No-Reference Image Quality Assessment via Feature Fusion and Multi-Task Learning
Abstract.
Blind or no-reference image quality assessment (NR-IQA) is a fundamental, unsolved, and yet challenging problem due to the unavailability of a reference image. It is vital to the streaming and social media industries that impact billions of viewers daily. Although previous NR-IQA methods leveraged different feature extraction approaches, the performance bottleneck still exists. In this paper, we propose a simple and yet effective general-purpose no-reference (NR) image quality assessment (IQA) framework based on multi-task learning. Our model employs distortion types as well as subjective human scores to predict image quality. We propose a feature fusion method to utilize distortion information to improve the quality score estimation task. In our experiments, we demonstrate that by utilizing multi-task learning and our proposed feature fusion method, our model yields better performance for the NR-IQA task. To demonstrate the effectiveness of our approach, we test our approach on seven standard datasets and show that we achieve state-of-the-art results on various datasets.
1. Introduction
Image and video compression and applications of visual media continue to be in high demand these days. There has been an increasing demand for accurate image and video quality assessment algorithms for different multimedia and computer vision applications, such as image/video compression, communication, printing, display, restoration, segmentation, and fusion (Dodge and Karam, 2016; Liu et al., 2017b; Guo and Chao, 2017; Zhang et al., 2017). Robustness of different multimedia and computer vision applications heavily relies on their input’s quality. Therefore, it is of great importance to be able to automatically evaluate image quality in the same way as it perceived by the human visual system (HVS). Furthermore, in many real-world applications, IQA task needs to be carried out in a timely fashion on a computationally limited platform.

Objective quality metrics can be divided into full-reference (reference available or FR), reduced-reference (RR), and no-reference (reference not available or NR) methods based on the availability of a reference image (Wang and Bovik, 2006). FR methods (Sheikh et al., 2005, 2006; Kim and Lee, 2017a; Zhang et al., 2018) usually provide the most precise evaluation results and perform well in predicting the quality scores of human subjects in comparison with RR and NR methods. RR methods (Soundararajan and Bovik, 2011; Golestaneh and Karam, 2016) provide a solution when the reference image is not fully accessible. These methods generally operate by extracting a minimal set of parameters from the reference image; these parameters are later used with the distorted image to estimate quality. However, in many practical applications, an IQA system does not have access to reference images. Without the reference image, IQA task becomes very challenging. The goal of the no-reference image quality assessment (NR-IQA) methods (Ghadiyaram and Bovik, 2017; Moorthy and Bovik, 2011; Ma et al., 2017b; Liang et al., 2016; Tang et al., 2011, 2014; Talebi and Milanfar, 2018; Liu et al., 2017a; Huang et al., 2018; Mittal et al., 2012b; Bosse et al., 2017; Zhang et al., 2015b; Ye et al., 2012; Kang et al., 2014; Ye et al., 2014; Saad et al., 2012; Wang et al., 2016; Xu et al., 2016; Kang et al., 2015; Wu et al., 2017; Kim and Lee, 2017b; Pan et al., 2018; Lin and Wang, 2018; Mittal et al., 2012a; Zhang and Chandler, 2018; Ma et al., 2017a; Wu et al., 2019; Fang et al., 2017; Gu et al., 2016b, 2017; Yue et al., 2018; Min et al., 2017; Kim et al., 2018; Gu et al., 2014; Wu et al., 2014; Li et al., 2019; Zhang et al., 2015a; Xue et al., 2013, 2014; He et al., 2012; Jiang et al., 2017; Ying et al., 2020) is to provide a solution when the reference image is not available.
NR-IQA methods are mainly divided into two groups, distortion-based and general-purpose methods. A distortion-based approach is to design NR algorithms for a specific type of distortion (e.g. blocking, blurring, or contrast distortions). Distortion-based approaches have limited applications in more diverse scenarios. A general-purpose approach is designed to evaluate image quality without being limited to distortion types. General-Purpose methods usually make use of extracted features that are informative for various types of distortions. Therefore, performance highly depends on designing elaborate features. Existing general-purpose NR-IQA methods can mainly be classified into two categories depending on the types of features used.
The first category is based on well-chosen handcrafted features that are sensitive to the image quality (e.g. natural scene statistics, or image gradients). Natural scene statistics (NSS) (Sheikh et al., 2005; Moorthy and Bovik, 2011) is one of the most widely used features for IQA. NSS has the assumption that natural images have statistical regularity that is altered when distortions are introduced. Various types of NSS features have been defined in transformation domain (Saad et al., 2012, 2012; Xue et al., 2014), and spatial domain (Mittal et al., 2012a, b; Zhang et al., 2015a; Li et al., 2019). The main constraint of NSS is its limitation in capturing and modeling the deviation among different similar distortions. Moreover, the limitation of using handcrafted features is the lack of generalizability for modeling the multiple complex distortion types or contents. As we will show in the results section, methods based on handcrafted features that are designed for natural images will not perform well for screen content images (SCIs) or high-dynamic-range- (HDR) processed images.
The second category is based on utilizing feature learning methods. Inspired by the performance of convolutional neural networks (CNNs) for different computer vision applications, different works utilize them for NR-IQA task. The key factor behind achieving good performance via deep neural networks (DNNs) is having massive labeled datasets (Deng et al., 2009) that can support the learning process (Krizhevsky et al., 2012). However, existing IQA datasets contain an extremely low number of labeled images. Moreover, unlike generating datasets for image recognition task, generating large-scale reliable human subjective labels for quality assessment is very difficult. Obtaining an IQA dataset requires a complex and time consuming psychometric experiment. Furthermore, applying different data augmentation methods to increase the number of data can affect perceptual quality scores. Nonetheless, different approaches such as transfer learning, generative adversarial networks (GANs), and proxy quality scores have been used to leverage the power of DNNs for NR-IQA. Many researchers achieved state-of-the-art results by using DNNs for NR-IQA task. With the exception of just a few number of algorithms (Kang et al., 2015; Wang et al., 2016; Ma et al., 2017b; Huang et al., 2018; Wu et al., 2014; Xu et al., 2016), existing NR-IQA methods heavily rely only on the subjective quality scores to predict the quality. Most of the learning-based methods ignore how utilizing distortion during training can be beneficial to predict the perceptual quality, similar to the way that HVS perceives the quality.
It is common to use multiple sources of information jointly in human learning. Babies learn a new language by listening, speaking, and writing it. The problem of using a single network to solve multiple tasks has been repeatedly pursued in the context of deep learning for computer vision. Multi-task learning has achieved great performance for a variety of vision tasks, such as surface normal and depth prediction (Ren and Jae Lee, 2018; Eigen and Fergus, 2015), object detection (Peng et al., 2015), and navigation (Zhu et al., 2017).
The perceptual process of the HVS includes multiple complex processes. The visual sensitivity of the HVS varies according to different factors, such as distortion type, scene context, and spatial frequency of stimuli (Daly, 1992; Legge and Foley, 1980; Watson and Ahumada, 2005). The HVS perceives image quality differently among various image contents (Alam et al., 2014; Chou and Li, 1995). Image quality assessment and distortion identification tasks are closely related. During the feature learning process, identifying the distortion not only helps the image quality assessment task, but also can open up the opportunity to enhance the quality of the distorted image based on the degradation type. By leveraging the distortion type for the IQA task, our model predicts the distortion type as well as the quality score of a distorted image during testing. Fig 1 shows example results of our proposed method.
