N-Cloth: Predicting 3D Cloth Deformation with Mesh-Based Networks
Abstract.
We present a novel mesh-based learning approach (N-Cloth) for plausible 3D cloth deformation prediction. Our approach is general and can handle cloth or obstacles represented by triangle meshes with arbitrary topologies. We use graph convolution to transform the cloth and object meshes into a latent space to reduce the non-linearity in the mesh space. Our network can predict the target 3D cloth mesh deformation based on the initial state of the cloth mesh template and the target obstacle mesh. Our approach can handle complex cloth meshes with up to K triangles and scenes with various objects corresponding to SMPL humans, non-SMPL humans or rigid bodies. In practice, our approach can be used to generate plausible cloth simulation at fps on an NVIDIA GeForce RTX 3090 GPU. We highlight its benefits over prior learning-based methods and physically-based cloth simulators.
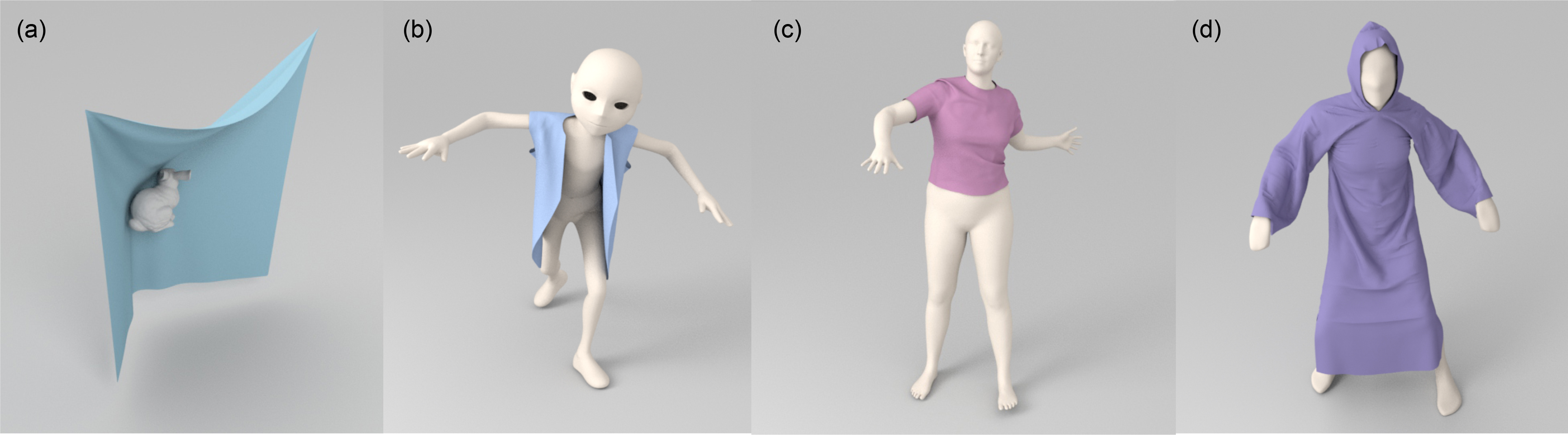
1. Introduction
Generating plausible cloth simulation has been an active research area for many decades. The driving applications include video games and VR, computer animation, special effects, the fashion industry, virtual try-on applications, etc. There is extensive literature on simulating cloth deformation using physically-based and data-driven methods.
Physically-based methods treat cloth simulation as a deformable modeling problem and solve is using techniques from scientific computing and geometric computing. These methods also perform collision handling for accurate simulation. The resulting algorithms can generate high-fidelity simulations and can be accelerated by exploiting GPU parallelism. However, they are mostly limited to offline simulations and are not considered fast or practical for interactive applications such as games and VR. There has been considerable interest in developing data-driven or learning-based approaches for interactive simulation. The data-driven methods use a large number of pre-computed simulated clothing samples to synthesize cloth deformation. Recently, many learning-based methods have been proposed for draping cloth or adjusting cloth deformation to human motion [Patel et al., 2020; Santesteban et al., 2019; Loper et al., 2015; Bertiche et al., 2020a, b; Wu et al., 2021; Santesteban et al., 2021]. While these methods can predict clothing deformation in 3D space at interactive rates, they may not work well for arbitrary scenarios with different types of objects exerting force on the cloth. In practice, these learning methods are mainly limited to predicting the deformation of clothes that conform to human movements. Moreover, many of these algorithms are limited to SMPL-based human body models [Loper et al., 2015] or virtual try-on applications. It is not clear whether these learning methods can extend to other types of irregular fabrics such as a table cloth wrapping around an arbitrary obstacle like a bunny. Often these methods also require some pre-processing such as skinning [Gundogdu et al., 2019, 2020], which can introduce artifacts into subsequent network training.
Main Results: We present a novel learning-based method (N-Cloth) to interactively predict cloth deformations in 3D. Our approach is designed for general scenes represented using triangle meshes and makes no assumption about the topology of the cloth or the shape/topology of the obstacle. Moreover, the simulation environment may consist of arbitrary rigid or deforming objects (e.g., humans in motion) that apply forces on the cloth and can result in complex deformations. Our learning method predicts the target3D cloth mesh deformation based on the initial state of the cloth mesh template and the target obstacle mesh.
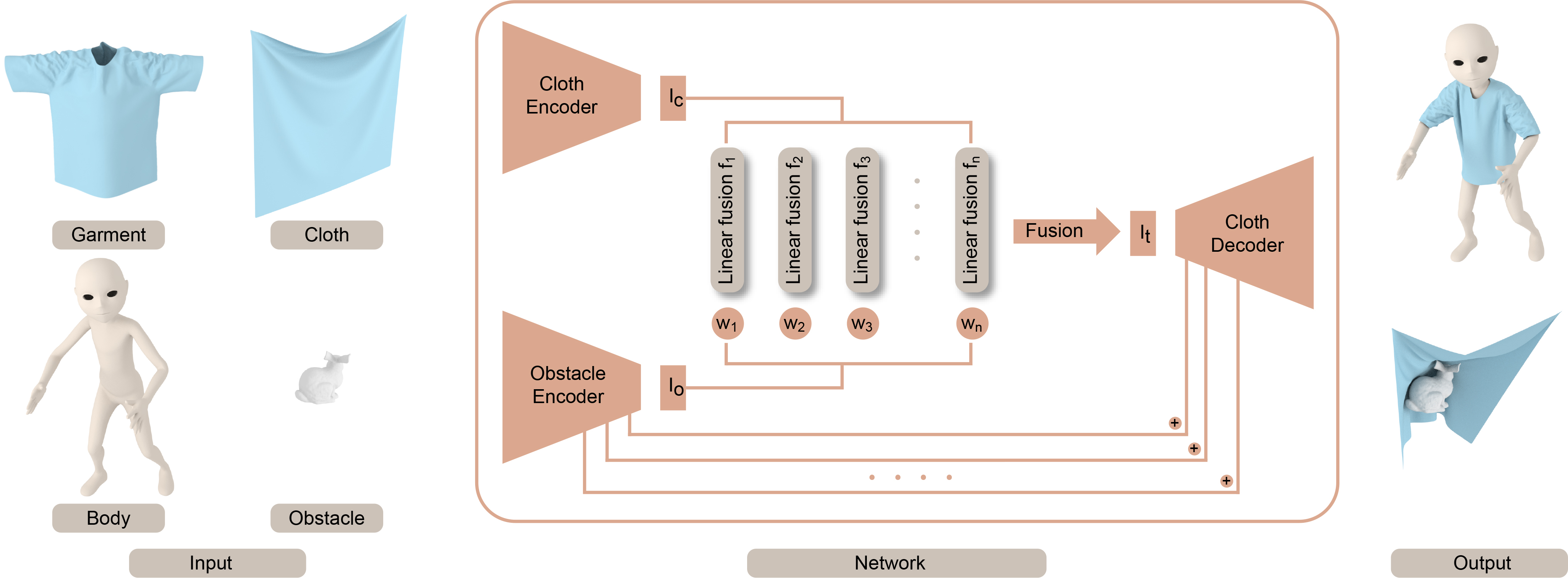
A key aspect of our learning-based approach is the use of a network that directly uses the input meshes and does not require pre-processing (e.g., mesh skinning). We extend the classic encoder-decoder architecture [Ranzato et al., 2007] with two major components: a graph-convolution-based encoder network and a fusion network. The first network transforms the input cloth and object meshes into latent vectors of a latent space and greatly reduces the input data size. This enables our algorithm to handle complex objects in the scenes defined using triangle meshes (e.g., with up to triangles). Our fusion network is used to derive the deforming mesh from the input cloth meshes and obstacle meshes in the latent space. This increases the accuracy of our overall learning-based method in terms of predicting arbitrary 3D cloth deformations. The connections between the outputs of an obstacle encoder and a cloth decoder are introduced to generate more accurate cloth deformations. Moreover, our learning method can also generate detailed features like wrinkles.
We qualitatively and quantitatively analyze the performance of the proposed mesh-based network in a variety of scenarios. These include cloth meshes corresponding to many types and topologies. Furthermore, the obstacles in the scene correspond to rigid objects or a human body. In practice, our approach can generate plausible cloth deformations for all these scenarios, even when the predicted meshes are different from the datasets used in training. We also compare the performance with TailorNet [Patel et al., 2020], a SMPL-based network, and observe lower error with respect to the ground truth.
The novel aspects of our learning-based approach include:
-
•
A novel mesh-based network for various scenes: Our approach can handle arbitrary obstacle meshes. This is in contrast to recent learning-based methods that are mainly limited to parametric human models [Patel et al., 2020; Santesteban et al., 2019; Loper et al., 2015; Bertiche et al., 2020a, b; Wu et al., 2021; Santesteban et al., 2021].
- •
- •
-
•
Plausible Results: We have evaluated the accuracy of our approach on a large number of complex cloth deformations and observe plausible results. Compared with TailorNet, our method can predict the cloth mesh with more wrinkles.
-
•
Lower Memory Overhead: Our approach can handle cloth meshes with up to triangles on commodity GPUs.
2. Related Work
In this section, we give a brief overview of prior work on cloth deformation using physically-based simulation and learning-based methods.
2.1. Physically-based Cloth Simulation
Physically-based algorithms use explicit Euler integration [Provot, 1995], implicit Euler integration [Baraff and Witkin, 1998], iteration optimization [Liu et al., 2013, 2017], or projective dynamics [Bouaziz et al., 2014] to calculate the cloth deformation under external/internal forces. Many techniques have been proposed for robust collision handling [Bridson et al., 2002; Brochu et al., 2012; Tang et al., 2014; Govindaraju et al., 2005]. Impulse-based methods and impact zones [Bridson et al., 2002; Harmon et al., 2008; Provot, 1997; Tang et al., 2018] are used for penetration handling. Recently many techniques have been proposed to accelerate these simulations using one or more GPUs [Tang et al., 2016; Li et al., 2020]. In practice, accurate cloth simulators can generate high–fidelity simulations, and we regard them as the ground truth for our learning approach.
2.2. Data-driven Approaches
Many data-driven approaches have been proposed for cloth deformation synthesis [Feng et al., 2010; Wang et al., 2010]. By combining high-quality wrinkles with a coarse cloth simulation [Zhang et al., 2021b; Chentanez et al., 2020], visually plausible results can be generated at interactive rates. These methods commonly need to simulate coarse deformed meshes. Furthermore, these methods need to precompute a large dataset, and their generalizability to arbitrary scenarios tends to be limited [de Aguiar et al., 2010; Kim et al., 2013; Zurdo et al., 2013].
2.3. Learning-based Algorithms
Recently, learning-based algorithms have been proposed for predicting cloth deformation in 3D. Using the synthetic training data generated using physics-based simulators, learning-based approaches can predict cloth deformation at interactive rates on commodity GPUs. A large number of learning-based algorithms [Patel et al., 2020; Santesteban et al., 2019; Loper et al., 2015; Bertiche et al., 2020a, b; Wu et al., 2021; Santesteban et al., 2021; Wang et al., 2019; Corona et al., 2021] have been designed for specific or parametric obstacle models such as SMPL-based [Loper et al., 2015] or skeleton-based human body models. This makes it difficult to use these methods in environments with arbitrary rigid or deformable objects that can interact with the cloth.
