©2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all
other uses, in any current or future media, including reprinting/republishing this material for advertising
or promotional purposes, creating new collective works, for resale or redistribution to servers or lists,
or reuse of any copyrighted component of this work in other works.
Multi-Agent Feedback Motion Planning using Probably Approximately Correct Nonlinear Model Predictive Control
Abstract
For many tasks, multi-robot teams often provide greater efficiency, robustness, and resiliency. However, multi-robot collaboration in real-world scenarios poses a number of major challenges, especially when dynamic robots must balance competing objectives like formation control and obstacle avoidance in the presence of stochastic dynamics and sensor uncertainty. In this paper, we propose a distributed, multi-agent receding-horizon feedback motion planning approach using Probably Approximately Correct Nonlinear Model Predictive Control (PAC-NMPC) that is able to reason about both model and measurement uncertainty to achieve robust multi-agent formation control while navigating cluttered obstacle fields and avoiding inter-robot collisions. Our approach relies not only on the underlying PAC-NMPC algorithm but also on a terminal cost-function derived from gyroscopic obstacle avoidance. Through numerical simulation, we show that our distributed approach performs on par with a centralized formulation, that it offers improved performance in the case of significant measurement noise, and that it can scale to more complex dynamical systems.
I Introduction
Unified control and path planning for multi-robot systems is a challenging problem to address, especially in the presence of complex stochastic dynamics and measurement uncertainty. Even in discrete state and action spaces, the complexity of finding an optimal solution to the multi-agent path planning problem is NP-hard [1], and the computation time increases exponentially with the number of robots. The computational complexity is only further exacerbated in more realistic scenarios characterized by continuous state and action spaces where the multi-robot team must achieve objectives like formation control, obstacle avoidance, and reason about stochastic underactuated nonlinear dynamics.
Centralized controllers, as referenced in [2], [3], [4], and [5] are commonly employed to address these issues. However, these centralized approaches can be slow and not scale as the team size increases. Another limitation is that centralized approaches may not be able to update quickly enough to accommodate changing environments or imperfect environmental data, which could compromise the effectiveness of the path plan.
This paper builds on the sampling-based Stochastic Nonlinear Model Predictive Control (SNMPC) algorithm, Probably Approximate Correct NMPC (PAC-NMPC), as cited in [6], to enable distributed multiple robot collaboration and feedback motion planning in the presence of static and dynamic obstacles. In particular, we introduce a set of costs and constraints that capture the expected behavior of teammates over a finite horizon and enable probabilistically-safe formation control in cluttered environments. Our contributions are:
-
•
A receding-horizon feedback motion planning framework for distributed, probabilistically-safe multi-robot formation control in obstacle fields under dynamics and measurement uncertainty.
-
•
A terminal cost inspired by gyroscopic obstacle avoidance to improve finite-horizon planning in the presence of static and dynamic obstacles.
-
•
The demonstration of the algorithm’s effectiveness through numerical simulation in complex environments and its ability to scale to higher dimensions.
II Related Work
Researchers have explored a wide variety of strategies for achieving unified formation control and obstacle avoidance [7] [8]. Behavior-based controllers are one class of methods that have tried to address this problem [9],[10], [11]. These controllers combine the outputs from a set of sub-controllers that promote separate objectives, such as formation error, obstacle avoidance, and goal error. Typically, these approaches suffer from poor robustness and generalizability.
Consensus-based approaches achieve formation control by relying on local information to facilitate the convergence of all agents to the same information state[12, 13]. Some approaches have explored the joint formation control and obstacle avoidance problem [14] and others have extended consensus-based formation control to simple non-holonomic systems (e.g., [15], [16]).
Artificial Potential Fields (APF) are a set of approaches stemming from the path planning approach by Khatib [17]. APFs have been used to achieve formations while avoiding obstacles [18] [19] [20]. These allow for fixed formation and re-updating the controller after every time step and can be used for both leader-follower and other formation types, but are often limited to simple dynamics models.
Virtual structures achieve formation control by reasoning about the geometric performance of a rigid structure [21] [22]. Virtual structures have been used to adapt Probabilistic Roadmaps (PRM) [23]. Typically, virtual structures offer limited flexibility and obstacle avoidance.
Machine Learning and Reinforcement Learning have been used to handle multi-agent formation. For swarm robotics, learning has been used on the dynamics of nonlinear systems to give bounds on formation error [24]. Other approaches use policy search to solve nonlinear optimization problems within formation control [25] [26]. Reinforcement learning for leader-follower and swarm robotics has been used, training Double Deep Q-Networks to obtain proper formation behavior [27] or to achieve multi-robot planning in the presence of dynamic obstacles [28]. Oftentimes, learning-based methods demonstrate degraded performance in out-of-distribution environments and during sim-to-real transfer.
In recent years, online trajectory optimization and Nonlinear Model Predictive Control (NMPC) have emerged a powerful approaches for achieving multi-robot planning and control. Some approaches have applied NMPC to achieve formation control [29, 30, 31, 32, 33]. Other approaches have explored inter-agent collision avoidance via distributed NMPC [34, 35] or by combining NMPC with conflict-based search [36]. A few approaches have explored NMPC to achieve formation control in the presence of obstacles. [37] employs a virtual structure framework and [38] is restricted to a linear dynamics model.
To our knowledge, our approach is the first method to employ SNMPC to achieve distributed, probabilistically-safe multi-agent collision avoidance and formation control in cluttered environments for a large class of stochastic nonlinear dynamical systems and measurement uncertainty.