From a modeling perspective, we are interested in answering: How does the additional distortion information influence NR-IQA and how much does it improve the overall performance? What is the best architecture for taking advantage of distortion information for NR-IQA? We examine these questions empirically by evaluating multiple DNN architectures that each take a different approach to combine information. Our proposed method improves upon the following limitations of recent works on multi-task learning for NR-IQA (Kang et al., 2015; Wang et al., 2016; Ma et al., 2017b; Huang et al., 2018; Wu et al., 2014; Xu et al., 2016). 1) The general trend among the recent multi-task NR-IQA methods (Kang et al., 2015; Wu et al., 2014; Wang et al., 2016; Ma et al., 2017b; Huang et al., 2018) are to use overparameterized sub-networks or fully connected layers (FCL) for different tasks to achieve higher performance. In many real-world applications (e.g. self-driving cars and VR/AR) IQA task needs to be carried out in a timely fashion on a computationally limited platform. We propose a pooling and fusion method along with convolution layer which replace the overparameterized FCL for each task. 2) Except for few methods, multi-task NR-IQA methods (Wu et al., 2014; Xu et al., 2016) use multi-stage training and optimize each task separately to achieve the best performance. In contrast, our method is simply trained end-to-end in one step without any multi-stage training. 3) Existing approaches without providing any analysis used the last layer of the network for all the tasks. They further use sub-networks or FCL for each task and rely on overparameterized learning layers to achieve good performance. In this work, we empirically investigate the effect of feature fusion for NR-IQA task. Using our design and feature fusion, we show that by using only convolution layers along with global average pooling (GAP) we can achieve a better performance. From a computational perspective, by using a smaller backbone in our experiments compared to existing models, our proposed model outperforms many of the existing state-of-the-art single-task and multi-task IQA algorithms.
We propose an end-to-end multi-task model, namely QualNet, for NR-IQA. During the training stage, our model makes use of distortion types as well as subjective human scores to predict the image quality. We evaluate our approach against different NR-IQA methods and achieve state-of-the-art results on several standard IQA datasets. We provide extensive experiments to demonstrate the effectiveness of our proposed method and architecture design.
In summary, our contributions are summarized as follows:
-
•
We propose an end-to-end multi-task learning approach for blind quality assessment and distortion prediction. We propose a feature fusion method to utilize distortion information for improving the quality score estimation task. Specifically, given an input image, our proposed model is designed to regress the quality and predict the distortion type (or distortion types).
-
•
We provide empirical experiments and evaluate different feature fusion choices to demonstrate the effectiveness of our proposed model.
-
•
We evaluate the performance of our proposed method on three well-known natural image datasets (LIVE, CSIQ, TID2013). While using a smaller backbone for feature extraction, our model outperforms the existing algorithms on two datasets (CSIQ and TID2013). We also test the performance of our method on the LIVE multi-distortion dataset and outperform the state-of-the-art NR-IQA methods. In addition to natural image datasets, we further evaluate the performance of our algorithm on two other datasets with different scene domains (screen content images and HDR-processed images) and achieve state-of-the-art results.
2. Related Work
We briefly review the literature related to our approach.
2.1. Single-Task NR-IQAs
Before the rise of deep neural networks (DNNs), NR-IQA methods utilize different machine learning techniques (e.g. dictionary learning) or image characteristics (e.g. NSS) to extract the features for predicting the quality score. CORNIA (Ye et al., 2012) used a dictionary learning method to encode the raw image patches to features. CORNIA features later were adopted in some NR-IQA models (Ye et al., 2014; Zhang et al., 2015b; Ma et al., 2017a).
With the progress of DNNs in different applications, more researchers have utilized them for NR-IQA. In (Kang et al., 2014) the authors proposed a shallow CNN for feature learning and quality regression. (Kim et al., 2018) developed a two-stage model that separated into an objective training stage followed by a subjective training stage. In the first stage, they used PSNR to produce proxy scores. Then, they generated the feature maps which were then regressed onto objective error maps. The second stage aggregated the feature maps by weighted averaging and finally regressed these global features onto ground-truth subjective scores. (Pan et al., 2018) proposed a deep learning based model (BPSQM) which consists of a fully convolutional neural network and a deep pooling network. Given a similarity index map, labels generated via a FR-IQA model, their model produced a quality map that model the similarity index in pixel distortion level. Hallucinated-IQA (Lin and Wang, 2018) proposed a NR-IQA method based on generative adversarial models. They first generated a hallucinated reference image to compensate for the absence of the true reference. Then, paired the information of hallucinated reference with the distorted image to estimate the quality score. Although (Kim et al., 2018; Pan et al., 2018; Lin and Wang, 2018) perform well for the NR-IQA task, they all used some sort of the reference image during their training which contradicts the NR-IQA purpose.
2.2. Multi-Task NR-IQAs
There are a few algorithms that attempt to do NR-IQA by leveraging the power of multi-task learning. (Kang et al., 2015; Wu et al., 2014; Wang et al., 2016) designed a multi-task CNN to predict the type of distortions and image quality from the last fully connected layer in the network. (Xu et al., 2016) developed a multi-task rank-learning-based IQA (MRLIQ) method. They constructed multiple IQA models, each of which is responsible for one distortion type. (Ma et al., 2017b) proposed MEON, which is a multi-task network where two sub-networks train in two stages for distortion identification and quality prediction. (Huang et al., 2018) proposed a model that used multi-task learning and dictionary learning for NR-IQA.
Among the aforementioned algorithms, (Wu et al., 2014; Xu et al., 2016) do not train end-to-end and requires multi-stage training. Although (Ma et al., 2017b) is an end-to-end method, the training process is performed in two steps. Existing methods mostly used just one fully connected layer for both tasks. To the best of our knowledge, none of the existing works investigate the effect of feature fusion for NR-IQA task. In this work, we investigate different feature fusion architectures to improve the performance of NR-IQA. While taking advantage of multi-task learning, we use feature fusion from different blocks of the network to estimate the quality score more accurately. Unlike the existing multi-task NR-IQA methods, we use global average pooling instead of fully connected layers which reduces learning parameters. We observe that using fully connected layers can cause overfitting and the network memorizes the training examples rather than generalizing from them.
3. Our Approach
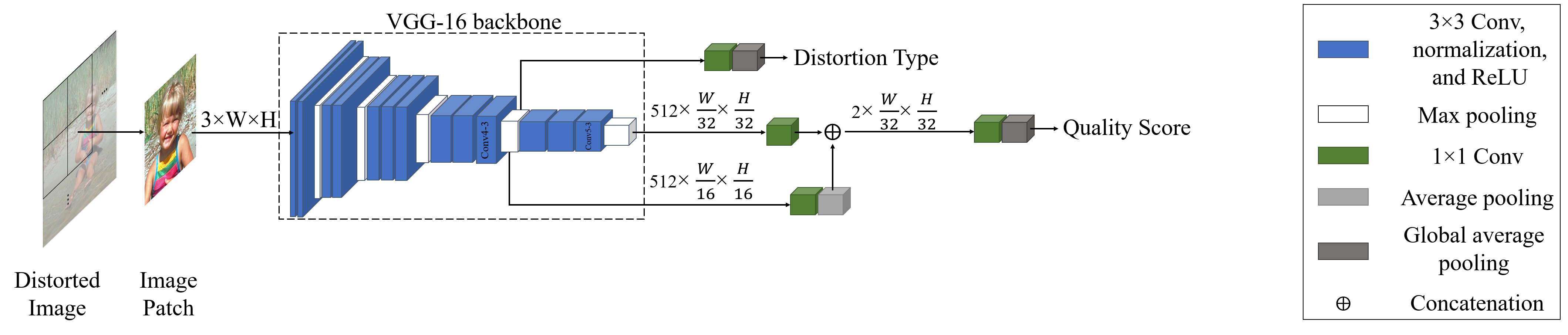
In this section, we introduce our proposed multi-task model, QualNet, for NR-IQA. QualNet jointly learns distortion prediction as well as quality score prediction tasks. Our proposed model is fully convolutional and is trained in an end-to-end manner. An overview of the QualNet architecture is given in Fig. 2.
