Multi-Image Steganography Using Deep Neural Networks
1 Abstract
Steganography is the science of hiding a secret message within an ordinary public message. Over the years, steganography has been used to encode a lower resolution image into a higher resolution image by simple methods like LSB manipulation. We aim to utilize deep neural networks for the encoding and decoding of multiple secret images inside a single cover image of the same resolution.
2 Introduction
Steganography refers to the technique to hide secret messages within a non-secret message in order to avoid detection during message transmission. The secret data is then extracted from the encoded non-secret message at its destination. The use of steganography can be combined with encryption as an extra step for hiding or protecting data. Traditionally, steganography is performed to embed low-resolution images onto a high-resolution image using naive methods like LSB manipulation.
Motivation for the project comes from the recent works, like that of (Baluja, 2017), (Hayes & Danezis, 2017), and (Zhu et al., 2018). These papers suggest the use of deep neural networks to model the data-hiding pipeline. These methods have significantly improved the efficiency in terms of maintaining the secrecy and quality of the encoded messages. Recently, similar work in terms of audio signal steganography, like (Kreuk et al., 2019), has shown that deep neural networks can be used to encode multiple audio messages onto a single cover message.
We aim to make an effort in a similar direction, by utilizing the ideas from the aforementioned papers to encode multiple images into the single cover image. Unlike traditional methods, we use the same resolution cover and secret images and we aim to keep the changes to the encoded cover image unnoticeable to human perception and statistical analysis, while at the same time keeping the decoded images highly intelligible.
The scripts have been made publicly available to the research community for further development here.
In what follows, we discuss the related prior work for such a problem in the next section (3), followed by Baseline Implementations in section (4) Datasets in section (5), our Proposed Methodology in section (6) followed with its Results and Discussion in section (7). Finally, we end the discussion with Future Directions, Conclusion and Acknowledgement in the sections (8), (9), and (10) respectively.
3 Related Work
Out of the several implementations, below two are most aligned and important to our goal.
3.1 Hiding Images in Plain Sight: Deep Steganography
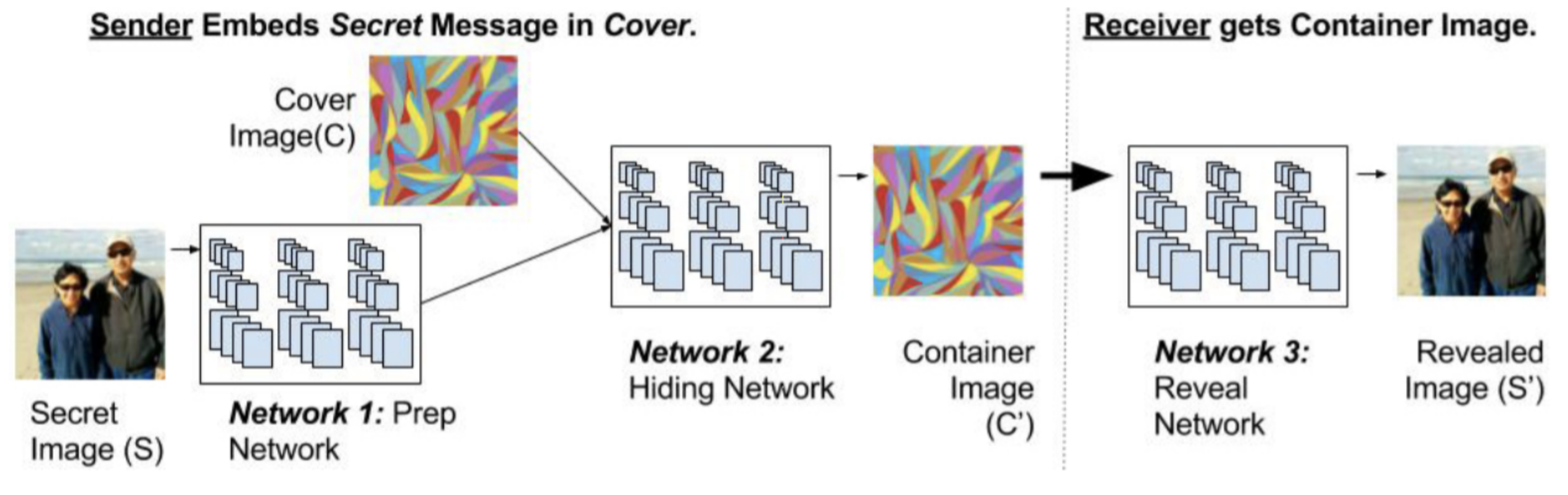
(Baluja, 2017) attempts to place a full-sized color image within another image of the same size. Deep neural networks are simultaneously trained to create the hiding and revealing processes and are designed to specifically work as a pair. The system is trained on images drawn randomly from the ImageNet database and works well on natural images from a wide variety of sources. Unlike many popular steganographic methods that encode the secret message within the least significant bits of the cover image, their approach compresses and distributes the secret image’s representation across all of the available bits.
