\ul
NER-to-MRC: Named-Entity Recognition Completely Solving as Machine Reading Comprehension
Abstract
Named-entity recognition (NER) detects texts with predefined semantic labels and is an essential building block for natural language processing (NLP). Notably, recent NER research focuses on utilizing massive extra data, including pre-training corpora and incorporating search engines. However, these methods suffer from high costs associated with data collection and pre-training, and additional training process of the retrieved data from search engines. To address the above challenges, we completely frame NER as a machine reading comprehension (MRC) problem, called NER-to-MRC, by leveraging MRC with its ability to exploit existing data efficiently. Several prior works have been dedicated to employing MRC-based solutions for tackling the NER problem, several challenges persist: i) the reliance on manually designed prompts; ii) the limited MRC approaches to data reconstruction, which fails to achieve performance on par with methods utilizing extensive additional data. Thus, our NER-to-MRC conversion consists of two components: i) transform the NER task into a form suitable for the model to solve with MRC in a efficient manner; ii) apply the MRC reasoning strategy to the model. We experiment on benchmark datasets from three domains and achieve state-of-the-art performance without external data, up to improvement on the WNUT- dataset.
1 Introduction
A fundamental topic in natural language processing (NLP) is named entity recognition (NER), which aims to detect the text with predefined semantic labels, such as a person, a position, and others Li et al. (2022). Given its importance, many methods have been published for this task and most of them can be viewed within a sequence labeling framework Li et al. (2020); Wang et al. (2021b); Fu et al. (2021); Devlin et al. (2019) that tags the input words, as shown in Fig. 1 (a). For example, with a given sentence, a properly working NER system should recognize three named entities with its inside–outside–beginning (IOB) format tagging Ramshaw and Marcus (1995): “France” is a location entity (B-LOC), “Britain” is a location entity (B-LOC), and “Fischler” is a person entity (B-PER). NER tasks provide only a single sequence with limited information as the model’s input. Consequently, several approaches Wang et al. (2021b); Antony and Suryanarayanan (2015); Nishida et al. (2022); Wang et al. (2022) consider how to efficiently utilize additional information to enhance the understanding of the input sequence, thereby improving model performance. However, the effective retrieval of supplementary information and training on this extra data require additional cost and effort.

The above contradiction poses a challenge, and hence the focus of our paper is to address this. The ability of reading comprehension can reflect human understanding and reasoning skills Davis (1944); Trassi et al. (2019), such as question-answering or multiple-choice. Additionally, recent studies show that machine reading comprehension (MRC) can improve various tasks, such as natural language inference and text classification Yang et al. (2022); Wei et al. (2022); Sanh et al. (2022). Inspired by these, we study the problem of how to harness MRC to address NER, resulting in bridging MRC reasoning strategy with NER task. To begin with, we require high-quality data reconstruction to convert NER as an MRC problem. Our preferred method for addressing this construction involves the use of artificially designed NER-to-MRC queries, including BERT-MRC Li et al. (2020) and KGQA Banerjee et al. (2021). However, this solution faces the following challenges, i) low-transferability: the lack of a unified data reconstruction paradigm makes it difficult to migrate to new datasets. ii) hand-crafted: high reproduction difficulty and unstable performance due to hand-crafted question templates; iii) insufficient information: the input ignores label semantics.
To address the above challenges, we frame the data construction as a multiple choice (MC) problem. Before detailing the solution, we first present an example of MC format as follows: given a triplet, the system chooses “Location” as the entity label for “France”. The MC format overcomes the counter-intuitive challenge mentioned above by allowing the model to predict possible entity labels through text descriptions. In essence, what matters the most for building the MC format is to generate appropriate questions for prompting language models. Inspired by the design principle (a less manual process) of UniMC Yang et al. (2022), we only provide a single prompt question, which implies stable results as opposed to inconsistent question templates in existing schemes to resolve the hand-crafted challenge. On the other hand, to address the insufficient information challenge, our design introduces label information as options, which conveys essential semantics in a variety of low-resource scenarios Luo et al. (2021); Mueller et al. (2022).
Recent state-of-the-art (SoTA) NER works rely on the assistance of external data, such as retrieved text from the Google search engine Wang et al. (2021b) and pre-training data Yamada et al. (2020). To achieve performance comparable to state-of-the-art external context retrieving approaches without relying on additional retrieved data, merely considering MRC methods in the data reconstruction phase is insufficient. We believe that MRC techniques can learn missing information from the dataset without any extra data. Therefore, we further integrated MRC reasoning strategies into the NER tasks. Specifically, we introduce a powerful human reading strategy, HRCA Zhang and Yamana (2022) (details in Sec. 3.2), instead of only inserting a Pre-trained Language Model (PLM) as BERT-MRC. To this end, we transfer the model choice to entity labels by matching the options.
To evaluate our framework, we carry out numerous experiments on challenging NER benchmarks, including three domains with general and specialized vocabulary. The results demonstrate that our approach improves SoTA baselines, such as WNUT- Strauss et al. (2016) (), WNUT- Derczynski et al. (2017) (), BCCDR Li et al. (2016) (), NCBI Dogan et al. (2014) (), CoNLL- Sang and Meulder (2003) () and CoNLL Wang et al. (2019a) (). Note that our MRC method achieves such performance without any extra data, which suggests the potential of mining text for intrinsic connections to complete complex tasks.
In summary, our contributions are:
-
•
We propose a new NER-to-MRC reconstruction solution by introducing a simple yet stable data reconstruction rule.
-
•
We apply MRC strategies to solve NER problems without retrieval systems or pre-training NER data, resulting in a concise process.
-
•
Our approach shows the SoTA performance on multiple popular NER datasets, including three domains with general (WNUT-, WNUT-, CoNLL- and CoNLL) and specialized (BCCDR and NCBI) vocabulary.
2 Related Work
We introduce the general development trend of the NER field in Sec. 2.1. Treating NLP tasks other than MRC as MRC problems can enhance the performance of corresponding tasks. We demonstrate how such schemes apply the MRC paradigm to other NLP tasks in Sec. 2.2.