Some learning-based algorithms are not limited to SMPL models. These approaches aim to process human bodies with skeleton. Holden et al. [Holden et al., 2019] obtain the vector of the vertex attributes of in the subspace through PCA and divide the deformation into linear and nonlinear to make assumptions and to predict the subsequent deformation. The GarNet network architecture proposed by Gundogdu et al. [Gundogdu et al., 2019, 2020] predicts the cloth deformation from the target posture with DQS (dual quaternion skinning) pre-processing [Kavan et al., 2007] from the initial state and uses it as the final cloth deformation. [Zhang et al., 2021a] learns to generate rendered characters and cloth on posed skeleton joints. All these methods focus on human bodies with skeleton and can not handle scenes without human skeletons. Our aim is to find an approach capable of processing many scenes with human meshes and other rigid body meshes.
3. Our Approach
3.1. Overview
Our goal is to predict the target deformed cloth mesh based on the target obstacle mesh and the initial cloth mesh. We assume that they are represented as 3D meshes. The initial cloth mesh provides a template for deformation. The target obstacle mesh is used to guide deformation. We do not make any assumptions about the initial topology of the cloth, though it remains fixed during the simulation or deformation. Thus, our network is an end-to-end method for predicting the cloth deformation. Formally, our approach can be described as:
| (1) |
where is the predicted deformed target cloth mesh and is the target obstacle mesh. is the initial, undeformed cloth mesh template which is undeformed and constant for one specific kind of cloth. During the prediction, the topologies of the cloth mesh and the obstacle mesh are invariable. is the mesh-based network and represents the network parameters obtained by training.
We extend the classic encoder-decoder neural network architecture [Ranzato et al., 2007] to generate the 3D cloth deformation. An overview of our approach is shown in Fig. 2. The deformation in mesh space is nonlinear and too complicated to be modeled. The nonlinearity of the mesh deformation is transformed to linear fusion in latent space through a cloth encoder and an obstacle encoder. Thus, we obtain the latent representation of the target cloth mesh by linear fusion. The target cloth mesh is obtained by a cloth decoder. We will describe the network in more detail.
3.2. Encoder Network
We use the encoder network to transform the input cloth mesh and the obstacle mesh from the 3D mesh space into a latent space. Our goal is to handle arbitrary triangle cloth meshes. A triangle mesh is similar to graph data. Therefore, the networks for processing graph data are applicable to resolving relevant mesh problems. Referring to [Gao and Ji, 2019], graph convolution is used in this paper to perform feature extraction on a mesh with abundant triangles. Both the cloth encoder and the obstacle encoder have similar network architectures.The first network block of our encoder network is shown in Fig. 3. Both the cloth encoder and the obstacle encoder have several network blocks similar to this initial block. Then we elaborate on the various parts of the first network block in the encoder. As shown in Fig. 3, we use the GCN layer [Kipf and Welling, 2016] to extract features from the geometry information (vertex coordinates) and topology information (edge connectivity) of the mesh. In this manner, the GCN layer maintains the topology of the mesh. The GCN layer can be formulated as in [Kipf and Welling, 2016]:
| (2) |
where , is the adjacency matrix of layer . is the identity matrix for adding self-loops. and are the feature matrices of the layer and , respectively. , and is a trainable weight matrix for layer .
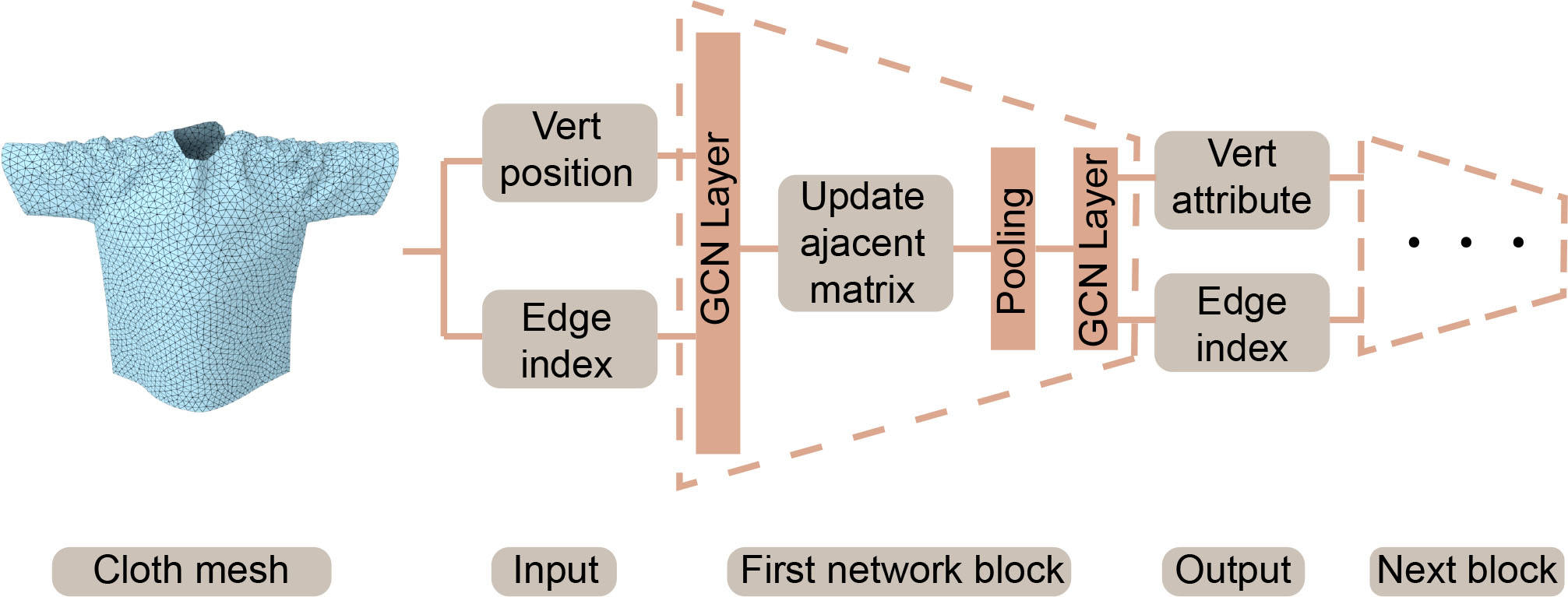
Since the output of the GCN layer has the same topology as the input, this formulation can result in a large number of training parameters for high-resolution meshes and thereby exceed the GPU memory budget. To reduce the model parameters and complex non-linearity in 3D space, we use top-k-pooling [Gao and Ji, 2019] to perform data down-sampling by outputting meshes with reduced topology information, i.e., with fewer vertices and connectivity information among them.
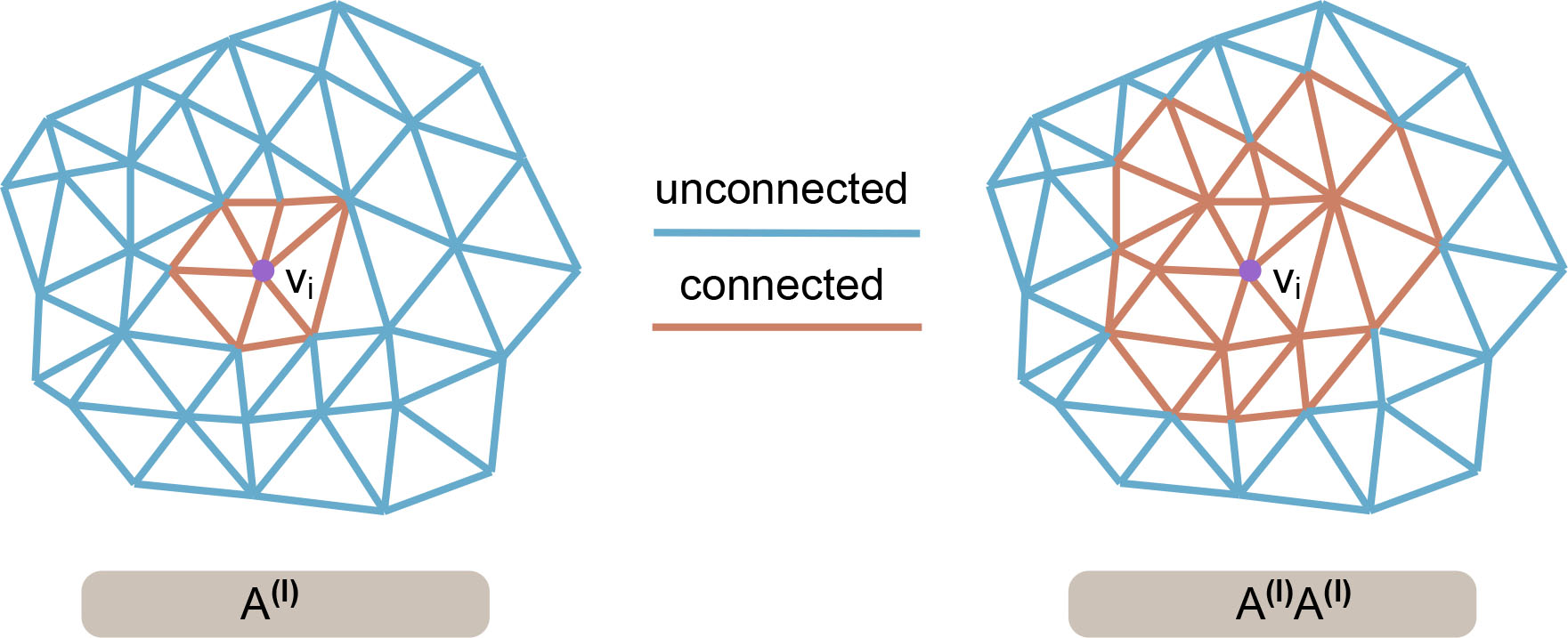
Top-k-pooling will pick vertices from the original vertex set and discard other vertices to perform down-sampling. This process may result in multiple isolated point sets, which may not work well for subsequent GCN layers because these layers extract features in terms of information related to the of the vertex. Thus, we recalculate the connectivity of mesh vertices before using a top-k-pooling layer to improve triangle connectivity. Therefore, we calculate the square of the adjacency matrix as follows [Gao and Ji, 2019]:
| (3) |
where is the new adjacency matrix for next top-k-pooling computation. The new adjacency matrix corresponds to introducing more vertices around a given vertex and will reduce the isolated points after pooling.
Fig. 4 shows the connectivity between a single vertex and surrounding vertices in the mesh where the adjacency matrix is or . The connectivity between vertices is strengthened with the adjacency matrix .
3.3. Fusion Network
The output of the cloth encoder and the obstacle encoder are and , respectively. and are vectors in the latent space extracted from the cloth mesh and the obstacle mesh, respectively. and are expressed as follows:
| (4) | ||||
where and represent the cloth encoder network and the obstacle encoder network, respectively. and are the dimensions of and , respectively. and are the component of latent vectors and , respectively.
We use the fusion network to generate , which corresponds to the vector of the target cloth mesh in the latent space from and . Our formulation of the fusion network is inspired by prior work in image processing and 3D character control. Rocco et al. [Rocco et al., 2017] added a correlation layer to the network for geometric matching between 2D images, and Holden et al. [Holden et al., 2017] proposed a phase-functioned network the weights of which are updated by a phase cyclic function for 3D character control.
We perform the fusion by linearly weighting a set of linear fusion functions , which all take as an input. Here is used as the linear weight. The linear fusion functions are defined as follows:
| (5) |
where is a set of trainable coefficients and . The overall fusion process can be expressed by the following formula:
| (6) | ||||
We use this formulation to obtain the vector of the target cloth mesh in the latent space. Thus, we obtain a linear latent space where the deformation can be expressed as a linear fusion. In practice, we observe that our linear formulation can predict plausible results, and the errors are rather small (see Section 4).
In the mesh space, the influence of the obstacle mesh on the deformed cloth mesh may be complex and non-linear (e.g., due to collisions between the cloth and the obstacle). With our fusion network, we are able to model the non-linearity as weighted combinations of latent vectors and obtain the parameters of the combination function by training. In addition, the dimensions and of and , respectively, also govern the accuracy of our predicted deformation. In our implementation, we set and for most benchmarks. We choose these dimensions by experiments and find that increasing them does not obviously improve the results.
