MultiAuto-DeepONet: A Multi-resolution Autoencoder DeepONet for Nonlinear Dimension Reduction, Uncertainty Quantification and Operator Learning of Forward and Inverse Stochastic Problems11footnotemark: 1
Abstract
A new data-driven method for operator learning of stochastic differential equations(SDE) is proposed in this paper. The central goal is to solve forward and inverse stochastic problems more effectively using limited data. Deep operator network(DeepONet) has been proposed recently for operator learning. Compared to other neural networks to learn functions, it aims at the problem of learning nonlinear operators. However, it can be challenging by using the original model to learn nonlinear operators for high-dimensional stochastic problems. We propose a new multi-resolution autoencoder DeepONet model referred to as MultiAuto-DeepONet to deal with this difficulty with the aid of convolutional autoencoder. The encoder part of the network is designed to reduce the dimensionality as well as discover the hidden features of high-dimensional stochastic inputs. The decoder is designed to have a special structure, i.e. in the form of DeepONet. The first DeepONet in decoder is designed to reconstruct the input function involving randomness while the second one is used to approximate the solution of desired equations. Those two DeepONets has a common branch net and two independent trunk nets. This architecture enables us to deal with multi-resolution inputs naturally. By adding regularization to our network, we found the outputs from the branch net and two trunk nets all have sparse structures. This reduces the number of trainable parameters in the neural network thus making the model more efficient. Finally, we conduct several numerical experiments to illustrate the effectiveness of our proposed MultiAuto-DeepONet model with uncertainty quantification.
keywords:
multi-resolution; operator learning; dimension reduction; autoencoder; uncertainty quantification; stochastic differential equations.1 Introduction
Nowadays the fast development of computational hardware and the ability to process vast amount of data efficiently has made data-driven techniques, especially deep learning one of the most popular method to solve complex problems across many disciplines. Moreover, machine learning(ML) models can be assisted by known physical information to increase the accuracy and alleviate the amount of data required. The additional physical knowledge often appears in the form of differential equations(DEs). There has been a vast amount of work recently with different approaches such as Gaussian process(GP) [50, 46, 16, 40, 45, 44] and deep neural networks(DNNs) [29, 30, 27, 47] for solving those kinds of problems. In this work, we consider a special kind of DEs, namely stochastic differential equations(SDEs) which generalized DEs by introducing randomness in coefficients or forcing terms. SDEs arise in a variety of applications naturally, for example mathematical biology, statistical mechanics, etc. The most popular approach to solve SDEs is the Monte Carlo method [35]. However as we known, it suffers from slow rate of convergence and often requires large amount of samples to achieve certain accuracy. Another approach is built on the truncation of stochastic polynomial chaos expansion(PCE). Interested readers are referred to [11, 20] for more information on this topic. Here, we want to learn stochastic operators in the setting of both the forward and inverse problems. The stochastic operators can be high-dimensional and classical numerical methods for solving this kind of problems suffer from the curse of dimensionality [2] because the reliance of the carefully generated spatio-temporal grids. However, modern ML based techniques without numerical discretization is easily scalable to high dimensions.
In this paper we focus on DeepONet, first introduced by Lu et al. in [31], for stochastic operator learning. We know that the universal approximation theorem insures that neural networks(NNs) of arbitrary width or depth can approximate any continuous function of real numbers. This is the reason why DNNs become one of the most popular paradigms to solve problems relate to DEs. In their paper, the authors have designed a new deep learning framework, i.e. DeepONet to learn continuous linear or nonlinear operators. DeepONet is inspired by a similar theorem, the universal operator approximation theorem [6]. This theorem guarantees that a single hidden layer NN can approximate any nonlinear continuous operators accurately. The network inputs consist of a series of function values at fixed sensor locations, while the output sensors can be placed at any locations. The architecture of the network mainly contains two parts: one or several branch networks(stacked or unstacked DeepONet) and a trunk network take the information contained in the input sensors and the output sensors respectively. The loss function is the mean square error(MSE) between the true values and the predictions by neural network. Specially, DeepONet can be applied to learn stochastic operators. In their numerical example, the Karhunen-Loève(KL) expansion is used to deal with the random process as the input of branch network:
| (1) |
where and are the -th largest eigenvalue and its normalized eigenfunction of the covariance function. In this way, the input of the branch network is of the form and the input of the trunk network is . Here, is the number of retained modes in KL expansion and are independent standard Gaussian random variables. Note that according to the author, the dimension of the problem is still very high because the input of the branch net is a set of eigenfunctions and the dimension for the input of the trunk net is the sum of dimensions of the physical and random space. As the dimension of the SDE problem increases, it will become unfeasible to solve the problem using original DeepONet. In our work, an encoder is proposed to conduct dimensionality reduction first before the inputs are fed into DeepONet. Then a new network called MultiAuto-DeepONet is built for nonlinear dimension reduction and stochastic operator learning. The encoder part of our model aims at discovering the hidden features of the inputs as well as reducing the dimension, while the decoder includes two DeepONets with a shared branch net. This branch net processes the inputs relate to the random process. Two different trunk nets can deal with the inputs with different resolution. For example, one trunk net for inputs in spatial domain and the other for inputs in temporal domain. Note that the sensor locations for these two trunk nets can also be different. The loss function of MultiAuto-DeepONet consists of the reconstruction error of the input functions and MSE of the SDE solution. Furthermore, we want to quantify the uncertainties associated with our quantities of interest (QOIs) coming from the stochastic process in SDEs. As we known, uncertainty quantification(UQ) is very crucial and has drawn increasing attention in machine learning methods applied to a various real life applications [1, 22, 37, 25]. In solving SDE problems, high-dimensional random variables are often the sources of uncertainty. In this paper, we mainly account for the uncertainties in solving SDEs through our MultiAuto-DeepONet model. This means we show the predicted mean and variance of the model predictions. We present four different examples to illustrate the performance of our model in the numerical example section.
Our objectives of this paper:
-
1.
Nonlinear dimensionality reduction for high-dimensional stochastic inputs using MultiAuto-DeepONet.
-
2.
Learning high-dimensional stochastic operators in the setting of solving forward and inverse stochastic problems.
-
3.
Uncertainty quantification for our proposed MultiAuto-DeepONet model in stochastic operator learning problems.
Our contributions of this paper:
-
1.
A special autoencoder with DeepONet as its decoder is constructed to perform nonlinear supervised dimensionality reduction thus discovering the nonlinear hidden features, i.e. the nonlinear representation of the high-dimensional random process. The model can effectively save computational cost in high-dimensional problems compared to PCA based DeepONet. Moreover, uncertainty quantification can be effectively carried out with much less computational cost using our MultiAuto-DeepONet model.
-
2.
A nonlinear basis of the random process and the SDE solutions can be automatically learned. The effectiveness of this method is demonstrated by comparing to polynomial chaos expansion (PCE). The numerical experiments show our model can achieve better accuracy than PCE with the same number of base.
-
3.
Different regularizers, i.e. , and etc., can be added to output layer of the decoder for different purposes. We consider the regularization to introduce sparsity for learned coefficients and bases.
-
4.
Multi-resolution data can be handled by our proposed MultiAuto-DeepONet model naturally to solve forward and inverse stochastic problems.
-
5.
Applying convolutional encoder enables our model to deal with high physical dimensional problems.
The paper is organized as follows. In Section 2.1, we give a brief introduction to autoencoder. Then our MultiAuto-DeepONet model is constructed in Section 2.2. In Section 3, four numerical examples are presented to illustrate the performance of proposed model. Conclusions and future works are provided in Section 4.
2 Methodology
In this section, the main building blocks of our MultiAuto-DeepONet model is introduced.
2.1 Autoencoder
As we known, autoencoders were first introduced by Hinton and the PDP group [49] in the 1980s. Together with Hebbian learning rules [19, 39], autoencoders lay the foundation of unsupervised learning. An autoencoder is a special type of feedforward neural network where the output is set to be the same as the input and it often consists of two main parts: an encoder and an decoder. The encoder is used to process the inputs and the decoder takes the output of encoder and uses it to reconstruct the inputs. The outputs from the encoder can be understood as a latent representation of the inputs. Autoencoder can be trained by minimizing the reconstruction error which measures the differences between the original input and output from the reconstruction process of decoder. Traditional application for autoencoder includes dimensionality reduction, feature learning and etc. We apply autoencoder in our model to find the hidden features in inputs from high-dimensional stochastic process.
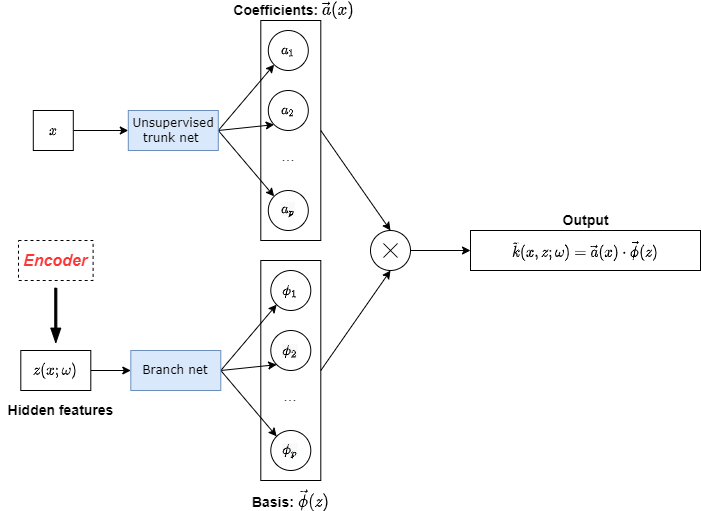
Suppose our target problem is a simple forward problem of stochastic DE, i.e. to find the solution . The randomness comes from the coefficient , where and is the random space. Figure 1 presents the unsupervised part of our MultiAuto-DeepONet model. We can see it is an autoencoder as stated above except that we use a convolutional encoder and the decoder part is in the form of a DeepONet. The encoder consists of several convolutional layers followed by a dense layer. The filter size, strides in convolutional layers and the activation functions in each layer depend on the specific problem and will be tuned to achieve the best performance. The hidden features discovered by the convolutional encoder are fed into the branch net of the decoder. Moreover, can be used to generate samples of input . This makes uncertainty quantification of our model much easier. Assume the number of training data is , the network loss function denoted by for unsupervised part is exactly the reconstruction error of this autoencoder,
| (2) |
where are training data and are network reconstruction of corresponding to each .
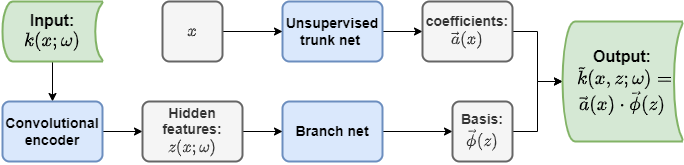
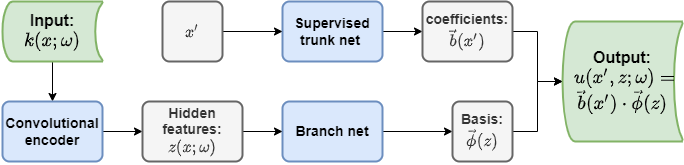
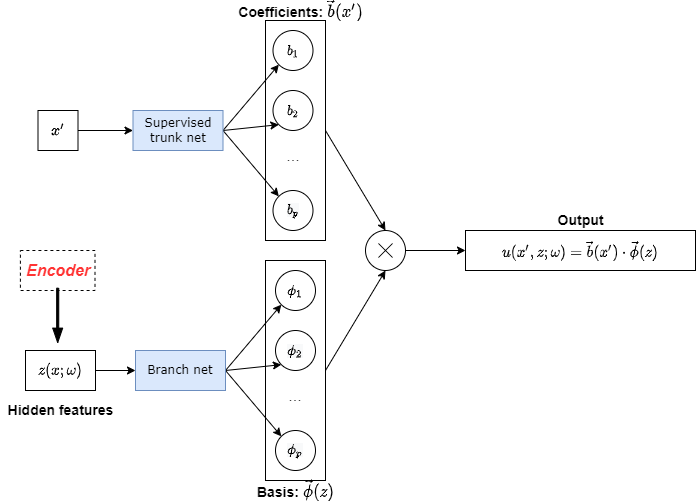
We also present the second supervised part of our MultiAuto-DeepONet model here in Figure 2. It has similar structure as unsupervised part in Figure 1 and they share one common branch net. The difference is that the output of supervised trunk net is used to approximate the SDE solution . So assume the number of training data is , loss function for this supervised part denoted by is,
| (3) |
where are training data and are network prediction of corresponding to each .
2.2 MultiAuto-DeepONet
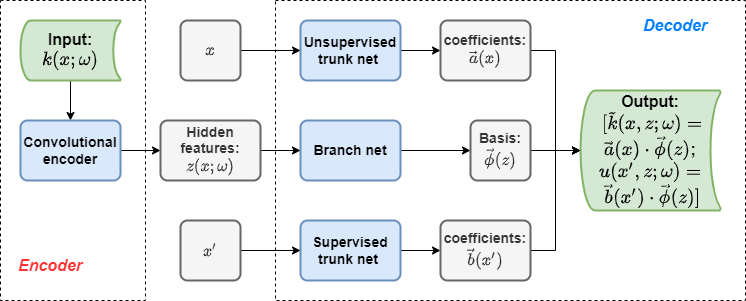
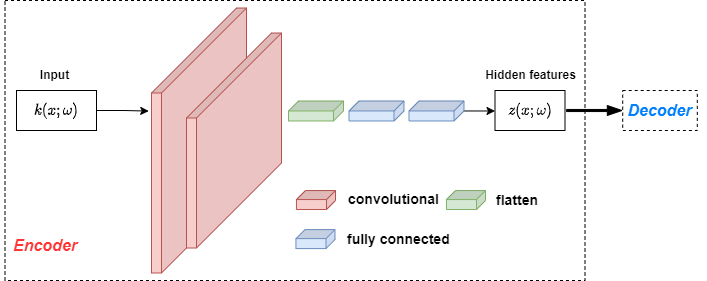
The authors in [31] introduce DeepONet, a universal operator approximator which has shown remarkable approximation and generalization capabilities. Furthermore, they demonstrate that DeepONet can learn both explicit and implicit operators including those representing SDEs. We use DeepONet as the building block in this paper. As stated in the section of learning stochastic operators in [31], the input of the branch net is a random process and its dimension can be very high. As shown in Figure 3, a convolutional autoencoder is used to reduce the dimensionality thus discovering the hidden features from the inputs first. Then is treated as the input to the common branch net of two DeepONets. The upper DeepONet in Figure 3 is exactly the unsupervised part in Figure 1 and the bottom DeepONet is the supervised part shown in Figure 2. Figure 4 presents the architecture of our convolutional encoder. The details of architectures of the two DeepONets is shown in Figures 5 and 6 respectively. Note that the unsupervised part of our MultiAuto-DeepONet model reconstructs from the inputs and the supervised part aims at learning the solution . The following is the loss function of our model:
| (4) |
Note that in MultiAuto-DeepONet model, DeepONet is used as the decoder to find a nonlinear basis for both and . This improves the interpretation of our model. We also add regularization in the two DeepONets to introduce the sparse structures. Thus a relative small number of basis is required to express the solution of a complex high-dimensional problem. Other regularization can be added similarly for different purposes. The network performance and uncertainty quantification of our model will be presented in next section.