III Probably Approximately Correct Nonlinear Model Predictive Control (PAC-NMPC)
Our proposed multi-agent formation controller utilizes Probably Approximately Correct Nonlinear Model Predictive Control (PAC-NMPC) [6]. PAC-NMPC uses Iterative Stochastic Policy Optimization (ISPO) [39] to formulate the search for a local time-varying feedback control policy of the form , as a stochastic optimization problem. This is achieved by sampling the policy parameters, , from a surrogate distribution given by the probability density function and defined by hyper-parameters . Here is the nominal trajectory computed using a nominal deterministic discrete-time dynamics model over time steps. and are the nominal states and control inputs at time index respectively. is the discrete time step and is a sequence of time-varying feedback gains computed using the finite horizon, discrete, time-varying linear quadratic regulator (TVLQR) [40]. The policy is parameterized only by the nominal input sequence, so that . The surrogate distribution, , is parameterized as a multivariate Gaussian, , with a mean, , and a covariance matrix, . Since the covariance matrix is diagonal, the hyperparameters can be written as . For a discrete-time trajectory sequence , one can define a non-negative trajectory cost function, , and a trajectory constraint violation function .
During each planning iteration, PAC-NMPC optimizes a weighted objective function where is the PAC bound on , is the PAC bound on , and is positive weighting coefficient. These PAC bounds, which are derived in [39], take the form
| (1) |
where is a robust estimator of the expected cost, is a distance between distributions, is a concentration-of-measure term, and is the bound confidence.
This optimization ensures that the chosen control policy satisfies performance and safety requirements with a specified confidence level. In essence, PAC-NMPC offers a robust and statistically guaranteed approach for controlling systems with uncertainties.
IV PAC-NMPC for Multi-Agent Control
This section presents a centralized and distributed approach for PAC-NMPC to control a team of agents in formation, navigating an obstacle-filled environment to a goal state .
IV-A Problem Formulation
For the centralized approach for formation control, we define the team state as where is the state of the agent on the team. To guide the team towards , we define a cost function for the team’s trajectory as
| (2) |
where is the cost at timestep and is the cost at the final time. Constraints to ensure collision avoidance and bound the state are formulated as
| (3) | ||||
Here is the lower and upper state bound, is the obstacle radius plus the maximum robot radius, is the obstacle position in the world frame. is a constraint to prevent collisions between dynamic agents and is formulated as
| (4) | ||||
where is the collision radius and is agent on the team.
IV-B Cost Function
We formulate our cost function for the agent as
| (5) |
where , is the position of agent at time , and is the final desired position of agent . , where is the desired velocity vector for the terminal state of agent , and is the final velocity of agent . The first term in the running cost encourages a desired velocity, while the second term applies a cost on action. The terminal cost includes , which is a desired final velocity vector inspired by the gyroscopic obstacle avoidance control in [41]. It is given as
| (6) |
where ,
| (7) |
and
| (8) | |||
Where is a proportional feedback gain, is a smooth sign function, is the attractive weighting, is the avoidance weighting, is the distance to static or dynamic obstacle , is the detection radius, is a tuning value for negligible obstacle gain at the detection radius and is the maximum desired velocity. is the cost for the full multi-agent system. is the set of static and dynamic obstacle positions, which includes the set of static obstacles and the set of dynamic obstacles represented by the final positions of the other agents . is the velocity of obstacle. For dynamic obstacles (i.e., other agents), this is the terminal velocity , and for static obstacles, it is zero.
To handle collisions with both static and dynamic obstacles (i.e., other agents), we choose based on [42] to maintain a consistent policy among team members for selecting a “give-way” direction. is given as follows:
-
C1.
If :
-
C2.
If :
-
C3.
If :
-
C4.
Else:
where is the angle between two vectors, and is defined as
Gyroscopic obstacle avoidance was used over AFP or no obstacle avoidance because it helped avoid local minima more effectively and allowed for trajectory deconflicting.
IV-C Distributed Multi-Agent PAC-NMPC
Both the cost function and the constraints are dependent on the full multi-robot system trajectory, . To enable a distributed control paradigm, the agents share their initial states, , and control policy distribution parameters, , at the beginning of each planning interval. Each agent then optimizes its own control policy distribution, assuming the policies of the other agents remain fixed during the planning interval. To reconstruct the trajectory and evaluate the joint costs and constraints, each agent samples trajectory predictions for the other agents using the received policies and states.
For formation control, the formation points can be specified in the cost function as the desired terminal positions, . In this paper, we explore several methods for computing these formation points.
V State Measurement Error
In real-world applications, relying solely on shared state information leads to discrepancies due to sensor noise, communication delays, and environmental uncertainties. These factors introduce discrepancies between an agent’s actual state and the state information received by other agents. Not accounting for the uncertainty in the state measurement could lead to collisions or worse performance.
We model the state measurement error as a zero-mean Gaussian noise with a covariance . The received state of agent is represented as where is the true state and is the received state. To reason about state measurement uncertainty, the algorithm samples the state from the normal distributions for each agent during trajectory rollouts. This approach enables an agent to consider other agents’ state uncertainties and plan its trajectory to enable robust, collision-free navigation under measurement uncertainty.
VI Simulation Experiments
We conducted Monte Carlo simulations to test the effectiveness of multi-agent PAC-NMPC for formation control and collision avoidance.
We simulate a stochastic bicycle model with acceleration and steering rate inputs for each agent. We denote as the state vector, as the control vector, as the wheel base, and as the covariance. The stochastic bicycle model is defined as
| (9) | ||||
The acceleration is limited to , the steering rate is limited , the velocity is limited to , the steering angle is limited to .
We generated fifty random obstacle fields of 10 non-overlapping circular obstacles with an inflated radius of 0.6 meters to test the formation control in obstacle-filled environments. The obstacles were between and . The fields were generated with free space before and after the obstacle field to allow the formation to converge. The desired formation was a 3-agent wedge. The formation goals were defined and calculated as
| (10) |
where is the distance in the x-direction behind the leader, and is the distance in the y-direction behind the leader. For these experiments, . We chose these distances to make a formation too small to wrap around obstacles but not large enough where the agents were too far away to interact.
We chose a goal at = [15, 0]. We sampled the leader agent state from a uniform distribution between = [-1,
-2, , 0.0, -0.2] and = [1, 2, , 1.0, 0.2]. The follower agents’ initial positions were placed in the wedge formation with some noise sampled from a uniform distribution with a bound of [0.5, 0.5, , 0.5, 0.2].
