Multiscale Inference for High-Frequency Data
Abstract
This paper proposes a novel multiscale estimator for the integrated volatility of an Itô process, in the presence of market microstructure noise (observation error). The multiscale structure of the observed process is represented frequency-by-frequency and the concept of the multiscale ratio is introduced to quantify the bias in the realized integrated volatility due to the observation error. The multiscale ratio is estimated from a single sample path, and a frequency-by-frequency bias correction procedure is proposed, which simultaneously reduces variance. We extend the method to include correlated observation errors and provide the implied time domain form of the estimation procedure. The new method is implemented to estimate the integrated volatility for the Heston and other models, and the improved performance of our method over existing methods is illustrated by simulation studies.
Index Terms:
Bias correction; market microstructure noise; realized volatility; multiscale inference; Whittle likelihood.I Introduction
Over the last few decades there has been an explosion of available data in diverse areas such as econometrics, atmosphere/ocean science and molecular biology. It is essential to use this available data when developing and testing mathematical models in physics, finance, biology and other disciplines. It is imperative, therefore, to develop accurate and efficient methods for making statistical inference in a parametric as well as a non-parametric setting.
Many interesting phenomena in the sciences are inherently multiscale in the sense that there is an abundance of characteristic temporal and spatial scales. It is quite often the case that a simplified, coarse-grained model is used to describe the essential features of the problem under investigation. Available data is then used to estimate parameters in this reduced model [12, 17, 18]. This renders the problem of statistical inference quite subtle, since the simplified models that are being used are compatible with the data only at sufficiently large scales. In particular, it is not clear how and if the high frequency data that is available should be used in the statistical inference procedure.
On the other hand in many applications such as econometrics [32] and oceanography [13] the observed data is contaminated by high frequency observation error. Statistical inference for data with a multiscale structure and for data contaminated by high frequency noise share common features. In particular the main difficulty in both problems is that the model that we wish to fit the data to is not compatible with the data at all scales. This is an example of a model misspecification problem [20, p. 192].
Parametric and non-parametric estimation for systems with multiple scales and/or the usage of high frequency data has been studied quite extensively in the last few years for the two different types of models. First, the problem of estimating the integrated stochastic volatility in the presence of high frequency observation noise has been considered by various authors [1, 36]. Similar models and inference problems have also been studied in the context of oceanic transport [13]. It was assumed in [1, 36] that the observed process consists of two parts, an Itô process (i.e. the solution of an SDE, which is a semimartingale) whose integrated stochastic volatility (quadratic variation ) we want to estimate, and a high frequency noise component
| (1) |
are the sampled observations. The additional noise was used to model market microstructure.
It was shown for the model of (1) that using high frequency data leads to asymptotically biased estimators. In particular if all available data is used for the estimation of the quadratic variation of then the realized integrated volatility converges to the aggregated variance of the differenced observation noise. Subsampling is therefore necessary for the accurate estimation of the integrated volatility. An algorithm for estimating the integrated volatility which consists of subsampling at an optimal sampling rate combined with averaging and an appropriate debiasing step was proposed in [1, 36]. Various other estimators were suggested in [36, 32, 11, 15] for processes contaminated by high frequency nuisance structure.
Secondly, parameter estimation for fast/slow systems of SDEs for which a limiting SDE for the slow variable can be rigorously shown to exist was studied in [25, 24, 26]. In these papers the problem of making inferences for the parameters of the limiting (coarse-grained) SDE for the slow variable from observed data generated by the fast/slow system was examined. It was shown that the maximum likelihood estimator is asymptotically biased. In order to correctly estimate the parameters in the drift and the diffusion coefficient of the coarse-grained model from observations of the slow/fast system using maximum likelihood, subsampling at an appropriate rate is necessary. The subsampling rate depends on the ratio between the characteristic time scales of the fast and slow variables. A similar problem, with no explicit scale separation, was studied in [7].
All of the papers mentioned above propose inference methods in the time domain. Yet, it would seem natural to analyse multiscale and high frequency properties of the data in the frequency domain. Most of the time domain methods can be put in a unified framework as linear filtering techniques, i.e. as a convolution with a linear kernel, of some time-domain quadratic function of the data. The understanding of these methods is enhanced by studying them directly in the frequency domain, as convolutions in time are multiplications in frequency. Fourier domain estimators of the integrated volatility have been proposed for observations devoid of microstructure features, see [14, 2, 21]. Fourier domain estimators have also been used for estimating noisy Itô processes (i.e. processes of the form 1), see [22, 29, 30], based on smoothing the time domain quantities by using only a limited number of frequencies in the reconstruction.
The bias in the realized integrated volatility of the observed process due to the observation noise can be understood directly in the frequency domain, since the energy associated with each frequency is contaminated by the microstructure noise process. This bias is particularly damaging at high frequencies. In this article we propose a frequency-by-frequency de-biasing procedure to improve the accuracy of the estimation of the integrated volatility. The proposed estimation method can also be viewed in the time domain as smoothing the estimated autocovariance of the increments of the process, but where the implied time domain smoothing kernel is itself estimated from the observed process.
In this paper we will consider a regularly sampled Itô process with additive white noise superimposed upon it at each observation point , cf (1). The Itô process satisfies an SDE of the form
| (2) |
denotes a standard one dimensional Brownian motion and , are (in general) Itô processes, see for example the Heston model which is studied in Section III. The Brownian motions driving the three Itô processes can be correlated. The observations and the process are related through
| (3) |
We assume the data is regularly spaced. The length of the path is fixed. The additive noise is initially taken to be a white noise process with variance , and it is assumed to be independent of the noise that drives the Itô process . Our main objective is to estimate the integrated volatility, of the Itô process , from the set of observations . In the absence of market microstructure noise (i.e., when ) the integrated volatility can be estimated from the realized integrated volatility of the process [32]. In the presence of market microstructure noise this is no longer true, see also [36], and a different estimation procedure is necessary.
The proposed estimator can be described roughly as follows. Let denote the Discrete Fourier Transform (DFT) of the differenced sampled process, and similarly for and . The integrated volatility can be written in terms of the inverse DFT of the variance of . We calculate the bias in the variance of , when using its sample estimator to estimate the variance of The high frequency coefficients are heavily contaminated by the microstructure noise. With a formula for the bias it is possible to debias the estimated variance of the Fourier transform at every frequency, with the unknown parameters of the bias estimated using the Whittle likelihood [34, 35]. This produces a debiased estimator of the integrated volatility via an aggregation of the estimated variance, and we show also that the variance of the proposed estimator is reduced by the debiasing.
Our estimator shows highly competitive mean square error performance; it also has several advantages over existing estimators. First, it is robust with respect to the signal to noise ratio; furthermore, it is easy to formulate and to implement; in addition, it readily generalizes to the case of correlated observation errors (in time). Finally, the properties of our estimator are transparent using frequency domain analysis.
The rest of the paper is organized as follows. In Section II we introduce our estimator and present some of its properties, stated in Theorems 1 and 2. We also discuss the time-domain understanding of the proposed method and the extension of the method to the case where the observation noise is correlated. In Section III we present the results of Monte Carlo simulations for our estimator. Section IV is reserved for conclusions. Various technical results are included in the appendices.
II Estimation Methods
Let be given by (3), where the noise is independent of , is zero-mean and its variance at any time is equal to . The simplest estimator of the integrated volatility of would ignore the high frequency component of the data and use the realized integrated volatility of the observed process. The realized integrated volatility is given by
| (4) |
This estimator is both inconsistent and biased, see [15]. For comparative purposes, we define also the realized integrated volatility of the sampled process :
| (5) |
This cannot be used in practice as is not directly observed. Both these are estimators of the integrated volatility (quadratic variation) of .
II-A Fourier Domain Properties
We shall start by deriving an alternative representation of (4) to motivate further development. Firstly we define the increment process of a sample from a generic time series by and then the discrete Fourier Transform of by as by [27][p. 206]
| (6) |
Our proposed estimator will be based on examining the second order properties of . is the periodogram [5] defined for a time series and is an inefficient estimator of . Firstly we examine the properties of . We have, with denoting the local average of ,
| (7) | |||||
We define
and this to leading order approximates as for all but a few frequencies. We can also note that, since is an Itô process, it has almost surely continuous paths, which implies that
| (8) | |||
| (9) |
as So we only need, to leading order, calculate when calculating the properties of from (8) and (9). More formally we note that
We need to determine the first and second order structure of In general is a complex-valued random vector, which may not be a sample from a multivariate Gaussian distribution. The covariance matrix of a complex random vector is given by [23, 28]. We have
Furthermore, with ,
In particular we have that
| (10) | |||||
where the error terms are due to the Riemann approximation to an integral and thus it follows that
| (11) |
does not depend on the value of but is constant irrespectively of the value of . Malliavin and Mancino [21] in contrast under very light assumptions show how the Fourier coefficients of can be calculated from the Fourier coefficients of , using a Parseval-Rayleigh relationship, see also [30, 22]. We can from (10) make a stronger link from the Fourier transform to the integrated volatility than that of the Parseval-Rayleigh relationship, and shall use this ‘uniformity of energy’ to estimate the microstructure bias.