3 Numerical Results
In this section, we present four numerical examples to illustrate the effectiveness of our model for nonlinear dimension reduction as well as learning stochastic operators.
3.1 Forward problem: learning stochastic operator
Let us first consider a pedagogical example, i.e. one dimensional stochastic ODE representing the population growth model:
| (5) |
Here, represents the random space and the initial condition is set to be . As in [31], the coefficient is modeled as the following Gaussian random process,
| (6) |
where is the mean funtion and the covariance function is in the squared exponential form . Here, is set to be and the correlation length is in .
The input in this problem comes from a random process and the authors in [31] employ the Karhunen-Loeve(KL) expansion as in Equation 1 to handle it. In their example, is chosen to be which can be viewed as a truncation process. Although they did not assume to know the covariance function, the KL expansion must be known in advance. In our MultiAuto-DeepONet model, we can directly treat the observations of as the inputs. The model automatically performs the nonlinear dimension reduction and discovers the hidden features first. The output of our model consists of both the solution of the equation and the reconstructed random process . Note that this reconstruction process of can be used to generate new samples once the model is well calibrated.
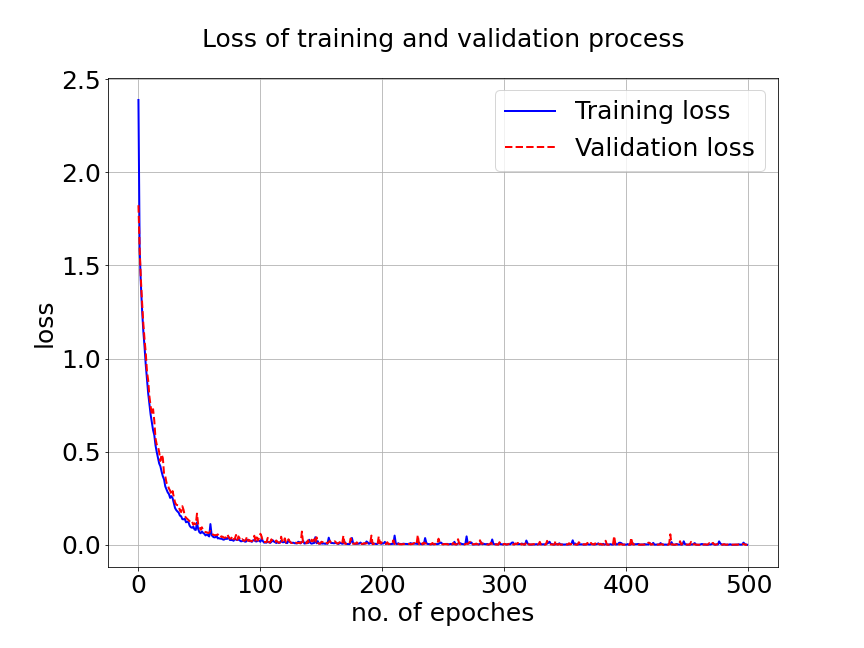
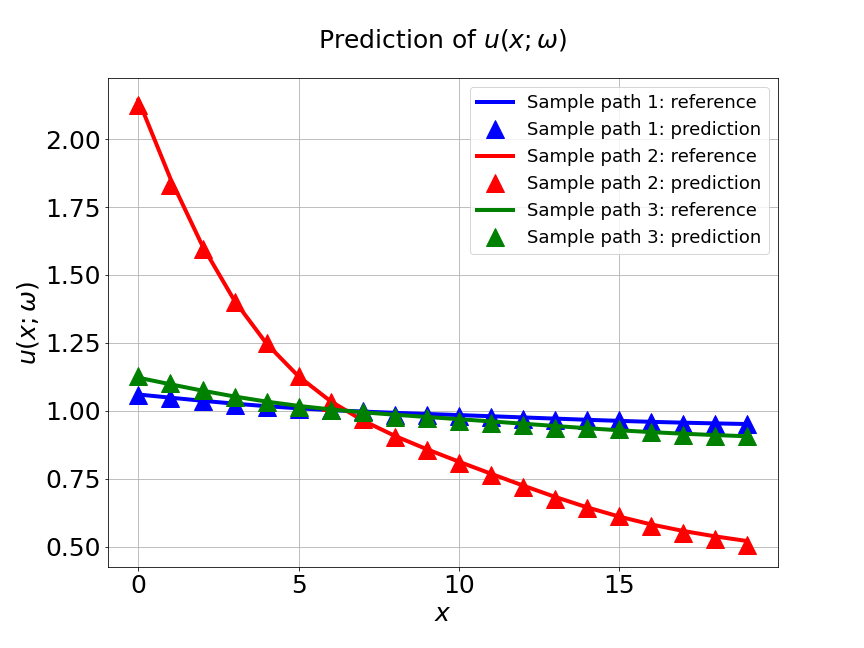
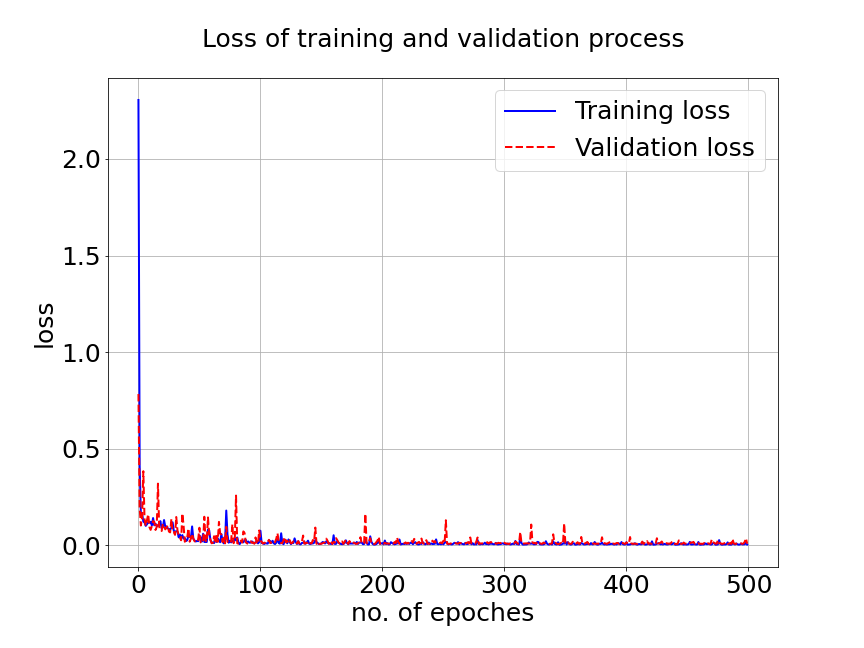
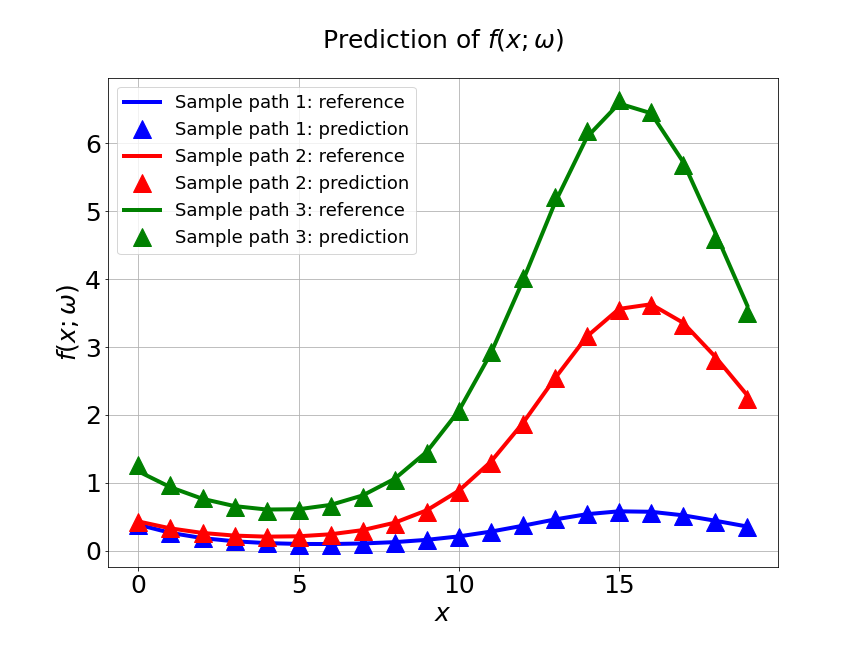
In our first experiment, we train MultiAuto-DeepONet model with a data set of different . The training data set consists of samples with input sensors for each trajectories. The test MSE is approximately and the average relative error is around . In Figure 7a, the blue solid line represents the training loss and the red dashed line represents the validation loss. The difference between the two losses can be ignored after hundreds of epoches. Part shows the predictions for three different random samples from . The reference solutions are solid lines with different colors and the model predictions are triangle up marker lines. We can see the predictions from MultiAuto-DeepONet model matches the reference pretty well. Table 1 shows the MSE and average relative error of MultiAuto-DeepONet model for different the number of input sensors. Both errors decrease as the number of sensors increases.
| MSE | Average relative error | |
|---|---|---|
| 0.00775 | 0.01122 | |
| 0.00126 | 0.00754 | |
| 0.00029 | 0.00578 | |
| 0.00026 | 0.00521 |
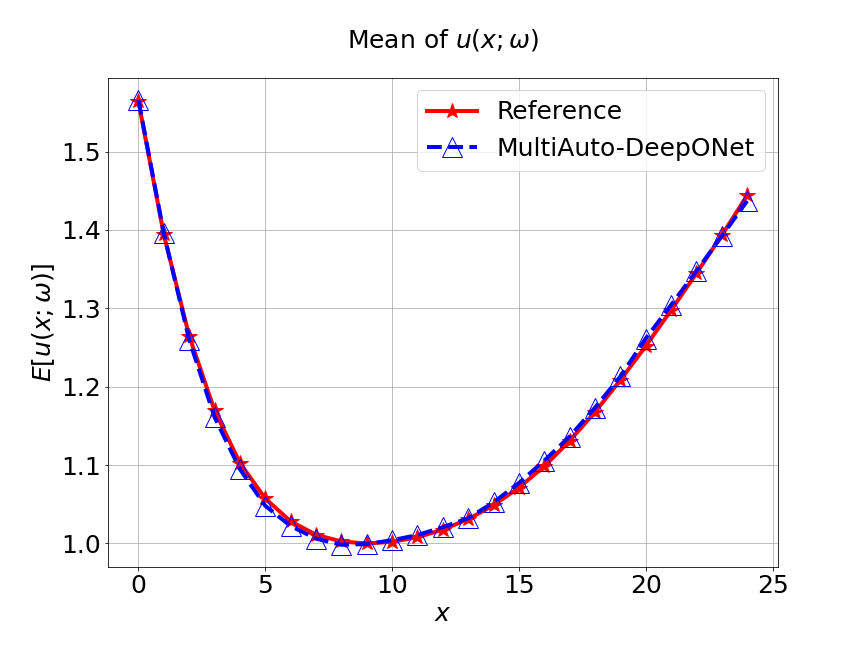
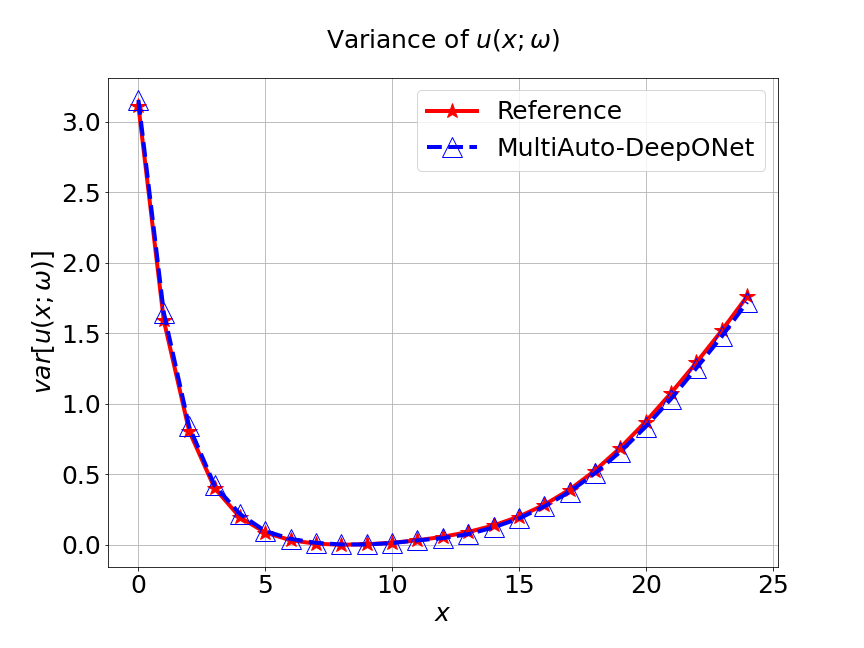
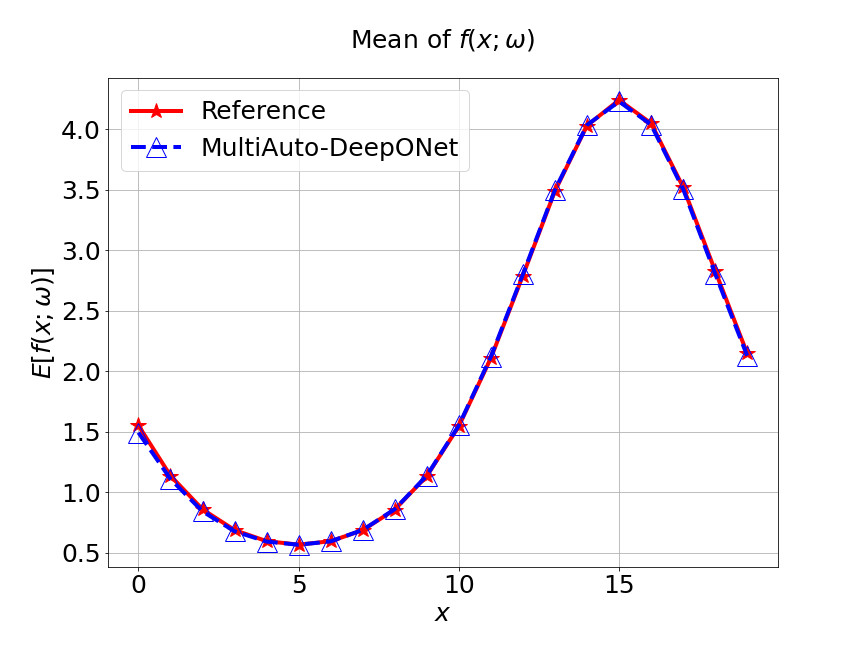
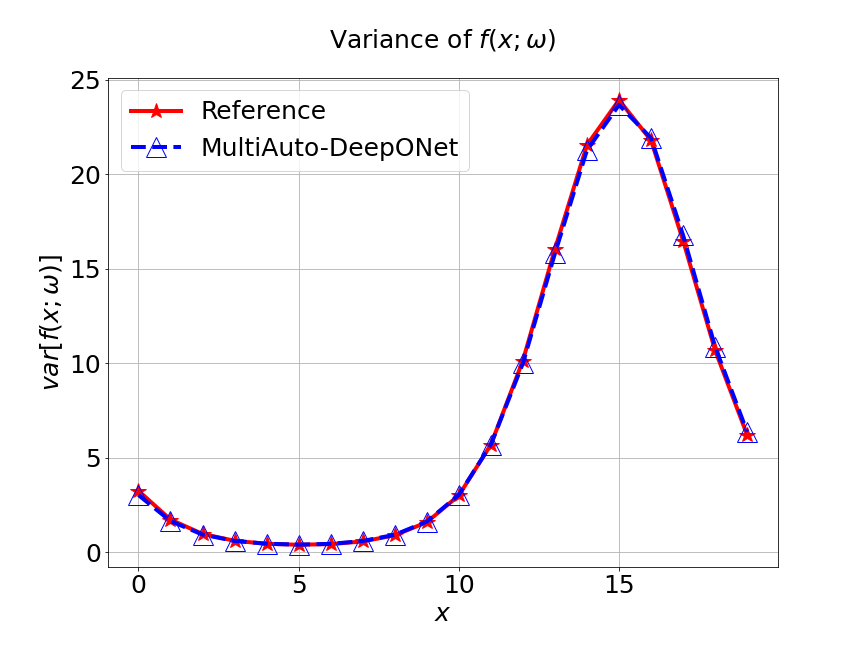
Next, we conduct a experiment to compare our model with the other two different models. The first one is the original DeepONet model. The second is PCA based DeepONet model which we call it PCA-DeepONet. This model performs PCA to the inputs from instead of reducing the spatial dimension using autoencoder. Figure 8 presents the predicted mean and variance of the solution for the reference and different methods. Table 2 lists the relative error of the predicted mean and variance when the number of input sensors is . From Figure 8 and Table 2, we can see that our MultiAuto-DeepONet model achieves the best accuracy for predicted mean and variance among all three models when the training data set is relatively small.