The three components involved in the system include-
-
1.
Preparation Network - prepares the secret image to be hidden. If the secret-image (size MM) is smaller than the cover image (NN), the preparation network progressively increases the size of the secret image to the size of the cover, thereby distributing the secret image’s bits across the entire N N pixels.
-
2.
Hiding Network - takes as input the output of the preparation-network and the cover image, and creates the Container image. The input to this network is an N N pixel field, with depth concatenated RGB channels of the cover image and the transformed channels of the secret image.
-
3.
Reveal Network - used by the receiver of the image; it is the decoder. It receives only the Container image (neither the cover nor the secret image). The decoder network removes the cover image to reveal the secret image.
The paper by (Baluja, 2017) talks about how a trained system must learn to compress the information from the secret image into the least noticeable portions of the cover image. However, no explicit attempt has been made to actively hide the existence of that information from machine detection. They trained the steganalysis networks as binary classifiers, using the unperturbed ImageNet images as negative samples, and their containers as positive examples. The paper serves a baseline for single secret image encoding. However, it does not talk about multi-image steganography.
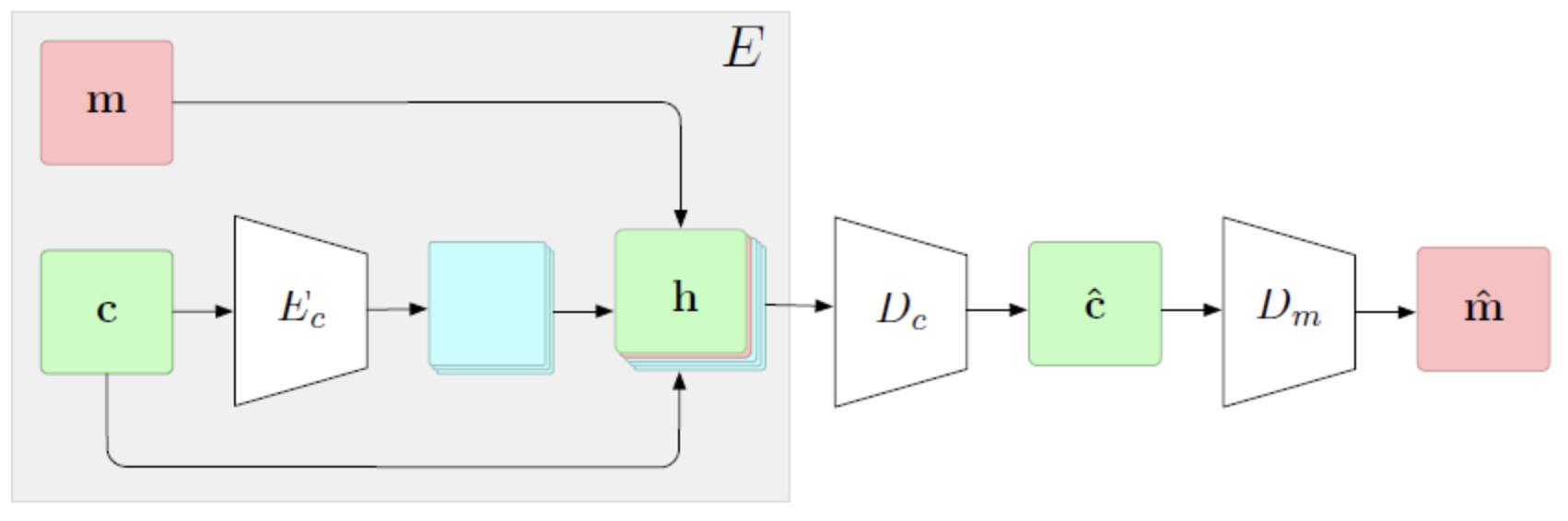
3.2 Hide and Speak: Deep Neural Networks for Speech Steganography
(Kreuk et al., 2019) implements steganography for speech data using deep neural networks. It is based on an architecture that comprises 3 subparts, i.e, Encoder Network, Carrier Decoder Network, and a Message Decoder Network. They utilize ideas from (Zhu et al., 2018) to extend the encoder network to audio signals. The architecture of the model comprises of 3 sub-parts:
-
1.