3.1. Problem Formulation
Given a distorted image , our goal is to estimate its distortion type (or distortion types) as well as quality score. We partition the distorted image into overlapped patches . Let represents proposed network with learnable parameters . Given an input image we have:
| (1) |
where is the input image to our network, and denotes the regressed quality score. is a vector, where indicates the total number of distortion types available in dataset. The element of with maximum value represents the index for the distortion type.
3.2. Network architecture
QualNet is not limited by the choice of network architecture, any of state-of-the-art DNNs (Simonyan and Zisserman, 2014; He et al., 2016; Szegedy et al., 2015) can be used as a backbone for our proposed method. However, in order to emphasize the advantage of our method, we choose VGG16 which is a relatively smaller network compared to VGG19, Resnet34, or Resnet50, which are the ones that mostly used in the recent proposed NR-IQA methods (Huang et al., 2018; Lin and Wang, 2018; Pan et al., 2018; Wu et al., 2017). Choosing a large network easily increases the number of parameters and makes the network prone to overfitting instead of learning a better representation.
We show the architecture of our proposed model in Fig. 2. We modified VGG16 network to be used as the backbone. We add instant normalization (IN) layer after each convolution layer. However, in order to not increase the number of learnable parameters we set the trainable parameters for IN layers to be False. Despite most of the existing deep learning based NR-IQA methods that use fully connected layers (FCL) for regressing the quality score, we did not use any fully connected layer in the head of our network, instead, we use global average pooling (GAP). The use of GAP allows networks to function with less computational power and have better generalization performance. In the head of our network, we use convolution layer along with GAP layer for each task.
The insight behind our network design comes from two observations. a) Typically, different FCL/sub-networks is used at the last layer of the backbone to separately compute each task. We empirically observe that selecting features from the same layer of the network can reduce the learning capability of that layer for both of the tasks. That explains why previous models needed additional overparameterized FCL/subnetwork in their architectures. Therefore, here we choose features from different layers for each task. b) Inspired by the work done in the field of understanding human visual perception and psychology, we know that human vision has different sensitivities to different levels and types of distortions (Daly, 1992; Legge and Foley, 1980; Watson and Ahumada, 2005). Thus, for quality score prediction task it is important to take advantage of the features used to predict the type of distortion. Fusion among features for tasks that are related can significantly capture the relative information and improve the performance by considering the relative information among all the different tasks. We proposed to fuse the features used for distortion prediction task with the quality prediction features. Using our proposed feature fusion, our method can perform efficiently and effectively well on different datasets without having overparameterized layers for each task.
3.3. Distortion Prediction
We use features of the max-pooling layer after layer for the distortion prediction task. The output of max-pooling layer has dimension; convolution along with GAP is used to compute the distortion type. The output of convolution has dimension, where is the total number of distortions available in the training data. GAP layer is used to convert the feature map to vector, which denotes by . In the case of single distortion type, the element of with maximum value represents the index for the distortion type.
3.4. Quality Score Regression
We use features of the max-pooling layer after and for the quality score regression task. We first regress and features separately to obtain two coarse quality scores maps. The average pooling layer is used to make sure that the output of convolutions after has the same dimension (i.e. ) with the output of convolutions after . Finally, we combine the computed quality score maps by concatenating them and send it to a convolution and GAP to achieve the final quality score.
The HVS perceive image quality differently based on different distortion types; by concatenating the features from the layer that is used to predict the distortion type we observe that our model can utilize distortion type information for quality score prediction. As shown in our ablation study, using our proposed feature fusion, we achieve the best performance.
3.5. Training
Here we describe the training details of the QualNet. Given d and as the output of our model, we use negative log-likelihood loss (which is simply a cross-entropy loss) and loss for optimizing distortion prediction and quality score regression tasks, respectively. In other words, the total loss for our network is defined as:
| (2a) | |||
| (2b) | |||
| (2c) |
where and are the losses for distortion type prediction and quality score regression, respectively. is a regularization parameter that in our network is set to 1. Eq. (2b) is the criterion that combines softmax and negative log-likelihood loss to train the distortion type classification problem with classes. In other words, is the number of distortion types. denotes class index in the range as the target for the input. is a vector which represents the output of the distortion type prediction task. In Eq. (2c), and are regressed quality score and subjective human score for the image , respectively.
In QualNet framework, the sizes of input images must be fixed to train the model on a GPU. Therefore, each input image should be divided into multiple patches of the same size. In our experiment, we choose patch size of , we set the step of the sliding window to , i.e. the neighboring patches are overlapped by pixels. We consider the patch size large enough to reflect the overall image quality, we set the quality score of each patch to its distorted images subjective ground-truth score. The effect of different patch sizes is provided in our ablation study. To expand the training data set, the horizontal flip is performed in our training process for data augmentation.
For both tasks, our network is optimized end-to-end simultaneously. The proposed network is trained iteratively via backpropagation over a number of 50 epochs. We set batch size to 1. For optimization, we use the adaptive moment estimation optimizer (ADAM) (Kingma and Ba, 2014) with = 0.9, = 0.999, we set the initially learning rate to . We set the learning rate decay to , and it applied after every 3 epochs. We fine-tune our model end-to-end while using pretrained Imagenet weights to initialize the weights of the VGG16 network, the rest of the weights in the network are randomly initialized. Similar to the existing NR-IQA models for all of our evaluations, to train and test the QualNet, we randomly divide the reference images into two subsets, for training and for testing. Then, the corresponding distorted images are divided into training and testing sets so that there are no overlaps between the two. All the experiments are under ten times random train-test splitting operation, and the median SROCC and LCC values are reported as final statistics.
4. Results
In this section, the performance of our proposed model is analyzed in terms of its ability to predict subjective ratings of image quality as well as distortion type. We evaluate the performance of our proposed model extensively. We use seven standard image quality datasets for our performance evaluation. For a distorted image , the final predicted quality score is simply defined by averaging the predicted quality scores over all the patches from . Also, the final image distortion is decided by a majority voting of the patches belong to , i.e. the most frequently occurring distortion on patches determines the distortion of the image.
First, we study the effectiveness of our proposed model in regards to its ability to predict the image quality in a manner that agrees with subjective perception. For performance evaluation, we employ two commonly used performance metrics. We measure the prediction monotonicity of QualNet via the Spearman rank-order correlation coefficient (SROCC). This metric operates only on the rank of the data points and ignores the relative distance between data points. We also apply regression analysis to provide a nonlinear mapping between the objective scores and either the subjective mean opinion scores (MOS) or difference of mean opinion scores (DMOS). We measure the Pearson linear correlation coefficient (LCC) between MOS (DMOS) and the objective scores after nonlinear regression.
We further provide accuracy of QualNet for the distortion type prediction task. Finally, we provide ablation studies to evaluate the performance of QualNet for different choices of architecture, fusion, patch sizes, and optimization strategy.