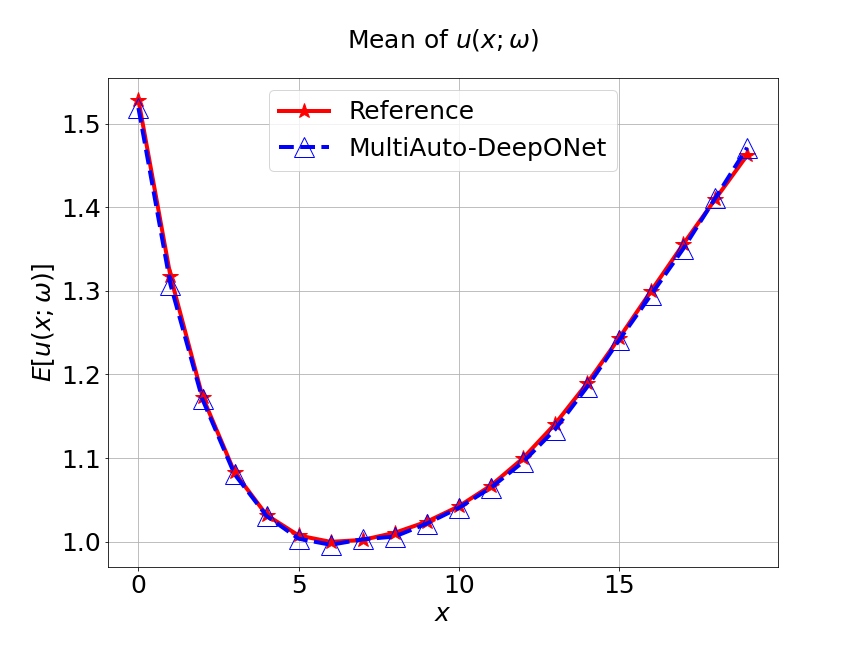
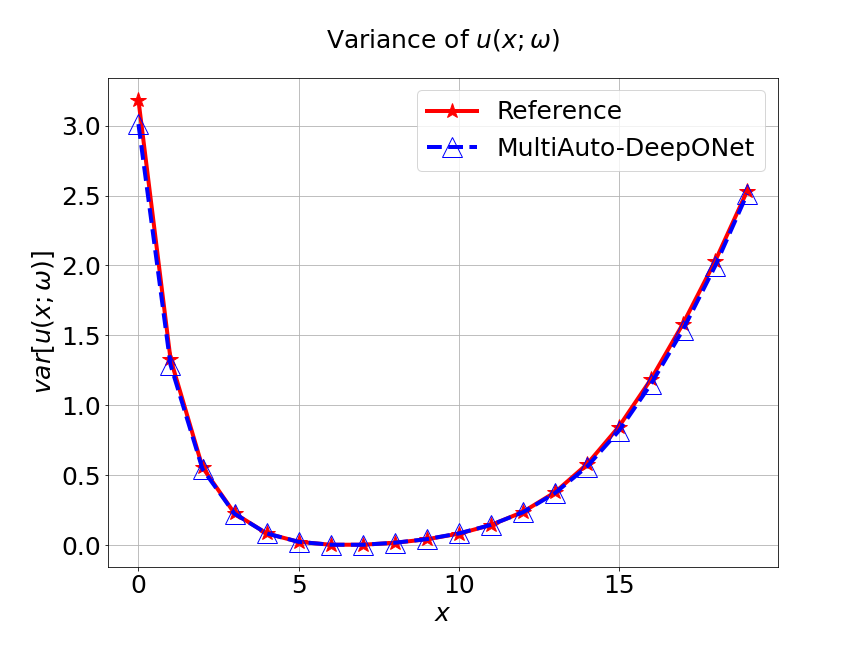
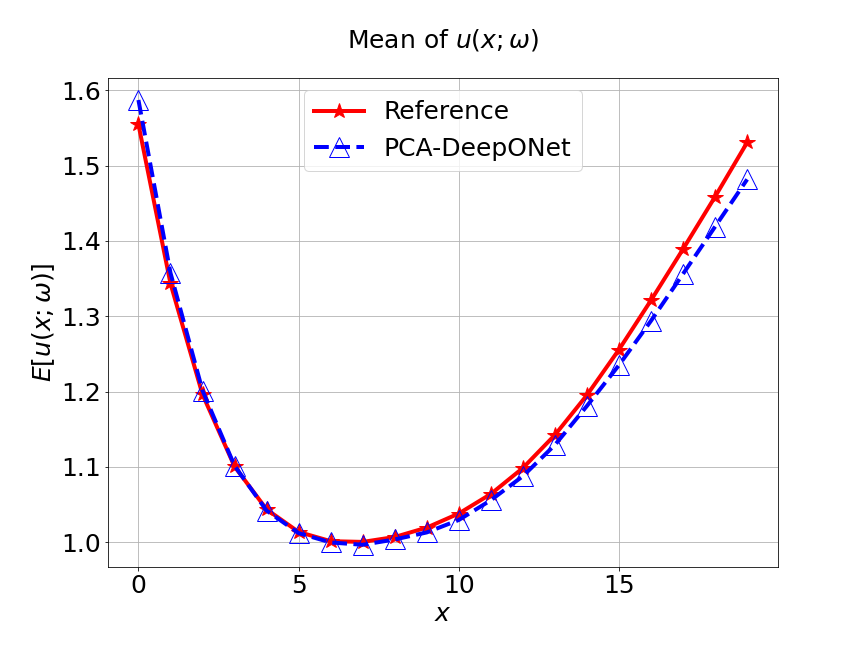
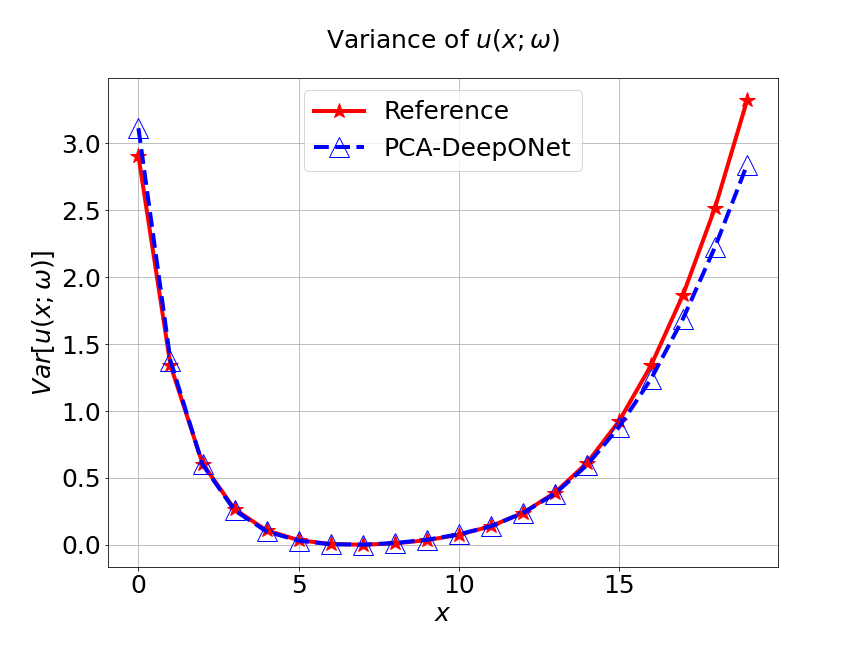
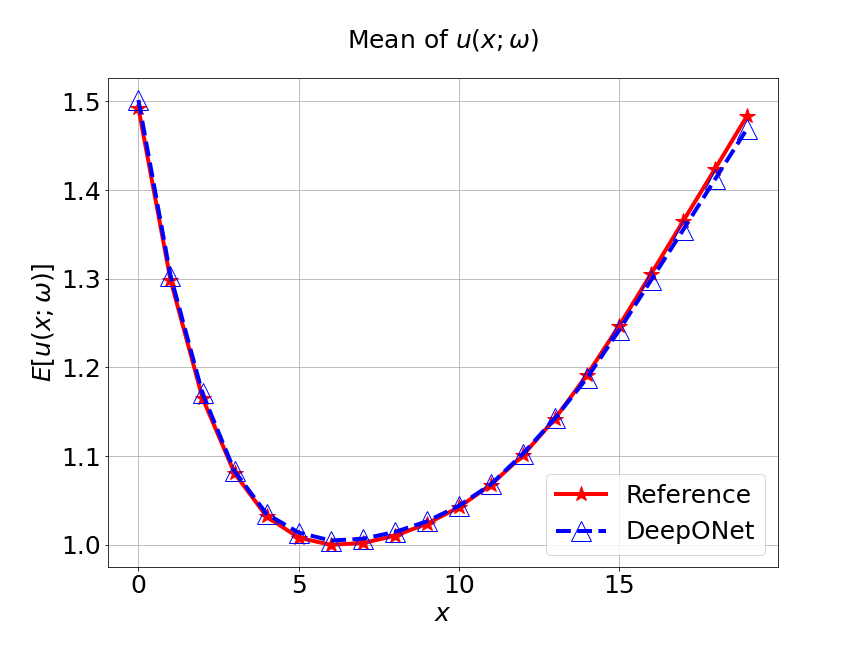
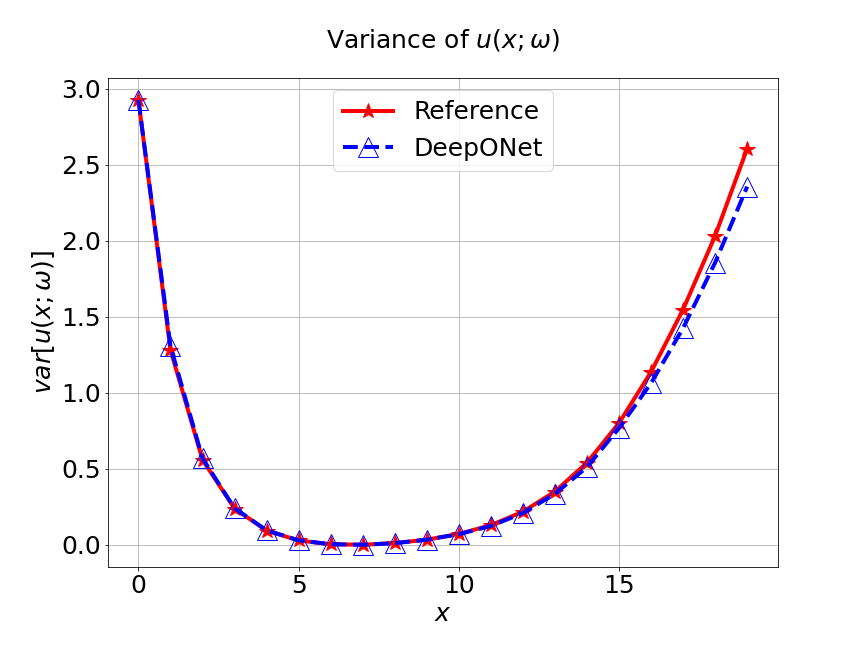
| DeepONet | PCA based DeepONet | MultiAuto-DeepONet | |
|---|---|---|---|
| Mean error | 0.00530 | 0.01686 | 0.00459 |
| Variance error | 0.0665 | 0.0918 | 0.0273 |
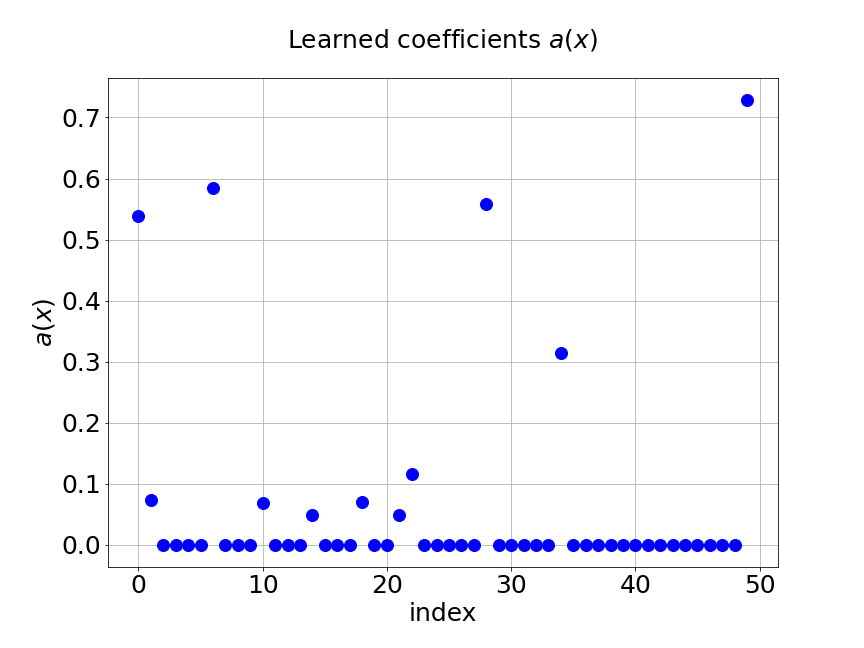
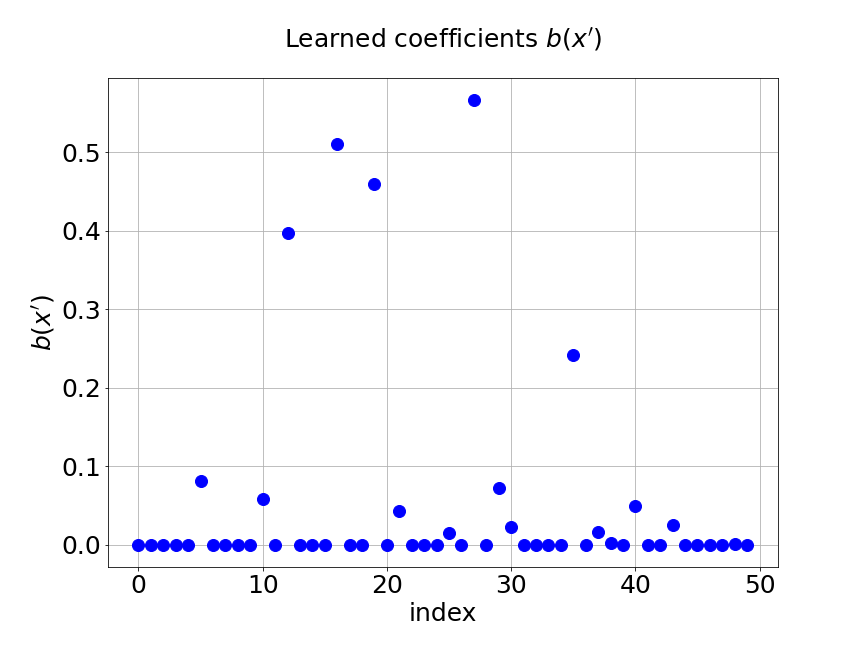
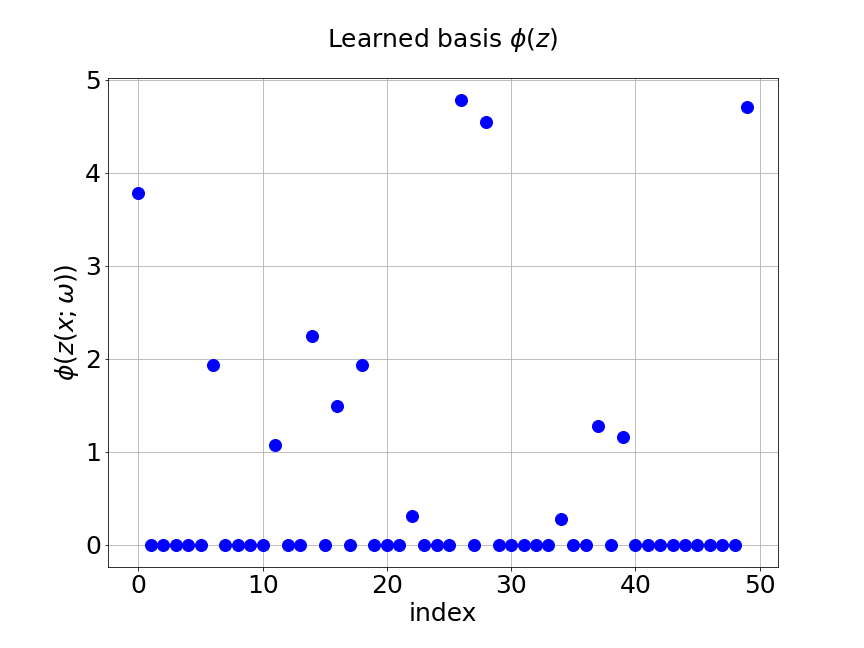
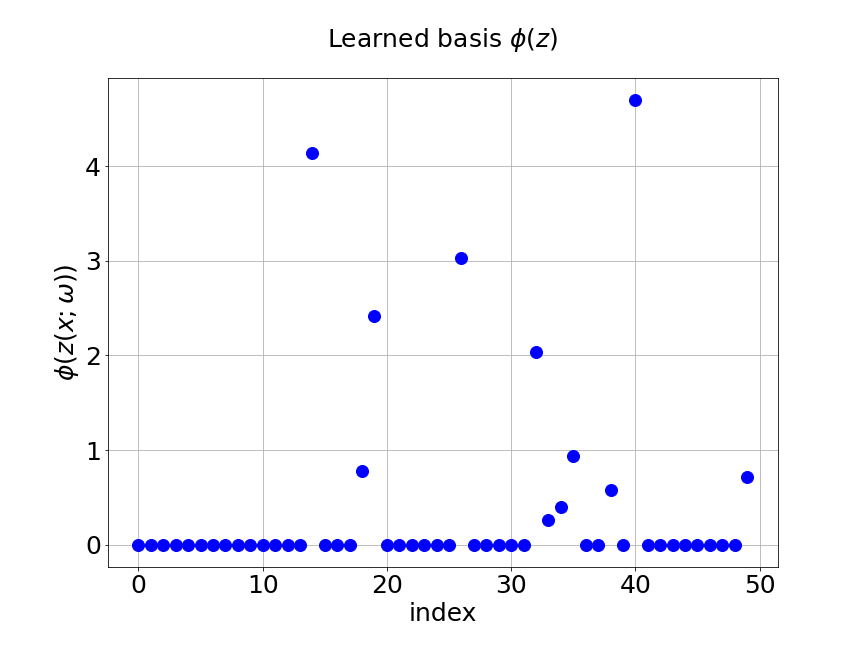
As we have mentioned, we add regularization in the two trunk nets of MultiAuto-DeepONet model in order to introduce the sparsity. Figure 9 shows the coefficients and basis learned from our model for one specific samples at the corresponding output sensor locations. Part shows the learned coefficients from the unsupervised trunk net and part is the learned coefficients from the supervised trunk net. The learned basis from the branch net is presented in part . The axes in the figures are the output sensor locations and the axes are corresponding values. We can see that only few numbers of them are not zero. This reduces the number of parameters in the network thus model training and calibration become much easier and faster.
One major difference between our model and original DeepONet model is that we can generate samples of and simultaneously after the network is trained. This is achieved by using the hidden features learned from the MultiAuto-DeepONet model and estimate the probability density function of to construct a generator. The method we apply in this paper is the kernel density estimation(KDE) and samples of are generated. We present the mean and variance of those samples in Figure 10. We can see the accuracy of the mean and variance of generated samples are relatively good considering the size of training data set.
3.2 Inverse problem: learning forcing term of stochastic operator
In this example, we consider a stochastic inverse problem, i.e. the following one-dimensional stochastic Poisson equation:
| (7) |
with homogeneous boundary conditions,
| (8) |
Here, and which is the random space and the randomness comes from the forcing term . We model as a Gaussian process,