We used an open environment to test the inter-agent collision avoidance further. Three agents were placed symmetrically around a 5-meter-radius circle, given a goal point antipodal to the start position. In these trials, the optimal paths of all three agents would meet in the center of the circle to encourage head-on collisions.
The parameters were , , = 3, , , , and
VI-A Centralized Model
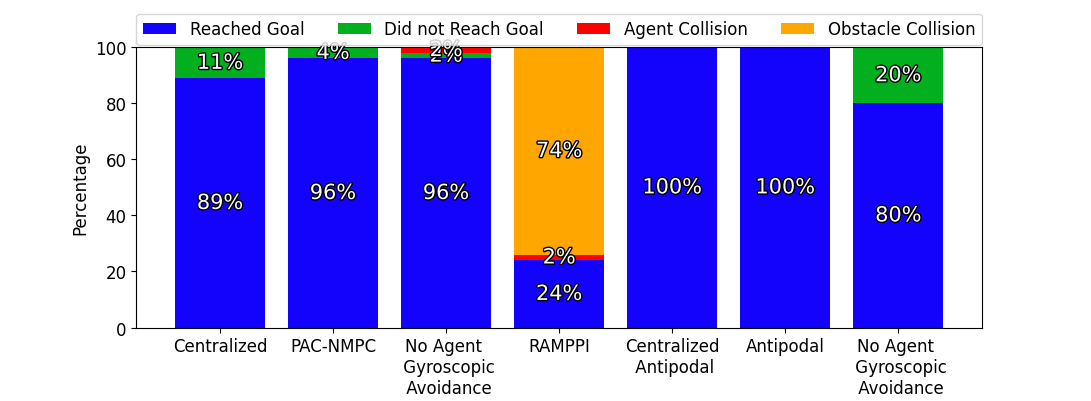
We tested the centralized model on the obstacle field, running 200 optimization iterations per planning cycle and 4096 trajectory samples per optimization iteration. The leader agent followed a path generated using the rapidly-exploring random trees (RRT) algorithm [43] from its initial position to the goal. The leader’s RRT defined the follower’s formation points. While the leader successfully navigated the obstacle field without collisions, the followers often became trapped in the obstacle field. The centralized model never violated its bounds on cost or constraints.
In the symmetric antipodal goal experiment, the centralized approach deconflicted its trajectories without inter-agent gyroscopic avoidance, allowing each agent to reach the goal without a collision.
VI-B Distributed Model
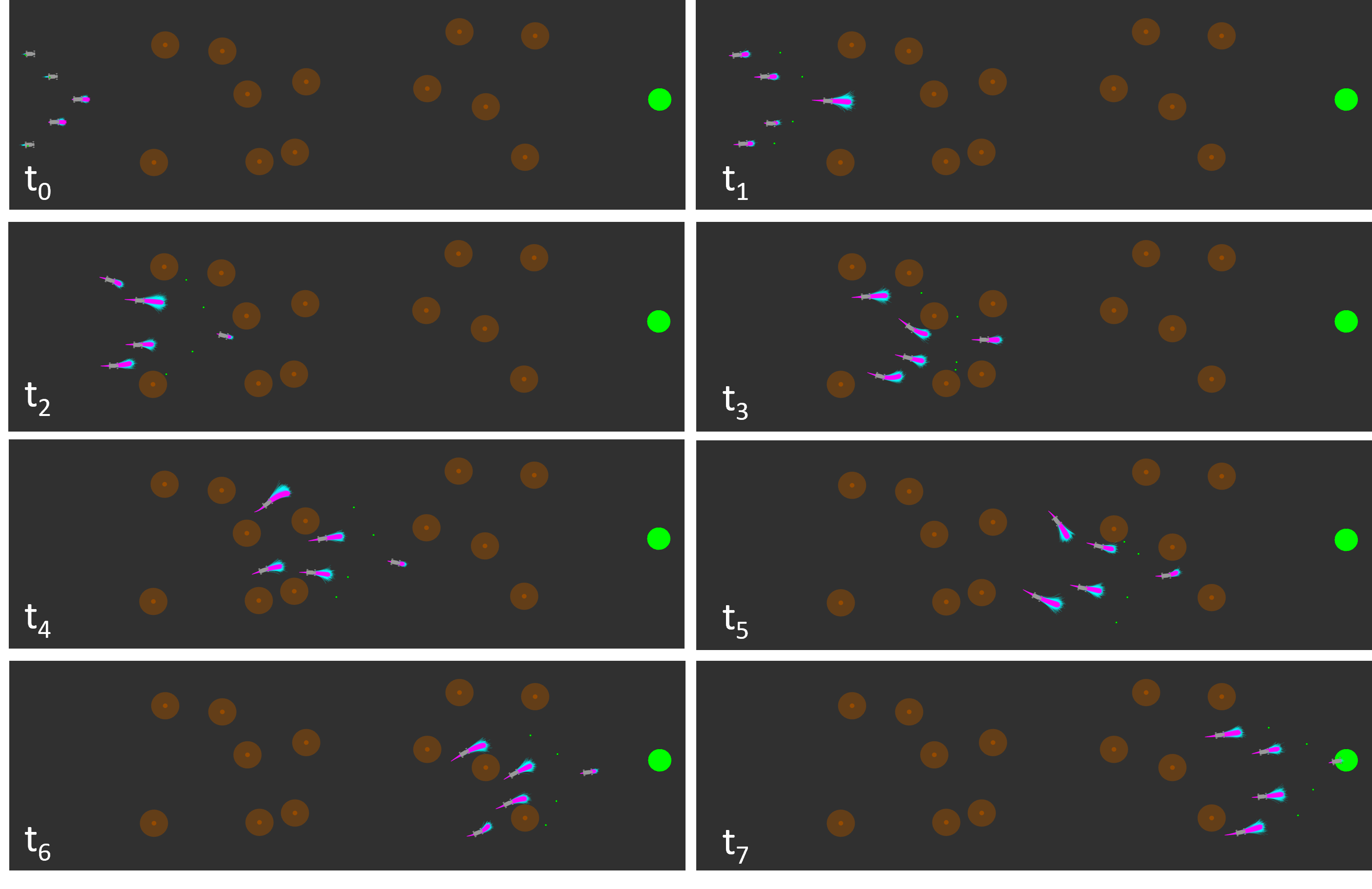
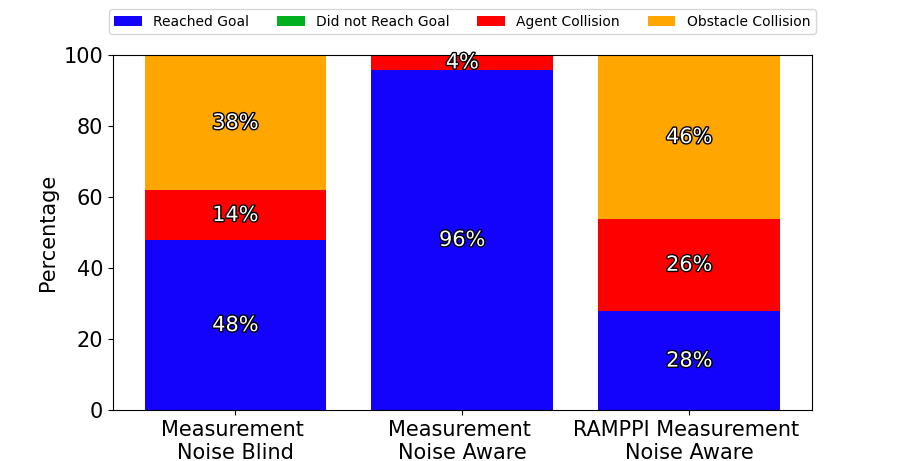
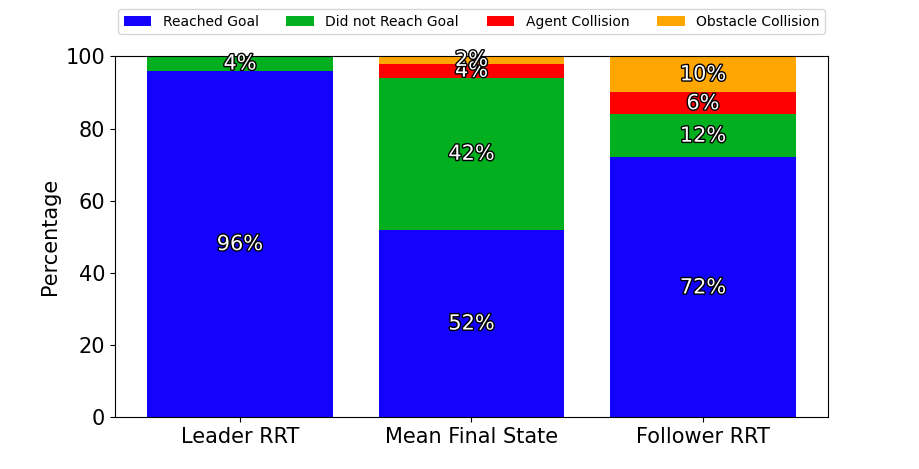