4.1. Datasets
The detailed information for datasets that we use for our evaluation is summarized in Table 1. Specifically, we perform experiments on seven widely used benchmark datasets. For natural images use LIVE (Sheikh et al., 2006), CSIQ (Larson and Chandler, 2010), TID2008 (Ponomarenko et al., 2009), TID2013 (Ponomarenko et al., 2013), LIVE-MD (Jayaraman et al., 2012). For SCIs we use SIQAD (Yang et al., 2015), and for images with different tone-mapping, multi-exposure fusion, and post-processing we use ESPL-LIVE HDR (Kundu et al., 2017a).
| Databases | # of Dist. | # of Dist. | Multiple Distortions | Score Type |
|---|---|---|---|---|
| Images | Types | per images? | ||
| LIVE | 799 | 5 | NO | DMOS |
| CSIQ | 866 | 6 | NO | DMOS |
| TID2008 | 1700 | 17 | NO | MOS |
| TID2013 | 3000 | 24 | NO | MOS |
| LIVE-MD1 | 255 | 2 | YES | DMOS |
| LIVE-MD2 | 255 | 2 | YES | DMOS |
| SIQAD | 980 | 7 | NO | DMOS |
| ESPL-LIVE HDR | 1811 | 11 | NO | MOS |
4.2. Natural Images
| Method | LIVE | CSIQ | TID2013 | LIVE-MD1 | LIVE-MD2 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SROCC | LCC | SROCC | LCC | SROCC | LCC | SROCC | LCC | SROCC | LCC | SROCC | LCC | |
| DIIVINE(Saad et al., 2012) | 0.892 | 0.908 | 0.804 | 0.776 | 0.643 | 0.567 | 0.909 | 0.931 | 0.831 | 0.874 | 0.815 | 0.811 |
| BRISQUE(Mittal et al., 2012a) | 0.929 | 0.944 | 0.812 | 0.748 | 0.626 | 0.571 | 0.904 | 0.936 | 0.861 | 0.888 | 0.826 | 0.817 |
| NIQE(Mittal et al., 2012b) | 0.908 | 0.948 | 0.812 | 0.629 | 0.421 | 0.330 | 0.861 | 0.911 | 0.782 | 0.844 | 0.765 | 0.732 |
| IL-NIQE(Zhang et al., 2015a) | 0.902 | 0.906 | 0.822 | 0.865 | 0.521 | 0.648 | 0.881 | 0.857 | 0.871 | 0.869 | 0.799 | 0.829 |
| BIECON(Kim and Lee, 2017b) | 0.958 | 0.961 | 0.815 | 0.823 | 0.717 | 0.762 | - | - | - | - | 0.830 | 0.848 |
| IQA-CNN++ (Kang et al., 2015) | 0.965 | 0.966 | 0.892 | 0.905 | 0.872 | 0.878 | 0.953 | 0.942 | 0.943 | 0.905 | 0.925 | 0.919 |
| CNN-SWA(Wang et al., 2016) | 0.982 | 0.974 | 0.887 | 0.891 | 0.880 | 0.851 | 0.934 | 0.921 | 0.931 | 0.921 | 0.922 | 0.891 |
| MEON(Ma et al., 2017b) | 0.951 | 0.955 | 0.852 | 0.864 | 0.808 | 0.824 | 0.915 | 0.934 | 0.953 | 0.949 | 0.895 | 0.905 |
| HFD-BIQA(Wu et al., 2017) | 0.951 | 0.972 | 0.842 | 0.890 | 0.764 | 0.681 | - | - | - | - | 0.852 | 0.847 |
| WaDIQaM-NR(Bosse et al., 2017) | 0.960 | 0.955 | 0.852 | 0.844 | 0.835 | 0.855 | - | - | - | - | 0.882 | 0.884 |
| BPSQM(Pan et al., 2018) | 0.973 | 0.963 | 0.874 | 0.915 | 0.862 | 0.885 | 0.867 | 0.898 | 0.891 | 0.912 | 0.893 | 0.914 |
| Hallucinated-IQA(Lin and Wang, 2018) | 0.982 | 0.982 | 0.885 | 0.910 | 0.879 | 0.880 | - | - | - | - | 0.915 | 0.924 |
| DIQA (Kim et al., 2018) | 0.975 | 0.977 | 0.884 | 0.915 | 0.825 | 0.850 | 0.945 | 0.951 | 0.932 | 0.944 | 0.912 | 0.927 |
| Ref. (Huang et al., 2018) | 0.970 | 0.971 | 0.889 | 0.894 | 0.862 | 0.884 | 0.927 | 0.926 | 0.932 | 0.939 | 0.916 | 0.922 |
| NRVPD(Li et al., 2019) | 0.956 | 0.960 | 0.886 | 0.918 | 0.749 | 0.808 | 0.937 | 0.942 | 0.924 | 0.941 | 0.890 | 0.913 |
| QualNet (proposed) | 0.980 | 0.984 | 0.907 | 0.921 | 0.890 | 0.901 | 0.961 | 0.965 | 0.960 | 0.952 | 0.938 | 0.943 |
Most of the existing NR-IQA designed to predict the quality of natural images. Table 2 shows the obtained performance evaluation results of our proposed algorithm on the LIVE, CSIQ, TID2013, LIVE-MD1, and LIVE-MD2 datasets in comparison with state-of-the-art general-purpose NR-IQA algorithms. As shown in Table 2, our proposed method outperforms state-of-the-art algorithms on several datasets while having a smaller backbone. We believe that this improvement is because of our feature fusing and taking advantage of multi-task learning. Although (Lin and Wang, 2018) achieved the best performance for SROCC on LIVE dataset, it has bigger backbone compared to us (VGG19 vs VGG16). Moreover, as shown in Table 2, our proposed model achieves the highest performance when we average the performances among all the datasets.
Cross-dataset evaluations. To evaluate the generalizability of the QualNet, we conduct cross dataset test. Training is performed on LIVE, and then the obtained model is tested on TID2008 (for comparability) without parameter adaptation. Both quality score regression and distortion type prediction tasks are tested. We follow the common experiment setting to test the results on the subsets of TID2008, where four distortion types (i.e., JPEG, JPEG2K, WN, and Blur) are included, and logistic regression is applied to match the predicted DMOS to MOS value (Rohaly et al., 2000; Sheikh et al., 2006).
| Methods | SROCC | LCC |
|---|---|---|
| CORNIA (Ye et al., 2012) | 0.880 | 0.890 |
| CNN (Kang et al., 2014) | 0.920 | 0.903 |
| SOM (Zhang et al., 2015b) | 0.923 | 0.899 |
| IQA-CNN++ (Kang et al., 2015) | 0.917 | 0.921 |
| CNN-SWA (Wang et al., 2016) | 0.915 | 0.922 |
| dipIQ (Ma et al., 2017a) | 0.916 | 0.918 |
| MEON (Ma et al., 2017b) | 0.921 | 0.918 |
| WaDIQaM-NR (Bosse et al., 2017) | 0.919 | 0.916 |
| DIQA (Kim et al., 2018) | 0.922 | - |
| BPSQM (Pan et al., 2018) | 0.910 | - |
| HIQA (Lin and Wang, 2018) | 0.934 | 0.917 |
| Ref. (Huang et al., 2018) | 0.935 | 0.936 |
| NRVPD (Li et al., 2019) | 0.904 | 0.908 |
| QualNet (Proposed) | 0.925 | 0.940 |
The results provided in Table 3 demonstrate the generalization ability of our approach. As shown in Table 3, QualNet outperforms all existing algorithms in terms of LCC. It also achieves comparable results in terms of SROCC. Although (Huang et al., 2018) and (Lin and Wang, 2018) achieved higher results compared to our method, it worth mentioning that they both use more learning parameters in their models. (Huang et al., 2018) and (Lin and Wang, 2018) used Resnet50 and VGG19 as their backbones, respectively. For the distortion type prediction task, QualNet predicted the distortion types of TID2008 images with accuracy while trained on LIVE images.

