MTSIC: Multi-stage Transformer-based GAN for Spectral Infrared Image Colorization
Abstract
Thermal infrared (TIR) images, acquired through thermal radiation imaging, are unaffected by variations in lighting conditions and atmospheric haze. However, TIR images inherently lack color and texture information, limiting downstream tasks and potentially causing visual fatigue. Existing colorization methods primarily rely on single-band images with limited spectral information and insufficient feature extraction capabilities, which often result in image distortion and semantic ambiguity. In contrast, multiband infrared imagery provides richer spectral data, facilitating the preservation of finer details and enhancing semantic accuracy. In this paper, we propose a generative adversarial network (GAN)-based framework designed to integrate spectral information to enhance the colorization of infrared images. The framework employs a multi-stage spectral self-attention Transformer network (MTSIC) as the generator. Each spectral feature is treated as a token for self-attention computation, and a multi-head self-attention mechanism forms a spatial-spectral attention residual block (SARB), achieving multi-band feature mapping and reducing semantic confusion. Multiple SARB units are integrated into a Transformer-based single-stage network (STformer), which uses a U-shaped architecture to extract contextual information, combined with multi-scale wavelet blocks (MSWB) to align semantic information in the spatial-frequency dual domain. Multiple STformer modules are cascaded to form MTSIC, progressively optimizing the reconstruction quality. Experimental results demonstrate that the proposed method significantly outperforms traditional techniques and effectively enhances the visual quality of infrared images.
Index Terms:
Infrared spectral image, Colorization technique, Transformer, Spectral self-attention mechanism, Multi-Scale wavelet blockI Introduction
Thermal infrared (TIR) imaging captures objects’ thermal radiation, enabling all-weather applications in areas such as security surveillance, automotive navigation, and nighttime traffic monitoring [1]. Unlike visible-light images, TIR images are typically grayscale, lacking both color and fine texture details [2]. The human visual system can discern thousands of hues and intensities, but only around two dozen shades of gray [3]. Prolonged viewing of grayscale images can also lead to visual fatigue, further highlighting the necessity of colorization. Colorization enhances visual expressiveness, improves information conveyance, and facilitates human-computer interaction. Much like the historical shift from black-and-white to color film, colorized images are better suited for object recognition, interpretation, and analysis. Colorization involves assigning colors to grayscale images, yet a single gray value can correspond to a wide range of plausible colors depending on the real-world context. For instance, a flower might appear red, yellow, or white, while a car could have numerous possible color schemes. As a result, the colorization task is inherently nonlinear and ill-posed [4]. An effective colorization does not require exact replication of the original colors but should instead appear natural and perceptually convincing [5]. The goal of natural colorization is to produce realistic and credible color distributions rather than a single ”ground truth.” Despite the subjective nature of this process, it must adhere to semantic constraints—for example, skies should not appear purple, nor should deserts be colored blue.
TIR image colorization is an image-to-image translation task that aims to learn an optimal mapping from the TIR domain (source) to the color visible domain (target) [6]. This task is particularly challenging due to fundamental differences in imaging mechanisms between IR and visible-light modalities. While TIR images encode thermal radiation as grayscale intensities, they lack chromatic information and often exhibit reduced structural detail compared to visible-light images [7]. Existing colorization methods designed for visible grayscale images are often inadequate for TIR data. For instance, in nighttime TIR images, occupants inside vehicles may blend into the background due to uniform thermal signatures, whereas visible grayscale images—even under low illumination—retain some structural cues. Moreover, even with pixel-aligned visible-light reference images, reconstructing missing chromatic and textural details during TIR colorization remains difficult [7]. Thus, TIR colorization fundamentally requires disentangling content from appearance, requiring both the enhancement of texture and semantic consistency.
An ideal TIR image colorization should produce natural colors while maintaining semantic consistency and sharp structural edges, which is crucial for downstream vision tasks. The colorization process typically consists of three stages—encoding, mapping, and rendering—each presenting distinct challenges [8]. In the encoding stage, due to the absence of color and textural cues in IR images, the network may suffer from neighborhood entanglement, where semantically distinct regions (e.g., vehicles and road surfaces) are incorrectly grouped due to similar thermal signatures. During mapping stage, constrained by semantic supervision, the model may oversimplify textures to fit broad categorical priors, leading to semantic distortion. This issue is particularly pronounced in small-sample categories, where limited training data exacerbates feature misalignment. In the rendering stage, small objects are prone to appearance distortion, as their limited pixel area and complex features make colorization unstable. This results in reduced naturalness and visual coherence.
Traditional colorization methods, such as manual coloring, lookup tables, histogram matching, and reference image fusion, rely on prior knowledge and struggle to adaptively align infrared images with semantics and colors [9]. Recent advances in deep learning have introduced new approaches, primarily CNN- and GAN-based methods [10]. CNNs achieve colorization through cross-domain mapping and pixel-level losses but often suffer from blurring, color shifts, and detail loss. GANs employ adversarial loss to constrain appearance and enhance detail expression with pixel loss. Although these methods continuously optimize architectures and strategies, performing well in simple scenes, they still face challenges in complex environments, such as semantic inconsistency, difficulty in small-object recognition, and feature confusion. The main reasons include: (1) limited model expressiveness, and (2) reliance on single-band input, leading to an information bottleneck that hinders compensation for source data deficiencies. In contrast, infrared spectral imaging captures radiation characteristics across multiple narrow bands, enhancing spectral dimensionality and information richness from the source. It provides stronger discriminative ability for materials, boundaries, and environments, facilitating realistic color restoration, semantic structure preservation, and improved interpretability [11]. Therefore, enhancing colorization performance depends not only on network design but also on improving input image quality. Spectral images, richer in details and semantics than single-band images, are widely used in road segmentation, environmental monitoring, and other tasks [12, 13, 14, 15].
However, due to the high dimensionality and strong inter-band correlation of spectral images, existing methods designed for single-band images fail to effectively model spectral dependencies, limiting their ability to fully extract informative features. High-dimensional feature extraction requires deeper networks, yet mainstream GAN generators often adopt UNet [16, 6], ResNet [17, 8], or their variants [7, 10, 4], which have limited representational capacity and tend to produce blurred or distorted textures. Moreover, with insufficient training samples, spectral images are prone to the “Hughes phenomenon,” leading to degraded model performance [13, 11, 18]. Thus, effectively modeling spatial-spectral information and optimizing networks to improve colorization accuracy remain key challenges.

To address these issues, this paper proposes a conditional GAN framework named MTSIC from two perspectives: spectral information enhancement and structural optimization. On one hand, multi-band infrared spectral images are utilized as input, expanding the input from a single spectral dimension to a higher-dimensional representation, which significantly enriches semantic perception and detail recovery. On the other hand, the network structure is optimized to improve feature extraction and mapping capabilities. Specifically, considering the spatial sparsity and high inter-band correlation of spectral images, a multi-head self-attention mechanism along the spectral dimension is introduced in the generator to enable collaborative modeling of multi-band features via query tokens. A single-stage spectral Transformer (STformer) is constructed using the SARB module as the basic unit. The STformer adopts a U-shaped architecture to extract contextual information, effectively alleviating detail loss and semantic confusion in complex backgrounds. To enhance colorization of small target regions, a multi-scale wavelet transform is integrated into the bottleneck layer, achieving cross-scale alignment in both frequency and spatial domains. Multiple STformers are cascaded to form the MTSIC network for progressive reconstruction refinement. In addition, frequency, edge, and spectral angle losses are incorporated into the conventional GAN loss to improve reconstruction quality in terms of texture, structure, and color.
As shown in Figure 1, the proposed method outperforms two classical single-band infrared colorization approaches in visual quality and semantic preservation. The first two subfigures show YOLOv7 detection results on the multispectral KAIST dataset. In the first, the thermal image lacks texture detail, making targets hard to detect, while the NVC image introduces false detections due to complex lighting (e.g., unclear vehicles, misclassified roads). By enhancing color and structure, the proposed method significantly improves detection. The second subfigure shows better preservation of building geometry, effectively reducing structural distortion.
In summary, the main contributions of this work are outlined as follows:
(1) A new GAN framework incorporating spectral information is proposed, marking the first deep learning-based approach for natural colorization of infrared hyperspectral images.
(2) A novel multi-stage Transformer-based generator, MTSIC, is proposed. At each stage, a spectral multi-head self-attention mechanism captures global spectral correlations, integrating spatial-spectral features to reduce semantic confusion and improve colorization performance.
(3) A multiscale wavelet transform is incorporated into the single-stage Transformer for frequency-domain feature mapping, enabling semantic alignment between frequency and spatial-domain features. This integration allows the model to better focus on regions with significant edge and texture variations.
(4) The infrared hyperspectral remote sensing dataset used for colorization was self-collected. In addition, multiple evaluation metrics were introduced to comprehensively validate the effectiveness of the proposed method.