2.1 Named Entity Recognition (NER)
NER is designed to detect words from passages by predefined entity labels Li et al. (2022), which serves as the foundation of complicated applications such as machine translation. The BiLSTM architecture is the most commonly used architecture for solving NER tasks in the early days of deep learning Li et al. (2022). In the bi-directional LSTM, each word’s representation can be derived from the contextual representation that connects its left and right directions, which is advantageous for many tagging applications Lample et al. (2016). Later, with the development of pre-trained language models represented by BERT Devlin et al. (2019), transformer-based pre-trained models quickly became the preferred model for the NLP area Lin et al. (2021). The embeddings learned by these transformer-based pre-trained language models are contextual and trained on a large corpus. As a result, for NER tasks that value input representation, pre-trained language models rapidly become a new paradigm. In recent years, introducing external data to PLMs becomes dominant and shows powerful contextual representations, such as NER-BERT Liu et al. (2021), LUKE Yamada et al. (2020) and CL-KL Wang et al. (2021b). LUKE Yamada et al. (2020) proposes an entity-aware self-attention mechanism and a pre-training task to predict masked words and entities in a sizeable entity-annotated corpus. CL-KL Wang et al. (2021b) finds the external contexts of query sentences by employing a search engine and then processes them by a cooperative learning method. However, large-scale external datasets consume considerable collection time and even labor costs. Therefore, we explore an extra-data-free framework by MRC strategies after transferring NER tasks to MRC problems.
2.2 Enhancing NLP Tasks via MRC perspective
Treating NLP tasks other than MRC as MRC problems strengthens neural networks’ reasoning processes, including event extraction Du and Cardie (2020); Liu et al. (2020), relation extraction Li et al. (2019); Levy et al. (2017), and named-entity recognition Li et al. (2020). The current mainstream approaches Li et al. (2020); Banerjee et al. (2021); Sun et al. (2021); Du and Cardie (2020); Li et al. (2019); Levy et al. (2017); Liu et al. (2020); Xue et al. (2020); Shrimal et al. (2022) utilizes data reconstruction to address NER tasks using MRC methodology. Specifically, those approach involves restructuring the input data into MRC format by incorporating MRC-style question prompts. These prompts encompass the direct utilization of entities as questions, human-designed question templates and unsupervised generated questions. However, those methods have missed important label semantics, which describe the entity labels from annotation guidelines in each NER dataset. On the other hand, even though all of these approaches explore the utilization of MRC for solving the NER problem, they merely employ the MRC scheme during the data reconstruction phase, rather than effectively leveraging the most critical reasoning strategy of MRC for the NER task. To address the problems above, our method inferences the possible entity type through: i) introducing label information; ii) applying MRC reasoning strategies.
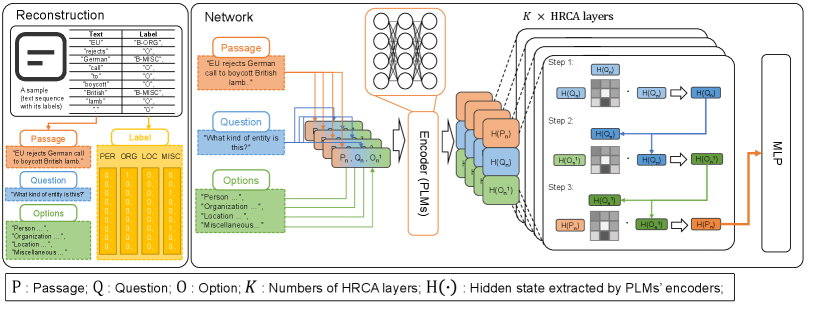
3 Complete NER-to-MRC Conversion
The current field of NER faces the following challenges: i) hand-crafted design and inadequate information; ii) failure to integrate crucial MRC reasoning strategies throughout the entire inference process. In this section, we outline the proposed NER-to-MRC framework, including input reconstruction (Sec. 3.1) to address the hand-crafted design challenge, MRC reasoning network (Sec. 3.2) to introduce essential MRC processes into NER tasks. We demonstrate the fine-tuning of our framework in Sec. 3.3.
3.1 Input Reconstruction
Input reconstruction is a key topic for facilitating the solution of NER tasks from a MRC perspective. We introduce a simple and instructional reconstruction rule (Details in Sec. A.2). Alternative to the question-and-answer format in previous work Li et al. (2020), we consider a multiple-choice (MC) format that incorporates label information, as shown in Fig. 2 (a). Given a common NER dataset, a sample includes a text sequence with words and the corresponded entity label for each word. Then, the transformed MC format ( triplets) is constructed by:
Passage: We obtain the passage part effortlessly, which comes from the text sequence in the original dataset.
Question: For less human-crafted processing, we only provide a universal question (“What kind of entity is this?”) for all types of entities. It is noteworthy that, due to the fixed inputs, our model produces stable results that are reproducible, in contrast to hand-crafted questions that can vary from individual to individual.
Options: We treat an entity type as significant input with semantic information rather than just a label. Specifically, we borrow the description of each entity label from the annotation guidelines.
Finally, an input sample consists of a passage , a question , and options with an entity description, where are the corresponding sequence lengths for passage, question, and options. Regarding labels, we remove the “B-” and “I-” tagging and only keep the entity type itself. Then, based on the sequence length of the passage and the number of entity types, the label is processed as a binary matrix with assigning to each corresponding entity type on the labels, to the other.
3.2 MRC Reasoning Network
Our framework employs PLMs with MRC strategies as the MRC reasoning network. Remarkable advances Banditvilai (2020); Baier (2005) suggest that reading methods improve participants to learn a deep understanding of reading comprehension. Note that the success of HRCA Zhang and Yamana (2022) on MRC tasks presents a human-like reasoning flow as a MRC strategy. However, HRCA only focuses on MRC tasks and does not support other NLP tasks. Therefore, we apply it to our NER-to-MRC framework to enhance reasoning ability. In particular, we firstly generate MRC triplets input by contacting each option and and (). Then, encoded by PLMs (), the hidden state is obtained as: . After that, the are separated into three parts corresponding to the MRC triplet and fed into HRCA layers. We process those three hidden states in the following steps: i) “reviewing” (question) by applying self-attention mechanism. ii) “reading” (options) with (question) by computing cross attention weights. iii) “finding” final results in (passages) with (options). Additionally, we apply multi-head operation Zhang and Yamana (2022) in all attention computation in the HRCA layer. After that, rich semantics from options and questions are embedded into the hidden states of the passage part.
