Noise Learning Based Denoising Autoencoder
Abstract
This letter introduces a new denoiser that modifies the structure of denoising autoencoder (DAE), namely noise learning based DAE (nlDAE). The proposed nlDAE learns the noise of the input data. Then, the denoising is performed by subtracting the regenerated noise from the noisy input. Hence, nlDAE is more effective than DAE when the noise is simpler to regenerate than the original data. To validate the performance of nlDAE, we provide three case studies: signal restoration, symbol demodulation, and precise localization. Numerical results suggest that nlDAE requires smaller latent space dimension and smaller training dataset compared to DAE.
Index Terms:
machine learning, noise learning based denoising autoencoder, signal restoration, symbol demodulation, precise localization.I Introduction
Machine learning (ML) has recently received much attention as a key enabler for future wireless communications [1, 2, 3]. While the major research effort has been put to deep neural networks, there are enormous number of Internet of Things (IoT) devices that are severely constrained on the computational power and memory size. Therefore, the implementation of efficient ML algorithms is an important challenge for IoT devices, as they are energy and memory limited. Denoising autoencoder (DAE) is a promising technique to improve the performance of IoT applications by denoising the observed data that consists of the original data and the noise [4]. DAE is a neural network model for the construction of the learned representations robust to an addition of noise to the input samples [vincent2008extracting, 5]. The representative feature of DAE is that the dimension of the latent space is smaller than the size of the input vector. It means that the neural network model is capable of encoding and decoding through a smaller dimension where the data can be represented.
The main contribution of this letter is to improve the efficiency and performance of DAE with a modification of its structure. Consider a noisy observation which consists of the original data and the noise , i.e., . From the information theoretical perspective, DAE attempts to minimize the expected reconstruction error by maximizing a lower bound on mutual information . In other words, should capture the information of as much as possible although is a function of the noisy input. Additionally, from the manifold learning perspective, DAE can be seen as a way to find a manifold where represents the data into a low dimensional latent space corresponding to . However, we often face the problem that the stochastic feature of to be restored is too complex to regenerate or represent. This is called the curse of dimensionality, i.e., the dimension of latent space for is still too high in many cases.
What can we do if is simpler to regenerate than ? It will be more effective to learn and subtract it from instead of learning directly. In this light, we propose a new denoising framework, named as noise learning based DAE (nlDAE). The main advantage of nlDAE is that it can maximize the efficiency of the ML approach (e.g., the required dimension of the latent space or size of training dataset) for capability-constrained devices, e.g., IoT, where is typically easier to regenerate than owing to their stochastic characteristics. To verify the advantage of nlDAE over the conventional DAE, we provide three practical applications as case studies: signal restoration, symbol demodulation, and precise localization.
The following notations will be used throughout this letter.
-
•
: the Bernoulli, exponential, uniform, normal, and complex normal distributions, respectively.
-
•
: the realization vectors of random variables , respectively, whose dimensions are .
-
•
: the dimension of the latent space.
-
•
: the weight matrices for encoding and decoding, respectively.
-
•
: the bias vectors for encoding and decoding, respectively.
-
•
: the sigmoid function, acting as an activation function for neural networks, i.e., , and where is an arbitrary input vector.
-
•
: the encoding function where the parameter is , i.e., .
-
•
: the decoding function where the parameter is , i.e., .
-
•
: the size of training dataset.
-
•
: the size of test dataset.
II Method of nlDAE
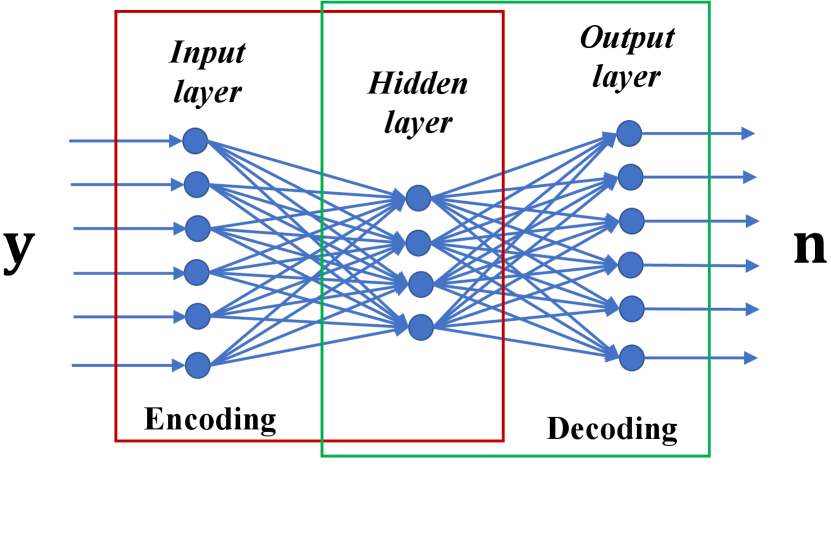
In the traditional estimation problem of signal processing, is treated as an obstacle to the reconstruction of . Therefore, most of the studies have focused on restoring as much as possible, which can be expressed as a function of and . Along with this philosophy, ML-based denoising techniques, e.g., DAE, have also been developed in various signal processing fields with the aim of maximizing the ability to restore from . Unlike the conventional approaches, we hypothesize that, if has a simpler statistical characteristic than , it will be better to subtract from after restoring .
