Multi-Hyperbolic Space-based Heterogeneous Graph Attention Network
Abstract
To leverage the complex structures within heterogeneous graphs, recent studies on heterogeneous graph embedding use a hyperbolic space, characterized by a constant negative curvature and exponentially increasing space, which aligns with the structural properties of heterogeneous graphs. However, despite heterogeneous graphs inherently possessing diverse power-law structures, most hyperbolic heterogeneous graph embedding models use a single hyperbolic space for the entire heterogeneous graph, which may not effectively capture the diverse power-law structures within the heterogeneous graph. To address this limitation, we propose Multi-hyperbolic Space-based heterogeneous Graph Attention Network (MSGAT), which uses multiple hyperbolic spaces to effectively capture diverse power-law structures within heterogeneous graphs. We conduct comprehensive experiments to evaluate the effectiveness of MSGAT. The experimental results demonstrate that MSGAT outperforms state-of-the-art baselines in various graph machine learning tasks, effectively capturing the complex structures of heterogeneous graphs.
Index Terms:
heterogeneous graph representation learning, graph neural networks, hyperbolic graph embeddingI Introduction
Recently, the demand for effective methods to learn semantic information and complex structures in heterogeneous graphs, which consist of various node and link types, has been steadily increasing due to their ability to represent real-world scenarios. In heterogeneous graphs, metapaths are defined as sequences of node/link types. Leveraging metapaths enables us to capture semantic information and complex structures within such graphs effectively. Accordingly, recent studies [1, 2, 3] have focused on efficiently learning heterogeneous graph representations by leveraging metapaths.
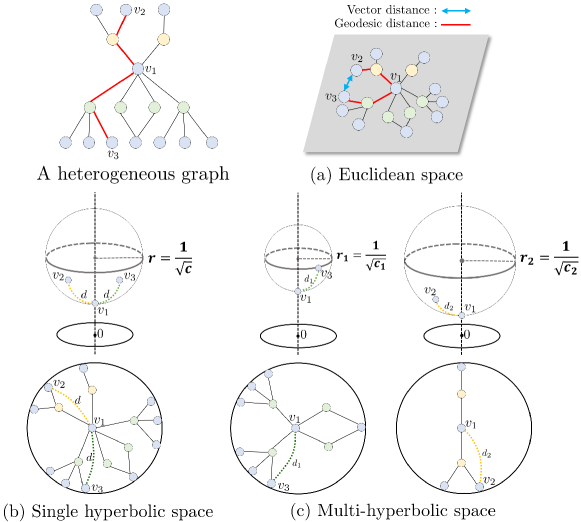
Despite their notable achievements, they may struggle to effectively capture complex structures (e.g., power-law structure) within heterogeneous graphs because they use Euclidean space as the embedding space. In heterogeneous graphs, we often observe hierarchical or power-law structures where the number of nodes grows exponentially, corresponding to specific metapaths. Using Euclidean space as the embedding space to learn such complex structures may result in distortions and limitations [4]. For example, as shown in Figure 1(a), given a graph with a hierarchical structure, distortions can occur where the geodesic distance between two nodes ( and ) is far, but the vector distance in the embedding space is represented as close.
Some recent heterogeneous graph embedding models address this challenge by using the hyperbolic space as the embedding space. Compared to Euclidean space, hyperbolic space has a constant negative curvature and grows exponentially. Some recent studies [5, 6, 7, 8, 9, 10] argue that these inherent properties of hyperbolic space offer a solution to represent complex structures effectively. While these studies achieved significant performance, would representing a heterogeneous graph with different complex structures based on semantic information in a single hyperbolic space be effective? In hyperbolic space, the extent to which hyperbolic space grows exponentially is determined by the negative curvature. Conversely, we can interpret negative curvature as indicating the degree of power-law distribution in hyperbolic space. Therefore, using multiple hyperbolic spaces with distinct negative curvatures that effectively represent each power-law structure within a heterogeneous graph would be more effective for heterogeneous graph representation learning.
( : 0.7892)
( : 0.3124)
As illustrated in Figure 1(b), if power-law structures with different degree distributions are learned in the same hyperbolic space, it will not be effective in capturing their structural properties. This is because, according to two different metapaths representing different degree distributions, they are represented at the same hyperbolic distance from the central embedding target node to its metapath-based neighbors. In contrast, as shown in Figure 1(c), if structures with more pronounced power-law distributions are learned in hyperbolic space with steeper curvature, and those with less pronounced power-law structures are learned in hyperbolic space with relatively softer curvature, the structural properties of each metapath can be effectively captured. This is because, according to two metapaths representing different degree distributions, they are represented at different distances and from the target node embedding to its metapath-based neighbors.