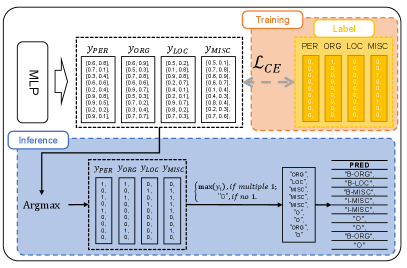
3.3 Fine-tuning
For model multiple downstream datasets, we fine-tune the NER-to-MRC framework, as shown in Fig. 3. In detail, we pass the encoded hidden states of the passage to a MLP layer, which includes sub MLP layers. Those sub MLP layers reduce the original dimensions to , which indicates select it or not. Therefore, after the MLP layer, we can obtain a prediction matrix .
3.3.1 Training
Considering the reconstructed golden label matrix and the prediction matrix , we apply the categorical cross-entropy (CCE) loss as training loss. The CCE loss can be calculated as follows:
| (1) | |||
where represents the number of span indexes, as well as the sequence length of the passage part; is a subset of , representing the label matrix corresponding to each class of entities; () is a subset of , representing the -th value along the last dimension of the prediction matrix corresponding to each class of entities.
Then, we calculate the overall training loss by summing the CCE loss for all entity types:
| (2) |
3.3.2 Inference
Since the output is a matrix , we design a simple recovering rule to generate the entity labels, as described in Algorithm 1 and Fig. 3. Recall that we remove IOB-format tagging such as“B-” and “I-” from the label and convert it using one-hot encoding in Sec. 3.1. Therefore, we employ a simple calculation on the last dimension of . After the calculation, becomes a binary matrix, where 1 indicates that the related class is selected, and 0 implies that it is not selected. The following two scenarios can be considered based on the selected conditions:
Case A: The case A has multiple categories with a predicted result of 1, indicating that the model considers multiple entity types as possible labels. We choose the entity type with the highest probability as the label for the current position based on before the calculation. When the predicted result only has one category with a value of , we take the category with a result of as the entity type of the current position.
Case B: All categories predict s. In this case, we predict the label of the current position to be “O”.
After assigning the possible entity types for each word, we add IOB-format tagging “B-” and “I-” to the entity labels. Specifically, we allocate ‘B-” to the first of each entity label and “I-” to the subsequent ones if they are consecutive identical labels. For example, given a predicted sequence of entity types (“LOC”, “LOC”, “PER”), the final prediction will be “B-LOC”, “I-LOC”, “B-PER”.
4 Experiments
4.1 Experimental Setup
Social Media News Biomedical WNUT-16 WNUT-17 CoNLL-03 CoNLL++ BC5CDR NCBI \ulIn-domain models DATNet-F Zhou et al. (2019) 53.43 42.83 - - - - InferNER Shahzad et al. (2021) 53.48 50.52 93.76 - - - BERTweet Nguyen et al. (2020) 52.10 56.50 - - - - SA-NER Nie et al. (2020) 55.01 50.36 - - - - RoBERTa-large + RegLER Jeong and Kang (2021) - 58.30 92.30 - CrossWeigh + Pooled Flair Wang et al. (2019b) - 50.03 93.43 94.28 - - ACE-sentencce-level Wang et al. (2021a) - - \ul93.60 - - - NER+PA+RL Nooralahzadeh et al. (2019) - - - - 89.93 - Bio-Flair Sharma and Jr. (2019) - - - - 89.42 88.85 Bio-BERT Lee et al. (2020) - - - - - 87.70 Bio-BERT + RegLER Jeong and Kang (2021) - - - - - 89.00 Bio-BERT + KGQA Banerjee et al. (2021) - - - - 89.21 89.05 \ulUniversal models LUKE Yamada et al. (2020) 54.04 55.22 92.42 93.99 89.18 87.62 BERT-MRC Li et al. (2020); Banerjee et al. (2021) - - 93.04 - 72.43 75.19 CL-KL w/o CONTEXT Wang et al. (2021b) 58.14 59.33 93.21 94.55 90.73 \ul89.24 CL-KL w CONTEXT Wang et al. (2021b) \ul58.98 \ul60.45 93.56 \ul94.81 \ul90.93 88.96 NER-to-MRC (ours) 65.61 60.91 93.91 95.23 92.25 90.38
Datasets. We evaluate our NER-to-MRC framework on several NER benchmarks that are widely used in the three domains:
-
•
Social Media: WNUT- (WNUT Twitter Named Entity Recognition Strauss et al. (2016)) dataset and WNUT- (WNUT Emerging and Rare Entity Recognition Derczynski et al. (2017)) dataset are two challenging datasets in the NER field, and most SoTA methods still struggle with around on F1 scores. Two factors make these datasets challenging, the first of which is that they contain a wide variety of entity types. For example, the WNUT- dataset has types of entities, while the WNUT- dataset has types of entities. In addition, they have a wide range of different entities, therefore remembering one particular entity will only be helpful for part of the task.
- •
- •
Evaluation metric. Based on our observations, common NER tasks comprise multiple entity types, resulting in an evaluation metric across them. Therefore, the micro-averaged F score is employed by avoiding potential unfair measurement Li et al. (2022).
Main baselines. Considering that our solution is a universal solution, we mainly compare a variety of baselines that are also universal models, including:
-
•
BERT-MRC develops a practical MRC framework with a similar idea to transform the NER task into the MRC task. Unfortunately, most of the results of BERT-MRC are on proprietary datasets. Therefore the only dataset we can compare the performance of BERT-MRC with our NER-to-MRC is CoNLL-.
-
•
LUKE is a powerful general-purpose entity representation pre-trained model. It employs several entity-specific pre-training strategies and achieves SoTA performance in several entity-related domains. In our experiments, we consider its sentence-level results for a fair comparison, which are reported by Wang et al. (2021b).
-
•
CL-KL allows the model to effectively merge information retrieved by search engines and utilize several strengthened strategies, such as cooperative learning, making it one of the most competitive NER models in recent years.
