MuseMorphose: Full-Song and Fine-Grained Piano Music Style Transfer with One Transformer VAE
Abstract
Transformers and variational autoencoders (VAE) have been extensively employed for symbolic (e.g., MIDI) domain music generation. While the former boast an impressive capability in modeling long sequences, the latter allow users to willingly exert control over different parts (e.g., bars) of the music to be generated. In this paper, we are interested in bringing the two together to construct a single model that exhibits both strengths. The task is split into two steps. First, we equip Transformer decoders with the ability to accept segment-level, time-varying conditions during sequence generation. Subsequently, we combine the developed and tested in-attention decoder with a Transformer encoder, and train the resulting MuseMorphose model with the VAE objective to achieve style transfer of long pop piano pieces, in which users can specify musical attributes including rhythmic intensity and polyphony (i.e., harmonic fullness) they desire, down to the bar level. Experiments show that MuseMorphose outperforms recurrent neural network (RNN) based baselines on numerous widely-used metrics for style transfer tasks.
Index Terms:
Transformer, variational autoencoder (VAE), deep learning, controllable music generation, music style transferI Introduction
Automatic music composition, i.e., the generation of musical content in symbolic formats such as MIDI,111Check https://midi.org/specifications for detailed specifications. has been an active research topic with endeavors dating back to more than half a century ago [1]. Due to the renaissance of neural networks, we have seen in recent years a proliferation of deep learning-based methods for music composition [2, 3, 4]. For such tasks, a commonly followed pipeline is to first transcribe recorded music performances [5] into sheet music, which can be stored as MIDI files, and then translate MIDI events into sequences of tokens [6, 7] that can be fed into neural sequence models. The latter step resembles how researchers in natural language processing (NLP) represent sentences of words with encodings [8]. Different network architectures have been employed depending on the target applications, but the state-of-the-art models are usually based on one of the following two architectures [9, 10, 11]—Transformers [12] and variational autoencoders (VAE) [13].
Transformers [12] are a family of neural sequence models that are generally thought of as the potent successors of recurrent neural networks (RNN) [14, 15]. Thanks to their self-attention mechanism to aggregate information from the hidden states of all previous tokens in a sequence, Transformers are able to compose coherent music of 35 minutes long (which mostly contains over 2K sequence tokens), as demonstrated by Music Transformer [9] and MuseNet [16]. Variants of Transformers have been employed to model multi-track music [10], pop piano performances [7], jazz lead sheets [17], and even guitar tabs [18]. Objective and subjective evaluations in [9, 10] and [19] have all proven Transformers to be the state-of-the-art model for long sequence generation.
VAEs [13] are a type of deep latent variable model comprising an encoder, a decoder, and a Kullback-Leibler (KL) divergence-regularized latent space in between. While neural sequence encoders/decoders, like RNNs and Transformers, gather and consume information from tokens in a sequence, VAE’s training objective restricts the amount of information the latent space may store. This induces better structuring of information in the latent space, and also leaves the sequence decoder with enough uncertainty to be creative. The resulting strength of VAEs is that they grant human users access to the generative process through operations on the learned latent space [11], where compact semantics of a musical excerpt are stored, making them a great choice for tasks like controllable music generation and music style (or, attribute) transfer. For example, MusicVAE [11] and Music FaderNets [20] showed respectively that low-level (e.g., note density) and high-level (e.g., arousal level) musical features of machine compositions can be altered via latent vector arithmetic. Music FaderNets, GLSR-VAE [21], and MIDI-VAE [22] imposed auxiliary losses on the latent space to force some latent dimensions to be discriminative of the musical style or attributes to be controlled. In contrast, Kawai et al. [23] used adversarial learning [24] to prevent the latent space from encoding attribute information, and delegated attribute control to learned embeddings fed to the decoder.
The aforementioned VAE models are, however, all based on RNNs, whose capabilities in modeling long sequences are known to be limited. On the other hand, conditional generation with Transformers are usually done by providing extra tokens. For instance, MuseNet [16] used composer and instrumentation tokens, prepended to the event sequence, to affect the composition’s style and restrict the instruments used. Sometimes, Transformers are given a composed melody (also as a token sequence) and are asked to generate an accompaniment. Such tasks have been addressed with encoder-decoder architectures [25, 26], or by training a decoder with interleaved subsequences of the melody and the full piece [27]. The two scenarios above can be seen as two extremes in terms of the restrictiveness of given conditions. Users may either only be able to decide the broad categories (e.g., genre, composer, etc.) of the generation, or have to be capable of coming up with a melody themselves. The middle ground of constraining the generation with high-level flow of musical ideas in the form of latent vectors, with which users may engage easily and extensively in the machine creative process as achieved by RNN-based VAEs, has not yet been studied for Transformers to the best of our knowledge.
The goal of this paper is therefore to construct such a model that attains all the aforementioned strengths of Transformers and VAEs. We take two steps to achieve the goal. First, we devise mechanisms to condition Transformer decoders [28] with segment-level (i.e., bar-level in our case), time-varying conditioning vectors during long sequence generation. Three methods, i.e., pre-attention, in-attention, and post-attention, which inject conditions into Transformers before, throughout, or after the attention layers respectively, are proposed (implementation details in Sec. III-B). We conduct an objective study to show that in-attention most effectively exerts control over the model. Next, we combine an in-attention-equipped Transformer decoder with a Transformer encoder [29], which learns to extract each bar’s high-level blueprint independently, to build our ultimate MuseMorphose model for fine-grained music style transfer. This encoder-decoder network is trained with the VAE objective [13], and enables music style transfer through attribute embeddings [30]. Experiments demonstrate that MuseMorphose excels in generating style-transferred versions of pop piano performances (i.e., music with expressive timing and dynamics, instead of plain sheet music) of 32 bars (or measures) long, in which users can freely control two ordinal musical attributes of each bar: rhythmic intensity and polyphony, which roughly represent the density of notes seen from the time/pitch axis respectively (see Eqs. (27) and (28) for formal definitions).
These two attributes are chosen for they largely affect the music’s feeling (e.g., agitated, calm, etc.) and are hence easily perceptible [31, 32]. Besides, we set the granularity of conditions to a bar for several reasons. From a musical perspective, bars are the basic unit of recurring strong/weak beat cycles, serving as the basis of all rhythmic patterns, but they are also long enough to expose a musical idea. Sudden changes of emotion often happens on boundaries between bars, too. From a machine learning viewpoint, we find that the number of bars in a piece, and the number of tokens in a bar share a similar order of magnitude (averaging at about 100 and 50, respectively, on our pop piano dataset), thus making bars a suitable target for learning intermediate representations.
Parameterizing VAEs with Transformers is a less explored direction. Optimus [33] successfully linked together a pair of pre-trained Transformer encoder (BERT) [29] and decoder (GPT-2) [28] with a VAE latent space, and devised mechanisms for the latent variable to exert control over the Transformer decoder. Linking Transformers and VAE for story completion [34] has also been attempted. However, both works above were limited to generating short texts (only one sentence), and conditioned the Transformer decoder at the global level. Our work extends the approaches above to tackle the case of long sequences, maintains VAEs’ fine-grained controllability, and verifies that such control can be achieved without a discriminator and auxiliary losses.
Our key contributions can be summarized as:
-
•
We devise the in-attention method to firmly harness Transformers’ generative process with segment-level conditions.
-
•
We pair a Transformer decoder featuring in-attention with a bar-level Transformer encoder to form MuseMorphose, our Transformer-based VAE, which marks an advancement over Optimus [33] in terms of conditioning mechanism, granularity of control, and accepted sequence length.
- •
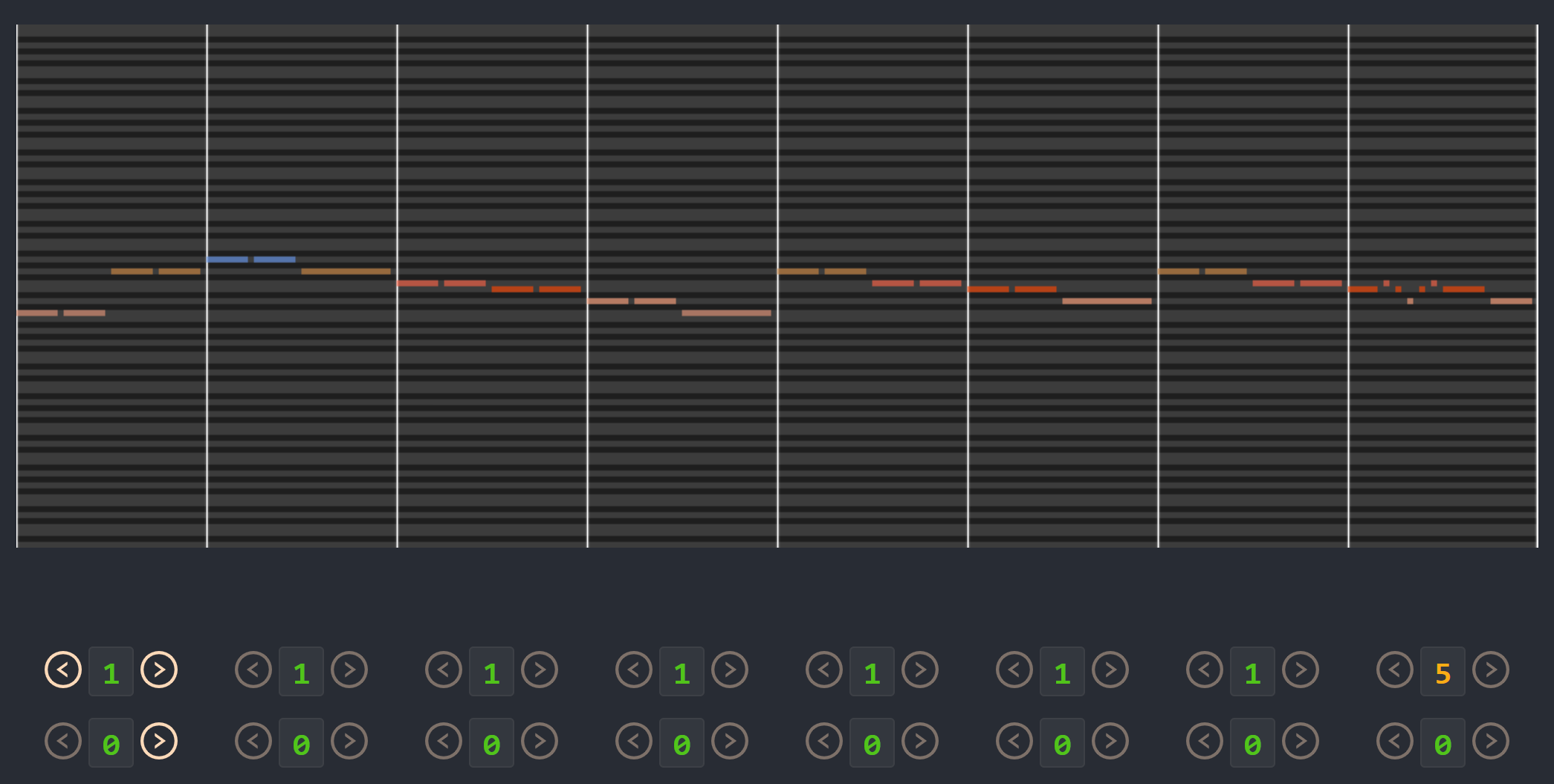
Fig. 1 displays one of MuseMorphose’s compositions,333Each tone in the chromatic scale (C, C#, …, B) is colored differently. in which the model responds precisely to the increasing rhythm intensity and polyphony settings, while keeping the contour of the original excerpt well. We encourage readers to visit our companion website444Companion website: slseanwu.github.io/site-musemorphose to listen to more generations by MuseMorphose. Moreover, we have also open-sourced our implementation of MuseMorphose.555Open-source code: github.com/YatingMusic/MuseMorphose In the interest of space, this paper contains some pointers to extra tables and figures released as online supplemental materials.666Supplemental: slseanwu.github.io/site-musemorphose/assets/supplement.pdf
The remainder of this paper is structured as follows. Section 2 provides a comprehensive walk-through of the technical background. Sections 3 and 4, which are the main body of our work, focus respectively on the segment-level conditioning for Transformer decoders, and the MuseMorphose Transformer-based VAE model for fine-grained music style transfer. In each of these two sections, we start from problem formulation; then, we elaborate on our method(s), followed by evaluation procedure and metrics; finally, we present the results and offer some discussion. Section 5 concludes the paper and provides potential directions to pursue in the future.