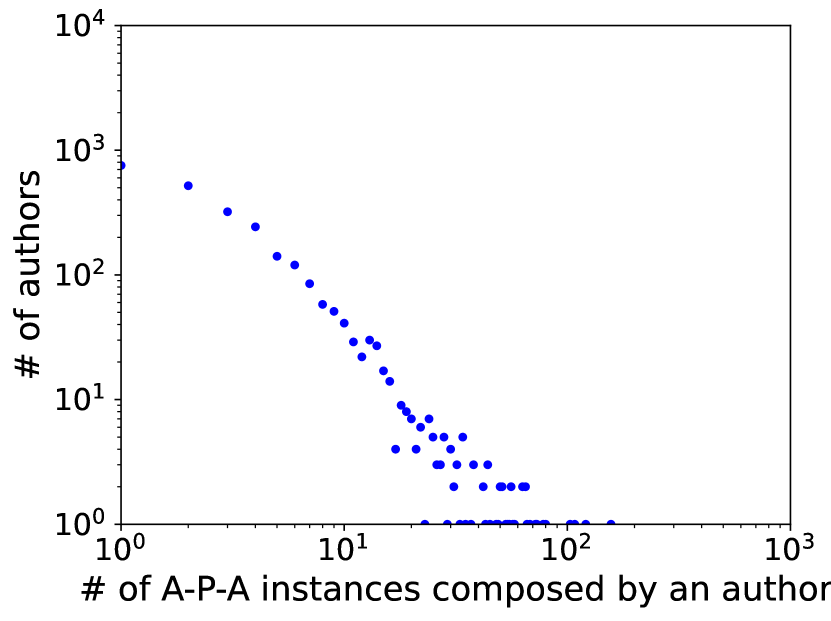
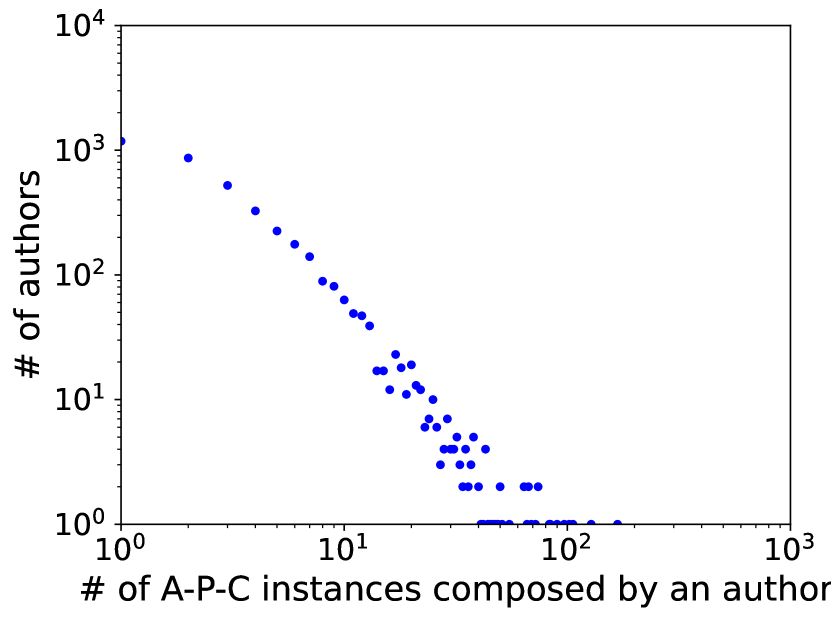
Additionally, as shown in Figure 2, in real-world heterogeneous graphs, we can observe multiple power-law structures corresponding to specific metapaths that are similar but distinct. Also, we calculate the average Gromov’s -hyperbolicity [11] of each metapath-based subgraph, where lower values indicate that the structure of the subgraph tends to exhibit more hierarchical structures. The average Gromov -hyperbolicity allows for identifying distinct hierarchical structures in power-law structures with similar distributions, despite their apparent similarity.
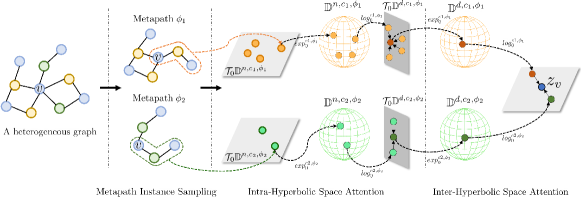
Based on these observations, we propose Multi-hyperbolic Space-based heterogeneous Graph Attention Network (MSGAT) to effectively learn various semantic structural properties in heterogeneous graphs with power-law structures. Specifically, MSGAT addresses metapath predefinition challenges by sampling metapath instances and utilizing intra-hyperbolic space attention to learn representations in metapath-specific hyperbolic spaces, where curvatures are learnable parameters. Also, we utilize inter-hyperbolic space attention to aggregate semantic information across distinct metapaths. Through these approaches, our model can effectively learn power-law structures and semantic information within the heterogeneous graph.