We first look into the mechanism of DAE to build neural networks. Recall that DAE attempts to regenerate the original data from the noisy observation via training the neural network. Thus, the parameters of a DAE model can be optimized by minimizing the average reconstruction error in the training phase as follows:
| (1) |
where is a loss function such as squared error between two inputs. Then, the -th regenerated data from in the test phase can be obtained as follows for all :
| (2) |
It is noteworthy that, if there are two different neural networks which attempt to regenerate the original data and the noise from the noisy input, the linear summation of these two regenerated data would be different from the input. This means that either or is more effectively regenerated from . Therefore, we can hypothesize that learning , instead of , from can be beneficial in some cases even if the objective is still to reconstruct . This constitutes the fundamental idea of nlDAE.
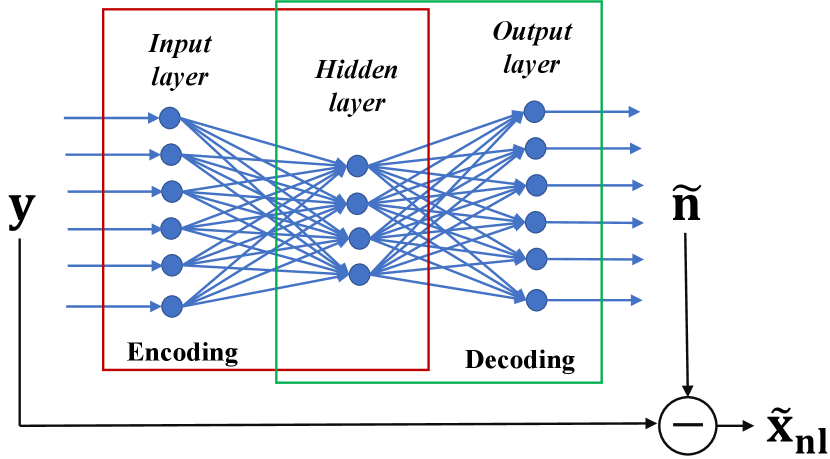
The training and test phases of nlDAE are depicted in Fig. 1. The parameters of nlDAE model can be optimized as follows for all :
| (3) |
Notice that the only difference from (1) is that is replaced by . Let denote the -th regenerated data based on nlDAE, which can be represented as follows for all :
| (4) |
To provide the readers with insights into nlDAE, we examine two simple examples where the standard deviation of is fixed as 1, i.e., , and that of varies. is comprised as follows:
-
•
Example 1: and .
-
•
Example 2: and .
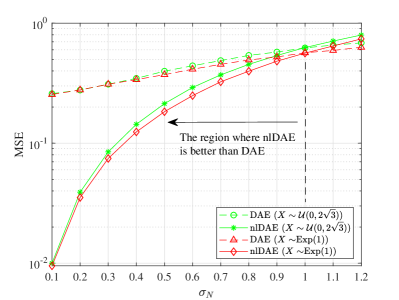
Fig. 2 describes the performance comparison between DAE and nlDAE in terms of mean squared error (MSE) for the two examples111Throughout this letter, the squared error and the scaled conjugate gradient are applied as the loss function and the optimization method, respectively.. Here, we set , , , and . It is observed that nlDAE is superior to DAE when is smaller than in Fig. 2. The gap between nlDAE and DAE widens with lower . This implies that the standard deviation is an important factor when we select the denoiser between DAE and nlDAE.
These examples show the consideration of whether or is easier to be regenerated, which is highly related to differential entropy of each random variable, and [marsh2013introduction]. The differential entropy is normally an increasing function over the standard deviation of the corresponding random variable, e.g., . Naturally, it is efficient to reconstruct a random variable with a small amount of information, and the standard deviation can be a good indicator.
III Case Studies
To validate the advantage of nlDAE over the conventional DAE in practical problems, we provide three applications for IoT devices in the following subsections. We assume that the noise follows Bernoulli and normal distributions, respectively, in the first two cases, which are the most common noise modeling. The third case deals with noise that follows a distribution expressed as a mixture of various random variables. For all the studied use cases, we select the DAE as the conventional denoiser as a baseline for performance comparison. We present the case studies in the first three subsections. Then, we discuss the experimental results in Sec. III-D.
