Multi-ACCDOA: Localizing and Detecting Overlapping Sounds from the Same Class with Auxiliary Duplicating Permutation Invariant Training
Abstract
Sound event localization and detection (SELD) involves identifying the direction-of-arrival (DOA) and the event class. The SELD methods with a class-wise output format make the model predict activities of all sound event classes and corresponding locations. The class-wise methods can output activity-coupled Cartesian DOA (ACCDOA) vectors, which enable us to solve a SELD task with a single target using a single network. However, there is still a challenge in detecting the same event class from multiple locations. To overcome this problem while maintaining the advantages of the class-wise format, we extended ACCDOA to a multi one and proposed auxiliary duplicating permutation invariant training (ADPIT). The multi-ACCDOA format (a class- and track-wise output format) enables the model to solve the cases with overlaps from the same class. The class-wise ADPIT scheme enables each track of the multi-ACCDOA format to learn with the same target as the single-ACCDOA format. In evaluations with the DCASE 2021 Task 3 dataset, the model trained with the multi-ACCDOA format and with the class-wise ADPIT detects overlapping events from the same class while maintaining its performance in the other cases. Also, the proposed method performed comparably to state-of-the-art SELD methods with fewer parameters.
Index Terms— Sound event localization and detection, activity-coupled Cartesian direction of arrival, permutation invariant training
1 Introduction
Sound event localization and detection (SELD) involves identifying the direction-of-arrival (DOA) and the type of sound events. SELD has played an essential role in many applications, such as surveillance [1, 2], bio-diversity monitoring [3], and context-aware devices [4, 5]. Recent competitions such as the DCASE challenge show significant progress in the SELD research area using neural-network (NN)-based methods [6].
NN-based SELD methods can be categorized into two output formats. The first is the class-wise output format, in which the model predicts activities of all event classes and corresponding locations [7, 8, 9, 10, 11, 12, 13]. Adavanne et al. proposed SELDnet, which detects sound events and estimates the corresponding DOAs using two branches: an sound event detection (SED) branch and a DOA branch [7, 8]. Activity-coupled Cartesian DOA (ACCDOA) assigns an event activity to the length of a corresponding Cartesian DOA vector [11, 12], which enables a SELD task to be solved without branching. In the evaluations on the SELD task for DCASE 2020 Task 3, the single-ACCDOA format outperformed the two-branch format with fewer parameters [11]. The second is the track-wise output format, where each track detects one event class and a corresponding location [14, 15, 16]. Cao et al. proposed an event independent network V2 (EINV2), which decomposes the SELD output into event-independent tracks [14]. They incorporate permutation invariant training (PIT) [17] into a SELD task to solve a track permutation problem, in which an event cannot be fixedly assigned to a track.
While the track-wise format enables the model to detect the same event class from multiple locations, the track-wise format only detects one event class and a corresponding location in each track [14]. ACCDOA vectors can be used only in the class-wise methods. Therefore, the track-wise format cannot exploit the advantage of the ACCDOA format, which enable us to solve a SELD task with a single target using a single network [11]. On the other hand, there is still a challenge in detecting overlapping events from the same class because the class-wise format assigns only one location to each event class.