3.4. Decoder Network
We use the decoder network to generate a cloth mesh in the world space from . The problem of recovering the cloth mesh from the latent space has been investigated by [Chen et al., 2020; Chentanez et al., 2020; Chen et al., 2021]. Although these methods use graph convolution networks, the resulting decoder networks use the same sampling information as the encoder networks. In addition, there is almost no deformation between the input mesh and the output mesh. However, this formulation does not work well when the target cloth mesh involves a large deformation relative to the initial mesh. In our formulation, we assume the cloth mesh maintain the same topology during deformation. As a result, we reduce the problem to only computing the geometric information of the deformed mesh (i.e., the vertex coordinates).
To compute the coordinates of the deformed vertices, we use a Multilayer Perceptron (MLP) network to decode the feature vector of the target deformed cloth. In each layer of cloth decoder, we apply dropout regularization by randomly disabling 20% of the hidden neurons to avoid overfitting the training data. The output of our decoder network is a one-dimensional vector that will be reshaped to as vertex coordinates of the target cloth mesh, where is the number of vertices of the target cloth mesh. In addition, we add the output of each layer of the obstacle encoder to the input of the corresponding layer of the decoder through a linear layer connection. In this way, we increase the effects of obstacles on the cloth decoder and find improved results.
3.5. Loss Functions
Loss function is a key component of our learning-based algorithm. We use different loss terms to achieve plausible results and overcome penetrations. We use the position information of the deformed cloth meshes as the ground truth and calculate the MSE loss between it and the network prediction output. The MSE loss on the positions can be expressed as:
| (7) |
where is the position of vertex on the predicted cloth mesh, is the position of vertex on the ground mesh, is the number of vertices, and is the distance.
In addition, we also use a new type of loss to remove penetrations between the generated cloth and the obstacle. Our goal is to generate non-colliding cloth meshes. The penetration loss between the cloth mesh and the obstacle mesh can be expressed as:
| (8) |
where is the position of vertex on the cloth mesh and is the nearest point to on the obstacle mesh. is the normal vector of on the obstacle mesh. is the minimum distance of penetration. is the number of vertices of the cloth mesh. As shown in Fig. 12, the penetration loss can greatly overcome penetrations between a cloth mesh and a human body. We build the AABB tree of the obstacle to find the nearest point on the obstacle mesh. Fig. 13 shows the effectiveness of the penetration loss on obstacles with different numbers of triangles (0.36k, 0.64k, and 2.75k).
To prevent self-penetrations in the generated cloth mesh, we use the following loss function:
| (9) |
where is the nearest vertex to on the cloth mesh. and . We concatenate two pieces of cloth with opposite normal vectors of vertices to validate the self-penetration loss in Fig. 14. However, the experiments reveal that Eq. 9 is limited and cannot handle all self-penetrations.
The overall loss function used to predict the cloth deformation is:
| (10) |
where and are blending coefficients. In practice, we use and observe good results for all the benchmarks with these values. Since the predictions tend to be random at the beginning of the training, Eq. 8 and Eq. 9 may result in inaccurate predictions. We use Eq. 10 to train the network at the beginning and add Eq. 8 and Eq. 9 during the final training process. The number of parameters of our network and the computed gradients will hinder the scalability of training on large meshes. Therefore, Eq. 7 is computed on a GPU, while Eq. 8 and Eq. 9 are computed on a CPU.
3.6. 3D Cloth Prediction
With the trained network, we can obtain the predicted cloth mesh by inputting the initial cloth mesh and the target obstacle mesh. Since the initial cloth mesh representation has a fixed topology for a specific cloth, we only need to input the target obstacle mesh; our network is used to predict the deformed target cloth mesh.
4. Implementation and Performance
In this section, we describe our implementation and highlight the results on many complex benchmarks. We also compare the performance with prior physics-based simulators and learning-based methods.
4.1. Implementation
We have implemented our algorithm on a standard PC (Ubuntu 18.04.4 LTS/Intel I7 CPU@4.2G Hz/8G RAM, NVIDIA GeForce RTX 3090 GPU). We perform both network training and cloth prediction on the same platform. Our implementation uses PyTorch 1.7.0 and Python 3.8.8 as the underlying development environment.
.
Datasets: Our mesh-based network can handle various types of cloth and obstacles. We evaluate its performance on many different cloth meshes and obstacle meshes. We consider three types of benchmark scenarios to evaluate our approach:
-
•
Rigid obstacles: We lead a rigid bunny model through a hanging cloth from different positions in the scene. The deformation of the cloth is obtained by the simulator ArcSim [Narain et al., 2012, 2013; Pfaff et al., 2014]. At each position, we relax the cloth for a period of time to generate a quasi-static deformation. We also simulate the results of the cloth on the bunny under different rotations and scales. The size of the bunny is scaled from 0.5 to 1.7. To ensure the uniqueness of the cloth covering on the bunny, we mark each side of the cloth as 1 or -1. We also label the side that is in contact with the bunny according to the vertex attributes of the bunny.
-
•
SMPL human body model: For the SMPL humans, we choose the representative data provided by TailorNet [Patel et al., 2020]. Considering that the SMPL bodies in Tailornet have various shapes and postures, we select two types of data. One is the SMPL body data with 2779 different postures in a fixed body shape, The other is the SMPL body data with 9 different body shapes in several fixed postures. This selection of data also facilitates comparison of results from our network and Tailornet. For these human bodies, we generate their triangle meshes from the SMPL parameters.
-
•
Non-SMPL human body model: We also generate non-SMPL humans, including a child Andy and an adult male Qman. We upload the humans with canonical poses to the mixamo website111https://www.mixamo.com/ and download about 90 different action sequences. For these action sequences, we use the physics-based simulator ArcSim [Narain et al., 2012, 2013; Pfaff et al., 2014] to generate clothes on them. To eliminate dynamic effects, we perform linear interpolation between the adjacent poses and relax the cloth on each pose for a period of time to ensure the cloth is as static as possible. We transform all the human body meshes to the origin of the coordinates to eliminate the absoluteness of the position. The relative coordinates will enhance the generalizability of the network.
Our network can also predict different types of clothes. The child, Andy, wears different types of clothes, including a t-shirt, pants, a jacket and a dress. The jacket and dress are loose, and their deformation is different from the t-shirt and pants. These clothing simulations are also obtained by ArcSim [Narain et al., 2012, 2013; Pfaff et al., 2014], as above.
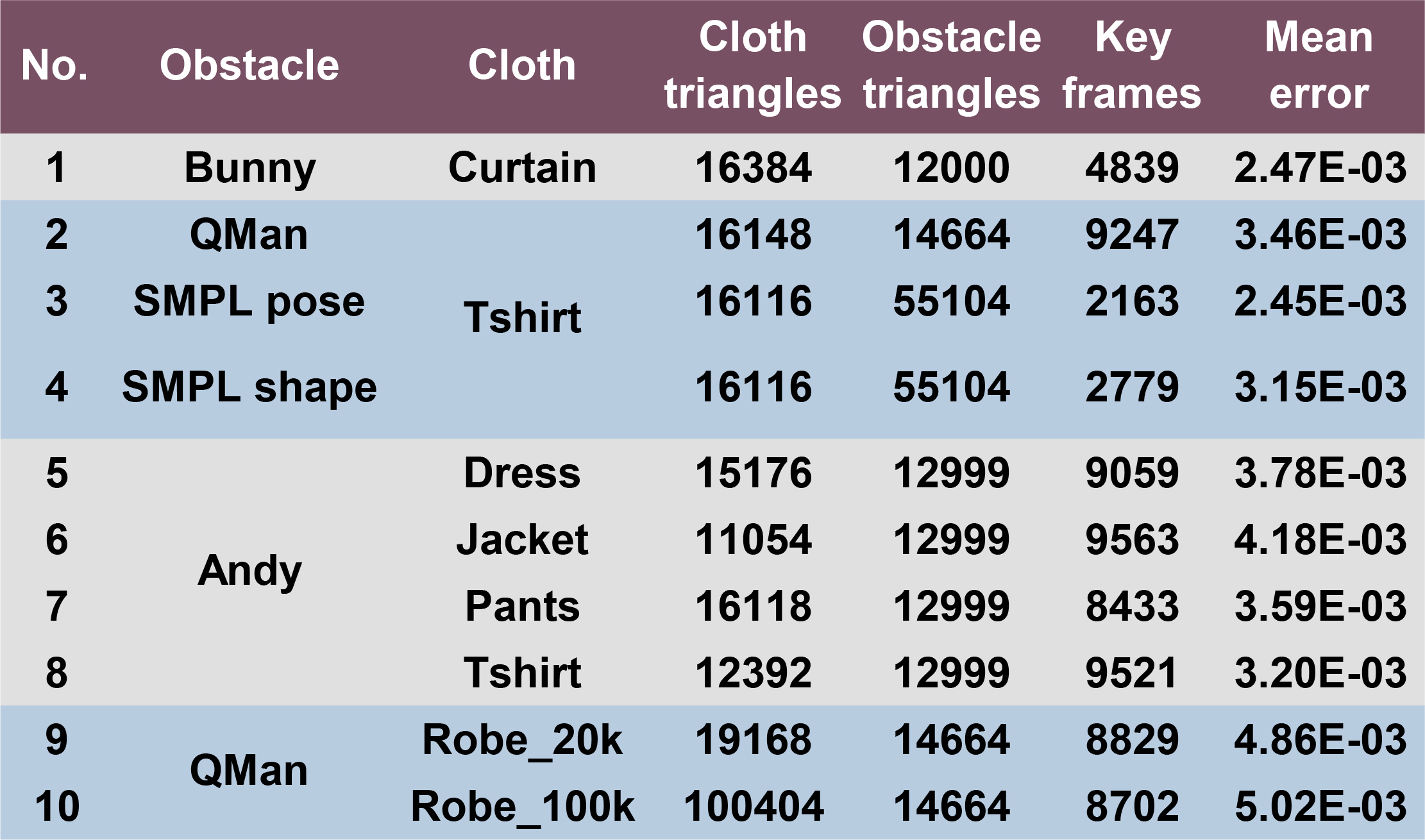
We evaluate the accuracy of our predicted meshes by measuring the mean error of each benchmark (as shown in Fig. 5) with the following equation:
| (11) |
where is the number of animation key frames. is the number of vertices in the 3D mesh, and and are the positions of vertex on frame . The unit of our mean error is meters. The details for each scene are shown in Fig 5.
Network Training: Following [Patel et al., 2020] and [Wang et al., 2019], the dataset is split for training and testing. For test data, we select 800 bunny models with different positions, rotations and scales that have not been seen during training. For the SMPL humans, we use the training and testing split provided in TailorNet [Patel et al., 2020]. For other action sequences obtained from mixamo website, 90 action sequences are used during training, which produce approximately 9,000 samples. To demonstrate the generalizability of our network, during the test, we download 10 other action sequences that were unseen during training from mixamo website and predict the results of these new action poses.
Moreover, the obstacle and cloth meshes in our scene have different vertices and topologies. Thus, networks used for different scenarios have different numbers of parameters. Therefore, we train an exclusive network for each scenario. The training time for each benchmark varies from hours to days.
To accelerate the convergence of the network, we perform data normalization. We normalize the input and output vertex positions to zero mean and unit variance for all frames. During training, we uniformly reduce the learning rate from to . We use an Adam optimizer [Kingma and Ba, 2014] to train the parameters of the neural network.

Penetrations: Our learning-based method uses the penetration loss function highlighted in Eq. 8, which is designed to prevent cloth-object penetrations or cloth self-collisions. In our benchmarks, we do not observe any deep or noticeable penetrations, though the learning-based method does not guarantee a non-penetrating final mesh. In our physics-based simulator, we use a large repulsion thickness (i.e., mm) so that the training data is not only collision-free but there is some distance between non-adjacent mesh elements. This use of repulsion distance further reduces the chances of self-penetrations or collisions in the predicted cloth mesh. If the predicted mesh has a few collisions, we can solve them by simple post-processing.
4.2. Results on Diverse Scenes
In this section, we highlight the performance of our method on different benchmarks and compare the accuracy with physically-based simulation results. All predictions are performed on new test sets that are different from the training data.