III-A Case Study I: Signal Restoration
In this use case, the objective is to recover the original signal from the noisy signal which is modeled by the corruptions over samples.
III-A1 Model
The sampled signal of randomly superposed sinusoids, e.g., the recorded acoustic wave, is the summation of samples of damped sinusoidal waves which can be represented as follows:
| (5) |
where , , and are the peak amplitude, the damping factor, and the frequency of the -th signal, respectively. Here, the time interval for sampling, , is set to satisfy the Nyquist theorem, i.e., . To consider the corruption of , let us assume that the probability of corruption for each sample follows the Bernoulli distribution , which indicates the corruption with the probability . In addition, let denote the realization of over samples. Naturally, the corrupted signal, , can be represented as follows:
| (6) |
where is a constant representing the sample corruption.
III-A2 Application of nlDAE
III-A3 Experimental Parameters
We evaluate the performance of the proposed nlDAE in terms of the MSE of restoration. For the experiment, the magnitude of noise is set to 1 for simplicity. In addition, , , and follow , , and , respectively, for all . The sampling time interval is set to second, and the number of samples is . We set , , and unless otherwise specified.
III-B Case Study II: Symbol Demodulation
Here, the objective is to improve the symbol demodulation quality through denoising the received signal that consists of channel, symbols, and additive noise.
III-B1 Model
Consider an orthogonal frequency-division multiplexing (OFDM) system with subcarriers where the subcarrier spacing is expressed by . Let be a sequence in frequency domain. is the -th element of and denotes the symbol transmitted over the -th subcarrier. In addition, let denote the pilot spacing for channel estimation. Furthermore, the channel impulse response (CIR) can be modeled by the sum of Dirac-delta functions as follows:
| (8) |
where , , and are the complex channel gain, the excess delay of -th path, and the number of multipaths, respectively. Let denote the discrete signal obtained by -point fast Fourier transform (FFT) after the sampling of the signal experiencing the channel at the receiver, which can be represented as follows:
| (9) |
where denotes the operator of the Hadamard product. Here, is the channel frequency response (CFR), which is the -point FFT of . In addition, let denote the realization of the random variable . Finally, is the noisy observed signal.
Our goal is to minimize the symbol error rate (SER) over by maximizing the quality of denoising . We assume the method of channel estimation is fixed as the cubic interpolation [6] to focus on the performance of denoising the received signal.
III-B2 Application of nlDAE
To consider the complex-valued data, we separate it into real and imaginary parts. and denote the operators capturing real and imaginary parts of an input, respectively. Thus, is the regenerated by denoising , which can be represented by
| (10) |
where
Finally, the receiver estimates with the predetermined pilot symbols, i.e., where , and demodulates based on the estimate of and the regenerated .
III-B3 Experimental Parameters
The performance of the proposed nlDAE is evaluated when . For the simulation parameters, we set QAM, , kHz, , and . We further assume that and . Furthermore, , SNR dB, and unless otherwise specified. We also provide the result of non-ML (i.e., only cubic interpolation).
III-C Case Study III: Precise Localization
The objective of this case study is to improve the localization quality through denoising the measured distance which is represented by the quantized value of the mixture of the true distance and error factors.
III-C1 Model
Consider a 2-D localization where reference nodes and a single target node are randomly distributed. We estimate the position of the target node with the knowledge of the locations of reference nodes. Let denote the vector of true distances from reference nodes to the target node when denotes the distance between two random points in a 2-D space. We consider three types of random variables for the noise added to the true distance as follows:
-
•
: ranging error dependent on signal quality.
-
•
: ranging error due to clock asynchronization.
-
•
: non line-of-sight (NLoS) event.
We assume that , , follow the normal, uniform, and Bernoulli distributions, respectively. Hence, we can define the random variable for the noise as follows:
| (11) |
where is the distance bias in the event of NLoS. Note that does not follow any known probability distribution because it is a convolution of three different distributions. Besides, we assume that the distance is measured by time of arrival (ToA). Thus, we define the quantization function to represent the measured distance with the resolution of , e.g., . In addition, the localization method based on multi-dimensional scaling (MDS) is utilized to estimate the position of the target node [7].
III-C2 Application of nlDAE
In this case study, we consider the discrete values quantized by the function . Here, can be represented as follows:
| (12) |
where
Thus, is utilized for the estimation of the target node position in nlDAE-assisted MDS-based localization.