An Encoder Network ()
-
2.
A Carrier Decoder Network ()
-
3.
A Message Decoder Network ()
In the Carrier/cover encoder network, the encoded carrier ((c)) is appended with the carrier (c) and the secret message (m), forming, [(c);c;m]. This output is fed to the Carrier Decoder () which outputs the carrier embedded with a hidden message. Finally, this is fed to the Message Decoder () which reconstructs the hidden message.
The first part learns to extract a map of potential redundancies from the carrier signal. The second part utilizes the map to best “stuff” a secret message into the carrier such that the carrier is minimally affected. The part third learns to extract the hidden message from the steganographically-modified carrier. All the components in these networks are Gated Convs. is composed of 3 blocks of Gated Convs, 4 and 6 blocks of Gated Convs. Each block contains 64 kernels of size 3*3.
This paper demonstrates the capability to hide multiple secret messages in a single carrier, which aligns with our goals. In the paper, five independent speech messages have been hidden in a single speech recording. This is achieved by 2 different approaches. One approach utilizes multiple decoders, with each decoder trained to decode a different message. The other approach utilizes a conditional decoder that also takes in as input a code indicating the message index to be encoded.

We borrowed the concept of multiple decoders from this paper and used it to fetch multiple secret images from the cover image which looks like the cover image but consists of the secret images being hidden inside the cover image via passing through separate prep networks and then concatenated together. For this, we utilize the loss as defined by this paper for the multiple decoders. For our case, we extend the loss function defined in this paper for our use case. We take the reveal loss for each decoder as
and for the entire system as summation of reveal losses for each decoder added with the loss calculated for cover image as well.
, where
We used this approach to introduce multi-image steganography using the above idea from this paper and extending it to images to add multiple images in one cover image and then retrieving it.
4 Baseline Implementations
We aimed to implement a baseline single image steganography model over which we could preform out extensions. Since (Baluja, 2017) has several implementations, we implemented two of the most popular implementations and analyzed them to be suitable for the extensions for our model. The details of these implementations are as follows:
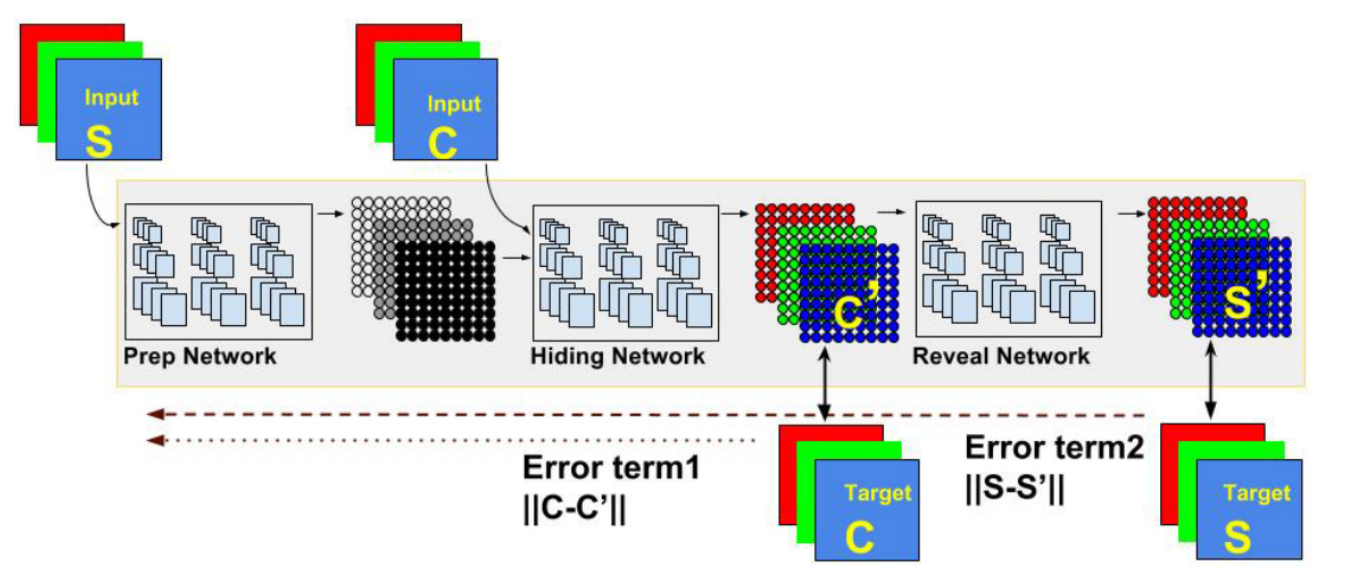
4.1 Ingham’s Implementation
(Ingham, ) is a PyTorch based implementation which follows the architecture shown in Figure 1. The architecture includes a Prep Network, a Hidden Network, and a Reveal Network and embeds a single secret image onto a single cover image. The model architecture is defined as follows:
-
1.
Prep Network - Two sets of three sequential layers consisting of (Conv2d - Relu) combinations, concatenated and fed into the next set.
-
2.
Hidden Network - Similar to the prep network above but includes an extra Conv2D sequential layer for adding Gaussian noise to the cover. This allows the hidden information to be encoded in bits other than the LSB of the cover image.
-
3.
Reveal Network - Similar to the above networks, with an extra Conv2d at the end.
4.1.1 Implementation Details
4.1.2 Results
The author of the implementation had shown desirable results for higher resolution images. Since we used low-resolution images with an equal resolution for both secret and cover, we did not see similar results in our implementations. See Figure 3. The implementation generated lossy secret images, [left-side images in results] while retaining the cover image almost completely [right-side images in results]. Since other baseline models performed significantly better, we decided not to proceed with this implementation.
4.2 Alexandre’s Implementation
Alexandre’s is another implementation (Muzio, ) of Baluja’s paper, based on Keras. There are new features introduced in this model that others have not implemented like noise addition, mean stabilization. We have tried various models to see which configuration provides the best results and is fastest. The model architecture has three parts:
-
1.
Preparation Network : Transforms secret image to be concatenated with cover.
-
2.
Hiding Network: Converts the concatenated image into encoded cover.
-
3.
Reveal Network: Extracts the secret image from the encoded cover.
Hiding and reveal networks use aggregated Conv2D layers: 5 layers of 65 filters [50 3x3 filters, 10 4x4 filters, and 5 5x5 filters]. Prep network uses 2 layers of similar structure. All Conv 2D layers are followed by ReLU activation.
4.2.1 Implementation Details
For full code please refer here. Model is explained below:
-
1.
Adam optimizer, with learning rate as 0.001 and a custom scheduler.
-
2.
Model has been trained for 800 epochs with a batch size of 256 and an additional 100 epochs with batch size of 32.
-
3.
To make sure weights are updated only once, reveal network weights are frozen before adding it to the full model.
-
4.
Gaussian noise with 0.01 standard deviation is added to the encoder’s output before passing it through the decoder.
-
5.
Mean sum of squared error has been used for calculating the decoder’s loss.
4.2.2 Results
As it can be seen in Figure 5, the model generates decent results in the Tiny ImageNet dataset. The generated images showed a minimal loss for both the cover and the secret images. Owing to the performance of the model with a single image steganography we decided to use this implementation for our work going ahead.