To validate if our proposed method is consistent with human visual perception, we visualize the feature maps of and blocks in Fig. 3. The first row in Fig. 3 shows five different distortion types from TID2013, including Local block-wise distortions of different intensity (first column), JPEG (second column), JPEG2000 (third column), JPEG transmission errors (fourth column), and Gaussian noise (fifth column). The second and third rows correspond to the feature maps of and blocks, respectively. In contrast to recent methods that used the reference images to teach their networks to focus on distorted areas and generate a quality map, Fig. 3 shows that our method automatically learns the distortions and highlight them. The dark areas in images in the second and third rows in Fig. 3 indicate distorted regions. We observe that our proposed model learns to focus on the distortions instead of the content of images. For instance, the last row of Fig. 3 clearly shows that for a noisy image our method captures the noise artifacts instead of the image texture/content.
4.3. Screen Content Images
Most of the NR-IQA algorithms were developed for natural images and they do not typically perform well on SCIs. Here we show that our proposed method not only performs well on natural images, but it also works well for images with other contents.
Unlike natural images, SCIs include diverse forms of visual content, such as pictorial and textual regions. Therefore, the characteristics of SCIs and those of natural images are greatly different. Recently, there have been some metrics that designed specifically for the visual quality prediction of SCIs (Gu et al., 2016b, 2017; Fang et al., 2017; Wu et al., 2019). Here we use SIQAD dataset to evaluate the performance of QualNet on SCIs. The SIQAD dataset includes 980 screen content images corrupted by conventional distortion types (e.g. JPEG, blur, noise, etc). Table 4 provides a comparison between our results and various modern NR-IQA algorithms designed either for natural images (Mittal et al., 2012b; Zhang et al., 2015a; Kang et al., 2015; Bosse et al., 2017; Huang et al., 2018) or specifically for SCIs (Gu et al., 2016b, 2017; Fang et al., 2017; Wu et al., 2019). The results show that our algorithm yields a high correlation with the subjective quality ratings and yields the best results in terms of both LCC and SROCC.
| Database | SIQAD | |
|---|---|---|
| Methods | SROCC | LCC |
| NIQE (Mittal et al., 2012b) | 0.482 | 0.500 |
| IL-NIQE (Zhang et al., 2015a) | 0.517 | 0.540 |
| IQA-CNN++ (Kang et al., 2015) | 0.702 | 0.721 |
| CNN-SWA (Wang et al., 2016) | 0.725 | 0.735 |
| BMS (Gu et al., 2016b) | 0.725 | 0.756 |
| ASIQE (Gu et al., 2017) | 0.757 | 0.788 |
| NRLT (Fang et al., 2017) | 0.820 | 0.844 |
| WaDIQaM-NR (Bosse et al., 2017) | 0.852 | 0.859 |
| Ref. (Wu et al., 2019) | 0.811 | 0.833 |
| Ref. (Huang et al., 2018) | 0.844 | 0.856 |
| QualNet (Proposed) | 0.853 | 0.862 |
4.4. HDR-processed images
There is a growing practice of acquiring/creating and displaying high dynamic range (HDR) images and other types of pictures created by multiple exposure fusion. These kinds of images allow for more pleasing representation and better use of the available luminance and color ranges in real scenes, which can range from direct sunlight to faint starlight (Reinhard et al., 2010). HDR images typically are obtained by blending a stack of Standard Dynamic Range (SDR) images at varying exposure levels, HDR images need to be tone-mapped to SDR for display on standard monitors. Multi Exposure Fusion (MEF) techniques are also used to bypass HDR creation by fusing an exposure stack directly to SDR images to achieve aesthetically pleasing luminance and color distributions. HDR images may also be post-processed (color saturation, color temperature, detail enhancement, etc.) for aesthetic purposes. Therefore, due to different types of tone mapping, multi-exposure fusion, and post-processing techniques, HDR images can go under different types of distortions that are different from conventional distortions.
To demonstrate the effectiveness of QualNet and its application for NR-IQA in different domains we conduct an experiment where we evaluate the performance of several state-of-the-art NR-IQA algorithms on the recently developed ESPL-LIVE HDR dataset. The images in the ESPL-LIVE HDR dataset were obtained using 11 HDR processing algorithms involving both tone-mapping and MEF. ESPL-LIVE HDR dataset also considered post-processing artifacts of HDR image creation, which typically occur in commercial HDR systems.
| Database | ESPL-LIVE HDR | |
|---|---|---|
| Methods | SROCC | LCC |
| DIIVINE (Saad et al., 2012) | 0.523 | 0.530 |
| GM-LOG (Xue et al., 2014) | 0.549 | 0.562 |
| IQA-CNN++ (Kang et al., 2015) | 0.673 | 0.685 |
| CNN-SWA (Wang et al., 2016) | 0.66 | 0.672 |
| Ref. (Huang et al., 2018) | 0.701 | 0.695 |
| BTMQI (Gu et al., 2016a) | 0.668 | 0.673 |
| WaDIQaM-NR (Bosse et al., 2017) | 0.752 | 0.762 |
| BLIQUE-TMI (Jiang et al., 2017) | 0.704 | 0.712 |
| HIGRADE (Kundu et al., 2017b) | 0.695 | 0.696 |
| Ref. (Chen et al., 2019) | 0.763 | 0.768 |
| QualNet (Proposed) | 0.796 | 0.786 |
Table 5 provides a comparison between our results and various modern NR-IQA algorithms designed either for natural images (Saad et al., 2012; Kang et al., 2015; Xue et al., 2014; Wang et al., 2016; Huang et al., 2018; Bosse et al., 2017) or specifically for HDR-processed images (Chen et al., 2019; Kundu et al., 2017b; Jiang et al., 2017; Gu et al., 2016a). The results show that our algorithm outperforms existing algorithms in terms of both SROCC and LCC and yields a high correlation with the subjective quality ratings.
4.5. Distortion Prediction
Although the main focus of this paper is on NR-IQA, in Table 6 we provide the results of the distortion type prediction task for our proposed model. As shown in Table 6, QualNet achieves good prediction accuracy over different datasets.
| datasets | LIVE | CSIQ | TID2008 | TID2013 |
|---|---|---|---|---|
| Distortion Prediction (%) | 83 | 93 | 89 | 91 |
| datasets | LIVE-MD1 | LIVE-MD2 | SIQAD | ESPL-LIVE HDR |
| Distortion Prediction (%) | 97 | 96 | 98 | 68 |
4.6. Ablation Studies
To investigate the effectiveness of our module and training scheme, we provide a comprehensive ablation study in this section. For each ablated model we train it on the subsets of the LIVE dataset and test it on the subsets of TID2013, where four distortion types (i.e., JPEG, JPEG2K, WN, and Blur) are included.
Fig. 4 demonstrates different network architectures for our ablation study. Fig. 4 (a) shows a model with just quality score regression task (single-task) while using fully connected layers for the regression task; Fig. 4 (b) is the same as Fig. 4 (a) while replacing the fully connected layers with convolution along with GAP. Fig. 4 (c) shows the model in a multi-task manner, but both quality score and distortion type prediction are done by using the features from the last layer without any feature fusion. Fig. 4 (d) shows the model in a multi-task manner, while the quality score and distortion prediction are done by using the features from different layers in the network without any feature fusion. Fig. 4 (e) shows the model in a multi-task manner, while feature fusion is performed from the last layer for quality estimation. Fig. 4 (f) is our proposed method.