II Related Work
II-A Existing Methods for Infrared Image Colorization
Infrared images often suffer from detail loss and low quality, making conventional grayscale colorization methods ineffective. Specialized models are needed to improve feature extraction and reconstruction. Current approaches fall into two categories: CNN-based and GAN-based methods [10]. CNNs, such as lightweight UNet variants like TIR [21], are efficient for simple scenes but lack detail recovery. Limmer et al. [22] introduced high-frequency feature transfer to preserve some details, but performance remains limited. GAN-based methods, leveraging strong generative capabilities, are widely adopted. Kuang et al. [6] enhanced Pix2Pix [16] with improved generators and loss functions to boost realism, but small target details were lost. Chen et al. [7] and Sigillo et al. [23] refined TICC-GAN [6] to enhance edges, yet unrealistic colors and texture loss persist. Lou et al.’s MornGAN [8] uses a ResNet generator and memory guidance to reduce feature aliasing. However, its segmentation loss relies heavily on the performance of the segmentation network, and the generated colors are unrealistic. He et al. [24] combined UNet with ViT for better semantic decoding, though small target confusion remained. Chen et al. [10] improved generator (UNet++) in FRAGAN for better detail and semantics, but small target colorization and structure reconstruction are still limited. Liao et al.’s MUGAN [4], merging UNet++ and UNet3+ variants as generator, also struggles with small target loss and geometric distortion in complex scenes.
Overall, despite progress in deep learning for infrared image colorization, two main challenges remain: (1) semantic confusion and unrealistic colors in cross-domain colorization, which hinder accurate small target recognition and content consistency; (2) reliance on single-band images and focus on vehicular scenes, limiting effectiveness in complex scenarios like remote sensing. As infrared images are widely used in remote sensing tasks such as object extraction, change detection, and environmental monitoring [2], integrating multi-band information is essential to improve colorization quality and address current limitations.
II-B Infrared spectral image colorization
Multi-band infrared spectral images offer richer radiative information, higher material identification accuracy, and better adaptability than single-band images [12]. By capturing responses across multiple narrow bands, they enable precise identification, especially for distinguishing similar hetero-isomers, and are widely used in applications like driver assistance and road segmentation [25].
Colorizing multi-band infrared images enhances visualization and detail perception. TeX Vision, introduced in HADAR [15], generates pseudo-color images in HSV space using a thermal signal equation based on temperature (T), emissivity (e), and texture (X). However, the multi-to-one mapping from thermal radiation (S) to T/e/X makes the problem ill-posed [26], reducing recognition accuracy in complex scenes and for small targets. TeX Vision also depends on pre-built material libraries, which may not generalize to new materials, and suffers from high computational complexity and sensitivity to environmental factors like temperature and humidity.
To address these issues, this paper proposes a deep learning-based, data-driven method that learns semantic and color mappings between multi-band infrared and visible images to generate natural-looking visible images. The approach generalizes well to complex scenes such as remote sensing and can also be applied to single-band infrared image colorization, improving the applicability of infrared image colorization.
II-C Vision Transformer and Wavelet Transform
Originally designed for machine translation, Transformers have been widely adopted in vision tasks like super-resolution [12], classification [27], and object detection [28]. However, traditional Transformers focus on spatial modeling and are less effective for spectral images due to spatial sparsity and strong spectral correlations, making them ill-suited for handling spectral redundancy. To address this, we introduce Spectral Multi-head Self-Attention (SMSA) for infrared image colorization. SMSA computes self-attention along the spectral dimension, capturing both local and global spectral dependencies for improved representation. While GAN-based generators typically use ResNet or UNet variants, Transformer-based approaches for multi-band spectral image colorization remain largely unexplored.
In addition, frequency-based deep learning methods have gained interest. Most infrared colorization methods rely on spatial features and overlook frequency information. CNNs are biased toward low-frequency components [13, 29], prompting recent efforts to incorporate high-frequency representations—such as Fourier [30] and Haar wavelet [31] transforms—into vision tasks [29]. Frequency-domain analysis complements spatial features, particularly in regions of infrared images with significant grayscale variations. Since wavelet transforms provide both spatial and frequency information, support multi-resolution analysis, and are computationally efficient [29]. In this work, we integrate wavelet transforms into the Transformer framework to enhance multi-band infrared spectral image colorization.
III Proposed Method
This section first provides an overview of the proposed MTSIC network architecture, followed by detailed introductions to the single-stage STformer, SARB, and the multi-scale wavelet block (MSWB). Finally, the design of the discriminator and the loss functions is described.
III-A Overall Architecture
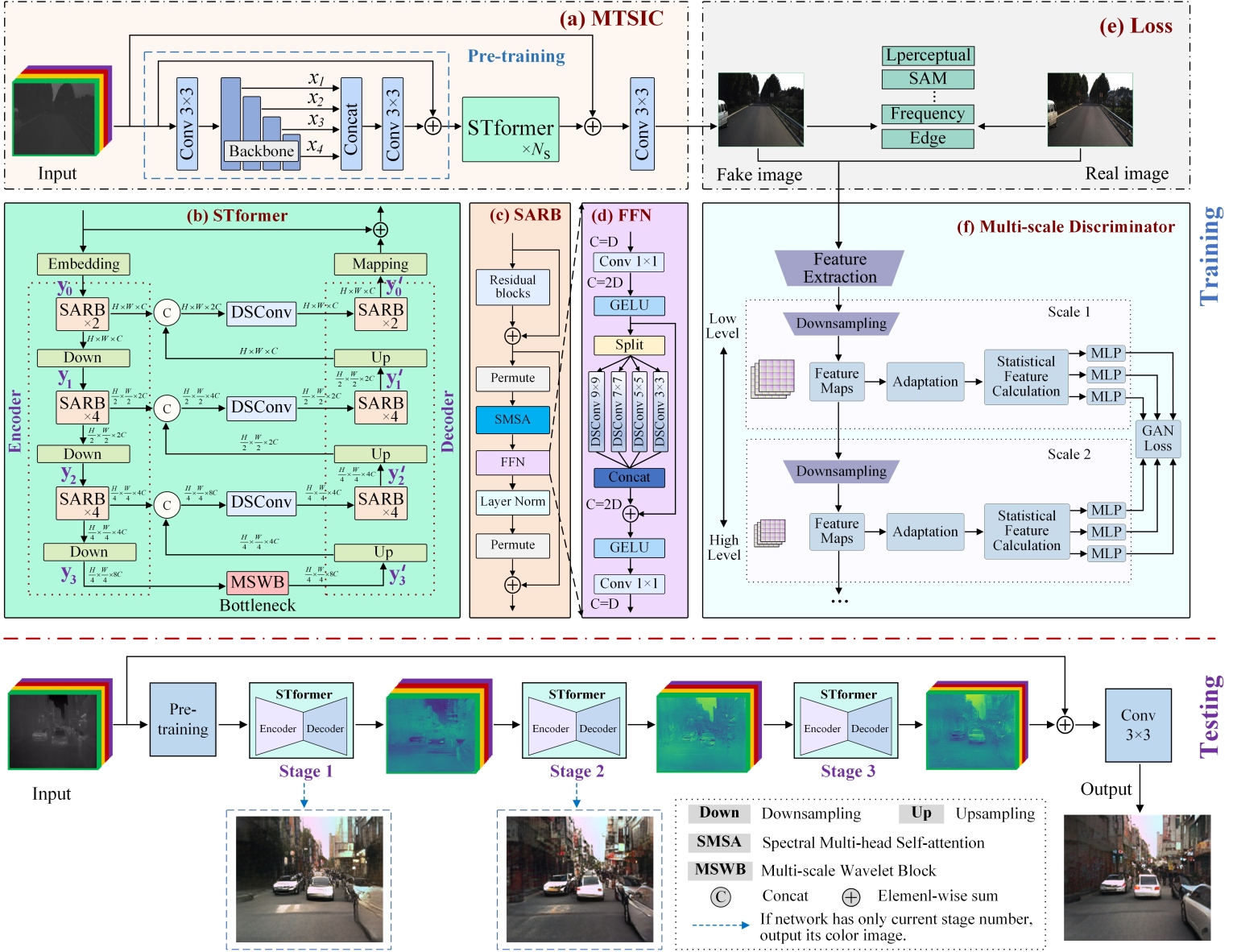
The overall architecture of MTSIC is shown in Figure 2 (a). A pre-trained ConvNeXt [32] is employed to efficiently extract spatial features, inspired by pixel-wise semantic segmentation to meet the fine-grained requirements of colorization. Given an input image , where is the number of spectral channels, a convolution is first applied to map the channels, followed by ConvNeXt to extract four hierarchical features: , , , , where . Features , , and are individually aligned via interpolation and then concatenated with the feature . The concatenated features are subsequently fused through convolution, enhancing the representation of both local details and global structures.
The MTSIC comprises cascaded STformer modules that reconstruct the corresponding daytime visible image from pre-trained spectral features. Local and global skip connections alleviate vanishing gradients and enhance feature reuse, improving training stability. The fusion of shallow and deep features further boosts convergence and representation.