II Technical Background
II-A Event-based Representation for Music
To facilitate the modeling of music with neural sequence models, an important pre-processing step is to tokenize a musical piece into a sequence of events, i.e., , where is the length of the music in the resulting event-based representation. Such tokenization process can be done straightforward with music in the symbolic format of MIDI. A MIDI file stores a musical piece’s tempo (in beats per minute, or bpm), time signature (e.g., 3/4, 4/4, 6/8, etc.), as well as each note’s onset and release timestamps and velocity (i.e., loudness). Multiple tracks can also be included for pieces with more than one playing instruments.
There exist several ways to represent symbolic music as token sequences [6, 11]. The representations adopted in our work are based on Revamped MIDI-derived events (REMI) [7]. It incorporated the intrinsic units of time in music, i.e., bars and beats, the former of which naturally define the segments to impose conditions. In REMI, a musical piece is represented as a sequence with the following types of tokens:
-
•
Bar and Sub-Beat (, denoting the time within a bar, in quarter beat, i.e., 16 note, increments) events denote the progression of time.
-
•
Tempo events explicitly set the pace (in beats per minute, or bpm) the music should be played at.
-
•
Pitch, Velocity, and Duration events, which always co-occur at each note’s onset, marks the pitch, loudness (in 32 levels), and duration (in 16 note increments) of a note.
The authors of REMI also suggested using rule-based chord recognition algorithms to add Chord events, e.g., Cmaj, G7, to inform the sequence model of local harmonic characteristics of the music. To suit our use cases, we introduce some modifications to REMI, as explained in Sections 3 and 4.
II-B Transformers
In general, a Transformer operates on an input sequence .777Combinations of Transformers operating on multiple sequences are also often seen. A token in the input sequence first becomes a token embedding , where is the model’s hidden state dimension. Then, goes through the core of the Transformer—a series of (self-)attention modules sharing the same architecture. An attention module888It is also often called a (self-)attention layer. However, we use the term module here for it actually involves multiple layers of operations. can be further divided into a multi-head attention (MHA) [12] sub-module, and a position-wise feedforward net (FFN) sub-module. Suppose has passed such attention modules to produce the hidden state , the operations that take place in the next (i.e., ) attention module can be summarized as follows:
| (1) | ||||
| (2) |
where , and . The presence of residual connections [35] and layer normalization (LayerNorm) [36] ensures that gradients back-propagate smoothly into the network. The MHA sub-module is the key component for each timestep to gather information from the entire sequence. In MHA, first, the query, key, and value matrices () are produced:
| (3) |
where are learnable weights. is further split into heads , where , and so are and . Then, the dot-product attention is performed in a per-head fashion:
| (4) |
where . Causal (lower-triangular) masking is applied before softmax in autoregressive sequence modeling tasks. The attention outputs (i.e., ) are then concatenated and linearly transformed by learnable weights , thereby concluding the the MHA sub-module.
However, the mechanism above is permutation-invariant, which is clearly not a desirable property for sequence models. This issue can be addressed by adding a positional encoding to the input token embeddings, i.e., , where can either be fixed sinusoidal waves [12], or learnable embeddings [29]. More sophisticated methods which inform the model of the relative positions between all pairs of tokens have also been invented [37, 38, 39, 40].
Due to attention’s quadratic memory complexity it is often impossible for Transformers to take sequences with over 23k tokens, leading to the context fragmentation issue. To resolve this, Transformer-XL [19] leveraged segment-level recurrence and hidden states cache to allow tokens in the current segment to refer to those in the preceding segment. Algorithms to estimate attention under linear complexity have also been proposed recently [41, 42].
II-C Variational Autoencoders (VAE)
VAEs [13] are based on the hypothesis that generative processes follow , where is the prior of some intermediate-level latent variable . It has been shown that generative modeling can be achieved through maximizing:
| (5) |
where denotes KL divergence, and is the estimated posterior distribution emitted by the encoder (parameterized by ), while is the likelihood modeled by the decoder (parameterized by ). It is often called the evidence lower bound (ELBO) objective since it can be proved that: For simplicity, we typically restrict to isotropic gaussians , and have the encoder emit the mean and standard deviation of , i.e., . The prior distribution is often set to be isotropic standard gaussian .
For practical considerations, -VAE [43] proposed that we may adjust the weight on the KL term of the VAE objective with an additional hyperparameter . Though using deviates from optimizing ELBO, it grants practitioners the freedom to trade off reconstruction accuracy for a smoother latent space and better feature disentanglement (by opting for ). It is worth mentioning that, in musical applications, is often set to [11, 22, 23].
In the literature, it has been repeatedly mentioned that VAEs suffer from the posterior collapse problem [44, 45, 46], in which case the estimated posterior fully collapses onto the prior , leading to an information-less latent space. The problem is especially severe when the decoder is powerful, or when the decoding is autoregressive, where previous tokens in the sequence reveal strong information. Numerous methods have been proposed to tackle this problem, either by tweaking the training objective [47, 48] or slightly modifying the model architecture [46]. Kingma et al. [47] introduced a hyperparameter to the VAE objective to ensure that each latent dimension may store nats (1 nat 1.44 bits) of information without being penalized by the KL term. Cyclical KL annealing [48] periodically adjusts (i.e., weight on the KL term) during training. Empirical evidence have shown that this simple technique benefited downstream tasks such as language modeling and text classification. Skip-VAE [46], on the other hand, addressed posterior collapse with slight architectural changes to the model. In Skip-VAEs, the latent condition is fed to all layers and timesteps instead of just the initial ones. Theoretically and empirically, it was shown that Skip-VAEs increases the mutual information between input and the estimated latent condition . In our work, we take advantage of all of the techniques above to facilitate the training of our Transformer-based VAE.
III Conditioning Transformer Decoders at the Segment Level
This section sets aside latent variable models first, and focuses on conditioning an autoregressive Transformer decoder with a series of pre-given, time-varying conditions , which are continuous vectors each belonging to a pre-defined, non-overlapping segment of the target sequence. We propose three mechanisms, namely, pre-attention, in-attention, and post-attention conditioning, to approach this problem. Experiments demonstrate that, in terms of offering tight control, in-attention surpasses the other two, as well as a baseline mechanism that is slightly tweaked from Optimus [33].
III-A Problem Formulation
Under typical settings, Transformer decoders [12] are employed for autoregressive generative modeling of sequences:
| (6) |
where is the element of a sequence to predict at timestep , and is all the (given) preceding elements of the sequence. Once a model is trained, the model can generate new sequences autoregressively, i.e., one new element at a time based on all previously generated elements [28].
The unconditional type of generation associated with Eq. (6), however, does not offer control mechanisms to guide the generation process of the Transformer. One alternative is to consider a conditional scenario where the model is informed of a global condition for the entire sequence to generate, as used by, for example, the CTRL model for text [49] or the MuseNet model for music [16]:
| (7) |
When the target sequence length is long, it may be beneficial to extend Eq. (7) by using instead a sequence of conditions , each belonging to different parts of the sequence, to offer fine-grained control through:
| (8) |
This can be implemented, for example, by treating representations of as additional memory for the Transformer decoder to attend to, which can be achieved with minimal modifications to [33].
In this paper, we particularly address the case where the target sequences can be, by nature, divided into multiple meaningful, non-overlapping segments, such as sentences in a text article, or bars (measures) in a musical piece. That is to say, for sequences with segments, each timestep index belongs to one of the sets of indices , where for and . Thus, we can provide the generative model with each segment-level condition during the corresponding time interval , leading to:
| (9) |