The distributed model was tested at 200 iterations per planning cycle and 1024 trajectory samples per optimization iteration. The gyroscopic obstacle avoidance for inter-agent collisions was turned on and off in two separate trials. Figure 3 illustrates the outcomes, including whether a trial resulted in an obstacle crash, a collision with another agent, an agent getting trapped behind an obstacle, or all agents successfully reaching the goal.
The distributed approach can travel through the obstacle-filled environment in the same number of iterations but much quicker, with fewer instances of agents getting trapped in local minima compared to the centralized approach. This improvement is likely due to the increased complexity of the optimization problem as the number of control inputs increases in the centralized model.
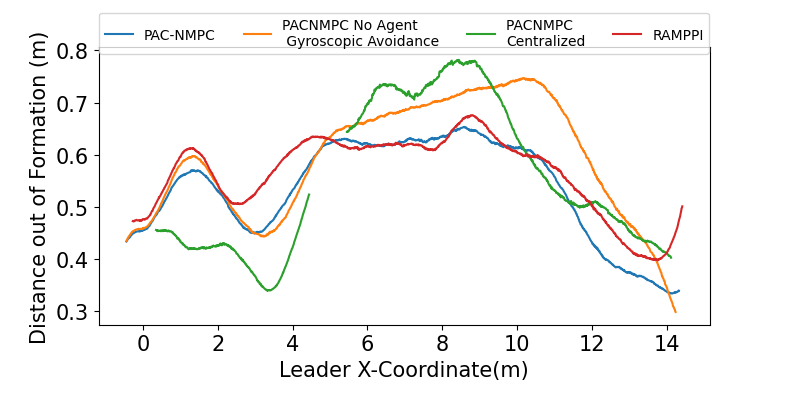
The trials with and without the inter-agent gyroscopic avoidance led to a similar number of successful trials. However, the trials without led to poorer formation control within the obstacle field, as seen in Figure 4. Not having gyroscopic avoidance led to agents avoiding collisions using a stop-and-go strategy, negatively impacting formations.
In the symmetric antipodal goal experiment, the distributed controller without inter-agent gyroscopic avoidance got stuck in deadlocks 20% of the time, where the three agents avoided the collision but could not move towards the goal. When gyroscopic avoidance was enabled, these deadlocks were prevented, allowing a performance similar to that of the centralized controller.
