Neural Network Pruning as Spectrum Preserving Process
Abstract.
Neural networks have achieved remarkable performance in various application domains. Nevertheless, a large number of weights in pre-trained deep neural networks prohibit them from being deployed on smartphones and embedded systems. It is highly desirable to obtain lightweight versions of neural networks for inference in edge devices. Many cost-effective approaches were proposed to prune dense and convolutional layers that are common in deep neural networks and dominant in the parameter space. However, a unified theoretical foundation for the problem mostly is missing. In this paper, we identify the close connection between matrix spectrum learning and neural network training for dense and convolutional layers and argue that weight pruning is essentially a matrix sparsification process to preserve the spectrum. Based on the analysis, we also propose a matrix sparsification algorithm tailored for neural network pruning that yields better pruning result. We carefully design and conduct experiments to support our arguments. Hence we provide a consolidated viewpoint for neural network pruning and enhance the interpretability of deep neural networks by identifying and preserving the critical neural weights.
1. Introduction
Deep neural network pruning(Gong et al., 2014) (Han et al., 2015b) (Han et al., 2015a) (Li et al., 2016) has been an essential topic in recent years due to the emerging desire of efficiently deploying pre-trained models on light-weight devices, for example, smartphones, edge devices (Nvidia Jetson and Raspberry Pi), and Internet of Things (IoTs). Neural network pruning dates back to last century when the initial attempts were made by optimal brain damage (LeCun et al., 1990) and optimal brain surgeon (Hassibi and Stork, 1993), and have achieved impressive results.
A larger body of work, namely, neural network compression (Cheng et al., 2017)(Kim et al., 2015)(Denton et al., 2014)(Lebedev et al., 2014), aims at removing a large number of parameters without significantly deteriorating the performance while benefiting from the reduced storage footprints for pre-trained networks and computing power. Because the dense layers and convolutional layers usually dominate the space and time complexity in neural networks, multiple approaches have been proposed to compress these two types of network. These approaches demonstrated surprising simplicity and superior efficacy in many situations of neural network pruning.
Nonetheless, existing works mostly are experiment-oriented and fall into distinct categories. Thoroughly studying these related work revealed several questions. Can the same approaches be applied to both dense layers and convolutional layers? What are the theory and mechanisms justifying the chosen pruning operations and providing the performance guarantee of the pruned networks? And can we gain a better insight to interpret deep learning models (Samek et al., 2017)(Du et al., 2019) from studying the topics of neural network pruning?
In this paper, we employ spectral theory and matrix sparsification techniques to provide an alternative perspective for neural network pruning and attempt to answer the questions mentioned above. Our contributions are as follows:
-
•
We discover the relationship between neural network training and the spectrum learning process of weight matrices. By tracking the evolution of matrix spectrum, we formalize neural network pruning as a spectrum preserving process.
-
•
We illustrate in detail the resemblance between dense layer and convolutional layer and essentially they both are matrix multiplication. Consequently, a unified viewpoint, namely matrix sparsification, is proposed to prune both types of layer.
-
•
Based on our analysis, we show the potential of customizing matrix sparsification algorithm for better neural network pruning by proposing a tailored sparsification algorithm.
-
•
We thoroughly conduct experimental tasks, each of which targets a specific argument to provide appropriate and solid empirical support.
The outline of this paper is as follows: Section 2 briefly reviews related literature. In section 3, we formulate the problem of neural network pruning and explain how we tackle it from spectral theory perspective; Section 4 provides matrix sparsification techniques that are suitable for neural network pruning. In section 5, we generalize the analysis schema to convolutional layers. Section 6 presents detailed empirical study; and finally the conclusions are offered.
2. Related Work
The essential objective of neural network pruning is to remove parameters from pre-trained models without incurring significant performance loss. Removing parameters from the weight matrix is equivalent to eliminate neuron connections from a neural layer. Our discussion is mainly concerned with two research topics: neural network pruning and matrix sparsification.
2.1. Neural Network Pruning
Early attempts in pruning neural networks dated back to optimal brain damage (LeCun et al., 1990) and optimal brain surgeon (Hassibi and Stork, 1993) where the authors employed the second-order partial derivative matrix to decide the importance of connections and remove those unimportant ones. The simple yet very effective magnitude-based approach was examined in (Han et al., 2015b) for both dense layers and convolutional layers, where small entries in terms of absolute value were removed from the network. The work was further expanded (Han et al., 2015a) with the quantization techniques,which was previously introduced by (Gong et al., 2014). Channel-wise pruning (Li et al., 2016) for convolution was also examined based on the -norm magnitude of the filters. The lottery ticket hypothesis (Frankle and Carbin, 2018) and a consequent work (Zhou et al., 2019) have again attracted the attention of the community on the magnitude-based pruning.
