Network Coding Capacity: A Functional Dependence Bound
Abstract
Explicit characterization and computation of the multi-source network coding capacity region (or even bounds) is long standing open problem. In fact, finding the capacity region requires determination of the set of all entropic vectors , which is known to be an extremely hard problem. On the other hand, calculating the explicitly known linear programming bound is very hard in practice due to an exponential growth in complexity as a function of network size. We give a new, easily computable outer bound, based on characterization of all functional dependencies in networks. We also show that the proposed bound is tighter than some known bounds.
I Introduction
The network coding approach introduced in [1, 2] generalizes routing by allowing intermediate nodes to forward packets that are coded combinations of all received data packets. This yields many benefits that are by now well documented in the literature [3, 4, 5, 6]. One fundamental open problem is to characterize the capacity region and the classes of codes that achieve capacity. The single session multicast problem is well understood. In this case, the capacity region is characterized by max-flow/min-cut bounds and linear network codes maximize throughput [2].
Significant complications arise in more general scenarios, involving more than one session. Linear network codes are not sufficient for the multi-source problem [7, 8]. Furthermore, a computable characterization of the capacity region is still unknown. One approach is to bound the capacity region by the intersection of a set of hyperplanes (specified by the network topology and sink demands) and the set of entropy functions (inner bound), or its closure (outer bound) [9, 10, 3]. An exact expression for the capacity region does exist, again in terms of [11]. Unfortunately, this expression, or even the bounds [9, 10, 3] cannot be computed in practice, due to the lack of an explicit characterization of the set of entropy functions for more than three random variables. In fact, it is now known that cannot be described as the intersection of finitely many half-spaces [12]. The difficulties arising from the structure of are not simply an artifact of the way the capacity region and bounds are written. In fact it has been shown that the problem of determining the capacity region for multi-source network coding is completely equivalent to characterization of [8].
One way to resolve this difficulty is via relaxation of the bound, replacing the set of entropy functions with the set of polymatroids (which has a finite characterization). In practice however, the number of variables and constraints increase exponentially with the number of links in the network, and this prevents practical computation for any meaningful case of interest.
In this paper, we provide an easily computable relaxation of the LP bound. The main idea is to find sets of edges which are determined by the source constraints and sink demands such that the total capacity of these sets bounds the total throughput. The resulting bound is tighter than the network sharing bound [13] and the bounds based on information dominance [14].
Section II provides some background on pseudo-variables and pseudo entropy functions (which generalize entropy functions) [8]. These pseudo variables are used to describe a family of linear programming bounds on the capacity region for network coding. In Section III we give an abstract definition of a functional dependence graph, which expresses a set of local dependencies between pseudo variables (in fact a set of constraints on the pseudo entropy). Our definition extends that introduced by Kramer [15] to accommodate cycles. This section also provides the main technical ingredients for our new bound. In particular, we describe a test for functional dependence, and give a basic result relating local and global dependence. The main result is presented in Section IV.
Notation: Sets will be denoted with calligraphic typeface, e.g. . Set complement is denoted by the superscript (where the universal set will be clear from context). Set subscripts identify the set of objects indexed by the subscript: . The power set is the collection of all subsets of . Where no confusion will arise, set union will be denoted by juxtaposition, , and singletons will be written without braces.
II Background
II-A Pseudo Variables
We give a brief revision of the concept of pseudo-variables, introduced in [8]. Let be a finite set, and let be a ground set associated with a real-valued function defined on subsets of , with . We refer to the elements of as pseudo-variables and the function as a pseudo-entropy function. Pseudo-variables and pseudo-entropy generalize the familiar concepts of random variables and entropy. Pseudo-variables do not necessarily take values, and there may be no associated joint probability distribution. A pseudo-entropy function may assign values to subsets of in a way that is not consistent with any distribution on a set of random variables. A pseudo-entropy function can be viewed as a point in a dimensional Euclidean space, where each coordinate of the space is indexed by a subset of .
A function is called polymatroidal if it satisfies the polymatroid axioms.
| (1) | |||||
| non-decreasing | (2) | ||||
| submodular | (3) | ||||
It is called Ingletonian if it satisfies Ingleton’s inequalities (note that Ingletonian are also polymatroids) [16]. A function is entropic if it corresponds to a valid assignment of joint entropies on random variables, i.e. there exists a joint distribution on discrete finite random variables with . Finally, is almost entropic if there exists a sequence of entropic functions such that . Let respectively denote the sets of all entropic, almost entropic, Ingletonian and polymatroidal, functions.
