ifaamas \acmConference[AAMAS ’25]Proc. of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2025)May 19 – 23, 2025 Detroit, Michigan, USAY. Vorobeychik, S. Das, A. Nowé (eds.) \copyrightyear2025 \acmYear2025 \acmDOI \acmPrice \acmISBN \acmSubmissionID946 \affiliation \institutionHarvard University \cityCambridge, MA \countryUSA \affiliation \institutionDuke University \cityDurham, NC \countryUSA \affiliation \institutionDuke University \cityDurham, NC \countryUSA
Multi-objective Reinforcement Learning with Nonlinear Preferences: Provable Approximation for Maximizing Expected Scalarized Return
Abstract.
We study multi-objective reinforcement learning with nonlinear preferences over trajectories. That is, we maximize the expected value of a nonlinear function over accumulated rewards (expected scalarized return or ESR) in a multi-objective Markov Decision Process (MOMDP). We derive an extended form of Bellman optimality for nonlinear optimization that explicitly considers time and current accumulated reward. Using this formulation, we describe an approximation algorithm for computing an approximately optimal non-stationary policy in pseudopolynomial time for smooth scalarization functions with a constant number of rewards. We prove the approximation analytically and demonstrate the algorithm experimentally, showing that there can be a substantial gap between the optimal policy computed by our algorithm and alternative baselines.
Key words and phrases:
Multi-objective Reinforcement Learning, Nonlinear Optimization, Algorithmic Fairness, Approximation Algorithms1. Introduction
Markov Decision Processes (MDPs) model goal-driven interaction with a stochastic environment, typically aiming to maximize a scalar-valued reward per time-step through a learned policy. Equivalently, this formulation asks the agent to maximize the expected value of a linear function of total reward. This problem can be solved with provable approximation guarantees in polynomial time with respect to the size of the MDP Kearns and Singh (2002); Brafman and Tennenholtz (2003); Auer et al. (2008); Azar et al. (2017); Agarwal et al. (2021).
We extend this framework to optimize a nonlinear function of vector-valued rewards in multi-objective MDPs (MOMDPs), aiming to maximize expected welfare where is a total reward vector for objectives. We note that this function is also called the utility or the scalarization function within the multi-objective optimization literature Hayes et al. (2023). Unlike the deep neural networks commonly used as function approximators for large state spaces, our nonlinearity lies entirely in the objective function.
Motivation.
Nonlinear welfare functions capture richer preferences for agents, such as fairness or risk attitudes. For example, the Nash Social Welfare function reflects a desire for fairness or balance across objectives and diminishing marginal returns Caragiannis et al. (2019). Even single-objective decision theory uses nonlinear utility functions to model risk preferences, like risk aversion with the Von Neumann-Morgenstern utility function Von Neumann and Morgenstern (1947).
Consider a minimal example with an autonomous taxi robot, Robbie, serving rides in neighborhoods and , as diagrammed in Figure 1. Each ride yields a reward in its respective dimension.
Suppose Robbie starts in neighborhood and has time intervals remaining before recharging. With no discounting, the Pareto Frontier of maximal (that is, undominated) policies can achieve cumulative reward vectors of , , or by serving alone, and , or alone respectively. If we want Robbie to prefer the second more balanced or “fair” option of serving one ride in each of the two neighborhoods then Robbie must have nonlinear preferences. That is, for any choice of weights on the first and second objective, the simple weighted average would prefer outcomes (3, 0) or (0, 2). However, the second option would maximize the Nash Social Welfare of cumulative reward, for example.
Nonlinear preferences complicate policy computation: Bellman optimality fails, and stationary policies may be suboptimal. Intuitively, a learning agent with fairness-oriented preferences to balance objectives should behave differently, even in the same state, depending on which dimension of reward is “worse off.” In the Figure 1 example, one policy to achieve the balanced objective is to complete a ride in , then travel from to , and finally to complete a ride in – note that this is not stationary with respect to the environment states.
Contributions.
In this work, we ask whether it is possible to describe an approximation algorithm (that is, with provable guarantees to approximate the welfare optimal policy) for MOMDPs with nonlinear preferences that has polynomial dependence on the number of states and actions, as is the case for linear preferences or scalar MDPs. To the best of our knowledge, ours is the first work to give provable guarantees for this problem, compared to other work that focuses on empirical evaluation of various neural network architectures.
We show this is possible for smooth preferences and a constant number of dimensions of reward. To accomplish this, we (i) derive an extended form of Bellman optimality (which may be of independent interest) that characterizes optimal policies for nonlinear preferences over multiple objectives, (ii) describe an algorithm for computing approximately optimal non-stationary policies, (iii) prove the worst-case approximation properties of our algorithm, and (iv) demonstrate empirically that our algorithm can be used in large state spaces to find policies that significantly outperform other baselines.
2. Related Work
Most reinforcement learning algorithms focus on a single scalar-valued objective and maximizing total expected reward Sutton and Barto (2018). Classic results on provable approximation and runtime guarantees for reinforcement learning include the E3 algorithm Kearns and Singh (2002). This result showed that general MDPs could be solved to near-optimality efficiently, meaning in time bounded by a polynomial in the size of the MDP (number of states and actions) and the horizon time. Subsequent results refined the achievable bounds Brafman and Tennenholtz (2003); Auer et al. (2008); Azar et al. (2017). We extend these results to the multi-objective case with nonlinear preferences.
Multi-objective reinforcement learning optimizes multiple objectives at once. So-called single-policy methods use a scalarization function to reduce the problem to scalar optimization for a single policy, and we follow this line of research. The simplest form is linear scalarization, applying a weighted sum to the Q vector Moffaert et al. (2013); Liu et al. (2014); Abels et al. (2019); Yang et al. (2019); Alegre et al. (2023).
A more general problem is to optimize the expected value of a potentially nonlinear function of the total reward, which may be vector-valued in a multi-objective optimization context. We refer to such a function as a welfare function Barman et al. (2023); Fan et al. (2023); Siddique et al. (2020), which is also commonly referred to as a utility or scalarization function Hayes et al. (2023); Agarwal et al. (2022). Recent works have explored nonlinear objectives; however, to our knowledge, ours is the first to provide an approximation algorithm with provable guarantees (on the approximation factor), for the expected welfare, leveraging a characterization of recursive optimality in this setting. Several other studies focus on algorithms that demonstrate desirable convergence properties and strong empirical performance by conditioning function approximators on accumulated reward, but without offering approximation guarantees Siddique et al. (2020); Fan et al. (2023); Cai et al. (2023); Reymond et al. (2023). Complementary to our approach, Reymond et al. (2022) uses Pareto Conditioned Networks to learn policies for Pareto-optimal solutions by conditioning policies on a preference vector. Lin et al. (2024) presents an offline adaptation framework that employs demonstrations to implicitly learn preferences and safety constraints, aligning policies with inferred preferences rather than providing theoretical guarantees.
Agarwal et al. (2022) describe another model-based algorithm that can compute approximately optimal policies for a general class of monotone and Lipschitz welfare functions, but rather than maximizing the expected welfare, they maximize the welfare of expected rewards (note the two are not equal for nonlinear welfare functions). Other works have formulated fairness in different ways or settings. For example, Jabbari et al. (2017) defines an analogue of envy freeness and Deng et al. (2023) studies a per-time-step fairness guarantee. Barman et al. (2023) studies welfare maximization in multi-armed bandit problems. Röpke et al. (2023) explores the concept of distributional multi-objective decision making for managing uncertainty in multi-objective environments.
Risk-sensitive RL approaches address scalar objectives by incorporating risk measures to minimize regret or control reward variance over accumulated rewards Bäuerle and Ott (2011); Bellemare et al. (2023); Bastani et al. (2022). While these approaches offer valuable tools for managing reward variability, their guarantees are primarily in terms of regret minimization or achieving bounded variance. In contrast, our work provides stronger theoretical assurances in terms of the approximation ratio on the expected welfare for multi-objective optimization. This difference in focus underscores the robustness of our method, which provides guarantees that extend beyond the risk-sensitive regime to cover complex, multi-dimensional utility functions Fan et al. (2023); Brafman and Tennenholtz (2003); Azar et al. (2017). Such problems remain computationally significant even in a deterministic environment where the notion of risk may not apply.
Lastly, while our single-agent setup with multiple objectives shares some aspects with multi-agent reinforcement learning (MARL), the objectives differ significantly. Much of the MARL literature has focused on cooperative reward settings, often using value-decomposition techniques like VDN and QMIX Sunehag et al. (2017); Rashid et al. (2018) or actor-critic frameworks to align agent objectives under a centralized training and decentralized execution paradigm Foerster et al. (2018). In contrast, our work parallels the more general Markov game setting, where each agent has a unique reward function and studies nonlinear objectives that require computational methods beyond linear welfare functions often assumed in MARL. While MARL research frequently uses linear summations of agent rewards, we demonstrate approximation guarantees for optimizing general, non-linear functions of multiple reward vectors, a distinct contribution in a single-agent setting Jabbari et al. (2017); Agarwal et al. (2022); Von Neumann and Morgenstern (1947).
3. Preliminaries
A finite Multi-objective Markov Decision Process (MOMDP) consists of a finite set of states, a starting state ,***In general we may have a distribution over starting states; we assume a single starting state for ease of exposition. a finite set of actions, and probabilities that determine the probability of transitioning to state from state after taking action . Probabilities are normalized so that .
We have a finite vector-valued reward function . Each of the dimensions of the reward vector corresponds to one of the multiple objectives that are to be maximized. At each time step , the agent observes state , takes action , and receives a reward vector . The environment, in turn, transitions to with probability .
To make the optimization objective well-posed in MOMDPs with vector-valued rewards, we must specify a scalarization function Hayes et al. (2023) which we denote as . For fair multi-objective reinforcement learning, we think of each of the dimensions of the reward vector as corresponding to distinct users. The scalarization function can thus be thought of as a welfare function over the users, and the learning agent is a welfare maximizer. Even when , a nonlinear function can be a Von Neumann-Morgenstern utility function Von Neumann and Morgenstern (1947) that expresses the risk-attitudes of the learning agent, with strictly concave functions expressing risk aversion.
Assumptions.
Here we clarify some preliminary assumptions we make about the reward function and the welfare function . The restriction to is simply a normalization for ease of exposition; the substantial assumption is that the rewards are finite and bounded. Note from the writing we assume the reward function is deterministic: While it suffices for linear optimization to simply learn the mean of random reward distributions, this does not hold when optimizing the expected value of a nonlinear function. Nevertheless, the environment itself may still be stochastic, as the state transitions may still be random.
We also assume that is smooth. For convenience of analysis, we will assume is uniformly continuous on the L1-norm (other parameterizations such as the stronger Lipshitz continuity or using the L2-norm are also possible). For all , there exists such that for all ,
The smoothness assumption seems necessary to give worst-case approximation guarantees as otherwise arbitrarily small changes in accumulated reward could have arbitrarily large differences in welfare. However, we note that this is still significantly more general than linear scalarization which is implicitly smooth. Practically speaking, our algorithms can be run regardless of the assumed level of smoothness; a particular smoothness is necessary just for the worst-case analysis.
4. Modeling Optimality
In this section, we expand the classic model of reinforcement learning to optimize the expected value of a nonlinear function of (possibly) multiple dimensions of reward. We begin with the notion of a trajectory of state-action pairs.
Definition 0.
Let be an MOMDP. A length trajectory in is a tuple of state-action pairs
For , let be the sub-trajectory consisting of pairs . Let denote the empty trajectory.
For a discount factor , we calculate the total discounted reward of a trajectory. Note that this is a vector in general.
Definition 0.
For length trajectory and discount factor , the total discounted reward along is the vector
For ease of exposition we will frequently leave implicit from context and simply write . ††† is necessary for the infinite horizon setting. In the experiments with a finite-horizon task we use for simplicity.
A policy is a function mapping past trajectories and current states to probability distributions over actions, that is, for all and . A stationary policy is the special case of a policy that depends only on the current state: .
