Multi-Point Positional Insertion Tuning
for Small Object Detection
Abstract
Small object detection aims to localize and classify small objects within images. With recent advances in large-scale vision-language pretraining, finetuning pretrained object detection models has emerged as a promising approach. However, finetuning large models is computationally and memory expensive. To address this issue, this paper introduces multi-point positional insertion (MPI) tuning, a parameter-efficient finetuning (PEFT) method for small object detection. Specifically, MPI incorporates multiple positional embeddings into a frozen pretrained model, enabling the efficient detection of small objects by providing precise positional information to latent features. Through experiments, we demonstrated the effectiveness of the proposed method on the SODA-D dataset. MPI performed comparably to conventional PEFT methods, including CoOp and VPT, while significantly reducing the number of parameters that need to be tuned.
Index Terms:
Parameter efficient finetuning, Small object detection, Positional encoding.I Introduction
Object detection has become a crucial component in real-world applications such as autonomous driving and surveillance owing to the remarkable advancements in deep neural networks. To accurately detect small objects within images, various methods have been developed, such as super-resolution methods [1, 2], similarity learning [3, 4, 5], and context exploration [6]. However, detecting extremely small objects is still challenging, mainly because of the insufficiency of training data, as manual annotation of the bounding boxes for these objects is time-consuming and costly.
To address this issue, a recent trend has relied on large-scale pretraining. Specifically, for object detection, some studies have proposed vision-language models pretrained on large-scale datasets, such as GLIP [7, 8] and Grounding DINO [9, 10]. These models are open-set object detectors capable of accepting natural language text or a sequence of object names as inputs. They can also be adapted as closed-set object detectors for detecting objects within a predefined category set by finetuning them on limited labeled datasets [9, 10]. Therefore, they are expected to be effective for small object detection.

When finetuning large models, a primary challenge remains in terms of parameter efficiency, as optimizing a large number of parameters is computationally and memory expensive. To improve parameter efficiency, adapter tuning [11, 12, 13, 14, 15] and prompt tuning [16, 17, 18, 19, 20, 21] are known to be effective. These methods insert lightweight learnable modules into a frozen pretrained model, allowing the model to adapt to new tasks with a minimal increase in the number of learnable parameters while avoiding overfitting.
Inspired by these studies, this paper introduces a novel parameter-efficient finetuning (PEFT) method for small object detection. Specifically, we propose multi-point positional insertion (MPI) tuning, which incorporates multiple positional embeddings into a pretrained frozen model, as shown in Figure 1, enabling the efficient detection of small objects by providing precise positional information to latent features. In our experiments, we demonstrated the effectiveness and parameter efficiency of MPI tuning on the SODA-D dataset [22]. We observed that MPI tuning performs comparably to conventional PEFT methods, while reducing the number of learnable parameters.
II Related work
Object detection. Over the last decade, numerous object detection models have been proposed [23, 24, 25, 26, 27]. There have been two major architectures: convolutional architectures, e.g., RetinaNet [23] and Sparse RCNN [26], and transformer-based architectures, e.g., DETR [27] and Deformable DETR [28]. Recently, vision-language pretrained models such as GLIP [7, 8] and Grounding DINO (GDINO) [9, 10] have demonstrated effectiveness in open-set object detection and visual grounding. For small object detection, convolutional architectures, such as CFINet [3] using coarse-to-fine region proposals, remain the primary approach [29, 30, 31, 32].
PEFT. Adapter tuning inserts lightweight learnable modules into a frozen pretrained model [11, 12, 13, 14, 15, 33]. For instance, encoder adapter tuning [15] incorporates small multilayer perceptrons (MLPs) into each encoder layers. Layer adapter tuning [33] inserts small modules between each layer and the downstream head. Prompt-based finetuning has also garnered attention because of its success in the field of natural language processing [16, 17, 18, 19, 20, 21]. Examples include context optimization (CoOp) [16] for text prompt tuning and visual prompt tuning (VPT) [18]. This study focuses on PEFT for small object detection, where encoding precise spatial positions within images is crucial.
III Method
This section presents MPI tuning, a PEFT method for small object detection. MPI tuning inserts positional embeddings into multiple points within a frozen pretrained model. This approach provides precise positional information for latent features, enabling efficient adaptation for detecting small objects.
III-A Notation and settings
Object detection aims to localize and classify objects within images. Specifically, the objective is to provide bounding boxes and categories for each object given an input image and predefined object categories. This study discusses the parameter efficiency of finetuning given a pretrained object detector . We assume that is a deep neural network and involves latent features. Given an input , we denote by the set of latent features in the neural network, where is the number of latent features.