We note that the covariance between different frequencies is given by:
Let . We can bound the size of as increases. As is smooth in the modulus of the covariance can be bounded for increasing , as the Fourier transform decays proportionally to where is the number of smooth derivatives of . We can also directly note that the variance of the discrete Fourier transform of the noise is precisely (this is not a large sample result)
| (12) |
by virtue of being the first difference of white noise (see also [4]). The naive estimator can therefore be rewritten as, with :
| (13a) | |||||
| (13b) | |||||
| (13c) | |||||
| (13d) | |||||
The Parseval-Rayleigh relationship in (13a) is discussed in [22], and is used in [21]. We shall now develop a frequency domain specification of the bias of the naive estimator.
Lemma 1
(Frequency Domain Bias of the Naive Estimator) Let be an Itô process and assume that the covariance of and to be with the chosen sampling. Then the naive estimator of the integrated volatility given by (13) has an expectation given by:
We notice directly from (1) that the relative frequency contribution of and , i.e. compared to the noise contribution determines the inherent bias of . Estimator (13) is inconsistent and biased since it is equivalent to estimator (4), and such a procedure would give an unbiased estimator of the integrated volatility only when . When the estimator is expressed in the time domain the microstructure cannot be disentangled from the Itô process. On the other hand in the frequency domain, from the very nature of a multiscale process, the contributions to can be disentangled.
II-B Multiscale Modelling
To correct the biased estimator we need to correct the usage of the biased estimator of at each frequency. We therefore define a new shrinkage estimator [33, p. 155] of by
| (15) |
is referred to as the multiscale ratio and its optimal form for perfect bias correction is for an arbitrary Itô process given by
| (16) |
This quantity cannot be calculated without explicit knowledge of and . We can however use (10) to simplify (16) to obtain
| (17) |
For a fixed
where the order terms follow from the continuity of . We can define a new estimator for the true via:
where
Recall that . Consequently, to leading order we can remove the bias from the naive estimator if we know the multiscale ratio. We shall now develop a multiscale understanding of the process under observation and use this to construct an estimator for the multiscale ratio.
II-C Estimation of the Multiscale Ratio
We have a two-parameter description on how the energy should be adjusted at each frequency. We only need to determine estimators of . We propose to implement the estimation using the Whittle likelihood methods (see [3] or [34, 35]). For a time-domain sample that is stationary, if suitable conditions are satisfied, see for example [8], then the Whittle likelihood approximates the time domain likelihood, with improving approximation as the sample size increases. It is possible to show a number of suitable properties of estimators based on the Whittle likelihood, see [34, 35]. For processes that are not stationary, such conditions are in general not met, and so the function can be used as an objective function to construct estimators, but not as a true likelihood. The Whittle log-likelihood is defined [34, 35] by
If is not stationary, then as long as the total contributions of the covariance of the incremental process can be bounded, using this likelihood will asymptotically (in ) produce suitable estimators, as we shall discuss further.
Definition II.1
(Multiscale Energy Likelihood)
The multiscale energy log-likelihood is then defined using (10) as:
| (18) |
We stress that strictly speaking this may not be a (log-)likelihood, but merely a device for determining the multiscale ratio. We maximise this function in to obtain a set of estimators .
Theorem 1
(The Estimated Multiscale Ratio)
The estimated multiscale ratio is given by
| (19) |
where and maximise given in (18). satisfies
| (20) |
Proof:
See Appendix A. ∎
Combining (15) with (19) the proposed estimator of the spectral density of is:
| (21) |
where is given by (19).
Theorem 2
Proof:
See Appendix B. ∎
We also note that
| (23) | |||||
unless . We note that the multiscale estimator has lower variance than the naive method of moments estimator due to the fact that . We have thus removed bias and simultaneously decreased the variance, the latter effect usually being the main purpose of shrinkage estimators. Note that if we knew the true multiscale ratio and used it rather than (i.e. used ) then we would expect an estimator from this quantity to recover the same variance as the estimator based on the noise-free observations. This loss of efficiency is inevitable, as we have to estimate . Finally we can also construct a Whittle estimator for the integrated volatility by starting from (10) and taking
| (24) |
The sampling properties of are found in Appendix A, and is asymptotically unbiased. The results in Appendix A imply that
| (25) |
We see that the variance depends on the length of the time course, the inverse of the signal to noise ratio, the square root of the sampling period and the fourth power of the “average standard deviation” of the process., We may compare the variance of (23) with the variance of (25), to determine which estimator of and is preferable. We shall return to this question of relative performance in the examples section, but intuitively argue that and are more or less the same estimator, with the latter estimator being more intuitive to explain.
II-D Time Domain Understanding of the Method
We may write the frequency domain estimator of the spectral density of in the time domain to clarify some of its properties. We define
which when is a stationary process corresponds to the estimated autocovariance sequence of using the method of moments estimator [5, Ch. 5]. We then have
| (26) |
and so the estimated autocovariance of the process, namely , is a smoothed version of . We can therefore view as the Fourier transform of a smoothed version of the autocovariance sequence of . We let
| (27) |
be the continuous analogue of . To find the smoothing kernel we are using we need to calculate
| (28) | |||||
Thus utilizing integration in the complex plane (see Appendix C) we obtain that
| (31) |
These are both decreasing sequences in . We write If we can additionally assume that decreases sufficiently rapidly to be near zero by then we find that
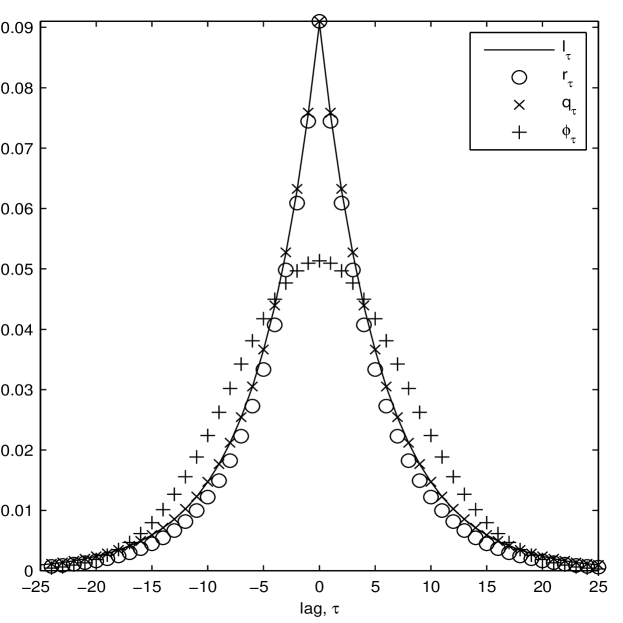
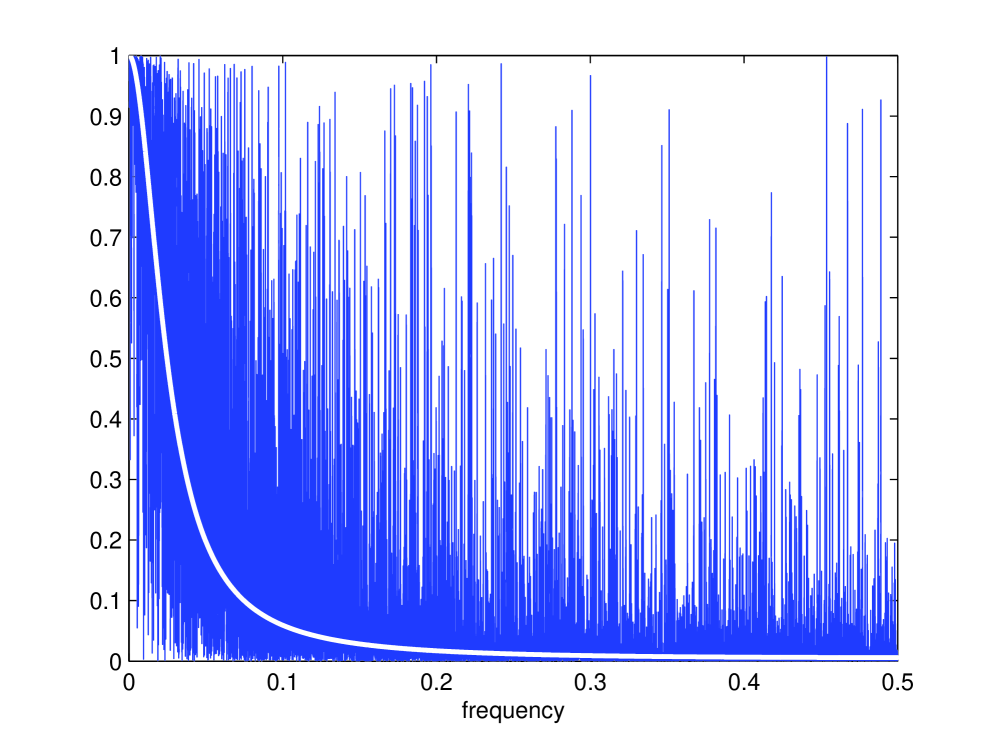
In the limit of no observation noise () then this sequence becomes a delta function centered at . Let us plot these functions, i.e. , and for a chosen case of (the approximate SNR used in a later example), in Figure 1 (left). We see that theory coincides very well with practise, and almost perfect agreement between the three functions. is however a strange choice of kernel, if dictated by the statistical inference problem: it has heavier tails than the common choice of the Gaussian kernel, and is extremely peaked around zero (a Gaussian kernel with the same variance has been overlaid in Figure 1). This is not strange, as we are trying to filter out correlations due to non-Itô behaviour, but counter to our intuition about suitable kernel functions, as the differenced Itô process exhibits very little covariance at any lag but zero, the sharp peak at zero is necessary.
