Near Real-time CO2 Emissions Based on Carbon Satellite And Artificial Intelligence
Abstract
To limit global warming to pre-industrial levels, global governments, industry and academia are taking aggressive efforts to reduce carbon emissions. The evaluation of anthropogenic carbon dioxide (CO2) emissions, however, depends on the self-reporting information that is not always reliable. Society need to develop an objective, independent, and generalized system to meter CO2 emissions. Satellite CO2 observation from space that reports column-average regional CO2 dry-air mole fractions has gradually indicated its potential to build such a system. Nevertheless, estimating anthropogenic CO2 emissions from CO2 observing satellite is bottlenecked by the influence of the highly complicated physical characteristics of atmospheric activities. Here we provide the first method that combines the advanced artificial intelligence (AI) techniques and the carbon satellite monitor to quantify anthropogenic CO2 emissions. We propose an integral AI based pipeline that contains both a data retrieval algorithm and a two-step data-driven solution. First, the data retrieval algorithm can generate effective datasets from multi-modal data including carbon satellite, the information of carbon sources, and several environmental factors. Second, the two-step data-driven solution that applies the powerful representation of deep learning techniques to learn to quantify anthropogenic CO2 emissions from satellite CO2 observation with other factors. Our work unmasks the potential of quantifying CO2 emissions based on the combination of deep learning algorithms and the carbon satellite monitor.
Keywords Carbon satellite Anthropogenic CO2 emissions Artificial Intelligence
1 Introduction
Human activities contribute to climate change by changing the amount of greenhouse gases, aerosols (fine particulate matter) and clouds in the atmosphere. The biggest contributor is the burning of fossil fuels Olivier et al. (2005), which emit carbon dioxide (CO2) gas into the atmosphere. Reducing these emissions is a core objective of the Paris Agreement of the United Nations Framework Convention on Climate Change (UNFCCC). The Paris Agreement requires all parties to report anthropogenic greenhouse gas emissions and removals at least every 2 years. In addition, an increasing number of corporates are required to provide annual report for CO2 emission accounts.
Although there are well-established self-reporting mechanisms, we still need alternative carbon emission observation methods to provide validation for the reported data and eliminate potential biases. Quantifying anthropogenic (CO2) emissions at the individual facility level has important implications. It can help to monitor emissions reductions or support regulation of carbon trading/pricing systems or other mitigation strategies. At present, most existing carbon emission estimation methods are based on corporates’ self-reporting information Gurney et al. (2021), regional or sector level carbon emission factors Shan et al. (2016), and other publicly available statistics data Shan et al. (2020). However, these methods need extra verification and the estimation frequency is unable to meet the requirements for real-time carbon emission estimation. In some industrial sectors, continuous emission monitoring systems (CEMS) are being deployed for accurate and real-time carbon emission estimation Jahnke (1997). But considering their high cost, it is impractical to build a comprehensive carbon emission monitoring system based on CEMS.
Recently, carbon satellite monitoring is a new technical means that can directly provide CO2 column-average dry-air mole fractions (XCO2), which denotes the column-average regional CO2 concentration in atmosphere. Owing to the potential of supporting CO2 emissions estimation, carbon satellite monitoring has been a fast-growing research topic. Previous studies qualified CO2 emissions by building a Gaussian plume model to simulate the CO2 flux movement in the atmosphere Nassar et al. (2017). In this paper, to estimate carbon emissions from carbon satellite observations at the individual facility level, we propose a pure data-driven methods based on a novel deep learning algorithm. To the best of our knowledge, this is the first carbon measurement method based on carbon satellite data and state-of-the-art artificial intelligence technologies. We anticipate this work to open up new research paradigms in carbon measurement.
Our research is based on the observations of NASA’s Orbiting Carbon Observatory 2 (OCO-2) satellite Crisp et al. (2017). OCO-2 makes high spectral resolution measurements of reflected solar radiation at wavelengths in the 0.76, 1.61, and 2.06 m regions to derive XCO2. OCO-2 has limited imaging capabilities, it measures XCO2 in 8 parallelogram footprints (each is about 1.29 2.25 km2) over a narrow swath (less than 10.3 km).
CO2 plumes derived from large emission sources may cause local enhancement in the OCO-2 observational near-source data because of diffusion and flow of gases, separating it from the background XCO2. This local enhancement recorded in satellite data is viewed as reflecting the patterns of CO2 emissions and subsequent movement. Thus we can utilize this pattern to estimate the emissions of carbon source. Detecting this enhancement and establishing the map from near-source satellite data to CO2 emissions are central to this task. We choose to design a deep neural network suitable for carbon satellite’s unique data structure based on a Transformer architecture Vaswani et al. (2017). After well-training, given a range of carbon satellite data with local enhancement, carbon source location, and some environmental information, this neural network directly predicts carbon emissions for the location it queried.
However, several challenges make this work not a naive utilization of deep learning on carbon satellite data.
-
•
First, the OCO-2 has only limited imaging capabilities, and its data is in the form of discrete measurement locations and the carbon concentrations measured at that location. This presents a challenge to the design of deep learning methods.
-
•
Second, the excess XCO2 generated by large emission sources typically reaches 1% at the best, which is about 4ppm compared with an instrument noise typically around 0.3–0.6ppm. This non-negligible noise in the XCO2 measurement hampers the imaging and detection of emission plumes and the precision of emission quantification. In the case of severe measurement noise, it is not even possible to confirm whether there is significant local enhancement with a single measurement. Similar to the case of carbon measurements, it is also extremely difficult to obtain an accurate wind field situation, which is another important basis for quantifying the plumes caused by carbon emissions. Usually, we can only obtain average wind speed and direction data over a large spatial scale and over a long period of time. And this only provides a very limited clue for estimating the emission plume.
-
•
Third, data acquisition is also challenged due to space satellites’ unique measurement orbital limitations. Only on rare occasions do the OCO-2 tracks cross CO2 plumes downwind of large cities or power plants, limiting the possibility of quantifying the corresponding CO2 emissions to a few cases within a year. This also limits our possibilities for multiple measurements of the same carbon source. By matching the location of known carbon sources, wind direction, and the location of the satellite detection swath, we are only able to match the hundreds of available data from millions of OCO-2 records, which also suffer from noise.
-
•
The last challenge is the complexity of emission source data. In this work, we select real hourly emission sources from continuous emission monitoring system (CEMS) data for our research. However, not only are the emissions data recorded by CMES facing missing and inaccurate challenges, but the situation of their emission sources is sometimes extremely complex. Multiple closely located emission sources may influence each other, making estimation more difficult.
To solve above problem, this work makes a three-step data retrieval algorithm and a two-step data-driven solution based on AI. The data retrieval algorithm is designed to find effective satellite data that contains local enhancement and to match auxiliary information geographically and temporally. We apply three steps to achieve this goals:(1) retrieval based on carbon sources for extracting satellite data near carbon source; (2) processing of abnormal data for filtering extremely noisy data; (3) retrieval based on pattern detection for finding effective satellite data with local enhancement. During data processing, we find that there is scarcity of data with real emission label. In contrast, we have massive amount of data without matched real emission label. To sufficiently utilize the properties of retrieved multi-modal data, We propose a novel data-driven solution. Our solution includes two steps: (1) masked pre-training for carbon emission estimation on large-scale of data without real emission label; (2) linear probing for the final prediction on a small-scale data with real emission labels.
The proposed data-driven method makes two important technical advances. Firstly, we present a new network architecture called CarbonNet for carbon emission estimation from OCO-2 XCO2 measurements. CarbonNet abandons the traditional neural network design paradigm using fully-connected layers or convolutional layers and adopts a novel strategy based on Transformer. The OCO-2 measurements can be viewed as independent measurements in different locations. We treat each measurement as a token containing the location information, the XCO2 number, the global wind information and the statistical background XCO2 number. In our CarbonNet, these tokens calculate self-attention and interact with each other, i.e. each token can interact with others, greatly improving its computing efficiency. More importantly, in CarbonNet, the order of tokens is variable, and tokens can be masked flexibly. This enables our second technical design called mask pre-training. Recall that of the vast amount of available satellite data, only a small fraction can be matched with recorded emissions sources. We have very little satellite data with emission labels, but a lot of data without labels. The distribution of these data is complex and full of noise. Learning directly with a small amount of data will undoubtedly lead to severe overfitting. To address this problem, we propose a masked pre-training method using satellite data that cannot match the emission record. For data without labels, we randomly mask a portion of it, e.g., 25% of the measurement points, and train the CarbonNet to predict the masked measurements based on the data provided. This forces the network to learn the distribution of satellite-measured XCO2 and can learn an efficient representation of the satellite data. Finally, we use linear regression to predict carbon emissions from satellite data representations on the labeled data. Our experiments show that the proposed solution can effectively predict carbon emissions and can avoid overfitting and noise data interference to a certain extent.