There is another line of efforts (Denton et al., 2014) (Vasilescu and Terzopoulos, 2002) (Lebedev et al., 2014) (Kim et al., 2015) (Liu et al., 2015) based on low-rank approximation, which has a similar taste to pruning but with a more clear theoretical support, falling within a larger scope of work namely neural network compression (Cheng et al., 2017). The low rank approximation was applied to the weight matrix or tensors (Kolda and Bader, 2009) in order to reduce the storage requirements or inference time for large pre-trained models. Some other works on neural network compression also include weight sharing (Chen et al., 2015) and hash trick (Chen et al., 2016), where they also look at the problem in the frequency domain.
2.2. Matrix Sparsification
Matrix sparsification is important in many numerical problems, e.g. low-rank approximation, semi-definite programming and matrix completion, which widely exist in data mining and machine learning problems. Matrix sparsification is to reduce the number of nonzero entries in a matrix without altering its spectrum. The original problem is NP-hard (McCormick, 1983)(Gottlieb and Neylon, 2010). The study of approximation solutions to this problem was pioneered by (Achlioptas and McSherry, 2007), and further expanded in (Achlioptas et al., 2013b) (Arora et al., 2006) (Achlioptas et al., 2013a) (Nguyen et al., 2009) (Drineas and Zouzias, 2011). An extensive study on the error bound was done in (Gittens and Tropp, 2009).
Since the spectrum of the sparsified matrix does not deviate significantly from that of the original matrix, serving as a linear operator the matrix retains its functionality, i.e. is a mapping . We can define the matrix sparsification process as the following optimization problem:
| (1) | ||||||
| s.t. |
where is the original matrix, is the sparsified matrix, is the -norm that equals the number of non-zero entries in a matrix, denotes matrix norm, is the error tolerance.
In matrix sparsification, we often use the spectral norm (2-norm) and the Frobenius norm (F-norm) to measure the deviation of the sparsified matrix from the original one.
3. Problem Formulation
Given a dense layer , where is the input signal, is the output signal, is the weight matrix, is the bias, denotes some activation function, we desire to obtain a sparse version of denoted by such that and have similar spectral structure and is as close to as possible.
Similarly for a convolution we want to find a sparse version of such that the convolution result is as close as possible, where could be a vector, matrix or higher-order array depending on the order of input signal and the number of output channel. By closeness, we use norms as metric. We start from the investigation on dense layers and then make generalization on convolutional layers.
3.1. Neural Net Training as Spectrum Learning Process
In a dense layer, we focus on the part since it contains most parameters. Neural network is essentially a function simulator that learns some artificial features, which is achieved by linear mappings, nonlinear activations, and some other customized units (e.g. recurrent unit). For the linear mapping, the analysis is usually done on the spectral domain.
Recall that Singular Value Decomposition (SVD) is optimal under both spectral norm (Eckart and Young, 1936) and Frobenius norm (Mirsky, 1960). The weight matrix as a linear operator can be decomposed as
where is the left singular matrix, is the right singular matrix and and contains the singular values in a non-increasing order.
Note that a input signal can be written into a linear combination of , i.e. where are the coefficients. Thus, the mapping from to is
where are non-increasingly ordered, since and .
We are especially interested in finding out how the spectrum , i.e., singular values, of the linear mapping evolve during neural network training. As a matter of fact, our empirical study shows that the neural network training process is a spectrum learning process. To investigate the spectral structure, we design the following task:
Task 1: check the spectra and norms of dense layer weight matrices and how they change during neural network training.
3.2. Neural Net Pruning as Spectrum Preserving Process
Following the logic, if the neural network training is a spectrum learning process, when we practise neural network pruning, we would like to preserve the spectrum in order to preserve the neural network performance. In other words, we want to obtain a sparse that has similar singular values to . How to measure the wellness of spectrum preservation? We can use the spectral norm (2-norm) which is the largest singular value since we care about the dominant principle component, and the Frobenius norm (F-norm)
which is usually considered an aggregation of the whole spectrum. Note that and .
Therefore the goal is to find a sparse such that or . To show that the pruning process is a spectrum preserving process, we design the following task.
Task2: apply magnitude-based thresholding at different sparsity levels and check the relationship between the resulting weight matrix spectra and the performance of the pruned neural networks.
3.3. Iterative Pruning and Retraining
From the optimization perspective, the pretrained neural network achieved satisfying local optimum. Once the weight matrix is sparsified, the spectrum to some extent deviates and the optimality no longer holds. We wish to retrain the neural network such that it returns to the satisfying local optimum and the performance is preserved. Apparently we don’t want the neural net deviate from the local optimum too far, otherwise it would be difficult to return to the optimum due to the nonconvex optimization process of neural network. Hence, iterative pruning and retraining has been a common practice for neural network pruning. We also design a task to elaborate from the spectrum perspective.
Task3: Inspect the weight matrix spectra in each pruning iteration, i.e. the weight matrix spectra after pruning and after retraining respectively, and compare the corresponding neural network performances. We also include a comparison to one-shot pruning.
4. Matrix Sparsification Algorithms
In the previous section, we identify the relationship between neural network pruning (removing parameters/connections) and the spectrum preserving process. Matrix sparsification plays a primary role in the spectrum preserving process and will guide the network pruning process. In this section, we present the practical techniques of matrix sparsification.
