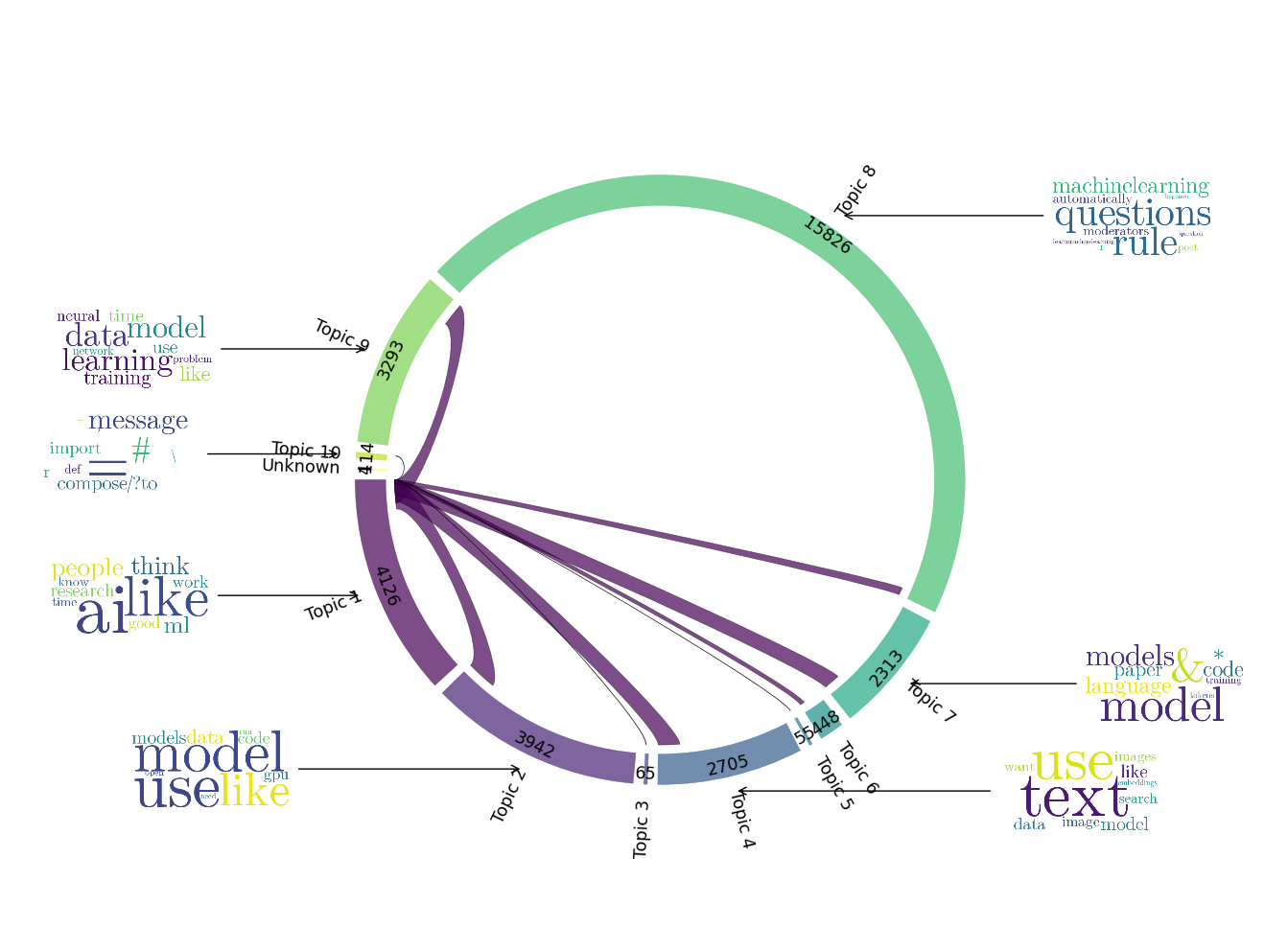
The default settings for symbol removal in the topic models were not flawless, and LDA was particularly impacted by this issue. This problem led to the inclusion of irrelevant symbols and mathematical characters in the topics, which affected the quality and meaningfulness of the clusters. For instance, P2 indicated that LDA often grouped irrelevant symbols and mathematical characters together, detracting from meaningful clustering: “They have a topic for just mathematical characters like equal sign and these are all like either code or Math quantifiers or symbols. This one has literally an asterisk. And also like just looking at these, not a lot of them really seem like clusters.” Another observation from P10 found LDA unrefined, noting the presence of irrelevant symbols and lack of meaningful topics: “The thing that bugs me the most is like I see sometimes there’s emojis. Sometimes there’s just like a hyphen or just a space” (Topic keywords: co, -, op, coop, work, program, job, university, cs, like).
9.2.2. NMF
The NMF models were valued for producing clear, relevant, and organized topics, making them a reliable choice for research. The models generated clean, usable clusters with an organized structure. However, they were sometimes too general, missing nuanced details that other advanced models captured. Overall, NMF balanced detail and usability, offering clear and relevant outputs that were easy to interpret, but fell short in capturing the full complexity of certain topics. Participants valued NMF for its relevance and clear organization, which made it straightforward and usable for understanding current trends. P2 appreciated the succinctness and statistical relevance of NMF.