III-B Single-stage Transformer-based Network
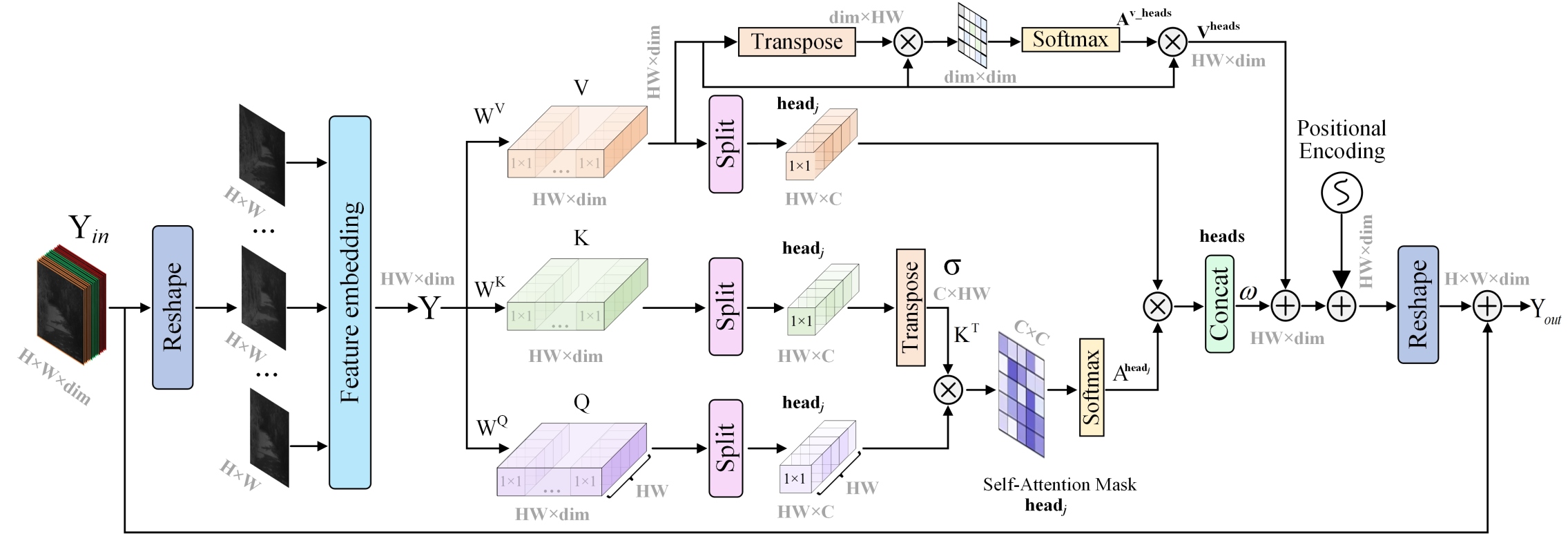
Figure 2 (b) illustrates the U-shaped STformer architecture, which consists of an encoder, decoder, and a bottleneck containing the MSWB module. Both the embedding and mapping layers use single-layer 33 convolutions. In the encoder, features pass through the embedding layer, two SARB modules, two downsampling convolutions (stride=4), and four additional SARB modules. The decoder mirrors this structure, using 22 transposed convolutions (stride = 2) for upsampling. Features from the encoder and decoder are fused via channel-wise concatenation followed by a 11 depthwise separable convolution (DSConv), enhancing multi-resolution representation and reducing computational complexity. This fusion strengthens the connection between local and global information, improving overall network performance.
Figure 2 (c) illustrates the structure of the SARB, which consists of a residual block, a feed-forward network (FFN, as shown in Figure 2 (d)), spectral multi-head self-attention, and two layer normalization operations.
Spatial-Spectral Attention Residual Block (SARB): The module fuses spatial-spectral information through multiple sub-units. Residual blocks first extract spatial features from the input , improving spatial information modeling. A spectral multi-head self-attention (SMSA) mechanism then captures inter-band correlations to enhance spectral features. Finally, a feed-forward network (FFN) learns the mapping between spatial and spectral features using nonlinear activation and fully connected layers. Residual connections ensure efficient information flow, boosting expressiveness and mitigating overfitting.
Spectral Multi-head Self-attention (SMSA): Assuming the input is used as the input to the SMSA, it is first reshaped into a matrix . Then, is linearly projected to obtain the Query matrix , Key matrix , and Value matrix , which are computed as follows:
| (1) |
The learnable projection weight matrices , , and are used for the Query, Key, and Value, respectively, forming the basis for spectral self-attention computation. For simplicity, biases are omitted. The model follows a U-shaped architecture with multiple SARB modules, where the feature dimension changes dynamically across layers. The number of heads is determined by the feature dimension dim and base dimension , with . The feature dimension doubles in the encoder and halves in the decoder, ensuring their symmetry. , , and are split into heads along the spectral channel: , , and , each with dimension .
Note that Figure 3 shows the case for , with some details omitted for simplicity. Unlike conventional multi-head self-attention (MSA), the proposed SMSA treats each spectral representation as an independent token. Efficient mapping across bands is achieved through learnable query tokens and multi-head spectral self-attention. The self-attention computation for the -th head (headj) is formulated as follows:
| (2) |
where, denotes the transpose of . Due to spectral density variation with wavelength, a learnable parameter is introduced to generate a new weight matrix via , which adjusts the self-attention weights for the -th head. The outputs of the heads are then concatenated, reorganized, and linearly projected to restore the original dimensionality. However, this ignores spectral correlations between heads. To address this, a dual-attention mechanism is introduced. First, before multi-head splitting, following the aforementioned procedure, spectral self-attention is computed from the matrix V, to capture correlations across the entire spectral range. Furthermore, is fused with the attention outputs of individual heads to enhance spectral continuity.
| (3) |
where, is a learnable weight matrix, and represents the position encoding function, implemented using two depthwise separable 3×3 convolutions followed by GELU activation. Position encoding captures the spectral channel’s positional information, as the spectral dimension is arranged by wavelength. By dynamically adjusting the number of heads, the model balances efficiency and capacity, effectively capturing spectral dependencies. The output from Equation (3) is reshaped and fused with shallow input features to enhance representation, producing the final output .
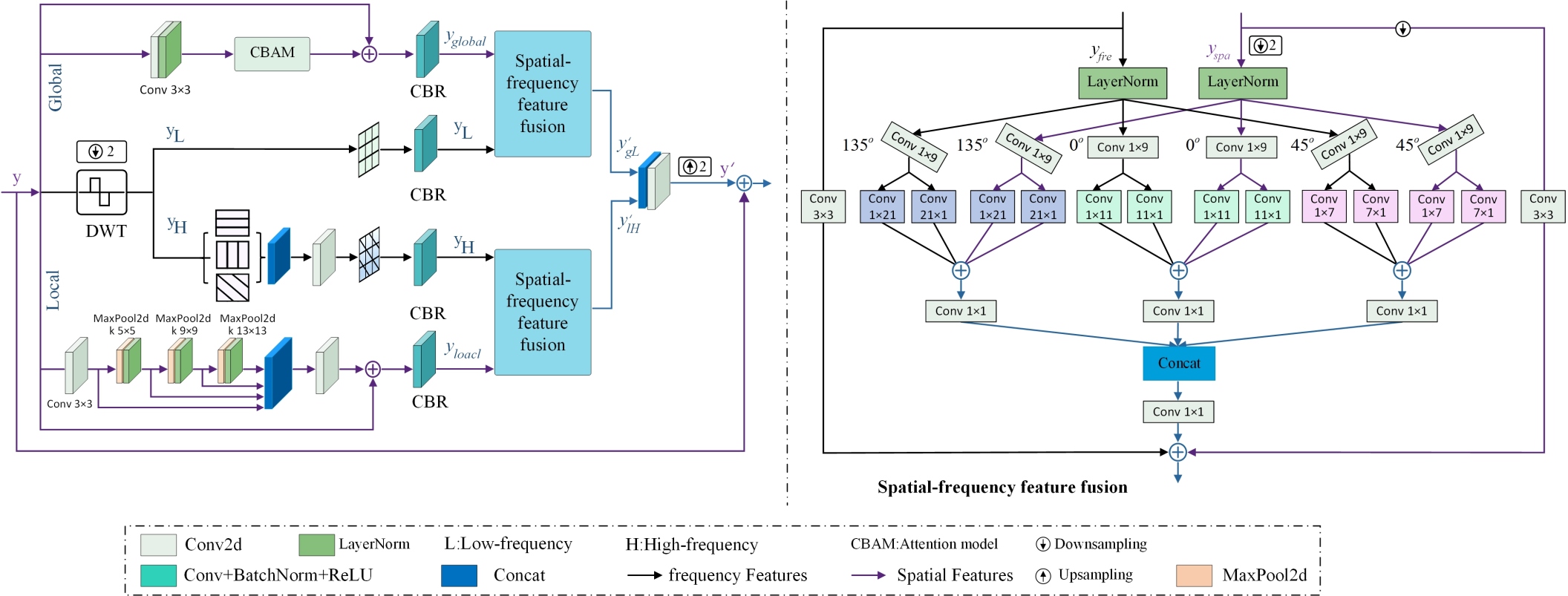
Multi-scale Wavelet Block (MSWB): As depicted in Figure 4, the MSWB consists of three branches to enhance feature selection and representation. The global branch employs CBAM [33] to enhance key feature identification through global spatial and channel recalibration, offering lower computational overhead compared to SMSA. The local branch employs consecutive multi-scale spatial pyramid pooling (55, 99, 1313) to extract features with varying receptive fields, while LayerNorm is incorporated to enhance the network’s nonlinear representation capability. Multi-scale information is fused through dimensional concatenation and convolution, effectively enriching detail representation. Since infrared images are discrete non-stationary signals containing multiple frequency components, the Haar wavelet transform is employed for multi-resolution decomposition to effectively capture local features and adapt to signal characteristics. In this work, the transform is used to map features into the frequency domain, decomposing them into a low-frequency component and three high-frequency components corresponding to horizontal, vertical, and diagonal directions, thereby enhancing edge and texture extraction. The wavelet branch converts spatial features into high-frequency features rich in local details and low-frequency features containing global information, providing more comprehensive frequency domain information. All branches utilize CBR units composed of convolution, Batch Normalization, and ReLU, where Batch Normalization improves training stability and ReLU enhances nonlinear representation capability.
| (4) |
where is the STformer encoder output, and , , and represent the global, local, and Haar wavelet transform branches, respectively. The features are denoted as (global), (multi-scale local), (low-frequency), and (high-frequency). The Haar wavelet transform downsamples by a factor of 2 ().