| (9) |
with mean function and covariance function . The standard deviation is chosen to be and the correlation length .
First, we train the model with a data set of different . The number of sample trajectories is and the number of input sensors is . The test MSE is approximately and the average relative error is around . In Figure 11a , the blue solid line represents the training loss and the red dashed line represents the validation loss. Part shows the predictions for three different random samples from . We can see the predictions from MultiAuto-DeepONet model is accurate. Table 3 shows the MSE and average relative errors of MultiAuto-DeepONet model for different number of input sensors. We see they both decrease as the number of input sensors increases.
| MSE | Average relative error | |
|---|---|---|
| 0.0324 | 0.0632 | |
| 0.0124 | 0.0464 | |
| 0.0082 | 0.0232 | |
| 0.0061 | 0.0162 |
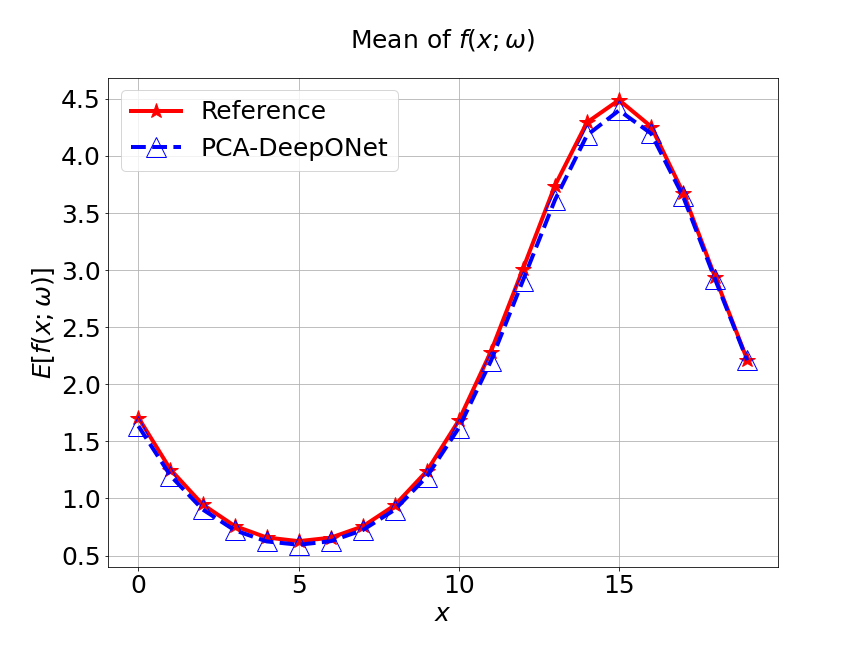
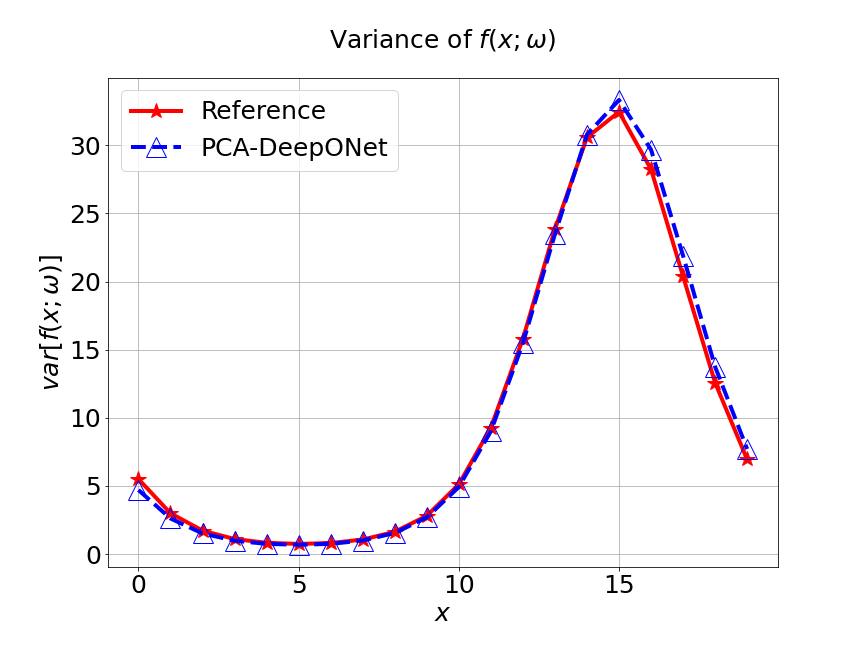
Now, a comparison between our model and PCA based DeepONet model is performed. Figure 12 presents the predicted mean and variance of unknown forcing term and the reference of different methods for the inverse stochastic Poisson equation. Table 4 lists the relative error of the predicted mean and variance when the number of input sensor is . We can see that our MultiAuto-DeepONet model achieves the best performance for predicted mean and variance.
| PCA based DeepONet | MultiAuto-DeepONet | |
|---|---|---|
| Mean error | 0.0257 | 0.0049 |
| Variance error | 0.0436 | 0.0136 |
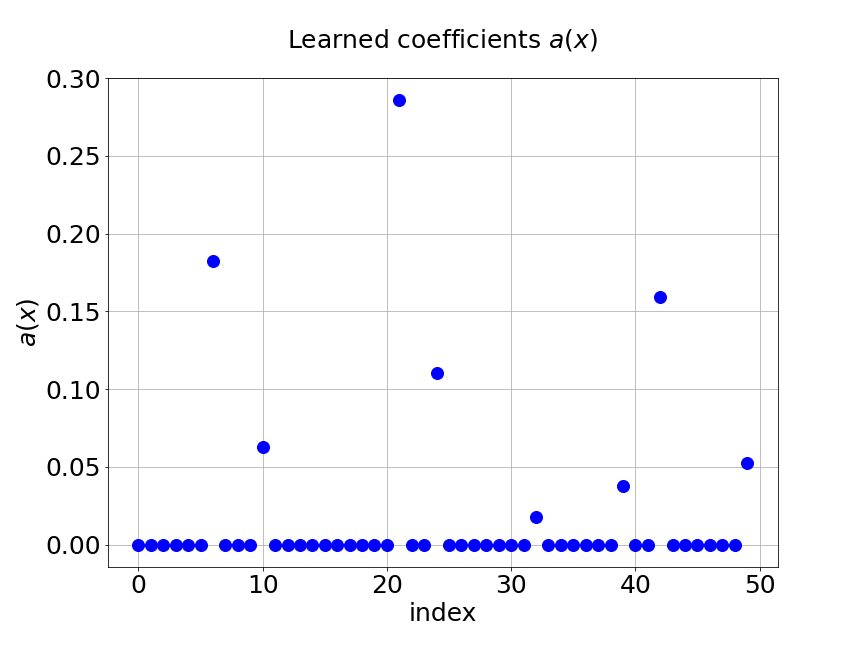
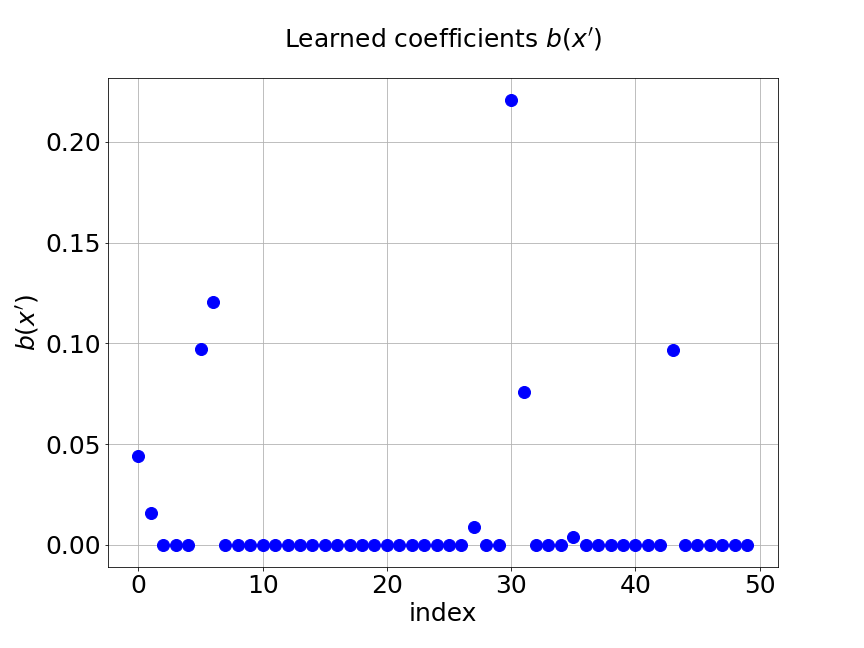
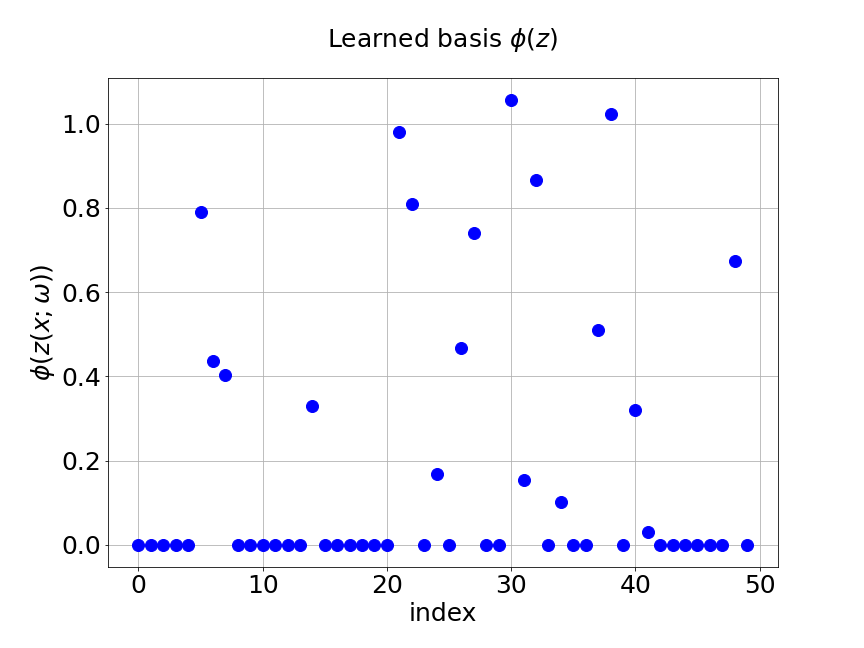
Figure 13 shows the coefficients learned from our model for one specific sample of at the corresponding output sensor locations. Part shows the learned coefficients from the unsupervised trunk net and part is the learned coefficients from the supervised trunk net. The learned basis from the branch net is presented in part . The axes in the figures are the output sensor locations and the axes are corresponding values. We can see that most of those value are zero in this problem. This results from the regularization in the trunk nets.
