Multi-Task Multi-Agent Shared Layers are Universal Cognition of Multi-Agent Coordination
Abstract
Multi-agent reinforcement learning shines as the pinnacle of multi-agent systems, conquering intricate real-world challenges, fostering collaboration and coordination among agents, and unleashing the potential for intelligent decision-making across domains. However, training a multi-agent reinforcement learning network is a formidable endeavor, demanding substantial computational resources to interact with diverse environmental variables, extract state representations, and acquire decision-making knowledge. The recent breakthroughs in large-scale pre-trained models ignite our curiosity: Can we uncover shared knowledge in multi-agent reinforcement learning and leverage pre-trained models to expedite training for future tasks? Addressing this issue, we present an innovative multi-task learning approach that aims to extract and harness common decision-making knowledge, like cooperation and competition, across different tasks. Our approach involves concurrent training of multiple multi-agent tasks, with each task employing independent front-end perception layers while sharing back-end decision-making layers. This effective decoupling of state representation extraction from decision-making allows for more efficient training and better transferability. To evaluate the efficacy of our proposed approach, we conduct comprehensive experiments in two distinct environments: the StarCraft Multi-agent Challenge (SMAC) and the Google Research Football (GRF) environments. The experimental results unequivocally demonstrate the smooth transferability of the shared decision-making network to other tasks, thereby significantly reducing training costs and improving final performance. Furthermore, visualizations authenticate the presence of general multi-agent decision-making knowledge within the shared network layers, further validating the effectiveness of our approach.
Keywords Multi-Agent Coordination Multi-Task Learning Common knowledge
1 Introduction
Cooperative multi-agent reinforcement learning (MARL) has garnered significant attention due to its vast potential in solving real-world challenges, including traffic light control [1], autonomous cars [2], and robot swarm control [3]. However, training a multi-agent network can be prohibitively expensive. It requires frequent communication with complex environmental variables and consumes substantial time and resources. For instance, AlphaStar [4], OpenAI Five [5], and JueWu [6] required hundreds of thousands of cores and several months to achieve satisfactory performance. Such computational demands pose barriers to general research, limiting the full utilization of this exciting progress in modern machine intelligence by academic institutions and the broader intelligence community. Consequently, exploring methods to effectively extract and leverage shared knowledge in multi-agent decision tasks has emerged as a prominent research direction.
Inspired by the remarkable advancements of large-scale pre-trained models, a fascinating and promising question arises: Can we separate shared knowledge from the multi-agent learning framework and store it in pre-trained networks to reduce the cost of task transfer?
The primary challenge in applying pre-trained models to multi-agent reinforcement learning arises from the frequent variations in the formats of state and action spaces, even within a single task. Pre-trained models typically require standardized input and output formats, such as image pixels in computer vision or text tokens in natural language processing. Fortunately, this paper successfully identifies unique shared knowledge in multi-agent reinforcement learning. Agents often exhibit shared decision-making priors for specific tasks, such as cooperation and competition, while certain global conditions influence the decisions of all agents across diverse scenarios and tasks. However, extracting and sharing this common decision-making knowledge is not a straightforward path. In decision tasks, neural networks serve dual roles in perception and decision-making, and these functions are tightly intertwined. Separating them and distilling a rich and universal decision-making knowledge across multi-agent tasks is a challenging endeavor.
This paper introduces a pioneering multi-task learning approach that effectively tackles the aforementioned challenges and extends the power of pre-training to the realm of multi-agent reinforcement learning. By employing task-specific front-end perception modules and a shared back-end decision-making module, this approach effectively decouples the decision process, enabling the efficient disentanglement and extraction of shared decision-making knowledge. To handle varying action spaces, actions are positioned at the input end of the network, ensuring consistency in network output dimensions, which is referred to as the action prepositioning network (APN). Additionally, dynamic adaptive weights for multi-task losses are introduced to enhance multi-task pre-training efficiency.
We conduct extensive experiments in StarCraft Multi-agent Challenge (SMAC) [7] and Google Research Football (GRF) [8] environments. Our findings demonstrate the effectiveness of our approach in extracting common decision knowledge across different tasks and efficiently transferring it to new tasks, significantly reducing training costs and improving network performance. Our method significantly benefits from increasing the number of pre-training tasks, showing potential in large-scale scenarios. Furthermore, through visualization, we validate that the extracted decision networks contain universal decision knowledge for multi-agent coordination, shedding new light on future research of pre-trained models in multi-agent reinforcement learning.
2 Related Work
2.1 Pre-trained Model
A pre-trained model is a model that’s already well-trained, and it shares its knowledge with a new model to speed up the new model’s training, without the need to start from scratch. Pretrained models [9, 10] extract common knowledge of a broad range of tasks from data. It can accelerate and improve training of downstream tasks, by leveraging the common knowledge stored in them in various means. Pre-trained models can be applied to a wide range of downstream tasks, such as image classification [11, 12, 13, 14], object detection [15, 16, 17, 18, 19], text classification [20, 21, 22, 23, 24] and more. When training for downstream tasks, we need to load the parameters of the pre-trained model’s feature layers. After that, keeping the feature layers (the initial layers) fixed and fine-tuning the parameters of the later layers [25] because the initial layers primarily focus on extracting generic information. For instance, in ResNet, the early layers are responsible for capturing low-level features like textures and shapes.
2.2 Pre-trained Model by SL
Traditionally, pre-trained models are usually trained through supervised learning (SL) on large data sets. They possess extensive language and visual knowledge, making them directly applicable to new tasks or amenable to fine-tuning for specific tasks. Using pre-trained models significantly reduces the time and computational resources required to build and train models from scratch, especially when data for new tasks is limited. In supervised learning, especially in the field of image processing, we often use large labeled datasets like ImageNet [26], Open Images dataset [27], and COCO [28] to pre-train models and obtain large pre-trained models such as AlexNet [29], VGG [30], and ResNet [31]. These pre-trained models typically learn generic features that can be useful for many downstream tasks. These features speed up the process of learning specific characteristics for the downstream tasks, making the overall training faster.