Subsequently, the spatial features and frequency-domain features are jointly fed into a spatial-frequency feature fusion module (SFFM), which aligns and integrates local high-frequency and global low-frequency information to obtain more discriminative hybrid features. Finally, the fused features are upsampled by a factor of 2 (), and a global skip connection integrates shallow features to further improve performance.
| (5) |
where, denotes the spatial-frequency feature fusion module. and represent the global features fused with frequency-domain information and the multi-scale local features, respectively. The final output is obtained by fusing the shallow input features and the hybrid features via a global residual connection.
The MSWB adopts a simple structure, avoiding the complexity of STformer. By fusing spatial and frequency features, it expands the representation space while retaining frequency information, improving accuracy and robustness in category recognition. Next, we introduce its core component—the SFFM module for semantic fusion.
The SFFM employs large strip convolution kernels ( and ) for multi-scale feature extraction, which expands the receptive field and reduces parameters. To overcome the fixed-direction limitation, direction-aware strip convolutions [34] (, , ) are introduced, enabling flexible multi-directional feature extraction. Feature fusion is performed via dimensional concatenation and convolutions. Additionally, the SFFM adopts a mirrored structure to fuse features from two branches. After extracting features with strip convolutions, the convolution results along the same direction are cross-fused between two branches. On this basis, local features extracted by 3×3 square convolutions are added to complement the linear features from the strip convolutions, further enhancing the feature representation capability.
| (6) |
| (7) | |||
| (8) |
where, denotes the spatial-domain input features after downsampling. To aggregate features from different branches, the spatial-scale features are downsampled at the same rate as in the wavelet transform, denoted as . represents the input features in the frequency domain. denotes a convolution, refers to asymmetric convolutions with kernel sizes of and , refers to directional strip convolutions applied along the directions (, , ), and represents layer normalization. , , and denote the output features of directional convolutions (, , ) with kernel sizes of and . denotes the output features of the multi-scale module, corresponding to and in Equation (5), respectively.
III-C Discriminator
The SPatchGAN [35] discriminator, depicted in Figure 2 (f), improves discrimination via multi-scale feature extraction and statistical computation. It takes an image (real or generated) and outputs , where is the scale index and is the statistical feature index. The structure consists of an initial feature extraction block and scale modules, each containing a downsampling block, an adaptation block, a statistical feature computation block, and MLPs. A simplified version with two scale modules is provided in Figure 2 (f). Feature maps are generated, reused at higher scales, and adjusted by the adaptation block. After extraction, image features go through downsampling, adaptation, statistical computation, and MLPs to produce scalar outputs.
Unlike traditional PatchGAN [16], which shares convolutional weights, SPatchGAN uses global statistical features for more stable and accurate discrimination, overcoming local receptive field limitations. Each feature is processed by an independent MLP, improving accuracy. Statistical matching is more reliable at lower scales, though harder at higher scales, where it approximates the input distribution. SPatchGAN aims to match the distribution of statistical features, not the input image distribution. We adopt key parameter settings from the SPatchGAN discriminator.
III-D Loss Function
The loss function measures the discrepancy between predictions and ground truth, guiding optimization. In infrared image colorization, a well-designed composite loss function improves translation quality. Based on this, a composite loss function for spectral infrared image colorization is developed:
cGAN Loss: The traditional GAN model maps random noise to a specific data distribution, but the process is unstable and the output is uncontrollable. Conditional GAN (cGAN) introduces constraints on both the generator and discriminator, providing additional guidance during learning [16]. The cGAN loss function is as follows:
| (9) | ||||
where, and denote the input spectral infrared image and its corresponding ground truth, respectively. The generator G seeks to minimize the objective function, while the discriminator D aims to maximize it.
Pixel Loss: In image reconstruction tasks, loss is commonly used as it penalizes pixel-level errors, aiding convergence. In this work, spatial pixel loss is employed to improve image detail recovery during colorization.
| (10) |
where, represents the learnable network parameters, and represents the Ground truth and the generated colorized image, respectively.
To minimize the chroma and luminance discrepancies between the generated colorized images and the ground truth, we introduce SAM loss [6], which measures channel similarity by computing the angle between spectral vectors. Based on pixel-space constraints, we incorporate a frequency-domain loss [36] to optimize low- and high-frequency components in both spatial and frequency domains, enhancing structure and details. Edge Loss [37] is introduced to penalize reconstruction errors in edge regions, improving edge detail recovery.
Objective Function: The combined loss model of , , , , and is adopted as the initial configuration of the proposed method. Building upon this setup and inspired by the high-performing loss functions in infrared image colorization tasks reported by Kuang et al. [6], perceptual loss , total variation loss , and structural similarity loss are incorporated as additional terms to enhance the realism and quality of the generated images. The objective function of the proposed method is defined as follows:
| (11) | ||||
where denotes the hyperparameter controlling the weighting of each loss function. Empirically, the values are set as , , , , and to ensure that all loss terms remain within the same order of magnitude. This hybrid loss function is designed to optimize network performance through spatial, spectral, and frequency domain reconstruction accuracy.
IV Experiments
This section introduces the infrared spectral dataset, evaluation metrics, and implementation details. It then compares the proposed method with existing approaches and conducts ablation studies to assess the contributions of individual modules and loss functions.
IV-A Datasets
(a) The KAIST dataset111https://github.com/SoonminHwang/rgbt-ped-detection is a multispectral pedestrian detection dataset containing 95,000 paired thermal and RGB images from day and night scenes in campus, road, and urban environments [38]. Due to low contrast and noise, thermal images pose detection challenges, which can be mitigated by colorization to enhance detail, contrast, and detection accuracy.
(b) The HSI ROAD dataset222NUST-Machine-Intelligence-Laboratory/hsi_road is a real-world hyperspectral road segmentation dataset with 28 spectral bands, consisting of 3,799 pairs of RGB and near-infrared images [39]. Unlike typical urban RGB datasets, it includes diverse road surfaces—such as asphalt, concrete, soil, and sand—under rural and natural conditions, enhancing diversity and representativeness for segmentation tasks.
(c) The IHSR dataset is a self-collected long-wave infrared hyperspectral remote sensing dataset captured in Hengdian Town, Zhejiang, China, covering diverse land-cover types including mountains, urban areas, rivers, parks, highways, and farmland. It offers 110 spectral bands spanning 8.0–11.3 m at a 1.0 m spatial resolution, with dimensions of . Corresponding labeled RGB images are .
IV-B Implementation details
Experiments were conducted on the KAIST, HSI ROAD, and IHSR datasets. For KAIST, nighttime campus, road, and urban scenes were used, with thermal-RGB pairs resized to and center-cropped to . HSI ROAD images, originally , were resized to , each containing RGB and near-infrared hyperspectral pairs. For IHSR, pixel-level registration in ENVI was followed by selecting 20 non-overlapping regions for testing and the rest for training. Due to limited spatial size, overlapping block sampling (stride 24) was used to extract training patches.
All datasets were augmented with random cropping to , rotation, and scaling. Models were trained for 60 epochs with an initial learning rate of , decaying linearly after epoch 30. A batch size of 1 and the Adam optimizer [40] were used. Experiments were run on Ubuntu 18.04 with PyTorch 2.0.1 and an RTX 3090 GPU.
IV-C Evaluation Metrics
Due to the absence of corresponding daytime visible-light labeled images in the KAIST dataset, semantic segmentation and object detection are used to evaluate the texture and color naturalness of the reconstructed images. For the HSI ROAD and IHSR datasets, network performance is evaluated using four image quality metrics (PQI): PSNR, SSIM [41], NIQE [42], and UIQI [43]. NIQE measures image naturalness by quantifying deviations from high-quality natural image models, while UIQI evaluates luminance, contrast, and structural similarity to the ground truth. PSNR and SSIM focus on content quality, with ideal values of and , respectively. NIQE and UIQI assess color quality, with ideal values of and .