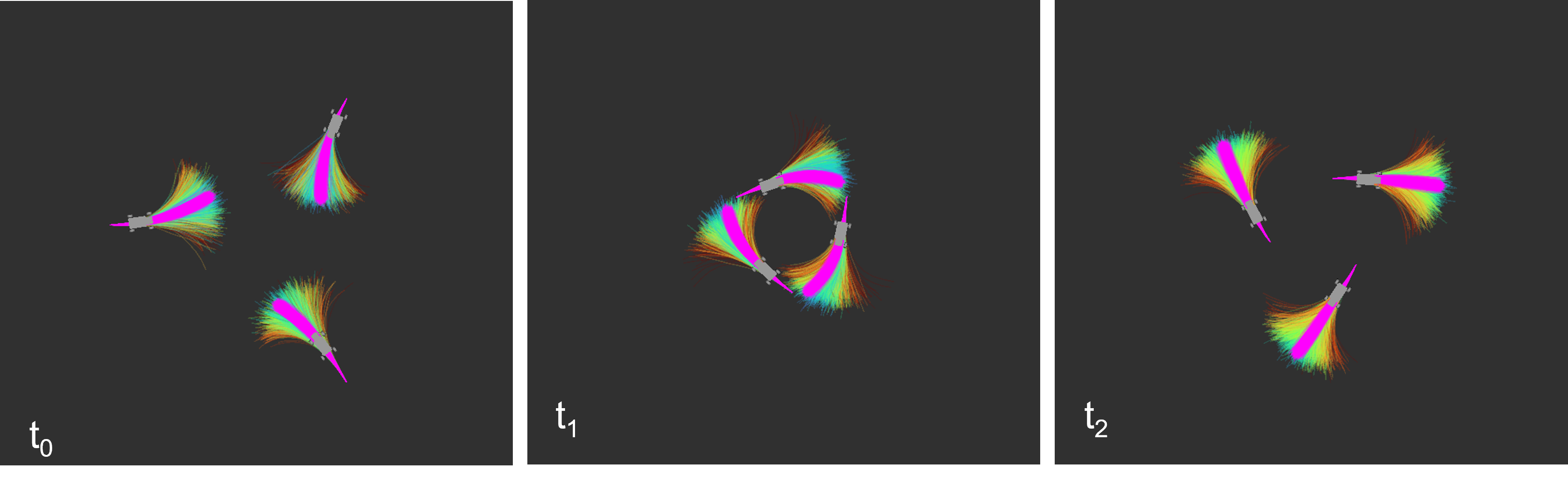
VI-C PAC-NMPC and RA-MPPI
We conducted additional trials with Risk Aware Model Predictive Path Integral (RA-MPPI) [44]. Figure 4 reveals RA-MPPI resulted in a slightly higher average formation error than PAC-NMPC. The followers struggled to avoid crashes with obstacles, as seen in Figure 3. Figures 5 and 6 show the trajectories through the environment, where we can see RA-MPPI cutting through obstacles as formation points change or getting turned around to avoid collisions. PAC-NMPC was able to keep the wedge formation through the same obstacle fields. Furthermore, PAC-NMPC performed with a lower probability of constraint violations in the follower’s planning than RA-MPPI. However, PAC-NMPC did run 23% slower and the centralized approach ran 453% slower per planning cycle, than RA-MPPI.
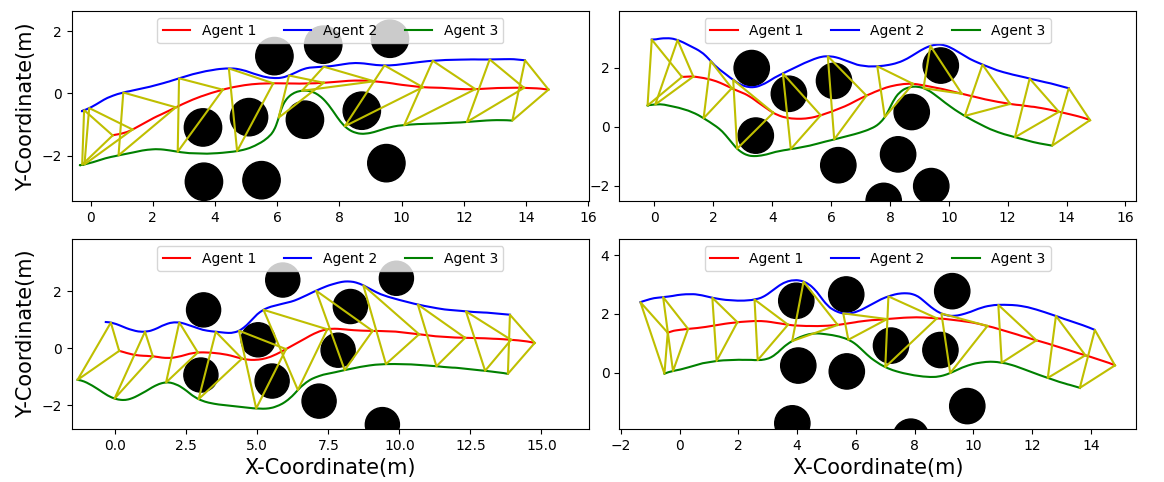
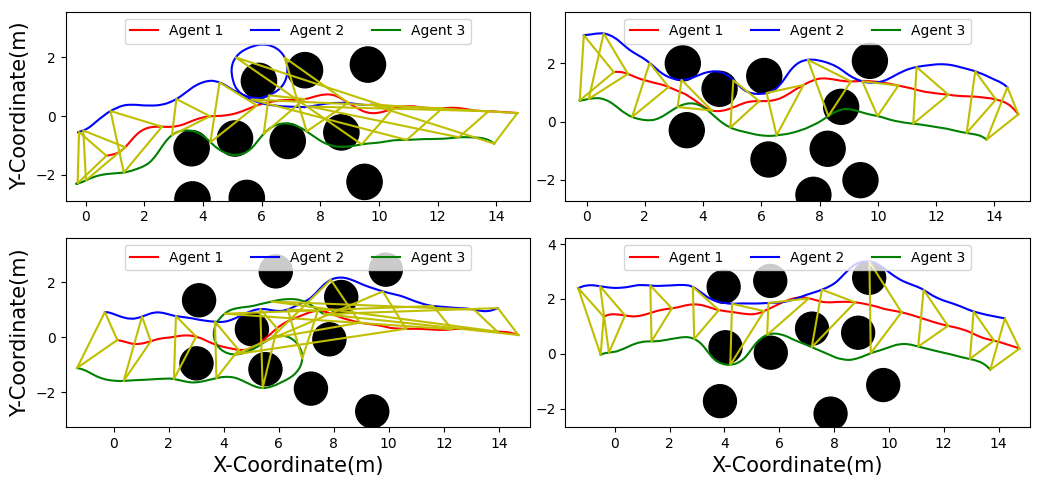
VI-D Impact of State Measurement Uncertainty
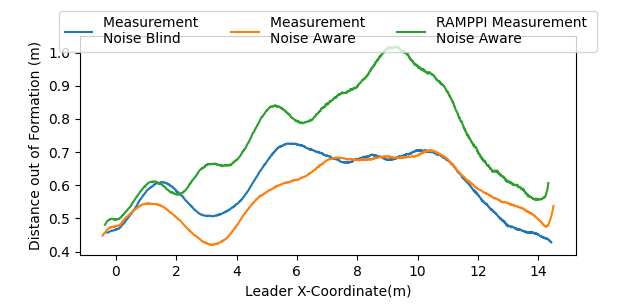
The trials were run with uncertain state positions, where the shared states were drawn from a normal distribution with a covariance of 0.9 meters in the x- and y-coordinates. As shown in Figure 8, PAC-NMPC experienced a significant increase in collisions with agents and obstacles when state measurement noise was not accounted for. These static obstacle collisions often occurred as the noise-blind controller attempted to avoid an agent that was not there, leading to constraint violations in nearly all sampled trajectories.
In contrast, the measurement noise-aware model successfully completed the same number of trials as the trial with ground truth measurements. While it did not eliminate collisions, it significantly reduced their frequency compared to the noise-blind case, preventing the agents from falling out of formation or colliding with each other as often. The noise blind controller also violated its cost bound in 10% of plans, whereas the noise aware controller violated cost bounds 2% of the time.