Both and are polyhedra. They can be expressed as the intersection of a finite number of half-spaces in . In particular, every satisfies, (1)-(3), which can be expressed minimally in terms of
linear inequalities involving variables [9]. Each satisfies an additional
linear inequalities [16].
Definition 1
Let be subsets of a set of pseudo-variables with pseudo-entropy . Define111Note that this yields the chain rule for pseudo-entropies to be true by definition.
| (4) |
A pseudo-variable is said to be a function of a set of pseudo-variables if .
Definition 2
Two subsets of pseudo-variables and are called independent if , denoted by .
II-B Network Coding and Capacity Bounds
Let the directed acyclic graph serve as a simplified model of a communication network with error-free point-to-point communication links. Edges have capacity . For edges , write as shorthand for . Similarly, for an edge and a node , the notations and respectively denote and .
Let be an index set for a number of multicast sessions, and let be the set of source variables. These sources are available at the nodes identified by the mapping . Each source may be demanded by multiple sink nodes, identified by the mapping . Each edge carries a variable which is a function of incident edge variables and source variables.
Definition 3
Given a network , with sessions , source locations and sink demands , and a subset of pseudo-entropy functions on pseudo-variables , let be the set of source rate tuples for which there exists a satisfying
| () | ||||
| () | ||||
| () | ||||
| () | ||||
It is known that and are inner and outer bounds for the set of achievable rates (i.e. rates for which there exist network codes with arbitrarily small probability of decoding error).
It is known that is an outer bound for the set of achievable rates [9]. Similarly, is an outer bound for the set of rates achievable with linear network codes [8]. Clearly . The sum-rate bounds induced by and can in principle be computed using linear programming, since they may be reformulated as
| (5) |
where is either or , and are the subsets of pseudo-entropy functions satisfying the so-labeled constraints above. Clearly the constraint set is linear.
One practical difficulty with computation of (5) is the number of variables and the number of constraints due to (or ), both of which increase exponentially with . The aim of this paper is to find a simpler outer bound. One approach is to use the functional dependence structure induced by the network topology to eliminate variables or constraints from [17]. Here we will take a related approach, that directly delivers an easily computable bound.
III Functional Dependence Graphs
Definition 4 (Functional Dependence Graph)
Let be a set of pseudo-variables with pseudo-entropy function . A directed graph with is called a functional dependence graph for if and only if for all
| (6) |
With an identification of and node , this Definition requires that each pseudo-variable is a function (in the sense of Definition 1) of the pseudo-variables associated with its parent nodes. To this end, define
Where it does not cause confusion, we will abuse notation and identify pseudo-variables and nodes in the FDG, e.g. (6) will be written .
Definition 4 is more general than the functional dependence graph of [15, Chapter 2]. Firstly, in our definition there is no distinction between source and non-source random variables. The graph simply characterizes functional dependence between variables. In fact, our definition admits cyclic directed graphs, and there may be no nodes with in-degree zero (which are source nodes in [15]). We also do not require independence between sources (when they exist), which is implied by the acyclic constraint in [15]. Our definition of an FDG admits pseduo-entropy functions with additional functional dependence relationships that are not represented by the graph. It only specifies a certain set of conditional pseudo-entropies which must be zero. Finally, our definition holds for a wide class of objects, namely pseudo-variables, rather than just random variables.
Clearly a functional dependence graph in the sense of [15] satisfies the conditions of Definition 4, but the converse is not true. Henceforth when we refer to a functional dependence graph (FDG), we mean in the sense of Definition 4. Furthermore, an FDG is acyclic if has no directed cycles. A graph will be called cyclic if every node is a member of a directed cycle.222In this paper we do not consider graphs that are neither cyclic or acyclic.
Definition 4 specifies an FDG in terms of local dependence structure. Given such local dependence constraints, it is of great interest to determine all implied functional dependence relations. In other words, we wish to find all sets and such that .
Definition 5
For disjoint sets we say determines in the directed graph , denoted , if there are no elements of remaining after the following procedure:
Remove all edges outgoing from nodes in and subsequently remove all nodes and edges with no incoming edges and nodes respectively.
For a given set , let be the set of nodes deleted by the procedure of Definition 5. Clearly is the largest set of nodes with .
Lemma 1 (Grandparent lemma)
Let be a functional dependence graph for a polymatroidal pseudo-entropy function . For any with
Proof:
By hypothesis, for any . Furthermore, note that for any , conditioning cannot increase pseudo-entropy333This is a direct consequence of submodularity, (3). and hence for any . Now using this property, and the chain rule
∎
We emphasize that in the proof of Lemma 1 we have only used the submodular property of polymatroids, together with the hypothesized local dependence structure specified by the FDG.