4.1. Magnitude Based Thresholding
Magnitude-based neural network pruning have attracted a lot of attention and show supprisingly simplicity and superior efficacy. In the context of matrix sparsification, this is a straightforward approach, namely magnitude-based matrix sparsification or hard thresholding. Given a matrix , let denote its sparsifier. Entry-wise we have
.
Fact 0.
Magnitude based thresholding always achieves sparsification optimality in terms of F-norm.
The fact can be trivially verified since using and using (on which F-norm is based) are equivalent in terms of deciding small entries in a matrix. However throwing away small entries does not always guarantee the optimal sparsification result in terms of 2-norm. And in many situations, we care more about the dominant singular value instead of the whole spectrum.
4.2. Randomized Algorithms
In randomized matrix sparsification, each entry is sampled according to some distribution independently and then rescaled. E.g. each entry is sampled according to a Berboulli distribution, and we either set it to zero or rescale it.
where can be a constant or positively correlated to the magnitude of the entry. The following theorem provides the justification to this type of matrix sparsification.
Theorem 4.1.
A matrix where each entry is sampled from a zero-mean bounded-variance distribution possesses weak spectrum with large probability.
By weak spectrum, it means small matrix norm. To be more concrete, since matrix norm is a metric and triangle inequality applies, we have
. We need to show that falls within the category of matrices described in Theorem 4.1. Since
and
, as long as is upper-bounded, which is true most of time, is bounded. Therefore the randomized matrix sparsification can guarantee the error bound.
4.3. Customize Matrix Sparsification Algorithm for Neural Network Pruning
In this section, we propose a customized matrix sparsification algorithm to show the potential of designing a better spectrum preservation process in neural network pruning. We do not intend to present a new state-of-the-art neural network pruning algorithm. There are two important points in our proposed algorithm: truncation and sampling based on the principal components of explicit truncated SVD. To the best of our knowledge, sampling based on probability proportional to principal components is employed for the first time in designing matrix sparsification for neural network pruning .
First, we adopt the truncation trick that is common in existing work. As clearly pointed out by (Achlioptas et al., 2013a), the spectrum of the random matrix is determined by its variance bound. Usually, the larger the variance, the stronger the spectrum of the random matrix. Existing works took advantage of the finding and proposed truncation (Arora et al., 2006)(Drineas and Zouzias, 2011) in sparsification, i.e. to set small entries to zero while leaving large entries as is and sampling on the remaining ones.
where , is decided by the quantile (leave large entries as is), and , the lower threshold for zeroing weights, as a constant could be set manually, and denotes Bernoulli distribution.
Second, instead of sampling based on the probability calculated from the magnitude of the original matrix entry, we do sampling based on the probability calculated from the principal component matrix entry magnitude with a little compromise on complexity, in order to better preserve the dominant singular values. Matrix sparsification was originally proposed for fast low-rank approximation on very large matrices, due to the fact that sparsity accelerates matrix-vector multiplication in power iteration. Essentially, we desire to find the sparse sketch of that preserves the dominant singular values well. This coincides with the goal of layer-wise neural network pruning from the spectrum preserving viewpoint – we desire to preserve the dominant singular values, based on the fact that we often consider information lies in the low-frequency domain while noises are in the high-frequency domain. The major difference is that weight matrices in neural network, either from dense layers or convolutional layers, are usually not too large, and therefore explicit SVD or truncated SVD on them is fairly affordable. Once we have access to the principle components of the weight matrices, we are able to preserve them better in the sparsification process. Note that preserving dominant singular values is a harmonic approach between preserving the 2-norm and the F-norm, since and .
The crutial part is to find the low-rank approximation to , where and are from SVD on A. We set the entry-wise sampling probability based on , i.e. . Alg 1 presents the sparification algorithm. The partition function is the one used in quicksort.
We need to demonstrate that the proposed sparsification algorithm preserves dominant singular values better and improves the generalization performance of the pruned network. We propose the following task to check whether it makes improvement based on our analysis.
Task 4 Apply the above algorithm on VGG19 layer-wise weight matrix sparsification, compare the generalization performance of the pruned network and the pruned network given by thresholding at the same sparsity level.
Here we provide a high level proof on sparsification error being upper bounded. Let denote the sparse sketch generated by setting smallest entries in to 0 and as usual the final sparsfied result. From Fact Fact we know that is the optimal sketch of in terms of F-norm, i.e. . Based on Theorem 4.1 and its illustration we know that satisfies the zero-mean and bounded-variance condition. Hence . Therefore if we apply triangle equality given matrix norm is a metric,
Some other techniques, e.g. quantization(Gong et al., 2014)(Han et al., 2015a), can be used together with sparsification to further compress matrices and neural networks. Essentially they are also spectrum preservation techniques (Achlioptas and McSherry, 2007)(Arora et al., 2006).