5 Datasets
Since our model does not have specific requirements pertaining to the classes of the images, we used the Tiny ImageNet (tin, ) dataset in order to obtain the secret and cover images. The dataset is the collection of 64643 images, used by the Stanford CS231 class. Further extensions of the final model can also be applied to larger images from datasets like ImageNet (Deng et al., 2009). We have also used Tiny ImageNet for faster training.
Our training set is made of a random subset of images from all 200 classes. 2000 images are randomly sampled. The image vectors are normalized across RGB values. We split the entire training data into four halves, one for the cover image and the other three halves for three secret images.
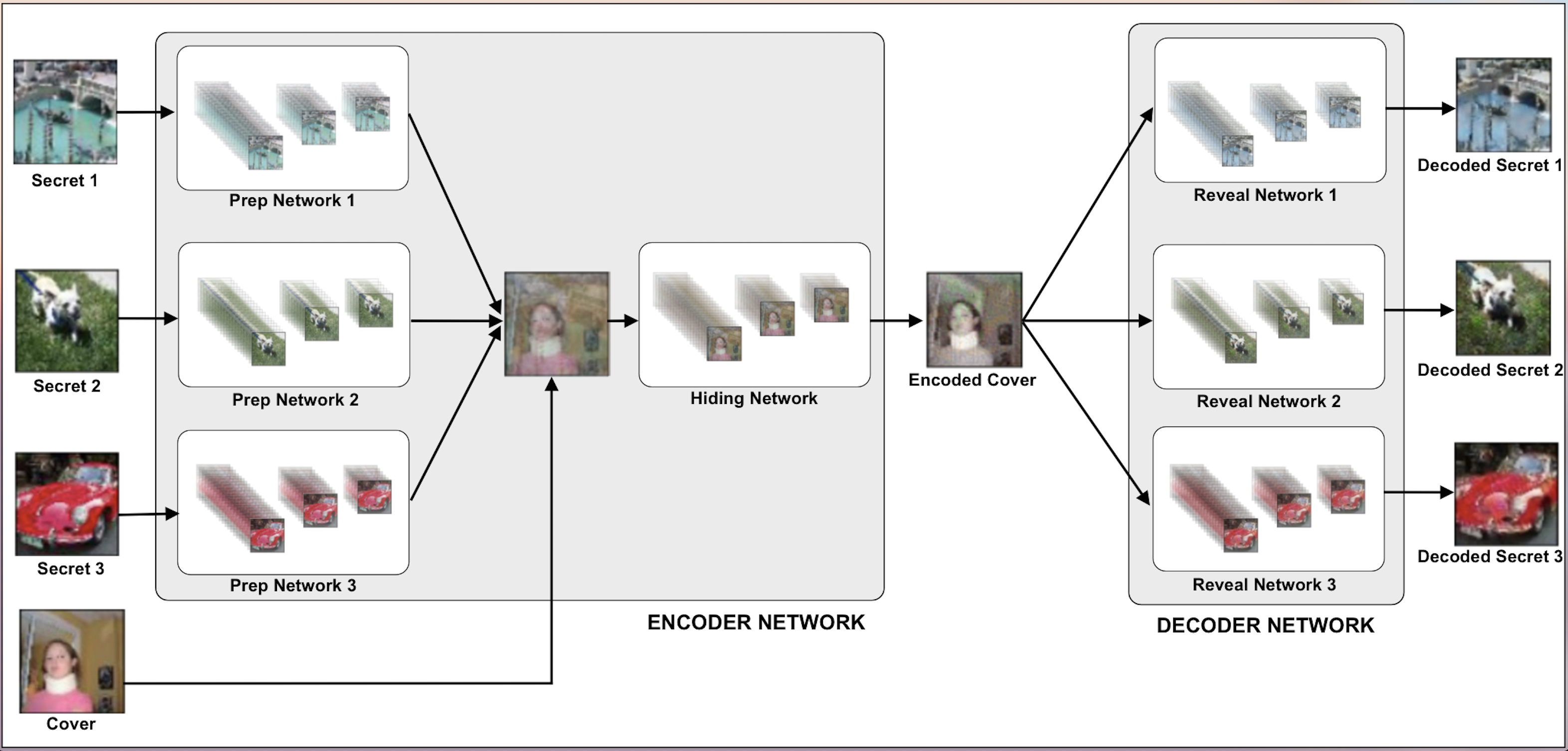
6 Proposed Methodology
We aim to perform multi-image steganography, hiding three or more images in a single cover image. The embedded secret images must be retrievable with minimum loss. The encoded cover image must look like the original cover image. To perform this, we combine the idea of (Baluja, 2017) and (Kreuk et al., 2019). We take the network implementation idea of having a prep and hiding network as an encoder and a reveal network as a decoder from (Baluja, 2017). To extend this for multiple images, we pass multiple secret images via the prep network and then concatenating these resulting data with the carrier image and then finally send this via the Hiding network. We then take the idea of having multiple decoders, one per secret image, from (Kreuk et al., 2019) to retrieve all the secret images from the container image.To improve the security of our image retrieval model, we extend the idea presented by (Baluja, 2017) of putting secret images with noise in the original cover image instead of putting the secret images at the LSBs of the original cover image.