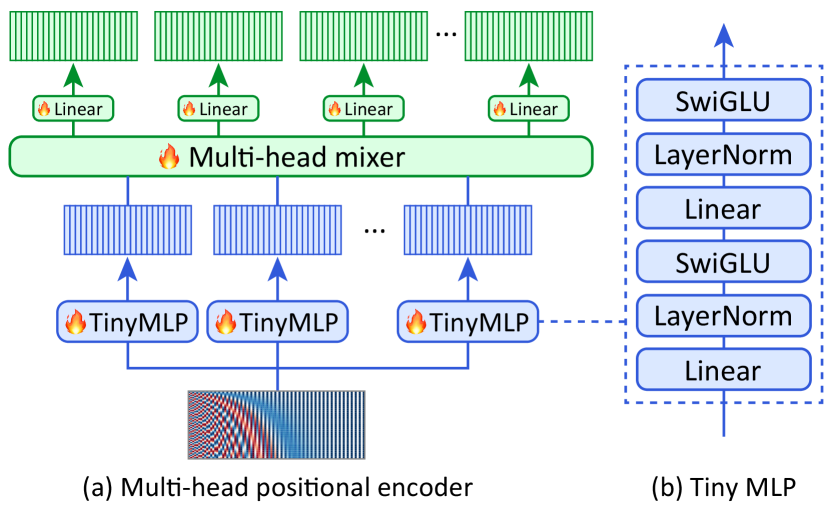
III-B Multi-point positional insertion tuning
MPI tuning inserts a multi-head positional (MHP) encoder, which is a lightweight learnable module that incorporates positional information into latent features. The MHP encoder produces output embeddings , each of which is added to the latent vanilla features as follows:
| (1) |
where denotes the adapted latent features. In the finetuning phase, the adapted features are used instead of the vanilla features, and only the parameters of the inserted MHP encoder are optimized.
III-C Architecture
Figure 2 shows the architecture of the MHP encoder, which consists of the following three components: 1) sinusoidal positional embeddings, 2) tiny MLPs, and 3) a multi-head mixer.
Sinusoidal positional embeddings [34]. The input of the MHP encoder is the sinusoidal positional embeddings , defined by
| (2) |
where is the dimension, is the position index, is the element index, and is a constant. We use , , and as the default values.
Tiny MLPs. The sinusoidal positional embeddings are fed into tiny MLPs. As shown in Figure 2b, each tiny MLP consists of two blocks of a linear layer, LayerNorm [35], and a Swish-Gated Linear Unit (SwiGLU) activation [36]. Both linear layers maintain dimension . This produces output embeddings for .
Multi-head mixer. Finally, the multi-head mixer produces the embeddings used in Eq. (1) from the embeddings obtained from the tiny MLPs. When , we can straightforwardly map each embedding to its corresponding using a one-to-one correspondence, such that , where is a simple transformation function such as a linear function. However, for parameter efficiency, reducing such that is beneficial. To this end, the multi-head mixer generates embeddings through a linear combination of the embeddings in . Specifically, it generates as follows:
| (3) |
where is a learnable matrix and is a linear layer. Each linear layer is designed to match the shapes of and ti ensure that can be added to .
III-D Application to Grounding DINO
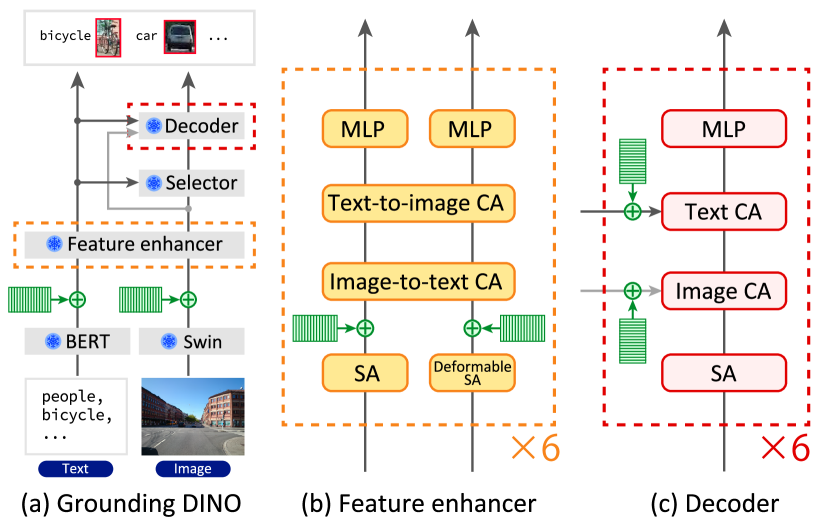
This subsection describes the application of MPI tuning to GDINO [9, 10], which is the model used in our experiments. Figure 3 shows the architecture of GDINO, which consists of the following five components: a BERT (text encoder) [37], a Swin transformer (image encoder) [38], a feature enhancer, a query selector, and a decoder. Because inserting positional information into all latent features can be redundant due to the complexity of this architecture, we selected points. These are highlighted in green colors in Figure 3.