2.3 Pre-trained Model in SSL
Because the cost of data annotation is too high, researchers use self-supervised learning (SSL) methods to train pre-trained models. Up to now, self-supervised pre-trained models are being applied in various domains, including NLP [20, 32, 33, 34], computer vision [35, 36, 37, 38], and audio [39]. Unlike supervised learning, self-supervised pre-training doesn’t require labeled data. There are two main approaches: one involves creating self-generated tasks to learn feature representations from the data, such as tasks like image completion, text generation, image rotation, and image augmentation. The other approach uses contrastive learning to bring similar samples closer in feature space, thus capturing common underlying features among similar samples.
2.4 Pre-trained Model in RL
Inspired by large-scale language modeling, DeepMind has applied a similar approach to create a unified intelligent agent called Gato [40]. Gato has been trained on over different tasks, each with varying patterns, observations, and action guidelines. However, Gato, despite integrating a variety of decision tasks, still lacks generalization abilities. This is because in the single-agent domain, different decision tasks require completely different knowledge. For example, in Atari games, tasks like pong and breakout have no shared knowledge between them. In contrast, in multi-agent tasks, such as to in SMAC, there exists strong shared knowledge, such as teammate attributes, enemy attributes, strategies like focus fire, hit and run, and more. In multi-agent reinforcement learning, there typically exists significant variation in the state space among different tasks. Current pre-trained methods yield universal perceptual models that cannot be shared across diverse multi-agent tasks. Different multi-agent tasks often involve more shared decision knowledge, such as agent cooperation. Therefore, we propose a multi-task, multi-agent pre-training approach aimed at acquiring pre-training models that encompass shared decision knowledge.
3 Preliminaries
We model multi-agent reinforcement learning (MARL) as a decentralized partially observable Markov decision process (Dec-POMDP) [41]. A multi-agent Dec-POMDP can be represented as a tuple . Here, denotes the agents in the multi-agent system. represents the state space, is the action space, and corresponds to the observation space. The reward function is denoted as . At each time step , each agent performs an action , collectively forming a joint action . After taking action in state , all agents receive rewards . represents the state transition probability that satisfies the Markov property: . Each agent , after taking action in state , observes based on the observation function . is the discount factor. Each agent has a policy to predict action based on its historical observations. denotes the joint policy for all agents. The ultimate goal is to learn an optimal joint policy that maximizes the discounted expected return .
Value-based MARL algorithms, such as VDN [42] and QMIX [43], collaborate by utilizing action-value functions and joint action-value functions to make optimal decisions that maximize the cumulative rewards for the entire group of agents. VDN endeavors to decompose the total action-value function, denoted as , into a composition of distinct local action-value functions :
| (1) |
where characterizes the action-value function of agent . In the training phase, the optimization of the policy is guided by . Simultaneously, each agent derives its local action-value function from the global value to make decisions. QMIX operates under the assumption that a global performed on is equivalent to a set of individual operations performed on each . To facilitate this, QMIX employs a mixing network as a functional expression to amalgamate values into the value, enabling it to meet:
| (2) |
4 Method
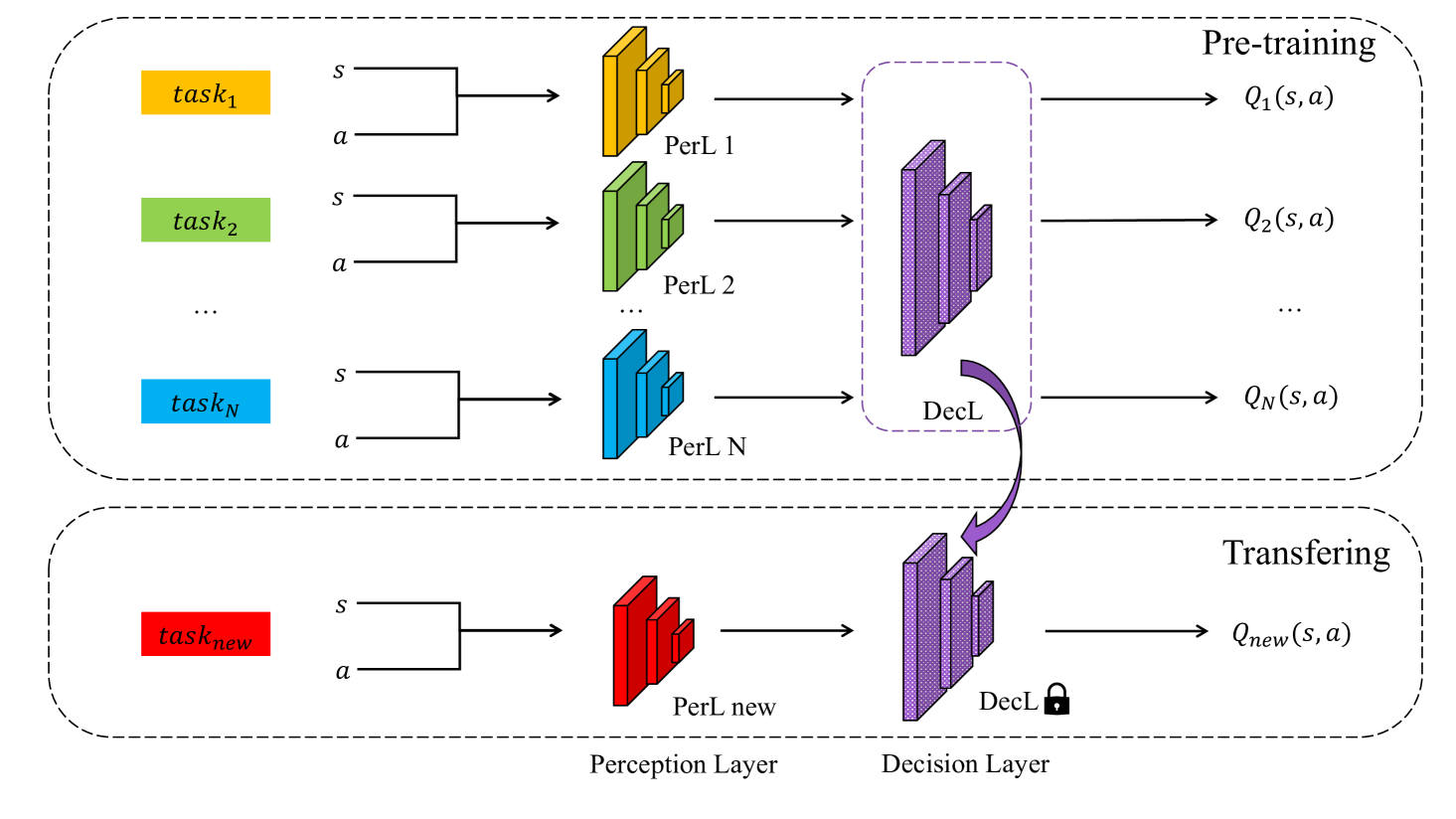
MARL employs neural networks for state representation extraction and decision-making, which are tightly coupled. We train multiple multi-agent tasks simultaneously, where each task utilizes independent front-end network layers alongside shared back-end network layers. The shared back-end network layers effectively decouple state representation extraction from decision-making, thus facilitating the training of back-end network layers encompassing common decision knowledge. When addressing new multi-agent tasks, we leverage the back-end network layers containing shared decision knowledge, keeping network parameters fixed and focusing solely on improving the front-end network layers’ ability to extract state representations. Through this approach, we substantially reduce training costs. The framework of our MTAPN approach is illustrated in Fig. 1.