3.3 Forward problem: two dimensional Poisson Equation
In this example, we consider the forward problem of a two-dimensional stochastic Poisson equation:
| (10) |
with homogeneous boundary conditions,
| (11) |
Here, is the random space and the randomness comes from the forcing term () as in the last example except that the spatial dimension is . Again as the previous example, is modelled as a Gaussian process:
| (12) |
with mean function and covariance function . The hyper-parameters and are set to be and respectively.
In this two dimensional problem, the latent dimension of the encoder is chosen to be . There are two convolutional layers and two dense layers with relu activation function. For convolution layers, the stride length is and the filter size is . We add regularization in the two trunk nets of the decoder to introduce the spasity. This step is crucial because the spatial dimension is two in this problem. The Adam optimizer is applied to train the network with batch size . For our training data set, the number of sample trajectories of is and the number of input sensors is , i.e. grid.
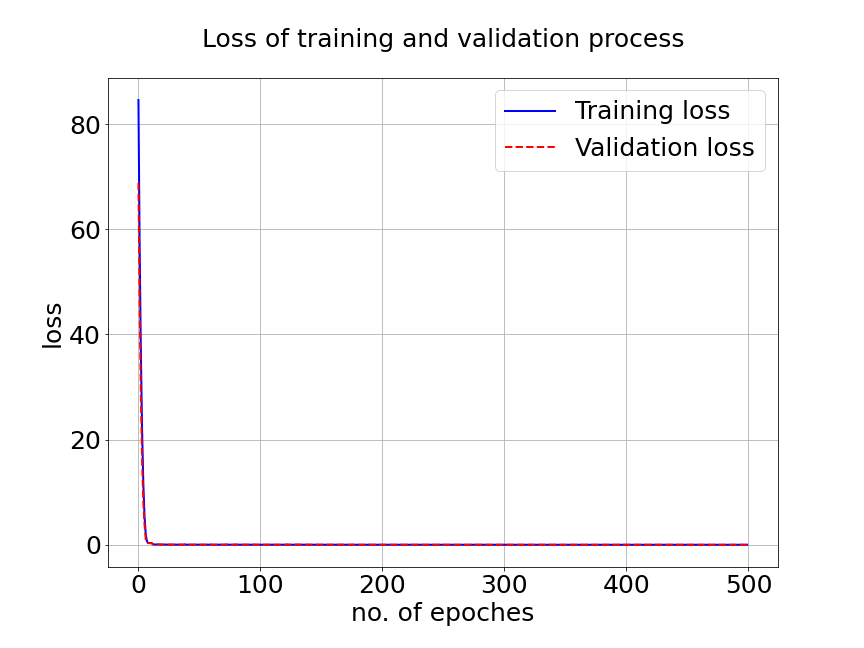
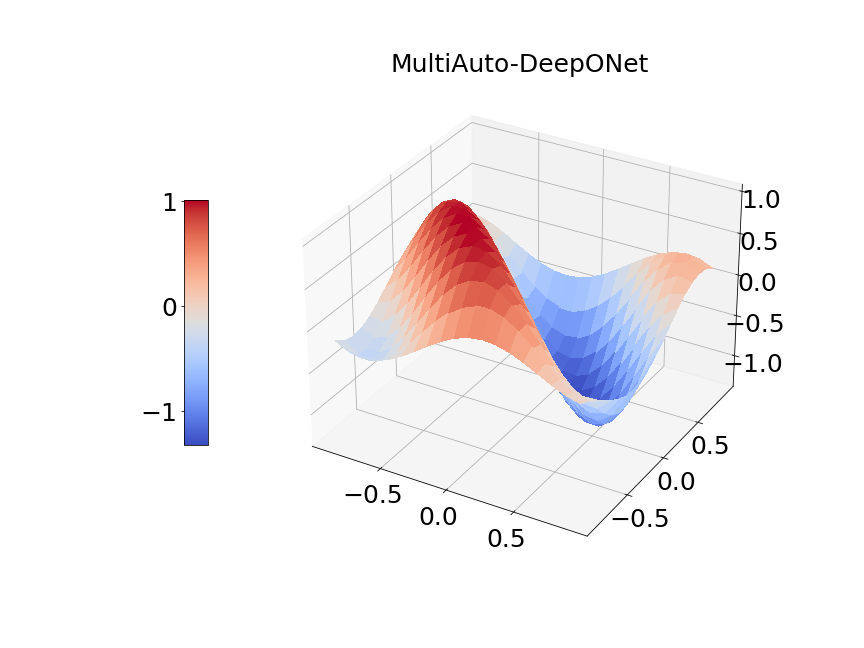
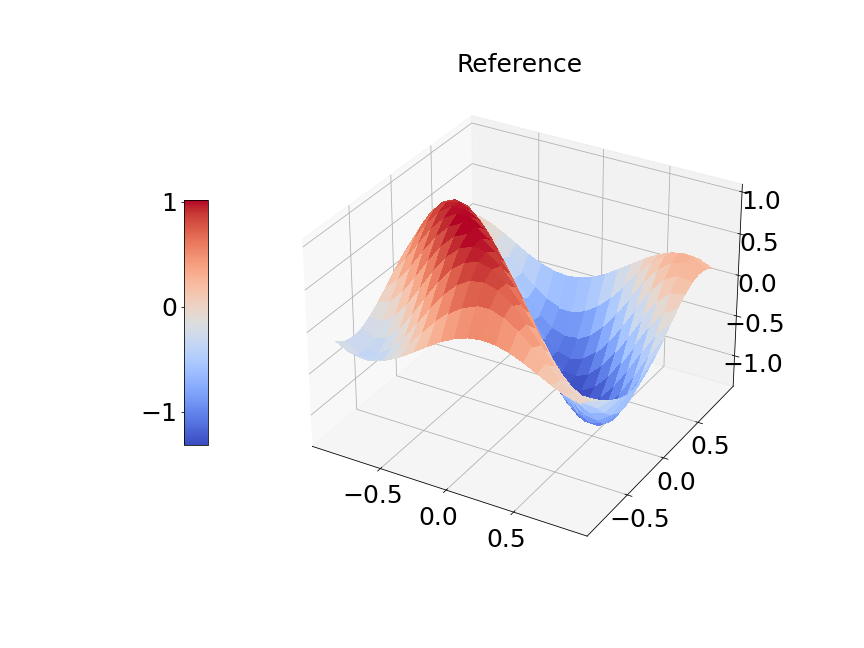
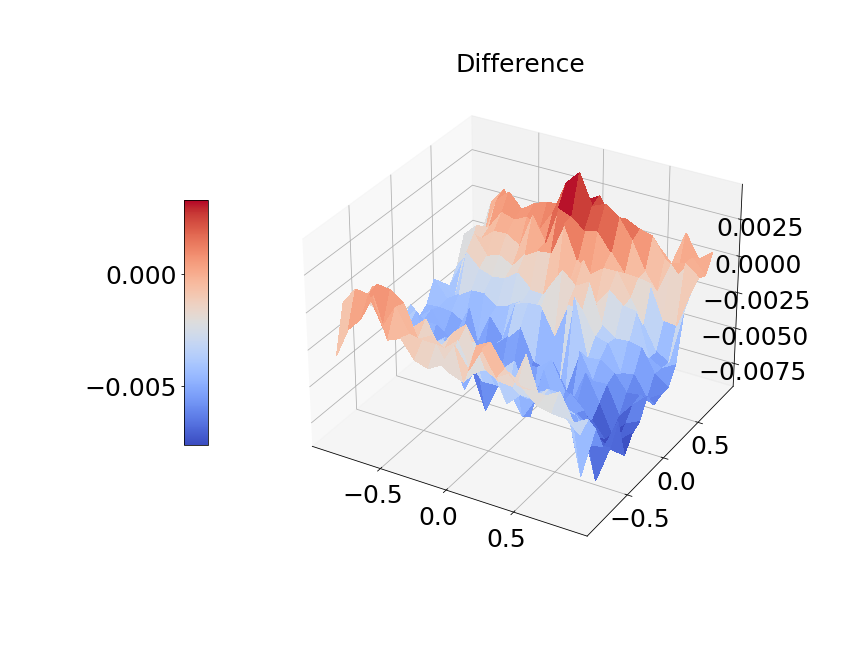
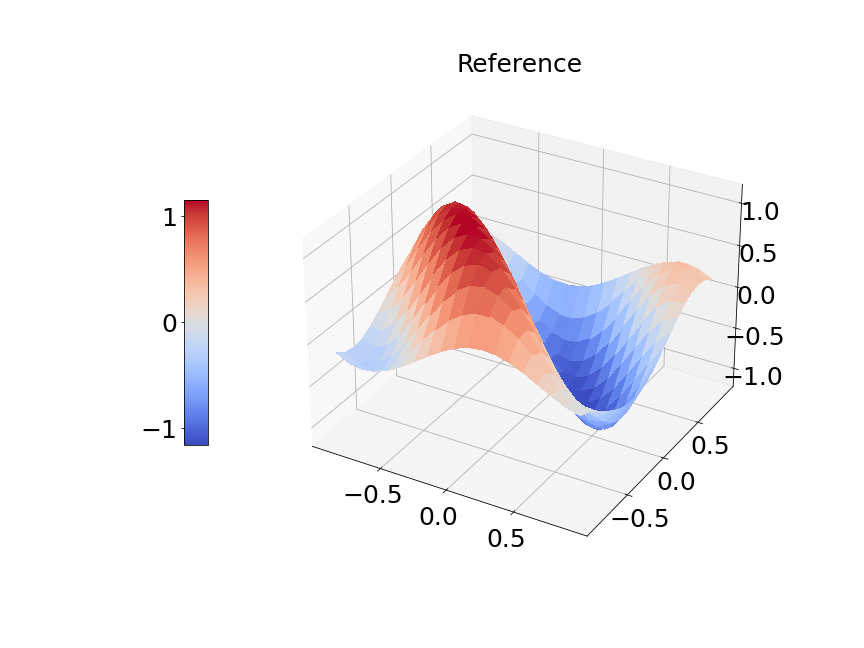
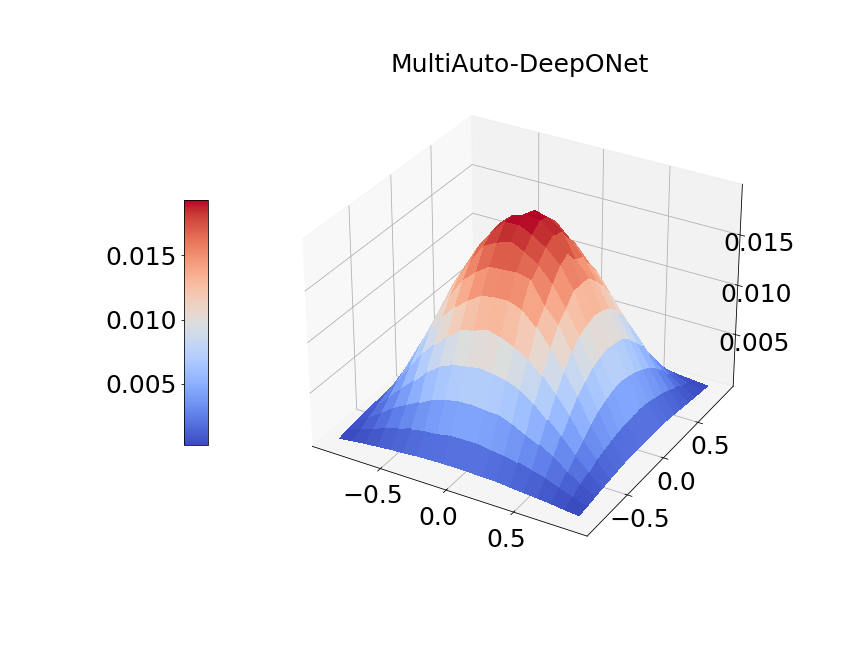
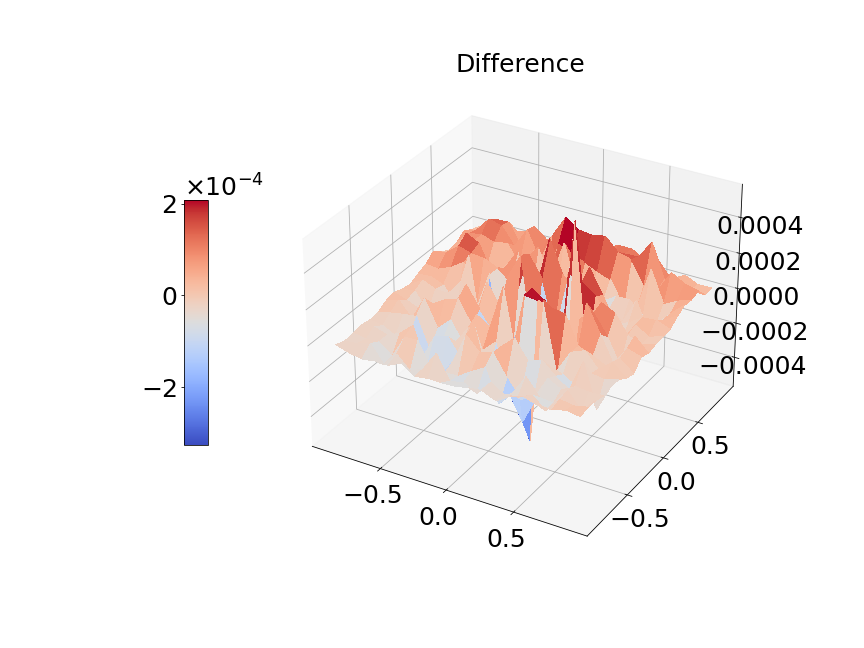
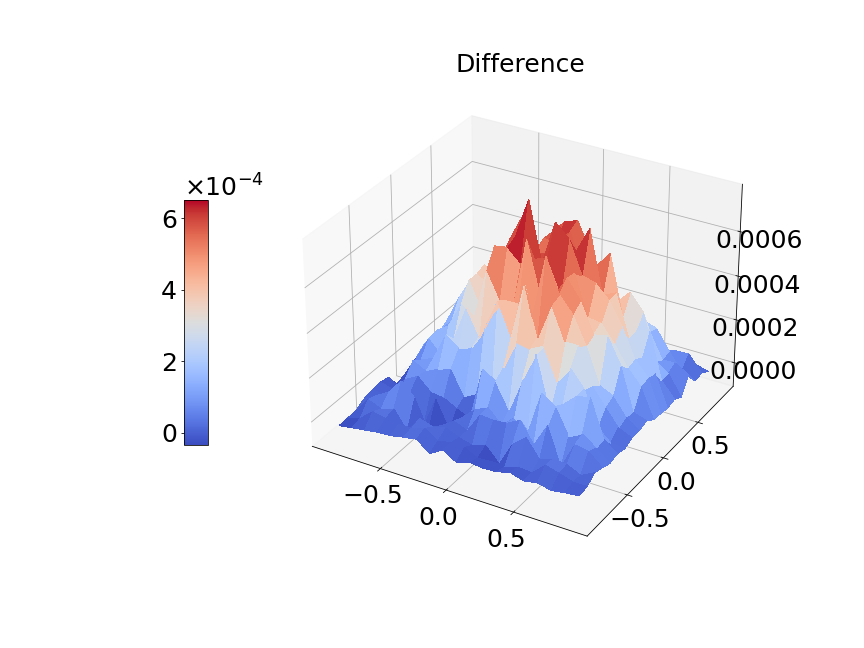
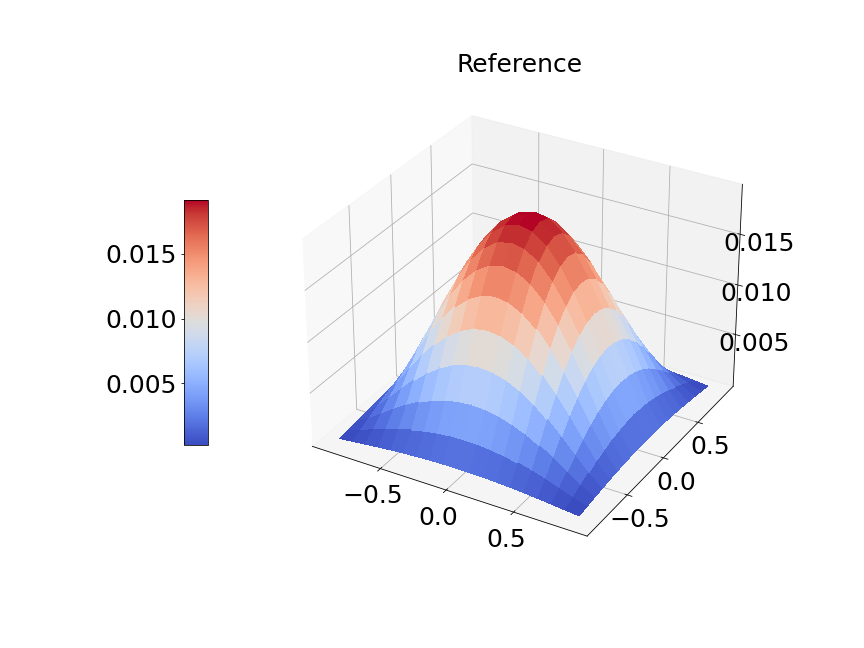
In Figure 14a, the blue solid line and red dashed line represent training and validation loss respectively. We can see the generalization error is very small. Figure 14b presents the model prediction of one particular sample path for the solution . Figure 14c is the ground true plot and Figure 14d shows the difference plot between MultiAuto-DeepONet approximation and reference solution. We can see they match pretty well. In Table 5, we list the test MSE and average relative error of MultiAuto-DeepONet model for different number of input sensors. The number of input sample path is fixed to be in this case. Table 6 shows the test MSE and average error for different number of input sample path. The number of input sensors is fixed to be . The results shown in the two tables illustrate the convergence of the model.