5. Generalization to Convolution
Extensive literatures argue that convolutional layers compression can be formalized as tensor algebra problems (Lebedev et al., 2014)(Denton et al., 2014) (Kim et al., 2015)(Liu et al., 2015)(Sun et al., 2016). However, it’s advantageous to explain convolutional layer pruning from the matrix viewpoint since the linear algebra have many nice properties that do not hold for multilinear algebra. We want to ask: can we still provide theoretical support to convolutional layer pruning using linear algebra we have discussed so far?
5.1. Pruning on Convolutional Filters
In this section we state and illustrate the following fact.
Fact 0.
Discrete convolution in neural networks can be represented by dot product between two dense matrices.
To see this, suppose we have a convolutional layer with input signal size of as width by height, and with input channels and output channels. Here we consider a 2-d convolution on the signal. The kernel is of size and there are such kernels. For the sake of simplicity in notations, suppose the striding step is 1, half-padding is applied and there is no dilation (for even and the above setting results in output signal of size as width by height). 2-d convolution means that the kernel is moving in two directions. Fact Fact has been utilized to optimize lower-level implementation of CNN on hardware (Chellapilla et al., 2006)(Chetlur et al., 2014). Here we take advantage of the idea to unify neural network pruning on dense layers and convolutional layers with matrix sparsification.
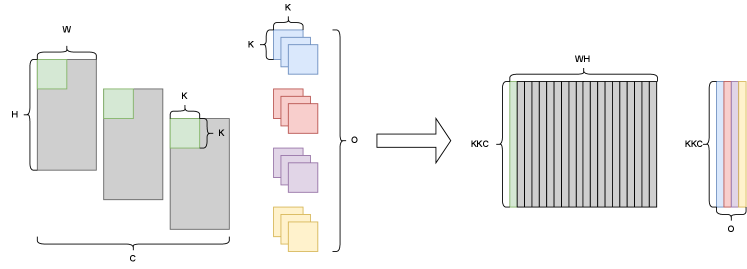
Let us focus on one single output channel, one step of the convolution operation is the summation of element-wise product of two higher-order array, i.e. the kernel and the receptive field of the signal of the same size . Note that taking the summation of element-wise product is equivalent to vector inner product. Therefore if we unfold the kernel for a single output channel to a vector and rearrange the receptive field of the signal accordingly to another vector, a single convolution step can be treated as two vector inner product, i.e. where . Since we have output channels in total, there are such kernels of the same size. All of them being unfolded, we then can convert the convolution into a matrix product , where being the kernels and being the rearranged input signals. And consequently the output signal (as mentioned before, stride 1, half padding and no dilation result in input signal and output signal being in the same shape). Figure 8 visualizes convolution as matrix multiplication.
The matrix multiplication representation of convolution discussed above generalizes to any other convolution settings. Also note that the way we unfold the filters does not affect the spectrum of the resulting matrix, since row and column permutations do not change matrix spectrum. Therefore, all the analyses based on simple linear algebra we have discussed so far generalize to convolutional layer pruning. To verify our analyses,
Task1,2,3 will also be conducted on convolutional layers. When we say weight matrix in a context of convolution, it refers to as the matrix unfolded from the convolution higher-order array in the way described in Figure 8.
5.2. Convolutional Filter Channel Pruning
Entry-wise pruning almost always results in unstructured sparsity that requires specific data structure design in network deployment in order to realize the complexity reduction from pruning. Therefore it’s desirable to prune entire channels from convolutional layers to achieve higher efficiency. There is another important work on pruning channels (Li et al., 2016). The approach is to take small where denotes the filter for a specific channel. This is equivalent to remove a column in we just discussed with small-magnitude values. It’s also a spectrum preserving process as is fairly a proximity to on which the F-norm is based. Hence pruning the whole filter with small is to preserve the F-norm of the convolution matrix we discussed in the previous subsection. To check the relation between and the F-norm of , we propose the following task.
Task5 Pruning different filters and check the relationship between and the resulted convolution matrix F-norm .
6. Empirical Study Details
In this section, we present the proposed task details and results. The experiments are mainly based on LeNet (LeCun et al., 1998) on MNIST and VGG19 (Simonyan and Zisserman, 2014) on CIFAR10 dataset (Krizhevsky et al., 2009). We trained the neural networks from scratch based on the official PyTorch (Paszke et al., 2019) implementation. Then we conducted our experiments based on the pre-trained neural networks.