This conditional generation task is different from the one outlined in Eq. (8) in that we know specifically which condition (among the conditions) is in force at each timestep. The segment-level condition may manifest itself as a sentence embedding in text, or a bar-level embedding in music. In our case, we consider the conditions to be bar-level embeddings of a musical piece, i.e., we represent each in the vector form , where is the dimensionality of the bar-level embedding. Collectively, the time-varying conditions offer a blueprint, or high-level planning, of the sequence to model. This is potentially helpful for generating long sequences, especially for generating music, as ancestral sampling from unconditional autoregressive models, which are trained only with long sequences of scattered tokens, may fail to exhibit the high-level flow and twists that are central to a catchy piece of music.
The segment-level conditional generation scenario associated with Eq. (9), though seemingly intuitive for long sequence modeling, has not been much studied in the literature. Hence, we aim to design methods that specifically tackle this task, and perform comprehensive evaluation to find out the most effective way.
III-B Method
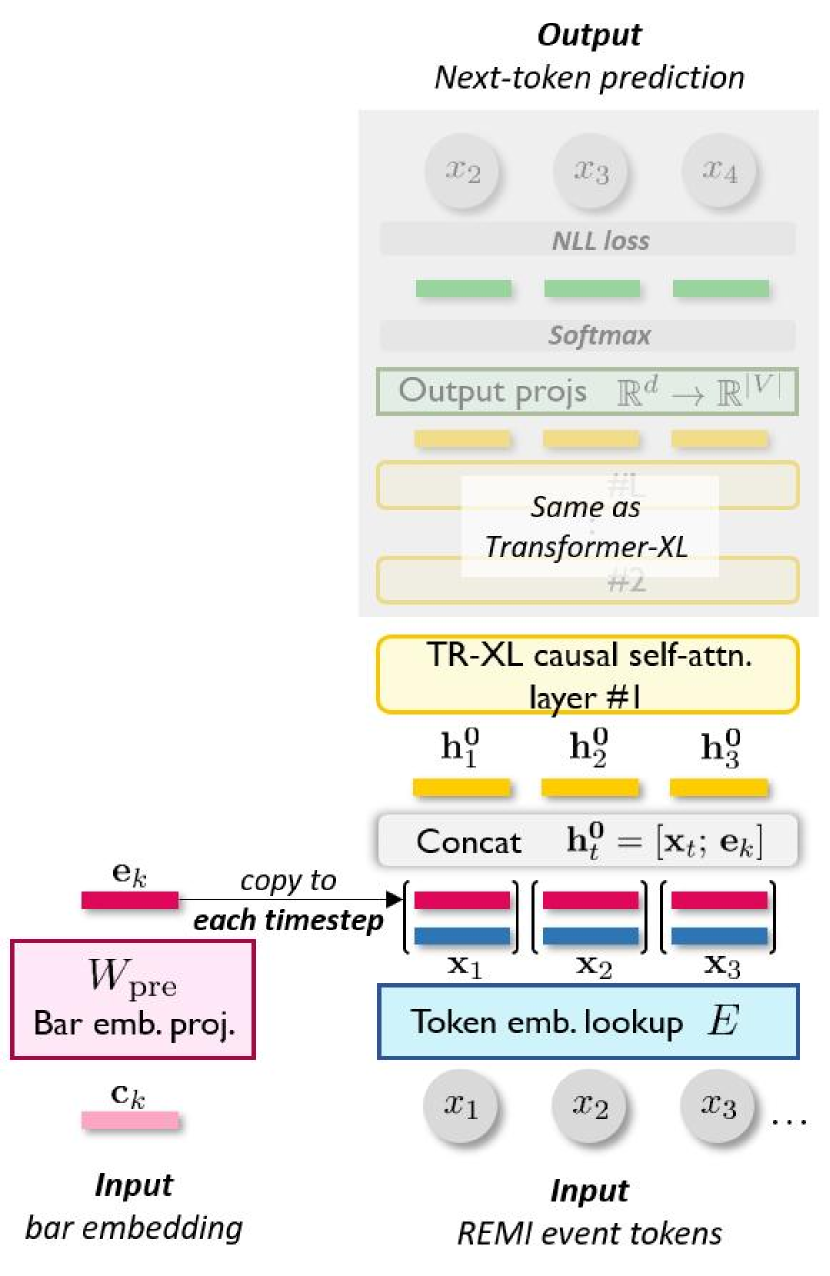
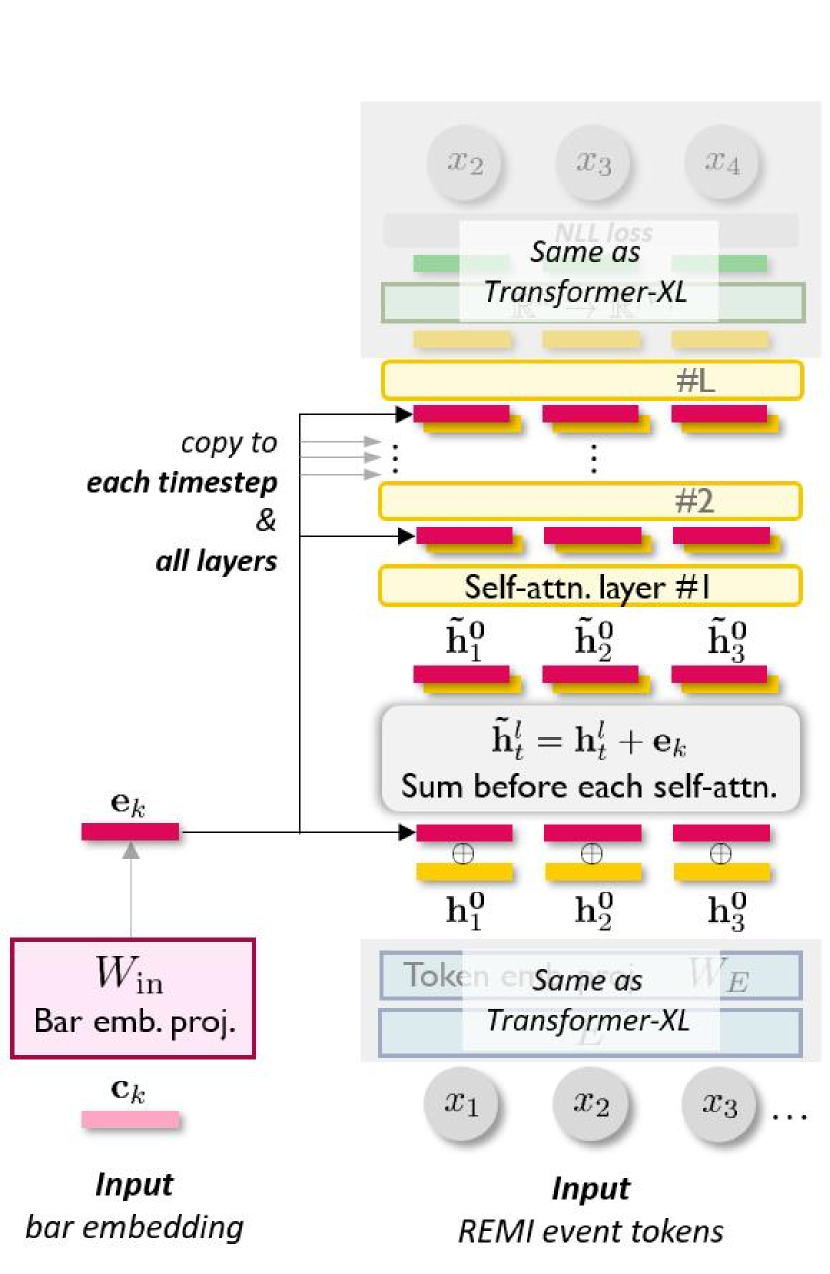
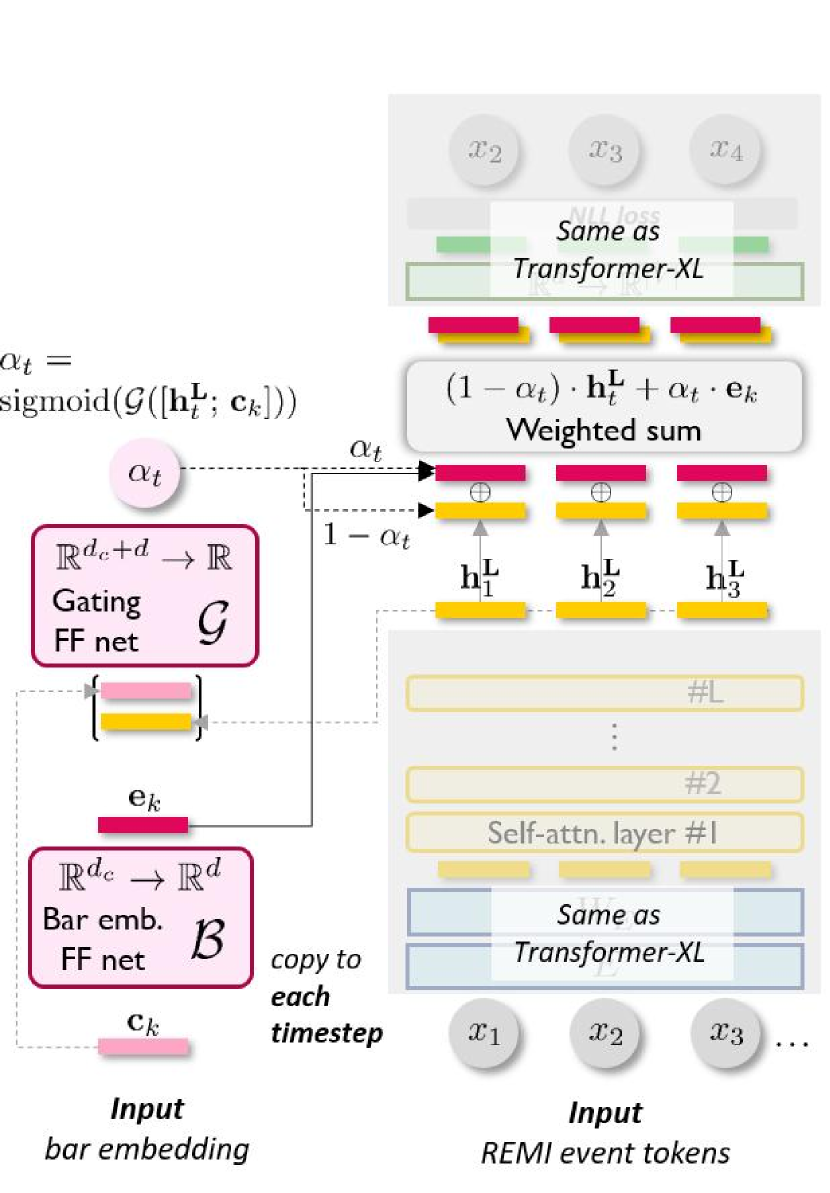
Here, we elaborate the three proposed mechanisms: pre-attention, in-attention, and post-attention (see Fig. 2 for a schematic comparison), to condition Transformer decoders at segment level. For simplicity, we assumed here that the bar-level conditions, i.e., ’s, can be extracted beforehand; the extraction method is also to be introduced. Finally, we explain the data representation and dataset adopted for this task.
Pre-attention Conditioning. Under pre-attention, the segment-level conditions enter the Transformer decoder only once before all the self-attention layers. The segment embedding is first transformed to a hidden condition state by a matrix . Then, it is concatenated with the token embedding of each timestep in the k bar (i.e., ) before the first self-attention layer, i.e.,
| (10) |
where is the dimensionality for token embeddings. Note that under this mechanism, the hidden dimension, , for attention modules is implicitly required to be .
The pre-attention conditioning is methodology-wise similar to the use of segment embeddings in BERT [29], except that BERT’s segment embedding is summed directly with the token embedding, while we use concatenation to strengthen the presence of the conditions.
In-attention Conditioning. The proposed in-attention mechanism more frequently reminds the Transformer decoder of the segment-level conditions throughout the self-attention layers. It projects the segment embedding to the same space as the self-attention hidden states via:
| (11) |
and then sums the obtained hidden condition state with the hidden states of all the self-attention layers but the last one, to form the input to the subsequent layer, i.e.,
| (12) |
We use summation rather than concatenation here to keep the residual connections intact. We anticipate that by copy-pasting the segment-level condition everywhere, its influence on the Transformer can be further aggrandized.
Post-attention Conditioning. Unlike the last two mechanisms, in post-attention, the segment embeddings do not interact with the self-attention layers at all. Instead, they are imposed afterwards on the final attention outputs (i.e., ) via two single-hidden-layer, parametric ReLU-activated feed-forward networks: the conditioning net , and the gating net . Specifically, the segment embedding is transformed by the conditioning net to become . Then, a gating mechanism, dictated by the gating net , determines “how much” of should be blended with the self-attention output at every timestep , i.e.,
| (13) |
Finally, proceeds to the output projections to form the probability distribution of .
This mechanism is adapted from the contextualized vocabulary bias proposed in the Insertion Transformer [50]. It is designed such that the segment-level conditions can directly bias the output event distributions, and that the model can freely decide how much it refers to the conditions for help at different timesteps within each bar.
Implementation and Training Details. We adopt a 12-layer Transformer-XL [19] as the backbone sequence model behind all of our conditioning mechanisms. To demonstrate the superiority of using Eq. (9), two baselines, dubbed unconditional and memory hereafter, are involved in our study. The former takes no ’s, thereby modeling Eq. (6) exactly. The latter models Eq. (8) with a conditioning mechanism largely resembling the memory scheme introduced in Optimus [33], differing only in that we have multiple conditions instead of one. In the memory baseline, the conditions are each transformed by matrix to become hidden states unique to each layer . These states are then fed to the decoder before the training sequence, allowing all tokens (i.e., ’s) to attend to them. Our implemented Transformer decoders have 58.762.6 million trainable parameters. Some common attributes shared among the five models are listed in Table IV in the supplemental materials published online.999slseanwu.github.io/site-musemorphose/assets/supplement.pdf
All these models are trained with the Adam optimizer [51] and teacher forcing, i.e., always feeding in correct inputs rather than those sampled from previous-timestep outputs from the model itself, to minimize negative log-likelihood:
| (14) |
(NLL) of the training sequences ( is present only in conditional models). Due to limited computational resources, we truncate each song to the first 32 bars, i.e., . We warm-up the learning rate linearly from to in the first 500 training steps, and use cosine learning rate decay (600,000 steps) afterwards. Trainable parameters are randomly initialized from the gaussian . Each model is trained on one NVIDIA Tesla V100 GPU (with 32GB memory) with a batch size of 4 for around 20 epochs, which requires 2 full days.
Extraction of Bar-level Embeddings. We extract the conditions from the sequences themselves through a separate network , which is actually a typical 12-layer Transformer decoder. The network takes a sequence of event tokens corresponding to a musical bar and outputs a -dimensional embedding vector representing the bar. We use a GPT-2 [28] like setup and train for autoregressive next-token prediction, and average-pool across all timesteps on the hidden states of a middle layer of the Transformer to obtain the segment-level condition embedding, namely,
| (15) |
where is the hidden state at timestep after self-attention layers, and is the # of tokens in the bar. According to [52], the hidden states in middle layers are the best contextualized representation of the input, so we set .
Our model has 39.6 million trainable parameters. We use all the bars associated with our training data (i.e., not limiting to the first 32 bars of the songs) for training , with teacher forcing and causal self-attention masking to also minimize the NLL, i.e., , as we do with our segment-level conditional Transformers.
Dataset and Data Representation. In our experiments, we consider modeling long sequences of symbolic music with up to 32 bars per sequence. Specifically, our data come from the LPD-17-cleansed dataset [53], a pop music MIDI dataset containing 20K songs with at most 17 instrumental tracks (e.g., piano, strings, and drums) per song. We take the subset of 10,626 songs with time signature 4/4 (i.e., four beats per bar), and in which the piano is playing at least half of the time. Considering only the first 32 bars of each song, our dataset contains 650 hours of music. We reserve 4% of the songs (i.e., 425 songs) as the validation set for objective evaluation.
Following REMI [7], we represent multi-track music in the form of event tokens. Separate sets of Note-related tokens, i.e., Pitch-[trk], Duration-[trk], and Velocity-[trk], are used to represent notes played by each track. Metric-related tokens, namely, Bar, Sub-beat, and Tempo are placed to represent the progression of time. The Sub-beat tokens divide a bar into 32 possible locations for the onset (i.e., starting time) of notes, laying an explicit time grid for the Transformer. The Bar token, which marks the start of a new bar, makes it easy to associate different bar-level conditions to subsequences belonging to different bars (i.e., different ’s). Our revised REMI representation leads to a vocabulary of 3,440 unique tokens. Detailed descriptions for all types of tokens can be found in Table VI in our online supplemental materials.
| Model | Fidelity | Quality | |||||
| random | 34.6 | 40.5 | 80.4 | 13.5 | — | — | — |
| unconditional | — | — | — | — | .047 | .228 | .219 |
| memory [33] | 60.7 | 62.7 | 90.7 | 10.3 | .021 | .061 | .006 |
| pre-attention | 94.5 | 92.9 | 93.0 | 7.10 | .006 | .009 | .034 |
| in-attention | 96.3∗∗∗ | 95.7∗∗∗ | 97.0∗∗∗ | 5.83∗∗∗ | .002 | .005 | .021 |
| post-attention | 92.4 | 85.7 | 95.0 | 8.27 | .016 | .054 | .056 |
| ∗∗∗: leads all other models with | |||||||
III-C Evaluation Metrics
To examine how well the segment-level conditional Transformers exploit given segment-level conditions, we let them generate 32-bar-long MIDI music, with the bar-level conditions (i.e., ) extracted from songs in the validation set. Hence, in essence, the models generate re-creations, or covers, of existing music. In what follows, we define and elaborate on the objective metrics that assess re-creations of music.