Definition 0.
The probability that a -trajectory is traversed in an MOMDP upon starting in state and executing policy is
Problem Formulation.
Given a policy, a finite time-horizon , and a starting state we can calculate the expected welfare of total discounted reward along a trajectory as follows. Our goal is to maximize this quantity. That is, we want to compute a policy that maximizes the expected -step discounted welfare.
Definition 0.
For a policy and a start state , the expected -step discounted welfare is
where the expectation is taken over all length trajectories beginning at .
Note that this objective is not equal to , which others have studied Agarwal et al. (2022); Siddique et al. (2020), for a nonlinear . The former (our objective) is also known as expected scalarized return (ESR) whereas the latter is also known as scalarized expected return (SER) Hayes et al. (2023). While SER makes sense for a repeated decision-making problem, it does not optimize for expected welfare for any particular trajectory. For concave , ESR SER by Jensen’s inequality. However, an algorithm for approximating SER does not provide any guarantee for approximating ESR. For example, a policy can be optimal on SER but achieve 0 ESR if it achieves high reward on one or the other of two objectives but never both in the same episode.
Form of Optimal Policy and Value Functions.
The optimal policy for this finite time horizon setting is a function also of the number of time steps remaining. We write such a policy as where is a trajectory (the history), is the current state, and is the number of time steps remaining, .
We can similarly write the extended value function of a policy . We write as the history or trajectory prior to some current state and as the future, the remaining steps determined by the policy and the environmental transitions.
Definition 0.
The value of a policy beginning at state after history and with more actions is
where the expectation is taken over all length trajectories beginning at . The optimal value function is
and the optimal policy is
Note that because is nonlinear, the value function cannot be decomposed in the same way as in the traditional Bellman equations. Before proceeding we want to provide some intuition for this point. The same reasoning helps to explain why stationary policies are not generally optimal.
Suppose we are optimizing the product of the reward between two objectives (i.e., the welfare function is the product or geometric mean), and at some state with some prior history we can choose between two policies or . Suppose that the future discounted reward vector under is , whereas it is under . So has greater expected future welfare and traditional Bellman optimality would suggest we should choose . However, if , we would actually be better off in terms of total welfare choosing . In other words, both past and future reward are relevant when optimizing for the expected value of a nonlinear welfare function.
We develop an extended form of Bellman optimality capturing this intuition by showing that the optimal value function can be written as a function of current state , accumulated discounted reward , and number of timesteps remaining in the task . The proof is included in the appendix. At a high level as a sketch, the argument proceeds inductively on where the base case follows by definition and the inductive step hinges on showing that the the expectation over future trajectories can be decomposed into an expectation over successor states and subsequent trajectories despite the nonlinear .
Lemma 0.
Let for all states and trajectories . For every state , history , and time steps remaining, let
Then .
By Lemma 6, we can parameterize the optimal value function by the current state , accumulated reward , and number of timesteps remaining . We will use this formulation of in the remainder of the paper.
Definition 0 (Recursive Formulation of ).
Let be the vector of accumulated reward along a history prior to some state . Let for all and . For ,
Horizon Time.
Note that an approximation algorithm for this discounted finite time horizon problem can also be used as an approximation algorithm for the discounted infinite time horizon problem. Informally, discounting by with bounded maximum reward implies that the first steps dominate overall returns. We defer the precise formulation of the lower bound on the horizon time and its proof in the appendix (Lemma 13).
Necessity of Conditioning on Remaining Timesteps
We illustrate the necessity of conditioning the optimal value function on the remaining timesteps using a counterexample in the appendix.
5. Computing Optimal Policies
Our overall algorithm is Reward-Aware Explore or Exploit (or RAEE for short) to compute an approximately optimal policy, inspired by the classical E3 algorithm Kearns and Singh (2002). At a high level, the algorithm explores to learn a model of the environment, periodically pausing to recompute an approximately optimal policy on subset of the environment that has been thoroughly explored. We call this optimization subroutine Reward-Aware Value Iteration (or RAVI for short). In both cases, reward-aware refers to the fact that the algorithms compute non-stationary policies in the sense that optimal behavior depends on currently accumulated vector-valued reward, in addition to the current state.
Of the two, the model-based optimization subroutine RAVI is the more significant. The integrated model-learning algorithm RAEE largely follows from prior work, given access to the RAVI subroutine. For this reason, we focus in this section on RAVI, and defer a more complete discussion and analysis of RAEE to Section 7 and the appendix.
A naive algorithm for computing a non-stationary policy would need to consider all possible prior trajectories for each decision point, leading to a runtime complexity containing the term , exponential in the size of the state space and time horizon. Instead, for a smooth welfare function on a constant number of objectives, our algorithm will avoid any exponential dependence on .
The algorithm is derived from the recursive definition of the optimal multi-objective value function in Definition 7, justified by Lemma 6, parameterized by the accumulated discounted reward vector instead of the prior history. Note that even if the rewards were integers, might not be due to discounting. We must therefore introduce a discretization that maps accumulated reward vectors to points on a lattice, parameterized by some where a smaller leads to a finer discretization but increases the runtime.
Definition 0.
For a given discretization precision parameter , define by
In other words, maps any -dimensional vector to the largest vector in that is less than or equal to the input vector, effectively rounding each component down to the nearest multiple of . We now describe the algorithm, which at a high level computes the dynamic program of approximately welfare-optimal value functions conditioned on discretized accumulated reward vectors.
Remark. Since we model the per-step reward as normalized to at most 1, we describe as lying within . However, the algorithm itself is well-defined for larger values of alpha (coarser than the per-step reward) and during implementation and experiments, we consider such larger , beyond what might give worst-case guarantees but still observing strong empirical performance.
The asymptotic runtime complexity is . However, observe that the resulting algorithm is extremely parallelizable: Given solutions to subproblems at , all subproblems for can in principle be computed in parallel. A parallel implementation of RAVI can leverage GPU compute to handle the extensive calculations involved in multi-objective value iteration. Each thread computes the value updates and policy decisions for a specific state and accumulated reward combination, which allows for massive parallelism. In practice, we observed an empirical speedup of approximately 560 times on a single NVIDIA A100 compared to the CPU implementation on an AMD Ryzen 9 7950x 16-core processor for our experimental settings. This drastic improvement in runtime efficiency makes it feasible to run RAVI on larger and more complex environments, where the computational demands would otherwise be prohibitive.
It remains to see how small needs to be, which will dictate the final runtime complexity. We first analyze the correctness of the algorithm and then return to the setting of for a given smoothness of to conclude the runtime analysis.
We begin analyzing the approximation of RAVI by showing an important structural property: the optimal value function will be smooth as long as the welfare function is smooth. The proof is included in the appendix.
Lemma 0 (Uniform continuity of multi-objective value function).
Let the welfare function be uniformly continuous. Fix and , then for all , there exists such that
We now present the approximation guarantee of RAVI, that it achieves an additive error that scales with the smoothness of and the number of remaining time steps. The proof of this lemma is deferred to the appendix.
Lemma 0 (Approximation Error of RAVI).
For uniformly continuous welfare function , for all , there exists such that
, where is computed by Algorithm 1 using .
While we can use any setting of empirically, this shows that for an approximation guarantee we should set the discretization parameter to where from the smoothness of the welfare function is sufficient to drive its bound to , that is, it should be
We thus arrive at the ultimate statement of the approximation and runtime of RAVI. The proof follows directly from Lemma 10 and the setting of .
Theorem 11 (Optimality Guarantee of RAVI).
For a given and welfare function that is uniformly continuous, RAVI with computes a policy , such that in time.
A concrete example of a particular welfare function, the setting of relevant parameters, and a derivation of a simplified runtime statement may help to clarify Theorem 11. Consider the smoothed proportional fairness objective: , a smoothed log-transform of the Nash Social Welfare (or geometric mean) with better numerical stability.
By taking the gradient, we can see that is -Lipschitz on , so we may pick to satisfy the uniform continuity requirement in Theorem 11. ‡‡‡Uniform continuity is a weaker modeling assumption than -Lipshitz continuity for constant . Note that for an -Lipshitz function, the correct value of is just , where is the desired approximation factor of the algorithm.
Plugging into the runtime and recalling that and up to constant factors, we get
To further simplify, if one takes the number of actions , discount factor , and dimension to be constants, then the asymptotic dependence of the runtime (in our running example) is
This dependence is significantly better than a naive brute-force approach, which scales at least as .
Intuitively, the key savings arise from discretizing the reward space (with granularity ) rather than enumerating all possible trajectories. This discretization is guided by the smoothness assumption on .
6. Experiments
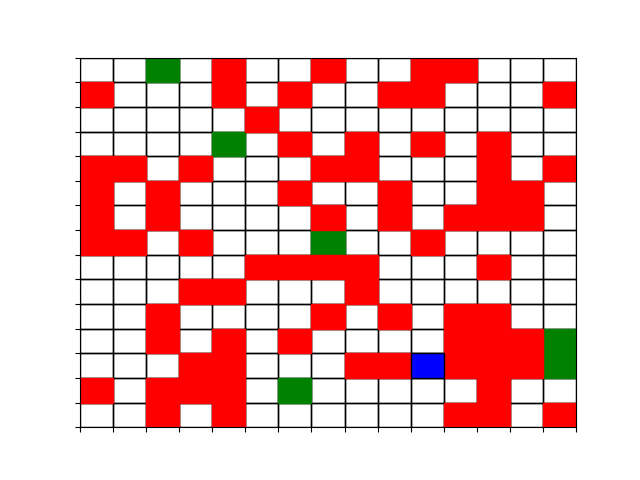
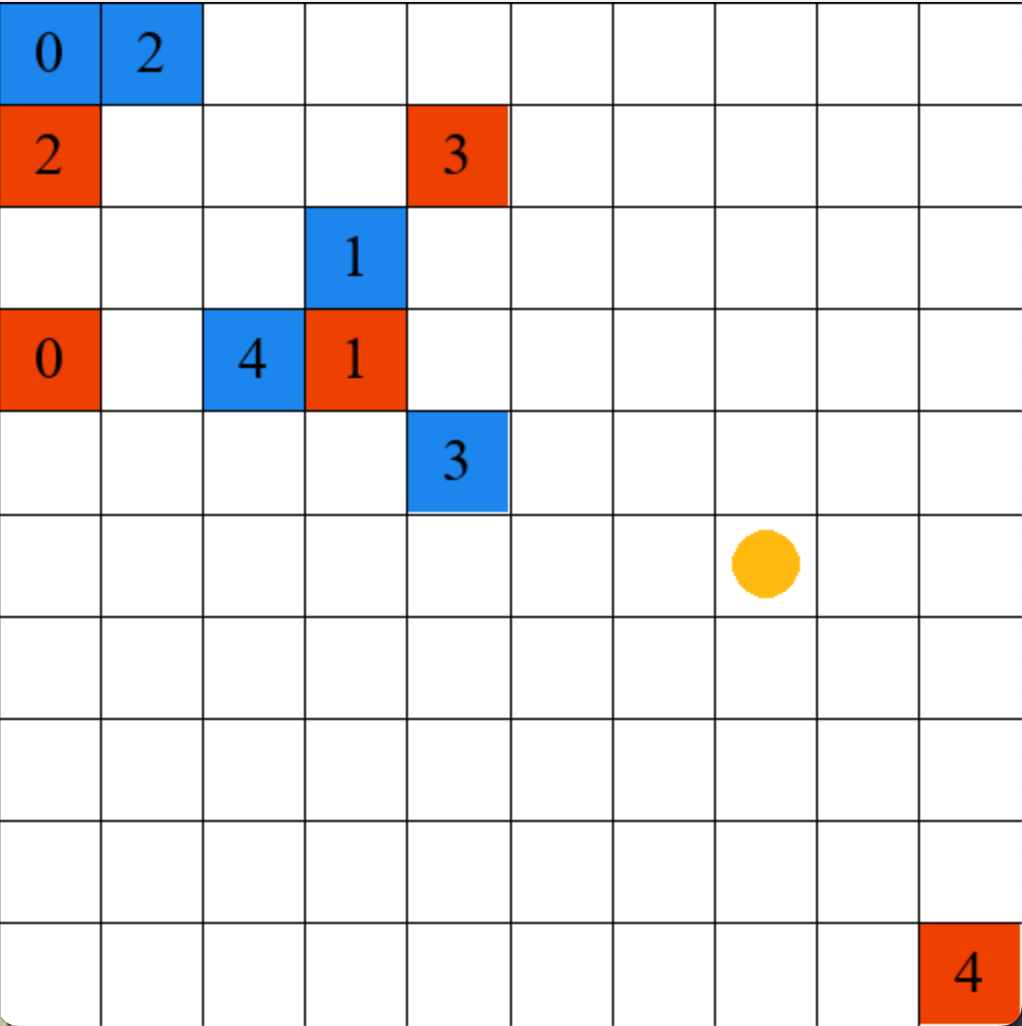
We test RAVI on two distinct interpretations of multi-objective reinforcement learning: (1) the fairness interpretation, where the agent tries to maximize rewards across all dimensions. (2) the objective interpretation, where the agent tries to maximize one while minimizing the other. In both scenarios, we show that RAVI can discover more optimal policies than other baselines for nonlinear multi-objective optimization. This holds even for coarser settings of in the algorithm than would be necessary for strong theoretical worst-case approximation guarantees.
