2.4cm2.0cm3.2cm3.0cm
Nâng cao hiệu quả ước lượng ảnh chiều sâu cho robot lặn kết hợp xử lý ảnh và học máy
Abstract
Ngày nay, thông tin độ sâu có vai trò quan trọng trong hệ thống tự trị nhận biết môi trường và ước tính trạng thái của robot. Với sự phát triển nhanh chóng của công nghệ mạng lưới thần kinh sâu, ước tính độ sâu đã được nghiên cứu rộng rãi và chứng minh được tiềm năng ứng dụng trong thực tế. Tuy nhiên, đối với môi trường đặc biệt khó khăn khi cường độ ánh sáng thấp và nhiễu như môi trường dưới nước, việc áp dụng trực tiếp các mô hình học máy có thể không mang lại hiệu quả như mong đợi. Do đó, trong bài báo này chúng tôi trình bày phương pháp cải thiện chất lượng hình ảnh trong môi trường dưới nước nhằm nâng cao hiệu quả ước lượng chiều sâu. Đầu tiên, hình ảnh dưới nước được xử lý thông qua các phương pháp bù màu, cân bằng sáng đồng thời làm tăng độ tương phản, độ nét của các vật thể trong hình. Sau đó, chúng tôi triển khai ước lượng ảnh chiều sâu thông qua mô hình Udepth đối với ảnh đã cải thiện. Cuối cùng, các kết quả được đánh giá và trình bày nhằm kiểm nghiệm hiệu quả cũng như độ chính xác của phương pháp cải thiện chất lượng hình ảnh chiều sâu cho robot lặn.
Index Terms:
Ảnh chiều sâu, cải thiện chất lượng hình ảnh, ước lượng ảnh chiều sâu.I GI´I THI.U
Với sự phát triển của khoa học công nghệ, robot đã dần được ứng dụng vào những nhiệm vụ thám hiểm, đặc biệt là các robot lặn dùng trong nhiệm vụ khám phá đại dương [1], [2]. Hoạt động trong môi trường đặc biệt như môi trường dưới nước nên robot thám hiểm thường đòi hỏi nguồn thông tin lớn về môi trường, đia hình hay sinh vật. Vì vậy, việc ước lượng hình ảnh chiều sâu trong môi trường dưới nước [1], [3] đã được nghiên cứu nhằm cung cấp thêm thông tin cho các nhiệm vụ như tái tạo địa hình 3D, điều hướng điều khiển của robot. Trước đây, các nghiên cứu xây dựng ước tính chiều sâu thường sử dụng các dạng cảm biến như Sonar [4] hay máy quét Laser [5]. Nhưng với việc chịu ảnh hưởng của nhiễu do hệ thống sinh vật dưới nước hay các phương tiện di chuyển đường biển và các hiện tượng như khúc xạ, phản xạ ánh sáng mà hiệu quả thường khá thấp. Do đó, sử dụng hình ảnh RGB trong việc tính toán chiều sâu môi trường dưới nước ngày càng được quan tâm và có nhiều bước phát triển trong các nghiên cứu [3], [6]. [7].
Không giống như robot trên mặt đất, robot dưới nước bị hạn chế bởi dẫn đường trực quan do hiện tượng hấp thụ và tán xạ ánh sáng [8]. Do đó, việc tăng chất lượng ảnh dưới nước đóng vai trò quan trọng. Các phương pháp nâng cao hình ảnh dưới nước cải thiện chất lượng hình ảnh bằng cách thay đổi giá trị của điểm ảnh. Nhiều phương pháp được mô tả trong các nghiên cứu như phương pháp chỉnh sửa màu sắc của hình ảnh dưới nước thông qua mô hình học không giám sát [9], phương pháp dựa trên Retinex để hiệu chỉnh màu sắc và tăng cường độ tương phản của hình ảnh dưới nước [10] hay đề xuất về phương pháp làm mờ hình ảnh dựa trên tích chập đa kênh MSRCR để nâng cao chất lượng hình ảnh dưới nước [11]. Các phương pháp cải thiện chất lượng hình ảnh dưới nước trên có những ưu điểm rõ ràng để cải thiện độ tương phản và độ sáng của hình ảnh dưới nước, đồng thời có ưu điểm là nhanh hơn và đơn giản hơn các phương pháp khôi phục hình ảnh dưới nước khác.