II-E Correlated Errors
In many applications we need to consider correlated observation noise. We assume that despite being dependent the is a stationary time series. Stationary processes can be conveniently represented in terms of aggregations of uncorrelated white noise processes, using the Wold decomposition theorem [6][p. 187]. We may therefore write the zero-mean observation as
| (32) |
where and satisfies and , a model also used in [31]. Common practise would involve approximating the variable by a finite number of elements in the sum, and thus we truncate (32) to some . We therefore model the noise as a Moving Average (MA) process specified by
| (33) |
and the covariance of the DFT of the differenced process takes the form:
| (34) |
This leads to defining a new multiscale ratio replacing of (17) with . We then obtain a new estimator of . In general the value of is not known. To simultaneously implement model choice, we need to penalize the likelihood. We define the corrected Aikake information criterion (AICC) by [6, p. 303] (refer to (18) for with replaced by )
| (35) |
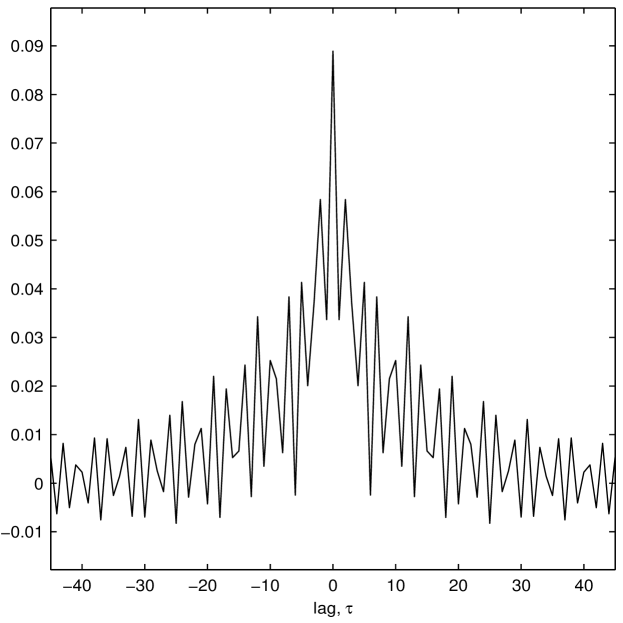
By minimizing this function, in , and , we obtain the best fitting model for the noise accounting for overfitting by using the penalty term. With this method we retrieve a new multiplier that is applied in the Fourier domain, which corresponds to a new smoother in the Fourier domain, where the smoothing window (and its smoothing width) have been automatically chosen by the data. See an example of such a smoothing window in in Figure 1 (right). Here has been estimated from an Itô process immersed in an MA noise process. The spectrum of the MA has a trough at frequency 0.42. We therefore expect to reinforce oscillations at period , which is evident from the oscillations of the estimated kernel. For more details of this process see section III-E.
III Monte Carlo Studies
In this section we demonstrate the performance of the multiscale estimator through Monte Carlo simulations. We first describe the de-biasing procedure of the estimator for the Heston Model using Fourier domain graphs. We then present bias, variance and mean square error results of various estimators (including the multiscale estimator, the naive estimator and the first-best estimator developed in [36]), for the Heston Model as well as Brownian and Ornstein Uhlenbeck processes. We then consider the case where the sample path in a Heston Model is much shorter and another case where the microstructure noise is greatly reduced. Finally, we consider the case of correlated errors and show how a stationary noise process can be captured using model choice methods and then the integrated volatility can be estimated using the adjusted multiscale estimator.
III-A The Heston Model
The Heston model is specified in [16]:
| (36) |
where , and and are correlated 1-D Brownian motions. We will use the same parameter values to the ones that were used in [36], namely and the correlation coefficient between the two Brownian motions B and W is . We set and , which is the long time limit of the expectation of the process .111
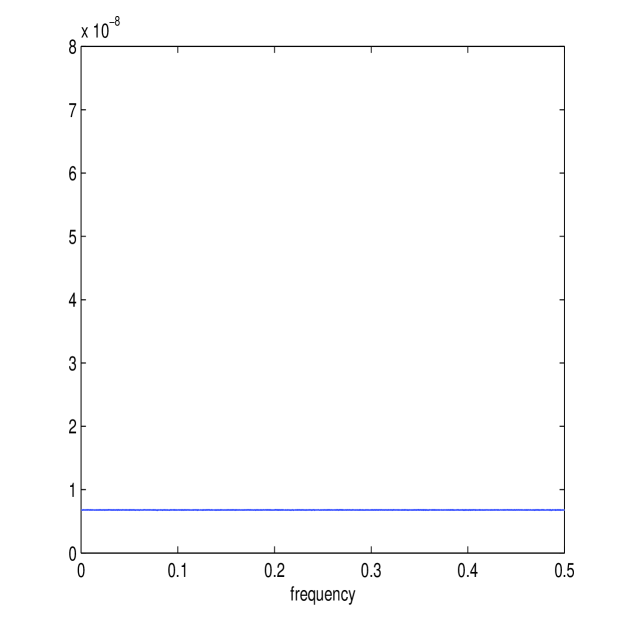
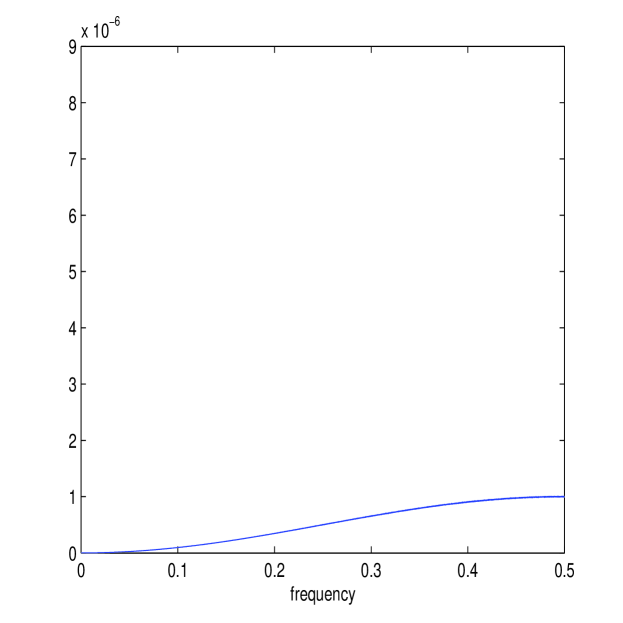
We calculate and directly from simulated data and average across realizations, producing Figure 2, where is indicated by its frequency , and only plotted for , as the spectrum (or ) is symmetric. We see directly from these plots that (on average as we showed) is constant whilst is strongly increasing with , completely dwarfing the other spectrum at large . (11) implies that an equal weighting is given to all frequencies for the differenced Itô process. The noise process will in contrast have a spectrum that is far from flat, and a suitable bias correction would shrink the estimator of at higher frequencies.
We also calculate and for one simulated path, displayed in Figure 3. Here we have used the same sample length and noise intensity as in [36]: day and . The length of the sample path, day or with , corresponds to one trading day, since we take one trading day to be long. Notice the different shape of the two periodograms. will not be distinguishable from at higher frequencies, despite the moderate to low intensity of the market microstructure noise. If we observed the two components and separately, then the multiscale ratio could be estimated from and using the method of moments formula. In this case, we would estimate by the sample Fourier Transform variances
| (37) |
The corresponding estimator of the integrated volatility becomes
| (38) |
The estimated multiscale ratio , for the Heston model with the specified parameters, is plotted in Figure 4.