The main contributions of our work can be summarized as follows:
-
•
We propose a novel hyperbolic heterogeneous graph attention network that uses multiple hyperbolic spaces as embedding spaces for distinct metapaths.
-
•
We design graph attention mechanisms in multiple hyperbolic spaces to enhance heterogeneous graph representations, capturing diverse degree distributions and semantic heterogeneity.
-
•
The experimental results demonstrate that MSGAT outperforms state-of-the-art baselines in various downstream tasks with heterogeneous graphs.
II Preliminaries
II-A Hyperbolic Space
Definition 1 (Poincaré ball model).
Poincaré ball model with curvature is defined by the Riemannian manifold , where
Here, is the open -dimensional unit ball with radius and is the Riemannian metric tensor where and is the identity matrix. We denote as the tangent space centered at point
Definition 2 (Möbius addition).
Given the point , Möbius addition which represents the equation for the addition operation in the Poincaré ball model with curvature is defined as follows:
where is the Euclidean inner product and is the Euclidean norm.
Definition 3 (Exponential and logarithmic maps).
In Poincaré ball model with curvature , the exponential map and logarithmic map are defined as shown below:
where x and y are the points in the hyperbolic space and . is a nonzero tangent vector in the tangent space .
Definition 4 (Hyperbolic matrix-vector multiplication).
Given a point and a matrix , the matrix multiplication operation in hyperbolic space is defined as follows:
where is a zero vector.
Definition 5 (Hyperbolic non-linear activation function).
Given the point , the hyperbolic non-linear activation function is defined as follows:
where is the Euclidean non-linear activation function.
III Methodology
III-A Metapath Instance Sampling
To capture the structural properties within a heterogeneous graph , we sample a metapath instance set for a given embedding target node in . Each metapath instance in starts from node and has a length within a maximum metapath length . We use breadth-first search for this procedure.
III-B Intra-Hyperbolic Space Attention
III-B1 Hyperbolic mean-linear encoder
After metapath instance sampling, we compose the hyperbolic mean-linear encoder to transform all the node features within a metapath instance into a single feature. This transformation function can be formulated as follows:
| (1) | ||||
| (2) |
In Equation (1), denotes the features of node , denotes the length of the metapath instance , denotes a transformation matrix, and denotes the Euclidean feature of the metapath instance .
In Equation (2), given Euclidean metapath instance feature , we first map to a metapath-specific hyperbolic space via the exponential map . To adopt exponential map, we assume is included in the tangent space at point . Note that, denotes hyperbolic metapath instance feature. Here, is a metapath-specific hyperbolic space that effectively represents structural properties of metapath instances following a specific metapath .
Additionally, is a learnable parameter that represents the negative curvature of hyperbolic space, and each metapath-specific hyperbolic space for metapath has a distinct negative curvature.
III-B2 Hyperbolic metapath instance embedding
We utilize hyperbolic linear transformation with a hyperbolic non-linear activation function to obtain metapath instance embedding in hyperbolic space. The formulation of this process is as follows:
| (3) |
In Equation (3), is a latent representation of metapath instance in metapath-specific hyperbolic space . Here, is the dimension of hyperbolic space for latent metapath instance representations. Additionally, is a weight matrix and is a bias vector.
III-B3 Intra-metapath specific hyperbolic space attention
To aggregate different latent metapath instance representations, we define attention mechanisms in metapath-specific hyperbolic space. First, we calculate the importance of each metapath instance as follows:
| (4) | ||||
| (5) |
In the above equations, denotes the importance of each metapath instance , where denotes logarithmic map function and denotes a subset of consisting of metapath instances that follow a specific metapath and is an attention vector for metapath instance. After calculating the importance of each metapath instance, we apply the softmax function to these values to obtain the weight of each metapath instance.
Then the metapath-specific embedding for node is obtained from the weight of each metapath instance and their latent representations in metapath-specific hyperbolic space. This process can be formulated as below:
| (6) |
where denotes metapath specific embedding for node . Note that, in Equation (3) and (6), denotes the hyperbolic non-linear activation function with LeakyReLU.
III-B4 Hyperbolic multi-head attention
As shown in the equation below, we adopt multi-head attention in hyperbolic space to enhance metapath-specific embeddings and stabilize the learning process. Specifically, we divide the attention mechanisms into independent attention mechanisms, conduct them in parallel, and then concatenate the metapath-specific embedding from each attention mechanism to obtain the final metapath-specific embedding .
| (7) |
III-C Inter-Hyperbolic Space Attention
III-C1 Node embedding space mapping
Once the metapath-specific embedding is obtained for each metapath in , we aggregate them using attention mechanisms to learn the importance of each metapath-specific embedding, which represents semantic structural information.