Các phương pháp ước lượng chiều sâu sử dụng mono-camera [12], [13] thường là các mô hình hình học dựa trên các cấu trúc chuyển động, stereo thị giác và kết hợp tính năng đa góc nhìn. Các phương pháp này yêu cầu sự tương ứng phù hợp và sức mạnh tính toán đáng kể, tuy nhiên chỉ tạo ra thông tin có chiều sâu thưa thớt. Từ những khó khăn đó, các phương pháp ứng dụng học máy được phát triển [14], [7]. Các mô hình học máy có thể học cách suy ra các bản đồ độ sâu dày đặc từ các hình ảnh RGB đơn lẻ. Từ đó làm tăng hiệu quả ước lượng thông tin chiều sâu trong hình ảnh.
Tuy nhiên, những hạn chế về dữ liệu chuẩn trong môi trường dưới nước, độ phức tạp trong quá trình xử lý và ước lượng hình ảnh cũng như những khó khăn về việc ước lượng tỷ lệ ranh giới độ sâu của các đối tượng trong hình ảnh. Để giải quyết những vấn đề trên, bài báo trình bày tập trung vào hai đóng góp chính như sau:
-
1.
Đề xuất phương pháp cải thiện chất lượng hình ảnh dựa trên quá trình cân bằng màu sắc và tăng cường độ tương phản, sắc nét cho vật thể trong hình.
-
2.
´ng dụng kết hợp mô hình học máy Udepth và quá trình xử lý ảnh trong ước lượng ảnh chiều sâu.
Cấu trúc của bài báo được sắp xếp theo thứ tự như sau: phần II và phần III lần lượt trình bày mô hình ước lượng ảnh chiều sâu và quá trình cải thiện chất lượng ảnh đầu vào dựa trên các thuật toán xử lý ảnh. Phần IV mô tả về tập dữ liệu huấn luyện và những kết quả đã đạt được cũng như so sánh với những mô hình liên quan. Cuối cùng, kết luận và đánh giá được nêu rõ trong phần V.
II Mô hình ước lượng ảnh chiều sâu
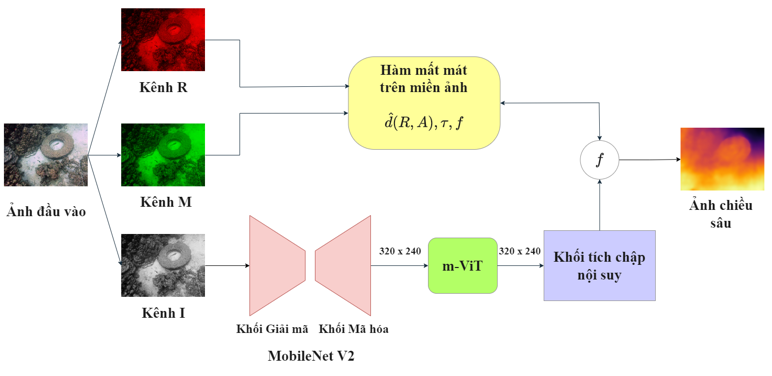
Trong phần này, chúng tôi trình bày mô hình học máy UDepth [15] như được minh họa trong Hình 1. Đây là mô hình sử dụng hình ảnh RGB để ước lượng chiều sâu của các vật thể trong hình từ mô hình tham chiếu đã được huấn luyện. Kiến trúc mạng của mô hình ước lượng ảnh chiều sâu bao gồm ba thành phần chính: Bộ mã hóa (Encoder) và giải mã (Decoder) dựa theo cấu trúc mạng MobileNetV2, Khối biến đổi m-Vision Transformer và Khối tích chập nội suy. Các thành phần này được liên kết tuần tự để thực hiện học có giám sát nhằm ước lượng chiều sâu hình ảnh.