6.1. Simulation Environments
Taxi: We use the taxi multi-objective simulation environment considered in Fan et al. (2023) for testing nonlinear ESR maximization. In this grid-world environment, the agent is a taxi driver whose goal is to deliver passengers. There are multiple queues of passengers, each having a given pickup and drop-off location. Each queue has a different objective or dimension of the reward. The taxi can only take one passenger at a time and wants to balance trips for passengers in the different queues. This environment models the fairness interpretation.
Scavenger: Inspired by the Resource Gathering environment Barrett and Narayanan (2008), the scavenger hunt environment is a grid-world simulation where the agent must collect resources while avoiding enemies scattered across the grid. The state representation includes the agent’s position and the status of the resources (collected or not). The reward function is vector-valued, where the first component indicates the number of resources collected, and the second component indicates the damage taken by encountering enemies. This environment is the objective interpretation.
6.2. Baseline Algorithms
Linearly Scalarized Policy (LinScal) Van Moffaert et al. (2013): A relatively straightforward technique for multi-objective RL optimization is to apply the linear combination on the Q-values for each objective. Given weights , , the scalarized objective is , where is the Q-value for the objective. -greedy policy is used on during action selection, and regular Q-learning updates are applied on each reward dimension.
Mixture Policy (Mixture) Vamplew et al. (2009): this baseline works by combining multiple Pareto optimal base policies into a single policy. Q-learning is used to optimize for each reward dimension separately (which is approximately Pareto optimal), and the close-to-optimal policy for each dimension is used for steps before switching to the next.
Welfare Q-learning (WelfareQ) Fan et al. (2023): this baseline extends Q-learning in tabular setting to approximately solve the nonlinear objective function by considering past accumulated rewards to perform non-stationary action selection.
Model-Based Mixture Policy (Mixture-M): Instead of using Q-learning to find an approximately Pareto optimal policy for each objective, value iteration Sutton et al. (1998) is used to calculate the optimal policy, and each dimension uses the corresponding optimal policy for steps before switching to the next.
6.3. Nonlinear Functions
Taxi: We use the following three functions on Taxi for fairness considerations: (1) Nash social welfare: . (2) Egalitarian welfare: . (3) -welfare§§§-welfare is equivalent to generalized mean. If , -welfare converges to Nash welfare; if , -welfare converges to egalitarian welfare; and -welfare is the utilitarian welfare when .: .
Scavenger: We use these two functions to reflect the conflicting nature of the objectives:
-
(1)
Resource-Damage Threshold Scalarization: , where is number of resources collected and is damage taken from enemies. The threshold parameter represents a budget after which the penalty from the damage starts to apply.
-
(2)
Cobb-Douglas Scalarization: . This function is inspired by economic theory and balances trade-offs between and .
6.4. Experiment Settings and Hyperparameters
We run all the algorithms using 10 random initializations with a fixed seed each. We set (uniform weight) for LinScal, for Mixture and Mixture-M, for RAVI, and learning rate of 0.1 for WelfareQ. Three of our baselines (Mixture, LinScal, and WelfareQ) are online algorithms. Thus, to ensure a fair comparison, we tuned their hyperparameters using grid-search and evaluated their performances after they reached convergence. For model-based approaches (RAVI and Mixture-M), we run the algorithms and evaluate them after completion. We set the convergence threshold to for Mixture-M. Some environment-specific settings are discussed below.
Taxi: To ensure numerical stability of , we optimize its smoothed log-transform , but during evaluations we still use . We set , . , size of the grid world to be with reward dimensions.
Scavenger: We set threshold for to 2 and for . The size of the grid world is with six resources scattered randomly and 1/3 of the cells randomly populated with enemies. We use and .
| Environment | Dimension | Function | RAVI | Mixture | LinScal | WelfareQ | Mixture-M |
|---|---|---|---|---|---|---|---|
| Taxi | 7.5550.502 | 5.1360.547 | 0.0000.000 | 5.3430.964 | 6.4060.628 | ||
| 3.0000.000 | 3.4830.894 | 0.0000.000 | 0.3870.475 | 4.0650.773 | |||
| 5.2790.000 | 3.6230.522 | 0.0000.000 | 2.4411.518 | 4.3560.829 | |||
| 7.4040.448 | 5.3630.844 | 0.0000.000 | 4.9771.514 | 6.4060.628 | |||