First, we map metapath-specific embeddings to the same embedding space because they are included in different metapath-specific hyperbolic spaces corresponding to specific metapaths . Since the curvatures of these metapath-specific hyperbolic spaces are different, it is difficult to aggregate them directly in their respective hyperbolic spaces. Instead, we map metapath-specific embeddings into the same tangent space from different hyperbolic spaces. The mapping operation can be formulated as follows:
| (8) |
In Equation (8), with the logarithmic map , we can map to tangent space which is a plane like Euclidean space. Then, with the transformation matrix , we can project metapath-specific embeddings within different metapath-specific tangent space into same semantic space .
III-C2 Metapath aggregation
Given mapped metapath-specific embeddings , we aggregate them by using attention mechanisms. First, we calculate the importance of each mapped metapath-specific embedding as follows:
| (9) | ||||
| (10) |
In the above equations, denotes the importance of each mapped metapath-specific embedding. After calculating , we normalize these values using the softmax function to obtain their weights. Note that, denotes a weight matrix for the mapped metapath-specific embeddings, is a bias vector, and is an attention vector. The embedding vector of node , is calculated as a weighted sum as shown below:
| (11) |
III-D Model Training
As shown in Equation (12), we employ the non-linear transformation to map node embedding vectors into a space with the desired output dimension, conducting various downstream tasks.
| (12) |
where denotes the weight matrix, denotes the dimension of the output vector, and is the activation function. Then, we train MSGAT by minimizing the loss function .
For node-level tasks, MSGAT is trained by minimizing the cross-entropy loss function which is defined as below:
| (13) |
where is the target node set extracted from the labeled node set, is the number of classes, is the one-hot encoded label vector for node , and is a vector predicting the label probabilities of node .
For a link-level task, MSGAT is trained by minimizing binary cross-entropy function which is defined as below:
| (14) | ||||
where is the set that includes both positive and negative node pairs, is the ground truth label for a node pair . is the sigmoid function, and are the embedding vectors of nodes and , respectively.
IV Experiments and Discussion
In this section, we assess the efficiency of our proposed model MSGAT, through experiments with four real-world heterogeneous graphs. We conduct comparative analyses between MSGAT and several state-of-the-art GNN models.
| Node Classification and Clustering | |||||||||
| Dataset | # Nodes | # Links | # Classes | # Features | |||||
| IMDB |
|
|
3 | 1,256 | |||||
| DBLP |
|
|
4 | 334 | |||||
| ACM |
|
|
3 | 1,902 | |||||
| Link Prediction | |||||||||
| Dataset | # Nodes | # Links | Target | # Features | |||||
| LastFM |
|
|
User-Artist | 20,612 | |||||
IV-A Datasets
To evaluate the performance of MSGAT on downstream tasks, we use four real-world heterogeneous graph datasets. Table I shows the statistics of these datasets. For node classification and clustering tasks, Movie, Author, and Paper types of nodes are labeled.
| Dataset | Metric | Train % | i | ii | iii | iv | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GCN | GAT | HGCN | HAN | MAGNN | GTN | HGT | GraphMSE | Simple-HGN | McH-HGCN | SHAN | HHGAT | MSGAT | |||