2 Data
In this section, we first introduce three types of raw data and their sources. Then we discuss the provided three-steps data retrieval algorithm in detail. Finally we give the information of generated dataset.
2.1 Data Acquisition
We collect three different modal data that contributes to CO2 emissions estimation: (1) carbon satellite observations; (2) the position and emissions of carbon source; (3) some environmental information that influences CO2 movements. Firstly, we use version 9r of the OCO-2 bias-corrected XCO2 retrievals, which is a level-2 satellite product that records XCO2 and a lot of supplementary information. We extract several key recordings from this data, including position, time, XCO2, XCO2 evaluation parameters, and recording angles of the carbon satellite. The position information is consist of the center and corner coordinates (in the geographic coordinate system) of each scan area. XCO2 is the most important key, which reflects the column-averaged regional concentration of carbon dioxide in the atmosphere detected by the carbon satellite. Two XCO2 evaluation parameters in OCO-2 product (xco2_quality_flag and xco2_uncertainty) are used to evaluate the quality of XCO2 recordings. Besides, we choose solar_zenith_angle and sensor_zenith_angle in recordings that can help us select worth data. The detailed explanations of these selected keys can be referred to Eldering et al. (2017). We could use these parameters both to find effective data and to estimate the emissions of carbon sources. On the other hand, we choose real hourly emission data from continuous emissions monitors (CEMS) released by EPA Air Markets Program Data () (EPA). It covers over 1303 power plants in the United States and their positions. Finally, some environmental information, including the average wind speed of u and v direction below 50m, solar radiation and surface pressure, is derived from the ERA5 reanalysis dataset () (C3S).
2.2 Data Retrieval
There are two reasons to develop a data retrieval algorithm before building model to estimate emissions. The first reason is that the quality of data is low, which indicates the low signal-noise rate of satellite observations, incomplete CEMS emissions recordings and low resolution of environmental data. The second reason is that our inversion framework relies on multi-modal data to jointly link the observed CO2 local enhancement with upwind local emission source. Matching of these data significantly limit the the number of effective data. We did a lot of analysis and filtering of the data. The data retrieval is mainly composed of three steps: (1) retrieval based on carbon source; (2) processing of abnormal data; (3) retrieval based on pattern (local enhancement in satellite data) detection. The details of this three-step data retrieval algorithm are depicted as following.
2.2.1 Retrieval Based on Carbon Sources
The first step is to filter some unreliable data by the information of carbon source. We first merge adjacent power plants to one carbon source if they are too closer to others (the distance between two emission sources is less than 3 km that is the spatial resolution of OCO-2 carbon satellite). For instance, in New York state, a power plant named Equus Power I is merely 0.7km from another named Freeport Power Plant No. 2. Thus, the least resolution of carbon source in our framework is equal to the spatial resolution of carbon satellite. After the combination, we obtain 1245 independent carbon sources from 1303 CEMS power plants with position information. We match all satellite data within (longitude latitude) wide moving windows centered on each independent carbon source. Then these satellite data in each window are divided into 63931 single satellite swath data by different recording times. Finally, we remove some satellite swath data if the distance between carbon source and satellite swath is greater than 40 km. This can increase the probability that the detected local enhancement within satellite swath data is associated with a specific carbon source. We have 46179 remains of swath data after retrieval based on carbon sources.
2.2.2 Processing of Abnormal Data
Although previous works Nassar et al. (2017); Zheng et al. (2020) choose to use the good-quality data (xco2_quality_flag equals 0), we use both the good-quality and bad-quality data (xco2_quality_flag equals 1) in our framework. Conversely, we encode the quality flag of XCO2 as part of the input of our model. The most important reason to do this is to balance the number and quality of the remaining data after data retrieval. Utilizing all quality data can significantly increase the number of effective data and make subsequent supervised learning possible. However, it also introduces a lot of extremely noisy recordings in swath data which is harmful for training model. Thus, the second step is to filter abnormal satellite swath data according to their statistical information.
We first control the number of effective recording points in each swath data. Figure 1(a) presents the distribution of the length of swath data after retrieval based on carbon source. We delete those satellite swath data if their length are less than 200 since they have a tendency to lack key information for emission estimation. In addition, the maximum length is restricted to 450 to avoid a rare case that a carbon satellite repeatedly scans the same area over a continuous period. As shown in Figure 1(c), we find that there are some outliers in swath data which are extremely large than the mean XCO2. These noisy recordings seemly caused by wrong recording or satellite retrieval error in carbon satellite Level 2 production, can significantly decrease the estimation ability of our model. Therefore, we directly remove those swath data if the maximum of recording XCO2 is greater than 1000 ppm. Finally, we exclude the extremely complex emission situations caused by multiple carbon sources within the matched area. Figure 1(e) shows the distribution of the number of carbon sources within each area. There may exist almost 40 carbon sources in a area (longitude latitude), which seems impossible to estimate the emissions of a single carbon source. Consequently, we limit the number of carbon sources in each area to 10 to lessen the difficulty of emission estimation. Finally, it is necessary to delete extremely slim satellite swaths (the weight of the swath is less than 8 km) generated by inappropriate satellite recording angles. The corresponding distributions after retrieval based on statistics are shown in Figure 1(b), 1(d) and 1(f) respectively. After processing of abnormal data, we eventually have about 10930 denoised swath data. These swaths can be used to form large-scale data without carbon emission labels for pre-training based on self-supervised learning.
2.2.3 Retrieval based on Pattern Detection
The above two steps have helped us to get high-quality swath data. However, these swaths may not carry on effective and sufficient information to support emission estimation of carbon sources. To avoid learning from data that inputs are irrelevant to outputs, we develop the third step to find out these satellite swath data that contains patterns for emission estimation. Previous works Nassar et al. (2017); Zheng et al. (2020) tend to fit on a Gaussian plume detected on a swath to estimate corresponding emissions. However, we merely obtain four swaths if limiting to classical Gaussian plumes on our data. Therefore, we design a specific pattern detection approach to ensure that the swath data is associated with a single carbon source.
We first filter these swath data either without recorded CEMS emissions or with matched emissions less than 100 tons/hours, and get 5304 remaining swath data. We set the maximum upwind direction to 60 as in Zheng et al. (2020) to ensure that the CO2 movement from a carbon source is reflected in carbon satellite swath data in term of local enhancement. Merely 1658 swath data are successfully matched within 60 upwind direction. We fit a curve to XCO2 retrieval data along the orbit which is centered on the intersection of swath data and carbon source along upwind direction. These swaths are considered as carrying potential local enhancemnet if the values of their intersection along wind direction exceed the standard deviation of spatial variability above the local average within 200km. Additionally, we remove some cases where several carbon sources contribute to the same potential XCO2 local enhancement. Only 220 effective swath data have been left after all filters. The number of cases remained after each filtering shown in Figure 1(g).