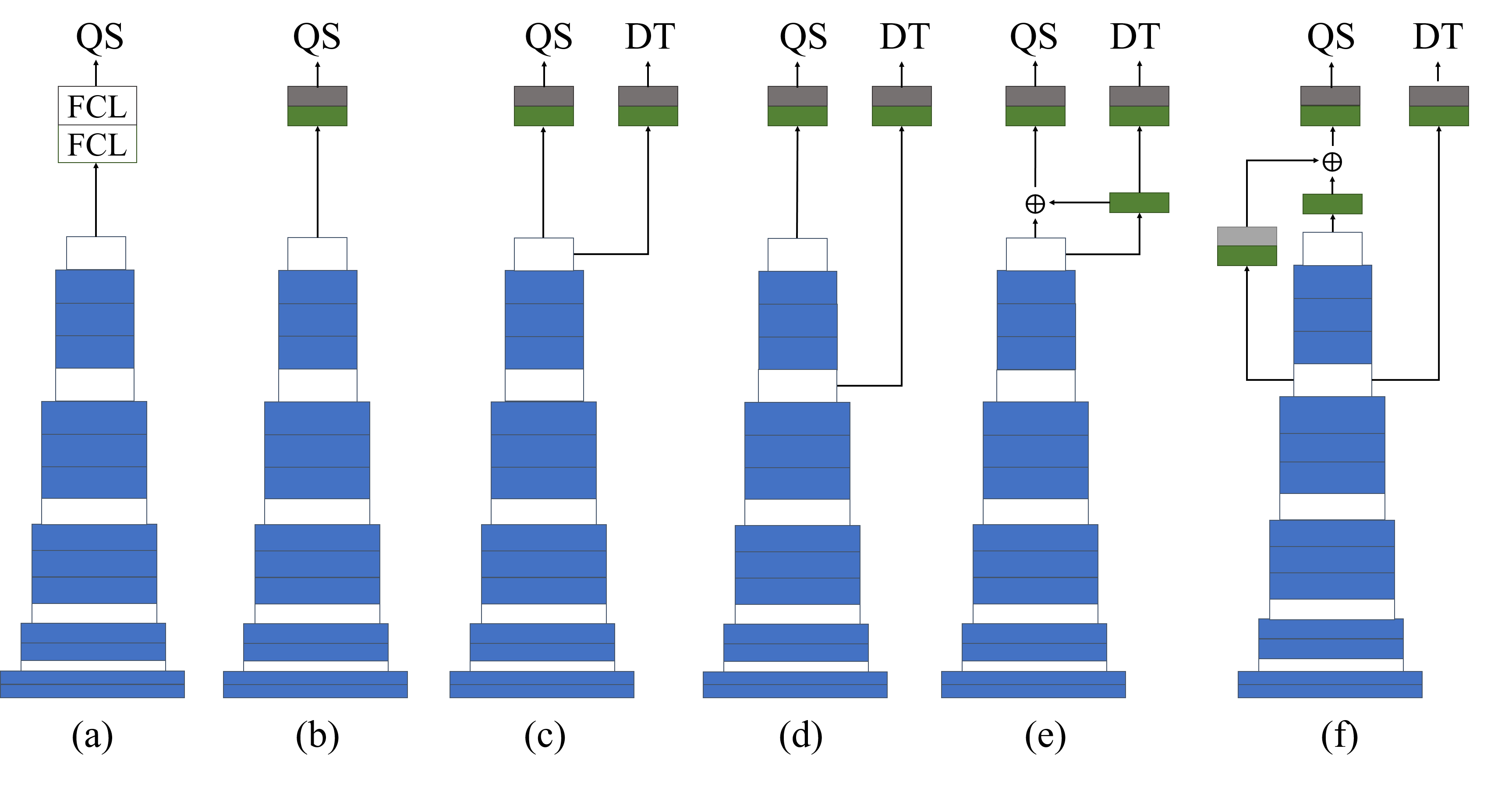
Table 7 shows the results of different ablated models from Fig. 4. As we can see model-a and model-b achieve the lowest performance comparing to the multi-task models. This proves our hypothesis that using distortion type knowledge along with quality score can improve the results. Moreover, we observe that model-b outperforms model-a; in our experiments, we observe that using fully connected layers while having limited training data will cause the model to overfit to the training data quickly which causes a lack of generality in the test phase. Furthermore, as shown in Table 7, both model-c and model-d achieve very similar results, but worse than model-f. This demonstrates the effectiveness of our feature fusion method. Finally, we observe that using the features from different layers for each task leads to better performance. In Table 7 we also provide the performance evaluation of our model via SGD for optimization, We observe that using SGD can cause the network to converge slower and lead to slightly worse results. Finally we provide results of our model while using different patch sizes as an input. We can see that while patch size of 128 leads to the best results as we move to 64 and 32 the performance degrades more. The main reason for dropping the performance while using smaller patch sizes is that the small patches do not have enough content information to represent the ground truth subjective score of the distorted image. In this paper, we select VGG16 as our backbone to show the effectiveness of our model to other methods that chose deeper backbones. However, as shown in Table 7 (Model-f-VGG-19) using a deeper network (e.g. VGG19) can improve our results even more.
5. Conclusion
In this paper, we proposed a simple yet effective multi-task model, QualNet, for general-purpose no-reference image quality assessment (NR-IQA). Our model exploits distortion type as well as subjective human scores. We demonstrate that by employing multi-task learning as well as our proposed feature fusion method, our model achieves better performance across different datasets. Our experimental results show that the proposed model achieves high accuracy while maintaining consistency with human perceptual quality assessments.
| Methods | Optmization | Patch Size | SROCC | LCC |
|---|---|---|---|---|
| Model-a | ADAM | 128128 | 0.862 | 0.882 |
| Model-b | ADAM | 128128 | 0.870 | 0.902 |
| Model-c | ADAM | 128128 | 0.905 | 0.918 |
| Model-d | ADAM | 128128 | 0.902 | 0.922 |
| Model-e | ADAM | 128128 | 0.906 | 0.920 |
| Model-f (Proposed) | ADAM | 128128 | 0.916 | 0.936 |
| Model-f-V2 | SGD | 128128 | 0.909 | 0.929 |
| Model-f-V3 | ADAM | 6464 | 0.891 | 0.911 |
| Model-f-V4 | ADAM | 3232 | 0.878 | 0.889 |
| Model-f-VGG-19 | ADAM | 128128 | 0.925 | 0.945 |
References
- (1)
- Alam et al. (2014) Md Mushfiqul Alam, Kedarnath P Vilankar, David J Field, and Damon M Chandler. 2014. Local masking in natural images: A database and analysis. Journal of vision 14, 8 (2014), 22–22.
- Bosse et al. (2017) Sebastian Bosse, Dominique Maniry, Klaus-Robert Müller, Thomas Wiegand, and Wojciech Samek. 2017. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Transactions on Image Processing 27, 1 (2017), 206–219.
- Chen et al. (2019) Pengfei Chen, Leida Li, Xinfeng Zhang, Shanshe Wang, and Allen Tan. 2019. Blind quality index for tone-mapped images based on luminance partition. Pattern Recognition 89 (2019), 108–118.
- Chou and Li (1995) Chun-Hsien Chou and Yun-Chin Li. 1995. A perceptually tuned subband image coder based on the measure of just-noticeable-distortion profile. IEEE Transactions on circuits and systems for video technology 5, 6 (1995), 467–476.
- Daly (1992) Scott J Daly. 1992. Visible differences predictor: an algorithm for the assessment of image fidelity. In Human Vision, Visual Processing, and Digital Display III, Vol. 1666. International Society for Optics and Photonics, 2–15.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
- Dodge and Karam (2016) Samuel Dodge and Lina Karam. 2016. Understanding how image quality affects deep neural networks. In 2016 eighth international conference on quality of multimedia experience (QoMEX). IEEE, 1–6.
- Eigen and Fergus (2015) David Eigen and Rob Fergus. 2015. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE international conference on computer vision. 2650–2658.
- Fang et al. (2017) Yuming Fang, Jiebin Yan, Leida Li, Jinjian Wu, and Weisi Lin. 2017. No reference quality assessment for screen content images with both local and global feature representation. IEEE Transactions on Image Processing 27, 4 (2017), 1600–1610.