| IMDB | Macro-F1 | 20% | 52.170.35 | 53.680.26 | 54.380.48 | 56.190.51 | 59.330.38 | 58.740.74 | 56.140.65 | 57.720.56 | 59.970.61 | 58.160.49 | 62.230.76 | 63.160.39 | 65.750.81 |
| 40% | 53.200.45 | 56.330.71 | 57.050.43 | 56.840.37 | 60.700.48 | 59.710.54 | 57.120.53 | 62.010.48 | 61.940.39 | 60.310.56 | 63.980.68 | 65.070.63 | 68.070.54 | ||
| 60% | 54.350.46 | 56.930.54 | 57.860.56 | 58.950.71 | 60.680.56 | 61.880.50 | 61.520.57 | 65.510.61 | 66.730.42 | 61.930.33 | 66.680.71 | 65.720.56 | 71.420.48 | ||
| 80% | 54.190.29 | 57.250.18 | 57.920.32 | 58.610.63 | 61.150.55 | 62.080.62 | 63.690.59 | 67.340.56 | 67.560.45 | 62.290.50 | 68.490.67 | 67.420.51 | 70.030.60 | ||
| Micro-F1 | 20% | 52.130.38 | 53.670.31 | 54.460.42 | 56.710.53 | 58.300.39 | 61.970.63 | 57.970.76 | 60.580.62 | 63.760.60 | 61.280.37 | 64.310.82 | 65.760.66 | 69.090.93 | |
| 40% | 53.340.41 | 53.990.65 | 57.020.46 | 56.680.70 | 58.340.58 | 62.100.53 | 58.800.65 | 64.870.63 | 65.600.46 | 63.090.12 | 66.560.73 | 66.340.70 | 70.950.54 | ||
| 60% | 54.610.42 | 56.260.51 | 58.010.50 | 58.260.82 | 60.710.70 | 63.550.39 | 62.630.58 | 68.860.86 | 69.290.74 | 64.160.29 | 69.570.76 | 70.400.51 | 73.600.39 | ||
| 80% | 54.370.33 | 57.230.29 | 58.540.93 | 59.350.65 | 61.700.39 | 65.570.91 | 67.010.47 | 69.540.59 | 69.350.66 | 64.960.42 | 69.420.56 | 69.610.89 | 73.370.59 | ||
| DBLP | Macro-F1 | 20% | 87.510.15 | 91.520.34 | 91.690.38 | 92.630.46 | 93.210.64 | 92.450.37 | 90.360.62 | 93.800.39 | 93.480.56 | 90.630.72 | 94.270.16 | 94.190.08 | 95.440.17 |
| 40% | 88.550.46 | 91.070.39 | 91.930.35 | 92.350.64 | 93.510.29 | 92.390.41 | 91.570.29 | 94.020.50 | 93.980.27 | 91.740.62 | 94.330.08 | 94.270.10 | 95.540.12 | ||
| 60% | 89.440.27 | 91.510.46 | 92.600.89 | 92.860.37 | 93.590.60 | 93.770.52 | 92.320.19 | 94.300.26 | 94.010.33 | 92.260.19 | 94.500.29 | 94.900.30 | 95.670.40 | ||
| 80% | 89.450.36 | 91.770.27 | 92.580.39 | 92.730.66 | 94.360.43 | 94.460.60 | 93.460.55 | 94.210.82 | 94.250.57 | 93.130.24 | 94.670.12 | 94.770.19 | 95.290.15 | ||
| Micro-F1 | 20% | 88.210.26 | 91.290.31 | 92.060.33 | 92.350.51 | 93.600.59 | 93.150.48 | 91.460.77 | 94.150.42 | 94.170.47 | 92.010.53 | 94.530.17 | 94.660.07 | 95.790.16 | |
| 40% | 88.680.52 | 91.600.50 | 92.310.40 | 92.870.39 | 93.750.44 | 93.800.56 | 92.050.48 | 94.320.81 | 93.870.42 | 92.730.51 | 94.600.22 | 94.720.10 | 95.900.11 | ||
| 60% | 90.010.48 | 92.090.41 | 93.160.36 | 93.420.12 | 94.200.51 | 94.220.51 | 92.720.24 | 94.380.31 | 94.710.56 | 93.500.26 | 94.920.35 | 95.150.36 | 95.980.36 | ||
| 80% | 90.140.39 | 92.390.41 | 93.210.35 | 93.540.60 | 94.090.52 | 94.230.54 | 92.570.72 | 94.540.63 | 94.680.55 | 93.310.12 | 95.360.23 | 95.340.17 | 95.850.16 | ||
| ACM | Macro-F1 | 20% | 83.080.37 | 86.140.49 | 87.291.06 | 87.880.42 | 88.430.51 | 91.100.39 | 89.120.46 | 92.130.27 | 92.250.39 | 89.860.83 | 92.560.21 | 91.340.39 | 92.730.52 |
| 40% | 87.340.41 | 87.110.22 | 89.190.72 | 90.540.08 | 90.160.91 | 91.340.44 | 89.150.49 | 92.760.37 | 92.640.61 | 90.520.69 | 92.880.19 | 92.920.32 | 93.950.51 | ||
| 60% | 88.800.51 | 88.920.36 | 90.010.42 | 91.220.36 | 90.730.39 | 91.340.26 | 90.570.34 | 93.390.28 | 93.060.22 | 91.030.76 | 94.100.37 | 94.280.35 | 94.830.16 | ||
| 80% | 88.430.29 | 88.060.16 | 90.030.77 | 91.350.45 | 92.120.51 | 91.140.78 | 93.450.65 | 93.570.49 | 93.550.44 | 91.970.55 | 94.940.62 | 93.910.31 | 94.010.30 | ||