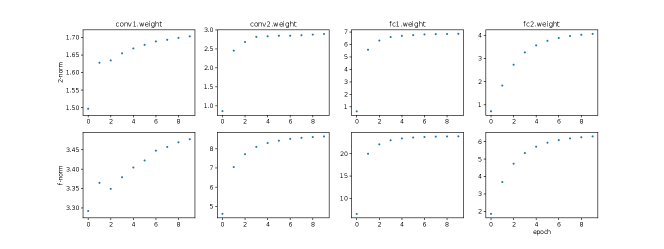
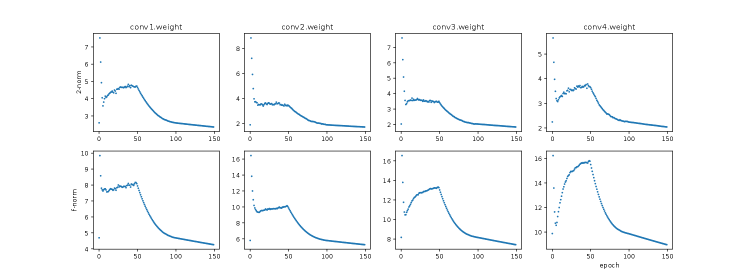
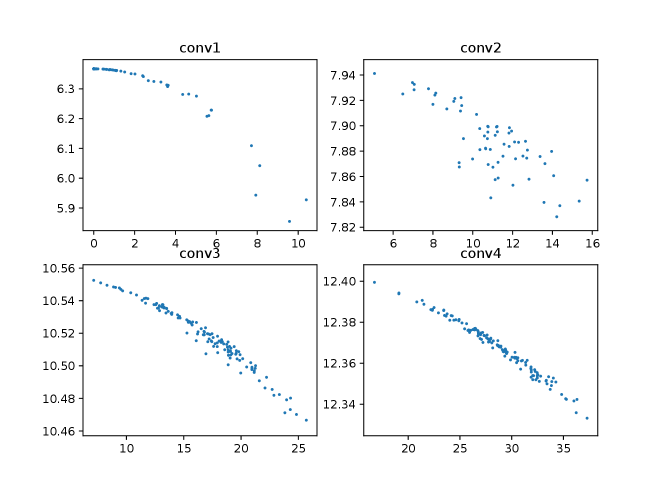
We trained LeNet with a reduced number of epochs of 10. All other hyperparameter settings are the ones used in the original implementation of the PyTorch example. The VGG19 was trained with the following hyperparameter setting: batch size 128, momentum 0.9, weight decay , and the learning rates of 0.1 for 50 epochs, 0.01 of 50 epochs, and 0.001 of another 50 epochs. The final testing accuracy for LeNet on MNIST and VGG19 on FICAR10 was 99.14% and 92.66%, respectively. We saved the layer weight matrices for each epoch of training, including two fully connected layers and two convolutional layers for LeNet and the first four convolutional layers for VGG19 (due to the limitation in the reporting space). We then study the evolvement of 2-norm and F-norm of weight matrices during training.
In Figures 1 and 2, we observe that the 2-norm and F-norm of a particular weight matrix change fast at the beginning of training and tend to stabilize as training proceeds. This observation provides concrete evidence that network training is essentially a spectrum learning process. Note that the initial spectrum is not necessarily flat (see Figures 10 and 11 in Appendix), but rather depends on the initialization. The stabilization also has its explanation from the optimization perspective: as training goes on we are trapped into a satisfying local optimum and the gradients are almost zero for layers when chain rule applied, which means the weight matrices are not being updated significantly.
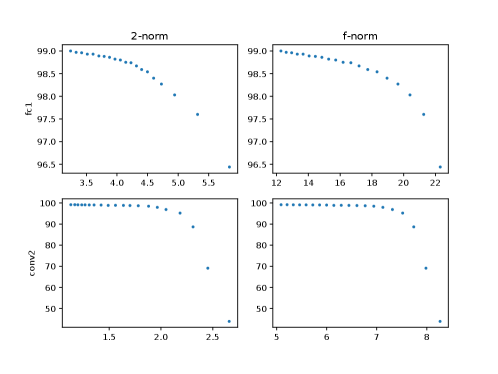
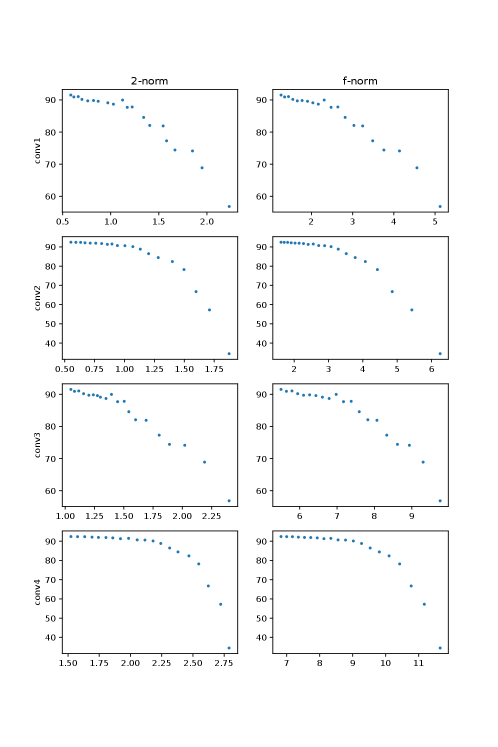
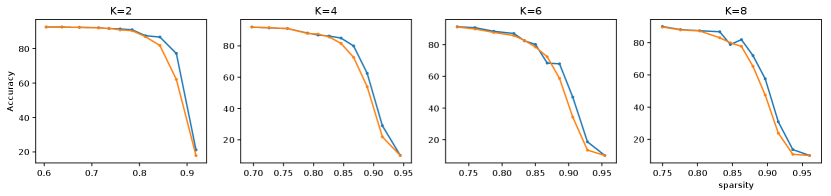
Task 2 We investigated the relationship between spectrum preservation and the performance of the pruned neural network. Matrix sparsification (hard thresholding) was employed to prune neural networks. We varied the percentage of parameter preservation from 20% to 1% to get different sparsities (the sparser, the larger and ). We pruned different layers in the pre-trained LeNet and VGG19 and checked their performance without retraining.