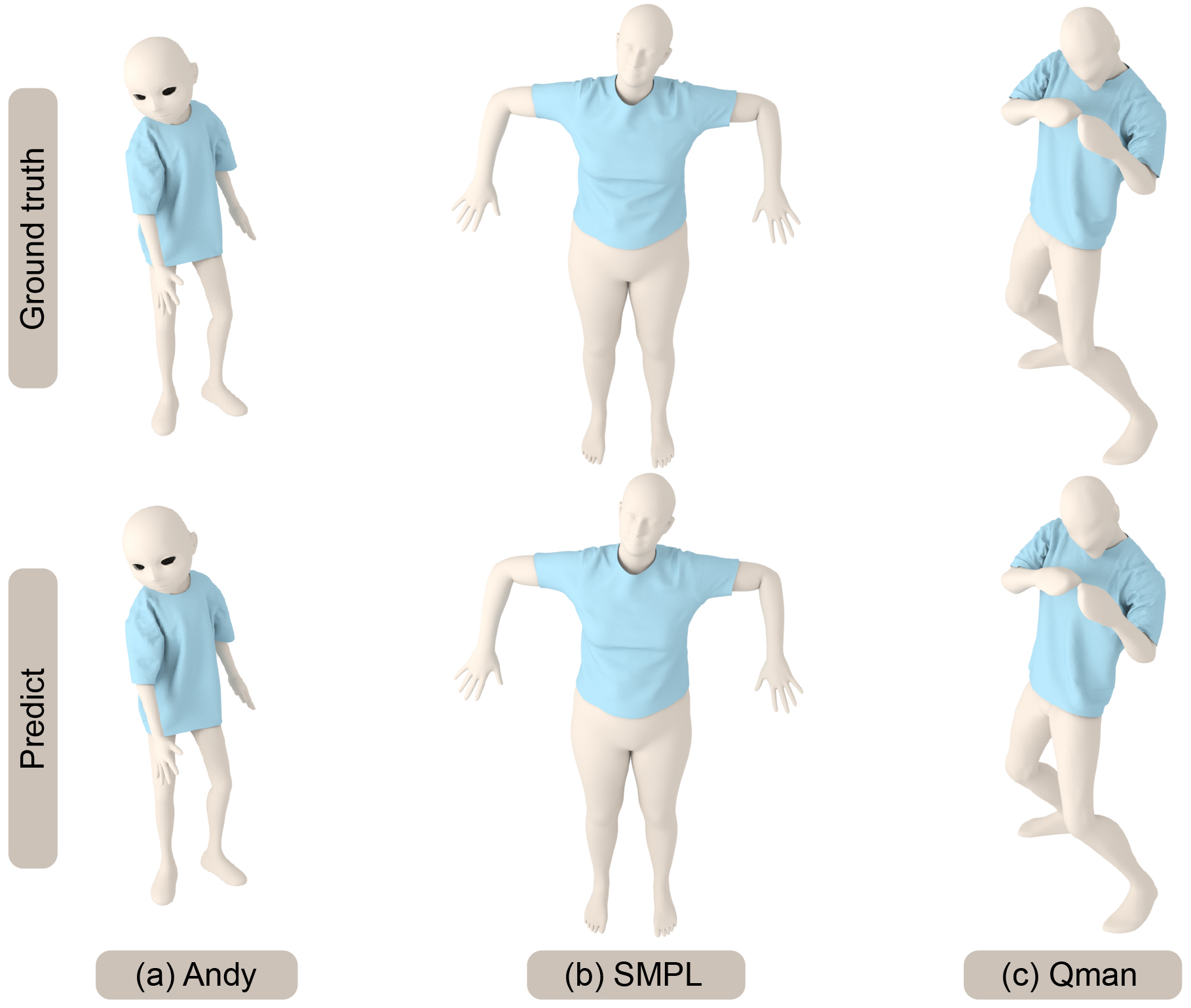
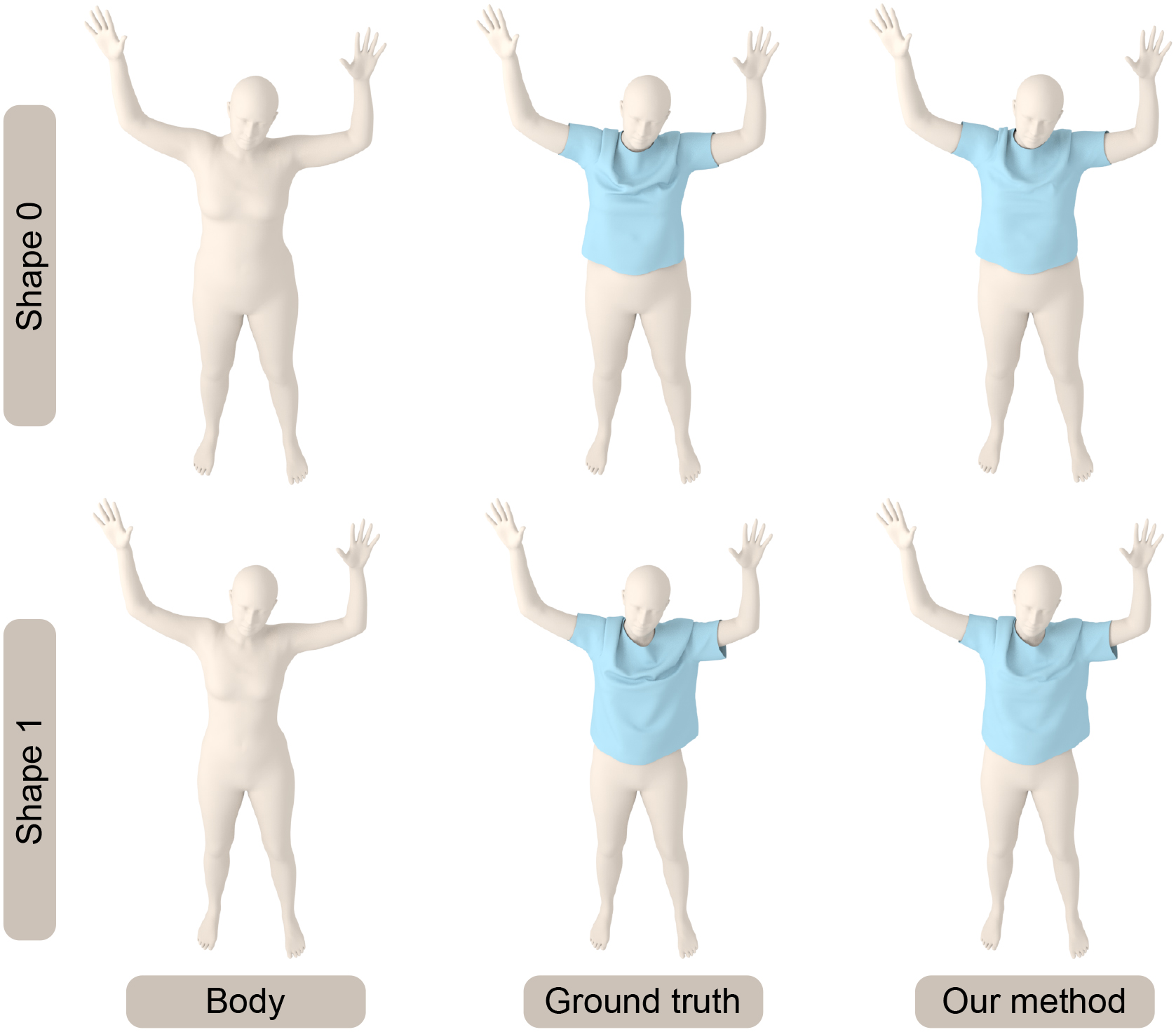
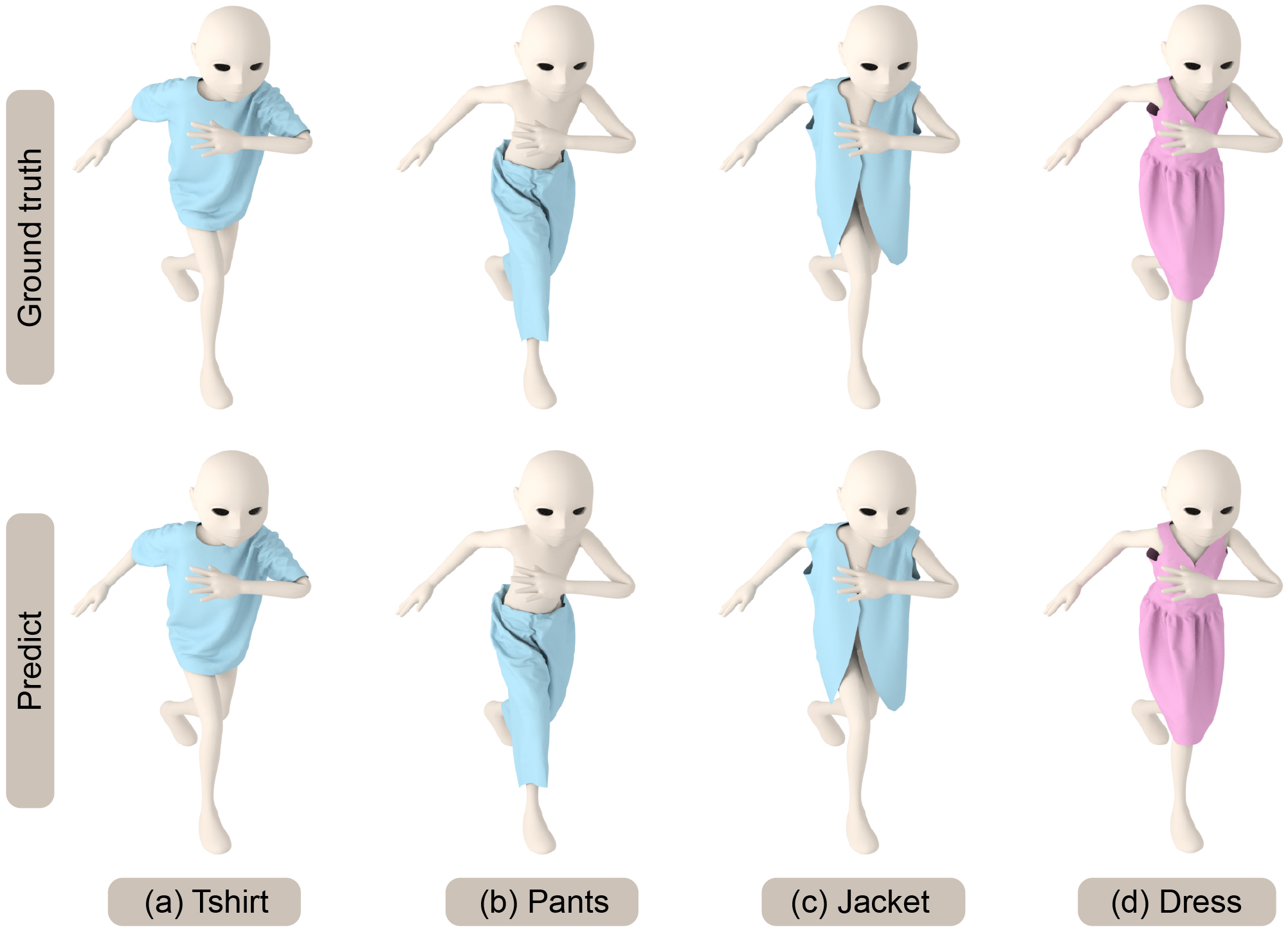


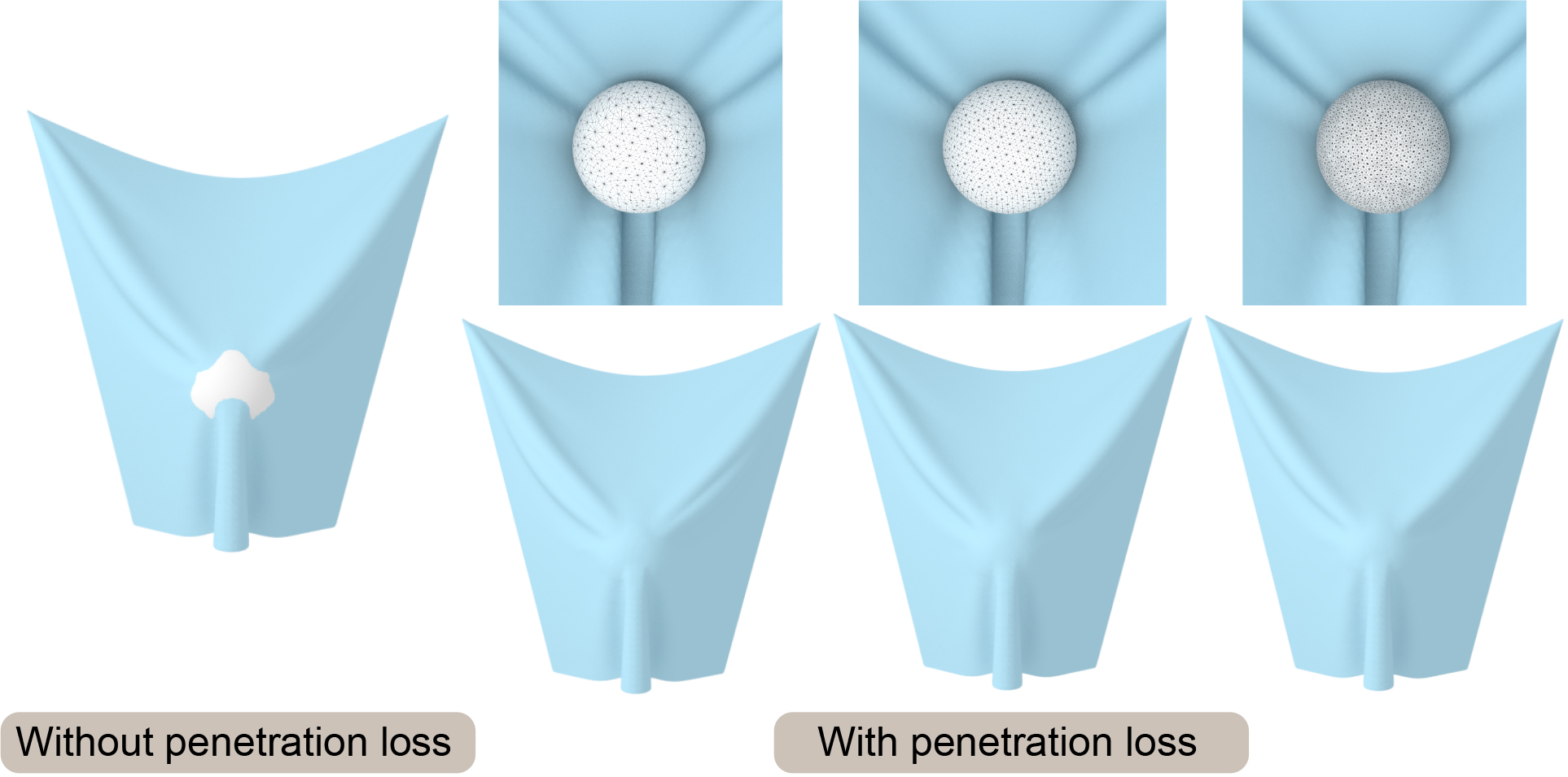
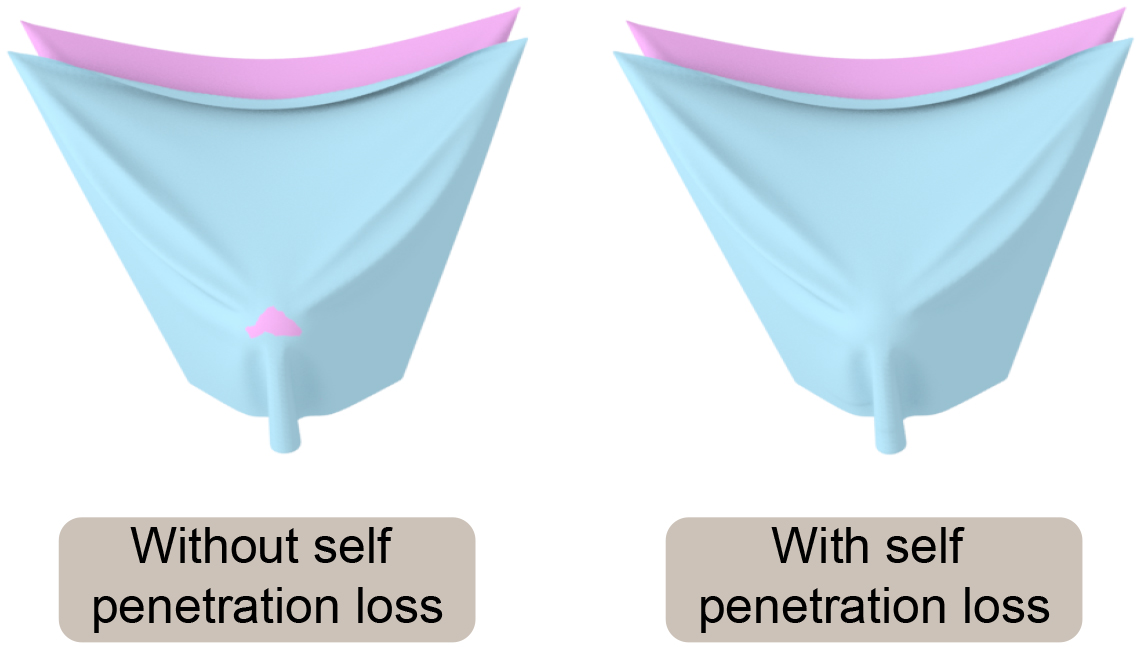
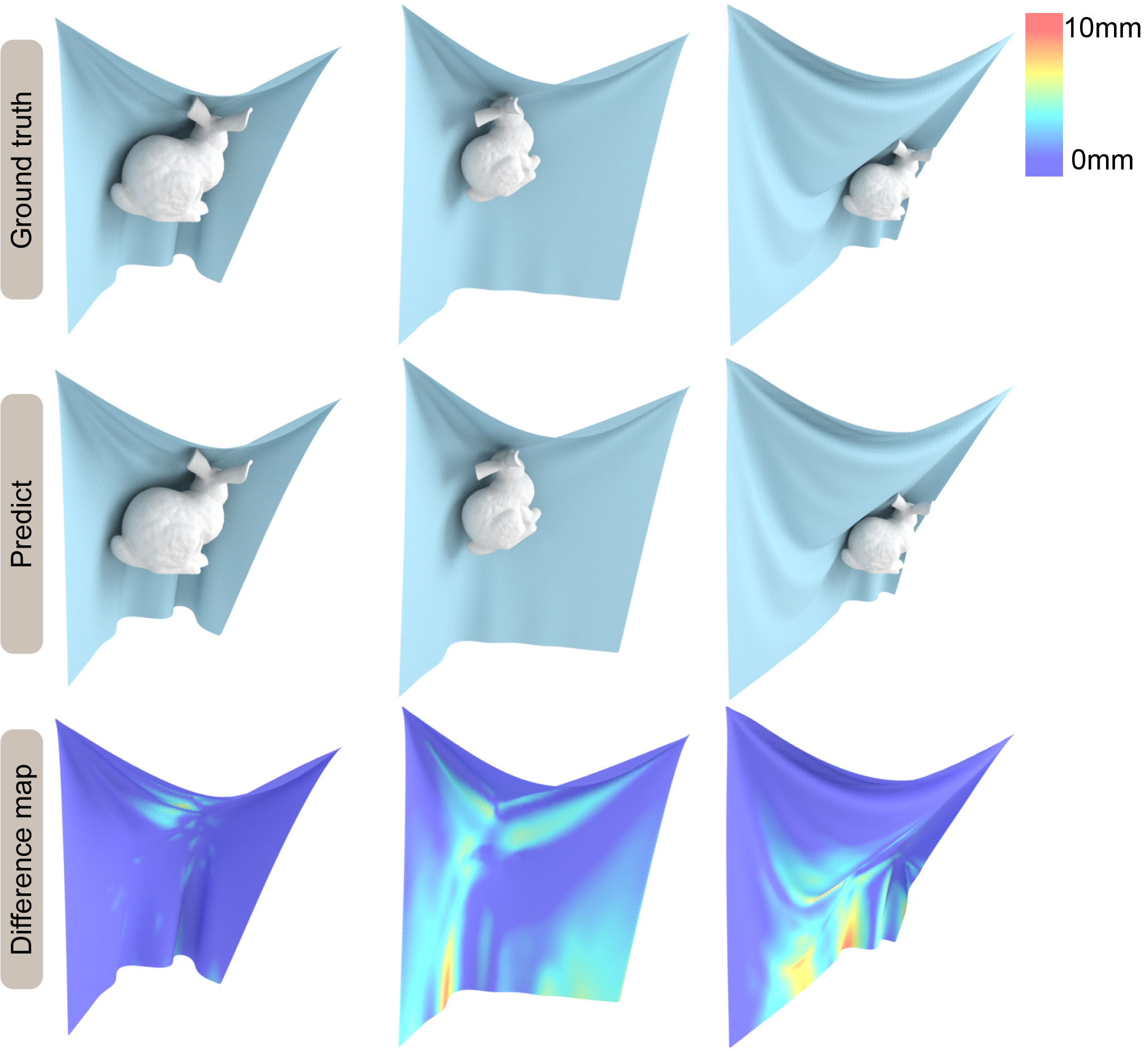
Fig. 6 highlights our results on scenes with obstacles unseen during training corresponding to moving, rotating, or scaling rigid bodies. Our network results in favorable generalization to obstacles with unseen locations, rotations, and scales. Our approach makes no assumption about the topology of the obstacles or the cloth. We also compare the accuracy with ArcSim (an accurate physics-based simulator) and observe a high level of similarity between our predicted 3D mesh and the ground truth mesh. The mean deviation error between the vertices is less than mm in our benchmarks. If there are multiple disjoint obstacles, we combine these obstacle meshes into a single mesh and generate the cloth predictions, as shown in Fig. 7. Fig. 8 highlights our results on different human body models. We use the same cloth mesh corresponding to a t-shirt on different human models. In Fig. 8, all the human bodies are represented with triangle meshes. All predictions are on an unseen test set. For example, the predictions of Andy and Qman are on the new action sequences downloaded from mixamo website. The results of SMPL are on the test data split from TailorNet. For all these benchmarks, our predicted results are visually close to the ground truth. Fig. 9 highlights the predictions of our method on unseen body shapes. We train a single network for bodies with different shapes since these meshes have the same topologies. Figs. 10 and 11 highlight our results on cloths of different types and resolutions. For all these benchmarks, our algorithm can generate plausible results that match the ground truth meshes. All predictions from test data are totally different from the training samples. Fig. 12 highlights the benefits of our penetration handling approach based on a loss function. By adding the penetration term into the loss function, our algorithm tends to alleviate the penetrations and self-collision artifacts. Although no penetration is unavailable in the predictions on the test set, it can reduce the degree of penetration and the subsequent processing work. Fig. 13 and Fig. 14 highlight the benefits of Eq. 8 (with different obstacle discretizations) and Eq. 9, where (self-)penetrations are effectively alleviated by these loss functions.