| 9.6280.349 | 5.9470.488 | 7.8330.908 | 7.9990.822 | 7.0520.412 | |||
| 4.9960.297 | 3.2500.584 | 0.0000.000 | 2.7981.462 | 3.4610.459 | |||
| 2.0000.000 | 2.0300.981 | 0.0000.000 | 0.0940.281 | 1.6600.663 | |||
| 3.1150.000 | 2.1290.878 | 0.0000.000 | 2.5580.812 | 1.8490.733 | |||
| 3.3070.000 | 3.1180.536 | 0.0000.000 | 3.3061.181 | 3.4620.458 | |||
| 6.2500.322 | 3.8830.329 | 5.1910.464 | 4.8340.797 | 4.0810.266 | |||
| 2.1910.147 | 0.5790.713 | 0.0000.000 | 1.6010.189 | 1.1220.781 | |||
| 1.7000.483 | 0.5450.445 | 0.0000.000 | 0.0000.000 | 0.6340.437 | |||
| 1.0290.000 | 0.4900.490 | 0.0000.000 | 0.6890.451 | 0.6880.475 | |||
| 2.1450.129 | 0.9610.628 | 0.0000.000 | 1.4400.511 | 1.1260.774 | |||
| 3.3690.173 | 1.2300.264 | 2.5460.174 | 2.5210.211 | 1.6890.320 | |||
| 2.3080.185 | 0.0000.000 | 0.0000.000 | 1.1810.613 | 0.0000.000 | |||
| 1.7000.483 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | |||
| 1.0230.000 | 0.0000.000 | 0.0000.000 | 0.4070.501 | 0.0000.000 | |||
| 2.0000.102 | 0.0180.020 | 0.0000.000 | 1.3090.490 | 0.0250.025 | |||
| 3.2890.147 | 1.2200.141 | 2.8440.250 | 2.8790.263 | 1.7610.148 | |||
| Scavenger | 1.3360.240 | 0.6550.558 | 0.8740.605 | 0.7130.645 | 0.7290.296 | ||
| 3.4000.843 | 0.9000.943 | 1.2000.872 | 1.4441.423 | 0.8452.938 |
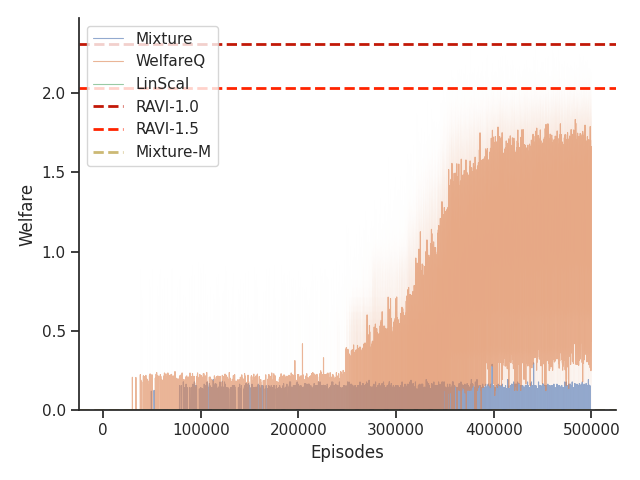
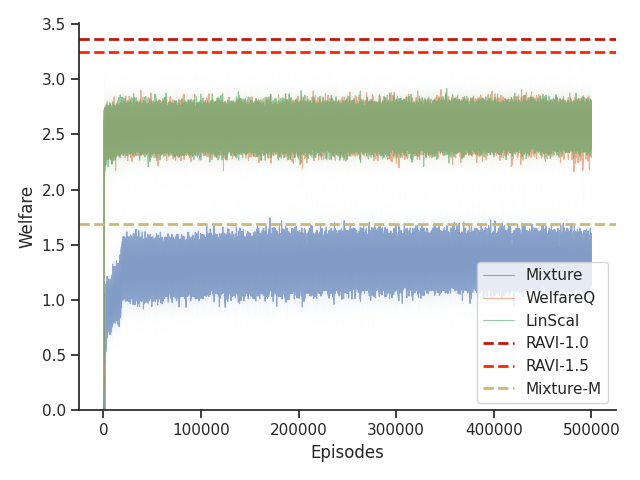
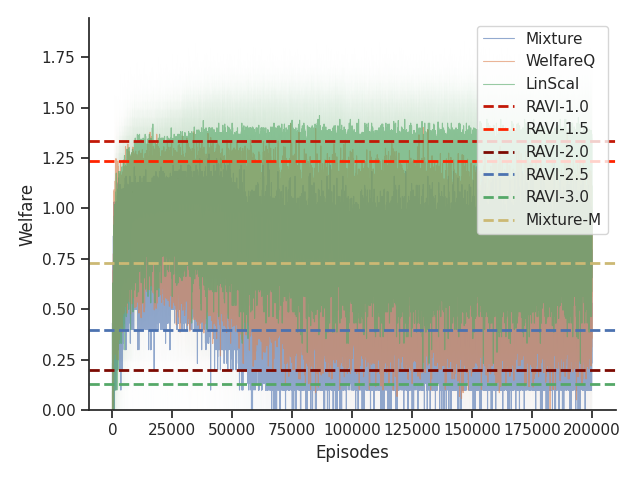
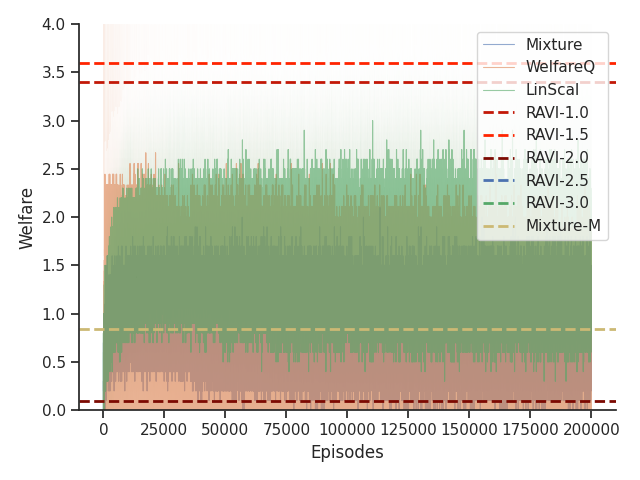
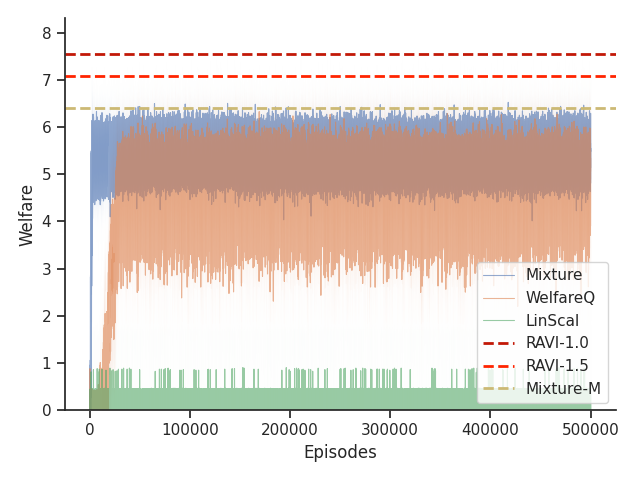
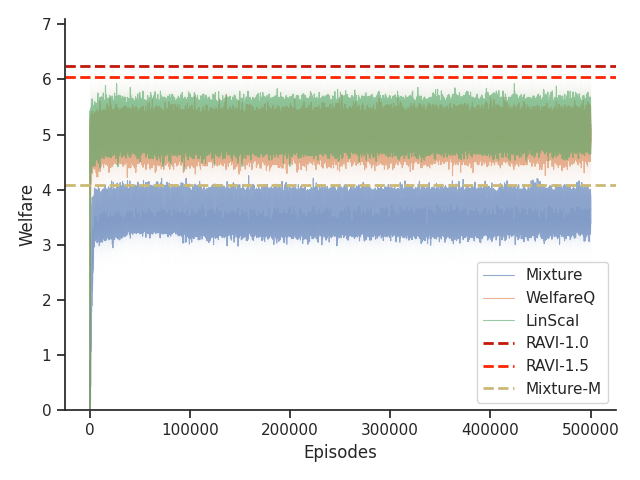
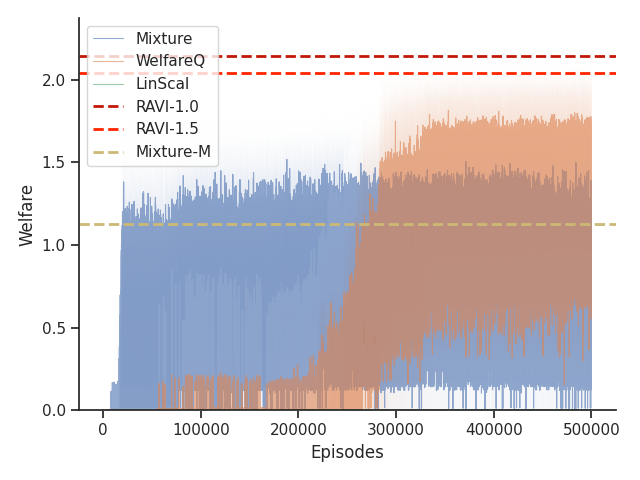
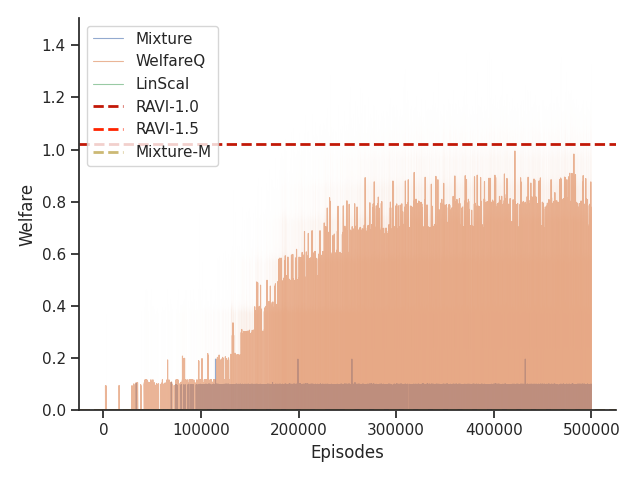
6.5. Results
As shown in Table 1, we found that RAVI is able to generally outperform all baselines across all settings in both Taxi and Scavenger environments in terms of optimizing our nonlinear functions of interest.
On the Taxi environment, we observe that LinScal is unable to achieve any performance except for . This is an expected behavior due to the use of a linearly scalarized policy and the fact that -welfare converges to utilitarian welfare when . Among the baseline algorithms, we observe that WelfareQ performs the best on , whereas Mixture and Mixture-M fail due to the use of a fixed interval length for each optimal policy. Furthermore, the advantage of RAVI becomes more obvious as increases.
On the Scavenger environment, due to and having a dense reward signal, all algorithms are able to achieve reasonable values for the welfare functions. We also observe that RAVI significantly outperforms all baselines.
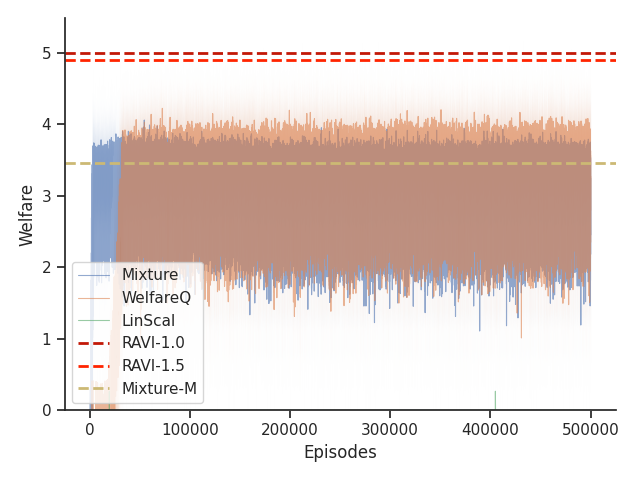
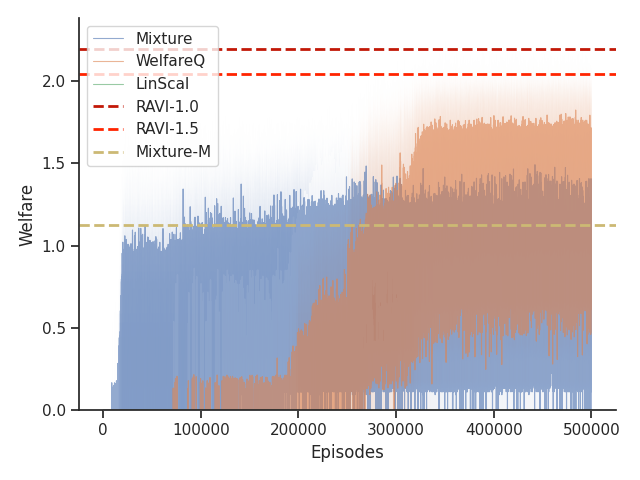
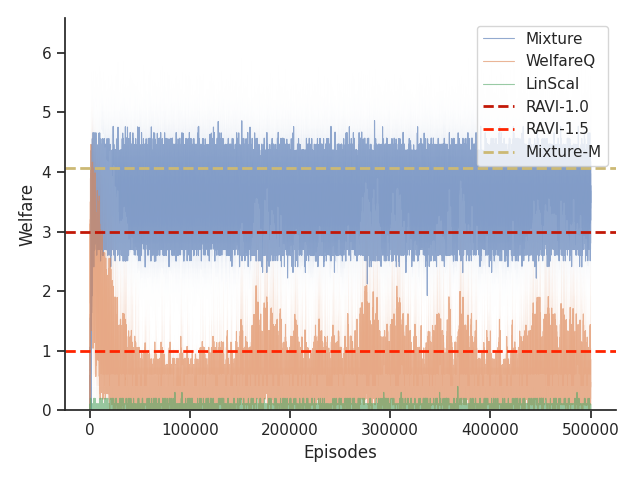
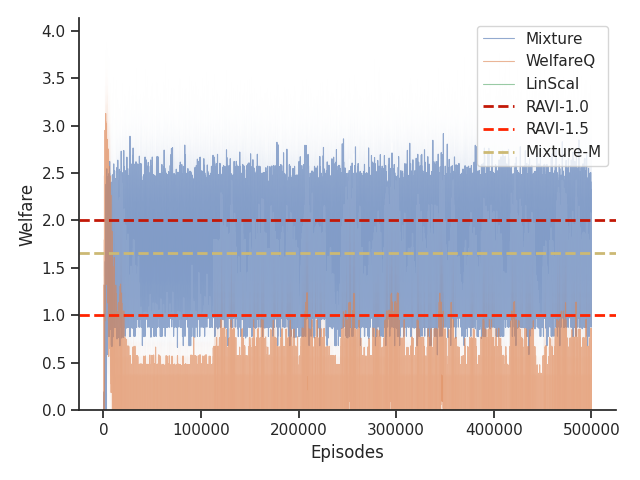
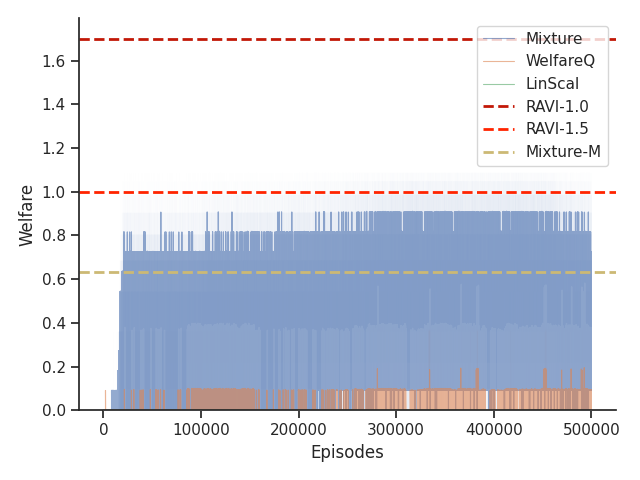
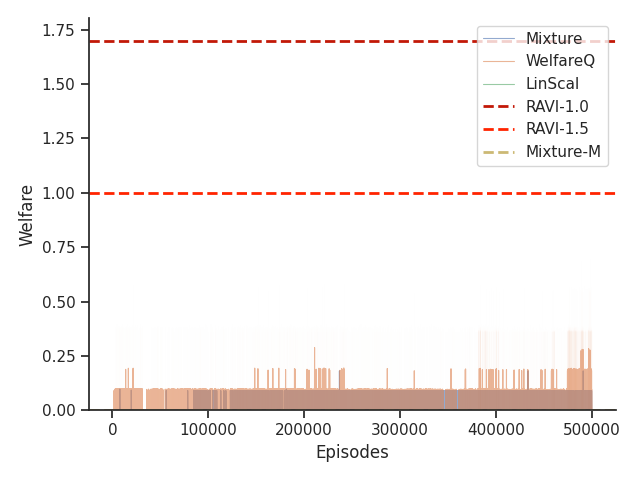
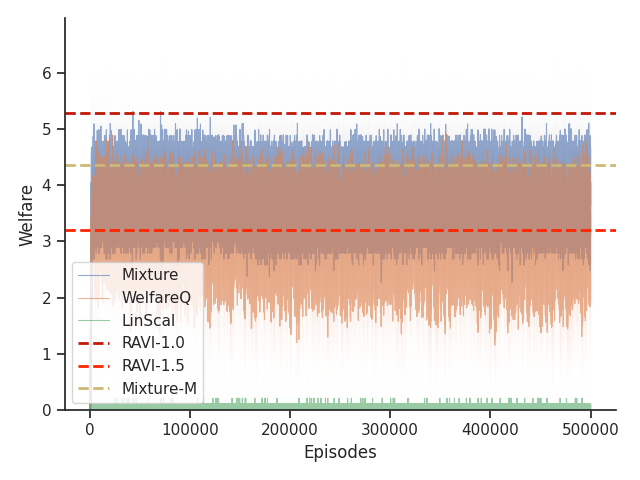
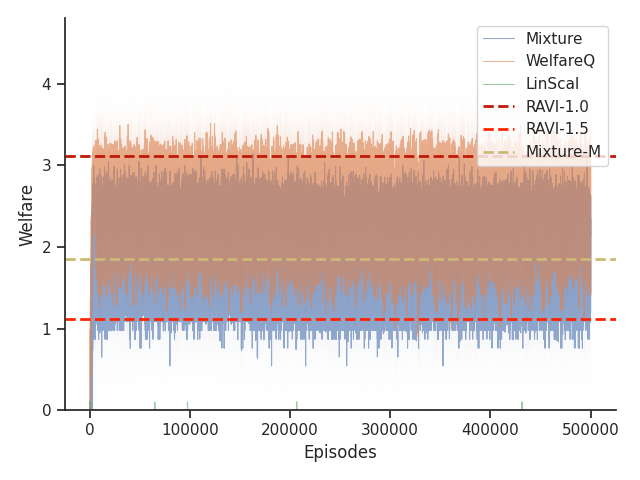
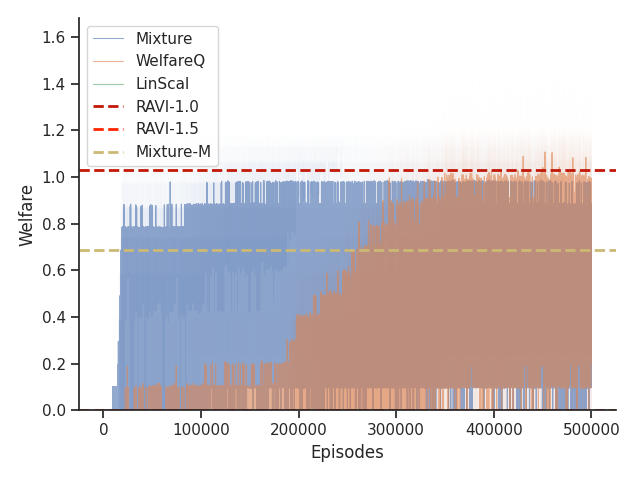
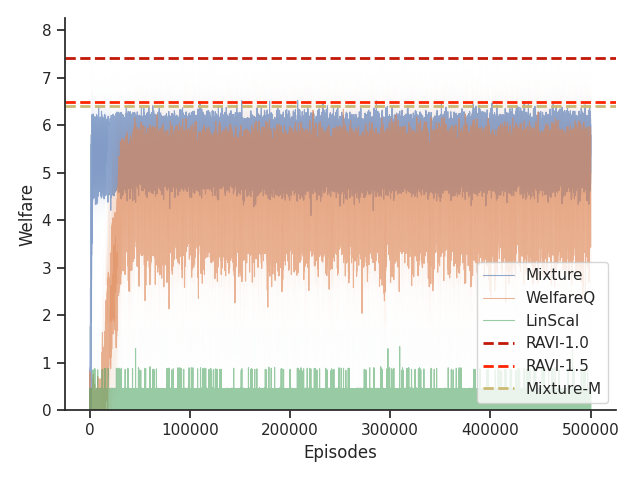
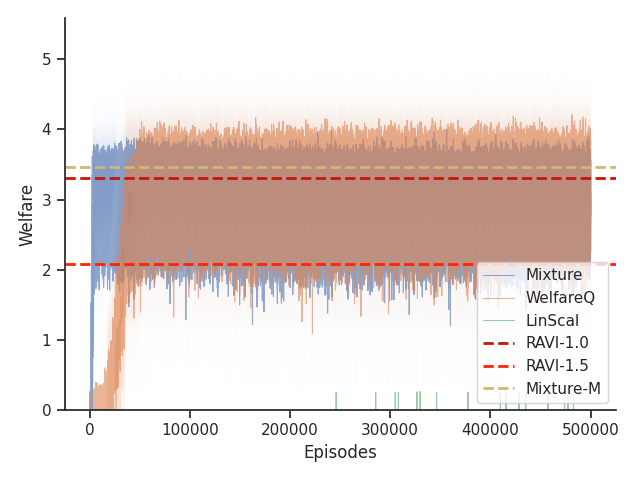
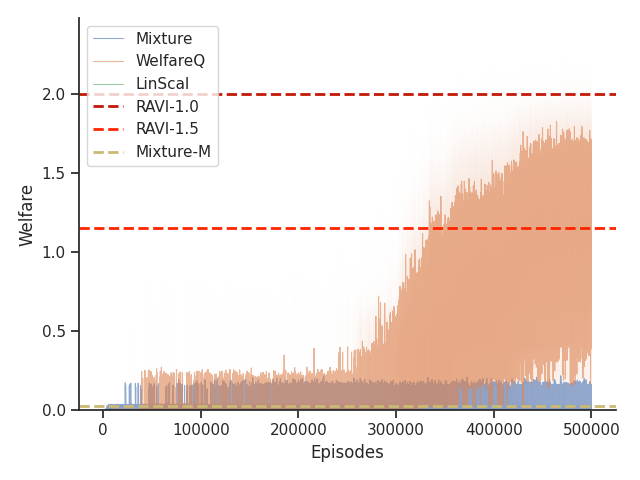
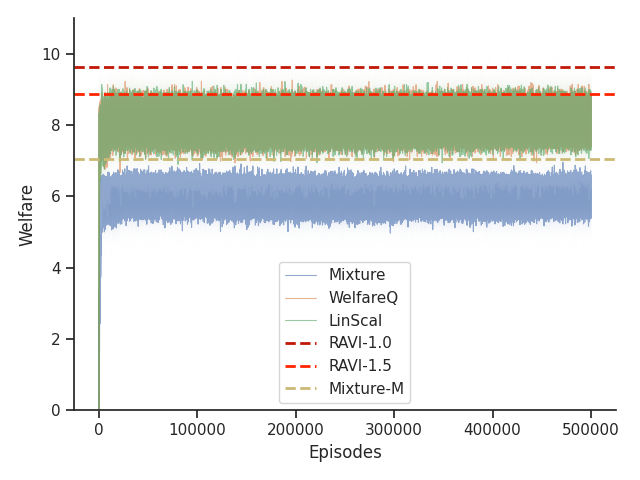
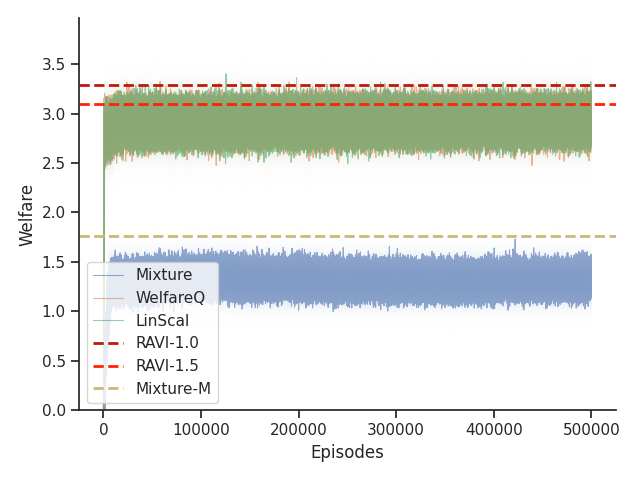
Given that Mixture, LinScal, and WelfareQ are online algorithms, for the sake of completeness, we provide the visualizations of the learning curves of the baseline algorithms compared with RAVI with different values in Figure 3, where the model-base approaches are shown as horizontal dotted lines. In general, we found that the online algorithms tend to converge early, and we observe a degradation in performance as increases. The full set of results can be found at Section C.3.
6.6. Ablation Study on Discretization Factor
To further evaluate the effect of on RAVI, we also run two sets of experiments:
-
(1)
we test RAVI performance on settings with and adopt values that are substantially greater than those necessary for worst-case theoretical guarantees from the previous analysis. This set of results can be found at Section C.1. Note that the empirical performance of RAVI is substantially better than is guaranteed by the previous theoretical analysis.
-
(2)
With , we evaluate RAVI using larger alpha values and investigate how much performance degradation occurs. This set of experiments can be found in Section C.2.
7. Removing Knowledge of the Model
We have shown that RAVI can efficiently find an approximately optimal policy given access to a model of the environment. In this section we observe that the model can be jointly learned by extending the classical E3 algorithm Kearns and Singh (2002) to the nonlinear multi-objective case by lifting the exploration algorithm to the multi-objective setting and using RAVI for the exploitation subroutine. We call the resulting combined algorithm Reward-Aware-Explore or Exploit (or RAEE for short). We briefly explain the high level ideas and state the main result here and defer further discussion to the appendix due to space constraints.