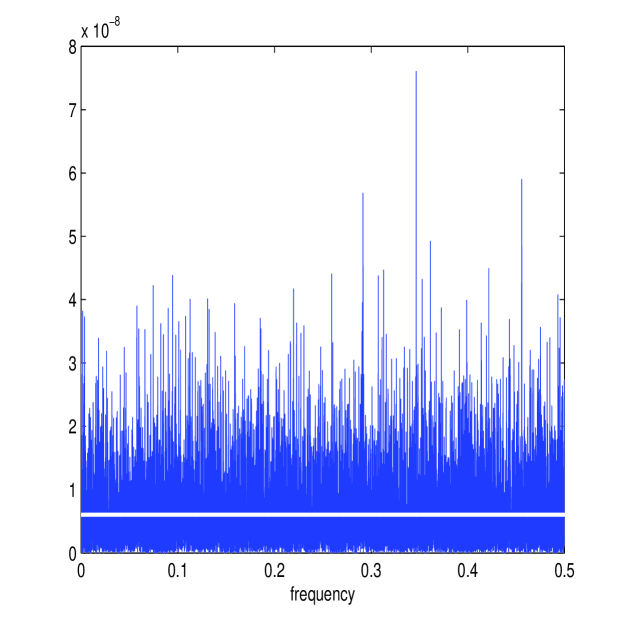
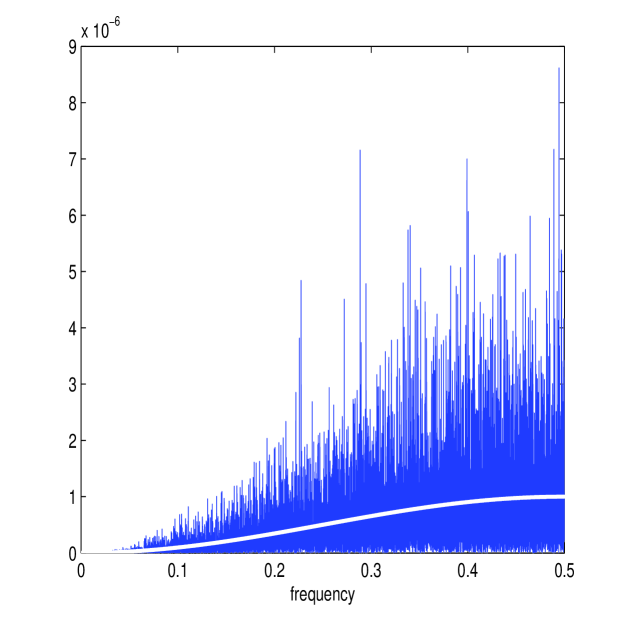
The multiscale ratio cannot be estimated using the method of moments in realistic scenarios, as we only observe the aggregated process and not the two processes and separately. Figure 3 displays the estimated multiscale ratio applied to over one path realisation. This plot suggests that the energy over the high frequencies has been shrunk and that is a good approximation to . It therefore seems not unreasonable that the summation of this function across frequencies should make a good approximation to the integrated volatility.
The parameters ( and ) are found separately for each path using the MATLAB function fmincon on (18). Figure 3 shows and (in white) plotted over the periodograms and for one simulated path. The approximated values of and are quite similar to the averaged periodograms of Figure 2; in fact the accuracy of the new estimator depends on how consistently these parameters are estimated in the presence of limited information from the sampled process . Figure 4 shows the corresponding estimated multiscale ratio (in white) from this simulated path, as defined in (19). The function decays, as expected, so that it will remove the high-frequency microstructure noise in the spectrum of ; the ratio is also a good approximation of . Figure 3 shows , which is again similar to . It would appear that the new estimator has successfully removed the microstructure effect from each frequency.
It is worth noting that the ratios and quantify the effect of the multiscale structure of the process. If is zero (ie. there is no microstructure noise), then no correction will be made to the spectral density function (the ratio will equal 1 at all frequencies). So in the case of zero microstructure noise, the estimate would recover and from (13) the estimate of the integrated volatility would simply be the realized integrated volatility of the observable process.
We investigate the performance of the multiscale estimator using Monte Carlo simulations. In this study 50,000 simulated paths are generated. Table I displays the results of our simulation, where biases, variances and errors are calculated using a Riemann sum approximation of the integral
| (39) |
The two estimators and (see (5) and (38) respectively) are both included for comparison, even though these require use of the unobservable process. The performance of the first-best estimator in [36] (denoted by ) is also included as a well-performing and tested estimator using only the process, as is the naive estimator of the realized volatility on at the highest frequency, , given in (4) (the fifth-best estimator in [36]). We also include the performance of , defined in (24).
Table I shows that the new estimator, , is competitive with the first-best approach in [36], , as an estimator of the integrated volatility for the Heston model with the stated parameters. For this simulation the new method performed marginally better. The similar performance of the two estimators is quite remarkable, given their different approach; both estimators involve a bias-correction, [36] perform this globally by weighting different sampling frequencies, whilst we correct locally at each frequency. The realized integrated volatility of at the highest frequency, , produces disastrous results, as expected.
| Sample bias | Sample variance | Sample RMSE | |
|---|---|---|---|
We also note that performs more or less identically to These two estimators can almost be used interchangeably due to the invariance property of a maximum likelihood estimator. This observation is born out by our simulation studies, and we henceforth only report results for . Note that the variance of can be found from (25). To compare theory with simulations we note that the average estimated standard deviation is whilst the expression for the variance to leading order gives an expression for the standard deviation of , using the parameter values of and .
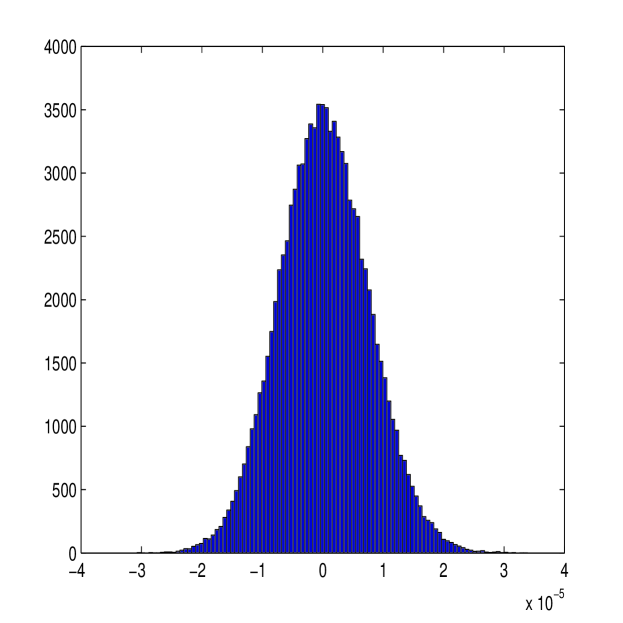
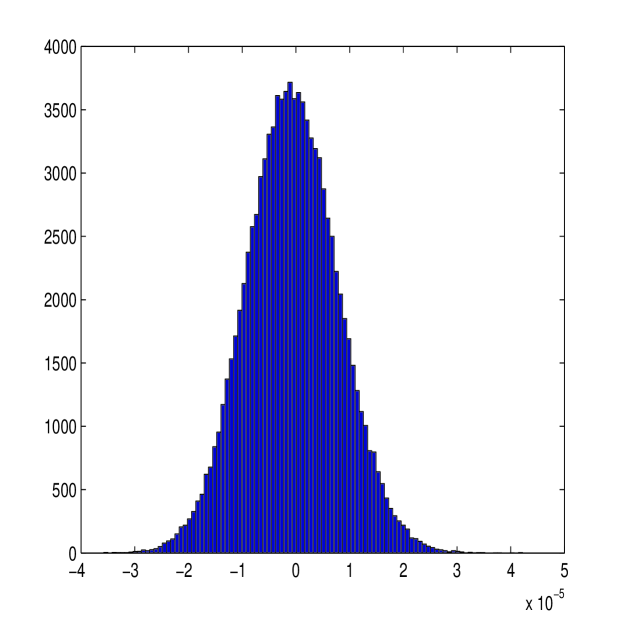
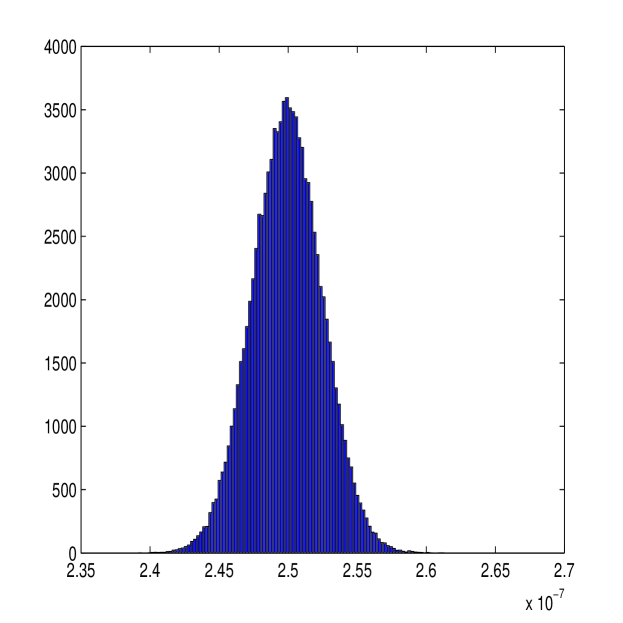
A histogram of the observed bias of the new estimator is plotted in Figure 5 along with a histogram of the observed bias of the first-best estimator in [36]. The observed bias of our estimator follows a Gaussian distribution centred at zero, suggesting that this estimator is unbiased, as out results claim to be true. Comparing our estimator to the first-best estimator, it can be seen that the new estimator has similar magnitudes of error also (hence the similar Root Mean Square Error (RMSE)).