Using of Multiple Prep and Reveal Networks. In their implementation for multiple audio signal steganography, (Kreuk et al., 2019), suggested the use of multiple decoders to derive the decoded secret from a single encoded cover. This technique is an extension of the same idea in the image domain. It does not require scaling down the size of the image or sacrificing on the color channels of the secret images.
There was another technique of using conditional decoders instead of multiple decoders but in this implementation, we have only worked on implementing multiple prep/reveal networks. Hence, we decided to build our extension based on this technique. A brief description of the encoder/decoder framework as per this technique is as follows:
-
•
ENCODER: Consists of multiple prep networks, each corresponding to separate secret image input. Prep network outputs are concatenated together with the cover image and then fed through the Hiding network.
-
•
DECODER: The decoder network comprises of multiple reveal networks, each of which is trained separately to decode its corresponding message.
6.1 Model Architecture
The model architecture is as described in the Figure 6. The underlying architecture of each of the sub-networks is as follows:
-
1.
Prep Networks: Each of the prep networks consists of the aggregation of 2 layers. With each of the layers made up of 3 separate Conv2D layers. The number of channels for these 3 Conv2D layers is 50, 10, and 5 respectively with the kernel sizes like 3, 4, and 5 for each layer. The stride length constantly remains 1 along both the axis. Appropriate padding is added to each Conv2D layer so as to keep output image in the same dimensions. Each Conv2d layer is followed with a ReLU activation.
-
2.
Hiding Network: The hiding network is an aggregation of 5 layers. With each of these layers made up of the 3 separate Conv2D layers. The underlying structure of the Conv2D layers in the hiding network is similar to the Conv2D layers in the Prep Network.
-
3.
Reveal Network: Each of the reveal networks shares a similar underlying architecture with the hiding network, using 5 layers of similarly formed Conv2D layers.

6.2 Implementation Details
For full code please refer here. The training details are explained below:
-
1.
Adam optimizer has been used with a custom LR scheduler.
-
2.
Learning rate remains constant with 0.001 till first 200 epochs, decreasing to 0.0003 from 200 epochs to 400 epochs and further decreasing it 0.00003 for remaining iterations.
-
3.
Model has been trained for 750 epochs with a batch size of 256 and an additional 400 epochs with a batch size of 32.
-
4.
Tiny Image Dataset has been used, where images are 64x64. Dataset is created by taking 10 images per class for train and 2000 images in total for train and test.
-
5.
Train set is divided into 2 sections. First 1000 images are used for training as secret images and rest 1000 for cover images.
-
6.
Preparation and Hiding networks share the same stacked Keras model and loss. Reveal network has its own stacked model and its own loss function.
-
7.
Currently, the learning rate is 0.001.
-
8.
To make sure weights are updated only once, reveal network weights are frozen before adding it to the full model.
-
9.
Gaussian noise with 0.01 standard deviation is added to encoder’s output before passing it through the decoder.
-
10.
Mean sum of squared error has been used for calculating decoder’s loss.