Evaluation Metrics for Re-creation Fidelity. Three bar-level metrics and a sequence-level metric are defined to quantitatively evaluate whether the re-creations of our models are similar to the original songs from which the segment-level conditions are extracted.
-
•
Chroma similarity, or , measures the closeness of two bars in tone via:
(16) where denotes dot-product, and is the chroma vector [54] representing the number of onsets for each of the 12 pitch classes (i.e., C, C#, …, B) within a bar, counted across octaves and tracks, with the drums track ignored. One of the bars in the pair is from the original song, while the other is from the re-creation.
-
•
Grooving similarity, or , examines the rhythmic resemblance between two bars with the same formulation as the chroma similarity, but measured on the grooving vectors recording the number of note onsets, counted across tracks, that occur at each of the 32 sub-beats in a bar [55].
-
•
Instrumentation similarity, or , quantifies whether two bars use similar instruments via:
(17) where is a binary vector indicating the presence of a track in a bar, i.e., at least one Pitch-[trk] for that [trk] occurs within the bar.
-
•
Self-similarity matrix distance, or , measures whether two 32-bar sequences have similar overall structure by comparing the mean absolute distance between the self-similarity matrices (SSM) [56] of the two sequences, i.e.,
(18) where is the SSM. In doing so, we firstly synthesize each 32-bar sequence into audio with a synthesizer. Then, we use constant-Q transform to extract acoustic chroma vectors indicating the relative strength of each pitch class for each half beat in an audio piece, and then calculate the cosine similarity among such beat-synchronized features; hence, for half beats and within the same music piece. Since each bar in 4/4 signature has 8 half-beats, we have for our data. An SSM depicts the self-repetition within a piece. Unlike the previous metrics, the value of is the closer to zero the better. We note that the values of all metrics above, i.e., , , and , are all in .
Evaluation Metrics for Re-creation Quality. It is worth mentioning that objective evaluation on the quality of generated music remains an open issue [17]. Nevertheless, we adopt here a recent idea that measures the quality of music by comparing the distributions of the generated content and the training data in feature spaces, using KL divergence [57].
While we employ , , to measure the similarity between a generated bar and the corresponding reference bar in Sec. III-C, here we instead use them to calculate either the (self-)similarity among the bars in a generated 32-bar sequence, or that among the bars in a real training sequence. For each sequence, we have such pairs, leading to a distribution. We discretize the distributions of and into 50 bins with evenly-spaced boundaries . The KL divergence is calculated on the probability mass functions , or for the distribution in terms of , and is defined as . We assume that the values are the closer to zero the better.
III-D Results and Discussion
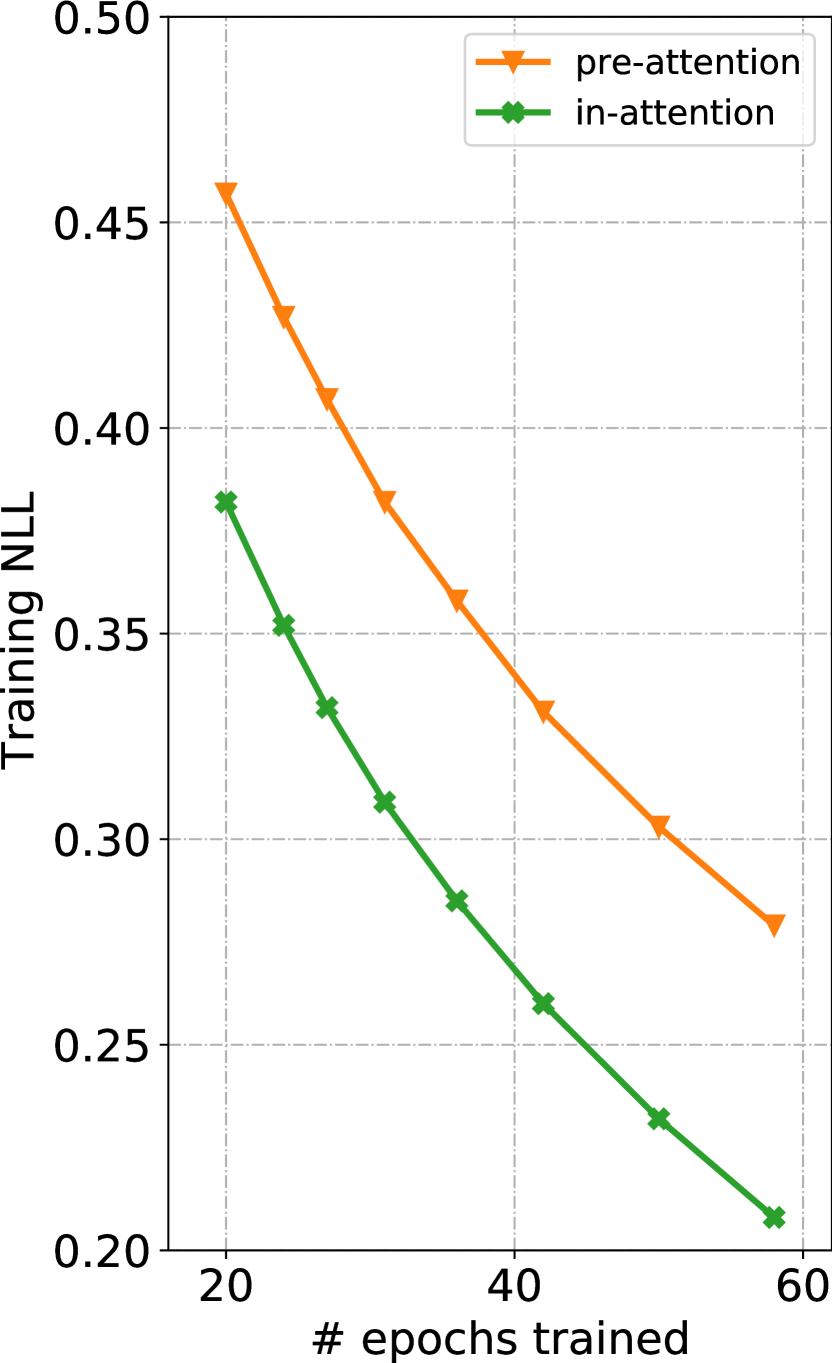
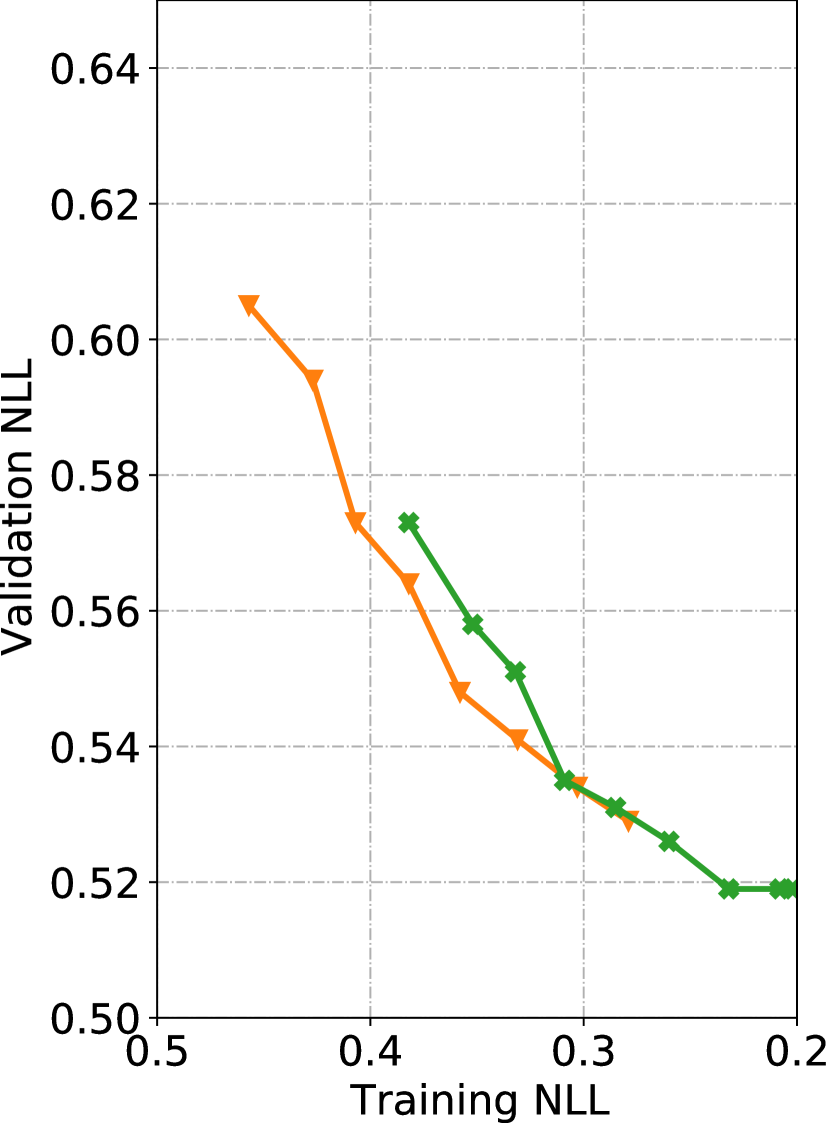
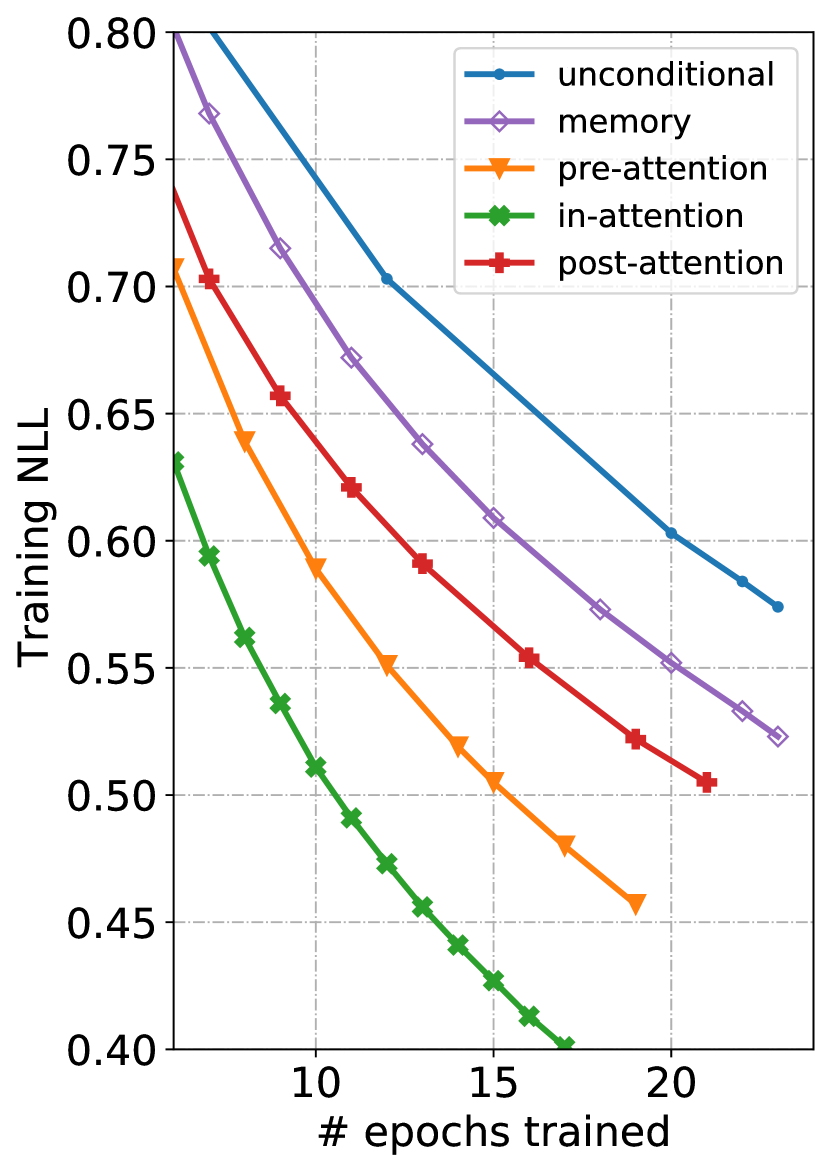
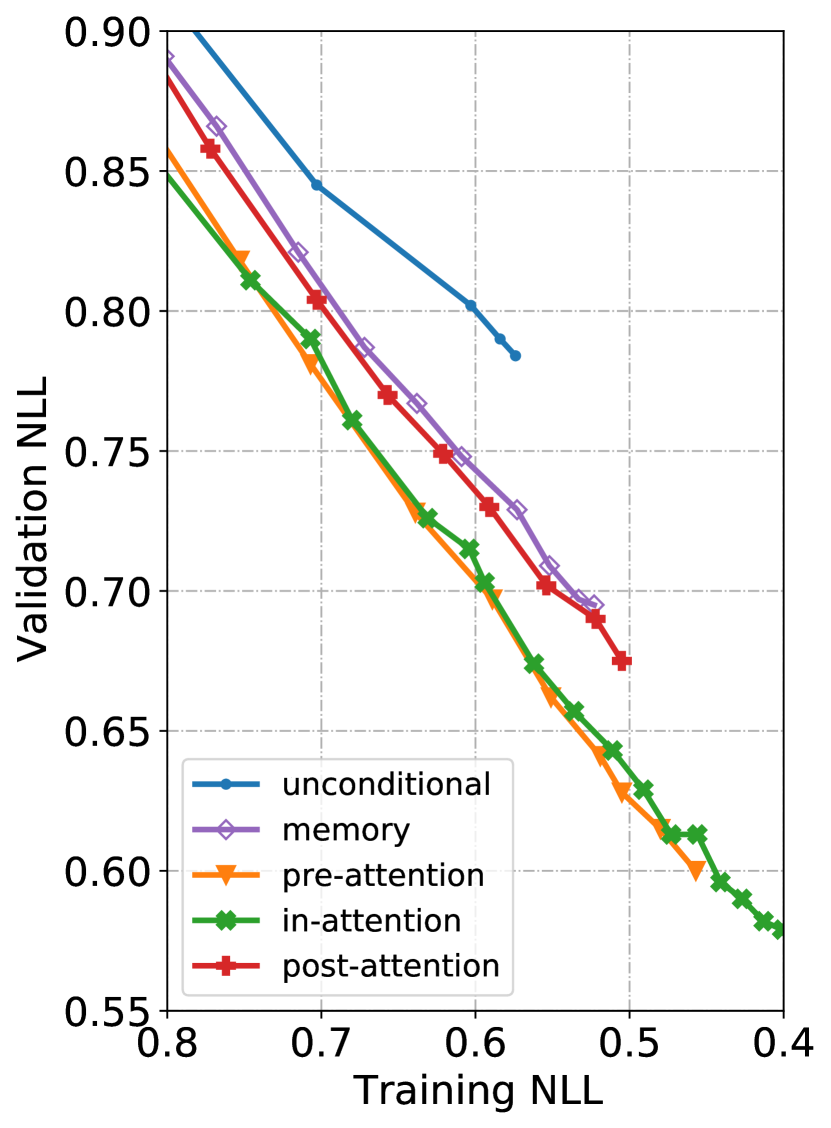
We begin with presenting the training dynamics of our models (see Fig. 3). From Fig. 3(a), we can see that the model whose loss drops the fastest, in-attention, achieves 0.41 training NLL after 16 epochs, while the unconditional and memory [33] models still have a loss of around 0.65 and 0.60 respectively. We also take validation loss into consideration. Fig. 3(b) shows that our models, especially pre- and in-attention, outperform both unconditional and memory at comparable training NLL. Given the overlapping lines of pre-attention and in-attention on Fig. 3(b), some readers may be interested in how they compare against each other with more training epochs. We plot the comparison (until the 58th epoch) in Fig. 6 in the online supplemental. We find that pre-attention’s validation NLL slowly catches up with that of in-attention, but has not quite match it after an additional week of training.101010In Sec. IV, we will show that pre-attention performs far worse than in-attention when paired with a VAE training objective.
Table I displays the objective evaluation results. The scores are calculated on 425 re-creations, each using the bar-level conditions from a unique song in the validation set. For comparison, we let the unconditional model randomly generate 400 32-bar pieces from scratch, and further include a random baseline, whose scores are computed over 400 random pairs of pieces drawn from the training set.
Focusing on the fidelity metrics first, all of our conditional models score quite high on bar-level , and , with in-attention significantly outperforming the rest. In-attention also attains the lowest , demonstrating effective and tight control. Moreover, it is worth noting that the memory model sits right in between ours and the random baseline in all metrics, offering limited conditioning ability.
Next, we shift attention to the quality metrics, where , , and represent the KL divergence calculated on the corresponding distributions. The conditional models clearly outperform the unconditional baseline, suggesting that our conditions do help Transformers in modeling music. Furthermore, once again, in-attention comes out on top, followed by pre-, post-attention, and then memory, except for metric , in which memory performs the best.
From the results presented above, we surmise that the generally worse performance of memory baseline compared to ours could be due to the advantages of using Eq. (9) over Eq. (8). Equation (9) informs the Transformer decoder of when exactly to exploit each of the conditions, and eliminates the bias caused by the positional encoding fed to Transformers, i.e., later tokens in the sequence are made more dissimilar to the conditions provided in the beginning of the sequence, thereby undermining the conditions’ effect in the attention process. Therefore, memory works well only for conditions that remain relatively unchanged throughout a sequence, such as the instrumentation of a song. Among the three proposed conditioning methods, we conjecture that post-attention works the worst because the conditions do not participate in the attention process. Therefore, the model has less chance to integrate information from them. Moreover, in-attention possesses an advantage over pre-attention reasonably because it feeds conditions to all attention layers instead of just once before the first attention layer. With the comprehensive evaluation conducted, we have sufficient evidence indicating that in-attention works the best in exerting control over Transformer decoders with segment-level, time-varying conditions.
IV MuseMorphose: Generating Music with Time-Varying User Controls
