Neural Tangent Kernel of Neural Networks with Loss Informed by Differential Operators
Abstract
Spectral bias is a significant phenomenon in neural network training and can be explained by neural tangent kernel (NTK) theory. In this work, we develop the NTK theory for deep neural networks with physics-informed loss, providing insights into the convergence of NTK during initialization and training, and revealing its explicit structure. We find that, in most cases, the differential operators in the loss function do not induce a faster eigenvalue decay rate and stronger spectral bias. Some experimental results are also presented to verify the theory.
Keywords: neural tangent kernel, physics-informed neural networks, spectral bias, differential operator
1 Introduction
In recent years, Physics-Informed Neural Networks (PINNs) [31] are gaining popularity as a promising alternative to solve Partial Differential Equations (PDEs). PINNs leverage the universal approximation capabilities of neural networks to approximate solutions while incorporating physical laws directly into the loss function. This approach eliminates the need for discretization and can handle high-dimensional problems more efficiently than traditional methods [14, 33]. Moreover, PINNs are mesh-free, making them particularly suitable for problems with irregular geometries [19, 39]. Despite these advantages, PINNs are not without limitations. One major challenge is their difficulty in training, often resulting in slow convergence or suboptimal solutions [6, 22]. This issue is particularly pronounced in problems with the underlying PDE solutions that contain high-frequency or multiscale features [11, 30, 40].
To explain the obstacles in training PINNs, a significant aspect is about the deficiency of neural networks in learning multifrequency functions, referred to as spectral bias [29, 38, 12, 32], which means that neural networks tend to learn the components of ”lower complexity” faster during training [29]. This phenomenon is intrinsically linked to the Neural Tangent Kernel (NTK) theory [18], as the NTK’s spectrum directly governs the convergence rates of different frequency components during training [7]. Specifically, neural networks are shown to converge faster in the directions defined by eigenfunctions of NTK with larger eigenvalues. Therefore, the components that are considered to have ”low complexity” empirically are actually eigenfunctions of NTK with large eigenvalues and vice versa for components of high complexity. The detrimental effects of spectral bias can be exacerbated by two primary factors: first, the target function inherently possesses significant components of high complexity, and second, there is a substantial disparity in the magnitudes of the NTK’s eigenvalues.
In the context of PINNs, the objective function corresponds to the solution of the PDE, rendering improvements in this aspect particularly challenging. A more promising avenue lies in refining the network architecture to ensure that the NTK exhibits a more favorable eigenvalue distribution. Several efforts have been made in this domain, such as the implementation of Fourier feature embedding [35, 20] and strategic weight balancing to harmonize the disparate components of the loss function [36].
Different from the l2 loss in standard NTK theory, PINNs generally consider the following physics informed loss
for PDE
In this paper, we only focus on the loss related to the interior euqation and neglect the boundary conditions, i.e.
This loss function may be adopted when is a closed manifold or the boundary conditions are already hard constraints on neural networks [8]. We first demonstrate the convergence of the neural network kernel at initialization. While most previous works only consider shallow networks. The idea based on functional analysis in [15] is applied so that we can process arbitrary high-order differential operator and deep neural networks. Another benefit of this approach is that we can show that the NTK related to is exactly where is the NTK for l2 loss . With this connection, we analyze the impact of on the decay rate of the NTK’s eigenvalues, which affects the convergence and generalization of the related kernel regression [26, 25]. We found that the additional differential operator in the loss function does not lead to a stronger spectral bias. Therefore, to improve the performance of PINNs from a spectral bias perspective, particular attention should be paid to the equilibrium among distinct components within the loss function [36, 27]. For the convergence in training, we present a sufficient condition for general and neural networks. This condition is verified in a simple but specific case. Through these results, we hope to advance the theoretical foundations of PINNs and pave the way for their broader application in scientific computing.
The remainder of the paper is organized as follows. In Section 2, we introduce the function space we consider, the settings of neural networks, and some previous results of the NTK theory. All theoretical results are demonstrated in Section 3, including the convergence of NTK during initialization and training and the impact of the differential operator within the loss on the spectrum of NTK. In Section 4, we design some experiments to verify our theory. Some conclusions are drawn in Section 5.