4.1 Multi-Task Pre-training
We refer to the front-end network layer as the Perception Layer (PerL) and the back-end network layer as the Decision Layer (DecL). During the pre-training phase, we simultaneously train multi-agent tasks. For each , , we collect data generated by the interaction between agents and the environment in and store it in the replay buffer . We then sample from for training. Samples are input into to extract perceptual features, followed by using DecL to predict . Each has its dedicated while sharing DecL. Once pre-training is complete, we obtain DecL containing common decision knowledge among different tasks. We fix the parameters of the pre-trained DecL and transfer it to a new task, subsequently training PerL for that task. This approach efficiently allows us to learn effective policies for new tasks, leading to a significant reduction in training costs.
4.2 Action Prepositioning Network
Value-based MARL algorithms, such as VDN and QMIX, estimate state-action values by taking the state as the network input and generating estimated values for each action under that state. The network’s output size remains fixed at the size of the task’s action space. Due to variations in action spaces across different multi-agent tasks, sharing the back-end network layer between tasks is infeasible. To address this challenge, we position the action at the forefront of the network’s input. The network takes state-action pairs as input and yields corresponding value estimates as output. This structural design maintains a fixed network output size of . By utilizing front-end network layers to map inputs from different tasks to a consistent dimension , we enable sharing the back-end network layer across different tasks. Pairing state and all actions as inputs to the network results in value estimates for all state-action pairs. This network architecture is referred to as the Action Prepositioning Network (APN).
Based on APN, we can share DecL across different tasks during multi-task pre-training. We will illustrate the training process of any task using APN at time step . For simplicity, we omit the subscripts for all variables. comprises agents, each with an action space size of . represents the observation of agent , is the action executed by agent in the previous time step, is the identifier of agent , and represents the -th executable action of agent , , . For each agent , perceptual features are extracted from the task’s input using independent :
| (3) |
where , with representing the dimension of perceptual features. Given that each agent can only partially observe the environment at each time step, we employ the GRU recurrent neural network in PerL to encode historical trajectories and address the issue of partial observability. These are inputted into the shared DecL to predict value estimates :
| (4) |
where . We select the maximum Q value, denoted as , for each individual agent and aggregate them through a mixer to predict the total Q value . In this context, we employ a mixer the same as VDN. We input the same data into the target APN network to generate the target total Q value . The APN is updated by minimizing the error between and .
4.3 Dynamic Adaptive Weighting for Multi-Task Losses
During multi-task training, not all tasks converge at the same pace. Typically, simpler tasks tend to converge faster than complex ones. To enhance the efficiency of multi-task training, it becomes essential to allocate larger loss weights to those tasks that exhibit slower convergence. We standardize evaluation metrics across different tasks. represents the normalized evaluation metric value for and is used to assess the current convergence status of . represents the inverse evaluation metric of , such as the negative or reciprocal value of . A smaller , or equivalently, a larger , indicates poorer convergence for the corresponding task. We introduce a method for dynamically and adaptively assigning weights to multi-task losses, wherein the weights are adjusted as change during the training process. Here, corresponds to the loss of , represents the weight of , and the total loss for all tasks is calculated as follows:
| (5) | |||
| (6) |
5 Experiments
We conducted experiments in the StarCraft Multi-agent Challenge (SMAC) [7] and Google Research Football (GRF) [8] environments. Unless otherwise specified, both the pre-training algorithm and downstream task algorithm utilized in the experiments are VDN [42]. Multiple tasks are employed to pre-train the VDN network based on APN, extracting the DecL containing common knowledge. Utilizing the common knowledge in DecL, we exclusively train the PerL on new tasks. In SMAC and GRF tasks, we employ win rate as and failure rate as . Each set of experimental results is obtained using random seeds. The solid line shows the mean win rate, and the shaded area represents the minimum to maximum win rate for 5 random seeds. Actions are chosen for exploration based on the estimated values using an -greedy policy. The algorithms we use are based on the Pymarl2 algorithm library [44]. Detailed hyperparameter settings and code are provided in the supplementary material.