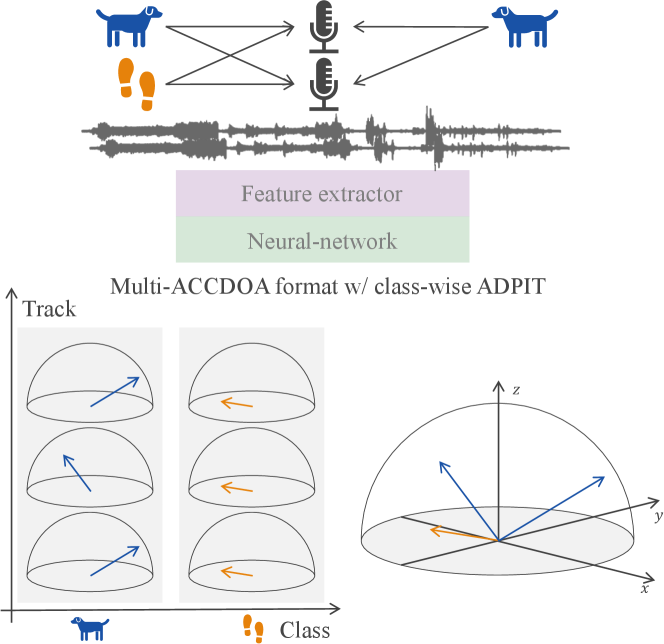
To overcome the overlap problem while maintaining the advantages of the class-wise format, we extended the single-ACCDOA format to a multi-ACCDOA format (a class- and track-wise output format). We also proposed auxiliary duplicating permutation invariant training (ADPIT), inspired by auxiliary autoencoding permutation invariant training (A2PIT) on a source separation task with a variable number of sources [18]. The class-wise ADPIT scheme enables us to solve the track permutation problem with duplicated ACCDOA vectors, which can help the model maintain the performance in the cases with no overlaps from the same class. Fig. 1 shows the overview of the proposed method. In experimental evaluations using the DCASE 2021 Task 3 dataset [12], the result shows the multi-ACCDOA method with the class-wise ADPIT detected overlapping events from the same class without any degradation in the other cases. Also, the proposed method performed comparably to state-of-the-art methods with fewer parameters.
2 Related work
The class-wise methods can output ACCDOA vectors, which assign an activity to the length of a corresponding Cartesian DOA vector [11]. When a class is active, an ACCDOA vector is set to be a unit vector; otherwise, it is set to be a zero vector. That enables the model to solve a SELD task with a single objective such as the mean squared error (MSE) using a single network. As the single-ACCDOA format outperforms the two-branch format in the joint SELD metrics with a simpler architecture [11], ACCDOA was adopted to the DCASE 2021 Task 3 baseline [12]. A convolutional recurrent neural-network (CRNN), consisting of convolution blocks, gated recurrent unit (GRU) layers, and a fully-connected layer, is used to estimate ACCDOA vectors in [11].
EINV2 uses the track-wise output format, where each event is exclusively assigned to one track [14]. That induces the track permutation problem, in which an event cannot be fixedly assigned to a track. To solve the problem, PIT [17] is incorporated into a SELD task [14]. PIT assigns targets to different tracks to constitute all possible permutations. Then the loss for each permutation is calculated. The lowest loss is selected as the actual loss. In the evaluation in [14], the frame-level PIT outperformed the chunk-level PIT. The network architecture consists of convolution blocks, multi-head self-attention (MHSA) blocks, fully connected layers, and soft parameter sharing (PS) between an SED branch and a DOA branch [14].
A2PIT is used in the source separation task with a variable number of sources [18]. With the scheme, the mixture signal itself is used as the auxiliary targets instead of low-energy random noise signals when there are fewer targets than tracks [18]. That enables the model to use any objective functions such as scale-invariant signal-to-distortion ratio (SI-SDR). The idea of replacing auxiliary targets inspires us to use another auxiliary target instead of a zero vector in the SELD task. A similarity threshold between the mixture and the outputs was used during inference to determine valid outputs [18].
3 Proposed Method
We formulate the multi-ACCDOA format and show how to train the model with the format using the class-wise ADPIT. Then we describe the inference step of the proposed method.
3.1 Multi-ACCDOA format
The multi-ACCDOA format is an extension of the single-ACCDOA format [11] to a track dimension; thus, it is a class- and track-wise format. While each track in the track-wise format only detects one event class and a corresponding location, each track in the multi-ACCDOA format is equivalent to the single-ACCDOA format, where a track predicts activities of all target classes and their corresponding locations.