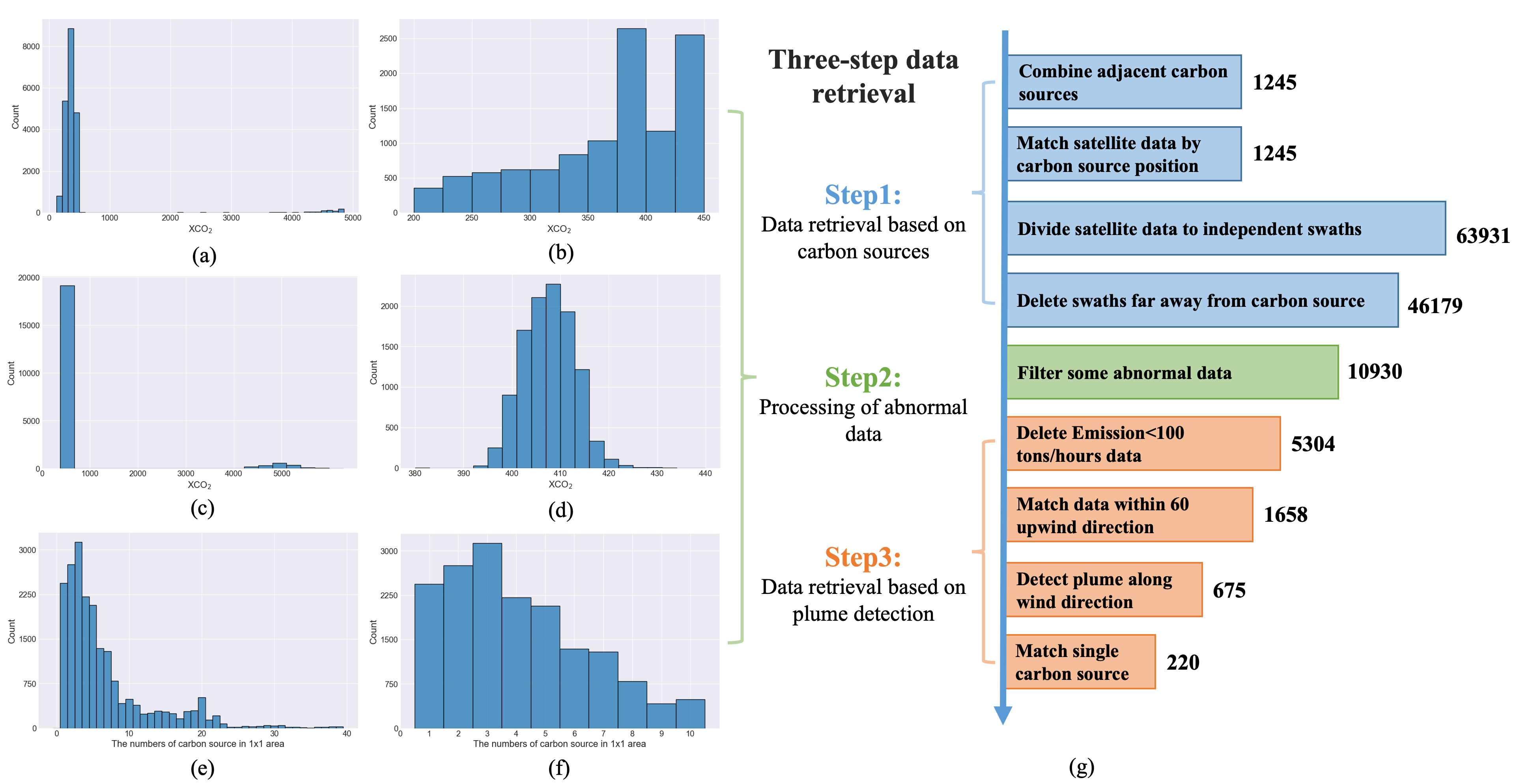
2.3 Datasets
According to above three-step data retrieval method, we have a large-scale unlabeled dataset and a small-scale real-emission labeled data. The unlabeled dataset that contains 10930 swath data is collected for pre-training to extract effective and efficient features. The light labeled swath data include only 220 swath data, we random choose 150 of them as training data used for fitting a linear model, and the other 70 of them are for testing performance.
3 Method
In this section, we describe our method in detail. First, we introduce the input data encoding and deep architecture of the proposed novel transformer-based CarbonNet. After that we provide a two-step solution to learn to estimate CO2 emissions. The first step adopt the mask pre-training strategy to learn sufficient representation on the large-scale unlabeled satellite data. We extract the deep features from well mask pre-training model on a small-scale real-emission labeled data for downstream prediction. The second step take the combination of deep features and some handcraft features on a small-scale real-emission labeled data as input, and learns a weighted linear model for predicting CO2 emissions.
3.1 The Transformer-based CarbonNet
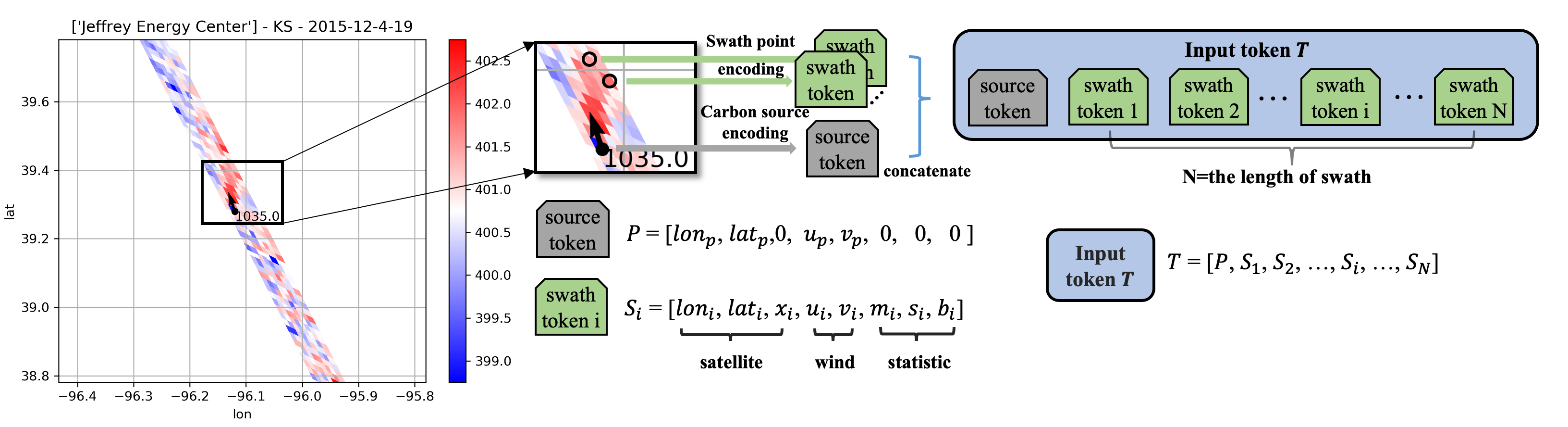
We propose a novel deep neural network architecture namely CarbonNet and associated data encoding approach. We first describe the process of encoding satellite swath data to the form for training. The XCO2 measurements from the OCO-2 satellite can be viewed as a collection of tuples , where and represents the longitude and the latitude of the th measurement point, is the XCO2 record at this point and is the number of measurements in swath data . As described in Section 2, is a number between 200 and 450 in our paper. We incorporate the wind information and other statistic information of swath into each tuple to provide the supporting information for prediction. The average wind below 50m for each point is denoted as , where and is the value of wind speed of the longitude and latitude components. We also incorporate some statistic information that includes the means and standard deviation XCO2 of each swath, and the background XCO2. The statistic information record is denoted as . For different data at the same time, the background carbon dioxide concentration is assumed to be a constant as mean and standard deviation . Because carbon dioxide concentrations vary primarily with time, they have increased periodically over the past few years.
In the proposed CarbonNet, we treat each tuple as a special vector namely token. We reorganize the data in each tuple as a vector , named swath token, and the whole swath data is represented as a sequence of vectors . For subsequent training CarbonNet, each vector sequence is padded with 0 to the same length N that is set to the maximum length of swath data (450 in our paper). Therefore, each swath is encoded as a sequence of vectors with constant length, denoted as . We also encode the position and wind information of carbon source as a vector , where and denote the longitude and latitude of carbon source, and denote the u and v wind at the position of carbon source. is named source token as the same length as each swath token. Finally, we use the the concatenation of source token and a sequence of swath token as input token of CarbonNet. A case of the input data encoding is as shown in Figure 2.
We start to introduce the architecture of proposed CarbonNet. Given a swath input we use a fully-connected embedding layer to extract feature as
where is the dimension of the feature. Then, we extract deep feature as
where is the deep feature extraction module and it contains K residual building blocks. More specifically, intermediate features , ,, and the output deep feature are extracted block by block as
where denotes the th building block and is obtained by taking the average over the dimension.