| MSE | Average relative error | |
|---|---|---|
| 1.41E-03 | 0.0709 | |
| 2.09E-04 | 0.0146 | |
| 1.43E-04 | 0.0082 | |
| 1.14E-04 | 0.0073 |
| MSE | Average relative error | |
|---|---|---|
| 4.93E-04 | 0.0104 | |
| 1.43E-04 | 0.0082 | |
| 1.22E-04 | 0.0078 |
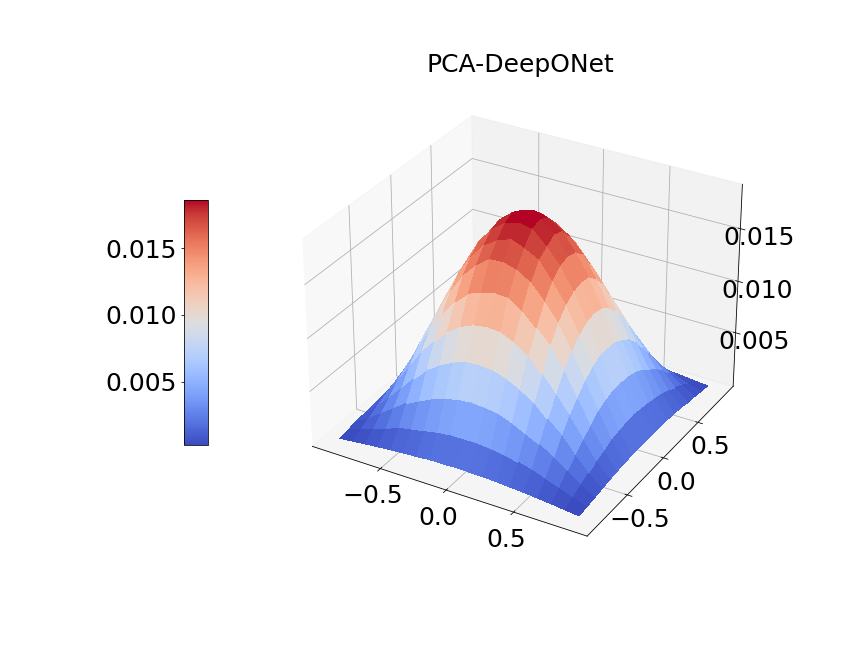
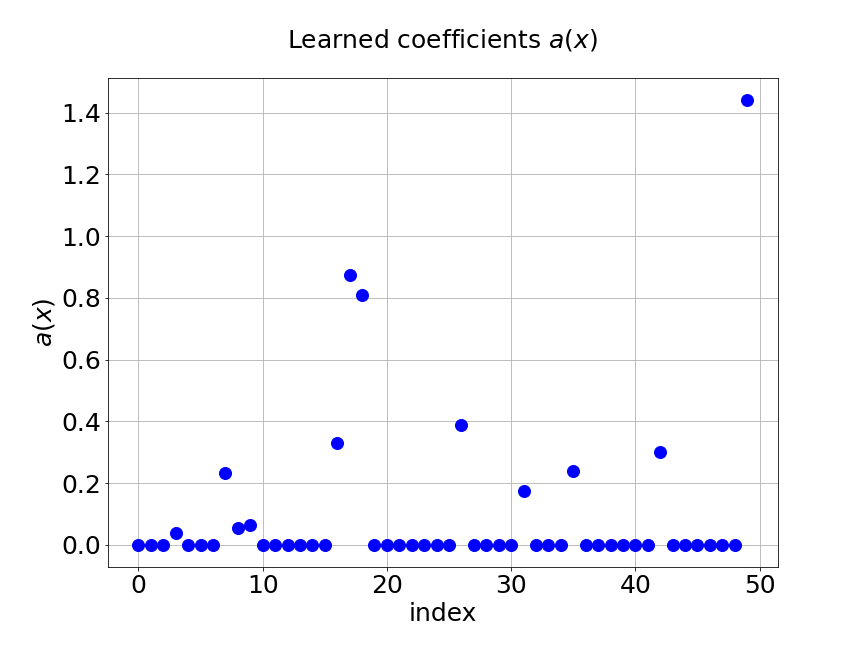
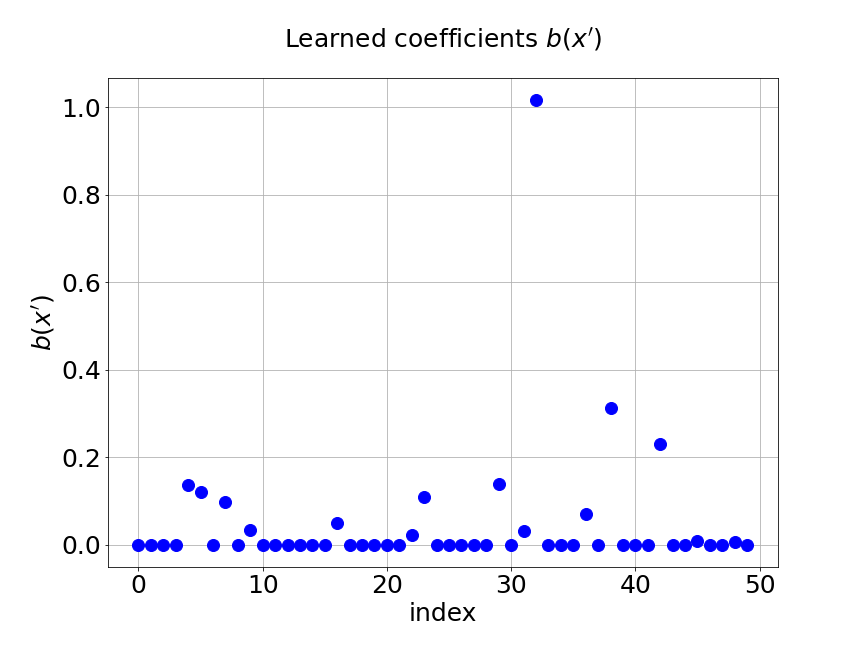
Now, we compare our model with PCA based DeepONet for the predicted mean and variance. The number of sample trajectories of is and the number of input sensors is for the test set. Figure 15a shows the predicted mean of our model and Figure 15b shows the difference between our model and the reference. Figure 15c presents the PCA based DeepONet predicted mean and Figure 15d is the corresponding difference. The mean of reference is shown in Figure 15e. In Figure 16, we present the predicted variance of our model, PCA based DeepONet model and their difference with the reference. Table 7 shows the relative errors of predicted mean and variance for the two models. We can see MultiAuto-DeepONet outperforms PCA based DeepONet in this case for both mean and variance. Figure 17 presents the coefficients and basis learned from MultiAuto-DeepONet model for one specific sample at corresponding sensor locations. We can see most of those values are zeros indicating a sparse structure.
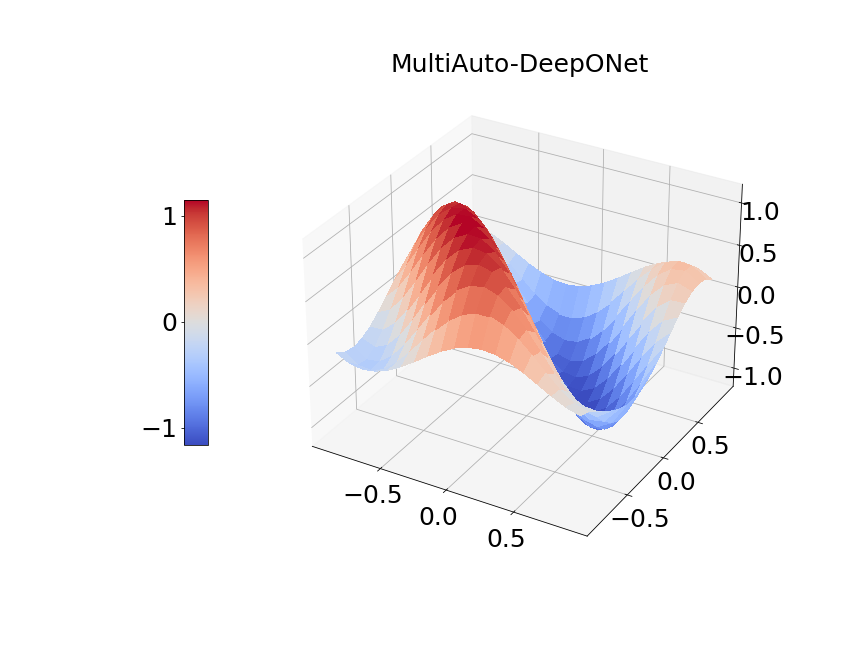
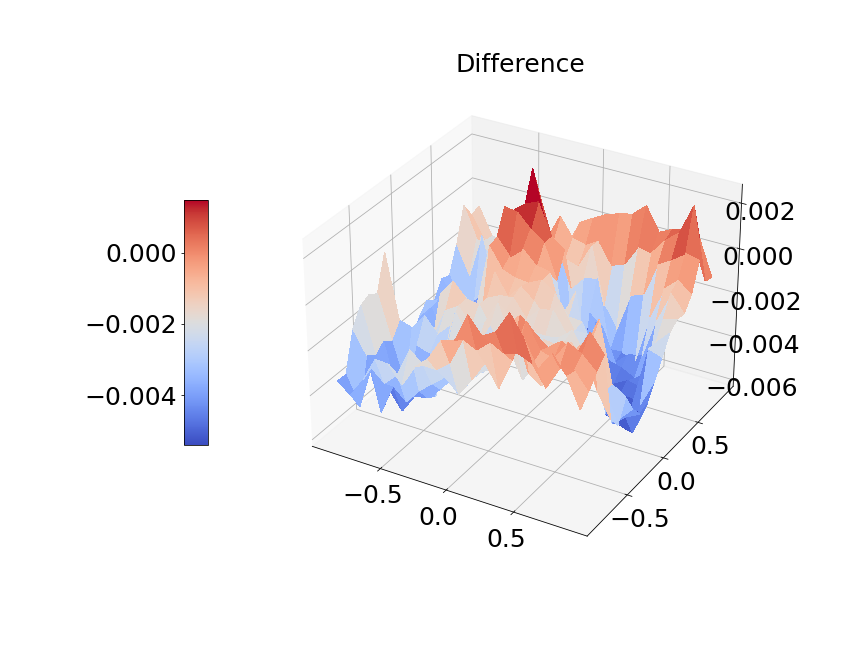
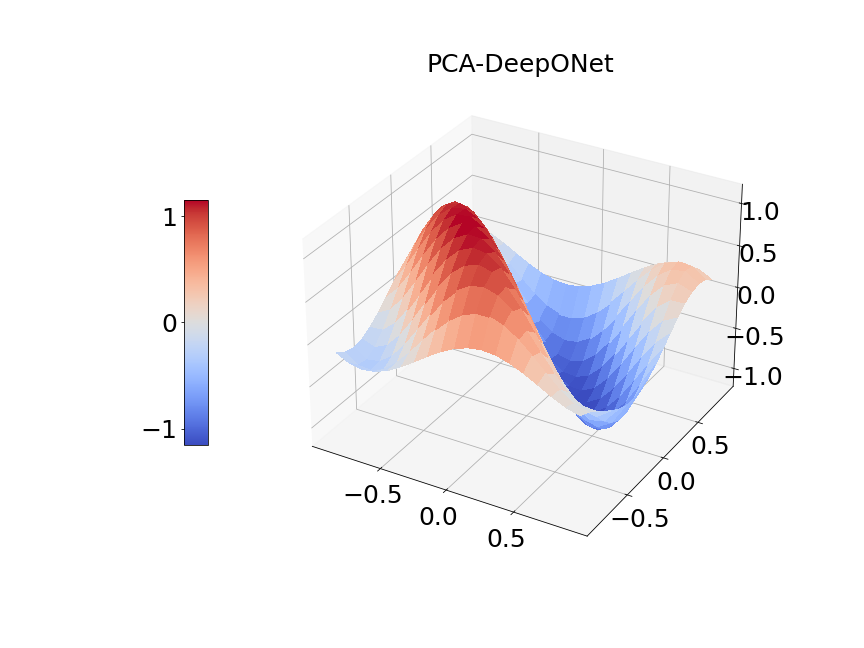
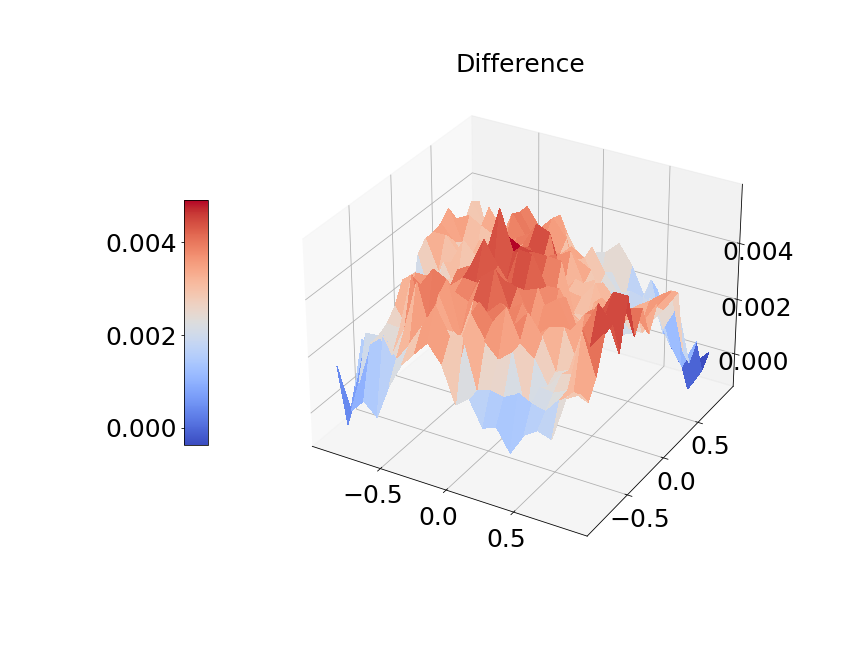
| PCA based DeepONet | MultiAuto-DeepONet | |
|---|---|---|
| Mean error | 0.0071 | 0.0046 |
| Variance error | 0.0300 | 0.0243 |
We perform another experiment in this section to show the effectiveness of prediction basis from the branch net in MultiAuto-DeepONet model. First we replace the branch net part, i.e. the basis with the basis learned using polynomial chaos expansion(PCE) and fix this part during the training process of network. Then the MSE of this method is compared with our original model. Note that we choose the order of Legendre polynomials in PCE method to be considering both the accuracy and computational efficiency in this case. During the training process of MultiAuto-DeepONet model, we adjust the number of basis and coefficients learned from the branch net and trunk nets to be the same with the number of basis in PCE method. The number of input sensors is and the number of input sample path is . The test MSE of PCE method and our model are approximately and respectively. This means MultiAuto-DeepONet model can capture the basis of the SDE solution better for this forward stochastic problem.