The -track -class -frame multi-ACCDOA format, , is formulated with activities and Cartesian DOAs. Each sound event class of a track is represented by three nodes corresponding to the sound event location in the , , and axes. Let be activities, whose reference value is , i.e., it is 1 when the event is active and 0 when inactive. indicates an output track number, a target class, and a time frame. Also, let be Cartesian DOAs, where the length of each Cartesian DOA is 1, i.e., when a class is active. is the L2 norm. An ACCDOA vector in the multi-ACCDOA format is formulated as follows:
| (1) |
In this study, to estimate the ACCDOA vectors in the multi-ACCDOA format , the CRNN architecture is used as in [11].
3.2 Class-wise auxiliary duplicated PIT
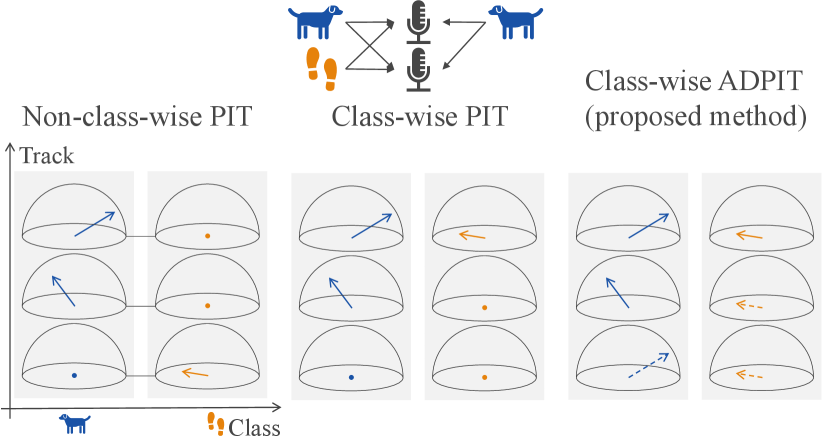
Similarly to the track-wise approaches, the multi-ACCDOA format also suffers from the track permutation problem. To overcome this issue, we adopt PIT for the training process. The frame-level PIT [14] is used in this study. Assume all possible permutations constitute a permutation set . is one possible frame-level permutation at frame . A PIT loss for the multi-ACCDOA format can be straightforwardly written as follows:
| (2) | ||||
| (3) |
where is an ACCDOA target of a permutation , and is an ACCDOA prediction at track , class , and frame . We refer this PIT as a non-class-wise PIT because the PIT loss in Eq. (3) exclusively assigns one sound event to one track regardless of the sound event class [14]. We use MSE as a loss function for the multi-ACCDOA format [11]. The left in Fig. 2 shows a possible permutation of a 3-track 2-class multi-ACCDOA format with the non-class-wise PIT. The blue and orange vectors indicate ACCDOA vectors of a barking dog and a footstep, respectively.
Because the multi-ACCDOA format has a class dimension, it is reasonable to set a permutation for each class. Therefore, we extend the non-class-wise PIT to a class-wise formulation, namely class-wise PIT. is one possible class-wise frame-level permutation at class and frame . The class-wise PIT loss for the multi-ACCDOA format can be written as follows:
| (4) | ||||
| (5) |
The center in Fig. 2 shows a permutation example for the class-wise PIT, where a permutation is set for each class.
The class-wise PIT assigns one active event to only one track for each class. When there are fewer active events than tracks in a event class, we need to assign zero vectors as auxiliary targets for the inactive tracks in the class. The class-wise PIT cannot enable every track of the multi-ACCDOA format to learn with the same target as the single one, i.e., a unit vector. As a result, the auxiliary targets for the class-wise PIT, i.e., zero vectors, might interfere the optimization of multi-ACCDOA training.