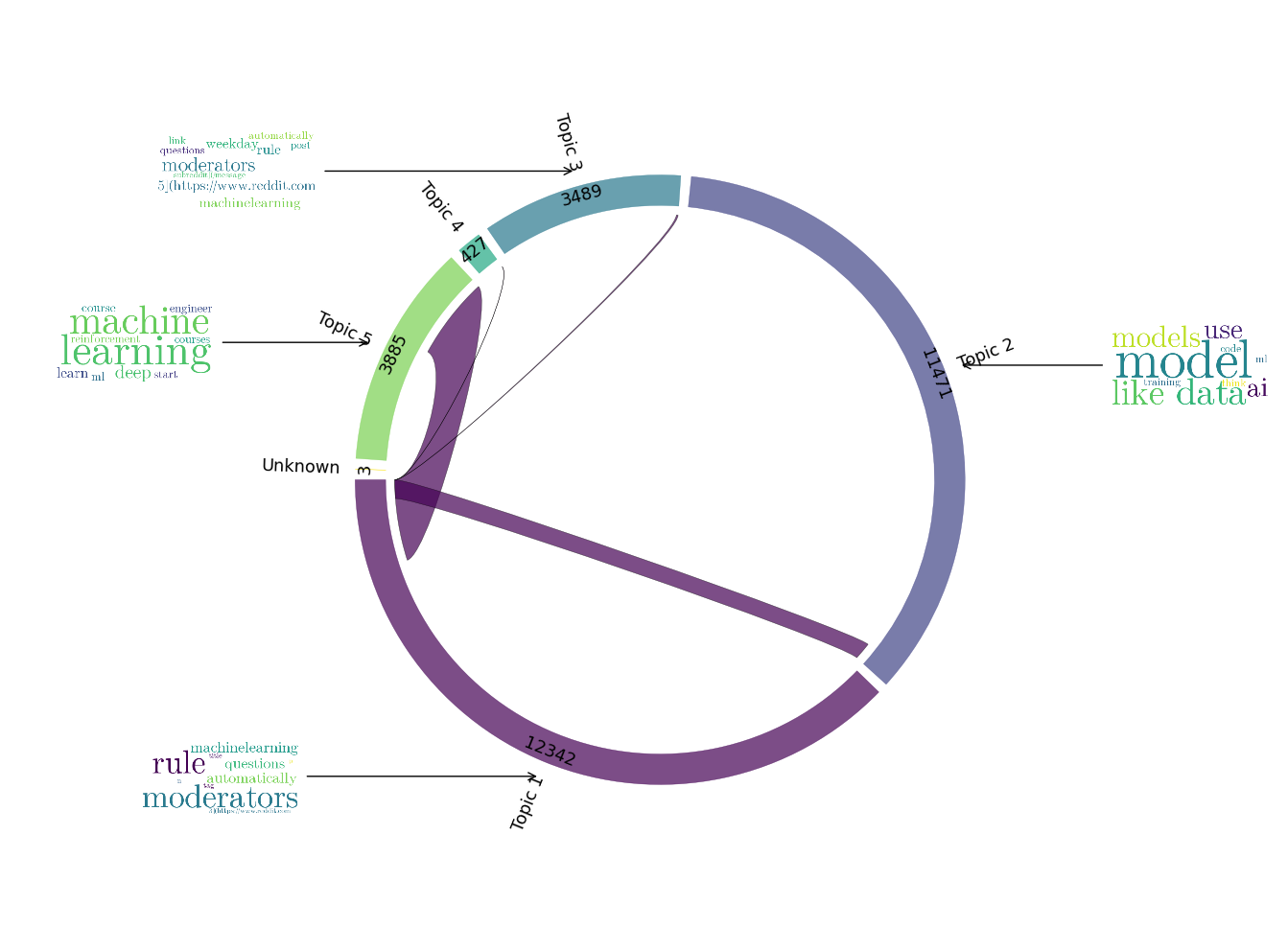
Researchers identified several limitations of NMF, highlighting its generality, topic overlap, and lack of semantic clarity. Despite being a useful model, NMF often fell short in providing detailed and relevant topics, particularly for large datasets. P1 mentioned that the number of topics was insufficient, stating, “This isn’t enough. So I think [number of topics as] 5 is definitely not enough for such a large dataset in my opinion.” P2 further criticized its semantic clarity, noting, “They [topic keywords] are not semantically meaningful or relevant. It needs a lot more refining at a semantic level”, as seen in Figure 3. This sentiment was echoed by P3, who pointed out the overlap between topics and suggested combining them. Additionally, P7 observed the presence of undesirable keywords and rigidity in the model, emphasizing that “There were a few clusters with undesirable keywords like cluster three (Topic keywords: message, compose/?to, #, import, &, remindmebot&subject, ; amp;#x200b, r). It could not capture some topics, so it’s a bit rigid in its organization.” P8 also found NMF too general and lacking specificity, stating, “NMF is kind of a bit too general. You can say that [some topics] for any university.” P9 noted that NMF did not capture keywords from other languages as compared to LDA and BERTopic for the r/Coronavirus data, and P11 described NMF as unrefined, confusing, time-consuming, and difficult, concluding, “Compared to the other two, this one was not pulling together themes relevant to the topic.”
9.2.3. BERTopic
Participants consistently highlighted BERTopic’s strengths in producing detailed, organized, and coherent topic clusters. For instance, P1 noted, “BERTopic had more detailed and organized topics that are usable.” Participants felt the topics were clearly separated and logically grouped, which made it easy for them to recognize relevant terms and understand related concepts. P12 highlighted the logical organization of topics, finding the clustering intuitive and easy to comprehend: “I like how the keywords are captured into 62 topics — and they seem to make more sense as groupings. But I like that they’ve broken it out that way because a lot of the [related] language clustered together makes sense.”
Additionally, participants felt that BERTopic’s topics provided more meaningful and interconnected insights into complex topics than the other two models. For instance, P6 noted, “Fabrications and dyes are very important topics within the sustainable fashion world because some dyes are more environmentally friendly, and historically, some dyes caused health issues for fashion workers. This is a very important topic that I believe the industry is not really talking a lot about, but it’s very interesting to see it here.” This level of detail was seen as crucial for understanding the nuances of specific subjects. Similarly, they also noted,“The ESG cluster informs me about investment. I can see the word governance and understand the impact,” which contrasts with the LDA model’s keywords that struggled to effectively link related concepts like ESG and sustainability.
Researchers were impressed by BERTopic’s capacity to reveal unexpected yet significant relationships within the data, showcasing its effectiveness in identifying connections that might otherwise be underexplored. P3, initially skeptical about the relevance of certain keywords, found BERTopic intriguing and effective for their analysis. They noted, “It’s very interesting. When I was doing the analysis, I would not have connected horses and dewormer and Apple ivermectin,” highlighting how BERTopic linked these terms within the context of a surge in demand at farm supply stores due to false claims that the apple-flavored paste could cure or prevent COVID-19. This example underscored BERTopic’s capacity to reveal meaningful connections that even the researchers had not anticipated.