Figure 3 and figure 4 show that when increases, the neural network performance deteriorates almost monotonically. It is also true for . The finding confirms that the better the spectrum of weight matrix is preserved during pruning, the better the performance of the pruned neural network performance is conserved. It is also interesting to note that the experiment observations (data points) tend to concentrate on the upper left side, rather than the lower right of plots, and there is a drop-off in each plot. The pattern indicates that the spectrum and neural network performance collapse when the sparsity of the matrix sketch goes beyond a certain point.
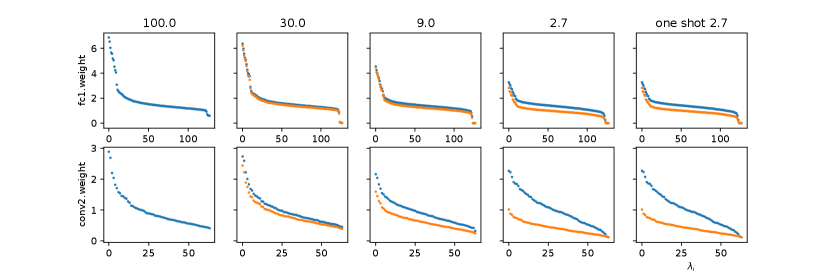
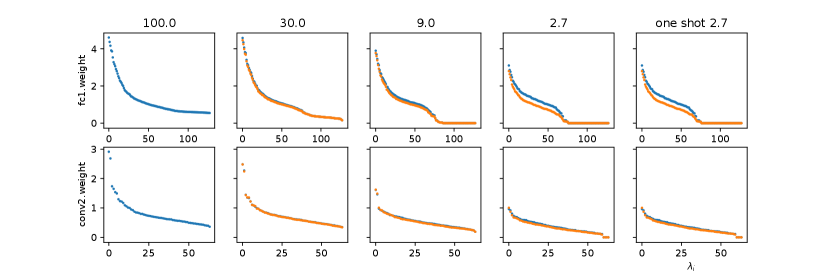
Task 3 We also inspected the spectra of the weight matrices during the iterative pruning and retraining. Specifically, we adopted the magnitude-based pruning (hard thresholding matrix sparsification) to retain 30% parameters in each iteration. We conducted experiments on the second convolutional layer and the first dense layer which contain most parameters in LeNet. Once the parameters were pruned, we applied a mask on that certain matrix to fix the zero values which correspond to the pruned connections between neurons. We also applied masks on all other layers during retraining in order to get a better assess on certain weight matrix spectrum change due to sparsification. The retraining process was done with two additional epochs.
Figure 5 shows a clear pattern of how the spectrum of a weight matrix evolves once we iteratively prune it. The first plot in each row is the spectrum of the original weight matrix. The orange dots denote the spectra of the weight matrices after each round of pruning, and the blues dots represent the spectra after retraining in each iteration. In the beginning, we can prune a large number of parameters from the weight matrix without altering the spectrum significantly, and we still can recover the spectrum to some extent by retraining. When the sparsity reaches a certain point, the spectrum seems to collapse and fail to recover its original shape and position even with retraining, which is consistent with the general observation neural network performance significantly drops when it’s too sparse.
Such a spectrum recovery behaviour is negligibly insignificant on VGG19. The spectra deviate from the original ones in pruning yet are rather slightly modified during retraining. This is mainly due to the widely adopted Batch Normalization(Ioffe and Szegedy, 2015), which rescales training batches to zero-mean unit-variance batches and hence significantly eliminates the need for shaping the matrix spectra. In the beginning, we managed to remove the batch normalization that comes after each convolutional layer in VGG19. However, this leads to a difficult training situation for deep neural networks, as the community is widely aware of (Ioffe and Szegedy, 2015). Hence, we adopted an alternative approach to demonstrate batch normalization effect on the learning process of spectra. We added batch normalization after each convolutional layer in LeNet, repeated the experiment aforementioned, and compared the results. For a detailed treatment of batch normalization, please refer to(Ioffe and Szegedy, 2015)(Bjorck et al., 2018).
In Figure 6, we observe that when batch normalization is applied, the spectrum recovery is less significant than that of without batch normalization, although both the trajectory and the ending status of the spectra for iterative pruning and one-shot pruning surprisingly reassemble to each other.