To enable every track of the multi-ACCDOA format to learn with the same target as the single one, we duplicate the original target as the auxiliary targets of the other tracks instead of zero vectors. We refer to the PIT framework with the duplicated targets as ADPIT. The multi-ACCDOA format tries to output original targets and duplicated targets in class and frame , and the PIT framework is applied to find the best permutations. The class-wise ADPIT loss is the same formula as the class-wise PIT in Eq. (4). The difference lies in their permutation set. We show a possible permutation in the right side in Fig. 2 for the class-wise ADPIT. Each track is trained with an original target or a duplicated target.
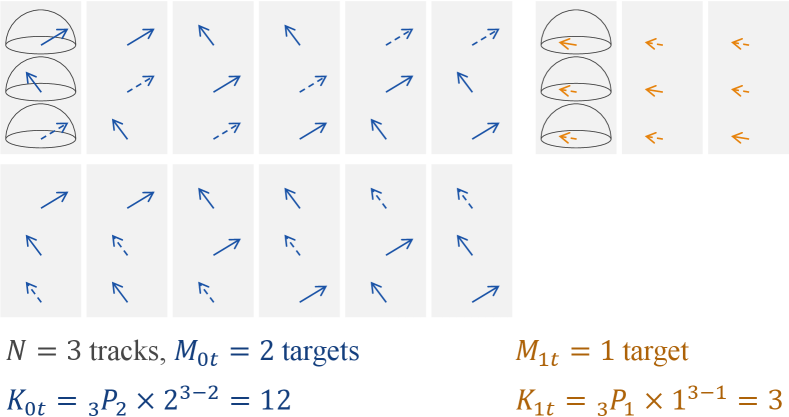
The possible number of permutations for the class-wise ADPIT in the permutation set, , is calculated as follows:
| (6) |
where denotes -permutations of . Fig. 3 shows all permutations for the class-wise ADPIT. In practice, original targets and duplicated targets cannot be distinguished. Therefore, the number of actual permutations is smaller than .
3.3 Unification of duplicated outputs during inference
After the training with the class-wise ADPIT, during inference, duplicated outputs are unified in three steps. First, we use threshold processing to determine whether each output is active or not. Second, if there are two or more active outputs from the same class, we calculate the similarity between the active outputs. In this study, we use angle difference as the similarity. Third, if an angle difference between the outputs is smaller than a threshold, i.e., the outputs are similar, we take the average of the outputs to a unified output.
4 Experimental evaluation
| Th of | # of | w/ ov | |||||||
| Format | unification | params | from the same class | w/o | |||||
| Single-ACCDOA | - | 5.89 M | 0.588 | 54.2 | 62.0 | 0.382 | 50.7 | 64.5 | |
| Multi-ACCDOA w/ non-class-wise PIT | - | 5.93 M | 0.650 | 41.6 | 52.7 | 0.459 | 51.6 | 52.9 | |
| Multi-ACCDOA w/ class-wise PIT | - | 5.93 M | 0.671 | 43.7 | 59.2 | 0.443 | 57.1 | 59.7 | |
| Multi-ACCDOA w/ class-wise ADPIT (proposed) | 5.93 M | 0.596 | 55.3 | 18.4∘ | 64.4 | 0.375 | 57.9 | 65.6 | |
| 5.93 M | 0.586 | 55.5 | 18.4∘ | 63.9 | 0.374 | 55.5 | 65.6 | ||
| 5.93 M | 0.584 | 55.4 | 63.7 | 0.374 | 54.6 | 65.6 |
| Th of | # of | w/ ov | |||||||
| Format | unification | params | from the same class | w/o | |||||
| Multi-ACCDOA w/ class-wise ADPIT (proposed) | 6.85 M | 0.635 | 55.3 | 18.5∘ | 67.0 | 0.379 | 56.9 | 69.2 | |
| Track-wise w/ PIT | - | 22.0 M | 0.676 | 55.0 | 17.4∘ | 69.1 | 0.383 | 62.6 | 70.4 |
We evaluated the multi-ACCDOA format trained with three PITs in Sec. 3, the single-ACCDOA format, and the track-wise format using TAU Spatial Sound Events 2021 [12]. The proposed method is also compared with state-of-the-art SELD methods.