We have developed in Section III the in-attention technique, which can exert firm control over a Transformer decoder’s generation with time-varying, predetermined conditioning vectors. However, that technique alone only enables Transformers to compose re-creations of music at random. No freedom has been given to users to interact with such a system to affect the music it generates as one wishes, thereby limiting its practical value. This section aims at alleviating such a limitation. We bridge the in-attention Transformer decoder and a jointly learned bar-wise Transformer encoder, which is tasked with learning the bar-level latent conditions. We train the encoder-decoder network with the variational autoencoder (VAE) training objective, and introduce attribute embeddings [30, 23], also working at the bar level, to the decoder to discourage the latent conditions from storing attribute-related information and realize fine-grained user controls over sequence generation. Experiments show that our resulting model, MuseMorphose, successfully allows users to harness two easily perceptible musical attributes, rhythmic intensity and polyphony, while maintaining fluency and high fidelity to the input reference song. Such combination of abilities is shown unattainable by existing methods [22, 23].
IV-A Problem Formulation
For clarity, we model our user-controllable conditional generation task as a style transfer problem without paired data [30]. This problem, in its most basic form, deals with an input instance , such as a sentence or a musical excerpt, and an attribute intrinsic to . The attribute can be either a nominal (e.g., composer style), or an ordinal (e.g., note density) variable with categories. As users, we would like to have a model that takes a tuple:
| (19) |
where is the user-specified attribute value that may be different from the original , and outputs a style-transferred instance . A desirable outcome is that the generated bears the specified attribute value (i.e., achieving effective control), and preserves the content other than the attribute (i.e., exhibiting high fidelity). Being able to generate diverse versions of ’s given the same or to ensure the fluency of generations, though not central to this problem, are also preferred characteristics of such models. This framework has been widely adopted by past works in both text [30, 58, 59] and music [22] domains.
A natural extension to the problem above is to augment the model such that it can process multiple attributes at a time, i.e., taking inputs in the form:
| (20) |
to produce , where , are the categorical attributes being considered. In this case, users have the freedom to alter single or multiple attributes. Hence, preferably, changing one attribute to should not affect an unaltered attribute . This multi-attribute variant has also been studied in [60, 23].
In some scenarios, the input sequence is long and can be partitioned into meaningful continuous segments, e.g., sentences in text or bars in music, through:
| (21) |
where is the length of , and constitute a partition of (cf. the paragraph about the formulation of Eq. (9) in Sec. III-A). For such cases, it could be a privilege if we can control each segment individually, since this allows, for example, users to make a musical section a lot more intense, and another much calmer, to achieve dramatic contrast. Therefore, we formulate here the style transfer problem with multiple, time-varying attributes. A model for this problem accepts:
| (22) |
and then generates a long, style-transferred , where are concerned specifically with the segment . Though Transformers [12, 28] are impressive in sequence generation, no prior work, to our knowledge, has addressed the problem above with them, reasonably because there has not been a well-known segment-level conditioning mechanism for Transformers. Thus, given our developed in-attention method, we are indeed in a privileged position to approach this task.
IV-B Method
In what follows, we describe how we pair an in-attention Transformer decoder with a bar-wise Transformer encoder, as well as attribute embeddings, to achieve fine-grained controllable music generation through optimizing the VAE objective. The musical attributes considered here are: rhythmic intensity () and polyphony (; i.e., harmonic fullness), whose calculation methods will also be detailed. After that, we present the implementation details and the pop piano dataset, AILabs.tw-Pop1K7, used for this task.
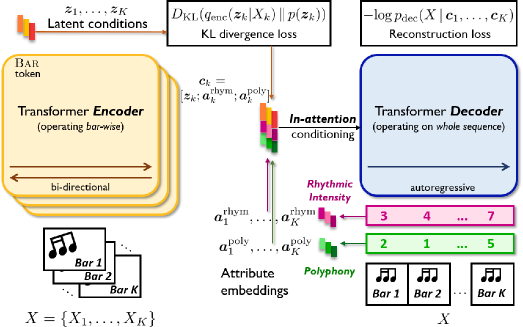
Model Architecture. Figure 4 illustrates our MuseMorphose model, which consists of a vanilla Transformer encoder (i.e., the version proposed by Vaswani et al. [12]) operating at bar level, a Transformer decoder that accepts segment-level conditions through the in-attention mechanism, and a KL divergence-regularized latent space for the representation of musical bars between them. In MuseMorphose, the input music is partitioned as , where houses the bar of the music. The encoder works on the musical bars, , in parallel, while the decoder sees the entire piece at once. The bar-level attributes, and , each consisting of 8 ordinal classes, are transformed into embedding vectors, , before entering the decoder through in-attention. On the whole, the operations taking place inside MuseMorphose can be summarized as follows:
| (23) |
where is the latent condition for the bar; are the bar’s attribute embeddings, stores the timestep indices (see Eq. (21)) of the bar; and, is the predicted probability distribution for . Note that though the input is split into bars on the encoder side, the decoder still deals with the entire sequence, thanks to both in-attention conditioning and . This asymmetric architecture is likely advantageous since it enables fine-grained conditions to be given, and also promotes the coherence of long generations.
Since we adopt the VAE framework here, we now elaborate more on how we construct the latent space for ’s. First, we treat the encoder’s attention output at the first timestep (corresponding to the Bar token), i.e., , as the contextualized representation of the bar. Then, following the conventional VAE setting [13], it is projected by two separate learnable weights , to the mean and std vectors:
| (24) |
where . Afterwards, we may sample the latent condition to be fed to the decoder from the isotropic gaussian defined by and :
| (25) |
For simplicity, the prior of latent conditions, i.e., , is set to the typically-used standard gaussian .
It is worthwhile to mention that the subsequent copy-paste of the ’s, done by the in-attention decoder, to every attention layer and every timestep in coincides with the design of Skip-VAE [46], which provably mitigates the posterior collapse problem, i.e., the case where the decoder completely ignores ’s and degenerates into autoregressive sequence modeling. Also, our work makes a notable advance over Optimus [33] in that we equip Transformer-based VAEs with the capability to model long sequences (with length in the order of ), under fine-grained changing conditions from the latent vector (i.e., ) and user controls (i.e., and ).
Training Objective. MuseMorphose is trained with the -VAE objective [43] with free bits [47]. It minimizes the loss, , which is written as:
| (26) |
The first term, , is the conditional negative log-likelihood (NLL) for the decoder to generate input given the conditions , hence referred to as reconstruction NLL hereafter. The second term, , is the KL divergence between the posterior distributions of ’s estimated by the encoder (i.e., ) and the prior . [43] and [47] are hyperparameters to be tuned (see Section II-C for explanations). We refer readers to Fig. 4 for a big picture of where the two loss terms act on the model.