-
11.
The loss used is for the full model is represented as:
-
12.
While training the reveal network we only consider the secret image component of the loss.
-
13.
During the full model training, the loss for both cover and secret image is taken into consideration.
-
14.
Currently we are taking both the and as 1.0.

7 Results and Discussion
Figure 7 depicts the results of hiding two secret images over a single cover image. The input images are depicted on the left side while the encoder/decoder outputs are presented on the left hand size. The encoded cover image looks similar to the original cover to a great extent, and it does not reveal information about the secret images.
The results of hiding three secret images are shown in Figure 8. The encoded cover is more lossy as compared to the case when only two secret images are used. The secret images are retrieved successfully in both cases.
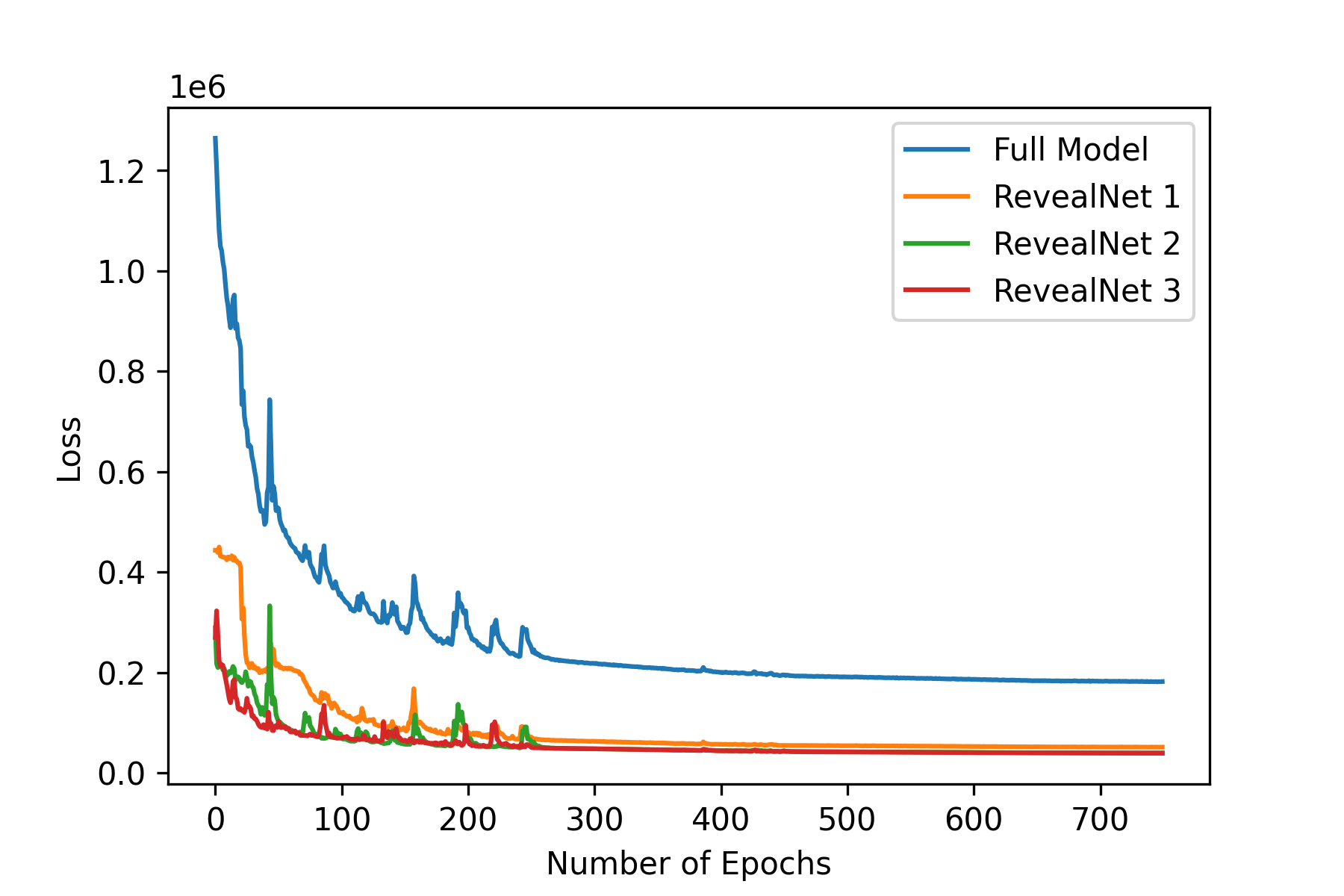
The losses received for the below results after 750 epochs were as below -
-
1.