The algorithm consists of two stages, exploration and exploitation. The algorithm alternates between two stages: exploration and exploitation. Each stage is outlined here at a high level, with more detailed steps provided in the appendix.
-
•
Explore. At a given state, choose the least experienced action and record the reward and transition. Continue in this fashion until reaching a known state, where we say a state is known if it has been visited sufficiently many times for us to have precise local statistics about the reward and transition functions in that state.
-
•
Exploit. Run RAVI from the current known state in the induced model comprising the known states and with a single absorbing state representing all unknown states. If the welfare obtained by this policy is within the desired error bound of , then we are done. Otherwise, compute a policy to reach an unknown state as quickly as possible and resume exploring.
Theorem 12 (RAEE).
Let denote the value function of the policy with the optimal expected welfare in the MOMDP starting at state , with accumulated reward and timesteps remaining. Then for a uniformly continuous welfare function , there exists an algorithm , taking inputs , , , , and , such that the total number of actions and computation time taken by is polynomial in , , , , the horizon time and exponential in the number of objectives , and with probability at least , will halt in a state , and output a policy , such that .
We provide additional details comparing our analysis with that of Kearns and Singh (2002) in the appendix.
As we do not regard the learning of the Multi-Objective Markov Decision Process (MOMDP) as our primary contribution, we choose to focus the empirical evaluation on the nonlinear optimization subroutine, which is the most crucial modification from the learning problem with a single objective. The environments we used for testing the optimality of RAVI are very interesting for optimizing a nonlinear function of the rewards, but are deterministic in terms of transitions and rewards, making the learning of these environments less interesting empirically.
8. Conclusion and Future Work
Nonlinear preferences in reinforcement learning are important, as they can encode fairness as the nonlinear balancing of priorities across multiple objectives or risk attitudes with respect to even a single objective. Stationary policies are not necessarily optimal for such objectives. We derived an extended form of Bellman optimality to characterize the structure of optimal policies conditional on accumulated reward. We introduced the RAVI and RAEE algorithms to efficiently compute an approximately optimal policy.
Our work is certainly not the first to study MORL including with nonlinear preferences. However, to the best of our knowledge, our work is among the first to provide worst-case approximation guarantees for optimizing ESR in MORL with nonlinear scalarization functions.
While our experiments demonstrate the utility of RAVI in specific settings, there are many possible areas of further empirical evaluation including stochastic environments and model learning alongside the use of RAVI as an exploitation subprocedure as described in theory in Section 7 with RAEE. Further details on the limitations of our experiments are discussed in Appendix E.
Our results introduce several natural directions for future work. On the technical side, one could try to handle the case of stochastic reward functions or a large number of objectives. Another direction would involve incorporating function approximation with deep neural networks into the algorithms to enable scaling to even larger state spaces and generalizing between experiences. Our theory suggests that it may be possible to greatly enrich the space of possible policies that can be efficiently achieved in these settings by conditioning function approximators on accumulated reward rather than necessarily considering sequence models over arbitrary past trajectories; we see this as the most exciting next step for applications.
References
- (1)
- Abels et al. (2019) Axel Abels, Diederik Roijers, Tom Lenaerts, Ann Nowé, and Denis Steckelmacher. 2019. Dynamic weights in multi-objective deep reinforcement learning. In International conference on machine learning. PMLR, 11–20.
- Agarwal et al. (2021) Alekh Agarwal, Sham M. Kakade, Jason D. Lee, and Gaurav Mahajan. 2021. On the Theory of Policy Gradient Methods: Optimality, Approximation, and Distribution Shift. J. Mach. Learn. Res. 22, 1, Article 98 (jan 2021), 76 pages.