In addition, a no-reference metric called Colorful is introduced, with an ideal value of 1, to subjectively assess the color richness of generated images. This indicator captures critical details affecting the visual experience and is based on the evaluation model proposed in [44]. To further evaluate the color distribution differences between the generated images and ground truth, this paper proposes a novel metric named ColorJSD. Unlike pixel-level metrics such as NIQE and UIQI, ColorJSD focuses on the similarity of overall color distributions based on probabilistic divergence. The expression of ColorJSD is defined as follows:
| (12) |
where, and represent the color distribution histograms of the generated and ground truth images, respectively, and denotes their average distribution. refers to the Kullback–Leibler (KL) divergence, calculated as follows:
| (13) |
The ideal value of ColorJSD is 0, indicating that the color distribution of the generated image closely matches that of the ground truth.
IV-D Comparisons With the State-of-the-Art Methods
To validate the superiority of our method, eight representative infrared image colorization approaches were compared, including pix2pix [16], TICC-GAN [6], ToDayGAN [17], FRAGAN_P [10], LKAT-GAN [24], DDGAN [7], MUGAN [4], and MornGAN [8]. Among them, pix2pix and ToDayGAN are general image-to-image translation frameworks, commonly applied to infrared colorization tasks. The others are specifically designed for single-band infrared images. We trained and evaluated all models using their official PyTorch implementations and original parameter settings on the same dataset.
(1) Experimental Results on the KAIST Multispectral Dataset
| Comparison | Road | Building | Sky | Person | Car | mIoU |
| Input NTIR image | 70.5 | 20.2 | 8.7 | 8.0 | 6.9 | 22.86 |
| Reference NVC image | 82.1 | 42.0 | 22.4 | 18.5 | 18.9 | 36.78 |
| pix2pix [16] | 75.2 | 19.7 | 10.3 | 9.3 | 12.8 | 25.46 |
| TICC-GAN [6] | 80.0 | 28.7 | 16.1 | 13.2 | 15.7 | 30.74 |
| TodayGAN [17] | 76.9 | 22.1 | 13.4 | 10.8 | 10.5 | 26.74 |
| DDGAN [7] | 75.5 | 24.2 | 11.5 | 8.7 | 9.7 | 25.92 |
| FRAGAN_P [10] | 79.7 | 29.9 | 15.8 | 11.3 | 13.1 | 29.96 |
| LKAT-GAN [24] | 81.2 | 32.4 | 17.1 | 14.6 | 17.1 | 32.48 |
| MUGAN [4] | 80.3 | 26.9 | 14.5 | 12.0 | 14.5 | 29.64 |
| MornGAN [8] | 70.7 | 20.2 | 30.2 | 15.9 | 15.0 | 30.40 |
| Ours | 81.5 | 38.2 | 30.4 | 18.9 | 19.2 | 37.64 |
| Comparison | Precision | Recall | mAP50 | Colorful |
| Input NTIR image | 63.6 | 39.5 | 40.6 | 0.01 |
| Reference NVC image | 63.9 | 39.4 | 40.0 | 0.29 |
| pix2pix [16] | 12.4 | 16.2 | 5.9 | 0.49 |
| TICC-GAN [6] | 40.6 | 25.3 | 22.7 | 0.31 |
| TodayGAN [17] | 31.9 | 21.9 | 16.1 | 0.34 |
| DDGAN [7] | 19.4 | 13.1 | 8.1 | 0.16 |
| FRAGAN_P [10] | 39.9 | 26.1 | 23.1 | 0.46 |
| LKAT-GAN [24] | 44.8 | 31.6 | 28.8 | 0.36 |
| MUGAN [4] | 32.5 | 20.4 | 16.5 | 0.18 |
| MornGAN [8] | 48.1 | 42.1 | 37.7 | 0.43 |
| Ours | 64.2 | 41.3 | 40.8 | 0.54 |


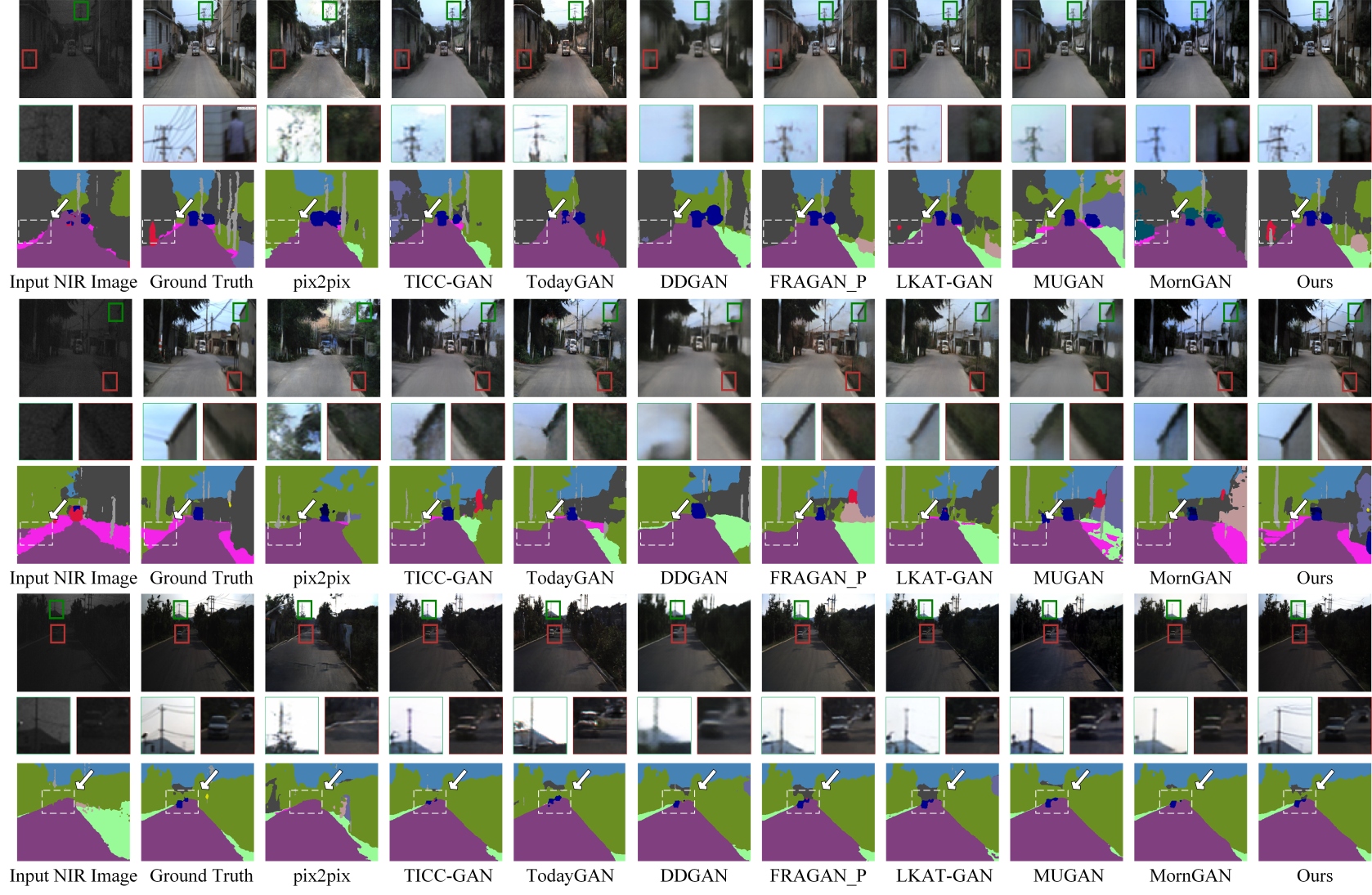
In the KAIST dataset test, we convert nighttime thermal infrared (NTIR) images into daytime RGB images. Lacking pixel-level aligned RGB labels, we use the Segformer model [45], trained on the Cityscape dataset [46], for semantic segmentation to assess the feature quality and semantic consistency of the converted images. As shown in Table I and Figure 5, our method significantly outperforms others in segmenting small targets (e.g., pedestrians, vehicles), even slightly surpassing the reference nighttime visible images (NVC). This advantage is especially clear in the “sky” category, where low illumination hampers segmentation in NTIR images.
Traditional methods (e.g., pix2pix [16], TodayGAN [17], DDGAN [7], MUGAN [4]) struggle with NTIR’s low contrast and complex structures, resulting in poor segmentation of small targets. While MornGAN [8] performs relatively well, it still misrepresents “building” and “vehicle” categories. In contrast, TICC-GAN [6], FRAGAN_P [10], LKAT-GAN [24], and our method achieve better reconstruction and segmentation, with our approach excelling in both small-target detail and color realism. For example, in Scene 1, our model accurately reconstructs small vehicles and distinguishes “tree trunks” and service lanes. It achieves the highest mIoU, surpassing NVC and exceeding the next-best method, LKAT-GAN [24], by 15.9%. This gain is due to our multi-stage Transformer combined with wavelet transform, which enhances feature extraction and reconstruction, leading to improved segmentation accuracy.