| Micro-F1 | 20% | 87.750.33 | 87.830.47 | 88.090.89 | 91.200.46 | 91.370.42 | 91.860.40 | 89.590.37 | 92.270.36 | 91.910.33 | 90.210.61 | 92.380.18 | 92.360.37 | 92.960.54 | |
| 40% | 87.860.42 | 87.390.41 | 90.060.73 | 91.780.28 | 92.600.48 | 91.890.46 | 90.700.43 | 93.050.36 | 92.860.84 | 90.630.52 | 93.370.26 | 93.460.50 | 93.910.48 | ||
| 60% | 88.400.56 | 87.780.33 | 90.510.63 | 92.390.42 | 92.210.18 | 92.070.48 | 91.180.15 | 93.380.47 | 93.330.21 | 91.200.48 | 94.460.35 | 94.340.39 | 94.880.16 | ||
| 80% | 88.560.33 | 87.870.51 | 91.100.44 | 92.030.16 | 92.140.48 | 92.210.66 | 91.770.57 | 93.370.36 | 93.530.42 | 92.060.66 | 94.560.11 | 93.720.32 | 94.050.31 | ||
| Dataset | Metric | i | ii | iii | iv | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GCN | GAT | HGCN | HAN | MAGNN | GTN | HGT | GraphMSE | Simple-HGN | McH-HGCN | SHAN | HHGAT | MSGAT | ||
| IMDB | NMI | 7.840.24 | 8.060.18 | 10.290.76 | 11.211.09 | 15.660.73 | 15.010.11 | 14.550.32 | 15.701.25 | 17.580.82 | 14.320.46 | 20.600.92 | 20.750.36 | 24.060.51 |
| ARI | 8.120.40 | 8.860.09 | 11.100.88 | 11.490.11 | 16.720.21 | 15.960.63 | 16.590.36 | 16.380.74 | 19.511.06 | 16.910.37 | 22.560.22 | 22.800.68 | 26.330.46 | |
| DBLP | NMI | 75.370.25 | 75.460.44 | 76.480.87 | 77.030.16 | 80.110.30 | 81.390.73 | 79.020.39 | 37.220.65 | 82.380.07 | 78.900.31 | 82.390.42 | 83.140.19 | 84.380.59 |
| ARI | 77.140.21 | 77.990.72 | 79.360.95 | 82.530.42 | 85.610.38 | 84.120.83 | 80.280.20 | 34.210.65 | 85.710.33 | 81.220.56 | 86.130.33 | 85.910.49 | 88.270.63 | |
| ACM | NMI | 51.730.21 | 58.060.46 | 60.190.69 | 61.240.12 | 64.730.47 | 65.060.35 | 67.880.20 | 66.650.44 | 69.910.68 | 66.760.38 | 72.900.93 | 72.490.44 | 73.330.79 |
| ARI | 53.420.48 | 59.610.42 | 62.060.70 | 64.110.26 | 66.840.25 | 65.800.49 | 72.560.13 | 73.890.33 | 72.070.51 | 71.840.48 | 77.730.44 | 77.920.80 | 78.28 1.07 | |
| Dataset | Metric | i | ii | iii | iv | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GCN | GAT | HGCN | HAN | MAGNN | HetSANN | HGT | Simple-HGN | HHGAT | MSGAT | ||
| LastFM | ROC-AUC | 43.680.30 | 44.520.22 | 46.710.78 | 48.320.28 | 49.370.59 | 50.280.45 | 47.780.23 | 53.850.47 | 54.370.51 | 55.770.62 |
| F1-Score | 56.150.16 | 56.840.07 | 57.230.66 | 57.110.49 | 58.370.32 | 60.610.54 | 61.160.57 | 63.020.35 | 62.850.48 | 63.390.76 | |
IV-B Baselines
We compare MSGAT with several state-of-the-art graph neural networks categorized into four groups- i) Euclidean homogeneous GNNs: GCN [12] and GAT [13], ii) Hyperbolic homogeneous GNNs: HGCN [14], iii) Euclidean heterogeneous GNNs: HAN [1], MAGNN [15], GTN [2], HetSANN [16], HGT [17], GraphMSE [3], and Simple-HGN [18], and iv) Hyperbolic heterogeneous GNNs: McH-HGCN [19], SHAN [9], and HHGAT [10]. For homogeneous GNNs, features are processed to be homogeneous for pair comparison with heterogeneous GNNs.
IV-C Node Classification and Clustering
Node classification was performed by applying support vector machines on embedding vectors of labeled nodes. Macro-F1 and Micro-F1 were used as the evaluation metrics for classification accuracy. The ratio of training data was varied within the range of 20% to 80%. For node clustering, the -means clustering algorithm was applied to embedding vectors of labeled nodes. Normalized Mutual Information (NMI) and Adjusted Rand Index (ARI) were used as the evaluation metrics for clustering accuracy.