BERT and Swin. The first two points correspond to the outputs of the BERT and Swin transformer (Figure 3a). They help learn the positions of the raw input data.
Feature enhancer. Each feature enhancer block has two points, one after the self-attention module and the other after the deformable self-attention module, as shown in Figure 3b. This results in twelve points because GDINO has six feature enhancer blocks.
Decoder. Each decoder block has two points for the cross-attention module, as shown in Figure 3c. This results in twelve points because GDINO has six decoder blocks.
III-E Loss function
IV Experiments
IV-A Experimental settings
Datasets. The SODA-D dataset [22] was used for finetuning and evaluation. It consists of 24,704 high-quality and high-resolution images of street scenes, along with 277,596 bounding box annotations for small objects across nine object categories. The official training and test splits were used. Parameter efficient finetuning experiments were conducted using the MM-Grounding DINO [10] model, which is pretrained on the union of the following four datasets: O365 [39], GoldG [40], GRIT [41] and V3Det [42].
| Method | Pretrained | #Params. | mAP | mAP50 | mAP75 | mAPeS | mAPrS | mAPgS | mAPN | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero-shot baseline | 0 | 14.0 | 31.7 | 10.6 | 3.7 | 10.7 | 18.6 | 27.1 | ||
| PEFT | CoOp w/ dec. | 12.00M | 25.8 | 54.7 | 21.2 | 10.5 | 22.1 | 31.6 | 41.8 | |
| VPT w/ dec. | 11.98M | 25.4 | 53.7 | 20.9 | 10.0 | 21.6 | 31.2 | 41.5 | ||
| CoOp w/o dec. | 1.01M | 18.8 | 40.6 | 15.2 | 6.0 | 15.0 | 24.2 | 32.9 | ||
| VPT w/o dec. | 0.99M | 18.2 | 39.3 | 14.6 | 5.9 | 14.3 | 23.4 | 32.5 | ||
| Adapter tuning | 0.79M | 22.8 | 49.6 | 18.2 | 8.3 | 19.1 | 28.3 | 38.0 | ||
| MPI tuning (Ours) | 0.50M | 25.7 | 53.7 | 21.6 | 9.8 | 22.1 | 31.7 | 41.4 | ||
| Full | Deformable-DETR | 35.17M | 19.2 | 44.8 | 13.7 | 6.3 | 15.4 | 24.9 | 34.2 | |
| Sparse RCNN | 105.96M | 24.2 | 50.3 | 20.3 | 8.8 | 20.4 | 30.2 | 39.4 | ||
| CFINet | 47.61M | 30.7 | 60.8 | 26.7 | 14.7 | 27.8 | 36.4 | 44.6 | ||
| Full fine-tuning | 172.97M | 32.7 | 64.1 | 29.2 | 15.3 | 28.8 | 39.2 | 50.4 | ||
| Method | mAP |
|---|---|
| MPI tuning | 26.5 |
| w/o input pos. | 26.3 |
| w/o FE pos. | 24.6 |
| w/o dec. pos. | 26.5 |
| #P | mAP | |
|---|---|---|
| 24 | 1.01M | 26.7 |
| 12 | 0.50M | 26.5 |
| 6 | 0.25M | 26.2 |
| 3 | 0.13M | 25.6 |
Evaluation metrics. The mean average precision (mAP) computed across multiple intersection over union (IoU) thresholds from 0.50 to 0.95 with an interval of 0.05 was used as a primary evaluation metric, reported along with mAPs at IoU thresholds of 0.50 and 0.75 referred to as mAP50 and mAP75, respectively. We also reported mAPs for extremely small objects (mAPeS), relatively small objects (mAPrS), generally small objects (mAPgS), and normal objects (mAPN). To evaluate the parameter efficiency, the number of learnable parameters (#Params) was reported.
Baselines. We selected four baselines: zero-shot detection, CoOp [16], VPT [18] and adapter tuning [15]. The zero-shot detection reports the performance before finetuning. CoOp and VPT are PEFT methods that are based on prompt tuning. Following [18], the head module (the decoder of GDINO) is also finetuned. The adapter tuning inserts learnable modules to each MLP and self-attention module in the decoder. Each adapter module consists of two linear layers with a RELU activation in between, followed by LayerNorm.