Clearly the lemma is recursive in nature. For example, it is valid for and so on. The implication of the lemma is that a pseudo-variable in an FDG is a function of for any with .
Theorem 1
Let be a functional dependence graph on the pseudo-variables with polymatroidal pseudo-entropy function . Then for disjoint subsets ,
Proof:
Definition 5 describes an efficient graphical procedure to find implied functional dependencies for pseudo-variables with local dependence specified by a functional dependence graph . It captures the essence of the chain rule (4) for pseudo-entropies and the fact that pseudo-entropy is non-increasing with respect to conditioning (3), which are the main arguments necessary for manual proof of functional dependencies.
One application of Definition 5 is to find a reduction of a given set , i.e. to find a disjoint partition of into and with , which implies . On the other hand, it also tells which sets are irreducible.
Definition 6 (Irreducible set)
A set of nodes in a functional dependence graph is irreducible if there is no with .
Clearly, every singleton is irreducible. In addition, in an acyclic FDG, irreducible sets are basic entropy sets in the sense of [17]. In fact, irreducible sets generalize the idea of basic entropy sets to the more general (and possibly cyclic) functional dependence graphs on pseudo-variables.
III-A Acyclic Graphs
In an acyclic graph, let denote the set of ancestral nodes, i.e. for every node , there is a directed path from to some .
Of particular interest are the maximal irreducible sets:
Definition 7
An irreducible set is maximal in an acyclic FDG if , and no proper subset of has the same property.
Note that for acyclic graphs, every subset of a maximal irreducible set is irreducible. Conversely, every irreducible set is a subset of some maximal irreducible set [17]. Irreducible sets can be augmented in the following way.
Lemma 2 (Augmentation)
Let in an acyclic FDG . Let . Then is irreducible for every .
This suggests a process of recursive augmentation to find all maximal irreducible sets in an acyclic FDG (a similar process of augmentation was used in [17]). Let be a topologically sorted444I.e. Order nodes such that if there is a directed edge from node to then [9, Proposition 11.5]. acyclic functional dependence graph . Its maximal irreducible sets can be found recursively via in Algorithm 1. In fact, finds all maximal irreducible sets containing .
III-B Cyclic Graphs
In cyclic graphs, the notion of a maximal irreducible set is modified as follows:
Definition 8
An irreducible set is maximal in a cyclic FDG if , and no proper subset of has the same property.
For cyclic graphs, every subset of a maximal irreducible set is irreducible. In contrast to acyclic graphs, the converse is not true. In fact there can be irreducible sets that are not maximal, and are not subsets of any maximal irreducible set. It is easy to show that
Lemma 3
All maximal irreducible sets have the same pseudo-entropy.
This fact will be used in development of our capacity bound for network coding in Section IV below. We are interested in finding every maximal irreducible set for cyclic graphs. This may be accomplished recursively via in Algorithm 2. Note that in contrast to Algorithm 1, finds all maximal irreducible sets that do not contain any node in .
Example 1 (Butterfly network)
Figure 1 shows the well-known butterfly network and Figure 2 shows the corresponding functional dependence graph. Nodes are labeled with node numbers and pseudo-variables (The sources variables are and . The are the edge variables, carried on links with capacity ). Edges in the FDG represent the functional dependency due to encoding and decoding requirements.
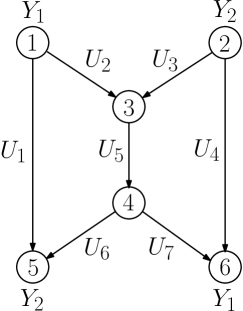
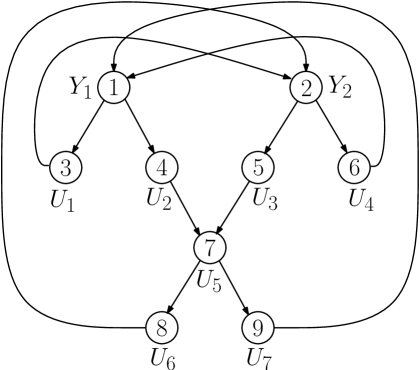
The maximal irreducible sets of the cyclic FDG shown in Figure 2 are
IV Functional Dependence Bound
We now give an easily computable outer bound for the total capacity of a network coding system.