- Ghadiyaram and Bovik (2017) Deepti Ghadiyaram and Alan C Bovik. 2017. Perceptual quality prediction on authentically distorted images using a bag of features approach. Journal of vision 17, 1 (2017), 32–32.
- Golestaneh and Karam (2016) SeyedAlireza Golestaneh and Lina J Karam. 2016. Reduced-reference quality assessment based on the entropy of DWT coefficients of locally weighted gradient magnitudes. IEEE Transactions on Image Processing 25, 11 (2016), 5293–5303.
- Gu et al. (2016a) Ke Gu, Shiqi Wang, Guangtao Zhai, Siwei Ma, Xiaokang Yang, Weisi Lin, Wenjun Zhang, and Wen Gao. 2016a. Blind quality assessment of tone-mapped images via analysis of information, naturalness, and structure. IEEE Transactions on Multimedia 18, 3 (2016), 432–443.
- Gu et al. (2016b) Ke Gu, Guangtao Zhai, Weisi Lin, Xiaokang Yang, and Wenjun Zhang. 2016b. Learning a blind quality evaluation engine of screen content images. Neurocomputing 196 (2016), 140–149.
- Gu et al. (2014) Ke Gu, Guangtao Zhai, Xiaokang Yang, and Wenjun Zhang. 2014. Using free energy principle for blind image quality assessment. IEEE Transactions on Multimedia 17, 1 (2014), 50–63.
- Gu et al. (2017) Ke Gu, Jun Zhou, Jun-Fei Qiao, Guangtao Zhai, Weisi Lin, and Alan Conrad Bovik. 2017. No-reference quality assessment of screen content pictures. IEEE Transactions on Image Processing 26, 8 (2017), 4005–4018.
- Guo and Chao (2017) Jun Guo and Hongyang Chao. 2017. Building an end-to-end spatial-temporal convolutional network for video super-resolution. In Thirty-First AAAI Conference on Artificial Intelligence.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- He et al. (2012) Lihuo He, Dacheng Tao, Xuelong Li, and Xinbo Gao. 2012. Sparse representation for blind image quality assessment. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 1146–1153.
- Huang et al. (2018) Yuge Huang, Xiang Tian, Yaowu Chen, and Rongxin Jiang. 2018. Multitask convolutional neural network for no-reference image quality assessment. Journal of Electronic Imaging 27, 6 (2018), 063033.
- Jayaraman et al. (2012) Dinesh Jayaraman, Anish Mittal, Anush K Moorthy, and Alan C Bovik. 2012. Objective quality assessment of multiply distorted images. In 2012 Conference record of the forty sixth asilomar conference on signals, systems and computers (ASILOMAR). IEEE, 1693–1697.
- Jiang et al. (2017) Qiuping Jiang, Feng Shao, Weisi Lin, and Gangyi Jiang. 2017. BLIQUE-TMI: Blind quality evaluator for tone-mapped images based on local and global feature analyses. IEEE Transactions on Circuits and Systems for Video Technology 29, 2 (2017), 323–335.
- Kang et al. (2014) Le Kang, Peng Ye, Yi Li, and David Doermann. 2014. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1733–1740.
- Kang et al. (2015) Le Kang, Peng Ye, Yi Li, and David Doermann. 2015. Simultaneous estimation of image quality and distortion via multi-task convolutional neural networks. In 2015 IEEE international conference on image processing (ICIP). IEEE, 2791–2795.
- Kim and Lee (2017a) Jongyoo Kim and Sanghoon Lee. 2017a. Deep learning of human visual sensitivity in image quality assessment framework. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1676–1684.
- Kim and Lee (2017b) Jongyoo Kim and Sanghoon Lee. 2017b. Fully Deep Blind Image Quality Predictor. IEEE Journal on Selected Topics in Signal Processing 11, 1 (2017), 206–220.
- Kim et al. (2018) Jongyoo Kim, Anh-Duc Nguyen, and Sanghoon Lee. 2018. Deep CNN-based blind image quality predictor. IEEE transactions on neural networks and learning systems 30, 1 (2018), 11–24.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems. 1097–1105.
- Kundu et al. (2017a) Debarati Kundu, Deepti Ghadiyaram, Alan C Bovik, and Brian L Evans. 2017a. Large-scale crowdsourced study for tone-mapped HDR pictures. IEEE Transactions on Image Processing 26, 10 (2017), 4725–4740.
- Kundu et al. (2017b) Debarati Kundu, Deepti Ghadiyaram, Alan C Bovik, and Brian L Evans. 2017b. No-reference quality assessment of tone-mapped HDR pictures. IEEE Transactions on Image Processing 26, 6 (2017), 2957–2971.
- Larson and Chandler (2010) Eric Cooper Larson and Damon Michael Chandler. 2010. Most apparent distortion: full-reference image quality assessment and the role of strategy. Journal of Electronic Imaging 19, 1 (2010), 011006.
- Legge and Foley (1980) Gordon E Legge and John M Foley. 1980. Contrast masking in human vision. Josa 70, 12 (1980), 1458–1471.
- Li et al. (2019) Qiaohong Li, Weisi Lin, Ke Gu, Yabin Zhang, and Yuming Fang. 2019. Blind image quality assessment based on joint log-contrast statistics. Neurocomputing 331 (2019), 189–198.
- Liang et al. (2016) Yudong Liang, Jinjun Wang, Xingyu Wan, Yihong Gong, and Nanning Zheng. 2016. Image quality assessment using similar scene as reference. In European Conference on Computer Vision. Springer, 3–18.
- Lin and Wang (2018) Kwan-Yee Lin and Guanxiang Wang. 2018. Hallucinated-IQA: No-reference image quality assessment via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 732–741.
- Liu et al. (2017a) Xialei Liu, Joost van de Weijer, and Andrew D Bagdanov. 2017a. Rankiqa: Learning from rankings for no-reference image quality assessment. In Proceedings of the IEEE International Conference on Computer Vision. 1040–1049.
- Liu et al. (2017b) Yu Liu, Junjie Yan, and Wanli Ouyang. 2017b. Quality aware network for set to set recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5790–5799.
- Ma et al. (2017a) Kede Ma, Wentao Liu, Tongliang Liu, Zhou Wang, and Dacheng Tao. 2017a. dipIQ: Blind image quality assessment by learning-to-rank discriminable image pairs. IEEE Transactions on Image Processing 26, 8 (2017), 3951–3964.
- Ma et al. (2017b) Kede Ma, Wentao Liu, Kai Zhang, Zhengfang Duanmu, Zhou Wang, and Wangmeng Zuo. 2017b. End-to-end blind image quality assessment using deep neural networks. IEEE Transactions on Image Processing 27, 3 (2017), 1202–1213.
- Min et al. (2017) Xiongkuo Min, Ke Gu, Guangtao Zhai, Jing Liu, Xiaokang Yang, and Chang Wen Chen. 2017. Blind quality assessment based on pseudo-reference image. IEEE Transactions on Multimedia 20, 8 (2017), 2049–2062.
- Mittal et al. (2012a) Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. 2012a. No-reference image quality assessment in the spatial domain. IEEE Transactions on image processing 21, 12 (2012), 4695–4708.
- Mittal et al. (2012b) Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. 2012b. Making a “completely blind” image quality analyzer. IEEE Signal Processing Letters 20, 3 (2012), 209–212.
- Moorthy and Bovik (2011) Anush Krishna Moorthy and Alan Conrad Bovik. 2011. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE transactions on Image Processing 20, 12 (2011), 3350–3364.
- Pan et al. (2018) Da Pan, Ping Shi, Ming Hou, Zefeng Ying, Sizhe Fu, and Yuan Zhang. 2018. Blind predicting similar quality map for image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6373–6382.