Previous works that employ autoencoders for style transfer tasks [59, 23, 61] often suggested adding adversarial losses [24] on the latent space, so as to discourage it from storing style-related, or attribute-related, information. However, a potential downside of this practice is that it introduces additional complications to the training of our Transformer-based network, which is already very complex itself. We instead demonstrate that by using suitable and to control the size of latent information bottleneck, both strong style transfer and good content preservation of input can be accomplished without auxiliary training losses.
Calculation of Musical Attributes. The attributes chosen for our task, rhythmic intensity () and polyphony (), are able to be perceived easily by people without intensive training in music. Meanwhile, they are also important determining factors of musical emotion. To obtain the ordinal classes and of each bar, we first compute the raw scores and .
-
•
Rhythmic intensity score, or , simply measures the percentange of sub-beats with at least one note onset, i.e.:
(27) where is the number of sub-beats in a bar and is the indicator function.
-
•
Polyphony score, or , is a bit more implicit, and is defined as the average number of notes being hit (onset) or held (not yet released) in a sub-beat, i.e.,
(28) This makes sense since if there are more notes pressed simultaneously, the music would feel harmonically fuller.
After we collect all bar-wise raw scores from the dataset, we divide them into 8 bins with roughly equally many samples, resulting in the 8 classes of and . For example, in our implementation, the cut-off ’s between the classes of are: , while the cut-offs for are: .
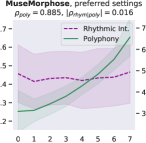
Implementation and Training Details. Both the encoder and decoder of our MuseMorphose model comprise 12 self-attention layers [12], which amount to 79.4 million trainable parameters in total. More architectural details are displayed in Table V in the online supplemental materials. For better training outcome, we introduce both cyclical KL annealing [48] and free bits [47] (both have been introduced in Sec. II-C) to our training objective (see Eq. (26)). After some trial and error, we set , and anneal , i.e., the weight on the term, in cycles of 5,000 training steps. The free bit for each dimension in is set to . This setup is referred to as preferred settings hereafter, for they strike a good balance between content preservation (i.e., fidelity) and diversity.111111Note that this is however judged by our ears. We also train MuseMorphose with the pure AE objective (i.e., , constant), and VAE objective (i.e., , constant; ), to examine how the model behaves on the two extremes. Also, to see how important it is to infuse conditions into all attention layers, we include a pre-attention121212 Review Fig. 2a and Sec. III-B for definition baseline trained under the same latent space constraints (i.e., ) as the preferred settings. Across all four settings, we do not add in the first 10,000 steps, to make it easier for the decoder to exploit the latent space in the beginning.
Furthermore, we set during training, meaning that we feed to the model a random 16-bar crop, truncated to maximum length , from each musical piece in every epoch. This is done mainly to save memory and speed up training. During inference, the model can still generate music of arbitrary length with a sliding window mechanism. As a data augmentation measure, the key of each sample is transposed randomly in the range of half notes in every epoch.
The models are trained with Adam optimizer [51] and teacher forcing. We use linear warm-up to increase the learning rate to in the first 200 steps, followed by a 200k-step cosine decay down to . Model parameters are initialized from the gaussian . Using a batch size of 4, we can fit our MuseMorphose into a single NVIDIA Tesla V100 GPU with 32GB memory. For all three loss variants (preferred settings, AE objective, VAE objective) alike, the training converges in less than 2 full days. At inference time, we perform nucleus sampling [62] to sample from the output distribution at each timestep, using a softmax temperature and truncating the distribution at cumulative probability .
Due to the affinities in training objective and application, we implement MIDI-VAE [22] and Attr-Aware VAE [23] as baselines.131313Optimus [33] is not included here since it was not designed for style transfer, and that its conditioning mechanism has been evaluated in Sec. III. Their RNN-based decoders, however, operates only on single bars (i.e., ’s) of music. Therefore, during inference, each bar is generated independently and then concatenated to form the full piece. We deem this acceptable since the bar-level latent conditions ’s should store sufficient information to link the piece together. We follow their specifications closely, add all auxiliary losses as required, and increase their number of trainable parameters by enlarging the RNN hidden state for fair comparison with MuseMorphose. The resulting number of parameters in our implementations of MIDI-VAE and Attr-Aware VAE, respectively, are 58.2 million and 60.0 million. For fair comparison, in our implementation the two baseline models are trained under the preferred settings for MuseMorphose, with teacher forcing as well.
Dataset and Data Representation. For this task, we consider generating expressive pop piano performances. The pop piano MIDI dataset used is AILabs.tw-Pop1K7, which was released in [27]. According to [27], the piano performances in the dataset are originally collected from the Internet in the MP3 (audio) format. They further employed Onsets and Frames piano transcription [5], madmom beat tracking tool [63], and chorder rule-based chord detection141414https://github.com/joshuachang2311/chorder to transcribe the audio into MIDI format with tempo, beat, and chord information. AILabs.tw-Pop1K7 encompasses 1,747 songs, or 108 hours of music, in total. We hold out 5% of the data (i.e., 87 songs) each for the validation and test sets. We utilize the validation set to monitor the training process, and the test set to generate style-transferred music for further evaluation.
The data representation for songs in AILabs.tw-Pop1K7 is largely identical to REMI [7] and the one used in Sec. III. Differences include: (1) an extended set of Chord tokens are used to mark the harmonic settings of each beat; (2) only a single piano track is present; and, (3) each bar contains 16 Sub-beat’s, rather than 32. The vocabulary size here is hence reduced to 330. Detail descriptions of all event tokens used are shown in Table VII in the online supplemental materials.
IV-C Evaluation Metrics
To evaluate the trained models, we ask them to generate style-transferred musical pieces, i.e., ’s, based on 32-bar-long excerpts, i.e., ’s, drawn from the test set.151515For better generation quality, during inference, we set the latent bar-level conditions , i.e., we do not add the random noise drawn from . Following the convention in text style transfer tasks [59, 61], the generated ’s are evaluated according to: (1) their fidelity w.r.t. input ; (2) the strength of attribute control given specified attributes and ; and, (3) their fluency. In addition, we include a (4) diversity criterion, which is measured across samples generated under the same inputs , and . The experiments are, therefore, conducted under two settings:
-
•
Setting #1: We randomly draw 20 excerpts from the test set, each being 32 bars long, and randomly assign to them 5 sets of different attribute inputs, i.e., , for a model to generate . This would result in samples on which we may compute the fidelity, control, and fluency metrics.
-
•
Setting #2: We draw 20 excerpts as in setting #1; however, here, we assign only 1 set of attribute inputs to them each, and have the model compose 5 different versions of with exactly the same inputs. By doing so, we would obtain pairs of generations on which we may compute the metrics on diversity.
Concerning the metrics, for fidelity and diversity, we directly employ the bar-wise chroma similarity and grooving similarity (i.e., and ) defined in Sec. III-C. We prefer them to be higher in the case of fidelity, but lower in the case of diversity. On the other hand, the metrics for control and fluency are defined in the following paragraphs.
Evaluation Metrics for Attribute Control. Since our attributes are ordinal in nature, following [23], we may directly compute the Spearman’s rank correlation, , between a specified input attribute class and the attribute raw score (see the definitions in Sec. IV-B, Calculation of Musical Attributes) computed from the resulting generation, to see if they are strongly and positively correlated. Taking rhythmic intensity as an example, we define:
| (29) |
where ’s are user-specified inputs, and ’s are computed from model generations given the ’s. The definition of is similar.
Additionally, in the multi-attribute scenario, we want to avoid side effects when tuning one attribute but not the others. More specifically, the model should be able to transfer an attribute without affecting other attributes . To evaluate this, we define another set of correlations, and , as:
| (30) |
and similarly for . We prefer these correlations to be close to zero (i.e., as small as possible), which suggest more independent control of each attribute.
Evaluation Metric for Fluency. In line with text style transfer research [61, 59], we evaluate the fluency of the generations by examining their perplexity (PPL), i.e., the exponentiation of entropy. A low PPL means such a sequence is rather likely to be seen in a language. (In our case, the language is pop piano music.) However, it is impossible to know the true perplexity of a language, so our best effort is to train a language model (LM) to check instead the perplexity for that LM to generate the sequence. This estimated perplexity was proven to upper-bound the true perplexity [64].
To this end, we train a stand-alone 24-layer Transformer decoder LM on the training set of AILabs.tw-Pop1K7, and compute the PPL of each (32-bar-long) generation with:
| (31) |
where is the length of , and is the probability given by the LM. Note that PPL is the only piece-level metric used for our evaluation. All other metrics are measured at bar level.
| Model | Fidelity | Control | Fluency∗ | Diversity | |||||
| PPL | |||||||||
| MIDI-VAE [22] | 75.6 | 85.4 | .719 | .261 | .134 | .056 | 8.84 | 74.8 | 86.5 |
| Attr-Aware VAE [23] | 85.0 | 76.8 | .997 | .781 | .239 | .040 | 10.7 | 86.5 | 84.7 |
| Ours, AE objective | 98.5 | 95.7 | .181 | .154 | .058 | .072 | 6.10 | 97.9 | 95.4 |
| Ours, VAE objective | 78.6 | 80.7 | .931 | .884 | .038 | .003 | 7.89 | 73.2 | 84.9 |
| Ours, pre-attention | 49.7 | 71.5 | .962 | .921 | .035 | .044 | 7.33 | 45.4 | 76.8 |
| Ours, preferred settings | 91.2 | 84.5 | .950 | .885 | .023 | .016 | 7.39 | 87.1 | 87.6 |
| ∗: For reference, the fluency computed on our test set (human-composed music) is 4.79. | |||||||||
| Model | Recons. NLL | KL divergence | ||
|---|---|---|---|---|
| Train | Val. | Train | Val. | |
| MIDI-VAE [22] | 0.676 | 0.894 | 0.697 | 0.682 |
| Attr-Aware VAE [23] | 0.470 | 0.688 | 0.710 | 0.697 |
| Ours, AE objective | 0.130 | 0.139 | 6.927 | 6.928 |
| Ours, VAE objective | 0.697 | 0.765 | 0.485 | 0.484 |
| Ours, pre-attention | 0.589 | 0.860 | 0.462 | 0.474 |
| Ours, preferred settings | 0.457 | 0.584 | 0.636 | 0.636 |
IV-D Results and Discussion
We commence with examining the models’ losses, which are displayed in Table III. Comparing MuseMorphose (preferred settings) and the RNN-based baselines, which are all trained under the same latent space KL constraints (i.e., free bits and cyclical scheduling on ), MuseMorphose attains lower validation reconstruction NLL and KL divergence at the same time. This is likely due to both the advantage of looking at the entire sequence, a trait that RNNs do not have; and, that a Transformer decoder can more efficiently exploit the information from latent space when paired with our in-attention conditioning. The latter argument can be supported by the considerably higher validation NLL of our pre-attention baseline. Next, turning attention to the three in-attention variants of MuseMorphose, we can observe clearly an inverse relationship between the amount of latent space constraint and reconstruction performance. When the latent space is completely free (i.e., the AE objective variant), the NLL can be reduced easily to a very low level. Yet, even when the strict VAE objective is used, MuseMorphose can still reach an NLL around those of the baselines.
Table II shows the evaluation results on our style transfer task. Fidelity-wise, our model mostly surpasses the baselines under the preferred settings, except in , where it scores a little lower than MIDI-VAE. Moreover, our AE objective variant sticks almost perfectly to the inputs, while VAE objective gets a much lower , which is an adverse effect of strong latent space constraint. Perceptually, we find that is a level where a generation often does not feel like the same piece as the input anymore. The pre-attention baseline, though achieving a fluency close to its in-attention counterparts, scores worse than both RNN-based methods on fidelity. This echoes with its high reconstruction NLL, and shows that in-attention is an indispensable part of MuseMorphose.