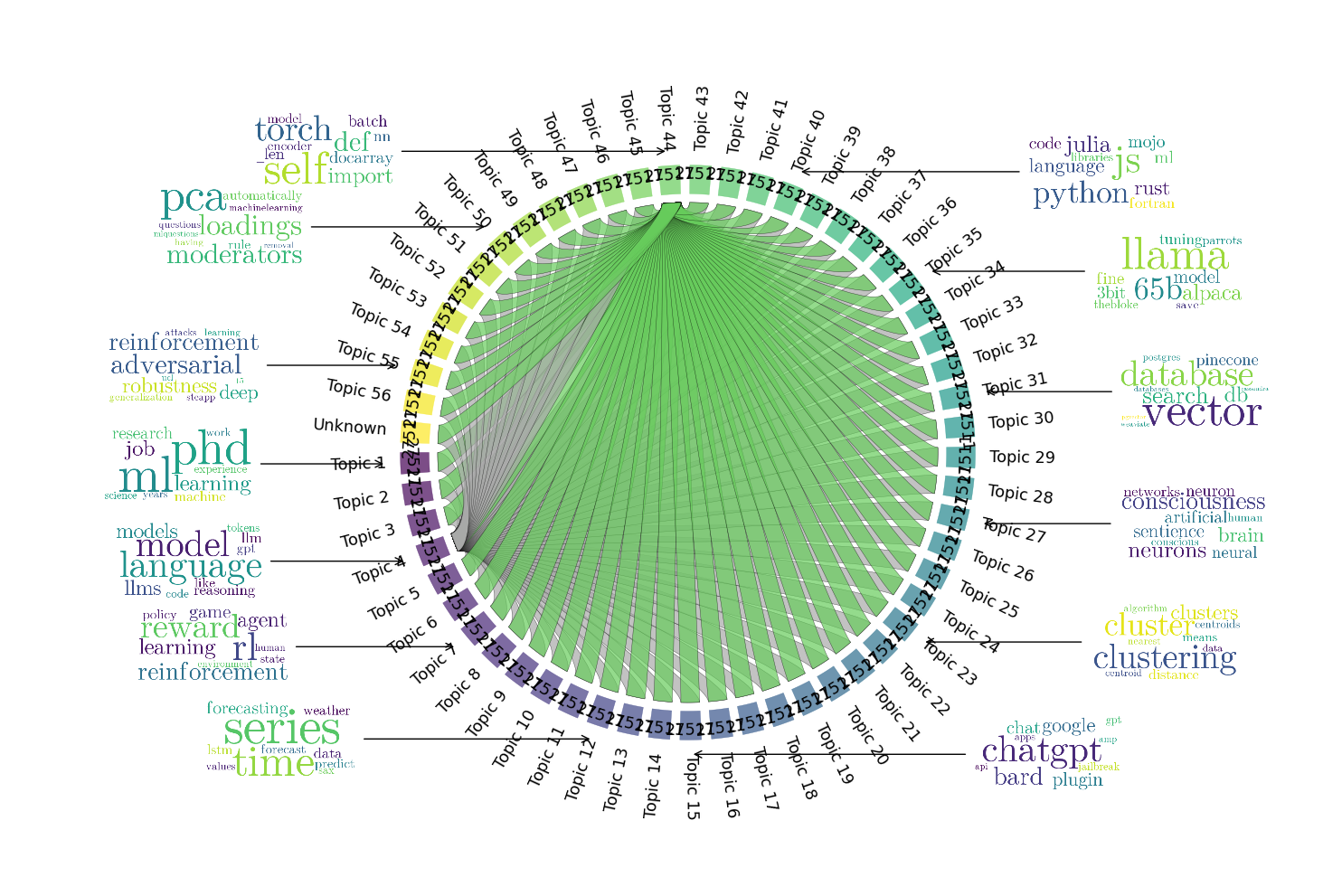
BERTopic’s effectiveness in parsing and differentiating topics made it particularly valuable for research, despite taking longer. P2 emphasized the importance of relevance and accuracy in academic work, stating, “In research, I don’t really care how much time I have to spend, but I wanna make sure what I write down on my papers or what I take from a paper has to be relevant. It has to be true”, as seen in Figure 4. Similarly, P9 noted that although BERTopic takes longer, the depth of insights justifies the extra time:“I see the reason and I don’t mind staying longer as it’s useful for my research.” P12’s request for topics generated “solely” by BERTopic for their analysis, underscores its superior capacity to deliver comprehensive and actionable insights, reflecting the high level of trust researchers place in its detailed analysis.
However, some researchers found the large number of topics generated by BERTopic overwhelming, which made navigating and digesting the information challenging. P3 stated, “I’m going to say overwhelming as my first one. It is meaningful and a lot of the topics are interesting and relevant, but it is overwhelming and overbearing because I don’t think all of those topics are necessary. It’s distracting and unrefined.” Due to its complexity, P3 ranked BERTopic lower compared to LDA and NMF. P2 appreciated BERTopic’s efficiency but found it slightly overwhelming, suggesting a need for more succinctness, “I feel like it could be more succinct, like there is room for improvement, but generally I really couldn’t complain because as a human, I can just choose to read one or two words.” P4 also encountered navigation challenges, finding it difficult to interact with the BERTopic diagram compared to LDA. P11 described BERTopic as unconventional, complex, and busy, although easier to use once understood, but criticized it for being unrefined due to content overload.
10. Discussion
We now discuss the results of our comparative analysis, evaluating the strengths and weaknesses of BERTopic, NMF, and LDA, and exploring their implications for topic modeling. We will examine why BERTopic outperformed other models, the trade-offs involved in using each technique, and the considerations for choosing the most suitable model and evaluation metric for topic modeling.
10.1. Can LLM-based topic modelling techniques support the thematic analysis workflow?
We successfully integrated BERTopic into the Computational Thematic Analysis (CTA) Toolkit and received positive feedback from participants. For instance, our interviews and hands-on evaluations indicated that BERTopic’s contextually rich and coherent topics were highly valuable to researchers. P7 stated, “The clusters [in BERTopic] are more fine-grained and easier to understand.” In turn, the detailed and coherent topic clusters provided a deeper understanding of intricate datasets. For instance, P3 highlighted the importance of BERTopic in uncovering semantic relationships between “horses,” “dewormer,” and “apple ivermectin” in their COVID-19 data, and P6 showed how BERTopic revealed connections between sustainable fashion topics like the relevance of “fabrications” and “dyes” in environmental contexts.
These findings contrast recent work in the HCI literature which suggests that qualitative researchers may be hesitant to adopt computational techniques in their work (Feuston and Brubaker, 2021; Jiang et al., 2021). Where in the past researchers have cited concerns about intimacy, ownership, and agency in their own analyses, our findings show how LLM-based techniques might enhance their ability to understand data, to reveal new trends, and prompt qualitative researchers to explore new aspects of collected data. Thus, integrating LLM-based unsupervised topic modelling techniques into qualitative thematic analysis workflows is not only feasible but can also be highly beneficial. We argue that future work should focus on understanding how computational methods can support qualitative researchers, while maintaining their agency in the process.
10.2. How does BERTopic compare to LDA and NMF?
When comparing BERTopic to conventional unsupervised modelling techniques, participants consistently highlighted its strengths in producing detailed, organized, and coherent topic clusters. They appreciated how BERTopic clearly separated and logically grouped topics, making it easier to recognize relevant terms and understand related concepts. Participants consistently praised BERTopic for being “comprehensive”,“satisfying,” and “sophisticated”, underscoring its capabilities. Further, our quantitative results showed that BERTopic consistently produced higher coherence scores, greater topic diversity, and more meaningful, relevant topics when compared to LDA. Indeed, 8 out of 12 researchers rated BERTopic as their preferred model.