Implementation details. All the models were trained under the same conditions. Specifically, the AdamW optimizer with a cosine annealing scheduler was used for 12 epochs. The initial learning rate was set to , and the batch size was set to 16.
IV-B Experimental results
Main results. Table I compares MPI tuning with the conventional PEFT methods. As shown, it achieved results comparable to CoOp and VPT using a learnable decoder head, while reducing the number of parameters to 0.50 million. Compared with the zero-shot baseline, the detection performance was significantly improved, highlighting the effectiveness and parameter efficiency of MPI tuning. Compared with the full training reported as a reference, there is still room for performance improvement. Full finetuning of GDINO performed better than CFINet [3], which is a convolutional neural network designed for small object detection; however, it is parameter inefficient. To achieve the accuracy of these methods with better parameter efficiency, modules that further enhance the learning efficiency and effectiveness are required in future studies.
Ablation study. Table III summarizes the results of an ablation study on the incorporation of the positional information. As shown, incorporating positional information into the feature enhancer was the most effective. This is because, with GDINO, the fusion of text and image features is the most important process. By inserting a learnable module at this stage, the model can be adapted efficiently to small object detection.
Number of tiny MLPs. Table III summarizes the results of a hyperparameter study in which the number of tiny MLPs varies. As shown, larger yielded better performance. Setting resulted in a decrease in the performance, but it still significantly outperformed the zero-shot baseline.
Image encoders. Table IV compares the results obtained by three different backbones: Swin-T, Swin-B and Swin-L. MPI tuning was more parameter-efficient and effective than CoOp without decoder finetuning.
| Method | #Params. | mAP | mAP50 | mAP75 | |
|---|---|---|---|---|---|
| Swin-T | Zero-shot | – | 14.3 | 32.1 | 11.0 |
| CoOp w/ dec. | 12.00M | 26.4 | 56.2 | 21.5 | |
| CoOp w/o dec. | 1.01M | 19.4 | 42.0 | 15.3 | |
| MPI tuning (Ours) | 0.50M | 26.5 | 55.1 | 22.0 | |
| Swin-B | Zero-shot | – | 15.1 | 34.2 | 11.5 |
| CoOp w/ dec. | 12.00M | 27.2 | 57.5 | 22.2 | |
| CoOp w/o dec. | 1.01M | 21.2 | 45.9 | 16.9 | |
| MPI tuning (Ours) | 0.50M | 26.8 | 56.4 | 22.2 | |
| Swin-L | Zero-shot | – | 17.6 | 41.3 | 12.9 |
| CoOp | 12.00M | 30.1 | 61.2 | 25.6 | |
| CoOp w/o dec. | 1.01M | 18.3 | 38.8 | 15.0 | |
| MPI tuning (Ours) | 0.50M | 30.5 | 60.9 | 26.9 | |

Qualitative examples. Figure 4 shows qualitative examples. As can be seen, our method enabled GDINO to detect extremely small objects.
V Conclusion
We proposed MPI tuning, a novel PEFT method for small object detection. The MHP encoder was introduced to incorporate positional information into the latent features in a frozen pretrained model. In experiments, MPI tuning was applied to GDINO. Its effectiveness was demonstrated on the SODA-D dataset in comparison with conventional PEFT methods.
Acknowledgment. This work was supported by JSPS KAKENHI Grant Numbers 23H00490, 22K12089.
References
- [1] J. Noh, W. Bae, W. Lee, J. Seo, and G. Kim, “Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 9725–9734.
- [2] Y. Bai, Y. Zhang, M. Ding, and B. Ghanem, “SOD-MTGAN: Small object detection via multi-task generative adversarial network,” in European Conference on Computer Vision (ECCV), 2018.
- [3] X. Yuan, G. Cheng, K. Yan, Q. Zeng, and J. Han, “Small object detection via coarse-to-fine proposal generation and imitation learning,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
- [4] J.-U. Kim, S. Park, and Y. M. Ro, “Robust small-scale pedestrian detection with cued recall via memory learning,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 3030–3039.
- [5] J. Wu, C. Zhou, Q. Zhang, M. Yang, and J. Yuan, “Self-mimic learning for small-scale pedestrian detection,” in ACM International Conference on Multimedia (ACMMM), 2020, pp. 2012–2020.