To sum up, our network can not only handle SMPL and non-SMPL human bodies, but also rigid obstacles. Our network can also process various types of clothes without providing predefined skin models for those clothes. Compared with the previous method, our network can handle more scenarios and has more applications. The predictions also show that our network can satisfactorily generalize to new, unseen data. Even when trained to predict a static deformed cloth mesh, our network generates a series of deformed cloth with fine temporal coherence on an obstacle sequence (shown in the video).
5. Comparisons
In this section, we qualitatively and quantitatively compare the performance of our network with prior learning-based cloth simulation methods.
| Method | SMPL | Non-SMPL | Triangle |
| body | body | mesh | |
| TailorNet[Patel et al., 2020] | ✔ | ✗ | ✗ |
| DeePSD [Bertiche et al., 2020a] | ✔ | ✗ | ✗ |
| [Santesteban et al., 2019] | ✔ | ✗ | ✗ |
| GarNet [Gundogdu et al., 2019] | ✔ | ✔ | ✗ |
| [Wang et al., 2019] | ✔ | ✔ | ✗ |
| [Bertiche et al., 2020b] | ✔ | ✗ | ✗ |
| DRAPE [Guan et al., 2012] | ✔ | ✗ | ✗ |
| Our method (N-Cloth) | ✔ | ✔ | ✔ |
5.1. Diverse Scenarios
In Table 1, we list the characteristics of different learning-based methods. We highlight the capabilities of different methods in terms of the kind of obstacles they can handle (e.g., SMPL models only or rigid objects). Compared to prior methods, our approach makes no assumptions about the type or topology of the cloth or the obstacles in the scene. Most previous methods [Patel et al., 2020; Bertiche et al., 2020a; Santesteban et al., 2019; Bertiche et al., 2020b] are based on the SMPL model, which limits results to the SMPL human model. Other methods [Gundogdu et al., 2019; Guan et al., 2012; Wang et al., 2019] are limited to human models represented using joints. Although they can handle the non-SMPL human body, they are unable to process other obstacles such as a bunny. [Holden et al., 2019] is a complimentary method that uses PCA and subspace-only physics simulation. However, it recurrently inputs the previous prediction and accumulates errors. This makes the predicted cloth mesh appear flat with fewer wrinkles. Our mesh-based method overcomes these limitations and can handle multiple, disjoint obstacles. Our predictions have no accumulation errors and can retain fine details like wrinkles and folds.