Task 4 We applied algorithm1 on all convolutional layers in VGG19 at the same time, varied algorithm settings to get different sparsities, recorded the corresponding testing performance of the pruned network, and compared with the performance of the pruned network via thresholding at the same sparsity level. Due to the randomness in our proposed algorithm, the sparsity in different layers is also different. We present the aggregated sparsity, i.e. the total number of nonzero parameters divided by total number of parameters in all convolutional weight matrices, in our empirical study result. To ease the implementation and focus on our arguments, we fixed parameter , varied the quantile parameter and the number of principal components .
From Figure 7 we can see that, our proposed algorithm almost always leads to better pruned network generalization performance without retraining compared to that given by thresholding, at different sparsity levels. This demonstrates the potential of designing and customizing matrix sparsification algorithms for better neural network pruning approaches. In addition, we also observed Alg 1 almost always yield smaller sparsification error compared to thresholding in terms of 2-norm, which is exactly the motivation of the algorithm design.
Task 5 To support the channel pruning mechanism interpretation, we inspected the relation between and . For this task, we checked the first four convolutional layers in VGG19. Based on our illustration on convolutional layer as dense matrix multiplication, we unfolded each channel filter from a 3rd-order array to a vector, and then concatenated all the channel vectors into a matrix. Therefore removing a filter channel is equivalent to removing a column in the so called convolution matrix in figure 8. We have shown the relation between spectrum preservation and neural network performance preservation. As long as we can show the relation between and , we can bridge the gap and associate and neural network performance.
Figure 9 shows that more or less of a convolution matrix is negatively correlated to , which is consistent to our analysis.
7. Conclusion and Future Work
In this work, we argue that neural network training has a strong interdependence with spectrum learning. The relationship provides neural network pruning with a theorical formulation based on spectrum preserving, to be more specific, matrix sparsification. We reviewed the existing primary efforts on neural network pruning and proposed a unified viewpoint for both dense layer and convolutional layer pruning. We also designed and conducted experiments to support the arguments, and hence provided more interpretability to deep learning related topic.
We anticipate that the superior algorithm design for neural network pruning rests upon the effective and efficient matrix sparsification using spectral theory and lower-level implementation of sparse neural network for the targeted systems. For future works, we will undertake further investigation on how activation functions affect pruning and more pruning algorithms on other types of network layers.
References
- (1)
- Achlioptas et al. (2013a) Dimitris Achlioptas, Zohar Karnin, and Edo Liberty. 2013a. Matrix entry-wise sampling: Simple is best. Submitted to KDD 2013, 1.1 (2013), 1–4.
- Achlioptas et al. (2013b) Dimitris Achlioptas, Zohar S Karnin, and Edo Liberty. 2013b. Near-optimal entrywise sampling for data matrices. In Advances in Neural Information Processing Systems. 1565–1573.
- Achlioptas and McSherry (2007) Dimitris Achlioptas and Frank McSherry. 2007. Fast computation of low-rank matrix approximations. Journal of the ACM (JACM) 54, 2 (2007), 9.
- Arora et al. (2006) Sanjeev Arora, Elad Hazan, and Satyen Kale. 2006. A fast random sampling algorithm for sparsifying matrices. In Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques. Springer, 272–279.
- Bjorck et al. (2018) Nils Bjorck, Carla P Gomes, Bart Selman, and Kilian Q Weinberger. 2018. Understanding batch normalization. In Advances in Neural Information Processing Systems. 7694–7705.
- Chellapilla et al. (2006) Kumar Chellapilla, Sidd Puri, and Patrice Simard. 2006. High performance convolutional neural networks for document processing.
- Chen et al. (2015) Wenlin Chen, James Wilson, Stephen Tyree, Kilian Weinberger, and Yixin Chen. 2015. Compressing neural networks with the hashing trick. In International conference on machine learning. 2285–2294.
- Chen et al. (2016) Wenlin Chen, James Wilson, Stephen Tyree, Kilian Q Weinberger, and Yixin Chen. 2016. Compressing convolutional neural networks in the frequency domain. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1475–1484.
- Cheng et al. (2017) Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. 2017. A survey of model compression and acceleration for deep neural networks. arXiv preprint arXiv:1710.09282 (2017).
- Chetlur et al. (2014) Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. cudnn: Efficient primitives for deep learning. arXiv preprint arXiv:1410.0759 (2014).
- Denton et al. (2014) Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. 2014. Exploiting linear structure within convolutional networks for efficient evaluation. In Advances in neural information processing systems. 1269–1277.
- Drineas and Zouzias (2011) Petros Drineas and Anastasios Zouzias. 2011. A note on element-wise matrix sparsification via a matrix-valued Bernstein inequality. Inform. Process. Lett. 111, 8 (2011), 385–389.
- Du et al. (2019) Mengnan Du, Ninghao Liu, and Xia Hu. 2019. Techniques for interpretable machine learning. Commun. ACM 63, 1 (2019), 68–77.