II-A Định dạng không gian ảnh đầu vào
Không gian hình ảnh đầu vào sẽ được chia thành các kênh R - kênh đơn sắc đỏ, kênh M - kênh biểu thị giá trị điểm ảnh lớn nhất giữa kênh đơn sắc xanh lá và xanh dương, kênh I - kênh biểu thị cường độ xám của hình ảnh. Mối tương quan giữa hai kênh R và kênh M là thông tin quan trong trong mô hình học ước lượng ảnh chiều sâu. Kênh I đóng vai trò cung cấp thông tin cường độ xám qua các mạng mã hóa MobileNetV2 và bộ biến đổi mViT để trích suất các thông tin về độ sâu của các điểm ảnh.
II-B MobileNetV2 Backbone
Mô hình ước lượng sử dụng bộ mã hóa và giải mã MobileNetV2. Mạng MobileNetV2 nhanh hơn đáng kể so với các lựa chọn thay thế SOTA khác mà chỉ có ảnh hưởng nhỏ về hiệu suất, điều này giúp cho việc triển khai với các robot hay thiết bị thực tế trở nên khả thi. Bộ mã hóa và giải mã được thế kế theo các lớp có dạng cổ chai ở cuối bộ mã hóa và đầu bộ giải mã. Các lớp mở rộng trung gian sử dụng các phép tích chập theo chiều sâu nhẹ để lọc các đặc điểm như một nguồn phi tuyến tính. Các lớp cuối cùng của bộ giải mã đã được điều chỉnh lớp giải mã tích chập cuối cùng để cuối cùng nó tạo ra 48 bộ lọc có độ phân giải 320 × 480, với đầu vào 3 kênh RMI.
II-C Khối biến đổi mViT
ViT là khối biến đổi Vision được lấy ý tưởng từ kiến trúc Transformer và các khối MLP (Multilayer Perceptron). ViT mang lại hiệu quả khá tốt khi so sánh với CNN nhưng cũng có hạn chế về kích thước mô hình và độ trễ không phù hợp với các nhiệm vụ yêu cầu độ nhanh và thời gian thực. Do đó, một dạng ViT được phát triển là mViT. Điểm khác biệt của mViT là mỗi patch thông thường sẽ được chia thành 9 m-patch nhỏ hơn , m-patch trung tâm sẽ khai thác thông tin từ các m-patch xung quanh và sẽ đại diện cho patch lớn đó. Các m-patch sẽ đóng vai trò như các patch đầu vào của mViT. Nhờ vậy sẽ làm giảm kích thước mô hình hơn bằng cách sử dụng ưu điểm của khổi Biến đổi và khối Tích chập. Khổi MLP sẽ nhận đầu vào là vectơ trạng thái từ mViT Encoder đưa ra vectơ đặc trưng .
II-D Khối tích chập nội suy
Cuối cùng, khối tích chập nội suy kết hợp các giá trị tập trung trong phạm vi patch và các vectơ đặc trưng để tạo ra hình ảnh đặc trưng . Để tránh sự rời rạc của các giá trị độ sâu, ước lượng của ảnh độ sâu D được tính bằng tổ hợp tuyến tính với giá trị , được biểu diễn trong công thức (1) như sau:
| (1) |
II-E Hàm mất mát mục tiêu
II-E1 Hàm bình phương sai số
Hàm bình phương sai số được sử dụng nhằm thực hiện tối ưu hóa giá trị sai số giữa ảnh ước lượng và ảnh tham chiếu được mô tả trong công thức (2) dưới đây, với N là tổng số lượng giá trị điểm ảnh:
| (2) |
II-E2 Hàm mất mát dữ liệu
Trong quá trình ước lượng ảnh chiều sâu, thông tin chiều sâu được thu thập chủ yếu trong các vùng hình ảnh vật thể gần với camera và khá thưa thớt trong các vùng không có vật thể hay vật thể ở xa camera. Điều đó có thể gây ra sai sót trong quá trình ước lượng chiều sâu. Để giảm bớt vấn đề mất cân bằng, hàm mất mát dữ liệu đươc trình bày trong công thức (3) thực hiện tính toán sự khác biệt giữa các giá trị độ sâu dự đoán với giá trị ground truth trong miền logarit:
| (3) |
Trong đó, . Giá trị cân bằng và hệ số được xác định trong nghiên cứu [16].