5.1 StarCraft Multi-Agent Challenge (SMAC)
We increase the number of tasks used for pre-training to explore whether incorporating more tasks can lead to improved acquisition of common knowledge. All our experiments were conducted specifically on the hard and super-hard difficulty levels of the SMAC task. The tasks involved in the experiments are detailed in table 1.
| Task | Map | Difficulty |
|---|---|---|
| 5m_vs_6m | Hard | |
| 8m_vs_9m | Hard | |
| 3s_vs_5z | Hard | |
| bane_vs_bane | Hard | |
| 2c_vs_64zg | Hard | |
| corridor | Super Hard | |
| MMM2 | Super Hard | |
| 3s5z_vs_3s6z | Super Hard | |
| 27m_vs_30m | Super Hard | |
| 6h_vs_8z | Super Hard |
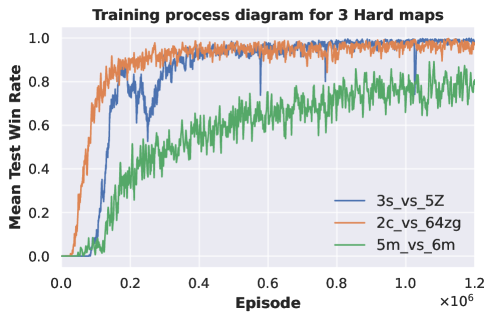
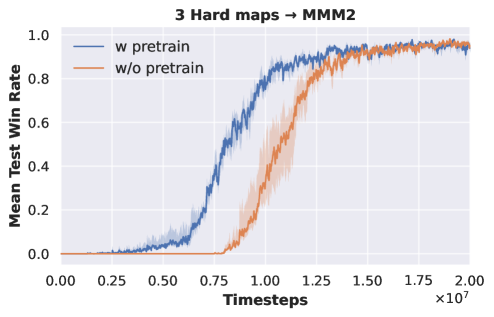
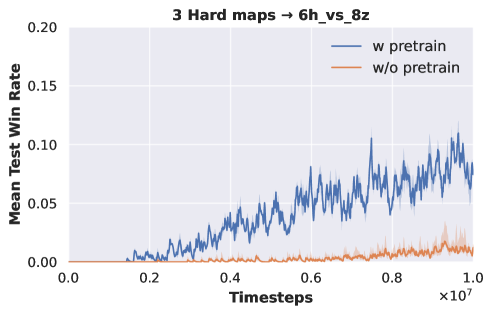
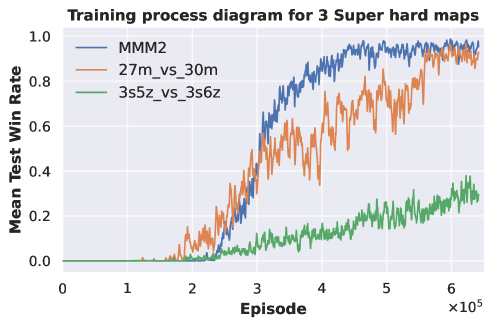
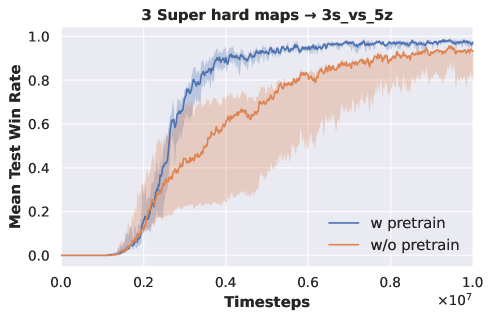
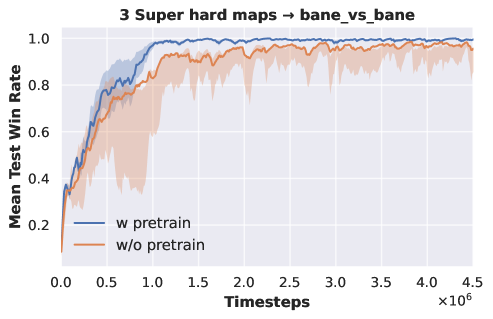
Three-task pre-training. We employ two sets of tasks for pre-training DecL: and . All tasks within are of hard difficulty, while those in are of super hard difficulty. The DecL pre-trained with is transferred and separately fine-tuned for PerL training on and . Similarly, the DecL pre-trained with is transferred and separately fine-tuned for PerL training on and . Experimental results are depicted in Fig. 2.
 |
 |
 |
| (a) pre-training of tasks | (b) from tasks to | (c) from tasks to |
 |
 |
 |
| (d) pre-training of tasks | (e) from tasks to | (f) from tasks to |
From Fig. 2 (a) and (b), it is evident that the APN network, during multi-task training, effectively learns strategies for each task. The DecL obtained from multi-task pre-training encompasses decision knowledge utilized in all tasks, namely, generic decision knowledge. Fig. 2 (c) shows that using the DecL pre-trained on three hard tasks results in faster convergence for compared to training from scratch. Fig. 2 (d) demonstrates that, with the DecL pre-trained on three hard tasks, achieves superior convergence compared to starting from scratch. Fig. 2 (e) shows that utilizing the DecL pre-trained on three super hard tasks leads to faster convergence and better final convergence results for compared to starting from scratch. However, Fig. 2 (f) reveals that, despite being pre-trained on three super hard tasks, exhibits convergence results and rates consistent with training from scratch, indicating no improvement. Clearly, in comparison to DecL pre-trained on a single task, DecL pre-trained on three tasks shows better performance when transferring to new tasks. This highlights the advantage of having more pre-training tasks in obtaining DecL with more comprehensive generic decision knowledge. The lack of improvement in the convergence performance of also suggests that the decision knowledge contained within DecL can only cover some tasks comprehensively, prompting further consideration of increasing the number of pre-training tasks.