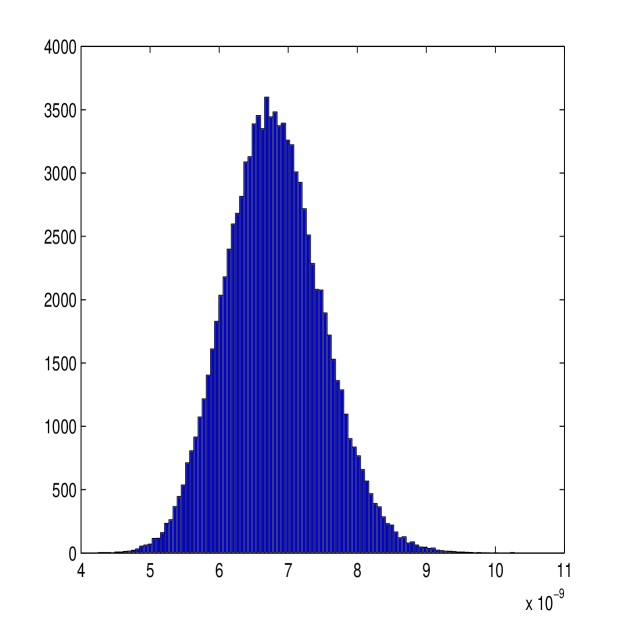
The new estimator requires calculation of and which will vary over each process due to the limited information given from the process. The stability of this estimation is of great importance if the estimator is to perform well. Figure 6 shows the distribution of the parameters and over the simulated paths. The parameter estimation is quite consistent, with all values estimated within a narrow range. Figure 2 suggests that these estimates are roughly unbiased; as and (as , at ).
III-B Brownian Process and Ornstein Uhlenbeck Process
We repeated our simulations for a Brownian Process given by:
| (40) |
where . We otherwise keep the same simulation setup as before with 50,000 simulated paths of length 23,400. The results are displayed in Table II. The new estimator, , again delivers a marked improvement on the naive estimator, , and performs marginally better than the first-best estimator in [36], .
| Sample bias | Sample variance | Sample RMSE | |
|---|---|---|---|
We also performed a Monte Carlo simulation for the Ornstein Uhlenbeck process given by:
| (41) |
where also . Again we retain the same simulation setup and the results are displayed in Table III. The results are almost identical to that of the Brownian process, with the new estimator again outperforming other time-domain estimators.
| Sample bias | Sample variance | Sample RMSE | |
|---|---|---|---|
III-C Comparing estimators over shorter sample lengths
This section compares estimators for a shorter sample length which will reduce the benefit of subsampling due to the variance issues of small-length data but will also affect the variance of the multiscale ratio (cf Theorem 1).
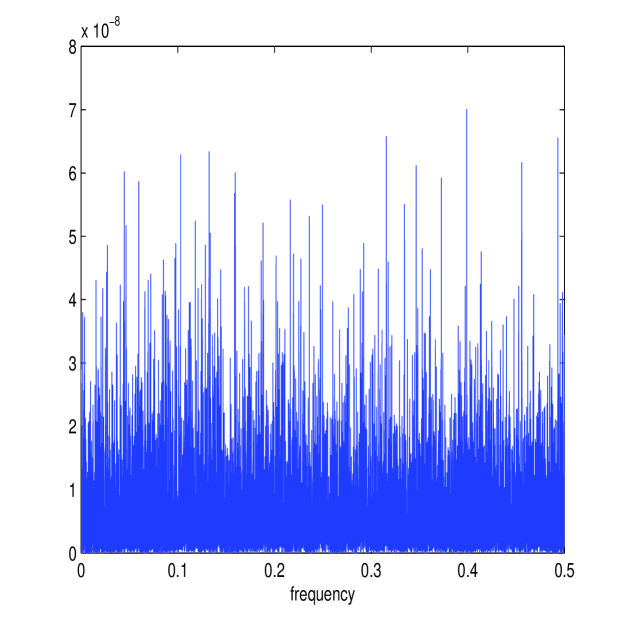
The simulation setup is exactly the same as before (using the Heston model with the same parameters) except that , the simulation length, is reduced by a factor of 10 to 0.1 days or . Before the results of the simulation are reported, it is of interest to see whether the frequency domain methods developed still model each process accurately. Figure 7 shows the calculated and (in white) together with the periodograms and for one simulated path. The estimator still approximates the energy structure of the processes accurately. Figure 7 also shows the corresponding estimate of the multiscale ratio (in white) from this simulated path (together with ) and the corresponding plot of . The new estimator has removed the microstructure noise effect and has formed a good approximation of . The approximation of the periodograms is still accurate despite the shortening of available data.
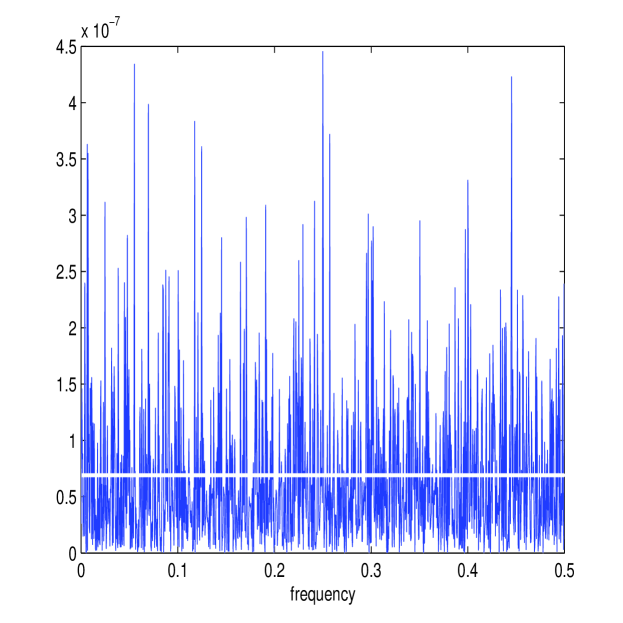
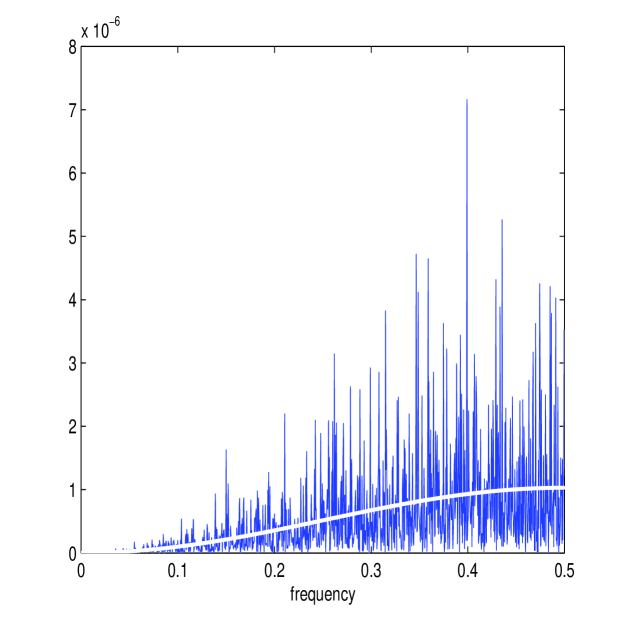
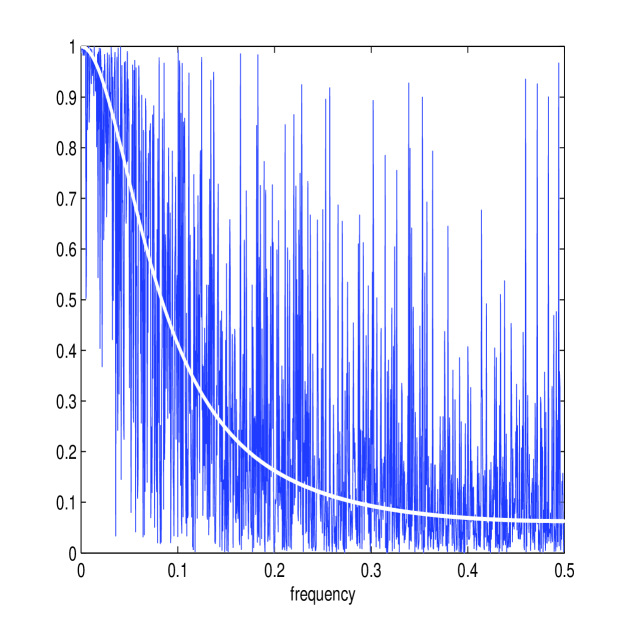
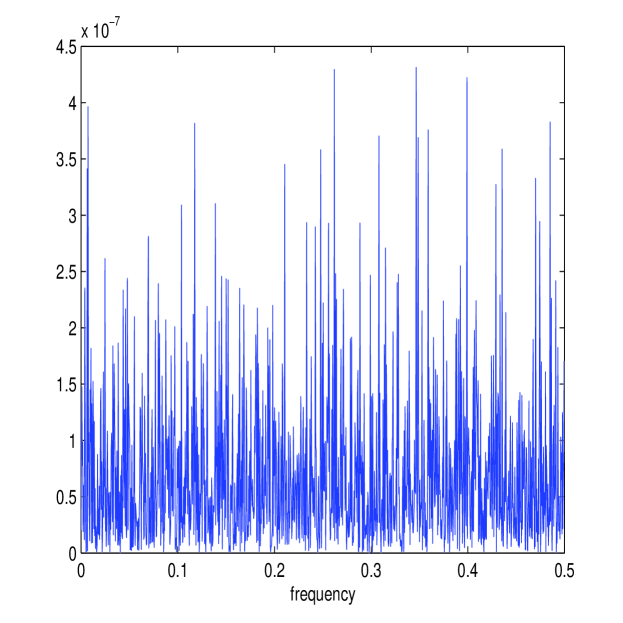
Table IV displays the accuracy of the estimators over the 50,000 simulated paths. The first-best estimator in [36], , and the new estimator, , are once again comparable in performance and both estimates are close to the best attainable RMSE given by, , the realized integrated volatility on .
| Sample bias | Sample variance | Sample RMSE | |
|---|---|---|---|
III-D Comparing estimators with a low-noise process
This section compares estimators for smaller levels of microstructure noise. Reducing the microstructure noise will reduce the need to subsample. The first-best estimator in [36], , will have a higher sampling frequency and the new estimator will reduce its estimate of accordingly. For very small levels of noise, however, the first-best estimator will become zero, as the optimal number of samples becomes (the highest available). This possibility is now examined, using the Heston model as before, with all parameters unchanged except the noise is reduced by a factor of 10, ie. . Note that the path length is kept at its original length of day.