RA-MPPI struggled to compensate for the state uncertainties as effectively as PAC-NMPC, resulting in collision frequency on par with the noise-blind PAC-NMPC configuration. RA-MPPI also showed much worse formation performance over the trials, as seen in Figure 7. Table I records the average constraint probability, showing that RA-MPPI had a higher average constraint violation, and the followers also had a higher probability of constraint violation than the leaders.
| Trial Type | Number of Collisions | Leader Constraint | Follower Constraint |
|---|---|---|---|
| PAC-NMPC | 0 | 0.00465 | 0.013 |
| RA-MPPI | 38 | 0.0521 | 0.1788 |
| PAC-NMPC State Noise Blind | 26 | 0.1208 | 0.148 |
| PAC-NMPC State Noise Aware | 2 | 0.0987 | 0.1854 |
| RA-MPPI State Noise Aware | 33 | 0.208 | 0.289 |
VI-E Formation Points
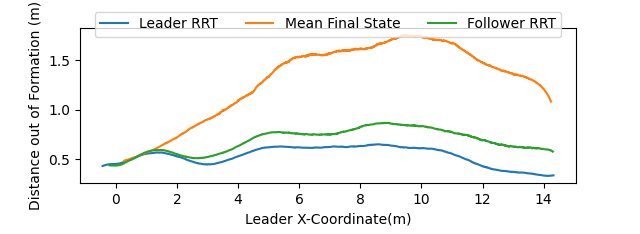
The trials were repeated using three different methods for calculating the followers’ formation points: they were defined directly from the leader’s RRT, calculated based on the final state of the leader’s mean trajectory, or calculated by the follower using its own RRT, with the goal point defined by the leader’s RRT.
Formation point calculation methods based on the leader’s RRT generally outperformed those using the mean final state in both successful trial percentage and formation error as seen in Figures 9 and 10. The follower RRT-based approach resulted in more agents trapped behind obstacles than when the formation point is only defined by the leader’s RRT.
VI-F Symmetric Antipodal Under State Uncertainty
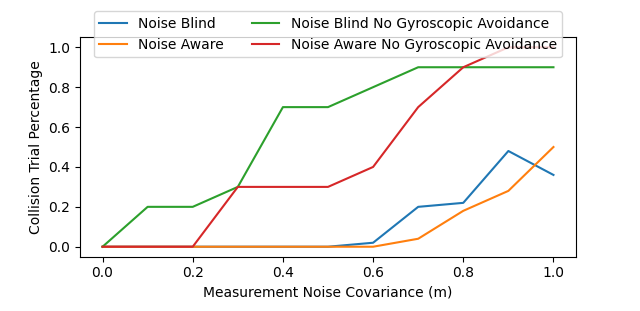
We ran fifty trials in the symmetric antipodal setup with measurement noise variance from 0 to 1.0 meters. Figure 11 shows that gyroscopic avoidance assists with avoiding collisions under measurement noise. The trials without the gyroscopic avoidance began to collide at 0.1 meters with the noise-blind controller but at 0.2 meters with the noise-aware controller. However, adding the gyroscopic avoidance increased the collision avoidance to 0.6 meters in the noise-blind case and 0.7 meters in the noise-aware case. The noise-aware controller reduced the number of collisions as the noise increased and achieved fewer constraint violations than the noise-blind controller.