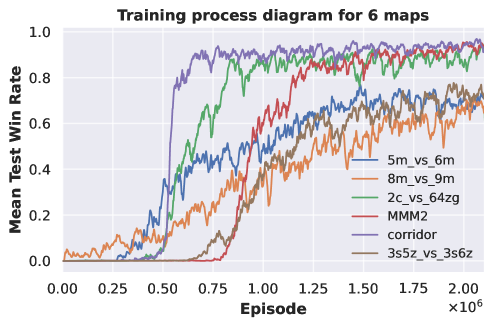
Six-task pre-training. We select six tasks for pre-training DecL:
. We fix the pre-trained DecL parameters and transfer them separately to and . The experimental results are depicted in Fig. 3.
 |
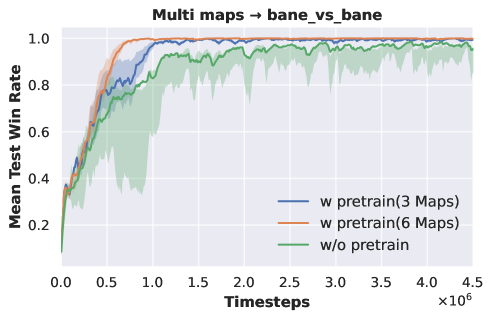 |
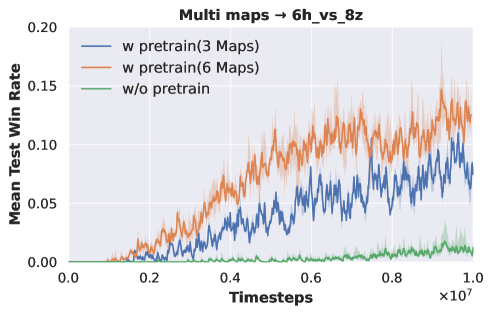 |
| (a) pre-training of tasks | (b) from tasks to | (c) from tasks to |
Fig. 3 (a) demonstrates that our proposed method continues to acquire effective policies across all tasks when the number of pre-training tasks increases to six. In Fig. 3 (b), we observe that training with DecL pre-trained based on tasks results in faster convergence and superior final performance compared to training from scratch. Furthermore, employing DecL pre-trained on tasks for converges more rapidly than using DecL pre-trained on tasks. The same result can also be found in Fig. 3 (c). Training with DecL pre-trained on leads to faster convergence and improved outcomes compared to using pre-trained DecL. In summary, through multi-task pre-training, we can extract DecL containing common decision knowledge, which becomes more generalized with increased pre-training tasks.
VDN to QMIX. To further validate the inclusion of common decision knowledge in the DecL pre-trained with the VDN algorithm, we migrate the pre-trained DecL from three hard difficulty and three super hard difficulty SAMC tasks to and , respectively. We employ the QMIX algorithm to train PerL on these new tasks. Experimental results are presented in Fig. 4.
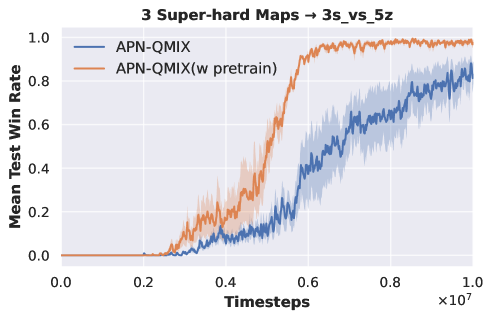 |
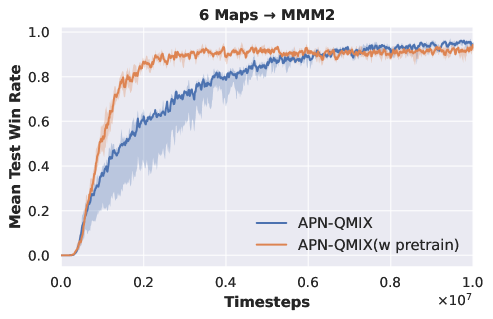 |
| (a) from tasks to | (b) from tasks to |
Fig. 4 demonstrates that when the DecL pre-trained on three tasks using the VDN algorithm is transferred to new tasks and trained with the QMIX algorithm, the final convergence results are superior to those of the QMIX algorithm trained from scratch. Consequently, the DecL obtained from multi-task pre-training indeed encompasses common decision knowledge. This common decision knowledge is applicable to various new tasks as well as new multi-agent reinforcement learning algorithms.
5.2 Ablation Study
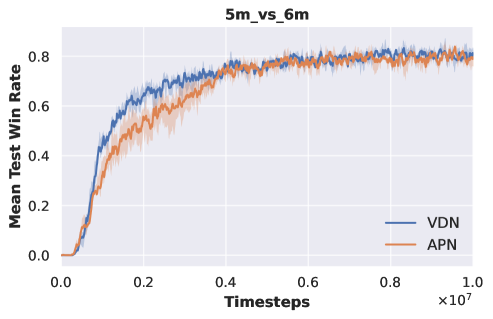
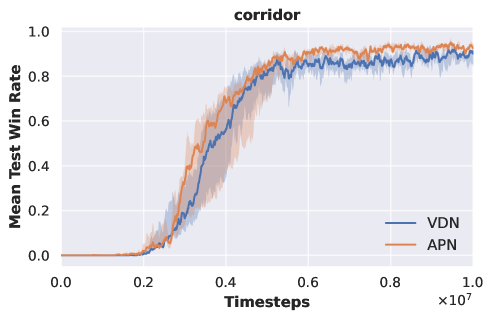
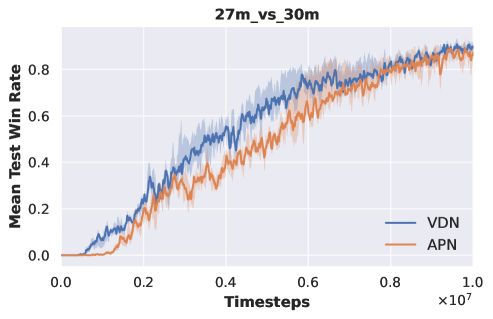
APN-VDN vs VDN. To enable multi-task training, we initially place the action at the front of the network input and maintain this structure when transitioning to new tasks. To illustrate the impact of adopting this structure on experimental performance, we train original VDN and APN-VDN on all SMAC tasks, with the results presented in Fig. 5 and table 2.