4.2 Implementation Setting
In our framework, we employ the DeBERTa-v-large He et al. (2021) as backbone models in all scenarios. Unless otherwise specified, the learning rate is , warming up first and then decaying linearly, and the training epoch number is . For the HRCA layers, we consider different settings of the multi-head attention to deal with different datasets. For the challenging datasets, WNUT- and WNUT-, we apply self-attention heads with dimensions in attention hidden states. For other datasets, we set self-attention heads with dimensions in attention hidden states. In our experiments, we run three times and take average scores as the final score, and they are done on a single A GPU.
Social Media News Biomedical WNUT-16 WNUT-17 CoNLL-03 CoNLL++ BC5CDR NCBI DeBERTa-v3-base He et al. (2021) Vanilla 52.10 55.93 91.43 94.11 88.99 85.01 NER-to-MRC 64.98 (+24.72%) 58.85 (+5.22%) 93.57 (+2.34%) 94.92 (+0.86%) 91.53 (+2.85%) 87.69 (+3.15%) XLM-RoBERTa-large Conneau et al. (2020) Vanilla 53.32 56.74 92.31 93.39 - - NER-to-MRC 64.31 (+15.96%) 58.01 (+2.24%) 93.39 (+1.17%) 94.54 (+1.23%) - - BioBERT-base Lee et al. (2020) Vanilla - - - - 89.44 86.16 NER-to-MRC - - - - 90.85 (+1.58%) 88.01 (+2.15%) DeBERTa-v3-large He et al. (2021) Vanilla 54.19 57.78 92.57 94.39 90.76 88.83 NER-to-MRC 65.61 (+21.07%) 60.91 (+5.42%) 93.91 (+1.45%) 95.31 (+0.97%) 92.25 (+1.64%) 90.38 (+1.74%)
4.3 Main Results
We examine the effectiveness of our framework in the axes of i) various domains and ii) models with different designing purposes, as shown in Table 1. In summary, our NER-to-MRC framework achieves the best performance across all datasets with improvement ranging from to .
Regarding domains, our framework only learns from the datasets without any extra information. Specifically, biomedical benchmarks require expert knowledge of specific vocabulary. Therefore, in-domain models such as Bio-BERT address this issue by introducing biomedical corpus. Interestingly, our general-purpose framework only employs a general-purpose PLM to solve specific problems. Moreover, our data processing workflow does not need to change for different domains.
Considering various NER methods, the most successful ones rely on additional knowledge from pre-training data (LUKE, Bio-BERT) or the Internet (CL-KL). In contrast, our method overcomes them with what is on hand. There are at least two potential explanations for our improvements. One is that our inputs include almost all information from the dataset, such as overlooked label information. Another explanation is that the MRC reasoning strategy helps learn powerful representations and then prompts networks to generate proper choices.
BERT-MRC is a well-known model that transforms NER tasks into MRC tasks in the data reconstruction stage. The comparison shows that our framework outperforms BERT-MRC on CoNLL-. Additionally, their input reconstruction requires hand-crafted question prompts, resulting in unstable predictions and complex extensions on other datasets.
4.4 Ablation Study
4.4.1 The effectiveness on NER-to-MRC across different backbones
As presented in Table 2, we explore the mainstream PLMs as our backbone models across various domains. Specifically, we consider DeBERTa He et al. (2021), XLM-RoBERTa Conneau et al. (2020) in the general vocabulary (social media and news) and BioBERT Lee et al. (2020) in the special vocabulary (biomedical). The detailed model architecture are shown in Sec. B.2. We design the “vanilla” framework as the typical token-level classification tasks by the similar setting in BERT Devlin et al. (2019). In detail, we incorporate PLMs with an additional classification layer for the hidden state corresponding to each word to generate the answer.
The results show the effectiveness of our framework, which improves all backbone models on all benchmarks. For example, DeBERTa-v3-base earns improvement gains on WNUT-16 by introducing the NER-to-MRC framework. In particular, the results on BC5CDR and NCBI imply that our framework also works well on domain-specific pre-training models, which verifies its cross-domain generalization capability. Specifically, in biomedical domain, the NER-to-MRC improves general-propose DeBERTa-v3-base more than specific-propose BioBERT-base. A possible reason is that our framework introduces the option information to assist PLMs in learning domain-specific information.
Another point worth noting is that our approach showed a relatively large improvement on the WNUT- dataset compared to other datasets, achieving an average improvement of across different backbones. WNUT- dataset has two distinctive characteristics: i) increased difficulty: compared to general datasets like CoNLL-, WNUT- includes some entity types that are very "challenging" for models, such as Sports team, TV show, Other entity, etc. These entities often have word combinations that are difficult for models to imagine, requiring higher contextual reasoning ability; ii) increased noise: the annotation guidelines for WNUT- have a lot of noise (as mentioned in Sec. B.4), which contaminates the labels to a certain extent. This requires models to have denoising and understanding capabilities, otherwise they cannot handle this dataset. Our framwork has stronger reasoning and understanding capabilities, which is why it achieved significant improvement on the WNUT- dataset.
4.4.2 Impact of the main modules
For a comprehensive understanding of our purposed NER-to-MRC, we consider two main designed modules: 1) MRC reconstruction and 2) MRC reasoning strategy (detailed setting in Sec. B.3). Table 3 reports the joint effect of the aforementioned modules. In a nutshell, both MRC reconstruction and MRC reasoning strategy cause positive effects on NER performance. Specifically, for a challenging dataset with massive entity classes such as WNUT-, MRC reasoning strategy provides more improvements than MRC reconstruction. A possible reason is that our reasoning method includes the option content to enhance the passage tokens for final predictions. Considering a dataset with few entity classes ( types), the vanilla case has achieved a high micro-averaged F score (). Furthermore, there are two potential explanations for MRC reconstruction to help more than the MRC reasoning strategy. One is that the PLMs can easily solve the issue with a small search space of entity labels. Therefore, the label information is good enough for PLMs to learn. Another is the small promotion space to limit the potentiality of the MRC reasoning strategy.