Each building block has a self-attention layer in Vaswani et al. (2017) and a fully-connected layer . In the self-attention layer of the th building block, the query , key and value are computed as
where are weight matrices, and is the number of projected vectors. Then, we use to query to generate the attention map as
where is the learnable relative positional encoding. This attention map is then used for the weighted sum of vectors in .
Next, a fully-connected layer with GELU non-linearity activation is used for further feature transformations as
where is the weight and is the bias. The LayerNorm (LN) layer is added before both and , and the residual connection is employed for both modules. The whole process is formulated as
3.2 Masked Pre-training for Carbon Emission Estimation
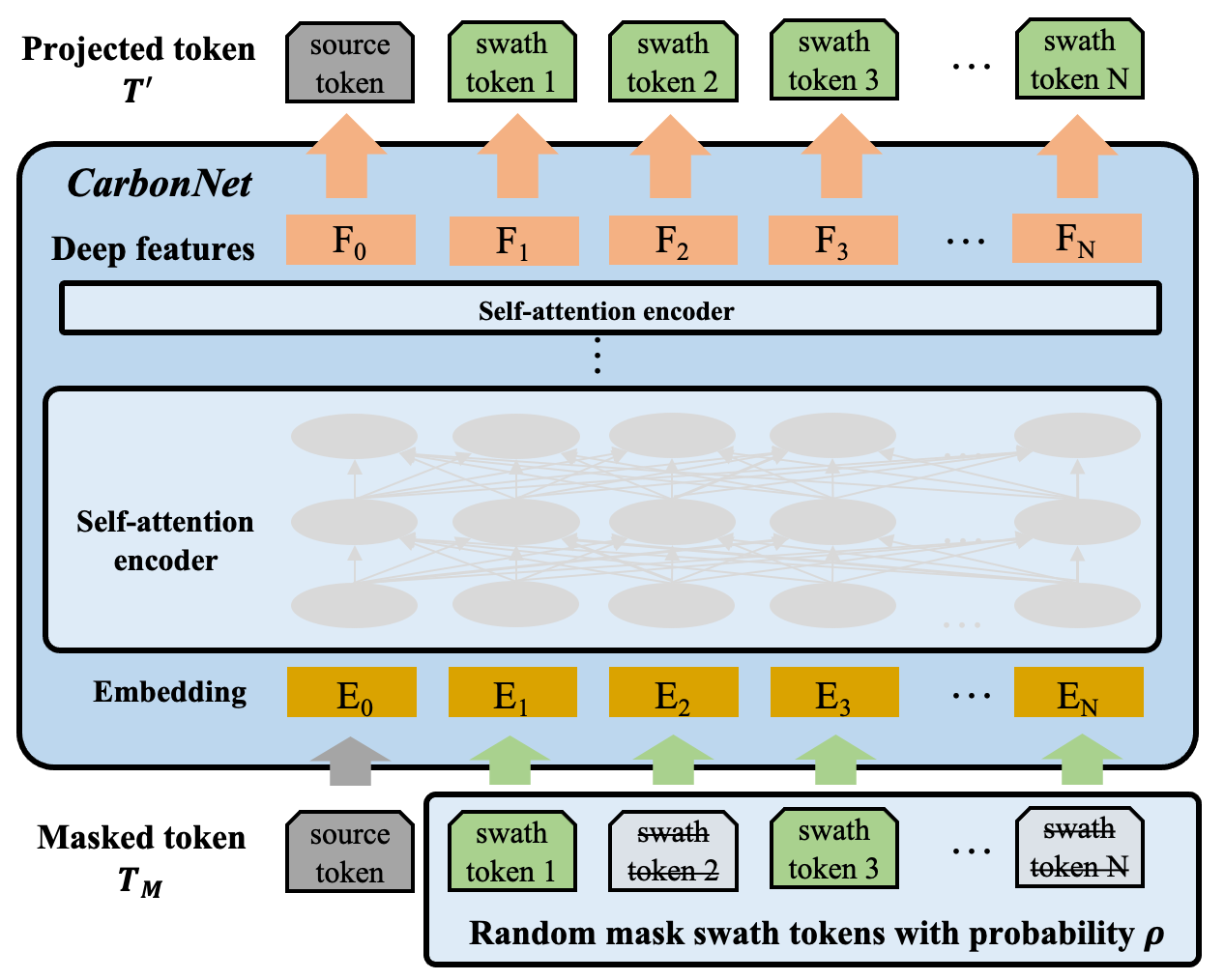
We next describe our method for masked pre-training strategy. Recall that we only have very limited labeled data, and a large number of unlabeled data. The masked pre-training method is to learn a meaningful representation for the downstream prediction through a mask-prediction pretext task. We assume a binary 0-1 mask that randomly masks each token with a probability , i.e. the values of masked tokens will be replaced by 0. This ratio can be large, depending on the redundancy of the data. For images, we can even safely mask out up to 90% of the pixels. For our OCO-2 satellite data, we can mask out 25% – 50% of the data to get the best pre-training results as shown in 3. The masked swath data is represented as and is sent into the CarbonNet to get the th intermediate features . We use another projector layer to project the dimensional features back to the 9-dimensional tokens as
where the is the projection weight, and is the projection bias. During the pre-training, we input the masked swath data into the CarbonNet and get the projected (predicted) tokens . We optimize the distance between and the unmasked input to complete the swath data based on part of known information. In this way, even in the absence of labeled data, CarbonNet still learns the patterns in the swath data and extracts a high-quality representation . After pre-training, the projection layer is discarded, but the rest of the parameterized part is reserved for feature extraction.
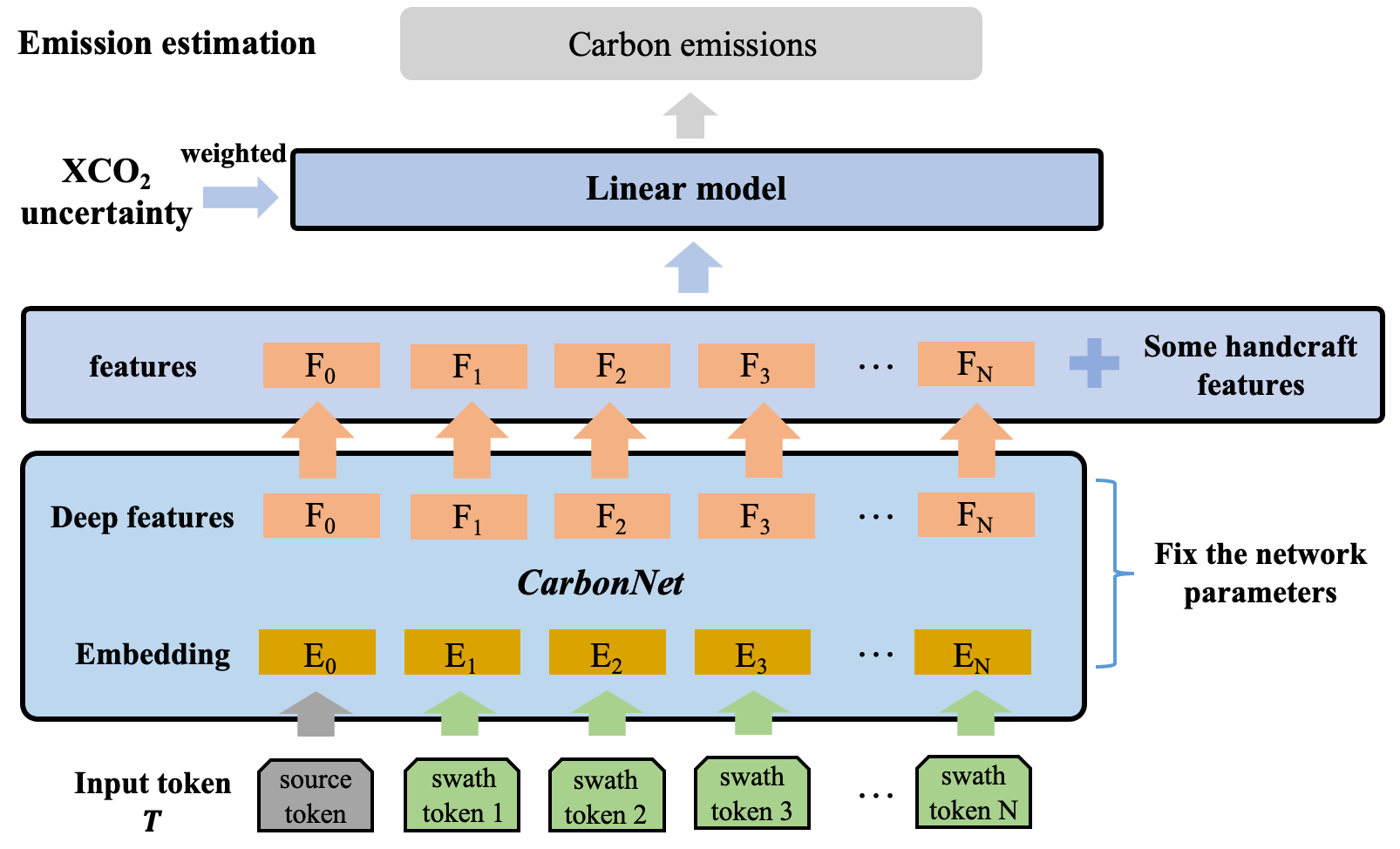
3.3 Linear Probing for the Final Prediction
The above pre-training strategy gives us a well-trained deep representation of OCO-2 swath data, we can simply obtain the carbon estimation results using the linear probing method as shown in Figure 3. Linear Probing refers to fixing the features of the representation layer and training the classifier or regressor only through supervised data. Given the well-trained CarbonNet, we extract the deep features for each labeled data in our dataset. Then we stack extracted deep features with some handcraft features, including the mean and deviation of swath, the position and wind information of carbon source, and the background XCO2 of swath. The final input features is a dimensional vector, where denotes the dimension of handcraft features. Combined with the carbon emissions records matched by these data, we obtain the paired data to learn a linear regression weighted by XCO2 uncertainty between the c-dimensional feature and the carbon emissions as
where is the linear weight, and is the bias term. The weights can be obtained in a variety of ways, in this work we simply use linear regression to train.