- Agarwal et al. (2022) Mridul Agarwal, Vaneet Aggarwal, and Tian Lan. 2022. Multi-Objective Reinforcement Learning with Non-Linear Scalarization. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems (Virtual Event, New Zealand) (AAMAS ’22). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 9–17.
- Alegre et al. (2023) Lucas N Alegre, Ana LC Bazzan, Diederik M Roijers, Ann Nowé, and Bruno C da Silva. 2023. Sample-efficient multi-objective learning via generalized policy improvement prioritization. arXiv preprint arXiv:2301.07784 (2023).
- Auer et al. (2008) Peter Auer, Thomas Jaksch, and Ronald Ortner. 2008. Near-Optimal Regret Bounds for Reinforcement Learning. In Proceedings of the 21st International Conference on Neural Information Processing Systems (Vancouver, British Columbia, Canada) (NIPS’08). Curran Associates Inc., Red Hook, NY, USA, 89–96.
- Azar et al. (2017) Mohammad Gheshlaghi Azar, Ian Osband, and Rémi Munos. 2017. Minimax Regret Bounds for Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 70), Doina Precup and Yee Whye Teh (Eds.). PMLR, 263–272. https://proceedings.mlr.press/v70/azar17a.html
- Barman et al. (2023) Siddharth Barman, Arindam Khan, Arnab Maiti, and Ayush Sawarni. 2023. Fairness and Welfare Quantification for Regret in Multi-Armed Bandits. Proceedings of the AAAI Conference on Artificial Intelligence 37, 6 (Jun. 2023), 6762–6769. https://doi.org/10.1609/aaai.v37i6.25829
- Barrett and Narayanan (2008) Leon Barrett and Srini Narayanan. 2008. Learning all optimal policies with multiple criteria. In Proceedings of the 25th International Conference on Machine Learning (Helsinki, Finland) (ICML ’08). Association for Computing Machinery, New York, NY, USA, 41–47. https://doi.org/10.1145/1390156.1390162
- Bastani et al. (2022) Osbert Bastani, Jason Yinglun Ma, Ethan Shen, and Weiran Xu. 2022. Regret bounds for risk-sensitive reinforcement learning. In Advances in Neural Information Processing Systems, Vol. 35. 36259–36269.
- Bäuerle and Ott (2011) Nicole Bäuerle and Jonathan Ott. 2011. Markov decision processes with average-value-at-risk criteria. Mathematical Methods of Operations Research 74 (2011), 361–379.
- Bellemare et al. (2023) Marc G Bellemare, Will Dabney, and Mark Rowland. 2023. Distributional Reinforcement Learning. MIT Press.
- Brafman and Tennenholtz (2003) Ronen I. Brafman and Moshe Tennenholtz. 2003. R-Max - a General Polynomial Time Algorithm for near-Optimal Reinforcement Learning. J. Mach. Learn. Res. 3, null (mar 2003), 213–231. https://doi.org/10.1162/153244303765208377
- Cai et al. (2023) Xin-Qiang Cai, Pushi Zhang, Li Zhao, Jiang Bian, Masashi Sugiyama, and Ashley Llorens. 2023. Distributional Pareto-Optimal Multi-Objective Reinforcement Learning. In Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 15593–15613. https://proceedings.neurips.cc/paper_files/paper/2023/file/32285dd184dbfc33cb2d1f0db53c23c5-Paper-Conference.pdf
- Caragiannis et al. (2019) Ioannis Caragiannis, David Kurokawa, Hervé Moulin, Ariel D Procaccia, Nisarg Shah, and Junxing Wang. 2019. The unreasonable fairness of maximum Nash welfare. ACM Transactions on Economics and Computation (TEAC) 7, 3 (2019), 1–32.
- Deng et al. (2023) Zhun Deng, He Sun, Steven Wu, Linjun Zhang, and David Parkes. 2023. Reinforcement Learning with Stepwise Fairness Constraints. In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 206), Francisco Ruiz, Jennifer Dy, and Jan-Willem van de Meent (Eds.). PMLR, 10594–10618. https://proceedings.mlr.press/v206/deng23a.html
- Fan et al. (2023) Ziming Fan, Nianli Peng, Muhang Tian, and Brandon Fain. 2023. Welfare and Fairness in Multi-Objective Reinforcement Learning. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems (London, United Kingdom) (AAMAS ’23). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 1991–1999.
- Foerster et al. (2018) Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. 2018. Counterfactual multi-agent policy gradients. Proceedings of the AAAI Conference on Artificial Intelligence 32, 1 (2018).
- Hayes et al. (2023) Conor F. Hayes, Roxana Rădulescu, Eugenio Bargiacchi, Johan Kallstrom, Matthew Macfarlane, Mathieu Reymond, Timothy Verstraeten, Luisa M. Zintgraf, Richard Dazeley, Fredrik Heintz, Enda Howley, Athirai A. Irissappane, Patrick Mannion, Ann Nowé, Gabriel Ramos, Marcello Restelli, Peter Vamplew, and Diederik M. Roijers. 2023. A Brief Guide to Multi-Objective Reinforcement Learning and Planning. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems (London, United Kingdom) (AAMAS ’23). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 1988–1990.
- Jabbari et al. (2017) Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie Morgenstern, and Aaron Roth. 2017. Fairness in reinforcement learning. In International conference on machine learning. PMLR, 1617–1626.
- Kearns and Singh (2002) Michael Kearns and Satinder Singh. 2002. Near-optimal reinforcement learning in polynomial time. Machine learning 49 (2002), 209–232.
- Lin et al. (2024) Qian Lin, Zongkai Liu, Danying Mo, and Chao Yu. 2024. An Offline Adaptation Framework for Constrained Multi-Objective Reinforcement Learning. In Advances in Neural Information Processing Systems 37 (NeurIPS 2024). https://neurips.cc/virtual/2024/poster/95257
- Liu et al. (2014) Chunming Liu, Xin Xu, and Dewen Hu. 2014. Multiobjective reinforcement learning: A comprehensive overview. IEEE Transactions on Systems, Man, and Cybernetics: Systems 45, 3 (2014), 385–398.
- Moffaert et al. (2013) Kristof Van Moffaert, Madalina M Drugan, and Ann Nowé. 2013. Hypervolume-based multi-objective reinforcement learning. In International Conference on Evolutionary Multi-Criterion Optimization. Springer, 352–366.
- Rashid et al. (2018) Tabish Rashid, Mikayel Samvelyan, Christian Schroeder de Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. 2018. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning.
- Reymond et al. (2022) M. Reymond, E. Bargiacchi, and A. Nowé. 2022. Pareto Conditioned Networks. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems. 1110–1118.
- Reymond et al. (2023) Mathieu Reymond, Conor F Hayes, Denis Steckelmacher, Diederik M Roijers, and Ann Nowé. 2023. Actor-critic multi-objective reinforcement learning for non-linear utility functions. Autonomous Agents and Multi-Agent Systems 37, 2 (2023), 23.
- Röpke et al. (2023) W. Röpke, C. F. Hayes, P. Mannion, E. Howley, A. Nowé, and D. M. Roijers. 2023. Distributional multi-objective decision making. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. 5711–5719.
- Siddique et al. (2020) Umer Siddique, Paul Weng, and Matthieu Zimmer. 2020. Learning Fair Policies in Multiobjective (Deep) Reinforcement Learning with Average and Discounted Rewards. In Proceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 826, 11 pages.
- Sunehag et al. (2017) Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech M Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, and Thore Graepel. 2017. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296 (2017).
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. 2018. Reinforcement learning: An introduction. MIT press.
- Sutton et al. (1998) Richard S Sutton, Andrew G Barto, et al. 1998. Introduction to reinforcement learning. (1998).
- Vamplew et al. (2009) Peter Vamplew, Richard Dazeley, Ewan Barker, and Andrei Kelarev. 2009. Constructing stochastic mixture policies for episodic multiobjective reinforcement learning tasks. In Australasian joint conference on artificial intelligence. Springer, 340–349.
- Van Moffaert et al. (2013) Kristof Van Moffaert, Madalina M Drugan, and Ann Nowé. 2013. Scalarized multi-objective reinforcement learning: Novel design techniques. In 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL). IEEE, 191–199.
- Von Neumann and Morgenstern (1947) John Von Neumann and Oskar Morgenstern. 1947. Theory of games and economic behavior, 2nd rev. Princeton university press.
- Yang et al. (2019) Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. 2019. A generalized algorithm for multi-objective reinforcement learning and policy adaptation. Advances in neural information processing systems 32 (2019).
Appendix
Appendix A Proofs of Technical Lemmas
A.1. Proof of Lemma 6
Lemma 6. Let for all states and trajectories . For every state , history , and time steps remaining, let
Then .
Proof.
We proceed by induction on . In the base case of , we have simply that by the definition of . But when , the trajectory has ended, so any in Definition 5 will be the empty trajectory . So
Suppose the equality holds for all states and histories for up to time steps remaining, i.e.
Then with steps remaining:
where the sum is taken over all length- trajectories beginning at , and is the probability that is traversed under policy . Note that we can further decompose into where denotes the state-action pair corresponding to the current timestep, concatenates, and denotes a trajectory of length beginning at some state transitioned from state via taking action . Since the transition to is independent of earlier states/actions once the current state and action are fixed, we can simplify the optimization by shifting the summation from trajectories conditioned on to actions and successor states and thus rewrite as
where the latter sum is taken over all length trajectories beginning at and the expectation is taken over the environmental transitions to from given .
Note that for all actions , can be chosen independently of any terms that appears in for any by the decomposition of above. This implies that at the current timestep, the maximizer (or the optimal policy) should choose action that maximizes the quantity
with probability 1. Therefore, the expression for can be rewritten as
where the second equality comes from the definition of , the third equality comes from the inductive hypothesis, and the fourth equality comes from the definition of . ∎
A.2. Proof of Lemma 9
Lemma 9. Let the welfare function be uniformly continuous. Fix and , then for all , there exists such that
Proof.
Without loss of generality, assume . Let be the induced optimal policy by , i.e.
Then by the optimality of ,
Since is uniformly continuous, there exists such that if . Then
where the sum is over all -trajectories that start in state . If then we have
Therefore,
since the sum of probabilities over all -trajectories in that start in state induced by must add up to . ∎
A.3. Proof of Lemma 10
Lemma 10 (Approximation Error of RAVI)
For uniformly continuous welfare function , for all , there exists such that
, where is computed by Algorithm 1 using .
Proof.
We prove this additive error bound by induction on the number of timesteps remaining in the task. Clearly and . Suppose that for all . Then consider with steps remaining.
Since is uniformly continuous, by Lemma 9 there exists such that
if
Hence, it suffices to choose , which implies
and so
∎
A.4. Lemma 13 (Horizon Time)
Lemma 0.
Let be any MOMDP, and let be any policy in . Assume the welfare function is uniformly continuous and . Then for all , there exists such that if
then for any state
We call the value of the lower bound on given above the -horizon time for the MOMDP .
Proof.
The lower bound on follows from the definitions, since all rewards are nonnegative and the welfare function should be monotonic. For the upper bound, fix any infinite trajectory that starts at and let be the -trajectory prefix of the infinite trajectory for some finite . Since is uniformly continuous, for all , there exists such that if , where denotes the usual Euclidean norm. But
Solving
for yields the desired bound on . Since the inequality holds for every fixed trajectory, it also holds for the distribution over trajectories induced by any policy . ∎
Appendix B Necessity of Conditioning on Remaining Timesteps
Our opening example in Figure 1 mentioned the necessity of conditioning on accumulated reward to model the optimal policy. However, the formulation of the optimal value function in Definition 7 also conditions on the number of time-steps remaining in the finite-time horizon task. One may naturally see this as undesirable in terms of adding computational overhead. Particularly in the continuing task setting with very close to 1, it is natural to ask whether this conditioning is necessary.