To evaluate the realism of object features in generated images, we use YOLOv7 [19], trained on the MS COCO dataset [20], for object detection. Results are presented in Table II and Figure 6. Methods like Pix2pix [16], TodayGAN [17], DDGAN [7], and MUGAN [4] struggle with complex structures, often producing blurred building edges due to semantic confusion. In contrast, TICC-GAN [6], FRAGAN_P [10], LKAT-GAN [24], and MornGAN [8] improve edge clarity through advanced loss functions and generator designs.
As illustrated in the first two subfigures of Figure 6, most methods fail to reconstruct small targets (e.g., vehicles, pedestrians) accurately. Our method, however, preserves fine details, sharp edges, and realistic colors. Under low-light conditions, YOLOv7 detects only some pedestrians in NVC images, while our method captures full crowd poses and reduces missed detections. Although our recall is slightly lower than MornGAN’s, we achieve higher precision, leading to an 8.2% gain in mean Average Precision (mAP). This confirms our model’s strengths in feature extraction, detail preservation, and colorization.
Additionally, as shown in Table II, although the input infrared images exhibit low Noise, their Colorful is relatively weak. After colorization, this metric is significantly improved, enhancing color representation and subjective perception, which demonstrates the necessity of the colorization process.
(2) Experimental Results on the HSI ROAD and IHSR Hyperspectral Datasets
| HSI ROAD dataset | IHSR dataset | |||||||||||
| Methods | PSNR↑ | SSIM↑ | NIQE↓ | UIQI↑ | Colorful↑ | ColorJSD↓ | PSNR↑ | SSIM↑ | NIQE↓ | UIQI↑ | Colorful↑ | ColorJSD↓ |
| pix2pix [16] | 16.93 | 0.51 | 4.25 | 0.83 | 0.31 | 0.09 | 17.94 | 0.40 | 8.32 | 0.65 | 0.59 | 0.12 |
| TICC-GAN [6] | 21.39 | 0.72 | 4.25 | 0.93 | 0.21 | 0.10 | 18.09 | 0.42 | 8.27 | 0.60 | 0.15 | 0.24 |
| TodayGAN [17] | 16.62 | 0.52 | 3.87 | 0.81 | 0.11 | 0.37 | 12.41 | 0.17 | 8.37 | 0.30 | 0.09 | 0.19 |
| DDGAN [7] | 15.36 | 0.54 | 4.25 | 0.74 | 0.10 | 0.10 | 21.07 | 0.60 | 8.25 | 0.83 | 0.28 | 0.11 |
| FRAGAN_P [10] | 21.53 | 0.72 | 4.23 | 0.94 | 0.17 | 0.07 | 21.20 | 0.68 | 8.24 | 0.83 | 0.44 | 0.18 |
| LKAT-GAN [24] | 21.69 | 0.74 | 4.23 | 0.94 | 0.20 | 0.08 | 19.98 | 0.55 | 8.27 | 0.76 | 0.22 | 0.13 |
| MUGAN [4] | 21.70 | 0.73 | 4.23 | 0.94 | 0.26 | 0.07 | 20.16 | 0.56 | 8.27 | 0.79 | 0.56 | 0.17 |
| MornGAN [8] | 20.69 | 0.61 | 4.25 | 0.93 | 0.11 | 0.16 | 18.06 | 0.42 | 8.29 | 0.60 | 0.10 | 0.23 |
| Ours | 22.54 | 0.77 | 3.32 | 0.95 | 0.24 | 0.05 | 23.87 | 0.81 | 8.21 | 0.94 | 0.62 | 0.07 |

Compared to the KAIST dataset, the HSI ROAD and IHSR hyperspectral datasets enable better performance in image colorization. HSI ROAD’s 28 spectral bands provide richer textures, helping most methods better reconstruct small object contours like vehicles, pedestrians, and buildings. As illustrated in Figure 7, Pix2pix [16], TodayGAN [17], and DDGAN [7] suffer from geometric distortions and missing details (e.g., Pix2pix fails to restore vehicle outlines; DDGAN omits building edges). While other methods retain global structure, they lack detail fidelity. In contrast, our method best preserves fine details such as utility poles, wires, and building edges. Segformer-based [45] semantic segmentation further validates this: segmentation results from our generated images closely match the ground truth and outperform those from raw infrared inputs, reflecting higher reconstruction quality.
Quantitative results in Table III confirm our advantage, with the highest PSNR, SSIM, UIQI, and lowest NIQE on HSI ROAD. Notably, our PSNR surpasses MUGAN [4] by 3.9%, and NIQE is optimized by 16.6% compared to TodayGAN [17], indicating more natural and visually realistic outputs.
Compared to the HSI ROAD dataset, the IHSR dataset presents greater challenges due to its large-scale coverage, low spatial resolution (1.0 m), and the presence of 110 thermal infrared spectral bands. These characteristics demand careful modeling of spectral correlations during the colorization process. Despite the limited spatial resolution, the rich spectral information enhances semantic discrimination. As shown in Figure 8, our method achieves superior texture restoration and edge clarity compared to Pix2pix [16], TICC-GAN [6], and MUGAN [4]. It also outperforms FRAGAN_P [10] and DDGAN [7] in detail sharpness and color fidelity, benefiting from targeted network optimizations. Although LKAT-GAN improves the generator architecture, it performs poorly on the IHSR dataset. This suggests that enhancing the generator alone, without adequately accounting for spectral correlations, leads to information loss during the infrared-to-color image cross-domain colorization process, thereby degrading reconstruction quality. As unsupervised methods, TodayGAN and MornGAN do not require labeled data; however, their texture and color restoration on the IHSR dataset are significantly inferior to supervised methods, highlighting the irreplaceable advantages of supervised learning. As shown in Table III, our method achieves the best performance on the IHSR dataset, surpassing the second-best method (FRAGAN_P) with improvements of 12.6% in PSNR, 19.1% in SSIM, and 13.3% in UIQI. Furthermore, it demonstrates notable advantages in the Colorful and ColorJSD metrics, especially in ColorJSD. These results suggest that our approach more effectively extracts deep spatial features and fully leverages spectral correlations, enabling the reconstruction of more natural and vivid colors.
IV-E Ablation study
| Comparison | Variant | Precision (%) | Recall (%) | mAP50 (%) | #Params (M) | FLOPs (G) |
| Stage number | Ns = 1 | 56.1 | 36.3 | 34.1 | 48.07 | 235.79 |
| Ns = 2 | 59.5 | 39.7 | 38.3 | 63.64 | 426.47 | |
| Ns = 3 | 64.2 | 41.3 | 40.8 | 79.22 | 617.14 | |
| Ns = 4 | 65.8 | 41.4 | 41.6 | 94.8 | 807.81 | |
| Attention Complexity | G-MSA [47] | 60.7 | 35.2 | 38.1 | 86.4 | 914.76 |
| W-MSA [48] | 60.1 | 31.9 | 34.1 | 67.12 | 507.54 | |
| SW-MSA [48] | 57.3 | 38.7 | 36.7 | 62.17 | 501.43 | |
| SMSA | 64.2 | 41.3 | 40.8 | 79.22 | 617.14 |
Stage Number Analysis: A multi-stage learning strategy is introduced by cascading multiple STformers to achieve coarse-to-fine reconstruction optimization. The effect of the number of stages, , on performance is analyzed (see Table IV). Results indicate that performance improves with higher , but computational cost (parameters and FLOPs) increases linearly. While offers slightly better performance than , it significantly increases computational cost. Thus, is chosen for MTSIC, balancing performance and efficiency, and used as the default in subsequent experiments. As illustrated in Table IV, and compared with Table II, even with , the proposed method outperforms several single-band methods and has fewer parameters than high-performance models like LKAT-GAN (83.69M) and FRAGAN_P (52.45M), highlighting the effectiveness and superiority of the proposed framework.
The Transformer-based STformer network includes two key modules: SARB and MSWB. For fair evaluation, only one variable was modified in each experiment while keeping other parameters consistent. Detailed analyses of SARB and MSWB follow.
Complexity Analysis of SMSA: According to [47], G-MSA computes correlations by treating all spatial tokens as queries and keys, with the number of tokens given by , resulting in high computational cost. In W-MSA [48], the feature map is divided into non-overlapping windows, and self-attention is computed within each window. This reduces the complexity but limits the ability to model global dependencies. SW-MSA addresses this limitation by alternating between regular and shifted windows to enhance long-range dependency modeling. However, due to the sparse spatial information in spectral images, its efficiency is lower than that of methods focusing on spectral correlation.
SMSA treats each spectral feature map as a token and computes attention along the spectral dimension, effectively capturing spectral dependencies. The computational complexity of W-MSA, SW-MSA, and SMSA scales linearly with spatial size, i.e., , which is significantly lower than the quadratic complexity of G-MSA. As summarized in Table IV, although SMSA exhibits slightly higher complexity than W-MSA and SW-MSA, it achieves better reconstruction performance, demonstrating a more favorable trade-off between efficiency and accuracy. This indicates that SMSA can more effectively exploit spectral features and is better suited for spectral image colorization than mechanisms focusing solely on spatial dimensions.