Theorem 2 (Functional Dependence Bound)
Let be given network coding constraint sets. Let be a functional dependence graph555This FDG will be cyclic due to the sink demands on the (source and edge) pseudo-variables with pseudo-entropy function . Let be the collection of all maximal irreducible sets not containing source variables. Then
Proof:
Maximal irreducible sets which do not contain source variables are “information blockers” from sources to corresponding sinks. They can be interpreted as information theoretic cuts in in the network. Note that an improved bound can in principle be obtained by using additional properties of (rather than just subadditivity). Similarly, bounds for linear network codes could be obtained by using .
Corollary 1
Example 2 (Butterfly network)
The functional dependence bound for the butterfly network of Figure 2 is
To the best of our knowledge, Theorem 2 is the tightest bound expression for general multi-source multi-sink network coding (apart from the computationally infeasible LP bound). Other bounds like the network sharing bound [13] and bounds based on information dominance [14] use certain functional dependencies as their main ingredient. In contrast, Theorem 2 uses all the functional dependencies due to network encoding and decoding constraints.
V Conclusion
Explicit characterization and computation of the multi-source network coding capacity region requires determination of the set of all entropic vectors , which is known to be an extremely hard problem. The best known outer bound can in principle be computed using a linear programming approach. In practice this is infeasible due to an exponential growth in the number of constraints and variables with the network size.
We gave an abstract definition of a functional dependence graph, which extends previous notions to accommodate not only cyclic graphs, but more abstract notions of dependence. In particular we considered polymatroidal pseudo-entropy functions, and demonstrated an efficient and systematic method to find all functional dependencies implied by the given local dependencies.
This led to our main result, which was a new, easily computable outer bound, based on characterization of all functional dependencies in networks. We also show that the proposed bound is tighter than some known bounds.
References
- [1] R. Ahlswede, N. Cai, S.-Y. R. Li, and R. W. Yeung, “Network information flow,” IEEE Trans. Inform. Theory, vol. 46, pp. 1204–1216, July 2000.
- [2] S.-Y. R. Li, R. Yeung, and N. Cai, “Linear network coding,” IEEE Trans. Inform. Theory, vol. 49, pp. 371–381, Feb. 2003.
- [3] R. W. Yeung, S.-Y. Li, N. Cai, and Z. Zhang, Network Coding Theory. now Publishers, 2006.
- [4] C. Fragouli and E. Soljanin, Network Coding Fundamentals. now Publishers, 2007.
- [5] C. Fragouli and E. Soljanin, Network Coding Applications. now Publishers, 2008.
- [6] T. Ho and D. S. Lun, Network Coding: An Introduction. Cambridge University Press, 2008.
- [7] R. Dougherty, C. Freiling, and K. Zeger, “Insufficiency of linear coding in network information flow,” IEEE Trans. Inform. Theory, vol. 51, Aug. 2005. To appear.
- [8] T. H. Chan and A. Grant, “Dualities between entropy functions and network codes,” IEEE Trans. Inform. Theory, vol. 54, pp. 4470–4487, Oct. 2008.
- [9] R. W. Yeung, A First Course in Information Theory. Information Technology: Transmission, Processing and Storage, New York: Kluwer Academic/Plenum Publishers, 2002.
- [10] L. Song, R. W. Yeung, and N. Cai, “Zero-error network coding for acyclic networks,” IEEE Trans. Inform. Theory, vol. 49, pp. 3129–3139, Dec. 2003.
- [11] X. Yan, R. W. Yeung, and Z. Zhang, “The capacity region for multi-source multi-sink network coding,” in IEEE Int. Symp. Inform. Theory, (Nice, France), pp. 116–120, Jun. 2007.
- [12] F. Matúš, “Infinitely many information inequalities,” in IEEE Int. Symp. Inform. Theory, 2007.
- [13] X. Yan, J. Yang, and Z. Zhang, “An outer bound for multisource multisink network coding with minimum cost consideration,” IEEE Trans. Inform. Theory, vol. 52, pp. 2373–2385, June 2006.
- [14] N. Harvey, R. Kleinberg, and A. Lehman, “On the capacity of information networks,” IEEE Trans. Inform. Theory, vol. 52, pp. 2345–2364, June 2006.
- [15] G. Kramer, Directed Information for Channels with Feedback. PhD thesis, Swiss Federal Institute of Technology, Zurich, 1998.
- [16] L. Guille, T. Chan, and A. Grant, “The minimal set of Ingleton inequalities,” in IEEE Int. Symp. Inform. Theory, pp. 2121–2125, July 2008.
- [17] I. Grivell, A. Grant, and T. Chan, “Basic entropy sets,” in Fourth Workshop on Network Coding, Theory and Applications, pp. 1–6, Jan. 2008.