2 Preliminary
In this section, we introduce the basic problem setup including the function space considered and the neural network structure, as well as some background on the NTK theory.
2.1 Continuously Differential Function Spaces
Let be a compact set, be a integer and be the -fold index set,
We denote and . Then, the -times continuously differentiable function space is defined as
If , we disregard for simplicty. The same applies to the following function spaces. can be equipped with norm
For a contant , we also define
and
is the familiar Lipschitz function space. can also be equipped with norm
For a function of two variables , we denote as a differential operator with respect to , and similarly for . We have analogous definitions,
with norm
and
with norm
With the chain rule and the fact that the composition of Lipschitz functions is still Lipschitz, the following lemmas can be verified.
Lemma 2.1.
Let , be two compact sets. Let and be two maps. Then, is also a map. And there exists a constant only depending on , and such that
Lemma 2.2.
Let , be two compact sets. Let and be of class and respectively. Then, is also a map. And there exists a constant only depending on , and such that
2.2 Settings of Neural Network
Let the input where is a convex bounded domain and the output . Let , be the width of hidden layers and . Define the pre-activations for by
| (1) |
where are the weights and is the activation function satisfying the following assumption for some non-negative integer.
Assumption 1.
There exists a nonnegative integer and positive constants such that activation and
for all .
The output of the neural network is then given by . Moreover, denoting by the -th component of , we have
We denote by the collection of all parameters flatten as a column vector. For simplicity, we also write . The neural network is initialized by i.i.d random variables. Specifically, all elements of are i.i.d with mean and variance .
In this paper, we consider to train neural network (1) with gradient descent and the following physics informed loss
| (2) |
where samples and is a known linear differential operator.
2.3 Training Dynamics
When training neural network with loss (2), the gradient flow is given by
Assuming that is sufficiently smooth, denoting , we have
Define the time-varying neural network kernel (NNK)
| (3) |
Then the gradient flow of is just
| (4) |
NTK theory suggests that this training dynamic of is very similar to that of kernel regression when neural network is wide enough. And is expected to converge to a time-invariant kernel as width tends to infinity. If this assertion is true, we can consider the approximate kernel gradient flow of by
| (5) |
where the initialization is not necessarily identically zero. This gradient flow can be solved explicitly by
where .
2.4 NTK Theory
When in (2) is the identity map (denoted by ), the training dynamic (4) has been widely studied with the NTK theory [18]. This theory describes the evolution of neural networks during training in the infinite-width limit, providing insight into their convergence and generalization properties. It shows that the training dynamics of neural networks under gradient descent can be approximated by a kernel method defined by the inner product of the network’s gradients. This theory has spurred extensive research, including studies on the convergence of neural networks with kernel dynamics [4, 2, 9, 24, 1], the properties of the NTK [13, 5, 26], and its statistical performance [2, 17, 23]. By bridging the empirical behavior of neural networks with their theoretical foundations, the NTK provides a framework for understanding gradient descent dynamics in function space. In this section, we review some existing conclusions that are significant in deriving our results.
The random feature and neural tangent kernel
For the finite-width neural network (1), let us define the random feature kernel and the neural tangent kernel for by
Note here that is deterministic and is random. Since , we denote .
Moreover, for the kernels associated with the infinite-width limit of the neural network, let us define
and the recurrence formula for ,
| (6) |
where the matrix is defined as:
The smoothness of the kernel and can be derived by the regularity of the activation function . The proof is presented in Section A.
Convergnce of NNK
The most basic and vital conclusion for NTK is that NNK defined as (3) converges to a time-invariant kernel when the width of the neural network tends to infinity.
Convergence at initialization
As the width tends to infinity, it has been demonstrated that the neural network converges to a Gaussian process at initialization.
Lemma 2.5 ([15]).
Fix a compact set . As the hidden layer width tends to infinity, the sequence of stochastic processes converges weakly in to a centered Gaussian process with covariance function .