In contrast, we found that LDA and NMF often produce topics with mixed themes, making them difficult to interpret (Egger and Yu, 2022). While LDA and NMF have been widely used for topic modelling in qualitative data analysis, our study suggests that it may be beneficial to reconsider this choice. Moreover, our results help us understand how quantitative measures might be used to improve topic models to support qualitative analysis. While measures like coherence have traditionally been used to quantitatively evaluate topic model performance, there has been criticism within the HCI community around this practice (Gauthier et al., 2022; Baumer et al., 2017). That is, in qualitative research models provide “scaffolding for human interpretation” (Baumer et al., 2017) and there is a risk of over-emphasizing the need to find optimal models rather than models that support qualitative research.
Notably, if we had optimized for coherence, in many cases we would have selected NMF over BERTopic. Similarly, NMF often provided high scores for topic diversity and the lowest execution time of all techniques. Instead we assert that participants preferred models that provided a high number of rich and distinct topics. BERTopic consistently provided the highest number of topics for each data set, while maintaining high topic diversity scores. In turn, participants consistently cited the specific and detailed topics as being what they found most useful in interpreting the data.
10.3. What are the needs and preferences of qualitative researchers and how can these be addressed through unsupervised topic modelling?
We identified three general needs among qualitative researchers:
10.3.1. Data Cleaning
The primary tradeoff in using LDA and NMF is the necessity for extensive data cleaning and preprocessing, which requires significant manual effort. This labour-intensive process, involving the removal of irrelevant symbols, stemming, and lemmatizing can be time-consuming and prone to human error (Gauthier and Wallace, 2022; Gauthier, 2020). In contrast, modern techniques like BERTopic are designed to streamline data cleaning and processing, potentially identifying and grouping overlooked keywords with less human intervention (Sawant et al., 2022; An et al., 2023). This approach aims to save time, improve consistency, and allow researchers to focus more on interpreting and applying insights. BERTopic’s ability to process raw data and produce coherent topic clusters with reduced preprocessing highlights its efficiency and robustness, leading to more efficient and insightful qualitative research by balancing human expertise.
But this raises a critical question: should we continue with manual data cleaning, or automate the process using advanced LLM-based topic modelling techniques? The benefits of automating data cleaning with BERTopic include reduced manual effort, minimized errors, and enhanced consistency, making it a compelling choice for modern qualitative research (Grootendorst, 2022). However, it is essential to consider whether the automated process can fully capture the nuances that human expertise brings to data interpretation (Vayansky and Kumar, 2020; Owoahene Acheampong and Nyaaba, 2024). Future research should explore the balance between automation and manual intervention to optimize both efficiency and depth of insight in topic modelling (Holzinger, 2016; Yang et al., 2021).
10.3.2. Execution Time is not a Priority
Participants valued BERTopic’s granularity and prioritized quality over speed in their research. As detailed in the section 9, LDA took significantly longer than NMF, and NMF took significantly less time than BERTopic, with no significant difference in execution time between LDA and BERTopic. It is important to acknowledge that participants did not create the models themselves and therefore did not need to consider processing time unless explicitly discussed. Despite NMF’s quicker processing times, many participants were willing to wait longer for BERTopic’s results due to its superior granularity and detailed insights. For instance, P9 noted, “I see the reason and I don’t mind staying longer as it’s useful for my research.” This suggests that while efficiency is important, the quality and depth of the results are essential for researchers, even if it means longer processing times. BERTopic outperformed LDA, the current “gold standard,” across all quantitative measures in our study, underscoring its significant potential and relevance in the field.
10.3.3. Navigating BERTopic’s Complexity for Deeper Insights
BERTopic’s complexity, while initially challenging, ultimately provides substantial efficacy in terms of insight and depth. As users become familiar with its structure, the model’s capacity to reveal nuanced patterns and relationships becomes evident, highlighting its potential for comprehensive analysis. This underscores the importance of user engagement and learning in maximizing the benefits of advanced topic modelling techniques like BERTopic, leading to more informed and meaningful research outcomes.
In our study, the methods like Hierarchical Edge Bundles (Pujara and Skomoroch, 2012; Dou et al., 2013), Interactive Topic Maps (Hu et al., 2014), and Force-Directed Layouts (Van der Maaten and Hinton, 2008) could have better facilitated navigation and interpretation of complex topic relationships by grouping the increased number of topics into hierarchical structures; thus reducing the overwhelming and complex visualization of BERTopic.
Furthermore, BERTopic can incorporate hierarchical topic modeling, addressing the limitations of flat topic clusters seen in LDA (Grootendorst, 2022). Visualizing the hierarchy enables researchers to gain a deeper understanding of the thematic organization within their corpus, facilitating more nuanced topic analysis. The lack of hierarchical visualization is a severe limitation of the CTA toolkit, as it restricts researchers from fully exploring and interacting with complex topic models. Our future research would aim to develop tools that provide capabilities for visualizing and interacting with hierarchical structures, allowing for a more comprehensive analysis and understanding of the data.
11. Limitations
Our study also uncovered several important limitations that highlight areas for improvement. Researchers highlighted the need for simplified interfaces and better visualizations, such as interactive chord diagrams and hierarchical representations, to manage large datasets. They also suggested future features, including a more in-depth search function, to further improve the design and guide the next phase of our project.
Optimizing LDA and NMF Models: Future research should focus on optimizing parameters and evaluation metrics, especially the criteria for determining the number of topics. While topic coherence proved to be a valuable metric, relying solely on it for model evaluation posed challenges. This was evident when we used coherence to determine the number of topics for LDA and NMF, potentially limiting their performance and applicability. The presence of irrelevant symbols and mathematical characters in the topics highlighted a need for more precise and automated data cleaning processes. Both LDA and NMF required extensive manual effort to clean the data accurately.
BERTopic’s Number of Topics: Participants often found the large number of topics generated by BERTopic to be overwhelming, which led some to prefer other models despite acknowledging BERTopic’s superior detail and depth. Exploring hierarchical topic models may provide more organized and interpretable results. However, those models would necessitate improved visualization techniques. Developing more intuitive and effective visual interfaces will help users better understand and interact with the topic models.