 |
 |
 |
| (a) | (b) | (c) |
| Map | Difficulty | original VDN | APN-VDN |
|---|---|---|---|
| 5m_vs_6m | Hard | 80.380.06 | 79.310.06 |
| 8m_vs_9m | Hard | 89.370.08 | 86.550.05 |
| 3s_vs_5z | Hard | 94.930.11 | 98.050.01 |
| bane_vs_bane | Hard | 97.160.02 | 99.970.00 |
| 2c_vs_64zg | Hard | 97.240.01 | 96.110.05 |
| corridor | Super Hard | 90.740.09 | 92.450.03 |
| MMM2 | Super Hard | 96.270.01 | 96.990.01 |
| 3s5z_vs_3s6z | Super Hard | 73.650.17 | 62.110.17 |
| 27m_vs_30m | Super Hard | 95.990.01 | 97.710.00 |
| 6h_vs_8z | Super Hard | 1.080.01 | 1.830.01 |
As shown in Fig. 5, adopting the APN structure has a slight impact on the convergence speed of the original VDN but does not affect the ultimate convergence results. Table 2 demonstrates that APN-VDN and original VDN achieve nearly identical convergence results across all SMAC tasks. Therefore, employing the APN structure does not influence the performance of multi-agent algorithms. Consequently, we use APN-VDN as the baseline algorithm for comparison in our experiments, with variations in algorithm performance stemming from the utilization of pre-trained DecL.
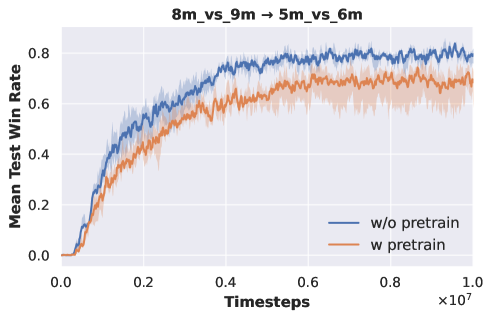
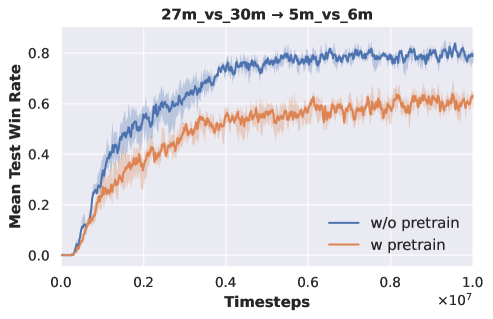
Single-task Pre-training. We conduct experiments on , , and . We perform pre-training on and to obtain DecL with task-specific decision knowledge. Subsequently, we freeze the parameters of DecL and transfer them to for retraining PerL. Experimental results are illustrated in Fig. 6.
 |
 |
| (a) from to | (b) from to |
Fig. 6 reveals that when using DecL pre-trained on and , the final convergence outcomes for are consistently worse compared to training from scratch. This occurs because pre-training DecL on a single task leads to overfitting on that specific task, preventing the acquisition of general decision knowledge. Consequently, when we transfer a DecL pre-trained on a single task to a new task, it fails to align with the new task, resulting in a deterioration of the final convergence performance for the new task. Therefore, we need to use more pre-training tasks to extract DecL containing general decision-making knowledge.
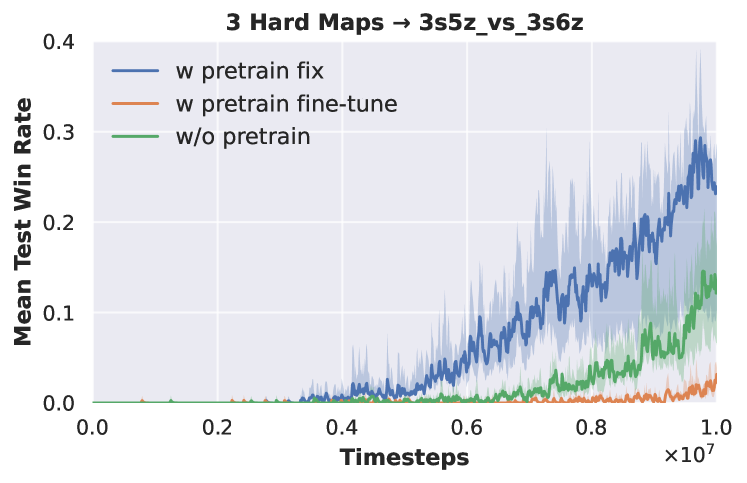
Fix vs Fine-tune. When employing pre-trained models, we typically face the choice between weight fixation and fine-tuning. Our experiments explore both scenarios when transferring pre-trained DecL weights on tasks to . The experimental results, as depicted in Fig. 7, demonstrate that fixing the pre-trained DecL weights leads to efficient convergence to superior results. During the backpropagation process, the loss diminishes as it propagates from the network’s output to the input. DecL is closer to the network’s output, resulting in more significant parameter updates compared to PerL. In the early stages of training, PerL has not yet developed robust perceptual capabilities. Consequently, the transmission of substantial losses can disrupt the pre-trained DecL, leading to decreased convergence speed and inferior results. Thus, we consistently opt for the fixed-weight approach when employing pre-trained DecL.
 |
 |
 |
| (a) w/o pre-trained DecL at M steps | (b) w/o pre-trained DecL at M steps | (c) w/o pre-trained DecL at M steps |
 |
 |
 |
| (d) with pre-trained DecL at M steps | (e) with pre-trained DecL at M steps | (f) with pre-trained DecL at M steps |
5.3 Visualization
To better illustrate how our proposed multi-task multi-agent reinforcement learning algorithm learns to share common decision knowledge between different tasks, we visualize the acquired policies in the SMAC tasks. The videos of the battle are provided in the supplementary material.