4.1 Task setups
We used the development set of TAU Spatial Sound Events 2021 - Ambisonic with the suggested setup for DCASE 2021 Task 3 [12]. The dataset contained 600 one-minute sound scene recordings: 400 for training, 100 for validation, and 100 for testing. The sound scene recordings were synthesized by adding sound event samples convolved with room impulse response (RIR) to spatial ambient noise. The sound event samples consisted of 12 event classes such as footsteps and a barking dog. The RIRs and ambient noise recordings were collected at 15 different indoor locations. Each event had an equal probability of being either static or moving. The moving sound events were synthesized with 10, 20, or 40 degrees per second. Up to three overlapping sound events are possible, temporally and spatially. In addition, there are simultaneous directional interfering sound events with their temporal activities, static or moving. Signal-to-noise ratios ranged from 6 to 30 dB.
Following the setup, five metrics were used for the evaluation [19]. The first was the localization error , which expresses the average angular distance between the same class’s predictions and references. The second was a simple localization recall metric , which tells the true positive rate of how many of these localization estimates were detected in a class out of the total number of class instances. The following two metrics were the location-dependent error rate and F-score , where predictions were considered true positives only when the distance from the reference was less than . We also adopted an aggregated SELD error, , which is defined as
| (7) |
4.2 Hyper-parameters
The sampling frequency was set to 24 kHz. The short-term Fourier transform (STFT) was applied with 20 ms frame length and 10 ms frame hop. Input features are segmented to have a fixed length of 1.27 seconds. The shift length was set to 0.2 seconds during inference. We used a batch size of 32, and each training sample was generated on the fly [20]. We used the Adam optimizer with a weight decay of . We gradually increased the learning rate to 0.001 with 50,000 iterations [21]. After the warm-up, the learning rate was decreased by 10% if the SELD error of the validation did not improve in 40,000 consecutive iterations. We validated and saved model weights in every 10,000 iterations up to 400,000 iterations. Finally, we applied stochastic weight averaging (SWA) [22] to the last 10 models. The threshold for activity is 0.5 to binarize predictions during inference.
4.3 Experimental settings
We compared the multi-ACCDOA format with the single one. The number of tracks in the multi-ACCDOA format was fixed at the maximum number of overlaps in the dataset, i.e., . The difference in network architecture between the multi- and single-ACCDOA formats was only the final fully-connected layer. We compared three PITs for the multi-ACCDOA format: the non-class-wise PIT, the class-wise PIT, and the class-wise ADPIT. We also investigated the threshold of unification from 15 to 45 degrees for inference. Other configurations mostly followed our DCASE 2021 challenge settings [23] in all methods. Multichannel amplitude spectrograms and inter-channel phase differences (IPDs) were used as features. Three data augmentation methods were applied: equalized mixture data augmentation (EMDA) [24, 25], rotation in the first-order Ambisonic (FOA) [26], and SpecAugment [27]. A conventional CRNN [10] was used for the experiments.
The multi-ACCDOA format was compared with the track-wise method called EINV2 [14]. We prepared the original EINV2 architecture [14]. Since the architecture uses MHSA blocks, we also replace GRU layers with MHSA blocks for the multi-ACCDOA format. We called the architecture CNN-MHSA.
Then we compared the proposed method with state-of-the-art SELD methods without model ensembles. Although model ensemble techniques effectively achieve high performance, we omitted this for pure comparison between single models. We used RD3Net [11] for comparison. We used cosIPDs, and sinIPDs [28], instead of the IPDs for this model. The STFT was applied with 40 ms frame length and 20 ms frame hop, and the input length was set to 5.11 seconds.