Loss of Entire Setup - 182053.70
-
2.
Loss secret1 - 51495.24
-
3.
Loss secret2 - 39911.16
-
4.
Loss secret3 - 39337.07
-
5.
Loss Cover - 51310.23
Currently, the above two results were taken for two and three secret images added to the cover image and then retrieved. As we increase the number of images the loss for all the values is expected to increase as more image features are being hidden in one single image. So, we need to find some threshold with respect to how many images can be added to the cover image to get decent results. We also have not explored the value for the secret messages and the for the cover image. This parameter may help incorrectly defining the loss equation and help in getting clearer results for the secret and encoded image. Currently for both the experiments we have taken the and as 1.
8 Future Directions
From the implementation perspective, we aim to,
-
1.
Increase the number of secret Images with lower loss.
-
2.
Exploring and to see how it affects our results.
-
3.
Use conditional decoders instead of multiple decoders.
-
4.
We have used visual inspection as our primary evaluation metric, we can improve this by passing the encoded cover image through security software for pixel details verification.
This project can enable exploration with steganography and, more generally, in placing supplementary information in images. Several previous methods have attempted to use neural networks to either augment or replace a small portion of an image-hiding system. We are trying to demonstrate a method to create a fully trainable system that provides visually excellent results in unobtrusively placing multiple full-size, color images into a carrier image. Extensions can be towards a complete steganographic system, hiding the existence of the message from statistical analyzers. This will likely necessitate a new objective in training and encoding smaller images within large cover images.
9 Conclusion
We got to understand Steganography in the image domain. The problem statement plays an important role in data security and we were able to gain more insights by reading various papers. Our implementation extended the single image steganography model proposed by (Baluja, 2017) by implementing multiple reveal networks corresponding to each secret image, as suggested by (Kreuk et al., 2019). We were able to encode and decode up to three different secret images over a single cover image of similar size while maintaining decent min loss for secret images. Our cover image loss was higher though.
We relied heavily on visual perception for overall loss and didn’t experiment with various types of losses which could have better suited for our model. A new method to validate the strength of the approach would help improve the results in the right direction. We plan to further extend the project with more secret images and work on various loss formulas. We plan to tweak the model to recover the encoded image with minimum loss. Our contribution of a deep neural network model in the field of Multi-Image Steganography can be extended further with GANs or even deeper neural networks.
10 Acknowledgements
We would like to express our heartfelt gratitude to Professor Bhiksha for providing us the topic and guiding us through the project. We would always like to thank our mentors Rohit Prakash Barnwal and Zhefan Xu for continuous support.
References
- (1) Tiny ImageNet Visual Recognition Challenge.
- Baluja (2017) Baluja, S. Hiding images in plain sight: Deep steganography. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30, pp. 2069–2079. Curran Associates, Inc., 2017.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
- Hayes & Danezis (2017) Hayes, J. and Danezis, G. Generating steganographic images via adversarial training. In NIPS, 2017.
- (5) Ingham, F. Deepsteg: Implementation of hidding images in plain sight: Deep steganography in pytorch.
- Kreuk et al. (2019) Kreuk, F., Adi, Y., Raj, B., Singh, R., and Keshet, J. Hide and speak: Deep neural networks for speech steganography, 2019.
- (7) Muzio, A. Deep-steg: Implementation of hidding images in plain sight: Deep steganography in keras.
- Zhu et al. (2018) Zhu, J., Kaplan, R., Johnson, J., and Fei-Fei, L. Hidden: Hiding data with deep networks. CoRR, abs/1807.09937, 2018. URL http://arxiv.org/abs/1807.09937.