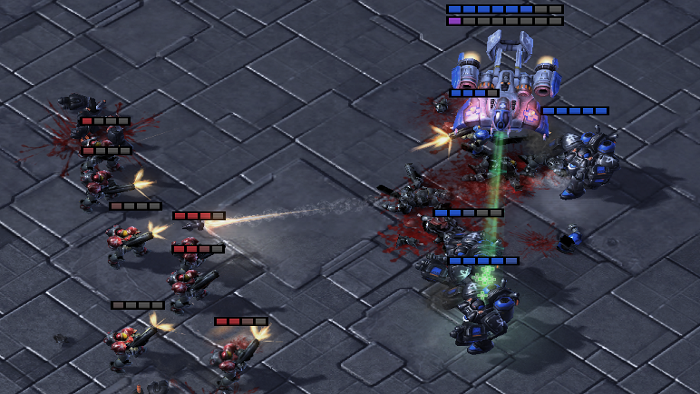
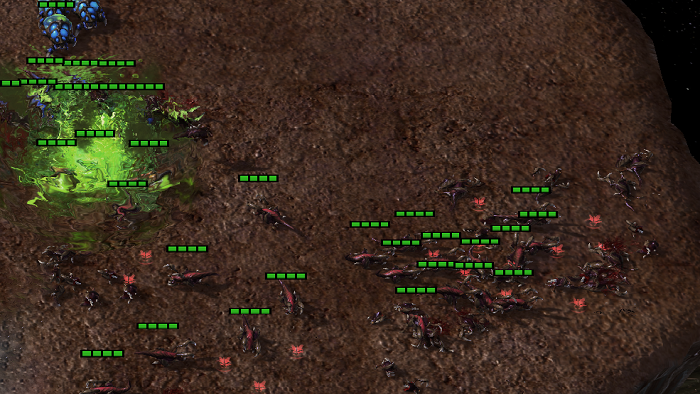
In Fig. 8(a) and (d), we visualize the performance on after training for million steps with and without the pre-trained DecL using tasks. In Fig. 8(a), the attack positions of all Marines remain nearly unchanged, displaying a lack of flexibility, even when their health is low. However, in Fig. 8(d), the Marines exhibit a more flexible policy by moving to disperse enemy fire and concentrating their attacks on a portion of the enemy forces.
Fig. 8(b) and (e) visualize the performance on after training for million steps without pre-trained DecL and with DecL pre-trained on tasks, respectively. In Fig. 8(b), the Medivac does not employ an evasive strategy, making it vulnerable to enemy attacks, resulting in losses to our Medivac, while the health of other agents cannot recover promptly. Additionally, the positioning of Marines and Marauders lacks strategic depth, failing to execute timely retreats when their health is low. However, in Fig. 8(e), the agents have acquired advanced policies: Marines with low health retreat promptly, while healthier Marines draw enemy Marauders’ fire, allowing other Marines to flank the enemy Marauders for surprise attacks stealthily.
In Fig. 8(c) and (f), we visualize the performance on after training for million steps, comparing scenarios with and without pre-trained DecL from tasks. In Fig. 8(c), all Banelings charge towards the opponent to detonate them, while some Zerglings also advance but are damaged by the Banelings’ explosions. However, in Fig. 8(f), all Banelings immediately rush towards the opposing camp, while Zerglings quickly retreat to avoid unintentional harm from the Banelings, resulting in minimal casualties.
In summary, by utilizing a pre-trained DecL incorporating generic decision knowledge to train for new tasks, we typically acquire more effective policies within the same training steps, thus achieving superior results more efficiently.
5.4 Google Research Football (GRF)
We conduct experiments on six tasks from GRF, as shown in table 3. We choose four tasks, including both easy and hard difficulties , for pre-training the DecL. Subsequently, we transfer the pre-trained DecL to of easy difficulty and of super hard difficulty. The experimental outcomes are depicted in Fig. 9.
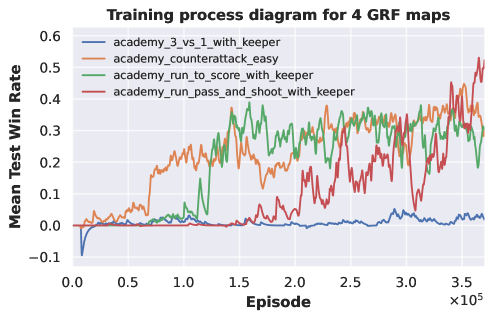 |
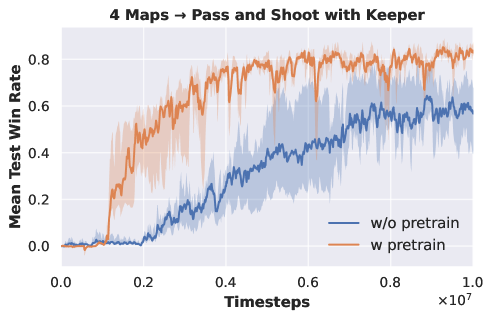 |
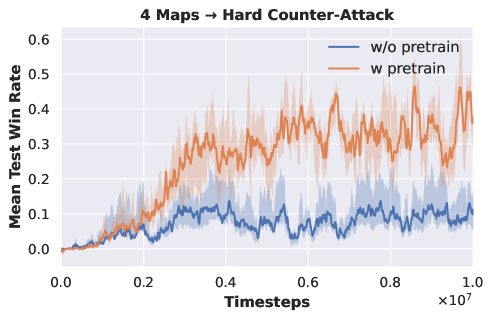 |
| (a) pre-training of 4 GRF tasks | (b) from four tasks to | (c) from four tasks to |
| Task | Map | Difficulty |
|---|---|---|
| Run to Score with Keeper | Easy | |
| Pass and Shoot with Keeper | Easy | |
| Run, Pass and Shoot with Keeper | Easy | |
| 3 versus 1 with Keeper | Hard | |
| Easy Counter-Attack | Hard | |
| Hard Counter-Attack | Super Hard |
Fig. 9 (a) illustrates that the APN network, during multi-task pre-training, effectively learns policies across various GRF tasks, each involving a different number of agents. Fig. 9 (b) demonstrates that with the pre-trained DecL, the convergence speed and final convergence results for of easy difficulty significantly improve compared to training from scratch. Fig. 9 (c) reveals that, with the pre-trained DecL, the final convergence results for of super hard difficulty are superior to those obtained from training from scratch. The utilization of pre-trained DecL renders training on new GRF tasks more efficient. Notably, fails to acquire effective policy when trained from scratch. In summary, through multi-task pre-training, we can obtain a DecL containing common decision knowledge, which enables us to more efficiently acquire policies for new tasks, substantially reducing training costs.