- Eckart and Young (1936) Carl Eckart and Gale Young. 1936. The approximation of one matrix by another of lower rank. Psychometrika 1, 3 (1936), 211–218.
- Frankle and Carbin (2018) Jonathan Frankle and Michael Carbin. 2018. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635 (2018).
- Gittens and Tropp (2009) Alex Gittens and Joel A Tropp. 2009. Error bounds for random matrix approximation schemes. arXiv preprint arXiv:0911.4108 (2009).
- Gong et al. (2014) Yunchao Gong, Liu Liu, Ming Yang, and Lubomir Bourdev. 2014. Compressing deep convolutional networks using vector quantization. arXiv preprint arXiv:1412.6115 (2014).
- Gottlieb and Neylon (2010) Lee-Ad Gottlieb and Tyler Neylon. 2010. Matrix sparsification and the sparse null space problem. In Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques. Springer, 205–218.
- Han et al. (2015a) Song Han, Huizi Mao, and William J Dally. 2015a. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149 (2015).
- Han et al. (2015b) Song Han, Jeff Pool, John Tran, and William Dally. 2015b. Learning both weights and connections for efficient neural network. In Advances in neural information processing systems. 1135–1143.
- Hassibi and Stork (1993) Babak Hassibi and David G Stork. 1993. Second order derivatives for network pruning: Optimal brain surgeon. In Advances in neural information processing systems. 164–171.
- Ioffe and Szegedy (2015) Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015).
- Kim et al. (2015) Yong-Deok Kim, Eunhyeok Park, Sungjoo Yoo, Taelim Choi, Lu Yang, and Dongjun Shin. 2015. Compression of deep convolutional neural networks for fast and low power mobile applications. arXiv preprint arXiv:1511.06530 (2015).
- Kolda and Bader (2009) Tamara G Kolda and Brett W Bader. 2009. Tensor decompositions and applications. SIAM review 51, 3 (2009), 455–500.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. Technical Report. Citeseer.
- Lebedev et al. (2014) Vadim Lebedev, Yaroslav Ganin, Maksim Rakhuba, Ivan Oseledets, and Victor Lempitsky. 2014. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv preprint arXiv:1412.6553 (2014).
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al. 1998. Gradient-based learning applied to document recognition. Proc. IEEE 86, 11 (1998), 2278–2324.
- LeCun et al. (1990) Yann LeCun, John S Denker, and Sara A Solla. 1990. Optimal brain damage. In Advances in neural information processing systems. 598–605.
- Li et al. (2016) Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2016. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710 (2016).
- Liu et al. (2015) Baoyuan Liu, Min Wang, Hassan Foroosh, Marshall Tappen, and Marianna Pensky. 2015. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 806–814.
- McCormick (1983) S Thomas McCormick. 1983. A Combinatorial Approach to Some Sparse Matrix Problems. Technical Report. STANFORD UNIV CA SYSTEMS OPTIMIZATION LAB.
- Mirsky (1960) L. Mirsky. 1960. Symmetric gauge functions and unitarily invariant norms. QJ Math., Oxf. II. Ser. 11 (1960), 50–59. https://doi.org/10.1093/qmath/11.1.50
- Nguyen et al. (2009) NH Nguyen, Petros Drineas, and TD Tran. 2009. Matrix sparsification via the Khintchine inequality. (2009).
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems. 8024–8035.
- Samek et al. (2017) Wojciech Samek, Thomas Wiegand, and Klaus-Robert Müller. 2017. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv preprint arXiv:1708.08296 (2017).
- Simonyan and Zisserman (2014) Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
- Sun et al. (2016) Yi Sun, Xiaogang Wang, and Xiaoou Tang. 2016. Sparsifying neural network connections for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4856–4864.
- Vasilescu and Terzopoulos (2002) M Alex O Vasilescu and Demetri Terzopoulos. 2002. Multilinear analysis of image ensembles: Tensorfaces. In European Conference on Computer Vision. Springer, 447–460.
- Zhou et al. (2019) Hattie Zhou, Janice Lan, Rosanne Liu, and Jason Yosinski. 2019. Deconstructing lottery tickets: Zeros, signs, and the supermask. arXiv preprint arXiv:1905.01067 (2019).
Appendix A Supplementary Materials for Reproducibility
A.1. python code for Alg1
def lowRankSampling(A, tao=0.3, n_comp=5):
A_ = np.array([i.flatten() for i in A])
U,sigma,V = randomized_svd(A_, n_comp)
B = np.zeros(A_.shape)
for i in range(n_comp):
B += np.outer(U[:,i],V[i])*sigma[i]
flat_B = abs(B.flatten())
thresh_B = int(flat_B.size*tao)-1
t_B = np.partition(flat_B, thresh_B)[thresh_B]
with np.nditer(A, op_flags=["readwrite"]) as it:
for x in it:
if abs(x) < t_B:
p = np.square(x/t_B)
if p < 0.5:
x[...] = 0
else:
x[...] = np.random.binomial(1,p,1) * x / p
return A
A.2. Additional Empirical Study Results