Generalizability: Ensuring the generalizability and practical utility of our findings requires a larger, more diverse participant base and longitudinal studies. Our study included a diverse group of researchers, but the sample size was relatively small, with only 12 participants. This limitation restricts the generalizability of our findings. A larger and more varied participant base would help validate and extend our conclusions, ensuring that the results are applicable across a broader spectrum of qualitative research contexts. Further, conducting longitudinal studies where researchers use the software over extended periods of time can provide deeper insights into its practical utility and areas for improvement.
12. Conclusion and Future Work
Integrating BERTopic into the Computational Thematic Analysis (CTA) Toolkit significantly enhanced its capabilities. Researchers praised BERTopic for generating detailed, coherent topics, their ease of interpretation, and their utility in uncovering hidden relationships within data. Evaluation metrics showed BERTopic’s superiority in topic coherence and topic diversity. This enhancement improved qualitative data analysis efficiency and depth, combining advanced computational methods with an intuitive interface for comprehensive and logical data representation.
In reflecting on our interviews, we found that researchers prefer models that produce detailed, organized, and coherent topic clusters, making it easier to recognize relevant terms and understand related concepts. They value models that reveal unexpected yet significant relationships within the data, providing comprehensive and actionable insights. The ability to capture a wide range of nuances and generate a larger number of topics is particularly important for deep understanding of complex subjects. Our results demonstrate the potential LLM-based methods like BERTopic for supporting qualitative analysis of large data sets.
References
- (1)
- Abram et al. (2020) Marissa D Abram, Karen T Mancini, and R David Parker. 2020. Methods to integrate natural language processing into qualitative research. International Journal of Qualitative Methods 19 (2020), 1609406920984608.
- Ahn and Shin (2013) Dohyun Ahn and Dong-Hee Shin. 2013. Is the social use of media for seeking connectedness or for avoiding social isolation? Mechanisms underlying media use and subjective well-being. Computers in Human Behavior 29, 6 (2013), 2453–2462.
- Albalawi et al. (2020) Rania Albalawi, Tet Hin Yeap, and Morad Benyoucef. 2020. Using topic modeling methods for short-text data: A comparative analysis. Frontiers in artificial intelligence 3 (2020), 42.
- Allen et al. (2014) Kelly A Allen, Tracii Ryan, DeLeon L Gray, Dennis M McInerney, and Lea Waters. 2014. Social media use and social connectedness in adolescents: The positives and the potential pitfalls. The Educational and Developmental Psychologist 31, 1 (2014), 18–31.
- Alsinet et al. (2021) Teresa Alsinet, Josep Argelich, Ramón Béjar, and Santi Martínez. 2021. Discovering Dominant Users’ Opinions in Reddit.. In CCIA. 113–122.
- Ammari et al. (2018) Tawfiq Ammari, Sarita Schoenebeck, and Daniel M Romero. 2018. Pseudonymous parents: Comparing parenting roles and identities on the Mommit and Daddit subreddits. In Proceedings of the 2018 CHI conference on human factors in computing systems. 1–13.
- An et al. (2023) Yusung An, Hayoung Oh, and Joosik Lee. 2023. Marketing insights from reviews using topic modeling with BERTopic and deep clustering network. Applied Sciences 13, 16 (2023), 9443.
- Andalibi et al. (2016) Nazanin Andalibi, Oliver L Haimson, Munmun De Choudhury, and Andrea Forte. 2016. Understanding social media disclosures of sexual abuse through the lenses of support seeking and anonymity. In Proceedings of the 2016 CHI conference on human factors in computing systems. 3906–3918.
- Andreotta et al. (2019) Matthew Andreotta, Robertus Nugroho, Mark J Hurlstone, Fabio Boschetti, Simon Farrell, Iain Walker, and Cecile Paris. 2019. Analyzing social media data: A mixed-methods framework combining computational and qualitative text analysis. Behavior research methods 51 (2019), 1766–1781.
- Angelov (2020) Dimo Angelov. 2020. Top2vec: Distributed representations of topics. arXiv preprint arXiv:2008.09470 (2020).
- Arif et al. (2018) Ahmer Arif, Leo G Stewart, and Kate Starbird. 2018. Acting the part: Examining information operations within #BlackLivesMatter discourse. In Proceedings of the ACM on Human-Computer Interaction, Vol. 2. 1–27.
- Baden et al. (2022) Christian Baden, Christian Pipal, Martijn Schoonvelde, and Mariken AC G van der Velden. 2022. Three gaps in computational text analysis methods for social sciences: A research agenda. Communication Methods and Measures 16, 1 (2022), 1–18.
- Bail et al. (2018) Christopher A Bail, Lisa P Argyle, Taylor W Brown, John P Bumpus, Haohan Chen, MB Fallin Hunzaker, Jaemin Lee, Marcus Mann, Friedolin Merhout, and Alexander Volfovsky. 2018. Exposure to opposing views on social media can increase political polarization. Proceedings of the National Academy of Sciences 115, 37 (2018), 9216–9221.
- Batrinca and Treleaven (2015) Bogdan Batrinca and Philip C Treleaven. 2015. Social media analytics: a survey of techniques, tools and platforms. Ai & Society 30 (2015), 89–116.
- Baumer et al. (2017) Eric PS Baumer, David Mimno, Shion Guha, Emily Quan, and Geri K Gay. 2017. Comparing grounded theory and topic modeling: Extreme divergence or unlikely convergence? Journal of the Association for Information Science and Technology 68, 6 (2017), 1397–1410.
- Baumgartner et al. (2020) Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. 2020. The pushshift reddit dataset. In Proceedings of the international AAAI conference on web and social media, Vol. 14. 830–839.
- Bi et al. (2018) Lifeng Bi et al. 2018. Topic modeling in software engineering research. Empirical Software Engineering 23, 6 (2018), 3801–3846.
- Blei et al. (2003) David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allocation. Journal of Machine Learning Research 3 (2003), 993–1022.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Burgess and Bruns (2012) Jean Burgess and Axel Bruns. 2012. Twitter archives and the challenges of” Big Social Data” for media and communication research. M/C Journal 15, 5 (2012).
- Chang et al. (2009) Jonathan Chang, Sean Gerrish, Chong Wang, Jordan L Boyd-Graber, and David M Blei. 2009. Reading tea leaves: How humans interpret topic models. In Advances in neural information processing systems. Curran Associates, Inc., 288–296.
- Cohen et al. (2014) Raphael Cohen, Iddo Aviram, Michael Elhadad, and Noémie Elhadad. 2014. Redundancy-aware topic modeling for patient record notes. PloS one 9, 2 (2014), e87555.
- Cordeiro (2012) Mário Cordeiro. 2012. Twitter event detection: combining wavelet analysis and topic inference summarization. In Doctoral symposium on informatics engineering, Vol. 1. 11–16.