III-C3 Experimental Parameters
The performance of the proposed nlDAE is evaluated via . In this simulation, reference nodes and one target node are uniformly distributed in a square. We assume that , and . The distance resolution is set to for the quantization function . Note that , , and unless otherwise specified. We also provide the result of non-ML (i.e., only MDS based localization).
III-D Analysis of Experimental Results
Fig. 3(a), Fig. 4(a), and Fig. 5(a) show the performance of the three case studies with respect to , respectively. nlDAE outperforms non-ML and DAE for all ranges of . Particularly with small values of , nlDAE continues to perform well, whereas DAE loses its merit. This means that nlDAE provides a good denoising performance even with an extremely small dimension of latent space if the training dataset is sufficient.
The impact of the size of training dataset is depicted in Fig. 3(b), Fig. 4(b), and Fig. 5(b). nlDAE starts to outperform non-ML with less than 100. Conversely, DAE requires about an order higher to perform better than non-ML. Furthermore, nlDAE converges faster than DAE, thus requiring less training data than DAE.
In Fig. 3(c), Fig. 4(c), and Fig. 5(c), the impact of a noise-related parameter for each case study is illustrated. When the noise occurs according to a Bernoulli distribution in Fig. 3(c), the performance of ML algorithms (both nlDAE and DAE) exhibits a concave behavior. This is because the variance of is given by . Similar phenomenon is observed in Fig. 5(c) because the Bernoulli event of NLoS constitutes a part of localization noise. As for non-ML, the performance worsens as the probability of noise occurrence increases in both cases. Fig. 4(c) shows that the SER performance of nlDAE improves rapidly as the SNR increases. In all experiments, nlDAE gives superior performance than other schemes.
Thus far, the experiments have been conducted with a single hidden layer. Fig. 3(d), Fig. 4(d), and Fig. 5(d) show the effect of the depth of the neural network. The performance of nlDAE is almost invariant, which suggests that nlDAE is not sensitive to the number of hidden layers. On the other hand, the performance of DAE worsens quickly as the depth increases owing to overfitting in two cases.
In summary, nlDAE outperforms DAE over the whole experiments. nlDAE is observed to be more efficient for the underlying use cases than DAE because it requires smaller latent space and less training data. Furthermore, nlDAE is more robust to the change of the parameters related to the design of the neural network, e.g., the network depth.
IV Conclusion and Future Work
We introduced a new denoiser framework based on the neural network, namely nlDAE. This is a modification of DAE in that it learns the noise instead of the original data. The fundamental idea of nlDAE is that learning noise can provide a better performance depending on the stochastic characteristics (e.g., standard deviation) of the original data and noise. We applied the proposed mechanism to the practical problems for IoT devices such as signal restoration, symbol demodulation, and precise localization. The numerical results support that nlDAE is more efficient than DAE in terms of the required dimension of the latent space and the size of training dataset, thus rendering it more suitable for capability-constrained conditions. Applicability of nlDAE to other domains, e.g., image inpainting, remains as a future work. Furthermore, information theoretical criteria of decision making for the selection between or a combination of DAE and nlDAE is an interesting further research.
References
- [1] U. Challita, H. Ryden, and H. Tullberg, “When machine learning meets wireless cellular networks: Deployment, challenges, and applications,” IEEE Communications Magazine, vol. 58, no. 6, pp. 12–18, 2020.
- [2] M. Chen, U. Challita, W. Saad, C. Yin, and M. Debbah, “Artificial neural networks-based machine learning for wireless networks: A tutorial,” IEEE Communications Surveys & Tutorials, vol. 21, no. 4, pp. 3039–3071, 2019.
- [3] A. Azari, M. Ozger, and C. Cavdar, “Risk-aware resource allocation for URLLC: Challenges and strategies with machine learning,” IEEE Communications Magazine, vol. 57, no. 3, pp. 42–48, 2019.
- [4] Y. Sun, M. Peng, Y. Zhou, Y. Huang, and S. Mao, “Application of machine learning in wireless networks: Key techniques and open issues,” IEEE Communications Surveys & Tutorials, vol. 21, no. 4, pp. 3072–3108, 2019.
- [5] Y. Bengio, L. Yao, G. Alain, and P. Vincent, “Generalized denoising auto-encoders as generative models,” Advances in neural information processing systems, pp. 899–907, 2013.
- [6] S. Coleri, M. Ergen, A. Puri, and A. Bahai, “Channel estimation techniques based on pilot arrangement in OFDM systems,” IEEE Transactions on broadcasting, vol. 48, no. 3, pp. 223–229, 2002.
- [7] I. Dokmanic, R. Parhizkar, J. Ranieri, and M. Vetterli, “Euclidean distance matrices: Essential theory, algorithms, and applications,” IEEE Signal Processing Magazine, vol. 32, no. 6, pp. 12–30, 2015.