4.4 Experimental results
Table 1 summarizes the performance in the single- and multi-ACCDOA formats. The multi-ACCDOA format with the class-wise ADPIT outperformed the single one for all metrics with only a few increases in parameters. The multi-ACCDOA format with the class-wise ADPIT showed 7.2 points higher than the single one in the cases with overlaps from the same class, while the multi-ACCDOA format with the class-wise ADPIT performed comparably in the other cases. The result shows the threshold value slightly affected the performance, especially . The result also shows that conventional PITs made it difficult to train the multi-ACCDOA format since the PITs cannot allow each track of the multi-ACCDOA format to learn with the same target as the single one. It is also shown that the multi-ACCDOA format with the class-wise ADPIT can successfully localize and detect the overlaps from the same class and maintain the performance in the other cases.
Table 2 summarizes the performance in the multi-ACCDOA format trained with the class-wise ADPIT and the track-wise format. The multi-ACCDOA format performed better in , , and . The result shows that the multi-ACCDOA format performed comparably to the track-wise format with considerably fewer parameters.
Table 3 shows the performances of the SELD methods without model ensembles. The RD3Net using the multi-ACCDOA format trained with the class-wise ADPIT performed the best in , , and for the DCASE 2021 Task 3 development set.
5 Conclusion
We extended the activity-coupled Cartesian direction-of-arrival (ACCDOA) format to a multi one and proposed auxiliary duplicating permutation invariant training (ADPIT). The multi-ACCDOA format (a class- and track-wise output format) enables the model to solve the cases with overlaps from the same class. The class-wise ADPIT makes each track of the multi-ACCDOA format be trained with original targets and duplicated targets. The scheme enables each track to learn with the same target as the single one. During inference, duplicated outputs are unified with their similarity. In the evaluations on the sound event localization and detection task for DCASE 2021 Task 3, the model using the multi-ACCDOA format trained with the class-wise ADPIT detects overlapping events from the same class while maintaining the performance in the other situations. The proposed method also performed comparably to state-of-the-art methods with fewer parameters.
References
- [1] M. Crocco, M. Cristani, A. Trucco, and V. Murino, “Audio surveillance: A systematic review,” ACM Computing Surveys, vol. 48, no. 4, pp. 1–46, 2016.
- [2] G. Valenzise, L. Gerosa, M. Tagliasacchi, F. Antonacci, and A. Sarti, “Scream and gunshot detection and localization for audio-surveillance systems,” in Proc. of IEEE AVSS, 2007, pp. 21–26.
- [3] S. Chu, S. Narayanan, and C.-C. J. Kuo, “Environmental sound recognition with time–frequency audio features,” IEEE Trans. on ASLP, vol. 17, no. 6, pp. 1142–1158, 2009.
- [4] N. Yalta, K. Nakadai, and T. Ogata, “Sound source localization using deep learning models,” Journal of Robotics and Mechatronics, vol. 29, no. 1, pp. 37–48, 2017.
- [5] H. Sun, X. Liu, K. Xu, J. Miao, and Q. Luo, “Emergency vehicles audio detection and localization in autonomous driving,” arXiv:2109.14797, 2021.
- [6] A. Politis, A. Mesaros, S. Adavanne, T. Heittola, and T. Virtanen, “Overview and evaluation of sound event localization and detection in dcase 2019,” IEEE/ACM Trans. on ASLP, vol. 29, pp. 684–698, 2020.
- [7] S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,” IEEE JSTSP, vol. 13, no. 1, pp. 34–48, 2018.
- [8] A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,” in Proc. of DCASE Workshop, 2020.
- [9] Q. Wang, J. Du, H.-X. Wu, J. Pan, F. Ma, and C.-H. Lee, “A four-stage data augmentation approach to resnet-conformer based acoustic modeling for sound event localization and detection,” arXiv:2101.02919, 2021.
- [10] Y. Cao, Q. Kong, T. Iqbal, F. An, W. Wang, and M. D. Plumbley, “Polyphonic sound event detection and localization using a two-stage strategy,” in Proc. of DCASE Workshop, 2019.