3 Main Results
In this section, we present our main results. We first establish a general theorem concerning the convergence of NTKs at initialization. A sufficient condition for convergence in training is proposed and validated in some simple cases. Finally, leveraging the aforementioned results, we examine the impact of differential operators within the loss function on the spectral properties of the NTK.
3.1 Convergence at initialization
Let be a metric space and be random variables taking values in . We recall that converges weakly to in , denoted by , iff
The first result is to show that if the activation function has a higher regularity, we can generalize Lemma 2.4 to the case of weak convergence in .
Theorem 3.1 (Convergence of initial function).
Let be a compact set. is an integer. satisfies Assumption 1 for . For any satisfying , fixed , fixing , as , the random process
converge weakly in to a Gaussian process in whose components are i.i.d. and have mean zero and covariance kernel .
With the aid of Theorem 3.1, the uniform convergence of NNK at initialization is demonstrated as follows.
Theorem 3.2.
Let be a convex compact set. is an integer. satisfies Assumption 1 for . For any satisfying , fixed , fixing , as sequentially, we have
| (7) |
under
Proof.
The proof is completed by induction. When , for any ,
Suppose that as , we have
For any ,
| (8) | ||||
With the induction hypothesis and Theorem 3.1, for any fixed , as sequentially,
under where is a Gaussian process in whose components are i.i.d. and have mean zero and covariance kernel . With weak law of large number, we obtain the finite-dimensional convergence
for any finite set . What we still need to prove is that for any ,
for some not depending on with probability at least . Suppose that this control holds. Then, with the finite-dimensional convergence and Lemma B.2, we obatin the conclusion (7). Note that is convex. We have
With the basic inequality , assumption for and Proposition B.7, we have
and
for any satisfying . With the induction hypothesis and Theorem 3.1, for any ,
Hence, there exists a constant not depending on and such that
and
For the second term on the right of (8), we do the decomposition,
For the terms on the right, it is similar to demonstrate that for any , there exists constants and such that
and
| (9) |
where both not depneding on . We define a map where the components of are given by
Then, with (9), for any , there exsits a constant such that
Using Lemma B.4 for the map , and Lemma 2.2(for details, it is similar to the proof of Lemma B.5), there also exists a constant such that
∎
There is no additional obstacle to generalize Theorem 3.2 to general linear differential operators.
Proposition 3.3.
Let be a convex compact set. is an integer. satisfies Assumption 1 for . For any satisfying and , fixed , fixing , as sequentially, we have
under
3.2 Convergence in training
In the following, we will use for the 2-norm of a vector and for the Frobinuous norm of a matrix. Moreover, let us shorthand . We also define as the NTK dynamics (5) with initialization .
To control the training process, we first assume the following condition and establish the convergence in the training process. We will present in Lemma 3.8 that this condition is verified for the neural network with and , while extension to general cases is straightforward but very cumbersome.
Condition 3.4 (Continuity of the gradient).
There are a function satisfying as and a monotonically increasing function such that for any , when
| (10) |
we have
The following theorem shows the uniform approximation (over ) between the training dynamics of the neural network and the corresponding kernel regression under the physics informed loss. The general proof idea follows the perturbation analysis in the NTK literature [4, 3, 1, 26], as long as we regard as a whole.
Theorem 3.5 (NTK training dynamics).
Remark 3.6.
To prove Theorem 3.5, we first show that a perturbation bound of the weights can imply a bound on the kernel function and the empirical kernel matrix.
Proposition 3.7.
Proof.
We note that
so the result just follows from the fact that
where we can substitute , , , and apply the conditions. ∎
Proof of Theorem 3.5.
The proof resembles the perturbation analysis in [4] but with some modifications. Using Theorem 3.1 and Theorem 3.2, there are constants such that the following holds at initialization with probability at least when is large enough:
| (14) | ||||
| (15) | ||||
| (16) |
Let be arbitrary. Using the (15) and also Proposition 3.7, we can choose some such that when ,
| (17) |
Combining them with (14) and (15) , we have
| (18) |
for some absolute constant , and
| (19) |
Now, we define
Using the gradient flow (4), we find that
so (19) implies that
Furthermore, we recall the gradient flow equation for that
so when , for any , we have
where we used the (18) in the last inequality. Now, as long as is large enough that
an argument by contradiction shows that .