5.2. Qualitative Comparisons
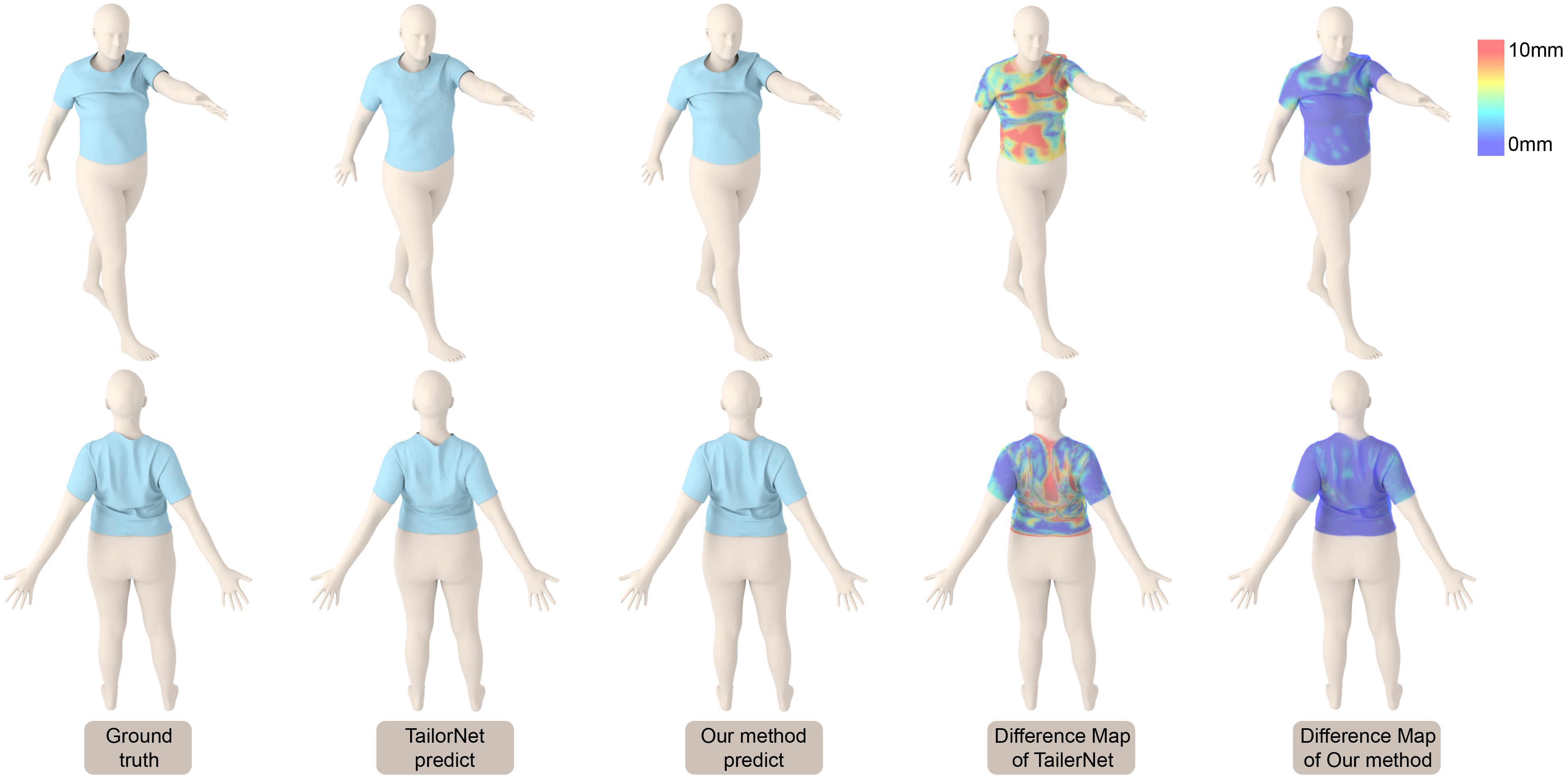
We perform a detailed comparison of our method with TailorNet [Patel et al., 2020], as the code and dataset are easily available. In Fig. 15, we use the same dataset as TailorNet for network training. We compare the accuracy of the predicted cloth meshes generated by our method and TailorNet. We compute the difference maps for each mesh by comparing the results with the ground truth mesh. We observe that our method predicts similar output meshes with richer details. In addition, our method produces fewer vertex errors compared to the ground truth than TailorNet. In benchmarks with many or detailed wrinkles, we observe that our network generates better results than TailorNet, as shown in Fig. 16. For example, our prediction of the cloth mesh has more wrinkles in the belly and shoulder areas, while TailorNet’s prediction is flatter.

5.3. Quantitative Comparisons
We use the following error metrics for quantitative comparison between our mesh-based network and TailorNet:
| (12) | ||||
where is the position of vertex of the predicted mesh . is the position of its corresponding vertex on the ground truth mesh . and are the normal vector at and , respectively. is the number of vertices of the cloth mesh. is the Laplace operator.
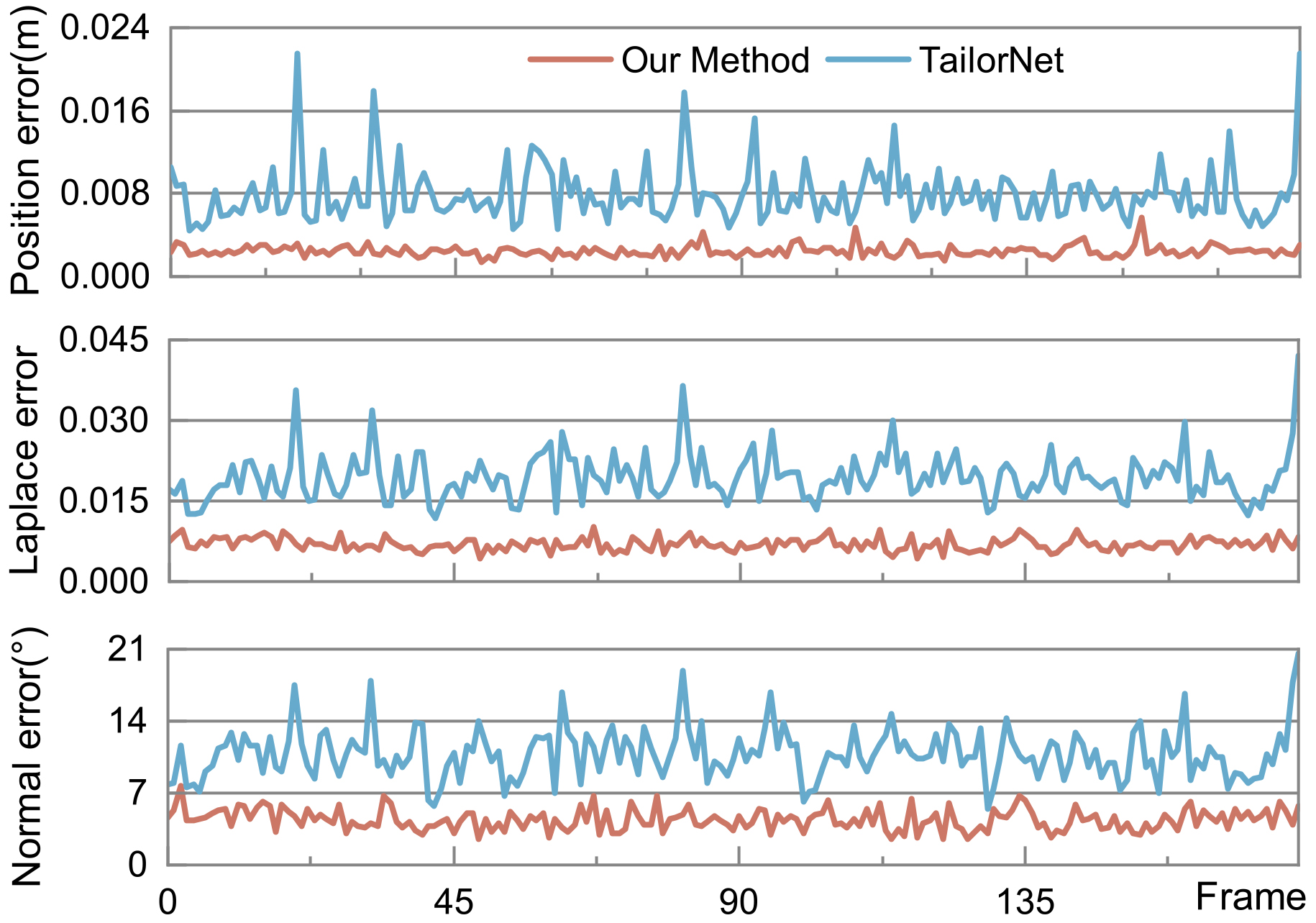
Figure 17 shows the error curve of our method and the predictions of Tailornet with ground truth on the test frames. The error is calculated as described above. From the curve, the trend of the errors of our network prediction is lower than TailorNet [Patel et al., 2020]. We also calculate the error mean and variance for all test frames, as shown in Table 2. The statistical value of the prediction error of our method is significantly lower than that of TailorNet.
| Evaluation | TailorNet | Our Method |
|---|---|---|
| mean (m) | 7.90E-3 | 2.45E-3 |
| std (m) | 2.74E-3 | 0.54E-3 |
| mean | 1.94E-2 | 6.97E-3 |
| std | 4.44E-3 | 1.20E-3 |
| mean (∘) | 10.81 | 4.40 |
| std (∘) | 2.45 | 1.02 |
5.4. Performance Analysis
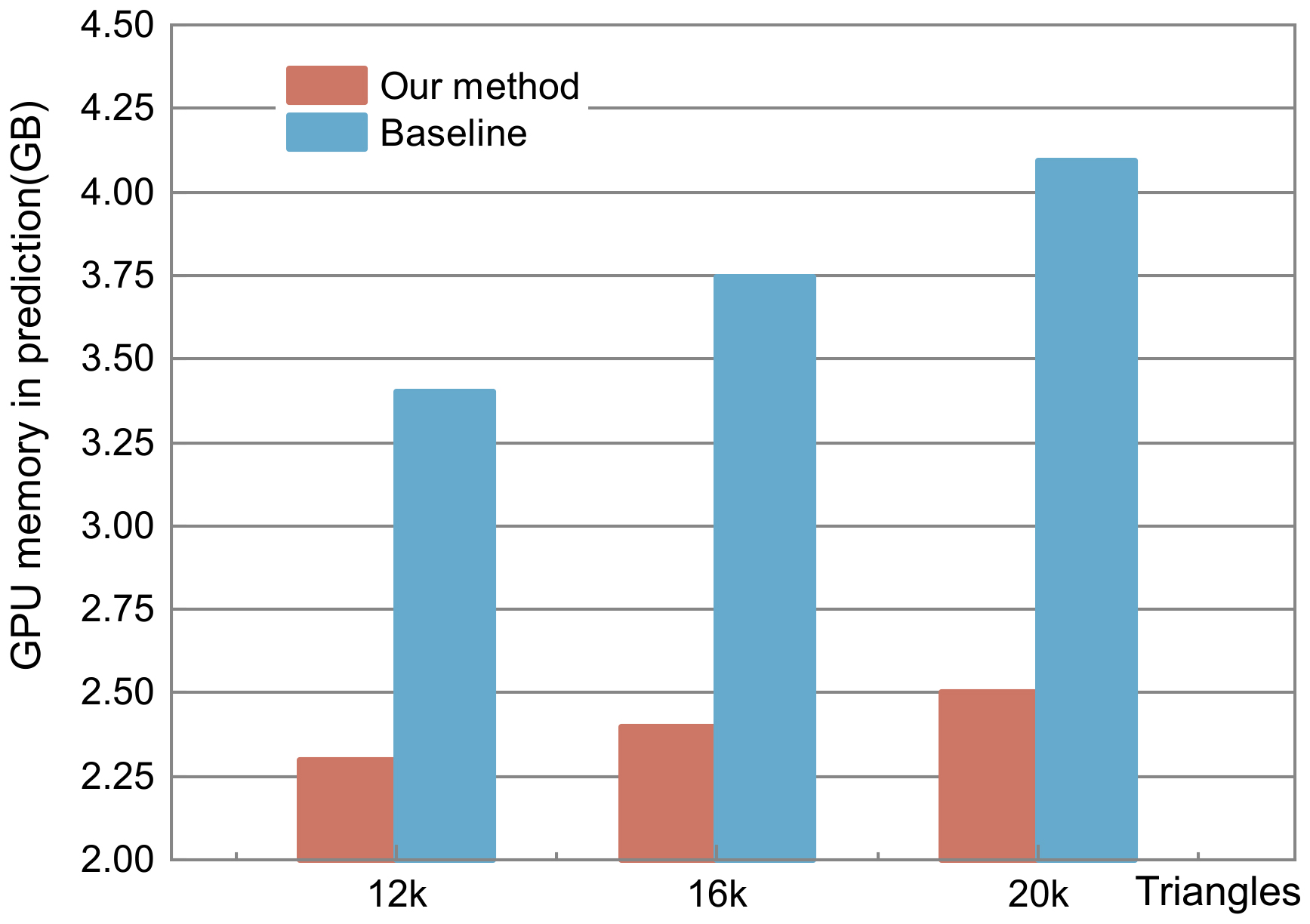
We implement each layer of the cloth encoder and obstacle encoder with MLP as the baseline. The decoder in our network uses MLP, so we keep it invariable. Figure 19 shows the GPU memory usage when our network and baseline predict a single mesh. Our network occupies less GPU memory when making predictions. In experiments, it is revealed that more GPU memory is required for baseline training, which makes it impossible to train meshes with higher resolutions. However, our method is able to train cloth meshes with more than 100k triangles.