Lemma 0.
In MORL with a nonlinear scalarization function , for any constant , there exists an MOMDP such that any policy that depends only on the current state and accumulated reward (and does not condition on the remaining timesteps ) achieves expected welfare , where is the expected welfare achieved by an optimal policy that conditions on .
Proof.
We construct an MOMDP where the optimal action at a decision point depends critically on the remaining timesteps . We show that any policy not conditioning on cannot, in general, approximate the optimal expected welfare within any constant factor.
Consider an MDP with states , , and , where the agent chooses between actions and at and before reaching terminal states or with no further actions or rewards after reaching them. Choosing action results in a reward and transition to . Choosing action results in a reward and transition to . The accumulated reward prior to reaching is , where . The scalarization function is , and we assume a discount factor .
The agent must choose between actions and at to maximize the expected welfare:
For action :
For action :
The difference in expected welfare is given by:
When (i.e., is close to , near the end of the horizon):
Since is large, dominates, and , making action optimal.
When is large (i.e., is small, far from ):
If we choose for some small , then:
Thus, , making action optimal.
Any policy that does not condition on must choose either action or at regardless of . If always chooses , it will be suboptimal for large , when action is optimal. If always chooses , it will be suboptimal for small , when action is optimal.
Let be the optimal policy that conditions on . When action is optimal, we have
As , , which grows quadratically with , while remains bounded. Therefore, the ratio approaches zero:
When action is optimal, the analysis is analogous, leading to a similar conclusion.
Thus, for any constant , we can choose parameters such that the expected welfare ratio . ∎
Appendix C Ablation Studies and Additional Experiments
C.1. Ablation Studies with
We conduct further studies on the empirical effects of the discretization factor . For , we set (the smoothing factor). We gradually increase the disctretization interval of accumulated reward gradually from to for a reward discount for Taxi and for Scavenger Hunt with the same settings as the experiments. As shown in Figure 4(a) and Figure 4(b), we observe that the solution quality is often very high (better than baselines considered in the main body) even for discretization values that are substantially greater than those needed for theoretical guarantees (with , we need ). Nonetheless, the results exhibit non-monotonic behavior with respect to , which suggests that factors such as the alignment of discretization granularity with the welfare function’s smoothness play a role, especially in this large regime where empirical performance exceeds the worst-case theoretical guarantees.
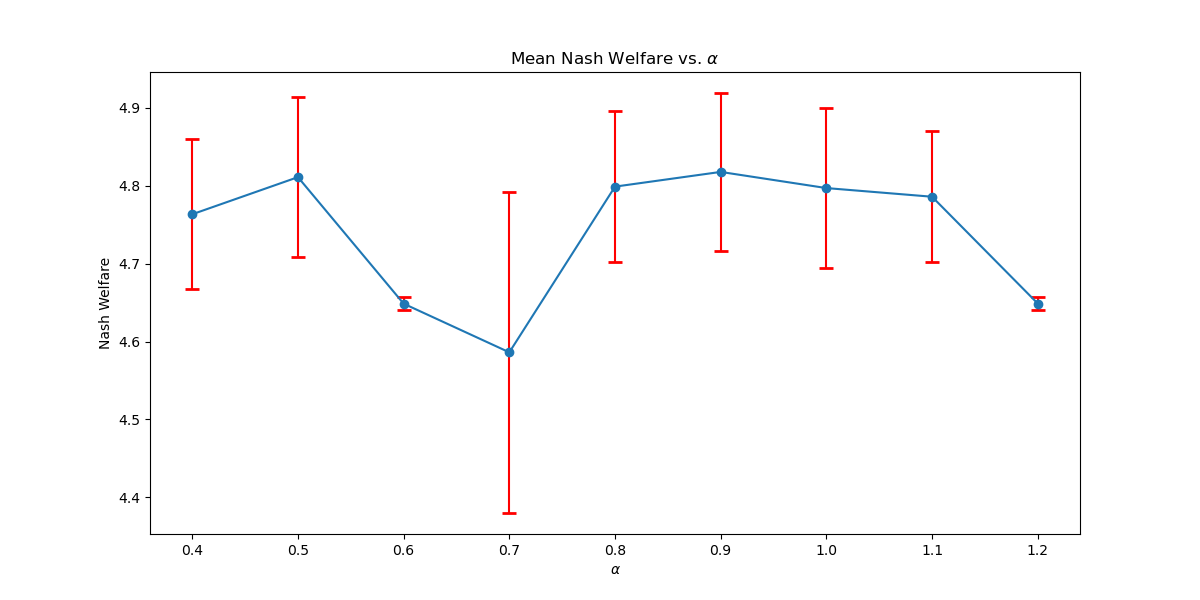
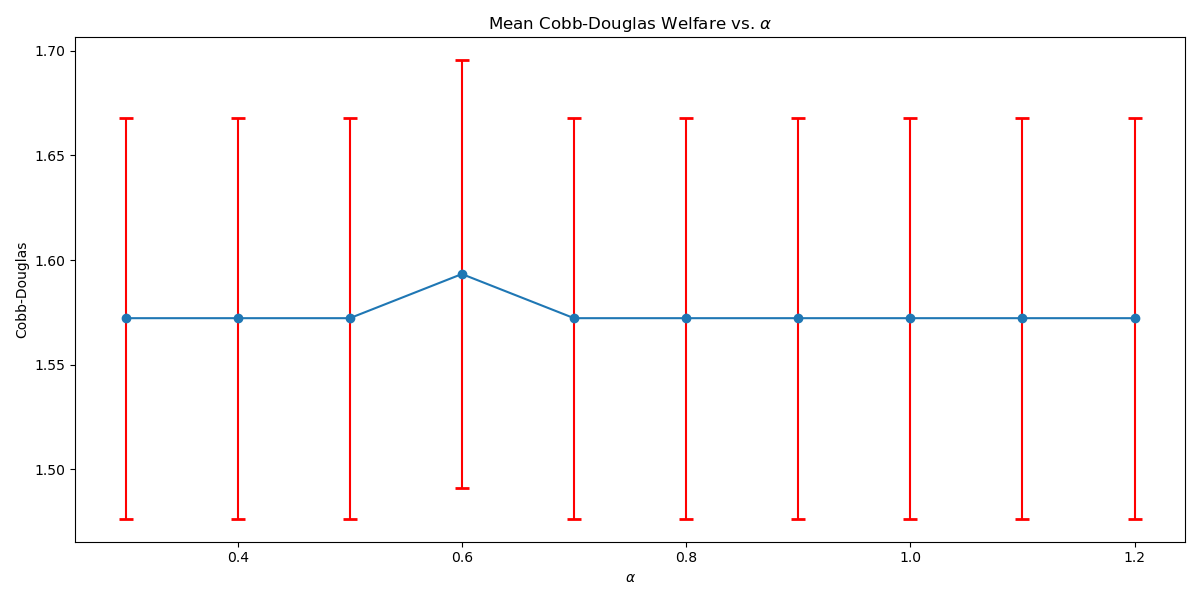
This set of ablation studies demonstrates that the RAVI algorithm is capable of finding high-quality policies for optimizing expected scalarized return despite using a larger discretization parameter than that needed for our theoretical analysis. The practical takeaway is that, while smaller values provide finer discretization and better theoretical guarantees, they incur increased computation costs. Conversely, larger values can coarsen the discretization but still result in competitive performance, as demonstrated empirically.
C.2. Ablation Studies with
We also conduct further ablation studies on environments with using coarser alpha values. We select and run 10 random initialization on each environment for each value. Note that the smallest possible in both Taxi and Scavenger is (which are the results we reported in the main text). Our results can be found at Table 2 and Table 3. We observe that there is a noticeable performance drop across both environments with a larger . Moreover, due to the nature of having a sparse reward signal in the Taxi environment, we observe no performance when . On Scavenger, for , we observe that the agent is under-performing when . This finding is also to be expected since the resources are scarce (only 6 resources in a grid), and enemies are plenty (33% of the grid world).
| Dimension | Alpha | |||||
|---|---|---|---|---|---|---|
| 7.5550.502 | 3.0000.000 | 5.2790.000 | 7.4040.448 | 9.6280.349 | ||
| 7.0790.318 | 1.0000.000 | 3.1980.000 | 6.4810.000 | 8.8770.528 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 4.9960.297 | 2.0000.000 | 3.1150.000 | 3.3070.000 | 6.2500.322 | ||
| 4.9020.273 | 1.0000.000 | 1.1160.000 | 2.0800.000 | 6.0370.322 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 2.1910.147 | 1.7000.483 | 1.0290.000 | 2.1450.129 | 3.3690.173 | ||
| 2.0440.157 | 1.0000.000 | 0.0000.000 | 2.0440.157 | 3.2470.183 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 2.3080.185 | 1.7000.483 | 1.0230.000 | 2.0000.102 | 3.2890.147 | ||
| 2.0340.122 | 1.0000.000 | 0.0000.000 | 1.1490.000 | 3.0970.139 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | ||
| 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 | 0.0000.000 |
| Dimension | Alpha | ||
|---|---|---|---|
| 1.3360.240 | 3.4000.843 | ||
| 1.2360.279 | 3.6000.699 | ||
| 0.1970.381 | 0.1000.316 | ||
| 0.4000.578 | -1.8893.480 | ||
| 0.1320.295 | -12.50022.405 |
| Environment | Dimension | Function | RAVI | Mixture | LinScal | WelfareQ | Mixture-M |
|---|---|---|---|---|---|---|---|
| Taxi | 0.03 | 0.76 0.20 | 1.98 0.28 | 4.82 1.65 | 0.15 | ||
| 0.01 | 0.69 0.22 | 2.00 0.31 | 2.61 0.50 | 0.15 | |||
| 0.01 | 0.70 0.24 | 2.11 0.09 | 4.72 1.81 | 0.15 | |||
| 0.02 | 0.65 0.29 | 2.10 0.09 | 5.10 1.75 | 0.15 | |||
| 0.08 | 0.64 0.21 | 2.11 0.09 | 4.96 1.77 | 0.15 | |||
| 0.30 | 0.60 0.29 | 2.14 0.39 | 4.92 1.91 | 0.32 | |||
| 0.01 | 0.72 0.21 | 2.09 0.30 | 2.26 0.58 | 0.32 | |||
| 0.02 | 0.64 0.27 | 2.18 0.06 | 5.44 1.91 | 0.32 | |||
| 0.02 | 0.75 0.11 | 2.10 0.26 | 5.73 1.80 | 0.32 | |||
| 2.10 | 0.74 0.28 | 2.18 0.11 | 5.47 1.79 | 0.32 | |||
| 0.65 | 0.82 0.14 | 2.19 0.13 | 5.44 1.62 | 0.53 | |||
| 0.06 | 0.71 0.33 | 2.18 0.13 | 2.47 0.64 | 0.53 | |||
| 0.02 | 0.69 0.20 | 2.12 0.31 | 5.66 1.58 | 0.53 | |||
| 0.23 | 0.72 0.23 | 2.21 0.11 | 5.11 1.80 | 0.53 | |||
| 36.72 | 0.73 0.22 | 2.21 0.07 | 6.15 1.78 | 0.53 | |||
| 1.46 | 0.70 0.21 | 2.25 0.10 | 4.93 1.72 | 0.75 | |||
| 0.28 | 0.71 0.18 | 2.23 0.05 | 2.37 0.51 | 0.75 | |||
| 0.04 | 0.82 0.08 | 2.21 0.09 | 5.40 1.83 | 0.75 | |||
| 0.26 | 0.68 0.17 | 2.05 0.41 | 5.45 1.77 | 0.75 | |||
| 118.63 | 0.67 0.27 | 2.16 0.30 | 4.75 1.59 | 0.75 | |||
| Scavenger | 0.11 | 0.30 0.05 | 0.25 0.06 | 0.34 0.05 | 4.71 | ||
| 0.09 | 0.25 0.06 | 0.30 0.05 | 0.29 0.06 | 4.39 |
C.3. Visualizations of RAVI and Baselines
Given that Table 1 in the main text solely contains results evaluated from algorithms trained until convergence, it misses other important information such as the rate of convergence and the learning process of some online algorithms such as WelfareQ. Thus, in this subsection, we provide our visualizations of the learning curve for these algorithms. The plot is created using mean over 10 random initializations with standard deviation as shaded regions. Note that we use horizontal lines for model-based approaches as they do not have an online learning phase. Our results can be found at Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, and Figure 10.