Now we have shown that holds for all , so the last inequality in (17) gives
Therefore, a standard perturbation analysis comparing the ODEs (4) and (5) yields the conclusion, see, e.g., Proof of Lemma F.1 in [4].
∎
In some simple cases, we can verify Condition 3.4 in a direct way.
Lemma 3.8.
Proof.
In this case, the neural network is defined as
Hence,
and
| (20) | ||||
We only need to demonstrate that for any , there exists and such that with probability at least , we have
for any and satisfying
For the last two terms to the right of (20), we can draw a similar conclusion using the same method since is a fixed integer and is a compact set. In fact, we first do the decomposition,
Note that
And with Assumption 1, denoting , we have
With Assumption 1, the fact that is compact and any moments of is finite, we have, for any ,
and similar conclusions for any summation above not depending on . Hence, for any , there exists a constant not depending on such that with probability at least ,
Therefore, selecting where and sufficiently small, we can obtain the conclusion. ∎
3.3 Impact on the Spectrum
In the previous section, we demonstrate that the NTK related to the physics-informed loss (2) is where is the NTK of the traditional l2 loss. In this section, we present some analysis and numerical experiments to explore the impact of differential operator on the spectrum of integral operator with kernel . Define as the integral operator with kernel , which means that for all ,
Since is compact and self-adjoint, it has a sequence of real eigenvalues tending to zero. In addition, we denote as the eigenvalue of . Then, the following lemma shows that for a large class of , the decay rate of is not faster than that of .
Lemma 3.10.
Suppose that . Let be symmetric, i.e.
for all and satisfy
Then,
Proof.
With the definition, for all ,
Note that is dense in . Hence,
Moreover,
Therefore,
∎
4 Experiments
In this section, we present experimental results to verify our theory. Throughout the task, data are sampled uniformly from .
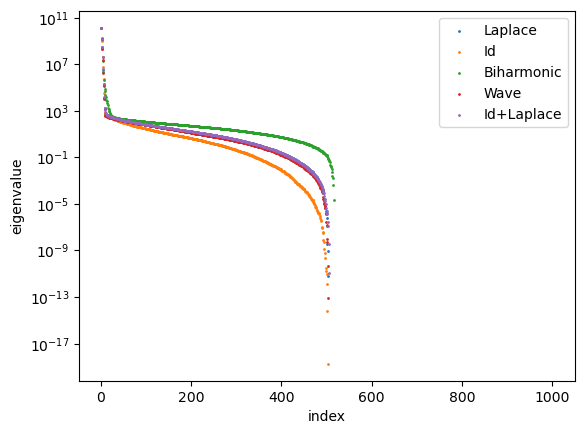
In Section 3.3, we show that the differential operator in the loss function does not make the decay rate of the eigenvalue of the integral operator related to the NTK faster. A natural inquiry arises as to whether this phenomenon persists for the NTK matrix , which is closer to the neural network training dynamics (4). We employ the network structure described in (1) with depth and width . All parameters are initialized as independent standard normal samples. Let . For , we select . For , we select . The activation function is Tanh or , i.e. . The eigenvalues of at initialization are shown in Figure 1. Normalization is adopted to ensure that the largest eigenvalues are equal. A common phenomenon is that the higher the order of the differential operator , the slower the decay of the eigenvalues of , which aligns with our theoretical predictions.