- Curiskis et al. (2020) Stephan A Curiskis, Barry Drake, Thomas R Osborn, and Paul J Kennedy. 2020. An evaluation of document clustering and topic modelling in two online social networks: Twitter and Reddit. Information Processing & Management 57, 2 (2020), 102034.
- De Choudhury and De (2014) Munmun De Choudhury and Shoubhik De. 2014. Mental health discourse on Reddit: Self-disclosure, social support, and anonymity. In Proceedings of the 8th International AAAI Conference on Weblogs and Social Media.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805 (2018).
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
- DiMaggio et al. (2013) Paul DiMaggio, Manish Nag, and David Blei. 2013. Exploiting affinities between topic modeling and the sociological perspective on culture: Application to newspaper coverage of US government arts funding. Poetics 41, 6 (2013), 570–606.
- Donnelly (2023) Hayoung Kim Donnelly. 2023. Disclosure of suicidal drivers on social media: a natural language processing and thematic analysis approach. Ph. D. Dissertation. Boston University.
- Dou et al. (2013) Wenwen Dou, Li Yu, Xiaoyu Wang, Zhiqiang Ma, and William Ribarsky. 2013. Hierarchicaltopics: Visually exploring large text collections using topic hierarchies. IEEE Transactions on Visualization and Computer Graphics 19, 12 (2013), 2002–2011.
- Dugan et al. (2008) Casey Dugan, Werner Geyer, Michael Muller, Joan DiMicco, Beth Brownholtz, and David R Millen. 2008. It’s all’about you’ diversity in online profiles. In Proceedings of the 2008 ACM conference on Computer supported cooperative work. 703–706.
- Egger and Yu (2022) Roman Egger and Jiang Yu. 2022. A topic modeling comparison between LDA, NMF, Top2Vec, and BERTopic to demystify Twitter posts. Frontiers in Sociology 7 (2022), 879667.
- Eysenbach (2005) Gunther Eysenbach. 2005. Patient-to-patient communication: support groups and virtual communities. In Consumer health informatics: Informing consumers and improving health care. Springer, 97–106.
- Fan and Gordon (2014) Weiguo Fan and Michael D Gordon. 2014. The power of social media analytics. Commun. ACM 57, 6 (2014), 74–81.
- Feuston and Brubaker (2021) Jessica L Feuston and Jed R Brubaker. 2021. Putting tools in their place: The role of time and perspective in human-AI collaboration for qualitative analysis. Proceedings of the ACM on Human-Computer Interaction 5, CSCW2 (2021), 1–25.
- Garg (2023) Muskan Garg. 2023. Mental health analysis in social media posts: A survey. Archives of Computational Methods in Engineering 30, 3 (2023), 1819–1842.
- Gauthier (2020) Robert Gauthier. 2020. I will not drink with you today. Mental Health Support (2020).
- Gauthier et al. (2022) Robert P Gauthier, Mary Jean Costello, and James R Wallace. 2022. “I Will Not Drink With You Today”: A Topic-Guided Thematic Analysis of Addiction Recovery on Reddit. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–17.
- Gauthier et al. (2023) Robert P Gauthier, Catherine Pelletier, Laurie-Ann Carrier, Maude Dionne, Ève Dubé, Samantha Meyer, and James R Wallace. 2023. Agency and amplification: a comparison of manual and computational thematic analyses by public health researchers. Proceedings of the ACM on Human-Computer Interaction 7, GROUP (2023), 1–22.
- Gauthier and Wallace (2022) Robert P. Gauthier and James R. Wallace. 2022. The computational thematic analysis toolkit. Proceedings of the ACM on Human-Computer Interaction 6, GROUP (2022), 1–15.
- Gillies et al. (2022) Marco Gillies, Dhiraj Murthy, Harry Brenton, and Rapheal Olaniyan. 2022. Theme and topic: How qualitative research and topic modeling can be brought together. arXiv preprint arXiv:2210.00707 (2022).
- Grimmer (2010) Justin Grimmer. 2010. Discovering Public Opinion with Topic Models. Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing 1 (2010), 246–249. https://journals.sagepub.com/doi/10.1177/1065912910367483
- Grootendorst (2022) Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794 (2022). https://arxiv.org/pdf/2203.05794
- Guerra and Karakuş (2023) Alessio Guerra and Oktay Karakuş. 2023. Sentiment analysis for measuring hope and fear from Reddit posts during the 2022 Russo-Ukrainian conflict. Frontiers in Artificial Intelligence 6 (2023), 1163577.
- Haghighi et al. (2018) N Nima Haghighi, Xiaoyue Cathy Liu, Ran Wei, Wenwen Li, and Hu Shao. 2018. Using Twitter data for transit performance assessment: a framework for evaluating transit riders’ opinions about quality of service. Public Transport 10 (2018), 363–377.
- Haimson et al. (2015) Oliver L Haimson, Jed R Brubaker, Lynn Dombrowski, and Gillian R Hayes. 2015. Disclosure, stress, and support during gender transition on Facebook. In Proceedings of the 18th ACM conference on computer supported cooperative work & social computing. 1176–1190.
- Han et al. (2021) Albert Tonghoon Han, Lucie Laurian, and Jim Dewald. 2021. Plans versus political priorities: Lessons from municipal election candidates’ social media communications. Journal of the American Planning Association 87, 2 (2021), 211–227.
- Heldman et al. (2013) Amy Burnett Heldman, Jessica Schindelar, and James B Weaver. 2013. Social media engagement and public health communication: implications for public health organizations being truly “social”. Public health reviews 35 (2013), 1–18.
- Hoffman et al. (2010) Matthew D. Hoffman, David M. Blei, and Francis Bach. 2010. Online Learning for Latent Dirichlet Allocation. In Advances in Neural Information Processing Systems, Vol. 23. 856–864. https://papers.nips.cc/paper/2010/hash/71f6278d140af599e06e3d2e91a2e1f5-Abstract.html
- Holzinger (2016) Andreas Holzinger. 2016. Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain informatics 3, 2 (2016), 119–131.
- Hong and Davison (2010) Liangjie Hong and Brian D Davison. 2010. Empirical study of topic modeling in Twitter. In Proceedings of the First Workshop on Social Media Analytics. 80–88.
- Hu et al. (2014) Yuening Hu, Jordan Boyd-Graber, Brianna Satinoff, and Alison Smith. 2014. Interactive topic modeling. Machine learning 95 (2014), 423–469.