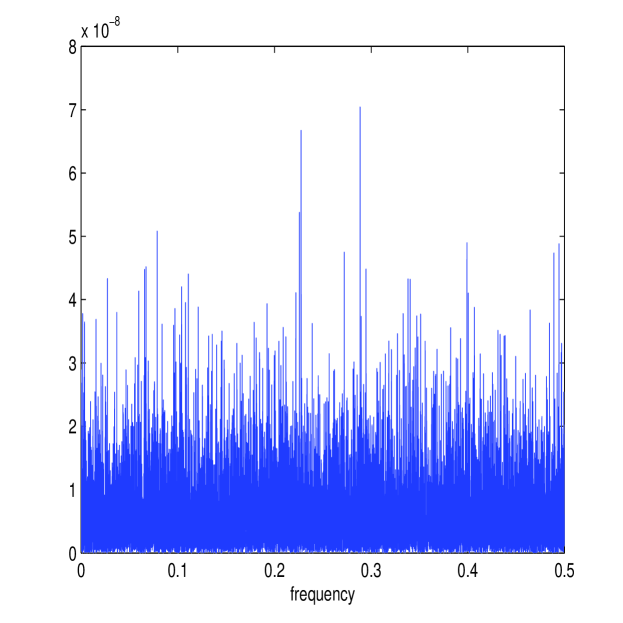
Figure 8 shows the estimates of and (in white) along with the periodograms and for one simulated path along with the corresponding estimate of the multiscale ratio (in white) (plotted over the approximated ) and the corresponding plot of . The estimation method works well again; notice how the magnitude of the microstructure noise has been greatly reduced (the scale is now of order rather than ) causing the multiscale ratio to be more tempered across the high frequencies than it was before, due to the smaller microstructure noise. Nonetheless, the new estimator has still detected the smaller levels of noise in the data.
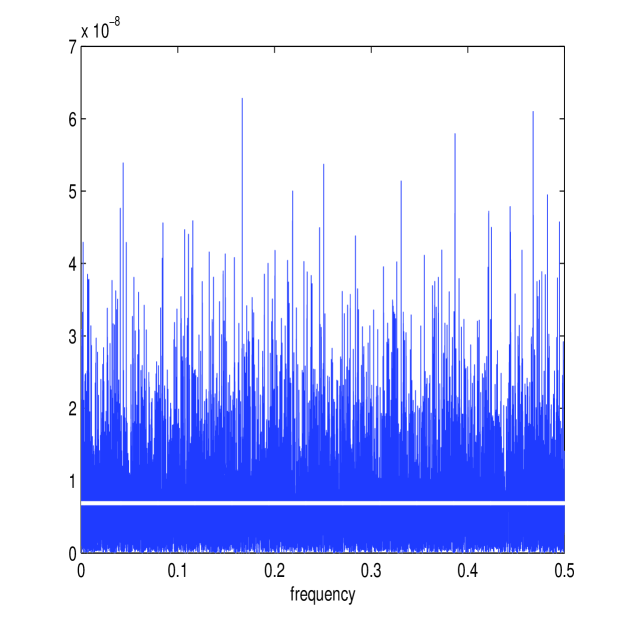
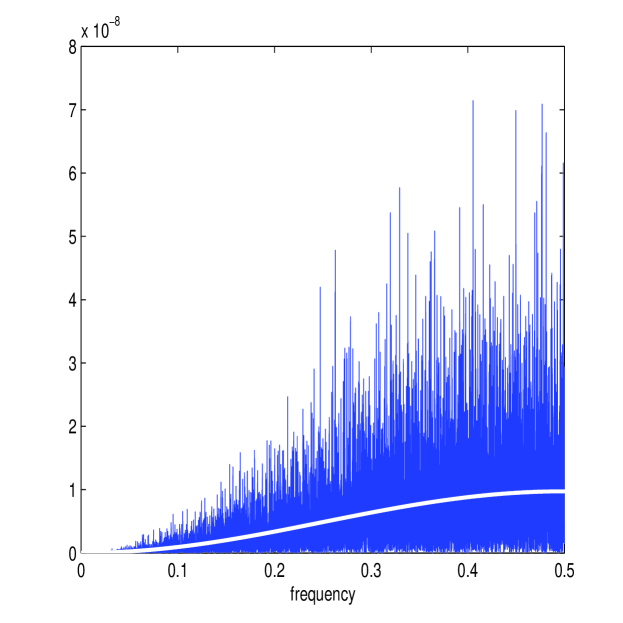
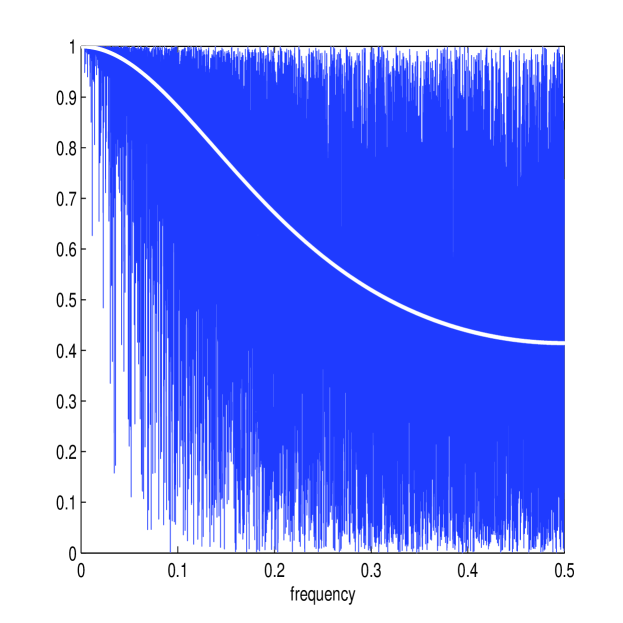
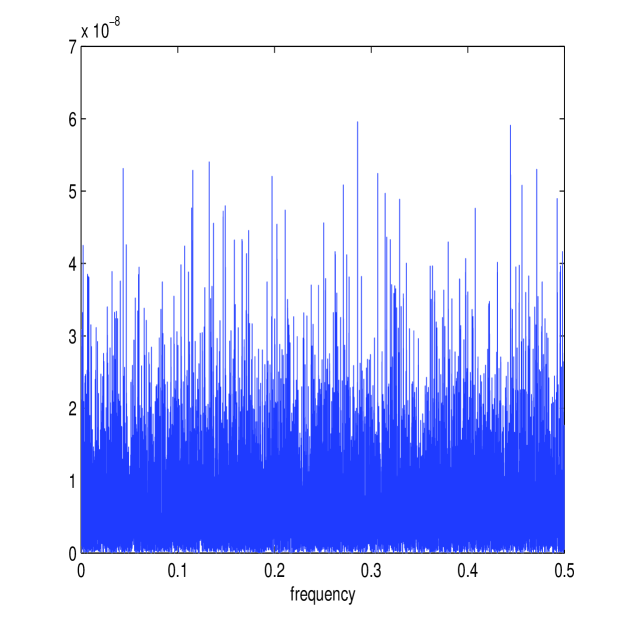
Table V reports on the results of 50,000 simulations performed as before. The first-best estimator of [36], , categorically failed for this model. This is due to the fact that the optimal number of samples was always equal to , the total number of samples available. Therefore, the first-best estimator was always zero. The second-best estimator in [36], denoted by , was reasonably effective. This is simply an estimator that averages estimates calculated from sub-sampled paths at different starting points and is therefore asymptotically biased. The new estimator, , was remarkably robust, with RMSE very close to the RMSE of estimators based on the process. The difference in performance between estimators using and estimators using is expected to become smaller with less microstructure noise and this can be seen by the similar order RMSE errors between all estimators. Nevertheless, the new estimator was much closer in performance to the realized integrated volatility on than it was to any other estimator on , a result that demonstrates the precision and robustness of this new estimator of integrated volatility.
| Sample bias | Sample variance | Sample RMSE | |
|---|---|---|---|
III-E Correlated Noise
In this section we consider microstructure noise that is correlated. If this process is stationary, the noise process can be modelled as an MA process (as described in Section II-E), and the corresponding parameters can be estimated by maximising the multiscale Whittle likelihood using (17) and (34). Figure 9 shows the multiscale estimator applied to the Heston Model (with the same parameters as before) with a microstructure noise that follows an MA(6) process (parameters given in the caption). The Whittle estimates (in white) form a good approximation of and despite the more complicated nuisance structure. The corresponding estimate of the multiscale ratio (in white) therefore removes energy from the correct frequencies and the corresponding plot of is a good approximation of . This is the same noise process and Itô process for which we calculated the optimal smoothing window in section II-E, and the trough in the noise at about corresponds to the oscillations in the kernel plotted in Figure 1.