The influence of differential operators within the loss function on the actual training process is also of considerable interest. We consider to approximate on with positive integer and three distinct loss functions,
where is a smooth distance function to ensure that fulfills the homogeneous Dirichlet boundary condition [8] and is the standard loss of PINNs with weight . In this task, we adopt a neural network setting that is more closely aligned with scenarios in practice. The network architecture in (1) is still used, but with the addition of bias terms. The parameter initialization follows the default of nn.Linear() in Pytorch. Let , , and the activation function be Tanh. We employ the Adam algorithm to train the network with learning rate 1e-5 and the nomarlized loss function for . The training loss for different is shown in Figure 2. For small such as , the l2 loss decays fastest at the beginning of the training process. As increases, the decrease rate of slows down due to the constraints imposed by the spectral bias. In comparison, the loss is less affected. This corroborates that the additional differential operator in the loss function does not impose a stronger spectral bias on the neural network during training. This behavior is also observed in standard PINNs with different weights .




5 Conclusion
In this paper, we develop the NTK theory for deep neural networks with physics-informed loss. We not only clarify the convergence of NTK during initialization and training, but also reveal its explicit structure. Using this structure, we prove that, in most cases, the differential operators in the loss function do not cause the neural network to face a stronger spectral bias during training. This is further supported by experiments. Therefore, if one wants to improve the performance of PINNs from the perspective of spectral bias, it may be more beneficial to focus on spectral bias caused by different terms of loss, as demonstrated in [36]. This does not mean that PINNs can better fit high-frequency functions. In fact, its training loss still decays slower when fitting a function with higher frequency, as shown in Figure 2. In instances where the solution exhibits pronounced high-frequency or multifrequency components, it is imperative to implement interventions to enhance the performance of PINNs [16, 20, 35]. It is also important to emphasize that spectral bias is merely one aspect of understanding the limitations of PINNs, and physics-informed loss has other drawbacks, such as making the optimizing problem more ill-conditioned [22]. Hence, the addition of higher-order differential operators to address the spectral bias in the loss function is not recommended.
References
- [1] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization, June 2019.
- [2] Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In International Conference on Machine Learning, pages 322–332. PMLR, 2019.
- [3] Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In International conference on machine learning, pages 322–332. PMLR, 2019.
- [4] Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [5] Alberto Bietti and Francis Bach. Deep equals shallow for ReLU networks in kernel regimes. arXiv preprint arXiv:2009.14397, 2020.
- [6] Andrea Bonfanti, Giuseppe Bruno, and Cristina Cipriani. The challenges of the nonlinear regime for physics-informed neural networks. Advances in Neural Information Processing Systems, 37:41852–41881, 2025.
- [7] Yuan Cao, Zhiying Fang, Yue Wu, Ding-Xuan Zhou, and Quanquan Gu. Towards understanding the spectral bias of deep learning. arXiv preprint arXiv:1912.01198, 2019.
- [8] Jiaxin Deng, Jinran Wu, Shaotong Zhang, Weide Li, You-Gan Wang, et al. Physical informed neural networks with soft and hard boundary constraints for solving advection-diffusion equations using fourier expansions. Computers & Mathematics with Applications, 159:60–75, 2024.
- [9] Simon S. Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. In International Conference on Learning Representations, September 2018.
- [10] Lawrence C Evans. Partial differential equations, volume 19. American Mathematical Society, 2022.
- [11] Olga Fuks and Hamdi A Tchelepi. Limitations of physics informed machine learning for nonlinear two-phase transport in porous media. Journal of Machine Learning for Modeling and Computing, 1(1), 2020.
- [12] Amnon Geifman, Meirav Galun, David Jacobs, and Basri Ronen. On the spectral bias of convolutional neural tangent and gaussian process kernels. Advances in Neural Information Processing Systems, 35:11253–11265, 2022.
- [13] Amnon Geifman, Abhay Yadav, Yoni Kasten, Meirav Galun, David Jacobs, and Basri Ronen. On the similarity between the Laplace and neural tangent kernels. In Advances in Neural Information Processing Systems, volume 33, pages 1451–1461, 2020.
- [14] Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018.
- [15] Boris Hanin. Random neural networks in the infinite width limit as Gaussian processes. arXiv preprint arXiv:2107.01562, 2021.
- [16] Saeid Hedayatrasa, Olga Fink, Wim Van Paepegem, and Mathias Kersemans. k-space physics-informed neural network (k-pinn) for compressed spectral mapping and efficient inversion of vibrations in thin composite laminates. Mechanical Systems and Signal Processing, 223:111920, 2025.