- Jacobi et al. (2018) Carina Jacobi, Wouter Van Atteveldt, and Kasper Welbers. 2018. Quantitative analysis of large amounts of journalistic texts using topic modelling. In Rethinking Research Methods in an Age of Digital Journalism. Routledge, 89–106.
- Jelodar et al. (2019) Hamed Jelodar, Yanchao Wang, Chi Yuan, Xiahui Feng, Xiaohui Jiang, Yong Li, and Liang Zhao. 2019. Latent Dirichlet Allocation (LDA) and topic modeling: models, applications, a survey. Multimedia Tools and Applications 78, 11 (2019), 15121–15137.
- Jiang et al. (2021) Jialun Aaron Jiang, Kandrea Wade, Casey Fiesler, and Jed R Brubaker. 2021. Supporting serendipity: Opportunities and challenges for Human-AI Collaboration in qualitative analysis. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (2021), 1–23.
- Kapoor et al. (2018) Kawaljeet Kaur Kapoor, Kuttimani Tamilmani, Nripendra P Rana, Pushp Patil, Yogesh K Dwivedi, and Sridhar Nerur. 2018. Advances in social media research: Past, present and future. Information Systems Frontiers 20 (2018), 531–558.
- Karas et al. (2022) Bradley Karas, Sue Qu, Yanji Xu, and Qian Zhu. 2022. Experiments with LDA and Top2Vec for embedded topic discovery on social media data—A case study of cystic fibrosis. Frontiers in Artificial Intelligence 5 (2022), 948313.
- Khan and Ali (2023) Aysha Khan and Rashid Ali. 2023. Measuring the Effectiveness of LDA-Based Clustering for Social Media Data. In 2023 International Conference on Advances in Intelligent Computing and Applications (AICAPS). IEEE, 1–8.
- Kumar et al. (2022) Navin Kumar, Isabel Corpus, Meher Hans, Nikhil Harle, Nan Yang, Curtis McDonald, Shinpei Nakamura Sakai, Kamila Janmohamed, Keyu Chen, Frederick L Altice, et al. 2022. COVID-19 vaccine perceptions in the initial phases of US vaccine roll-out: an observational study on reddit. BMC public health 22, 1 (2022), 446.
- Lee and Seung (1999) Daniel D. Lee and H. Sebastian Seung. 1999. Learning the parts of objects by non-negative matrix factorization. In Nature, Vol. 401. 788–791.
- Lee and Seung (2001) Daniel D. Lee and H. Sebastian Seung. 2001. Algorithms for non-negative matrix factorization. Advances in Neural Information Processing Systems 13 (2001), 556–562.
- Lewis et al. (2013) Seth C Lewis, Rodrigo Zamith, and Alfred Hermida. 2013. Content analysis in an era of big data: A hybrid approach to computational and manual methods. Journal of broadcasting & electronic media 57, 1 (2013), 34–52.
- Lochmiller (2021) Chad R Lochmiller. 2021. Conducting thematic analysis with qualitative data. The Qualitative Report 26, 6 (2021), 2029–2044.
- Ma and Kim (2023) Ruijundi Ma and Yong Jin Kim. 2023. Tracing the evolution of green logistics: A latent dirichlet allocation based topic modeling technology and roadmapping. Plos one 18, 8 (2023), e0290074.
- Mandava et al. (2023) Shreya Mandava, Isabelle Ciaverelli, Casey Resnick, and James Daniero. 2023. Characterizing Gender-Affirming Voice Intervention Discussion on Social Media: A Cross-Platform Analysis. Journal of Voice (2023).
- Mazarura and De Waal (2016) Jocelyn Mazarura and Alta De Waal. 2016. A comparison of the performance of latent Dirichlet allocation and the Dirichlet multinomial mixture model on short text. In 2016 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech). IEEE, 1–6.
- Melton et al. (2021) Chad A Melton, Olufunto A Olusanya, Nariman Ammar, and Arash Shaban-Nejad. 2021. Public sentiment analysis and topic modeling regarding COVID-19 vaccines on the Reddit social media platform: A call to action for strengthening vaccine confidence. Journal of Infection and Public Health 14, 10 (2021), 1505–1512. https://doi.org/10.1016/j.jiph.2021.08.010
- Morris et al. (2010) Meredith Morris, Jaime Teevan, and Katrina Panovich. 2010. A comparison of information seeking using search engines and social networks. In Proceedings of the International AAAI Conference on Web and Social Media, Vol. 4. 291–294.
- Mu et al. (2024) Yida Mu, Chun Dong, Kalina Bontcheva, and Xingyi Song. 2024. Large Language Models Offer an Alternative to the Traditional Approach of Topic Modelling. arXiv preprint arXiv:2403.16248 (2024).
- Newman et al. (2010) David Newman, Jey Han Lau, Karl Grieser, and Timothy Baldwin. 2010. Automatic evaluation of topic coherence. In Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 100–108.
- Owoahene Acheampong and Nyaaba (2024) Kwame Owoahene Acheampong and Matthew Nyaaba. 2024. Review of Qualitative Research in the Era of Generative Artificial Intelligence. Matthew, Review of Qualitative Research in the Era of Generative Artificial Intelligence (January 7, 2024) (2024).
- O’Callaghan et al. (2015) Derek O’Callaghan, Derek Greene, Maura Conway, Joe Carthy, and Pádraig Cunningham. 2015. Down the (white) rabbit hole: The extreme right and online recommender systems. Social Science Computer Review 33, 4 (2015), 459–478.
- Paatero and Tapper (1994) Pentti Paatero and Unto Tapper. 1994. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 5, 2 (1994), 111–126.
- Parsa et al. (2022) Mohammad S Parsa, Haoqi Shi, Yihao Xu, Aaron Yim, Yaolun Yin, and Lukasz Golab. 2022. Analyzing climate change discussions on reddit. In 2022 International Conference on Computational Science and Computational Intelligence (CSCI). IEEE, 826–832.
- Pousti et al. (2021) Hamid Pousti, Cathy Urquhart, and Henry Linger. 2021. Researching the virtual: A framework for reflexivity in qualitative social media research. Information Systems Journal 31, 3 (2021), 356–383.
- Pretorius et al. (2020) Cacinda Pretorius, David Chambers, and David Coyle. 2020. Designing for mental health: Data privacy and user experience in digital interventions. In Proceedings of the 2020 CHI conference on human factors in computing systems.
- Proferes et al. (2021) Nicholas Proferes, Naiyan Jones, Sarah Gilbert, Casey Fiesler, and Michael Zimmer. 2021. Studying reddit: A systematic overview of disciplines, approaches, methods, and ethics. Social Media+ Society 7, 2 (2021), 20563051211019004.