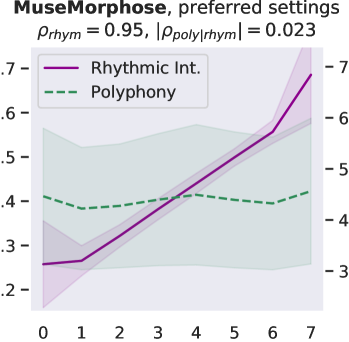
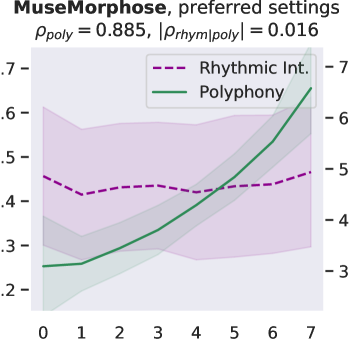
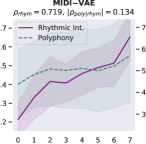
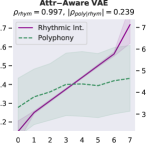
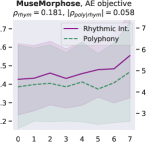
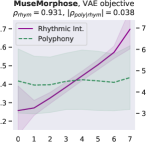
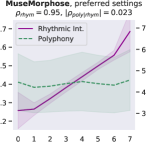
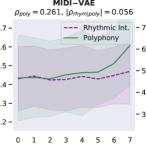
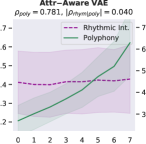
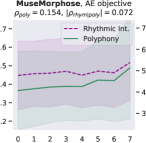
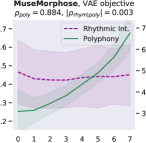
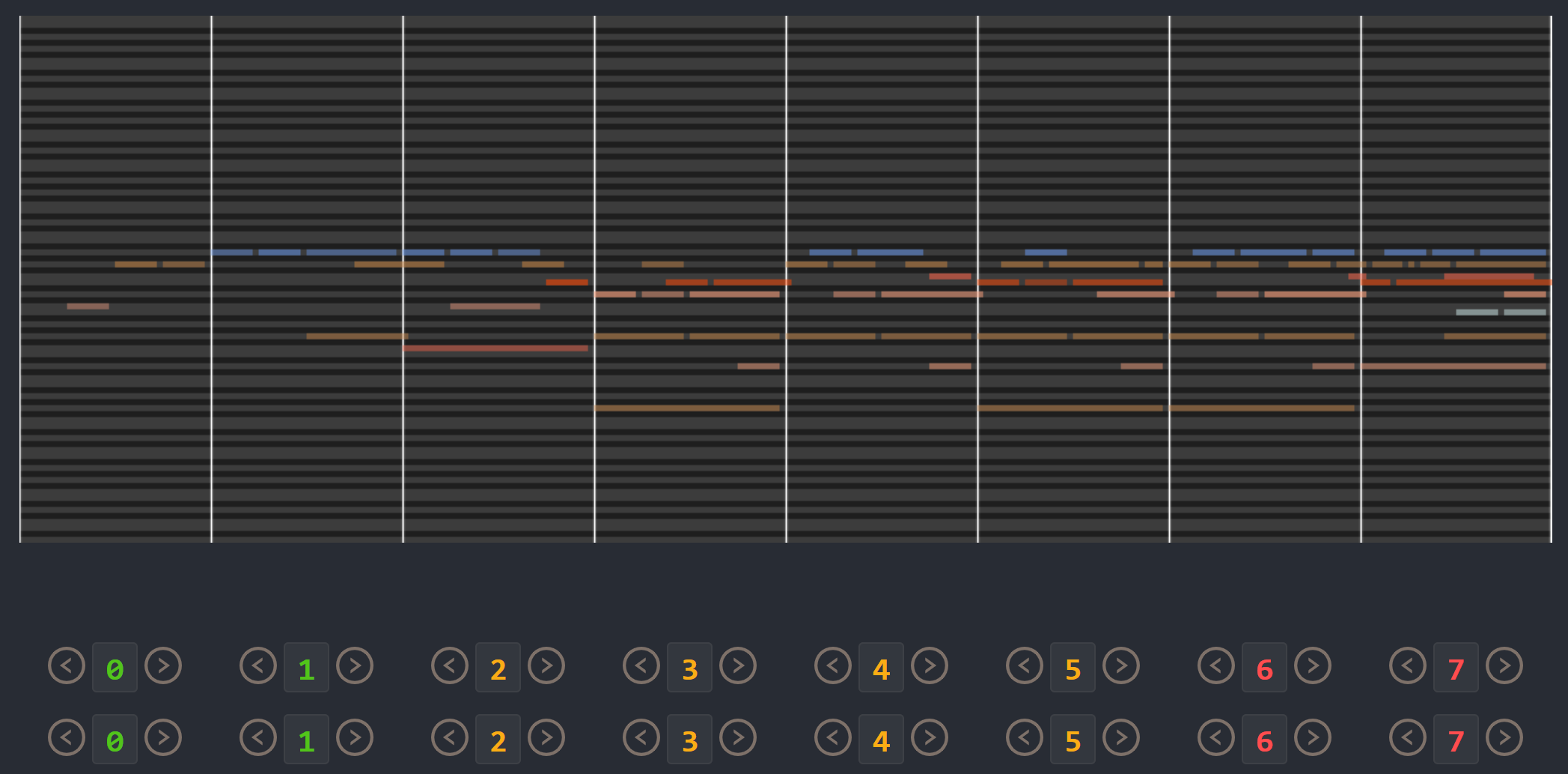
Attribute control is the aspect where AE objective fails; meanwhile, MuseMorphose under preferred settings and VAE objective exhibit equally strong attribute control with and . This suggests that, in the absence of style control-targeted losses, having a narrow enough latent space bottleneck is a key to successful style control. When the latent space is unconstrained, as in the case of AE objective, the latent conditions may carry all necessary information for the decoder to reconstruct the music, rendering the other source of conditions, i.e., the attribute embeddings, which do not connect to the encoder, fruitless. The KL divergence penalty that VAE imposes, on the other hand, forces disentanglement of conditions. It implicitly allows only the information unrelated to user-controlled attributes to stay in the latent space, thereby necessitating attribute embeddings during reconstruction. Comparing with the baselines, MuseMorphose is the only model capable of tightly controlling both attributes, despite the closer competitor, Attr-Aware VAE, achieving a really high . We surmise that rhythmic intensity is an easier attribute for the models to capture, since it only involves counting the number of Sub-beat’s appearing in a bar. However, although the RNN-based methods have satisfactory control on rhythmic intensity, the polyphony scores of their generations are more or less undesirably affected ( or ) when only rhythmic intensity is tuned. This is reasonable since the two musical attributes are correlated by nature (, and computed from AILabs.tw-Pop1K7 are both about ). On the other hand, MuseMorphose (VAE and preferred settings) is able to maintain and while having a firm grip on both attributes, revealing its strengths of both strong and independent attribute control. Fig. 5 well visualizes such strengths. Due to space constraint, more plots comparing the attribute controllability of different settings and models are shown in Fig. 8 in the online supplemental materials.
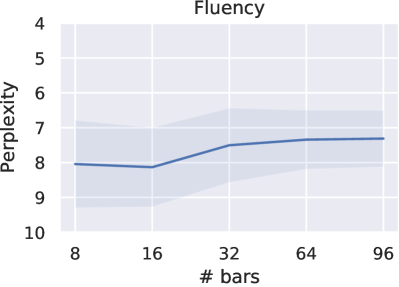
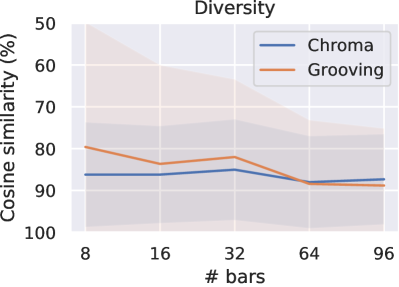
On fluency, MuseMorphose significantly () beats the previous works under all settings. Diversity-wise, though our model does not seem to have an edge over them, we note that there exists an inherent trade-off between diversity and fidelity. If we compare our preferred settings with Attr-Aware VAE, the closer competitor, we can notice that the margins by which MuseMorphose wins over Attr-Aware VAE on fidelity ( for ; for ) is somewhat larger than those by which it loses on diversity ( for ; for ).
It is worth mentioning that manipulating the fidelity-diversity is possible both at training and inference time. During training, we may adjust VAE-related hyperparameters like and free bits (). The comparison between preferred settings and VAE objective offers us a glimpse of the resulting effect. During inference, to boost diversity, we may draw noises from std vectors (i.e., ’s, which may be enlarged or shrunk by multiplying by a constant) and add them to latent conditions, increase sampling temperature, or, alter the distribution truncation point for nucleus sampling. The respective impact of these measures is an interesting direction for future studies.
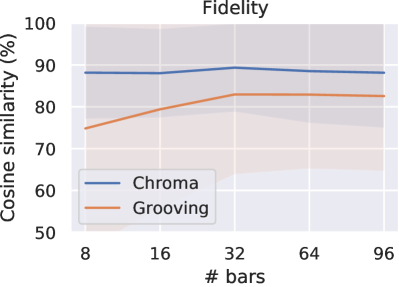
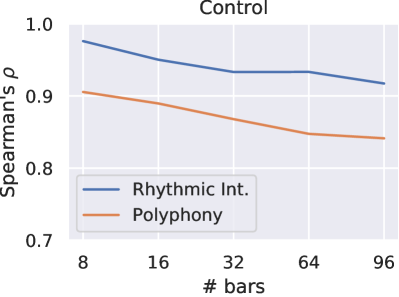
To show that MuseMorphose is able to perform style transfer on arbitrarily long music excerpts, we run evaluation on 896 bar-long generations by our preferred settings model. The results are plotted in Fig. 7 in the online supplemental. The scores stay rather consistent as generation length increases, except for slight downward trends of attribute control and grooving diversity. These trends are reasonable since the higher number of bar-level blueprints given to the model could collectively place stronger restrictions on the generated content.
To summarize, our MuseMorphose model, underpinned by Transformers and the in-attention conditioning mechanism, outperforms both baselines and ticks all the boxes in our controllable music generation task—in particular, it accomplishes high fidelity, strong and independent attribute control, good sequence-level fluency, and adequate diversity, all at once. Nevertheless, we also emphasize that using a combination of VAE training techniques, i.e., cyclical KL annealing and free bits, and picking suitable values for the hyperparameters and , are indispensable to the success of MuseMorphose.
V Conclusion and Future Directions
In this paper, we developed MuseMorphose, a sequence variational autoencoder with Transformers as its backbone, which delivered a stellar performance on controllable conditional generation of pop piano performances. In achieving so, we set off from defining a novel segment-level conditioning problem for generative Transformers, and devised three mechanisms, namely, pre-attention, in-attention, and post-attention conditioning, to approach it. Conducted objective evaluations demonstrated that in-attention came out on top in terms of offering firm control with time-varying conditioning vectors. Subsequently, we leveraged in-attention to bring together a Transformer encoder and Transformer decoder, forming the foundation of MuseMorphose model. Experiments have shown that, when trained with a carefully tuned VAE objective, MuseMorphose emerged as a solid all-rounder on the music style transfer task with long inputs, where we considered controlling two musical attributes, i.e., rhythmic intensity and polyphony, at the bar level. Our model outperformed two previous methods [22, 23] on commonly accepted style transfer evaluation metrics, without using any auxiliary objectives tailored for style control.
Nevertheless, whether in-attention would perform best across more kinds of musical conditions (e.g., tonality, instrumentation, which vary less frequently than the two studied attributes), and why it achieves so remain underexplored in the current work. Besides, it is somewhat unclear how much performance gain actually comes from replacing the RNN sequence models with Transformers, rather than from our proposed conditioning and training mechanisms. Experimenting on shorter music excerpts (e.g., 24 bars, which RNNs can process at once) may shed light on this. We hope future studies may address the unanswered aspects above.
Our research can also be extended in the following directions:
-
•
Applications in Natural Language Processing (NLP): The framework of MuseMorphose is easily generalizable to texts by, for example, treating sentences as segments (i.e., ’s) and an article as the full sequence (i.e., ). As for attributes, possible options include sentiments [30, 61] and text difficulty [65]. Success in controlling the latter, for example, is of high practical value since it would enable us to rewrite articles or literary works to cater to the needs of pupils across all stages of education.
-
•
Music generation with long-range structures: Being inspired by the two astounding works of high-resolution image generation [66, 67], in which Transformers are used to generate the high-level latent semantics of an image (i.e., ’s, the sequence of latent conditions), we conjecture that long range musical structures, e.g., motivic development, recurrence of themes, contrasting sections, etc., may be better generated in a similar fashion. To this end, it is likely that we need to learn a vector-quantized latent space [68] instead, so that the latent conditions can be represented in token form for another Transformer to model.
To conclude, our work not only bridged Transformers and VAEs for controllable sequence modeling, where potentials for further applications exist, but also laid the foundation for a pathway to long sequence generation never explored before.
References
- [1] L. A. Hiller and L. M. Isaacson, Experimental Music; Composition with an Electronic Computer, 1959.
- [2] G. Hadjeres, F. Pachet, and F. Nielsen, “DeepBach: a steerable model for Bach chorales generation,” in Proc. ICML, 2017.