- [6] Z. Zhang, P. Gong, H. Sun, P. Wu, and X. Yang, “Dynamic local and global context exploration for small object detection,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [7] L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, K.-W. Chang, and J. Gao, “Grounded language-image pre-training,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [8] H. Zhang, P. Zhang, X. Hu, Y.-C. Chen, L. H. Li, X. Dai, L. Wang, L. Yuan, J.-N. Hwang, and J. Gao, “GLIPv2: Unifying localization and vision-language understanding,” in Annual Conference on Neural Information Processing Systems (NeurIPS), 2022.
- [9] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” in European Conference on Computer Vision (ECCV), 2024.
- [10] X. Zhao, Y. Chen, S. Xu, X. Li, X. Wang, Y. Li, and H. Huang, “An open and comprehensive pipeline for unified object grounding and detection,” arXiv preprint arXiv:2401.02361, 2024.
- [11] Z. Long, G. Killick, R. McCreadie, and G. A. Camarasa, “Multiway-adapter: Adapting multimodal large language models for scalable image-text retrieval,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [12] H. Zhou, X. Wan, I. Vulić, and A. Korhonen, “Automatic design of adapter architectures for enhanced parameter-efficient fine-tuning,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [13] Y. Zhang and C. Zhang, “Test-time distribution learning adapter for cross-modal visual reasoning,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [14] C. Gao, Q. Xu, P. Qiao, K. Xu, X. Qian, and Y. Dou, “Adapter-based incremental learning for face forgery detection,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [15] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” in International Conference on Machine Learning (ICML), 2019, pp. 2790–2799.
- [16] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision-language models,” International Journal of Computer Vision (IJCV), 2022.
- [17] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16816–16825.
- [18] M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” in European Conference on Computer Vision (ECCV), 2022.
- [19] P. Lin, Z. Yu, M. Lu, F. Feng, R. Li, and X. Wang, “Visual prompt tuning for weakly supervised phrase grounding,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [20] M. Xu, Z. Guo, Y. Zeng, and D. Xiong, “Enhanced transfer learning with efficient modeling and adaptive fusion of knowledge via prompt tuning,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [21] F. Cai, Z. Zhang, D. Liu, X. Fang, and J. Tong, “Cophtc: Contrastive learning with prompt tuning for hierarchical text classification,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [22] G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, X. Xie, and J. Han, “Towards large-scale small object detection: Survey and benchmarks,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), pp. 1–20, 2023.
- [23] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988.
- [24] Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: Fully convolutional one-stage object detection,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 9627–9636.
- [25] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Annual Conference on Neural Information Processing Systems (NeurIPS), 2015.
- [26] P. Sun, R. Zhang, Y. Jiang, T. Kong, C. Xu, W. Zhan, M. Tomizuka, L. Li, Z. Yuan, C. Wang, and P. Luo, “Sparse R-CNN: End-to-end object detection with learnable proposals,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [27] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision (ECCV), 2020.
- [28] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” in International Conference on Learning Representations (ICLR), 2020.
- [29] J. Shi and W. Wu, “Srp-uod: Multi-branch hybrid network framework based on structural re-parameterization for underwater small object detection,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 2715–2719.
- [30] Y. Li, Y. Wang, Z. Ma, X. Wang, and Y. Tang, “Sod-uav: Small object detection for unmanned aerial vehicle images via improved yolov7,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [31] J. Zhu, Y. Yang, and Y. Cheng, “Small object detection on the water surface based on radar and camera fusion,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [32] Z. Zhang, P. Gong, H. Sun, P. Wu, and X. Yang, “Dynamic local and global context exploration for small object detection,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
- [33] S. Otake, R. Kawakami, and N. Inoue, “Parameter efficient transfer learning for various speech processing tasks,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
- [34] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Annual Conference on Neural Information Processing Systems (NeurIPS), 2017, pp. 6000–6010.
- [35] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” in NeurIPS Deep Learning Symposium, 2016.
- [36] N. Shazeer, “GLU variants improve transformer models,” arXiv preprint arXiv:2002.05202, 2020.
- [37] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019.
- [38] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- [39] S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, X. Zhang, J. Li, and J. Sun, “Objects365: A large-scale, high-quality dataset for object detection,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [40] A. Kamath et al., “Mdetr-modulated detection for end-to-end multi-modal understanding,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 1780–1790.
- [41] Z. Peng, W. Wang, L. Dong, Y. Hao, S. Huang, S. Ma, and F. Wei, “Kosmos-2: Grounding multimodal large language models to the world,” arXiv preprint arXiv:2306.14824, 2023.
- [42] J. Wang, P. Zhang, T. Chu, Y. Cao, Y. Zhou, T. Wu, B. Wang, C. He, and D. Lin, “V3det: Vast vocabulary visual detection dataset,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 19844–19854.