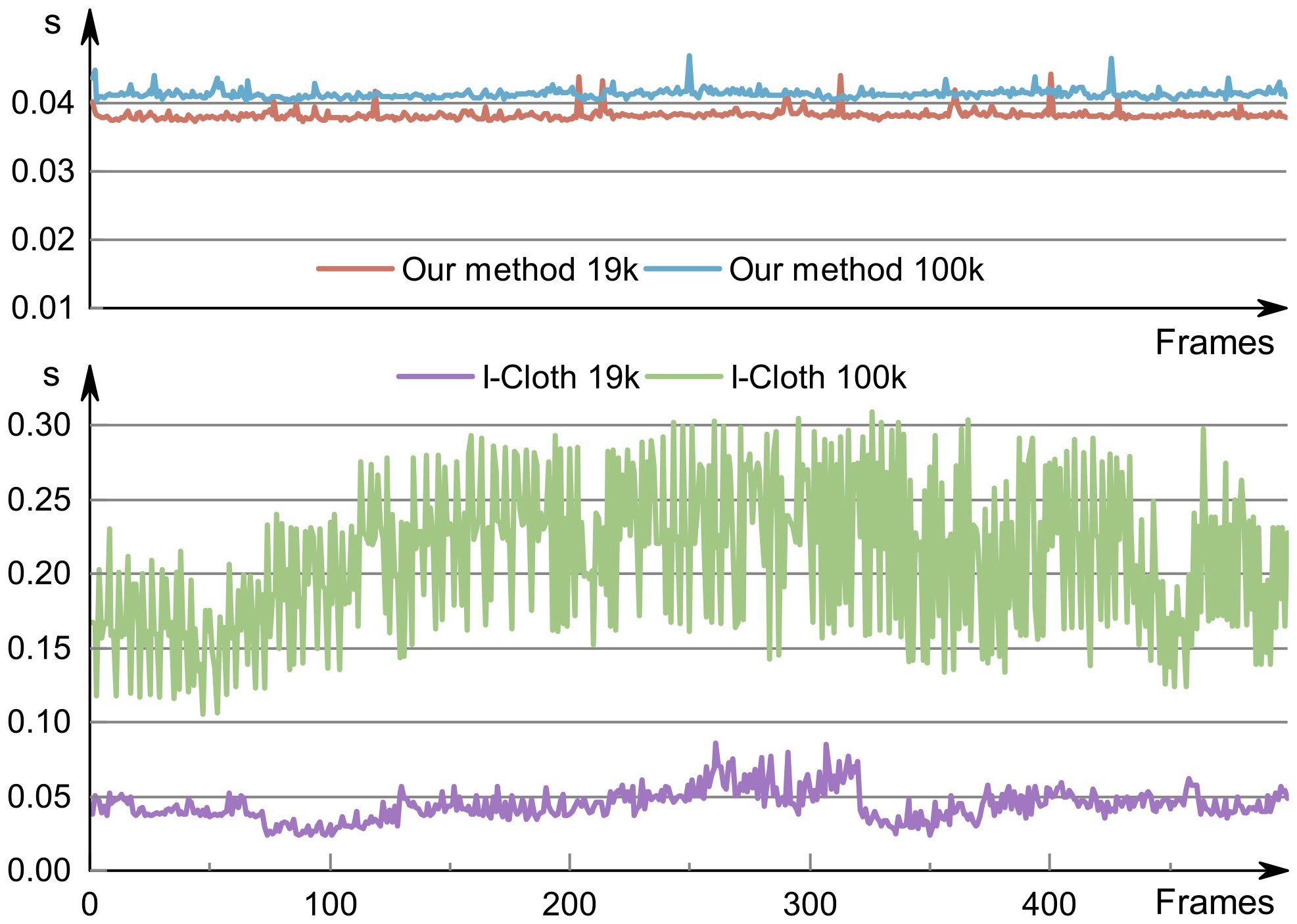
We have compared the running time of our method with a GPU-based physics-based simulator called I-Cloth [Tang et al., 2018], as shown in Figure 20. Compared to I-Cloth, our network achieves an order of magnitude performance improvement. Furthermore, the running time of our method does not change much with a higher resolution mesh. The overall accuracy and visual fidelity of the cloth mesh generated by our method are similar to those of I-Cloth.
We observe that our approach can obtain an interactive frame rate (about fps on an NVIDIA GeForce RTX 3090 GPU). Compared with TailorNet, our method has no obvious advantage in running time. This is because the input of the SMPL model is a small number of parameters, while our method inputs a mesh with all the vertex and edge information. The human mesh provided by TailorNet has 55k triangles, which will increase the calculation time of our network. In practice, we concentrate more on the deformation of the cloth mesh. Therefore, we can simplify the human body mesh, which will accelerate our network.
5.5. Ablation Experiments
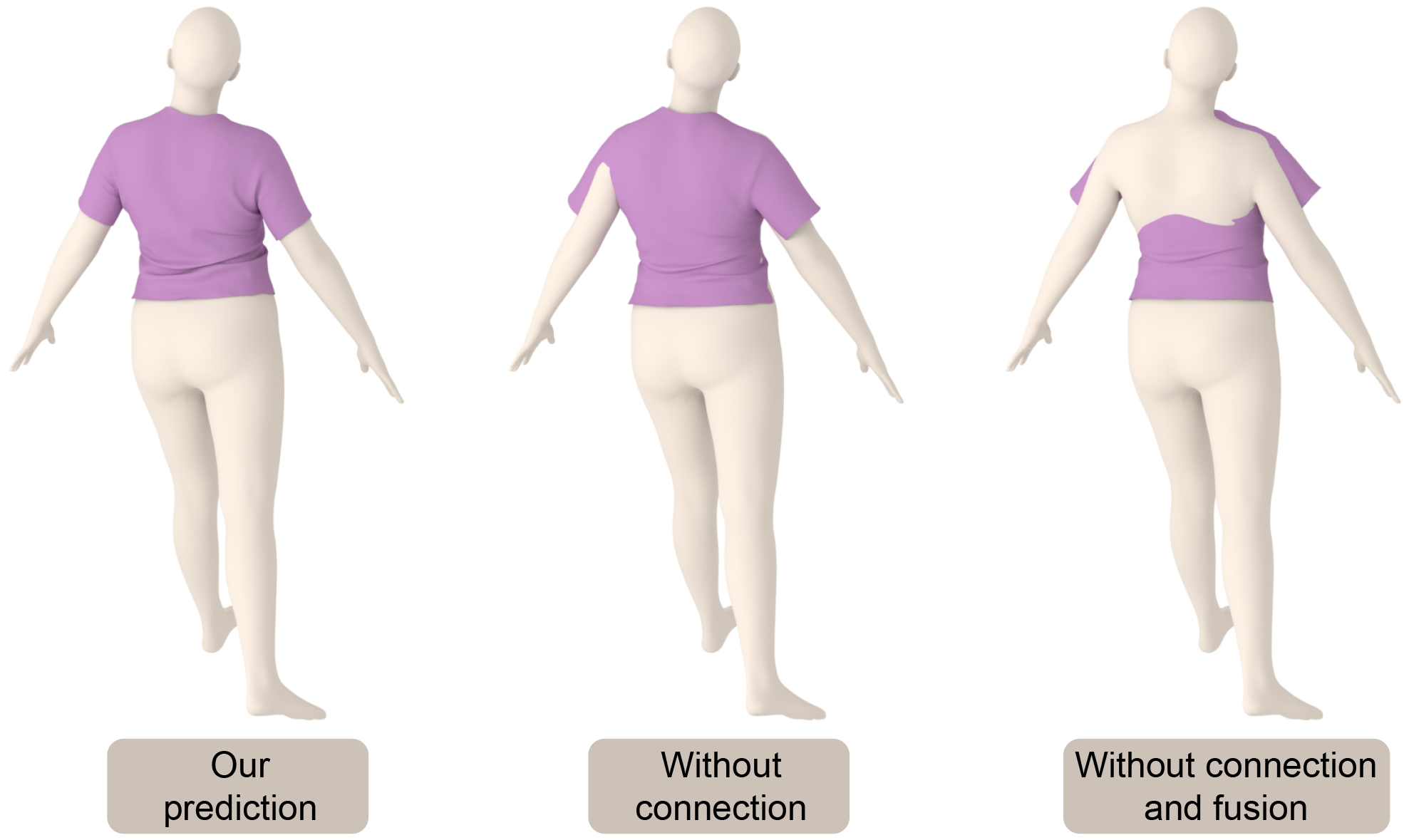
We implement a series of ablation experiments to verify the effectiveness of our network architecture. We remove the connections of each layer of the obstacle encoder in the decoder as a variant of our network. Furthermore, we discard the fusion network and use simple concatenation in the latent space as another variant. Figure 18 shows the predictions of our network and its two variants. Our network architecture plays an indispensable role in the convergence of results.
6. Conclusion, Limitations, and Future Work
We present a novel mesh-based network for interactive 3D cloth prediction. Our approach is general and does not make any assumption about the topology or connectivity of the cloth or the obstacles in the scene. Our approach can handle complex cloth simulation benchmarks and predict the deformed 3D mesh at about fps on a commodity mesh. To the best of our knowledge, ours is the first general learning-based method that can handle arbitrary obstacle meshes and many types of cloths.
Limitations: Our approach has some limitations. It requires considerable time to generate the training data, and it can take a few days to generate synthetic training datasets using a physics-based simulator. Furthermore, our approach assumes that the topology and connectivity of the cloth mesh is fixed. If the topology changes, we need to repeat the training step. This approach may work well for human models used for virtual try-on or dressing, as they have fixed topologies. Like prior learning-based methods, we cannot provide any rigorous guarantees in terms of absolute accuracy or collisions in our predicted mesh. The effectiveness of our self-penetration is limited and may introduce undesirable new collisions. The computation of self-penetration depends on the discretization of the cloth mesh. We propose to different loss functions in the future to handle such self-penetrations. Or we can combine our approach with learning-based methods for collision handling [Tan et al., 2021a, b]. Moreover, compared with the SMPL model which only uses a few parameters, our network performs feature extraction and fusion on the complete mesh. This results in slower performance of our network, though we observe interactive performance of 30-45fps.