4 Results
To estimate CO2 emissions from single carbon source, we use multi-modal data, including some parameters from version 9r of the OCO-2 bias-corrected XCO2 retrievals, hourly real CO2 emissions and power plant information from CEMS data, and wind data collected from ERA5-land. We provide three-step data retrieval method to generate effective satellite data that contains patterns. Then we propose a two-step solution to estimate CO2 emissions. The first step can extract sufficient deep features of satellite data from the layer before the final dense layer of the well-trained model. The trend of training loss and the visualization of recovery satellite data can demonstrate the effectiveness of mask pre-training. Second, we learn a weighted linear model, which takes the combination of deep features and handcraft features as input and directly outputs the estimated emissions of given carbon source. Our experiments show that the proposed method can effectively predict CO2 emissions and be robust to noisy data to a certain extent. Finally, we compared the proposed solution with an existing method called Gaussian Plume Model (GPM). The conducted experiments show that our method can outperform GPM on the test set.
4.1 Representation Extraction of CarbonNet Based on Masked Pre-training
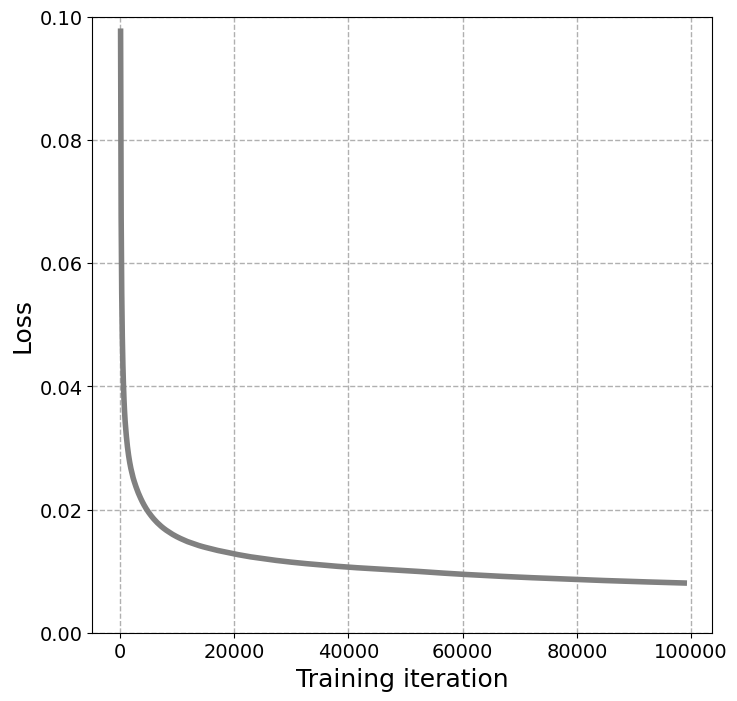
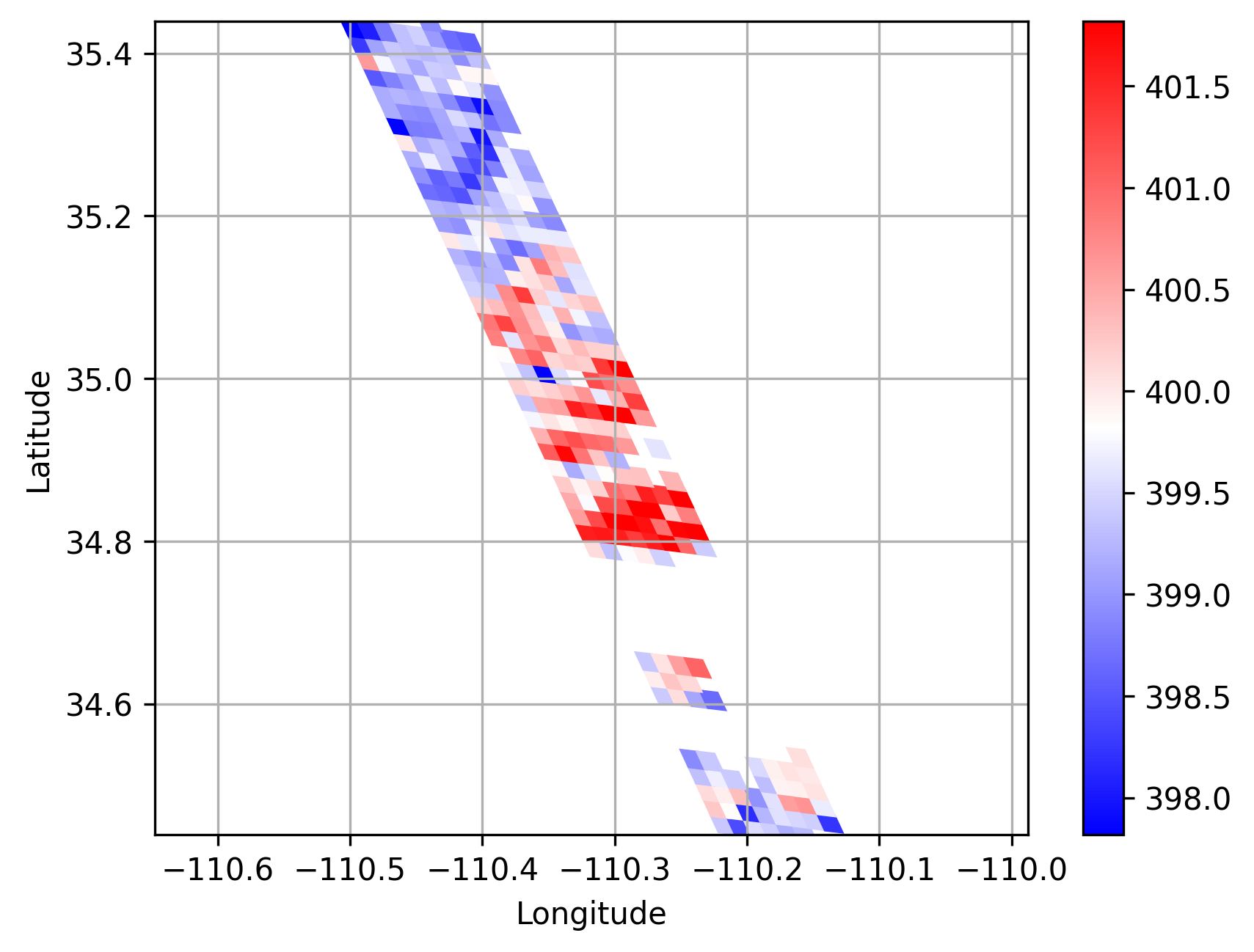
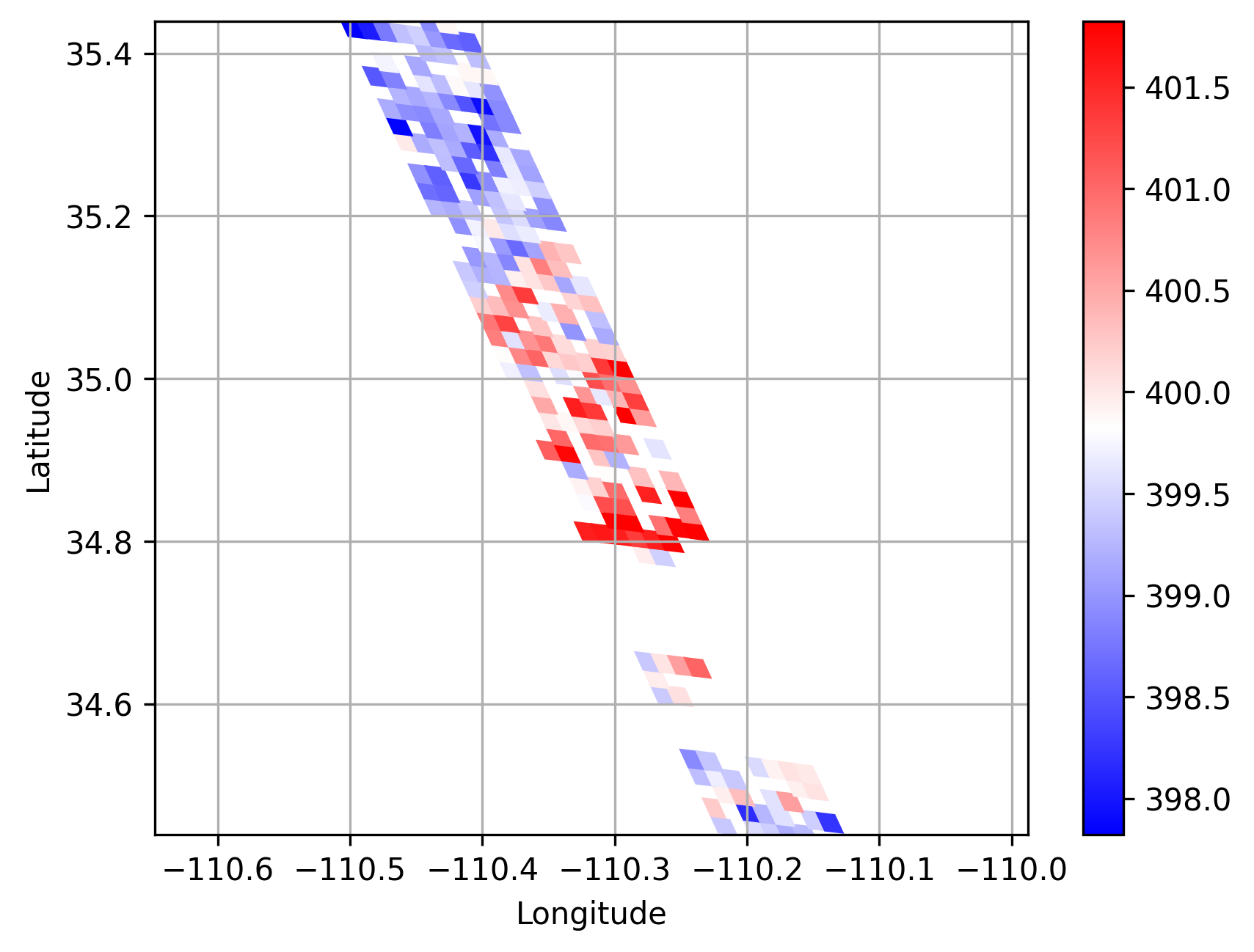
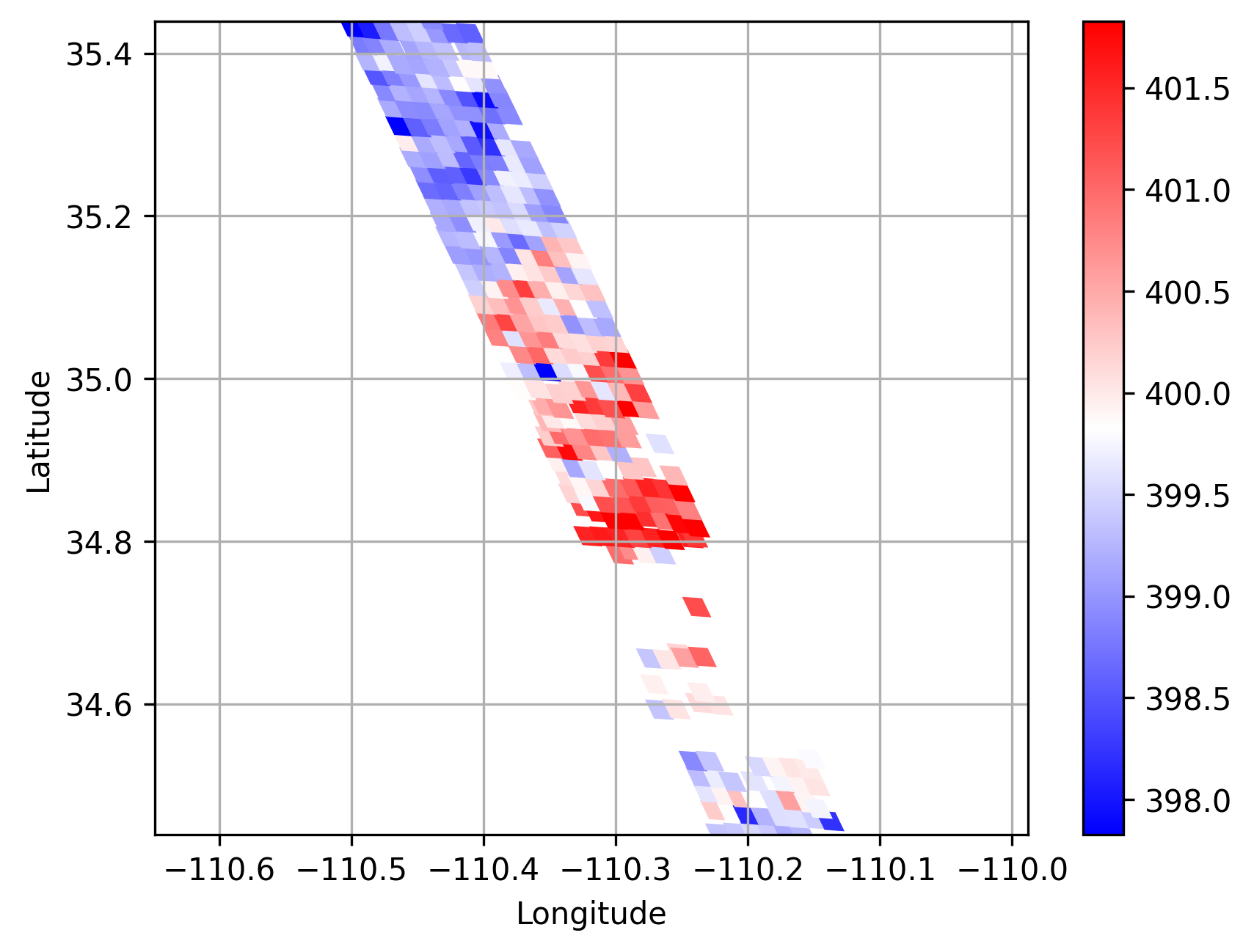
In the mask pre-training stage, we set the probability of random mask to 25%. Figure 4 shows the L1 loss descending trend with the training iterations. It is easy to see that our approach, after 100000 iterations, achieves the lowest Loss value equals about 0.8% over all 5304 unlabeled satellite data. This demonstrates that our pre-trained method has the ability to recover masked swath information from the unmasked parts. Thus, the features extracted from pre-trained CarbonNet can serve as an efficient representation of the satellite swath data. Figure 5 tries to provide a case of visualized comparison between original swath data and the recovered data predicted by pre-trained CarbonNet. On 25 February 2015 at about 20 local time in state Arizona near a power plant named Cholla, the original satellite XCO2 data, masked data and retrieved data from masked input are presented in Figure 5, 5 and 5 respectively. Intuitively, we obtain the same conclusion that the masked parts are successfully recovered in the retrieved satellite data.