- Pujara and Skomoroch (2012) Jay Pujara and Peter Skomoroch. 2012. Large-scale hierarchical topic models. In NIPS Workshop on Big Learning, Vol. 128.
- Rahmadan et al. (2020) M Choirul Rahmadan, Achmad Nizar Hidayanto, Dika Swadani Ekasari, Betty Purwandari, et al. 2020. Sentiment analysis and topic modelling using the lda method related to the flood disaster in jakarta on twitter. In 2020 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS). IEEE, 126–130.
- Rana et al. (2016) Toqir A Rana, Yu-N Cheah, and Sukumar Letchmunan. 2016. Topic Modeling in Sentiment Analysis: A Systematic Review. Journal of ICT Research & Applications 10, 1 (2016).
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019).
- Rocha-Silva et al. (2023) Tiago Rocha-Silva, Conceição Nogueira, and Liliana Rodrigues. 2023. Passive data collection on Reddit: a practical approach. Research Ethics (2023), 17470161231210542.
- Rotolo et al. (2022) Eve Rotolo, Bobbi, Maryline Vivion, Shannon E MacDonald, and Samantha B Meyer. 2022. Hesitancy towards COVID-19 vaccines on social media in Canada. Vaccine 40, 19 (2022), 2790–2796.
- Rubya and Yarosh (2017) Sadia Rubya and Svetlana Yarosh. 2017. Video-mediated peer support in an online community for recovery from substance use disorders. In Proceedings of the 2017 ACM conference on computer supported cooperative work and social computing. 1454–1469.
- Ryan et al. (2017) Tracii Ryan, Kelly A Allen, DeLeon L Gray, and Dennis M McInerney. 2017. How social are social media? A review of online social behaviour and connectedness. Journal of Relationships Research 8 (2017), e8.
- Sawant et al. (2022) Sahil Sawant, Jinhong Yu, Kirtikumar Pandya, Chun-Kit Ngan, and Rolf Bardeli. 2022. An Enhanced BERTopic Framework and Algorithm for Improving Topic Coherence and Diversity. In 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys). IEEE, 2251–2257.
- Siiman et al. (2023) Leo A Siiman, Meeli Rannastu-Avalos, Johanna Pöysä-Tarhonen, Päivi Häkkinen, and Margus Pedaste. 2023. Opportunities and challenges for AI-assisted qualitative data analysis: An example from collaborative problem-solving discourse data. In International Conference on Innovative Technologies and Learning. Springer, 87–96.
- Skeels and Grudin (2009) Meredith M Skeels and Jonathan Grudin. 2009. When social networks cross boundaries: a case study of workplace use of facebook and linkedin. In Proceedings of the 2009 ACM International Conference on Supporting Group Work. 95–104.
- Steinfield et al. (2009) Charles Steinfield, Joan M DiMicco, Nicole B Ellison, and Cliff Lampe. 2009. Bowling online: social networking and social capital within the organization. In Proceedings of the fourth international conference on Communities and technologies. 245–254.
- Stieglitz et al. (2020) Stefan Stieglitz, Christian Meske, Björn Ross, and Milad Mirbabaie. 2020. Going back in time to predict the future-the complex role of the data collection period in social media analytics. Information Systems Frontiers 22 (2020), 395–409.
- Tadesse et al. (2019) Michael M Tadesse, Hongfei Lin, Bo Xu, and Liang Yang. 2019. Detection of depression-related posts in reddit social media forum. Ieee Access 7 (2019), 44883–44893.
- Teh et al. (2006) Yee Whye Teh, Michael I. Jordan, Matthew J. Beal, and David M. Blei. 2006. Hierarchical Dirichlet Processes. J. Amer. Statist. Assoc. 101, 476 (2006), 1566–1581. https://www.jstor.org/stable/27644680
- Tsou et al. (2015) Ming-Hsiang Tsou et al. 2015. Social media analytics and research: Applications in crisis management. Transactions in GIS 19, 5 (2015), 768–788.
- Van der Maaten and Hinton (2008) Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, 11 (2008).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Vayansky and Kumar (2020) Ike Vayansky and Sathish AP Kumar. 2020. A review of topic modeling methods. Information Systems 94 (2020), 101582.
- Wallace et al. (2017) Jayne Wallace, Peter Wright, John McCarthy, and Patrick Olivier. 2017. Ageing, chronic illness, and the role of social media. Proceedings of the ACM on Human-Computer Interaction 1, CSCW (2017), 1–21.
- Wallach et al. (2009) Hanna M Wallach, Iain Murray, Ruslan Salakhutdinov, and David Mimno. 2009. Evaluation methods for topic models. In Proceedings of the 26th annual international conference on machine learning. 1105–1112.
- Wu et al. (2008) Zhi-li Wu, Chi-wa Cheng, and Chun-hung Li. 2008. Social and semantics analysis via non-negative matrix factorization. In Proceedings of the 17th international conference on World Wide Web. 1245–1246.
- Xu et al. (2015) Jiaming Xu, Peng Wang, Guanhua Tian, Bo Xu, Jun Zhao, Fangyuan Wang, and Hongwei Hao. 2015. Short text clustering via convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing. 62–69.
- Yan et al. (2013) Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. 2013. A biterm topic model for short texts. In Proceedings of the 22nd international conference on World Wide Web. ACM, 1445–1456.
- Yang et al. (2021) J. Yang, J. Guo, and H. Sun. 2021. A Multimodal Approach to Analyzing Social Media Data: Combining Machine Learning and Qualitative Methods. Social Science Computer Review 39, 1 (2021), 3–20. https://doi.org/[invalidURLremoved]
- Zhang et al. (2024) Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B Hashimoto. 2024. Benchmarking large language models for news summarization. Transactions of the Association for Computational Linguistics 12 (2024), 39–57.
- Zhang et al. (2017) Yin Zhang, Min Chen, Dijiang Huang, Di Wu, and Yong Li. 2017. iDoctor: Personalized and professionalized medical recommendations based on hybrid matrix factorization. Future Generation Computer Systems 66 (2017), 30–35.
- Zhao et al. (2011) Wayne X Zhao, Jing Jiang, Jianshu Weng, Jing He, Ee-Peng Lim, Hongfei Yan, and Xiaoming Li. 2011. Comparing twitter and traditional media using topic models. In Advances in Information Retrieval. Springer, 338–349.
- Zou and Song (2016) Luyi Zou and William Wei Song. 2016. LDA-TM: A two-step approach to Twitter topic data clustering. In 2016 IEEE international conference on cloud computing and big data analysis (ICCCBDA). IEEE, 342–347.