II-E3 Hàm mất mát trên miền ảnh
Hàm mất mát trên miền ảnh được xây dựng từ mối tương quan giữa kênh màu R-M với giá trị điểm ảnh chiều sâu. Giá trị tương quan giữa các giá trị điểm ảnh trong hai kênh R và kênh M được mô tả như một hàm tuyến tính trong công thức (4):
| (4) |
Sau đó thực hiện tối ưu hóa giá trị bằng hàm tối ưu giá trị bình phương nhỏ nhất trong công thức (5):
| (5) |
Cuối cùng, hàm mất mát trên miền ảnh được trình bày trong công thức (6):
| (6) |
III Cải thiện chất lượng hình ảnh đầu vào trong môi trường dưới nước
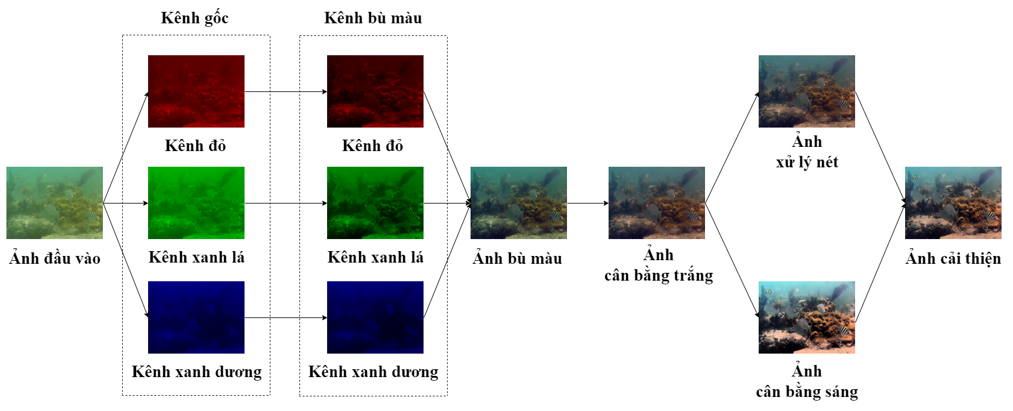
Hình ảnh trong môi trường dưới nước thường có những dặc điểm rất đặc trưng như bị lóa sáng hay tối sáng do hiện tượng khúc xạ, bị biến dạng màu sắc do sự hấp thụ ánh sáng. Những đặc điểm đó đã ảnh hưởng tới hiệu quả ước lượng chiều sâu. Trong phần này, chúng tôi trình bày về phương pháp cải thiện hiệu suất ước lượng ảnh chiều sâu dựa trên phương pháp xử lý ảnh theo cấu trúc trong Hình 2.
Hình ảnh đầu vào sẽ được chia tách thành ba kênh màu là kênh đỏ, kênh xanh dương và kênh xanh lá, sau đó thực hiện bù màu xanh lá cho các kênh màu đỏ và xanh dương. Tại mỗi điểm ảnh của kênh đỏ và kênh xanh dương chúng tôi thực hiện bù màu trong công thức (8) và (9):
| (8) |
| (9) |
Trong đó, , và biểu thị cho giá trị màu tại điểm của các kênh đỏ, kênh xanh dương và kênh xanh lá; , và là các giá trị trung bình của , và .