Appendix D Details on the RAEE Algorithm
In this section, we give a detailed description of the RAEE algorithm, extending from Kearns and Singh (2002) and demonstrating Theorem 12, the main theorem for the RAEE algorithm.
D.1. Introducing RAEE
The extension works as follows. The algorithm starts off by doing balanced wandering Kearns and Singh (2002): when encountering a new state, the algorithm selects a random action. However, when revisiting a previously visited state, it chooses the least attempted action from that state, resolving ties by random action selection. At each state-action pair it tries, the algorithm stores the reward received and an estimate of the transition probabilities derived from the empirical distribution of next states reached during balanced wandering.
Next, we introduce the notion of a known state Kearns and Singh (2002), which refers to a state that the algorithm has explored to the extent that the estimated transition probabilities for any action from that state closely approximate their actual values. Denote the number of times a state needs to be visited as . We will specify the value later in our runtime characterization.
States are thus categorized into three groups: known states, which the algorithm has extensively visited and obtained reliable transition statistics; states that have been visited before but remain unknown due to limited trials and therefore unreliable data; and states that have not been explored at all. By the Pigeonhole Principle, accurate statistics will eventually accumulate in some states over time, leading to their becoming known. Let be the set of currently known states, the algorithm can build the current known-state MOMDP that is naturally induced on by the full MOMDP with all “unknown” states merged into a single absorbing state. Although the algorithm cannot access directly, it will have an approximation by the definition of the known states. By the simulation lemma Kearns and Singh (2002), will be an accurate model in the sense that the expected -step welfare of any policy in is close to its expected -step return in . (Here is the horizon time.) Hence, at any timestep, functions as an incomplete representation of , specifically focusing on the part of that the algorithm possesses a strong understanding of.
This is where we insert RAVI. The algorithm performs the two off-line optimal policy computations; i) first on using RAVI to compute an exploitation policy that yields an approximately optimal welfare and ii) second performing traditional value iteration on , which has the same transition probabilities as , but different payoffs: in , the absorbing state (representing “unknown” states) has scalar reward and all other states have scalar reward . The optimal policy in simply exits the known model as rapidly as possible, rewarding exploration.
By the explore or exploit lemma Kearns and Singh (2002), the algorithm is guaranteed to either output a policy with approximately optimal return in , or to improve the statistics at an unknown state. Again by the Pigeonhole Principle, a new state becomes known after the latter case occurs for some finite number of times, and thus the algorithm is always making progress. In the worst case, the algorithm builds a model of the entire MOMDP . Having described the elements, we now outline the entire extended algorithm, where the notations are consistent with Kearns and Singh (2002).
RAEE Algorithm:
-
•
(Initialization) Initially, the set of known states is empty.
-
•
(Balanced Wandering) Any time the current state is not in , the algorithm performs balanced wandering
-
•
(Discovery of New Known States) Any time a state has been visited Kearns and Singh (2002) times during balanced wandering, it enters the known set , and no longer participates in balanced wandering.
-
•
(Off-line Optimizations) Upon reaching a known state during balanced wandering, the algorithm performs the two off-line optimal policy computations on and described above:
-
–
(Attempted Exploitation) Use RAVI algorithm to compute an -optimal policy on . If the resulting exploitation policy achieves return from in that is at least , the algorithm halts and outputs .
-
–
(Attempted Exploration) Otherwise, the algorithm executes the resulting exploration policy derived from the off-line computation on for steps in .
-
–
-
•
(Balanced Wandering) Any time an attempted exploitation or attempted exploration visits a state not in , the algorithm resumes balanced wandering.
This concludes the description of the algorithm.
D.2. Runtime Analysis
In this subsection, we comment on additional details of the analysis of Theorem 12, the main theorem for the RAEE algorithm.
Theorem 12 (RAEE).
Let denote the value function for the policy with the optimal expected welfare in the MOMDP starting at state , with accumulated reward and timesteps remaining. Then for a uniformly continuous welfare function , there exists an algorithm , taking inputs , , , , and , such that the total number of actions and computation time taken by is polynomial in , , , , the horizon time and exponential in the number of objectives , and with probability at least , will halt in a state , and output a policy , such that .
We begin by defining approximation of MOMDPs. Think of as the true MOMDP, that is, a perfect model of transition probabilities. Think of , on the other hand, as the current best estimate of an MOMDP obtained through exploration. In particular, in the RAEE algorithm will consist of the set of known states.
Definition 0.
Kearns and Singh (2002) Let and be two MOMDPs over the same state space with the same deterministic reward function . is an approximation of if for any state and and any action ,
where the subscript denotes the model.
We now extend the Simulation Lemma Kearns and Singh (2002), which tells us how close the approximation of an MOMDP needs to be in order for the expected welfare, or ESR, of a policy to be close in an estimated model. The argument is similar to Kearns and Singh (2002), but in our case the policy may not be stationary and we want to bound the deviation in expected welfare rather than just accumulated reward.
Recall that is defined to be the maximum possible welfare achieved on a -step trajectory - is at most where equals times the identity vector, in our model.
Lemma 0 (Extended Simulation Lemma).
Let be an
-approximation of . Then for any policy , any state , and horizon time , we have
Proof.
Fix a policy and a start state . Let be an -approximation of (we will later show that has the same bound as the Lemma statement). Call the transition probability from a state to a state under action to be -small in if . Then the probability that a -trajectory starting from a state following policy contains at least one -small transition is at most . This is because the total probability of all -small transitions in is at most (assuming all transition probabilities are -small), and there are timesteps. Note that in our case, the optimal policy may not be necessarily stationary, thus the agent does not necessarily choose the same action (and hence the same transition probability) upon revisiting any state. So we cannot bound the total probability by like in the original proof.
The total expected welfare of the trajectories of that consist of at least one -small transition of is at most . Recall that be an -approximation of . Then for any -small transition in , we have . So the total welfare of the trajectories of that consist of at least one -small transition of is at most . We can thus bound the difference between and restricted to these trajetories by . We will later choose and bound this value by to solve for .
Next, consider trajectories of length starting at that do not contain any -small transitions, i.e. in these trajectories. Choose , we may write
because is an -approximation of and . Thus for any -trajectory that does not cross any -small transitions under , we have
which follows from the definition of the probability along a trajectory and the fact that is the same policy in all terms. Since we assume reward functions are deterministic in our case, for any particular -trajectory , we also have
Since these hold for any fixed -trajectory that does not traverse any -small transitions in under , they also hold when we take expectations over the distributions over such -trajectories in and induced by . Thus
where the terms account for the contributions of the -trajectories that traverse at least one -small transitions under . It remains to show how to choose , , and to obtain the desired approximation. For the upper bound, we solve for
By taking on both sides and using Taylor expansion, we can upper bound .
Choose . Then
Choosing solves the system. The lower bound can be handled similarly, which completes the proof of the lemma. ∎
We now define a “known state.” This is a state that has been visited enough times, and its actions have been trialed sufficiently many times, that we have accurate estimates of the transition probabilities from this state.
Definition 0.
Kearns and Singh (2002) Let be an MOMDP. A state of is considered known if it has be visited a number of times equal to
By applying Chernoff bounds, we can show that if a state has been visited times then its empircal estimation of the transition probabilities satisfies the accuracy required by the Lemma 16.
Lemma 0.
Kearns and Singh (2002) Let be an MOMDP. Let be a state of that has been visited at least times, with each action having been executed at least times. Let denote the empirical transition probability estimates obtained from the visits to . Then if
then with probability , we have
for all .
Proof.
The sampling version of Chernoff bounds states that if the number of independent, uniformly random samples that we use to estimate the fraction of a population with certain property satisfies
the our estimate satisfies
By the Extended Simulation Lemma, it suffices to choose .
Note that we need to insert an extra factor of compared to the original analysis since we treat the size of the action space as a variable instead of a constant, and a state is categorized as “known” only if the estimates of transition probability of all actions are close enough. ∎
We have specified the degree of approximation required for sufficient simulation accuracy. It remains to directly apply the Explore or Exploit Lemma from Kearns and Singh (2002) to conclude the analysis.
Lemma 0 (Explore or Exploit Lemma Kearns and Singh (2002)).
Let be any MOMDP, let be any subset of the states of , and let be the MOMDP on . For any , any , and any , either there exists a policy in such that , or there exists a policy in such that the probability that a -trajectory following will lead to the exit state exceeds .
This lemma guarantees that either the -step return of the optimal exploitation policy in the simulated model is very close to the optimal achievable in , or the agent choosing the exploration policy can reach a previously unknown state with significant probability.
Note that unlike the original E3 algorithm, which uses standard value iteration to compute the exactly optimal policy (optimizing a linear function of a scalar reward) on the sub-model , we use our RAVI algorithm to find an approximately optimal policy. Therefore, we need to allocate error to both the simulation stage and the exploitation stage, which gives a total of error for the entire algorithm.
It remains to handle the failure parameter in the statement of the main theorem, which can be done similarly to Kearns and Singh (2002). There are two sources of failure for the algorithm:
-
•
The algorithm’s estimation of the next state distribution for some action at a known state is inaccurate, resulting being an inaccurate model of .
-
•
Despite doing attempted explorations repeatedly, the algorithm fails to turn a previously unknown state into a known state because of an insufficient number of balanced wandering.
It suffices to allocate probabilities to each source of failure. The first source of failure are bounded by Lemma 18. By choosing , we ensure that the probability that the first source of failure happens to each of the known states in is sufficiently small such that the total failure probability is bounded by for .
For the second source of failure, by the Explore or Exploit Lemma, each attempted exploration results in at least one step of balanced wandering with probability at least , i.e. when this leads the agent to an unknown state. The agent does at most steps of balanced wandering, since this makes every state known. By Chernoff bound, the probability that the agent does fewer than steps of balanced wandering (attempted explorations that actually leads to an unknown state) will be smaller than if the number of attempted explorations is
where (recall we choose for the first source of failure).
Thus, the total computation time is bounded by (the time required for RAVI during off-line computations with precision by Lemma 10) times times the maximum number of attempted explorations, giving
This concludes the proof of Theorem 12.
Appendix E More Discussion about experiments
Deterministic Transitions: Deterministic settings are common in many state-of-the-art environments in MORL, particularly when focusing on episodic tasks with short time horizons. These settings are often used to emphasize the core algorithmic contributions without introducing additional complexities from stochastic transitions or long horizons. Nonetheless, we acknowledge that incorporating stochastic environments would better showcase the generality of our approach and highlight this as an important direction for future work.
Model Sizes and Scalability: We recognize that the model sizes used in the experiments are relatively small, primarily due to memory limitations in the tabular setting, and that function approximation would be needed to move to large state space environments as highlighted in our future work.
RAEE Algorithm: RAVI is a model-based approach, and one of the baselines, “Mixture-M” for a model-based mixture policy, uses the model. For the others model-free baselines, we only compare performance at convergence with RAVI to achieve a more fair comparison. To the best of our knowledge, there are no other model-based algorithms in the field specifically designed for optimizing ESR objectives. Due to computational and space constraints, we focused our empirical evaluation on RAVI, as the optimization subroutine is the core algorithmic contribution. That said, we acknowledge this limitation and believe benchmarking RAEE empirically is a worthwhile direction for future research.
Model Accuracy and RAEE: While it is true that RAVI’s performance depends on model accuracy, the central goal of RAEE is precisely to ensure it learns a sufficiently accurate model of the environment to provably guarantee an approximation factor. For future work, comparing RAVI with RAEE would provide valuable insights into the trade-offs between leveraging accurate models and learning them through exploration.