- Peng et al. (2015) Xingchao Peng, Baochen Sun, Karim Ali, and Kate Saenko. 2015. Learning deep object detectors from 3d models. In Proceedings of the IEEE International Conference on Computer Vision. 1278–1286.
- Ponomarenko et al. (2013) Nikolay Ponomarenko, Oleg Ieremeiev, Vladimir Lukin, Karen Egiazarian, Lina Jin, Jaakko Astola, Benoit Vozel, Kacem Chehdi, Marco Carli, Federica Battisti, et al. 2013. Color image database TID2013: Peculiarities and preliminary results. In european workshop on visual information processing (EUVIP). IEEE, 106–111.
- Ponomarenko et al. (2009) Nikolay Ponomarenko, Vladimir Lukin, Alexander Zelensky, Karen Egiazarian, Marco Carli, and Federica Battisti. 2009. TID2008-a database for evaluation of full-reference visual quality assessment metrics. Advances of Modern Radioelectronics 10, 4 (2009), 30–45.
- Reinhard et al. (2010) Erik Reinhard, Wolfgang Heidrich, Paul Debevec, Sumanta Pattanaik, Greg Ward, and Karol Myszkowski. 2010. High dynamic range imaging: acquisition, display, and image-based lighting. Morgan Kaufmann.
- Ren and Jae Lee (2018) Zhongzheng Ren and Yong Jae Lee. 2018. Cross-domain self-supervised multi-task feature learning using synthetic imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 762–771.
- Rohaly et al. (2000) Ann Marie Rohaly, Philip J Corriveau, John M Libert, Arthur A Webster, Vittorio Baroncini, John Beerends, Jean-Louis Blin, Laura Contin, Takahiro Hamada, David Harrison, et al. 2000. Video quality experts group: Current results and future directions. In Visual Communications and Image Processing 2000, Vol. 4067. International Society for Optics and Photonics, 742–753.
- Saad et al. (2012) Michele A Saad, Alan C Bovik, and Christophe Charrier. 2012. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE transactions on Image Processing 21, 8 (2012), 3339–3352.
- Sheikh et al. (2005) Hamid R Sheikh, Alan C Bovik, and Gustavo De Veciana. 2005. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Transactions on image processing 14, 12 (2005), 2117–2128.
- Sheikh et al. (2006) Hamid R Sheikh, Muhammad F Sabir, and Alan C Bovik. 2006. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Transactions on image processing 15, 11 (2006), 3440–3451.
- Simonyan and Zisserman (2014) Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
- Soundararajan and Bovik (2011) Rajiv Soundararajan and Alan C Bovik. 2011. RRED indices: Reduced reference entropic differencing for image quality assessment. IEEE Transactions on Image Processing 21, 2 (2011), 517–526.
- Szegedy et al. (2015) Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1–9.
- Talebi and Milanfar (2018) Hossein Talebi and Peyman Milanfar. 2018. Nima: Neural image assessment. IEEE Transactions on Image Processing 27, 8 (2018), 3998–4011.
- Tang et al. (2011) Huixuan Tang, Neel Joshi, and Ashish Kapoor. 2011. Learning a blind measure of perceptual image quality. In CVPR 2011. IEEE, 305–312.
- Tang et al. (2014) Huixuan Tang, Neel Joshi, and Ashish Kapoor. 2014. Blind image quality assessment using semi-supervised rectifier networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2877–2884.
- Wang et al. (2016) Hanli Wang, Lingxuan Zuo, and Jie Fu. 2016. Distortion recognition for image quality assessment with convolutional neural network. In 2016 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6.
- Wang and Bovik (2006) Zhou Wang and Alan C Bovik. 2006. Modern image quality assessment. Synthesis Lectures on Image, Video, and Multimedia Processing 2, 1 (2006), 1–156.
- Watson and Ahumada (2005) Andrew B Watson and Albert J Ahumada. 2005. A standard model for foveal detection of spatial contrast. Journal of vision 5, 9 (2005), 6–6.
- Wu et al. (2019) Jun Wu, Zhaoqiang Xia, Huiqing Zhang, and Huifang Li. 2019. Blind quality assessment for screen content images by combining local and global features. Digital Signal Processing 91 (2019), 31–40.
- Wu et al. (2017) Jinjian Wu, Jichen Zeng, Yongxu Liu, Guangming Shi, and Weisi Lin. 2017. Hierarchical feature degradation based blind image quality assessment. In Proceedings of the IEEE International Conference on Computer Vision. 510–517.
- Wu et al. (2014) Qingbo Wu, Hongliang Li, King N Ngan, Bing Zeng, and Moncef Gabbouj. 2014. No reference image quality metric via distortion identification and multi-channel label transfer. In 2014 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 530–533.
- Xu et al. (2016) Long Xu, Jia Li, Weisi Lin, Yongbing Zhang, Lin Ma, Yuming Fang, and Yihua Yan. 2016. Multi-task rank learning for image quality assessment. IEEE Transactions on Circuits and Systems for Video Technology 27, 9 (2016), 1833–1843.
- Xue et al. (2014) Wufeng Xue, Xuanqin Mou, Lei Zhang, Alan C Bovik, and Xiangchu Feng. 2014. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Transactions on Image Processing 23, 11 (2014), 4850–4862.
- Xue et al. (2013) Wufeng Xue, Lei Zhang, and Xuanqin Mou. 2013. Learning without human scores for blind image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 995–1002.
- Yang et al. (2015) Huan Yang, Yuming Fang, and Weisi Lin. 2015. Perceptual quality assessment of screen content images. IEEE Transactions on Image Processing 24, 11 (2015), 4408–4421.
- Ye et al. (2014) Peng Ye, Jayant Kumar, and David Doermann. 2014. Beyond human opinion scores: Blind image quality assessment based on synthetic scores. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4241–4248.
- Ye et al. (2012) Peng Ye, Jayant Kumar, Le Kang, and David Doermann. 2012. Unsupervised feature learning framework for no-reference image quality assessment. In 2012 IEEE conference on computer vision and pattern recognition. IEEE, 1098–1105.
- Ying et al. (2020) Zhenqiang Ying, Haoran Niu, Praful Gupta, Dhruv Mahajan, Deepti Ghadiyaram, and Alan Bovik. 2020. From Patches to Pictures (PaQ-2-PiQ): Mapping the Perceptual Space of Picture Quality. (2020).
- Yue et al. (2018) Guanghui Yue, Chunping Hou, Ke Gu, Nam Ling, and Beichen Li. 2018. Analysis of structural characteristics for quality assessment of multiply distorted images. IEEE Transactions on Multimedia 20, 10 (2018), 2722–2732.
- Zhang et al. (2017) Kai Zhang, Wangmeng Zuo, Shuhang Gu, and Lei Zhang. 2017. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE conference on computer vision and pattern recognition. 3929–3938.
- Zhang et al. (2015a) Lin Zhang, Lei Zhang, and Alan C Bovik. 2015a. A feature-enriched completely blind image quality evaluator. IEEE Transactions on Image Processing 24, 8 (2015), 2579–2591.
- Zhang et al. (2015b) Peng Zhang, Wengang Zhou, Lei Wu, and Houqiang Li. 2015b. SOM: Semantic obviousness metric for image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2394–2402.
- Zhang et al. (2018) Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 586–595.
- Zhang and Chandler (2018) Yi Zhang and Damon M Chandler. 2018. Opinion-unaware blind quality assessment of multiply and singly distorted images via distortion parameter estimation. IEEE Transactions on Image Processing 27, 11 (2018), 5433–5448.
- Zhu et al. (2017) Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. 2017. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 3357–3364.