4.2 CO2 emissions estimates by Linear Regression
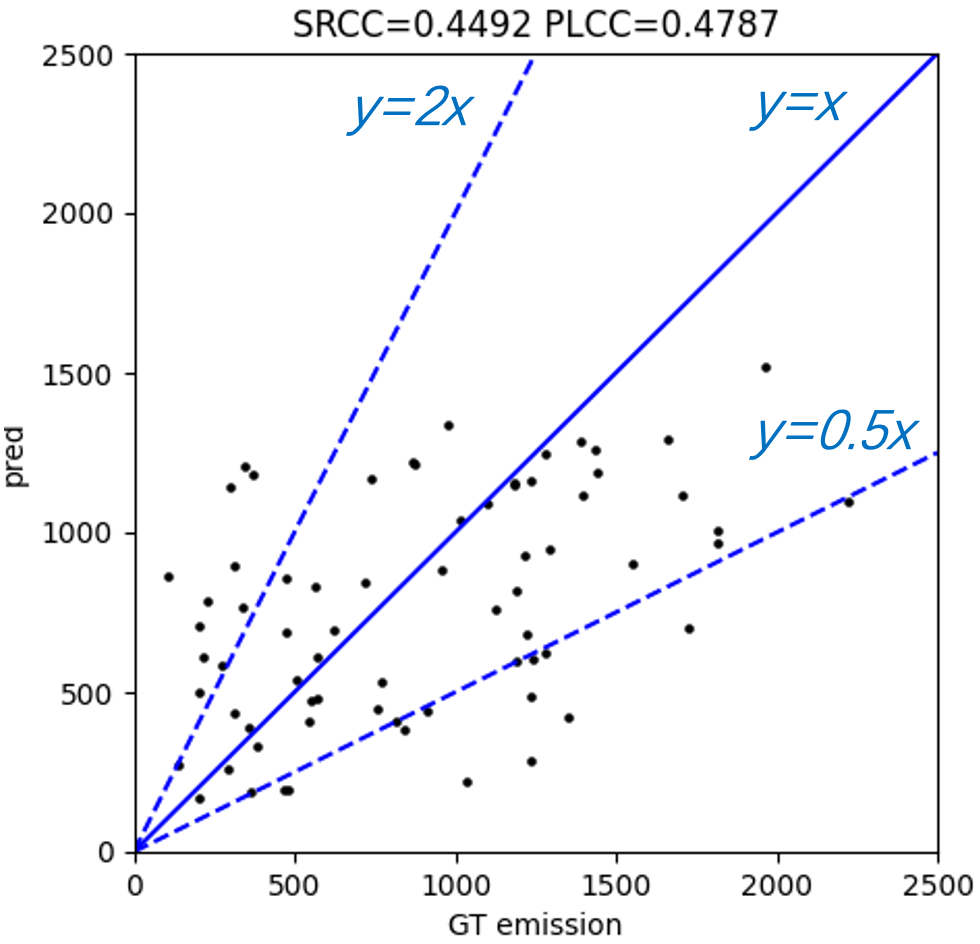
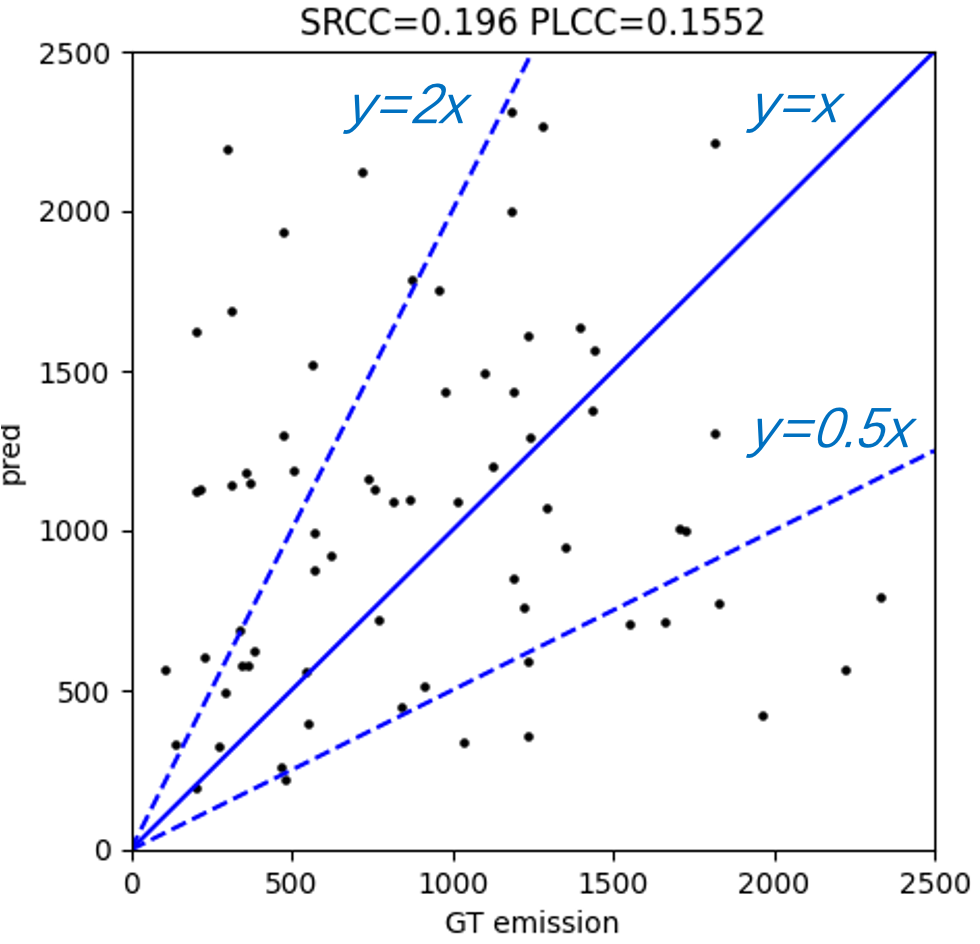
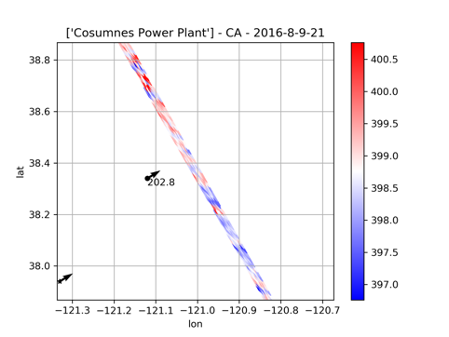
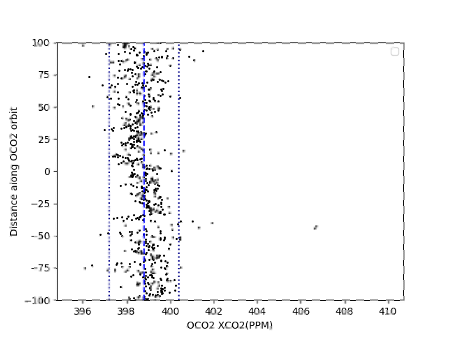
In contrast to pre-training on large-scale swath data, a weighted linear model is learned on small-scale labeled swath data to estimate CO2 emissions. We first extract and save features of each labeled swath data from the layer before the final dense layer of pre-trained CarbonNet. Then we concatenate these features to some handcraft features that include longitude and latitude of carbon source, u and v direction wind speed at the position of carbon source, the mean and standard deviation of this satellite swath data, monthly background mean and standard deviation. we fit a linear model weighted by XCO2 uncertainty and XCO2 quality flags which takes concatenated features as input and labeled emissions as output. Figure 6 shows the final test performance of weighted linear regression on 70 test set. On the other hand, we test the performance by applying the Gaussian plume model method proposed in Nassar et al. (2017) as shown in Figure 6. We use Spearman rank-order correlation coefficient (SRCC) and Pearson linear correlation coefficient (PLCC) to evaluate the correlation between the estimation and the ground truth. The results show that our method can achieve higher correlation coefficients (both SRCC and PLCC) than the Gaussian plume model method. Moreover, it is obvious that our method has fewer outliers which are out of the blue lines ( and ). As shown in Figure 7, a case with 202.8 tons/hour emission label that does not an contain explicit Gaussian plume is predicted to be 262.7 tons/hour by our model. However, the prediction of fitting Gaussian plume model method is 1184.2 tons/hour which surpasses five-fold true emissions.