6 Conclusion
In this paper, we propose a multi-task multi-agent reinforcement learning algorithm that aims to obtain shared decision modules through multi-task pre-training. To ensure consistency in the format of shared knowledge across tasks and action spaces, we introduce the action repositioning network (APN). By relocating actions from the output of the decision-making module to the input of the perception module, we maintain a consistent output dimension for the decision-making module across various agents and tasks. Additionally, we address the challenge of disparate training speeds among different tasks during multi-task training by dynamically adjusting task weights, resulting in accelerated pre-training.
Through extensive experiments, we demonstrate that the pre-trained shared decision-making module contains general multi-agent decision-making knowledge. Moreover, as we increase the number of tasks used for pre-training, we observe that the shared decision layer contains more general decision knowledge, further improving the training efficiency for new tasks. By leveraging a decision module that incorporates this general decision knowledge, we significantly reduce the training cost for new tasks.
In future work, we plan to expand the number of pre-training tasks and train a larger decision-making module that encompasses a broader spectrum of general decision-making knowledge. Additionally, we aim to explore the transferability of decision-making knowledge across different domains, such as applying knowledge from StarCraft to tasks in Dota or Honor of Kings. Given the existence of common decision-making knowledge between these tasks, we strongly believe this idea holds considerable promise for future research.
References
- [1] Tong Wu, Pan Zhou, Kai Liu, Yali Yuan, Xiumin Wang, Huawei Huang, and Dapeng Oliver Wu. Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks. IEEE Transactions on Vehicular Technology, 69(8):8243–8256, 2020.
- [2] Yongcan Cao, Wenwu Yu, Wei Ren, and Guanrong Chen. An overview of recent progress in the study of distributed multi-agent coordination. IEEE Transactions on Industrial Informatics, 9(1):427–438, 2012.
- [3] Maximilian Hüttenrauch, Adrian Šošić, and Gerhard Neumann. Guided deep reinforcement learning for swarm systems. arXiv preprint arXiv:1709.06011, 2017.
- [4] Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- [5] Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning. 2019.
- [6] Deheng Ye, Guibin Chen, Wen Zhang, Sheng Chen, Bo Yuan, Bo Liu, Jia Chen, Zhao Liu, Fuhao Qiu, Hongsheng Yu, et al. Towards playing full moba games with deep reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 621–632, 2020.
- [7] Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. arXiv preprint arXiv:1902.04043, 2019.
- [8] Karol Kurach, Anton Raichuk, Piotr Stańczyk, Michał Zając, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al. Google research football: A novel reinforcement learning environment. In AAAI Conference on Artificial Intelligence (AAAI), volume 34, pages 4501–4510, 2020.
- [9] Karl Weiss, Taghi M Khoshgoftaar, and DingDing Wang. A survey of transfer learning. Journal of Big Data, 3(1):1–40, 2016.
- [10] Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. A comprehensive survey on transfer learning. Proceedings of the IEEE, 109(1):43–76, 2020.
- [11] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
- [12] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [13] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning (ICML), pages 1597–1607. PMLR, 2020.
- [14] Sasha Targ, Diogo Almeida, and Kevin Lyman. Resnet in resnet: Generalizing residual architectures. arXiv preprint arXiv:1603.08029, 2016.
- [15] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
- [16] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), pages 213–229. Springer, 2020.
- [17] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems (NeurIPS), 28, 2015.
- [18] Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficientdet: Scalable and efficient object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10781–10790, 2020.
- [19] Yifu Zhang, Chunyu Wang, Xinggang Wang, Wenjun Zeng, and Wenyu Liu. Fairmot: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision (IJCV), 129:3069–3087, 2021.
- [20] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [21] Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. Ernie: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129, 2019.
- [22] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
- [23] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351, 2019.
- [24] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
- [25] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? Advances in Neural Information Processing Systems (NeurIPS), 27, 2014.
- [26] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255. Ieee, 2009.
- [27] Ivan Krasin, Tom Duerig, Neil Alldrin, Vittorio Ferrari, Sami Abu-El-Haija, Alina Kuznetsova, Hassan Rom, Jasper Uijlings, Stefan Popov, Andreas Veit, et al. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github. com/openimages, 2(3):18, 2017.
- [28] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), pages 740–755. Springer, 2014.
- [29] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems (NeurIPS), 25, 2012.
- [30] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [31] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- [32] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- [33] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [34] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems (NeurIPS), 33:1877–1901, 2020.
- [35] Taesung Park, Alexei A Efros, Richard Zhang, and Jun-Yan Zhu. Contrastive learning for unpaired image-to-image translation. In European Conference on Computer Vision (ECCV), pages 319–345. Springer, 2020.
- [36] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- [37] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 9729–9738, 2020.
- [38] Yuandong Tian, Xinlei Chen, and Surya Ganguli. Understanding self-supervised learning dynamics without contrastive pairs. In International Conference on Machine Learning, pages 10268–10278. PMLR, 2021.
- [39] Janne Spijkervet and John Ashley Burgoyne. Contrastive learning of musical representations. arXiv preprint arXiv:2103.09410, 2021.
- [40] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
- [41] Daniel S Bernstein, Robert Givan, Neil Immerman, and Shlomo Zilberstein. The complexity of decentralized control of markov decision processes. Mathematics of Operations Research, 27(4):819–840, 2002.
- [42] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017.
- [43] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research (JMLR), 21(1):7234–7284, 2020.
- [44] Jian Hu, Siyang Jiang, Seth Austin Harding, Haibin Wu, and Shih-wei Liao. Rethinking the implementation tricks and monotonicity constraint in cooperative multi-agent reinforcement learning. arXiv preprint arXiv:2102.03479, 2021.