- [3] H.-W. Dong, W.-Y. Hsiao, L.-C. Yang, and Y.-H. Yang, “MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,” in Proc. AAAI, 2018.
- [4] S. Ji, J. Luo, and X. Yang, “A comprehensive survey on deep music generation: Multi-level representations, algorithms, evaluations, and future directions,” arXiv preprint arXiv:2011.06801, 2020.
- [5] C. Hawthorne, E. Elsen, J. Song, A. Roberts, I. Simon, C. Raffel, J. Engel, S. Oore, and D. Eck, “Onsets and Frames: Dual-objective piano transcription,” in Proc. ISMIR, 2018.
- [6] S. Oore, I. Simon, S. Dieleman, D. Eck, and K. Simonyan, “This time with feeling: Learning expressive musical performance,” arXiv preprint arXiv:1808.03715, 2018.
- [7] Y.-S. Huang and Y.-H. Yang, “Pop Music Transformer: Generating music with rhythm and harmony,” in Proc. ACM Multimedia, 2020.
- [8] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proc. ACL, 2016.
- [9] C. A. Huang, A. Vaswani, J. Uszkoreit, I. Simon, C. Hawthorne, N. Shazeer, A. M. Dai, M. D. Hoffman, M. Dinculescu, and D. Eck, “Music Transformer: Generating music with long-term structure,” in Proc. ICLR, 2019.
- [10] C. Donahue, H. H. Mao, Y. E. Li, G. W. Cottrell, and J. McAuley, “LakhNES: Improving multi-instrumental music generation with cross-domain pre-training,” in Proc. ISMIR, 2019.
- [11] A. Roberts, J. Engel, C. Raffel, C. Hawthorne, and D. Eck, “A hierarchical latent vector model for learning long-term structure in music,” in Proc. ICML, 2018.
- [12] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. NeurIPS, 2017.
- [13] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proc. ICLR, 2014.
- [14] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [15] K. Cho, B. van Merriënboer, D. Bahdanau, and Y. Bengio, “On the properties of neural machine translation: Encoder–decoder approaches,” in Proc. Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, 2014.
- [16] C. M. Payne, “MuseNet,” OpenAI Blog, 2019.
- [17] S.-L. Wu and Y.-H. Yang, “The Jazz Transformer on the front line: Exploring the shortcomings of AI-composed music through quantitative measures,” in Proc. ISMIR, 2020.
- [18] Y.-H. Chen, Y.-H. Huang, W.-Y. Hsiao, and Y.-H. Yang, “Automatic composition of guitar tabs by Transformers and groove modeling,” in Proc. ISMIR, 2020.
- [19] Z. Dai, Z. Yang, Y. Yang, J. G. Carbonell, Q. Le, and R. Salakhutdinov, “Transformer-XL: Attentive language models beyond a fixed-length context,” in Proc. ACL, 2019.
- [20] H. H. Tan and D. Herremans, “Music FaderNets: Controllable music generation based on high-level features via low-level feature modelling,” in Proc. ISMIR, 2020.
- [21] G. Hadjeres, F. Nielsen, and F. Pachet, “GLSR-VAE: Geodesic latent space regularization for variational autoencoder architectures,” in Proc. IEEE Symposium Series on Computational Intelligence, 2017.
- [22] G. Brunner, A. Konrad, Y. Wang, and R. Wattenhofer, “MIDI-VAE: Modeling dynamics and instrumentation of music with applications to style transfer,” in Proc. ISMIR, 2018.
- [23] L. Kawai, P. Esling, and T. Harada, “Attributes-aware deep music transformation,” in Proc. ISMIR, 2020.
- [24] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” in Proc. NeurIPS, 2014.
- [25] K. Choi, C. Hawthorne, I. Simon, M. Dinculescu, and J. Engel, “Encoding musical style with Transformer autoencoders,” in Proc. ICML, 2020.
- [26] Y. Ren, J. He, X. Tan, T. Qin, Z. Zhao, and T.-Y. Liu, “PopMAG: Pop music accompaniment generation,” in Proc. ACM Multimedia, 2020.
- [27] W.-Y. Hsiao, J.-Y. Liu, Y.-C. Yeh, and Y.-H. Yang, “Compound Word Transformer: Learning to compose full-song music over dynamic directed hypergraphs,” in Proc. AAAI, 2021.
- [28] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, 2019.
- [29] J. Devlin, M.-W. Chang, K. Lee, and K. N. Toutanova, “BERT: Pre-training of deep bidirectional Transformers for language understanding,” in Proc. NAACL-HLT, 2018.
- [30] Z. Fu, X. Tan, N. Peng, D. Zhao, and R. Yan, “Style transfer in text: Exploration and evaluation,” in Proc. AAAI, 2018.
- [31] R. Panda, R. Malheiro, and R. P. Paiva, “Novel audio features for music emotion recognition,” IEEE Transactions on Affective Computing, 2018.
- [32] R. Panda, R. M. Malheiro, and R. P. Paiva, “Audio features for music emotion recognition: a survey,” IEEE Transactions on Affective Computing, 2020.
- [33] C. Li, X. Gao, Y. Li, B. Peng, X. Li, Y. Zhang, and J. Gao, “Optimus: Organizing sentences via pre-trained modeling of a latent space,” in Proc. EMNLP, 2020.
- [34] T. Wang and X. Wan, “T-CVAE: Transformer-based conditioned variational autoencoder for story completion.” in Proc. IJCAI, 2019.
- [35] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. CVPR, 2016.
- [36] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016.
- [37] P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” in Proc. NAACL, 2018.
- [38] G. Ke, D. He, and T.-Y. Liu, “Rethinking the positional encoding in language pre-training,” in Proc. ICLR, 2021.
- [39] B. Wang, L. Shang, C. Lioma, X. Jiang, H. Yang, Q. Liu, and J. G. Simonsen, “On position embeddings in bert,” in Proc. ICLR, 2021.
- [40] A. Liutkus, O. Cífka, S.-L. Wu, U. Şimşekli, Y.-H. Yang, and G. Richard, “Relative positional encoding for Transformers with linear complexity,” in Proc. ICML, 2021.
- [41] A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are RNNs: Fast autoregressive Transformers with linear attention,” in Proc. ICML, 2020.
- [42] K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser et al., “Rethinking attention with performers,” in Proc. ICLR, 2021.
- [43] I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-VAE: Learning basic visual concepts with a constrained variational framework,” in Proc. ICLR, 2017.
- [44] C. K. Sønderby, T. Raiko, L. Maaløe, S. K. Sønderby, and O. Winther, “Ladder variational autoencoders,” in Proc. NeurIPS, 2016.
- [45] S. Bowman, L. Vilnis, O. Vinyals, A. Dai, R. Jozefowicz, and S. Bengio, “Generating sentences from a continuous space,” in Proc. SIGNLL, 2016.
- [46] A. B. Dieng, Y. Kim, A. M. Rush, and D. M. Blei, “Avoiding latent variable collapse with generative skip models,” in Proc. AISTATS, 2019.
- [47] D. P. Kingma, T. Salimans, R. Jozefowicz, X. Chen, I. Sutskever, and M. Welling, “Improving variational inference with inverse autoregressive flow,” arXiv preprint arXiv:1606.04934, 2016.
- [48] H. Fu, C. Li, X. Liu, J. Gao, A. Celikyilmaz, and L. Carin, “Cyclical annealing schedule: A simple approach to mitigating KL vanishing,” in Proc. NAACL-HLT, 2019.
- [49] N. S. Keskar, B. McCann, L. R. Varshney, C. Xiong, and R. Socher, “CTRL: A conditional Transformer language model for controllable generation,” arXiv preprint arXiv:1909.05858, 2019.
- [50] M. Stern, W. Chan, J. Kiros, and J. Uszkoreit, “Insertion Transformer: Flexible sequence generation via insertion operations,” in Proc. ICML, 2019.
- [51] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [52] M. Chen, A. Radford, J. Wu, H. Jun, P. Dhariwal, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Proc. ICML, 2020.
- [53] H.-W. Dong and Y.-H. Yang, “Convolutional generative adversarial networks with binary neurons for polyphonic music generation,” in Proc. ISMIR, 2018.
- [54] T. Fujishima, “Realtime chord recognition of musical sound: A system using common Lisp,” in Proc. International Computer Music Conf. (ICMC), 1999.
- [55] S. Dixon, F. Gouyon, and G. Widmer, “Towards characterisation of music via rhythmic patterns,” in Proc. ISMIR, 2004.
- [56] J. Foote, “Visualizing music and audio using self-similarity,” in Proc. ACM Multimedia, 1999.
- [57] L.-C. Yang and A. Lerch, “On the evaluation of generative models in music,” Neural Computing and Applications, vol. 32, no. 9, pp. 4773–4784, 2020.
- [58] Z. Yang, Z. Hu, C. Dyer, E. P. Xing, and T. Berg-Kirkpatrick, “Unsupervised text style transfer using language models as discriminators,” in Proc. NeurIPS, 2018.
- [59] V. John, L. Mou, H. Bahuleyan, and O. Vechtomova, “Disentangled representation learning for non-parallel text style transfer,” in Proc. ACL, 2019.
- [60] G. Lample, S. Subramanian, E. Smith, L. Denoyer, M. Ranzato, and Y.-L. Boureau, “Multiple-attribute text rewriting,” in Proc. ICLR, 2019.
- [61] N. Dai, J. Liang, X. Qiu, and X.-J. Huang, “Style Transformer: Unpaired text style transfer without disentangled latent representation,” in Proc. ACL, 2019.
- [62] A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi, “The curious case of neural text degeneration,” in Proc. ICLR, 2019.
- [63] S. Böck, F. Korzeniowski, J. Schlüter, F. Krebs, and G. Widmer, “Madmom: A new Python audio and music signal processing library,” in Proc. ACM Multimedia, 2016.
- [64] P. F. Brown, S. A. Della Pietra, V. J. Della Pietra, J. C. Lai, and R. L. Mercer, “An estimate of an upper bound for the entropy of english,” Computational Linguistics, vol. 18, no. 1, pp. 31–40, 1992.
- [65] S. Surya, A. Mishra, A. Laha, P. Jain, and K. Sankaranarayanan, “Unsupervised neural text simplification,” in Proc. ACL, 2019.
- [66] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” arXiv preprint arXiv:2102.12092, 2021.
- [67] P. Esser, R. Rombach, and B. Ommer, “Taming Transformers for high-resolution image synthesis,” in Proc. CVPR, 2021.
- [68] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” in Proc. NeurIPS, 2017.
VI Supplemental Materials:
Extra Tables and Figures
| Attr. | Description | Value |
| target sequence length | 1,024 | |
| Transformer-XL memory length | 1,024 | |
| # self-attention layers | 12 | |
| # self-attention heads | 10 | |
| token embedding dimension | 320 | |
| hidden state dimension | 640 | |
| feed-forward dimension | 2,048 | |
| condition embedding dimension | 512 | |
| # params | 58.762.6 mil. | |
| Attr. | Description | Value |
| target sequence length | 1,280 | |
| # self-attention layers | 24 | |
| # encoder self-attention layers | 12 | |
| # decoder self-attention layers | 12 | |
| # self-attention heads | 8 | |
| token embedding dimension | 512 | |
| hidden state dimension | 512 | |
| feed-forward dimension | 2,048 | |
| latent condition dimension | 128 | |
| attribute embedding dimension (each) | 64 | |
| # params | — | 79.4 mil. |
| Event type | Description | # tokens |
|---|---|---|
| Bar | beginning of a new bar | 1 |
| Sub-beat | position in a bar, in 32nd note steps (\musThirtySecond) | 32 |
| Tempo | 32224 bpm, in steps of 3 bpm | 64 |
| Pitch∗ | MIDI note numbers (pitch) 0127 | 1,757 |
| Velocity∗ | MIDI velocities 3127 | 544 |
| Duration∗ | multiples (164 times) of \musThirtySecond | 1,042 |
| All events | — | 3,440 |
| ∗: unique for each of the 17 tracks (instruments) | ||
| Event type | Description | # tokens |
|---|---|---|
| Bar | beginning of a new bar | 1 |
| Sub-beat | position in a bar, in 16th note steps (\musSixteenth) | 16 |
| Tempo | 32224 bpm, in steps of 3 or 6 bpm | 54 |
| Pitch | MIDI note numbers (pitch) 22107 | 86 |
| Velocity | MIDI velocities 4086 | 24 |
| Duration | multiples (116 times) of \musSixteenth | 16 |
| Chord | chord markings (root & quality) | 133 |
| All events | — | 330 |