WNUT-17 CoNLL Vanilla 57.78 94.39 MRC reconstruction 58.65 (+1.51%) 95.01 (+0.66%) MRC reconstruction & MRC reasoning strategy 60.91 (+5.42%) 95.31 +(0.97%)
Option content source WNUT-17 CoNLL Entity names only 58.43 94.98 Def. from the Int. 60.09 95.22 Annotation guidelines 60.91 95.31
4.4.3 Influence of option content
Introducing label information as options improves our MRC framework on NER datasets. Therefore, Table 4 ablates the effect of input reconstruction with different option contents. Here, we study three option constructions with different sources: i) annotation guidelines, ii) definitions from the Internet (Def. from the Int.), and iii) Entity names only. Specifically, annotation guidelines are the annotation descriptions of entities appended in the dataset. For Def. from the Int., we collect the retrieval text from the Google search engine where the queries are the entity names. The specific compositions are given in Sec. B.5.
Table 4 shows that providing the descriptions of entities prompts PLMs to learn better than just the entity names. Providing more instructions to models will enable them to gain a deeper understanding of the text. Moreover, the annotation guidelines work better because the annotators understand the task and construct the dataset based on this.
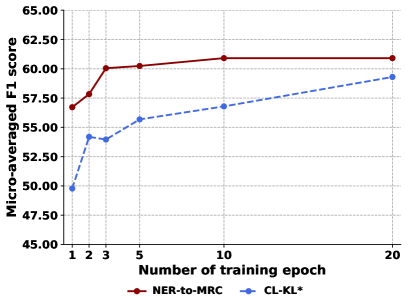
4.4.4 Convergence speed
We explore the detailed comparisons of the performance v.s. training epochs trade-off as shown in Fig. 4. Our framework only passes epochs to converge around percent of the micro-averaged F1 score. In contrast, CL-KL∗ requires at least epochs to converge and presents an unstable disturbance on early epochs. The outcome verifies that our method learns better while viewing fewer samples, which implies better usability for further deployment.
5 Conclusions
In this paper, we have proposed a complete NER-to-MRC conversion by considering NER problems via a MRC perspective. Our approach first reconstructs the NER data into MRC inputs, and then applies the MRC reasoning strategy to predict a rational choice. Furthermore, it shows the state-of-the-art performance on benchmarks across three domains. Note that this success is based on a single general-purpose PLM without external data. Moreover, our experimental results demonstrate that the NER-to-MRC framework is compatible with a set of different PLMs and that our design is efficient in terms of performance enhancement and convergence speed.
Limitations
Most existing NER datasets do not feature nested tags Yadav and Bethard (2018). In a nested NER dataset, multiple entities can be found inside an entity. Though we provide a NER-to-MRC framework with generalization ability in the NER task, we only evaluate our method with flat NER datasets, which might lead to a less comprehensive scope of our benchmarks. Our solution can be naturally and conveniently applied to handle nested NER tasks. Specifically, we only need to set a threshold so that each word outputs a label for each entity category, allowing a word to have multiple labels to handle nested NER problems. In the future, we will provide the related instructions and further evaluate more NER datasets.
Ethical Considerations
Our NER-to-MRC framework brings a powerful tool to the real-world across multiple domains such as social media, news, and biomedical. Therefore, the ethical influence of this work might spread to many applications. The ethical implications involve two main points: i) the bias from the backbone networks and ii) training datasets. For the networks, several analyses point out that ethnic biases are included in the PLMs such as BERT Milios and BehnamGhader (2022) and GPT3 Lucy and Bamman (2021). The potential risks are unpredictable after deployments with those PLMs. Fortunately, our backbones are replaceable as described in Sec. 3.2. Therefore, we encourage the users to install unbiased language models and provide model cards for the details. Beyond the backbone PLMs, it is necessary to pay attention to our downstream tasks, such as gender, race, and sexual orientation. In real-world deployments, we suggest it is necessary to design a slew of cleaning procedures such as SampleClean and CPClean Lee et al. (2021). After that, we encourage open discussions about its utilization, hoping to reduce potential malicious behaviors.
References
- Antony and Suryanarayanan (2015) Betina Antony and Mahalakshmi G. Suryanarayanan. 2015. Content-based information retrieval by named entity recognition and verb semantic role labelling. J. Univers. Comput. Sci., 21(13):1830–1848.
- Baier (2005) Rebecca J Baier. 2005. Reading comprehension and reading strategies. Psychology, 24(3-4):323–335.
- Banditvilai (2020) Choosri Banditvilai. 2020. The effectiveness of reading strategies on reading comprehension. International Journal of Social Science and Humanity, 10(2):46–50.
- Banerjee et al. (2021) Pratyay Banerjee, Kuntal Kumar Pal, Murthy V. Devarakonda, and Chitta Baral. 2021. Biomedical named entity recognition via knowledge guidance and question answering. ACM Trans. Comput. Heal., 2(4):33:1–33:24.
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In ACL, pages 8440–8451. Association for Computational Linguistics.
- Dai et al. (2019) Zhenjin Dai, Xutao Wang, Pin Ni, Yuming Li, Gangmin Li, and Xuming Bai. 2019. Named entity recognition using BERT bilstm CRF for chinese electronic health records. In CISP-BMEI, pages 1–5. IEEE.
- Davis (1944) Frederick B. Davis. 1944. Fundamental factors of comprehension in reading.
- Derczynski et al. (2017) Leon Derczynski, Eric Nichols, Marieke van Erp, and Nut Limsopatham. 2017. Results of the WNUT2017 shared task on novel and emerging entity recognition. In NUT@EMNLP, pages 140–147. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1), pages 4171–4186. Association for Computational Linguistics.
- Dogan et al. (2014) Rezarta Islamaj Dogan, Robert Leaman, and Zhiyong Lu. 2014. NCBI disease corpus: A resource for disease name recognition and concept normalization. J. Biomed. Informatics, 47:1–10.
- Du and Cardie (2020) Xinya Du and Claire Cardie. 2020. Event extraction by answering (almost) natural questions. In EMNLP (1), pages 671–683. Association for Computational Linguistics.