5 Related Work and Discussion
Based on the traditional global greenhouse gas ground-based observation network, it is hard to understand the anthropogenic sources and sinks of greenhouse gas. Monitoring greenhouse gas from space by carbon satellite has trend to be a critical part of the new generation of carbon metering system. It is a great challenge to extract anthropogenic emissions data from XCO2 data measured by carbon satellites. The measurement of gas such as nitrogen dioxide (NO2) and sulfur dioxide (SO2) based on satellite imaging spectrometers has already been demonstrated in Liu et al. (2016, 2017). However, the precision of CO2 measurement is obviously interior to NO2 or SO2, which brings to a great challenge to quantifying CO2 emissions. Some studies use synthetically generated CO2 emissions of power plants Bovensmann et al. (2010) and cities Pillai et al. (2016) to prove the ability to perceive CO2 emissions from carbon satellites. An alternative is to estimate CO2 emissions by first getting accurate NO2 emissions and then finding the relationship between CO2 emissions and NO2 emissions of a power plant. Moreover, there are some works to quantify CO2 emissions by fitting real measured emissions from CEMS installed on power plants Nassar et al. (2017). Nevertheless, all previous CO2 emission estimation methods are based on establishing an atmospheric physics model. To our knowledge, no attempt has been made yet to infer CO2 emissions based on the data-driven method before this paper. As shown above, we propose a two-step data-driven solution to quantifying CO2 emissions from the carbon source. The main limitation of our method is lack of explicit interpretability as all black-box models. It aggravates the difficulty in evaluating the error of emission estimation by our model.
6 Conclusion
In this paper, we first reveal the potential of the data-driven AI method to quantify CO2 emissions from space. We first design a three-step data retrieval algorithm to find effective multi-modal data with patterns that enable to map from satellite data to emissions. The provided data retrieval algorithm can generate a large-scale unlabeled data and light-scale data with real emission label matched from CEMS data. According to the properties of data, we propose a novel deep architecture namely CarbonNet and a two-step solution to utilize both large-scale unlabeled data and small-scale labeled data for CO2 emissions estimation. The first step based on mask pre-training strategy can obtain sufficient deep features for downstream prediction. The second step predicts emissions by learning a weighted linear model that takes the combination of deep features and some handcraft features as input. Owing to the design of encoding multi-modal data as special vector namely token, our method can easily benefit from more accumulated swath data and higher precision data from the new generation of carbon monitors. For future work, we intend to collect more relevant information, such as the topography of the selected area, temperature, and moisture, to further improve the accuracy of emission estimation of our solutions.
References
- Olivier et al. [2005] Jos GJ Olivier, John A Van Aardenne, Frank J Dentener, Valerio Pagliari, Laurens N Ganzeveld, and Jeroen AHW Peters. Recent trends in global greenhouse gas emissions: regional trends 1970–2000 and spatial distributionof key sources in 2000. Environmental Sciences, 2(2-3):81–99, 2005.
- Gurney et al. [2021] Kevin Robert Gurney, Jianming Liang, Geoffrey Roest, Yang Song, Kimberly Mueller, and Thomas Lauvaux. Under-reporting of greenhouse gas emissions in us cities. Nature communications, 12(1):1–7, 2021.
- Shan et al. [2016] Yuli Shan, Jianghua Liu, Zhu Liu, Xinwanghao Xu, Shuai Shao, Peng Wang, and Dabo Guan. New provincial co2 emission inventories in china based on apparent energy consumption data and updated emission factors. Applied Energy, 184:742–750, 2016.
- Shan et al. [2020] Yuli Shan, Qi Huang, Dabo Guan, and Klaus Hubacek. China co2 emission accounts 2016–2017. Scientific data, 7(1):1–9, 2020.
- Jahnke [1997] James A Jahnke. Handbook, Continuous Emission Monitoring Systems for Non-criteria Pollutants. Center for Environmental Research Information, National Risk Management …, 1997.
- Nassar et al. [2017] Ray Nassar, Timothy G Hill, Chris A McLinden, Debra Wunch, Dylan BA Jones, and David Crisp. Quantifying co2 emissions from individual power plants from space. Geophysical Research Letters, 44(19):10–045, 2017.
- Crisp et al. [2017] David Crisp, Harold R Pollock, Robert Rosenberg, Lars Chapsky, Richard AM Lee, Fabiano A Oyafuso, Christian Frankenberg, Christopher W O’Dell, Carol J Bruegge, Gary B Doran, et al. The on-orbit performance of the orbiting carbon observatory-2 (oco-2) instrument and its radiometrically calibrated products. Atmospheric Measurement Techniques, 10(1):59–81, 2017.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Eldering et al. [2017] A Eldering, PO Wennberg, D Crisp, DS Schimel, MR Gunson, A Chatterjee, J Liu, FM Schwandner, Y Sun, CW O’dell, et al. The orbiting carbon observatory-2 early science investigations of regional carbon dioxide fluxes. Science, 358(6360):eaam5745, 2017.
- [10] United States Environmental Protection Agency (EPA). Washington, dc:office of atmospheric programs, clean air markets division. https://campd.epa.gov/. 27 June 2022.
- [11] Copernicus Climate Change Service (C3S). Era5: Fifth generation of ecmwf atmospheric reanalyses of the global climate, copernicus climate change service climate data store (cds). https://cds.climate.copernicus.eu/cdsapp#!/home. last access: 8 September 2022.
- Zheng et al. [2020] Bo Zheng, Frédéric Chevallier, Philippe Ciais, Grégoire Broquet, Yilong Wang, Jinghui Lian, and Yuanhong Zhao. Observing carbon dioxide emissions over china’s cities and industrial areas with the orbiting carbon observatory-2. Atmospheric Chemistry and Physics, 20(14):8501–8510, 2020.
- Liu et al. [2016] Fei Liu, Steffen Beirle, Qiang Zhang, Steffen Dörner, Kebin He, and Thomas Wagner. Nox lifetimes and emissions of cities and power plants in polluted background estimated by satellite observations. Atmospheric Chemistry and Physics, 16(8):5283–5298, 2016.
- Liu et al. [2017] Fei Liu, Steffen Beirle, Qiang Zhang, Ronald J Van Der A, Bo Zheng, Dan Tong, and Kebin He. Nox emission trends over chinese cities estimated from omi observations during 2005 to 2015. Atmospheric Chemistry and Physics, 17(15):9261–9275, 2017.
- Bovensmann et al. [2010] H Bovensmann, M Buchwitz, JP Burrows, M Reuter, T Krings, K Gerilowski, O Schneising, J Heymann, A Tretner, and Joerg Erzinger. A remote sensing technique for global monitoring of power plant co2 emissions from space and related applications. Atmospheric Measurement Techniques, 3(4):781–811, 2010.
- Pillai et al. [2016] Dhanyalekshmi Pillai, Michael Buchwitz, Christoph Gerbig, Thomas Koch, Maximilian Reuter, Heinrich Bovensmann, Julia Marshall, and John P Burrows. Tracking city co2 emissions from space using a high-resolution inverse modelling approach: a case study for berlin, germany. Atmospheric Chemistry and Physics, 16(15):9591–9610, 2016.