There are many avenues to improve the performance in the future. Our current approaches for synthetic data generation, training, and runtime prediction are not optimized, and it is therefore possible to improve the performance. We would like to incorporate better geometric learning-based methods that can account for highly dynamic obstacles as well as small changes in mesh topology or connectivity. It will be interesting to use visual knowledge [Pan, 2021] for cloth deformation prediction. Finally, we would like to integrate our approach with different applications corresponding to virtual try-on or gaming and evaluate the performance.
References
- [1]
- Baraff and Witkin [1998] David Baraff and Andrew Witkin. 1998. Large steps in cloth simulation. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques. 43–54.
- Bertiche et al. [2020a] Hugo Bertiche, Meysam Madadi, and Sergio Escalera. 2020a. DeePSD: Automatic Deep Skinning And Pose Space Deformation For 3D Garment Animation. arXiv preprint arXiv:2009.02715 (2020).
- Bertiche et al. [2020b] Hugo Bertiche, Meysam Madadi, and Sergio Escalera. 2020b. Physically Based Neural Simulator for Garment Animation. arXiv preprint arXiv:2012.11310 (2020).
- Bouaziz et al. [2014] Sofien Bouaziz, Sebastian Martin, Tiantian Liu, Ladislav Kavan, and Mark Pauly. 2014. Projective Dynamics: Fusing Constraint Projections for Fast Simulation. ACM Trans. Graph. (SIGGRAPH) 33, 4, Article 154 (July 2014), 11 pages.
- Bridson et al. [2002] Robert Bridson, Ronald Fedkiw, and John Anderson. 2002. Robust Treatment of Collisions, Contact and Friction for Cloth Animation. ACM Trans. Graph. 21, 3 (2002), 594–603.
- Brochu et al. [2012] Tyson Brochu, Essex Edwards, and Robert Bridson. 2012. Efficient Geometrically Exact Continuous Collision Detection. ACM Trans. Graph. 31, 4 (2012), 96:1–96:7.
- Chen et al. [2021] Lan Chen, Lin Gao, Jie Yang, Shibiao Xu, Juntao Ye, Xiaopeng Zhang, and Yu-Kun Lai. 2021. Deep Deformation Detail Synthesis for Thin Shell Models. arXiv preprint arXiv:2102.11541 (2021).
- Chen et al. [2020] Lan Chen, Xiaopeng Zhang, and Juntao Ye. 2020. Multi-feature super-resolution network for cloth wrinkle synthesis. arXiv preprint arXiv:2004.04351 (2020).
- Chentanez et al. [2020] Nuttapong Chentanez, Miles Macklin, Matthias Müller, Stefan Jeschke, and Tae-Yong Kim. 2020. Cloth and skin deformation with a triangle mesh based convolutional neural network. In Computer Graphics Forum, Vol. 39. Wiley Online Library, 123–134.
- Corona et al. [2021] Enric Corona, Albert Pumarola, Guillem Alenya, Gerard Pons-Moll, and Francesc Moreno-Noguer. 2021. SMPLicit: Topology-aware generative model for clothed people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11875–11885.
- de Aguiar et al. [2010] Edilson de Aguiar, Leonid Sigal, Adrien Treuille, and Jessica K. Hodgins. 2010. Stable spaces for real-time clothing. ACM Trans. Graph. (SIGGRAPH) 29, Article 106 (July 2010), 9 pages. Issue 4.
- Feng et al. [2010] Wei-Wen Feng, Yizhou Yu, and Byung-Uck Kim. 2010. A deformation transformer for real-time cloth animation. ACM Trans. Graph. (SIGGRAPH) 29, 4, Article 108 (July 2010), 9 pages.
- Gao and Ji [2019] Hongyang Gao and Shuiwang Ji. 2019. Graph U-Nets. In international conference on machine learning. PMLR, 2083–2092.
- Govindaraju et al. [2005] Naga K Govindaraju, Ming C Lin, and Dinesh Manocha. 2005. Quick-cullide: Fast inter-and intra-object collision culling using graphics hardware. In IEEE Proceedings. VR 2005. Virtual Reality, 2005. IEEE, 59–66.
- Guan et al. [2012] Peng Guan, Loretta Reiss, David A Hirshberg, Alexander Weiss, and Michael J Black. 2012. Drape: Dressing any person. ACM Transactions on Graphics (TOG) 31, 4 (2012), 1–10.
- Gundogdu et al. [2020] Erhan Gundogdu, Victor Constantin, Shaifali Parashar, Amrollah Seifoddini Banadkooki, Minh Dang, Mathieu Salzmann, and Pascal Fua. 2020. GarNet++: Improving Fast and Accurate Static 3D Cloth Draping by Curvature Loss. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020).
- Gundogdu et al. [2019] Erhan Gundogdu, Victor Constantin, Amrollah Seifoddini, Minh Dang, Mathieu Salzmann, and Pascal Fua. 2019. GarNet: A two-stream network for fast and accurate 3d cloth draping. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8739–8748.
- Harmon et al. [2008] David Harmon, Etienne Vouga, Rasmus Tamstorf, and Eitan Grinspun. 2008. Robust Treatment of Simultaneous Collisions. ACM Trans. Graph. 27, 3 (2008), 23:1–23:4.
- Holden et al. [2019] Daniel Holden, Bang Chi Duong, Sayantan Datta, and Derek Nowrouzezahrai. 2019. Subspace neural physics: Fast data-driven interactive simulation. In Proceedings of the 18th annual ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 1–12.
- Holden et al. [2017] Daniel Holden, Taku Komura, and Jun Saito. 2017. Phase-functioned neural networks for character control. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–13.
- Kavan et al. [2007] Ladislav Kavan, Steven Collins, Jiri Zara, and Carol O’Sullivan. 2007. Skinning with Dual Quaternions. In Proceedings of the 2007 Symposium on Interactive 3D Graphics and Games (I3D ’07). New York, NY, USA, 39–46.
- Kim et al. [2013] Doyub Kim, Woojong Koh, Rahul Narain, Kayvon Fatahalian, Adrien Treuille, and James F. O’Brien. 2013. Near-exhaustive Precomputation of Secondary Cloth Effects. ACM Trans. Graph (SIGGRAPH). 32, 4, Article 87 (July 2013), 8 pages.
- Kingma and Ba [2014] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kipf and Welling [2016] Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
- Li et al. [2020] Cheng Li, Min Tang, Ruofeng Tong, Ming Cai, Jieyi Zhao, and Dinesh Manocha. 2020. P-cloth: interactive complex cloth simulation on multi-GPU systems using dynamic matrix assembly and pipelined implicit integrators. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–15.
- Liu et al. [2013] Tiantian Liu, Adam W Bargteil, James F O’Brien, and Ladislav Kavan. 2013. Fast simulation of mass-spring systems. ACM Transactions on Graphics (TOG) 32, 6 (2013), 1–7.
- Liu et al. [2017] Tiantian Liu, Sofien Bouaziz, and Ladislav Kavan. 2017. Quasi-newton methods for real-time simulation of hyperelastic materials. Acm Transactions on Graphics (TOG) 36, 3 (2017), 1–16.
- Loper et al. [2015] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. 2015. SMPL: A skinned multi-person linear model. ACM transactions on graphics (TOG) 34, 6 (2015), 1–16.
- Narain et al. [2013] Rahul Narain, Tobias Pfaff, and James F O’Brien. 2013. Folding and crumpling adaptive sheets. ACM Transactions on Graphics (TOG) 32, 4 (2013), 1–8.
- Narain et al. [2012] Rahul Narain, Armin Samii, and James F O’brien. 2012. Adaptive anisotropic remeshing for cloth simulation. ACM transactions on graphics (TOG) 31, 6 (2012), 1–10.
- Pan [2021] Yunhe Pan. 2021. Miniaturized five fundamental issues about visual knowledge. Frontiers Inf. Technol. Electron. Eng. 22, 5 (2021), 615–618.
- Patel et al. [2020] Chaitanya Patel, Zhouyingcheng Liao, and Gerard Pons-Moll. 2020. TailorNet: Predicting clothing in 3d as a function of human pose, shape and garment style. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7365–7375.
- Pfaff et al. [2014] Tobias Pfaff, Rahul Narain, Juan Miguel De Joya, and James F O’Brien. 2014. Adaptive tearing and cracking of thin sheets. ACM Transactions on Graphics (TOG) 33, 4 (2014), 1–9.
- Provot [1995] Xavier Provot. 1995. Deformation Constraints in a Mass-spring Model to Describe Rigid Cloth Behavior. In Proc. of Graphics Interface. 147–154.
- Provot [1997] Xavier Provot. 1997. Collision and Self-collision Handling in Cloth Model Dedicated to Design Garments. In Graphics Interface. 177–189.
- Ranzato et al. [2007] Marc’Aurelio Ranzato, Fu Jie Huang, Y-Lan Boureau, and Yann LeCun. 2007. Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition. In 2007 IEEE Conference on Computer Vision and Pattern Recognition. 1–8.
- Rocco et al. [2017] Ignacio Rocco, Relja Arandjelovic, and Josef Sivic. 2017. Convolutional neural network architecture for geometric matching. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6148–6157.
- Santesteban et al. [2019] Igor Santesteban, Miguel A Otaduy, and Dan Casas. 2019. Learning-based animation of clothing for virtual try-on. In Computer Graphics Forum, Vol. 38. Wiley Online Library, 355–366.
- Santesteban et al. [2021] Igor Santesteban, Nils Thuerey, Miguel A Otaduy, and Dan Casas. 2021. Self-Supervised Collision Handling via Generative 3D Garment Models for Virtual Try-On. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021).
- Tan et al. [2021a] Qingyang Tan, Zherong Pan, and Dinesh Manocha. 2021a. LCollision: Fast Generation of Collision-Free Human Poses using Learned Non-Penetration Constraints. arXiv:cs.GR/2011.03632
- Tan et al. [2021b] Qingyang Tan, Zherong Pan, Breannan Smith, Takaaki Shiratori, and Dinesh Manocha. 2021b. Active Learning of Neural Collision Handler for Complex 3D Mesh Deformations. arXiv:cs.CV/2110.07727
- Tang et al. [2014] Min Tang, Ruofeng Tong, Zhendong Wang, and Dinesh Manocha. 2014. Fast and Exact Continuous Collision Detection with Bernstein Sign Classification. ACM Trans. Graph. (SIGGRAPH Asia) 33 (November 2014), 186:1–186:8. Issue 6.
- Tang et al. [2016] Min Tang, Huamin Wang, Le Tang, Ruofeng Tong, and Dinesh Manocha. 2016. CAMA: Contact-aware matrix assembly with unified collision handling for GPU-based cloth simulation. In Computer Graphics Forum, Vol. 35. Wiley Online Library, 511–521.
- Tang et al. [2018] Min Tang, Tongtong Wang, Zhongyuan Liu, Ruofeng Tong, and Dinesh Manocha. 2018. I-Cloth: Incremental collision handling for GPU-based interactive cloth simulation. ACM Transactions on Graphics (TOG) 37, 6 (2018), 1–10.
- Wang et al. [2010] Huamin Wang, Florian Hecht, Ravi Ramamoorthi, and James O’Brien. 2010. Example-based wrinkle synthesis for clothing animation. ACM Trans. Graph. (SIGGRAPH) 29, 4, Article 107 (July 2010), 8 pages.
- Wang et al. [2019] Tuanfeng Y Wang, Tianjia Shao, Kai Fu, and Niloy J Mitra. 2019. Learning an intrinsic garment space for interactive authoring of garment animation. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–12.
- Wu et al. [2021] Nannan Wu, Qianwen Chao, Yanzhen Chen, Weiwei Xu, Chen Liu, Dinesh Manocha, Wenxin Sun, Yi Han, Xinran Yao, and Xiaogang Jin. 2021. Example-based Real-time Clothing Synthesis for Virtual Agents. arXiv preprint arXiv:2101.03088 (2021).
- Zhang et al. [2021a] Meng Zhang, Duygu Ceylan, Tuanfeng Wang, and Niloy J Mitra. 2021a. Dynamic Neural Garments. arXiv preprint arXiv:2102.11811 (2021).
- Zhang et al. [2021b] Meng Zhang, Tuanfeng Wang, Duygu Ceylan, and Niloy J Mitra. 2021b. Deep detail enhancement for any garment. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 399–411.
- Zurdo et al. [2013] Javier S. Zurdo, Juan P. Brito, and Miguel A. Otaduy. 2013. Animating Wrinkles by Example on Non-Skinned Cloth. IEEE Trans. Vis. Comp. Graph. 19, 1 (2013), 149–158.