3.4 Forward problem: Korteweg–De Vries(KdV) Equation
In last example, we consider the forward problem of the Korteweg–De Vries (KdV) equation with time-dependent additive noise. It is a more complicated and nonlinear equation modeling waves on shallow water surfaces,
| (13) |
with initial condition,
| (14) |
Here, is the random space in this example. We know the analytical solution is,
| (15) |
where is defined to be,
| (16) |
Here, we use KL expansion to model as a Gaussian random field,
| (17) |
where is a constant and we set it to be , and are largest eigenvalues and corresponding eigenfunctions of the covariance kernel:
| (18) |
In this example, is set to be and . We also limit the spatial and the final time is set to be s. The input of our encoder is similar to the previous examples. The unsupervised trunk net is used to process the temporal input and the supervised trunk net is used to process the input of both spatial and temporal inputs . This also illustrates the capability of our model to deal with inputs of different dimensions.
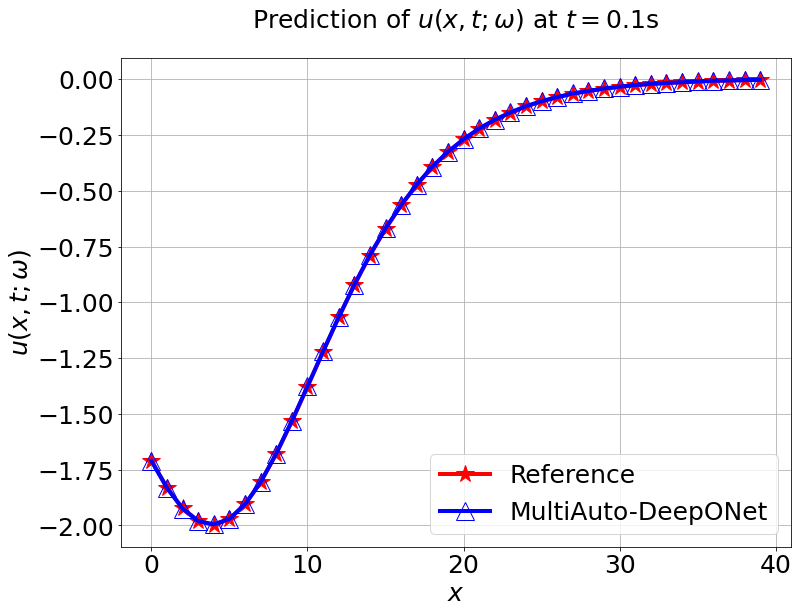
We first train the model with sample trajectories of . The number of input sensor for is , i.e. grid for . The latent dimension for the encoder is fixed to be . Other settings are the same as in two dimensional Poisson example. Figure 18a shows the training and validation loss. The red and blue lines match well meaning generalization error is very small. In Figure 18b, we present the model prediction and the reference solution at s of for one sample trajectory of . The test MSE is about and average relative error is around .
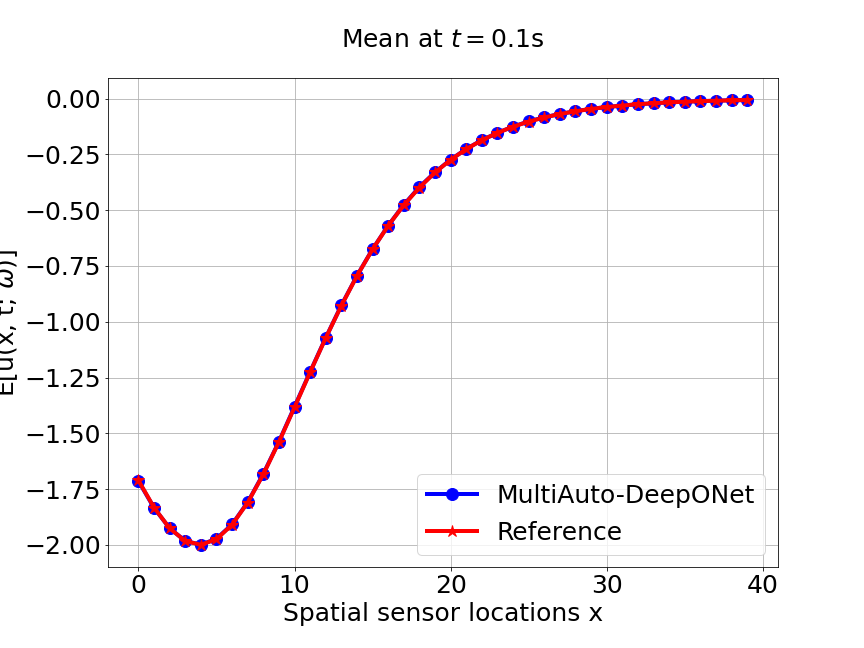
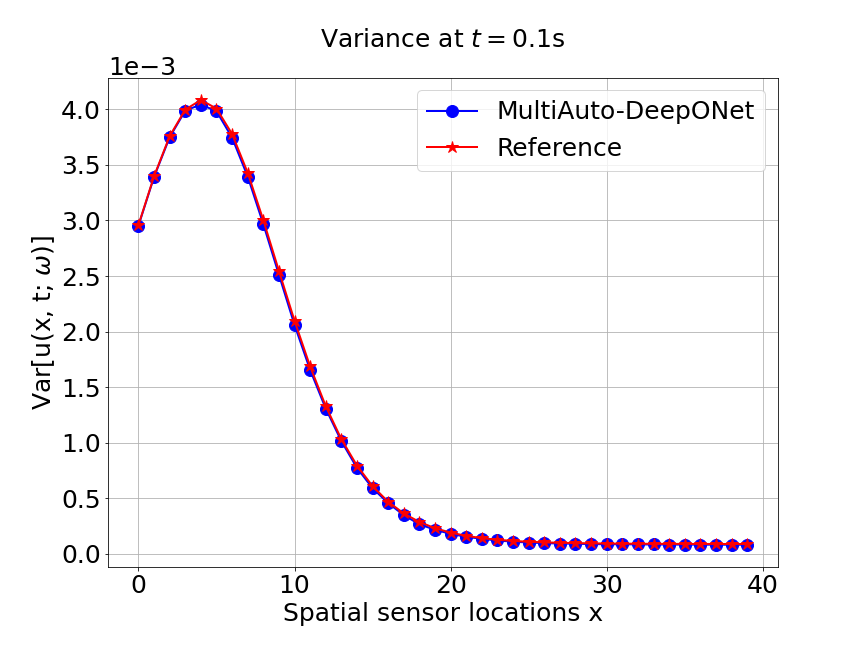
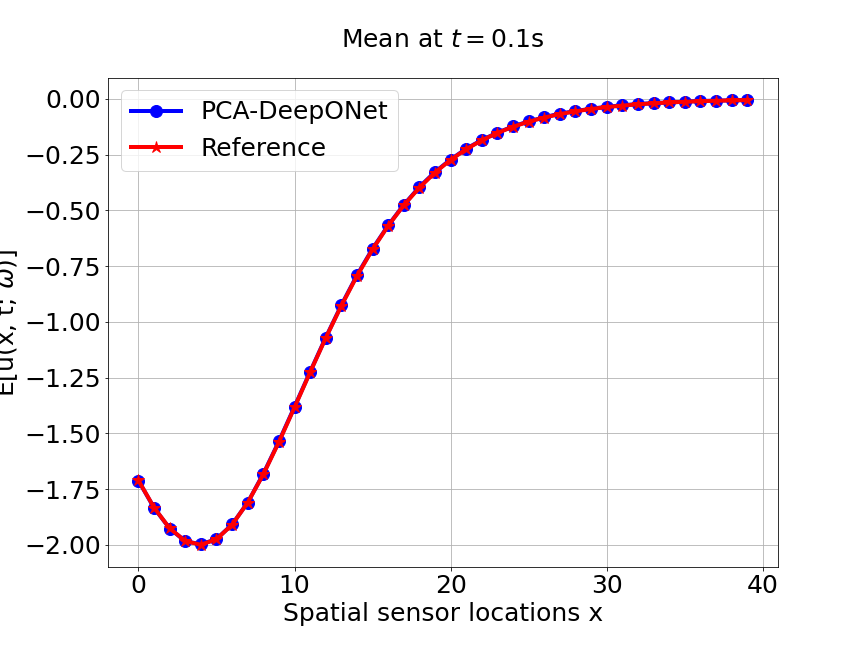
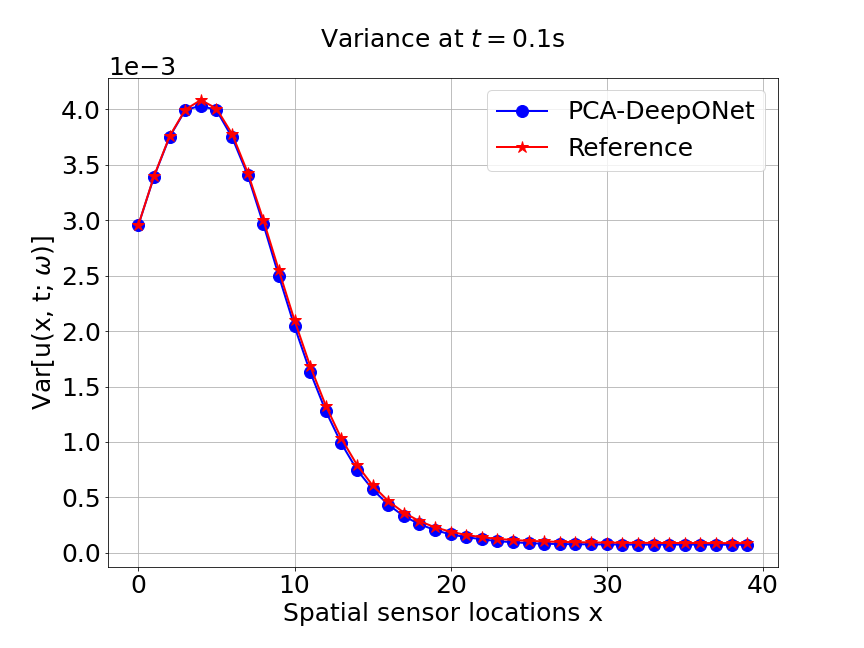
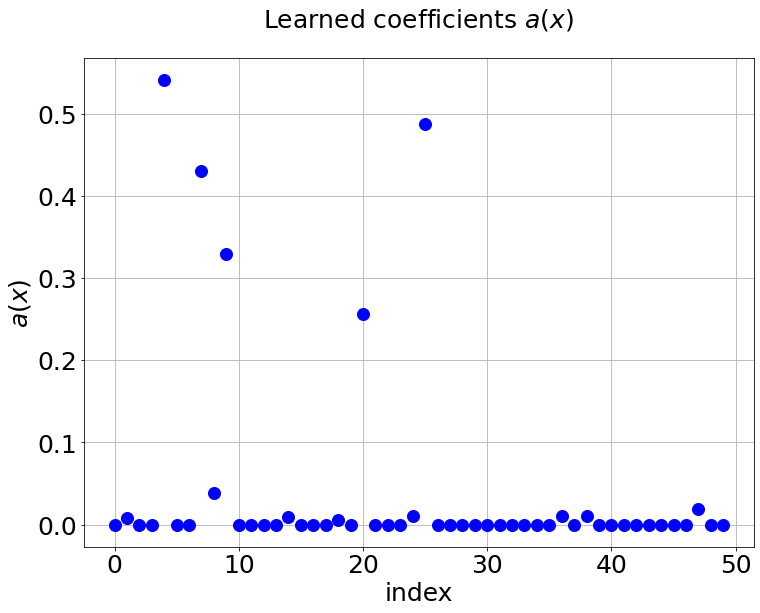
Now, we compare our model with PCA based DeepONet for the predicted mean and variance. The number of sample trajectories of is for the test set and the number of input sensor is the same as training data set. Figure 19a shows the predicted mean of our model and Figure 19c shows the predicted mean of PCA based DeepONet model at final time s. In Figures 19b and 19d, the predicted variance of our model and PCA based DeepONet model are presented. Table 8 shows the relative errors of predicted mean and variance for the two models. We can conclude that our model achieves better accuracy in terms of predicted mean and variance in this example. Again, Figure 20 presents the sparse coefficients and basis learned from MultiAuto-DeepONet model for one specific sample at corresponding sensor locations.