As shown in Table II and III, MSGAT achieved better performance than other baselines in most cases. The results from MSGAT and HHGAT indicate the effectiveness of using multi-hyperbolic space to learn metapath instances. Specifically, because HHGAT employs a single hyperbolic space to learn metapath instances, it cannot effectively capture the complex structures following various power-law distributions of metapath instances in a single hyperbolic space. In contrast, MSGAT effectively captures various complex structures by using multi-hyperbolic space to learn metapath instances. In each metapath-specific hyperbolic space corresponding to a distinct metapath, a learned negative curvature effectively represents the distribution of node degrees for metapath instances following that metapath. Furthermore, through intra-hyperbolic space attention and inter-hyperbolic space attention, MSGAT effectively captures important complex structures and semantic information within a heterogeneous graph, respectively. Moreover, a comparison of MSGAT and McH-HGCN demonstrates that MSGAT effectively captures a broader range of semantic information and structural properties by extensively sampling the surrounding structure of the target node, in contrast to McH-HGCN.
On the one hand, a comparison of Euclidean homogeneous GNNs and hyperbolic homogeneous GNNs demonstrates the effectiveness of hyperbolic space in representing complex structures within heterogeneous graphs. However, from a comparison of hyperbolic homogeneous GNNs and Euclidean heterogeneous GNNs, we observe that while hyperbolic homogeneous GNNs can learn complex structures, they struggle to capture the heterogeneity within heterogeneous graphs, thus failing to learn semantic information effectively. In contrast, Euclidean heterogeneous GNNs excel at learning semantic information within such graphs. At last, comparing Euclidean heterogeneous GNNs and hyperbolic heterogeneous GNNs, we can conclude that hyperbolic heterogeneous GNNs are more effective than Euclidean heterogeneous GNNs because hyperbolic heterogeneous GNNs can simultaneously learn the complex structures and heterogeneity of heterogeneous graphs.
| Dataset | IMDB | DBLP | ACM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Macro-F1 | Micro-F1 | NMI | ARI | Macro-F1 | Micro-F1 | NMI | ARI | Macro-F1 | Micro-F1 | NMI | ARI |
| MSGAT | 71.420.48 | 73.600.39 | 24.060.51 | 26.330.46 | 95.670.40 | 95.980.36 | 84.380.59 | 88.270.63 | 94.830.16 | 94.880.16 | 73.330.79 | 78.281.07 |
| MSGAT | 68.030.44 | 70.750.44 | 22.240.55 | 24.910.53 | 94.230.50 | 94.540.47 | 82.060.79 | 84.650.88 | 93.330.07 | 93.910.26 | 72.730.44 | 75.820.27 |
| MSGAT | 64.720.10 | 67.170.12 | 16.720.18 | 14.650.44 | 93.090.35 | 93.510.33 | 79.320.94 | 83.841.09 | 90.021.15 | 90.091.18 | 70.241.93 | 73.182.26 |
| MSGAT | 66.060.56 | 68.770.61 | 21.650.59 | 25.910.80 | 93.760.42 | 93.940.33 | 80.950.32 | 86.060.56 | 92.390.29 | 92.670.26 | 73.160.07 | 77.930.38 |
IV-D Link Prediction
We also conducted a link prediction task on the LastFM dataset. To predict the probabilities of relations between user-type nodes and artist-type nodes, we used a dot product operation applied to the embeddings of the two types of nodes. The area under the ROC curve (ROC-AUC) and F1-score were used as the evaluation metrics for prediction accuracy. We considered all connected user-artist pairs as positive samples, while unconnected user-artist pairs were considered as negative samples. For model training, an equal number of positive and negative samples were used.
As shown in Table IV, MSGAT outperforms the other baselines. Compared MSGAT with HHGAT, in link prediction, when predicting the connection between two nodes of different types, the metapath defined around each type of node changes completely, and the distribution of metapath instances also differs. Consequently, while MSGAT can flexibly learn from various metapath instance distributions, HHGAT is unable to do so, making MSGAT superior to HHGAT in link prediction.
IV-E Ablation Study
We compose three variants of MSGAT to validate the effectiveness of each component of MSGAT. MSGAT concatenates node features within metapath instances, instead of using hyperbolic mean-linear encoder, MSGAT uses Euclidean space for embedding space instead of hyperbolic space, and MSGAT uses only one hyperbolic space to learn metapath instance embeddings. Note that, the training percentage for node classification is set to 60%.
We report the results of the ablation study in Table V. Comparing MSGAT with MSGAT, we observe that transforming node features to the metapath-specific hyperbolic space is more effective than simply concatenating node features within the metapath instance. Next, a comparison of MSGAT and MSGAT demonstrates that using hyperbolic space as the embedding space is more effective for learning heterogeneous graphs than using Euclidean space. Moreover, comparing MSGAT with MSGAT, we can see that the use of multi-hyperbolic space leads to significant performance improvements. This is due to the ability of MSGAT to effectively learn the complex structures of diverse distributions within heterogeneous graphs.