- Fu et al. (2021) Jinlan Fu, Xuanjing Huang, and Pengfei Liu. 2021. Spanner: Named entity re-/recognition as span prediction. In ACL/IJCNLP (1), pages 7183–7195. Association for Computational Linguistics.
- He et al. (2021) Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. Deberta: decoding-enhanced bert with disentangled attention. In ICLR. OpenReview.net.
- Jeong and Kang (2021) Minbyul Jeong and Jaewoo Kang. 2021. Regularization for long named entity recognition. arXiv preprint arXiv:2104.07249.
- Lample et al. (2016) Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. In HLT-NAACL, pages 260–270. The Association for Computational Linguistics.
- Lee et al. (2021) Ga Young Lee, Lubna Alzamil, Bakhtiyar Doskenov, and Arash Termehchy. 2021. A survey on data cleaning methods for improved machine learning model performance. CoRR, abs/2109.07127.
- Lee et al. (2020) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinform., 36(4):1234–1240.
- Levy et al. (2017) Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-shot relation extraction via reading comprehension. In CoNLL, pages 333–342. Association for Computational Linguistics.
- Li et al. (2016) Jiao Li, Yueping Sun, Robin J. Johnson, Daniela Sciaky, Chih-Hsuan Wei, Robert Leaman, Allan Peter Davis, Carolyn J. Mattingly, Thomas C. Wiegers, and Zhiyong Lu. 2016. Biocreative V CDR task corpus: a resource for chemical disease relation extraction. Database J. Biol. Databases Curation, 2016.
- Li et al. (2022) Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li. 2022. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng., 34(1):50–70.
- Li et al. (2020) Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. 2020. A unified MRC framework for named entity recognition. In ACL, pages 5849–5859. Association for Computational Linguistics.
- Li et al. (2019) Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, and Jiwei Li. 2019. Entity-relation extraction as multi-turn question answering. In ACL (1), pages 1340–1350. Association for Computational Linguistics.
- Lin et al. (2021) Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. 2021. A survey of transformers. CoRR, abs/2106.04554.
- Liu et al. (2020) Jian Liu, Yubo Chen, Kang Liu, Wei Bi, and Xiaojiang Liu. 2020. Event extraction as machine reading comprehension. In EMNLP (1), pages 1641–1651. Association for Computational Linguistics.
- Liu et al. (2021) Zihan Liu, Feijun Jiang, Yuxiang Hu, Chen Shi, and Pascale Fung. 2021. NER-BERT: A pre-trained model for low-resource entity tagging. CoRR, abs/2112.00405.
- Lucy and Bamman (2021) Li Lucy and David Bamman. 2021. Gender and representation bias in GPT-3 generated stories. In Proceedings of the Third Workshop on Narrative Understanding, pages 48–55, Virtual. Association for Computational Linguistics.
- Luo et al. (2021) Qiaoyang Luo, Lingqiao Liu, Yuhao Lin, and Wei Zhang. 2021. Don’t miss the labels: Label-semantic augmented meta-learner for few-shot text classification. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2773–2782, Online. Association for Computational Linguistics.
- Milios and BehnamGhader (2022) Aristides Milios and Parishad BehnamGhader. 2022. An analysis of social biases present in BERT variants across multiple languages. CoRR, abs/2211.14402.
- Mueller et al. (2022) Aaron Mueller, Jason Krone, Salvatore Romeo, Saab Mansour, Elman Mansimov, Yi Zhang, and Dan Roth. 2022. Label semantic aware pre-training for few-shot text classification. In ACL (1), pages 8318–8334. Association for Computational Linguistics.
- Nguyen et al. (2020) Dat Quoc Nguyen, Thanh Vu, and Anh Tuan Nguyen. 2020. Bertweet: A pre-trained language model for english tweets. In EMNLP (Demos), pages 9–14. Association for Computational Linguistics.
- Nie et al. (2020) Yuyang Nie, Yuanhe Tian, Xiang Wan, Yan Song, and Bo Dai. 2020. Named entity recognition for social media texts with semantic augmentation. In EMNLP (1), pages 1383–1391. Association for Computational Linguistics.
- Nishida et al. (2022) Kosuke Nishida, Naoki Yoshinaga, and Kyosuke Nishida. 2022. Self-adaptive named entity recognition by retrieving unstructured knowledge. CoRR, abs/2210.07523.
- Nooralahzadeh et al. (2019) Farhad Nooralahzadeh, Jan Tore Lønning, and Lilja Øvrelid. 2019. Reinforcement-based denoising of distantly supervised NER with partial annotation. In DeepLo@EMNLP-IJCNLP, pages 225–233. Association for Computational Linguistics.
- Ramshaw and Marcus (1995) Lance A. Ramshaw and Mitch Marcus. 1995. Text chunking using transformation-based learning. In VLC@ACL.
- Sang and Meulder (2003) Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. In CoNLL, pages 142–147. ACL.
- Sanh et al. (2022) Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal V. Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Févry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M. Rush. 2022. Multitask prompted training enables zero-shot task generalization. In ICLR. OpenReview.net.
- Shahzad et al. (2021) Moemmur Shahzad, Ayesha Amin, Diego Esteves, and Axel-Cyrille Ngonga Ngomo. 2021. Inferner: an attentive model leveraging the sentence-level information for named entity recognition in microblogs. In FLAIRS.
- Sharma and Jr. (2019) Shreyas Sharma and Ron Daniel Jr. 2019. Bioflair: Pretrained pooled contextualized embeddings for biomedical sequence labeling tasks. CoRR, abs/1908.05760.
- Shrimal et al. (2022) Anubhav Shrimal, Avi Jain, Kartik Mehta, and Promod Yenigalla. 2022. NER-MQMRC: formulating named entity recognition as multi question machine reading comprehension. In NAACL-HLT (Industry Papers), pages 230–238. Association for Computational Linguistics.
- Strauss et al. (2016) Benjamin Strauss, Bethany Toma, Alan Ritter, Marie-Catherine de Marneffe, and Wei Xu. 2016. Results of the WNUT16 named entity recognition shared task. In NUT@COLING, pages 138–144. The COLING 2016 Organizing Committee.
- Sun et al. (2021) Cong Sun, Zhihao Yang, Lei Wang, Yin Zhang, Hongfei Lin, and Jian Wang. 2021. Biomedical named entity recognition using BERT in the machine reading comprehension framework. J. Biomed. Informatics, 118:103799.