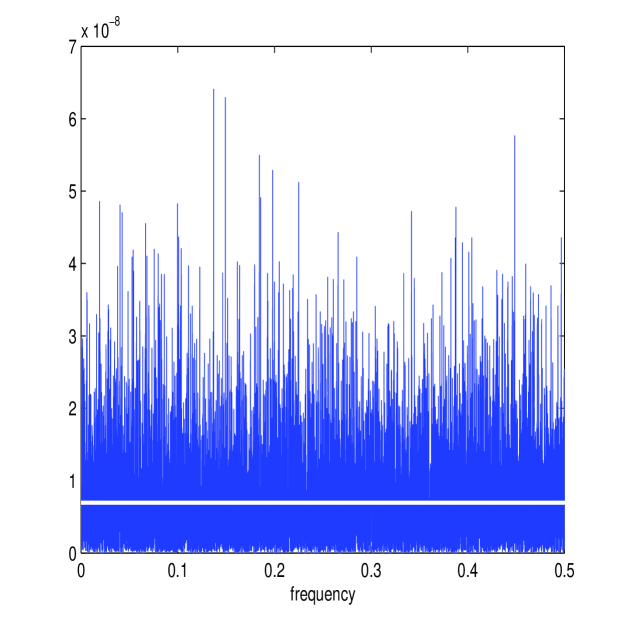
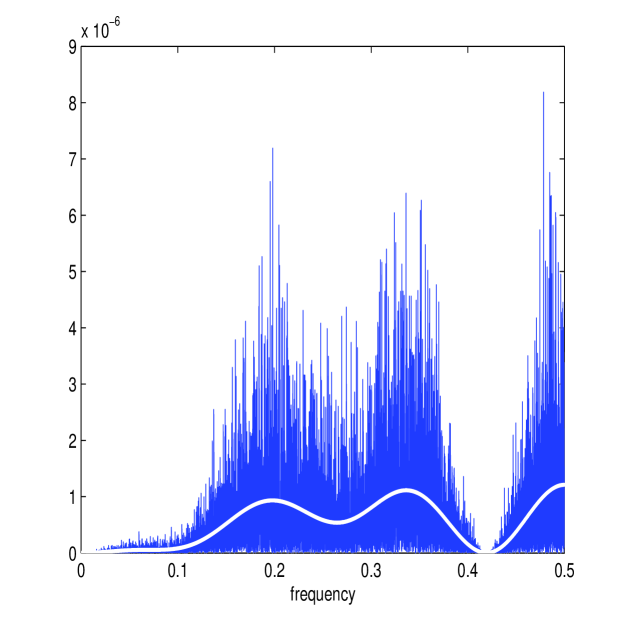
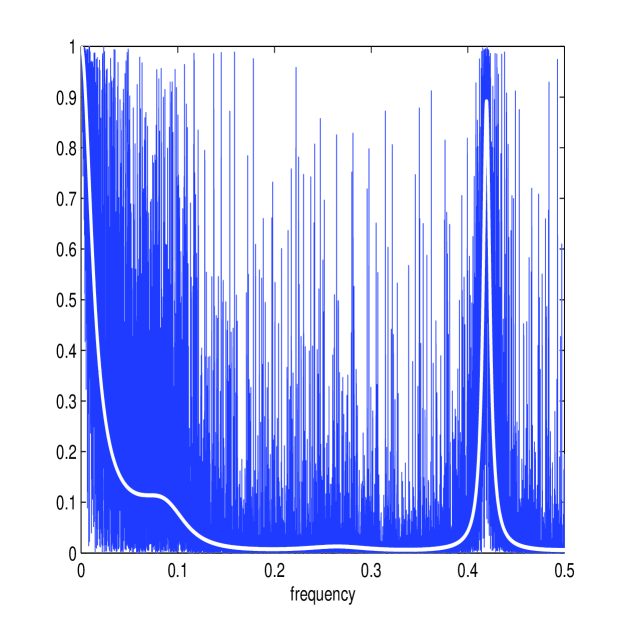
If the length of the MA process is unknown, then can be determined using (35). In Table VI we show an example with with paramaters , , , , Clearly is identified as the best fitting model yielding near to perfect estimates of the noise parameters. The estimator is therefore robust to removing the effect of microstructure noise when this process is correlated (and stationary), even if the length of the MA process is not explicitly known.
| MA() | AICC | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.935 | |||||||||
| 0.624 | -0.445 | ||||||||
| 0.658 | -0.459 | -0.046 | |||||||
| 0.806 | -0.603 | -0.101 | 0.410 | ||||||
| 0.813 | -0.606 | -0.101 | 0.411 | -0.008 | |||||
| 0.815 | -0.604 | -0.097 | 0.420 | -0.003 | 0.000 | ||||
| 0.807 | -0.613 | -0.114 | 0.413 | 0.002 | -0.002 | -0.005 | |||
| 0.817 | -0.614 | -0.128 | 0.427 | 0.005 | 0.011 | -0.009 | -0.017 |
We also tested our estimator using Monte Carlo simulations in [31] for a variety of MA(1) processes and the results showed a significant reduction in error compared with not only the naive estimator, but also the estimators based on a white-noise assumption. Furthermore, the adjusted multiscale estimator performed almost identically to our multiscale estimator when we set and recovered a white-noise process, meaning the loss in precision from searching for a parameter unnecessarily was negligible (as to be expected for ). Notice also that in Table VI there appears to be little loss in precision from estimating more parameters in the MA process then is required as for is always estimated to be very close to zero. This further demonstrates the robustness and precision of our estimation technique.
IV Conclusions
The problem of estimating the integrated stochastic volatility of an Itô process from noisy observations was studied in this paper. Unlike most previous works on this problem, see [36, 26], the method for estimating the integrated volatility developed in this paper is based on the frequency domain representation of both the Itô process and the noisy observations. The integrated volatility can be represented as a summation of variation in the process of interest over all frequencies (or scales). In our estimator we adjust the raw sample variance at each frequency. Such an estimator is truly multiscale, as it corrects the estimated energy directly at every scale. In other words, the estimator is debiased locally at each frequency, rather than globally.
To estimate the degree of scale separation in the data we used the Whittle likelihood, and quantified the noise contribution by the multiscale ratio. Various properties of the multiscale estimator were determined, see Theorems 1 and 2. As was illustrated by the set of examples, our estimator performs extremely well on data simulated from the Heston model, and is competitive with the methods proposed by [36], under varying signal-to-noise and sampling scenarios. The proposed estimator is truly multiscale in nature and adapts automatically to the degree of noise contamination of the data, a clear strength. It is also easily implemented and computationally efficient.
The new estimator for the integrated stochastic volatility can be written as
where the kernel is given by (28). We can compare this estimator with kernel estimators, see [10]. There the estimated increment square is locally smoothed to estimate the diffusion coefficient using a kernel function, . Contrary to this approach we estimate the integrated volatility by smoothing the estimated autocovariance of . In particular, we use a data-dependent choice of smoothing window. We show that, from a minimum bias perspective, using a Laplace window to smooth is optimal. This data-dependent choice of smoothing window becomes more interesting after relaxing the assumptions on the noise process, and treating correlated observation error.
Inference procedures implemented in the frequency domain are still very underdeveloped for problems with a multiscale structure. The modern data deluge has caused an excess of high frequency observations in a number of application areas, for example finance and molecular dynamics. More flexible models could also be used for the high frequency nuisance structure. In this paper we have introduced a new frequency domain based estimator and applied it to a relatively simple problem, namely the estimation of the integrated stochastic volatility, for data contaminated by high frequency noise. There are many extensions and potential applications of the new estimator. Here we list a few which seem interesting to us and which are currently under investigation.
-
•
Study parameter estimation for noisily observed SDEs which are driven by more general noise processes, for example Lévy processes.
- •
-
•
Study the combined effects of high-frequency and multiscale structure in the data. A first step in this direction was taken in [7].
References
- [1] Y. Ait-Sahalia, P. A. Mykland, and L Zhang, How often to sample a continuous-time process in the presence of market microstructure noise, Rev. Financ. Studies, 18 (2005), pp. 351–416.
- [2] E. Barucci and R. Reno, On measuring volatility of diffusion processes with high frequency data, Economics Letters, 74 (2002), pp. 371–378.