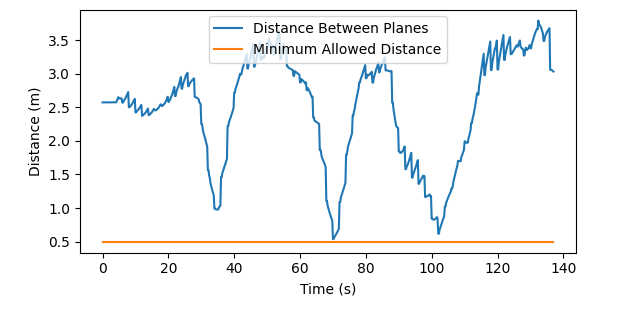
VI-G Extension to Higher Dimensions
Two fixed-wing planes were simulated following the same path in opposite directions. The fixed wing is described by a complex nonlinear dynamics model with a 17-dimension state and four control inputs [45]. PAC-NMPC avoided collisions at 100 iterations using 3D gyroscopic avoidance. Figure 12 shows the distance between planes as they follow a rectangular path in opposite directions.
VII Discussion
In this paper, we presented a distributed receding-horizon SNMPC approach for navigating a multi-robot team through an obstacle field in formation. We demonstrated in simulation that using a gyroscopic avoidance-based cost enables the controller to keep formation by avoiding collisions and local minima. Further, we showed that control policy sharing could enable collision avoidance under state measurement uncertainty. Future work could explore heterogeneous teams and apply this model to more complex environments and dynamics.
ACKNOWLEDGMENT
We gratefully acknowledge the support of the Army Research Laboratory under grant W911NF-22-2-0241.
References
- [1] R. Stern, “Multi-agent path finding–an overview,” Artificial Intelligence: 5th RAAI Summer School, Dolgoprudny, Russia, July 4–7, 2019, Tutorial Lectures, pp. 96–115, 2019.
- [2] S. Kumar and S. Chakravorty, “Multi-agent generalized probabilistic roadmaps: Magprm,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012, pp. 3747–3753.
- [3] Y. Wu, B. Jiang, and H. Xu, “Formation control strategy of multi-agent system with improved probabilistic roadmap method applied in restricted environment,” in 2021 6th International Conference on Computational Intelligence and Applications (ICCIA), 2021, pp. 233–237.
- [4] B. R. Hikmet Beyoglu, Stephan Weiss, “Multi-agent path planning and trajectory generation for confined environments,” International Conference on Unmanned Aircraft Systems, 2022.
- [5] X. Liu, S. S. Ge, and C.-H. Goh, “Formation potential field for trajectory tracking control of multi-agents in constrained space,” International Journal of Control, vol. 90, no. 10, pp. 2137–2151, 2017. [Online]. Available: https://doi.org/10.1080/00207179.2016.1237044
- [6] A. Polevoy, M. Kobilarov, and J. Moore, “Probably approximately correct nonlinear model predictive control (pac-nmpc),” IEEE Robotics and Automation Letters, pp. 1–8, 2023.
- [7] H. T., H. Do, H. T. Hua, H. T. Hua, H. Hua, M. T. Nguyen, M. T. Nguyen, M. T. H. Nguyen, M. T. Nguyen, C. V. Nguyen, C. Nguyen, C. V. Nguyen, C. Nguyen, H. Q. Nguyen, H. Nguyen, H. Nguyen, H. T. Nguyen, N. K. Nguyen, N. Nguyen, N. T. T. Nguyen, N. T. Nguyen, and N. T. T. Nguyen, “Formation control algorithms for multiple-uavs: A comprehensive survey,” EAI Endorsed Trans. Ind. Networks Intell. Syst., 2021.
- [8] Q. jie Chen, Y. Wang, Y. Jin, T. Wang, X. Nie, and T. Yan, “A survey of an intelligent multi-agent formation control,” Applied Sciences, 2023.
- [9] T. Balch, T. Balch, R. C. Arkin, and R. C. Arkin, “Behavior-based formation control for multirobot teams,” null, 1998.
- [10] G. Lee, G. Lee, D. Chwa, D. Chwa, and D. Chwa, “Decentralized behavior-based formation control of multiple robots considering obstacle avoidance,” Intelligent Service Robotics, 2018.
- [11] M. B. Emile, M. B. Emile, O. M. Shehata, O. M. Shehata, A. El-Badawy, and A. A. El-Badawy, “A decentralized control of multiple unmanned aerial vehicles formation flight considering obstacle avoidance,” International Conference on Control, Mechatronics and Automation, 2020.
- [12] W. Ren, “Consensus based formation control strategies for multi-vehicle systems,” in 2006 American Control Conference. IEEE, 2006, pp. 6–pp.
- [13] F. Xiao, F. Xiao, F. Xiao, F. Xiao, L. Wang, L. Wang, J. Chen, J. Chen, J. Chen, J. Chen, J. Chen, Y. Gao, and Y. Gao, “Brief paper: Finite-time formation control for multi-agent systems,” Automatica, 2009.
- [14] R. O. Saber and R. M. Murray, “Flocking with obstacle avoidance: Cooperation with limited communication in mobile networks,” in 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03CH37475), vol. 2. IEEE, 2003, pp. 2022–2028.
- [15] W. Wang, W. Wang, W. Wang, W. Wang, J. Huang, J. Huang, W. Chen, C. Wen, H. Fan, and H. Fan, “Distributed adaptive control for consensus tracking with application to formation control of nonholonomic mobile robots,” Automatica, 2014.
- [16] J. G. Romero, E. Nuño, E. Restrepo, and I. Sarras, “Global consensus-based formation control of nonholonomic mobile robots with time-varying delays and without velocity measurements,” IEEE Transactions on Automatic Control, 2023.
- [17] O. Khatib, Real-Time Obstacle Avoidance for Manipulators and Mobile Robots. New York, NY: Springer New York, 1990, pp. 396–404. [Online]. Available: https://doi.org/10.1007/978-1-4613-8997-2_29
- [18] M. Colledanchise, M. Colledanchise, D. V. Dimarogonas, D. V. Dimarogonas, P. Ögren, and P. Ögren, “Obstacle avoidance in formation using navigation-like functions and constraint based programming,” 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2013.
- [19] X. Liu, X. Liu, S. S. Ge, S. S. Ge, C. H. Goh, and C.-H. Goh, “Formation potential field for trajectory tracking control of multi-agents in constrained space,” International Journal of Control, 2017.