- Trassi et al. (2019) Angélica Polvani Trassi, Katya Luciane de Oliveira, and Amanda Lays Monteiro Inácio. 2019. Reading comprehension, learning strategies and verbal reasoning: Possible relationships.
- Wang et al. (2022) Xinyu Wang, Jiong Cai, Yong Jiang, Pengjun Xie, Kewei Tu, and Wei Lu. 2022. Named entity and relation extraction with multi-modal retrieval. In EMNLP (Findings), pages 5925–5936. Association for Computational Linguistics.
- Wang et al. (2021a) Xinyu Wang, Yong Jiang, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, and Kewei Tu. 2021a. Automated concatenation of embeddings for structured prediction. In ACL/IJCNLP (1), pages 2643–2660. Association for Computational Linguistics.
- Wang et al. (2021b) Xinyu Wang, Yong Jiang, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, and Kewei Tu. 2021b. Improving named entity recognition by external context retrieving and cooperative learning. In ACL/IJCNLP (1), pages 1800–1812. Association for Computational Linguistics.
- Wang et al. (2019a) Zihan Wang, Jingbo Shang, Liyuan Liu, Lihao Lu, Jiacheng Liu, and Jiawei Han. 2019a. Crossweigh: Training named entity tagger from imperfect annotations. In EMNLP/IJCNLP (1), pages 5153–5162. Association for Computational Linguistics.
- Wang et al. (2019b) Zihan Wang, Jingbo Shang, Liyuan Liu, Lihao Lu, Jiacheng Liu, and Jiawei Han. 2019b. Crossweigh: Training named entity tagger from imperfect annotations. In EMNLP/IJCNLP (1), pages 5153–5162. Association for Computational Linguistics.
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022. Finetuned language models are zero-shot learners. In ICLR. OpenReview.net.
- Xue et al. (2020) Mengge Xue, Bowen Yu, Zhenyu Zhang, Tingwen Liu, Yue Zhang, and Bin Wang. 2020. Coarse-to-fine pre-training for named entity recognition. In EMNLP (1), pages 6345–6354. Association for Computational Linguistics.
- Yadav and Bethard (2018) Vikas Yadav and Steven Bethard. 2018. A survey on recent advances in named entity recognition from deep learning models. In COLING, pages 2145–2158. Association for Computational Linguistics.
- Yamada et al. (2020) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, and Yuji Matsumoto. 2020. LUKE: deep contextualized entity representations with entity-aware self-attention. In EMNLP (1), pages 6442–6454. Association for Computational Linguistics.
- Yang et al. (2022) Ping Yang, Junjie Wang, Ruyi Gan, Xinyu Zhu, Lin Zhang, Ziwei Wu, Xinyu Gao, Jiaxing Zhang, and Tetsuya Sakai. 2022. Zero-shot learners for natural language understanding via a unified multiple choice perspective. CoRR, abs/2210.08590.
- Zhang and Yamana (2022) Yuxiang Zhang and Hayato Yamana. 2022. HRCA+: advanced multiple-choice machine reading comprehension method. In LREC, pages 6059–6068. European Language Resources Association.
- Zhou et al. (2019) Joey Tianyi Zhou, Hao Zhang, Di Jin, Hongyuan Zhu, Meng Fang, Rick Siow Mong Goh, and Kenneth Kwok. 2019. Dual adversarial neural transfer for low-resource named entity recognition. In ACL (1), pages 3461–3471. Association for Computational Linguistics.
Appendix A Dataset Details
A.1 Dataset statistics
We summarize the statistics of the datasets used in this paper in Table 6. Specifically, “Avg. Length” implies the average of the lengths across all dataset splits with including train set, development set, and test set. Since our method create options with label information as described in Sec. 3.1, we collect their average lengths.
A.2 Examples of input reconstruction
As presented in Table 7, we outline a sample reconstructed MRC triplet of passage, question, and options from the WNUT- dataset.
Appendix B Experimental Settings
B.1 Evaluation metric library
In Sec. 4.1, we explained how we selected the evaluation metric. To enable easy and comprehensive comparison of both past and future schemes, we computed all of the span-based micro F1 score results presented in this paper using seqeval111https://github.com/chakki-works/seqeval, an open-source Python framework for sequence labeling evaluation.
B.2 Backbone model architecture
We test the performance of our NER-to-MRC framework using different PLMs as the backbone model in Sec. 4.4.1, including DeBERTa-V3-base, DeBERTa-V3-large, XLM-RoBERTa-large and BioBERT-base. We give the detailed model architectures as follows:
DeBERTa-V3-base: Number of Layers , Hidden size , Attention heads , Total Parameters = M.
DeBERTa-V3-large: Number of Layers , Hidden size , Attention heads , Total Parameters = M.
XLM-RoBERTa-large: Number of Layers , Hidden size , Attention heads , Total Parameters = M.
BioBERT-base: Number of Layers , Hidden size , Attention heads , Total Parameters = M.
B.3 Ablation experiment setup
In Sec. 4.4.2, we perform ablation experiments for the main modules of our proposed NER-to-MRC. The detailed settings are:
Vanilla: we fine-tune the hidden state of the PLMs.
MRC reconstruction: we reconstruct the NER dataset into the MRC reconstruction. However, this setting plugs a MLP layer to do multiple choice without MRC reasoning strategy.
MRC reconstruction & MRC reasoning strategy: it follows the same instructions as the NER-to-MRC desgin.
B.4 Sources in our inputs
As discussion in Sec. 3.1, we take the same descriptions in dataset papers or their released homepages. We apply this setting on WNUT-, CoNLL-, CoNLL, BCCDR and NCBI. For all the datasets we used in this paper, we follow the license terms of the corresponding papers. In particular, WNUT- dataset only provide a google document222https://docs.google.com/document/d/12hI-2A3vATMWRdsKkzDPHu5oT74_tG0-PPQ7VN0IRaw as the annotation guidelines. Unfortunately, this document is inadequate in entity types and contains a lot of noisy text, resulting not applicable label information. Therefore, we collect the definitions of each entity from the Internet, which is the same approaches in Sec. 4.4.3. In detail, we put the full information in Table 8.