- [17] Tianyang Hu, Wenjia Wang, Cong Lin, and Guang Cheng. Regularization matters: A nonparametric perspective on overparametrized neural network. In International Conference on Artificial Intelligence and Statistics, pages 829–837. PMLR, 2021.
- [18] Arthur Jacot, Franck Gabriel, and Clement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
- [19] Ameya D Jagtap and George Em Karniadakis. Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations. Communications in Computational Physics, 28(5), 2020.
- [20] Ge Jin, Jian Cheng Wong, Abhishek Gupta, Shipeng Li, and Yew-Soon Ong. Fourier warm start for physics-informed neural networks. Engineering Applications of Artificial Intelligence, 132:107887, 2024.
- [21] Olav Kallenberg. Foundations of Modern Probability. Number 99 in Probability Theory and Stochastic Modelling. Springer, Cham, Switzerland, 2021.
- [22] Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. Advances in neural information processing systems, 34:26548–26560, 2021.
- [23] Jianfa Lai, Manyun Xu, Rui Chen, and Qian Lin. Generalization ability of wide neural networks on R, February 2023.
- [24] Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [25] Yicheng Li, Weiye Gan, Zuoqiang Shi, and Qian Lin. Generalization error curves for analytic spectral algorithms under power-law decay. arXiv preprint arXiv:2401.01599, 2024.
- [26] Yicheng Li, Zixiong Yu, Guhan Chen, and Qian Lin. On the eigenvalue decay rates of a class of neural-network related kernel functions defined on general domains. Journal of Machine Learning Research, 25(82):1–47, 2024.
- [27] Qiang Liu, Mengyu Chu, and Nils Thuerey. Config: Towards conflict-free training of physics informed neural networks. arXiv preprint arXiv:2408.11104, 2024.
- [28] Athanasios Papoulis and S Unnikrishna Pillai. Probability, random variables, and stochastic processes. McGraw-Hill Europe: New York, NY, USA, 2002.
- [29] Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. In International conference on machine learning, pages 5301–5310. PMLR, 2019.
- [30] Maziar Raissi. Deep hidden physics models: Deep learning of nonlinear partial differential equations. Journal of Machine Learning Research, 19(25):1–24, 2018.
- [31] Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019.
- [32] Basri Ronen, David Jacobs, Yoni Kasten, and Shira Kritchman. The convergence rate of neural networks for learned functions of different frequencies. Advances in Neural Information Processing Systems, 32, 2019.
- [33] Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations. Journal of computational physics, 375:1339–1364, 2018.
- [34] Roman Vershynin. High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47. Cambridge university press, 2018.
- [35] Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 384:113938, 2021.
- [36] Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449:110768, 2022.
- [37] Jon Wellner et al. Weak convergence and empirical processes: with applications to statistics. Springer Science & Business Media, 2013.
- [38] Zhi-Qin John Xu, Yaoyu Zhang, and Yanyang Xiao. Training behavior of deep neural network in frequency domain. In Neural Information Processing: 26th International Conference, ICONIP 2019, Sydney, NSW, Australia, December 12–15, 2019, Proceedings, Part I 26, pages 264–274. Springer, 2019.
- [39] Lei Yuan, Yi-Qing Ni, Xiang-Yun Deng, and Shuo Hao. A-pinn: Auxiliary physics informed neural networks for forward and inverse problems of nonlinear integro-differential equations. Journal of Computational Physics, 462:111260, 2022.
- [40] Yinhao Zhu, Nicholas Zabaras, Phaedon-Stelios Koutsourelakis, and Paris Perdikaris. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. Journal of Computational Physics, 394:56–81, 2019.
Appendix A Smoothness of the NTK
In this section, we verify the smoothness of kernel and defined as (6). For the convenience of reader, we first recall the definition.
and for ,
where the matrix is defined as:
Proposition A.1.
Let be two functions that . Denoting
Then,
Proof.
Denote by the Hermite polynomial basis with respect to the normal distribution. Let us consider the Hermite expansion of :
and also :
Using the fact that , we derive and for .