Sau khi tiến hành quá trình bù màu cho các kênh đỏ và xanh dương, ảnh sẽ được chỉnh sửa màu và cân bằng trắng bởi thuật toán Gray Wolrd. Thuật toán Gray Wolrd tạo ra ước tính độ chiếu sáng bằng cách tính giá trị trung bình của từng kênh của hình ảnh. Ban đầu, giá trị màu ở các kênh màu đơn sẽ được lấy giá trị trung bình theo như công thức (10), (11) và (12):
| (10) |
| (11) |
| (12) |
Với các , và là các giá trị màu trung bình trong các kênh màu đơn. Sau đó, phương trình (13) và (14) thực hiện quá trình chia thành ba ngưỡng tỉ lệ với và .
| (13) |
| (14) |
Trong đó, và là các hằng số và có giá trị tối ưu hóa lần lượt là 0.005 và 0.995. Các giá trị ngưỡng trên được lượng tử hóa bởi hàm lượng tử thấp như được trình bày trong công thức (15) và (16):
| (15) |
| (16) |
Giá trị là giá trị màu RGB trong tại điểm ảnh . Để thực hiện quá trình loại bỏ vùng tối mờ hay vùng bóng, trên mỗi kênh màu thực hiện chuẩn hóa giá trị như mô tả trong công thức (17):
| (17) |
Khi đó, giá trị ảnh đã được cân bằng trắng và chỉnh sửa màu được tính toán theo công thức (18):
| (18) |
 |
|
 |
 |
 |
 |
 |

|
 |
 |
 |
 |

|
 |
 |
 |
 |

|
 |
 |
| Ảnh thực | Ảnh WaterNet | Ảnh Histogram | Ảnh Unsharp Marking | Ảnh kết quả |
Sau đó, hình ảnh được tăng độ tương phản và lọc nhiễu của hình ảnh nhằm tăng độ sắc nét. Độ tương phản được cải thiện bằng phương pháp lượng tử hóa histogram toàn cục (GHE). GHE là một phương pháp ở đó hình ảnh RGB được chuyển đổi sang miền HSV và thực hiện lượng tử hóa thành phần Value, giữ nguyên thành phần Hue và Saturation. Song song với đó quá trình thực hiện tăng độ sắc nét cho hình ảnh của được thực hiện. Quá trình này sử dụng kỹ thuật Unsharp Marking. Công thức (19) thể hiện phương pháp Unsharp Marking.
| (19) |
Trong đó và lần lượt là giá trị điểm ảnh tại trước khi làm nét và sau khi làm nét. Khi đó, quá trình đã có được hai dạng ảnh là ảnh được tăng độ tương phản và ảnh được tăng độ sắc nét. Cuối cùng, ảnh được cải thiện chất lượng thu được bằng các lấy giá trị trung bình của hai dạng ảnh kể trên theo công thức (20) với , và lần lượt là các giá trị điểm ảnh tại của ảnh cải thiện, ảnh tương phản và ảnh lấy nét.
| (20) |
Quá trình cải thiện chất lượng ảnh chiều sâu là quá trình tiền xử lý cho ảnh đầu vào của mô hình ước lượng ảnh chiều sâu. Quá trình này có một vai trò qua trọng việc nâng cao hiệu quả ước lượng và kết quả đánh giá.
IV K´T QUẢ
IV-A Tập dữ liệu huấn luyện
Trong quá trình huấn luyện, chúng tôi đã sử dụng bộ dữ liệu USOD10K [17] chứa hình ảnh RGB và hình ảnh chiều sâu tham chiếu cho các cảnh dưới nước khác nhau được chụp ở độ phân giải 640 × 480 điểm ảnh. Bộ dữ liệu chứa 9229 mẫu huấn luyện và 1026 mẫu thử nghiệm bao gồm các ảnh chiều sâu, ảnh RGB và các ảnh mặt nạ của các vật thể.
IV-B Thông số đánh giá
Các thông số tiêu chuẩn đánh giá được trình bài trong các công thức dưới đây:
-
•
Giá trị trung bình của sai số tương quan tuyệt đối (Abs Rel):
-
•
Sai số bình phương tương quan (Sq Rel):
-
•
Trung bình sai số bình phương gốc (RMSE):
-
•
Sai số :
Trong đó, là giá trị điểm ảnh ground truth chiều sâu , là giá trị điểm ảnh của ảnh ước lượng chiều sâu , n là số lượng điểm ảnh trong ảnh tham chiếu cũng như ảnh ước lượng.