Analysis of STformer: The overall architecture of the MTSIC generator is shown in Figure 2(a), where ConvNeXt[32] is used for pretraining to extract spatial features. To establish a baseline, STformer is removed, leaving only the ConvNeXt backbone. To evaluate STformer’s effectiveness, ResNet [49] and UNet++ [50] replace it, while the rest of the architecture remains unchanged. Performance comparisons, presented in Table V, show that removing or replacing STformer results in performance degradation, emphasizing its ability to integrate spatial and spectral features. As illustrated in Figure 9, without STformer, small objects are often missed, and boundary ambiguity arises, further confirming its superiority in feature representation and detail preservation.


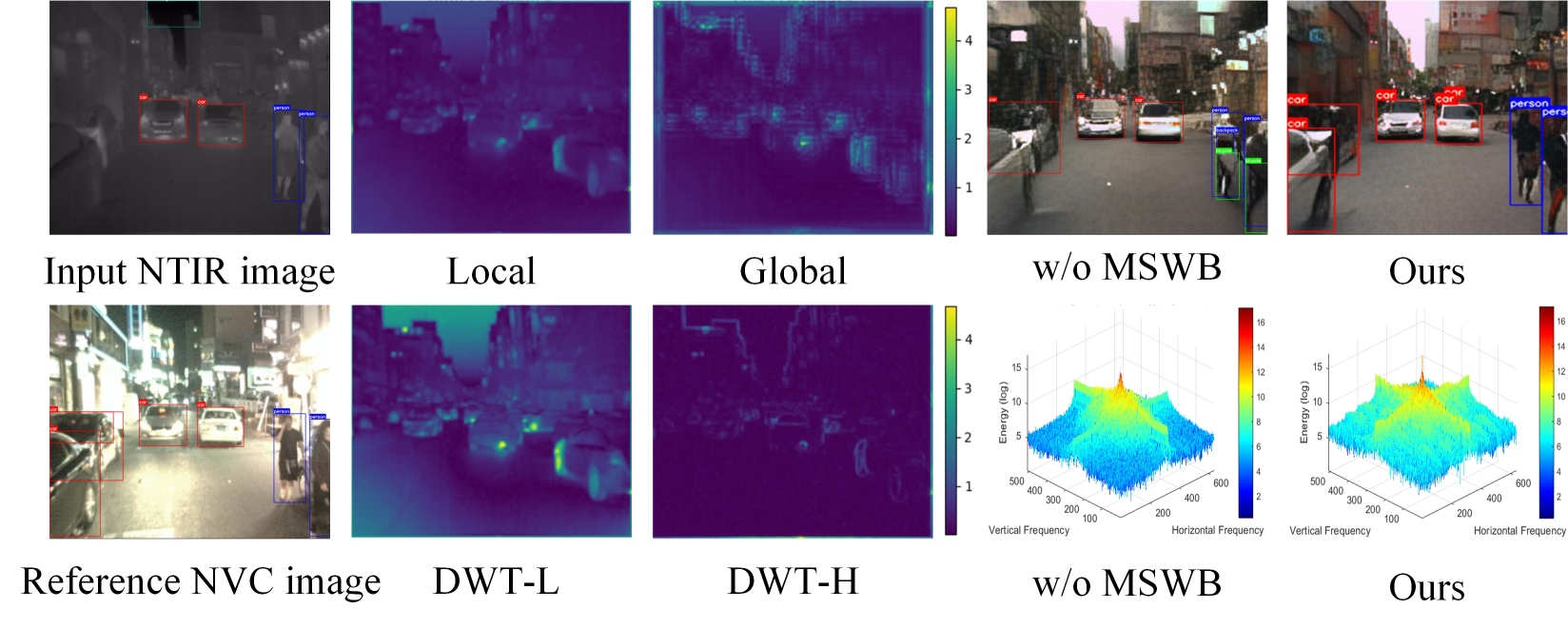

| Comparison | Variant | Precision | Recall | mAP50 |
| STformer Analysis | Baseline | 21.6 | 17.3 | 11.2 |
| w/o STformer, with ResNet | 34.2 | 24.7 | 20.9 | |
| w/o STformer, with UNet++ | 52.7 | 35.9 | 36.3 | |
| Ours | 64.2 | 41.3 | 40.8 | |
| MSWB Analysis | w/o MSWB | 53.7 | 31.0 | 32.9 |
| w/o Global | 61.2 | 36.7 | 38.4 | |
| w/o Local | 60.7 | 33.5 | 36.3 | |
| w/o DWT-L | 59.1 | 40.5 | 38.1 | |
| w/o DWT-H | 55.6 | 36.7 | 37.6 | |
| w/o SFFM, with Concat | 62.3 | 40.1 | 39.3 | |
| w/o SFFM, with Add | 59.6 | 39.7 | 38.9 | |
| Ours (with MSWB) | 64.2 | 41.3 | 40.8 | |
| Loss Analysis | w/o | 63.5 | 40.2 | 39.7 |
| w/o | 61.9 | 38.7 | 37.3 | |
| w/o | 63.4 | 39.6 | 38.1 | |
| Ours | 64.2 | 41.3 | 40.8 |
Analysis of the MSWB: Table V presents the impact of progressively removing sub-modules from MSWB. ”Global” and ”Local” represent the global and local branches, while ”DWT-L” and ”DWT-H” denote low- and high-frequency features from DWT decomposition. ”SFFM” refers to the spatial-frequency feature fusion module. To validate SFFM’s effectiveness, we compared performance with SFFM removed, and frequency-domain and spatial-domain features fused by concatenation (”w/o SFFM, with Concat”) or element-wise addition (”w/o SFFM, with Add”). Note that spatial-scale features are downsampled according to the wavelet transform scaling ratio to achieve fusion between spatial and frequency domains. Moreover, if any branch of SFFM is removed, its corresponding SFFM alignment module is also eliminated and replaced with an Add operation.
Figure 10 illustrates the impact of removing sub-modules, showing a performance drop in all cases, emphasizing the importance of each component. Replacing SFFM with Concat or Add caused significant degradation on the KAIST dataset due to the semantic gap between frequency-domain and spatial-domain features, which simple fusion methods fail to align effectively. The proposed fusion strategy, however, better captures semantic correlations, improving semantic consistency and segmentation accuracy in cross-domain image colorization.
Figure 11 presents feature maps for each submodule, demonstrating their roles in enhancing feature representation. The Local branch captures fine details (e.g., vehicles), while the Global branch targets larger regions. DWT-H highlights local edge information, and DWT-L improves global perception. However, the Local branch is less effective for complex textures (e.g., buildings). Removing any branch causes structural distortion in reconstructed images and reduces segmentation performance. Compared to removing the MSWB module (“w/o MSWB”), incorporating it (“Ours”) enhances frequency-domain energy and significantly improves spatial visualization, as seen in Figure 11.
Loss Analysis: As described in Section 3, we propose a composite loss function combining , , and , improving upon the strategy of Kuang et al. [6]. To evaluate the contribution of each component, we conducted three ablation studies on the KAIST dataset, each excluding one loss term while keeping the network architecture and training data unchanged. The results in Table V and Figure 12 demonstrate that removing leads to the most significant performance degradation, highlighting the importance of spatial-frequency optimization. Omitting results in a slight decline in Precision and Recall, suggesting its role in enhancing spectral consistency through angular similarity; moreover, including results in more natural-looking images. Although has limited impact on detection performance, it aids in preserving edge structures and semantic consistency. In Figure 12, contours with and without edge loss are overlaid on the input image. The version with edge loss (“Ours”) better preserves contours and and mitigates boundary artifacts.
V Conclusion
This study proposes a novel method for multi-band infrared spectral image colorization, named MTSIC. It exploits the spatial sparsity and spectral self-similarity of multi-band infrared images. Each spectral feature map is treated as a token for self-attention within the SARB unit. Multiple SARB units are stacked to form the STformer, and several STformer modules are cascaded to construct the MTSIC framework. A multi-stage learning strategy is employed to progressively refine the reconstruction, from coarse to fine. Within the STformer, an MSWB module applies the Haar wavelet transform for frequency-domain feature mapping, while the SFFM module integrates low-frequency and global features with high-frequency and local features, bridging the semantic gap between the frequency and spatial domains.
Experimental results demonstrate that the proposed method significantly improves reconstruction quality. This work addresses challenges in infrared image colorization by leveraging spectral properties and encourages future research into combining Transformer architectures with wavelet transforms for infrared hyperspectral image colorization, opening new directions for further exploration.
References
- [1] R. Gade and T. B. Moeslund, “Thermal cameras and applications: a survey,” Machine Vision and Applications, vol. 25, no. 1, pp. 245–262, Jan 2014. [Online]. Available: https://doi.org/10.1007/s00138-013-0570-5
- [2] T. Jiang, X. Kuang, S. Wang, T. Liu, Y. Liu, X. Sui, and Q. Chen, “Cross-domain colorization of unpaired infrared images through contrastive learning guided by color feature selection attention,” Optics Express, vol. 32, 04 2024.