B.5 Details of different option types
In Sec. 4.4.3, we ablate the impact of different sources of option type composition on the model performance. The annotation guidelines can be easily found and utilized in the paper or homepage corresponding to the dataset. Consequently, we do not repeat the examples of annotation guidelines compositions. Instead, we only demonstrate examples of compositions defined from the Internet and examples of compositions using only entity names for the WNUT- dataset in Table 9 and the CoNLL dataset in Table 10.
Appendix C Inference speed
In order to simultaneously address the flat NER and nested NER tasks, our proposed approach predicts the probability of each entity type separately. Considering that inference time is an important consideration in NER task, our strategy may exhibit less-than-optimal performance in terms of inference speed compared to those approaches that handle all entity types together. Therefore, we compared several baseline approaches, including traditional BiLSTM Lample et al. (2016), PLM + BiLSTM scheme Dai et al. (2019), and the current state-of-the-art approach CL-KL, in terms of their inference speed and accuracy on the WNUT-17 dataset in Table 5.
Model Inference speed (samples/s) Span-based F1 Single BiLSTM 64 43.10 XLM-RoBERTa-large + BiLSTM 23 57.8 NER-to-MRC 22 60.91 CL-KL 18 60.45
We conducted tests on all of the aforementioned results using our own implementation. Based on the results, our approach has a similar inference speed to XLM-RoBERTa-large+BiLSTM, and the model’s inference speed is faster than CL-KL. It is worth mentioning that compared to CL-KL, our training cost (our: 3 epoch v.s CL-KL 20 epoch) is relatively better. Our method achieves a better computational resources v.s. performance trade-off.
| Domain | Dataset | # Train set | # Dev set | # Test set | # Entity Types | Avg. Length |
|
||
| Social Media | WNUT-16 | 2,394 | 1,000 | 3,850 | 10 | 17.2 | 19.0 | ||
| WNUT-17 | 3,394 | 1,009 | 1,287 | 6 | 17.9 | 33.8 | |||
| News | CoNLL-2003 | 14,041 | 3,250 | 3,453 | 4 | 14.5 | 156.5 | ||
| CoNLL++ | 14,041 | 3,250 | 3,453 | 4 | 14.5 | 156.5 | |||
| Biomedical | BC5CDR | 5,228 | 5,330 | 5,865 | 2 | 20.4 | 367.0 | ||
| NCBI | 5,432 | 923 | 940 | 1 | 25.3 | 550.0 |
| Passage: |
| Watched your video ! Great work ! Thumbs up ! ! ! Welcome to my channel ! |
| Question: |
| What kind of entity is this? |
| Options: |
| - Names of corporations (e.g. Google). Don’t mark locations that don’t have their own name. Include punctuation in the middle of names. |
| - Names of creative works (e.g. Bohemian Rhapsody). Include punctuation in the middle of names. The work should be created by a human, and referred to by its specific name. |
| - Names of groups (e.g. Nirvana, San Diego Padres). Don’t mark groups that don’t have a specific, unique name, or companies (which should be marked corporation). |
| - Names that are locations (e.g. France). Don’t mark locations that don’t have their own name. Include punctuation in the middle of names. Fictional locations can be included, as long as they’re referred to by name (e.g. Hogwarts). |
| - Names of people (e.g. Virginia Wade). Don’t mark people that don’t have their own name. Include punctuation in the middle of names. Fictional people can be included, as long as they’re referred to by name (e.g. Harry Potter). |
| - Name of products (e.g. iPhone). Don’t mark products that don’t have their own name. Include punctuation in the middle of names. Fictional products can be included, as long as they’re referred to by name (e.g. Everlasting Gobstopper). It’s got to be something you can touch, and it’s got to be the official name. |
| Options composition for the WNUT- dataset |
| - Compnay entities, or business entities, describes any organization formed to conduct business. |
| - Facility, or facilities are places, buildings, or equipments used for a particular purpose or activity. |
| - Geolocation refers to the use of location technologies such as GPS or IP addresses to identify and track the whereabouts of connected electronic devices. |
| - Musicartist is One who composes, conducts, or performs music, especially instrumental music. |
| - Other entities are entities other than company, facility, geolocation, music artist, person, product, sports team and tv show. |
| - Person entities are named persons or family. |
| - Product entities are name of products (e.g. iPhone**) which you can touch it, buy it and it’s the technical or manufacturer name for it. Not inclduing products that don’t have their own name. Include punctuation in the middle of names., - Sports team is a group of individuals who play sports (sports player). |
| - Tv show is any content produced for viewing on a television set which can be broadcast via over-the-air, satellite, or cable, excluding breaking news, advertisements, or trailers that are typically placed between shows. |
| Option type: Def. from the Int. |
| - Corporate entities are business structures formed specifically to perform activities, such as running an enterprise or holding assets. Although it may be comprised of individual directors, officers, and shareholders, a corporation is a legal entity in and of itself. |
| - Creative work entities are performance, musical composition, exhibition, writing (poetry, fiction, script or other written literary forms), design, film, video, multimedia or other new media technologies and modes of presentation. |
| - Group entities are specific, unique names, or companies. |
| - Location entities are the name of politically or geographically defined locations such as cities, provinces, countries, international regions, bodies of water, mountains, etc. |
| - Person entities are named persons or family. |
| - Product entities are name of products (e.g. iPhone**) which you can touch it, buy it and it’s the technical or manufacturer name for it. Not inclduing products that don’t have their own name. Include punctuation in the middle of names. |
| Option type: Entity name only |
| - Corporate |
| - Creative-work |
| - Group |
| - Location |
| - Person |
| - Product |
| Option type: Def. from the Int. |
| - Person entities are named persons or family. |
| - Organization entities are limited to named corporate, governmental, or other organizational entities. |
| - Location entities are the name of politically or geographically defined locations such as cities, provinces, countries, international regions, bodies of water, mountains, etc. |
| - Miscellaneous entities include events, nationalities, products and works of art. |
| Option type: Entity name only |
| - Person |
| - Organization |
| - Location |
| - Miscellaneous |