- [11] K. Shimada, Y. Koyama, N. Takahashi, S. Takahashi, and Y. Mitsufuji, “ACCDOA: Activity-coupled cartesian direction of arrival representation for sound event localization and detection,” in Proc. of IEEE ICASSP, 2021, pp. 915–919.
- [12] A. Politis, S. Adavanne, D. Krause, A. Deleforge, P. Srivastava, and T. Virtanen, “A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection,” arXiv:2106.06999, 2021.
- [13] P. Emmanuel, N. Parrish, and M. Horton, “Multi-scale network for sound event localization and detection,” in Tech. report of DCASE Challenge, 2021.
- [14] Y. Cao, T. Iqbal, Q. Kong, F. An, W. Wang, and M. D. Plumbley, “An improved event-independent network for polyphonic sound event localization and detection,” in Proc. of ICASSP. IEEE, 2021, pp. 885–889.
- [15] T. N. T. Nguyen, D. L. Jones, and W.-S. Gan, “A sequence matching network for polyphonic sound event localization and detection,” in Proc. of IEEE ICASSP, 2020, pp. 71–75.
- [16] Y. He, N. Trigoni, and A. Markham, “SoundDet: polyphonic moving sound event detection and localization from raw waveform,” in Proc. of ICML, 2021.
- [17] M. Kolbæk, D. Yu, Z.-H. Tan, and J. Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Trans. on ASLP, vol. 25, no. 10, pp. 1901–1913, 2017.
- [18] Y. Luo and N. Mesgarani, “Separating varying numbers of sources with auxiliary autoencoding loss,” in Proc. of Interspeech, 2020.
- [19] A. Mesaros, S. Adavanne, A. Politis, T. Heittola, and T. Virtanen, “Joint measurement of localization and detection of sound events,” in Proc. of IEEE WASPAA, 2019.
- [20] H. Erdogan and T. Yoshioka, “Investigations on data augmentation and loss functions for deep learning based speech-background separation,” in Proc. of Interspeech, 2018, pp. 3499–3503.
- [21] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He, “Accurate, large minibatch SGD: Training ImageNet in 1 hour,” arXiv:1706.02677, 2017.
- [22] P. Izmailov, D. Podoprikhin, T. Garipov, D. Vetrov, and A. G. Wilson, “Averaging weights leads to wider optima and better generalization,” in Proc. of UAI, 2018.
- [23] K. Shimada, N. Takahashi, Y. Koyama, S. Takahashi, E. Tsunoo, M. Takahashi, and Y. Mitsufuji, “Ensemble of ACCDOA- and EINV2-based systems with D3Nets and impulse response simulation for sound event localization and detection,” in Tech. report of DCASE Challange, 2021.
- [24] N. Takahashi, M. Gygli, and L. Van Gool, “AENet: Learning deep audio features for video analysis,” IEEE Trans. on Multimedia, vol. 20, pp. 513–524, 2017.
- [25] N. Takahashi, M. Gygli, B. Pfister, and L. V. Gool, “Deep convolutional neural networks and data augmentation for acoustic event detection,” in Proc. of Interspeech, 2016, pp. 2982–2986.
- [26] L. Mazzon, Y. Koizumi, M. Yasuda, and N. Harada, “First order ambisonics domain spatial augmentation for DNN-based direction of arrival estimation,” in Proc. of DCASE Workshop, 2019.
- [27] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “SpecAugment: A simple data augmentation method for automatic speech recognition,” in Proc. of Interspeech, 2019, pp. 2613–2617.
- [28] Z.-Q. Wang, J. Le Roux, and J. R. Hershey, “Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker-independent speech separation,” in Proc. of IEEE ICASSP, 2018, pp. 1–5.
- [29] T. N. T. Nguyen, K. Watcharasupat, N. K. Nguyen, D. L. Jones, and W. S. Gan, “DCASE 2021 task 3: Spectrotemporally-aligned features for polyphonic sound event localization and detection,” in Tech. report of DCASE Challange, 2021.