IV-C Kết quả thực nghiệm
Bộ dữ liệu được cải thiện chất lượng qua quá trình tiền xử lý hình ảnh và huấn luyện với mô hình Udepth với khoảng hơn 16 triệu tham số. Quá trình huấn luyện được thực hiện trên máy trạm có cấu hình gồm CPU Intel Core i3-10105F, RAM Lexar 8G Buss 3200/DDR4, card đồ họa Asus Tuf GTX 1060 Super và mạch chính MSI H510M. Thời gian huấn luyện trung bình của mỗi chu trình là 26 giờ. Các kết quả được so sánh với phương pháp cải thiện chất lượng hình ảnh WaterNet, phương pháp lượng tử Histogram và phương pháp làm nét hình ảnh Unsharp Marking.
| Abs Rel | Sq Rel | RMSE | ||
|---|---|---|---|---|
| Ảnh thực | 1.379 | 0.382 | 0.376 | 0.278 |
| Ảnh WaterNet | 0.745 | 0.176 | 0.174 | 0.219 |
| Ảnh Histogram | 0.621 | 0.165 | 0.159 | 0.234 |
| Ảnh Unsharp Marking | 0.767 | 0.204 | 0.232 | 0.256 |
| Ảnh kết quả | 0.598 | 0.132 | 0.126 | 0.186 |
Từ Bảng I cho thấy kết quả của mô hình kết hợp tốt hơn với các giá trị tham số nhỏ hơn từ 8% - 10%. Giá trị sai số tuyệt đối Abs Rel và sai số tương quan Sq Rel cho thấy ảnh kết quả của phương pháp đề xuất tốt hơn giữa các chi tiết vật thể trong ảnh. Giá trị trung bình sai số RMSE thể hiện ảnh kết quả rõ ràng hơn và có giá trị chiều sâu cao hơn so với các ảnh còn lại.
Trong hình 3, hình ảnh thực bị ảnh hưởng của biến dạng màu sắc nên ảnh chiều sâu xuất hiện các cạnh mờ và không rõ các vật thể nhỏ. Hình ảnh của phương pháp đề xuất có ưu điểm là độ sắc nét hơn so với ảnh WaterNet và Unsharp Marking và có độ tương phản tốt hơn ảnh Histogram, thể hiện ranh giới độ sâu rõ ràng của các chi tiết vật thể. Từ đó cho thấy, quá trình cải thiện chất lượng hình ảnh đã giúp nâng cao hiệu quả ước lượng chiều sâu của mô hình.
Bên cạnh đó, do cần cải thiện chất lượng hình ảnh dưới nước nên khi kết hợp với mô hình ước lượng ảnh chiều sâu sẽ làm tăng thời gian tính toán ước lượng và tăng độ phức tạp của cả quá trình. Cùng với đó, những hạn chế về dữ liệu hình ảnh trong các môi trường dưới nước cũng như độ chính xác của dữ liệu hình ảnh chiều sâu tham chiếu cho quá trình huấn luyện đã làm giảm đi hiệu quả ước lượng chiều sâu và khả năng ứng trong nhiều môi trường nước khác nhau. Đây cũng là những tiền đề để mở ra những hướng cải thiện mới cho mô hình ước lượng ảnh chiều sâu.
V K´T LU.N
Trong bài báo, chúng tôi đề xuất phương pháp cải thiện chất lượng hình ảnh dưới nước dựa trên việc bù màu, cân bằng sáng và tăng độ tương phản, đô sắc nét cho hình. Phương pháp xử lý hình ảnh dưới nước trên được kết hợp với mô hình học máy ước lượng ảnh chiều Udepht đã cho thấy những kết quả khả quan trong việc ước lượng ảnh chiều sâu. Trong tương lai, chúng tôi sự định ứng dụng mô hình học sâu trong quá trình cải thiện chất lượng hình ảnh dưới nước và nâng cao độ hiệu quả của mô hình ước lượng ảnh chiều sâu để có thể sử dụng cho robot lặn trong thời gian thực.