Now, we use the fact that for to obtain
and thus
∎
Lemma A.2.
Proof.
We first prove the case for . Let us consider parameterizing
where and . Then,
Consequently,
Then, using Assumption 1, we have
for some constant . For , we apply Proposition A.1 to get
Hence,
for some constant .
Now, using , and , it is easy to see that the partial derivatives , and are bounded by a constant depending only on . Applying the chain rule finishes the proof for .
Finally, the case of general follows by induction with replaced.
∎
Appendix B Auxiliary results
The following lemma gives a sufficient condition for the weak convergence in .
Lemma B.1 (Convergence of processes).
Let be an open set. Let be random processes with paths a.s. and be a Gaussian field with mean zero and covariance kernel. Denote by the derivative with respect to for multi-index . Suppose that
-
1.
For any , the finite dimensional convergence holds:
-
2.
For any satisfying and , there exists such that
-
3.
For any satisfying and , there exists such that
Then, for any compact set and satisfying , we have
Proof.
With condition 2, 3 for and condition 1 (We refer to [21, Section 23] for more details),
which is equivalent to
for any bounded, nonnegative and Lipschitz continuous (see, for example, in Theorem 1.3.4 of [37]). For satisfying , condition also derive the tightness of . Hence, we only need to show the finite dimensional convergence:
| (21) |
for any . For large enough , define smoothing map
where is a kernel with compact support set satisfying . is the scaled kernel. For any satisfying , denote . Define . With condition 2, for any , we can select large enough so that for all . For any bounded, nonnegative and Lipschitz continuous , we have
| (22) | ||||
For the next part, we first consider satisfying . Without loss of generality, we can assume that . Since is a Gaussian field, exists in the sense of mean square(see, for example, Appendix 9A in [28]), i.e.
where . Moreover, this convergence is uniform with respect to since covariance kernel of belongs to . Therefore, we can demonstrate that
| (23) |
for any . In fact,
Hence,
Since is also a Gaussian field, it a.s. has uniformly continuous path . As a result,
as . Note that with Proposition B.7,
which means that is uniformly integrable and
Combining with (23), we have
| (24) |
as . For any fixed , note that is still a bounded, nonnegative and Lipschitz continuous functional in . We have
The finite dimensional convergence (21) is obtained for . The general situation can be processed by induction with respect to . ∎
Lemma B.2 (Convergence of processes).
Let be an open set. Let be random processes with paths a.s. and be a deterministic function. Denote by the derivative with respect to for multi-index . Suppose that
-
1.
For any , the finite dimensional convergence holds:
-
2.
For any satisfying and , there exists such that
-
3.
For any satisfying and , there exists such that
Then, for any compact set and satisfying , we have
Proof.
Let us recall our structure of neural network (1),
where . For the components,
And the NNK is defined as
Lemma B.3.
Fix an even integer . Suppose that is a probability measure on with mean and finite higher moments. Assume also that is a vector with i.i.d. components, each with distribution . Fix an integer . Let be a compact set in . And is the image of under a map with . Then, there exists a constant such that for all ,
Proof.
For any fixed ,
With Lemma 2.9 and Lemma 2.10 in [15], both two terms on the right can be bounded by a constant not depending on . ∎
Lemma B.4.
Fix an integer . Let be a compact set in . Consider a map defined as
where with components drawn i.i.d. from a distribution with mean 0, variance 1 and finite higher moments. and is the image of under a map with . satisfies Assumption 1. Then, for any , there exists a positive constant such that
with probability at least .
Proof.
Lemma B.5.
Proof.
Lemma B.6.
Proposition B.7.
Let be a centered Gaussian process on a compact set with covariance function . Suppose that is Holder-continuous, then for any we have
| (25) |
Proof.
It is a standard application of Dudley’s integral, see Theorem 8.1.6 in [34]. Since is Holder-continuous, the canonical metric of this Gaussian process
is also Holder-continuous. Consequently, the covering number and the Dudley’s integral is finite. The results then follow from the tail bound
∎