- [20] Y. Sun, Y. Sun, X. Hu, X. Hu, J. Xiao, J. Xiao, J. Xiao, G. Zhang, G. Zhang, G. Zhang, S. Wang, S. Wang, L. Liu, and L. Liu, “Multi-agent cluster systems formation control with obstacle avoidance,” 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), 2020.
- [21] K.-H. Tan, K.-H. Tan, M. A. Lewis, and M. Lewis, “Virtual structures for high-precision cooperative mobile robotic control,” Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. IROS ’96, 1996.
- [22] M. A. Lewis, M. A. Lewis, K.-H. Tan, and K.-H. Tan, “High precision formation control of mobile robots using virtual structures,” Autonomous Robots, 1997.
- [23] Y. Wu, Y. Wu, B. Jiang, B. Jiang, H. Xu, and H. Xu, “Formation control strategy of multi-agent system with improved probabilistic roadmap method applied in restricted environment,” International Conference on Computer and Information Application, 2021.
- [24] T. Beckers, T. Beckers, S. Hirche, S. Hirche, L. Colombo, and L. Colombo, “Online learning-based formation control of multi-agent systems with gaussian processes,” IEEE Conference on Decision and Control, 2021.
- [25] J. V. C. F. de Lima, J. F. de Lima, E. M. Belo, E. M. Belo, V. A. da Silva Marques, V. A. da Silva Marques, and V. A. da Silva Marques, “Multi-agent path planning with nonlinear restrictions,” Evolutionary Intelligence, 2021.
- [26] G. Ryou, E. Tal, and S. Karaman, “Cooperative multi-agent trajectory generation with modular bayesian optimization,” Robotics: Science and Systems, 2022.
- [27] J. Obradović, M. Križmančić, and S. Bogdan, “Decentralized multi-robot formation control using reinforcement learning,” International Symposium on Information, Communication and Automation Technologies, 2023.
- [28] J. Xue, X. Kong, B. Dong, and M. Xu, “Multi-agent path planning based on mpc and ddpg,” arXiv.org, 2021.
- [29] V. Roldao, V. Roldão, R. Cunha, R. Cunha, D. Cabecinhas, D. Cabecinhas, C. Silvestre, C. Silvestre, P. Oliveira, and P. Oliveira, “A leader-following trajectory generator with application to quadrotor formation flight,” Robotics and Autonomous Systems, 2014.
- [30] H. Xiao, H. Xiao, Z. Li, Z. Li, C. L. P. Chen, and C. L. P. Chen, “Formation control of leader–follower mobile robots’ systems using model predictive control based on neural-dynamic optimization,” IEEE Transactions on Industrial Electronics, 2016.
- [31] H. Xiao, H. Xiao, C. L. P. Chen, and C. L. P. Chen, “Leader-follower multi-robot formation system using model predictive control method based on particle swarm optimization,” Youth Academic Annual Conference of Chinese Association of Automation, 2017.
- [32] H. Xiao, H. Xiao, H. Xiao, C. L. P. Chen, C. L. P. Chen, and C. Chen, “Leader-follower consensus multi-robot formation control using neurodynamic-optimization-based nonlinear model predictive control,” IEEE Access, 2019.
- [33] T. Xu, J. K. Liu, Z. Zhang, G. Chen, D. Cui, and H. Li, “Distributed mpc for trajectory tracking and formation control of multi-uavs with leader-follower structure,” IEEE Access, 2023.
- [34] C. E. Luis, M. Vukosavljev, A. P. Schoellig, and A. P. Schoellig, “Online trajectory generation with distributed model predictive control for multi-robot motion planning,” IEEE Robotics and Automation Letters, 2020.
- [35] E. Trevisan and J. Alonso-Mora, “Biased-mppi: Informing sampling-based model predictive control by fusing ancillary controllers,” IEEE Robotics and Automation Letters, vol. 9, no. 6, pp. 5871–5878, 2024.
- [36] A. Tajbakhsh, L. T. Biegler, and A. M. Johnson, “Conflict-based model predictive control for scalable multi-robot motion planning,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 14 562–14 568.
- [37] N. Nfaileh, N. Nfaileh, K. Alipour, K. Alipour, B. Tarvirdizadeh, B. Tarvirdizadeh, A. Hadi, and A. Hadi, “Formation control of multiple wheeled mobile robots based on model predictive control,” Robotica, 2022.
- [38] S. Satir, Y. F. Aktaş, S. Atasoy, M. M. Ankaralı, and E. Sahin, “Distributed model predictive formation control of robots with sampled trajectory sharing in cluttered environments,” IEEE/RJS International Conference on Intelligent RObots and Systems, 2023.
- [39] M. Kobilarov, “Sample complexity bounds for iterative stochastic policy optimization,” Advances in Neural Information Processing Systems, vol. 28, 2015.
- [40] R. Tedrake, Underactuated Robotics, 2023. [Online]. Available: https://underactuated.csail.mit.edu
- [41] G. Garimella, M. Sheckells, and M. Kobilarov, “A stabilizing gyroscopic obstacle avoidance controller for underactuated systems,” in 2016 IEEE 55th Conference on Decision and Control (CDC), 2016, pp. 5010–5016.
- [42] D. E. Chang and J. E. Marsden, “Gyroscopic forces and collision avoidance with convex obstacles,” in New Trends in Nonlinear Dynamics and Control and their Applications, W. Kang, C. Borges, and M. Xiao, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2003, pp. 145–159.
- [43] S. M. LaValle, “Rapidly-exploring random trees: A new tool for path planning,” 1998.
- [44] J. Yin, Z. Zhang, and P. Tsiotras, “Risk-aware model predictive path integral control using conditional value-at-risk,” 09 2022.
- [45] M. Basescu and J. Moore, “Direct nmpc for post-stall motion planning with fixed-wing uavs,” 2020. [Online]. Available: https://arxiv.org/abs/2001.11478