- [3] J. Beran, Statistics for long-memory Processes, Chapman and Hall, London, 1994.
- [4] Peter Bloomfield, Fourier Analysis of Time Series, Wiley-IEEE, New York, 2004.
- [5] D. Brillinger, Time series: data analysis and theory, Society for Industrial and Applied Mathematics, Philadelphia, USA, 2001.
- [6] P. J. Brockwell and R. A. Davis, Time Series: Theory and Methods, Springer-Verlag, New York, 1991.
- [7] C. J. Cotter and G. A. Pavliotis, Estimating Eddy diffusivities from Lagrangian Observations, Preprint, 2009.
- [8] K. O Dzhamparidze and A. M. Yaglom, Spectrum parameter estimation in time series analysis, in Developments in Statistics, PR Krishnaiah, ed., vol. 4, New York: Academic Press., 1983, pp. 1–181.
- [9] J. Fan and Y. Wang, Multi-scale jump and volatility analysis for high-frequency financial data, J. of the American Statistical Association, 102 (2007), pp. 1349–1362.
- [10] D. Florens-Zmirou, On estimating the diffusion coefficient from discrete observations, Journal of Applied Probability, 30 (1993), pp. 790–804.
- [11] J.-P. Fouque, G. Papanicolaou, K. R. Sircar, and K. Solna, Short time-scale in SP-500 volatility, J. Comp. Finance, 6 (2003), pp. 1–23.
- [12] D. Givon, R. Kupferman, and A. M. Stuart, Extracting macroscopic dynamics: model problems and algorithms, Nonlinearity, 17 (2004), pp. R55–R127.
- [13] A. Griffa, K. Owensa, L. Piterbarg, and B. Rozovskii, Estimates on turbulence parameters from lagrangian data using a stochastic particle model, J. Marine Research, 53 (1995), pp. 371–401.
- [14] P. R. Hansen and A. Lunde, A forecast comparison of volatility models: does anything beat a GARCH(1,1)?, Journal of Applied Econometrics, 20 (2005), pp. 873–889.
- [15] , Realized variance and market microstructure noise, J. Business & Economic Statistics, 24 (2006), pp. 127–161.
- [16] S. L. Heston, A closed form solution for options with stochastic volatility with applications to bond and currency options, Review of Financial Studies, 6 (1993), pp. 327–343.
- [17] I. Horenko, C. Hartmann, C. Schütte and F. Noe, Data-based parameter estimation of generalized multidimensional Langevin processes, Physical Review E, 76 (2007), no. 016706.
- [18] I. Horenko and C. Schütte, Likelihood-based estimation of multidimensional Langevin Models and its Application to biomolecular dynamics, Multiscale Modeling and Simulation, 7 (2008), 731–773.
- [19] I. Karatzas and S. E. Shreve, Brownian Motion and Stochastic Calculus, Springer-Verlag, New York, 1991.
- [20] Y. A. Kutoyants, Statistical inference for ergodic diffusion processes, Springer Series in Statistics, London, 2004.
- [21] P. Malliavin and M. E. Mancino, Fourier series for measurements of multivariate volatilities, Finance and Stochastics, 6 (2002), pp. 49–61.
- [22] M. E. Mancino and S. Sanfelici, Robustness of Fourier estimators of integrated volatility in the presence of microstructure noise, tech. report, University of Firenze, 2006.
- [23] F. Neeser and J. Massey, Proper complex random processes with applications to information theory, IEEE Trans. Info. Theory, 39 (1993), 1293–1302.
- [24] T. Papavasiliou, G. A. Pavliotis, and A.M. Stuart, Maximum likelihood estimation for multiscale diffusions, 2008.
- [25] G. A. Pavliotis, Y. Pokern, and A.M. Stuart, Parameter estimation for multiscale diffusions: an overview, 2008.
- [26] G. A. Pavliotis and A. M. Stuart, Parameter estimation for multiscale diffusions, J. Stat. Phys., 127 (2007), pp. 741–781.
- [27] D. B. Percival and A. T. Walden, Spectral Analysis for Physical Applications, Cambridge University Press, Cambridge, UK, 1993.
- [28] B. Picinbono, Second-Order Complex Random Vectors and Normal Distributions, IEEE Trans. Signal Proc., 44 (1996), pp. 2637–2640.
- [29] R. Renò, Volatility estimate via Fourier analysis, PhD thesis, Scuola Normale Superiore, 2005.
- [30] , Nonparametric estimation of the diffusion coefficient of stochastic volatility models, Econometric Theory, 24 (2008), pp. 1174–1206.
- [31] A. Sykulski, S. Olhede, and G. A. Pavliotis, High frequency variability and microstructure bias, in Inference and Estimation in Probabilistic Time-Series Models, D. Barber, A. T. Cemgil, and S. Chiappa, eds., Cambridge, UK, 2008, Issac Newton Institute for Mathematical Sciences. Proceedings available at http://www.newton.ac.uk/programmes/SCH/schw05-papers.pdf.
- [32] R. S. Tsay, Analysis of Financial Time Series, John Wiley & Sons, New York, USA, 2005.
- [33] L. Wasserman, All of Nonparametric Statistics, Springer, Berlin, 2007.
- [34] P. Whittle, Estimation and information in stationary time series, Arkiv för Matematik, 2 (1953), pp. 423–434.
- [35] P. Whittle, Gaussian estimation in stationary time series, Bull. Inst. Statist. Inst., 39 (1962), pp. 105–129.
- [36] L. Zhang, P. A. Mykland, and Y. Ait-Sahalia, A tale of two time scales: Determining integrated volatility with noisy high-frequency data, J. Am. Stat. Assoc., 100 (2005), pp. 1394–1411.
A Proof of Theorem 1
Let the true value of be denoted We differentiate the multiscale energy likelihood function (18) with respect to to obtain
To remove implicit dependence we let and denote derivatives with respect to by subscript . Then , and so on. We calculate the expectation and variance of the score functions evaluated at and find that the bias of is order and the bias of is order These contributions become negligible, and are of lesser importance compared to the variance.
To show large sample properties we Taylor expand the multiscale likelihood with corresponding to the estimated maximum likelihood, and is lying between and . Then
We note with the observed Fisher information
that
| (A-42) |
We henceforth ignore the term as this will not contribute to leading order, and write where formally we would write or . We can observe the suitability of this directly from (18) and use bounds for , where we could formally apply these to get bounds on each derivative of (note that we cannot differentiate bounds). To avoid needless technicalities, the details of this approach will not be reported. To leading order
We now need to calculate which is
| (A-43) | |||||
Furthermore
We therefore need to calculate the individual terms of this expression. We note
Then it follows
| (A-44) |
We therefore only need to worry about We need
where and . Since Brownian motion has independent increments, we have that , if and , otherwise. Consequently,
We use standard bounds on moments of stochastic integrals [19] to obtain the bound
since, by assumption, 222 in this paper denotes a generic constant, rather than the same constant.. We have:
Since is a smooth function of time we can bound the decay of so that:
| (A-45) |
We combine the foregoing calculations with (A-44)
| (A-46) |
We note that
Thus it follows that:
The extra order terms acknowledge potential effects from the drift. We need to establish the size of . Using (A-44) we find that:
This is negligible in size compared to . Similar calculations can bound contributions from the off diagonals in the other two calculations. Also as
| (A-48) | ||||
The order terms follow from usual spectral theory on the white noise process, as well as bounds on . We can also by considering the variance of the observed Fisher information deduce that renormalized versions of the entries of the observed Fisher information converge in probability to a constant, or
and thus using Slutsky’s theorem we can deduce that:
where the entries of can be found from (A-48), (A-46) and (A), and
We have
| (A-49) |
This expression follows by direct calculation. Asymptotic normality of both and follows by the usual arguments. We can determine the asymptotic variance of via
| (A-50) | |||||
We see that the variance depends on the length of the time course, the inverse of the signal to noise ratio, the square root of the sampling period and the fourth power of the “average standard deviation” of the process.
B Proof of Theorem 2
We now wish to use these results to deduce properties of . Firstly using the well known invariance of maximum likelihood estimators to transfer the estimators of and to estimators of . We therefore take
It therefore follows that with and
This implies that the estimator is asymptotically unbiased. We can also note that the variance of the new estimator is given by:
Then
By looking at the individual terms of this expression, and noting that the estimated renormalized variance and are linear combinations of we can deduce the stated order terms, by again noting the order of the important terms. However to leading order, this estimator will perform identically to in terms of variance.
C Proof of Time Domain Form
The integral can be calculated from first principles using complex-variables with . Thus or . (28) takes the form
| (C-51) |
We need the poles, or:
If we have
We then note that:
If on the other hand you consider which in many scenarios is more realistic then we find that:
In this case we find that
In both cases the decay of the filter is geometric. We note that in most practical examples decays very rapidly in . Therefore, we do not need to integrate between to , and only need to integrate over to . In this range of we find that for smallish remainder term we have: . Then we note
Thus we are smoothing the autocovariance sequence with a smoothing window that becomes a delta function as . It is reasonable that this non-dimensional quantity arises as an important factor.