| PCA based DeepONet | MultiAuto-DeepONet | |
|---|---|---|
| Mean error | 0.00166 | 0.00107 |
| Variance error | 0.0153 | 0.0099 |
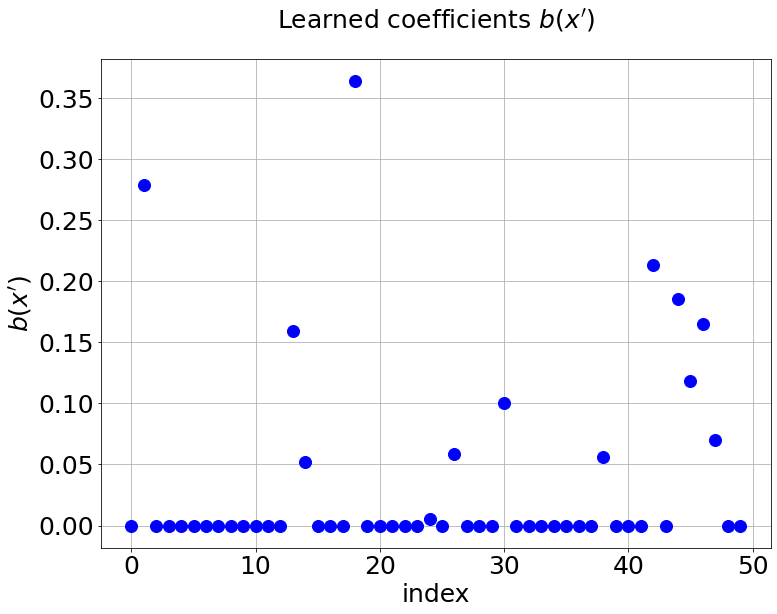
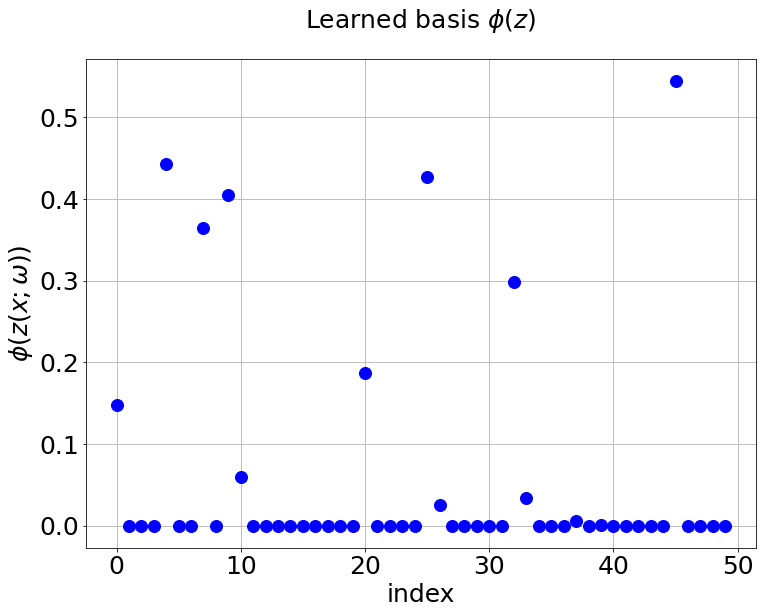
4 Conclusion
In this paper, we proposes the MultiAuto-DeepONet model to solve forward and inverse problem of stochastic differential equations. In particular, we design a new network structure which equips DeepONet with convolutional autoencoder. This design solves the SDE problems with DeepONet under high-dimensional settings. It also enables us to perform nonlinear dimension reduction and operator learning simultaneously. We also show the hidden features discovered by encoder can be used to generate samples of the input function. Furthermore, we perform uncertainty quantification and compare our model with PCA based DeepONet in our numerical experiments. The first numerical example is a forward problem of a simple stochastic ODE, the goal is to demonstrate the workflow of our method in detail. We also made a comparison with the original DeepONet and PCA based DeepONet in this example. The next two examples involve one and two dimensional stochastic Poisson equation respectively. PCA based DeepONet is compared with our model to show the effectiveness of MultiAuto-DeepONet in high-dimensional settings. In the two dimensional Poisson equation case, we also conduct an experiment of using polynomial chaos expansion to learn the basis for SDE solutions and compare it with our model to show the effectiveness of our method to learn the nonlinear basis. Finally, we present the forward problem of KdV equation to show our model can deal with inputs from different domains or with different scales. We add regularization in our network to introduce sparsity in this paper. The future work includes investigating the impact of different regularization terms, for example, and physics-informed regularization to the performance of our model. We will also present our works on learning more complex, especially higher dimensional stochastic operators in the future.
References
- [1] M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi, U. R. Acharya, et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information Fusion, 2021.
- [2] R. Bellman. Dynamic programming. Science, 153(3731):34–37, 1966.
- [3] S. Cai, Z. Wang, L. Lu, T. A. Zaki, and G. E. Karniadakis. Deepm&mnet: Inferring the electroconvection multiphysics fields based on operator approximation by neural networks. Journal of Computational Physics, 436:110296, 2021.
- [4] R. T. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equations. arXiv preprint arXiv:1806.07366, 2018.
- [5] T. Chen and H. Chen. Approximations of continuous functionals by neural networks with application to dynamic systems. IEEE Transactions on Neural networks, 4(6):910–918, 1993.
- [6] T. Chen and H. Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Transactions on Neural Networks, 6(4):911–917, 1995.
- [7] T. Chen, B. Rozovskii, and C.-W. Shu. Numerical solutions of stochastic pdes driven by arbitrary type of noise. Stochastics and Partial Differential Equations: Analysis and Computations, 7(1):1–39, 2019.
- [8] Y. Chen, L. Lu, G. E. Karniadakis, and L. Dal Negro. Physics-informed neural networks for inverse problems in nano-optics and metamaterials. Optics express, 28(8):11618–11633, 2020.
- [9] J. del Águila Ferrandis, M. S. Triantafyllou, C. Chryssostomidis, and G. E. Karniadakis. Learning functionals via lstm neural networks for predicting vessel dynamics in extreme sea states. Proceedings of the Royal Society A, 477(2245):20190897, 2021.
- [10] Y. Desmond Zhong, B. Dey, and A. Chakraborty. Symplectic ode-net: Learning hamiltonian dynamics with control. arXiv e-prints, pages arXiv–1909, 2019.
- [11] G. Di Nunno, B. K. Øksendal, and F. Proske. Malliavin calculus for Lévy processes with applications to finance, volume 2. Springer, 2009.
- [12] S. Dong and Z. Li. Local extreme learning machines and domain decomposition for solving linear and nonlinear partial differential equations. Computer Methods in Applied Mechanics and Engineering, 387:114129, 2021.
- [13] J. Fang, Y. Zhou, Y. Yu, and S. Du. Fine-grained vehicle model recognition using a coarse-to-fine convolutional neural network architecture. IEEE Transactions on Intelligent Transportation Systems, 18(7):1782–1792, 2016.
- [14] R. Ghanem and P. D. Spanos. Polynomial chaos in stochastic finite elements. 1990.
- [15] S. Goswami, M. Yin, Y. Yu, and G. E. Karniadakis. A physics-informed variational deeponet for predicting crack path in quasi-brittle materials. Computer Methods in Applied Mechanics and Engineering, 391:114587, 2022.
- [16] T. Graepel. Solving noisy linear operator equations by gaussian processes: Application to ordinary and partial differential equations. In ICML, volume 3, pages 234–241, 2003.
- [17] B. Hanin. Universal function approximation by deep neural nets with bounded width and relu activations. Mathematics, 7(10):992, 2019.
- [18] A. Hasan, J. M. Pereira, S. Farsiu, and V. Tarokh. Identifying latent stochastic differential equations with variational auto-encoders. arXiv preprint arXiv:2007.06075, 2020.
- [19] D. O. Hebb. The organization of behavior: A neuropsychological theory. Psychology Press, 2005.
- [20] H. Holden, B. Øksendal, J. Ubøe, and T. Zhang. Stochastic partial differential equations. In Stochastic partial differential equations, pages 141–191. Springer, 1996.
- [21] K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- [22] E. Hüllermeier and W. Waegeman. Aleatoric and epistemic uncertainty in machine learning: A tutorial introduction. 2019.
- [23] J. Jia and A. R. Benson. Neural jump stochastic differential equations. arXiv preprint arXiv:1905.10403, 2019.
- [24] H. Jin, J. Yang, and S. Zhang. Efficient action recognition with introducing r (2+ 1) d convolution to improved transformer. In 2021 4th International Conference on Information Communication and Signal Processing (ICICSP), pages 379–383. IEEE, 2021.
- [25] H. Kabir, M. Abdar, S. M. J. Jalali, A. Khosravi, A. F. Atiya, S. Nahavandi, and D. Srinivasan. Spinalnet: Deep neural network with gradual input. arXiv preprint arXiv:2007.03347, 2020.
- [26] A. Kendall, V. Badrinarayanan, and R. Cipolla. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv preprint arXiv:1511.02680, 2015.
- [27] Y. Khoo, J. Lu, and L. Ying. Solving parametric pde problems with artificial neural networks. European Journal of Applied Mathematics, 32(3):421–435, 2021.
- [28] D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [29] I. E. Lagaris, A. Likas, and D. I. Fotiadis. Artificial neural networks for solving ordinary and partial differential equations. IEEE transactions on neural networks, 9(5):987–1000, 1998.
- [30] I. E. Lagaris, A. C. Likas, and D. G. Papageorgiou. Neural-network methods for boundary value problems with irregular boundaries. IEEE Transactions on Neural Networks, 11(5):1041–1049, 2000.
- [31] L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, 2021.
- [32] L. Lu, Y. Shin, Y. Su, and G. E. Karniadakis. Dying relu and initialization: Theory and numerical examples. arXiv preprint arXiv:1903.06733, 2019.
- [33] Z. Mao, L. Lu, O. Marxen, T. A. Zaki, and G. E. Karniadakis. Deepm&mnet for hypersonics: Predicting the coupled flow and finite-rate chemistry behind a normal shock using neural-network approximation of operators. Journal of Computational Physics, 447:110698, 2021.
- [34] F. R. Menter. Two-equation eddy-viscosity turbulence models for engineering applications. AIAA journal, 32(8):1598–1605, 1994.
- [35] G. Milstein and M. Tretyakov. Solving parabolic stochastic partial differential equations via averaging over characteristics. Mathematics of computation, 78(268):2075–2106, 2009.
- [36] M. Mitzenmacher and E. Upfal. Probability and computing: Randomization and probabilistic techniques in algorithms and data analysis. Cambridge university press, 2017.
- [37] J. Mukhoti and Y. Gal. Evaluating bayesian deep learning methods for semantic segmentation. arXiv preprint arXiv:1811.12709, 2018.
- [38] M. A. Nabian and H. Meidani. A deep neural network surrogate for high-dimensional random partial differential equations. arXiv preprint arXiv:1806.02957, 2018.
- [39] E. Oja. Simplified neuron model as a principal component analyzer. Journal of mathematical biology, 15(3):267–273, 1982.
- [40] G. Pang, L. Yang, and G. E. Karniadakis. Neural-net-induced gaussian process regression for function approximation and pde solution. Journal of Computational Physics, 384:270–288, 2019.
- [41] T. Qin, Z. Chen, J. D. Jakeman, and D. Xiu. Deep learning of parameterized equations with applications to uncertainty quantification. International Journal for Uncertainty Quantification, 11(2), 2021.
- [42] J. Qu, W. Cai, and Y. Zhao. Learning time-dependent pdes with a linear and nonlinear separate convolutional neural network. Journal of Computational Physics, page 110928, 2022.
- [43] L. Qu, J. Lyu, W. Li, D. Ma, and H. Fan. Features injected recurrent neural networks for short-term traffic speed prediction. Neurocomputing, 451:290–304, 2021.
- [44] M. Raissi and G. E. Karniadakis. Hidden physics models: Machine learning of nonlinear partial differential equations. Journal of Computational Physics, 357:125–141, 2018.
- [45] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Machine learning of linear differential equations using gaussian processes. Journal of Computational Physics, 348:683–693, 2017.
- [46] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Numerical gaussian processes for time-dependent and nonlinear partial differential equations. SIAM Journal on Scientific Computing, 40(1):A172–A198, 2018.
- [47] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019.
- [48] S. H. Rudy, S. L. Brunton, J. L. Proctor, and J. N. Kutz. Data-driven discovery of partial differential equations. Science Advances, 3(4):e1602614, 2017.
- [49] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. Technical report, California Univ San Diego La Jolla Inst for Cognitive Science, 1985.
- [50] S. Särkkä. Linear operators and stochastic partial differential equations in gaussian process regression. In International Conference on Artificial Neural Networks, pages 151–158. Springer, 2011.
- [51] Y. Wang, W. Deng, and G. Lin. Bayesian sparse learning with preconditioned stochastic gradient mcmc and its applications. Journal of Computational Physics, 432:110134, 2021.
- [52] E. Weinan. Principles of multiscale modeling. Cambridge University Press, 2011.
- [53] N. Winovich, K. Ramani, and G. Lin. Convpde-uq: Convolutional neural networks with quantified uncertainty for heterogeneous elliptic partial differential equations on varied domains. Journal of Computational Physics, 394:263–279, 2019.
- [54] D. Xiu and G. E. Karniadakis. The wiener–askey polynomial chaos for stochastic differential equations. SIAM journal on scientific computing, 24(2):619–644, 2002.
- [55] X. Yang, H. Lei, N. A. Baker, and G. Lin. Enhancing sparsity of hermite polynomial expansions by iterative rotations. Journal of Computational Physics, 307:94–109, 2016.
- [56] D. Zhang, L. Lu, L. Guo, and G. E. Karniadakis. Quantifying total uncertainty in physics-informed neural networks for solving forward and inverse stochastic problems. Journal of Computational Physics, 397:108850, 2019.
- [57] Y. Zhang, Y. Chen, and C. Gao. Deep unsupervised multi-modal fusion network for detecting driver distraction. Neurocomputing, 421:26–38, 2021.
- [58] Y. Zhang, X. Zhu, and J. Gao. Hidden physics model for parameter estimation of elastic wave equations. Computer Methods in Applied Mechanics and Engineering, 381:113814, 2021.
- [59] Z. Zhou and Z. Yan. Solving forward and inverse problems of the logarithmic nonlinear schrödinger equation with pt-symmetric harmonic potential via deep learning. Physics Letters A, 387:127010, 2021.
- [60] Y. Zhu and N. Zabaras. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification. Journal of Computational Physics, 366:415–447, 2018.
- [61] Y. Zhu, N. Zabaras, P.-S. Koutsourelakis, and P. Perdikaris. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. Journal of Computational Physics, 394:56–81, 2019.