- [3] T. Kumar and K. Verma, “A theory based on conversion of rgb image to gray image,” International Journal of Computer Applications, vol. 7, no. 2, pp. 7–10, 2010.
- [4] H. Liao, Q. Jiang, X. Jin, L. Liu, L. Liu, S.-J. Lee, and W. Zhou, “Mugan: Thermal infrared image colorization using mixed-skipping unet and generative adversarial network,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 4, pp. 2954–2969, 2023.
- [5] Y. Yang, J. Pan, Z. Peng, X. Du, Z. Tao, and J. Tang, “Bistnet: Semantic image prior guided bidirectional temporal feature fusion for deep exemplar-based video colorization,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5612–5624, 2024.
- [6] X. Kuang, J. Zhu, X. Sui, Y. Liu, C. Liu, Q. Chen, and G. Gu, “Thermal infrared colorization via conditional generative adversarial network,” Infrared Physics & Technology, vol. 107, p. 103338, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1350449519311387
- [7] Y. Chen, W. Zhan, Y. Jiang, D. Zhu, R. Guo, and X. Xu, “Ddgan: Dense residual module and dual-stream attention-guided generative adversarial network for colorizing near-infrared images,” Infrared Physics & Technology, vol. 133, p. 104822, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1350449523002803
- [8] F.-Y. Luo, Y.-J. Cao, K.-F. Yang, G. Wang, and Y.-J. Li, “Memory-guided collaborative attention for nighttime thermal infrared image colorization of traffic scenes,” IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 11, pp. 15 841–15 855, 2024.
- [9] X. Kuang, J. Zhu, X. Sui, Y. Liu, C. Liu, Q. Chen, and G. Gu, “Thermal infrared colorization via conditional generative adversarial network,” Infrared Physics & Technology, vol. 107, p. 103338, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1350449519311387
- [10] Y. Chen, W. Zhan, Y. Jiang, D. Zhu, X. Xu, Z. Hao, J. Li, and J. Guo, “A feature refinement and adaptive generative adversarial network for thermal infrared image colorization,” Neural Networks, vol. 173, p. 106184, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0893608024001084
- [11] T. Liu, X. Pu, Y. Shi, Y. Liu, G. Chen, X. Sui, and Q. Chen, “Hyperspectral image super-resolution based on mamba and bidirectional feature fusion network,” Expert Systems with Applications, p. 127905, 2025.
- [12] Y. Cai, J. Lin, Z. Lin, H. Wang, Y. Zhang, H. Pfister, R. Timofte, and L. V. Gool, “Mst++: Multi-stage spectral-wise transformer for efficient spectral reconstruction,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2022, pp. 744–754.
- [13] T. Liu, Y. Liu, C. Zhang, L. Yuan, X. Sui, and Q. Chen, “Hyperspectral image super-resolution via dual-domain network based on hybrid convolution,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–18, 2024.
- [14] Y. Huang, Q. Shen, Y. Fu, and S. You, “Weakly-supervised semantic segmentation in cityscape via hyperspectral image,” in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 1117–1126.
- [15] F. Bao, X. Wang, S. H. Sureshbabu, et al., “Heat-assisted detection and ranging,” Nature, vol. 619, no. 7971, pp. 743–748, 2023. [Online]. Available: https://doi.org/10.1038/s41586-023-06174-6
- [16] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5967–5976.
- [17] A. Anoosheh, T. Sattler, R. Timofte, M. Pollefeys, and L. V. Gool, “Night-to-day image translation for retrieval-based localization,” 2019. [Online]. Available: https://arxiv.org/abs/1809.09767
- [18] T. Liu, T. Jiang, C. Zhang, Y. Liu, X. Sui, and Q. Chen, “A band grouping-based hybrid convolution for hyperspectral image super-resolution,” Neurocomputing, p. 130510, 2025.
- [19] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 7464–7475.
- [20] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft coco: Common objects in context,” 2015. [Online]. Available: https://arxiv.org/abs/1405.0312
- [21] A. Berg, J. Ahlberg, and M. Felsberg, “Generating visible spectrum images from thermal infrared,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 1224–122 409.
- [22] M. Limmer and H. P. A. Lensch, “Infrared colorization using deep convolutional neural networks,” 2016. [Online]. Available: https://arxiv.org/abs/1604.02245
- [23] L. Sigillo, E. Grassucci, and D. Comminiello, “Stawgan: Structural-aware generative adversarial networks for infrared image translation,” in 2023 IEEE International Symposium on Circuits and Systems (ISCAS), 2023, pp. 1–5.
- [24] Y. He, X. Jin, Q. Jiang, Z. Cheng, P. Wang, and W. Zhou, “Lkat-gan: A gan for thermal infrared image colorization based on large kernel and attentionunet-transformer,” IEEE Transactions on Consumer Electronics, vol. 69, no. 3, pp. 478–489, 2023.
- [25] J. Lu, H. Liu, Y. Yao, S. Tao, Z. Tang, and J. Lu, “Hsi road: A hyper spectral image dataset for road segmentation,” in 2020 IEEE International Conference on Multimedia and Expo (ICME), 2020, pp. 1–6.
- [26] F. Bao, S. Jape, A. Schramka, J. Wang, T. E. McGraw, and Z. Jacob, “Why thermal images are blurry,” Optics Express, vol. 32, no. 3, pp. 3852–3865, Jan 2024. [Online]. Available: https://doi.org/10.1364/OE.506634
- [27] C.-F. R. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi-scale vision transformer for image classification,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 347–356.
- [28] Q. Zhou, X. Li, L. He, Y. Yang, G. Cheng, Y. Tong, L. Ma, and D. Tao, “Transvod: End-to-end video object detection with spatial-temporal transformers,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 7853–7869, 2023.
- [29] Y. Yang, G. Yuan, and J. Li, “Sffnet: A wavelet-based spatial and frequency domain fusion network for remote sensing segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–17, 2024.
- [30] P. J. K. Senapati, P. Boggarapu, S. S. Mondal, and H. Mejjaoli, “Restriction theorem for the fourier–dunkl transform and its applications to strichartz inequalities,” The Journal of Geometric Analysis, vol. 34, no. 3, p. 74, Jan 2024. [Online]. Available: https://doi.org/10.1007/s12220-023-01530-4
- [31] W. Yu, W. Ling, W. Shumao, and Z. Junsheng, “Synchronous acceleration method of the load spectrum for tractor rotary tillage based on wavelet transform,” International Journal of Agricultural and Biological Engineering, vol. 18, no. 1, pp. 124–133, 2025. [Online]. Available: https://www.aeeisp.com/ijabe/en/article/doi/10.25165/j.ijabe.20251801.8468
- [32] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 11 966–11 976.
- [33] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” in Computer Vision – ECCV 2018, V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss, Eds. Cham: Springer International Publishing, 2018, pp. 3–19.
- [34] Y. Wang, L. Tong, S. Luo, F. Xiao, and J. Yang, “A multiscale and multidirection feature fusion network for road detection from satellite imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–18, 2024.
- [35] X. Shao and W. Zhang, “Spatchgan: A statistical feature based discriminator for unsupervised image-to-image translation,” 2021. [Online]. Available: https://arxiv.org/abs/2103.16219
- [36] M. Cai, H. Zhang, H. Huang, Q. Geng, Y. Li, and G. Huang, “Frequency domain image translation: More photo-realistic, better identity-preserving,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 13 910–13 920.
- [37] G. Seif and D. Androutsos, “Edge-based loss function for single image super-resolution,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 1468–1472.
- [38] S. Hwang, J. Park, N. Kim, Y. Choi, and I. S. Kweon, “Multispectral pedestrian detection: Benchmark dataset and baseline,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1037–1045.
- [39] J. Lu, H. Liu, Y. Yao, S. Tao, Z. Tang, and J. Lu, “Hsi road: A hyper spectral image dataset for road segmentation,” in 2020 IEEE International Conference on Multimedia and Expo (ICME), 2020, pp. 1–6.
- [40] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
- [41] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
- [42] A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a “completely blind” image quality analyzer,” IEEE Signal Processing Letters, vol. 20, no. 3, pp. 209–212, 2013.
- [43] Z. Wang and A. Bovik, “A universal image quality index,” IEEE Signal Processing Letters, vol. 9, no. 3, pp. 81–84, 2002.
- [44] J. Wang, K. C. Chan, and C. C. Loy, “Exploring clip for assessing the look and feel of images,” in Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, ser. AAAI’23/IAAI’23/EAAI’23. AAAI Press, 2023. [Online]. Available: https://doi.org/10.1609/aaai.v37i2.25353
- [45] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,” 2021. [Online]. Available: https://arxiv.org/abs/2105.15203
- [46] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [47] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” ArXiv, vol. abs/2010.11929, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:225039882
- [48] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” arXiv preprint arXiv:2103.14030, 2021.
- [49] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [50] Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: Redesigning skip connections to exploit multiscale features in image segmentation,” IEEE Transactions on Medical Imaging, vol. 39, no. 6, pp. 1856–1867, 2020.