V Conclusion
In this paper, we propose the Multi-hyperbolic Space-based heterogeneous Graph Attention Network (MSGAT). Instead of the Euclidean space, MSGAT uses multiple hyperbolic spaces to capture various power-law structures effectively, and finally MSGAT aggregates metapath-specific embeddings to obtain more enhanced node representations.
We conduct comprehensive experiments to evaluate the effectiveness of MSGAT with widely used real-world heterogeneous graph datasets. The experimental results demonstrate that MSGAT outperforms the other state-of-the-art baselines. Additionally, it has been shown that using multiple hyperbolic spaces for learning various power-law distributions is effective.
For the future work, we plan to develop methods to enhance the interpretability of the hyperbolic spaces learned for each metapath in heterogeneous graphs.
Acknowledgement
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No.RS-2023-00214065) and by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2022 00155857, Artificial Intelligence Convergence Innovation Human Resources Development (Chungnam National University)).
References
- [1] X. Wang, H. Ji, C. Shi, B. Wang, Y. Ye, P. Cui, and P. S. Yu, “Heterogeneous graph attention network,” in WWW, 2019, pp. 2022–2032.
- [2] S. Yun, M. Jeong, R. Kim, J. Kang, and H. J. Kim, “Graph transformer networks,” in NeurIPS, 2019, pp. 11 960–11 970.
- [3] Y. Li, Y. Jin, G. Song, Z. Zhu, C. Shi, and Y. Wang, “Graphmse: Efficient meta-path selection in semantically aligned feature space for graph neural networks,” in AAAI, 2021, pp. 4206–4214.
- [4] H. Pei, B. Wei, K. Chang, C. Zhang, and B. Yang, “Curvature regularization to prevent distortion in graph embedding,” in NeurIPS, 2020, pp. 20 779–20 790.
- [5] M. Nickel and D. Kiela, “Poincaré embeddings for learning hierarchical representations,” in NIPS, 2017, pp. 6338–6348.
- [6] I. Balazevic, C. Allen, and T. Hospedales, “Multi-relational poincaré graph embeddings,” in NeurIPS, 2019, pp. 4465–4475.
- [7] Z. Pan and P. Wang, “Hyperbolic hierarchy-aware knowledge graph embedding for link prediction,” in Findings of EMNLP, 2021, pp. 2941–2948.
- [8] X. Wang, Y. Zhang, and C. Shi, “Hyperbolic heterogeneous information network embedding,” in AAAI, 2019, pp. 5337–5344.
- [9] J. Li, Y. Sun, and M. Shao, “Multi-order relations hyperbolic fusion for heterogeneous graphs,” in CIKM, 2023, pp. 1358–1367.
- [10] J. Park, S. Han, S. Jeong, and S. Lim, “Hyperbolic heterogeneous graph attention networks,” in WWW, 2024, pp. 561–564.
- [11] A. B. Adcock, B. D. Sullivan, and M. W. Mahoney, “Tree-like structure in large social and information networks,” in ICDM, 2013, pp. 1–10.
- [12] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in ICLR, 2017.
- [13] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio, “Graph attention networks,” in ICLR, 2018.
- [14] I. Chami, Z. Ying, C. Ré, and J. Leskovec, “Hyperbolic graph convolutional neural networks,” in NeurIPS, 2019, pp. 4869–4880.
- [15] X. Fu, J. Zhang, Z. Meng, and I. King, “Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding,” in WWW, 2020, pp. 2331–2341.
- [16] H. Hong, H. Guo, Y. Lin, X. Yang, Z. Li, and J. Ye, “An attention-based graph neural network for heterogeneous structural learning,” in AAAI, vol. 34, no. 04, 2020, pp. 4132–4139.
- [17] Z. Hu, Y. Dong, K. Wang, and Y. Sun, “Heterogeneous graph transformer,” in WWW, 2020, pp. 2704–2710.
- [18] Q. Lv, M. Ding, Q. Liu, Y. Chen, W. Feng, S. He, C. Zhou, J. Jiang, Y. Dong, and J. Tang, “Are we really making much progress? revisiting, benchmarking and refining heterogeneous graph neural networks,” in KDD, 2021, pp. 1150–1160.
- [19] Y. Liu and B. Lang, “Mch-hgcn: Multi-curvature hyperbolic heterogeneous graph convolutional network with type triplets,” Neural Computing and Applications, vol. 35, no. 20, pp. 15 033–15 049, 2023.