References
- [1] F. Shkurti, A. Xu, M. Meghjani, J. C. G. Higuera, Y. Girdhar, P. Giguere, B. B. Dey, J. Li, A. Kalmbach, C. Prahacs et al., “Multi-domain monitoring of marine environments using a heterogeneous robot team,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 1747–1753.
- [2] Y. Girdhar, P. Giguère, and G. Dudek, “Autonomous adaptive exploration using realtime online spatiotemporal topic modeling,” The International Journal of Robotics Research, vol. 33, pp. 645–657, 04 2013.
- [3] B. Champion, M. Jamshidi, and M. Joordens, “Depth estimation of an underwater object using a single camera,” KnE Engineering, vol. 2, p. 112, 02 2017.
- [4] K. Mantani, T. Katayama, T. Song, and T. Shimamoto, “Depth estimation with sonar-based correction for low-cost underwater drone,” in OCEANS 2022, Hampton Roads. IEEE, 2022, pp. 1–4.
- [5] A. Palomer, P. Ridao, J. Forest, and D. Romagós, “Underwater laser scanner: Ray-based model and calibration,” IEEE/ASME Transactions on Mechatronics, vol. PP, pp. 1–1, 07 2019.
- [6] A. Mertan, D. Duff, and G. Unal, “Single image depth estimation: An overview,” Digital Signal Processing, vol. 123, p. 103441, 01 2022.
- [7] X. Ye, J. Zhang, Y. Yuan, R. Xu, Z. Wang, and H. Li, “Underwater depth estimation via stereo adaptation networks,” IEEE Transactions on Circuits and Systems for Video Technology, vol. PP, pp. 1–1, 09 2023.
- [8] R. Schettini and S. Corchs, “Underwater image processing: State of the art of restoration and image enhancement methods,” EURASIP Journal on Advances in Signal Processing, vol. 2010, 12 2010.
- [9] K. Iqbal, M. Odetayo, A. James, R. Abdul Salam, and A. Talib, “Enhancing the low quality images using unsupervised colour correction method,” in Conference Proceedings - IEEE International Conference on Systems, Man and Cybernetics, 10 2010, pp. 1703–1709.
- [10] X. Fu, P. Zhuang, Y. Huang, Y. Liao, X.-P. Zhang, and X. Ding, “A retinex-based enhancing approach for single underwater image,” 2014 IEEE International Conference on Image Processing, ICIP 2014, pp. 4572–4576, 01 2015.
- [11] W. Zhang, L. Dong, X. Pan, J. Zhou, L. Qin, and W. Xu, “Single image defogging based on multi-channel convolutional msrcr,” IEEE Access, vol. 7, pp. 72 492–72 504, 06 2019.
- [12] C. Godard, O. Aodha, and G. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 07 2017.
- [13] C. Godard, O. Aodha, M. Firman, and G. Brostow, “Digging into self-supervised monocular depth estimation,” in Proceedings of the IEEE/CVF international conference on computer vision, 11 2019.
- [14] J.-J. Jiang, Z.-Y. Li, and X.-M. Liu, “Deep learning based monocular depth estimation: A survey,” Jisuanji Xuebao/Chinese Journal of Computers, vol. 45, pp. 1276–1307, 06 2022.
- [15] B. Yu, J. Wu, and M. J. Islam, “Udepth: Fast monocular depth estimation for visually-guided underwater robots,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 3116–3123.
- [16] S. Bhat, I. Alhashim, and P. Wonka, “Adabins: Depth estimation using adaptive bins,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 06 2021, pp. 4008–4017.
- [17] L. Hong, X. Wang, G. Zhang, and M. Zhao, “Usod10k: A new benchmark dataset for underwater salient object detection,” IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, vol. PP, 04 2023.